JVM解密: 解构类加载与GC垃圾回收机制
文章目录
- 一. JVM内存划分
- 二. 类加载机制
- 1. 类加载过程
- 2. 双亲委派模型
- 三. GC垃圾回收机制
- 1. 找到需要回收的内存
- 1.1 哪些内存需要回收?
- 1.2 基于引用计数找垃圾(Java不采取该方案)
- 1.3 基于可达性分析找垃圾(Java采取方案)
- 2. 垃圾回收算法
- 2.1 标记-清除算法
- 2.2 标记-复制算法
- 2.3 标记-整理算法
- 2.4 分代回收
一. JVM内存划分
JVM 其实是一个 Java 进程,该进程会从操作系统中申请一大块内存区域,提供给 Java 代码使用,申请的内存区域会进一步做出划分,给出不同的用途。
其中最核心的是栈,堆,方法区这几个区域:
- 堆,用来放置 new 出来的对象,类成员变量。
- 栈,维护方法之间的调用关系,放置局部变量。
- 方法区(旧)/元数据区(新):放的是类加载之后的类对象(
.class文件),静态变量,二进制指令(方法)。
细分下来 JVM 的内存区域包括以下几个:程序计数器,栈,堆,方法区,图中的元数据区可以理解为方法区。
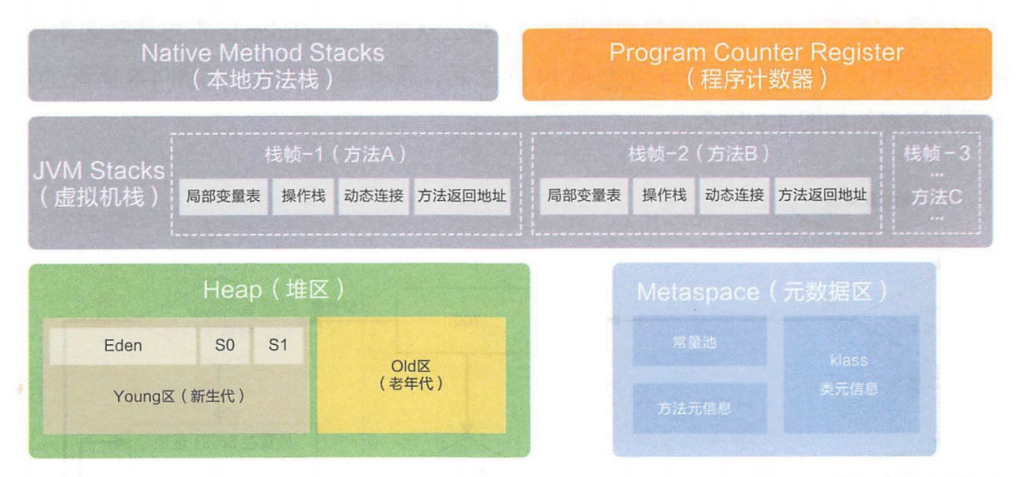
🍂程序计数器:内存最小的一块区域,保存了下一条要执行的指令(字节码)的地址,每个线程都有一份。
🍂栈:储存局部变量与方法之间的调用信息,每一个线程都有一份,但要注意“栈是线程私有的”这种说法是不准确的,私有的意思是我的你是用不了的,但实际上,一个线程栈上的内容,是可以被另一个线程使用到的。
栈在 JVM 区域划分中分为两种,一种是 Java 虚拟机栈,另外一种是本地方法栈,这两种栈功能非常类似,当方法被调用时,都会同步创建栈帧来存储局部变量表、操作数栈、动态连接、方法出口等信息。
只不过虚拟机栈是为虚拟机执行 Java 方法(也就是字节码)服务,而本地方法栈则是给 JVM 内部的本地(Native)方法服务的(JVM 内部通过 C++ 代码实现的方法)。

🍂堆:储存对象以及对象的成员变量,一个 JVM 进程只有一个,多个线程共用一个堆,是内存中空间最大的区域,Java 堆是垃圾回收器管理的内存区域,后文介绍 GC 的时候细说。
🍂方法区: JDK 1.8 开始,叫做元数据区,存储了类对象,常量池,静态成员变量,即时编译器编译后的代码缓存等数据;所谓的“类对象”,就是被static修饰的变量或方法就成了类属性,.java文件会被编译成.class文件,.class会被加载到内存中,也就被 JVM 构造成类对象了,类对象描述了类的信息,如类名,类有哪些成员,每个成员叫什么名字,权限是什么,方法名等;同样一个 JVM 进程只有一个元数据区,多个线程共用一块元数据区内存。
要注意 JVM 的线程和操作系统的线程是一对一的关系,每次在 Java 代码中创建的线程,必然会在系统中有一个对应的线程。
二. 类加载机制
1. 类加载过程
类加载就是把.java文件使用javac编译为.class文件,从文件(硬盘)被加载到内存中(元数据区),得到类对象的过程。(程序要想运行,就需要把依赖的“指令和数据”加载到内存中)。
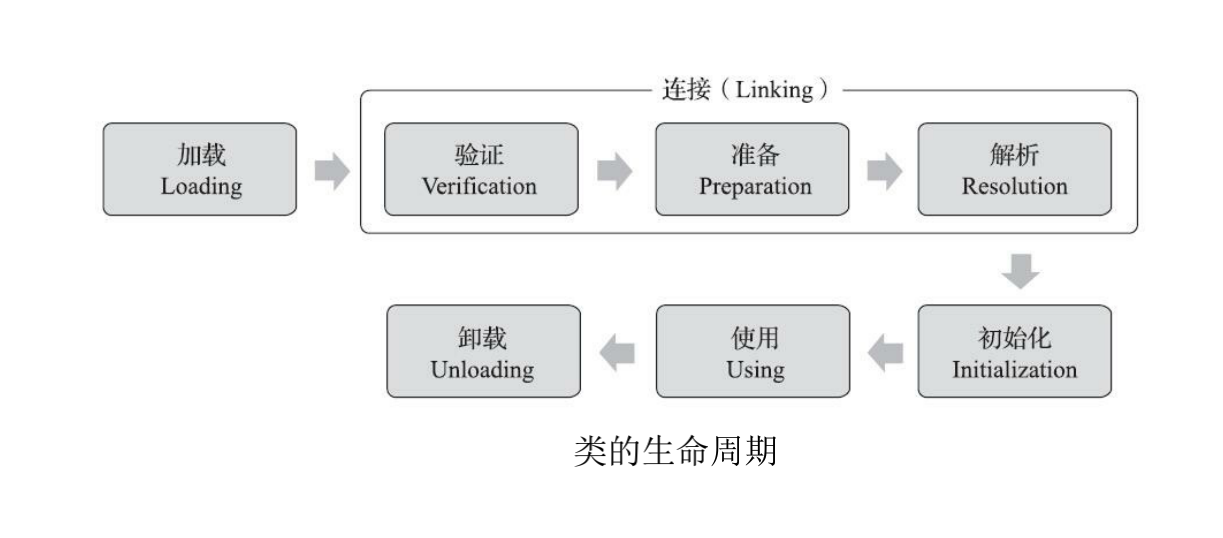
这个图片所示的类加载过程来自官方文档,类加载包括三个步骤:Loading, Linking, Initialization。
官方文档:https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-5.html
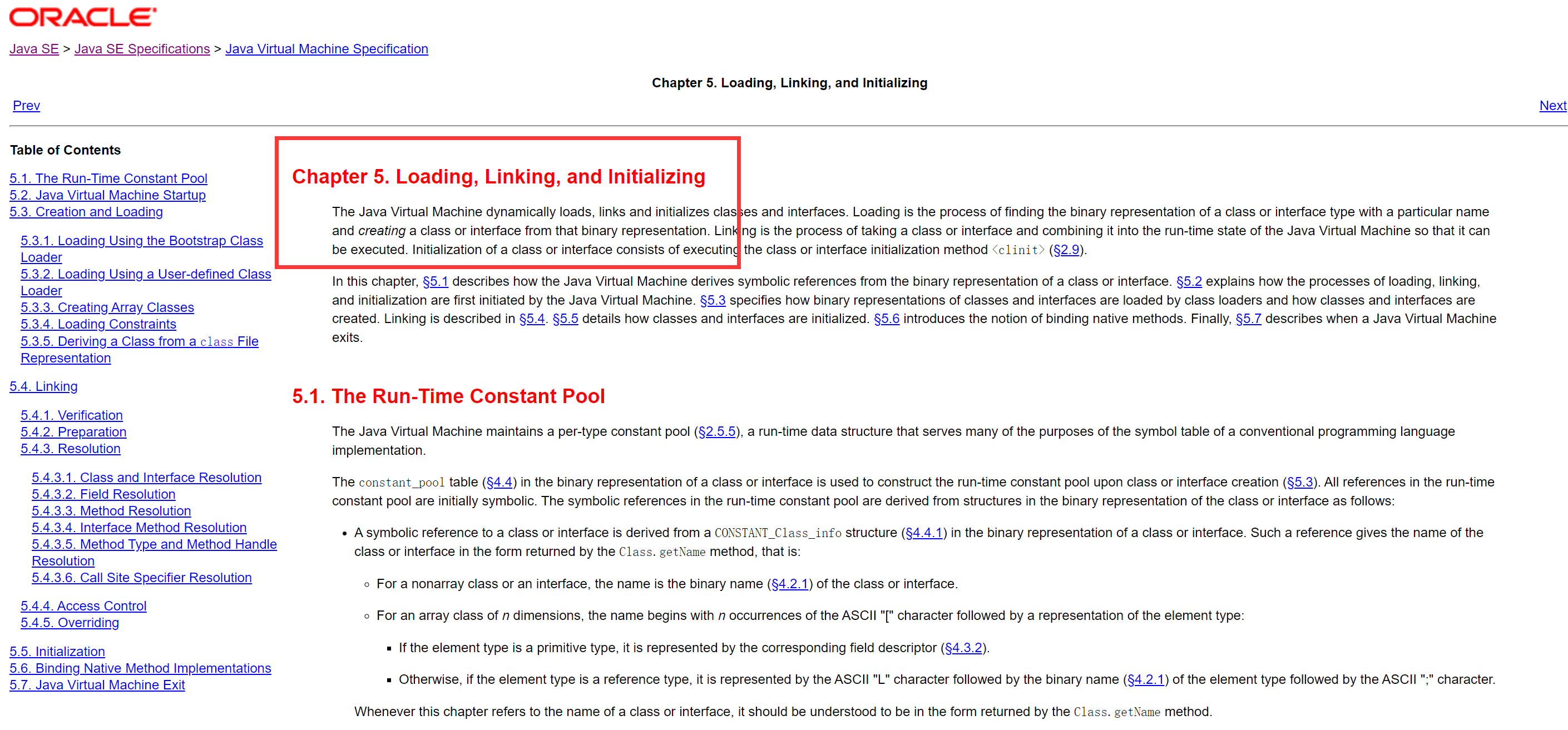
下面就来了解一下这三步是在干什么:
第一步,加载(Loading),找到对应的.class文件,打开并读取文件到内存中,同时通过解析文件初步生成一个代表这个类的 java.lang.Class 对象。
第二步,连接(Linking),作用是建立多个实体之间的联系,该过程有包含三个小过程:
- 验证(
Verification),主要就是验证读取到的内容是不是和规范中规定的格式完全匹配,如果不匹配,那么类加载失败,并且会抛出异常;一个.class文件的格式如下: 通过观察
通过观察.class文件结构,其实.class文件把.java文件的核心信息都保留了下来,只不过是使用二进制的方式重新进行组织了,.class文件是二进制文件,这里的格式有严格说明的,哪几个字节表示什么,java官方文档都有明确规定。 来自官方文档:https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-4.html#jvms-4.1 - 准备(
Preparation),给类对象分配内存空间(先在元数据区占个位置),并为类中定义的静态变量分配内存,此时类变量初始值也就都为 0 值了。 - 解析(
Resolution),针对字符串常量初始化,将符号引用转为直接引用;字符串常量,得有一块内存空间,存这个字符的实际内容,还得有一个引用来保存这个内存空间的起始地址;在类加载之前,字符串常量是在.class文件中的,此时这个引用记录的并非是字符串常量真正的地址,而是它在文件的偏移量/占位符(符号引用),也就是说,此时常量之间只是知道它们彼此之间的相对位置,不知道自己在内存中的实际地址;在类加载之后,才会真正的把这个字符串常量给填充到特定的内存地址上中,这个引用才能被真正赋值成指定内存地址(直接引用),此时字符串常量之间相对位置还是一样的;这个场景可以想象你看电影时拿着电影票入场入座。
第三步,初始化(Initialization),这里是真正地对类对象进行初始化,特别是静态成员,调用构造方法,进行成员初始化,执行代码块,静态代码块,加载父类…
🎯类加载的时机:
类加载并不是 Java 程序(JVM)一运行就把所有类都加载了,而是真正用到哪个类才加载哪个;整体是一个“懒加载”的策略;只有需要用的时候才加载(非必要,不加载),就会触发以下的加载:
- 构造类的实例
- 调用这个类的静态方法/使用静态属性
- 加载子类就会先加载其父类
一旦加载过后后续使用就不必加载了。
2. 双亲委派模型
双亲委派模型是类加载中的一个环节,属于加载阶段,它是描述如何根据类的全限定名找到.class文件的过程。
在 JVM 里面提供了一组专门的对象,用来进行类的加载,即类加载器,当然既然双亲委派模型是类加载中的一部分,所以其所描述找.class文件的过程也是类加载器来负责的。
但是想要找全.class文件可不容易,毕竟.class文件可能在 jdk 目录里面,可能在项目的目录里面,还可能在其他特定的位置,因此 JVM 提供了多个类加载器,每一个类加载器负责在一个片区里面找。
默认的类加载器主要有三个:
- BootStrapClassLoader,负责加载 Java 标准库里面的类,如 String,Random,Scanner 等。
- ExtensionClassLoader,负责加载 JVM 扩展库中的类,是规范之外,由实现 JVM 的组织(Sun/Oracle),提供的额外的功能。
- ApplicationClassLoader,负责加载当前项目目录中自己写的类以及第三方库中的类。
除了默认的几个类加载器,程序员还可以自定义类加载器,来加载其他目录的类,此时也不是非要遵守双亲委派模型,如 Tomcat 就自定义了类加载器,用来专门加载webapps目录中的.class文件就没有遵守。
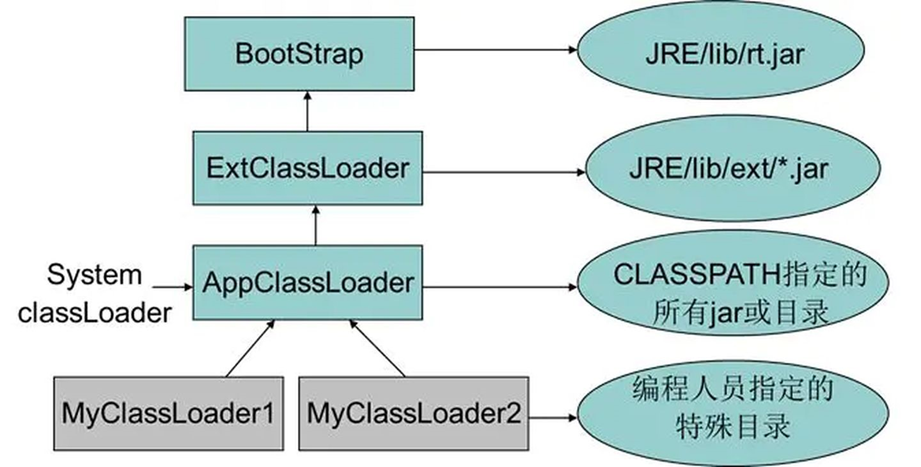
双亲委派模型就描述了类加载过程中的找目录的环节,它的过程如下:
如果一个类加载器收到了类加载的请求,首先需要先给定一个类的全限定类名,如:“java.lang.String”。
根据类的全限定名找的过程中它不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,每一个层次的类加载器都是如此。
因此所有的加载请求最终都应该传送到顶层的启动类加载器中,只有当父加载器反馈自己无法完成这个加载请求(它的搜索范围中没有找到所需的类)时,子加载器才会尝试自己去加载(去自己的片区搜索)。
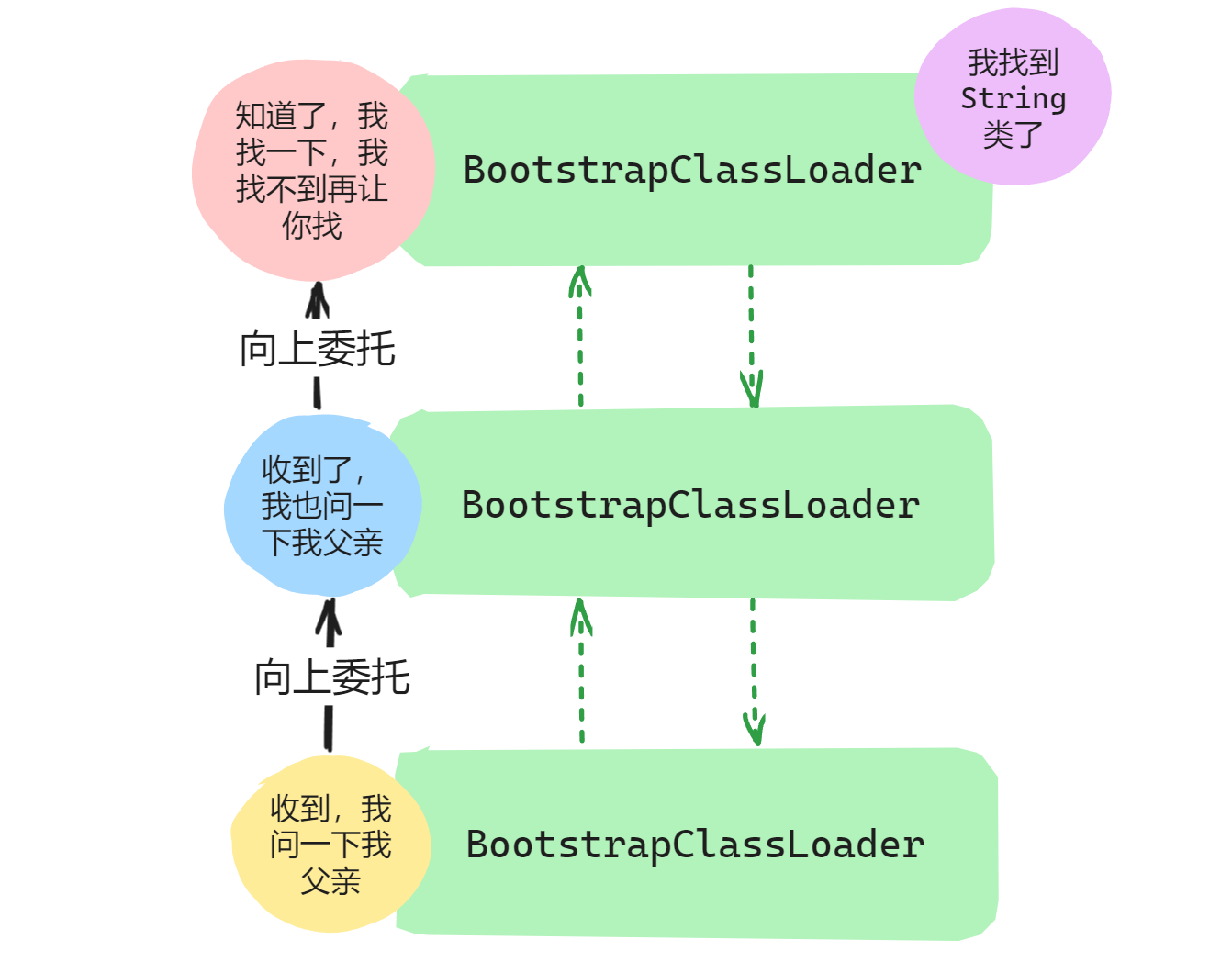
举个例子:我们要去找标准库里面的String.class文件,它的过程大致如下:
- 首先
ApplicationClassLoader类收到类加载请求,但是它先询问父类加载器是否加载过,即询问ExtensionClassLoader类是否加载过。 - 如果
ExtensionClassLoader类没有加载过,请求就会向上传递到ExtensionClassLoader类,然后同理,询问它的父加载器BootstrapClassLoader是否加载过。 - 如果
BootstrapClassLoader没有加载过,则加载请求就会到BootstrapClassLoader加载器这里,由于BootstrapClassLoader加载器是最顶层的加载器,它就会去标准库进行搜索,看是否有String类,我们知道String是在标准库中的,因此可以找到,请求的加载任务完成,这个过程也就结束了。
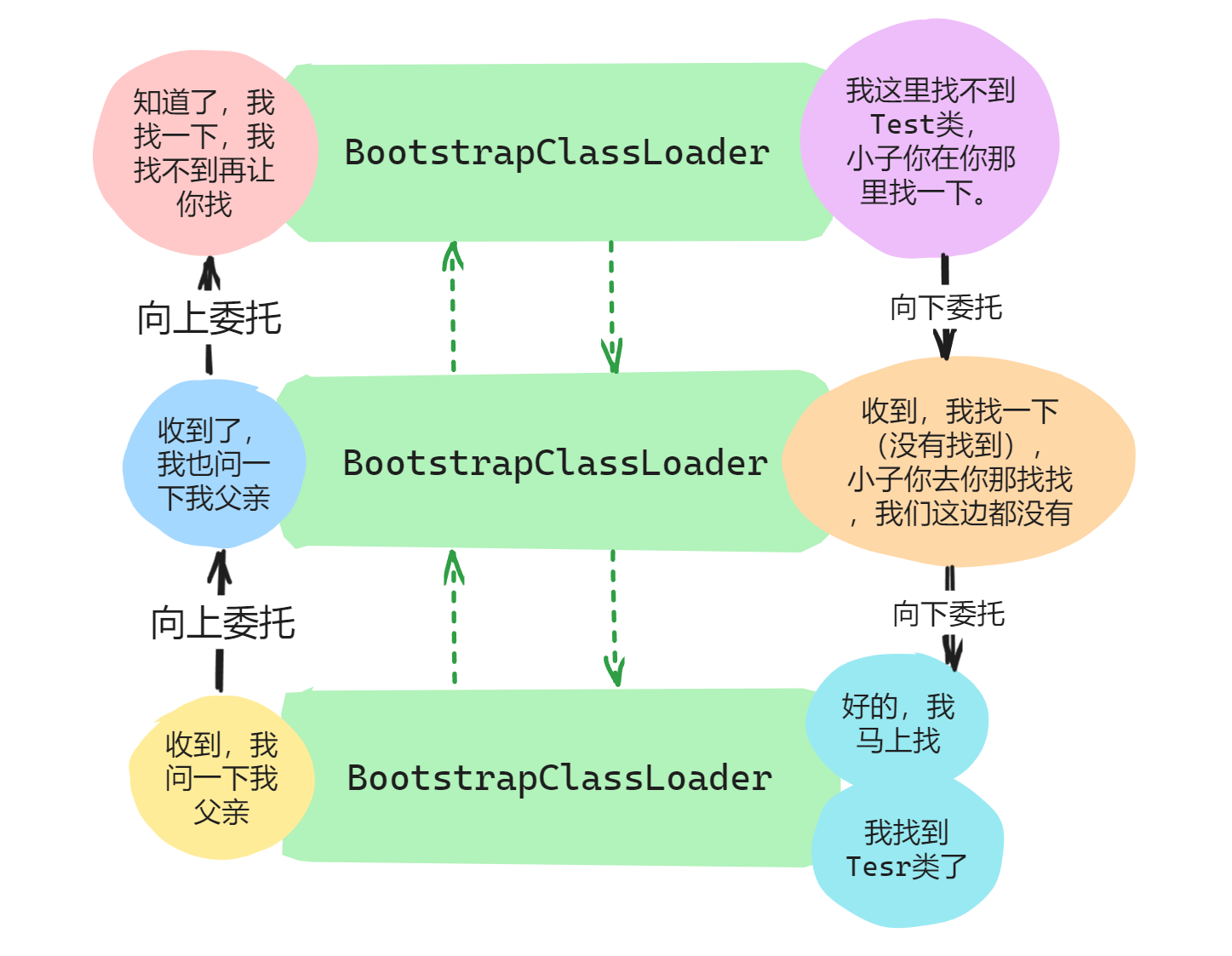
再比如,这里要加载我自己写的的Test类,过程如下:
- 首先
ApplicationClassLoader类收到类加载请求,但是它先询问父类加载器是否加载过,即询问ExtensionClassLoader类是否加载过。 - 如果
ExtensionClassLoader类没有加载过,请求就会向上传递到ExtensionClassLoader类,然后同理,询问它的父加载器BootstrapClassLoader是否加载过。 - 如果
BootstrapClassLoader没有加载过,则加载请求就会到BootstrapClassLoader加载器这里,由于BootstrapClassLoader加载器是最顶层的加载器,它就会去标准库进行搜索,看是否有Test类,我们知道Test类不在标准库,所以会回到子加载器里面搜索。 - 同理,
ExtensionClassLoader加载器也没有Test类,会继续向下,到ApplicationClassLoader加载器中寻找,由于ApplicationClassLoader加载器搜索的就是项目目录,因此可以找到Test类,全过程结束。
如果在ApplicationClassLoader还没有找到,就会抛出异常。
总的来说,双亲委派模型就是找.class文件的过程,其实也没啥,就是名字挺哄人。
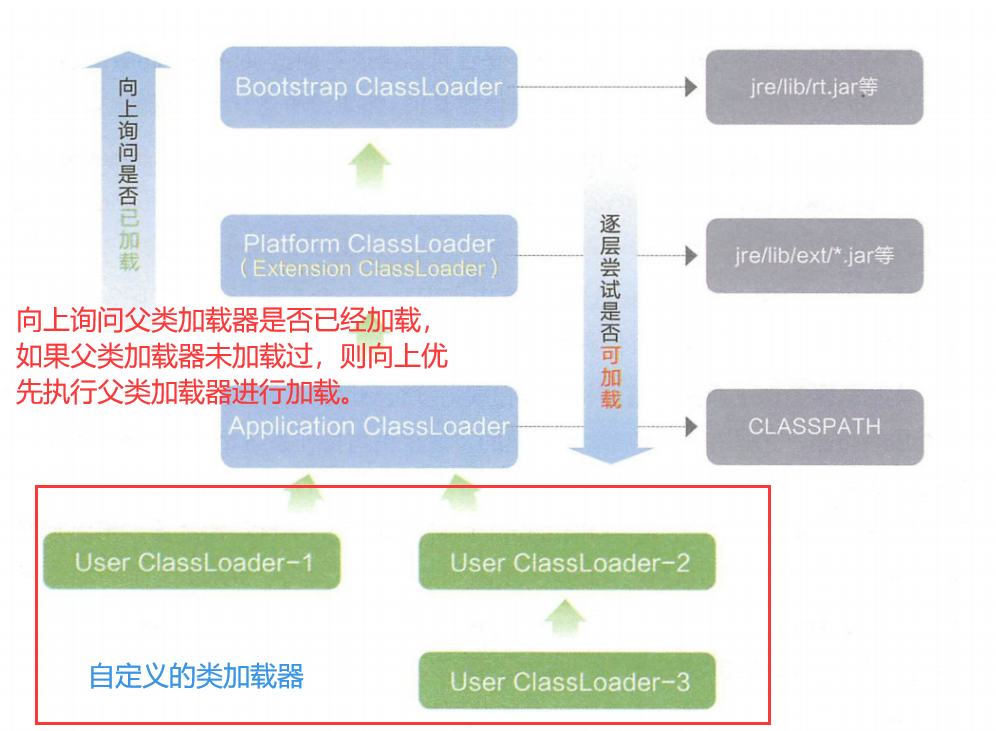
之所以有上述的查找顺序,大概是因为 JVM 代码是按照类似于递归的方式来实现的,就导致了从下到上,又从上到下过程,这个顺序,最主要的目的,就是为了保证 Bootstrap 能够先加载,Application 能够后加载,这就可以避免说因为用户创建了一些奇怪的类,引起不必要的 bug。
三. GC垃圾回收机制
在 C/C++ 中内存空间是需要进行手动释放,如果没有手动去释放那么这块内存空间就会持续存在,一直到进程结束,并且堆的内存生命周期比较长,不像栈随着方法执行结束自动销毁释放,堆默认是不能自动释放的,这就可能导致内存泄露的问题,进一步导致后续的内存申请操作失败。
而在 Java 中引入了 GC 垃圾回收机制,垃圾指的是我们不再使用的内存,垃圾回收就是把我们不用的内存自动释放了。
GC的好处:
- 非常省心,使程序员写代码更简单一些,不容易出错。
GC的坏处:
- 需要消耗额外的系统资源,也有额外的性能开销。
- GC 这里还有一个严重的 STW(stop the world)问题,如果有时候,内存中的垃圾已经很多了,这个时候触发一次 GC 就会消耗大量系统资源,其他程序可能就无法正常执行了;GC 可能会涉及一些锁操作,就可能导致业务代码无法正常执行;极端情况下可会卡顿几十毫秒甚至上百毫秒。
GC 的实际工作过程包含两部分:
- 找到/判定垃圾。
- 再进行垃圾的释放。
1. 找到需要回收的内存
1.1 哪些内存需要回收?
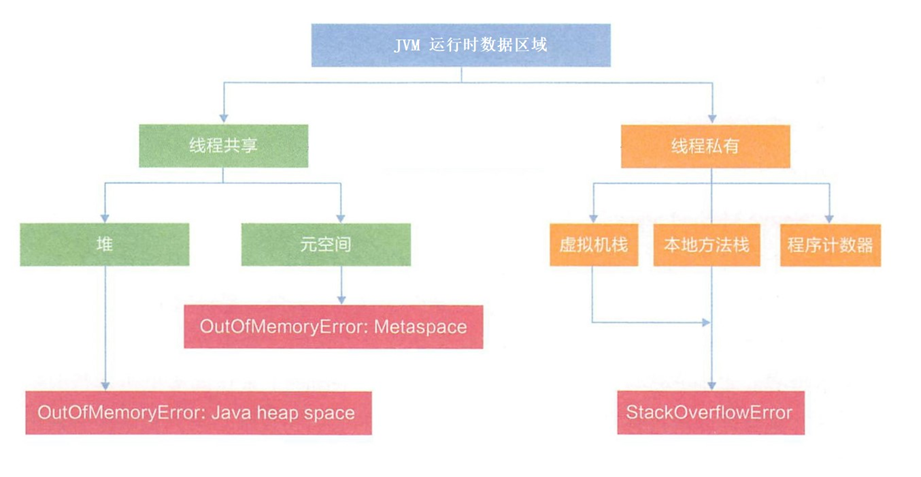
Java 程序运行时,内存分为四个区,分别是程序计数器,栈,堆,方法区。
对于程序计数器,它占据固定大小的内存,它是随着线程一起销毁的,不涉及释放,那么也就用不到 GC;对于栈空间,函数执行完毕,对应的栈帧自动销毁释放了,也不需要 GC;对于方法区,主要进行类加载,虽然需要进行“类卸载”,此时需要释放内存,但是这个操作的频率是非常低的;最后对于堆空间,经常需要释放内存,GC 也是主要针对堆进行释放的。
在堆空间,内存的分布有三种,一是正在使用的内存,二是不用了但未回收的内存,三是未分配的内存,那内存中的对象,也有三种情况,对象内存全部在使用(相当于对象整体全部在使用),对象的内存部分在使用(相当于对象的一部分在使用),对象的内存不使用(对象也就使用完毕了),对于这三类对象,前两类不需要回收,只有最后一类是需要回收的。
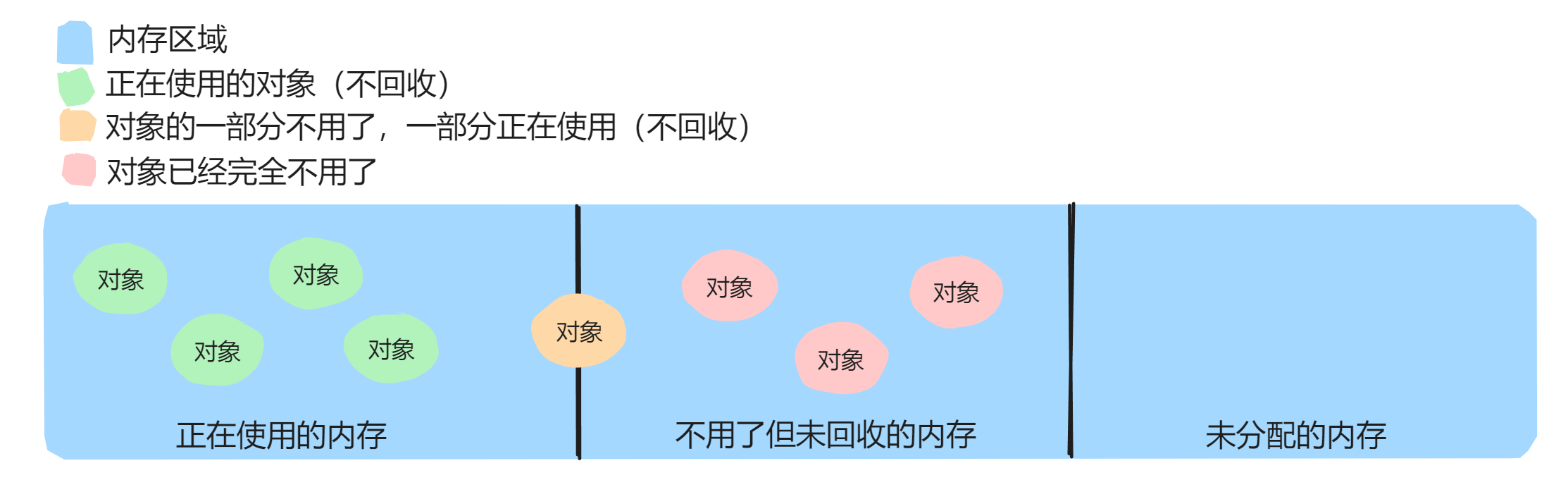
所以,垃圾回收的基本单位是对象,而不是字节,对于如何找到垃圾,常用有引用计数法与可达性分析法两种方式,关键思路是,抓住这个对象,看看到底有没有“引用”指向它,没有引用了,它就是需要被释放的垃圾。
1.2 基于引用计数找垃圾(Java不采取该方案)
所谓基于引用计数判断垃圾,就是给每一个对象分配一个计数器(整数),来记录该对象被多少个引用变量所指,每次创建一个引用指向该对,,计数器就+1,每次该引用被销毁了计数器就–1,如果这个计数器的值为0则表示该对象需要回收,比如有一个Test对象,它被三个引用所指,所以这个 Test 对象所带计数器的值就是3。
//伪代码:
Test t1 = new Test();
Test t2 = t1;
Test t3 = t1;
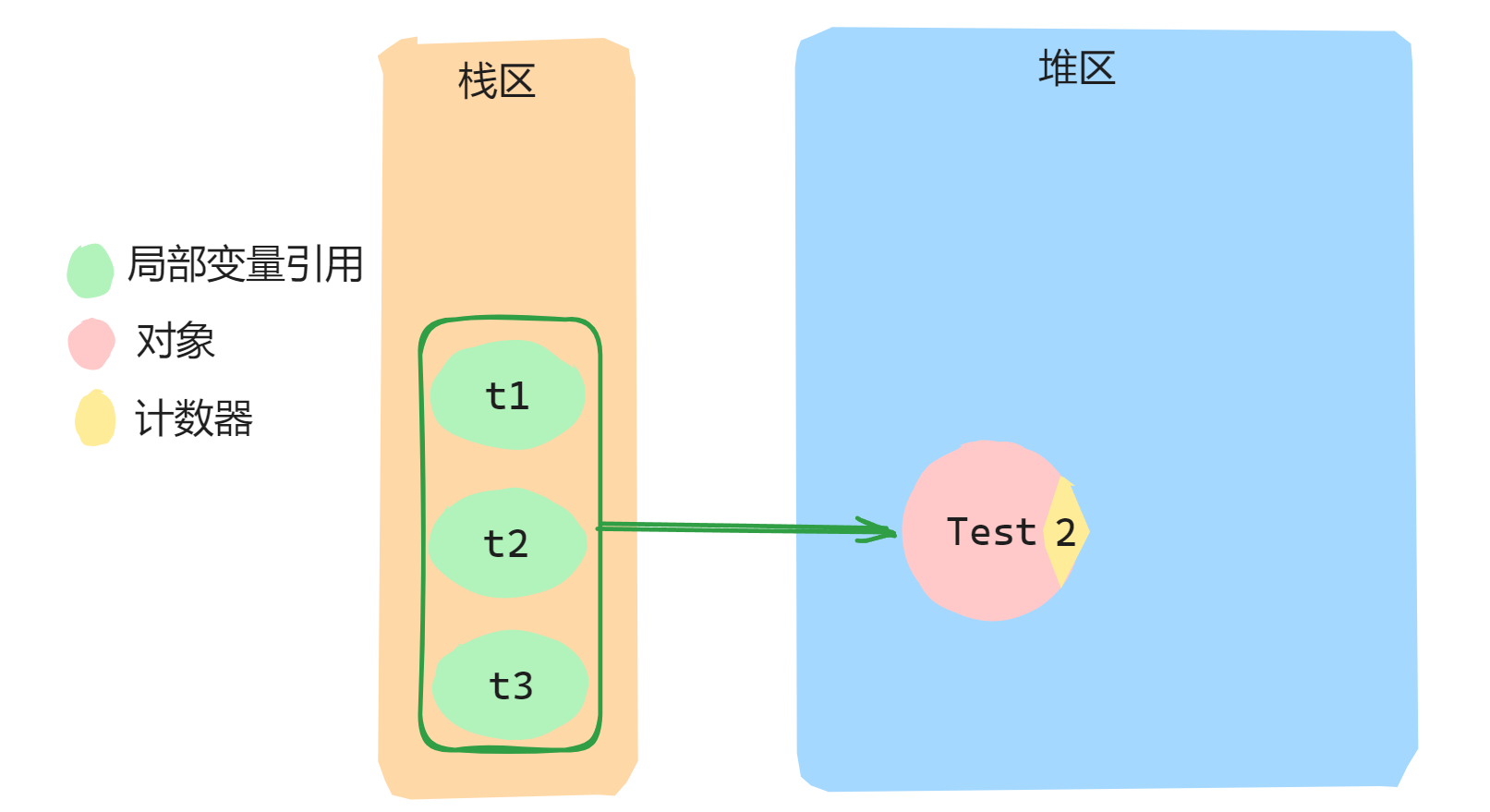
如果上述的伪代码是在一个方法中,待方法执行完毕,方法中的局部引用变量被销毁,那么Test对象的引用计数变为0,此时就会被回收。
由此可见,基于引用计数的方案非常简单高效并且可靠,但是它拥有两个致命缺陷:
- 内存空间浪费较多(利用率低), 需要给每个对象分配一个计数器,如果按照4个字节来算;代码中的对象非常少时无所谓,但如果对象特别多了,占用的额外空间就会很多,尤其是每个对象都比较小的情况下。
- 存在循环引用的问题,会出现对象既不使用也不释放的情况,看下面举例子来分析一下。
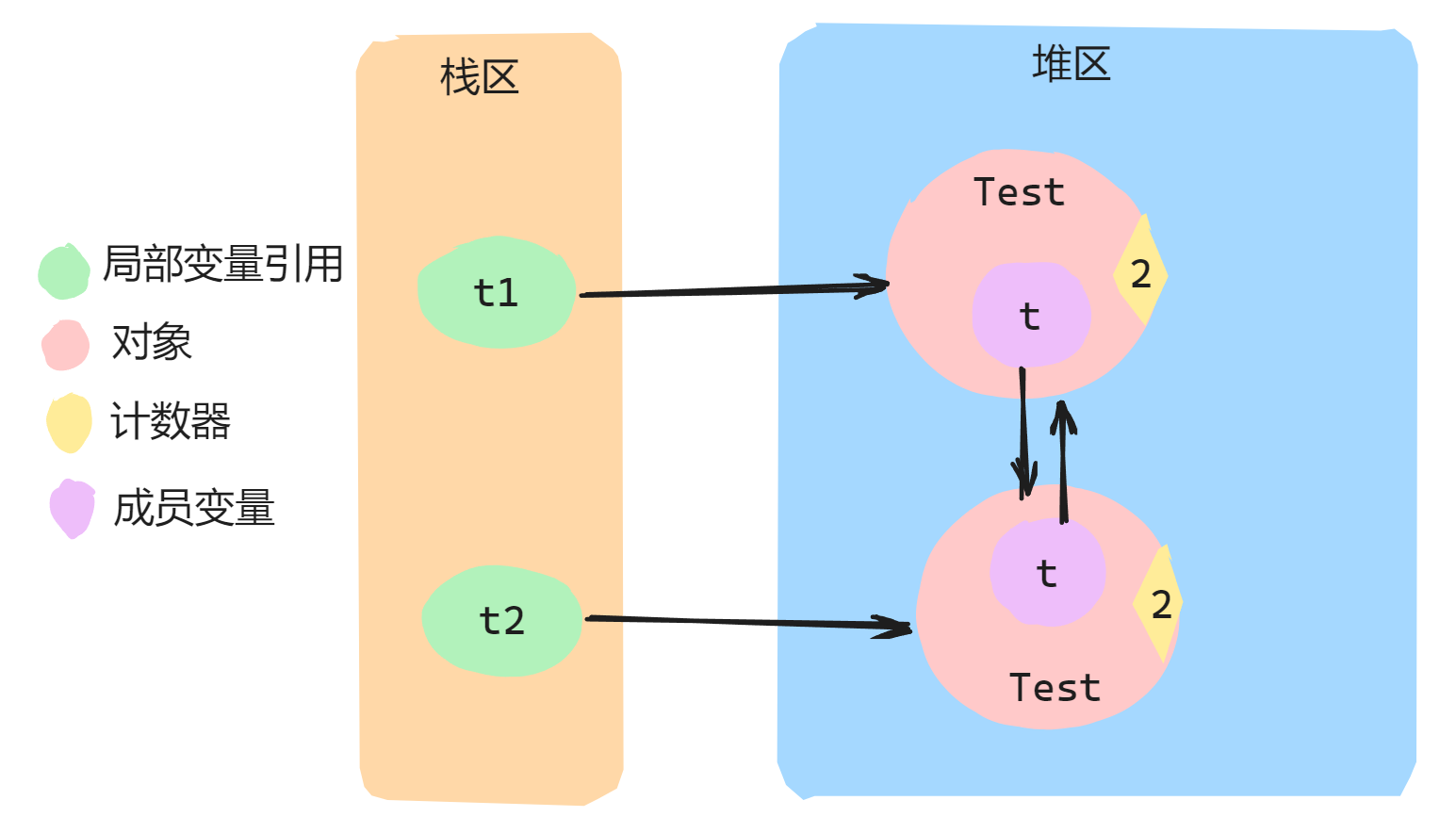
有以下一段伪代码:
class Test {Test t = null;
}//main方法中:
Test t1 = new Test(); // 1号对象, 引用计数是1
Test t2 = new Test(); // 2号对象, 引用计数是1
t1.t = t2; // t1.t指向2号对象, 此时2号对象引用计数是2
t2.t = t1; // t1.t指向1号对象, 此时1号对象引用计数是2
执行上述伪代码,运行时内存图如下:
然后,我们把变量t1与t2置为null,伪代码如下:
//伪代码:
t1 = null;
t2 = null;
执行完上面伪代码,运行时内存图如下:
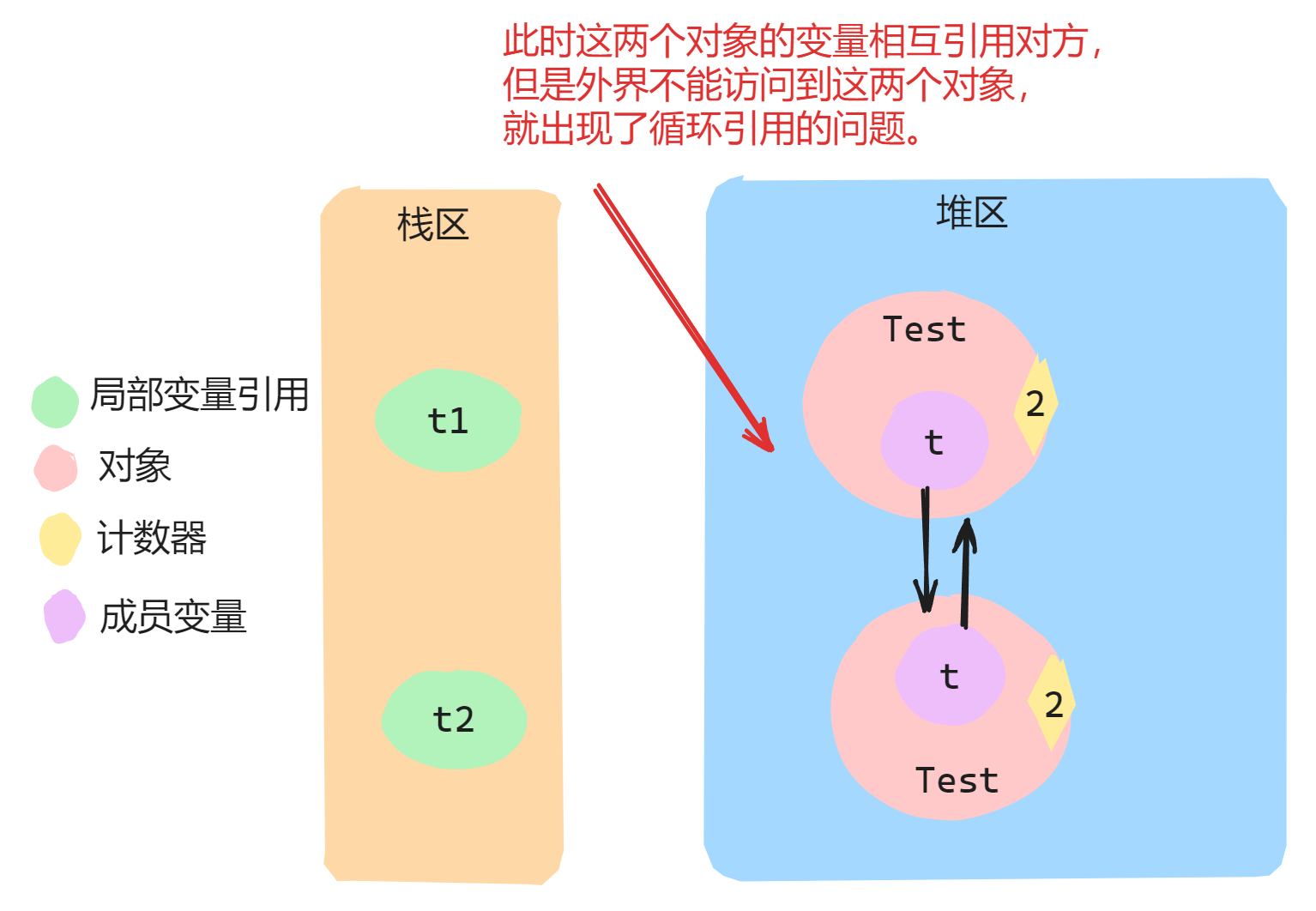
此时 t1 和 t2 引用销毁了,一号对象和二号对象的引用计数都-1,但由于两个对象的属性相互指向另一个对象,计数器结果都是1而不是0造成对象无法及时得到释放,而实际上这个两个对象已经获取不到了(应该销毁了)。
1.3 基于可达性分析找垃圾(Java采取方案)
Java 中的对象都是通过引用来指向并访问的,一个引用指向一个对象,对象里的成员又指向别的对象。
所谓可达性分析,就是通过额外的线程,将整个 Java 程序中的对象用链式/树形结构把所有对象串起来,从根节点出发去遍历这个树结构,所有能访问到的对象,标记成“可达”,不能访问到的,就是“不可达”,JVM 有一个所有对象的名单(每 new 一个对象,JVM 都会记录下来,JVM 就会知道一共有哪些对象,每个对象的地址是什么),通过上述遍历,将可达的标记出来,剩下的不可达的(未标记的)就可以作为垃圾进行回收了。
可达性分析的起点称为GC Roots(就是一个Java对象),一个代码中有很多这样的起点,把每个起点都遍历一遍就完成了一次扫描。
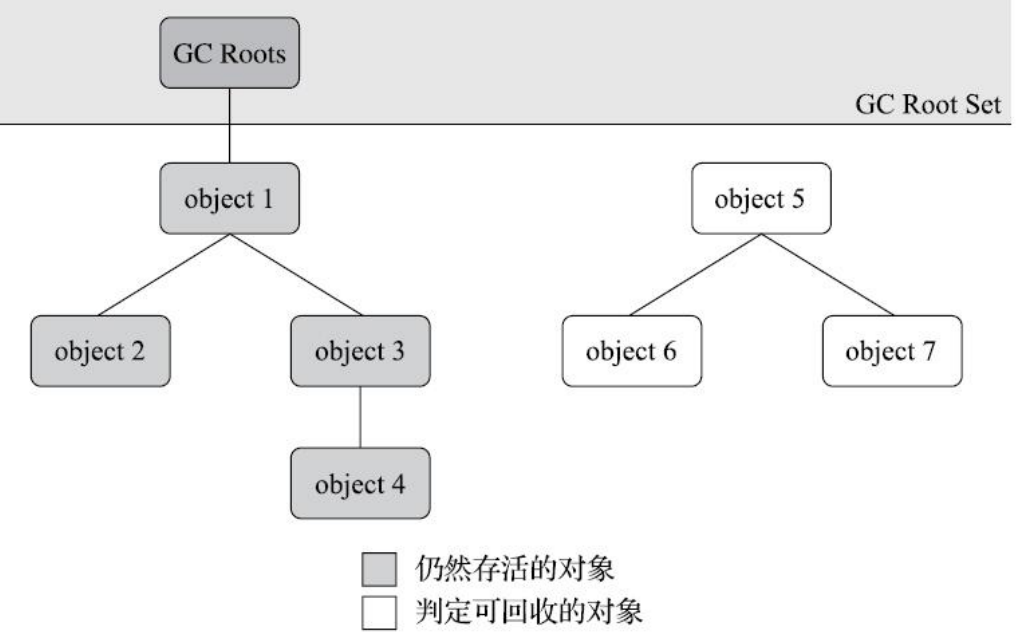
对于这个GCRoots,一般很难被回收,它来源可以分为以下几种:
- 在虚拟机栈(栈帧中的本地变量表)中引用的对象,例如各个线程被调用的方法堆栈中使用到的参数、局部变量、临时变量等。
- 在本地方法栈中 JNI(即通常所说的Native方法)引用的对象。
- 常量池中引用所指向的对象。
- 方法区中静态成员所指向的对象。
- 所有被同步锁(synchronized 关键字)持有的对象。
可达性分析克服了引用计数的两个缺点,但它有自己的问题:
- 需要进行类似于 “树遍历”的过程,消耗更多的时间,但可达性分析操作并不需要一直执行,只需要隔一段时间执行一次寻找不可达对象,确定垃圾就可以,所以,慢一下点也是没关系的,虽迟,但到。
- 可达性分析过程,当前代码中的对象的引用关系发生变化了,还比较麻烦,所以为了准确的完成这个过程,就需要让其他的业务暂停工作(STW问题),但 Java 发展这么多年,垃圾回收机制也在不断的更新优化,STW 这个问题,现在已经能够比较好的应对了,虽不能完全消除,但也已经可以让 STW 的时间尽量短了。
2. 垃圾回收算法
垃圾回收的算法最常见的有以下几种:
- 标记-清除算法
- 标记-复制算法
- 标记-整理算法
- 分代回收算法(本质就是综合上述算法,在堆的不同区采取不同的策略)
2.1 标记-清除算法
标记其实就是可达性分析的过程,在可达性分析的过程中,会标记可达的对象,其不可达的对象,都会被视为垃圾进行回收。
比如经过一轮标记后,标记状态和回收后状态如图:

我们发现,内存是释放了,但是回收后,未分配的内存空间是零散的不是连续的,我们知道申请内存的时候得到的内存得是连续的,虽然内存释放后总的空闲空间很大,但由于未分配的内存是碎片化的,就有可能申请内存失败;假设你的主机有 1GB 空闲内存,但是这些内存是碎片形式存在的,当申请 500MB 内存的时候,也可能会申请失败,毕竟不能保证有一块大于 500MB 的连续内存空间,这也是标记-清除算法的缺陷(内存碎片问题)。
2.2 标记-复制算法
为了解决标记-清除算法所带来的内存碎片化的问题,引入了复制算法。
它将可用内存按容量划分为大小相等的两块,每次只使用其中的一块,每次清理,就将还存活着的对象复制到另外一块上面,然后再把已使用过的这一块内存空间一次清理掉。
复制算法的第一步还是要通过可达性分析进行标记,得到哪一部分需要进行回收,哪一部分需要保留,不能回收。
标记完成后,会将还在使用的内存连续复制到另外一块等大的内存上,这样得到的未分配内存一直都是连续的,而不是碎片化的。

但是,复制算法也有缺陷:
- 空间利用率低。
- 如果垃圾少,有效对象多,复制成本就比较大。
2.3 标记-整理算法
标记-整理算法针对复制算法做出进一步改进,其中的标记过程仍然与“标记-清除”算法一致,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向内存空间一端移动,然后直接清理掉边界以外的内存。

回收时是将存活对象按照某一顺序(比如从左到右,从上到下的顺序)拷贝到非存活对象的内存区域,类似于顺序表的删除操作,会将后面的元素搬运到前面。
解决了标记-复制算法空间利用率低的问题,也没有内存碎片的问题,但是复制的开销问题并没有得到解决。
2.4 分代回收
上述的回收算法都有一定的缺陷,分代回收就是将上述三种算法结合起来分区使用,分代回收会针对对象进行分类,以熬过的 GC 扫描轮数作为“年龄”,然后针对不同年龄采取不同的方案。
分代是基于一个经验规律,如果一个东西存在时间长了,那么接下来大概率也会存在(要没有早就没有了)。
我们知道 GC 主要是回收堆上的无用内存,我们先来了解一下堆的划分,堆包括新生代(Young)、老年代(Old),而新生代包括一个伊甸区(Eden)与两个幸存区(Survivor),分代回收算法就会根据不同的代去采取不同的标记-xx算法。
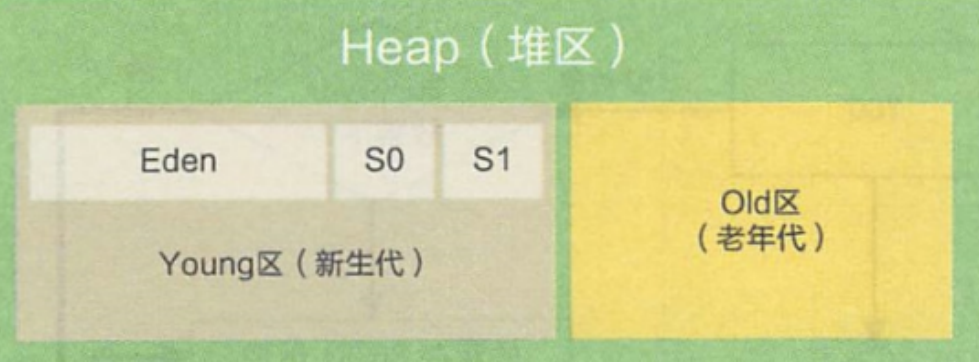
在新生代,包括一个伊甸区与两个幸存区,伊甸区存储的是未经受 GC 扫描的对象(年龄为 0),也就是刚刚 new 出来的对象。
幸存区存储了经过若干轮 GC 扫描的对象,通过实际经验得出,大部分的 Java 对象具有“朝生夕灭”的特点,生命周期非常短,也就是说只有少部分的伊甸区对象才能熬过第一轮的 GC 扫描到幸存区,所以到幸存区的对象相比于伊甸区少的多,正因为大部分新生代的对象熬不过 GC 第一轮扫描,所以伊甸区与幸存区的分配比例并不是1:1的关系,HotSpot 虚拟机默认一个 Eden 和一个 Survivor 的大小比例是 8∶1,正因为新生代的存活率较小,所以新生代使用的垃圾回收算法为标记-复制算法最优,毕竟存活率越小,对于标记-复制算法,复制的开销也就很小。
不妨我们将第一个 Survivor 称为活动空间,第二个 Survivor 称为空闲空间,一旦发生 GC,会将 10% 的活动区间与另外 80% 伊甸区中存活的对象复制到 10% 的空闲空间,接下来,将之前 90% 的内存全部释放,以此类推。
在后续几轮 GC 中,幸存区对象在两个 Survivor 中进行标记-复制算法,此处由于幸存区体积不大,浪费的空间也是可以接受的。
在继续持续若干轮 GC 后(这个对象已经再两个幸存区中来回考贝很多次了),幸存区的对象就会被转移到老年代,老年代中都是年龄较老的对象,根据经验,一个对象越老,继续存活的可能性就越大(要挂早挂了),因此老年代的 GC 扫描频率远低于新生代,所以老年代采用标记-整理的算法进行内存回收,毕竟老年代存活率高,对于标记-整理算法,复制转移的开销很低。
还要注意一个特殊情况,如果对象非常大,就直接进入老年代,因为大对象进行复制算法,成本比较高,而且大对象也不会很多。
相关文章:
JVM解密: 解构类加载与GC垃圾回收机制
文章目录 一. JVM内存划分二. 类加载机制1. 类加载过程2. 双亲委派模型 三. GC垃圾回收机制1. 找到需要回收的内存1.1 哪些内存需要回收?1.2 基于引用计数找垃圾(Java不采取该方案)1.3 基于可达性分析找垃圾(Java采取方案) 2. 垃圾回收算法2.1 标记-清除算法2.2 标记…...

【Spring Boot】Spring Boot结合MyBatis简单实现学生信息管理模块
实战:实现学生信息管理模块 环境准备 JDKSpring BootMyBatis 创建Spring Boot项目 使用Spring Initializr创建一个新的Spring Boot项目,并添加以下依赖: Spring WebMyBatis FrameworkMySQL Driver 数据库设计 在MySQL数据库中创建一个名…...
)
【Java List与Map】List<T> Map与Map List<T>的区别(126)
List<T> Map:List里面的数据类型包含Map; Map List<T>:Map里面value的数据类型包含List; 测试案例: import java.util.ArrayList; import java.util.HashMap; import j…...

【FreeRTOS】常用函数总结
xTaskCreate(): 用法: xTaskCreate(taskFunction, taskName, stackSize, parameters, priority, taskHandle)参数: taskFunction:任务函数,即任务的入口函数。taskName:任务的名称。stackSize:任…...

The Cherno——OpenGL
The Cherno——OpenGL 1. 欢迎来到OpenGL OpenGL是一种跨平台的图形接口(API),就是一大堆我们能够调用的函数去做一些与图像相关的事情。特殊的是,OpenGL允许我们访问GPU(Graphics Processing Unit 图像处理单元&…...
linux中学习控制进程的要点
1. 进程创建 1.1 fork函数 #include <unistd.h> pid_t fork(void); 返回值:自进程中返回0,父进程返回子进程id,出错返回-1 进程调用fork,当控制转移到内核中的fork代码后,内核会做以下操作 分配新的内存块和…...

C++Qt QSS要注意的坑
qss源自css,相当于css的一个子集,主要支持的是css2标准,很多网上的css3的标准的写法在qss这里是不生效的,所以不要大惊小怪。 qss也不是完全支持所有的css2,比如text-align官方文档就有说明,只支持 QPushB…...
)
LeetCode每日一题:56. 合并区间(2023.8.27 C++)
目录 56. 合并区间 题目描述: 实现代码与解析: 排序 贪心 原理思路: 56. 合并区间 题目描述: 以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] [starti, endi] 。请你合并所有重叠的区间&…...

电视盒子什么牌子好?经销商整理线下热销电视盒子品牌排行榜
在面对众多品牌和型号时,不知道电视盒子哪个牌子好的消费者超多,很多人进店都会问我电视盒子哪款好?我根据店铺内近两年的销量情况整理了电视盒子品牌排行榜,看看实体店哪些电视盒子最值得入手吧。 TOP 1.泰捷WEBOX 40Pro Max电视…...
JavaScript关于函数的小挑战
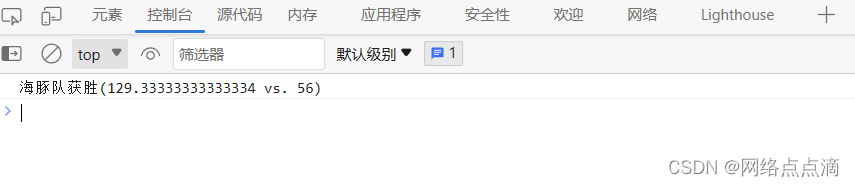
题目 回到两个体操队,即海豚队和考拉队! 有一个新的体操项目,它的工作方式不同。 每队比赛3次,然后计算3次得分的平均值(所以每队有一个平均分)。 只有当一个团队的平均分至少是另一个团队的两倍时才会获胜。否则&…...
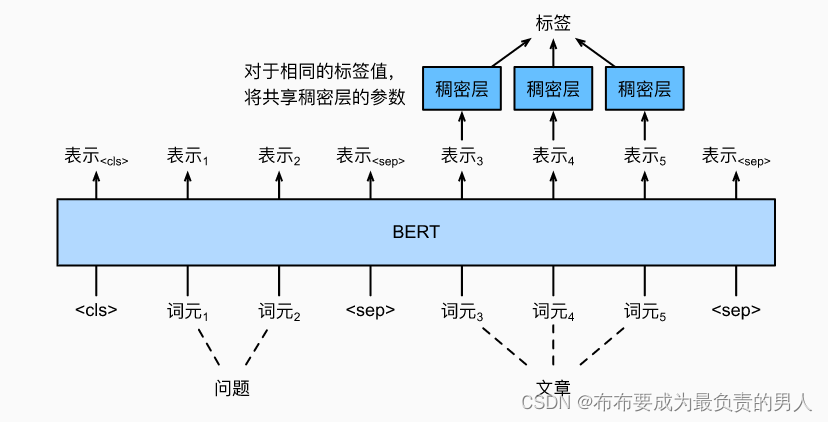
机器学习深度学习——针对序列级和词元级应用微调BERT
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er 🌌上期文章:机器学习&&深度学习——NLP实战(自然语言推断——注意力机制实现) 📚订阅专栏:机…...

重启Mysql时报错rm: cannot remove ‘/var/lock/subsys/mysql‘: Permission denied
只有用mysql重启时报错,用root不报错 [mysqlt3-dtpoc-dtpoc-web04 bin]$ service mysql restart Shutting down MySQL.. SUCCESS! rm: cannot remove /var/lock/subsys/mysql: Permission denied Starting MySQL.. SUCCESS! [roott3-dtpoc-dtpoc-web04 ~]# serv…...

[C/C++]指针详讲-让你不在害怕指针
个人主页:北海 🎐CSDN新晋作者 🎉欢迎 👍点赞✍评论⭐收藏✨收录专栏:C/C🤝希望作者的文章能对你有所帮助,有不足的地方请在评论区留言指正,大家一起学习交流!ǹ…...

无涯教程-Android - Frame Layout函数
Frame Layout 旨在遮挡屏幕上的某个区域以显示单个项目,通常,应使用FrameLayout来保存单个子视图,因为在子视图彼此不重叠的情况下,难以以可扩展到不同屏幕尺寸的方式组织子视图。 不过,您可以使用android:layout_grav…...
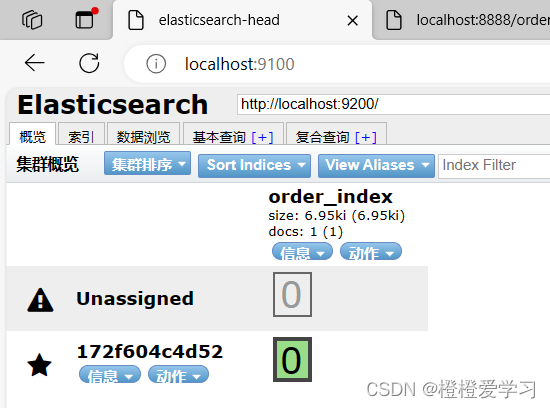
docker desktop安装es 并连接elasticsearch-head:5
首先要保证docker安装成功,打开cmd,输入docker -v,出现如下界面说明安装成功了 下面开始安装es 第一步:拉取es镜像 docker pull elasticsearch:7.6.2第二步:运行容器 docker run -d --namees7 --restartalways -p 9…...
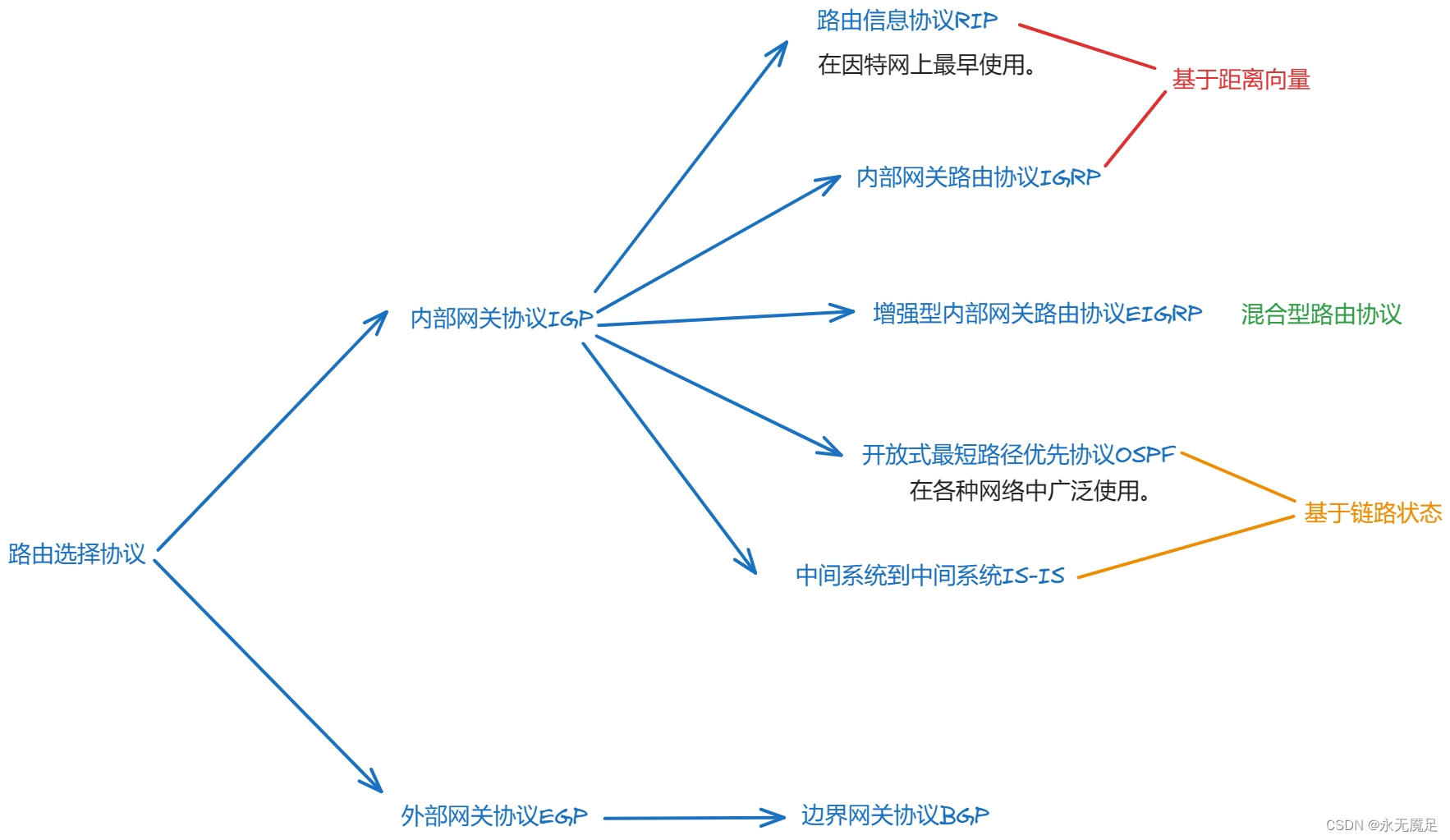
计网(第四章)(网络层)(六)
目录 一、路由选择协议(动态路由自动获取路由信息)概述: 二、因特网采用的路由协议 主要特点: 1.自适应 2.分布式 3.分层次 因特网采用分层次的路由选择协议: 三、常见的路由选择协议 一、路由选择协议ÿ…...

科研无人机平台P600进阶版,突破科研难题!
随着无人机技术日益成熟,无人机的应用领域不断扩大,对无人机研发的需求也在不断增加。然而,许多开发人员面临着无法从零开始构建无人机的时间和精力压力,同时也缺乏适合的软件平台来支持他们的开发工作。为了解决这个问题…...
Apache的简单介绍(LAMP架构+搭建Discuz论坛)
文章目录 1.Apache概述1.1什么是apache1.2 apache的功能及特性1.2.1功能1.2.2特性 1.3 MPM 工作模式1.3.1 prefork模式1.3.2 worker模式1.3.3 event模式 2.LAMP概述2.1 LAMP的组成2.2 LAMP各组件的主要作用2.3 LAMP的工作过程2.4CGI和FastCGI 3.搭建Discuz论坛所需4.编译安装Ap…...
CDL基础原理
一、CDL简介 CDL(全称Change Data Loader)是一个基于Kafka Connect框架的实时数据集成服务。 CDL服务能够从各种OLTP数据库中捕获数据库的Data Change事件,并推送到kafka,再由sink connector推送到大数据生态系统中。 CDL目前支…...
WPF基础入门-Class7-WPF-MVVN框架
WPF基础入门 Class7-MVVN框架 使用框架可以省掉如Class6中的ViewModelBase.cs的OnPropertyChanged,亦方便命令传参 1、NuGet安装CommunityToolkit.Mvvm(原Mircrosoft.Toolkit.Mvvm)也可以安装MVVMLight等其他集成库 2、显示页面࿱…...

RT-Trace升级:集成GDB Server与一键烧录,打造嵌入式开发调试平台
1. 项目概述:嵌入式开发的“瑞士军刀”再进化如果你是一名嵌入式开发者,最近可能被一个词刷屏了——RT-Trace。这已经不是它第一次带来惊喜了。最初,它以非侵入式的实时追踪和性能分析能力,在RT-Thread社区里掀起了一阵热潮&#…...

5分钟学会AnyFlip电子书一键下载:免费PDF转换终极指南
5分钟学会AnyFlip电子书一键下载:免费PDF转换终极指南 【免费下载链接】anyflip-downloader Download anyflip books as PDF 项目地址: https://gitcode.com/gh_mirrors/an/anyflip-downloader 你是否曾经在AnyFlip上找到一本精彩的电子书,想要永…...

奇门对接顺丰电子面单:从200行“祖传代码”到优雅重构的经验分享
一、背景:那年写下的“能跑就行” 在我们的电商WMS系统中,发货环节需要通过菜鸟奇门电子面单接口向顺丰等快递公司申请运单号。这段核心代码写于多年前,当时的业务需求比较简单:只支持淘宝/天猫订单,快递也只有顺丰。…...

Cadence新手村任务:5分钟搞定嘉立创LED封装,让你的OrCAD原理图不再‘裸奔’
Cadence新手村任务:5分钟搞定嘉立创LED封装,让你的OrCAD原理图不再‘裸奔’ 刚安装好Cadence软件的新手设计师,面对空白的OrCAD原理图界面时,往往会感到无从下手。就像游戏角色初入新手村需要第一把武器,你的第一个电子…...

端口映射配置后连不上?别慌!按这4步排查,一学就会
一、什么是端口映射监控端口映射监控是指对端口映射规则的状态、流量及连通性进行全面监测,确保映射规则正常生效,及时发现并排查故障。它涵盖两个层面:本机端口监听状态检测和网络层端口映射连通性验证。二、本机端口监控(服务端…...

如何快速上手OpenBoardView:免费开源PCB查看器的完整指南
如何快速上手OpenBoardView:免费开源PCB查看器的完整指南 【免费下载链接】OpenBoardView View .brd files 项目地址: https://gitcode.com/gh_mirrors/op/OpenBoardView OpenBoardView是一款完全免费开源的PCB文件查看器,专门用于查看和分析各种…...

智赋能源 安筑未来|济南昊安光电亮相 2026 第六届中国贵州国际能源产业博览交易会
2026 年 5 月 18 日 —5月 20日,2026 第六届中国贵州国际能源产业博览交易会(简称 “贵州能源博览会”)在贵阳国际会议展览中心盛大启幕。本届展会聚焦能源产业数字化转型、绿色低碳发展与安全高效生产,汇聚能源领域全产业链优质企…...

从一次失败的App上线,看我们如何用PDCA循环在3个月内实现用户留存翻倍
从一次失败的App上线,看我们如何用PDCA循环在3个月内实现用户留存翻倍 去年夏天,我们的团队经历了一次刻骨铭心的产品滑铁卢——一款投入半年研发的社交类App在上线首周就遭遇了用户留存率暴跌至8%的危机。这个数字远低于行业平均25%的水平线,…...

5分钟快速搭建Windows RTMP流媒体服务器:新手完整指南
5分钟快速搭建Windows RTMP流媒体服务器:新手完整指南 【免费下载链接】nginx-rtmp-win32 Nginx-rtmp-module Windows builds. 项目地址: https://gitcode.com/gh_mirrors/ng/nginx-rtmp-win32 想要在Windows系统上搭建自己的直播服务器吗?nginx…...

【更新 v 2.7.5 版本】桌面版 Open Claw 本地一键部署指南
✨ 核心亮点 零代码门槛|全程可视化|无需手动配环境|内置所有依赖|28 万 Tokens 额度 🔗 下载地址 https://xiake.yun/api/download/package/16?promoCodeIV8E496E2F7A 📝 前言 开源圈热门的「数字员…...