Linux 下 DMA 内存映射浅析
序
系统 I/O 设备驱动程序通常调用其特定子系统的接口为 DMA 分配内存,但最终会调到 DMA 子系统的dma_alloc_coherent()/dma_alloc_attrs() 等接口。
关于 dma_alloc_coherent 接口详细的代码讲解、调用流程,可以参考这篇文章,我觉得写的非常好!
深入浅出 Linux 中的 ARM IOMMU SMMU III
注:本篇文章代码,均节选自 Linux 6.53 版本
1、DMA 映射类型
Linux系统支持两种 DMA 映射类型:一致性 DMA 映射(Consistent DMA Mapping)和流式 DMA映射(Streaming DMA Mapping)。二者的核心差异在于:
- 一致性 DMA 映射情况下,无论是 CPU 还是设备,在访问 DMA 内存时,全程都不使用 Cache,从而避免数据一致性问题;
- 流式 DMA 映射则只在 DMA 传输数据时,通过软件操作来处理 Cache 的同步,以减轻关闭 Cache 对性能的影响。
2、一致性 DMA
一致性 DMA 映射本质上是利用了硬件的支持,禁用了 DMA 内存缓存区的 Cache 功能。 CPU 和 DMA controller 在发起对 DMA 缓冲区的并行访问的时候不需要考虑 cache 的影响,也就是说不需要软件进行 Cache 操作,CPU 和 DMA controller 都可以看到对方对 DMA 缓冲区的更新。
dma_alloc_coherent
DMA 一致性映射使用 dma_alloc_coherent 接口来分配 DMA 内存,实现流程如下:
dma_alloc_coherent(dma_alloc_attrs)--> dma_alloc_from_dev_coherent (如果 Device 绑定了Reserved Memory)--> dma_direct_alloc (如果 Device 没有绑定 Reserved Memory )--> dma_ops->alloc (如果 Device 绑定了 IOMMU,使用 IOMMU 申请接口)
2.1 Device 绑定了 Reserved Memory
dma_alloc_from_dev_coherent 函数从设备的 coherent 内存池中分配内存。coherent 内存池由设备驱动程序通过dma_declare_coherent_memory 接口创建,这个接口实现 (位于 kernel/dma/coherent.c 文件中) 如下:
static struct dma_coherent_mem *dma_init_coherent_memory(phys_addr_t phys_addr,dma_addr_t device_addr, size_t size, bool use_dma_pfn_offset)
{struct dma_coherent_mem *dma_mem;int pages = size >> PAGE_SHIFT;void *mem_base;if (!size)return ERR_PTR(-EINVAL);mem_base = memremap(phys_addr, size, MEMREMAP_WC);if (!mem_base)return ERR_PTR(-EINVAL);......
}void *memremap(resource_size_t offset, size_t size, unsigned long flags)
{......if (!addr && (flags & MEMREMAP_WT))addr = ioremap_wt(offset, size);if (!addr && (flags & MEMREMAP_WC))addr = ioremap_wc(offset, size);......
}
从 mem_base = memremap(phys_addr, size, MEMREMAP_WC); 这行代码不难看出,默认情况下,该接口分配的内存类型是 WC(Write Combine),最终调用到的是 ioremap_wc 接口。对于 ARM64 架构而言,这里分配的地址类型是 PROT_NORMAL_NC。
2.2 Device 没有绑定 Reserved Memory

void *dma_direct_alloc(struct device *dev, size_t size,dma_addr_t *dma_handle, gfp_t gfp, unsigned long attrs)
{....../* For non-coherent device */if (!dev_is_dma_coherent(dev)) {/* 首先尝试调用 arch 目录下的 dma_alloc */if (!IS_ENABLED(CONFIG_ARCH_HAS_DMA_SET_UNCACHED) &&!IS_ENABLED(CONFIG_DMA_DIRECT_REMAP) &&!dev_is_dma_coherent(dev))return arch_dma_alloc(dev, size, dma_handle, gfp, attrs);/** If there is a global pool, always allocate from it for* non-coherent devices.*/if (IS_ENABLED(CONFIG_DMA_GLOBAL_POOL))return dma_alloc_from_global_coherent(dev, size,dma_handle);/** Otherwise remap if the architecture is asking for it. But* given that remapping memory is a blocking operation we'll* instead have to dip into the atomic pools.*/remap = IS_ENABLED(CONFIG_DMA_DIRECT_REMAP);if (remap) {if (dma_direct_use_pool(dev, gfp))return dma_direct_alloc_from_pool(dev, size,dma_handle, gfp);} else {if (!IS_ENABLED(CONFIG_ARCH_HAS_DMA_SET_UNCACHED))return NULL;set_uncached = true;}}....../* we always manually zero the memory once we are done *//* 从软件管理的 page 内存池中获取对应大小的 page */page = __dma_direct_alloc_pages(dev, size, gfp & ~__GFP_ZERO, true);if (!page)return NULL;/** dma_alloc_contiguous can return highmem pages depending on a* combination the cma= arguments and per-arch setup. These need to be* remapped to return a kernel virtual address.*/if (PageHighMem(page)) {remap = true;set_uncached = false;}/* For coherent device */if (remap) {/* 设备页表属性(内存属性) */pgprot_t prot = dma_pgprot(dev, PAGE_KERNEL, attrs);if (force_dma_unencrypted(dev))prot = pgprot_decrypted(prot);/* remove any dirty cache lines on the kernel alias */arch_dma_prep_coherent(page, size);/* create a coherent mapping *//* 对刚刚申请的 page,重新 remap,建立页表属性 */ret = dma_common_contiguous_remap(page, size, prot,__builtin_return_address(0));if (!ret)goto out_free_pages;} else {ret = page_address(page);if (dma_set_decrypted(dev, ret, size))goto out_free_pages;}......
}
2.2.1 dma-coherent
关于设备是否是 dma-coherent(注意,dma-coherent 表示的是硬件维护一致性!),即 if (!dev_is_dma_coherent(dev)) ,由 dts 传入 dma-coherent 标志决定。例如,rk3568 dts 中的 rga 节点:
rga: rga@ff680000 {compatible = "rockchip,rga2";dev_mode = <1>;reg = <0x0 0xff680000 0x0 0x1000>;interrupts = <GIC_SPI 55 IRQ_TYPE_LEVEL_HIGH 0>;clocks = <&cru ACLK_RGA>, <&cru HCLK_RGA>, <&cru SCLK_RGA_CORE>;clock-names = "aclk_rga", "hclk_rga", "clk_rga";power-domains = <&power RK3399_PD_RGA>;dma-coherent;status = "okay";};
2.2.2 dma_alloc_from_global_coherent
当设备不支持硬件一致性时,若其支持 global dma pool,则将从 global dma pool 中分配 dma 内存。其中若要支持 global dma pool,需要在 dts 的 reserved-memory 中保留 compatible 值为 shared-dma-pool。以 rk3568 为例:
reserved-memory {#address-cells = <2>;#size-cells = <2>;ranges;/* Reserve 128MB memory for hdmirx-controller@fdee0000 */cma {compatible = "shared-dma-pool";reusable;reg = <0x0 (256 * 0x100000) 0x0 (128 * 0x100000)>;linux,cma-default;};};
当 dts 包含以上节点时,则在 linux 内核初始化时,会通过以下接口为其初始化 global dma pool,并将相应的保留内存设置到该内存池中:
dma_init_reserved_memory --> dma_init_global_coherent--> dma_init_coherent_memory (该函数 2.1 章节有讲解)
2.2.3 dma_pgprot
dma_direct_alloc 接口中调用的 dma_pgprot 接口,默认情况下,调用的是 pgprot_dmacoherent 接口
/** Return the page attributes used for mapping dma_alloc_* memory, either in* kernel space if remapping is needed, or to userspace through dma_mmap_*.*/
pgprot_t dma_pgprot(struct device *dev, pgprot_t prot, unsigned long attrs)
{if (dev_is_dma_coherent(dev))return prot;
#ifdef CONFIG_ARCH_HAS_DMA_WRITE_COMBINEif (attrs & DMA_ATTR_WRITE_COMBINE)return pgprot_writecombine(prot);
#endifreturn pgprot_dmacoherent(prot);
}
在 arch/arm64/include/asm/pgtable.h 文件中:
/** DMA allocations for non-coherent devices use what the Arm architecture calls* "Normal non-cacheable" memory, which permits speculation, unaligned accesses* and merging of writes. This is different from "Device-nGnR[nE]" memory which* is intended for MMIO and thus forbids speculation, preserves access size,* requires strict alignment and can also force write responses to come from the* endpoint.*/
#define pgprot_dmacoherent(prot) \__pgprot_modify(prot, PTE_ATTRINDX_MASK, \PTE_ATTRINDX(MT_NORMAL_NC) | PTE_PXN | PTE_UXN)
到这可以看到,使用 Direct 申请接口,默认情况下分配的 DMA 内存,是 MT_NORMAL_NC 类型的,和 2.1 章节一样。
2.3 使用 iommu
通过已注册的 dev 设备内存分配操作函数分配(ops->alloc)
当设备注册了 dma_ops,则该设备需要通过其 ops 对应的接口分配 dma 内存。以 armv8 的 iommu 为例,该接口的注册流程如下:
of_dma_configure(由设备驱动调用)--> of_dma_configure_id (这一步会去解析设备树节点,看是否有 “iommus” 属性)--> arch_setup_dma_ops-->iommu_setup_dma_ops
arch/arm64/mm/dma-mapping.c
void arch_setup_dma_ops(struct device *dev, u64 dma_base, u64 size,const struct iommu_ops *iommu, bool coherent)
{int cls = cache_line_size_of_cpu();WARN_TAINT(!coherent && cls > ARCH_DMA_MINALIGN,TAINT_CPU_OUT_OF_SPEC,"%s %s: ARCH_DMA_MINALIGN smaller than CTR_EL0.CWG (%d < %d)",dev_driver_string(dev), dev_name(dev),ARCH_DMA_MINALIGN, cls);dev->dma_coherent = coherent;if (iommu)iommu_setup_dma_ops(dev, dma_base, dma_base + size - 1);xen_setup_dma_ops(dev);
}
其中 iommu 对应的 dma_ops 定义如下:
const struct dma_map_ops iommu_dma_ops = {.flags = DMA_F_PCI_P2PDMA_SUPPORTED,.alloc = iommu_dma_alloc,.free = iommu_dma_free,.alloc_pages = dma_common_alloc_pages,.free_pages = dma_common_free_pages,.alloc_noncontiguous = iommu_dma_alloc_noncontiguous,.free_noncontiguous = iommu_dma_free_noncontiguous,.mmap = iommu_dma_mmap,.get_sgtable = iommu_dma_get_sgtable,.map_page = iommu_dma_map_page,.unmap_page = iommu_dma_unmap_page,.map_sg = iommu_dma_map_sg,.unmap_sg = iommu_dma_unmap_sg,.sync_single_for_cpu = iommu_dma_sync_single_for_cpu,.sync_single_for_device = iommu_dma_sync_single_for_device,.sync_sg_for_cpu = iommu_dma_sync_sg_for_cpu,.sync_sg_for_device = iommu_dma_sync_sg_for_device,.map_resource = iommu_dma_map_resource,.unmap_resource = iommu_dma_unmap_resource,.get_merge_boundary = iommu_dma_get_merge_boundary,.opt_mapping_size = iommu_dma_opt_mapping_size,
};
3、流式 DMA
与一致性映射接口不同,流式 DMA 映射接口不会分配内存,而是将输入参数中传入的内存映射为 DMA 地址。由于在 CPU 视角下,它也可能被映射成了 cache 类型的内存,故其对应的 cache 中可能含有 dirty 数据。为了确保 DMA 和 CPU 都能获取到正确的数据,则在 DMA 操作流程中,软件需要维护 cache 与主存数据的一致性。
流式 DMA 最大的一个特点就是带 cache,这会带来 cache 和内存的一致性问题。如果处理不好,会触发各种问题,使用的时候必须小心!!!
关于 cache 一致性问题,我前面有篇文章已经做了总结:ARM 架构下 cache 一致性问题整理
流式 DMA 包括以下两类接口:
3.1 内存映射接口
#define dma_map_single(d, a, s, r) dma_map_single_attrs(d, a, s, r, 0)
#define dma_unmap_single(d, a, s, r) dma_unmap_single_attrs(d, a, s, r, 0)
#define dma_map_sg(d, s, n, r) dma_map_sg_attrs(d, s, n, r, 0)
#define dma_unmap_sg(d, s, n, r) dma_unmap_sg_attrs(d, s, n, r, 0)
#define dma_map_page(d, p, o, s, r) dma_map_page_attrs(d, p, o, s, r, 0)
#define dma_unmap_page(d, a, s, r) dma_unmap_page_attrs(d, a, s, r, 0)
这里以 dma_map_single 接口说明 DMA 内存的映射流程:
dma_map_single--> dma_map_single_attrs--> dma_map_page_attrs--> dma_map_direct (直接映射方式,使用SWIOTLB机制)--> get_dma_ops-->map_page (设备支持IOMMU,通过IOMMU提供的操作接口映射内存)
3.2 cache 维护接口
inline void dma_sync_single_for_cpu(struct device *dev, dma_addr_t addr,size_t size, enum dma_data_direction dir)
inline void dma_sync_single_for_device(struct device *dev,dma_addr_t addr, size_t size, enum dma_data_direction dir)
inline void dma_sync_sg_for_cpu(struct device *dev,struct scatterlist *sg, int nelems, enum dma_data_direction dir)
inline void dma_sync_sg_for_device(struct device *dev,struct scatterlist *sg, int nelems, enum dma_data_direction dir)dma_direct_sync_single_for_cpu
如果你需要多次访问同一个流式映射DMA缓冲区,并且在DMA传输之间读写DMA缓冲区上的数据,这时候你需要使用dma_sync_single_for_cpu进行DMA缓冲区的sync操作,以便CPU和设备可以看到最新的、正确的数据。
dma_direct_sync_single_for_cpu 接口,最终调用的 arch_sync_dma_for_cpu。以 ARM64 架构为例,其实最终就是刷 cache。
arch/arm64/mm/dma-mapping.c
void arch_sync_dma_for_device(phys_addr_t paddr, size_t size,enum dma_data_direction dir)
{unsigned long start = (unsigned long)phys_to_virt(paddr);dcache_clean_poc(start, start + size);
}void arch_sync_dma_for_cpu(phys_addr_t paddr, size_t size,enum dma_data_direction dir)
{unsigned long start = (unsigned long)phys_to_virt(paddr);if (dir == DMA_TO_DEVICE)return;dcache_inval_poc(start, start + size);
}void arch_dma_prep_coherent(struct page *page, size_t size)
{unsigned long start = (unsigned long)page_address(page);dcache_clean_poc(start, start + size);
}
dma_direct_sync_single_for_device
如果CPU操作了DMA缓冲区的数据,然后你又想让硬件设备访问DMA缓冲区,这时候,在真正让硬件设备去访问DMA缓冲区之前,你需要调用dma_direct_sync_single_for_device接口以便让硬件设备可以看到cpu更新后的数据。
dma_direct_sync_single_for_device 接口,最终调用的就是 arch_sync_dma_for_device。
总结:
流式 DMA 映射根据数据方向对 cache 进行 “flush/invalid”,既保证了数据一致性,也避免了完全关闭 cache 带来的性能影响。
相关文章:
Linux 下 DMA 内存映射浅析
序 系统 I/O 设备驱动程序通常调用其特定子系统的接口为 DMA 分配内存,但最终会调到 DMA 子系统的dma_alloc_coherent()/dma_alloc_attrs() 等接口。 关于 dma_alloc_coherent 接口详细的代码讲解、调用流程,可以参考这篇文章,我觉得写的非常…...

第八部分:阶段项目 6:构建 React 前端应用
现在,是时候将你学到的 React 基础知识付诸实践,构建一个简单的前端应用来模拟与后端 API 的交互了。在这个阶段,你可以先使用模拟数据,或者如果你的后端 API(阶段项目 5)已经搭建好,可以直接连…...

6️⃣Go 语言中的哈希、加密与序列化:通往区块链世界的钥匙
Go 语言中的哈希、加密与序列化:通往区块链世界的钥匙 一、前言:离区块链还有多远? 区块链听起来可能遥不可及,似乎是只有密码学专家和资深工程师才能涉足的领域。但事实上,构建一个区块链的核心并不复杂,尤其当你已经掌握了一门系统编程语言,比如 Go。 要真正理解区…...
macOS 终端智能代理检测
🧠 终端智能代理检测:自动判断是否需要设置代理访问 GitHub 在开发中,使用 GitHub 是非常常见的需求。但有时候我们会发现某些命令失败、插件无法更新,例如: fatal: unable to access https://github.com/ohmyzsh/oh…...

前端高频面试题2:浏览器/计算机网络
本专栏相关链接 前端高频面试题1:HTML/CSS 前端高频面试题2:浏览器/计算机网络 前端高频面试题3:JavaScript 1.什么是强缓存、协商缓存? 强缓存: 当浏览器请求资源时,首先检查本地缓存是否命中。如果命…...

智能职业发展系统:AI驱动的职业规划平台技术解析
智能职业发展系统:AI驱动的职业规划平台技术解析 引言:数字时代的职业革命 在当今瞬息万变的就业市场中,传统的职业规划方法已无法满足个人和企业的需求。据统计,全球每年有超过2亿人面临职业转型困境,而企业也因此遭…...
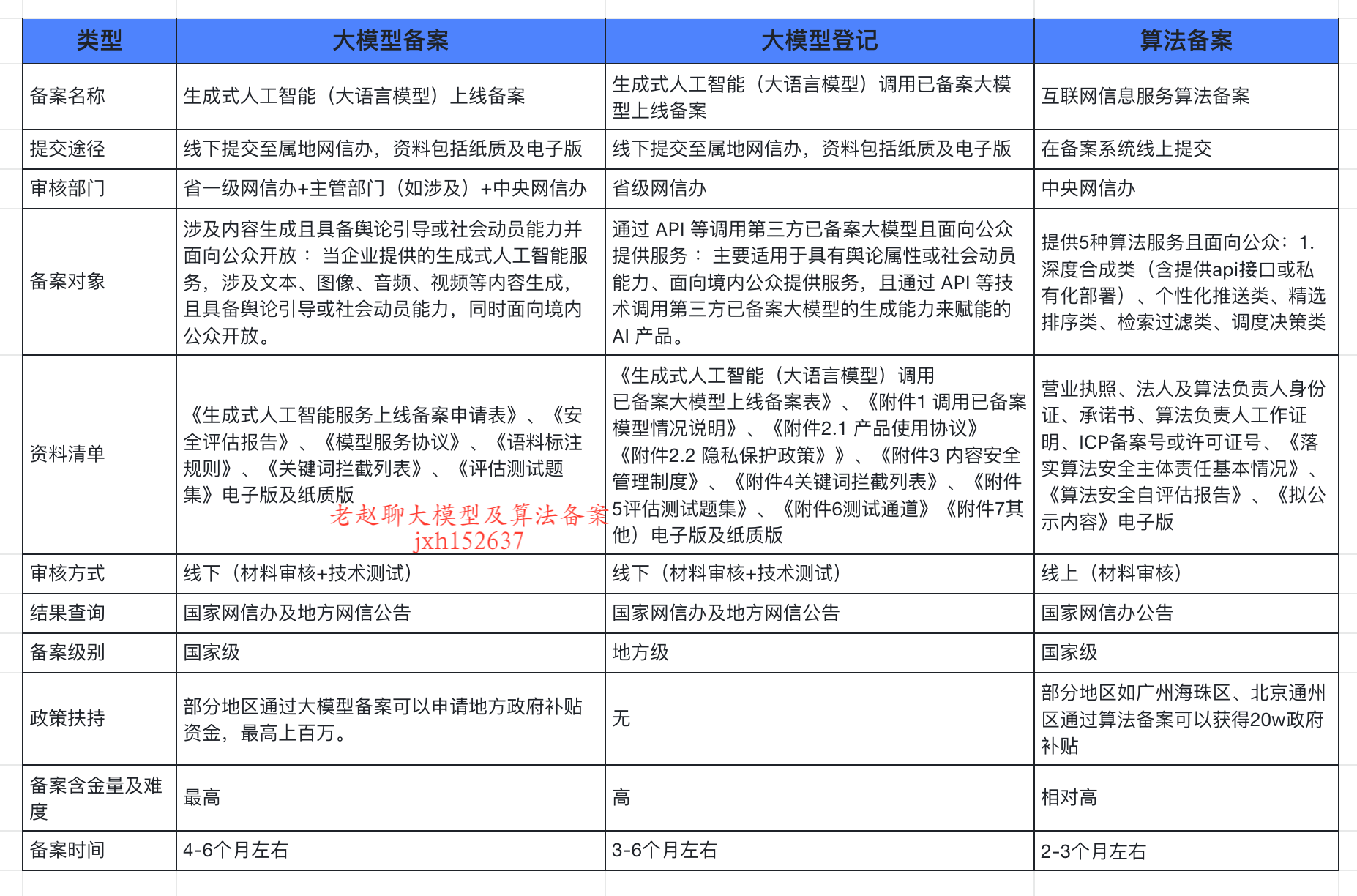
企业大模型服务合规指南:深度解析备案与登记制度
伴随AI技术的爆炸式发展,尤其是大模型(LLM)在各行各业的深度应用和整合,企业利用AI技术提升效率、创新服务的步伐不断加快。无论是像DeepSeek这样的前沿技术提供者,还是积极拥抱AI转型的传统企业,在面向公众…...

高防服务器价格高原因分析
高防服务器的价格较高,主要是由于其特殊的防御机制、硬件配置、运营维护等多方面的综合成本。以下从技术、资源和服务三个维度详细解析高防服务器昂贵的原因: 一、硬件与技术投入 大带宽需求 DDoS攻击通过占用大量带宽资源瘫痪目标服务器,因此…...

Unity VR/MR开发-VR开发与传统3D开发的差异
视频讲解链接:【XR马斯维】VR/MR开发与传统3D开发的差异【UnityVR/MR开发教程--入门】_哔哩哔哩_bilibili...
在 Visual Studio Code 中使用驭码 CodeRider 提升开发效率:以冒泡排序为例
目录 前言1 插件安装与配置1.1 安装驭码 CodeRider1.2 初始配置建议 2 示例代码:冒泡排序3 驭码 CodeRider 功能详解3.1 功能概览3.2 代码解释功能3.3 自动注释生成3.4 逻辑修改功能3.5 单元测试自动生成3.6 代码优化建议 4 驭码的实际应用建议5 常见问题与解决建议…...

Pydantic + Function Calling的结合
1、Pydantic Pydantic 是一个 Python 库,用于数据验证和设置管理,通过 Python 类型注解强制执行数据类型。它广泛用于 API 开发(如 FastAPI)、配置管理和数据解析,核心功能包括: 数据验证:通过…...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现指南针功能
指南针功能是许多位置服务应用的基础功能之一。下面我将详细介绍如何在HarmonyOS 5中使用DevEco Studio实现指南针功能。 1. 开发环境准备 确保已安装DevEco Studio 3.1或更高版本确保项目使用的是HarmonyOS 5.0 SDK在项目的module.json5中配置必要的权限 2. 权限配置 在mo…...
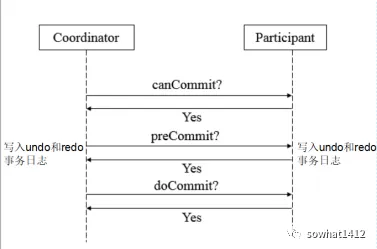
解析两阶段提交与三阶段提交的核心差异及MySQL实现方案
引言 在分布式系统的事务处理中,如何保障跨节点数据操作的一致性始终是核心挑战。经典的两阶段提交协议(2PC)通过准备阶段与提交阶段的协调机制,以同步决策模式确保事务原子性。其改进版本三阶段提交协议(3PC…...

Spring Boot + MyBatis 集成支付宝支付流程
Spring Boot MyBatis 集成支付宝支付流程 核心流程 商户系统生成订单调用支付宝创建预支付订单用户跳转支付宝完成支付支付宝异步通知支付结果商户处理支付结果更新订单状态支付宝同步跳转回商户页面 代码实现示例(电脑网站支付) 1. 添加依赖 <!…...

云安全与网络安全:核心区别与协同作用解析
在数字化转型的浪潮中,云安全与网络安全作为信息安全的两大支柱,常被混淆但本质不同。本文将从概念、责任分工、技术手段、威胁类型等维度深入解析两者的差异,并探讨它们的协同作用。 一、核心区别 定义与范围 网络安全:聚焦于保…...
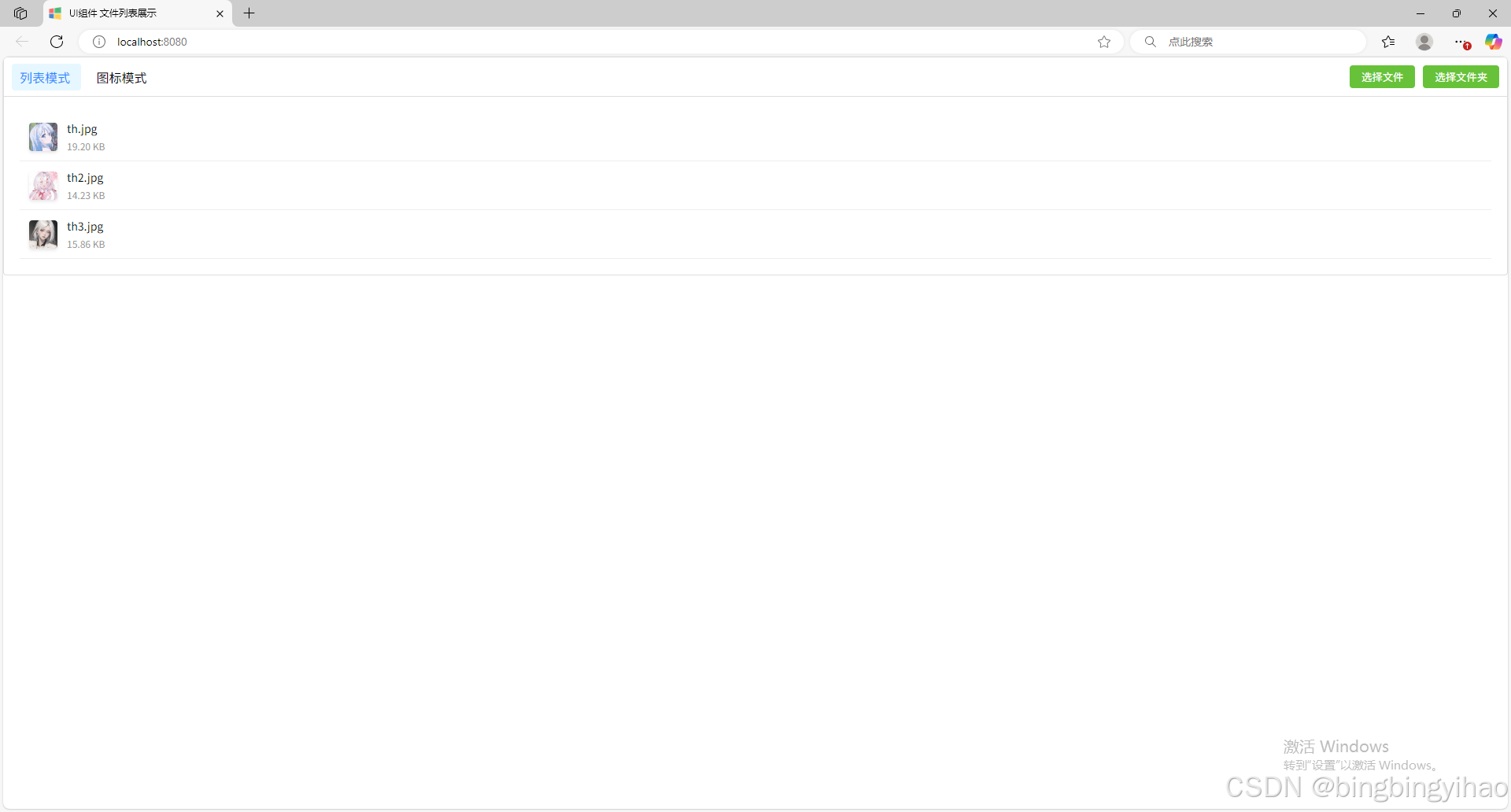
ui框架-文件列表展示
ui框架-文件列表展示 介绍 UI框架的文件列表展示组件,可以展示文件夹,支持列表展示和图标展示模式。组件提供了丰富的功能和可配置选项,适用于文件管理、文件上传等场景。 功能特性 支持列表模式和网格模式的切换展示支持文件和文件夹的层…...
QT开发技术【ffmpeg + QAudioOutput】音乐播放器
一、 介绍 使用ffmpeg 4.2.2 在数字化浪潮席卷全球的当下,音视频内容犹如璀璨繁星,点亮了人们的生活与工作。从短视频平台上令人捧腹的搞笑视频,到在线课堂中知识渊博的专家授课,再到影视平台上扣人心弦的高清大片,音…...

算术操作符与类型转换:从基础到精通
目录 前言:从基础到实践——探索运算符与类型转换的奥秘 算术操作符超级详解 算术操作符:、-、*、/、% 赋值操作符:和复合赋值 单⽬操作符:、--、、- 前言:从基础到实践——探索运算符与类型转换的奥秘 在先前的文…...

DAY 26 函数专题1
函数定义与参数知识点回顾:1. 函数的定义2. 变量作用域:局部变量和全局变量3. 函数的参数类型:位置参数、默认参数、不定参数4. 传递参数的手段:关键词参数5 题目1:计算圆的面积 任务: 编写一…...
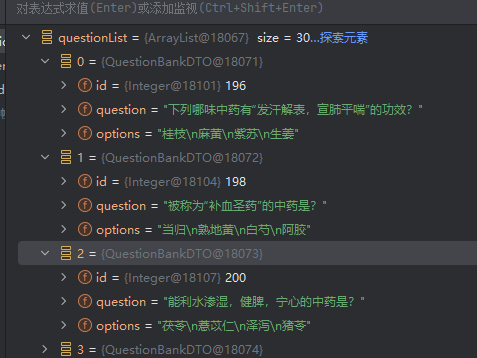
jdbc查询mysql数据库时,出现id顺序错误的情况
我在repository中的查询语句如下所示,即传入一个List<intager>的数据,返回这些id的问题列表。但是由于数据库查询时ID列表的顺序与预期不一致,会导致返回的id是从小到大排列的,但我不希望这样。 Query("SELECT NEW com…...
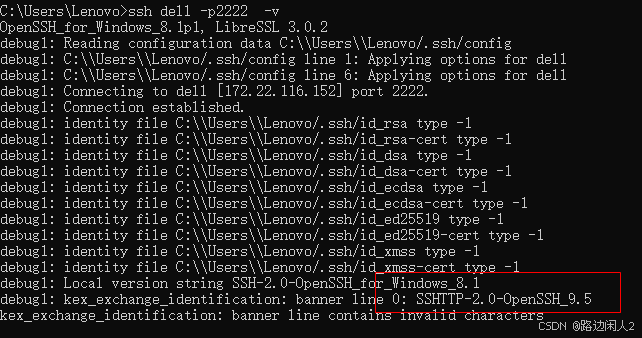
sshd代码修改banner
sshd服务连接之后会收到字符串: SSH-2.0-OpenSSH_9.5 容易被hacker识别此服务为sshd服务。 是否可以通过修改此banner达到让人无法识别此服务的目的呢? 不能。因为这是写的SSH的协议中的。 也就是协议规定了banner必须这么写。 SSH- 开头,…...
前端开发者常用网站
Can I use网站:一个查询网页技术兼容性的网站 一个查询网页技术兼容性的网站Can I use:Can I use... Support tables for HTML5, CSS3, etc (查询浏览器对HTML5的支持情况) 权威网站:MDN JavaScript权威网站:JavaScript | MDN...

在golang中如何将已安装的依赖降级处理,比如:将 go-ansible/v2@v2.2.0 更换为 go-ansible/@v1.1.7
在 Go 项目中降级 go-ansible 从 v2.2.0 到 v1.1.7 具体步骤: 第一步: 修改 go.mod 文件 // 原 v2 版本声明 require github.com/apenella/go-ansible/v2 v2.2.0 替换为: // 改为 v…...

如何在Windows本机安装Python并确保与Python.NET兼容
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...
快速排序算法改进:随机快排-荷兰国旗划分详解
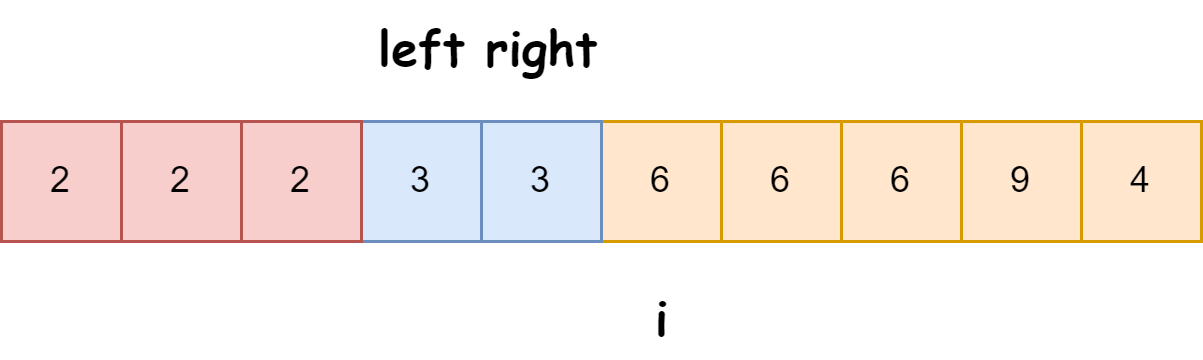
随机快速排序-荷兰国旗划分算法详解 一、基础知识回顾1.1 快速排序简介1.2 荷兰国旗问题 二、随机快排 - 荷兰国旗划分原理2.1 随机化枢轴选择2.2 荷兰国旗划分过程2.3 结合随机快排与荷兰国旗划分 三、代码实现3.1 Python实现3.2 Java实现3.3 C实现 四、性能分析4.1 时间复杂度…...
篇章二 论坛系统——系统设计
目录 2.系统设计 2.1 技术选型 2.2 设计数据库结构 2.2.1 数据库实体 1. 数据库设计 1.1 数据库名: forum db 1.2 表的设计 1.3 编写SQL 2.系统设计 2.1 技术选型 2.2 设计数据库结构 2.2.1 数据库实体 通过需求分析获得概念类并结合业务实现过程中的技术需要&#x…...

加密通信 + 行为分析:运营商行业安全防御体系重构
在数字经济蓬勃发展的时代,运营商作为信息通信网络的核心枢纽,承载着海量用户数据与关键业务传输,其安全防御体系的可靠性直接关乎国家安全、社会稳定与企业发展。随着网络攻击手段的不断升级,传统安全防护体系逐渐暴露出局限性&a…...
与文本切分器(Splitter)详解《二》)
LangChain 中的文档加载器(Loader)与文本切分器(Splitter)详解《二》
🧠 LangChain 中 TextSplitter 的使用详解:从基础到进阶(附代码) 一、前言 在处理大规模文本数据时,特别是在构建知识库或进行大模型训练与推理时,文本切分(Text Splitting) 是一个…...

Monorepo架构: Nx Cloud 扩展能力与缓存加速
借助 Nx Cloud 实现项目协同与加速构建 1 ) 缓存工作原理分析 在了解了本地缓存和远程缓存之后,我们来探究缓存是如何工作的。以计算文件的哈希串为例,若后续运行任务时文件哈希串未变,系统会直接使用对应的输出和制品文件。 2 …...
32单片机——基本定时器
STM32F103有众多的定时器,其中包括2个基本定时器(TIM6和TIM7)、4个通用定时器(TIM2~TIM5)、2个高级控制定时器(TIM1和TIM8),这些定时器彼此完全独立,不共享任何资源 1、定…...