DevOps系列文章之 Python基础
列表
Python中的列表类似于C语言中的数组的概念,列表由内部的元素组成,元素可以是任何对象
Python中的列表是可变的
简单的理解就是:被初始化的列表,可以通过列表的API接口对列表的元素进行增删改查
1、定义列表
1.可以将列表当成普通的“数组”,它能保存任意数量任意类型的python对象
2.像字符串一样,列表也支持下标和切片操作
3.列表中的项目可以改变
# 列表的初始化lst = list()lst = []lst = [1,2,3]lst = list(range(10))
2、列表操作
1.使用in或not in判断成员关系
2.使用append方法向列表中追加元素
3、创建及访问列表
1.列表是有序、可变的数据类型
2.列表中可以包含不同类型的对象
3.列表可以由[]或工厂函数创建
4、列表操作符
由于列表也是序列类型,所以+、*、in、not in都适用于列表,但是需要注意参与运算的对象属于同一类型
>>> ['hello', 'world'] * 2 ['hello', 'world', 'hello', 'world'] >>> ['hello', 'world'] + 'new' Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: can only concatenate list (not "str") to list >>> ['hello', 'world'] + ['new'] ['hello', 'world', 'new']
5、作用于列表的函数
与字符串类似,列表也支持如下函数:
1、len()
2、max()
3、min()
4、sorted()
5、enumerate()
6、sum()
6、zip()
1、列表元素用中括号[]包裹,元素的个数及元素的值可以改变
Python包含以下函数:
| 序号 | 函数 |
|---|---|
| 1 | cmp(list1, list2) 比较两个列表的元素 |
| 2 | len(list) 列表元素个数 |
| 3 | max(list) 返回列表元素最大值 |
| 4 | min(list) 返回列表元素最小值 |
| 5 | list(seq) 将元组转换为列表 |
Python包含以下方法:
| 序号 | 方法 |
|---|---|
| 1 | list.append(obj) 在列表末尾添加新的对象 |
| 2 | list.count(obj) 统计某个元素在列表中出现的次数 |
| 3 | list.extend(seq) 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) |
| 4 | list.index(obj) 从列表中找出某个值第一个匹配项的索引位置 |
| 5 | list.insert(index, obj) 将对象插入列表 |
| 6 | list.pop([index]) 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 |
| 7 | list.remove(obj) 移除列表中某个值的第一个匹配项 |
| 8 | list.reverse() 反向列表中元素 |
| 9 | list.sort([func]) 对原列表进行排序 |
一, list()方法
list()方法将元组转换为列表
注意:元祖与列表是非常相似的,区别在于元组的元素值不能修改,元祖是放在小括号中,列表是放在中括号里面的。
a_tuple = ('123','abc',123)
a_list = list(a_tuple)
print(a_tuple)
print(a_list)
结果:
('123', 'abc', 123)
['123', 'abc', 123]
二,创建一个列表
只要把逗号分隔的不同的数据项使用方括号括起来即可。如下:
a_list = [1,2,3,4,5,6] b_list = ['a','b','c','d'] c_list = ['a','b','c',1,2,3,4]
三,访问列表中的值
与字符串的索引一样,列表索引从0开始。列表可以进行截取、组合等。使用下标索引来访问列表中的值,同样你也可以使用方括号的形式截取字符,如下所示:
a_list = [1,2,3,4,5,6] b_list = ['a','b','c','d'] c_list = ['a','b','c',1,2,3,4] print(a_list[0]) print(b_list[1:3]) print(c_list[:]) 结果: 1 ['b', 'c'] ['a', 'b', 'c', 1, 2, 3, 4]
四,更新列表
可以对列表的数据项进行修改或更新,你也可以使用append()方法来添加列表项,如下所示:
#!/usr/bin/env python
#-*- coding:utf-8 -*-a_list = [1,2,3,4,5,6]
b_list = ['a','b','c','d']
c_list = ['a','b','c',1,2,3,4]
a_list.append(b_list)
print a_list
a_list[0] = 123
print(a_list)
b_list.append("efg")
print(b_list)结果:[1, 2, 3, 4, 5, 6, ['a', 'b', 'c', 'd']]
[123, 2, 3, 4, 5, 6, ['a', 'b', 'c', 'd']]
['a', 'b', 'c', 'd', 'efg']
五,删除列表元素
1,可以使用 del 语句来删除列表的的元素,
2,可以使用pop()移除某元素并返回该元素,
3,使用remove()删除从左找到的第一个指定元素,
如下实例:
#!/usr/bin/env python #-*- coding:utf-8 -*-a_list = [1,2,3,4,5,6] b_list = ['a','b','c','d'] c_list = ['a','b','c',1,2,3,4,1] del a_list[2] print(a_list) b = b_list.pop() print(b) c = c_list.pop(2) #也可以删除指定元素,并返回 print(c) d = c_list.remove(1) print(c_list) 结果: [1, 2, 4, 5, 6] d c ['a','b','c',2,3,4,1]
六,列表脚本操作符
列表对 + 和 * 的操作符与字符串相似。+ 号用于组合列表,* 号用于重复列表。
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| len([1, 2, 3]) | 3 | 长度 |
| [1, 2, 3] + [4, 5, 6] | [1, 2, 3, 4, 5, 6] | 组合 |
| ['Hi!'] * 4 | ['Hi!', 'Hi!', 'Hi!', 'Hi!'] | 重复 |
| 3 in [1, 2, 3] | True | 元素是否存在于列表中 |
| for x in [1, 2, 3]: print x, | 1 2 3 | 迭代 |
七,列表操作函数
1、cmp(list1, list2):比较两个列表的元素
2、len(list):列表元素个数
3、max(list):返回列表元素最大值
4、min(list):返回列表元素最小值
5、list(seq):将元组转换为列表
八,列表排序
注意排序优先级:数字>大写字母>小写字母>符号>中文
1,永久性排序:sort()
2,临时性排序:sorted()
3,反转排序:reverse()
l1 = ["排序","?","123","w","W"] l2 = ['1','2','3'] a = l1.sort() #永久性排序,就是这个列表就变了 print(l1) b =sorted(l2) #临时性排序,就是可以赋值某个变量 print(b) c = l1.reverse() print(l1) 结果: ['123', '?', 'W', 'w', '排序'] ['1', '2', '3'] ['排序', 'w', 'W', '?', '123']
注意:如果出现列表输出编码问题,可按照下面这个方法
l1 = ["排序","?","123","w","W"]
l2 = ['1','2','3']
a = l1.sort() #永久性排序,就是这个列表就变了
print str(l1).decode('string_escape')
b =sorted(l2) #临时性排序,就是可以赋值某个变量
print b
c = l1.reverse()
print str(l1).decode("string_escape")
或者:
#!/usr/bin/env python #coding:utf-8 import json l1 = ["排序","?","123","w","W"] l2 = ['1','2','3'] a = l1.sort() #永久性排序,就是这个列表就变了 print json.dumps(l1,encoding="utf8",ensure_ascii=False) b =sorted(l2) #临时性排序,就是可以赋值某个变量 print b c = l1.reverse() print json.dumps(l1,encoding="utf8",ensure_ascii=False)
执行结果:
['123', '?', 'W', 'w', '排序'] ['1', '2', '3'] ['排序', 'w', 'W', '?', '123']
参考:http://www.caotama.com/57501.html
九,遍历列表
除了一般的遍历,还可以遍历切片列表
list=['1','2','3'] for value in list:#末尾加上冒号print(value)#每次循环都把list列表中的值赋给value,赋值从索引号0开始#循环的语句需要缩进结果: 1 2 3list=['1','2','3','4','5','6','7'] for value in list[3:]:#遍历索引3之后的数值print(value)结果: 4 5 6 7
十,创建数值列表
1,使用range()函数生成一系列数值
2,遍历range()函数生成的数值
#range()生成0~5的数值,list()函数把数值转换成列表
value=list(range(0,6)) print(value) 结果: [0, 1, 2, 3, 4, 5]for value in range(0,6):#range(0,6)顺序生成从0到5的数值print(value) 结果: 0 1 2 3 4 5>>> range(1,5)#代表从1到5(不包含5)----------------[1, 2, 3, 4] >>> range(1,5,2) #代表从1到5,每次加2(不包含5)-----[1, 3] >>> range(5) #代表从0到5(不包含5)-----------------[0, 1, 2, 3, 4]
总结:左闭右开
十一,复制列表
1,复制整个列表
2,复制切片列表
list=['1','2','3','4','5'] list_2=list[:]#从起始索引到末尾索引 print(list_2) 结果: ['1', '2', '3', '4', '5']list=['1','2','3','4','5']
#从起始索引到索引3 list_2=list[:3] print(list_2) #输出['1','2','3']
十二,列表切片
切片操作(slice)可以从一个字符串中获取子字符串(字符串的一部分)。我们使用一对方括号、起始偏移量start、终止偏移量end 以及可选的步长step 来定义一个分片。
格式: [start:end:step]
[:] 提取从开头(默认位置0)到结尾(默认位置-1)的整个字符串 [start:] 从start 提取到结尾 [:end] 从开头提取到end - 1 [start:end] 从start 提取到end - 1 [start:end:step] 从start 提取到end - 1,每step 个字符提取一个 左侧第一个字符的位置/偏移量为0,右侧最后一个字符的位置/偏移量为-1
例子:
list = [1, 2, 3, 4, 5, 6, 7] >>> list[0:] #列出索引0以后的---------[1, 2, 3, 4, 5, 6, 7] >>> list[1:] #列出索引1以后的---------[2, 3, 4, 5, 6, 7] >>> list[:-1] #列出索引-1之前的-------[1, 2, 3, 4, 5, 6] >>> list[1:3] #列出索引1到3之间的-----[2]#形成reverse函数的效果: >>> list[::-1]#[7, 6, 5, 4, 3, 2, 1] >>> list[::-2]#[7, 5, 3, 1]>>> range(1,5)#代表从1到5(不包含5)----------------[1, 2, 3, 4] >>> range(1,5,2) #代表从1到5,每次加2(不包含5)-----[1, 3] >>> range(5) #代表从0到5(不包含5)-----------------[0, 1, 2, 3, 4]
![]()
十四,列表的练习
写代码,要求实现下面每一个功能
li=['alex','eric','rain']
1,计算列表长度并输出
2,列表中追加元素“servn",并输出添加后的列表
3,请在列表的第一个位置插入元素‘tony’,并输出添加后的列表
4,请修改列表位置元素‘kelly’,并输出修改后的列表
5,请在列表删除元素‘eric’,并输出删除后的列表
6,请删除列表中的第2个元素,并输出删除后的元素的值和删除元素后的列表
7,请删除列表中的第三个元素,并输出删除后的列表
8,请删除列表的第2到4个元素,并输出删除元素后的列表
9,请用for len range输出列表的索引
10,请使用enumrate输出列表元素和序号
11,请使用for循环输出列表中的所有元素
十五、具体实现:
#!/usr/bin/env python
#coding:utf8li = ['alex','eric','rain']
# 1,计算列表长度并输出
print(len(li))
# 列表中追加元素“seven”,并输出添加后的列表
li.append('seven')
print(li)
# 请在列表的第1个位置插入元素“Tony”,并输出添加后的列表
li.insert(1,'tony')
print(li)
#请修改列表第2个位置的元素为“Kelly”,并输出修改后的列表
li[1] ='kelly'
print(li)
# 请删除列表中的元素“eric”,并输出修改后的列表
a =li.pop(2)
print(li)
#或:
#li.remove('eric')
#print(li)# 请删除列表中的第2个元素,并输出删除元素后的列表
b =li.pop(1)
print(b)
print(li)
# 请删除列表中的第2至4个元素,并输出删除元素后的列表
c = li[2:4]
d = set(li)-set(c)
print(list(d))
del li[1:4]
print(li)
# 请将列表所有的元素反转,并输出反转后的列表
e = li.reverse()
print(li)
# 请使用for、len、range输出列表的索引
for i in range(len(li)):print(i)# 请使用enumrate输出列表元素和序号(序号从100开始)
for index in enumerate(li):print(index)
for index,i in enumerate(li,100):print(index,i)
for i in li:print(i)
十六,list中的append和extend的区别
list.append(object) 向列表中添加一个对象object
list.extend(sequence) 把一个序列seq的内容添加到列表中
举例如下:
使用append的时候,是将bList看作一个对象,整体打包添加到aList对象中
aList = ['11', '22', '33'] bList = ['44', '55'] aList.append(bList) print aList
执行结果:
['11', '22', '33', ['44', '55']]
使用extend的时候,是将bList看作一个序列,将这个序列和aList序列合并,并放在其后面。
aList = ['11', '22', '33'] bList = ['44', '55']
aList.extend(bList) print aList
执行结果:
['11', '22', '33', '44', '55']
清空列表参考:
https://www.cnblogs.com/BackingStar/p/10986775.html
列表操作实例:
>>> a = ["apple","banana","cat","dog"]
>>> b = ["banana","egg","fruit"]>>> a.append("glass") #追加,即在最后一个元素中新添加一个元素
>>> a
['apple', 'banana', 'cat', 'dog', 'glass']
>>>
>>>
>>> a.extend(b) #把b列表中的内容扩展到a列表中,但b列表中的内容在a内容后面
>>> a
['apple', 'banana', 'cat', 'dog', 'glass', 'banana', 'egg', 'fruit']>>> a.count("banana") #统计banana的个数
2
>>> a.index("banana") #返回列表中第一个匹配项的索引位置,
1
>>> a.index("banana")
1
>>> a.index("cat")
2
>>>
>>> >>> a.insert(5,"hair") #在索引为5的位置插入hair
>>> a
['apple', 'banana', 'cat', 'dog', 'glass', 'hair', 'banana', 'egg', 'fruit']
>>> >>> a.pop() #默认移除列表中的最后一项,并显示出来
'fruit'
>>> a.pop(5) #移除索引为5的元素
'hair'
>>> a
['apple', 'banana', 'cat', 'dog', 'glass', 'banana', 'egg']
>>>
>>> a.remove('glass') #移除列表中的第一个匹配项
>>> a
['apple', 'banana', 'cat', 'dog', 'banana', 'egg']
>>>
>>> a.reverse() #反序
>>> a
['egg', 'banana', 'dog', 'cat', 'banana', 'apple']
>>> a.sort() #排序
>>> a
['apple', 'banana', 'banana', 'cat', 'dog', 'egg']
>>> 列表嵌套:列表嵌套字典
>>> li = ['alex',123,{"k1":"v1","k2":{"vv":(11,22,123),"li":456}}]
>>> li[2]
{'k2': {'vv': (11, 22, 123), 'li': 456}, 'k1': 'v1'}
>>> li[2]['k2']
{'vv': (11, 22, 123), 'li': 456}
>>> li[2]['k2']['vv']
(11, 22, 123)
>>> li[2]['k2']['vv'][2]
123
>>>
练习1:
编写一个石头、剪刀、布的游戏。你和计算机各出一项,判断输赢。
提示:计算机出什么,可以使用random模块中的choice随机在一个列表中选择某一项
例子1:
#!/usr/bin/env python #-*- coding:utf-8 -*-import randomch_list = ["石头","剪刀","布"] computer = random.choice(ch_list) #random.choice从序列中获取一个随机元素。其函数原型为:random.choice(sequence) win_list = [["石头","剪刀"],["剪刀","布"],["布","石头"]] #列表嵌套列表prompt = """(0)石头 (1)剪刀 (2)布 请选择(012):"""ind = int(raw_input(prompt)) #输入0、1或2 player = ch_list[ind] #从ch_list列表中取出某一个值赋值给player变量print "Your choice : %s,Computer choice: %s" %(player,computer) if [player,computer] in win_list:print 'You Win!!!' elif player == computer:print '平局' else:print "You Lose"
执行结果:
(0)石头 (1)剪刀 (2)布 请选择(012):0 Your choice : 石头,Computer choice: 剪刀 You Win!!!
例子2:给结果添加颜色
#!/usr/bin/env python #-*- coding:utf-8 -*-import randomch_list = ["石头","剪刀","布"]
computer = random.choice(ch_list)win_list = [["石头","剪刀"],["剪刀","布"],["布","石头"]]prompt = """(0)石头 (1)剪刀 (2)布 请选择(012):"""ind = int(raw_input(prompt)) player = ch_list[ind]print "Your choice : %s,Computer choice: %s" %(player,computer) if [player,computer] in win_list:print '\033[31;1mYou Win!!!\033[0m' elif player == computer:print '\033[32;1m平局\033[0m' else:print "\033[31;You Lose\033[0m"
执行结果:
例子3:
#!/usr/bin/env python # coding: utf8import randomchoiceList = ['石头', '剪刀', '布'] winList = [['石头', '剪刀'], ['剪刀', '布'], ['布', '石头']] prompt = """\033[34;1m可选项如下: (0)石头 (1)剪刀 (2)布 请输入您的选择(输入数字即可):\033[0m""" cchoice = random.choice(choiceList) #random.choice从序列中获取一个随机元素。此处即从choiceList列表中获取一个元素赋值给cchoice变量 uchoice = choiceList[int(raw_input(prompt))] #把输入的数字转换成整数,从choiceList中获取某个值再赋值给uchoice变量 bothChoice = [uchoice, cchoice] #把uchoice的值和cchoice的值放到列表bothChoice中print '您选择了%s, 我选择了%s' % (uchoice, cchoice) if cchoice == uchoice:print '\033[32;1m平手\033[0m' elif bothChoice in winList:print '\033[31;1mYou WIN!!!\033[0m' else:print '\033[31;1mYou LOSE!!!\033[0m'
执行结果:
可选项如下: (0)石头 (1)剪刀 (2)布 请输入您的选择(输入数字即可):0 您选择了石头, 我选择了剪刀 You WIN!!!
比较2个文件中的内容,列出相同的元素和不同的元素:
注意:
1、有些知识涉及文件操作,不懂的话建议熟悉一下
2、通过粗略测试,这个脚本暂时只支持数字对比,
[root@host-192-168-3-6 work]# cat a.txt
123
456
789
234
567
345[root@host-192-168-3-6 work]# cat b.txt
123
345
456
567思路:
step1:打印出
#!/usr/bin/env python
#coding:utf-8
with open("/root/work/a.txt") as f1,open("/root/work/b.txt") as f2:for i in f1.readlines(): #读取所有行,以列表方式返回,然后遍历出列表中每个元素print i.strip('\n') #打印列表中每个元素step2:打印新列表
[root@host-192-168-3-6 work]# vim zgy.py
#!/usr/bin/env python
#coding:utf-8new_a = []
new_b = []same_list = []
diff_list = []with open("/root/work/a.txt") as f1,open("/root/work/b.txt") as f2:for i in f1.readlines():new_i = i.strip("\n")new_a.append(new_i)for j in f2.readlines():new_j = j.strip("\n")new_b.append(new_j)print new_a
print new_b[root@host-192-168-3-6 work]# python zgy.py
['123', '456', '789', '234', '567', '345']
['345', '456', '123', '567']step3:
[root@host-192-168-3-6 work]# vim zgy.py
#!/usr/bin/env python
#coding:utf-8new_a = []
new_b = []same_list = []
diff_list = []with open("/root/work/a.txt") as f1,open("/root/work/b.txt") as f2:for i in f1.readlines():new_i = i.strip("\n")new_a.append(new_i)for j in f2.readlines():new_j = j.strip("\n")new_b.append(new_j)if new_i in new_b:same_list.append(new_i)else:diff_list.append(new_i)#print new_a
#print new_b#print same_list
print diff_listroot@host-192-168-3-6 work]# python zgy.py
['789', '234']step4:[root@host-192-168-3-6 work]# vim zgy.py
#!/usr/bin/env python
#coding:utf-8new_a = []
new_b = []same_list = []
diff_list = []with open("/root/work/a.txt") as f1,open("/root/work/b.txt") as f2:for i in f1.readlines():new_i = i.strip("\n")new_a.append(new_i)for j in f2.readlines():new_j = j.strip("\n")new_b.append(new_j)if new_i in new_b:same_list.append(new_i)else:diff_list.append(new_i)#print new_a
#print new_b#print same_list
#print diff_list#打印相同的元素
for line in same_list:print line#打印不同的元素
for line in diff_list:print line
备注:这个脚本不完善
有bug的脚本:还是有bug;这个脚本适合长度一致的文件,一行一条数据;但是行尾出现多个空格,就会有bug
#!/usr/bin/env python
#coding:utf-8new_a = []
new_b = []#a.txt为全部元素,b.txt为部分元素
with open("G:/PycharmProject/fullstack2/week1/a.txt") as f1,open("G:/PycharmProject/fullstack2/week1/b.txt") as f2:for i in f1.readlines():new_i = i.strip("\n")new_a.append(new_i)for j in f2.readlines():new_j = j.strip("\n")new_b.append(new_j)set1 = set(new_a) #将list转换为set
set2 = set(new_b) #将list转换为set
#print set1 -set2 #打印set1中有的元素,但是set2没有的元素
#print set2 - set1 #打印set2中有的元素,但是set1没有的元素#a = set1 -set2for i in a: #遍历set2中有的元素,但是set1没有的元素print i
有bug的脚本2:这个脚本适合长度一致的文件,一行一条数据;但是行尾出现多个空格,就会有bug
#!/usr/bin/env python
#coding:utf-8new_a = []
new_b = []all_sum = "G:/PycharmProject/fullstack2/week1/a.txt"
part_sum = "G:/PycharmProject/fullstack2/week1/b.txt"with open(all_sum) as f1,open(part_sum) as f2:for i in f1.readlines():new_i = i.strip("\n")new_a.append(new_i)for j in f2.readlines():new_j = j.strip("\n")new_b.append(new_j)set1 = set(new_a)
set2 = set(new_b)
#print set1 -set2
#print set2 - set1a = set1 - set2for i in a:print i
完善的脚本1:
#!/usr/bin/env python
# coding:utf-8import renew_a = []
new_b = []all_sum = "G:/PycharmProject/test/a.txt"
part_sum = "G:/PycharmProject/test/b.txt"with open(all_sum) as f1, open(part_sum) as f2:for i in f1.readlines():new_i = re.sub('\s+','',i)new_a.append(new_i)for j in f2.readlines():new_j = re.sub('\s+','',j)new_b.append(new_j)set1 = set(new_a)
set2 = set(new_b)
# print set1 -set2
# print set2 - set1a = set1 - set2for i in a:print i
完善的脚本2:
#!/usr/bin/env python
# coding:utf-8import rep = re.compile('\s+')new_a = []
new_b = []all_sum = "G:/PycharmProject/test/a.txt"
part_sum = "G:/PycharmProject/test/b.txt"with open(all_sum) as f1, open(part_sum) as f2:for i in f1.readlines():new_i = re.sub(p, '', i) # sub(pattern, repl, string, count=0, flags=0)new_a.append(new_i)for j in f2.readlines():new_j = re.sub(p, '', j)new_b.append(new_j)set1 = set(new_a)
set2 = set(new_b)
# print set1 -set2
# print set2 - set1a = set1 - set2for i in a:print i
附加:
#compile:对正则表达式模式进行编译,返回一个正则表达式对象;不是必须要用这种方式,但是在大量匹配的情况下,可以提升效率 #re.compile(pattern,flags=0) #\s:匹配任何空白符
re.sub 函数详解命令:re.sub(pattern, repl, string, count=0, flags=0)re.sub 用于替换字符串的匹配项。如果没有匹配到规则,则原字符串不变。第一个参数:规则 第二个参数:替换后的字符串 第三个参数:字符串 第四个参数:替换个数。默认为0,表示每个匹配项都替换
练习:
第一题:
1,写代码,有如下列表,按照要求实现每一个功能
li = ['alex','wusir','eric','rain','alex']1)计算列表的长度并输出li = ['alex','wusir','eric','rain','alex']
s1 = len(li)2)列表中追加元素'seven',并输出添加后的列表li = ['alex','wusir','eric','rain','alex']
s2 = li.append('seven')
print(li)3)请在列表的第1个位置插入元素'Tony',并输出添加后的列表li = ['alex','wusir','eric','rain','alex']
li = ['alex','wusir','eric','rain','alex']
s3 = li.insert(1,'Tony')
print(li)4)请修改列表第2个位置的元素为'Kelly',并输出修改后的列表li = ['alex','wusir','eric','rain','alex']
li[2] = 'Kelly'
print(li)5)请将列表l2=[1,'a',3,4,'heart']的每一个元素添加到列表li中,一行代码实现,不允许循环添加。li = ['alex','wusir','eric','rain','alex']
l2=[1,'a',3,4,'heart']
li.extend(l2)
print(li)6)请将字符串s = 'qwert'的每一个元素添加到列表li中,一行代码实现,不允许循环添加。li = ['alex','wusir','eric','rain','alex']
s = 'qwert'
li.extend(s)
print(li)7)请删除列表中的元素'eric',并输出添加后的列表li = ['alex','wusir','eric','rain','alex']
li.remove('eric')
print(li)8)请删除列表中的第2个元素,并输出删除的元素和删除元素后的列表li = ['alex','wusir','eric','rain','alex']
print(li.pop(2))
print(li)9)请删除列表中的第2至4个元素,并输出删除元素后的列表li = ['alex','wusir','eric','rain','alex']
del li[2:4]
print(li)10)请将列表所有得元素反转,并输出反转后的列表li = ['alex','wusir','eric','rain','alex']
li.reverse()
print(li)11)请计算出'alex'元素在列表li中出现的次数,并输出该次数。li = ['alex','wusir','eric','rain','alex']
print(li.count('alex'))
第2题
2,写代码,有如下列表,利用切片实现每一个功能 li = [1,3,2,'a',4,'b',5,'c']1)通过对li列表的切片形成新的列表l1,l1 = [1,3,2]li = [1,3,2,'a',4,'b',5,'c'] li1 = li[:3] print(li1)2)通过对li列表的切片形成新的列表l2,l2 = ['a',4,'b']li = [1,3,2,'a',4,'b',5,'c'] li2 = li[3:6] print(li1)3)通过对li列表的切片形成新的列表l3,l3 = ['1,2,4,5]li = [1,3,2,'a',4,'b',5,'c'] li3 = li[::2] print(li3)4)通过对li列表的切片形成新的列表l4,l4 = [3,'a','b']li = [1,3,2,'a',4,'b',5,'c'] li4 = li[1:6:2] print(li3)5)通过对li列表的切片形成新的列表l5,l5 = ['c']li = [1,3,2,'a',4,'b',5,'c'] li5 = li[-1] print(li3)6)通过对li列表的切片形成新的列表l6,l6 = ['b','a',3]li = [1,3,2,'a',4,'b',5,'c'] li6 = li[-3:-8:-2] print(li6)
第三题:
3,写代码,有如下列表,按照要求实现每一个功能。 lis = [2,3,'k',['qwe',20,['k1',['tt',3,'1']],89],'ab','adv']1)将列表lis中的'tt'变成大写(用两种方式)。lis = [2,3,'k',['qwe',20,['k1',['tt',3,'1']],89],'ab','adv'] lis[3][2][1][0] = lis[3][2][1][0].upper() print(lis)lis = [2,3,'k',['qwe',20,['k1',['tt',3,'1']],89],'ab','adv'] lis[3][2][1][0] = 'TT' print(lis)2)将列表中的数字3变成字符串'100'(用两种方式)。lis = [2,3,'k',['qwe',20,['k1',['tt',3,'1']],89],'ab','adv'] lis[1] = 100 lis[3][2][1][1] = '100' print(lis)lis = [2,3,'k',['qwe',20,['k1',['tt',3,'1']],89],'ab','adv'] lis[1] = '100' lis[3][2][1][1] = str(lis[3][2][1][1] + 97) print(lis)3)将列表中的字符串'1'变成数字101(用两种方式)。lis = [2,3,'k',['qwe',20,['k1',['tt',3,'1']],89],'ab','adv'] lis[3][2][1][2] = 101 print(lis)lis = [2,3,'k',['qwe',20,['k1',['tt',3,'1']],89],'ab','adv'] lis[3][2][1][2] = 1 + 100 print(lis)
第4题答案
4,请用代码实现:li = ['alex','eric','rain'] 利用下划线将列表的每一个元素拼接成字符串"alex_eric_rain"li = ['alex','eric','rain'] li_new = '_'.join(li) print(li_new)
第5题
查找列表li中的元素,移除每个元素的空格,并找出以'A'或者'a'开头,并以'c'结尾的所有元素,并添加到一个新列表中,最后循环打印这个新列表。
li = ['taibai ','alexC','AbC ','egon',' Ritian',' Wusir',' aqc']
分析:
先输出每一个元素,每把每个元素去除空格
li = ['taibai ','alexC','AbC ','egon',' Ritian',' Wusir',' aqc'] for i in li:s = i.strip()print(s)
执行输出:
taibai alexC AbC egon Ritian Wusir aqc
找到以'A'或者'a'开头的
li = ['taibai ','alexC','AbC ','egon',' Ritian',' Wusir',' aqc']
for i in li:s = i.strip()if s.startswith("A") or s.startswith("a"):print(s)
执行输出:
alexC AbC aqc
并以'c'结尾的,使用endswith()方法。打印出匹配的结果
li = ['taibai ','alexC','AbC ','egon',' Ritian',' Wusir',' aqc']
for i in li:s = i.strip()if s.startswith("A") or s.startswith("a"):if s.endswith("c"):print(s)
执行输出:
aqc
将匹配的元素添加到一个新列表中,最后循环打印这个新列表,最终代码如下:
li = ['taibai ','alexC','AbC ','egon',' Ritian',' Wusir',' aqc']
#定义新列表
li_new = []
for i in li:#去除空格s = i.strip()#找出以'A'或者'a'开头if s.startswith("A") or s.startswith("a"):#找出以'c'结尾的所有元素if s.endswith("c"):#将匹配的元素追加到新列表中li_new.append(s)for j in li_new:print(j)
执行输出:
aqc
第6题
开发敏感词语过滤程序,提示用户输入评论内容,如果用户输入的内容中包含特殊的字符:
敏感词列表 li = ["苍老师","东京热","武藤兰","波多野结衣"]
则将用户输入的内容中的敏感词汇替换成***,并添加到一个列表中;如果用户输入的内容没有敏感词汇,则直接添加到上述的列表中。
解题过程
先定义2个变量,一个是敏感词,一个是用户输入内容
并设置一个含有敏感词的内容,判断是否含有敏感词
li = ["苍老师","东京热","武藤兰","波多野结衣"]
comment = "我要苍老师"
for i in li:if i in comment:print("含有敏感词")
执行输出:
含有敏感词
将敏感词替换成***,使用replace()方法替换,打印出输入内容
li = ["苍老师","东京热","武藤兰","波多野结衣"]
comment = "我要苍老师"
for i in li:if i in comment:print("含有敏感词")comment = comment.replace(i, "***")print(comment)
执行输出:
含有敏感词 我要***
将输入内容写入到新列表中,打印列表:
li = ["苍老师","东京热","武藤兰","波多野结衣"] comment = "我要苍老师" #新列表 comment_list = []for i in li:if i in comment:#将敏感词替换成***comment = comment.replace(i,"***")#添加到新列表 comment_list.append(comment)for j in comment_list:print(j)
执行输出:
我要***
将用户输入替换成input,完整代码如下:
li = ["苍老师","东京热","武藤兰","波多野结衣"]
comment = input("请输入评论:").strip()
#新列表
comment_list = []for i in li:if i in comment:#将敏感词替换成***comment = comment.replace(i,"***")#添加到新列表
comment_list.append(comment)
#打印列表
for j in comment_list:print(j)
执行输出:

第7题
有如下列表li = [1,3,4',alex',[3,7,8,'taibai'],5,'ritian']
循环打印列表中的每个元素,遇到列表则再循环打印出它里面的元素。
我想要的结果是(用两种方法实现,其中一种用range做):
1 3 4 'alex' 3 7, 8 'taibai' 5 ritian
for循环 代码如下:
li = [1,3,4,'alex',[3,7,8,'taibai'],5,'ritian'] for i in li:#判断是否为列表if type(i) == list:#遍历子列表for j in i:print(j)else:print(i)
执行输出:
1 3 4 alex 3 7 8 taibai 5 ritian
range方式,代码如下:
li = [1,3,4,'alex',[3,7,8,'taibai'],5,'ritian'] for i in range(len(li)):#判断是否为列表if type(li[i]) == list:#遍历子列表for j in li[i]:print(j)else:print(li[i])
执行程序,效果同上。
2,默写第七题的两个方法实现的代码。
for循环 :
li = [1,3,4,'alex',[3,7,8,'taibai'],5,'ritian'] for i in li:#判断是否为列表if type(i) == list:#遍历子列表for j in i:print(j)else:print(i)
range方式:
li = [1,3,4,'alex',[3,7,8,'taibai'],5,'ritian'] for i in range(len(li)):#判断是否为列表if type(li[i]) == list:#遍历子列表for j in li[i]:print(j)else:print(li[i])
相关文章:
DevOps系列文章之 Python基础
列表 Python中的列表类似于C语言中的数组的概念,列表由内部的元素组成,元素可以是任何对象 Python中的列表是可变的 简单的理解就是:被初始化的列表,可以通过列表的API接口对列表的元素进行增删改查 1、定义列表 1.可以将列表当成…...

代码随想录第五十天
代码随想录第五十天 Leetcode 123. 买卖股票的最佳时机 IIILeetcode 188. 买卖股票的最佳时机 IV Leetcode 123. 买卖股票的最佳时机 III 题目链接: 买卖股票的最佳时机 III 自己的思路:想不到!!!!高维dp数组!&#x…...
redis缓存雪崩、穿透、击穿解决方案
redis缓存雪崩、穿透、击穿解决方案 背景缓存雪崩缓存击穿缓存穿透总结背景 关于缓存异常,我们常见的有三个问题:缓存雪崩、缓存击穿、缓存穿透。这三个问题一旦发生,会导致大量请求直接落到数据库层面。如果请求的并发量很大,会影响数据库的运行,严重的会导致数据库宕机…...

基于HarmonyOS ArkUI实现七夕壁纸轮播
七夕情人节,为了Ta,你打算用什么方式表达爱?是包包、鲜花、美酒、巧克力,还是一封充满爱意的短信?作为程序员,以代码之名,表达爱。本节将演示如何在基于HarmonyOS ArkUI的SwiperController、Ima…...
FusionAD:用于自动驾驶预测和规划任务的多模态融合
论文背景 自动驾驶(AD)任务通常分为感知、预测和规划。在传统范式中,AD中的每个学习模块分别使用自己的主干,独立地学习任务。 以前,基于端到端学习的方法通常基于透视视图相机和激光雷达信息直接输出控制命令或轨迹…...

C# 序列化json数据,datatabel转对象
datatabel直接转对象 转对象逻辑 1.将datatabel转为json格式 2.将json格式的内容转化为模型data_model的list对象 JsonConvert.DeserializeObject<List<data_model>>(JsonConvert.SerializeObject(dt))...

axios引入的详细讲解
1.安装axios:npm install axios,等待安装完毕即可 2.引用axios:在需要使用的页面中引用 import axios from axios 即可 axios请求的时候有两种方式:一种是get请求,另一种是post请求 get请求: axios({…...
16- flask-bootstrap模板的使用
Flask 中支持 flask-bootstrap模板 和 bootstrap-flask模板 # 不使用: bootstrap-flask # pip install bootstrap-flask1.3.1 # 支持bootstrap 4 # pip install flask-bootstrap # 支持bootstrap3# 中文文档:https://flask-bootstrap-zh.readthedocs.io/zh/latest/ # 样式文档…...

机器学习-神经网络(西瓜书)
神经网络 5.1 神经元模型 在生物神经网络中,神经元之间相互连接,当一个神经元受到的外界刺激足够大时,就会产生兴奋(称为"激活"),并将剩余的"刺激"向相邻的神经元传导。 神经元模型…...
Apache StreamPark系列教程第二篇——项目打包和开发
一、项目打包 项目依赖maven、jdk8.0、前端(node、npm) //下载代码 git clone//maven打包相关内容 mvn -N io.takari:maven:wrapper //前端打包相关内容 curl -sL https://rpm.nodesource.com/setup_16.x | bash - yum -y install nodejs npm -v npm install -g pnpm默认是h2…...
Visual Studio 2022的MFC框架——WinMain函数
我是荔园微风,作为一名在IT界整整25年的老兵,今天我们来重新审视一下Visual Studio 2022下开发工具的MFC框架知识。 大家还记得创建Win32应用程序是怎么弄的吗? Win32应用程序的建立到运行是有一个个关系分明的步骤的: 1.进入W…...
9. 解谜游戏
目录 题目 Description Input Notes 思路 暴力方法 递归法 注意事项 C代码(递归法) 关于DFS 题目 Description 小张是一个密室逃脱爱好者,在密室逃脱的游戏中,你需要解开一系列谜题最终拿到出门的密码。现在小张需要打…...
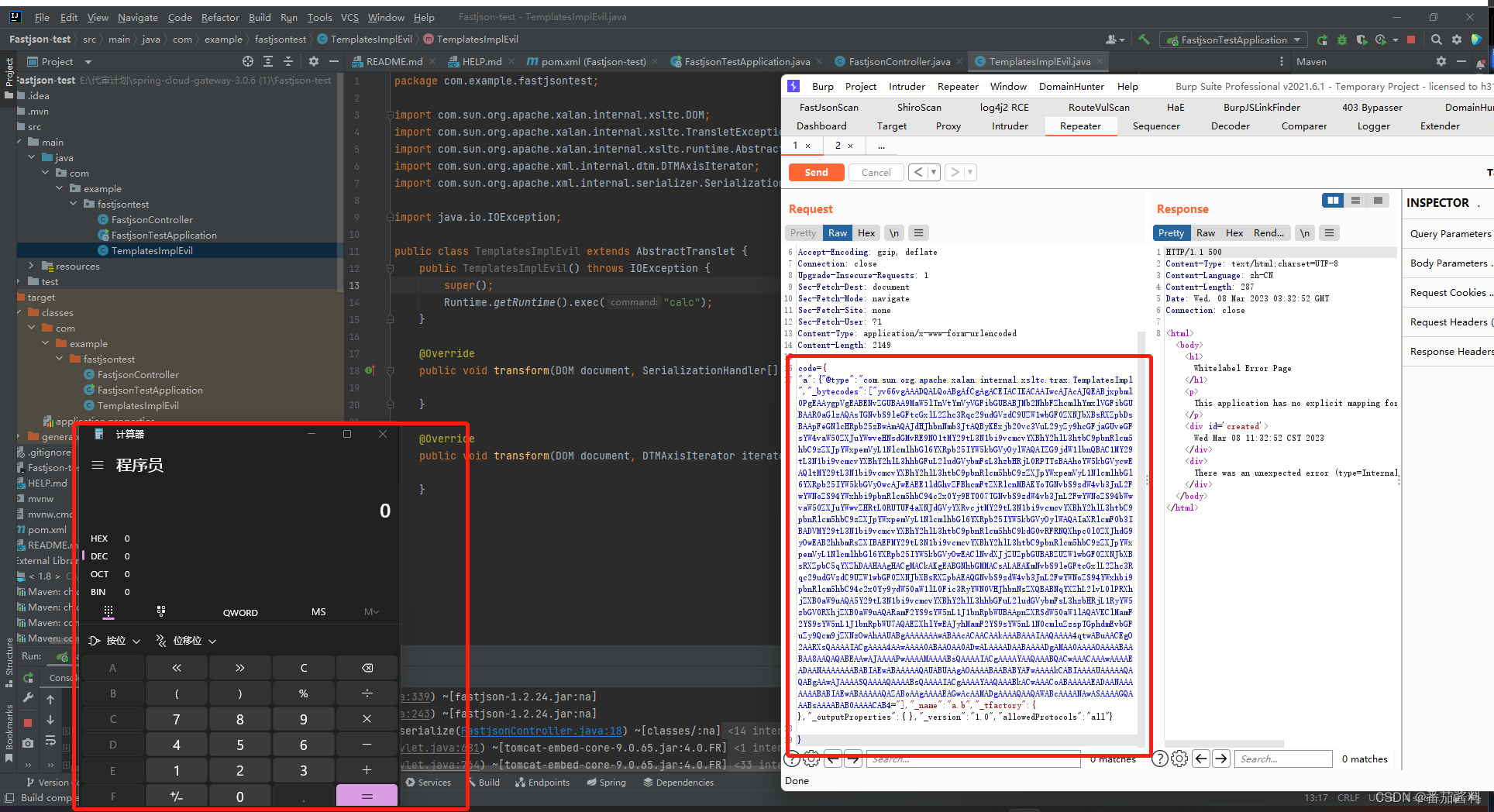
fastjson利用templatesImpl链
fastjson1.2.24 环境: pom.xml: <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLoc…...

OpenCV 开启O3优化
opencv默认没有开启O3优化选项,需要进行手动设置,下面是一种优化方法: 方法一 在 /opencv-4.5.5/cmake/OpenCVCompilerOptions.cmake 中的第 269 行做出以下修改: # 修改前 set(OPENCV_EXTRA_FLAGS_RELEASE "${OPENCV_EXT…...

css background实现四角边框
2023.8.27今天我学习了如何使用css制作一个四角边框,效果如下: .style{background: linear-gradient(#33cdfa, #33cdfa) left top,linear-gradient(#33cdfa, #33cdfa) left top,linear-gradient(#33cdfa, #33cdfa) right top,linear-gradient(#33cdfa, #…...

摆动序列【贪心算法】
摆动序列 如果连续数字之间的差严格地在正数和负数之间交替,则数字序列称为 摆动序列 。第一个差(如果存在的话)可能是正数或负数。仅有一个元素或者含两个不等元素的序列也视作摆动序列。 class Solution {public int wiggleMaxLength(int…...
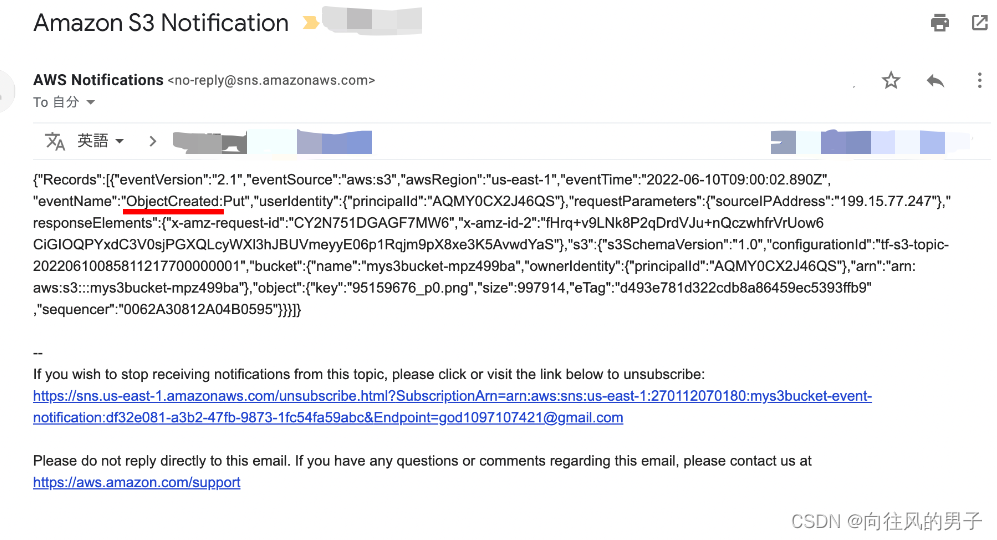
【Terraform学习】使用 Terraform创建 S3 存储桶事件(Terraform-AWS最佳实战学习)
本站以分享各种运维经验和运维所需要的技能为主 《python》:python零基础入门学习 《shell》:shell学习 《terraform》持续更新中:terraform_Aws学习零基础入门到最佳实战 《k8》暂未更新 《docker学习》暂未更新 《ceph学习》ceph日常问题解…...

自定义String字符串工具类 StringUtils.java
自定义String字符串工具类 StringUtils.java 简介 自定义String字符串工具类 api 是否为空 checkEmpty(String str);目标字符串是目标数组中的一个 checkContains(String str, String[] target);限制最大长度 checkMaxLength(String str, Long l);是否纯数字的字符串 check…...

mongTemplate实现group分组查询aggregation
MongoService封装 <T> List<T> group(Class<T> clazz, Aggregation aggregation,String documentName); MongoServiceImpl实现类 Overridepublic <T> List<T> group(Class<T> clazz, Aggregation aggregation,String documentName) {//…...

防御网络攻击风险的4个步骤
如今,人们正在做大量工作来保护 IT 系统免受网络犯罪的侵害。令人担忧的是,对于运营技术系统来说,情况却并非如此,运营技术系统用于运行从工厂到石油管道再到发电厂的所有业务。 组织应该强化其网络安全策略,因为针对…...

从零到一:在个人PC上部署并集成ChatGLM-6B到Unity应用
1. 环境准备与模型下载 在个人PC上部署ChatGLM-6B需要先搞定三件事:硬件检查、软件环境搭建和模型文件获取。我的老款游戏本(i7-9750H RTX2060 6GB显存)实测可以流畅运行,关键在于正确的量化配置。 硬件检查要点: 显存…...

网盘下载新革命:九大平台一键直链,告别客户端束缚
网盘下载新革命:九大平台一键直链,告别客户端束缚 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘…...

Go语言开源漏洞扫描器Abyss-Scanner:架构解析与CI/CD集成实践
1. 项目概述:一个为安全而生的开源漏洞扫描器最近在整理自己的开源项目工具箱,发现一个挺有意思的工具,叫 Abyss-Scanner。这名字起得挺有深意,“深渊扫描器”,听起来就有点探索未知、发现潜在风险的味道。简单来说&am…...

快速免费解锁网易云音乐NCM格式:ncmdumpGUI完整使用指南
快速免费解锁网易云音乐NCM格式:ncmdumpGUI完整使用指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾在网易云音乐下载了心爱的歌曲&am…...

小红书无水印下载工具XHS-Downloader:3种使用模式全解析
小红书无水印下载工具XHS-Downloader:3种使用模式全解析 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户链接&a…...

终极qmcdump指南:5分钟掌握QQ音乐加密格式解密技巧
终极qmcdump指南:5分钟掌握QQ音乐加密格式解密技巧 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump qmcdump是…...

告别网络依赖:CircuitJS1桌面版带你体验离线电路仿真的自由
告别网络依赖:CircuitJS1桌面版带你体验离线电路仿真的自由 【免费下载链接】circuitjs1 Standalone (offline) version of the Circuit Simulator with small modifications based on modified NW.js. 项目地址: https://gitcode.com/gh_mirrors/circ/circuitjs1…...
)
乌尔都语语音合成落地难?揭秘ElevenLabs未公开的ur-PK语言代码陷阱与ISO 639-3双标适配规范(仅限首批127家认证开发者知晓)
更多请点击: https://intelliparadigm.com 第一章:乌尔都语语音合成落地难?揭秘ElevenLabs未公开的ur-PK语言代码陷阱与ISO 639-3双标适配规范(仅限首批127家认证开发者知晓) ElevenLabs 官方文档中仅标注 ur 为乌尔…...

基于语义搜索的AI代码理解工具copaw-code深度解析
1. 项目概述:一个面向代码搜索与理解的AI工具 最近在GitHub上看到一个挺有意思的项目,叫 QSEEKING/copaw-code 。乍一看这个标题,可能会有点摸不着头脑,“copaw”是什么?但结合“code”和项目托管在QSEEKING这个组织…...

Claude-Code-KnowCraft:轻量级代码知识库构建与智能问答实践
1. 项目概述与核心价值最近在跟几个做AI应用开发的朋友聊天,大家普遍有个痛点:想把Claude这类大语言模型(LLM)的能力深度集成到自己的代码库分析工具里,但发现现有的方案要么太重,要么太浅。太重的是指那些…...