流处理详解
【今日】

目录
一 Stream接口简介
Optional类
Collectors类
二 数据过滤
1. filter()方法
2.distinct()方法
3.limit()方法
4.skip()方法
三 数据映射
四 数据查找
1. allMatch()方法
2. anyMatch()方法
3. noneMatch()方法
4. findFirst()方法
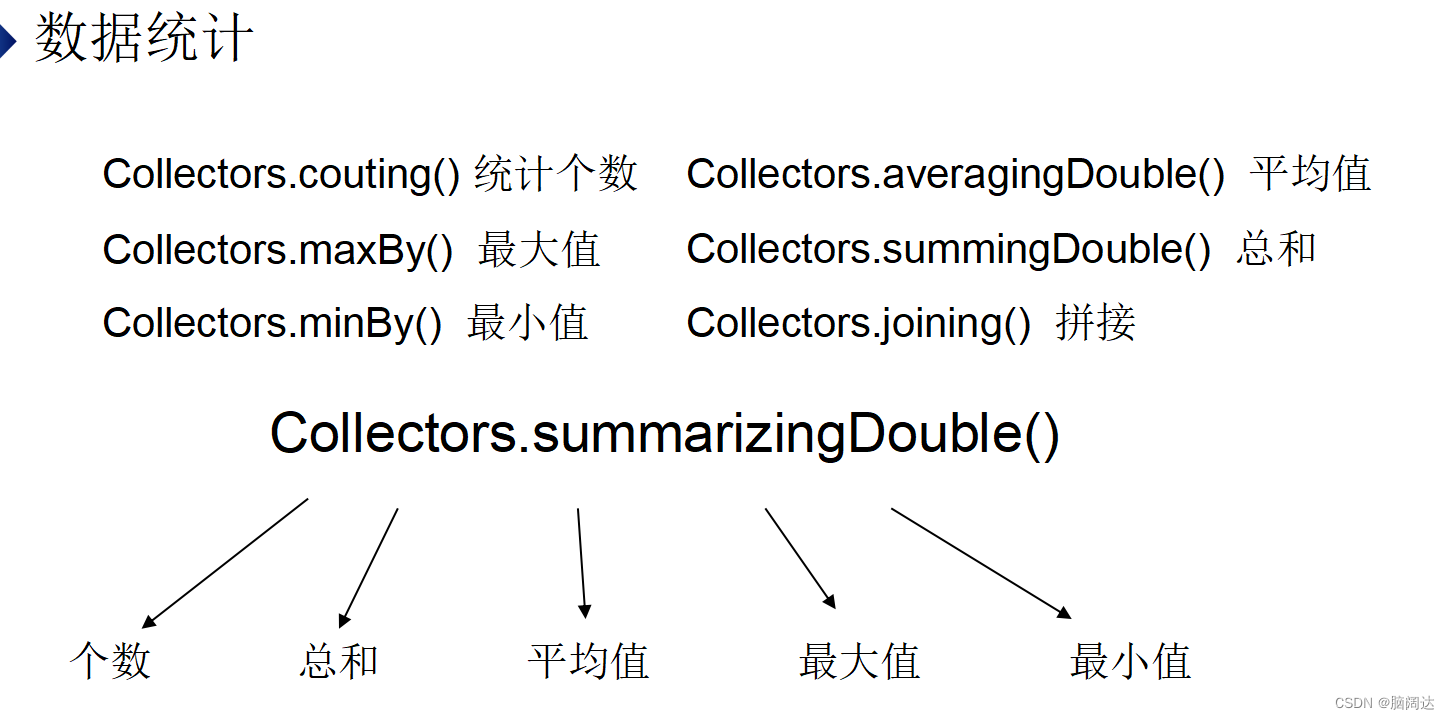
五 数据收集
1.数据统计
2.数据分组
流处理有点类似数据库的SQL语句,可以执行非常复杂的过滤、映射、查找和收集功能,并且代码量很少。唯一的缺点是代码可读性不高,如果开发者基础不好,可能会看不懂流API所表达的含义。
我们再这里先创建一个公共类----Employee 员工类,方便后续的流处理。
员工的集合数据
| 姓名(name) | 年龄(age) | 薪资(salary) | 性别(sex) | 部门(dept) |
| 老张 | 40 | 9000 | 男 | 运营部 |
| 小刘 | 24 | 5000 | 女 | 开发部 |
| 大刚 | 32 | 7500 | 男 | 销售部 |
| 翠花 | 28 | 5500 | 女 | 销售部 |
| 小马 | 21 | 3000 | 男 | 开发部 |
| 老王 | 35 | 6000 | 女 | 人事部 |
| 小王 | 21 | 3000 | 女 | 人事部 |
import java.util.ArrayList;
import java.util.List;public class Employee {//员工类private String name; //姓名private int age; //年龄private double salary; //薪资private String sex; //性别private String dept; //部门public Employee(String name, int age, double salary, String sex, String dept) {//构造方法this.name = name;this.age = age;this.salary = salary;this.sex = sex;this.dept = dept;}public String toString() {//重写toString()方法,输出员工信息return "姓名:" + name + ", 年龄:" + age + ", 薪资:" + salary + ", 性别:" + sex + ", 部门:" + dept;}//以下是获得员工相关信息的方法public String GetName() {//获得名字的方法return name;}public int GetAge() {//获得年龄的方法return age;}public double GetSalary() {//获得薪资的方法return salary ;}public String GetSex() {//获得性别的方法return sex;}public String Getdept() {//获得部门的方法return dept;}static List<Employee>GetEmpList(){List<Employee> list = new ArrayList<>();list.add(new Employee("老张",40,9000,"男","运营部"));list.add(new Employee("小刘",24,5000,"女","开发部"));list.add(new Employee("大刚",32,7500,"男","销售部"));list.add(new Employee("翠花",28,5500,"女","销售部"));list.add(new Employee("小马",21,3000,"男","开发部"));list.add(new Employee("老王",35,6000,"女","人事部"));list.add(new Employee("小王",21,3000,"女","人事部"));return list; }
}一 Stream接口简介
流处理的接口都定义在java.uil.stream包下。BaseStream接口是最基础的接口,但最常用的是BaseStream接口的一个子接口——Stream接口,基本上绝大多数的流处理都是在Stream接口上实现的。所忆, Stream接口是泛型接口,所以流中操作的元素可以是任何类的对象。
Stream接口的常用
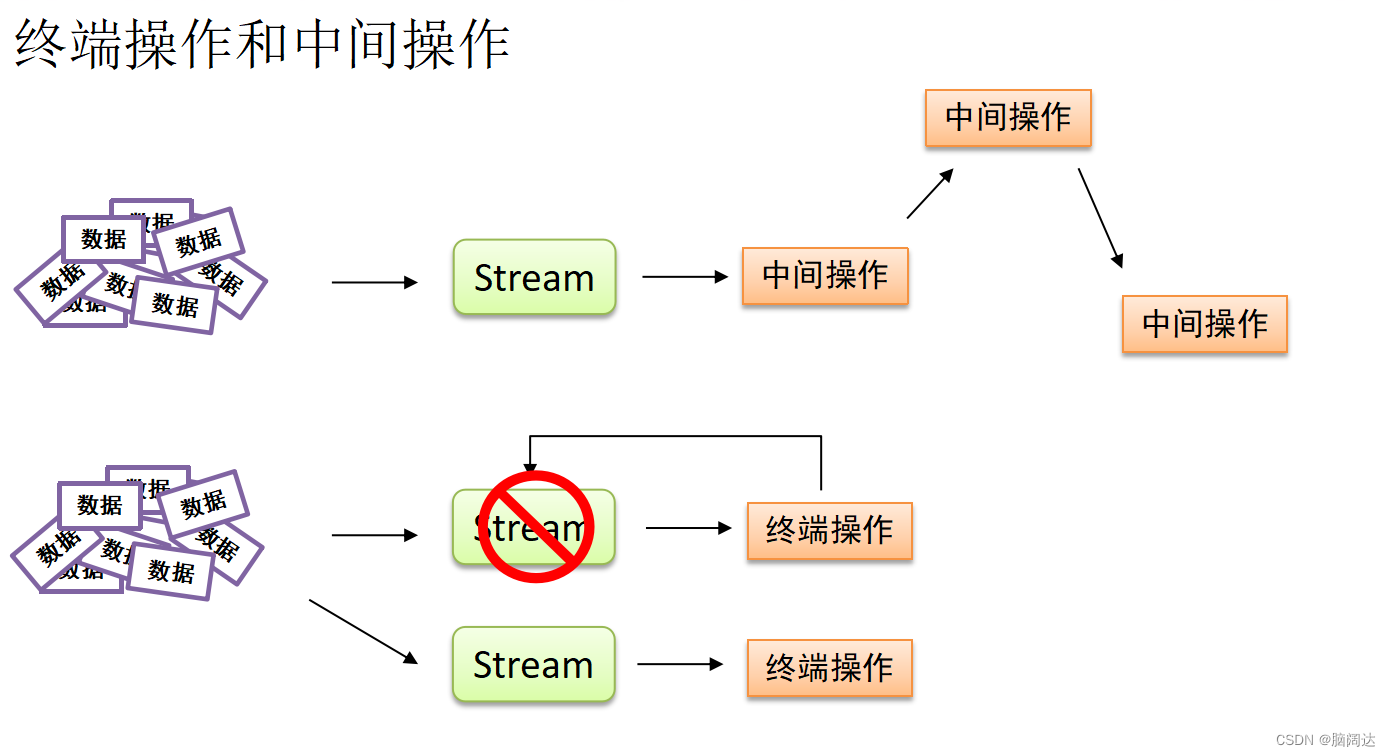
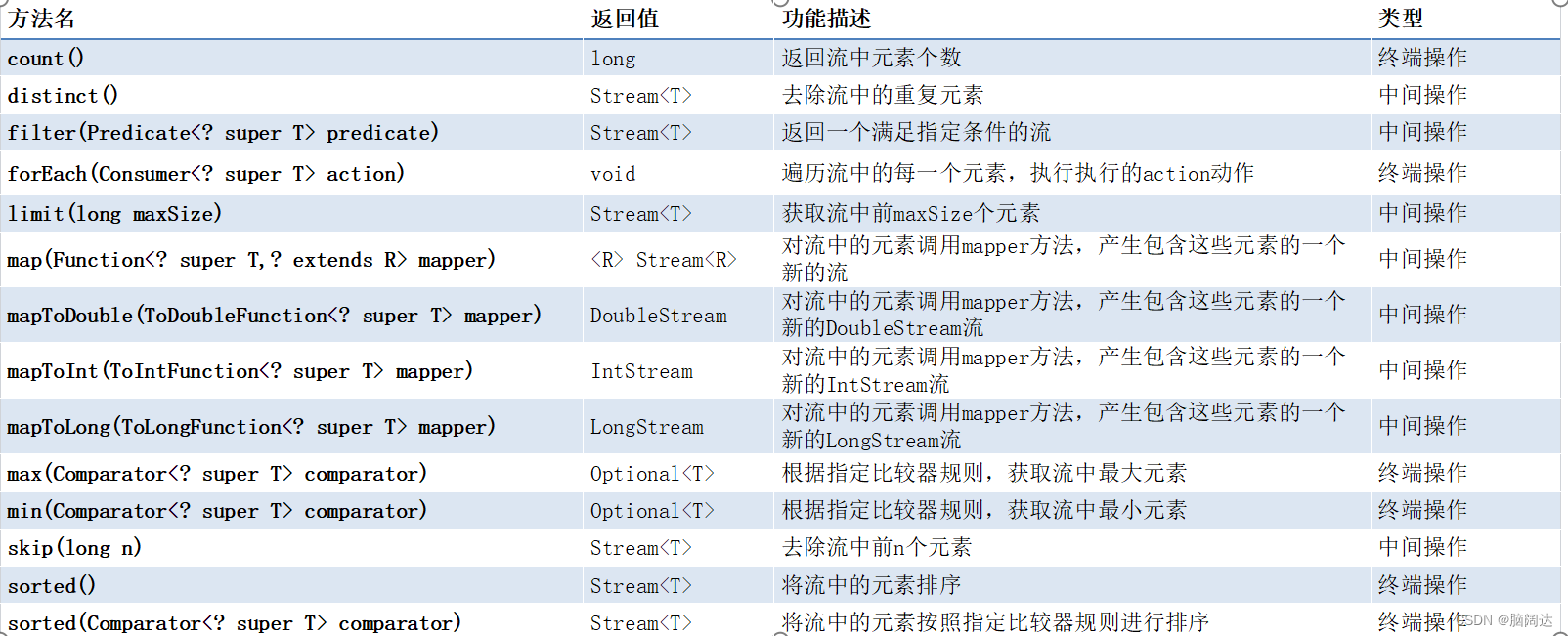 中间操作和终端操作。中间操作类型的方法会生成一个新的流对象,被操作的流对象仍然可以执行其他操作;终端操作会消费流,操作结束之后,被操作的流对象就不能再次执行其他操作了。这是两者的最大区别。
中间操作和终端操作。中间操作类型的方法会生成一个新的流对象,被操作的流对象仍然可以执行其他操作;终端操作会消费流,操作结束之后,被操作的流对象就不能再次执行其他操作了。这是两者的最大区别。
collection接口新增两个可以获取流对象的方法。第一个方法最常用,可以获取集合的顺序流,方下:
Stream<E> stream();第二个方法可以获取集合的并行流,方法如下:
Stream<E> parallelstream();因为所有集合类都是Collection接口的子类,如ArrayList类、HashSet类等,所以这些类都可以进行流处理。例如:
List<Integer> list = new ArrayList<Integer>(); //创建集合 Stream<Integer> s = list.stream(); //获取集合流对象
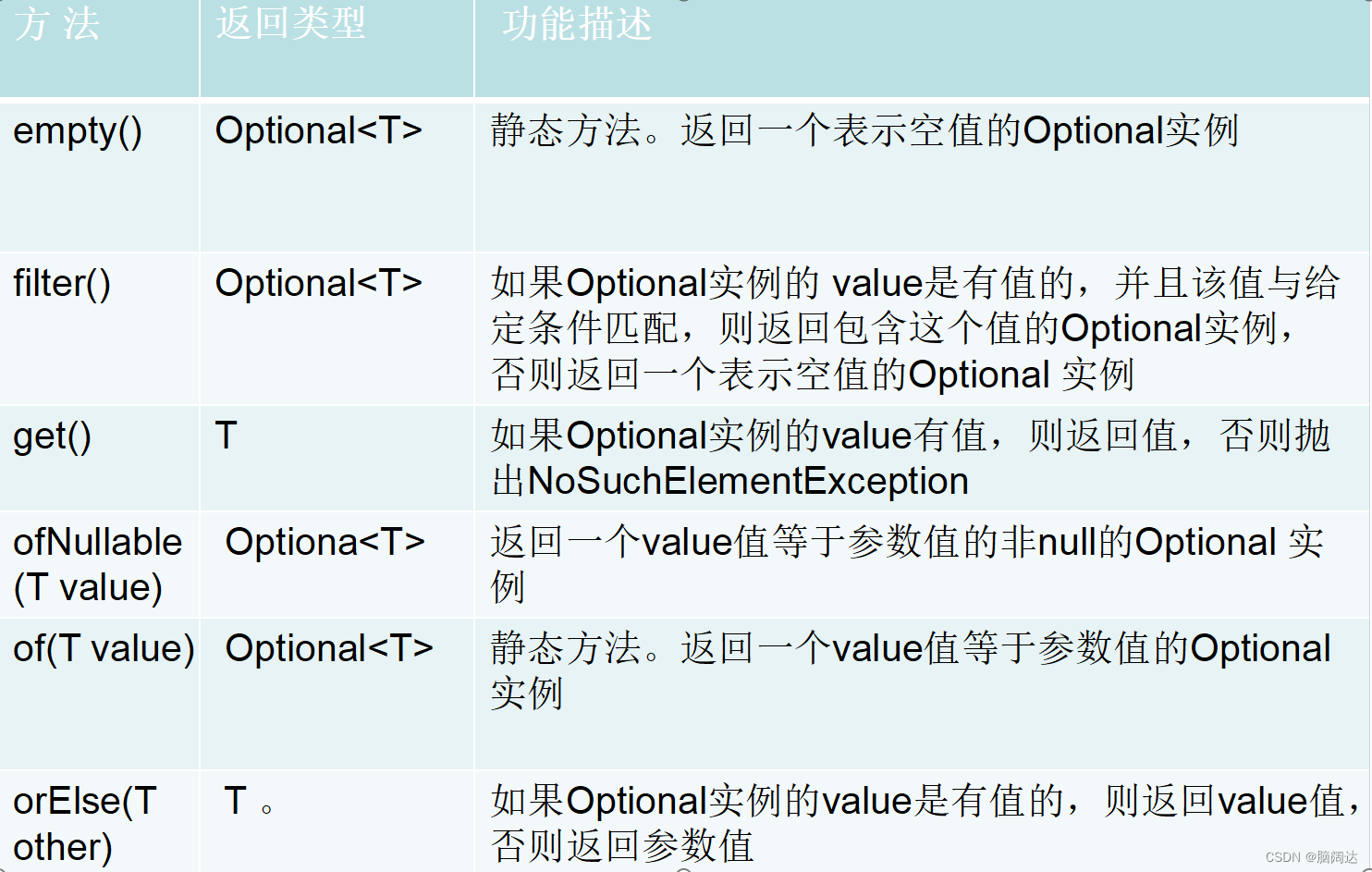
Optional类
Optional类像是一个容器,可以保存任何对象,并且针对 NullPointerException空指针异常做了化,保证Optional类保存的值不会是null。因此,Optional类是针对“对象可能是null也可能不是mlr的场景为开发者提供了优质的解决方案,减少了烦琐的异常处理。Optional类是用final修饰的,所以不能有子类。Optional类是带有泛型的类,所以该类可以保任何对象的值。
从Optional类的声明代码中就可以看出这些特性,JDK中的部分代码如下:
public final class Optional<T>(private final T value;......... //省略其他代码 }Optional类中有一个叫作value的成员属性,这个属性就是用来保存具体值的。value 是用泛型T修饰的,并且还用了final修饰,这表示一个Optional对象只能保存一个值。
Optional类提供的常用方法
Collectors类
collectors类为收集器类,该类实现了java.util.Colleetor接口,可以将Stream流对象进行各种各样的封装、归集、分组等操作。同时,Collectors类还提供了很多实用的数据加工方法,如数据统计计算等.
collecctors类的方法 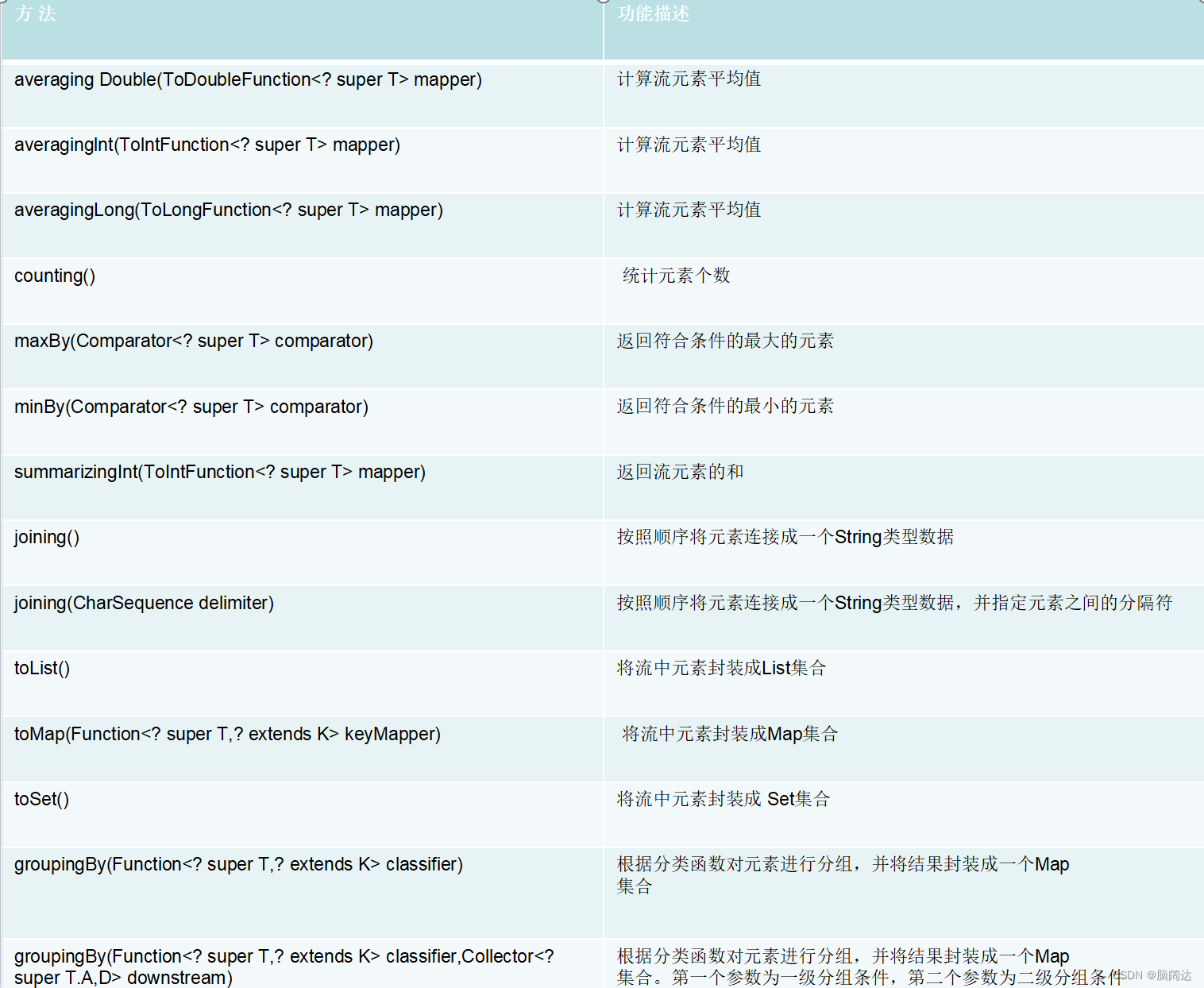
二 数据过滤
数据过滤就是在杂乱的数据中筛选出需要的数据,类似SQL语句中的WHERE关键字,给出一的条件,将符合条件的数据过滤并展示出来。
1. filter()方法
filter()方法是Stream接口提供的过滤方法。该方法可以将lambda表达式作为参数,然后按照lambà表达式的逻辑过滤流中的元素。过滤出想要的流元素后,还需使用Stream提供的collect0方法按照指定方法重新封装。
基于Employee 员工类实现:
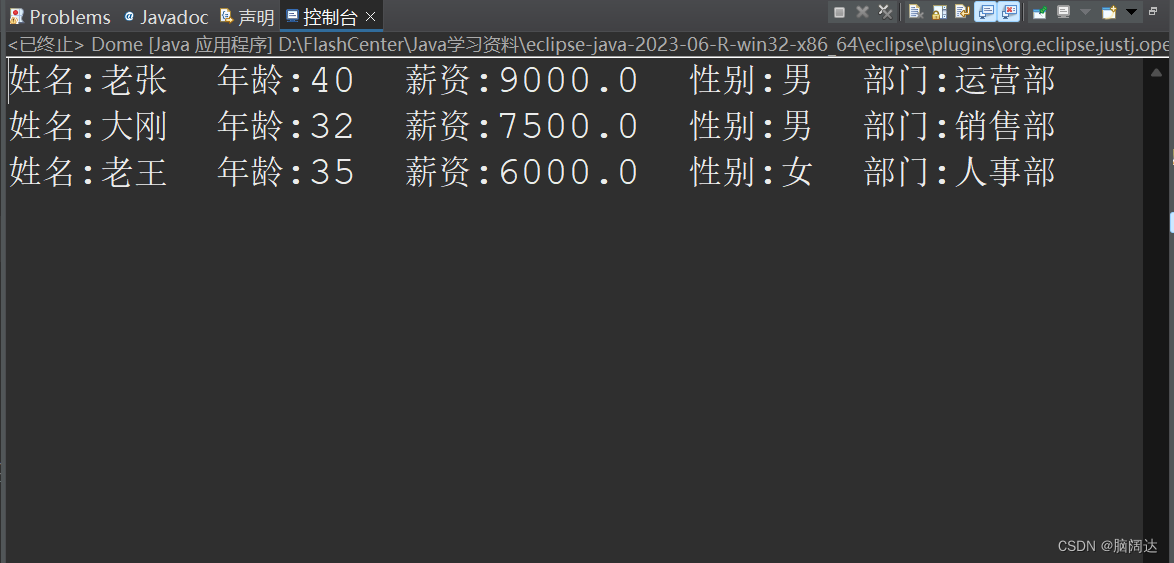
找出年龄大于30的员工
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;public class Dome{public static void main(String[] args) {//找出年龄大于30的员工List<Employee> list = Employee.GetEmpList();//先获取所有的员工测试信息Stream<Employee> stream = list.stream();//获取集合流对象stream = stream.filter(e->e.GetAge()>30);List<Employee> result = stream.collect(Collectors.toList());for(Employee emp:result) {System.out.println(emp);}}
}
2.distinct()方法
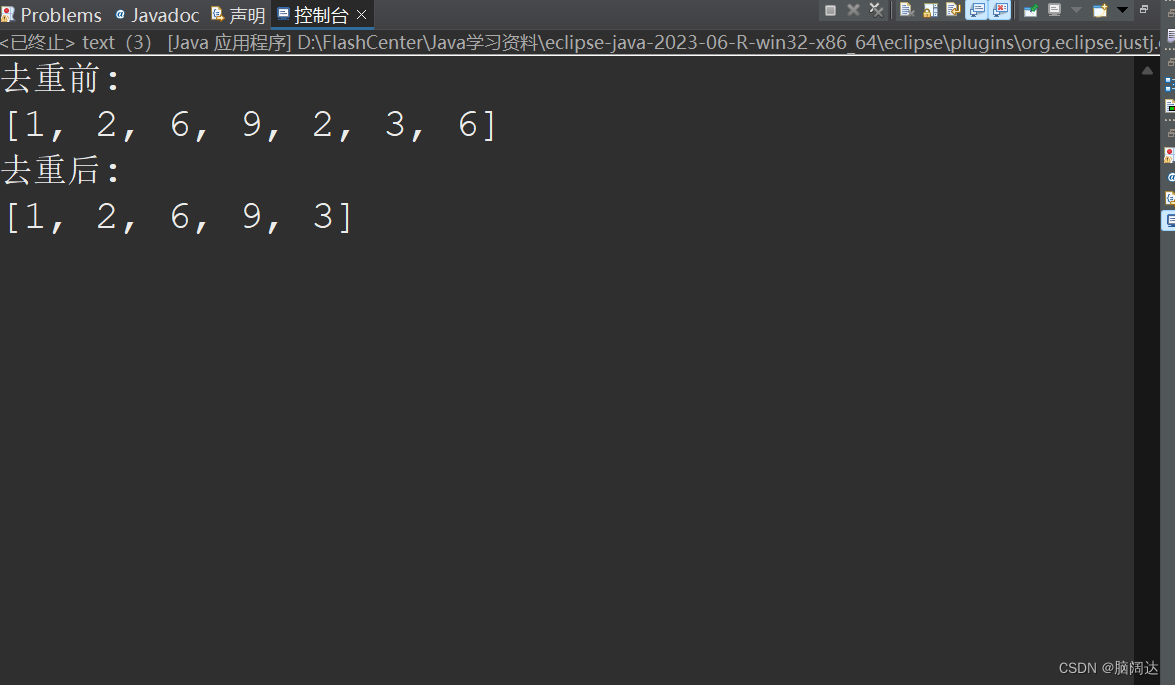
distinct)方法是Stream接口提供的过滤方法。该方法可以去除流中的重复元素,效果与SQL语句中的DISTINCT关键字一样。
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;public class text {public static void main(String[] args) {List<Integer> list = new ArrayList<>();list.add(1);list.add(2);list.add(6);list.add(9);list.add(2);list.add(3);list.add(6);System.out.println("去重前:");System.out.println(list);List<Integer> result = list.stream().distinct().collect(Collectors.toList());System.out.println("去重后:");System.out.println(result);}
}
3.limit()方法
limit()方法是Stream接口提供的方法,该方法可以获取流中前N个元素。
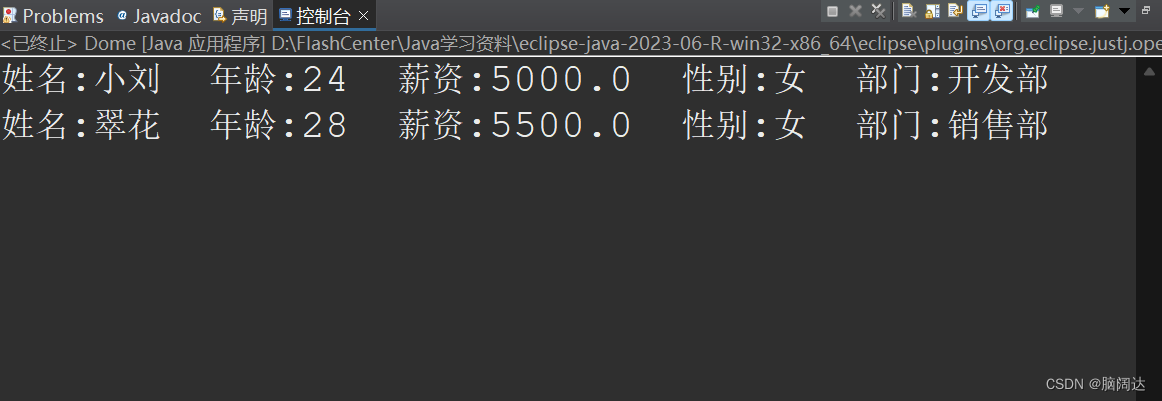
找出性别为女的前两名员工
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;public class Dome{public static void main(String[] args) {//找出性别为女的前两名员工List<Employee> list = Employee.GetEmpList();//先获取所有的员工测试信息Stream<Employee> stream = list.stream();//获取集合流对象stream=stream.filter(e->e.GetSex().equals("女")).limit(2);List<Employee> result = stream.collect(Collectors.toList());for(Employee emp:result) {System.out.println(emp);}}
}
4.skip()方法
skip()方法是Stream接口提供的方法,该方法可以忽略流中的N个元素。
取出所有男员工,并忽略前两个。
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;public class Dome{public static void main(String[] args) {//找出性别为女的前两名员工List<Employee> list = Employee.GetEmpList();//先获取所有的员工测试信息Stream<Employee> stream = list.stream();//获取集合流对象stream=stream.filter(e->e.GetSex().equals("男")).skip(2);List<Employee> result = stream.collect(Collectors.toList());for(Employee emp:result) {System.out.println(emp);}}
}// List<Employee> list = Employee.GetEmpList();list.stream().filter(e->e.GetSex().equals("男")).skip(2).forEach(n->{System.out.println(n);
这段代码可以替代上述的主代码实现相同功能
三 数据映射
数据的映射和过滤概念不同:过滤是在流中找到符合条件的元素,映射是在流中获得具体的数量Stream接口提供了map()方法用来实现数据映射,map()方法会按照参数中的函数逻辑获取新的对象,新的流对象中元素类型可能与旧流对象元素类型不相同。

import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
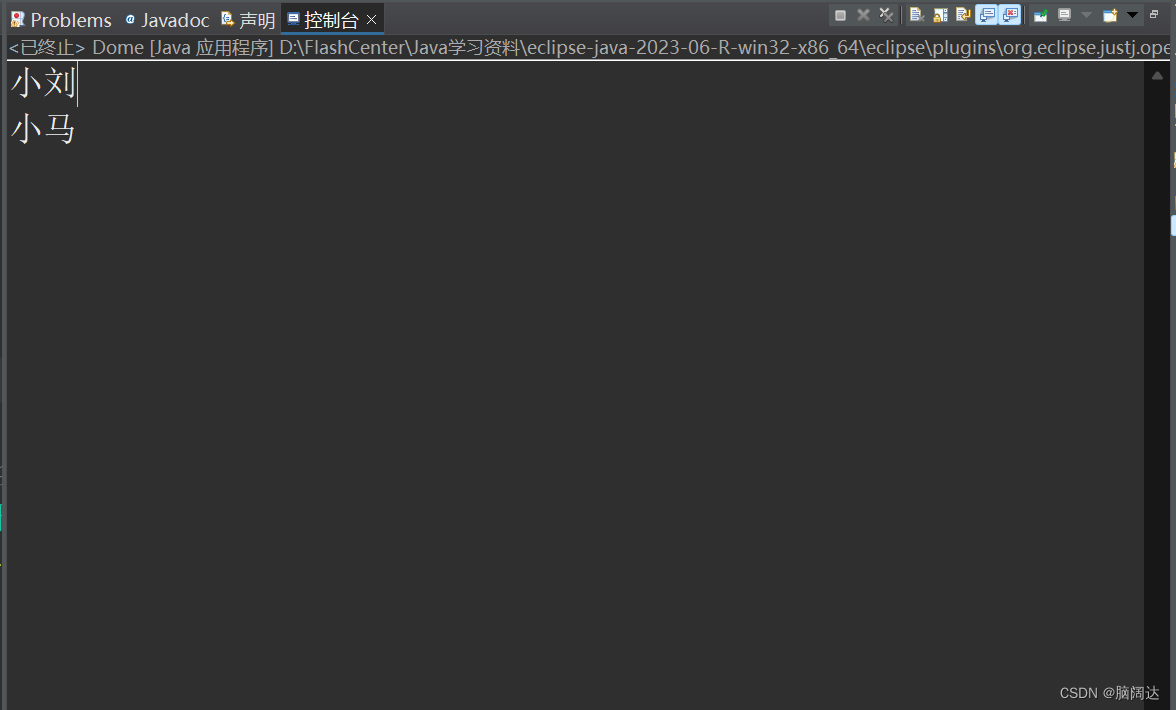
import java.util.stream.Stream;public class Dome{public static void main(String[] args) {//获取开发部的所有员工的名单List<Employee> list = Employee.GetEmpList();//先获取所有的员工测试信息Stream<Employee> stream = list.stream();//获取集合流对象stream=stream.filter(e->e.Getdept().equals("开发部"));Stream<String> names = stream.map(Employee::GetName);//获取集合流对象List<String> result = names.collect(Collectors.toList());for(String emp:result) {System.out.println(emp);}}
}
四 数据查找
1. allMatch()方法
allMatchO方法是Stream接口提供的方法,该方法会判断流中的元素是否全部符合某一条件,返回结果是boolean值。如果所有元素都符合条件则返回true,否则返回false。
【代码实列】
import java.util.List;public class Dome{public static void main(String[] args) {List<Employee> list = Employee.GetEmpList();//先获取所有的员工测试信息boolean result= list.stream().allMatch(n->n.GetAge()>25);System.out.println("所有员工是否都大于25岁:"+result);}
}【运行结果】 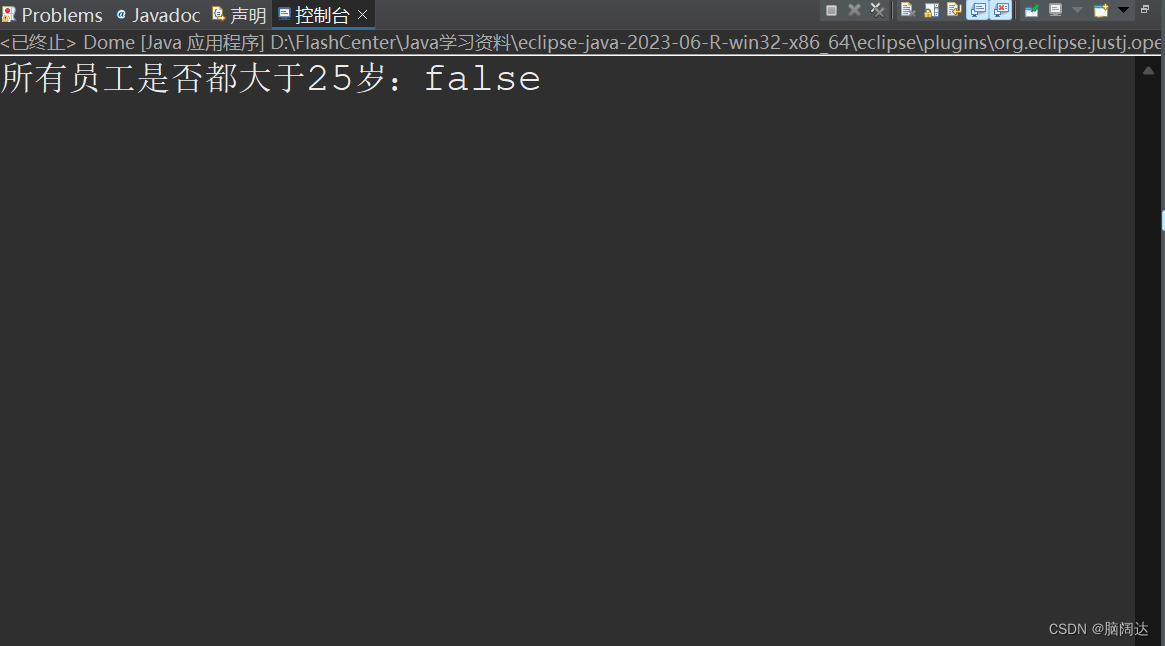
2. anyMatch()方法
anyMatchO方法是Stream接口提供的方法,该方法会判断流中的元素是否有符合某一条件,只要有一个元素符合条件就返回true,如果没有元素符合条件才会返回false。
【代码实列】
import java.util.List;public class Dome{public static void main(String[] args) {List<Employee> list = Employee.GetEmpList();//先获取所有的员工测试信息boolean result= list.stream().anyMatch(n->n.GetAge()>=40);System.out.println("该公司员工是否有40或以上的工岁吗?:"+result);}
} 【运行结果】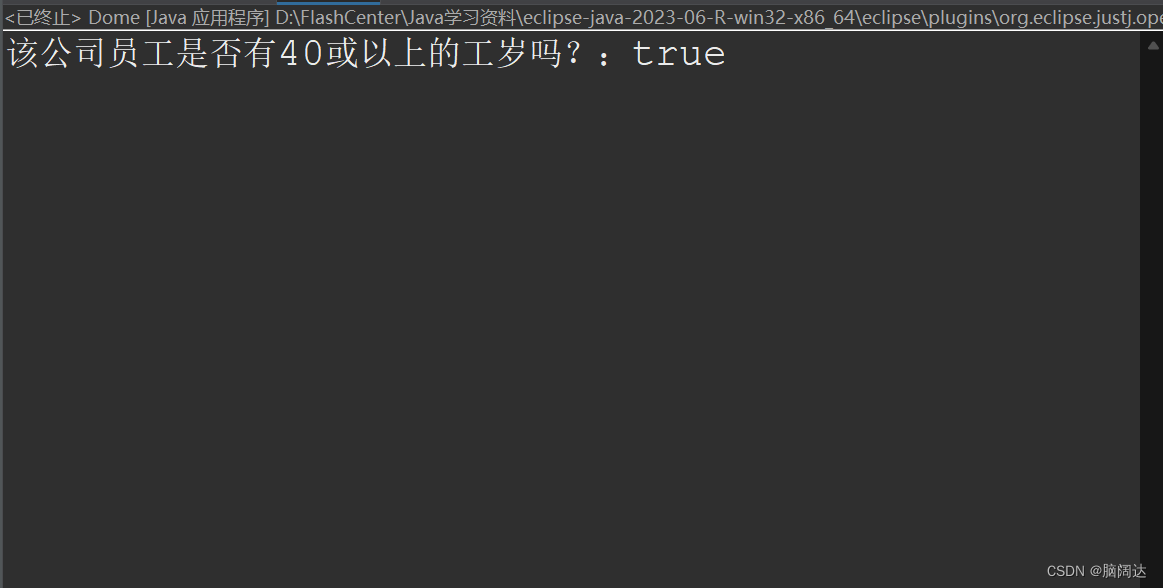
3. noneMatch()方法
noneMatch()方法是Stream接口提供的方法,该方法会判断流中的所有元素是否都不符合某一条件。这个方法的逻辑和allMatch()方法正好相反。
【代码实列】
import java.util.List;public class Dome{public static void main(String[] args) {List<Employee> list = Employee.GetEmpList();//先获取所有的员工测试信息boolean result= list.stream().noneMatch(e->e.GetSalary()<2000);System.out.println("该公司员工是否不存在工资低于2000的员工?:"+result);}
} 【运行结果】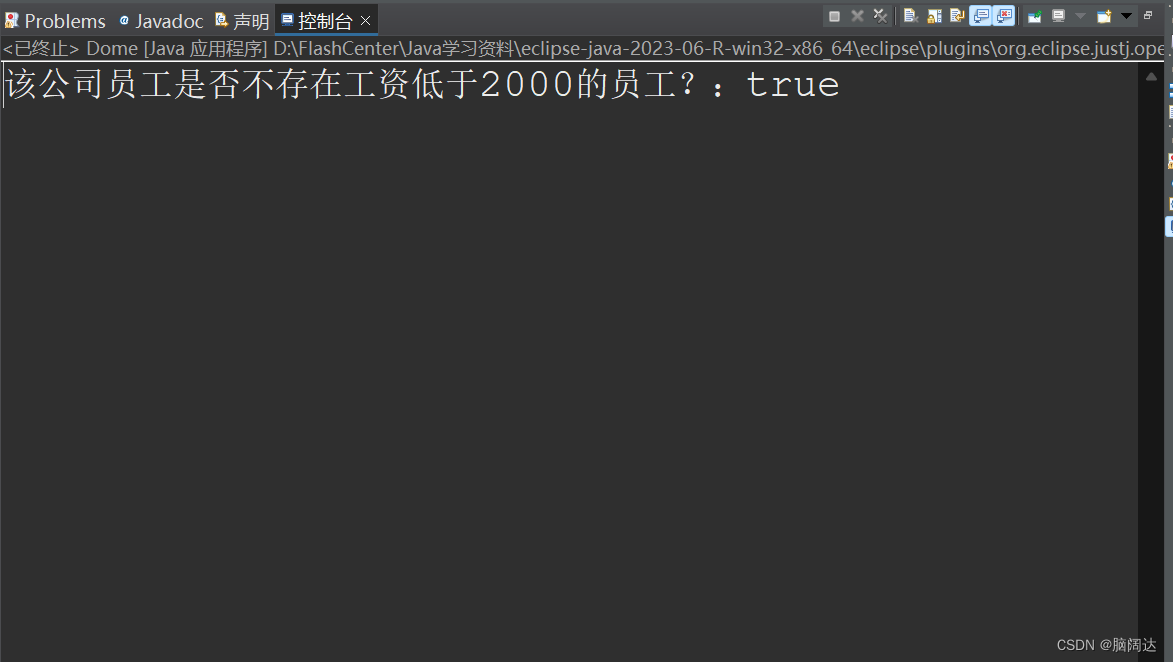
4. findFirst()方法
findFirst方法是Stream接口提供的方法,这个方法会返回符合条件的第一个元素。
【代码实列】
import java.util.List;
import java.util.Optional;
import java.util.stream.Stream;public class Dome{public static void main(String[] args) {List<Employee> list = Employee.GetEmpList();//先获取所有的员工测试信息Stream<Employee> stream= list.stream().filter(e->e.GetAge()==21);Optional<Employee> e =stream.findFirst();System.out.println(e);}
} 【运行结果】
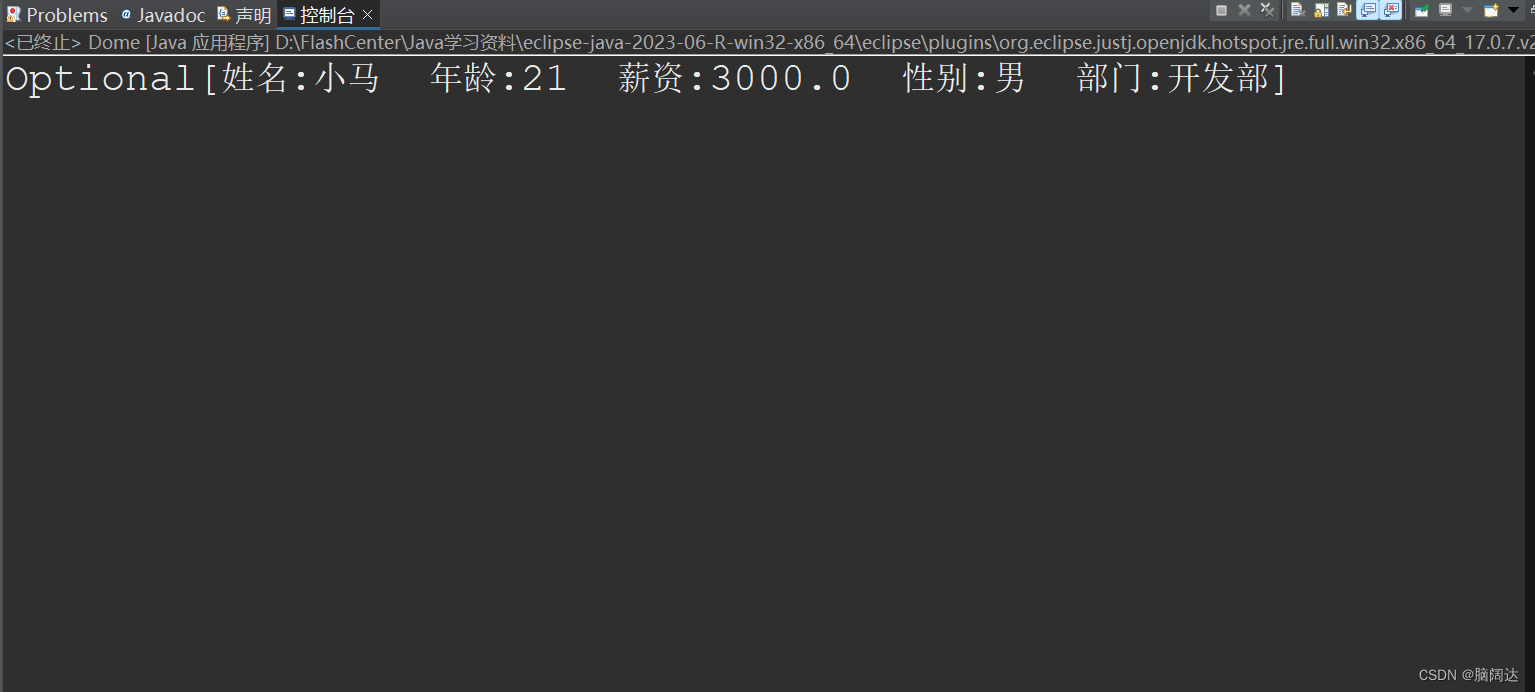
五 数据收集
1.数据统计
数据统计不仅可以筛选出特殊元素,还可以对元素的属性进行统计计算。这种复杂的统计操作不是由Stream实现的,而是由Collectors收集器类实现的,收集器提供了非常丰富的API,有着强大的数据挖掘能力。
【代码实列】
import java.util.Comparator;
import java.util.List;
import java.util.Optional;
import java.util.stream.Collector;
import java.util.stream.Collectors;
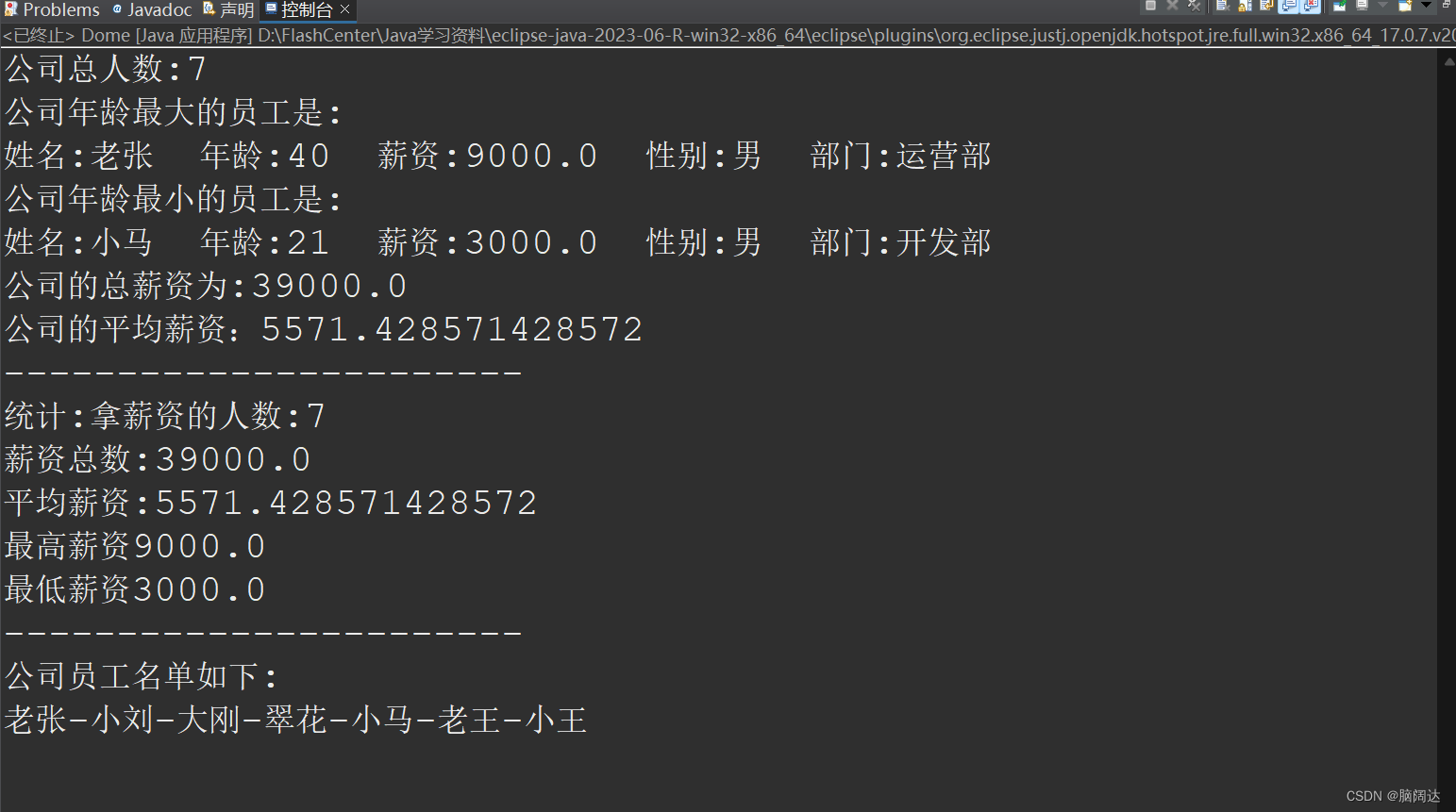
import java.util.stream.Stream;public class Dome{public static void main(String[] args) {List<Employee> list = Employee.GetEmpList();//先获取所有的员工测试信息//输出公司总人数long count = list.stream().collect(Collectors.counting());count = list.stream().count();System.out.println("公司总人数:"+count);//输出公司年龄最大的员工Optional<Employee> ageMax= list.stream().collect(Collectors.maxBy(Comparator.comparing(Employee::GetAge)));Employee oder = ageMax.get();System.out.println("公司年龄最大的员工是:");System.out.println(oder);//输出公司年龄最大的Optional<Employee> ageMin= list.stream().collect(Collectors.minBy(Comparator.comparing(Employee::GetAge)));Employee younger = ageMin.get();System.out.println("公司年龄最小的员工是:");System.out.println(younger);//输出公司的总薪资double sum = list.stream().collect(Collectors.summingDouble(Employee::GetSalary));System.out.println("公司的总薪资为:"+sum);//统计公司薪资的平均值double Avg = list.stream().collect(Collectors.averagingDouble(Employee::GetSalary));System.out.println("公司的平均薪资:"+Avg);System.out.println("-----------------------");java.util.DoubleSummaryStatistics s = list.stream().collect(Collectors.summarizingDouble(Employee::GetSalary));System.out.println("统计:拿薪资的人数:"+s.getCount()+" ");System.out.println("薪资总数:"+s.getSum()+" ");System.out.println("平均薪资:"+s.getAverage()+" ");System.out.println("最高薪资"+s.getMax()+" ");System.out.println("最低薪资"+s.getMin()+" ");System.out.println("-----------------------");String nameList = list.stream().map(Employee::GetName).collect(Collectors.joining("-"));System.out.println("公司员工名单如下:\n"+nameList);}
} 【运行结果】
2.数据分组
😶🌫️😶🌫️😶🌫️数据分组就是将流中元素按照指定的条件分开保存,类似SQL语言中的“GROUPBY”关键字。分组之后的数据会按照不同的标签分别保存成一个集合,然后按照“键值”关系封装在Map对象中。数据分组有一级分组和多级分组两种场景,首先先来介绍一级分组。
一级分组,就是将所有数据按照一个条件进行归类。例如,学校有100个学生,这些学生分布在3个年级中。学生按照年级分成了3组,然后就不再细分了,这就属于一级分组。
Collectors类提供的groupingBy0方法就是用来进行分组的方法,方法参数是一个Function接口对象,收集器会按照指定的函数规则对数据进行分组。

一级分组:
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;public class Dome{public static void main(String[] args) {List<Employee> list = Employee.GetEmpList();//先获取所有的员工测试信息Map<String,List<Employee>> map = list.stream().collect(Collectors.groupingBy(Employee::Getdept));for(String key:map.keySet()) {System.out.println("【"+key+"】");List<Employee> deptList = map.get(key);for(Employee e:deptList) {System.out.println(e);}}}
} 
二级分组:
import java.util.List;
import java.util.Map;
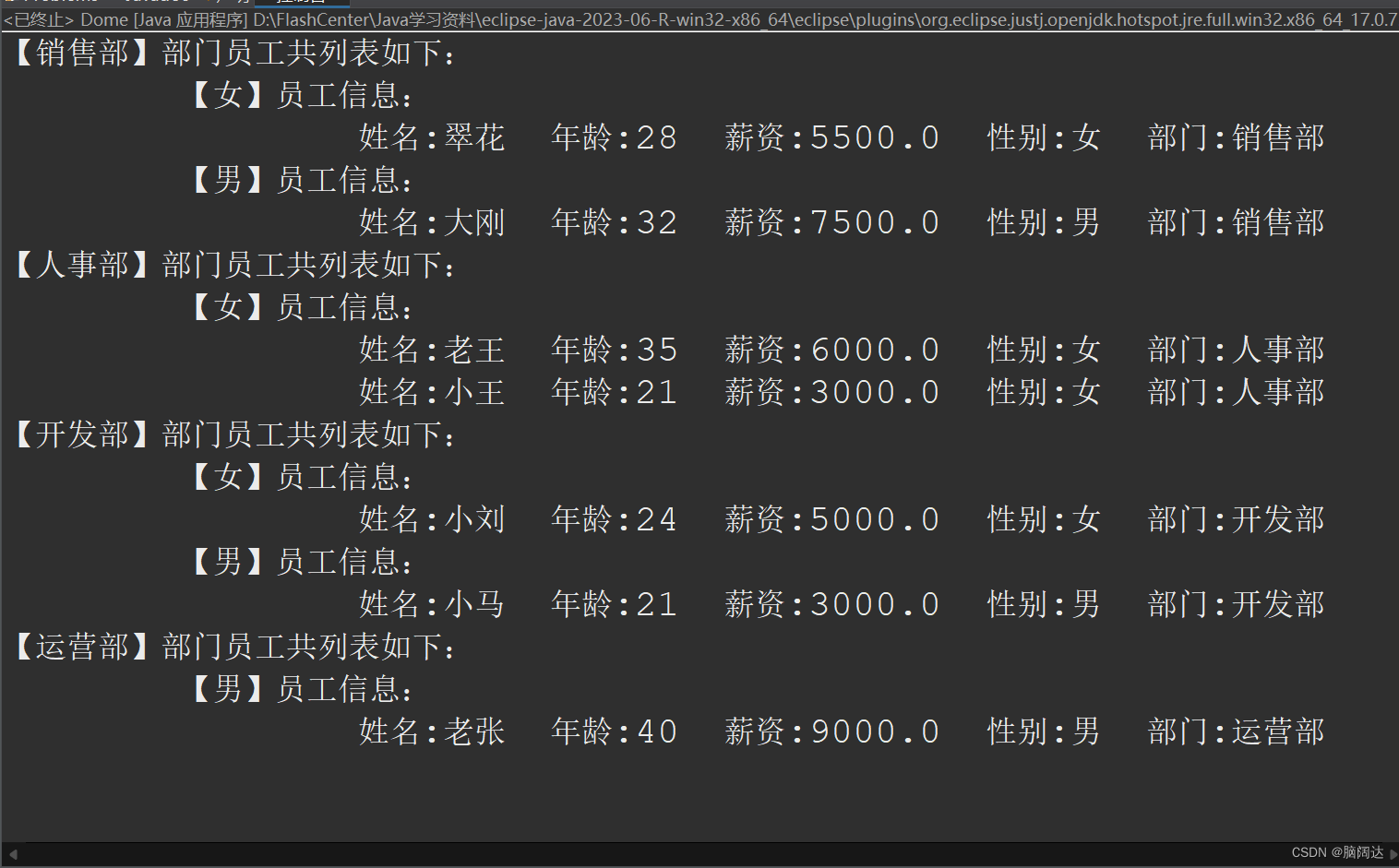
import java.util.stream.Collectors;public class Dome{public static void main(String[] args) {List<Employee> list = Employee.GetEmpList();//先获取所有的员工测试信息Map<String,Map<String,List<Employee>>> map1 = list.stream().collect(Collectors.groupingBy(Employee::Getdept,Collectors.groupingBy(Employee::GetSex)));for(String key1:map1.keySet()) {System.out.println("【"+key1+"】"+"部门员工共列表如下:");Map<String,List<Employee>> map2 = map1.get(key1);for(String key2:map2.keySet()) {System.out.println("\t【"+key2+"】"+"员工信息:");for(Employee e:map2.get(key2)) {System.out.println("\t\t"+e);}}}}
} 
相关文章:
流处理详解
【今日】 目录 一 Stream接口简介 Optional类 Collectors类 二 数据过滤 1. filter()方法 2.distinct()方法 3.limit()方法 4.skip()方法 三 数据映射 四 数据查找 1. allMatch()方法 2. anyMatch()方法 3. noneMatch()方法 4. findFirst()方法 五 数据收集…...
Qt中XML文件创建及解析
一 环境部署 QT的配置文件中添加xml选项: 二 写入xml文件 头文件:#include <QXmlStreamWriter> bool MyXML::writeToXMLFile() {QString currentTime QDateTime::currentDateTime().toString("yyyyMMddhhmmss");QString fileName &…...
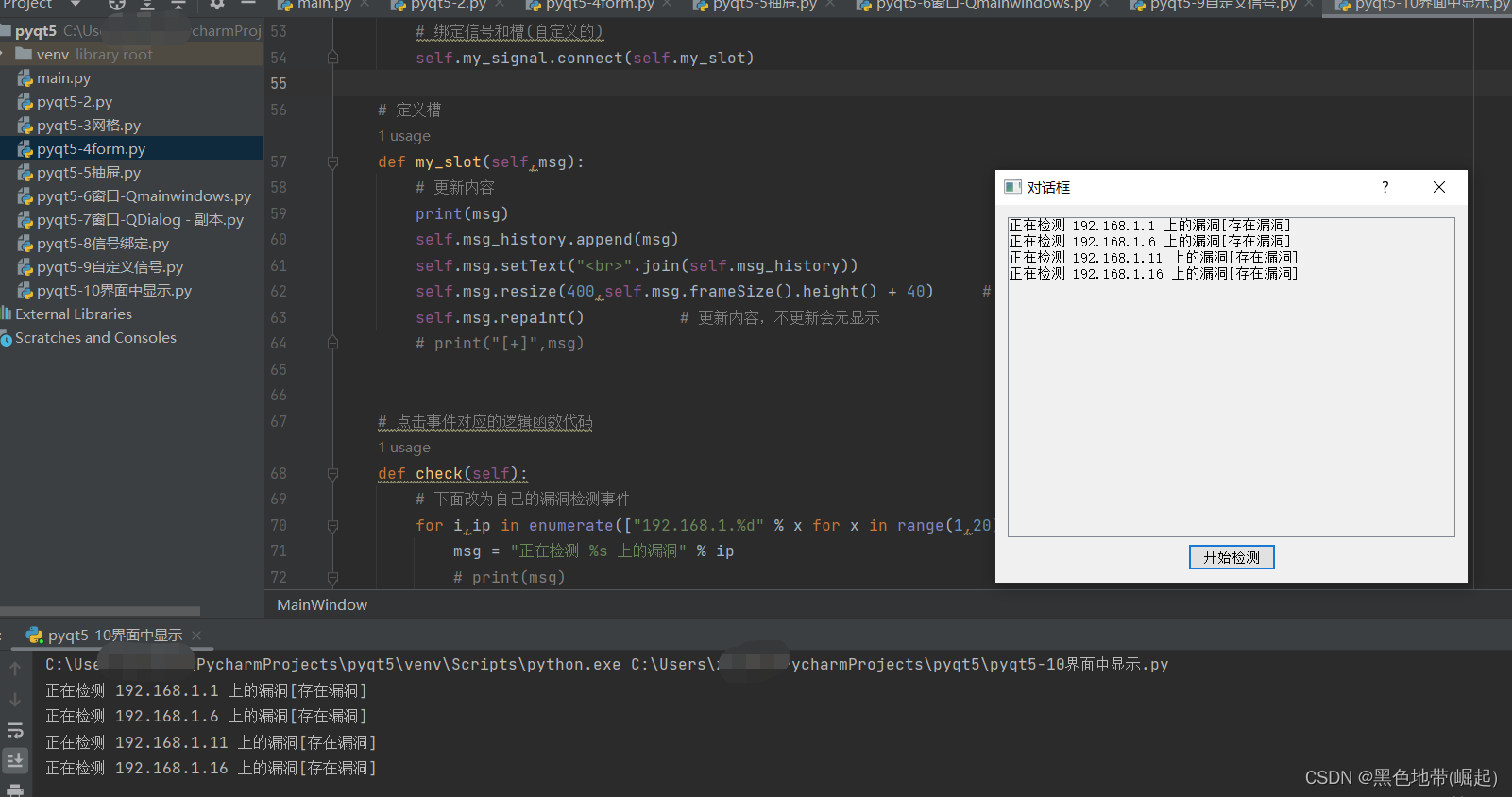
【pyqt5界面化工具开发-11】界面化显示检测信息
目录 0x00 前言: 一、布局的设置 二、消息的显示 0x00 前言: 我们在10讲的基础上,需要将其输出到界面上 思路: 1、消息的传递 2、布局的设置 先考虑好消息的传递,再来完善布局 其实先完善布局,再来设置消…...

Batbot电力云平台在智能配电室中的应用
智能配电室管理系统是物联网应用中的底层应用场景,无论是新基建下的智能升级,还是双碳目标下的能源管理,都离不开智能配电运维对传统配电室的智慧改造。Batbot智慧电力(运维)云平台通过对配电室关键电力设备部署传感器…...
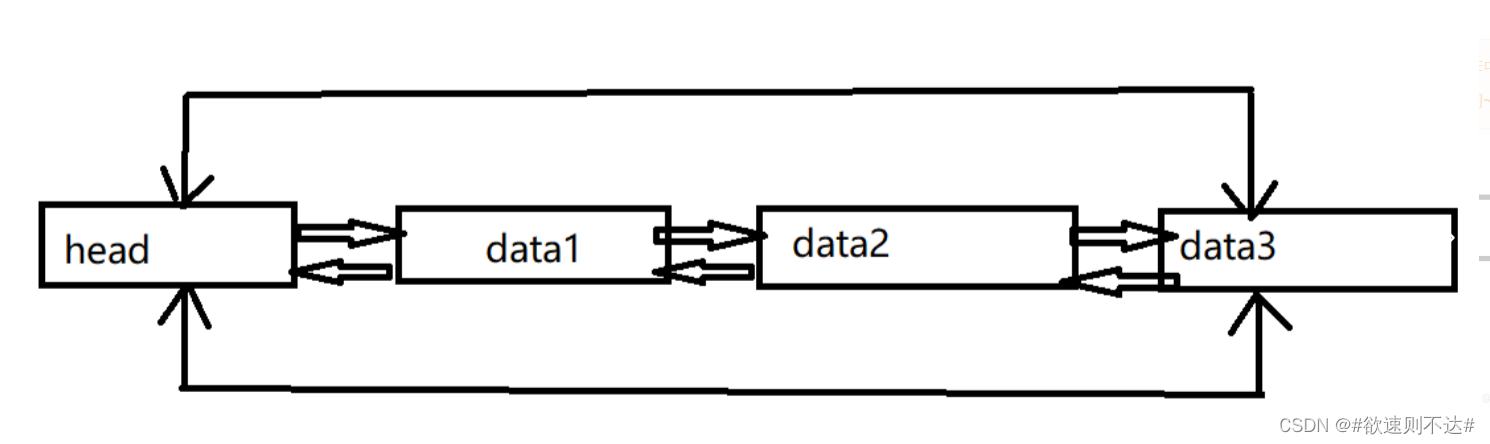
链表(详解)
一、链表 1.1、什么是链表 1、链表是物理存储单元上非连续的、非顺序的存储结构,数据元素的逻辑顺序是通过链表的指针地址实现,有一系列结点(地址)组成,结点可动态的生成。 2、结点包括两个部分:&#x…...
最简单vue获取当前地区天气--高德开放平台实现
目录 前言 一、注册成为高德平台开发者 二、注册天气key 1.点击首页右上角打开控制台 2.创建新应用 三、vue项目使用 1.打开vue项目找到public下的index.html,如果是vue3的话直接在主目录打开index.html文件就行,主要就是打开出口文件 编辑 2.根据高德…...

大数据处理 正则表达式去除特殊字符 提取中文英文数字
在文本处理中,经常会碰到含有特殊字符的字符串。 比如用户昵称, 小红书文案,等等 都包含了大量表情特殊字符。 这些特殊字符串在ETL处理过程中,经常会引起程序报错,导致致命错误,程序崩溃;或者导…...

Python装饰器(decorators)
本文改编自以下文章:Decorators in Python 装饰器是一个很强大的工具,它允许我们很便捷地修改已有函数或者类的功能,我们可以用装饰器把另一个函数包装起来,扩展一些功能而不需要去修改这个函数代码。 预备知识 在Python中&…...

[halcon] 局部图片保存 gen_circle 和 gen_rectangle2 对比 这怕不是bug吧
背景 我想实现一个功能,获取图片中瑕疵的位置,将瑕疵周边的一块区域抠图并保存。 上代码 一开始我代码这么写的: gen_circle (Rectangle, Row[i], Column[i], 256) reduce_domain(Image,Rectangle,GrayEllipse) crop_domain(GrayEllipse,…...
解析msvcp100.dll丢失的原因及修复方法,教你快速解决的方案
msvcp100.dll文件的丢失,其实也是属于dll丢失的其中一种,因为它是dll文件,大家记住,只要是后缀是dll的文件那么它就是dll文件,只要丢失了dll文件,那么其解决的方法都是大同小异的,唯一不同的是&…...

算法:模拟思想算法
文章目录 实现原理算法思路典型例题替换所有问号提莫攻击N字型变换外观序列 总结 本篇总结的是模拟算法 实现原理 模拟算法的实现原理很简单,就是依据题意实现题意的目的即可,考察的是你能不能实现题目题意的代码能力 算法思路 没有很明显的算法思路…...
【base64】JavaScriptuniapp 将图片转为base64并展示
Base64是一种用于编码二进制数据的方法,它将二进制数据转换为文本字符串。它的主要目的是在网络传输或存储过程中,通过将二进制数据转换为可打印字符的形式进行传输 JavaScript 压缩图片 <html><body><script src"https://code.j…...

根据一个List生成另外一个List,修改其中一个,导致另外一个List也在变化
1、两个List复制 SysDic aSysDic new SysDic(); aSysDic.setDkey("1"); aSysDic.setDnote("12"); SysDic bSysDic new SysDic(); bSysDic.setDkey("2"); bSysDic.setDnote("23"); …...
Cesium 加载 geojson 文件并对文件中的属性值进行颜色设置
文章目录 需求分析解决 需求 Cesium 加载 geojson 文件并对文件中的属性值进行颜色设置 分析 在搜寻多种解决方案后,最后总结出 自己的解决方案 方案一,没看懂 var geojsonOptions {clampToGround : true //使数据贴地};var entities;promise Cesium…...
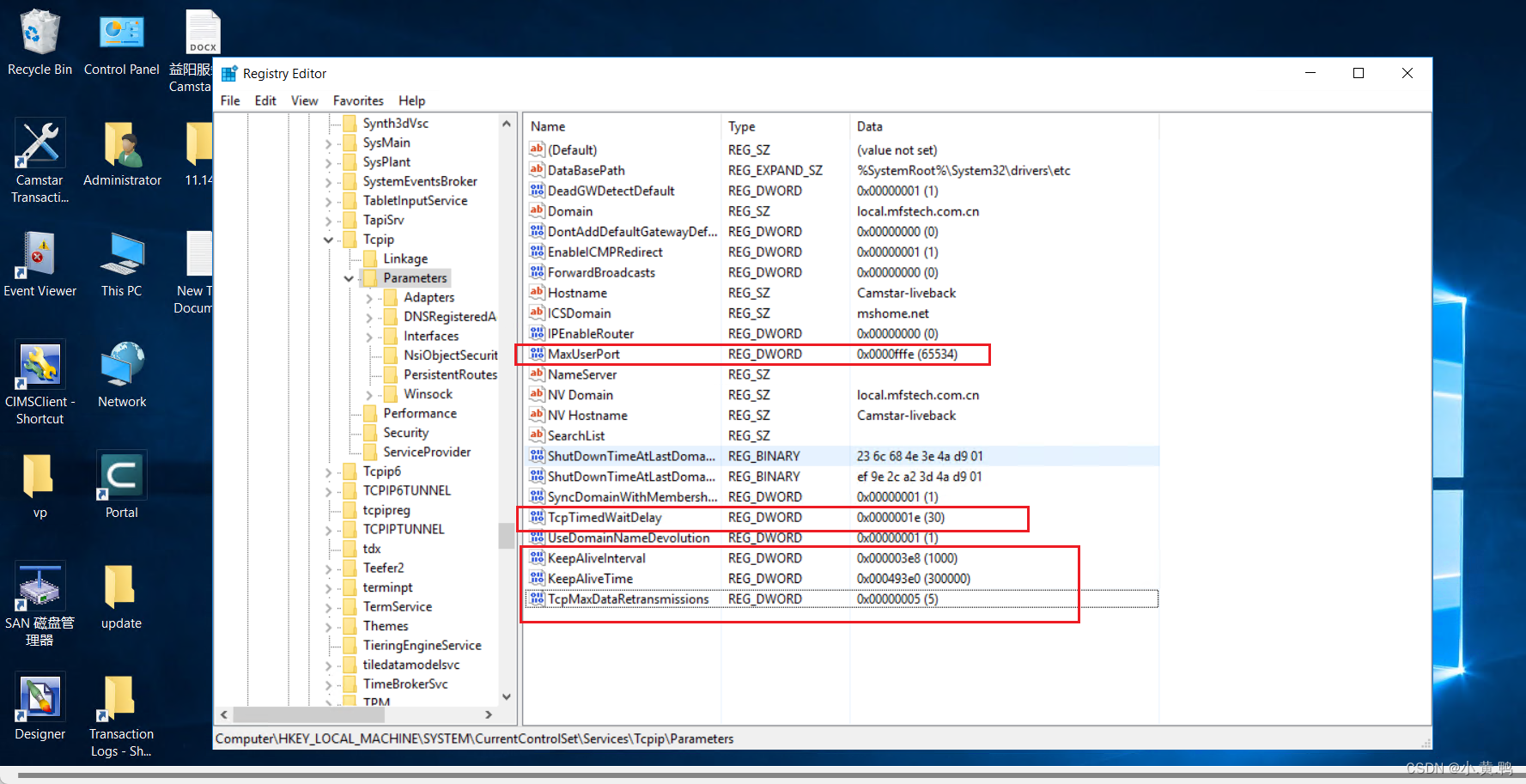
windows系统配置tcp最大连接数
打开注册表 运行->regedit HKLM\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters目录下 增加一个MaxUserPort(默认值是5000,端口范围是1025至5000)MaxUserPort设置为65534(需重启服务器) 执行dos命令&…...

SQL存储过程中 SET ANSI_NULLS ON 和 SET QUOTED_IDENTIFIER ON的作用和详解
今天在写SQL Server存储过程中遇到的,做个整理归纳 USE [ABInbevDB] GO SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO实际上,我们在创建存储过程的时候,这几行的代码是会自动创建出来的,那么先解释下两个标准的概念。 两个…...
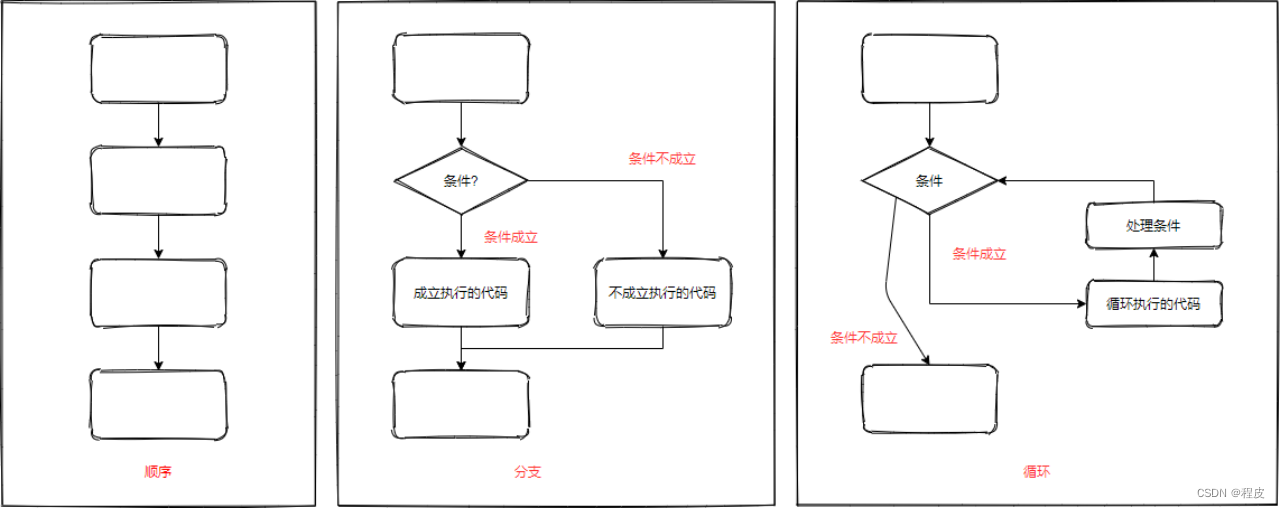
C语言——程序执行的三大流程
顺序 : 从上向下, 顺序执行代码分支 : 根据条件判断, 决定执行代码的分支循环 : 让特定代码重复的执行...
二级MySQL(十)——单表查询
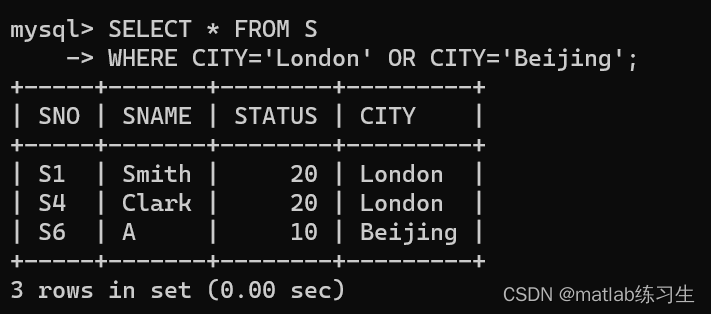
这里我们只在一个表内查询,用到的是较为简单的SELECT函数形式 1、查询指定的字段: 用到的数据库是之前提到的S、P、SP数据库 S表格用到的总数据: 首先我们查询所有供应商的序号和名字 这时都是独立的,没有关系,我们找…...

机器学习:无监督学习
文章目录 线性学习方法聚类ClusteringKmeansHAC 分布表示降维PCAMatrix FactorizationManifold LearningLLELaplacian Eigenmapst-SEN 线性学习方法 聚类Clustering Kmeans 随机选取K个中心,然后计算每个点与中心的距离,找最近的,然后更新中…...

计算机网络之5层网络协议
文章目录 引言一、OSI七层模型二、TCP/IP参考模型三、网络协议的概念和作用四、TCP/IP参考模型每层详细介绍1.物理层2.数据链路层1. 基本概念2.MAC地址3.ARP协议 3. 网络层1. 基本概念2.ip协议3.子网掩码 4. 传输层1. 基本概念2. 协议3. TCP(三次握手四次挥手&#…...

NVIDIA CUDA 在深度学习中的代码结构分析与性能优化
1. 深度学习场景下 CUDA 代码结构概述1.1 CUDA 在深度学习中的应用场景CUDA(Compute Unified Device Architecture)是 NVIDIA 推出的通用并行计算架构,通过利用 GPU 的大规模并行处理能力来加速深度学习工作负载。在深度学习领域,…...

告别本科论文 “从零焦虑”:okbiye AI 写作如何用 “全流程定制” 终结熬夜改稿循环
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 本科论文写到崩溃,是每个毕业生都懂的痛。 我见过凌晨三点的宿舍走廊,有人对着 Word 文档掉眼泪;也见过…...

微信好友关系检测完整指南:快速找出谁删了你
微信好友关系检测完整指南:快速找出谁删了你 【免费下载链接】WechatRealFriends 微信好友关系一键检测,基于微信ipad协议,看看有没有朋友偷偷删掉或者拉黑你 项目地址: https://gitcode.com/gh_mirrors/we/WechatRealFriends 你是否曾…...

微信单向好友检测:3分钟找出谁悄悄删了你
微信单向好友检测:3分钟找出谁悄悄删了你 【免费下载链接】WechatRealFriends 微信好友关系一键检测,基于微信ipad协议,看看有没有朋友偷偷删掉或者拉黑你 项目地址: https://gitcode.com/gh_mirrors/we/WechatRealFriends 你是否曾经…...

3步完成AI化学逆合成规划:让复杂分子合成变得简单高效的终极指南
3步完成AI化学逆合成规划:让复杂分子合成变得简单高效的终极指南 【免费下载链接】aizynthfinder A tool for retrosynthetic planning 项目地址: https://gitcode.com/gh_mirrors/ai/aizynthfinder 你是否曾为设计复杂分子的合成路线而烦恼?传统…...
)
【ElevenLabs方言语音工程实战】:山东话TTS落地全流程(含音色克隆、韵律校准、鲁南/胶东口音适配)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs山东话语音工程全景概览 ElevenLabs 作为全球领先的AI语音合成平台,原生支持英语、西班牙语、法语等数十种主流语言,但对中文方言(如山东话)暂…...
)
保姆级教程:用ENVI+SNAP搞定哨兵1号雷达数据预处理(附水稻监测实战)
从零掌握哨兵1号雷达数据处理:ENVI与SNAP双软件协同实战指南 当第一次接触哨兵1号雷达数据时,许多研究者都会被其独特的成像机制和处理流程所困扰。与光学遥感不同,雷达数据需要经过一系列专业预处理才能用于分析。本文将带你系统掌握ENVI和…...

Steam创意工坊下载终极指南:无需Steam账号也能畅玩海量模组
Steam创意工坊下载终极指南:无需Steam账号也能畅玩海量模组 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL WorkshopDL是一款跨平台Steam创意工坊下载工具ÿ…...
)
从一次‘迷路’说起:手把手调试LTE终端TAU失败问题(附Wireshark抓包分析)
从一次‘迷路’说起:手把手调试LTE终端TAU失败问题(附Wireshark抓包分析) 清晨的地铁站里,一位工程师盯着手机屏幕上反复跳出的"无服务"提示皱起眉头——这已经是本周第三次收到用户投诉在A区到B区的通勤路上出现信号中…...

YimMenu:GTA V终极开源菜单的完整实战指南
YimMenu:GTA V终极开源菜单的完整实战指南 【免费下载链接】YimMenu YimMenu, a GTA V menu protecting against a wide ranges of the public crashes and improving the overall experience. 项目地址: https://gitcode.com/GitHub_Trending/yi/YimMenu Yi…...