第62步 深度学习图像识别:多分类建模(Pytorch)
基于WIN10的64位系统演示
一、写在前面
上期我们基于TensorFlow环境做了图像识别的多分类任务建模。
本期以健康组、肺结核组、COVID-19组、细菌性(病毒性)肺炎组为数据集,基于Pytorch环境,构建SqueezeNet多分类模型,因为它建模速度快。
同样,基于GPT-4辅助编程,这次改写过程就不展示了。
二、多分类建模实战
使用胸片的数据集:肺结核病人和健康人的胸片的识别。其中,健康人900张,肺结核病人700张,COVID-19病人549张、细菌性(病毒性)肺炎组900张,分别存入单独的文件夹中。
(a)直接分享代码
######################################导入包###################################
# 导入必要的包
import copy
import torch
import torchvision
import torchvision.transforms as transforms
from torchvision import models
from torch.utils.data import DataLoader
from torch import optim, nn
from torch.optim import lr_scheduler
import os
import matplotlib.pyplot as plt
import warnings
import numpy as npwarnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 设置GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")################################导入数据集#####################################
import torch
from torchvision import datasets, transforms
import os# 数据集路径
data_dir = "./MTB-1"# 图像的大小
img_height = 100
img_width = 100# 数据预处理
data_transforms = {'train': transforms.Compose([transforms.RandomResizedCrop(img_height),transforms.RandomHorizontalFlip(),transforms.RandomVerticalFlip(),transforms.RandomRotation(0.2),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),'val': transforms.Compose([transforms.Resize((img_height, img_width)),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
}# 加载数据集
full_dataset = datasets.ImageFolder(data_dir)# 获取数据集的大小
full_size = len(full_dataset)
train_size = int(0.7 * full_size) # 假设训练集占70%
val_size = full_size - train_size # 验证集的大小# 随机分割数据集
torch.manual_seed(0) # 设置随机种子以确保结果可重复
train_dataset, val_dataset = torch.utils.data.random_split(full_dataset, [train_size, val_size])# 将数据增强应用到训练集
train_dataset.dataset.transform = data_transforms['train']# 创建数据加载器
batch_size = 32
train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=4)
val_dataloader = torch.utils.data.DataLoader(val_dataset, batch_size=batch_size, shuffle=True, num_workers=4)dataloaders = {'train': train_dataloader, 'val': val_dataloader}
dataset_sizes = {'train': len(train_dataset), 'val': len(val_dataset)}
class_names = full_dataset.classes###############################定义SqueezeNet模型################################
# 定义SqueezeNet模型
model = models.squeezenet1_1(pretrained=True) # 这里以SqueezeNet 1.1版本为例
num_ftrs = model.classifier[1].in_channels# 根据分类任务修改最后一层
model.classifier[1] = nn.Conv2d(num_ftrs, len(class_names), kernel_size=(1,1))# 修改模型最后的输出层为我们需要的类别数
model.num_classes = len(class_names)model = model.to(device)# 打印模型摘要
print(model)#############################编译模型#########################################
# 定义损失函数
criterion = nn.CrossEntropyLoss()# 定义优化器
optimizer = optim.Adam(model.parameters())# 定义学习率调度器
exp_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)# 开始训练模型
num_epochs = 50# 初始化记录器
train_loss_history = []
train_acc_history = []
val_loss_history = []
val_acc_history = []for epoch in range(num_epochs):print('Epoch {}/{}'.format(epoch, num_epochs - 1))print('-' * 10)# 每个epoch都有一个训练和验证阶段for phase in ['train', 'val']:if phase == 'train':model.train() # 设置模型为训练模式else:model.eval() # 设置模型为评估模式running_loss = 0.0running_corrects = 0# 遍历数据for inputs, labels in dataloaders[phase]:inputs = inputs.to(device)labels = labels.to(device)# 零参数梯度optimizer.zero_grad()# 前向with torch.set_grad_enabled(phase == 'train'):outputs = model(inputs)_, preds = torch.max(outputs, 1)loss = criterion(outputs, labels)# 只在训练模式下进行反向和优化if phase == 'train':loss.backward()optimizer.step()# 统计running_loss += loss.item() * inputs.size(0)running_corrects += torch.sum(preds == labels.data)epoch_loss = running_loss / dataset_sizes[phase]epoch_acc = (running_corrects.double() / dataset_sizes[phase]).item()# 记录每个epoch的loss和accuracyif phase == 'train':train_loss_history.append(epoch_loss)train_acc_history.append(epoch_acc)else:val_loss_history.append(epoch_loss)val_acc_history.append(epoch_acc)print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))print()# 保存模型
torch.save(model.state_dict(), 'model.pth')# 加载最佳模型权重
#model.load_state_dict(best_model_wts)
#torch.save(model, 'shufflenet_best_model.pth')
#print("The trained model has been saved.")
###########################Accuracy和Loss可视化#################################
epoch = range(1, len(train_loss_history)+1)fig, ax = plt.subplots(1, 2, figsize=(10,4))
ax[0].plot(epoch, train_loss_history, label='Train loss')
ax[0].plot(epoch, val_loss_history, label='Validation loss')
ax[0].set_xlabel('Epochs')
ax[0].set_ylabel('Loss')
ax[0].legend()ax[1].plot(epoch, train_acc_history, label='Train acc')
ax[1].plot(epoch, val_acc_history, label='Validation acc')
ax[1].set_xlabel('Epochs')
ax[1].set_ylabel('Accuracy')
ax[1].legend()#plt.savefig("loss-acc.pdf", dpi=300,format="pdf")####################################混淆矩阵可视化#############################
from sklearn.metrics import classification_report, confusion_matrix
import math
import pandas as pd
import numpy as np
import seaborn as sns
from matplotlib.pyplot import imshow# 定义一个绘制混淆矩阵图的函数
def plot_cm(labels, predictions):# 生成混淆矩阵conf_numpy = confusion_matrix(labels, predictions)# 将矩阵转化为 DataFrameconf_df = pd.DataFrame(conf_numpy, index=class_names ,columns=class_names) plt.figure(figsize=(8,7))sns.heatmap(conf_df, annot=True, fmt="d", cmap="BuPu")plt.title('Confusion matrix',fontsize=15)plt.ylabel('Actual value',fontsize=14)plt.xlabel('Predictive value',fontsize=14)def evaluate_model(model, dataloader, device):model.eval() # 设置模型为评估模式true_labels = []pred_labels = []# 遍历数据for inputs, labels in dataloader:inputs = inputs.to(device)labels = labels.to(device)# 前向with torch.no_grad():outputs = model(inputs)_, preds = torch.max(outputs, 1)true_labels.extend(labels.cpu().numpy())pred_labels.extend(preds.cpu().numpy())return true_labels, pred_labels# 获取预测和真实标签
true_labels, pred_labels = evaluate_model(model, dataloaders['val'], device)# 计算混淆矩阵
cm_val = confusion_matrix(true_labels, pred_labels)
a_val = cm_val[0,0]
b_val = cm_val[0,1]
c_val = cm_val[1,0]
d_val = cm_val[1,1]# 计算各种性能指标
acc_val = (a_val+d_val)/(a_val+b_val+c_val+d_val) # 准确率
error_rate_val = 1 - acc_val # 错误率
sen_val = d_val/(d_val+c_val) # 灵敏度
sep_val = a_val/(a_val+b_val) # 特异度
precision_val = d_val/(b_val+d_val) # 精确度
F1_val = (2*precision_val*sen_val)/(precision_val+sen_val) # F1值
MCC_val = (d_val*a_val-b_val*c_val) / (np.sqrt((d_val+b_val)*(d_val+c_val)*(a_val+b_val)*(a_val+c_val))) # 马修斯相关系数# 打印出性能指标
print("验证集的灵敏度为:", sen_val, "验证集的特异度为:", sep_val,"验证集的准确率为:", acc_val, "验证集的错误率为:", error_rate_val,"验证集的精确度为:", precision_val, "验证集的F1为:", F1_val,"验证集的MCC为:", MCC_val)# 绘制混淆矩阵
plot_cm(true_labels, pred_labels)# 获取预测和真实标签
train_true_labels, train_pred_labels = evaluate_model(model, dataloaders['train'], device)
# 计算混淆矩阵
cm_train = confusion_matrix(train_true_labels, train_pred_labels)
a_train = cm_train[0,0]
b_train = cm_train[0,1]
c_train = cm_train[1,0]
d_train = cm_train[1,1]
acc_train = (a_train+d_train)/(a_train+b_train+c_train+d_train)
error_rate_train = 1 - acc_train
sen_train = d_train/(d_train+c_train)
sep_train = a_train/(a_train+b_train)
precision_train = d_train/(b_train+d_train)
F1_train = (2*precision_train*sen_train)/(precision_train+sen_train)
MCC_train = (d_train*a_train-b_train*c_train) / (math.sqrt((d_train+b_train)*(d_train+c_train)*(a_train+b_train)*(a_train+c_train)))
print("训练集的灵敏度为:",sen_train, "训练集的特异度为:",sep_train,"训练集的准确率为:",acc_train, "训练集的错误率为:",error_rate_train,"训练集的精确度为:",precision_train, "训练集的F1为:",F1_train,"训练集的MCC为:",MCC_train)# 绘制混淆矩阵
plot_cm(train_true_labels, train_pred_labels)################################模型性能参数计算################################
from sklearn import metricsdef test_accuracy_report(model, dataloader, device):true_labels, pred_labels = evaluate_model(model, dataloader, device)print(metrics.classification_report(true_labels, pred_labels, target_names=class_names)) test_accuracy_report(model, dataloaders['val'], device)def train_accuracy_report(model, dataloader, device):true_labels, pred_labels = evaluate_model(model, dataloader, device)print(metrics.classification_report(true_labels, pred_labels, target_names=class_names)) train_accuracy_report(model, dataloaders['train'], device)################################AUC曲线绘制####################################
from sklearn import metrics
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.pyplot import imshow
from sklearn.metrics import classification_report, confusion_matrix
import seaborn as sns
import pandas as pd
import math
from sklearn.metrics import roc_auc_score, auc
from sklearn.preprocessing import LabelBinarizerdef multiclass_roc_auc_score(y_test, y_pred, average="macro"):# 判断 y_test 是否需要进行标签二值化if len(np.unique(y_test)) > 2: # 假设 y_test 是类别标签,且类别数大于 2lb = LabelBinarizer()lb.fit(y_test)y_test = lb.transform(y_test)return roc_auc_score(y_test, y_pred, average=average)def plot_roc(name, labels, predictions, **kwargs):lb = LabelBinarizer()labels = lb.fit_transform(labels) # one-hot 编码# predictions 不需要进行标签二值化# 计算ROC曲线和AUC值fpr = dict()tpr = dict()roc_auc = dict()class_num = len(class_names)for i in range(class_num): # class_num是类别数目fpr[i], tpr[i], _ = metrics.roc_curve(labels[:, i], predictions[:, i])roc_auc[i] = metrics.auc(fpr[i], tpr[i])for i in range(class_num):plt.plot(fpr[i], tpr[i], label='ROC curve of class {0} (area = {1:0.2f})' ''.format(i, roc_auc[i]))plt.plot([0, 1], [0, 1], 'k--')plt.xlim([0.0, 1.0])plt.ylim([0.0, 1.05])plt.xlabel('False Positive Rate')plt.ylabel('True Positive Rate')plt.title('Receiver operating characteristic example')plt.legend(loc="lower right")plt.show()# 确保模型处于评估模式
model.eval()def evaluate_model_pre(model, data_loader, device):model.eval()predictions = []labels = []with torch.no_grad():for inputs, targets in data_loader:inputs = inputs.to(device)targets = targets.to(device)outputs = model(inputs)# 使用 softmax 函数,转换成概率值prob_outputs = torch.nn.functional.softmax(outputs, dim=1)predictions.append(prob_outputs.detach().cpu().numpy())labels.append(targets.detach().cpu().numpy())return np.concatenate(predictions, axis=0), np.concatenate(labels, axis=0)val_pre_auc, val_label_auc = evaluate_model_pre(model, dataloaders['val'], device)
train_pre_auc, train_label_auc = evaluate_model_pre(model, dataloaders['train'], device)auc_score_val = multiclass_roc_auc_score(val_label_auc, val_pre_auc)
auc_score_train = multiclass_roc_auc_score(train_label_auc, train_pre_auc)plot_roc('validation AUC: {0:.4f}'.format(auc_score_val), val_label_auc, val_pre_auc, color="red", linestyle='--')
plot_roc('training AUC: {0:.4f}'.format(auc_score_train), train_label_auc, train_pre_auc, color="blue", linestyle='--')print("训练集的AUC值为:",auc_score_train, "验证集的AUC值为:",auc_score_val)(b)输出结果:学习曲线
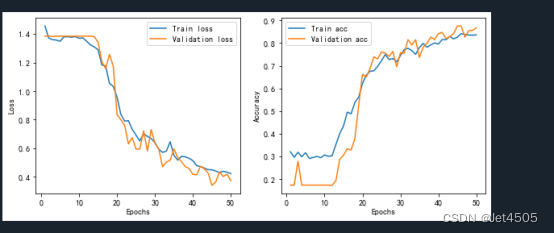
(c)输出结果:混淆矩阵

(d)输出结果:性能参数

(e)输出结果:ROC曲线
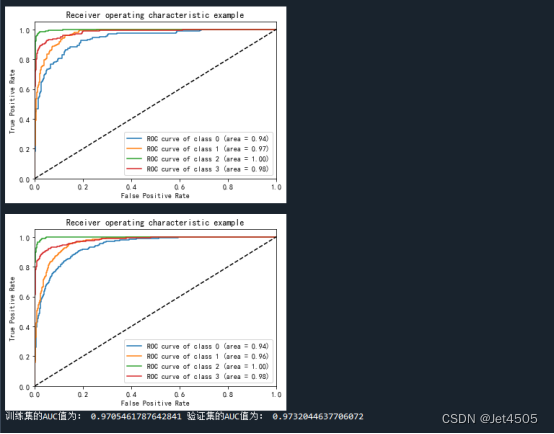
三、数据
链接:https://pan.baidu.com/s/1rqu15KAUxjNBaWYfEmPwgQ?pwd=xfyn
提取码:xfyn
相关文章:
第62步 深度学习图像识别:多分类建模(Pytorch)
基于WIN10的64位系统演示 一、写在前面 上期我们基于TensorFlow环境做了图像识别的多分类任务建模。 本期以健康组、肺结核组、COVID-19组、细菌性(病毒性)肺炎组为数据集,基于Pytorch环境,构建SqueezeNet多分类模型࿰…...

GPT带我学-设计模式-适配器模式
1 什么是适配器设计模式 适配器设计模式是一种结构性设计模式,用于在不兼容的接口之间进行转换。它允许将一个类的接口转换成客户端所期望的接口。 适配器模式包含以下几个角色: 目标接口(Target):定义客户端所期望…...
:使用pyecharts创建堆叠柱状图的示例)
Pyecharts教程(七):使用pyecharts创建堆叠柱状图的示例
Pyecharts教程(七):使用pyecharts创建堆叠柱状图的示例 作者:安静到无声 个人主页 目录 Pyecharts教程(七):使用pyecharts创建堆叠柱状图的示例完整代码推荐专栏在数据可视化中,柱状图是一种常见的图表类型,它可以清晰地展示各类别之间的比较关系。然而,如果我们想要在同…...

C++中的强制转换的常用类型及应用场景详解
C中的强制转换的常用类型及应用场景详解 文章目录 C中的强制转换的常用类型及应用场景详解一、静态转换(static_cast)二、动态转换(dynamic_cast)三、常量转换(const_cast)四、重新解释转换(rei…...

ubuntu调整时区
ubuntu在新装系统的时候,所用的时区不一定是8的时区,需要设置一下,否则执行cron等定时任务的时候,时间就会不对 查看当前系统的时区 date -R tzselect 选择时区,但是没用 ,作用可能就是 选择时区 设置时区:…...
mybatis:动态sql【2】+转义符+缓存
目录 一、动态sql 1.set、if 2.foreach 二、转义符 三、缓存cache 1. 一级缓存 2. 二级缓存 一、动态sql 1.set、if 在update语句中使用set标签,动态更新set后的sql语句,,if作为判断条件。 <update id"updateStuent" pa…...

2021年09月 C/C++(五级)真题解析#中国电子学会#全国青少年软件编程等级考试
第1题:抓牛 农夫知道一头牛的位置,想要抓住它。农夫和牛都位于数轴上,农夫起始位于点N(0<=N<=100000),牛位于点K(0<=K<=100000)。农夫有两种移动方式: 1、从X移动到X-1或X+1,每次移动花费一分钟 2、从X移动到2*X,每次移动花费一分钟 假设牛没有意识到农夫的…...

Ansible学习笔记1
公司的服务器越来越多,维护一些简单的事情都会变得很繁琐。用Shell脚本来管理少量服务器效率还行,服务器多了,Shell脚本无法实现高效率运维。这种情况下,我们需要引入自动化运维工具,对多台服务器实现高效运维。 配置服…...

解决centos离线安装cmake找不到OpenSSL问题
安装方法:见另外一篇文章 https://blog.csdn.net/zhongxj183/article/details/118488629 按照文章下载了离线gcc 和OpenSSL,以及在cmake官网下载了最新版 cmake-3.27.4.tar.gz 顺利安装gcc 和OpenSSL 但执行编译cmake时,报错找不到OpenSSL…...

Java 中数据结构ArrayList的用法
Java ArrayList ArrayList 类是一个可以动态修改的数组,与普通数组的区别就是它是没有固定大小的限制,我们可以添加或删除元素。 方法集合样例代码 import java.util.*;public class list_set_iterator {public static void main(String[] args) {Lis…...
UDP 多播(组播)
前言(了解分类的IP地址) 1.组播(多播) 单播地址标识单个IP接口,广播地址标识某个子网的所有IP接口,多播地址标识一组IP接口。单播和广播是寻址方案的两个极端(要么单个要么全部)&am…...
分布式环境集成JWT(Java Web Token)
目录 一,说明:二,Token、Session和Cookie比较三,Spring Boot项目集成JWT1,引入依赖2,Token工具类3,定义拦截器4,注册拦截器5,编写登录代码6,测试 四ÿ…...

Python实战之数据表提取和下载自动化
在网络爬虫领域,动态渲染类型页面的数据提取和下载自动化是一个常见的挑战。本文将介绍如何利用Pyppeteer库完成这一任务,帮助您轻松地提取动态渲染页面中的数据表并实现下载自动化。 一、环境准备 首先,确保您已经安装了Python环境。接下来…...

Midjourney学习(三)6个高级应用
使用Remix Mode在原图片的基础上进行二次创作 通过prompt得到大图之后,点击Make Variations按钮,输入Remix Prompt,即可得到意想不到的效果! 局部内容重绘 通过局部重绘可以实现对画面内容更加精细化的控制,同样也是需…...

C语言:指针类型的意义
1.指针的类型决定了解引用时访问几个字节 2.指针的类型决定了指针1、-1跳过几个字节 一、指针的类型决定指针解引用时访问几个字节 例如 int 型指针解引用时访问4个字节 char 型指针解引用时访问1个字节 详解代码如下: int b 0x11223344(十六进制&…...
如何将 PDF 转换为 Word:前 5 个应用程序
必须将 PDF 转换为 Word 才能对其进行编辑和自定义。所以这里有 5 种很棒的方法 PDF 文件被广泛使用,因为它非常稳定且难以更改。这在处理法律合同、财务文件和推荐信等重要文件时尤其重要。但是,有时您可能需要编辑 PDF 文件。最好的方法是使用应用程序…...
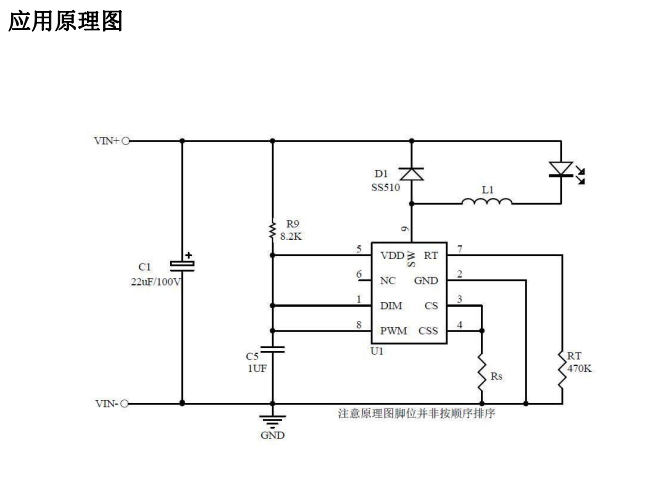
AP5192 DC-DC降压恒流LED汽车头灯摩托车电动车大灯电源驱动
AP5192是一款PWM工作模式,高效率、外围简单、 内置功率MOS管,适用于4.5-100V输入的高精度 降压LED恒流驱动芯片。最大电流1.5A。 AP5192可实现线性调光和PWM调光,线性调光 脚有效电压范围0.55-2.6V. AP5192 工作频率可以通过RT 外部电阻编程 来设定&…...

Python Opencv实践 - Canny边缘检测
import cv2 as cv import numpy as np import matplotlib.pyplot as pltimg cv.imread("../SampleImages/pomeranian.png", cv.IMREAD_GRAYSCALE) print(img.shape)#图像Canny边缘检测 #cv.Canny(image, threshold1, threshold2[, edges[, apertureSize[, L2gradien…...

Python编程练习与解答 练习119:低于和高于平均水平
编写一个程序,从用户处读取数字,直到用户输入空行。程序应该显示用户输入的所有值的平均值。然后所有程序应该显示所有平均值的值,然后显示所有平均值(若有),最后显示所有高于平均值的值。再每个值列表之前…...

vue中的nextTick的作用
vue里面,常用的事件onMounted里,总喜欢用一个nextTick: onMounted(() > {nextTick(() > {init();}); });这个东西有啥用呢?我总搞不懂。 今天我忽然有点明白了。这是一个跟前面语句有关的方法。意思是,等前面的…...

从一次任务到一次进化:完整拆解 Skill 创建、复用、修补链路
点击上方 前端Q,关注公众号回复加群,加入前端Q技术交流群写到这一篇,第二章的拼图终于齐了。 前面四篇我把 Hermes 的自学习系统拆成了 4 个零件:Memory(记知识)、Skill(记做法)、Nu…...

每天节省20分钟:淘宝淘金币自动化脚本的终极效率革命
每天节省20分钟:淘宝淘金币自动化脚本的终极效率革命 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taojinbi 你是否…...

Nodejs后端服务如何集成Taotoken提供稳定的AI功能接口
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Node.js 后端服务如何集成 Taotoken 提供稳定的 AI 功能接口 在构建现代后端服务时,集成大模型能力已成为提升应用智能…...
)
JS 异步 从零讲(大白话 + 真实场景 + 可运行案例)
按顺序:回调函数 → Promise → async/await,工作最常用,直接上手。1. 回调函数(最原始,缺点:回调地狱)2. Promise(解决回调地狱,链式调用)new Promise((reso…...
用C++实现信奥题 P9027 [CCC 2021 S5] Math Homework)
打卡信奥刷题(3295)用C++实现信奥题 P9027 [CCC 2021 S5] Math Homework
P9027 [CCC 2021 S5] Math Homework 题目描述 构造一个长度为 NNN 的整数序列 AAA,使得: ∀i1,2,⋯,N,1≤Ai≤109\forall i1,2,\cdots,N,1\leq A_i\leq 10^9∀i1,2,⋯,N,1≤Ai≤109;∀i1,2,⋯,M,gcd(AXi,AXi1,⋯,AYi)Zi\forall i1,2,\c…...

MLP-Mixer真的比CNN简单吗?深入拆解它的计算开销与内存瓶颈
MLP-Mixer真的比CNN简单吗?深入拆解它的计算开销与内存瓶颈 当谷歌研究院在2021年提出MLP-Mixer架构时,整个计算机视觉社区都为它的极简设计感到惊艳——没有注意力机制、没有卷积操作,仅用多层感知机(MLP)就实现了媲…...

ComfyUI InstantID终极指南:5分钟掌握AI人像风格化核心技术
ComfyUI InstantID终极指南:5分钟掌握AI人像风格化核心技术 【免费下载链接】ComfyUI_InstantID 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI_InstantID 你是否曾经想过,如何将自己或朋友的照片变成一幅精美的艺术作品,同时…...

别再只写CRUD了!用SpringBoot+MySQL设计一个高并发预约挂号系统,这些架构细节你得知道
高并发预约挂号系统架构实战:SpringBootMySQL核心技术解析 1. 系统架构设计挑战与解决方案 在医疗信息化高速发展的今天,预约挂号系统作为医院服务的"第一窗口",其稳定性与性能直接影响患者就医体验。传统CRUD架构在面对挂号早高峰…...

从Cityscapes到遥感图像:用MMSegmentation v1.0.0搞定不同领域语义分割数据集的完整配置流程
跨领域语义分割实战:MMSegmentation多场景数据集配置全解析 当计算机视觉工程师需要将语义分割技术从自动驾驶领域迁移到遥感图像分析时,最常遇到的障碍不是模型架构的选择,而是数据集的适配难题。不同领域的图像在分辨率、类别分布、标注格式…...

3步掌握StreamCap:开源直播录制工具的终极使用指南
3步掌握StreamCap:开源直播录制工具的终极使用指南 【免费下载链接】StreamCap Multi-Platform Live Stream Automatic Recording Tool | 多平台直播流自动录制客户端 基于FFmpeg 支持监控/定时/转码 项目地址: https://gitcode.com/gh_mirrors/st/StreamCap …...