【教程】DGL中的子图分区函数partition_graph讲解
转载请注明出处:小锋学长生活大爆炸[xfxuezhang.cn]
目录
函数形式
函数作用
函数内容
函数入参
函数返参
使用示例
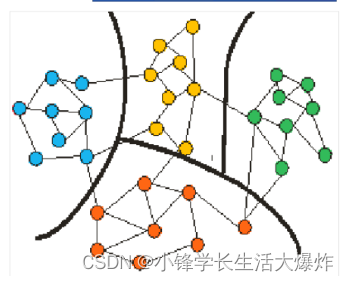
实际上官方的函数解释中就已经非常详细了。
函数形式
def partition_graph(g, graph_name, num_parts, out_path, num_hops=1, part_method="metis",reshuffle=True, balance_ntypes=None, balance_edges=False, return_mapping=False,num_trainers_per_machine=1, objtype='cut')函数作用
为分布式训练对图形进行分区,并将分区存储在文件中。
函数内容
分区分为三个步骤:
1) 运行分区算法(如 Metis)将节点分配到分区中;
2) 根据节点分配构建分区图结构;
3) 根据分区结果分割节点特征和边特征。
在对图进行分区时,每个分区都可能包含HALO节点,这些节点被分配给其他分区,但为了提高效率而被包含在本分区中。
在本文中,local nodes/edges指的是真正属于某个分区的节点和边。其余的都是HALO nodes/edges。
分区数据存储在多个文件中,组织结构如下:
data_root_dir/|-- graph_name.json # partition configuration file in JSON|-- node_map.npy # partition id of each node stored in a numpy array (optional)|-- edge_map.npy # partition id of each edge stored in a numpy array (optional)|-- part0/ # data for partition 0|-- node_feats.dgl # node features stored in binary format|-- edge_feats.dgl # edge features stored in binary format|-- graph.dgl # graph structure of this partition stored in binary format|-- part1/ # data for partition 1|-- node_feats.dgl|-- edge_feats.dgl|-- graph.dgl 首先,原始图形和分区的元数据存储在一个以"graph_name"命名的 JSON 文件中。
该 JSON 文件包含原始图的信息以及存储每个分区的文件路径。
下面是一个示例。
{"graph_name" : "test","part_method" : "metis","num_parts" : 2,"halo_hops" : 1,"node_map": {"_U": [ [ 0, 1261310 ],[ 1261310, 2449029 ] ]},"edge_map": {"_V": [ [ 0, 62539528 ],[ 62539528, 123718280 ] ]},"etypes": { "_V": 0 },"ntypes": { "_U": 0 },"num_nodes" : 1000000,"num_edges" : 52000000,"part-0" : {"node_feats" : "data_root_dir/part0/node_feats.dgl","edge_feats" : "data_root_dir/part0/edge_feats.dgl","part_graph" : "data_root_dir/part0/graph.dgl",},"part-1" : {"node_feats" : "data_root_dir/part1/node_feats.dgl","edge_feats" : "data_root_dir/part1/edge_feats.dgl","part_graph" : "data_root_dir/part1/graph.dgl",},
}- graph_name:是用户给出的图形名称。
- part_method:是将节点分配到分区的方法。目前,支持 "random "和 "metis"。
- num_parts:是分区的数量。
- halo_hops:是分区中作为 HALO 节点的节点跳数。
- node_map:是节点分配映射表,它显示了节点被分配到的分区 ID。
- edge_map:是边的分配映射,它告诉我们边被分配到的分区 ID。
- num_nodes:是全局图中的节点数。
- num_edges:是全局图中的边数。
- part-*:存储一个分区的数据。
如果reshuffle=False,分区的节点 ID 和边 ID 将不属于连续的 ID 范围。在这种情况下,DGL 会将节点/边映射(从节点/边 ID 到分区 ID)存储在单独的文件(node_map.npy 和 edge_map.npy)中。节点/边映射存储在 numpy 文件中。注意,这种格式已被弃用,下一版本将不再支持。换句话说,未来的版本在分割图形时将始终对节点 ID 和边 ID 进行打乱。
如果reshuffle=True,则``node_map``和``edge_map``包含将全局节点/边ID 映射到分区本地节点/边ID 的信息。对于异构图,``node_map``和``edge_map``中的信息还可用于计算节点类型和边类型。
"node_map"和"edge_map"中的数据格式如下:
{"node_type": [ [ part1_start, part1_end ],[ part2_start, part2_end ],... ],...
},本质上,``node_map``和`edge_map``是字典。键是节点/边类型。值是成对的列表,包含分区中相应类型的 ID 范围的起点和终点。列表的长度是分区的数量;列表中的每个元素都是一个元组,存储了分区中特定节点/边类型的 ID 范围的起点和终点。
分区的图结构以DGLGraph格式存储在文件中。每个分区中的节点都经过*relabeled*,始终以0开头。我们将原始图中的节点ID称为 "global ID",而将每个分区中重新标记的 ID 称为 "local ID"。每个分区图都有一个整数节点数据张量,存储名为 "dgl.NID",每个值都是节点的全局 ID。同样,边也被重新标记,本地 ID 到全局 ID 的映射被存储为名为 `dgl.EID` 的整数边数据张量。对于异构图,DGLGraph 还包含表示节点类型的节点数据 `dgl.NTYPE`和表示边类型的边数据`dgl.ETYPE`。
分区图包含额外的节点数据("inner_node "和 "orig_id")和边数据("inner_edge"):
- inner_node:表示节点是否属于某个分区。
- inner_edge:表示一条边是否属于一个分区。
- orig_id:在 reshuffle=True 时存在。它表示重新洗牌前原始图中的原始节点 ID。
节点和边的特征被分割开来,与每个图形分区一起存储。分区中的所有节点/边特征都以 DGL 格式存储在一个文件中。节点/边特征存储在字典中,其中键是节点/边数据的名称,值是张量。我们不存储 HALO 节点和边的特征。
在执行 Metis 分区时,我们可以对分区施加一些约束。目前,它支持两种平衡分区的约束条件。默认情况下,Metis 总是尝试平衡每个分区中的节点数。
- balance_ntypes:平衡每个分区中不同类型节点的数量。
- balance_edges:平衡每个分区中的边数。
为了平衡节点类型,用户需要传递一个包含 N 个元素的向量来表示每个节点的类型。N 是输入图中的节点数。
函数入参
- g : DGLGraph
要分割的输入图
- graph_name : str
图的名称。该名称将用于构建 dgl.distributed.DistGraph
- num_parts : int
分区数
- out_path : str
存储所有分区数据文件的路径
- num_hops : int, optional
我们在分区图结构上构建的 HALO 节点的跳数。默认值为 1
- part_method : str, optional
分区方法。支持 "random"和 "metis"。默认值为 "metis"
- reshuffle : bool, optional
是否打乱节点和边,使分区中的节点和边处于连续的 ID 范围内。默认值为 True。该参数已被弃用,将在下一版本中删除
- balance_ntypes : tensor, optional
每个节点的节点类型。这是一个一维整数数组。其值表示每个节点的节点类型。Metis分区使用此参数。指定该参数后,Metis 算法将尝试把输入图分割成多个分区,每个分区中每个节点类型的节点数大致相同。默认值为 "None",这意味着 Metis 只对图进行分区,以平衡节点数量。
- balance_edges : bool
指示是否平衡每个分区中的边。该参数用于 Metis 算法使用。
- return_mapping : bool
如果 `reshuffle=True` 表示返回洗牌后的节点/边 ID 与原始节点/边 ID 之间的映射。
- num_trainers_per_machine : int, optional
每台机器的trainer数量。如果不是 1,则会先将整个图划分给每个trainer,即 num_parts*num_trainers_per_machine parts。每个节点的trainer ID 将存储在节点特征 "trainer_id "中。然后,同一台机器上trainer的分区将被合并成一个更大的分区。分区的最终数量为 "num_part"。
- objtype : str, "cut" or "vol"
将目标设置为边缘切割最小化或通信量最小化。Metis 算法会使用这一参数。
函数返参
- Tensor or dict of tensors, optional
如果 "return_mapping=True",则返回一个一维张量,表示同构图中经过洗牌的节点 ID 与原始节点 ID 之间的映射;如果是异构图,则返回一个一维张量的 dict,其 key 是节点类型,value 是每个节点类型的经过洗牌的节点 ID 与原始节点 ID 之间的一维张量映射。
- Tensor or dict of tensors, optional
如果 "return_mapping=True",则返回一个一维张量,表示同质图中经过洗牌的边 ID 与原始边 ID 之间的映射;如果是异质图,则返回一个一维张量的 dict,其 key 是边类型,value 是每个边类型的经过洗牌的边 ID 与原始边 ID 之间的 1D 张量映射。
使用示例
>>> dgl.distributed.partition_graph(g, 'test', 4, num_hops=1, part_method='metis',out_path='output/', reshuffle=True,balance_ntypes=g.ndata['train_mask'],balance_edges=True)
>>> g, node_feats, edge_feats, gpb, graph_name = dgl.distributed.load_partition('output/test.json', 0)相关文章:
【教程】DGL中的子图分区函数partition_graph讲解
转载请注明出处:小锋学长生活大爆炸[xfxuezhang.cn] 目录 函数形式 函数作用 函数内容 函数入参 函数返参 使用示例 实际上官方的函数解释中就已经非常详细了。 函数形式 def partition_graph(g, graph_name, num_parts, out_path, num_hops1, part…...

关于layui table回显以及选择下一页时记住上一页数据的问题
代码如下 <div class"layui-form-item"><label class"layui-form-label">选择商品</label><div class"layui-input-inline"><input type"text" name"keyword" id"keyword" placehold…...
kafka消息系统实战
kafka是什么? 是一种高吞吐量的、分布式、发布、订阅、消息系统 1.导入maven坐标 <dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>2.4.1</version></dependency&…...

Kafka3.0.0版本——Leader故障处理细节原理
目录 一、服务器信息二、服务器基本信息及相关概念2.1、服务器基本信息2.2、LEO的概念2.3、HW的概念 三、Leader故障处理细节 一、服务器信息 三台服务器 原始服务器名称原始服务器ip节点centos7虚拟机1192.168.136.27broker0centos7虚拟机2192.168.136.28broker1centos7虚拟机…...
BI系统框架模型
一 技术架构 二 数据源 主数据 :组织|岗位|人员|大区|三大主数据(客户、物料、供应商)财务主数据(科目|成本中心|利润中心|资产)|工作中心|工艺路线 业务数据 :线索|业务机会|合同|订单|采购|生产|发…...
双向交错CCM图腾柱无桥单相PFC学习仿真与实现(3)硬件功能实现
前言 前面介绍了双向交错CCM图腾柱的系统设计仿真实现,仿真很理想 双向交错CCM图腾柱无桥单相PFC学习仿真与实现(1)系统问题分解_卡洛斯伊的博客-CSDN博客 然后又介绍了SOG锁相环仿真实现的原理 双向交错CCM图腾柱无桥单相PFC学习仿真与实…...

微软用 18 万行 Rust 重写了 Windows 内核
微软正在使用 Rust 编程语言重写其核心 Windows 库。 5 月 11 日——Azure 首席技术官 Mark Russinovich 表示,最新的 Windows 11 Insider Preview 版本是第一个包含内存安全编程语言 Rust 的版本。 “如果你参加了 Win11 Insider 环,你将在 Windows 内…...
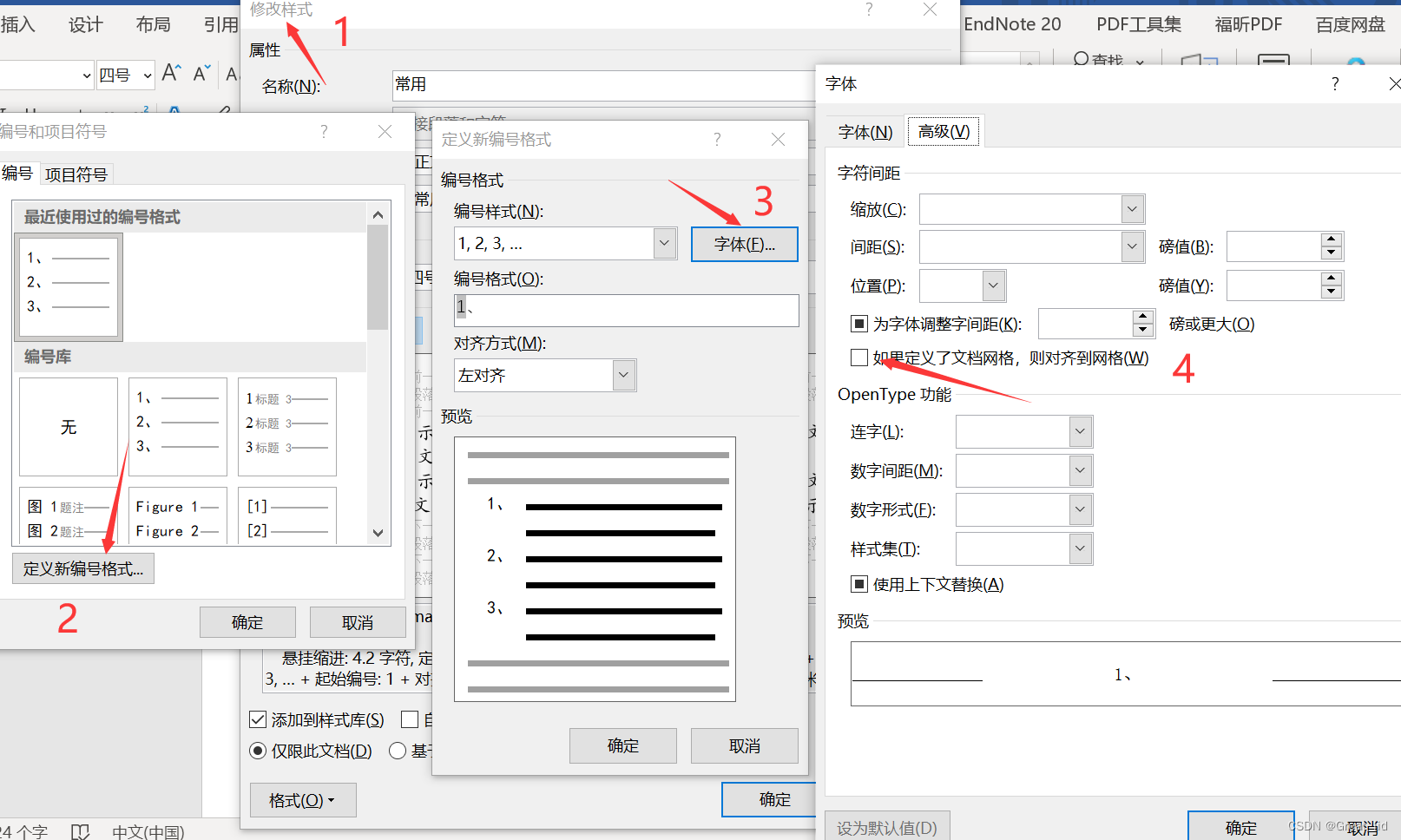
word 调整列表缩进
word 调整列表缩进的一种方法,在试了其他方法无效后,按下图所示顺序处理,编号和文字之间的空白就没那么大了。 即右键word上方样式->点击修改格式->定义新编号格式->字体->取消勾选 “……对齐到网格”->确定...

nginx学习
一、nginx常用版本 Nginx开源版: http://nginx.org/ nginx plus商业版本(好像功能支持更多) https://www.nginx.com/ openresty (免费,用的也是这个) https://openresty.org/cn/ Tengine https://tengine.…...
python+TensorFlow实现人脸识别智能小程序的项目(包含TensorFlow版本与Pytorch版本)(一)
pythonTensorFlow实现人脸识别智能小程序的项目(包含TensorFlow版本与Pytorch版本)(一) 一:TensorFlow基础知识内容部分(简明扼要,快速适应)1、下载Cifar10数据集,并进行…...

ChatGPT怎么用于政府和公共服务?
将ChatGPT用于政府和公共服务领域是一种创新的应用方式,可以改善政府与公众之间的互动,提升公共服务的效率和质量。ChatGPT作为一个自然语言处理模型,可以在政府信息传递、公共参与、服务支持等方面发挥积极作用。以下将详细探讨ChatGPT如何用…...
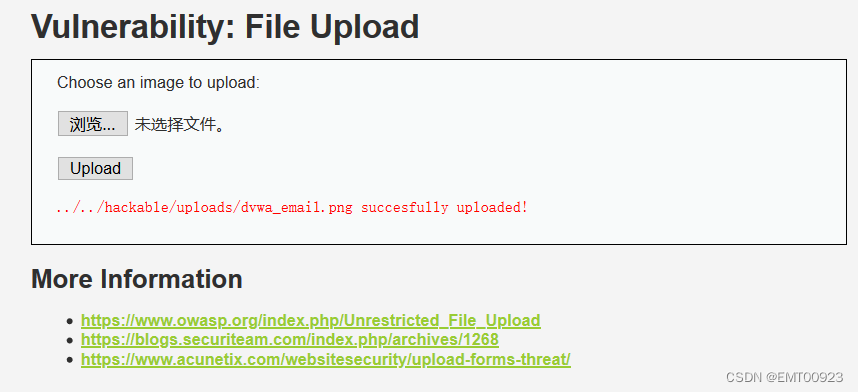
dvwa文件上传通关及代码分析
文章目录 low等级medium等级high等级Impossible等级 low等级 查看源码: <?phpif( isset( $_POST[ Upload ] ) ) {// Where are we going to be writing to?$target_path DVWA_WEB_PAGE_TO_ROOT . "hackable/uploads/";$target_path . basename( …...
数字孪生:重塑政府决策与公共服务
在之前的文章中为大家分享了数字孪生在很多行业的应用场景,本文和大家一起探讨一下数字孪生在政务管理方面能有哪些应用,以及其对公共服务提供的积极影响。 1)城市规划方面 数字孪生技术可用于模拟城市的发展和规划。政府可以建立城市的虚拟…...

Leetcode:【448. 找到所有数组中消失的数字】题解
题目 给你一个含 n 个整数的数组 nums ,其中 nums[i] 在区间 [1, n] 内。请你找出所有在 [1, n] 范围内但没有出现在 nums 中的数字,并以数组的形式返回结果。 难度:简单 题目链接:448. 找到所有数组中消失的数字 示例1 输入&…...

2023年中,量子计算产业现状——
2023年上半年,量子计算(QC)领域取得了一系列重要进展和突破,显示出量子计算技术的快速发展和商业应用的不断拓展。在iCV TAnk近期发表的一篇报告中,团队从制度进步、产业生态、投融资形势、总结与展望四个方面对量子计…...

微信小程序智慧流调微信小程序设计与实现
摘 要 自从2020年新冠疫情爆发以来,对全国人民的健康和全国各地区的经济发展都带来了很大的影响,并且新冠肺炎对各个领域带来的影响还未完全消除。近三年以来,全国各地区多次爆发新的疫情,导致许多人被隔离,也导致全国…...

分布式集群框架——有关zookeeper的面试考点
3.掌握Zookeeper的概念 当涉及到大规模分布式系统的协调和管理时,Zookeeper是一个非常重要的工具。 1. 分布式协调服务:Zookeeper是一个分布式协调服务,它提供了一个高可用和高性能的环境,用于协调和同步分布式系统中的各个节点…...
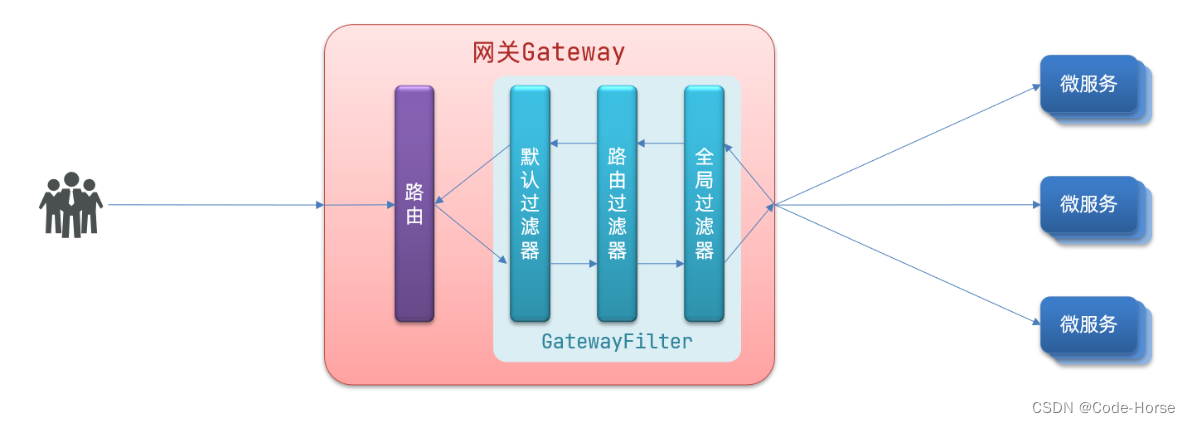
Spring Cloud Gateway的快速使用
环境前置搭建Nacos:点击跳转 Spring Cloud Gateway Docs 新建gateway网关模块 pom.xml导入依赖 <!-- 网关 --> <dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-gateway</artifact…...

VSCode-C++环境配置+Cmake
文章目录 一、环境配置二、Win10 Cmake 一、环境配置 转载链接 二、Win10 Cmake 创建CMakeLists.txt cmake_minimum_required(VERSION 3.26) project(graph_algorithm)set(CMAKE_CXX_STANDARD 17)add_executable(main main.cppshared_variable.cpp )cmake . -G "MinGW…...

python爬虫14:总结
python爬虫14:总结 前言 python实现网络爬虫非常简单,只需要掌握一定的基础知识和一定的库使用技巧即可。本系列目标旨在梳理相关知识点,方便以后复习。 申明 本系列所涉及的代码仅用于个人研究与讨论,并不会对网站产生不好…...

定向井轨迹控制关键技术:200℃高温定向传感器的随钻测量应用指南
一、引言 定向井钻井技术是现代油气资源开发的核心支撑技术之一,通过精确控制井眼轨迹,可以实现从地表向地下油气藏的精准穿藏,最大化油气产量和采收率。200℃定向传感器作为随钻测量系统的核心感知器件,在深井、超深井以及复杂结…...
)
告别手写解析!用Python Cantools 39.4.5一键生成CAN/CANFD DBC的C代码(附批处理脚本)
从DBC到C代码:Python Cantools全自动转换实战指南 在汽车电子和嵌入式开发领域,CAN总线通信是核心基础设施,而DBC文件则是定义CAN/CANFD通信协议的行业标准。传统开发流程中,工程师需要手动解析DBC文件并编写大量信号打包/解包代码…...

Uniapp网络请求进阶:手把手教你用uni.addInterceptor实现全局请求管理与错误处理
Uniapp网络请求工程化实战:基于uni.addInterceptor的全局管控体系 在移动开发生态中,网络请求如同项目的血脉系统。当Uniapp项目规模扩展到企业级时,原始的直接调用uni.request方式会暴露出诸多痛点:重复的配置代码、分散的错误处…...

别再踩坑了!手把手教你解决RPM安装时的‘.rpm.lock’事务锁定报错
RPM事务锁机制深度解析:从原理到避坑实战 在Linux系统管理中,RPM包管理器的.rpm.lock报错堪称经典"拦路虎"——据统计,超过63%的运维人员至少遭遇过一次这类锁定问题。这个看似简单的错误背后,隐藏着RPM设计精妙的事务隔…...
)
人工智能导论:模型与算法(未来发展与趋势)
9 人工智能未来发展和趋势 人工智能作为引领新一轮科技革命和产业变革的战略性技术,正在深刻改变人类社会。本章从类脑计算、自动化机器学习、神经网络压缩、人工智能芯片、量子机器学习、人工智能伦理与治理、人工智能算法开发框架等方面,简要总结人工智…...

淘金币全自动脚本终极指南:每天节省20分钟,淘宝任务一键完成
淘金币全自动脚本终极指南:每天节省20分钟,淘宝任务一键完成 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/t…...

如何用四探针精确测量半导体电阻率
在半导体行业中,准确测量晶圆电阻率是材料研发和制程质量控制的关键环节。随着工艺节点不断缩小,器件对电性一致性的要求日益严格,仅靠经验无法满足现代制造的需求。因此工程师们大量采用四探针方法对电阻率进行高精度测量。相比传统测量方式…...

别再手动转换时间了!用Jackson和Spring的这两个注解,搞定Java日期序列化所有坑
彻底告别Java日期转换噩梦:Jackson与Spring注解实战指南 如果你曾在Java项目中处理过日期时间转换,一定对以下场景不陌生:前端传过来的字符串日期需要手动解析成Date对象,返回给前端的日期格式乱七八糟,时区问题导致时…...

TruckSim 仿真工作流实战:从参数修改到结果对比
1. TruckSim仿真工作流基础入门 第一次打开TruckSim时,很多新手会被复杂的界面吓到。其实只要掌握几个核心概念,就能快速上手这个强大的车辆动力学仿真工具。我刚开始使用时也走过不少弯路,现在把这些经验分享给大家。 TruckSim的工作流可以简…...
)
Unity交通仿真入门:从零到一搭建十字路口红绿灯与车辆AI(附完整C#源码)
Unity交通仿真实战:十字路口红绿灯与车辆AI开发指南 在游戏开发和城市模拟领域,交通仿真一直是个充满挑战又极具实用价值的课题。想象一下,你正站在一个繁忙的十字路口,观察着红绿灯有节奏地变换,车辆井然有序地通过—…...