golang-bufio 缓冲读
缓冲 IO
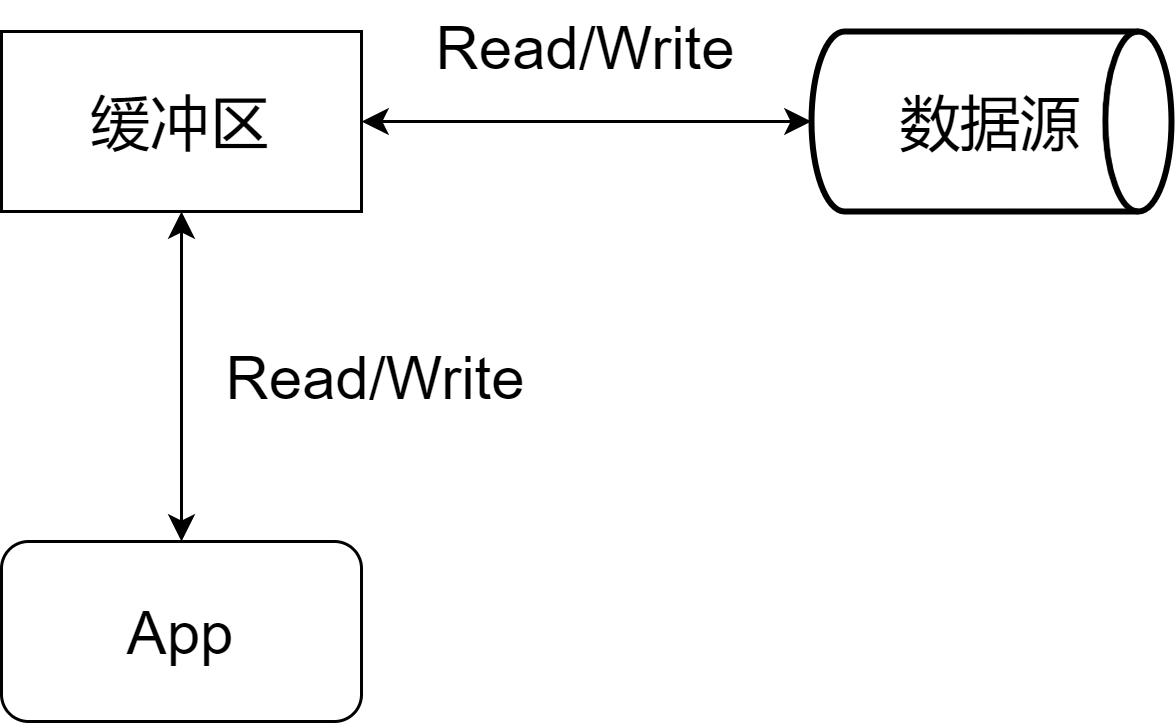
计算机中我们常听到这样的两种程序优化方式:
- 以时间换空间
- 以空间换时间
今天要来看的缓冲IO就是典型的以空间换时间,它的基本原理见上图。简单的解释就是:程序不再直接去读取底层的数据源,而是通过一个缓冲区来进行读取。即先把数据从底层数据源读取到缓冲区,然后再从缓冲区进行读取。这样一分析,似乎有点多此一举了,本来一次的数据读写变成了两次?其实,不是这样的,因为这里的两个读写的成本或者说代价不同。我们都知道存储器是分级的,硬盘读写速度和内存读写速度之间的差距是巨大的:内存读写 >> 硬盘读写或者网络读写。
所以缓冲区的真正作用是减少了硬盘或者网络读写的次数(读写的数据量没变)。
举一个例子:我有1024 个字节的数据,每次读取 32 个byte,那么需要访问硬盘或者网络 32次。如果一次读取 1024 个字节呢,最终只需要一次硬盘或者网络访问就够了(内存访问的次数增加,但是总的耗时是减少的)。不过,我们再扩展一点,既然内存读写这么快,我们直接把文件一次性读入内存不就好了?这样的想法是好的,但是对于大文件(GB级或者更大的),我想你是不会全部读取进内存的,因为内存资源也是有限的。
好了,前面是一些基本的概念的复习,简单回顾一下,有助于我们理解接下来的内容。今天来记录一下我阅读 golang 的 bufio 包的理解:
Package
bufioimplements buffered I/O. It wraps anio.Readerorio.Writerobject, creating another object (Reader or Writer) that also implements the interface but provides buffering and some help for textual I/O.
这是 bufio 包自己的介绍,从它的名字来理解就是缓冲 IO。
缓冲读
因为这个 bufio.go 文件还是蛮大的,所以准备分成两个缓冲读和写部分进行阅读。接下来会介绍几个我认为比较重要的方法,会有一些自己的理解。
Buffered input 缓冲输入
const (defaultBufSize = 4096
)// Buffered input.// Reader implements buffering for an io.Reader object.
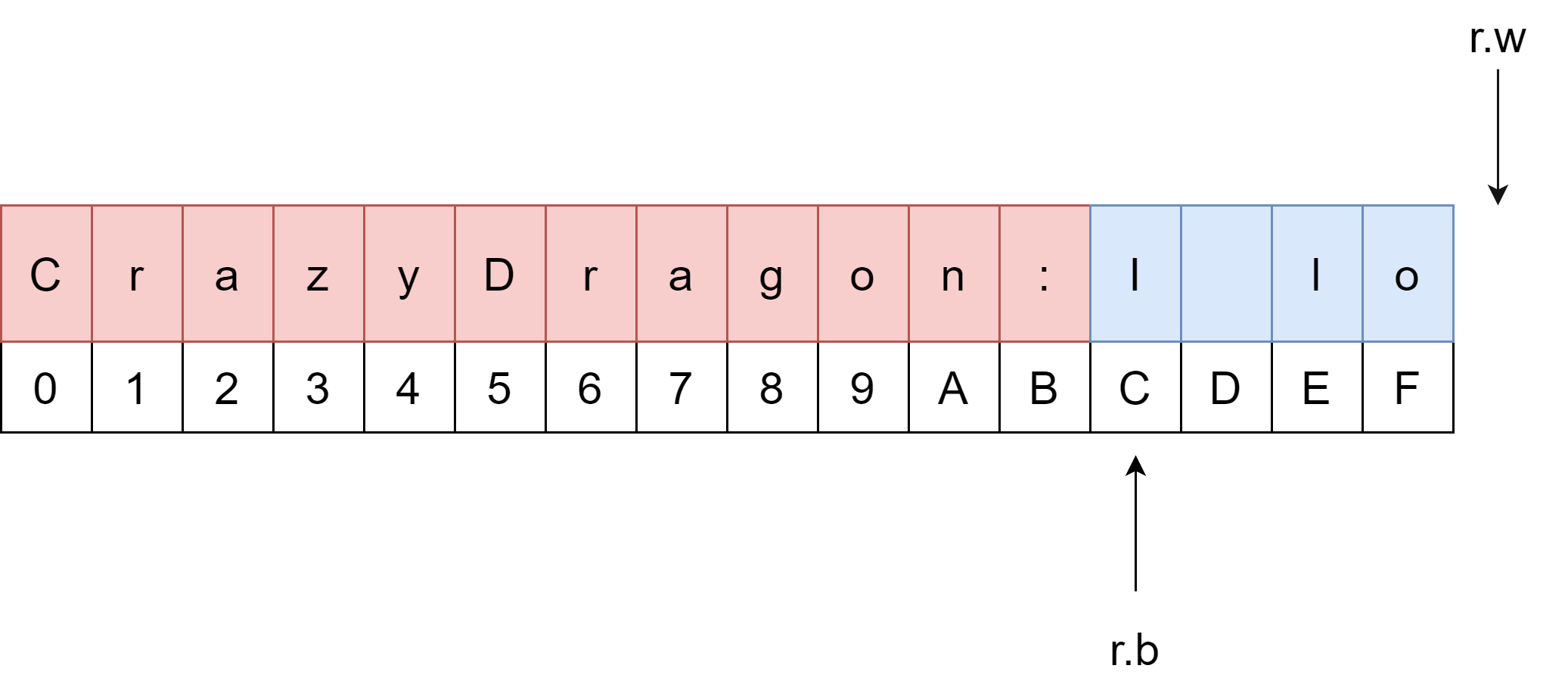
type Reader struct {buf []byterd io.Reader // reader provided by the clientr, w int // buf read and write positionserr errorlastByte int // last byte read for UnreadByte; -1 means invalidlastRuneSize int // size of last rune read for UnreadRune; -1 means invalid
}const minReadBufferSize = 16
const maxConsecutiveEmptyReads = 100
这就是缓冲输入 Reader 的结构体,它有一个 buf 字节切片(默认的长度是4096,即 4KB),并且依赖 io.Reader 实现的。这里可以看出来,所谓的缓冲区其实就是一个字节切片。
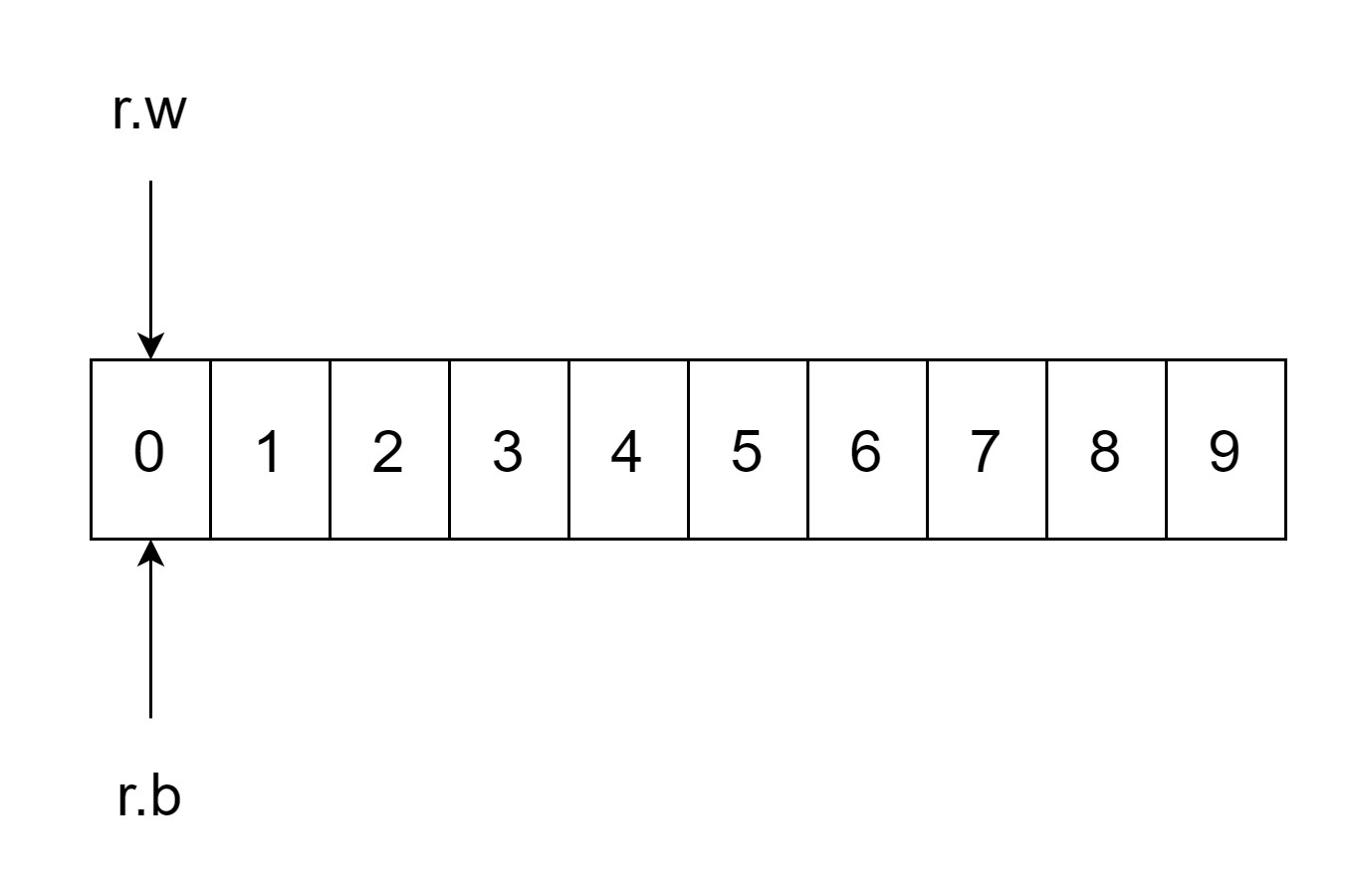
所以如果缓冲区是空的判断条件即是:r.b == r.w。
fill 填充数据
fill() 是内部用来填充缓冲区的方法,可以说能实现缓冲就是依赖它来实现的。
// fill reads a new chunk into the buffer.
func (b *Reader) fill() {// Slide existing data to beginning.if b.r > 0 {copy(b.buf, b.buf[b.r:b.w])b.w -= b.rb.r = 0}if b.w >= len(b.buf) {panic("bufio: tried to fill full buffer")}// Read new data: try a limited number of times.for i := maxConsecutiveEmptyReads; i > 0; i-- {n, err := b.rd.Read(b.buf[b.w:])if n < 0 {panic(errNegativeRead)}b.w += nif err != nil {b.err = errreturn}if n > 0 {return}}b.err = io.ErrNoProgress
}
这里是我从源码中的理解:
-
如果
b.r > 0,这说明缓冲区已经被读取了一些数据,所以要把后面未读取的数据搬到前面来,然后b.w就要减少b.r,同时b.r需要置零(因为已经搬到前面了)。 -
如果
b.w >= len(b.buf),这种属于异常情况,会发生panic("bufio: tried to fill full buffer")。也就是说,当你尝试向一个满的buf切片填充数据时,这是不允许的。这是出于程序正确性的角度考虑的。 -
然后就可以尝试进行填充数据了。这里很有意思,填充数据本身是在一个循环中进行的,它最多会执行 100 次([1, 100])。
循环体内的内容:
-
从底层的 reader 中读取数据,把读取的数据存入缓冲区的切片中,b.w 开始。
-
如果读取的
n < 0,那么会发生 panic。这种都是专门针对各种异常情况的处理,通常是不会发生的。 -
把数据写入缓冲区后,
b.w同时向后移动到数据的最后面。 -
如果读取数据时发生了错误,那么就返回。
如果 n > 0,那么就返回。这里很奇怪,为什么要单独 n > 0 时返回呢?因为,还有一种可能是 n == 0,如果出现这种情况,说明没有读取到数据。那么,怎么办呢?这就是前面循环的作用了,它会再次尝试读取,如果尝试 100 次都失败了,那么就停止读取,并且返回错误。(这种情况通常是因为一个错误的 reader 实现导致的)
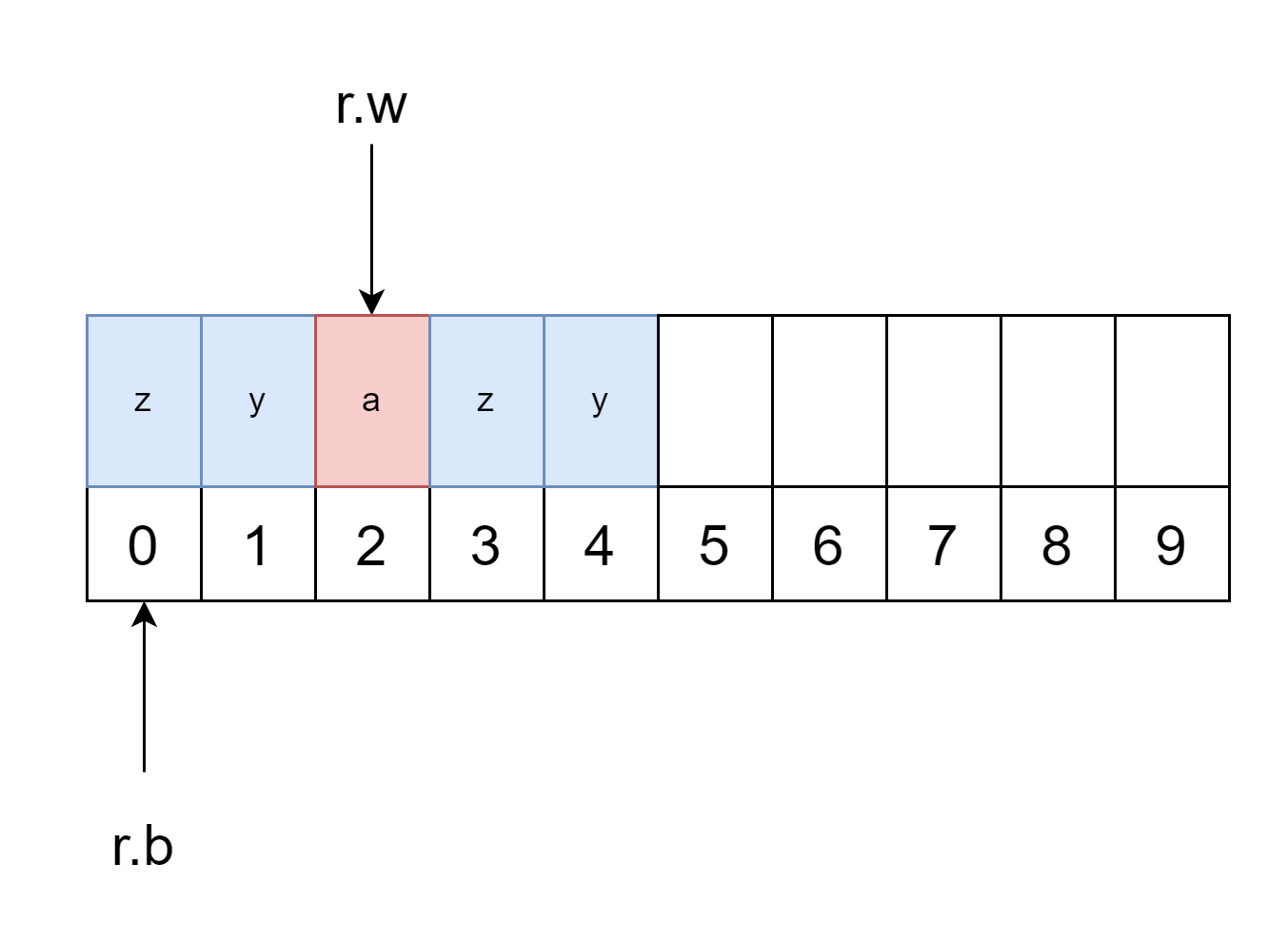
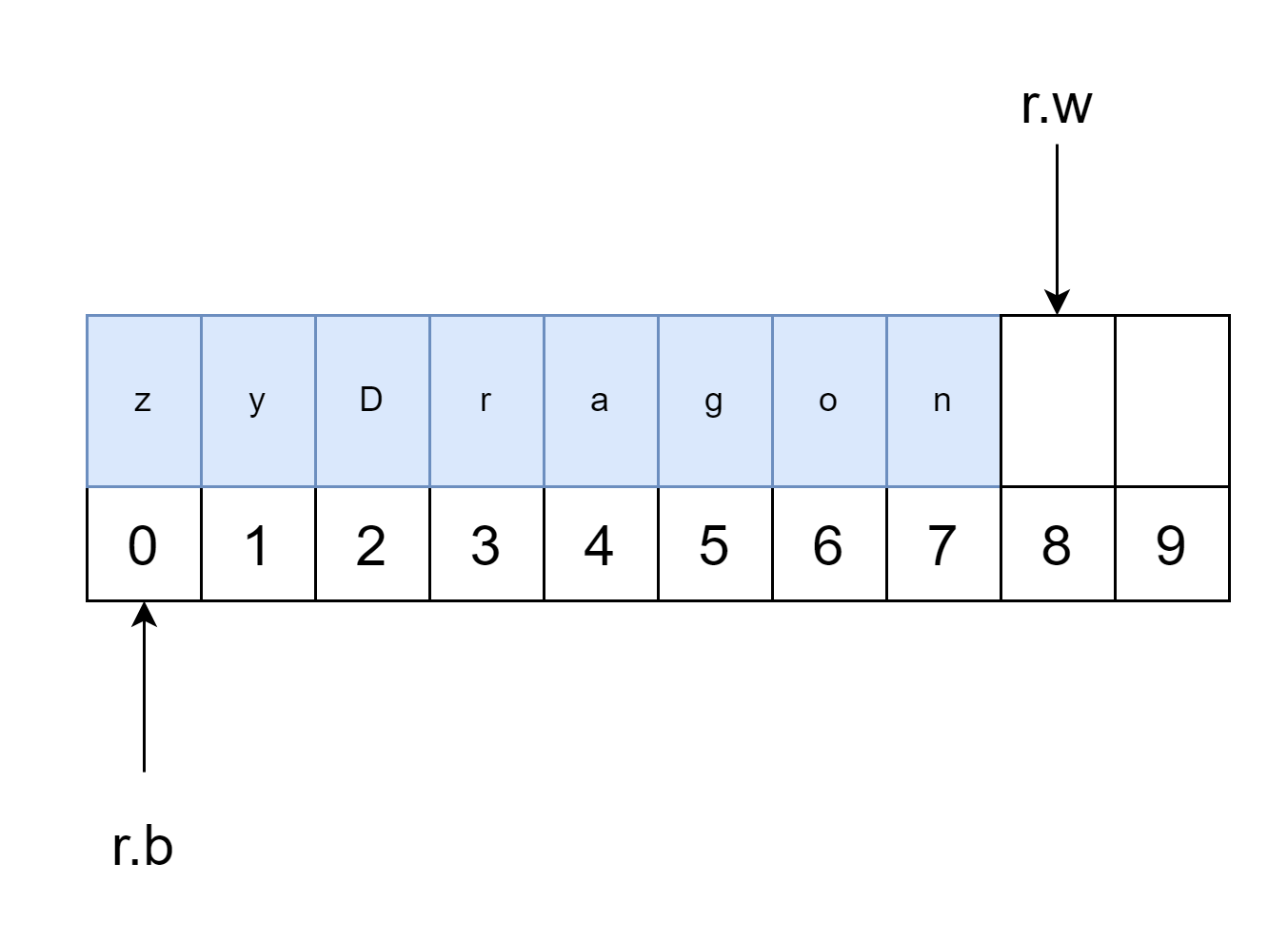
这里举一个例子:测试字符串 CrazyDragon,假设初始缓冲区容量为10,现在开始第一次填充数据(r.b = r.w = 0),假设它读取了Crazy 这 5 个数据(这里的读取是从底层数据源读取,对于缓冲区来说它是指写入)。因为还没有开始读取(这里的读取指的是对缓冲区的读取),所以 r.b 为 0,r.w 为 5(这里你可以思考一下,为什么不是 4 呢?)。
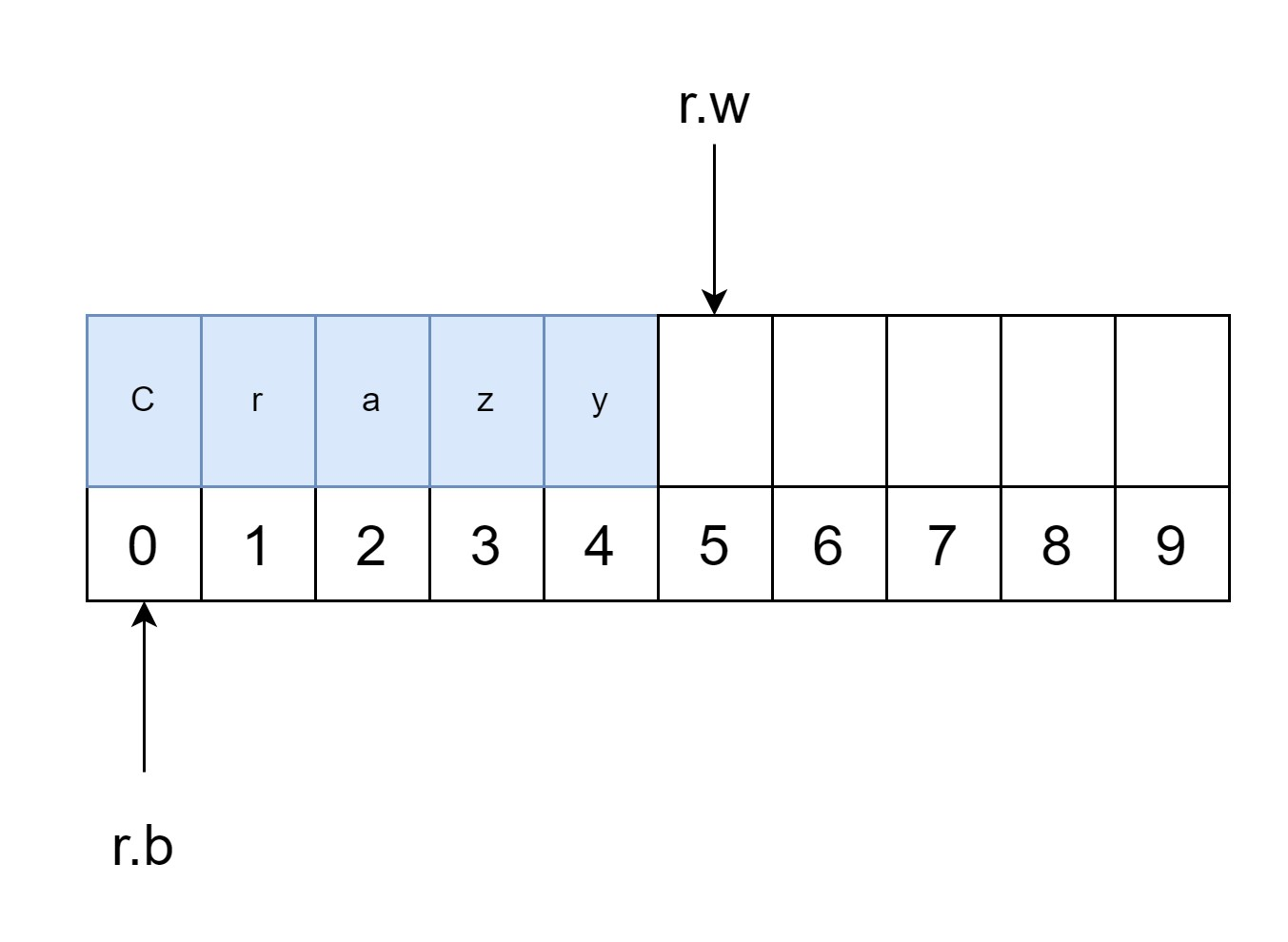
然后的操作的是:
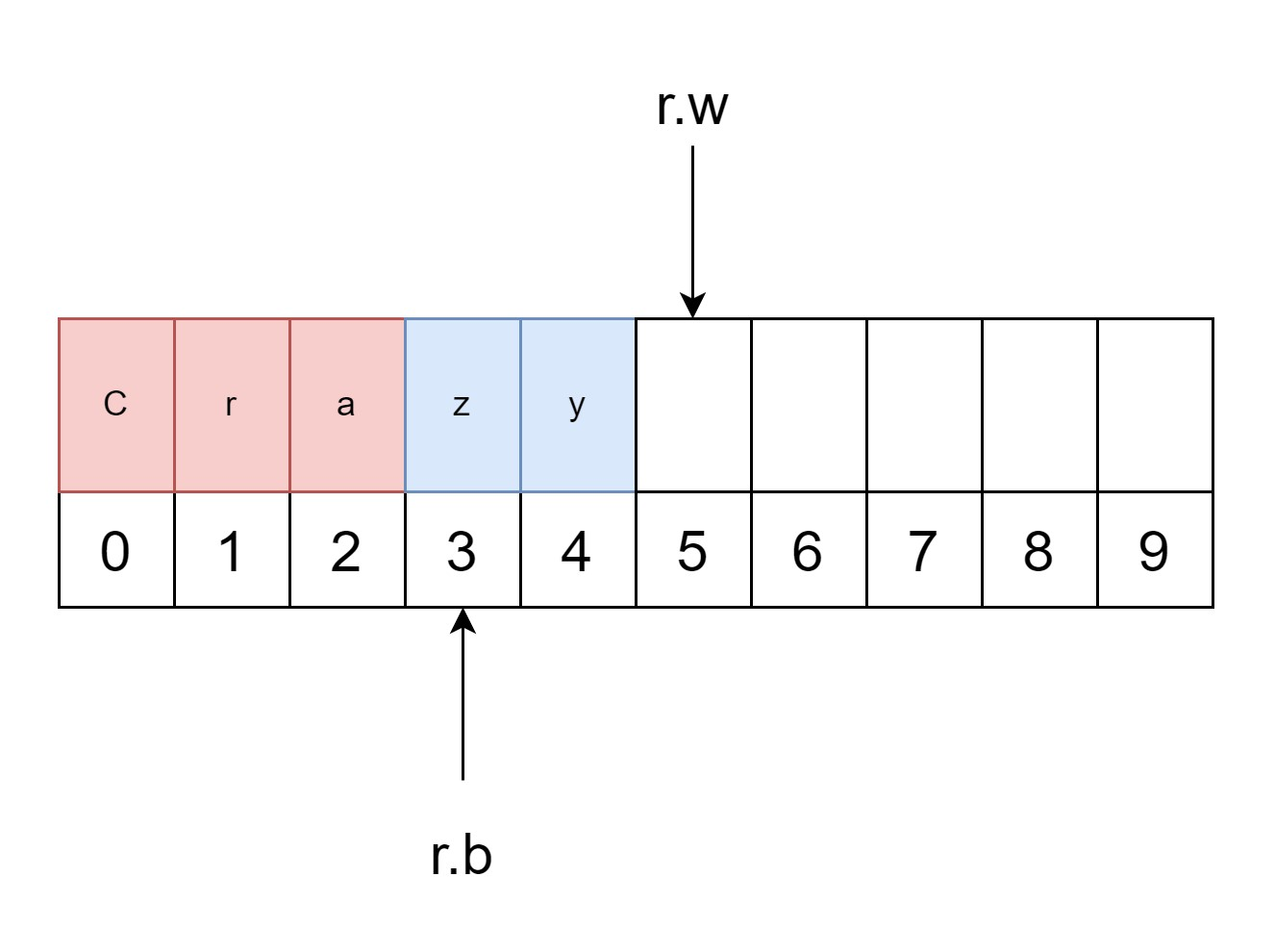
- 用户读取了 3 个数据,那么现在
r.b移动到 3 的位置,然后再次触发填充函数。 - 它会首先把从
r.b到r.w的数据搬到(或者说复制)缓冲切片的开头. - 然后从底层数据源读取
Dragon这 6 个数据,并将其填充进缓冲区,r.w向后移动 6。
Peak 查看但不读取数据
注:// Tip: 以这个开头的中文注释,是我添加的理解。
// Peek returns the next n bytes without advancing the reader. The bytes stop
// being valid at the next read call. If Peek returns fewer than n bytes, it
// also returns an error explaining why the read is short. The error is
// ErrBufferFull if n is larger than b's buffer size.
//
// Calling Peek prevents a UnreadByte or UnreadRune call from succeeding
// until the next read operation.
func (b *Reader) Peek(n int) ([]byte, error) {if n < 0 {return nil, ErrNegativeCount}b.lastByte = -1b.lastRuneSize = -1// Tip:如果 n 大于缓冲区剩余的数据且缓冲区未满,会调用 fill() 将其填满for b.w-b.r < n && b.w-b.r < len(b.buf) && b.err == nil {b.fill() // b.w-b.r < len(b.buf) => buffer is not full}// Tip:如果 n 大于缓冲区的长度,会报错 ErrBufferFullif n > len(b.buf) {return b.buf[b.r:b.w], ErrBufferFull}// 0 <= n <= len(b.buf)var err error// Tip:如果最终还是剩余数据小于需要读取的数据,那么就返回剩余数据和相应的错误if avail := b.w - b.r; avail < n {// not enough data in buffern = availerr = b.readErr()if err == nil {err = ErrBufferFull}}// Tip:这才是最关键的代码,只是返回缓冲区中数据的切片,其他的都错误处理相关的return b.buf[b.r : b.r+n], err
}
Peek 有偷看的意思,它的作用就是查看当前读取位置之后的 n 字节数据,但是不移动读取的下标。如果它返回的字节少于 n 个,它会返回一个错误来解释原因。如果 n 大于缓冲区的大小,那么会返回一个 ErrBufferFull 错误。通过调用 Peek() 可以阻止 UnreadByte 或者 UnreadRune 调用成功,直到下一次读取操作。
Discard 丢弃数据
// Discard skips the next n bytes, returning the number of bytes discarded.
//
// If Discard skips fewer than n bytes, it also returns an error.
// If 0 <= n <= b.Buffered(), Discard is guaranteed to succeed without
// reading from the underlying io.Reader.
func (b *Reader) Discard(n int) (discarded int, err error) {if n < 0 {return 0, ErrNegativeCount}if n == 0 {return}b.lastByte = -1b.lastRuneSize = -1// Tip:因为缓冲区里面不一定有足够的数据,所以它也是会在底层调用 fill 来填充数据的remain := nfor {skip := b.Buffered()if skip == 0 {b.fill()skip = b.Buffered()}if skip > remain {skip = remain}b.r += skipremain -= skipif remain == 0 {return n, nil}if b.err != nil {return n - remain, b.readErr()}}
}
discard 就是丢弃的意思,这个词在 IT 领域还是很常见的,特别是和网络相关的。它的作用就是丢弃指定的 n 个字节,返回实际丢弃的字节数和相应的错误。
Read 读取数据
这个方法使用起来和正常的 IO 的 Read 是一样的,主要区别在于是先从缓冲区取数据,可能会调用一次 fill 函数填充缓存区。ReadByte 它返回下一个字节,ReadRune,它返回下一个 Unicode 字符。
UnReadByte 和 UnrReadRune 往前读
这里我把它称为往前读,因为它的作用是把读取指针向前移动。这两个方法类似,不过一个是向前移动一个字节,另一个是向前移动一个字符。
这里可以看到向前移动一个字节后,读取指针又指向了 :,本来这个字符已经被读取出来了,指针已经执行它后面的那个位置了。
package mainimport ("bufio""fmt""strings"
)func main() {reader := strings.NewReader("CrazyDragon: I love you yesterday and today.")bufReader := bufio.NewReaderSize(reader, 16)// 长度设置为 12,正好读取到 CrazyDragon:line := make([]byte, 12)n, err := bufReader.Read(line)if err != nil {fmt.Println(err)}fmt.Println(string(line[:n]))// 缓冲区大小是 16,读取 12,还剩下 4fmt.Println("剩余缓冲数据:", bufReader.Buffered())// 调用 UnreadByte,读取指针前移一位,此时缓冲区还剩下 5bufReader.UnreadByte()fmt.Println(bufReader.Buffered())n, err = bufReader.Read(line[:1])if err != nil {fmt.Println(err)}fmt.Println(string(line[:n]))

ReadSlice 读取一个切片
// ReadSlice reads until the first occurrence of delim in the input,
// returning a slice pointing at the bytes in the buffer.
// The bytes stop being valid at the next read.
// If ReadSlice encounters an error before finding a delimiter,
// it returns all the data in the buffer and the error itself (often io.EOF).
// ReadSlice fails with error ErrBufferFull if the buffer fills without a delim.
// Because the data returned from ReadSlice will be overwritten
// by the next I/O operation, most clients should use
// ReadBytes or ReadString instead.
// ReadSlice returns err != nil if and only if line does not end in delim.
func (b *Reader) ReadSlice(delim byte) (line []byte, err error) {s := 0 // search start indexfor {// Search buffer.if i := bytes.IndexByte(b.buf[b.r+s:b.w], delim); i >= 0 {i += sline = b.buf[b.r : b.r+i+1]b.r += i + 1break}// Pending error?if b.err != nil {line = b.buf[b.r:b.w]b.r = b.werr = b.readErr()break}// Buffer full?if b.Buffered() >= len(b.buf) {b.r = b.wline = b.buferr = ErrBufferFullbreak}s = b.w - b.r // do not rescan area we scanned beforeb.fill() // buffer is not full}// Handle last byte, if any.if i := len(line) - 1; i >= 0 {b.lastByte = int(line[i])b.lastRuneSize = -1}return
}
这个方法的作用是从缓冲区中读取数据,在第一次遇到指定的分隔符后停止,并返回一个指向缓冲区中这些字节的切片。ReadSlice 如果缓冲区填满数据但是没有一个分隔符,它会返回一个 ErrBufferFull 错误。
因为从 ReadSlice 返回的数据会被下一次的 IO 操作覆盖,所以大多数客户端应该使用 ReadBytes 或者 ReadString 来替代。
ReadSlice 只有在 line 没有结束在分隔符时,才会返回 err != nil。
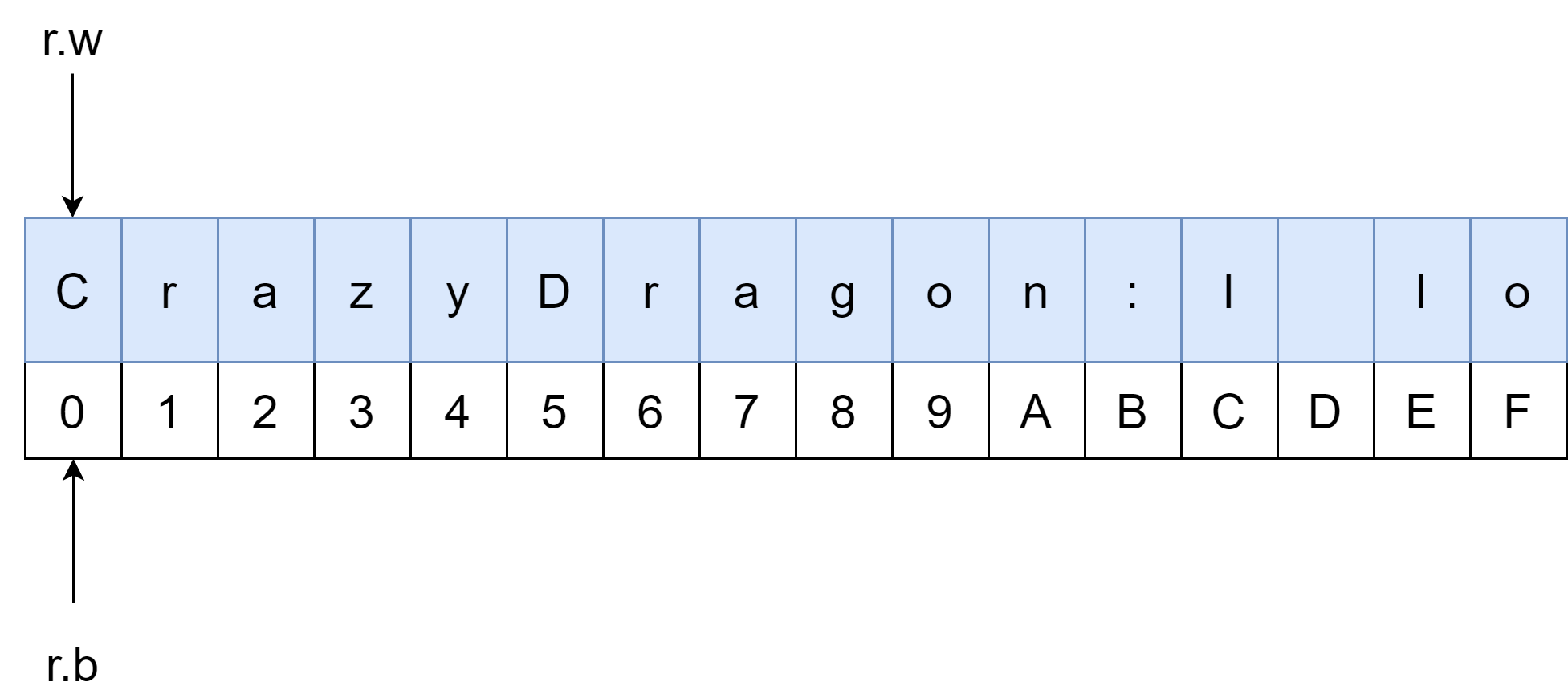
这里来做一个实验:测试数据为:CrazyDragon: I love you yesterday and today,因为默认的缓冲区大小是 4096 字节,这个对于测试代码太大了。但是,它也是可以设置的,最小值是 16 字节,这里我就设置成最小值来测试。
package mainimport ("bufio""fmt""strings"
)func main() {reader := strings.NewReader("CrazyDragon: I love you yesterday and today.")bufReader := bufio.NewReaderSize(reader, 16)// 此时还没有开始填充,如果缓冲区是空的,输出是 0fmt.Println("Buffered: ", bufReader.Buffered())// 开始从缓冲区读取,底层会调用 fill() 函数进行填充的line, err := bufReader.ReadSlice(':')if err != nil {fmt.Println(err)}// 这时 r.b 已经移动到相应的位置了,此时缓冲区的长度为 4fmt.Println("Buffered: ", bufReader.Buffered())fmt.Println(string(line))// 再次尝试读取,因为找不到分隔符,所以报错了_, err = bufReader.ReadSlice(':')if err != nil {fmt.Println("Error: ", err)}// 查看此时整个缓冲区的数据line, err = bufReader.Peek(16)if err != nil {fmt.Println("Error: ", err)}fmt.Printf("len(line) = %d, line = %s", len(line), string(line))
}
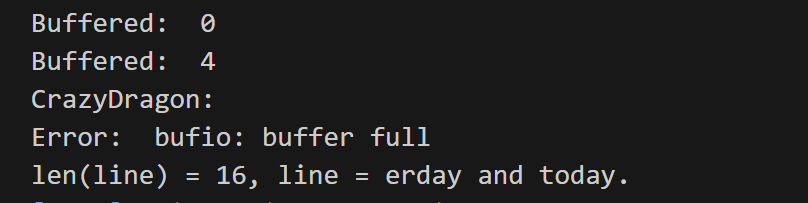
所以,可见 Buffered() 输出结果是 4,r.w 为 16,r.b 为 12。不过,这种情况就是从头开始读取一个满的缓冲区,如果缓冲区本身是未满的,那么它会将缓冲区填满(不一定是一次填满,可能会多次执行 fill(),这里的情况还是很复杂的,对于网络流来说,每次你都不一定可以读取到数据),但是如果缓存区满了还是没有发现分隔符,那么就会报错。
ReadLine 读取一行
ReadLine 是一个低级的读取行方法。大多数调用者应该使用 ReadBytes('\n') 或者 ReadString('\n') 替代或者使用扫描器 Scanner。实际上,它在内部是这样调用的:line, err = b.ReadSlice('\n')。 不过也要注意它的不同点,它是不会返回行结束符字节的。也就是说: ReadSlice('\n') 返回的数据是包含 \n,但是 ReadLine() 是不会包含的。
如果遇到了 ErrBufferFull 错误,说明整个缓存区都没有遇到 \n。但是它还会考虑是否存在 \r\n 横跨缓冲区的情况,即 \r 是缓冲区的最后一个字节,然后 \n 还没有到来,不过这只能等待下一次调用取检查了,可以通过第二个返回值来判断是否是这种情况。
这里来测试一下:
func ReadLineTest(s string) {reader := strings.NewReader(s)bufReader := bufio.NewReaderSize(reader, 16)line, isPrefix, err := bufReader.ReadLine()if err != nil {fmt.Println(err)}fmt.Printf("line = %s, isPrefix = %v\n", string(line), isPrefix)
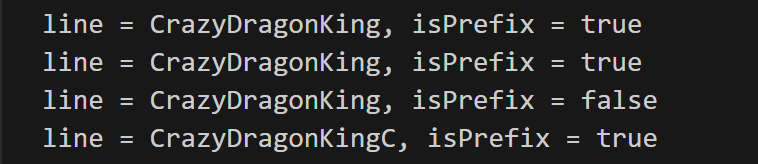
}ReadLineTest("CrazyDragonKing\r\n")
ReadLineTest("CrazyDragonKing\r")
ReadLineTest("CrazyDragonKing\n")
ReadLineTest("CrazyDragonKingCrazyDragonKingCrazyDragonKing")
这里来总结一下,各种可能的情况(注:缓冲区大小为 16,CrazyDragonKing 长度是 15)
"CrazyDragonKing\r\n" => "CrazyDragonKing", true, nil
"CrazyDragonKing\r" => "CrazyDragonKing", true, nil
"CrazyDragonKing\n" => "CrazyDragonKing", false, nil
"CrazyDragonKingCrazyDragonKingCrazyDragonKing" => CrazyDragonKingC, true, nil
ReadBytes 和 ReadString 读取字节切片和读取字符串
ReadSlice 是当遇到分隔符之后返回字节切片(包含分隔符本身),它会尝试填满缓冲区,如果没有遇到分隔符,会返回 ErrBufferFull 错误。
ReadLine 内部依赖 ReadSlice 实现,它返回的也是字节切片(不包含分隔符本身)。
ReadBytes 和 ReadString 它们两个一个返回字节切片,一个返回字符串。不同的地方在于,如果一个缓冲区没有找到,它们不会返回 ErrBufferFull 错误。而是继续读取底层的数据源,直到遇到分隔符或者文件结束。
这里来做一个实验:
func ReadStringTest(s string) {reader := strings.NewReader(s)bufReader := bufio.NewReaderSize(reader, 16)line, err := bufReader.ReadString('\n')if err != nil {fmt.Println(err)}fmt.Printf("line = %s\n", line)
}ReadLineTest("CrazyDragonKingCrazyDragonKingCrazyDragonKing")
ReadStringTest("CrazyDragonKingCrazyDragonKingCrazyDragonKing\nCrazyDragonKing\n")

collectFragments 收集片段
// collectFragments reads until the first occurrence of delim in the input. It
// returns (slice of full buffers, remaining bytes before delim, total number
// of bytes in the combined first two elements, error).
// The complete result is equal to
// `bytes.Join(append(fullBuffers, finalFragment), nil)`, which has a
// length of `totalLen`. The result is structured in this way to allow callers
// to minimize allocations and copies.
func (b *Reader) collectFragments(delim byte) (fullBuffers [][]byte, finalFragment []byte, totalLen int, err error) {var frag []byte// Use ReadSlice to look for delim, accumulating full buffers.for {var e errorfrag, e = b.ReadSlice(delim)if e == nil { // got final fragmentbreak}if e != ErrBufferFull { // unexpected errorerr = ebreak}// Make a copy of the buffer.buf := bytes.Clone(frag)fullBuffers = append(fullBuffers, buf)totalLen += len(buf)}totalLen += len(frag)return fullBuffers, frag, totalLen, err
}
这个方法初看起来还是蛮复杂的,特别是它返回值有 4 个,不过它这样的目的是为了调用者减少内存分配和拷贝。它的内部是依赖 ReadSlice 实现的,如果直接读取到了,那么就直接返回了。否则,下面就是不同的地方了。通常,如果返回 ErrBufferFull 是说明整个缓冲区没有遇到分隔符(如果不是,说明遇到了非预期错误,直接返回),它会保存已经读取的数据,然后再调用 ReadSlice,直到遇到分隔符或者其他错误。
对比上面这行代码的执行结果:
ReadStringTest("CrazyDragonKingCrazyDragonKingCrazyDragonKing\nCrazyDragonKing\n")
总结
好了,到这里就结束了。这里至少 Reader 相关的部分,后面还会继续 Writer 相关的部分。不过,目前还没有特别好的记录方式,只是大致挑几个代码贴出来,写一些自己的理解,然后配一些示意图,再加上一些测试代码。这篇博客不是为了说明这个包是怎么使用的,而是为什么要用它,以及它的一些实现的细节。现这样写吧,以后再探索是不是有更好的方式。
相关文章:
golang-bufio 缓冲读
缓冲 IO 计算机中我们常听到这样的两种程序优化方式: 以时间换空间以空间换时间 今天要来看的缓冲IO就是典型的以空间换时间,它的基本原理见上图。简单的解释就是:程序不再直接去读取底层的数据源,而是通过一个缓冲区来进行读取…...

前端 js实现 选中数据 动态 添加在表格中
如下图展示,表格上方有属性内容,下拉选中后,根据选中的内容,添加在下方的表格中。 实现方式,(要和后端约定,因为这些动态添加的字段都是后端返回的,后端自己会做处理,…...

MySQL—MySQL主从如何保证强一致性
一、前言 涉及到的东西:两阶段提交,binlog三种格式 1、两阶段提交 在持久化 redo log 和 binlog 这两份日志的时候,如果出现半成功的状态,就会造成主从环境的数据不一致性。这是因为 redo log 影响主库的数据,binlog…...
Lora升级!ReLoRa!最新论文 High-Rank Training Through Low-Rank Updates
目录 摘要1 引言2 相关工作3 方法4 实验5 结果6 结论7 局限性和未来工作 关注公众号TechLead,分享AI与云服务技术的全维度知识。作者拥有10年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员࿰…...

gateway动态路由和普通路由+负载均衡,借助eureka
gateway 中的动态路由和普通路由是相互独立配置的注意consumer使用了openFeign远程调用的配置文件中 prefer-ip-address: false 必须为false 否则 gateway的动态路由和负载均衡无法实现 spring:cloud:gateway:enabled: truediscovery:locator:enabled: true #表示动态路由&a…...
HTTP原理与实现
一、基本概念 一、基本原理* 1、全称: HyperText Transfer Protocol (超文本传输协议) 2、底层实现协议:建立在 TCP/IP 上的无状态连接。 3、基本作用:用于客户端与服务器之间的通信,规定客户端和服务器之间的通信格式。包括请…...

现在软件开发app制作还值得做吗
软件开发和制作App还是值得做的,但成功与否取决于多种因素。以下是一些影响你在软件开发和App制作领域发展的因素: 1、市场需求: 开发的App是否满足市场需求?是否解决了用户的问题或提供了有价值的功能?成功的App通常…...

java八股文面试[JVM]——类初始化过程
回顾类加载过程: 知识来源: 【2023年面试】Class初始化过程是什么_哔哩哔哩_bilibili...

什么是SQL注入攻击,解释如何防范SQL注入攻击?
1、什么是SQL注入攻击,解释如何防范SQL注入攻击。 SQL注入攻击是一种常见的网络攻击方式,攻击者通过在Web应用程序的查询语句中插入恶意代码,从而获取数据库中的敏感信息或者执行其他恶意操作。 为了防范SQL注入攻击,可以采取以…...
)
StringBuilder类分享(2)
一、StringBuilder说明 StringBuilder是一个可变的字符序列。这个类提供了一个与StringBuffer兼容的API,但不保证同步,即StringBuilder不是线程安全的,而StringBuffer是线程安全的。显然,StringBuilder要运行的更快一点。 这个类…...
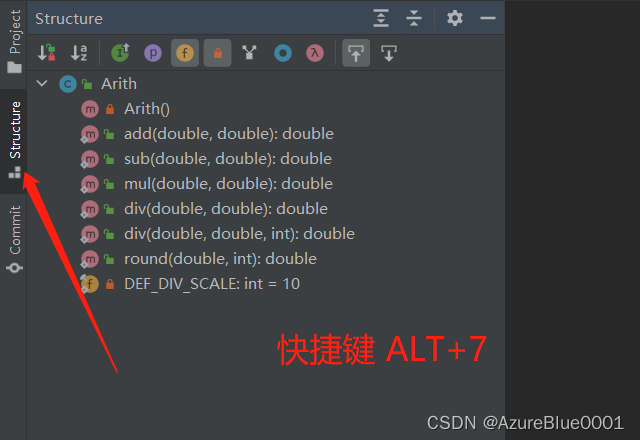
IDEA查看类中的方法
做个记录 直接查看类中的方法,在打开的时候都会有。 查看单个类中的方法...

MySQL日期格式及日期函数实践
目录 日期格式 日期函数 CURDATE()和CURRENT_DATE()CURTIME()和CURRENT_TIME()NOW()和CURRENT_TIMESTAMP()DATE_FORMAT()DATE_ADD()和DATE_SUB()DATEDIFF()DATE()DAYNAME()和MONTHNAME() 1. 日期格式 在MySQL中,日期可以使用多种格式进行存储和表示。常见的日期格式…...

MySQL项目迁移华为GaussDB PG模式指南
文章目录 0. 前言1. 数据库模式选择(B/PG)2.驱动选择2.1. 使用postgresql驱动2.1. 使用opengaussjdbc驱动 3. 其他考虑因素4. PG模式4.1 MySQL和OpenGauss不兼容的语法处理建议4.2 语法差异 6. 高斯数据库 PG模式JDBC 使用示例验证6. 参考资料 本章节主要…...
流处理详解
【今日】 目录 一 Stream接口简介 Optional类 Collectors类 二 数据过滤 1. filter()方法 2.distinct()方法 3.limit()方法 4.skip()方法 三 数据映射 四 数据查找 1. allMatch()方法 2. anyMatch()方法 3. noneMatch()方法 4. findFirst()方法 五 数据收集…...
Qt中XML文件创建及解析
一 环境部署 QT的配置文件中添加xml选项: 二 写入xml文件 头文件:#include <QXmlStreamWriter> bool MyXML::writeToXMLFile() {QString currentTime QDateTime::currentDateTime().toString("yyyyMMddhhmmss");QString fileName &…...
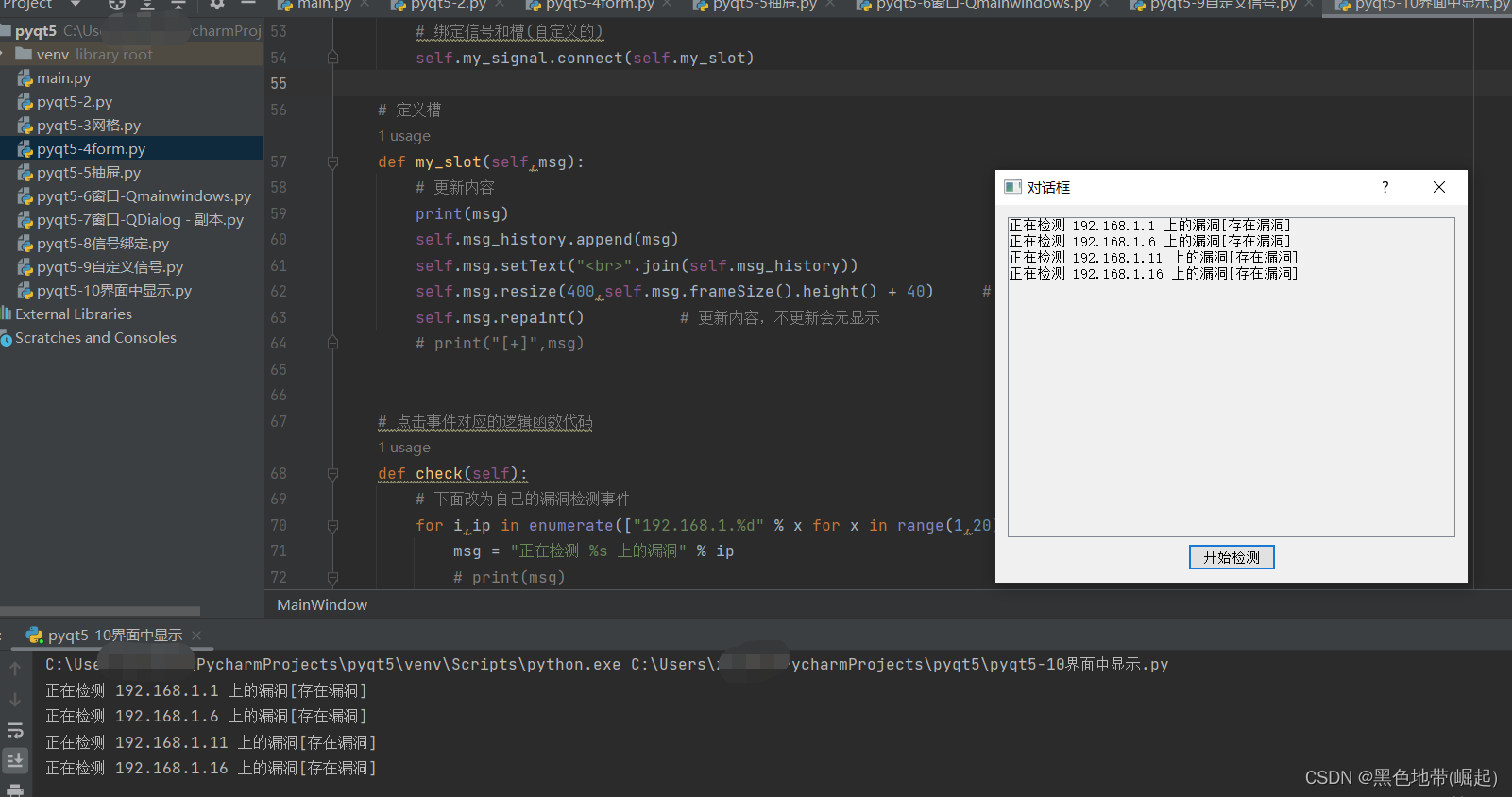
【pyqt5界面化工具开发-11】界面化显示检测信息
目录 0x00 前言: 一、布局的设置 二、消息的显示 0x00 前言: 我们在10讲的基础上,需要将其输出到界面上 思路: 1、消息的传递 2、布局的设置 先考虑好消息的传递,再来完善布局 其实先完善布局,再来设置消…...

Batbot电力云平台在智能配电室中的应用
智能配电室管理系统是物联网应用中的底层应用场景,无论是新基建下的智能升级,还是双碳目标下的能源管理,都离不开智能配电运维对传统配电室的智慧改造。Batbot智慧电力(运维)云平台通过对配电室关键电力设备部署传感器…...
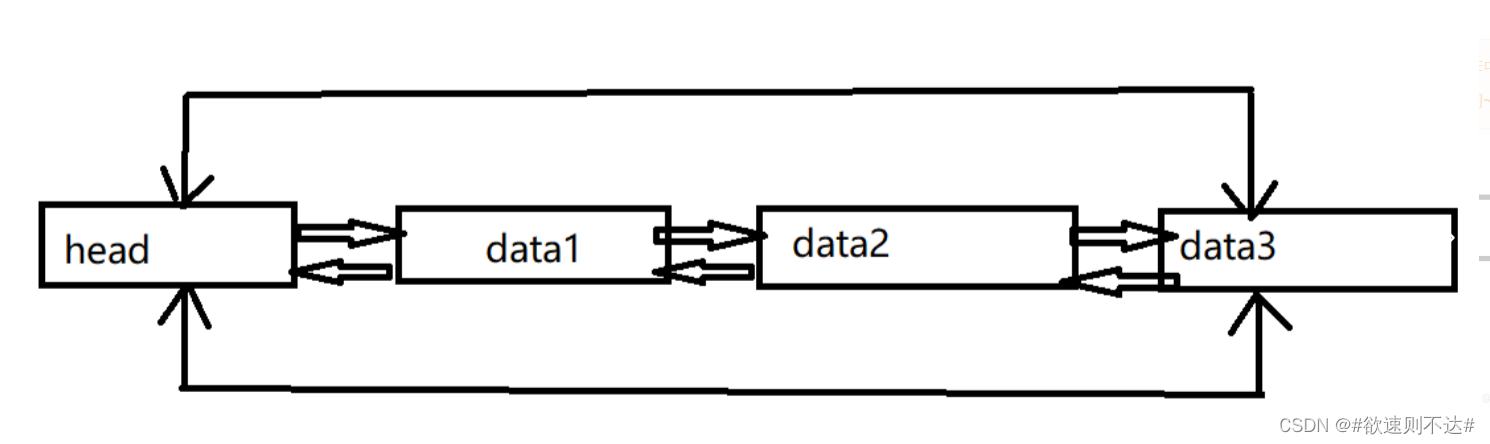
链表(详解)
一、链表 1.1、什么是链表 1、链表是物理存储单元上非连续的、非顺序的存储结构,数据元素的逻辑顺序是通过链表的指针地址实现,有一系列结点(地址)组成,结点可动态的生成。 2、结点包括两个部分:&#x…...
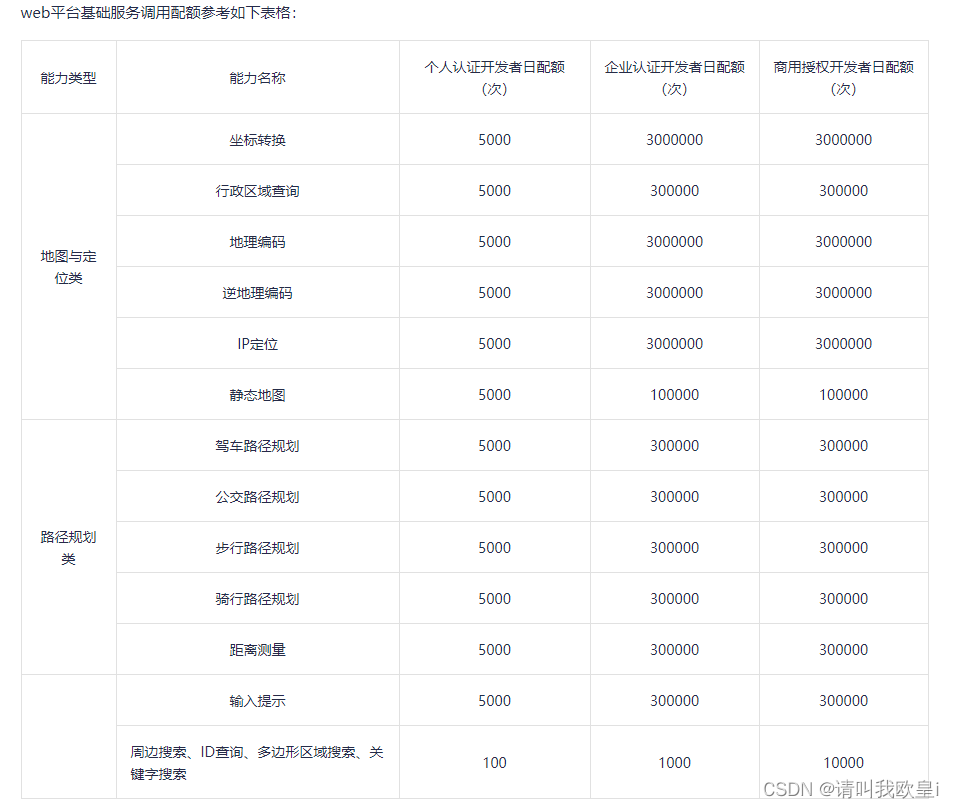
最简单vue获取当前地区天气--高德开放平台实现
目录 前言 一、注册成为高德平台开发者 二、注册天气key 1.点击首页右上角打开控制台 2.创建新应用 三、vue项目使用 1.打开vue项目找到public下的index.html,如果是vue3的话直接在主目录打开index.html文件就行,主要就是打开出口文件 编辑 2.根据高德…...

大数据处理 正则表达式去除特殊字符 提取中文英文数字
在文本处理中,经常会碰到含有特殊字符的字符串。 比如用户昵称, 小红书文案,等等 都包含了大量表情特殊字符。 这些特殊字符串在ETL处理过程中,经常会引起程序报错,导致致命错误,程序崩溃;或者导…...
](https://towardsdatascience.com/the-ultimate-guide-to-finding-outliers-in-yo)
[寻找时间序列数据中异常值终极指南(第三部分)](https://towardsdatascience.com/the-ultimate-guide-to-finding-outliers-in-yo
原文:towardsdatascience.com/the-ultimate-guide-to-finding-outliers-in-your-time-series-data-part-3-0ff73ce28ca3...

python高校学生党员信息管理系统_829h59n3
目录同行可拿货,招校园代理 ,本人源头供货商项目背景核心功能技术实现项目特点应用价值项目技术支持源码获取详细视频演示 :同行可合作点击我获取源码->获取博主联系方式->进我个人主页-->同行可拿货,招校园代理 ,本人源头供货商 项目背景 高校学生党员信…...

阅读APP书源导入与使用完全指南:26个高质量书源一键获取
阅读APP书源导入与使用完全指南:26个高质量书源一键获取 【免费下载链接】Yuedu 📚「阅读」自用书源分享 项目地址: https://gitcode.com/gh_mirrors/yu/Yuedu 还在为「阅读」APP找不到稳定的小说书源而烦恼吗?这款开源阅读工具需要自…...

如何用Python快速接入Taotoken平台调用多款大模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何用Python快速接入Taotoken平台调用多款大模型 对于希望便捷使用多种大语言模型的开发者而言,逐一对接不同厂商的AP…...

别再傻傻分不清了!GIS新手必看:WGS84和UTM到底怎么选?附QGIS/ArcGIS实操对比
GIS坐标系选择指南:WGS84与UTM的核心差异与实战决策 刚接触地理信息系统(GIS)时,坐标系的选择往往令人困惑。为什么同样的位置数据,在不同坐标系下显示的数值完全不同?为什么测量同一个区域的面积会得到差异巨大的结果?…...
)
保姆级教程:用ENVI+SNAP搞定哨兵1号雷达数据预处理(附水稻监测实战)
从零掌握哨兵1号雷达数据处理:ENVI与SNAP双软件协同实战指南 当第一次接触哨兵1号雷达数据时,许多研究者都会被其独特的成像机制和处理流程所困扰。与光学遥感不同,雷达数据需要经过一系列专业预处理才能用于分析。本文将带你系统掌握ENVI和…...

猫抓Cat-Catch:浏览器资源嗅探技术的3大架构演进与实战解析
猫抓Cat-Catch:浏览器资源嗅探技术的3大架构演进与实战解析 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓Cat-Catch作为一款专业…...
)
ElevenLabs甘肃话语音合成技术解析(西北方言TTS工程化白皮书)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs甘肃话语音合成技术概览 ElevenLabs 是全球领先的语音合成平台,原生支持英语、西班牙语、法语等数十种主流语言,但**不直接内置甘肃话(属中原官话秦陇片&a…...

CANNBot Triton-Ascend Amin归约原子操作优化案例
【免费下载链接】cannbot-skills CANNBot 是面向 CANN 开发的用于提升开发效率的系列智能体,本仓库为其提供可复用的 Skills 模块。 项目地址: https://gitcode.com/cann/cannbot-skills name: triton-ascend-case-reduction-amin-atomic description: "…...

制造业数据架构设计顶层规划方案:数据资源规划、基础数据管理、数据分析应用、数据治理体系 、实施路线图
该方案针对企业数据架构空白、缺乏统一模型与治理体系的问题,提出了以数据资源规划、主数据与元数据管理、数据分析应用及数据治理为核心的整体架构。通过明确数据分布与流向、构建企业级数据仓库与治理平台,最终实现数据驱动决策与业务规范化࿰…...