Flink CDC介绍
1.CDC概述
CDC(Change Data Capture)是一种用于捕获和处理数据源中的变化的技术。它允许实时地监视数据库或数据流中发生的数据变动,并将这些变动抽取出来,以便进行进一步的处理和分析。
传统上,数据源的变化通常通过周期性地轮询整个数据集进行检查来实现。但是,这种轮询的方式效率低下且不能实时反应变化。而 CDC 技术则通过在数据源上设置一种机制,使得变化的数据可以被实时捕获并传递给下游处理系统,从而实现了实时的数据变动监控。
Flink 作为一个强大的流式计算引擎,提供了内置的 CDC 功能,能够连接到各种数据源(如数据库、消息队列等),捕获其中的数据变化,并进行灵活的实时处理和分析。
通过使用 Flink CDC,我们可以轻松地构建实时数据管道,对数据变动进行实时响应和处理,为实时分析、实时报表和实时决策等场景提供强大的支持。
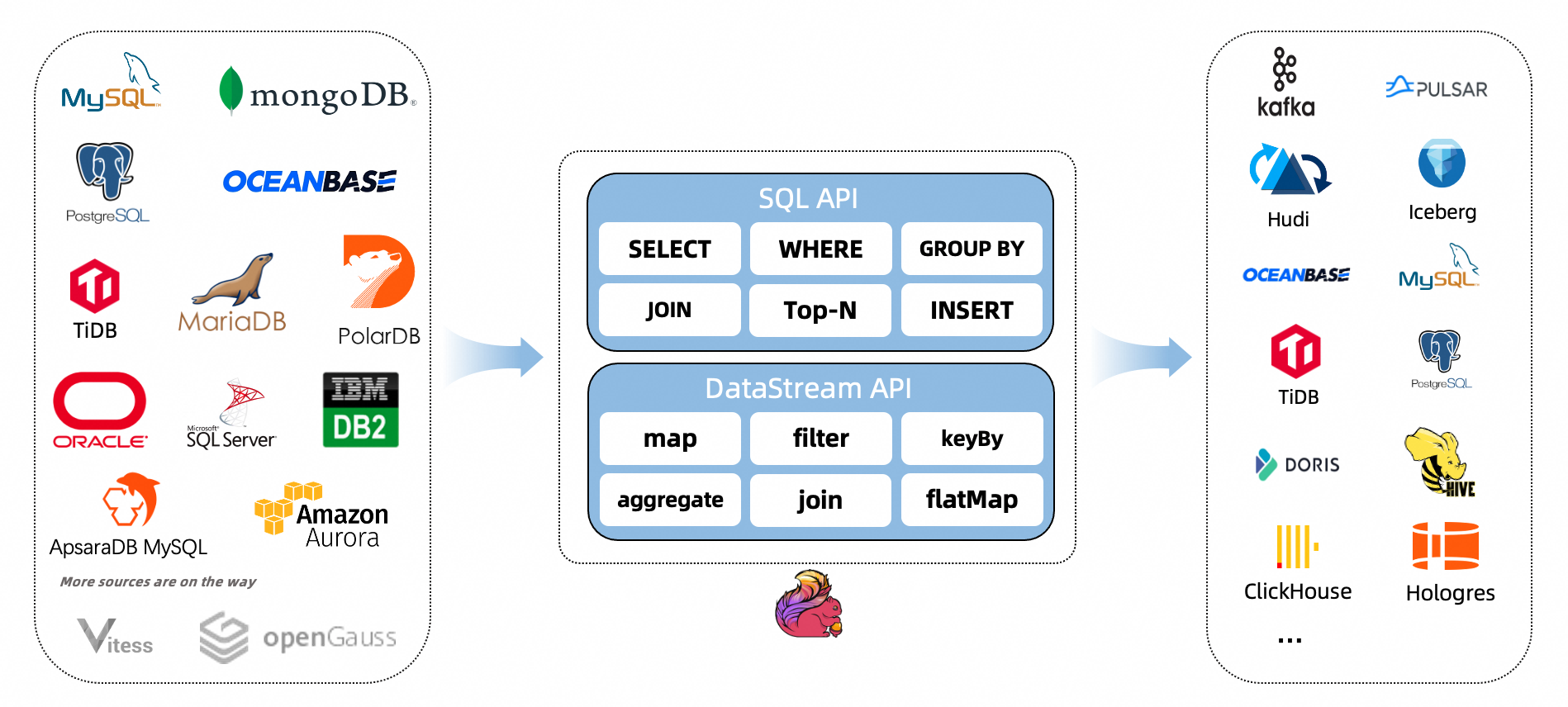
2.CDC 的实现原理
通常来讲,CDC 分为主动查询和事件接收两种技术实现模式。对于主动查询而言,用户通常会在数据源表的某个字段中,保存上次更新的时间戳或版本号等信息,然后下游通过不断的查询和与上次的记录做对比,来确定数据是否有变动,是否需要同步。这种方式优点是不涉及数据库底层特性,实现比较通用;缺点是要对业务表做改造,且实时性不高,不能确保跟踪到所有的变更记录,且持续的频繁查询对数据库的压力较大。事件接收模式可以通过触发器(Trigger)或者日志(例如 Transaction log、Binary log、Write-ahead log 等)来实现。当数据源表发生变动时,会通过附加在表上的触发器或者 binlog 等途径,将操作记录下来。下游可以通过数据库底层的协议,订阅并消费这些事件,然后对数据库变动记录做重放,从而实现同步。这种方式的优点是实时性高,可以精确捕捉上游的各种变动;缺点是部署数据库的事件接收和解析器(例如 Debezium、Canal 等),有一定的学习和运维成本,对一些冷门的数据库支持不够。综合来看,事件接收模式整体在实时性、吞吐量方面占优,如果数据源是 MySQL、PostgreSQL、MongoDB 等常见的数据库实现,建议使用Debezium来实现变更数据的捕获(下图来自Debezium 官方文档如果使用的只有 MySQL,则还可以用Canal。
3.为什么选 Flink
从上图可以看到,Debezium 官方架构图中,是通过 Kafka Streams 直接实现的 CDC 功能。而我们这里更建议使用 Flink CDC 模块,因为 Flink 相对 Kafka Streams 而言,有如下优势:
强大的流处理引擎: Flink 是一个强大的流处理引擎,具备高吞吐量、低延迟、Exactly-Once 语义等特性。它通过基于事件时间的处理模型,支持准确和有序的数据处理,适用于实时数据处理和分析场景。这使得 Flink 成为实现 CDC 的理想选择。
内置的 CDC 功能: Flink 提供了内置的 CDC 功能,可以直接连接到各种数据源,捕获数据变化,并将其作为数据流进行处理。这消除了我们自行开发或集成 CDC 解决方案的需要,使得实现 CDC 变得更加简单和高效。
多种数据源的支持: Flink CDC 支持与各种数据源进行集成,如关系型数据库(如MySQL、PostgreSQL)、消息队列(如Kafka、RabbitMQ)、文件系统等。这意味着无论你的数据存储在哪里,Flink 都能够轻松地捕获其中的数据变化,并进行进一步的实时处理和分析。
灵活的数据处理能力: Flink 提供了灵活且强大的数据处理能力,可以通过编写自定义的转换函数、处理函数等来对 CDC 数据进行各种实时计算和分析。同时,Flink 还集成了 SQL 和 Table API,为用户提供了使用 SQL 查询语句或 Table API 进行简单查询和分析的方式。
完善的生态系统: Flink 拥有活跃的社区和庞大的生态系统,这意味着你可以轻松地获取到丰富的文档、教程、示例代码和解决方案。此外,Flink 还与其他流行的开源项目(如Apache Kafka、Elasticsearch)深度集成,提供了更多的功能和灵活性。
4.支持的连接器
5.支持的 Flink 版本

6.Flink CDC特性
支持读取数据库快照,即使出现故障也能继续读取binlog,并进行Exactly-once处理
DataStream API 的 CDC 连接器,用户可以在单个作业中使用多个数据库和表的更改,而无需部署 Debezium 和 Kafka
Table/SQL API 的 CDC 连接器,用户可以使用 SQL DDL 创建 CDC 源来监视单个表上的更改
下表显示了连接器的当前特性: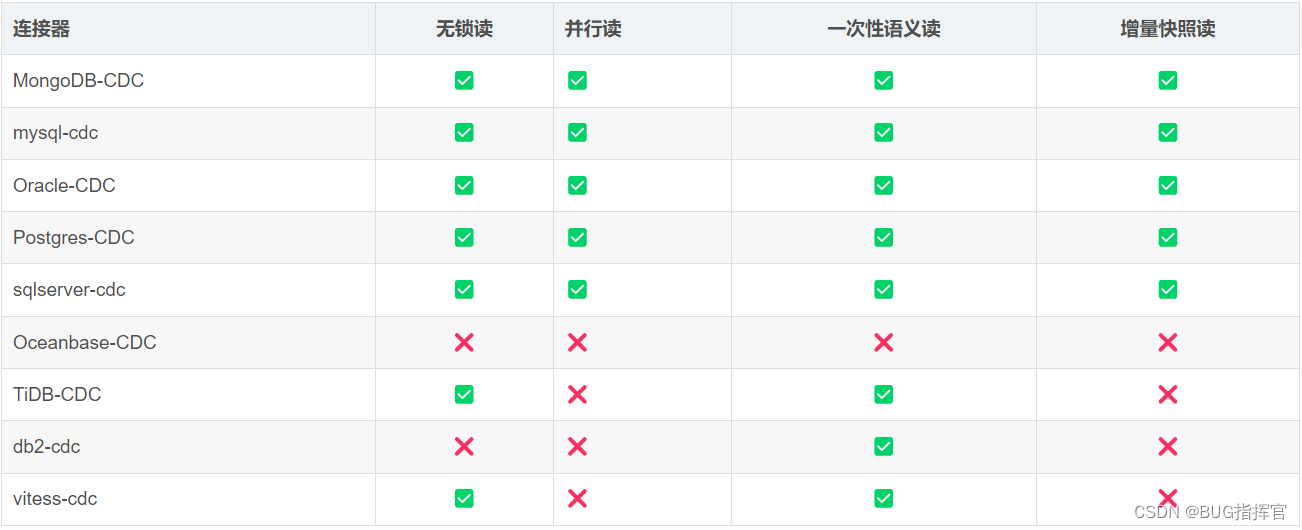
7.用法实例
7.1DataStream API 的用法(推荐)
请严格按照上面的《5.支持的 Flink 版本》搭配来使用Flink CDC
<properties><flink.version>1.13.0</flink.version><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependency><groupId>com.ververica</groupId><artifactId>flink-connector-mysql-cdc</artifactId><version>${flinkcdc.version}</version>
</dependency>
<!-- flink核心API -->
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_2.12</artifactId><version>${flink.version}</version>
</dependency>
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version>
</dependency>
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-scala_2.12</artifactId><version>${flink.version}</version>
</dependency>
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_2.12</artifactId><version>${flink.version}</version>
</dependency>
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-scala_2.12</artifactId><version>${flink.version}</version>
</dependency>
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-common</artifactId><version>${flink.version}</version>
</dependency>
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner-blink_2.12</artifactId><version>${flink.version}</version>
</dependency>
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java-bridge_2.12</artifactId><version>${flink.version}</version>
</dependency>
请提前开启MySQL中的binlog,配置my.cnf文件,重启mysqld服务即可
my.cnf
[client]
default_character_set=utf8
[mysqld]
server-id=1
collation_server=utf8_general_ci
character_set_server=utf8
log-bin=mysql-bin
binlog_format=row
expire_logs_days=30
ddl&dml.sql
create table test_cdc
(id int not nullprimary key,name varchar(100) null,age int null
);INSERT INTO flink.test_cdc (id, name, age) VALUES (1, 'Daniel', 25);
INSERT INTO flink.test_cdc (id, name, age) VALUES (2, 'David', 38);
INSERT INTO flink.test_cdc (id, name, age) VALUES (3, 'James', 16);
INSERT INTO flink.test_cdc (id, name, age) VALUES (4, 'Robert', 27);
FlinkDSCDC.java
package com.daniel.util;import com.ververica.cdc.connectors.mysql.MySqlSource;
import com.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.ververica.cdc.debezium.DebeziumSourceFunction;
import com.ververica.cdc.debezium.StringDebeziumDeserializationSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;/*** @Author Daniel* @Date: 2023/7/25 10:03* @Description DataStream API CDC**/
public class FlinkDSCDC {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DebeziumSourceFunction<String> sourceFunction = MySqlSource.<String>builder().hostname("localhost").port(3306).username("root").password("123456").databaseList("flink")// 这里一定要是db.table的形式.tableList("flink.test_cdc").deserializer(new StringDebeziumDeserializationSchema()).startupOptions(StartupOptions.initial()).build();DataStreamSource<String> dataStreamSource = env.addSource(sourceFunction);dataStreamSource.print();env.execute("FlinkDSCDC");}
}UPDATE flink.test_cdc t SET t.age = 24 WHERE t.id = 1;
UPDATE flink.test_cdc t SET t.name = 'Andy' WHERE t.id = 3;
打印出的日志
SourceRecord{sourcePartition={server=mysql_binlog_source}, sourceOffset={transaction_id=null, ts_sec=1690272544, file=mysql-bin.000001, pos=7860, row=1, server_id=1, event=2}} ConnectRecord{topic='mysql_binlog_source.flink.test_cdc', kafkaPartition=null, key=Struct{id=1}, keySchema=Schema{mysql_binlog_source.flink.test_cdc.Key:STRUCT}, value=Struct{before=Struct{id=1,name=Daniel,age=25},after=Struct{id=1,name=Daniel,age=24},source=Struct{version=1.5.2.Final,connector=mysql,name=mysql_binlog_source,ts_ms=1690272544000,db=flink,table=test_cdc,server_id=1,file=mysql-bin.000001,pos=7989,row=0},op=u,ts_ms=1690272544122}, valueSchema=Schema{mysql_binlog_source.flink.test_cdc.Envelope:STRUCT}, timestamp=null, headers=ConnectHeaders(headers=)}
SourceRecord{sourcePartition={server=mysql_binlog_source}, sourceOffset={transaction_id=null, ts_sec=1690272544, file=mysql-bin.000001, pos=7860, row=1, server_id=1, event=4}} ConnectRecord{topic='mysql_binlog_source.flink.test_cdc', kafkaPartition=null, key=Struct{id=3}, keySchema=Schema{mysql_binlog_source.flink.test_cdc.Key:STRUCT}, value=Struct{before=Struct{id=3,name=James,age=16},after=Struct{id=3,name=Andy,age=16},source=Struct{version=1.5.2.Final,connector=mysql,name=mysql_binlog_source,ts_ms=1690272544000,db=flink,table=test_cdc,server_id=1,file=mysql-bin.000001,pos=8113,row=0},op=u,ts_ms=1690272544122}, valueSchema=Schema{mysql_binlog_source.flink.test_cdc.Envelope:STRUCT}, timestamp=null, headers=ConnectHeaders(headers=)}
可以得出的结论:
1、日志中的数据变化操作类型(op)可以表示为 ‘u’,表示更新操作。在第一条日志中,发生了一个更新操作,对应的记录的 key 是 id=1,更新前的数据是 {id=1, name=Daniel, age=25},更新后的数据是 {id=1, name=Daniel, age=24}。在第二条日志中,也发生了一个更新操作,对应的记录的 key 是 id=3,更新前的数据是 {id=3, name=James, age=16},更新后的数据是 {id=3, name=Andy, age=16}。
2、每条日志还提供了其他元数据信息,如数据源(source)、版本号(version)、连接器名称(connector)、时间戳(ts_ms)等。这些信息可以帮助我们追踪记录的来源和处理过程。
3、日志中的 sourceOffset 包含了一些关键信息,如事务ID(transaction_id)、文件名(file)、偏移位置(pos)等。这些信息可以用于确保数据的准确顺序和一致性。
7.2Table/SQL API的用法
FlinkSQLCDC.java
package com.daniel.util;import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;/*** @Author Daniel* @Date: 2023/7/25 15:25* @Description**/
public class FlinkSQLCDC {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);tableEnv.executeSql("CREATE TABLE test_cdc (" +" id int primary key," +" name STRING," +" age int" +") WITH (" +" 'connector' = 'mysql-cdc'," +" 'scan.startup.mode' = 'latest-offset'," +" 'hostname' = 'localhost'," +" 'port' = '3306'," +" 'username' = 'root'," +" 'password' = '123456'," +" 'database-name' = 'flink'," +" 'table-name' = 'test_cdc'" +")");Table table = tableEnv.sqlQuery("select * from test_cdc");DataStream<Tuple2<Boolean, Row>> dataStreamSource = tableEnv.toRetractStream(table, Row.class);dataStreamSource.print();env.execute("FlinkSQLCDC");}
}UPDATE flink.test_cdc t SET t.age = 55 WHERE t.id = 2;
UPDATE flink.test_cdc t SET t.age = 22 WHERE t.id = 3;
UPDATE flink.test_cdc t SET t.name = 'Alice' WHERE t.id = 4;
UPDATE flink.test_cdc t SET t.age = 18 WHERE t.id = 1;
INSERT INTO flink.test_cdc (id, name, age) VALUES (5, 'David', 29);
打印出的日志
(false,-U[2, David, 38])
(true,+U[2, David, 55])
(false,-U[3, Andy, 16])
(true,+U[3, Andy, 22])
(false,-U[4, Robert, 27])
(true,+U[4, Alice, 27])
(false,-U[1, Daniel, 24])
(true,+U[1, Daniel, 18])
(true,+I[5, David, 29])
相关文章:
Flink CDC介绍
1.CDC概述 CDC(Change Data Capture)是一种用于捕获和处理数据源中的变化的技术。它允许实时地监视数据库或数据流中发生的数据变动,并将这些变动抽取出来,以便进行进一步的处理和分析。 传统上,数据源的变化通常通过…...
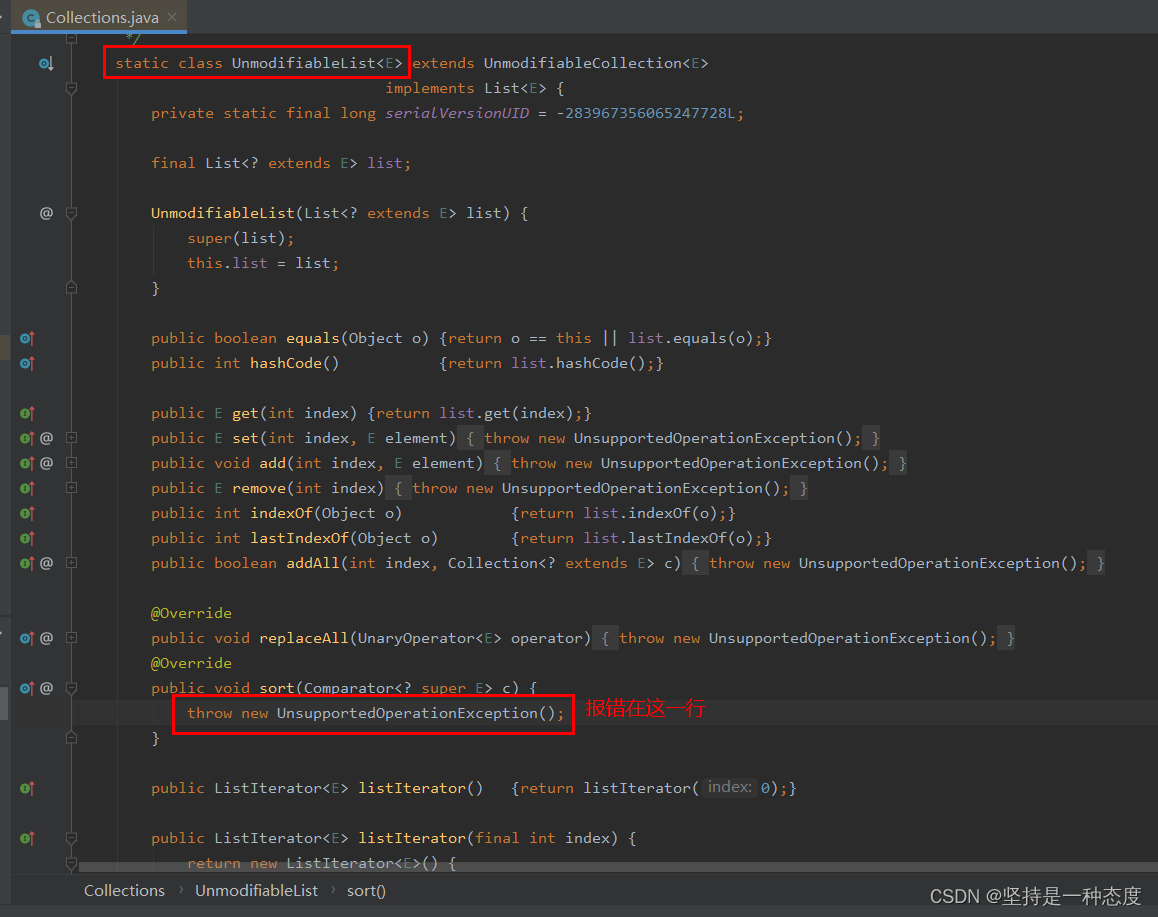
Java集合sort排序报错UnsupportedOperationException处理
文章目录 报错场景排查解决UnmodifiableList类介绍 报错场景 我们使用的是PostgreSQL数据库,存储业务数据,业务代码使用的是Spring JPA我们做的是智慧交通信控平台,有个功能是查询展示区域的交通态势,需要按照不同维度排序展示区…...
安防监控/磁盘阵列存储/视频汇聚平台EasyCVR调用rtsp地址返回的IP不正确是什么原因?
安防监控/云存储/磁盘阵列存储/视频汇聚平台EasyCVR可拓展性强、视频能力灵活、部署轻快,可支持的主流标准协议有GB28181、RTSP/Onvif、RTMP等,以及厂家私有协议与SDK接入,包括海康Ehome、海大宇等设备的SDK等,能对外分发RTSP、RT…...

Spring boot开启定时任务
Cron表达式生成器 基于接口的方式 使用Scheduled 注解很方便,但缺点是当我们调整了执行周期的时候,需要重启应用才能生效,这多少有些不方便。为了达到实时生效的效果,那么可以使用接口来完成定时任务,统一将定时器信…...

package.json相关知识记录
一、相关字段 npm官方字段介绍 🍧 bin > 简单理解:指定命令的名称及路径 🍉 相当于想path中添加路径,局部安装是在./node_modules/.bin/,全局安装是在全局的bin目录 🍉 bin指定的文件必须…...
)
VueRouter使用详解(5000字通关大全)
Vue Router是一个官方的路由管理器,它可以让我们在Vue应用中实现单页面应用(SPA)的效果,即通过改变URL而不刷新页面来显示不同的内容。Vue Router可以让我们定义多个路由,每个路由对应一个组件,当URL匹配到…...

vue axios实现下载文件及responseType:blob注意事项
需要使用axios和js-file-download组件 npm install js-file-download --save npm install axios --save import fileDownload from fileDownload; // 引入fileDownload import axios from axios; // 引入axios axios({method: get,url: xxxxxxx,responseType: blob }).then(r…...

StringBuilder类分享(1)
一、StringBuilder说明 StringBuilder是一个可变的字符序列。这个类提供了一个与StringBuffer兼容的API,但不保证同步,即StringBuilder不是线程安全的,而StringBuffer是线程安全的。显然,StringBuilder要运行的更快一点。 这个类…...

Qt 打开文件列表选择文件,实现拖拽方式打开文件
1. 实现打开文件列表选择文件 1.1. 创建 Qt 工程,并添加几个简单控件 这里笔者选用的是 QMainWindow,创建好工程后在 ui 界面设计中添加 QLineEdit、QPushBtton至少这两个控件,如下图摆放。 1.2. 头文件中添加相关操作 在 mainwindow.h 中…...

[C/C++]天天酷跑游戏超详细教程-上篇
个人主页:北海 🎐CSDN新晋作者 🎉欢迎 👍点赞✍评论⭐收藏✨收录专栏:C/C🤝希望作者的文章能对你有所帮助,有不足的地方请在评论区留言指正,大家一起学习交流!ǹ…...
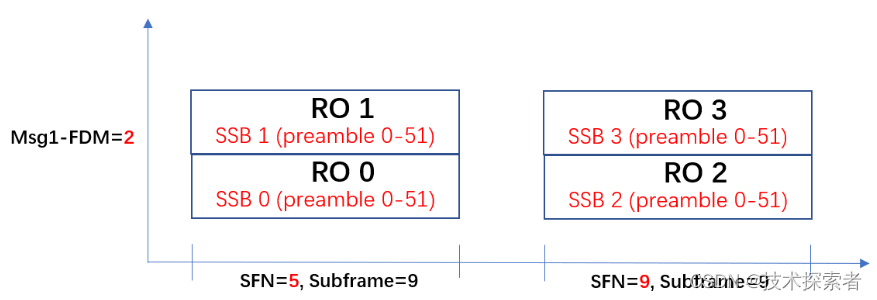
5G NR:RACH流程 -- Msg1之选择正确的PRACH时频资源
PRACH的时域资源是如何确定的 PRACH的时域资源主要由参数“prach-ConfigurationIndex”决定。拿着这个参数的取值去协议38211查表6.3.3.2-2/3/4,需要注意根据实际情况在这三张表中进行选择: FR1 FDD/SULFR1 TDDFR2 TDD Random access preambles can onl…...
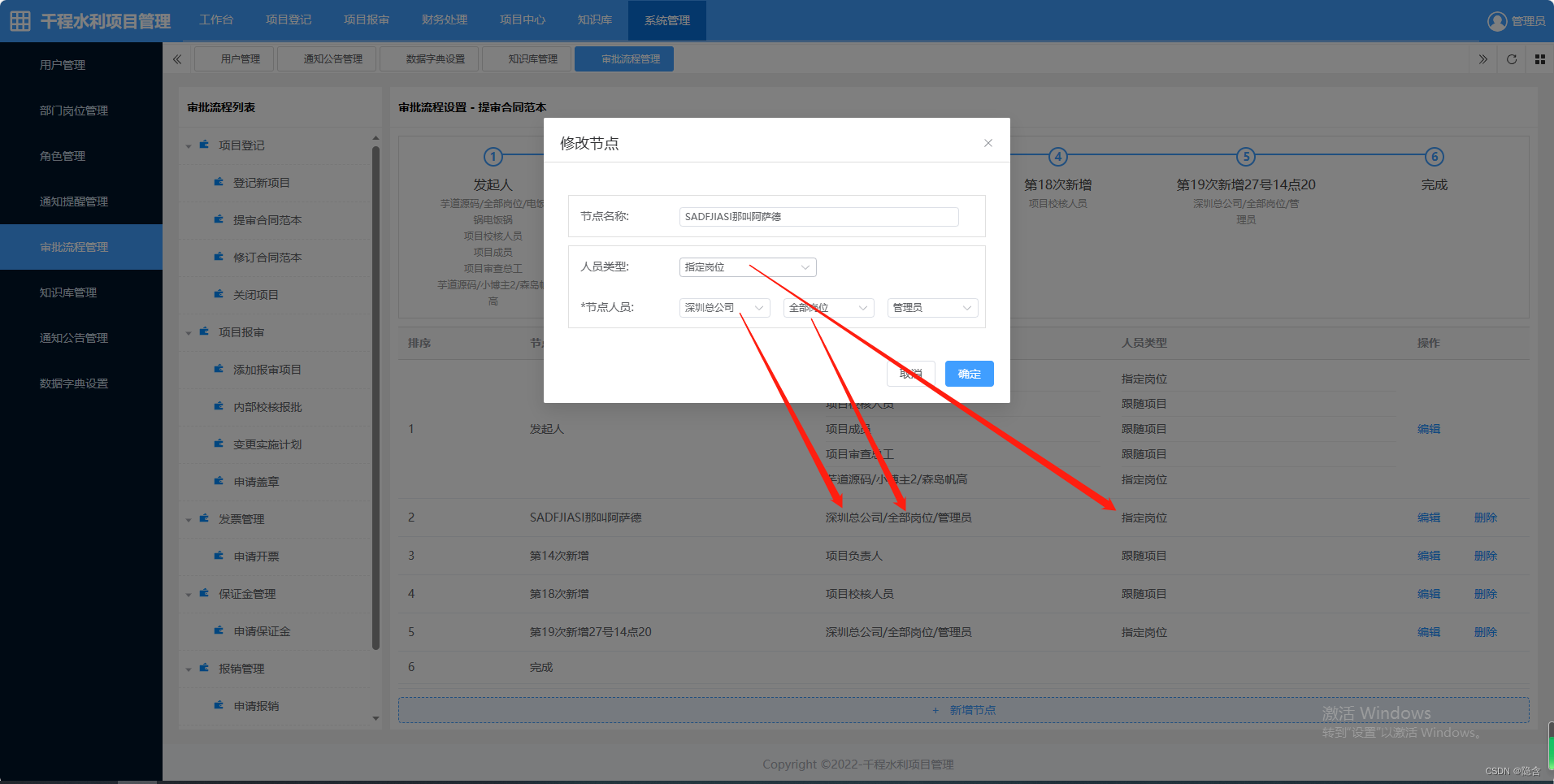
在vue3项目中编辑的时候,解决对话框里边的数据和列表中的数据联动了。深复制
//分析原因是从列表中拿到的数据直接复制去修改就涉及到堆里变的内容是一样的,直接复制其实只是把引用地址赋值给变量了,解决方法是 浅复制和深复制。<!-- 审批流程管理 --> <template><div style"float: left; width: 250px;backgr…...

循环结构(个人学习笔记黑马学习)
while循环语句 在屏幕中打印0~9这十个数字 #include <iostream> using namespace std;int main() {int i 0;while (i < 10) {cout << i << endl;i;}system("pause");return 0; } 练习案例: 猜数字 案例描述:系统随机生成一个1到100之间的数字&…...
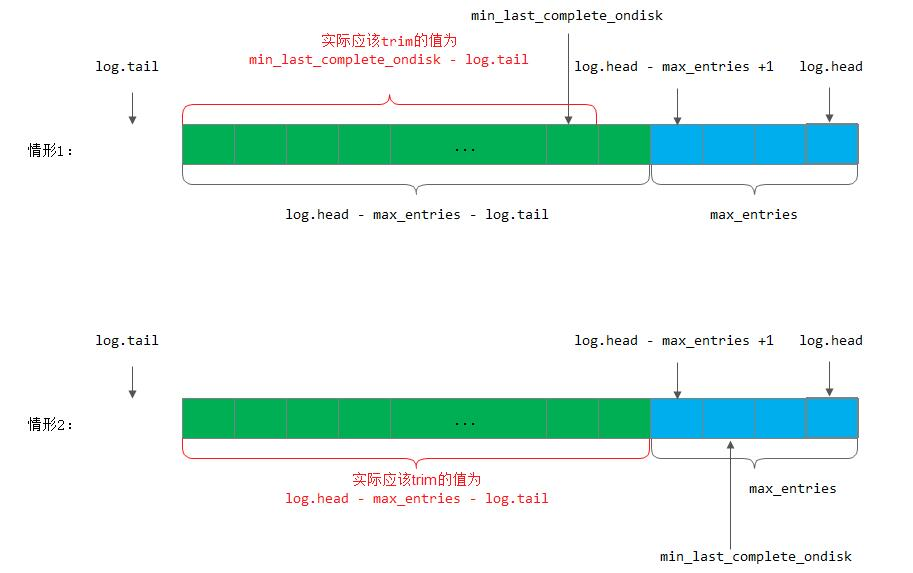
ceph中PGLog处理流程
正文 struct pg_log_entry_t {ObjectModDesc mod_desc; //用于保存本地回滚的一些信息,用于EC模式下的回滚操作bufferlist snaps; //克隆操作,用于记录当前对象的snap列表hobject_t soid; …...
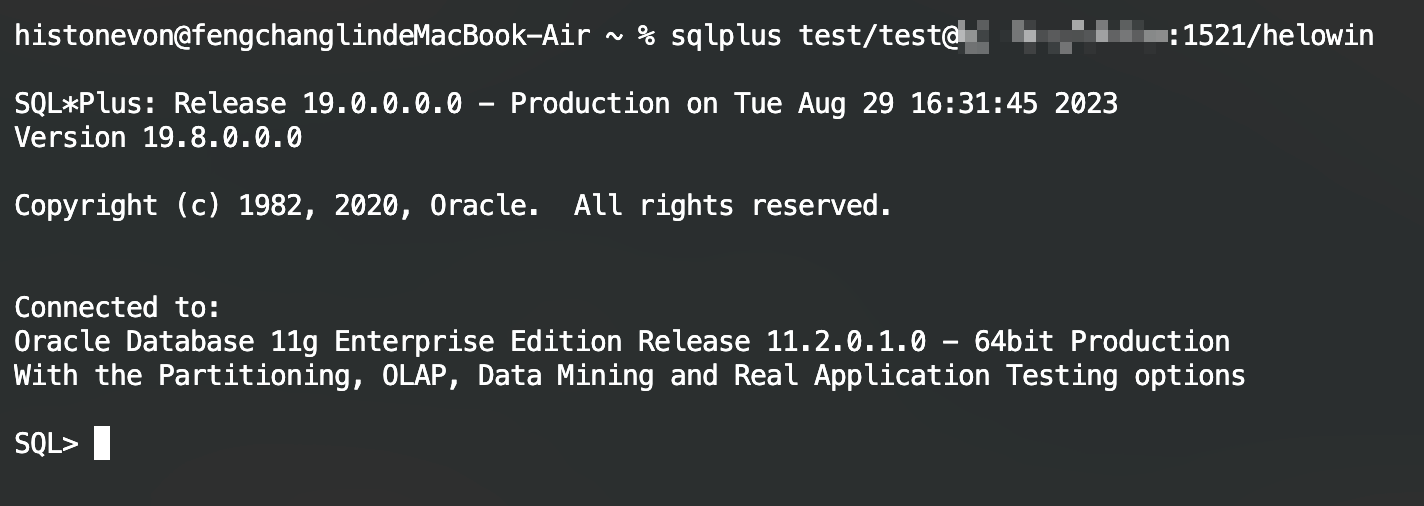
macOS使用命令行连接Oracle(SQL*Plus)
Author: histonevonzohomail.com Date: 2023/08/25 文章目录 SQL\*Plus安装下载环境配置 SQL\*Plus远程连接数据库参考文献 原文地址:https://histonevon.top/archives/oracle-mac-sqlplus数据库安装:Docker安装Oracle数据库 (histonevon.top) SQL*Plus…...
Mac下使用Homebrew安装MySQL5.7
Mac下使用Homebrew安装MySQL5.7 1. 安装Homebrew & Oh-My-Zsh2. 查询软件信息3. 执行安装命令4. 开机启动5. 服务状态查询6. 初始化配置7. 登录测试7.1 终端登录7.2 客户端登录 参考 1. 安装Homebrew & Oh-My-Zsh mac下如何安装homebrew MacOS安装Homebrew与Oh-My-Zsh…...

centos安装Nginx配置Nginx
1. 查看操作系统有没有安装Nginx which nginx 2. 使用epel的方式进行安装(方法二) 先安装epel sudo yum install yum-utils 安装完成后,查看安装的epel包即可 sudo yum install epel 3 开始安装nginx 上面的两个方法不管选择哪个&…...

Linux环境下搭建使用缓存中间件Redis
缓存中间件Redis搭建与使用 前言正文1 提供安装环境2 下载安装3 修改启动配置4 启动服务5 使用6 关闭服务7 卸载 前言 redis服务将在linux系统中部署,本文前提是已经搭建一个linux系统,并配置好网络等。使用vmware搭建一个linux系统,可以参考…...

Oracle 本地客户端连接远程 Oracle 服务端并使用 c# 连接测试
这里写自定义目录标题 前言Oracle 客户端安装先决条件下载 Oracle 客户端Oracle 客户端环境变量配置 PL/SQLPL/SQL 下载PL/SQL 配置 配置远程连接tnsnames.ora 文件配置 使用 PL/SQL 连接远程数据库使用 C# 远程访问 Oracle 数据库结语 前言 最近有一个需要使用本地的 Oracle …...

java中上传文件先下载到本地再上传还有就是直接通过文件流url地址进行上传优缺点?
在Java中上传文件到SFTP服务器时,有两种常见的方法:先下载到本地再上传和直接使用文件流URL地址进行上传。每种方法都有其优点和缺点,下面是对它们的简要比较: 先下载到本地再上传: 优点: 可以在本地对文件…...
)
【独家首发】Midjourney 6.6+新增--depth-map指令实战手册:从单通道灰度图到可编辑景深层次(含Blender预处理模板)
更多请点击: https://codechina.net 第一章:Midjourney景深效果控制 景深(Depth of Field)是图像中清晰区域与虚化区域的过渡表现,在 Midjourney 中虽无原生 DSLR 式光圈参数,但可通过提示词工程、版本特性…...

AI识别+yolo11室内监控系统 AI办公室监控系统
办公室监控系统 一个基于 Flask 的 Web 应用程序,通过计算机视觉和 YOLO 对象检测来监控办公室工作区域。系统跟踪人员在不同工作区域的存在情况,并记录在每个区域停留的时间。 功能 使用 YOLOv8 实现实时人员检测和跟踪监控多个工作区域跟踪每个定义工…...

环保设备系统控制柜制造:从工艺联动到稳定达标的完整解析
一、什么是环保设备系统控制柜制造?环保设备系统控制柜制造,是指根据废气治理、污水处理、粉尘治理、喷淋塔、活性炭吸附、催化燃烧、RTO/RCO、除尘器、风机水泵、加药系统、污泥处理、在线监测和环保设备联动控制等实际需求,对PLC、变频器、…...

Beyond Compare 5密钥生成终极指南:5分钟免费激活完整教程
Beyond Compare 5密钥生成终极指南:5分钟免费激活完整教程 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen Beyond Compare 5作为专业的文件对比工具,在30天试用期结束后会…...

【职场】职场里,“被喜欢“和“被重用“是两件完全不同的事
职场里,"被喜欢"和"被重用"是两件完全不同的事我见过太多这样的人。 在公司里人缘极好,谁都说他靠谱,谁都愿意跟他合作。 开会时第一个帮人倒水,群里消息第一个回复,同事生日永远记得,…...

紧急停止与异常停机:天勤策略里的断线保护与人工兜底
前言 网络闪断、进程被 kill、策略异常未捕获,都可能让持仓暴露在无人管理状态。天勤文档里有紧急停止相关能力(见 advanced/emergency_stop.rst),我把它和自建「停机即平仓/撤单」脚本配合使用。下面写工程清单,不替代…...

魔百盒CM311-1s刷机后体验:安卓9.0固件到底香不香?附5621DS无线实测
魔百盒CM311-1s刷机实战:安卓9.0系统深度评测与无线性能揭秘 当手中的魔百盒CM311-1s遇上安卓9.0系统,这场硬件与软件的碰撞会擦出怎样的火花?作为一款搭载S905L3B芯片的电视盒子,其原生系统往往受限于运营商定制化限制࿰…...
)
LangChain学习之提示词模板 Prompts(2/8)
模块 2: 提示词模板 (Prompts) 2.1 提示词 (Prompts) 概述 在与大型语言模型(LLM)交互时,提示词 (Prompt) 是向模型发出的指令或问题。一个好的提示词能够引导模型生成高质量、符合预期的输出。LangChain 提供了强大的提示词管理功能&#…...

工业物联网主板布局设计:从i.MX28x核心到无线模块的硬件规划
1. 项目概述:从一块板卡看工业物联网的“骨架”拿到一块名为“IoT-A28LI”的主板,标题里还带着“i.MX28x系列”和“无线工控板”这样的关键词,这立刻让我这个在工业控制和嵌入式领域摸爬滚打多年的老工程师来了兴致。这不仅仅是一块电路板&am…...

NoFences桌面整理工具:5步打造高效整洁的Windows桌面
NoFences桌面整理工具:5步打造高效整洁的Windows桌面 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 还在为Windows桌面上杂乱无章的图标而烦恼吗?NoF…...