C++_哈希表
本篇文章是对C++学习的哈希表部分的学习分享
相信一定会对你有所帮助~
那咱们废话不多说,直接开始吧!
一、基础概念
1. 哈希核心思想:
- 哈希函数的作用:通过此函数建立一个Key与存储位置之间的映射关系。
- 理想目标:实现O(1)时间复杂度的查找
2.直接定址法
本质:⽤关键字计算出⼀个绝对位置或者相对位置
适用场景:Key 范围集中(如 [0,99])
二、关键问题与解决方案
1.哈希冲突:
-
根本原因:不同 Key 映射到同一位置
-
负载因子(Load Factor):
α = N/M(N为已映射存储的值,M为哈希表的大小)-
α↑→ 冲突概率↑,空间利用率↑ -
α↓→ 冲突概率↓,空间利用率↓
-
2. 哈希函数设计原则:
-
目标:均匀分布、减少冲突
-
除法散列法 / 除留余数法(重点):
-
h(key) = key % M -
M的选择:避免2^n或10^n,因为 key%M 会仅保留 key 的最后 n 位(二进制或十进制),导致不同 key 可能映射到同一位置。例如:
-
M=16(2^4)时,63(00111111)和31(00011111)的后4位均为 1111,哈希值均为15。
M=100(10^2)时,112和12312的后两位均为12,哈希值相同。
-
理论上建议选择远离 2^n 的质数作为哈希表大小 M,以减少冲突。但实践中可灵活优化,如 Java 的
HashMap采用 2^16 作为 M,通过位运算((key ^ (key >> 16)) & (M-1))替代取模,既提升效率又让高位参与计算,分散哈希值。核心在于均匀分布,而非机械套用理论。 -
其他方法(了解):乘法散列法、全域散列法
3. 非整数Key的处理
有些数据类型无法直接用整形的哈希函数,比如string字符串类型,这时我们便可以尝试将字符串转证书(BKDR哈希思路)
size_t hash = 0;
for (char c : str) {hash = hash * 131 + c; // 质数 131 减少冲突
}三、 冲突解决策略
1. 开放定址法
线性探测:
- 从发⽣冲突的位置开始,依次线性向后探测,直到寻找到下⼀个没有存储数据的位置为⽌,如果⾛ 到哈希表尾,则回绕到哈希表头的位置
- 冲突后公式:
hashi = (hash0 + i) % M - 缺点:易产生聚集(Clustering)
二次探测:
-
从发⽣冲突的位置开始,依次左右按⼆次⽅跳跃式探测,直到寻找到下⼀个没有存储数据的位置为 ⽌,如果往右⾛到哈希表尾,则回绕到哈希表头的位置;如果往左⾛到哈希表头,则回绕到哈希表 尾的位置
- 公式:
hashi = (hash0 ± i²) % M - 缓解聚集,但可能错过空位
删除优化:
-
状态标记(
EXIST/EMPTY/DELETE)
-
EXIST:当前槽位存储有效数据。 -
EMPTY:槽位从未使用过,查找时可终止探测。 -
DELETE:槽位数据已删除,但探测链不能中断(需继续向后查找)。
enum STATE
{EMPTY,DELETE,EXIST
};扩容机制
1. 负载因子与扩容条件
-
负载因子(Load Factor):
α = 元素数量 / 哈希表大小 -
扩容阈值:当
α ≥ 0.7时扩容,以降低冲突概率。 -
扩容倍数:通常扩容为原大小的 2倍。
2. 质数大小的必要性
-
理论要求:哈希表大小
M应为质数,使key % M分布更均匀(减少聚集)。 -
问题:若初始
M是质数(如 7),2倍扩容后(14)不再是质数,可能引发更多冲突。
3.解决方案
-
SGI 版本的质数表:
预定义质数表:按近似2倍递增的质数序列扩容
//写出来的28个素数(每一个都差不多为前一个的两倍)
static const int __stl_num_primes = 28;
static const unsigned long __stl_prime_list[__stl_num_primes] =
{53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291
};//取素数的函数
inline unsigned long __stl_next_prime(unsigned long n)
{const unsigned long* first = __stl_prime_list;const unsigned long* last = __stl_prime_list + __stl_num_primes;const unsigned long* pos = lower_bound(first, last, n);return pos == last ? *(last - 1) : *pos;
}-
扩容步骤:
-
当前大小为
53(质数),负载因子 ≥0.7 时,从表中取下一个质数97(≈53×1.8)。 -
重新哈希所有元素到新表。
-
-
例子:在插入函数中,发现负载因子>=0.7后的操作:
-
bool Insert(const pair<K, V>& kv) {//Check(_tables);//如果负载因子 >=0.7 时就需要扩容了if ((double)_n / (double)_tables.size() >= 0.7){HashTable<K, V,Hash> newHT(__stl_next_prime(_tables.size()+1));for (size_t i = 0; i < _tables.size(); i++){if (_tables[i]._state == EXIST){newHT.Insert(_tables[i]._kv);}}_tables.swap(newHT._tables);return true;}完整代码实现
-
#pragma once #include<iostream> #include<vector> using namespace std;//写出来的28个素数(每一个都差不多为前一个的两倍) static const int __stl_num_primes = 28; static const unsigned long __stl_prime_list[__stl_num_primes] = {53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291 };//取素数的函数 inline unsigned long __stl_next_prime(unsigned long n) {const unsigned long* first = __stl_prime_list;const unsigned long* last = __stl_prime_list + __stl_num_primes;const unsigned long* pos = lower_bound(first, last, n);return pos == last ? *(last - 1) : *pos; }enum STATE {EMPTY,DELETE,EXIST };template<class K,class V> struct HashData {pair<K, V> _kv;STATE _state; };template<class K> struct HashFunc {size_t operator()(const K& key){return (size_t)key;} };//因为用string类型的数值做key的情况十分常见,但是在unordered_map中却没有在另外写一个仿函数 //是因为直接将HashFunc 特化 了 template<> struct HashFunc<string> {size_t operator()(const string& s){size_t hashi = 0;for (auto e : s){hashi += e;}return hashi;} };template<class K,class V,class Hash = HashFunc<K>> class HashTable { public://构造函数HashTable(size_t size = __stl_next_prime(0)):_n(0), _tables(size){}//将一些非整形的数值强转成整形一次方便映射关系的计算void Check(vector<HashData<K,V>>& table){double fuzai = _n / table.size();if (fuzai >= 0.7){cout << "负载过大" << endl;}else{cout << "负载正常" << endl;}}bool Insert(const pair<K, V>& kv){//Check(_tables);//如果负载因子 >=0.7 时就需要扩容了if ((double)_n / (double)_tables.size() >= 0.7){HashTable<K, V,Hash> newHT(__stl_next_prime(_tables.size()+1));for (size_t i = 0; i < _tables.size(); i++){if (_tables[i]._state == EXIST){newHT.Insert(_tables[i]._kv);}}_tables.swap(newHT._tables);return true;}Hash hs;size_t hash0 = hs(kv.first) % _tables.size();size_t hashi = hash0;size_t i = 1;//如果映射的位置已经被占用了while (_tables[hashi]._state == EXIST){hashi = (hashi + i) % _tables.size();++i;}_tables[hashi]._kv = kv;_tables[hashi]._state = EXIST;++_n;return true;}HashData<K,V>* Find(const K& key){Hash hs;size_t hash0 = hs(key) % _tables.size();size_t hashi = hash0;size_t i = 1;while (_tables[hashi]._state != EMPTY){if (_tables[hashi]._kv.first == key && _tables[hashi]._state != DELETE){return &_tables[hashi];}hashi = (hashi + i) % _tables.size();++i;}cout << " 找不到找不到 " ;return nullptr;}bool Erase(const K& key ){HashData<K, V>* ret = Find(key);if (ret){ret->_state = DELETE;cout << "成功删除!" << endl;return true;}else{cout << "删除失败奥" << endl;return false;}}private:vector<HashData<K, V>> _tables;size_t _n; }; -
2.链地址法
-
核心思想:冲突位置挂链表(桶)

-
扩容时机:负载因子
α ≥ 1(STL 风格) -
极端场景优化:
-
链表过长 → 转红黑树(Java 8 HashMap 策略)
-
-
扩容技巧:
-
直接移动旧节点(避免重复创建):
-
// 旧节点重新映射到新表
cur->_next = newTable[hashi];
newTable[hashi] = cur;- 例子:在哈希桶版本的Insert函数中发现负载因子过大
-
bool Insert(const pair<K, V>& kv) {if (_n == _tables.size()){vector<Node*> newTables(__stl_next_prime(0), nullptr);for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;size_t hashi = cur->_kv.first % newTables.size();cur->_next = newTables[hashi];newTables[hashi] = cur;cur = next;}_tables[i] = nullptr;}_tables.swap(newTables);}size_t hashi = kv.first % _tables.size();Node* newnode = new Node(kv);newnode->_next = _table[hashi];_tables[hashi] = newnode;++_n;return true; }完整代码实现
-
template<class K, class V> struct HashNode {pair<K, V> _kv;HashNode* _next;HashNode(const pair<K,V>& key):_kv(key),_next(nullptr){} };template<class K,class V> class HashTable {typedef HashNode<K, V> Node; public:HashTable(size_t size = __stl_next_prime(0)):_tables(size,nullptr){}~HashTable(){for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;}}bool Insert(const pair<K, V>& kv){if (_n == _tables.size()){vector<Node*> newTables(__stl_next_prime(0), nullptr);for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;size_t hashi = cur->_kv.first % newTables.size();cur->_next = newTables[hashi];newTables[hashi] = cur;cur = next;}_tables[i] = nullptr;}_tables.swap(newTables);}size_t hashi = kv.first % _tables.size();Node* newnode = new Node(kv);newnode->_next = _table[hashi];_tables[hashi] = newnode;++_n;return true;}Node* Find(const K& key){size_t hashi = key % _tables.size();Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){return cur;}cur = cur->_next;}return nullptr;}bool Erase(const K& key) {size_t hashi = key % _tables.size();Node* prev = nullptr;Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){if (prev == nullptr){cur->_next = _tables[hashi];}else{prev->_next = cur->_next;}delete cur;return true;}prev = cur;cur = cur->_next;}return false;} private:vector<Node*> _tables;size_t _n = 0; };
那么本次关于哈希表的知识分享就此结束了~
非常感谢你能够看到这里~
如果感觉对你有些许的帮助也请给我三连 这会给予我莫大的鼓舞!
之后依旧会继续更新C++学习分享
那么就让我们
下次再见~
相关文章:
C++_哈希表
本篇文章是对C学习的哈希表部分的学习分享 相信一定会对你有所帮助~ 那咱们废话不多说,直接开始吧! 一、基础概念 1. 哈希核心思想: 哈希函数的作用:通过此函数建立一个Key与存储位置之间的映射关系。理想目标:实现…...

WEB3全栈开发——面试专业技能点P7前端与链上集成
一、Next.js技术栈 ✅ 概念介绍 Next.js 是一个基于 React 的 服务端渲染(SSR)与静态网站生成(SSG) 框架,由 Vercel 开发。它简化了构建生产级 React 应用的过程,并内置了很多特性: ✅ 文件系…...
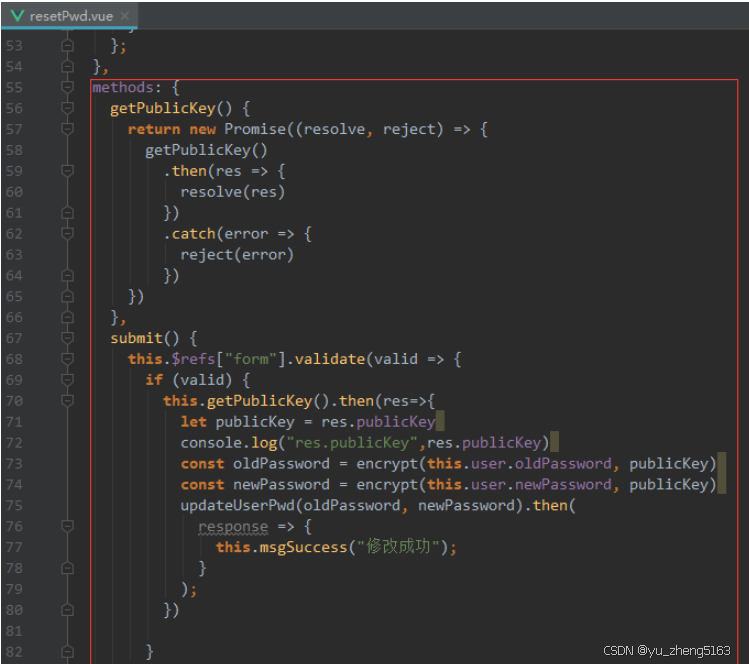
若依登录用户名和密码加密
/*** 获取公钥:前端用来密码加密* return*/GetMapping("/getPublicKey")public RSAUtil.RSAKeyPair getPublicKey() {return RSAUtil.rsaKeyPair();}新建RSAUti.Java package com.ruoyi.common.utils;import org.apache.commons.codec.binary.Base64; im…...

Linux 下 DMA 内存映射浅析
序 系统 I/O 设备驱动程序通常调用其特定子系统的接口为 DMA 分配内存,但最终会调到 DMA 子系统的dma_alloc_coherent()/dma_alloc_attrs() 等接口。 关于 dma_alloc_coherent 接口详细的代码讲解、调用流程,可以参考这篇文章,我觉得写的非常…...

第八部分:阶段项目 6:构建 React 前端应用
现在,是时候将你学到的 React 基础知识付诸实践,构建一个简单的前端应用来模拟与后端 API 的交互了。在这个阶段,你可以先使用模拟数据,或者如果你的后端 API(阶段项目 5)已经搭建好,可以直接连…...

6️⃣Go 语言中的哈希、加密与序列化:通往区块链世界的钥匙
Go 语言中的哈希、加密与序列化:通往区块链世界的钥匙 一、前言:离区块链还有多远? 区块链听起来可能遥不可及,似乎是只有密码学专家和资深工程师才能涉足的领域。但事实上,构建一个区块链的核心并不复杂,尤其当你已经掌握了一门系统编程语言,比如 Go。 要真正理解区…...
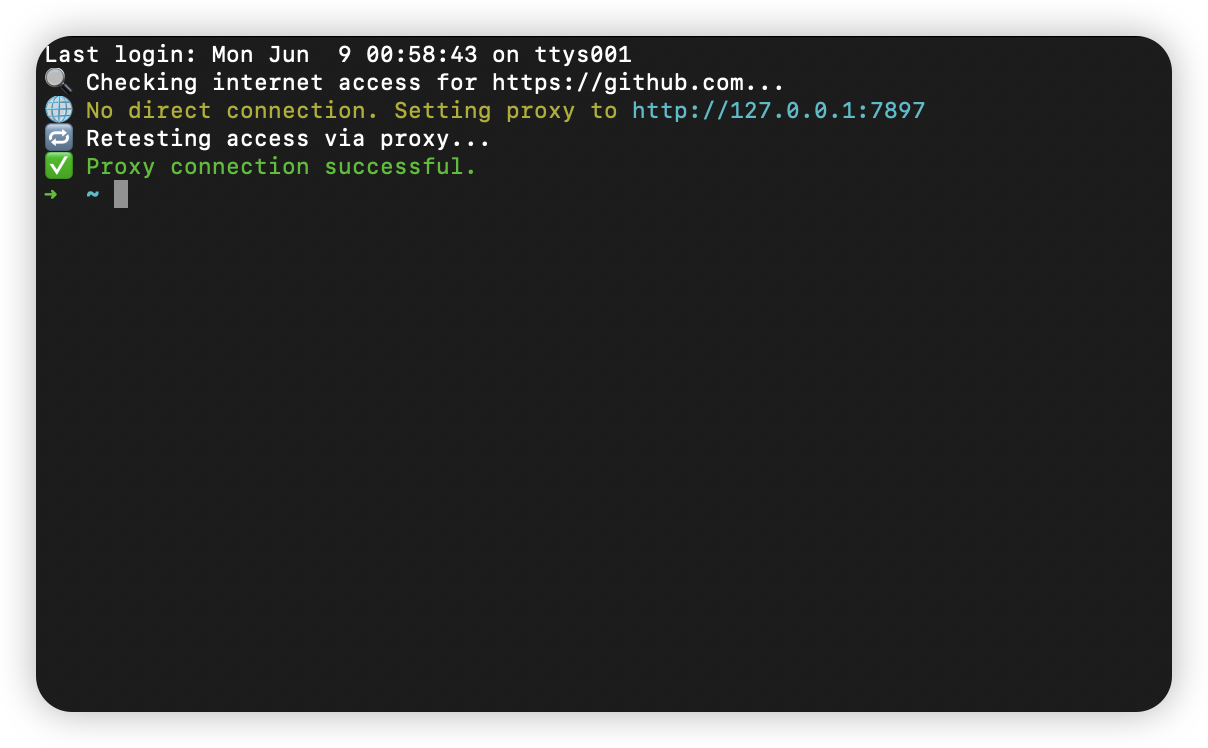
macOS 终端智能代理检测
🧠 终端智能代理检测:自动判断是否需要设置代理访问 GitHub 在开发中,使用 GitHub 是非常常见的需求。但有时候我们会发现某些命令失败、插件无法更新,例如: fatal: unable to access https://github.com/ohmyzsh/oh…...

前端高频面试题2:浏览器/计算机网络
本专栏相关链接 前端高频面试题1:HTML/CSS 前端高频面试题2:浏览器/计算机网络 前端高频面试题3:JavaScript 1.什么是强缓存、协商缓存? 强缓存: 当浏览器请求资源时,首先检查本地缓存是否命中。如果命…...

智能职业发展系统:AI驱动的职业规划平台技术解析
智能职业发展系统:AI驱动的职业规划平台技术解析 引言:数字时代的职业革命 在当今瞬息万变的就业市场中,传统的职业规划方法已无法满足个人和企业的需求。据统计,全球每年有超过2亿人面临职业转型困境,而企业也因此遭…...
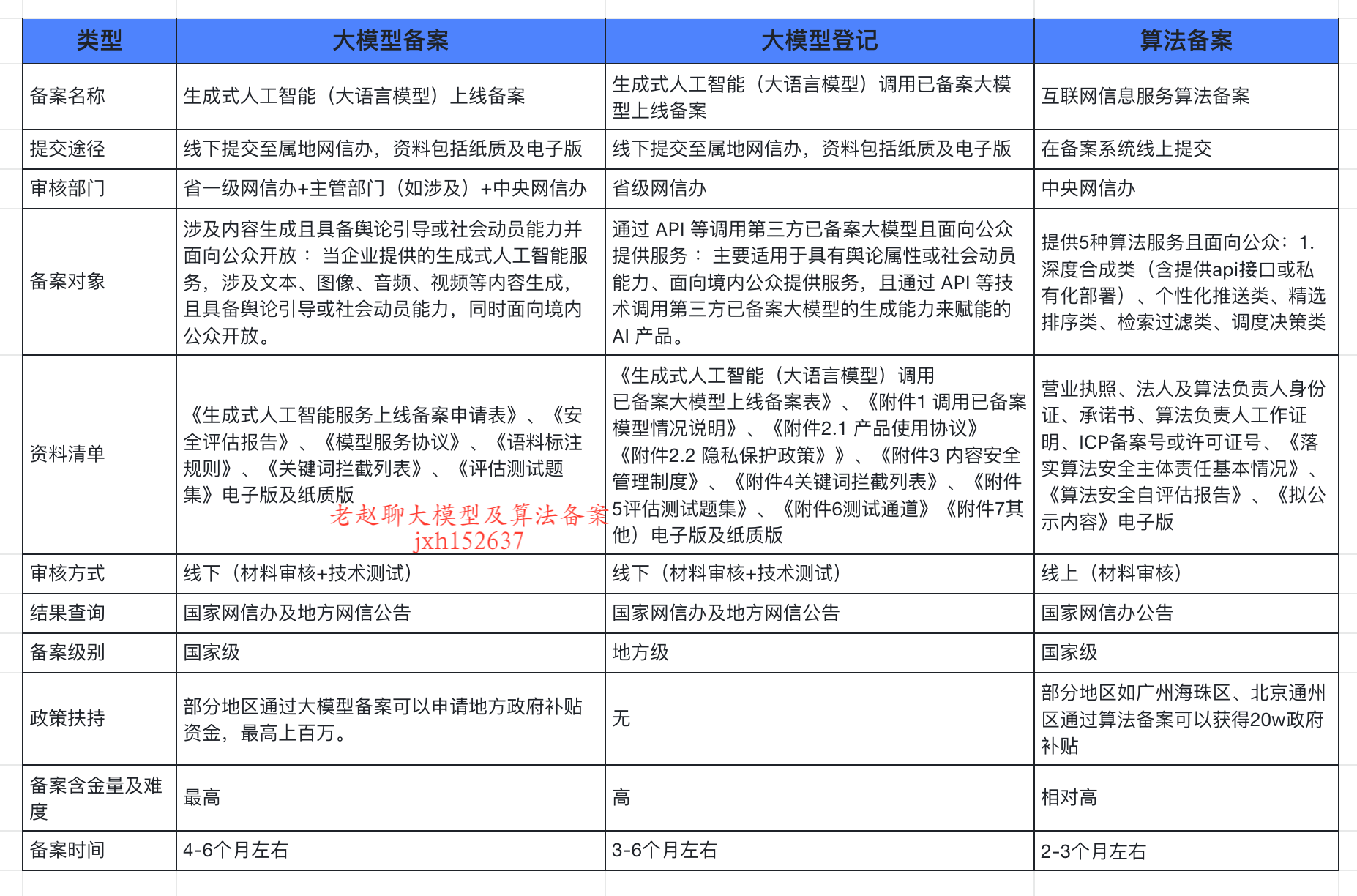
企业大模型服务合规指南:深度解析备案与登记制度
伴随AI技术的爆炸式发展,尤其是大模型(LLM)在各行各业的深度应用和整合,企业利用AI技术提升效率、创新服务的步伐不断加快。无论是像DeepSeek这样的前沿技术提供者,还是积极拥抱AI转型的传统企业,在面向公众…...

高防服务器价格高原因分析
高防服务器的价格较高,主要是由于其特殊的防御机制、硬件配置、运营维护等多方面的综合成本。以下从技术、资源和服务三个维度详细解析高防服务器昂贵的原因: 一、硬件与技术投入 大带宽需求 DDoS攻击通过占用大量带宽资源瘫痪目标服务器,因此…...

Unity VR/MR开发-VR开发与传统3D开发的差异
视频讲解链接:【XR马斯维】VR/MR开发与传统3D开发的差异【UnityVR/MR开发教程--入门】_哔哩哔哩_bilibili...
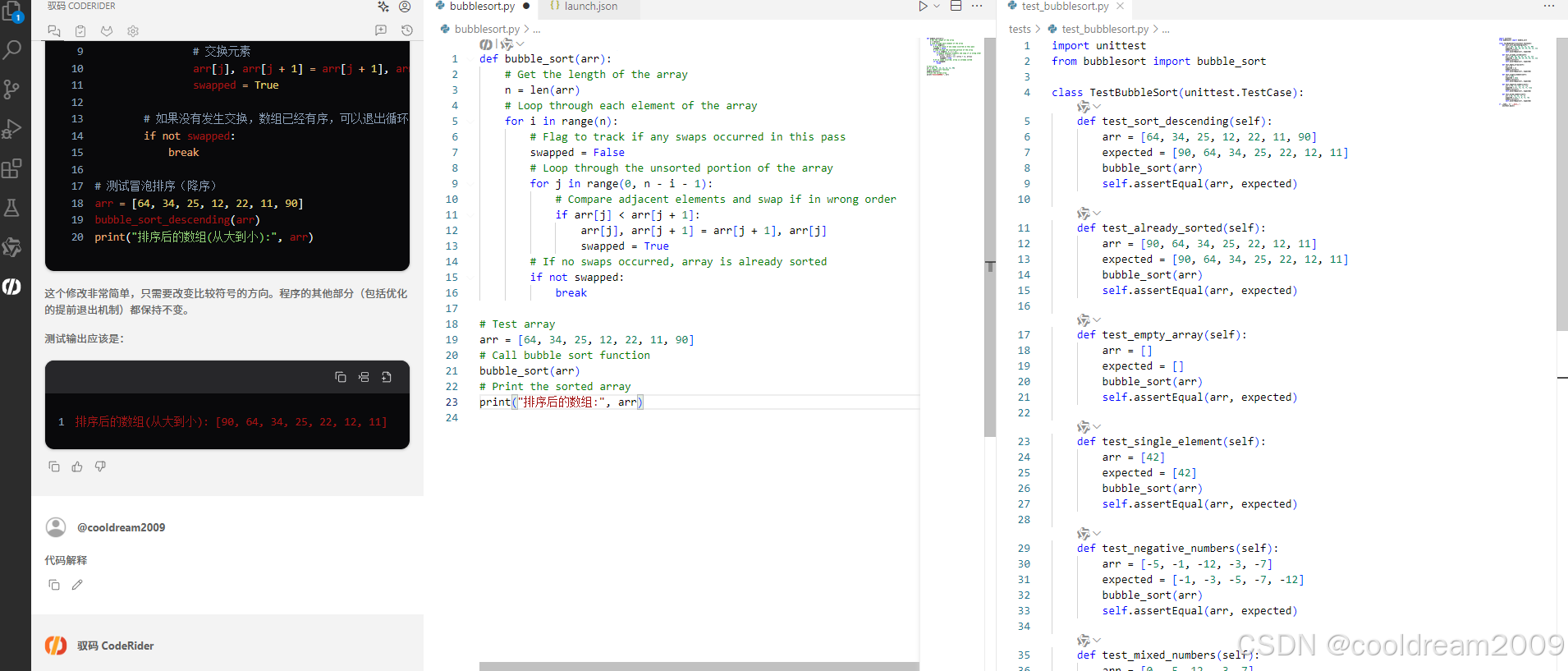
在 Visual Studio Code 中使用驭码 CodeRider 提升开发效率:以冒泡排序为例
目录 前言1 插件安装与配置1.1 安装驭码 CodeRider1.2 初始配置建议 2 示例代码:冒泡排序3 驭码 CodeRider 功能详解3.1 功能概览3.2 代码解释功能3.3 自动注释生成3.4 逻辑修改功能3.5 单元测试自动生成3.6 代码优化建议 4 驭码的实际应用建议5 常见问题与解决建议…...

Pydantic + Function Calling的结合
1、Pydantic Pydantic 是一个 Python 库,用于数据验证和设置管理,通过 Python 类型注解强制执行数据类型。它广泛用于 API 开发(如 FastAPI)、配置管理和数据解析,核心功能包括: 数据验证:通过…...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现指南针功能
指南针功能是许多位置服务应用的基础功能之一。下面我将详细介绍如何在HarmonyOS 5中使用DevEco Studio实现指南针功能。 1. 开发环境准备 确保已安装DevEco Studio 3.1或更高版本确保项目使用的是HarmonyOS 5.0 SDK在项目的module.json5中配置必要的权限 2. 权限配置 在mo…...
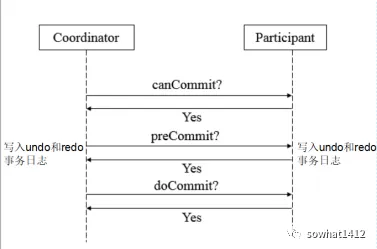
解析两阶段提交与三阶段提交的核心差异及MySQL实现方案
引言 在分布式系统的事务处理中,如何保障跨节点数据操作的一致性始终是核心挑战。经典的两阶段提交协议(2PC)通过准备阶段与提交阶段的协调机制,以同步决策模式确保事务原子性。其改进版本三阶段提交协议(3PC…...

Spring Boot + MyBatis 集成支付宝支付流程
Spring Boot MyBatis 集成支付宝支付流程 核心流程 商户系统生成订单调用支付宝创建预支付订单用户跳转支付宝完成支付支付宝异步通知支付结果商户处理支付结果更新订单状态支付宝同步跳转回商户页面 代码实现示例(电脑网站支付) 1. 添加依赖 <!…...

云安全与网络安全:核心区别与协同作用解析
在数字化转型的浪潮中,云安全与网络安全作为信息安全的两大支柱,常被混淆但本质不同。本文将从概念、责任分工、技术手段、威胁类型等维度深入解析两者的差异,并探讨它们的协同作用。 一、核心区别 定义与范围 网络安全:聚焦于保…...
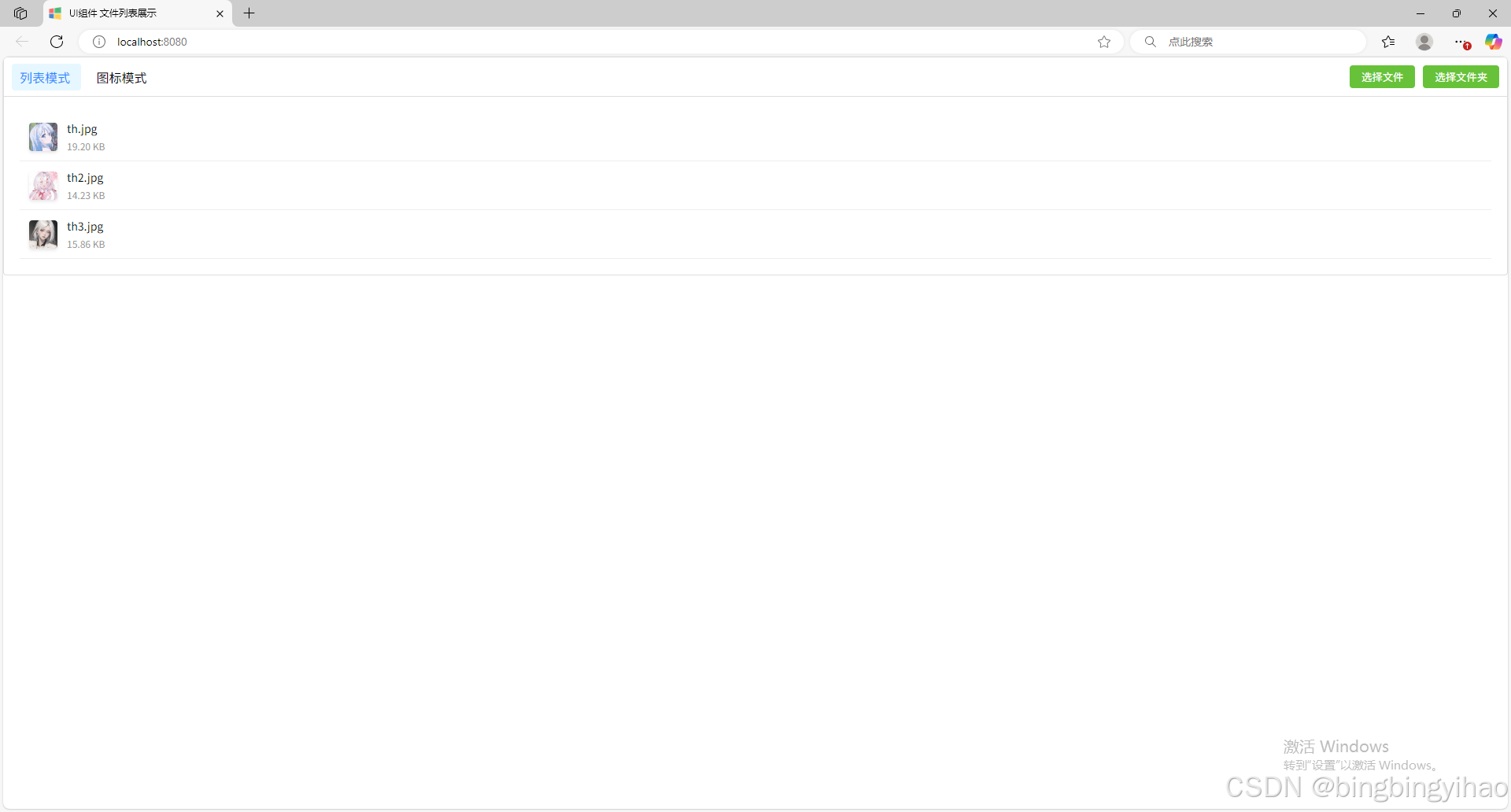
ui框架-文件列表展示
ui框架-文件列表展示 介绍 UI框架的文件列表展示组件,可以展示文件夹,支持列表展示和图标展示模式。组件提供了丰富的功能和可配置选项,适用于文件管理、文件上传等场景。 功能特性 支持列表模式和网格模式的切换展示支持文件和文件夹的层…...
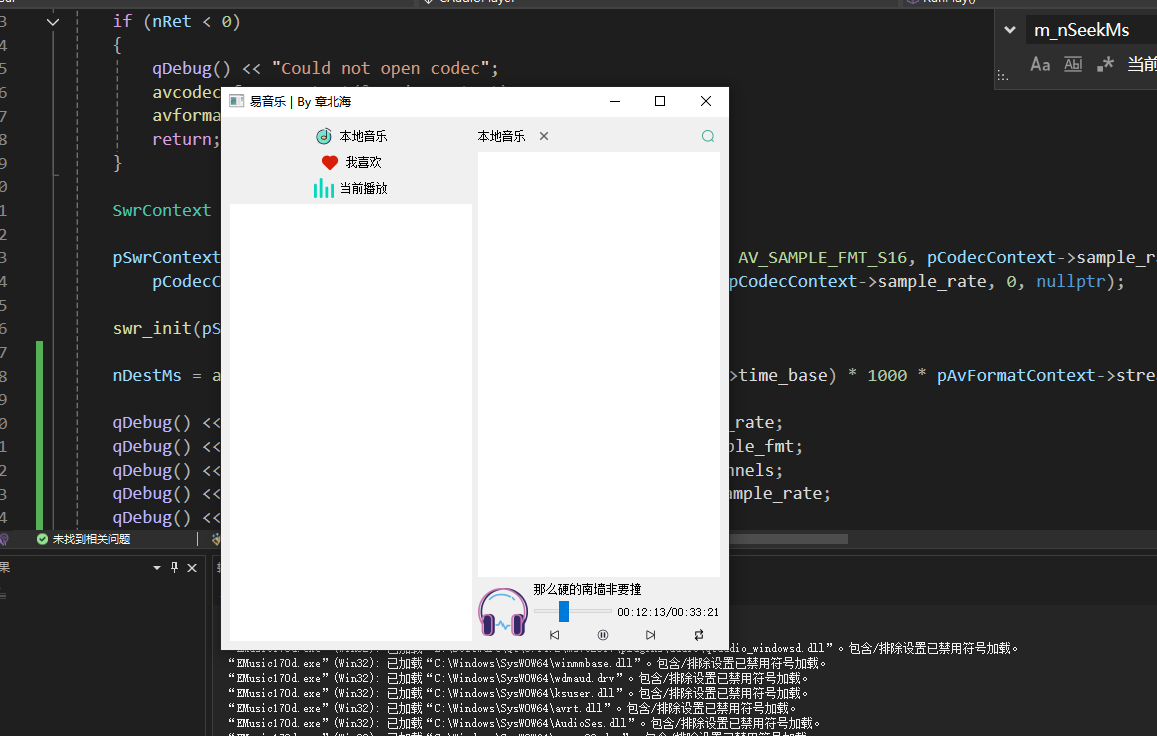
QT开发技术【ffmpeg + QAudioOutput】音乐播放器
一、 介绍 使用ffmpeg 4.2.2 在数字化浪潮席卷全球的当下,音视频内容犹如璀璨繁星,点亮了人们的生活与工作。从短视频平台上令人捧腹的搞笑视频,到在线课堂中知识渊博的专家授课,再到影视平台上扣人心弦的高清大片,音…...

算术操作符与类型转换:从基础到精通
目录 前言:从基础到实践——探索运算符与类型转换的奥秘 算术操作符超级详解 算术操作符:、-、*、/、% 赋值操作符:和复合赋值 单⽬操作符:、--、、- 前言:从基础到实践——探索运算符与类型转换的奥秘 在先前的文…...

DAY 26 函数专题1
函数定义与参数知识点回顾:1. 函数的定义2. 变量作用域:局部变量和全局变量3. 函数的参数类型:位置参数、默认参数、不定参数4. 传递参数的手段:关键词参数5 题目1:计算圆的面积 任务: 编写一…...
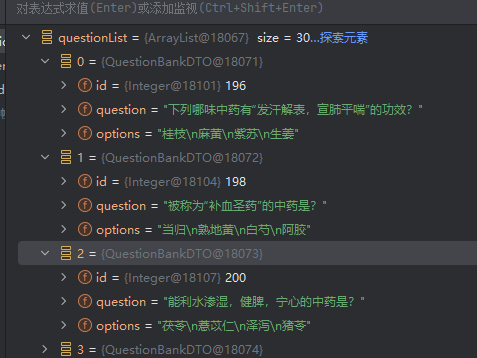
jdbc查询mysql数据库时,出现id顺序错误的情况
我在repository中的查询语句如下所示,即传入一个List<intager>的数据,返回这些id的问题列表。但是由于数据库查询时ID列表的顺序与预期不一致,会导致返回的id是从小到大排列的,但我不希望这样。 Query("SELECT NEW com…...
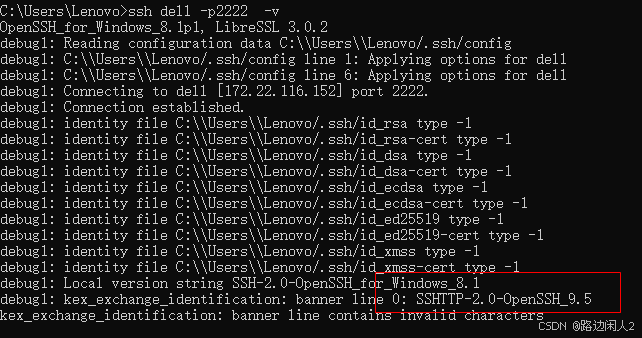
sshd代码修改banner
sshd服务连接之后会收到字符串: SSH-2.0-OpenSSH_9.5 容易被hacker识别此服务为sshd服务。 是否可以通过修改此banner达到让人无法识别此服务的目的呢? 不能。因为这是写的SSH的协议中的。 也就是协议规定了banner必须这么写。 SSH- 开头,…...
前端开发者常用网站
Can I use网站:一个查询网页技术兼容性的网站 一个查询网页技术兼容性的网站Can I use:Can I use... Support tables for HTML5, CSS3, etc (查询浏览器对HTML5的支持情况) 权威网站:MDN JavaScript权威网站:JavaScript | MDN...

在golang中如何将已安装的依赖降级处理,比如:将 go-ansible/v2@v2.2.0 更换为 go-ansible/@v1.1.7
在 Go 项目中降级 go-ansible 从 v2.2.0 到 v1.1.7 具体步骤: 第一步: 修改 go.mod 文件 // 原 v2 版本声明 require github.com/apenella/go-ansible/v2 v2.2.0 替换为: // 改为 v…...

如何在Windows本机安装Python并确保与Python.NET兼容
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...
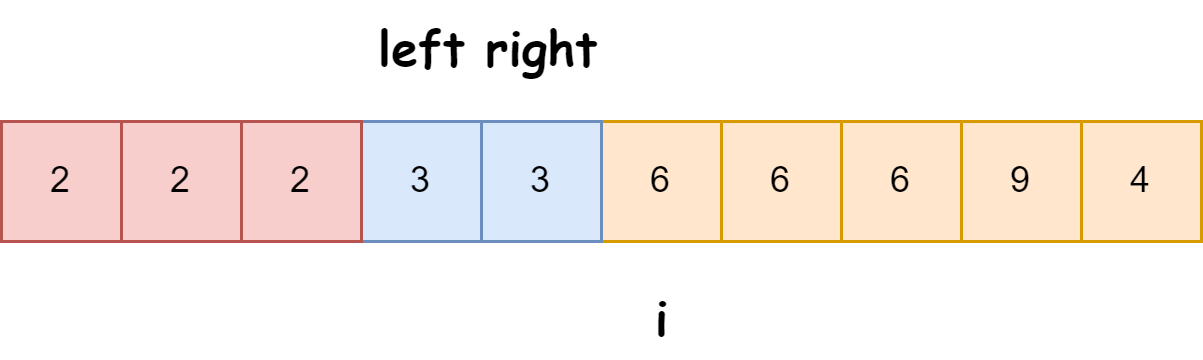
快速排序算法改进:随机快排-荷兰国旗划分详解
随机快速排序-荷兰国旗划分算法详解 一、基础知识回顾1.1 快速排序简介1.2 荷兰国旗问题 二、随机快排 - 荷兰国旗划分原理2.1 随机化枢轴选择2.2 荷兰国旗划分过程2.3 结合随机快排与荷兰国旗划分 三、代码实现3.1 Python实现3.2 Java实现3.3 C实现 四、性能分析4.1 时间复杂度…...
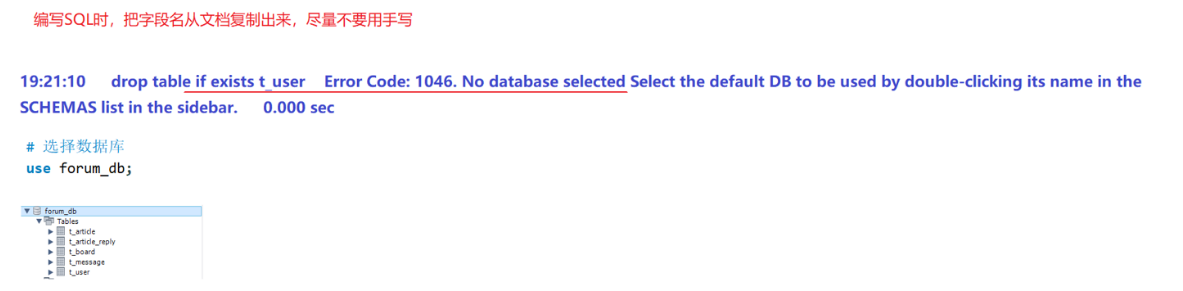
篇章二 论坛系统——系统设计
目录 2.系统设计 2.1 技术选型 2.2 设计数据库结构 2.2.1 数据库实体 1. 数据库设计 1.1 数据库名: forum db 1.2 表的设计 1.3 编写SQL 2.系统设计 2.1 技术选型 2.2 设计数据库结构 2.2.1 数据库实体 通过需求分析获得概念类并结合业务实现过程中的技术需要&#x…...

加密通信 + 行为分析:运营商行业安全防御体系重构
在数字经济蓬勃发展的时代,运营商作为信息通信网络的核心枢纽,承载着海量用户数据与关键业务传输,其安全防御体系的可靠性直接关乎国家安全、社会稳定与企业发展。随着网络攻击手段的不断升级,传统安全防护体系逐渐暴露出局限性&a…...