算法打卡第18天
从中序与后序遍历序列构造二叉树
(力扣106题)
给定两个整数数组 inorder 和 postorder ,其中 inorder 是二叉树的中序遍历, postorder 是同一棵树的后序遍历,请你构造并返回这颗 二叉树 。
示例 1:
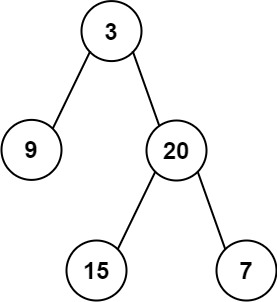
输入:inorder = [9,3,15,20,7], postorder = [9,15,7,20,3]
输出:[3,9,20,null,null,15,7]
示例 2:
输入:inorder = [-1], postorder = [-1]
输出:[-1]
提示:
1 <= inorder.length <= 3000postorder.length == inorder.length-3000 <= inorder[i], postorder[i] <= 3000inorder和postorder都由 不同 的值组成postorder中每一个值都在inorder中inorder保证是树的中序遍历postorder保证是树的后序遍历
解题思路
这道题的解题思路是利用二叉树的中序遍历和后序遍历结果来重建二叉树。中序遍历的特点是左根右,后序遍历的特点是左右根。通过这两个遍历结果,可以唯一确定一棵二叉树。
- 确定根节点:后序遍历的最后一个元素是当前子树的根节点。
- 切割中序遍历:在中序遍历中找到根节点的位置,其左侧是左子树的中序遍历,右侧是右子树的中序遍历。
- 切割后序遍历:根据左子树的中序遍历长度,从后序遍历中切分出左子树和右子树的后序遍历。
- 递归构建:对左子树和右子树分别递归执行上述步骤,直到所有子树都被构建完成。
通过递归的方式,利用中序和后序遍历的特性,可以高效地重建出原始的二叉树。
代码
#include <iostream>
#include <vector>
#include <queue>
using namespace std;
struct TreeNode
{int val;TreeNode *left;TreeNode *right;TreeNode() : val(0), left(nullptr), right(nullptr) {}TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}~TreeNode(){delete left;delete right;}
};class Solution
{// 递归地构建二叉树// 函数直接操作原始的vector对象,而不是创建一个副本
private:TreeNode *traversal(vector<int> &inorder, vector<int> &postorder){// 空数组if (postorder.size() == 0){return NULL;}// 后序遍历数组最后一个元素,就是当前的根节点int rootValue = postorder[postorder.size() - 1];// 构建根节点TreeNode *root = new TreeNode(rootValue);// 当前子树只有一个节点(即叶子节点)if (postorder.size() == 1){return root;}// 找到中序遍历的切割点int delimiterIndex = 0;for (delimiterIndex; delimiterIndex < inorder.size(); delimiterIndex++){if (inorder[delimiterIndex] == rootValue){break;}}// 切中序数组// 左闭右开区间:[0, delimiterIndex)// 是C++标准库中对范围的约定是左闭右开vector<int> leftInorder(inorder.begin(), inorder.begin() + delimiterIndex);// [delimiterIndex + 1, end)vector<int> rightInorder(inorder.begin() + delimiterIndex + 1, inorder.end());// postorder 舍弃末尾元素,因为这个元素就是中间节点,已经用过了// resize调整数组大小postorder.resize(postorder.size() - 1);// 左闭右开,注意这里使用了左中序数组大小作为切割点:[0, leftInorder.size)vector<int> leftPostorder(postorder.begin(), postorder.begin() + leftInorder.size());vector<int> rightPostorder(postorder.begin() + leftInorder.size() , postorder.end());cout << "----------" << endl;cout << "leftInorder :";for (int i : leftInorder){cout << i << "";}cout << endl;cout << "rightInorder :";for (int i : rightPostorder){cout << i << "";}cout << endl;cout << "leftPostorder :";for (int i : leftPostorder){cout << i << "";}cout << endl;cout << "rightPostorder :";for (int i : rightPostorder){cout << i << "";}cout << endl;// 递归root->left = traversal(leftInorder, leftPostorder);root->right = traversal(rightInorder, rightPostorder);return root;}public:TreeNode *buildTree(vector<int> &inorder, vector<int> &postorder){if (inorder.size() == 0 || postorder.size() == 0){return NULL;}return traversal(inorder, postorder);}
};
// 打印函数
void printTree(TreeNode *root)
{if (root == nullptr){return;}queue<TreeNode *> que;que.push(root);while (!que.empty()){TreeNode *current = que.front(); // 取出队列中的当前节点que.pop(); // 从队列中移除当前节点// 打印当前节点的值cout << current->val << "";// 如果当前节点有左子节点,将左子节点加入队列if (current->left){que.push(current->left);}if (current->right){que.push(current->right);}}
}
最大二叉树
(力扣654题)
给定一个不重复的整数数组 nums 。 最大二叉树 可以用下面的算法从 nums 递归地构建:
- 创建一个根节点,其值为
nums中的最大值。 - 递归地在最大值 左边 的 子数组前缀上 构建左子树。
- 递归地在最大值 右边 的 子数组后缀上 构建右子树。
返回 nums 构建的 *最大二叉树* 。
示例 1:
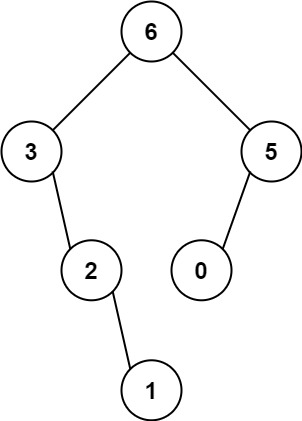
输入:nums = [3,2,1,6,0,5]
输出:[6,3,5,null,2,0,null,null,1]
解释:递归调用如下所示:
- [3,2,1,6,0,5] 中的最大值是 6 ,左边部分是 [3,2,1] ,右边部分是 [0,5] 。- [3,2,1] 中的最大值是 3 ,左边部分是 [] ,右边部分是 [2,1] 。- 空数组,无子节点。- [2,1] 中的最大值是 2 ,左边部分是 [] ,右边部分是 [1] 。- 空数组,无子节点。- 只有一个元素,所以子节点是一个值为 1 的节点。- [0,5] 中的最大值是 5 ,左边部分是 [0] ,右边部分是 [] 。- 只有一个元素,所以子节点是一个值为 0 的节点。- 空数组,无子节点。
示例 2:
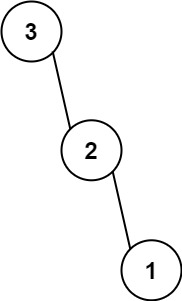
输入:nums = [3,2,1]
输出:[3,null,2,null,1]
提示:
1 <= nums.length <= 10000 <= nums[i] <= 1000nums中的所有整数 互不相同
解题思路
这道题的解题思路是利用递归构建最大二叉树。最大二叉树的定义是:对于每个节点,其左子树上的所有值都小于该节点的值,右子树上的所有值都大于该节点的值。
- 递归终止条件:如果输入数组的大小为1,则直接创建一个值为该元素的节点并返回,因为此时已经到达叶子节点。
- 寻找最大值及其索引:遍历数组,找到最大值及其索引。最大值将作为当前子树的根节点。
- 构建根节点:根据最大值创建根节点。
- 递归构建左右子树:
- 左子树:最大值左侧的数组元素用于构建左子树。如果最大值索引大于0,则递归调用函数构建左子树。
- 右子树:最大值右侧的数组元素用于构建右子树。如果最大值索引小于数组长度减1,则递归调用函数构建右子树。
- 返回根节点:递归完成后,返回构建好的根节点。
通过递归的方式,每次选择数组中的最大值作为当前子树的根节点,并分别用其左侧和右侧的数组元素构建左右子树,最终构建出满足条件的最大二叉树。
代码
#include <iostream>
#include <vector>
#include <queue>
using namespace std;
// 最大二叉树
struct TreeNode
{int val;TreeNode *left;TreeNode *right;TreeNode() : val(0), left(nullptr), right(nullptr) {}TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}~TreeNode(){delete left;delete right;}
};class Solution
{
public:TreeNode *constructMaximumBinaryTree(vector<int> &nums){// 确定终止条件 果传入的数组大小为1,说明遍历到了叶子节点了TreeNode *node = new TreeNode(0);if (nums.size() == 1){node->val = nums[0];return node;}// 找到数组中最大的值和对应的下标 构建根节点int maxValue = 0; // 数组中最大的值int maxIndex = 0; // 数组中最大的值索引for (int i = 0; i < nums.size(); i++){if (nums[i] > maxValue){maxValue = nums[i];maxIndex = i;}}node->val = maxValue;// 上面的是创建根节点的逻辑// 最大值所在的下标左区间 构造左子树if (maxIndex > 0){vector<int> newVec(nums.begin(), nums.begin() + maxIndex);node->left = constructMaximumBinaryTree(newVec);}// 最大值所在的下标右区间 构造右子树if (maxIndex < nums.size() - 1){vector<int> newVec(nums.begin() + maxIndex + 1, nums.end());node->right = constructMaximumBinaryTree(newVec);}return node;}
};
// 打印函数
void printTree(TreeNode *root)
{if (root == nullptr){return;}queue<TreeNode *> que;que.push(root);while (!que.empty()){TreeNode *current = que.front(); // 取出队列中的当前节点que.pop(); // 从队列中移除当前节点// 打印当前节点的值cout << current->val << "";// 如果当前节点有左子节点,将左子节点加入队列if (current->left){que.push(current->left);}if (current->right){que.push(current->right);}}
}
int main()
{TreeNode *root = new TreeNode(3);root->left = new TreeNode(9);root->right = new TreeNode(20);root->right->left = new TreeNode(15);root->right->right = new TreeNode(7);vector<int> inorder = {9, 3, 15, 20, 7};vector<int> postorder = {9, 15, 7, 20, 3};Solution s;return 0;
}合并二叉树
(力扣617题)
给你两棵二叉树: root1 和 root2 。
想象一下,当你将其中一棵覆盖到另一棵之上时,两棵树上的一些节点将会重叠(而另一些不会)。你需要将这两棵树合并成一棵新二叉树。合并的规则是:如果两个节点重叠,那么将这两个节点的值相加作为合并后节点的新值;否则,不为 null 的节点将直接作为新二叉树的节点。
返回合并后的二叉树。
注意: 合并过程必须从两个树的根节点开始。
示例 1:
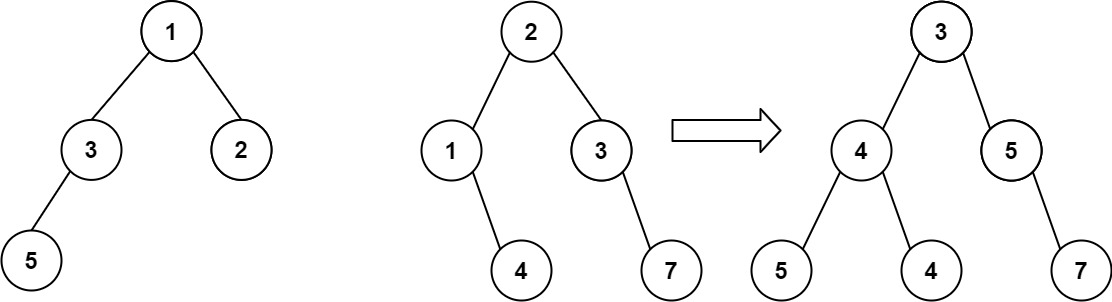
输入:root1 = [1,3,2,5], root2 = [2,1,3,null,4,null,7]
输出:[3,4,5,5,4,null,7]
示例 2:
输入:root1 = [1], root2 = [1,2]
输出:[2,2]
提示:
- 两棵树中的节点数目在范围
[0, 2000]内 -104 <= Node.val <= 104
解题思路
这道题的解题思路是通过递归合并两棵二叉树。合并规则是:对于两个树的每个对应节点,将它们的值相加,并将结果存储在一个新的节点中。如果某个节点在其中一棵树中不存在,则直接使用另一棵树中的节点。
- 递归终止条件:
- 如果
root1为空,则直接返回root2,因为root2就是合并后的结果。 - 如果
root2为空,则直接返回root1,因为root1就是合并后的结果。
- 如果
- 合并节点:
- 如果两个节点都不为空,将它们的值相加,并存储在
root1中(也可以选择存储在root2中,但这里选择root1作为主树)。
- 如果两个节点都不为空,将它们的值相加,并存储在
- 递归合并左右子树:
- 递归地合并左子树:
root1->left = mergeTrees(root1->left, root2->left)。 - 递归地合并右子树:
root1->right = mergeTrees(root1->right, root2->right)。
- 递归地合并左子树:
- 返回合并后的树:
- 最终返回
root1,它已经包含了合并后的所有节点。
- 最终返回
通过递归的方式,逐层合并两棵树的节点,最终得到一棵新的二叉树,其中每个节点的值是两棵树对应节点值的和。这种方法既简洁又高效,充分利用了二叉树的递归结构。
代码
#include <iostream>
// 合并二叉树
struct TreeNode
{int val;TreeNode *left;TreeNode *right;TreeNode() : val(0), left(nullptr), right(nullptr) {}TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}~TreeNode(){delete left;delete right;}
};
// 合并二叉树
class Solution
{
public:TreeNode *mergeTrees(TreeNode *root1, TreeNode *root2){// 终止条件// 如果t1为空,合并之后就应该是t2if (root1 == NULL){return root2;}// 如果t2为空,合并之后就应该是t1if (root2 == NULL){return root1;}// 单层递归 节点都不是空// 修改了t1的数值和结构root1->val += root2->val; //根root1->left = mergeTrees(root1->left, root2->left); //左root1->right = mergeTrees(root1->right, root2->right); //右return root1;}
};
相关文章:
算法打卡第18天
从中序与后序遍历序列构造二叉树 (力扣106题) 给定两个整数数组 inorder 和 postorder ,其中 inorder 是二叉树的中序遍历, postorder 是同一棵树的后序遍历,请你构造并返回这颗 二叉树 。 示例 1: 输入:inorder [9,3,15,20,7…...

Visual Studio Code 扩展
Visual Studio Code 扩展 change-case 大小写转换EmmyLua for VSCode 调试插件Bookmarks 书签 change-case 大小写转换 https://marketplace.visualstudio.com/items?itemNamewmaurer.change-case 选中单词后,命令 changeCase.commands 可预览转换效果 EmmyLua…...
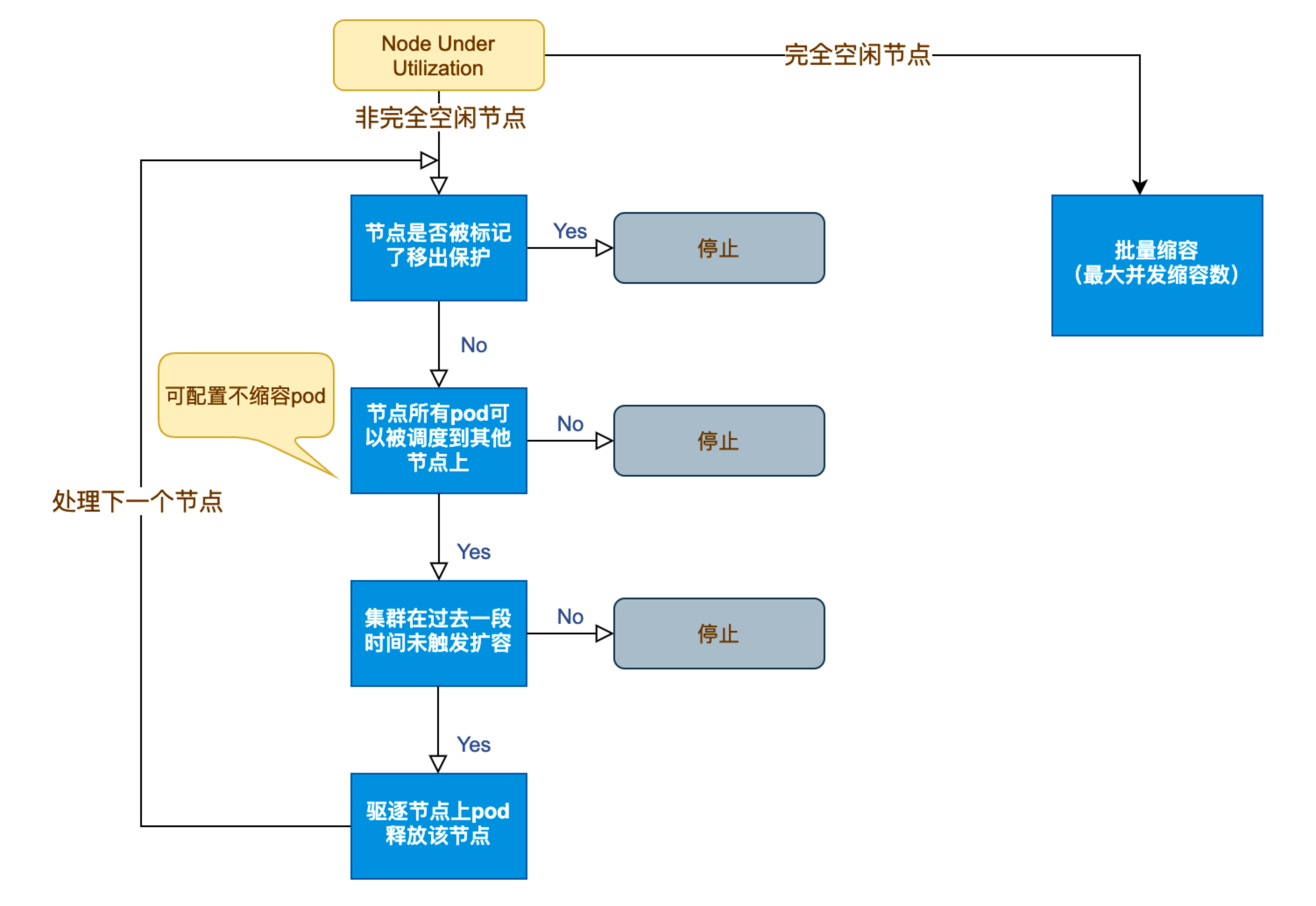
Kubernetes 节点自动伸缩(Cluster Autoscaler)原理与实践
在 Kubernetes 集群中,如何在保障应用高可用的同时有效地管理资源,一直是运维人员和开发者关注的重点。随着微服务架构的普及,集群内各个服务的负载波动日趋明显,传统的手动扩缩容方式已无法满足实时性和弹性需求。 Cluster Auto…...

【深度学习新浪潮】什么是credit assignment problem?
Credit Assignment Problem(信用分配问题) 是机器学习,尤其是强化学习(RL)中的核心挑战之一,指的是如何将最终的奖励或惩罚准确地分配给导致该结果的各个中间动作或决策。在序列决策任务中,智能体执行一系列动作后获得一个最终奖励,但每个动作对最终结果的贡献程度往往…...
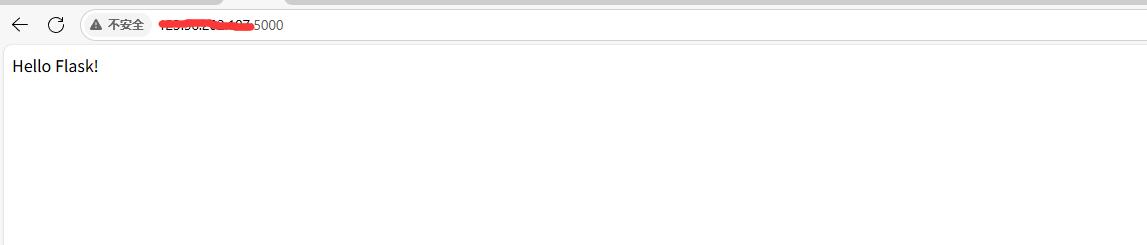
阿里云Ubuntu 22.04 64位搭建Flask流程(亲测)
cd /home 进入home盘 安装虚拟环境: 1、安装virtualenv pip install virtualenv 2.创建新的虚拟环境: virtualenv myenv 3、激活虚拟环境(激活环境可以在当前环境下安装包) source myenv/bin/activate 此时,终端…...

面试高频问题
文章目录 🚀 消息队列核心技术揭秘:从入门到秒杀面试官1️⃣ Kafka为何能"吞云吐雾"?性能背后的秘密1.1 顺序写入与零拷贝:性能的双引擎1.2 分区并行:数据的"八车道高速公路"1.3 页缓存与批量处理…...

xmind转换为markdown
文章目录 解锁思维导图新姿势:将XMind转为结构化Markdown 一、认识Xmind结构二、核心转换流程详解1.解压XMind文件(ZIP处理)2.解析JSON数据结构3:递归转换树形结构4:Markdown层级生成逻辑 三、完整代码 解锁思维导图新…...

【WebSocket】SpringBoot项目中使用WebSocket
1. 导入坐标 如果springboot父工程没有加入websocket的起步依赖,添加它的坐标的时候需要带上版本号。 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-websocket</artifactId> </dep…...
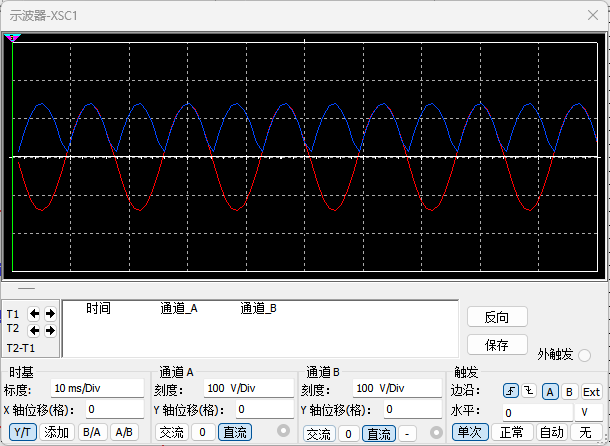
恶补电源:1.电桥
一、元器件的选择 搜索并选择电桥,再multisim中选择FWB,就有各种型号的电桥: 电桥是用来干嘛的呢? 它是一个由四个二极管搭成的“桥梁”形状的电路,用来把交流电(AC)变成直流电(DC)。…...
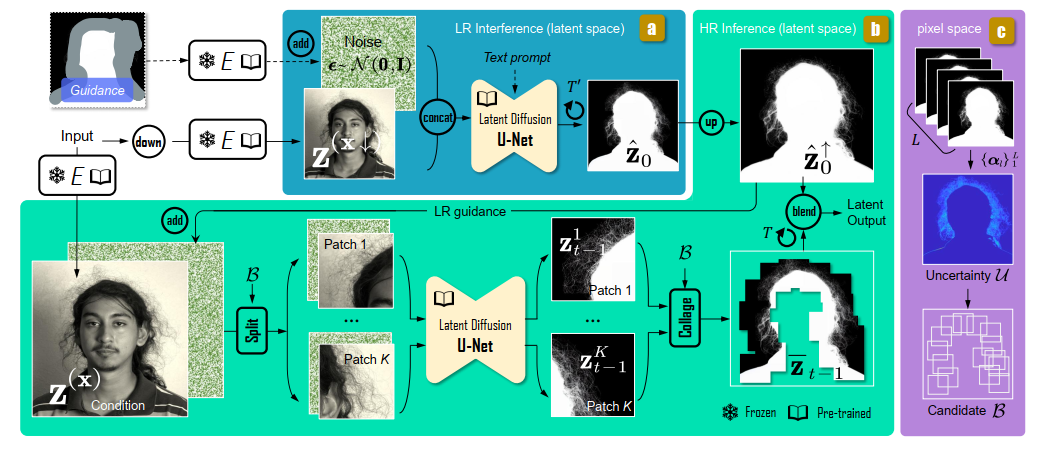
论文阅读:Matting by Generation
今天介绍一篇关于 matting 抠图的文章,抠图也算是计算机视觉里面非常经典的一个任务了。从早期的经典算法到如今的深度学习算法,已经有很多的工作和这个任务相关。这两年 diffusion 模型很火,大家又开始用 diffusion 模型做各种 CV 任务了&am…...

Neko虚拟浏览器远程协作方案:Docker+内网穿透技术部署实践
前言:本文将向开发者介绍一款创新性协作工具——Neko虚拟浏览器。在数字化协作场景中,跨地域的团队常需面对实时共享屏幕、协同编辑文档等需求。通过本指南,你将掌握在Ubuntu系统中使用容器化技术部署该工具的具体方案,并结合内网…...

实战设计模式之模板方法模式
概述 模板方法模式定义了一个操作中的算法骨架,并将某些步骤延迟到子类中实现。模板方法使得子类可以在不改变算法结构的前提下,重新定义算法中的某些步骤。简单来说,就是在一个方法中定义了要执行的步骤顺序或算法框架,但允许子类…...

【Linux】Linux安装并配置RabbitMQ
目录 1. 安装 Erlang 2. 安装 RabbitMQ 2.1.添加 RabbitMQ 仓库 2.2.安装 RabbitMQ 3.配置 3.1.启动和管理服务 4. 访问管理界面 5.安装问题 6.修改密码 7.修改端口 7.1.找到文件 7.2.修改文件 1. 安装 Erlang 由于 RabbitMQ 是用 Erlang 编写的,需要先安…...
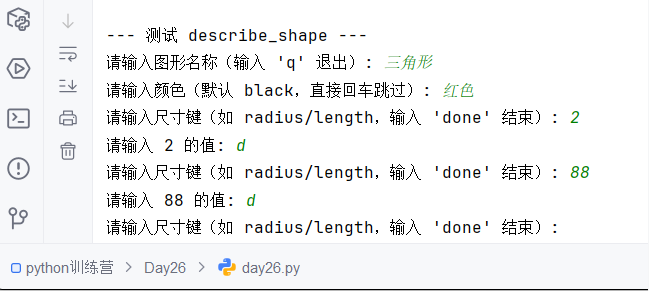
Python训练营-Day26-函数专题1:函数定义与参数
题目1:计算圆的面积 任务: 编写一个名为 calculate_circle_area 的函数,该函数接收圆的半径 radius 作为参数,并返回圆的面积。圆的面积 π * radius (可以使用 math.pi 作为 π 的值)要求:函数接收一个位置参数 radi…...

【Kafka】Kafka从入门到实战:构建高吞吐量分布式消息系统
Kafka从入门到实战:构建高吞吐量分布式消息系统 一、Kafka概述 Apache Kafka是一个分布式流处理平台,最初由LinkedIn开发,后成为Apache顶级项目。它被设计用于高吞吐量、低延迟的消息处理,能够处理来自多个生产者的海量数据,并将这些数据实时传递给消费者。 Kafka核心特…...

Android写一个捕获全局异常的工具类
项目开发和实际运行过程中难免会遇到异常发生,系统提供了一个可以捕获全局异常的工具Uncaughtexceptionhandler,它是Thread的子类(就是package java.lang;里线程的Thread)。本文将利用它将设备信息、报错信息以及错误的发生时间都…...

人工智能 - 在Dify、Coze、n8n、FastGPT和RAGFlow之间做出技术选型
在Dify、Coze、n8n、FastGPT和RAGFlow之间做出技术选型。这些平台各有侧重,适用场景差异显著。下面我将从核心功能定位、典型应用场景、真实体验痛点、选型决策关键点进行拆解,并提供具体场景下的推荐方案。 一、核心功能定位速览 平台核心定位技术栈亮…...

绕过 Xcode?使用 Appuploader和主流工具实现 iOS 上架自动化
iOS 应用的发布流程一直是开发链路中最“苹果味”的环节:强依赖 Xcode、必须使用 macOS、各种证书和描述文件配置……对很多跨平台开发者来说,这一套流程并不友好。 特别是当你的项目主要在 Windows 或 Linux 下开发(例如 Flutter、React Na…...

C++_哈希表
本篇文章是对C学习的哈希表部分的学习分享 相信一定会对你有所帮助~ 那咱们废话不多说,直接开始吧! 一、基础概念 1. 哈希核心思想: 哈希函数的作用:通过此函数建立一个Key与存储位置之间的映射关系。理想目标:实现…...

WEB3全栈开发——面试专业技能点P7前端与链上集成
一、Next.js技术栈 ✅ 概念介绍 Next.js 是一个基于 React 的 服务端渲染(SSR)与静态网站生成(SSG) 框架,由 Vercel 开发。它简化了构建生产级 React 应用的过程,并内置了很多特性: ✅ 文件系…...
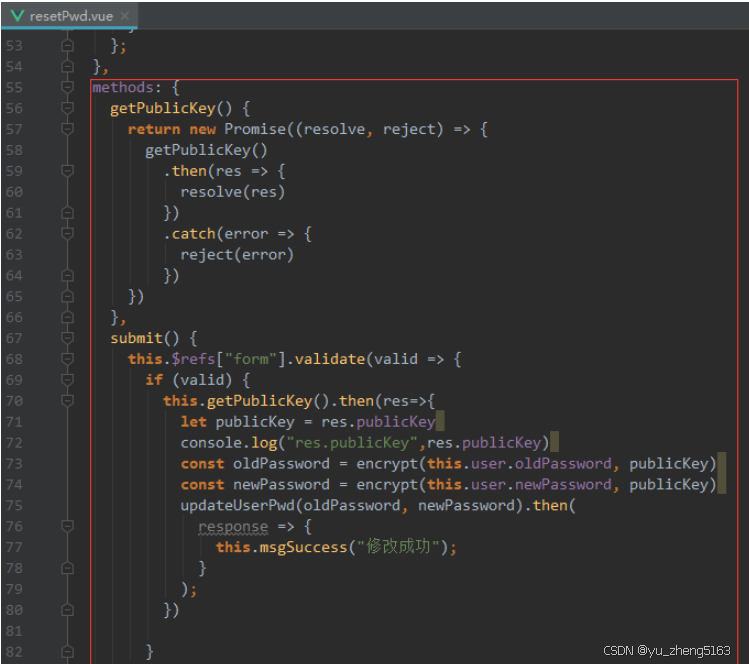
若依登录用户名和密码加密
/*** 获取公钥:前端用来密码加密* return*/GetMapping("/getPublicKey")public RSAUtil.RSAKeyPair getPublicKey() {return RSAUtil.rsaKeyPair();}新建RSAUti.Java package com.ruoyi.common.utils;import org.apache.commons.codec.binary.Base64; im…...

Linux 下 DMA 内存映射浅析
序 系统 I/O 设备驱动程序通常调用其特定子系统的接口为 DMA 分配内存,但最终会调到 DMA 子系统的dma_alloc_coherent()/dma_alloc_attrs() 等接口。 关于 dma_alloc_coherent 接口详细的代码讲解、调用流程,可以参考这篇文章,我觉得写的非常…...

第八部分:阶段项目 6:构建 React 前端应用
现在,是时候将你学到的 React 基础知识付诸实践,构建一个简单的前端应用来模拟与后端 API 的交互了。在这个阶段,你可以先使用模拟数据,或者如果你的后端 API(阶段项目 5)已经搭建好,可以直接连…...

6️⃣Go 语言中的哈希、加密与序列化:通往区块链世界的钥匙
Go 语言中的哈希、加密与序列化:通往区块链世界的钥匙 一、前言:离区块链还有多远? 区块链听起来可能遥不可及,似乎是只有密码学专家和资深工程师才能涉足的领域。但事实上,构建一个区块链的核心并不复杂,尤其当你已经掌握了一门系统编程语言,比如 Go。 要真正理解区…...
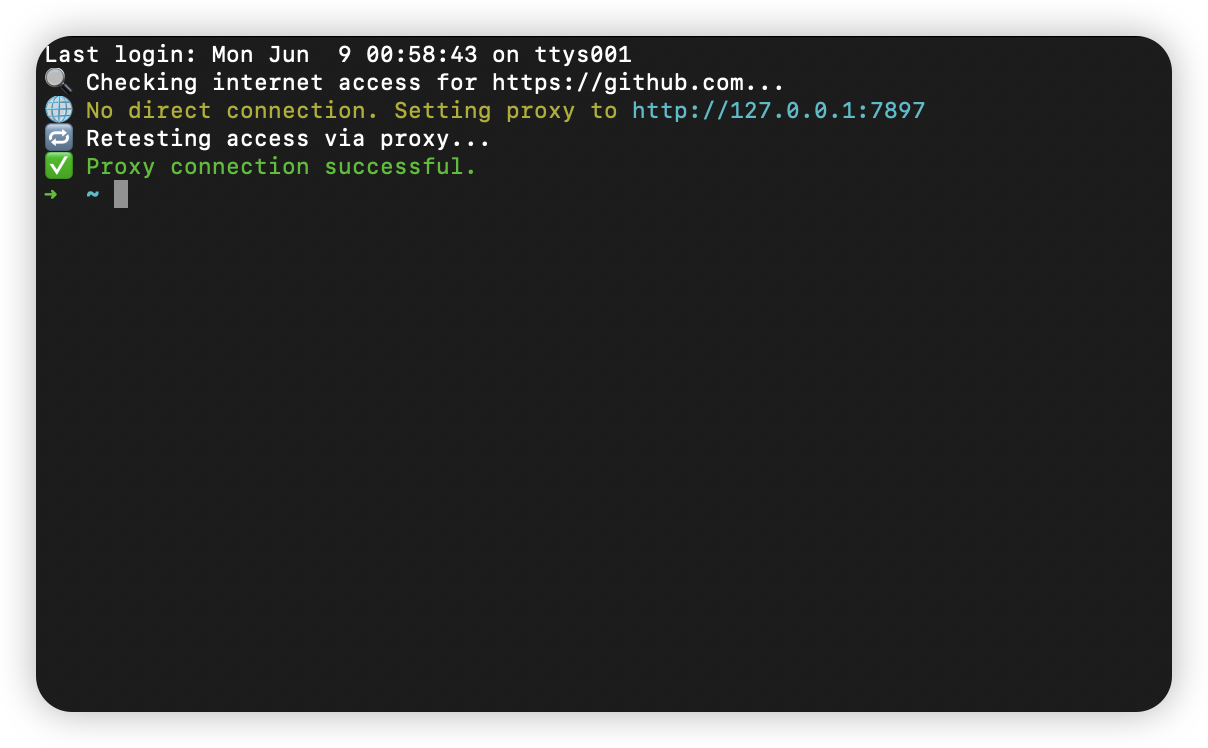
macOS 终端智能代理检测
🧠 终端智能代理检测:自动判断是否需要设置代理访问 GitHub 在开发中,使用 GitHub 是非常常见的需求。但有时候我们会发现某些命令失败、插件无法更新,例如: fatal: unable to access https://github.com/ohmyzsh/oh…...

前端高频面试题2:浏览器/计算机网络
本专栏相关链接 前端高频面试题1:HTML/CSS 前端高频面试题2:浏览器/计算机网络 前端高频面试题3:JavaScript 1.什么是强缓存、协商缓存? 强缓存: 当浏览器请求资源时,首先检查本地缓存是否命中。如果命…...

智能职业发展系统:AI驱动的职业规划平台技术解析
智能职业发展系统:AI驱动的职业规划平台技术解析 引言:数字时代的职业革命 在当今瞬息万变的就业市场中,传统的职业规划方法已无法满足个人和企业的需求。据统计,全球每年有超过2亿人面临职业转型困境,而企业也因此遭…...
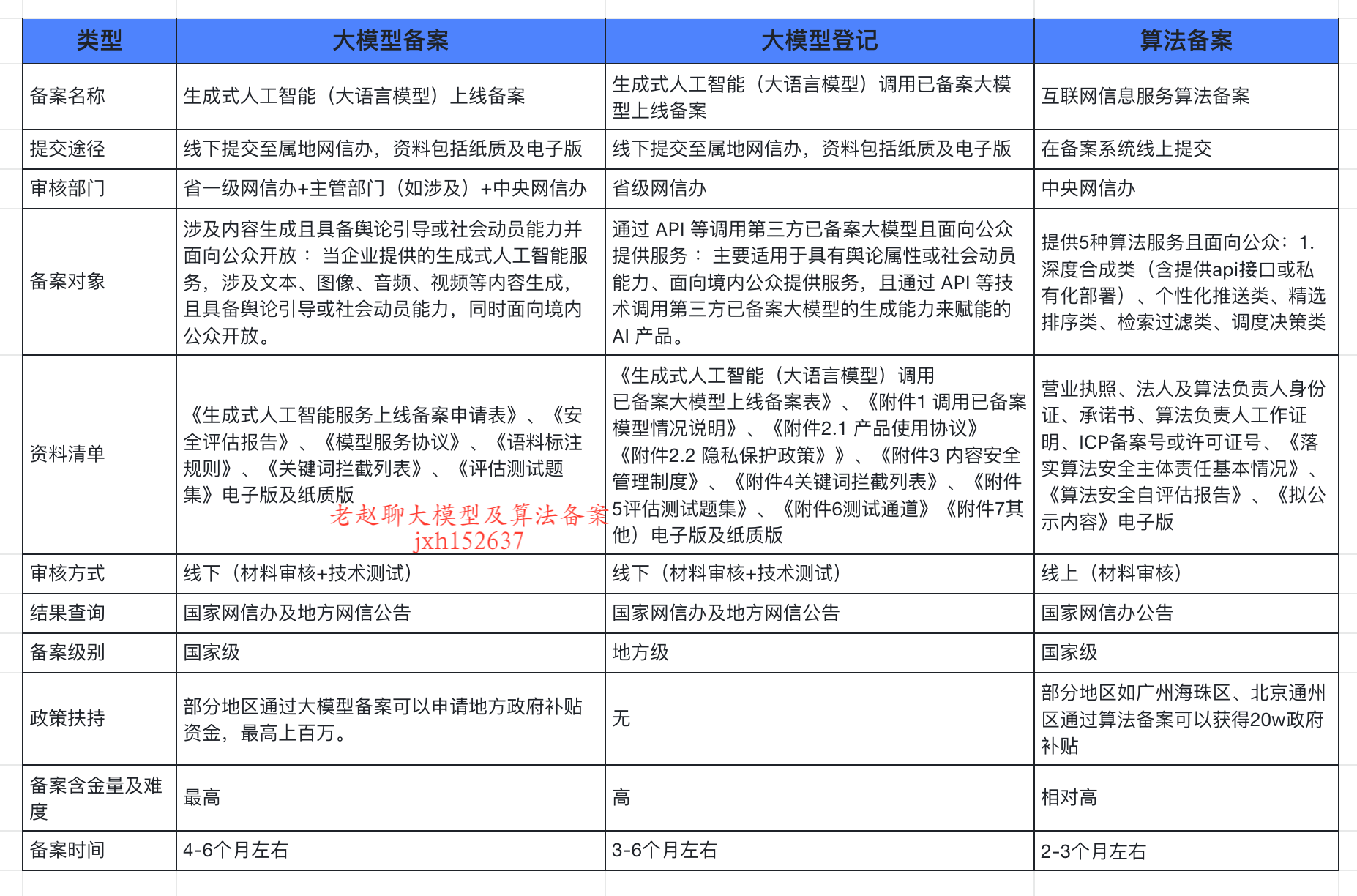
企业大模型服务合规指南:深度解析备案与登记制度
伴随AI技术的爆炸式发展,尤其是大模型(LLM)在各行各业的深度应用和整合,企业利用AI技术提升效率、创新服务的步伐不断加快。无论是像DeepSeek这样的前沿技术提供者,还是积极拥抱AI转型的传统企业,在面向公众…...

高防服务器价格高原因分析
高防服务器的价格较高,主要是由于其特殊的防御机制、硬件配置、运营维护等多方面的综合成本。以下从技术、资源和服务三个维度详细解析高防服务器昂贵的原因: 一、硬件与技术投入 大带宽需求 DDoS攻击通过占用大量带宽资源瘫痪目标服务器,因此…...

Unity VR/MR开发-VR开发与传统3D开发的差异
视频讲解链接:【XR马斯维】VR/MR开发与传统3D开发的差异【UnityVR/MR开发教程--入门】_哔哩哔哩_bilibili...