阿里云Ubuntu 22.04 64位搭建Flask流程(亲测)
cd /home 进入home盘
安装虚拟环境:
1、安装virtualenv
pip install virtualenv
2.创建新的虚拟环境:
virtualenv myenv
3、激活虚拟环境(激活环境可以在当前环境下安装包)
source myenv/bin/activate
此时,终端会更改为显示已被激活的虚拟环境名称,(myenv)
4、退出虚拟环境
deactivate
特别的为虚拟环境制定python版本
virtualenv -p=/usr/bin/python<version> path/to/new/virtualenv/
安装的过程:
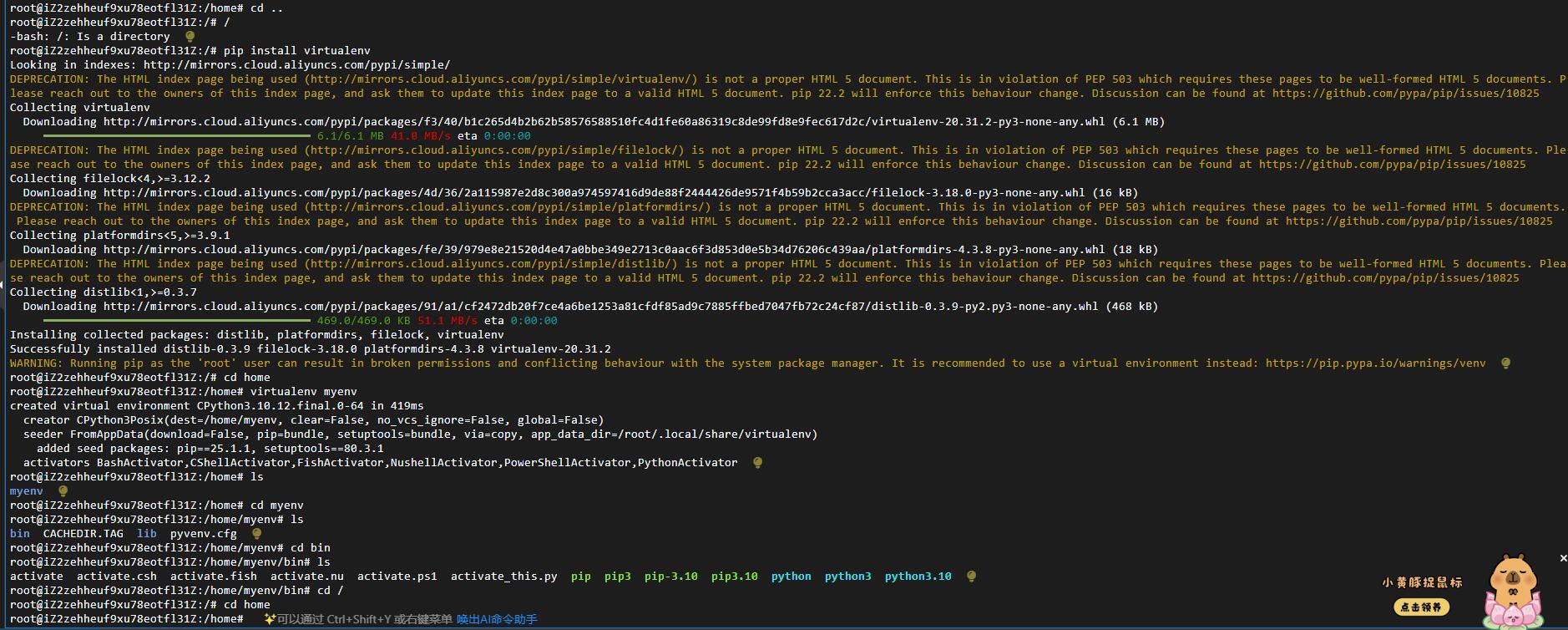

创建python文件(app.py)
cd /home/myenv
touch app.py
安装flask
pip install Flask
编写app.py文件
nano app.py
from flask import Flaskapp = Flask(__name__)@app.route('/', methods=['GET'])
def hello_world():return 'Hello Flask!'if __name__ == '__main__':app.run(host='0.0.0.0', port=5000)
编写完成
ctrl+O 保存,提示然后回车
ctrl+x 退出
安装gunicorn
pip install gunicorn
gunicorn的一些使用命令:
查看gunicorn的进程数树:
pstree -ap|grep gunicorn
关闭gunicorn:
kill -9 3308
重启gunicorn;
kill -HUP 3308
然后用gunicorn启动app.py文件
gunicorn -w 4 -b 0.0.0.0:5000 app:app
参数含义
-w:工作进程数-b:绑定的地址和端口app:Flask 启动的 Python 文件名app:脚本中创建的 Flask 对象名
然后报错了,提示超时tiomeout
[2025-06-09 16:29:31 +0800] [48889] [CRITICAL] WORKER TIMEOUT (pid:48892)
[2025-06-09 16:29:31 +0800] [48892] [ERROR] Error handling request (no URI read)
Traceback (most recent call last):File "/home/myenv/lib/python3.10/site-packages/gunicorn/workers/sync.py", line 133, in handlereq = next(parser)File "/home/myenv/lib/python3.10/site-packages/gunicorn/http/parser.py", line 41, in __next__self.mesg = self.mesg_class(self.cfg, self.unreader, self.source_addr, self.req_count)File "/home/myenv/lib/python3.10/site-packages/gunicorn/http/message.py", line 259, in __init__super().__init__(cfg, unreader, peer_addr)File "/home/myenv/lib/python3.10/site-packages/gunicorn/http/message.py", line 60, in __init__unused = self.parse(self.unreader)File "/home/myenv/lib/python3.10/site-packages/gunicorn/http/message.py", line 271, in parseself.get_data(unreader, buf, stop=True)File "/home/myenv/lib/python3.10/site-packages/gunicorn/http/message.py", line 262, in get_datadata = unreader.read()File "/home/myenv/lib/python3.10/site-packages/gunicorn/http/unreader.py", line 36, in readd = self.chunk()File "/home/myenv/lib/python3.10/site-packages/gunicorn/http/unreader.py", line 63, in chunkreturn self.sock.recv(self.mxchunk)File "/home/myenv/lib/python3.10/site-packages/gunicorn/workers/base.py", line 204, in handle_abortsys.exit(1)
SystemExit: 1解决办法:
错误原因:接口返回时间超时。默认情况下,Gunicorn 超时时间为30秒。如果接口30秒内没有返回结果,Gunicorn 会弹出超时错误,并且会杀死flask服务重启。
解决方法
解决方法是在启动命令中加大超时参数--timeout。样例,设置超时时间为200秒
# 单位是秒gunicorn -w 4 -b 0.0.0.0:5000 --timeout 200 app:app
重新启动
gunicorn -w 4 -b 0.0.0.0:5000 --timeout 200 app:app
注意启动文件必须实在myenv文件夹下,否则不会成功
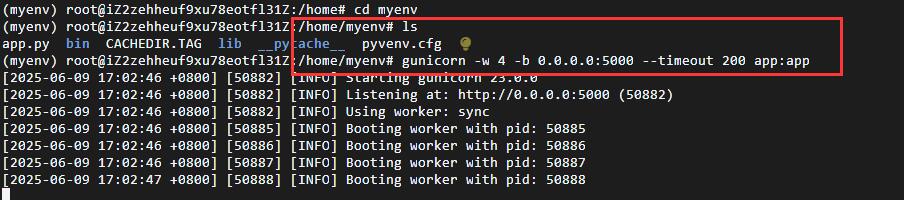
再次启动就成功了!!
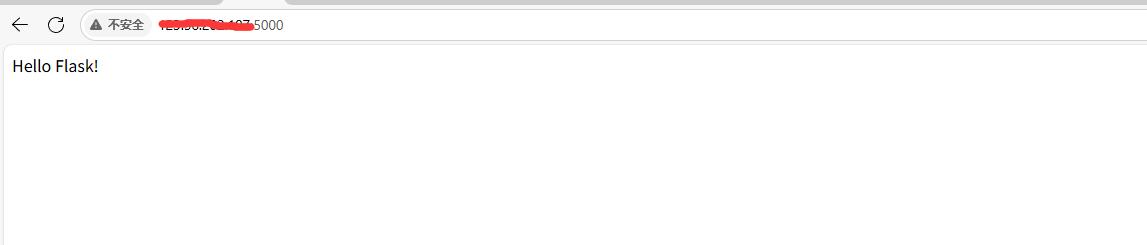
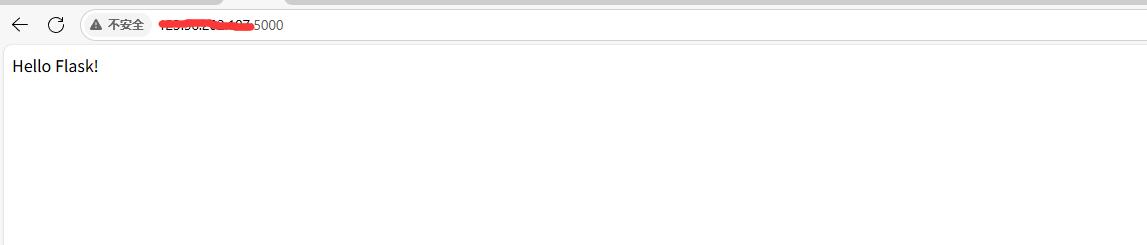
直接访问:记得使用阿里云公网ip,加端口号。(安全组添加5000端口)
文件配置 Gunicorn 参数:
myenv下创建gunconf.py
# 是否开启debug模式
debug = False
# 访问地址
bind = "0.0.0.0:5000"
# 工作进程数
workers = 4
# 工作线程数
threads = 2
# 超时时间
timeout = 200
# 输出日志级别
loglevel = 'debug'
# 存放日志路径
pidfile = "log/gunicorn.pid"
# 存放日志路径
accesslog = "log/access.log"
# 存放日志路径
errorlog = "log/debug.log"
# gunicorn + apscheduler场景下,解决多worker运行定时任务重复执行的问题
preload_app = True
myenv下分别创建"log/gunicorn.pid"、"log/access.log"、"log/debug.log"


然后用文件启动:
至此搭建完毕!
gunicorn的一些参考命令介绍:
https://cloud.tencent.com/developer/article/1902723
一些unbantu的命令:
复制文件:
cp example.txt /home/user/documents/
删除文件命令:
rm app.py
创建文件命令:
touch app.py
创建文件夹:
mkdir myfolder
查看端口被占用的情况:
1、查找特定端口的占用情况:如果您知道某个特定端口被占用,可以结合grep命令来查找。例如,如果您想查找80端口的使用情况,可以输入以下命令。
netstat -tln | grep 802、查找占用端口的进程:使用以下命令来查找占用特定端口的进程。例如,如果您想查找占用80端口的进程,可以输入以下命令。
lsof -i:80
3、终止进程
kill -9 80
相关文章:
阿里云Ubuntu 22.04 64位搭建Flask流程(亲测)
cd /home 进入home盘 安装虚拟环境: 1、安装virtualenv pip install virtualenv 2.创建新的虚拟环境: virtualenv myenv 3、激活虚拟环境(激活环境可以在当前环境下安装包) source myenv/bin/activate 此时,终端…...

面试高频问题
文章目录 🚀 消息队列核心技术揭秘:从入门到秒杀面试官1️⃣ Kafka为何能"吞云吐雾"?性能背后的秘密1.1 顺序写入与零拷贝:性能的双引擎1.2 分区并行:数据的"八车道高速公路"1.3 页缓存与批量处理…...

xmind转换为markdown
文章目录 解锁思维导图新姿势:将XMind转为结构化Markdown 一、认识Xmind结构二、核心转换流程详解1.解压XMind文件(ZIP处理)2.解析JSON数据结构3:递归转换树形结构4:Markdown层级生成逻辑 三、完整代码 解锁思维导图新…...

【WebSocket】SpringBoot项目中使用WebSocket
1. 导入坐标 如果springboot父工程没有加入websocket的起步依赖,添加它的坐标的时候需要带上版本号。 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-websocket</artifactId> </dep…...
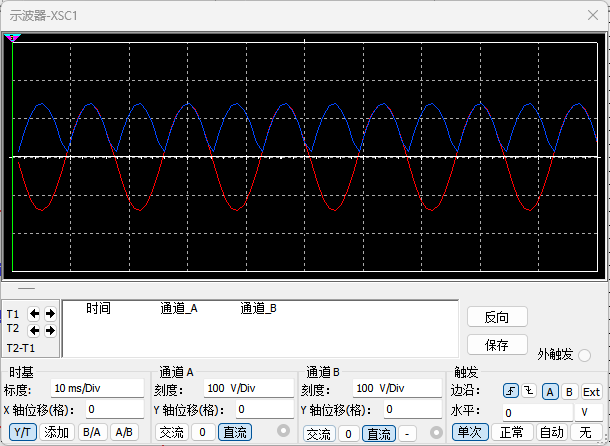
恶补电源:1.电桥
一、元器件的选择 搜索并选择电桥,再multisim中选择FWB,就有各种型号的电桥: 电桥是用来干嘛的呢? 它是一个由四个二极管搭成的“桥梁”形状的电路,用来把交流电(AC)变成直流电(DC)。…...
论文阅读:Matting by Generation
今天介绍一篇关于 matting 抠图的文章,抠图也算是计算机视觉里面非常经典的一个任务了。从早期的经典算法到如今的深度学习算法,已经有很多的工作和这个任务相关。这两年 diffusion 模型很火,大家又开始用 diffusion 模型做各种 CV 任务了&am…...

Neko虚拟浏览器远程协作方案:Docker+内网穿透技术部署实践
前言:本文将向开发者介绍一款创新性协作工具——Neko虚拟浏览器。在数字化协作场景中,跨地域的团队常需面对实时共享屏幕、协同编辑文档等需求。通过本指南,你将掌握在Ubuntu系统中使用容器化技术部署该工具的具体方案,并结合内网…...

实战设计模式之模板方法模式
概述 模板方法模式定义了一个操作中的算法骨架,并将某些步骤延迟到子类中实现。模板方法使得子类可以在不改变算法结构的前提下,重新定义算法中的某些步骤。简单来说,就是在一个方法中定义了要执行的步骤顺序或算法框架,但允许子类…...

【Linux】Linux安装并配置RabbitMQ
目录 1. 安装 Erlang 2. 安装 RabbitMQ 2.1.添加 RabbitMQ 仓库 2.2.安装 RabbitMQ 3.配置 3.1.启动和管理服务 4. 访问管理界面 5.安装问题 6.修改密码 7.修改端口 7.1.找到文件 7.2.修改文件 1. 安装 Erlang 由于 RabbitMQ 是用 Erlang 编写的,需要先安…...
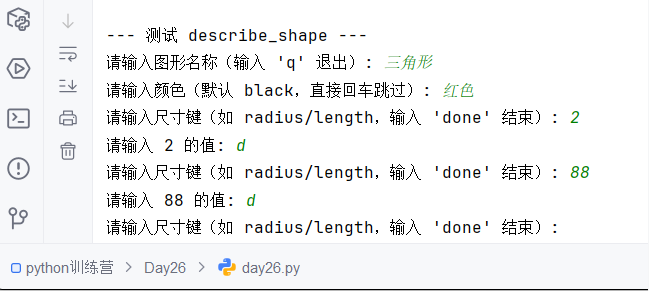
Python训练营-Day26-函数专题1:函数定义与参数
题目1:计算圆的面积 任务: 编写一个名为 calculate_circle_area 的函数,该函数接收圆的半径 radius 作为参数,并返回圆的面积。圆的面积 π * radius (可以使用 math.pi 作为 π 的值)要求:函数接收一个位置参数 radi…...

【Kafka】Kafka从入门到实战:构建高吞吐量分布式消息系统
Kafka从入门到实战:构建高吞吐量分布式消息系统 一、Kafka概述 Apache Kafka是一个分布式流处理平台,最初由LinkedIn开发,后成为Apache顶级项目。它被设计用于高吞吐量、低延迟的消息处理,能够处理来自多个生产者的海量数据,并将这些数据实时传递给消费者。 Kafka核心特…...

Android写一个捕获全局异常的工具类
项目开发和实际运行过程中难免会遇到异常发生,系统提供了一个可以捕获全局异常的工具Uncaughtexceptionhandler,它是Thread的子类(就是package java.lang;里线程的Thread)。本文将利用它将设备信息、报错信息以及错误的发生时间都…...

人工智能 - 在Dify、Coze、n8n、FastGPT和RAGFlow之间做出技术选型
在Dify、Coze、n8n、FastGPT和RAGFlow之间做出技术选型。这些平台各有侧重,适用场景差异显著。下面我将从核心功能定位、典型应用场景、真实体验痛点、选型决策关键点进行拆解,并提供具体场景下的推荐方案。 一、核心功能定位速览 平台核心定位技术栈亮…...

绕过 Xcode?使用 Appuploader和主流工具实现 iOS 上架自动化
iOS 应用的发布流程一直是开发链路中最“苹果味”的环节:强依赖 Xcode、必须使用 macOS、各种证书和描述文件配置……对很多跨平台开发者来说,这一套流程并不友好。 特别是当你的项目主要在 Windows 或 Linux 下开发(例如 Flutter、React Na…...

C++_哈希表
本篇文章是对C学习的哈希表部分的学习分享 相信一定会对你有所帮助~ 那咱们废话不多说,直接开始吧! 一、基础概念 1. 哈希核心思想: 哈希函数的作用:通过此函数建立一个Key与存储位置之间的映射关系。理想目标:实现…...

WEB3全栈开发——面试专业技能点P7前端与链上集成
一、Next.js技术栈 ✅ 概念介绍 Next.js 是一个基于 React 的 服务端渲染(SSR)与静态网站生成(SSG) 框架,由 Vercel 开发。它简化了构建生产级 React 应用的过程,并内置了很多特性: ✅ 文件系…...
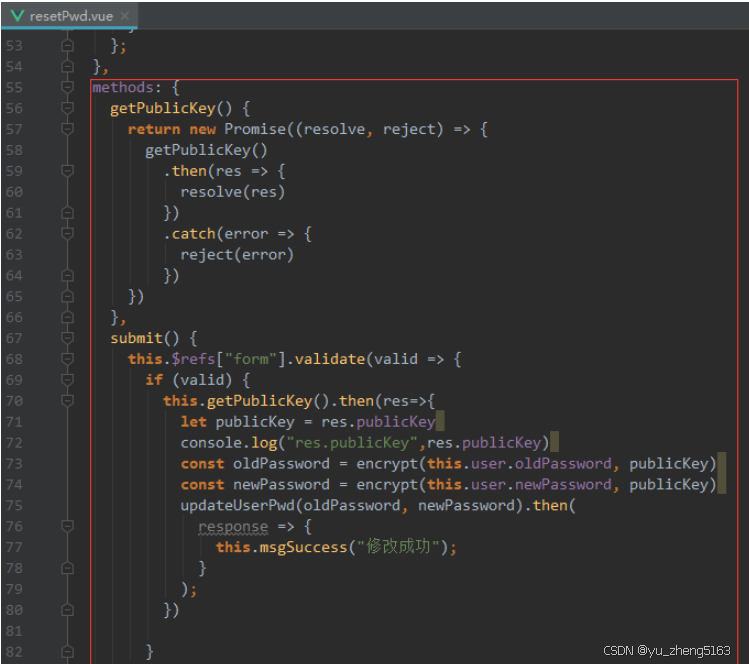
若依登录用户名和密码加密
/*** 获取公钥:前端用来密码加密* return*/GetMapping("/getPublicKey")public RSAUtil.RSAKeyPair getPublicKey() {return RSAUtil.rsaKeyPair();}新建RSAUti.Java package com.ruoyi.common.utils;import org.apache.commons.codec.binary.Base64; im…...

Linux 下 DMA 内存映射浅析
序 系统 I/O 设备驱动程序通常调用其特定子系统的接口为 DMA 分配内存,但最终会调到 DMA 子系统的dma_alloc_coherent()/dma_alloc_attrs() 等接口。 关于 dma_alloc_coherent 接口详细的代码讲解、调用流程,可以参考这篇文章,我觉得写的非常…...

第八部分:阶段项目 6:构建 React 前端应用
现在,是时候将你学到的 React 基础知识付诸实践,构建一个简单的前端应用来模拟与后端 API 的交互了。在这个阶段,你可以先使用模拟数据,或者如果你的后端 API(阶段项目 5)已经搭建好,可以直接连…...

6️⃣Go 语言中的哈希、加密与序列化:通往区块链世界的钥匙
Go 语言中的哈希、加密与序列化:通往区块链世界的钥匙 一、前言:离区块链还有多远? 区块链听起来可能遥不可及,似乎是只有密码学专家和资深工程师才能涉足的领域。但事实上,构建一个区块链的核心并不复杂,尤其当你已经掌握了一门系统编程语言,比如 Go。 要真正理解区…...
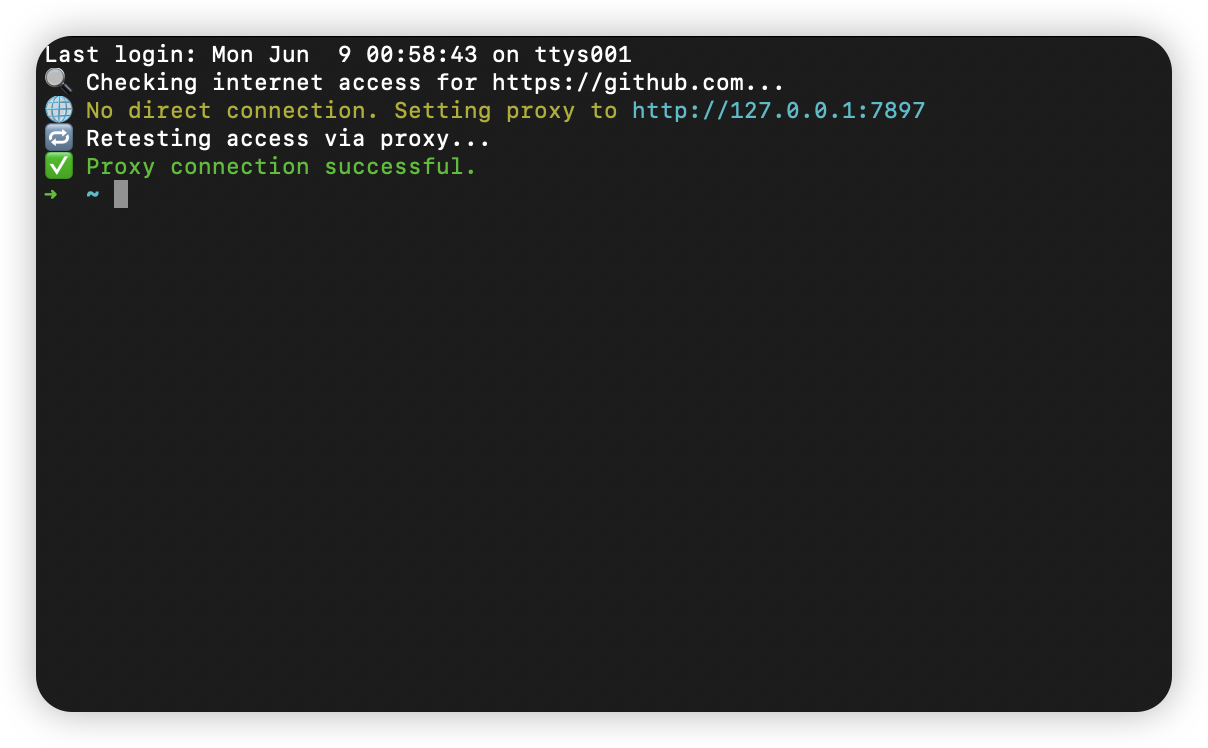
macOS 终端智能代理检测
🧠 终端智能代理检测:自动判断是否需要设置代理访问 GitHub 在开发中,使用 GitHub 是非常常见的需求。但有时候我们会发现某些命令失败、插件无法更新,例如: fatal: unable to access https://github.com/ohmyzsh/oh…...

前端高频面试题2:浏览器/计算机网络
本专栏相关链接 前端高频面试题1:HTML/CSS 前端高频面试题2:浏览器/计算机网络 前端高频面试题3:JavaScript 1.什么是强缓存、协商缓存? 强缓存: 当浏览器请求资源时,首先检查本地缓存是否命中。如果命…...

智能职业发展系统:AI驱动的职业规划平台技术解析
智能职业发展系统:AI驱动的职业规划平台技术解析 引言:数字时代的职业革命 在当今瞬息万变的就业市场中,传统的职业规划方法已无法满足个人和企业的需求。据统计,全球每年有超过2亿人面临职业转型困境,而企业也因此遭…...
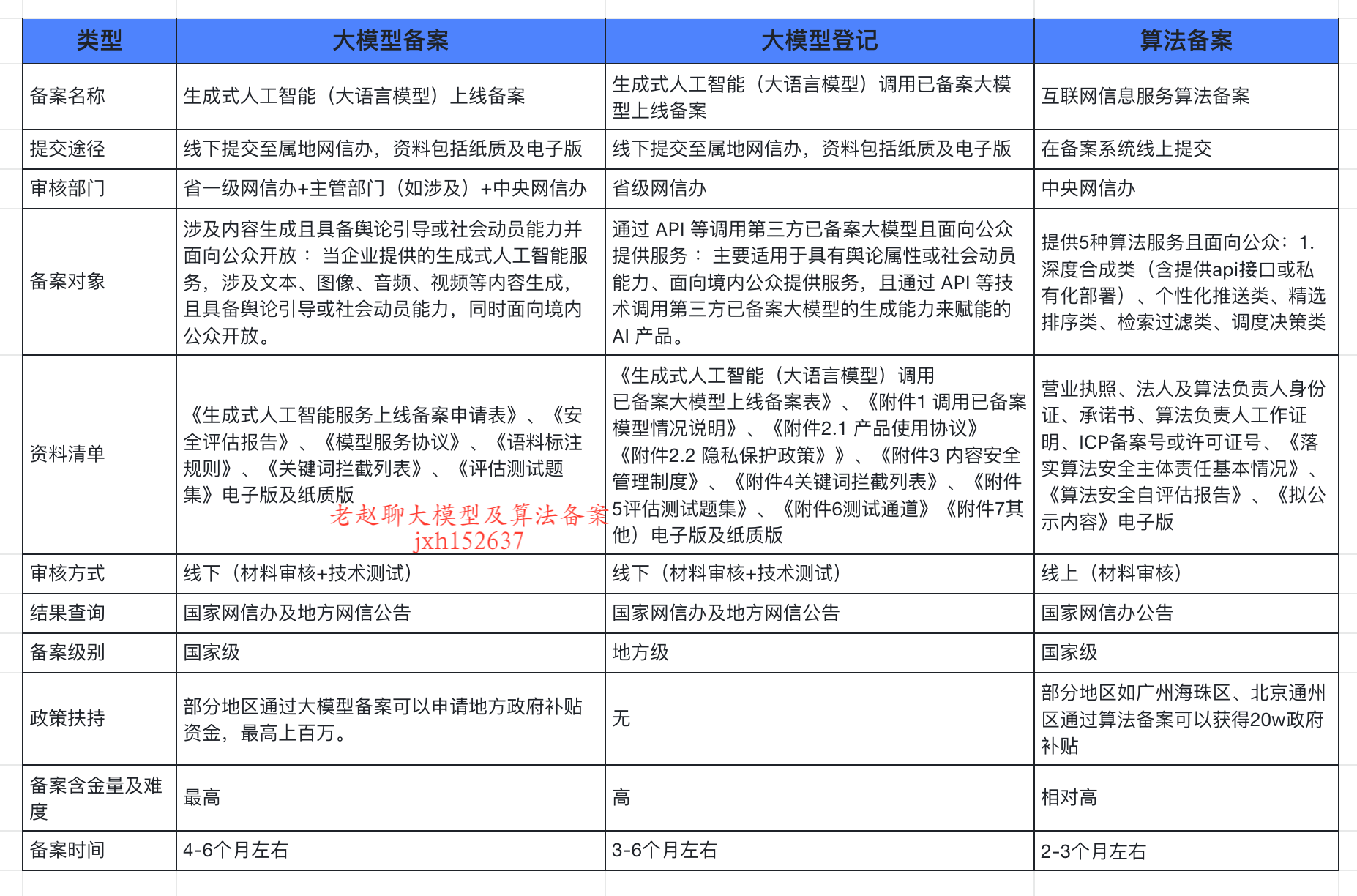
企业大模型服务合规指南:深度解析备案与登记制度
伴随AI技术的爆炸式发展,尤其是大模型(LLM)在各行各业的深度应用和整合,企业利用AI技术提升效率、创新服务的步伐不断加快。无论是像DeepSeek这样的前沿技术提供者,还是积极拥抱AI转型的传统企业,在面向公众…...

高防服务器价格高原因分析
高防服务器的价格较高,主要是由于其特殊的防御机制、硬件配置、运营维护等多方面的综合成本。以下从技术、资源和服务三个维度详细解析高防服务器昂贵的原因: 一、硬件与技术投入 大带宽需求 DDoS攻击通过占用大量带宽资源瘫痪目标服务器,因此…...

Unity VR/MR开发-VR开发与传统3D开发的差异
视频讲解链接:【XR马斯维】VR/MR开发与传统3D开发的差异【UnityVR/MR开发教程--入门】_哔哩哔哩_bilibili...
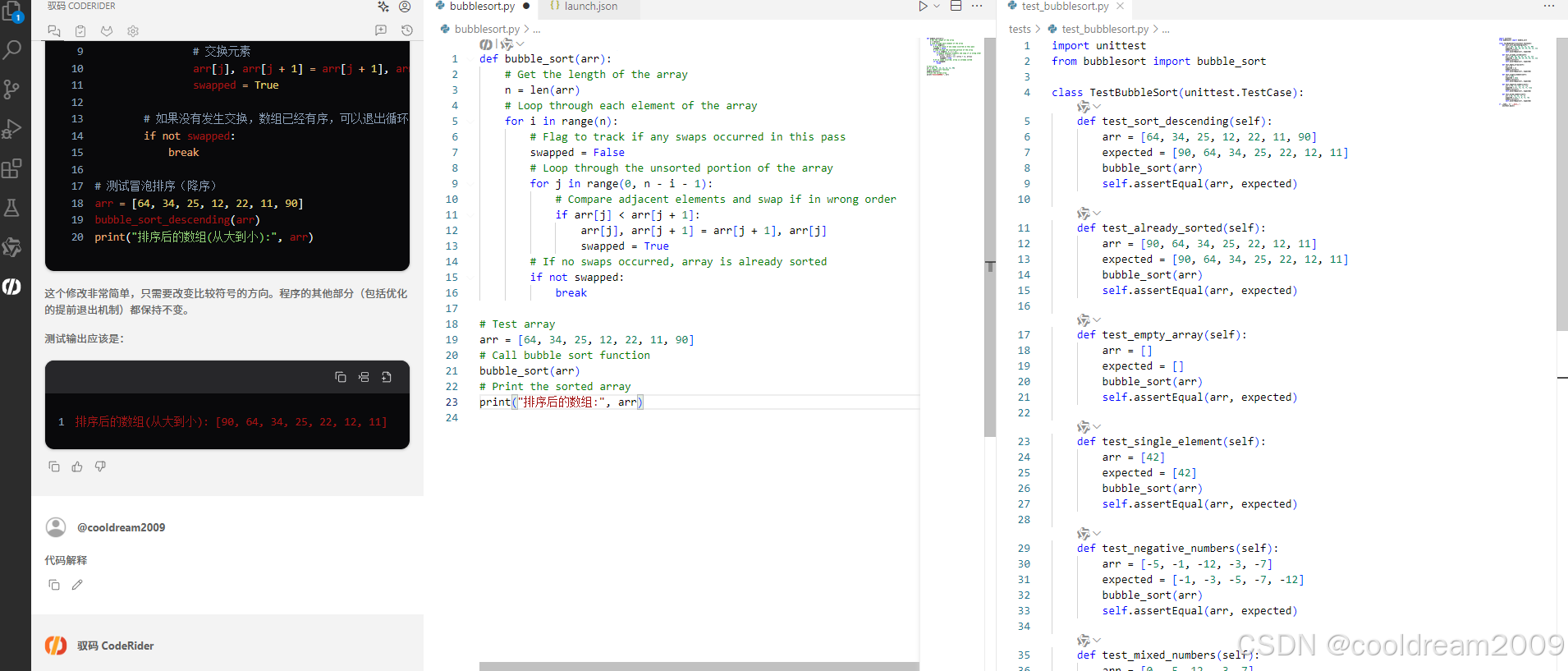
在 Visual Studio Code 中使用驭码 CodeRider 提升开发效率:以冒泡排序为例
目录 前言1 插件安装与配置1.1 安装驭码 CodeRider1.2 初始配置建议 2 示例代码:冒泡排序3 驭码 CodeRider 功能详解3.1 功能概览3.2 代码解释功能3.3 自动注释生成3.4 逻辑修改功能3.5 单元测试自动生成3.6 代码优化建议 4 驭码的实际应用建议5 常见问题与解决建议…...

Pydantic + Function Calling的结合
1、Pydantic Pydantic 是一个 Python 库,用于数据验证和设置管理,通过 Python 类型注解强制执行数据类型。它广泛用于 API 开发(如 FastAPI)、配置管理和数据解析,核心功能包括: 数据验证:通过…...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现指南针功能
指南针功能是许多位置服务应用的基础功能之一。下面我将详细介绍如何在HarmonyOS 5中使用DevEco Studio实现指南针功能。 1. 开发环境准备 确保已安装DevEco Studio 3.1或更高版本确保项目使用的是HarmonyOS 5.0 SDK在项目的module.json5中配置必要的权限 2. 权限配置 在mo…...
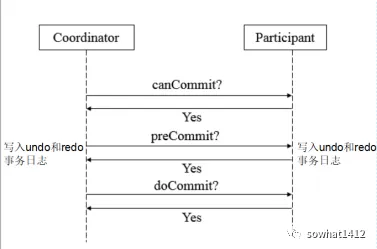
解析两阶段提交与三阶段提交的核心差异及MySQL实现方案
引言 在分布式系统的事务处理中,如何保障跨节点数据操作的一致性始终是核心挑战。经典的两阶段提交协议(2PC)通过准备阶段与提交阶段的协调机制,以同步决策模式确保事务原子性。其改进版本三阶段提交协议(3PC…...