面试高频问题
文章目录
- 🚀 消息队列核心技术揭秘:从入门到秒杀面试官
- 1️⃣ Kafka为何能"吞云吐雾"?性能背后的秘密
- 1.1 顺序写入与零拷贝:性能的双引擎
- 1.2 分区并行:数据的"八车道高速公路"
- 1.3 页缓存与批量处理:性能的加速器
- 1.4 性能提升有多大?数据告诉你真相
- 2️⃣ RocketMQ事务消息:分布式事务的"优雅舞者"
- 2.1 事务消息流程:四步曲
- 2.2 代码实战:事务消息的魔法
- 2.3 一致性保障:各种场景全覆盖
- 3️⃣ Exactly-Once:消息处理的"完美主义者"
- 3.1 生产者端:消息发送的"保险箱"
- 幂等性发送:消息的"防重复锁"
- 事务消息:原子性的保障
- 3.2 消费者端:处理的"精确制导"
- 3.3 端到端Exactly-Once:方案全解析
- 4️⃣ 百万级消息积压:消息队列的"急诊室"
- 4.1 问题诊断:找出"病因"
- 4.2 紧急扩容:消息队列的"加速带"
- 增加分区和消费者:并行处理的威力
- 批量处理:消息的"批发模式"
- 4.3 临时队列转储:消息的"紧急疏散"
- 4.4 死信队列:问题消息的"隔离病房"
- 5️⃣ 消息顺序性:数据流的"交通指挥官"
- 5.1 全局顺序与分区顺序:不同级别的"秩序"
- 5.2 生产者顺序性保障:发送端的"交通规则"
- 5.3 消费者顺序性保障:接收端的"有序处理"
- 5.4 顺序性与性能的权衡:鱼和熊掌
- 6️⃣ Kafka vs RabbitMQ:消息队列的"双雄之争"
- 6.1 架构模型:设计理念的碰撞
- 6.2 性能特性:数字会说话
- 6.3 适用场景:各显神通
- Kafka的主战场
- RabbitMQ的主战场
- 6.4 选型决策矩阵:实战指南
- 7️⃣ 消息重试机制:系统的"安全网"
- 7.1 重试策略:不同场景的"应对之道"
- 即时重试:快速修复的尝试
- 延时重试:给系统喘息的机会
- 7.2 重试间隔策略:时间的艺术
- 7.3 重试次数与死信处理:知道何时放弃
- 7.4 重试最佳实践:实战经验总结
- 8️⃣ 消息队列与分布式事务:最终一致性的艺术
- 8.1 本地消息表:可靠的"双重保险"
- 8.2 事务消息:中间件原生支持
- 8.3 TCC模式:更细粒度的控制
- 8.4 分布式事务方案对比:选择最适合的武器
- 🌟 总结与展望:消息队列的未来之路
🚀 消息队列核心技术揭秘:从入门到秒杀面试官
🔥 编辑私享:消息队列已成为互联网架构的"流量神器",但你真的懂它吗?本文将带你深入消息队列的核心技术迷宫,让你在技术面试中所向披靡!不仅是面试题,更是实战经验的结晶!
1️⃣ Kafka为何能"吞云吐雾"?性能背后的秘密
还在为系统性能发愁?Kafka的"火箭式"性能不是偶然,而是精心设计的结果。它是如何做到每秒处理百万级消息的?让我们揭开这个秘密!
1.1 顺序写入与零拷贝:性能的双引擎
想象一下,传统数据库像在纸上随机写字,而Kafka则像在卷轴上连续书写 - 这就是顺序写入的魔力!现代操作系统对顺序I/O的优化让它几乎达到了内存操作的速度。
而零拷贝技术则像是一条直达高速公路,数据从磁盘到网卡一气呵成,不再绕道用户空间:
// 传统数据复制像是"曲线救国":
File.read(fileDesc, buf, len); // 磁盘 → 内核缓冲区 → 用户缓冲区
Socket.send(socket, buf, len); // 用户缓冲区 → 内核缓冲区 → 网卡// 零拷贝则是"一步到位":
transferTo(fileDesc, position, count, socketDesc); // 磁盘 → 内核缓冲区 → 网卡
💡 实战经验:在我们的电商平台中,仅仅通过启用零拷贝,就将消息处理延迟降低了40%,系统吞吐量提升了近一倍!
1.2 分区并行:数据的"八车道高速公路"
Kafka的主题分区就像是将一条拥堵的单行道变成了多车道高速公路,每个分区都是一个独立的数据通道,多分区并行处理让数据流动畅通无阻。
1.3 页缓存与批量处理:性能的加速器
Kafka巧妙地"借用"了操作系统的页缓存,避开了Java GC的性能陷阱。同时,它的批量处理机制就像是快递合并配送,大幅减少了网络往返次数:
// 生产者批量发送配置 - 性能调优的制胜法宝
Properties props = new Properties();
props.put("bootstrap.servers", "broker1:9092,broker2:9092");
props.put("batch.size", 16384); // 16KB的批次大小
props.put("linger.ms", 5); // 等待5ms收集更多消息
props.put("compression.type", "snappy"); // 使用Snappy压缩
1.4 性能提升有多大?数据告诉你真相
| 优化技术 | 性能提升 | 资源消耗 | 实战体验 |
|---|---|---|---|
| 顺序写入 | 🚀 写入性能提升5-10倍 | 磁盘空间利用率降低 | 系统峰值期间写入不再是瓶颈 |
| 零拷贝 | ⚡ 网络传输性能提升30-50% | 几乎无额外消耗 | CPU使用率显著下降 |
| 批量处理 | 📈 吞吐量提升2-5倍 | 轻微增加延迟 | 适合大数据量、非实时场景 |
| 页缓存利用 | 🔥 读取性能提升10倍以上 | 占用系统内存 | 重启后需要预热时间 |
2️⃣ RocketMQ事务消息:分布式事务的"优雅舞者"
分布式事务一直是架构师的噩梦,但RocketMQ的事务消息机制像一位优雅的舞者,巧妙地协调了各个环节,让一致性不再是梦想。
2.1 事务消息流程:四步曲
RocketMQ事务消息的处理流程就像一场精心编排的芭蕾:
- 发送半消息:先抛出"信号弹",但对消费者不可见
- 执行本地事务:完成自己的"家务事"
- 提交或回滚:根据结果决定是否"公开信息"
- 状态回查:如果长时间没有回应,主动"打电话询问"
🔍 深度思考:这种设计本质上是两阶段提交的变种,但比传统2PC更加轻量和高效,你能分析出为什么吗?
2.2 代码实战:事务消息的魔法
// RocketMQ事务消息实战代码
TransactionMQProducer producer = new TransactionMQProducer("transaction_producer_group");
producer.setNamesrvAddr("127.0.0.1:9876");// 设置事务监听器 - 这是整个魔法的核心
producer.setTransactionListener(new TransactionListener() {@Overridepublic LocalTransactionState executeLocalTransaction(Message msg, Object arg) {try {// 执行本地事务 - 比如创建订单orderService.createOrder((Order)arg);return LocalTransactionState.COMMIT_MESSAGE;} catch (Exception e) {return LocalTransactionState.ROLLBACK_MESSAGE;}}@Overridepublic LocalTransactionState checkLocalTransaction(MessageExt msg) {// 事务状态回查 - 消息队列的"安全网"String orderId = msg.getKeys();Order order = orderService.getOrderById(orderId);return order != null ? LocalTransactionState.COMMIT_MESSAGE : LocalTransactionState.ROLLBACK_MESSAGE;}
});producer.start();// 发送事务消息 - 启动整个事务流程
Order order = new Order(...);
Message message = new Message("order_topic", order.toString().getBytes());
producer.sendMessageInTransaction(message, order);
2.3 一致性保障:各种场景全覆盖
| 场景 | 本地事务 | 消息状态 | 最终结果 | 一致性保障 |
|---|---|---|---|---|
| 正常流程 | ✅ 成功 | ✅ 提交 | ✅ 消费者可见 | ✓ 完美一致 |
| 本地事务失败 | ❌ 失败 | ❌ 回滚 | ❌ 消息丢弃 | ✓ 安全保障 |
| 提交阶段网络中断 | ✅ 成功 | ❓ 未知 | ✅ 通过回查确认提交 | ✓ 最终一致 |
| 回查阶段仍无响应 | ❓ 未知 | ❌ 回滚 | ❌ 消息丢弃 | ✓ (安全优先) |
3️⃣ Exactly-Once:消息处理的"完美主义者"
在分布式系统的世界里,"恰好一次"处理就像是追求完美的艺术品 - 既不能多也不能少。如何实现这个看似不可能的任务?
3.1 生产者端:消息发送的"保险箱"
幂等性发送:消息的"防重复锁"
Kafka的幂等性生产者就像给每条消息配了一把独一无二的钥匙,确保即使重复发送也只会被存储一次:
// Kafka幂等性生产者配置 - 一行代码激活强大特性
Properties props = new Properties();
props.put("enable.idempotence", true); // 启用幂等性
props.put("acks", "all"); // 需要所有副本确认
props.put("retries", Integer.MAX_VALUE); // 无限重试
🚨 踩坑警告:幂等性只能保证单个生产者会话内的幂等,跨会话、跨分区的幂等需要额外机制!
事务消息:原子性的保障
// Kafka事务生产者 - 全有或全无的保证
props.put("transactional.id", "my-transactional-id");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);producer.initTransactions();
try {producer.beginTransaction();producer.send(record1); // 发送订单创建消息producer.send(record2); // 发送库存减少消息// 执行其他操作...producer.commitTransaction(); // 一次性提交所有操作
} catch (Exception e) {producer.abortTransaction(); // 出错时回滚所有操作
}
3.2 消费者端:处理的"精确制导"
消费者端实现Exactly-Once的核心在于将消费位移和处理结果绑定在一起,就像是将收货签收和货物使用捆绑在同一个原子操作中:
// 消费位移与结果存储的原子提交 - 消费者端的"完美主义"
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(consumerProps);
KafkaProducer<String, String> producer = new KafkaProducer<>(producerProps);producer.initTransactions();
while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));if (!records.isEmpty()) {try {producer.beginTransaction();// 处理消息并产生结果for (ConsumerRecord<String, String> record : records) {// 处理消息 - 例如更新订单状态ProducerRecord<String, String> result = processRecord(record);producer.send(result);}// 神奇之处:提交消费位移和处理结果在同一事务中Map<TopicPartition, OffsetAndMetadata> offsets = currentOffsets(consumer);producer.sendOffsetsToTransaction(offsets, consumer.groupMetadata());producer.commitTransaction();} catch (Exception e) {producer.abortTransaction(); // 任何环节出错,整体回滚}}
}
3.3 端到端Exactly-Once:方案全解析
| 方案 | 生产者保证 | 消费者保证 | 适用场景 | 性能影响 | 实战评价 |
|---|---|---|---|---|---|
| Kafka事务 | 事务消息 | 事务性消费位移提交 | 流处理 | 中等 | 配置简单,但需要理解事务语义 |
| 幂等性+去重 | 幂等性发送 | 消费端去重 | 通用场景 | 轻微 | 实现灵活,适合大多数业务 |
| 业务主键去重 | 普通发送 | 基于业务主键去重 | 有唯一键业务 | 轻微 | 最简单实用的方案,但依赖业务特性 |
4️⃣ 百万级消息积压:消息队列的"急诊室"
系统深夜告警,消息队列积压了上百万条消息,消费者严重滞后,这是每个开发者都可能面临的噩梦。如何快速"止血"并恢复系统?
4.1 问题诊断:找出"病因"
就像医生看病,首先要找出积压的根本原因:
- 消费者处理能力不足:单条消息处理时间过长,就像"消化不良"
- 消费者数量不足:并行度不够,就像"人手不足"
- 消费者异常:频繁抛出异常导致重试,就像"反复呕吐"
- 分区分配不均:部分消费者负载过重,就像"分工不均"
📊 监控经验:设置消费延迟监控是预防积压的第一道防线!我们的经验是,当延迟超过5分钟时就应该触发告警。
4.2 紧急扩容:消息队列的"加速带"
增加分区和消费者:并行处理的威力
// 动态增加Kafka分区 - 系统的"紧急扩容"
AdminClient adminClient = AdminClient.create(adminProps);
NewPartitions newPartitions = NewPartitions.increaseTo(32); // 增加到32个分区
Map<String, NewPartitions> newPartitionsMap = new HashMap<>();
newPartitionsMap.put("my-topic", newPartitions);
adminClient.createPartitions(newPartitionsMap);
批量处理:消息的"批发模式"
// 批量处理消息 - 从"零售"到"批发"
List<Message> messageBatch = new ArrayList<>(1000);
while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {messageBatch.add(convertToMessage(record));// 达到批处理阈值,进行批量处理if (messageBatch.size() >= 1000) {processBatch(messageBatch); // 一次性处理1000条消息messageBatch.clear();consumer.commitSync();}}
}
4.3 临时队列转储:消息的"紧急疏散"
面对百万级积压,有时需要像疏散人群一样,先将消息快速转移到安全区域:
// 消息转储处理流程 - 消息队列的"应急预案"
public void emergencyProcess() {// 步骤1: 创建临时队列 - 消息的"避难所"createTemporaryQueue("temp_storage");// 步骤2: 快速消费原队列消息并转储 - "疏散人群"fastConsumeAndStore();// 步骤3: 启动多线程慢慢处理临时队列 - "有序安置"startBatchProcessors(10); // 启动10个处理线程
}
🔧 实战案例:在一次电商大促中,我们的订单队列积压了超过200万条消息。通过临时队列转储 + 20倍的消费者扩容,我们在30分钟内解决了积压,避免了大面积订单处理延迟。
4.4 死信队列:问题消息的"隔离病房"
// 死信队列处理 - 问题消息的"特殊通道"
try {processMessage(message);acknowledgeMessage(message);
} catch (Exception e) {if (message.getRetryCount() > MAX_RETRY) {// 超过最大重试次数,发送到死信队列 - "专科治疗"sendToDeadLetterQueue(message);acknowledgeMessage(message); // 确认原消息已处理} else {// 增加重试计数并重新入队 - "再次尝试"message.incrementRetryCount();requeueMessage(message);}
}
5️⃣ 消息顺序性:数据流的"交通指挥官"
在很多业务场景中,消息处理顺序就像是一场精心编排的舞蹈,一步错,满盘皆输。如何确保消息按照正确的顺序被处理?
5.1 全局顺序与分区顺序:不同级别的"秩序"
消息顺序性可分为两种级别:
- 全局顺序:整个主题的所有消息都按照发送顺序被消费,就像单车道的公路
- 分区顺序:同一分区内的消息按照发送顺序被消费,就像多车道高速公路的单个车道
💡 架构师提示:全局顺序虽然概念简单,但性能代价极高。在绝大多数场景下,分区顺序已经能满足业务需求,同时保持较高性能。
5.2 生产者顺序性保障:发送端的"交通规则"
// Kafka生产者顺序性保障 - 发送端的"交通规则"
Properties props = new Properties();
// 方案1: 禁用重试 - 简单但可能丢消息
props.put("retries", 0);
// 方案2: 允许重试但限制同时发送的请求数为1 - 更可靠但性能降低
props.put("retries", Integer.MAX_VALUE);
props.put("max.in.flight.requests.per.connection", 1);// 使用自定义分区器确保相关消息进入同一分区 - 顺序的关键
props.put("partitioner.class", "com.example.OrderPartitioner");
自定义分区器 - 消息的"分道扬镳":
public class OrderPartitioner implements Partitioner {@Overridepublic int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {// 获取订单ID作为分区键 - 同一订单的消息必须进入同一分区String orderId = extractOrderId(key, value);// 计算分区号int partitionCount = cluster.partitionCountForTopic(topic);return Math.abs(orderId.hashCode()) % partitionCount;}
}
5.3 消费者顺序性保障:接收端的"有序处理"
// 单线程消费确保处理顺序 - 消费端的"单行道"
public void consumeInOrder() {while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (TopicPartition partition : records.partitions()) {List<ConsumerRecord<String, String>> partitionRecords = records.records(partition);for (ConsumerRecord<String, String> record : partitionRecords) {// 单线程顺序处理同一分区的消息 - 保证顺序的关键processRecord(record);}// 处理完一个分区的所有消息后再提交位移 - 避免部分提交consumer.commitSync(Collections.singletonMap(partition, new OffsetAndMetadata(partitionRecords.get(partitionRecords.size() - 1).offset() + 1)));}}
}
5.4 顺序性与性能的权衡:鱼和熊掌
| 顺序保障级别 | 实现方式 | 性能影响 | 适用场景 | 实战建议 |
|---|---|---|---|---|
| 全局顺序 | 单分区+单消费者 | 🐢 严重 | 对顺序要求极高且吞吐量较低的场景 | 几乎不用,除非绝对必要 |
| 分区顺序 | 哈希分区+单线程消费 | 🚶 中等 | 按业务键分组的顺序处理场景 | 最常用的顺序保障方式 |
| 局部顺序 | 会话粘性+本地缓存排序 | 🏃 轻微 | 只关心特定消息间顺序的场景 | 性能与顺序的最佳平衡 |
6️⃣ Kafka vs RabbitMQ:消息队列的"双雄之争"
Kafka和RabbitMQ就像是两种不同风格的武术,各有所长。如何选择最适合你的那一个?
6.1 架构模型:设计理念的碰撞
| 特性 | Kafka | RabbitMQ | 实战对比 |
|---|---|---|---|
| 设计理念 | 分布式提交日志 | AMQP协议实现 | Kafka像流水线,RabbitMQ像邮局 |
| 消息存储 | 基于磁盘的持久化日志 | 内存+磁盘 | Kafka适合海量数据,RabbitMQ响应更快 |
| 消息投递 | 拉模式为主 | 推模式为主 | Kafka消费者自主控制,RabbitMQ主动推送 |
| 消息路由 | 基于主题和分区 | 基于交换机和路由键 | Kafka简单直接,RabbitMQ灵活多变 |
| 消息确认 | 批量确认 | 单条确认 | Kafka吞吐量高,RabbitMQ可靠性强 |
6.2 性能特性:数字会说话
| 性能指标 | Kafka | RabbitMQ | 真实体验 |
|---|---|---|---|
| 吞吐量 | 🚀 极高 (100K+ msg/s) | 🚗 中等 (10K+ msg/s) | Kafka在大数据场景下更胜一筹 |
| 延迟 | ⏱️ 毫秒级 | ⚡ 微秒级 | RabbitMQ在低延迟场景更有优势 |
| 消息大小 | 适合中小消息 | 适合各种大小消息 | Kafka不适合大消息传输 |
| 消息保留 | 可长期保留 | 通常即时消费 | Kafka可作为数据存储,RabbitMQ不行 |
🔍 深度分析:在我们的实际项目中,日志收集和监控数据使用Kafka,可以轻松处理每秒10万+的事件;而对于需要复杂路由的业务消息,如订单通知、用户操作等,则选择RabbitMQ,利用其灵活的交换机机制。
6.3 适用场景:各显神通
Kafka的主战场
- 日志收集与分析:就像是数据的"无尽河流",Kafka可以持续接收并存储
- 流式处理:与Spark Streaming、Flink等无缝集成,构建实时数据管道
- 事件溯源:长期保留消息的能力让历史重现成为可能
- 监控数据处理:高吞吐适合处理海量监控指标
RabbitMQ的主战场
- 复杂路由需求:就像是一个智能的邮件分拣中心,可以根据各种规则路由消息
- 优先级队列:重要消息优先处理,就像VIP通道
- 延迟消息:定时投递功能,适合提醒、定时任务等场景
- 可靠性要求高的业务:支持事务和发布确认机制,消息不丢失
6.4 选型决策矩阵:实战指南
| 业务需求 | 推荐选择 | 理由 | 实战案例 |
|---|---|---|---|
| 日志/事件流处理 | Kafka | 高吞吐、持久化存储、流处理生态 | 用户行为分析平台 |
| 工作队列/任务分发 | RabbitMQ | 灵活路由、公平调度、任务确认 | 分布式任务调度系统 |
| 微服务解耦 | 两者皆可 | 根据吞吐量和路由复杂度选择 | 根据具体微服务特性决定 |
| 实时分析 | Kafka | 与大数据生态系统集成良好 | 实时推荐引擎 |
| 订单处理 | RabbitMQ | 可靠投递、死信处理、优先级支持 | 电商订单处理系统 |
7️⃣ 消息重试机制:系统的"安全网"
在分布式系统中,失败是不可避免的。一个设计良好的重试机制就像是系统的"安全网",确保消息不会因为临时故障而丢失。
7.1 重试策略:不同场景的"应对之道"
即时重试:快速修复的尝试
// 即时重试示例 - 处理瞬时错误的"急救措施"
public void processWithImmediateRetry(Message message) {int retryCount = 0;boolean success = false;while (!success && retryCount < MAX_IMMEDIATE_RETRIES) {try {processMessage(message); // 尝试处理消息success = true; // 处理成功} catch (Exception e) {retryCount++;log.warn("处理失败,立即重试 {}/{}", retryCount, MAX_IMMEDIATE_RETRIES);// 可以添加短暂延迟,避免立即重试可能遇到的同样问题Thread.sleep(10);}}if (!success) {// 即时重试失败,进入延时重试队列 - "升级治疗"sendToDelayedQueue(message);}
}
延时重试:给系统喘息的机会
// RabbitMQ延时重试实现 - 系统的"冷静期"
public void setupDelayedRetry() {// 声明死信交换机 - 重试消息的"中转站"channel.exchangeDeclare("retry.exchange", "direct");// 为不同重试级别创建队列,重试间隔逐级增加for (int i = 1; i <= 3; i++) {Map<String, Object> args = new HashMap<>();args.put("x-dead-letter-exchange", "main.exchange"); // 过期后转发到主交换机args.put("x-dead-letter-routing-key", "main.routing"); // 使用主路由键args.put("x-message-ttl", getRetryDelay(i)); // 设置递增的延迟时间channel.queueDeclare("retry.queue." + i, true, false, false, args);channel.queueBind("retry.queue." + i, "retry.exchange", "retry." + i);}
}private long getRetryDelay(int retryLevel) {// 指数退避策略: 1秒, 10秒, 100秒 - 给系统恢复的时间return (long) Math.pow(10, retryLevel) * 1000;
}
🔥 实战经验:在我们的支付系统中,对于第三方支付网关的调用,我们采用"3+5+10"的重试策略:先进行3次即时重试(间隔100ms),如果仍然失败,则进入延时重试,分别延迟5秒和10秒。这种策略在网关偶发性故障时非常有效。
7.2 重试间隔策略:时间的艺术
| 策略 | 实现方式 | 优点 | 缺点 | 最佳使用场景 |
|---|---|---|---|---|
| 固定间隔 | 每次重试使用相同延迟 | 实现简单,行为可预测 | 不适应系统负载变化 | 稳定的系统环境 |
| 递增间隔 | 重试间隔线性增加 | 逐渐减轻系统压力 | 恢复较慢 | 系统负载较重时 |
| 指数退避 | 重试间隔指数增长 | 快速适应系统压力 | 后期间隔可能过长 | 外部依赖不稳定时 |
| 随机退避 | 在基础间隔上增加随机量 | 避免重试风暴和惊群效应 | 不够确定性 | 高并发系统 |
7.3 重试次数与死信处理:知道何时放弃
// Kafka消费者重试与死信处理 - 消息的"生命周期管理"
public void consumeWithRetryAndDLQ() {while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {try {processRecord(record); // 尝试处理消息} catch (Exception e) {// 从消息头获取重试次数Headers headers = record.headers();int retryCount = getRetryCount(headers);if (retryCount < MAX_RETRY) {// 增加重试计数并发送到重试主题headers.add("retry-count", ByteBuffer.allocate(4).putInt(retryCount + 1).array());sendToRetryTopic(record, headers);} else {// 超过最大重试次数,发送到死信主题 - "最后的归宿"sendToDLQTopic(record, "最大重试次数已达到: " + e.getMessage());// 记录详细错误信息,便于后续分析logDeadLetterDetails(record, e);}}}consumer.commitSync(); // 提交消费位移}
}
7.4 重试最佳实践:实战经验总结
-
区分错误类型:不同错误,不同对待
- 瞬时错误(网络抖动):积极重试,短间隔
- 业务错误(数据不符合要求):直接进入死信队列,无需重试
- 系统错误(依赖服务不可用):延时重试,指数退避
-
监控与告警:重试是"救命稻草",不是"万能药"
- 设置重试次数和死信队列监控
- 当重试率超过阈值时及时告警
-
重试幂等性:确保重试操作是幂等的,避免"重复下单"等问题
-
记录重试日志:详细记录每次重试的上下文信息,成为问题排查的"时光机"
💡 架构师提示:优秀的重试机制不是为了掩盖问题,而是为了在问题发生时提供缓冲,同时收集足够信息帮助开发者定位和解决根本问题。
8️⃣ 消息队列与分布式事务:最终一致性的艺术
分布式事务是分布式系统中的"圣杯",而消息队列提供了一种基于最终一致性的优雅解决方案。
8.1 本地消息表:可靠的"双重保险"
本地消息表就像是在银行转账时,先在纸上记录转账信息,确保即使系统故障也能追踪到转账意图:
// 本地消息表实现 - 分布式事务的"纸质记录"
@Transactional
public void createOrderWithLocalMessageTable(Order order) {// 步骤1: 创建订单(本地事务)- "主要业务"orderRepository.save(order);// 步骤2: 写入本地消息表(同一事务)- "备份记录"MessageRecord message = new MessageRecord();message.setTopic("order-created");message.setPayload(JSON.toJSONString(order));message.setStatus(MessageStatus.PENDING); // 标记为待发送messageRepository.save(message);
}// 定时任务发送消息 - "异步确保"
@Scheduled(fixedDelay = 1000) // 每秒检查一次
public void sendPendingMessages() {List<MessageRecord> pendingMessages = messageRepository.findByStatus(MessageStatus.PENDING);for (MessageRecord message : pendingMessages) {try {// 发送消息到消息队列 - "实际通知"kafkaTemplate.send(message.getTopic(), message.getPayload());// 更新消息状态 - "标记完成"message.setStatus(MessageStatus.DELIVERED);messageRepository.save(message);} catch (Exception e) {// 发送失败,记录重试次数 - "失败不放弃"message.setRetryCount(message.getRetryCount() + 1);messageRepository.save(message);}}
}
🔍 深度思考:本地消息表本质上是将分布式事务拆分为多个本地事务 + 可靠消息,是一种"柔性事务"的实现。你能想到它与两阶段提交(2PC)相比有哪些优势吗?
8.2 事务消息:中间件原生支持
事务消息是RocketMQ等消息队列提供的特性,简化了分布式事务的实现:
// RocketMQ事务消息实现 - 中间件级的事务支持
public void createOrderWithTransactionMessage(Order order) {// 构建消息 - "意图声明"Message message = new Message("order-topic", order.toString().getBytes());// 发送事务消息 - "一气呵成"transactionProducer.sendMessageInTransaction(message, new LocalTransactionExecuter() {@Overridepublic LocalTransactionState executeLocalTransaction(Message msg, Object arg) {try {// 执行本地事务 - "实际操作"orderService.createOrder(order);return LocalTransactionState.COMMIT_MESSAGE; // 提交事务} catch (Exception e) {return LocalTransactionState.ROLLBACK_MESSAGE; // 回滚事务}}}, null);
}
8.3 TCC模式:更细粒度的控制
TCC(Try-Confirm-Cancel)是一种补偿型事务模式,与消息队列结合使用可以实现更灵活的分布式事务:
// TCC与消息队列结合 - 更细粒度的事务控制
public void createOrderWithTCC(Order order) {// Try阶段 - "资源预留"String txId = tccCoordinator.begin(); // 开始事务try {// 预留资源 - "占位但不实际执行"orderService.tryCreate(order, txId); // 尝试创建订单inventoryService.tryReduce(order.getProductId(), order.getQuantity(), txId); // 尝试扣减库存// 发送确认消息 - "提交意向"Message confirmMessage = new Message("tcc-confirm", txId.getBytes());producer.send(confirmMessage);// 提交事务 - "最终确认"tccCoordinator.confirm(txId);} catch (Exception e) {// 发送取消消息 - "回滚意向"Message cancelMessage = new Message("tcc-cancel", txId.getBytes());producer.send(cancelMessage);// 回滚事务 - "释放资源"tccCoordinator.cancel(txId);throw e;}
}
8.4 分布式事务方案对比:选择最适合的武器
| 方案 | 一致性级别 | 实现复杂度 | 性能影响 | 适用场景 | 实战评价 |
|---|---|---|---|---|---|
| 本地消息表 | 最终一致性 | 🔶 中等 | 🟢 轻微 | 单体应用拆分微服务 | 最容易实现,适合大多数场景 |
| 事务消息 | 最终一致性 | 🟢 低 | 🟢 轻微 | 支持事务消息的MQ | 依赖特定MQ,但使用简单 |
| TCC+消息队列 | 最终一致性 | 🔴 高 | 🔶 中等 | 复杂业务流程 | 实现复杂,但控制粒度最细 |
| Saga模式 | 最终一致性 | 🔶 中等 | 🟢 轻微 | 长事务流程 | 适合多步骤业务流程 |
🌟 总结与展望:消息队列的未来之路
消息队列技术已经成为现代分布式系统的核心基础设施,掌握其核心原理和最佳实践对于构建高可用、高性能的系统至关重要。本文深入探讨了消息队列领域的八大核心问题,从性能优化到分布式事务,希望能为你的技术之路提供一盏明灯。
随着云原生技术的发展,消息队列也在不断演进,未来将呈现以下趋势:
- 云原生消息队列:与Kubernetes深度集成,支持自动扩缩容,弹性伸缩
- 多协议融合:单一消息系统支持多种协议,统一消息基础设施
- 流批一体化:消息队列与流处理引擎的边界逐渐模糊,数据处理更加灵活
- 边缘计算支持:支持在边缘节点部署轻量级消息处理,降低延迟
- AI驱动的智能运维:自动检测异常模式并进行优化,减轻运维负担
🚀 个人观点:消息队列的未来不仅是技术演进,更是与业务深度融合的过程。真正的价值不在于消息的传递,而在于如何通过消息驱动业务流程,实现更灵活、更有弹性的系统架构。
希望本文能够帮助你在技术面试中脱颖而出,也为实际工作中的消息队列应用提供参考。技术之路漫长,但每一步的深入理解都会让你走得更远!
💻 关注我的更多技术内容
如果你喜欢这篇文章,别忘了点赞、收藏和分享!有任何问题,欢迎在评论区留言讨论!我会持续分享更多分布式系统、高并发架构的深度技术内容!
本文首发于我的技术博客,转载请注明出处
相关文章:

面试高频问题
文章目录 🚀 消息队列核心技术揭秘:从入门到秒杀面试官1️⃣ Kafka为何能"吞云吐雾"?性能背后的秘密1.1 顺序写入与零拷贝:性能的双引擎1.2 分区并行:数据的"八车道高速公路"1.3 页缓存与批量处理…...

xmind转换为markdown
文章目录 解锁思维导图新姿势:将XMind转为结构化Markdown 一、认识Xmind结构二、核心转换流程详解1.解压XMind文件(ZIP处理)2.解析JSON数据结构3:递归转换树形结构4:Markdown层级生成逻辑 三、完整代码 解锁思维导图新…...

【WebSocket】SpringBoot项目中使用WebSocket
1. 导入坐标 如果springboot父工程没有加入websocket的起步依赖,添加它的坐标的时候需要带上版本号。 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-websocket</artifactId> </dep…...
恶补电源:1.电桥
一、元器件的选择 搜索并选择电桥,再multisim中选择FWB,就有各种型号的电桥: 电桥是用来干嘛的呢? 它是一个由四个二极管搭成的“桥梁”形状的电路,用来把交流电(AC)变成直流电(DC)。…...
论文阅读:Matting by Generation
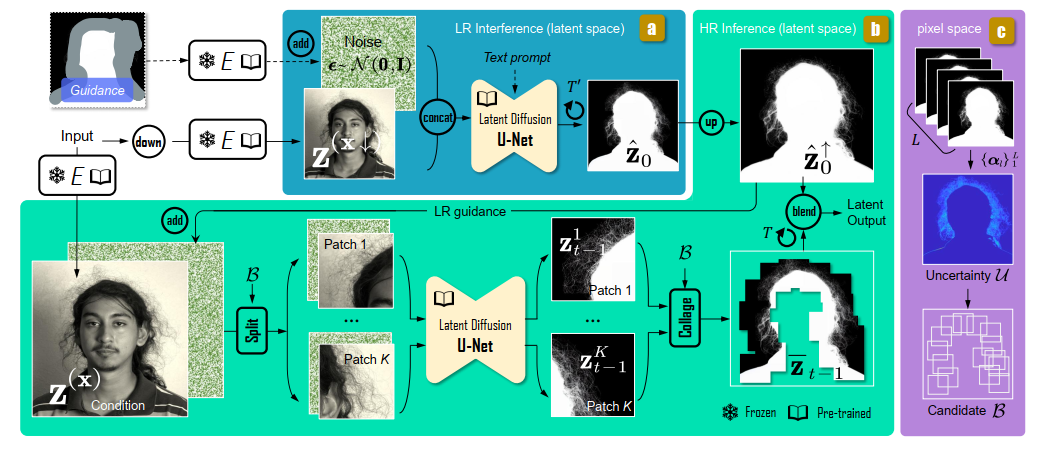
今天介绍一篇关于 matting 抠图的文章,抠图也算是计算机视觉里面非常经典的一个任务了。从早期的经典算法到如今的深度学习算法,已经有很多的工作和这个任务相关。这两年 diffusion 模型很火,大家又开始用 diffusion 模型做各种 CV 任务了&am…...

Neko虚拟浏览器远程协作方案:Docker+内网穿透技术部署实践
前言:本文将向开发者介绍一款创新性协作工具——Neko虚拟浏览器。在数字化协作场景中,跨地域的团队常需面对实时共享屏幕、协同编辑文档等需求。通过本指南,你将掌握在Ubuntu系统中使用容器化技术部署该工具的具体方案,并结合内网…...

实战设计模式之模板方法模式
概述 模板方法模式定义了一个操作中的算法骨架,并将某些步骤延迟到子类中实现。模板方法使得子类可以在不改变算法结构的前提下,重新定义算法中的某些步骤。简单来说,就是在一个方法中定义了要执行的步骤顺序或算法框架,但允许子类…...

【Linux】Linux安装并配置RabbitMQ
目录 1. 安装 Erlang 2. 安装 RabbitMQ 2.1.添加 RabbitMQ 仓库 2.2.安装 RabbitMQ 3.配置 3.1.启动和管理服务 4. 访问管理界面 5.安装问题 6.修改密码 7.修改端口 7.1.找到文件 7.2.修改文件 1. 安装 Erlang 由于 RabbitMQ 是用 Erlang 编写的,需要先安…...
Python训练营-Day26-函数专题1:函数定义与参数
题目1:计算圆的面积 任务: 编写一个名为 calculate_circle_area 的函数,该函数接收圆的半径 radius 作为参数,并返回圆的面积。圆的面积 π * radius (可以使用 math.pi 作为 π 的值)要求:函数接收一个位置参数 radi…...

【Kafka】Kafka从入门到实战:构建高吞吐量分布式消息系统
Kafka从入门到实战:构建高吞吐量分布式消息系统 一、Kafka概述 Apache Kafka是一个分布式流处理平台,最初由LinkedIn开发,后成为Apache顶级项目。它被设计用于高吞吐量、低延迟的消息处理,能够处理来自多个生产者的海量数据,并将这些数据实时传递给消费者。 Kafka核心特…...

Android写一个捕获全局异常的工具类
项目开发和实际运行过程中难免会遇到异常发生,系统提供了一个可以捕获全局异常的工具Uncaughtexceptionhandler,它是Thread的子类(就是package java.lang;里线程的Thread)。本文将利用它将设备信息、报错信息以及错误的发生时间都…...

人工智能 - 在Dify、Coze、n8n、FastGPT和RAGFlow之间做出技术选型
在Dify、Coze、n8n、FastGPT和RAGFlow之间做出技术选型。这些平台各有侧重,适用场景差异显著。下面我将从核心功能定位、典型应用场景、真实体验痛点、选型决策关键点进行拆解,并提供具体场景下的推荐方案。 一、核心功能定位速览 平台核心定位技术栈亮…...

绕过 Xcode?使用 Appuploader和主流工具实现 iOS 上架自动化
iOS 应用的发布流程一直是开发链路中最“苹果味”的环节:强依赖 Xcode、必须使用 macOS、各种证书和描述文件配置……对很多跨平台开发者来说,这一套流程并不友好。 特别是当你的项目主要在 Windows 或 Linux 下开发(例如 Flutter、React Na…...

C++_哈希表
本篇文章是对C学习的哈希表部分的学习分享 相信一定会对你有所帮助~ 那咱们废话不多说,直接开始吧! 一、基础概念 1. 哈希核心思想: 哈希函数的作用:通过此函数建立一个Key与存储位置之间的映射关系。理想目标:实现…...

WEB3全栈开发——面试专业技能点P7前端与链上集成
一、Next.js技术栈 ✅ 概念介绍 Next.js 是一个基于 React 的 服务端渲染(SSR)与静态网站生成(SSG) 框架,由 Vercel 开发。它简化了构建生产级 React 应用的过程,并内置了很多特性: ✅ 文件系…...
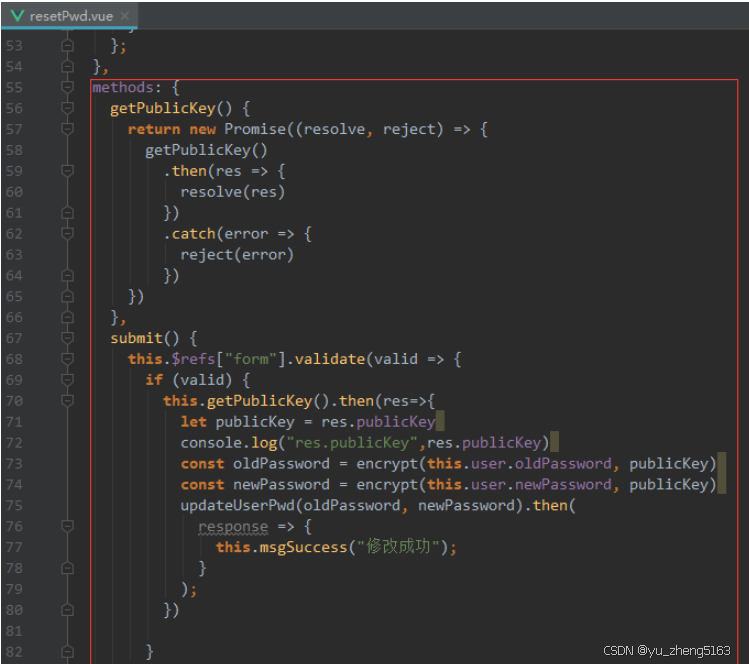
若依登录用户名和密码加密
/*** 获取公钥:前端用来密码加密* return*/GetMapping("/getPublicKey")public RSAUtil.RSAKeyPair getPublicKey() {return RSAUtil.rsaKeyPair();}新建RSAUti.Java package com.ruoyi.common.utils;import org.apache.commons.codec.binary.Base64; im…...

Linux 下 DMA 内存映射浅析
序 系统 I/O 设备驱动程序通常调用其特定子系统的接口为 DMA 分配内存,但最终会调到 DMA 子系统的dma_alloc_coherent()/dma_alloc_attrs() 等接口。 关于 dma_alloc_coherent 接口详细的代码讲解、调用流程,可以参考这篇文章,我觉得写的非常…...

第八部分:阶段项目 6:构建 React 前端应用
现在,是时候将你学到的 React 基础知识付诸实践,构建一个简单的前端应用来模拟与后端 API 的交互了。在这个阶段,你可以先使用模拟数据,或者如果你的后端 API(阶段项目 5)已经搭建好,可以直接连…...

6️⃣Go 语言中的哈希、加密与序列化:通往区块链世界的钥匙
Go 语言中的哈希、加密与序列化:通往区块链世界的钥匙 一、前言:离区块链还有多远? 区块链听起来可能遥不可及,似乎是只有密码学专家和资深工程师才能涉足的领域。但事实上,构建一个区块链的核心并不复杂,尤其当你已经掌握了一门系统编程语言,比如 Go。 要真正理解区…...
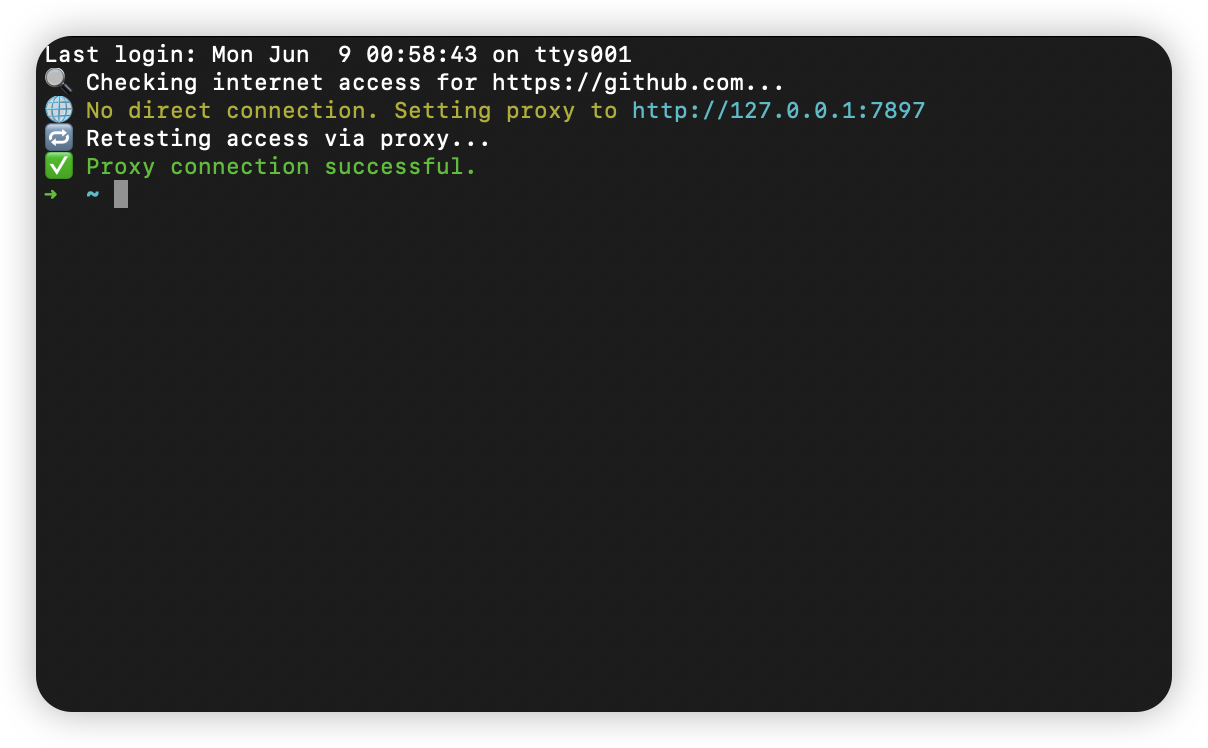
macOS 终端智能代理检测
🧠 终端智能代理检测:自动判断是否需要设置代理访问 GitHub 在开发中,使用 GitHub 是非常常见的需求。但有时候我们会发现某些命令失败、插件无法更新,例如: fatal: unable to access https://github.com/ohmyzsh/oh…...

前端高频面试题2:浏览器/计算机网络
本专栏相关链接 前端高频面试题1:HTML/CSS 前端高频面试题2:浏览器/计算机网络 前端高频面试题3:JavaScript 1.什么是强缓存、协商缓存? 强缓存: 当浏览器请求资源时,首先检查本地缓存是否命中。如果命…...

智能职业发展系统:AI驱动的职业规划平台技术解析
智能职业发展系统:AI驱动的职业规划平台技术解析 引言:数字时代的职业革命 在当今瞬息万变的就业市场中,传统的职业规划方法已无法满足个人和企业的需求。据统计,全球每年有超过2亿人面临职业转型困境,而企业也因此遭…...
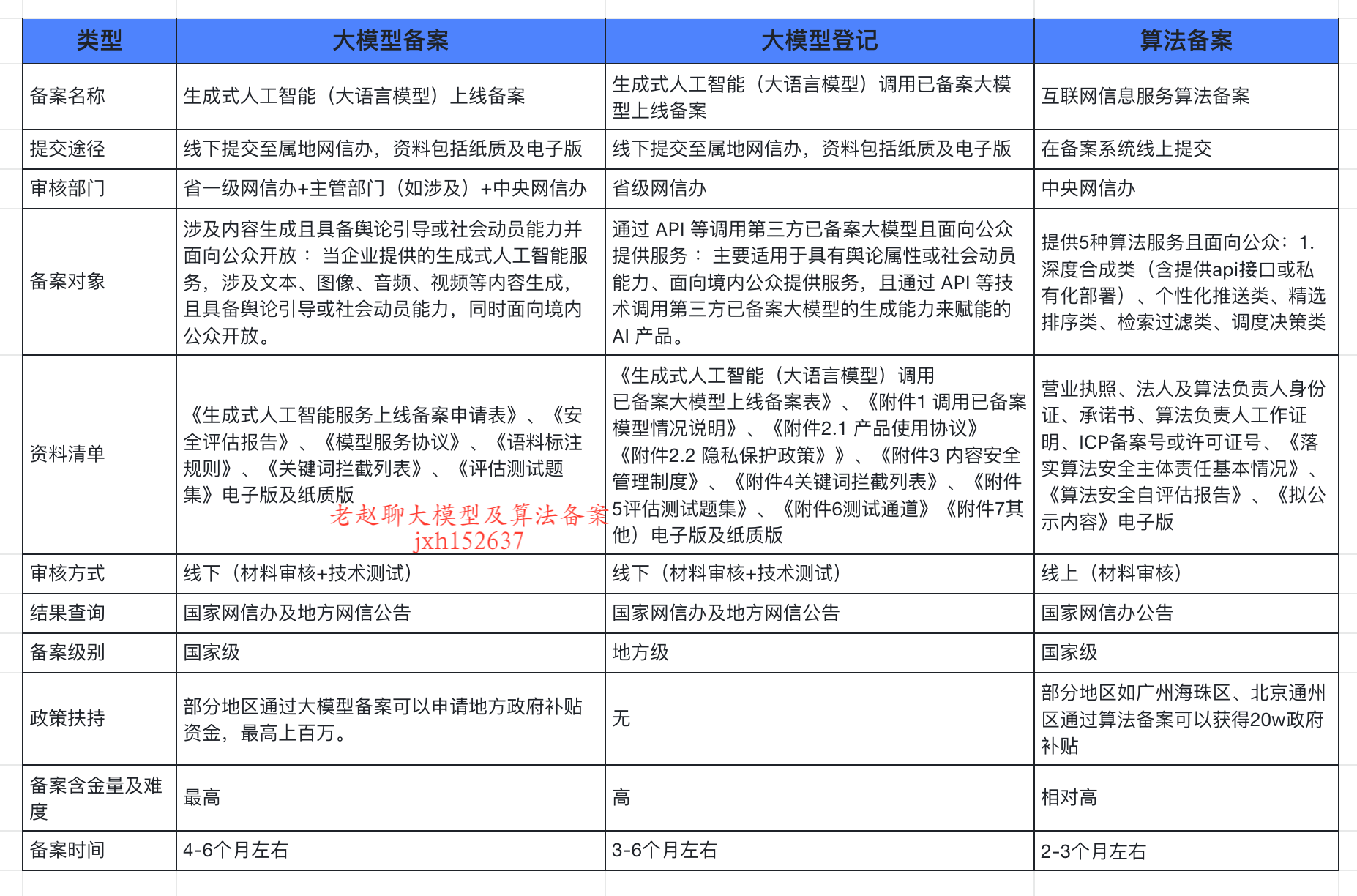
企业大模型服务合规指南:深度解析备案与登记制度
伴随AI技术的爆炸式发展,尤其是大模型(LLM)在各行各业的深度应用和整合,企业利用AI技术提升效率、创新服务的步伐不断加快。无论是像DeepSeek这样的前沿技术提供者,还是积极拥抱AI转型的传统企业,在面向公众…...

高防服务器价格高原因分析
高防服务器的价格较高,主要是由于其特殊的防御机制、硬件配置、运营维护等多方面的综合成本。以下从技术、资源和服务三个维度详细解析高防服务器昂贵的原因: 一、硬件与技术投入 大带宽需求 DDoS攻击通过占用大量带宽资源瘫痪目标服务器,因此…...

Unity VR/MR开发-VR开发与传统3D开发的差异
视频讲解链接:【XR马斯维】VR/MR开发与传统3D开发的差异【UnityVR/MR开发教程--入门】_哔哩哔哩_bilibili...
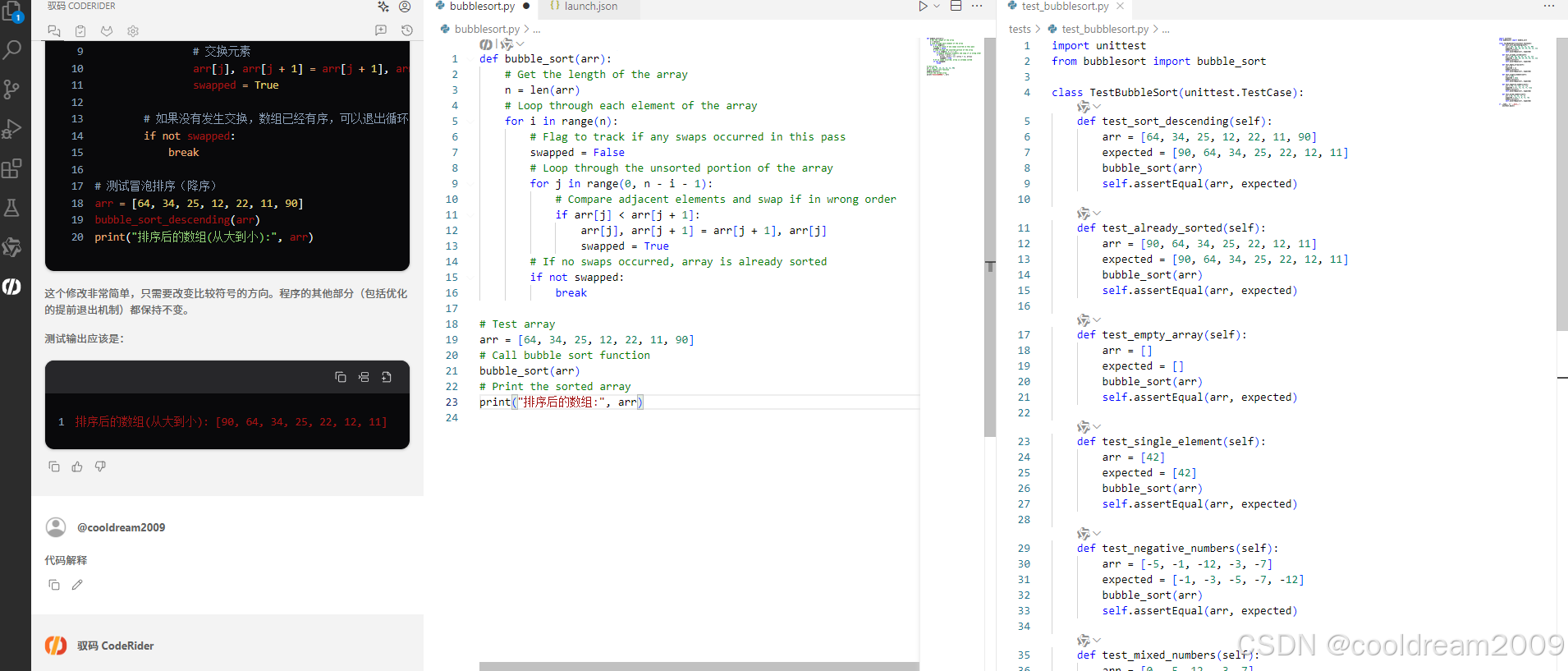
在 Visual Studio Code 中使用驭码 CodeRider 提升开发效率:以冒泡排序为例
目录 前言1 插件安装与配置1.1 安装驭码 CodeRider1.2 初始配置建议 2 示例代码:冒泡排序3 驭码 CodeRider 功能详解3.1 功能概览3.2 代码解释功能3.3 自动注释生成3.4 逻辑修改功能3.5 单元测试自动生成3.6 代码优化建议 4 驭码的实际应用建议5 常见问题与解决建议…...

Pydantic + Function Calling的结合
1、Pydantic Pydantic 是一个 Python 库,用于数据验证和设置管理,通过 Python 类型注解强制执行数据类型。它广泛用于 API 开发(如 FastAPI)、配置管理和数据解析,核心功能包括: 数据验证:通过…...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现指南针功能
指南针功能是许多位置服务应用的基础功能之一。下面我将详细介绍如何在HarmonyOS 5中使用DevEco Studio实现指南针功能。 1. 开发环境准备 确保已安装DevEco Studio 3.1或更高版本确保项目使用的是HarmonyOS 5.0 SDK在项目的module.json5中配置必要的权限 2. 权限配置 在mo…...
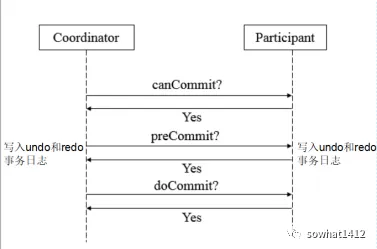
解析两阶段提交与三阶段提交的核心差异及MySQL实现方案
引言 在分布式系统的事务处理中,如何保障跨节点数据操作的一致性始终是核心挑战。经典的两阶段提交协议(2PC)通过准备阶段与提交阶段的协调机制,以同步决策模式确保事务原子性。其改进版本三阶段提交协议(3PC…...

Spring Boot + MyBatis 集成支付宝支付流程
Spring Boot MyBatis 集成支付宝支付流程 核心流程 商户系统生成订单调用支付宝创建预支付订单用户跳转支付宝完成支付支付宝异步通知支付结果商户处理支付结果更新订单状态支付宝同步跳转回商户页面 代码实现示例(电脑网站支付) 1. 添加依赖 <!…...