python爬虫12:实战4
python爬虫12:实战4
前言
python实现网络爬虫非常简单,只需要掌握一定的基础知识和一定的库使用技巧即可。本系列目标旨在梳理相关知识点,方便以后复习。
申明
本系列所涉及的代码仅用于个人研究与讨论,并不会对网站产生不好影响。
目录结构
文章目录
- python爬虫12:实战4
- 1. 目标
- 2. 详细流程
- 2.1 目标确定
- 2.2 请求网页
- 2.3 模拟滑动滚轮
- 2.4 下载图片
- 2.5 完整代码
- 3. 总结
1. 目标
这次爬虫实战,采用的库为:selenium,这次就以那种动态加载的图片网页为目标,本次的网站就是家大业大的百度图片。
再次说明,案例本身并不重要,重要的是如何去使用和分析,另外为了避免侵权之类的问题,我不会放涉及到网站的图片,希望能理解。
2. 详细流程
2.1 目标确定
写爬虫第一件事情,就是确定目标网页地址。这里,我们的目标是百度图片,因此直接打开百度图片搜索美女,然后观察它的url:
https://image.baidu.com/search/index?tn=baiduimage&ps=1&ct=201326592&lm=-1&cl=2&nc=1&ie=utf-8&dyTabStr=MCwxLDMsMiw0LDUsLDYsOCw3LDk%3D&word=美女
这个链接非常的长,因为它有很多无关的参数,所以我们第一件事情就是化繁为简,大胆的删除一些无关参数(之前讲解过参数形式都是&xxx=value),得到结果如下:
https://image.baidu.com/search/index?tn=baiduimage&word=美女
另外,观察这个网页,你会发现:随着滚轮往下滚,图片越来越多。这就是动态网页,也是我们常用的requests库难以处理的场景,这同样告诉我们使用selenium这个库。
2.2 请求网页
这部分就是中规中矩了,看过前面关于selenium 讲解的应该都可以轻松写出来。
代码如下:
# 请求百度图片
def get_baidu_images():# 初始化driver = webdriver.Chrome()# 网址base_url = 'https://image.baidu.com/search/index?tn=baiduimage&word='target = input('请输入想要下载的图片名字:')url = base_url + target# 请求driver.get(url)
2.3 模拟滑动滚轮
本次代码有很多实现思路,我这里想的是:首先,滚轮滚动一定距离,然后获取图片的下载地址,接着询问是否还需要滚动,如果不,则停止加载,开始下载图片,否则继续滚动。
想要实现滚动,需要执行js代码。肯定有些人没有学习过,没关系,虽然我学过的,但是也已经忘得差不多了。
所以,我们直接百度js代码实现滚动条向下滚动,即可找到js代码如下:
window.scrollBy(0,100)
# 这个是移动多少的距离,即每次移动100像素
那么,可以来写代码了,如下:
#( 接着上面的函数写的 )
# 是否滚动
flag = True
while flag:# 先让滚动条滚动五次.每次间隔0.5秒,给浏览器一定的加载时间for i in range(5):driver.execute_script('window.scrollBy(0,300)')time.sleep(0.5)# 询问是否继续滚动decision = input('是否继续滚动(Y/N):')if decision == 'N':flag = False
给大家展示一下运行效果:

可以看出,没有什么问题,那么继续,下一步就是解析网页,获取所有的图片链接。
首先,看下图:

我们可以通过xpath来解析代码:
//div[@class="imgbox-border"]//img
那么,代码如下:
# (接着上面写)
# 解析
img_list = driver.find_elements(by=By.XPATH,value='//div[@class="imgbox-border"]//img')
href = [img.get_attribute('src') for img in img_list]
# 退出
driver.close()
return href
运行结果如下图所示:

2.4 下载图片
最后一步,就是下载图片,我们可以重新写一个函数来实现。
下载图片很简单,流程就是:
1. 请求图片网址
2. 获取图片源码
3. 将图片以二进制的形式写入文件即可
但是,这里需要注意,不能使用selenium去请求图片,不然你相当于打开了图片所在的网页,并没有真正的打开图片,建议还是使用requests去访问。
代码如下:
# 下载图片
def download_image(url,index):''':param url: 下载图片的链接:param index: 索引,用于文件名'''# 参数headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36',}# 请求response = requests.get(url,headers=headers)source_code = response.content# 保存到文件with open('image'+str(index)+'.jpg','wb') as f:f.write(source_code)
运行结果如下:

2.5 完整代码
# 导包
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
import requests# 请求百度图片
def get_baidu_images():# 初始化driver = webdriver.Chrome()# 网址base_url = 'https://image.baidu.com/search/index?tn=baiduimage&word='target = input('请输入想要下载的图片名字:')url = base_url + target# 请求driver.get(url)# 是否滚动flag = Truewhile flag:# 先让滚动条滚动五次.每次间隔0.5秒,给浏览器一定的加载时间for i in range(5):driver.execute_script('window.scrollBy(0,300)')time.sleep(0.5)# 询问是否继续滚动decision = input('是否继续滚动(Y/N):')if decision == 'N':flag = False# 解析img_list = driver.find_elements(by=By.XPATH,value='//div[@class="imgbox-border"]//img')href = [img.get_attribute('src') for img in img_list]# 退出driver.close()return href# 下载图片
def download_image(url,index):''':param url: 下载图片的链接:param index: 索引,用于文件名'''# 参数headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36',}# 请求response = requests.get(url,headers=headers)source_code = response.content# 保存到文件with open('image'+str(index)+'.jpg','wb') as f:f.write(source_code)if __name__ == '__main__':url_list = get_baidu_images()for i,url in enumerate(url_list):download_image(url,i)
3. 总结
本篇讲解了selenium的主要用途,处理动态网页。另外告诉了大家如何使用selenium执行js代码,还有一点就是如何爬取图片并保存到本地。
相关文章:
python爬虫12:实战4
python爬虫12:实战4 前言 python实现网络爬虫非常简单,只需要掌握一定的基础知识和一定的库使用技巧即可。本系列目标旨在梳理相关知识点,方便以后复习。 申明 本系列所涉及的代码仅用于个人研究与讨论,并不会对网站产生不好…...
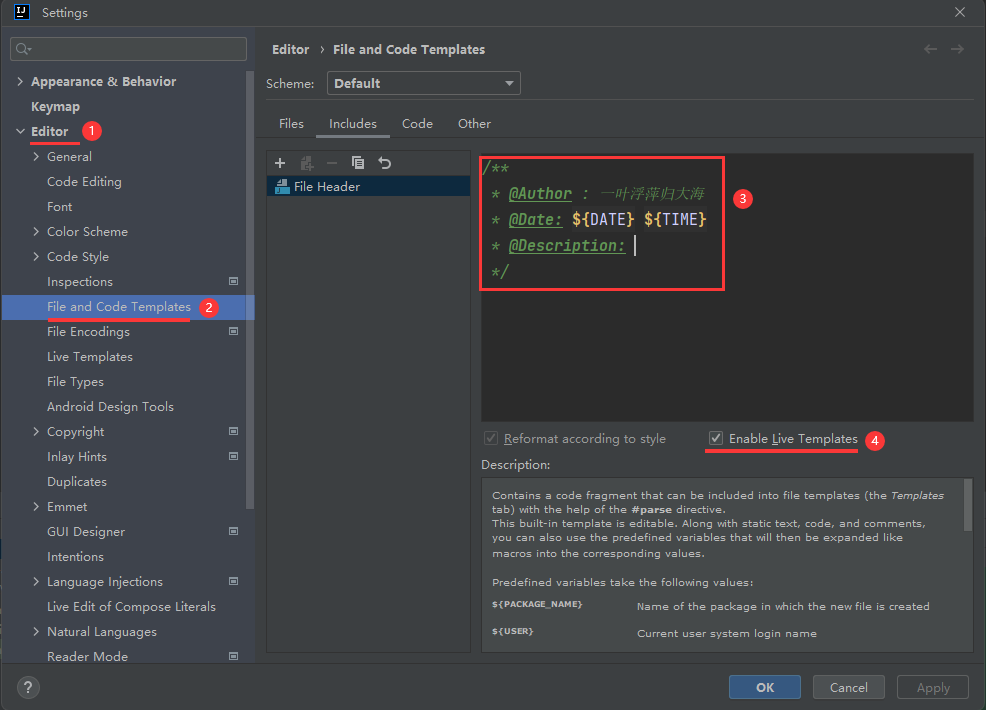
系列十三、idea创建文件自动生成作者信息
File>Settings>Editor>File and Code Templates>Includes>File Header /*** Author : 一叶浮萍归大海* Date: ${DATE} ${TIME}* Description: */...

spring websocket demo
一 java依赖 gradle 配置 implementation "org.springframework.boot:spring-boot-starter-websocket" implementation "org.springframework.security:spring-security-messaging" 二 配置WebSocketConfig import org.springframework.beans.factory.a…...

C语言的发展及特点
1. C语言的发展历程 C语言作为计算机编程领域的重要里程碑,其发展历程承载着无数开发者的智慧和创新。C语言诞生于20世纪70年代初,由计算机科学家Dennis Ritchie在贝尔实验室首次推出。当时,Ritchie的目标是为Unix操作系统开发一门能够更方便…...
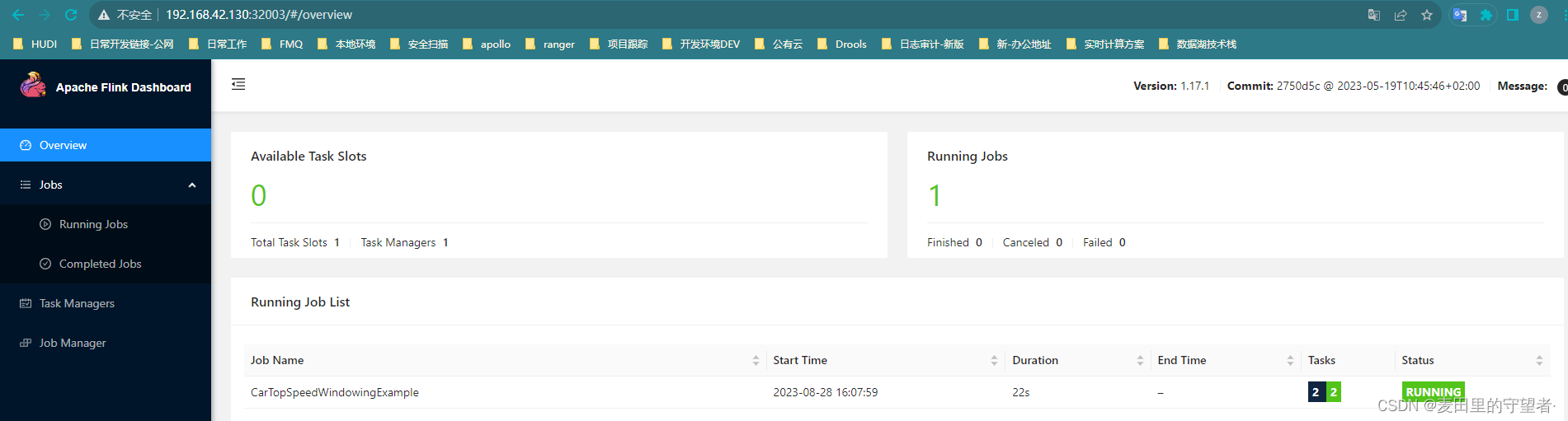
Flink Kubernates Native - 入门
创建 namespace [rootCentOSA flink-1.17.1]# kubectl create ns flink-native [rootCentOSA flink-1.17.1]# kubectl config set-context --current --namespaceflink-native命令空间添加资源限制 [rootCentOSA flink-1.17.1]# vim namespace-ResourceQuota.yamlapiVersion:…...
-LVS 集群)
Ceph入门到精通-大流量10GB/s支持OSPF(ECMP)-LVS 集群
Keepalived-LVS 能够提高集群的高可用性并增加后端检测功能、简化配置,满足常规需求。但Keepalived-LVS集群中,同一个VIP只能由一台设备进行宣告,为一主多备的架构,不能横向拓展集群的性能,为此我们引入OSPF来解决该问…...

IDEA、git如何修改历史提交commit的邮箱
第一种情况:当前提交不是从其他分支clone过来的: step1: git log 查看提交日志,获取commit ID step2: git rebase -i [你的commitID] git rebase -i c2ef237854290051bdcdb50ffbdbb78481d254bb step3:…...
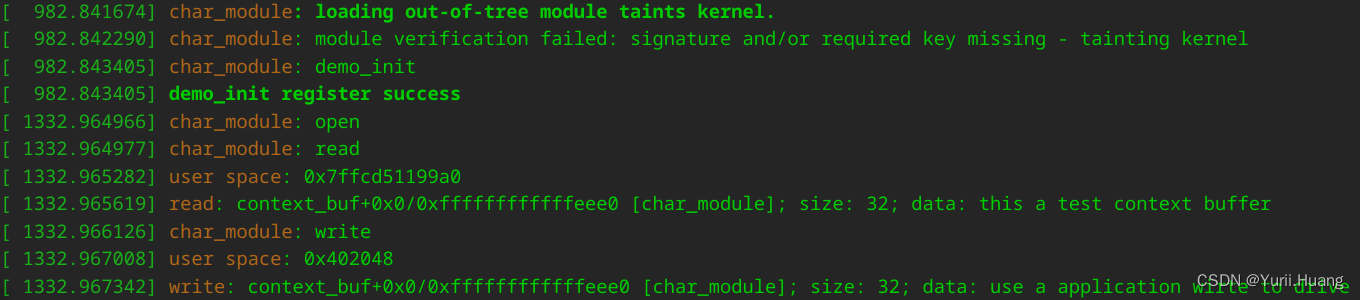
字符设备驱动(内核态用户态内存交互)
前言 内核驱动:运行在内核态的动态模块,遵循内核模块框架接口,更倾向于插件。 应用程序:运行在用户态的进程。 应用程序与内核驱动交互通过既定接口,内核态和用户态访问依然遵循内核既定接口。 环境搭建 系统&#…...

Qt基础 线程池
目录 QThreadPool类 QRunnable类 应用场景示例 QThreadPool类 主要属性: 1、activeThreadCount: 此属性表示线程池中的活动线程数,通过activeThreadCount() 调用。 2、expiryTimeout: 线程活着的时间。没有设置expiryTimeout毫秒的线程会自动退出&am…...

Django(8)-静态资源引用CSS和图片
除了服务端生成的 HTML 以外,网络应用通常需要一些额外的文件——比如图片,脚本和样式表——来帮助渲染网络页面。在 Django 中,我们把这些文件统称为“静态文件”。 我们使用static文件来存放静态资源,django会在每个 INSTALLED…...

C++ list模拟实现
list模拟实现代码: namespace djx {template<class T>struct list_node{T _data;list_node<T>* _prev;list_node<T>* _next;list_node(const T& x T()):_data(x),_prev(nullptr),_next(nullptr){}};template<class T,class Ref,class Pt…...

中国建筑出版传媒许少辉博士八一新书乡村振兴战略下传统村落文化旅游设计日京东当当畅销榜自由营九三学
中国建筑出版传媒许少辉博士八一新书乡村振兴战略下传统村落文化旅游设计日京东当当畅销榜自由营九三学...

C语言(第三十二天)
1. 递归是什么? 递归是学习C语言函数绕不开的一个话题,那什么是递归呢? 递归其实是一种解决问题的方法,在C语言中,递归就是函数自己调用自己。 写一个史上最简单的C语言递归代码: #include <stdio.h>…...
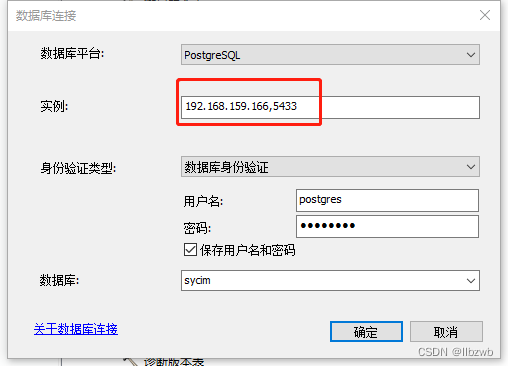
arcgis+postgresql+postgis使用介绍
关于arcgis在postgresql创建地理数据库我分享一下自己的经历: 众所周知,arcgis如果在oracle中创建地理数据库,必须要使用ArcToolbox里面的地理数据库工具去创建,在里面发现它还可以创建sql_server, postgresql数据库类型…...

机器视觉之开运算和闭运算
开运算(Opening)和闭运算(Closing)是数学形态学中常用的图像处理操作,通常用于去除图像中的噪声、连接物体、分离物体等操作。它们分别由两个基本操作组成:腐蚀(Erosion)和膨胀&…...

【python爬虫】—URL管理器的实现
python爬虫-url管理器 url管理器的作用python实现 url管理器的作用 在Python爬虫中,URL管理器(URL Manager)是一个重要的组件,用于有效管理爬取过程中所涉及的URL。它主要负责以下几个方面的任务: URL去重(…...

Oracle 19C RAC安装PSU oui-patch.xml权限错误
Oracle 19C RAC安装PSU时,节点2安装失败,经排查错误原因为oui-patch.xml文件权限错误。 Oracle官方建议oui-patch.xml文件权限,改成660或者666: chmod 660 oui-patch.xml权限修改完成后,安装psu还是失败,…...

华为数通方向HCIP-DataCom H12-821题库(单选题:161-180)
第161题 以下关于 URPF(Unicast Reverse Path Forwarding) 的描述, 正确的是哪一项 A、部署了严格模式的 URPF,也能够可以同时部署允许匹配缺省路由模式 B、如果部署松散模式的 URPF,默认情况下不需要匹配明细路由 C、如果部署松散模式的…...

ResNet详解:网络结构解读与PyTorch实现教程
目录 一、深度残差网络(Deep Residual Networks)简介深度学习与网络深度的挑战残差学习的提出为什么ResNet有效? 二、深度学习与梯度消失问题梯度消失问题定义为什么会出现梯度消失?激活函数初始化方法网络深度 如何解决梯度消失问…...
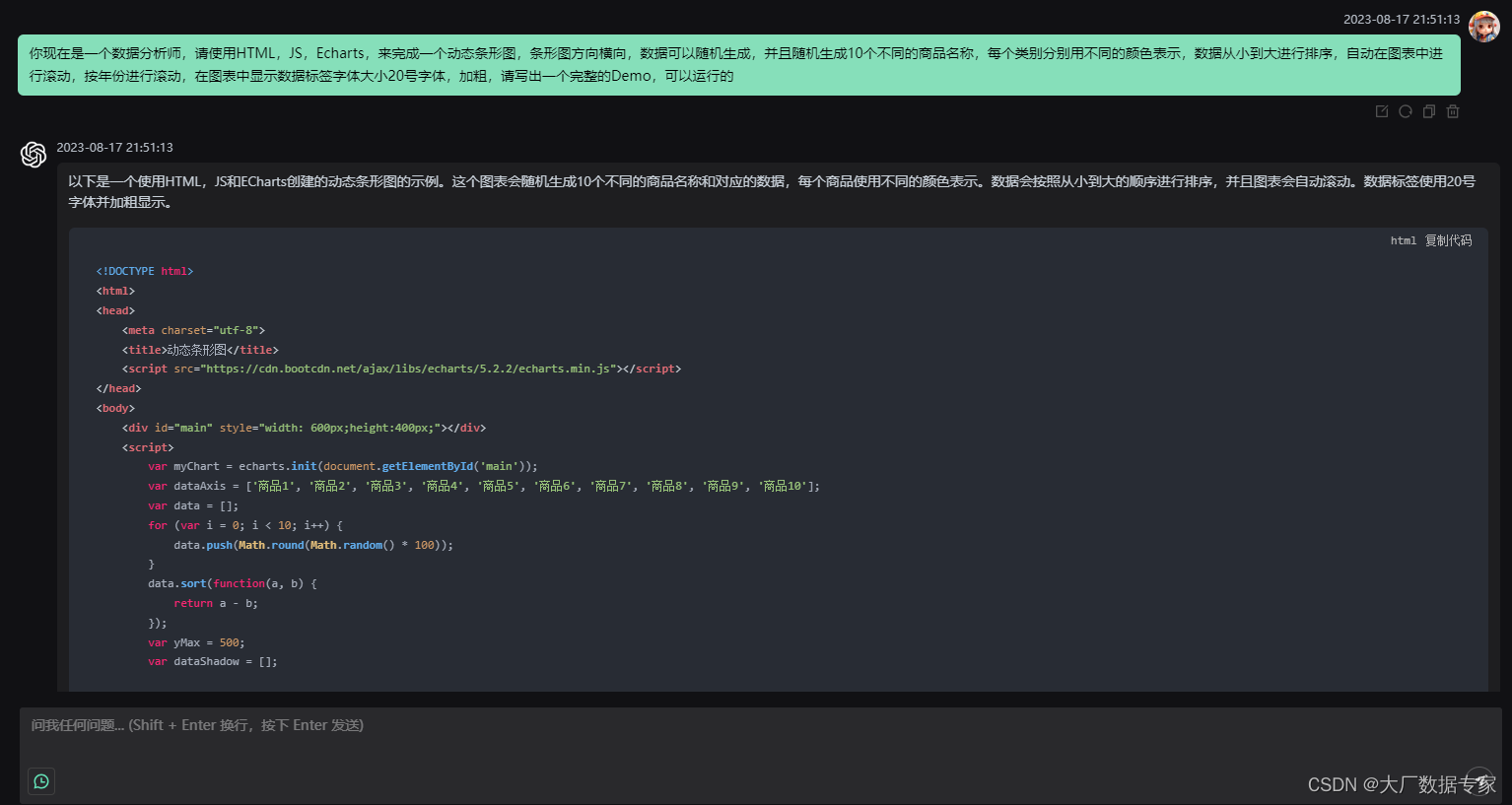
ChatGPT 随机动态可视化图表分析
动态可视化图表分析实例如下图: 这样的动态可视化图表可以使用ChatGPT OpenAI 来实现。 给ChatGPT发送指令: 你现在是一个数据分析师,请使用HTML,JS,Echarts,来完成一个动态条形图,条形图方向横向,数据可以随机生成,并且随机生成10个不同的商品名称,每个类别分别用…...

Untrunc代码架构深度剖析:理解C++实现的视频修复引擎
Untrunc代码架构深度剖析:理解C实现的视频修复引擎 【免费下载链接】untrunc Restore a damaged (truncated) mp4, m4v, mov, 3gp video. Provided you have a similar not broken video. 项目地址: https://gitcode.com/gh_mirrors/unt/untrunc Untrunc是一…...

taskwarrior-tui键盘绑定完全手册:成为效率达人的秘密武器
taskwarrior-tui键盘绑定完全手册:成为效率达人的秘密武器 【免费下载链接】taskwarrior-tui taskwarrior-tui: A terminal user interface for taskwarrior 项目地址: https://gitcode.com/gh_mirrors/ta/taskwarrior-tui taskwarrior-tui是一款功能强大的终…...

FOWFP封装技术:移动设备半导体的尺寸与性能突破
1. 移动设备半导体封装的演进与挑战在智能手机和平板电脑的电路板上,PMIC电源管理芯片的封装尺寸往往决定了主板布局的极限。2016年我在参与某旗舰手机项目时,主板工程师指着BOM表上那个44mm的QFN封装芯片说:"如果能再缩小1mm࿰…...

如何快速上手小米手表表盘设计:免费工具Mi-Create的终极指南
如何快速上手小米手表表盘设计:免费工具Mi-Create的终极指南 【免费下载链接】Mi-Create Unofficial watchface creator for Xiaomi wearables ~2021 and above 项目地址: https://gitcode.com/gh_mirrors/mi/Mi-Create 还在为小米手表找不到心仪的表盘而烦恼…...

8B模型做生物实验:实验步骤顺序不乱、剂量无幻觉|ICLR 2026
Thoth团队 投稿量子位 | 公众号 QbitAI人类研究员做实验,从来不是把几句步骤随手拼起来。一份真正可复现的实验protocol,需要明确每一步做什么、对什么对象操作、用什么参数,以及步骤之间的先后依赖。一旦顺序错了、剂量错了、对象错了&#…...
)
从设备树到驱动:在RK3566上点亮一个LED的完整实战(GPIO0_B4为例)
从设备树到驱动:在RK3566上点亮一个LED的完整实战(GPIO0_B4为例) 当你第一次拿到一块Rockchip RK3566开发板时,最令人兴奋的莫过于让硬件真正"活"起来。而点亮一个LED,就像嵌入式世界的"Hello World&q…...
)
STM32 I2C驱动AT24C02 EEPROM:手把手教你搞定页边界对齐与连续读写(附完整代码)
STM32 I2C驱动AT24C02 EEPROM:页边界对齐与连续读写实战指南 在嵌入式开发中,EEPROM因其非易失性存储特性成为参数保存的首选方案。而AT24C02作为经典的I2C接口EEPROM,其页写入机制却暗藏玄机——许多开发者第一次遭遇"写入数据丢失&quo…...

Live Server深度解析:如何用实时重载技术提升前端开发效率300%
Live Server深度解析:如何用实时重载技术提升前端开发效率300% 【免费下载链接】vscode-live-server Launch a development local Server with live reload feature for static & dynamic pages. 项目地址: https://gitcode.com/gh_mirrors/vs/vscode-live-se…...

桌面级机械臂DIY全攻略:从运动学建模到PID控制实战
1. 项目概述:一个桌面级机械臂的诞生最近在逛GitHub的时候,发现了一个挺有意思的项目,叫“ClawPuter”。光看名字,你可能会有点摸不着头脑,Claw是爪子,Puter是计算机,合起来是“爪式计算机”&am…...
)
别再乱点JIRA后台了!手把手教你配置项目专属的工单创建界面(附界面方案关联避坑点)
JIRA界面配置实战:从零构建高可用工单系统的避坑指南 当团队规模扩张到15人以上时,随意创建的JIRA工单开始暴露致命问题——用户故事缺少"验收标准"字段,缺陷报告漏填"重现步骤",而技术债务卡片却显示着完全不…...