Centos7搭建hadoop3.3.4分布式集群
文章目录
- 1、背景
- 2、集群规划
- 2.1 hdfs集群规划
- 2.2 yarn集群规划
- 3、集群搭建步骤
- 3.1 安装JDK
- 3.2 修改主机名和host映射
- 3.3 配置时间同步
- 3.4 关闭防火墙
- 3.5 配置ssh免密登录
- 3.5.1 新建hadoop部署用户
- 3.5.2 配置hadoopdeploy用户到任意一台机器都免密登录
- 3.7 配置hadoop
- 3.7.1 创建目录(3台机器都执行)
- 3.7.2 下载hadoop并解压(hadoop01操作)
- 3.7.3 配置hadoop环境变量(hadoop01操作)
- 3.7.4 hadoop的配置文件分类(hadoop01操作)
- 3.7.5 配置 hadoop-env.sh(hadoop01操作)
- 3.7.6 配置core-site.xml文件(hadoop01操作)(核心配置文件)
- 3.7.7 配置hdfs-site.xml文件(hadoop01操作)(hdfs配置文件)
- 3.7.8 配置yarn-site.xml文件(hadoop01操作)(yarn配置文件)
- 3.7.9 配置mapred-site.xml文件(hadoop01操作)(mapreduce配置文件)
- 3.7.10 配置workers文件(hadoop01操作)
- 3.7.11 3台机器hadoop配置同步(hadoop01操作)
- 1、同步hadoop文件
- 2、hadoop02和hadoop03设置hadoop的环境变量
- 3、启动集群
- 3.1 集群格式化
- 3.2 集群启动
- 3.2.1 逐个启动进程
- 3.2.2 脚本一键启动
- 3.3 启动集群
- 3.3.1 启动hdfs集群
- 3.3.2 启动yarn集群
- 3.3.3 启动JobHistoryServer
- 3.4 查看各个机器上启动的服务是否和我们规划的一致
- 3.5 访问页面
- 3.5.1 访问NameNode ui (hdfs集群)
- 3.5.2 访问SecondaryNameNode ui
- 3.5.3 查看ResourceManager ui(yarn集群)
- 3.5.4 访问jobhistory
- 4、参考链接
1、背景
最近在学习hadoop,本文记录一下,怎样在Centos7系统上搭建一个3个节点的hadoop集群。
2、集群规划
hadoop集群是由2个集群构成的,分别是hdfs集群和yarn集群。2个集群都是主从结构。
2.1 hdfs集群规划
| ip地址 | 主机名 | 部署服务 |
|---|---|---|
| 192.168.121.140 | hadoop01 | NameNode,DataNode,JobHistoryServer |
| 192.168.121.141 | hadoop02 | DataNode |
| 192.168.121.142 | hadoop03 | DataNode,SecondaryNameNode |
2.2 yarn集群规划
| ip地址 | 主机名 | 部署服务 |
|---|---|---|
| 192.168.121.140 | hadoop01 | NodeManager |
| 192.168.121.141 | hadoop02 | ResourceManager,NodeManager |
| 192.168.121.142 | hadoop03 | NodeManager |
3、集群搭建步骤
3.1 安装JDK
安装jdk步骤较为简单,此处省略。需要注意的是hadoop需要的jdk版本。 https://cwiki.apache.org/confluence/display/HADOOP/Hadoop+Java+Versions
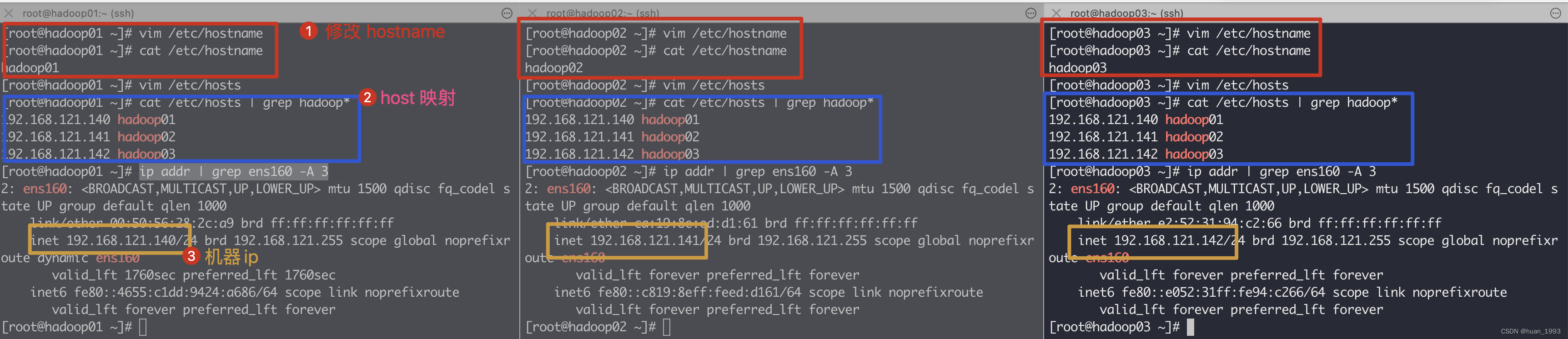
3.2 修改主机名和host映射
| ip地址 | 主机名 |
|---|---|
| 192.168.121.140 | hadoop01 |
| 192.168.121.141 | hadoop02 |
| 192.168.121.142 | hadoop03 |
3台机器上同时执行如下命令
# 此处修改主机名,3台机器的主机名需要都不同
[root@hadoop01 ~]# vim /etc/hostname
[root@hadoop01 ~]# cat /etc/hostname
hadoop01
[root@hadoop01 ~]# vim /etc/hosts
[root@hadoop01 ~]# cat /etc/hosts | grep hadoop*
192.168.121.140 hadoop01
192.168.121.141 hadoop02
192.168.121.142 hadoop03
3.3 配置时间同步
集群中的时间最好保持一致,否则可能会有问题。此处我本地搭建,虚拟机是可以链接外网,直接配置和外网时间同步。如果不能链接外网,则集群中的3台服务器,让另外的2台和其中的一台保持时间同步。
3台机器同时执行如下命令
# 将centos7的时区设置成上海
[root@hadoop01 ~]# ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
# 安装ntp
[root@hadoop01 ~]# yum install ntp
已加载插件:fastestmirror
Loading mirror speeds from cached hostfile
base | 3.6 kB 00:00
extras | 2.9 kB 00:00
updates | 2.9 kB 00:00
软件包 ntp-4.2.6p5-29.el7.centos.2.aarch64 已安装并且是最新版本
无须任何处理
# 将ntp设置成缺省启动
[root@hadoop01 ~]# systemctl enable ntpd
# 重启ntp服务
[root@hadoop01 ~]# service ntpd restart
Redirecting to /bin/systemctl restart ntpd.service
# 对准时间
[root@hadoop01 ~]# ntpdate asia.pool.ntp.org
19 Feb 12:36:22 ntpdate[1904]: the NTP socket is in use, exiting
# 对准硬件时间和系统时间
[root@hadoop01 ~]# /sbin/hwclock --systohc
# 查看时间
[root@hadoop01 ~]# timedatectlLocal time: 日 2023-02-19 12:36:35 CSTUniversal time: 日 2023-02-19 04:36:35 UTCRTC time: 日 2023-02-19 04:36:35Time zone: Asia/Shanghai (CST, +0800)NTP enabled: yes
NTP synchronized: noRTC in local TZ: noDST active: n/a
# 开始自动时间和远程ntp时间进行同步
[root@hadoop01 ~]# timedatectl set-ntp true
3.4 关闭防火墙
3台机器上同时关闭防火墙,如果不关闭的话,则需要放行hadoop可能用到的所有端口等。
# 关闭防火墙
[root@hadoop01 ~]# systemctl stop firewalld
systemctl stop firewalld
# 关闭防火墙开机自启
[root@hadoop01 ~]# systemctl disable firewalld.service
Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service.
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
[root@hadoop01 ~]#
3.5 配置ssh免密登录
3.5.1 新建hadoop部署用户
[root@hadoop01 ~]# useradd hadoopdeploy
[root@hadoop01 ~]# passwd hadoopdeploy
更改用户 hadoopdeploy 的密码 。
新的 密码:
无效的密码: 密码包含用户名在某些地方
重新输入新的 密码:
passwd:所有的身份验证令牌已经成功更新。
[root@hadoop01 ~]# vim /etc/sudoers
[root@hadoop01 ~]# cat /etc/sudoers | grep hadoopdeploy
hadoopdeploy ALL=(ALL) NOPASSWD: ALL
[root@hadoop01 ~]#

3.5.2 配置hadoopdeploy用户到任意一台机器都免密登录
配置3台机器,从任意一台到自身和另外2台都进行免密登录。
| 当前机器 | 当前用户 | 免密登录的机器 | 免密登录的用户 |
|---|---|---|---|
| hadoop01 | hadoopdeploy | hadoop01,hadoop02,hadoop03 | hadoopdeploy |
| hadoop02 | hadoopdeploy | hadoop01,hadoop02,hadoop03 | hadoopdeploy |
| hadoop03 | hadoopdeploy | hadoop01,hadoop02,hadoop03 | hadoopdeploy |
此处演示从 hadoop01到hadoop01,hadoop02,hadoop03免密登录的shell
# 切换到 hadoopdeploy 用户
[root@hadoop01 ~]# su - hadoopdeploy
Last login: Sun Feb 19 13:05:43 CST 2023 on pts/0
# 生成公私钥对,下方的提示直接3个回车即可
[hadoopdeploy@hadoop01 ~]$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hadoopdeploy/.ssh/id_rsa):
Created directory '/home/hadoopdeploy/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/hadoopdeploy/.ssh/id_rsa.
Your public key has been saved in /home/hadoopdeploy/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:PFvgTUirtNLwzDIDs+SD0RIzMPt0y1km5B7rY16h1/E hadoopdeploy@hadoop01
The key's randomart image is:
+---[RSA 2048]----+
|B . . |
| B o . o |
|+ * * + + . |
| O B / = + |
|. = @ O S o |
| o * o * |
| = o o E |
| o + |
| . |
+----[SHA256]-----+
[hadoopdeploy@hadoop01 ~]$ ssh-copy-id hadoop01
...
[hadoopdeploy@hadoop01 ~]$ ssh-copy-id hadoop02
...
[hadoopdeploy@hadoop01 ~]$ ssh-copy-id hadoop03
3.7 配置hadoop
此处如无特殊说明,都是使用的hadoopdeploy用户来操作。
3.7.1 创建目录(3台机器都执行)
# 创建 /opt/bigdata 目录
[hadoopdeploy@hadoop01 ~]$ sudo mkdir /opt/bigdata
# 将 /opt/bigdata/ 目录及它下方所有的子目录的所属者和所属组都给 hadoopdeploy
[hadoopdeploy@hadoop01 ~]$ sudo chown -R hadoopdeploy:hadoopdeploy /opt/bigdata/
[hadoopdeploy@hadoop01 ~]$ ll /opt
total 0
drwxr-xr-x. 2 hadoopdeploy hadoopdeploy 6 Feb 19 13:15 bigdata
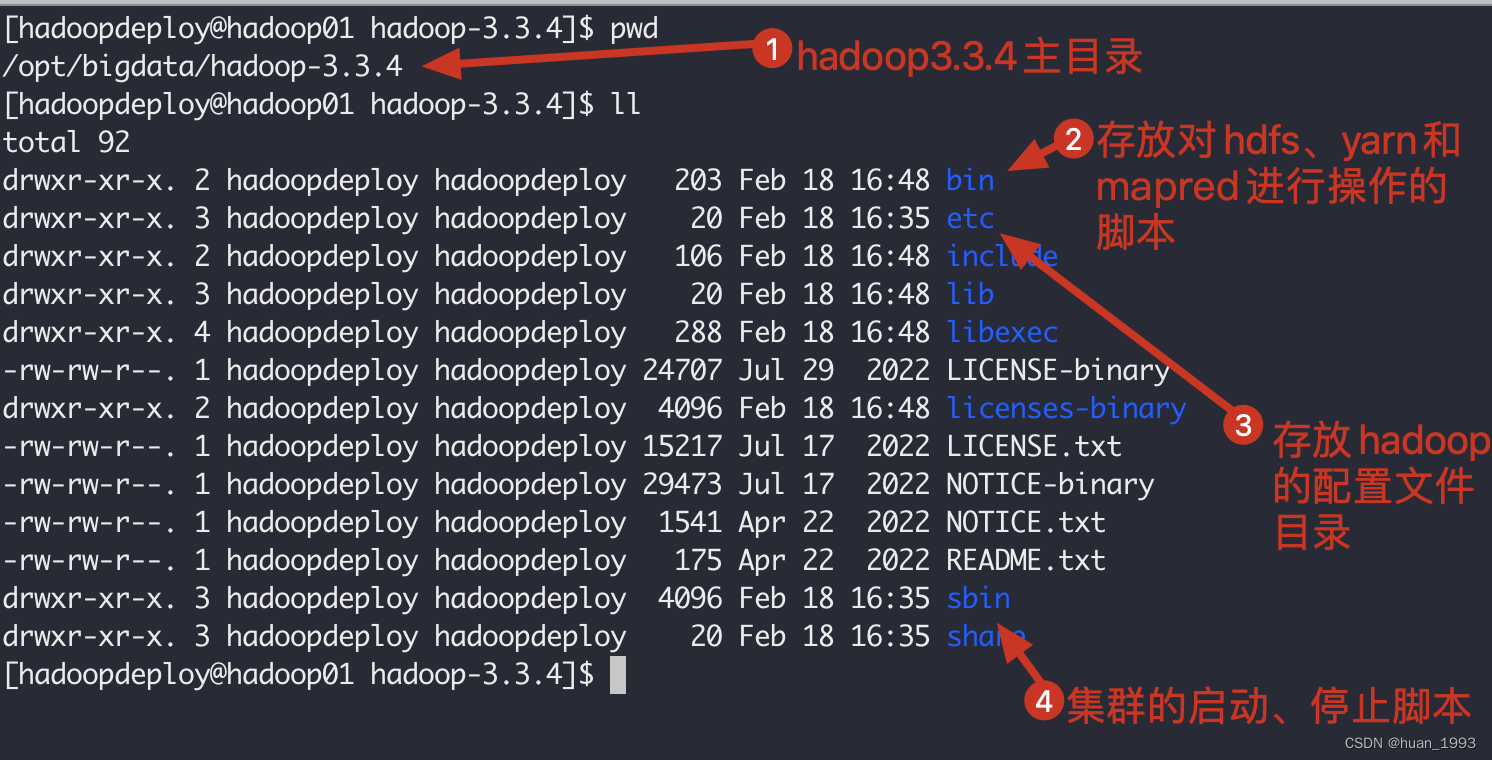
3.7.2 下载hadoop并解压(hadoop01操作)
# 进入目录
[hadoopdeploy@hadoop01 ~]$ cd /opt/bigdata/
# 下载
[hadoopdeploy@hadoop01 ~]$ https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz
# 解压并压缩
[hadoopdeploy@hadoop01 bigdata]$ tar -zxvf hadoop-3.3.4.tar.gz && rm -rvf hadoop-3.3.4.tar.gz
3.7.3 配置hadoop环境变量(hadoop01操作)
# 进入hadoop目录
[hadoopdeploy@hadoop01 hadoop-3.3.4]$ cd /opt/bigdata/hadoop-3.3.4/
# 切换到root用户
[hadoopdeploy@hadoop01 hadoop-3.3.4]$ su - root
Password:
Last login: Sun Feb 19 13:06:41 CST 2023 on pts/0
[root@hadoop01 ~]# vim /etc/profile
# 查看hadoop环境变量配置
[root@hadoop01 ~]# tail -n 3 /etc/profile
# 配置HADOOP
export HADOOP_HOME=/opt/bigdata/hadoop-3.3.4/
export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
# 让环境变量生效
[root@hadoop01 ~]# source /etc/profile
3.7.4 hadoop的配置文件分类(hadoop01操作)
在hadoop中配置文件大概有这么3大类。
- 默认的只读配置文件:
core-default.xml, hdfs-default.xml, yarn-default.xml and mapred-default.xml. - 自定义配置文件:
etc/hadoop/core-site.xml, etc/hadoop/hdfs-site.xml, etc/hadoop/yarn-site.xml and etc/hadoop/mapred-site.xml会覆盖默认的配置。 - 环境配置文件:
etc/hadoop/hadoop-env.sh and optionally the etc/hadoop/mapred-env.sh and etc/hadoop/yarn-env.sh比如配置NameNode的启动参数HDFS_NAMENODE_OPTS等。

3.7.5 配置 hadoop-env.sh(hadoop01操作)
# 切换到hadoopdeploy用户
[root@hadoop01 ~]# su - hadoopdeploy
Last login: Sun Feb 19 14:22:50 CST 2023 on pts/0
# 进入到hadoop的配置目录
[hadoopdeploy@hadoop01 ~]$ cd /opt/bigdata/hadoop-3.3.4/etc/hadoop/
[hadoopdeploy@hadoop01 hadoop]$ vim hadoop-env.sh
# 增加如下内容
export JAVA_HOME=/usr/local/jdk8
export HDFS_NAMENODE_USER=hadoopdeploy
export HDFS_DATANODE_USER=hadoopdeploy
export HDFS_SECONDARYNAMENODE_USER=hadoopdeploy
export YARN_RESOURCEMANAGER_USER=hadoopdeploy
export YARN_NODEMANAGER_USER=hadoopdeploy
3.7.6 配置core-site.xml文件(hadoop01操作)(核心配置文件)
默认配置文件路径:https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/core-default.xml
vim /opt/bigdata/hadoop-3.3.4/etc/hadoop/core-site.xml
<configuration><!-- 指定NameNode的地址 --><property><name>fs.defaultFS</name><value>hdfs://hadoop01:8020</value></property><!-- 指定hadoop数据的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/bigdata/hadoop-3.3.4/data</value></property><!-- 配置HDFS网页登录使用的静态用户为hadoopdeploy,如果不配置的话,当在hdfs页面点击删除时>看看结果 --><property><name>hadoop.http.staticuser.user</name><value>hadoopdeploy</value></property><!-- 文件垃圾桶保存时间 --><property><name>fs.trash.interval</name><value>1440</value></property>
</configuration>
3.7.7 配置hdfs-site.xml文件(hadoop01操作)(hdfs配置文件)
默认配置文件路径:https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
vim /opt/bigdata/hadoop-3.3.4/etc/hadoop/hdfs-site.xml
<configuration><!-- 配置2个副本 --><property><name>dfs.replication</name><value>2</value></property><!-- nn web端访问地址--><property><name>dfs.namenode.http-address</name><value>hadoop01:9870</value></property><!-- snn web端访问地址--><property><name>dfs.namenode.secondary.http-address</name><value>hadoop03:9868</value></property></configuration>
3.7.8 配置yarn-site.xml文件(hadoop01操作)(yarn配置文件)
默认配置文件路径:https://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
vim /opt/bigdata/hadoop-3.3.4/etc/hadoop/yarn-site.xml
<configuration><!-- Site specific YARN configuration properties --><!-- 指定ResourceManager的地址 --><property><name>yarn.resourcemanager.hostname</name><value>hadoop02</value></property><!-- 指定MR走shuffle --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 是否对容器实施物理内存限制 --><property><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value></property><!-- 是否对容器实施虚拟内存限制 --><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property><!-- 设置 yarn 历史服务器地址 --><property><name>yarn.log.server.url</name><value>http://hadoop02:19888/jobhistory/logs</value></property><!-- 开启日志聚集--><property><name>yarn.log-aggregation-enable</name><value>true</value></property><!-- 聚集日志保留的时间7天 --><property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value></property>
</configuration>
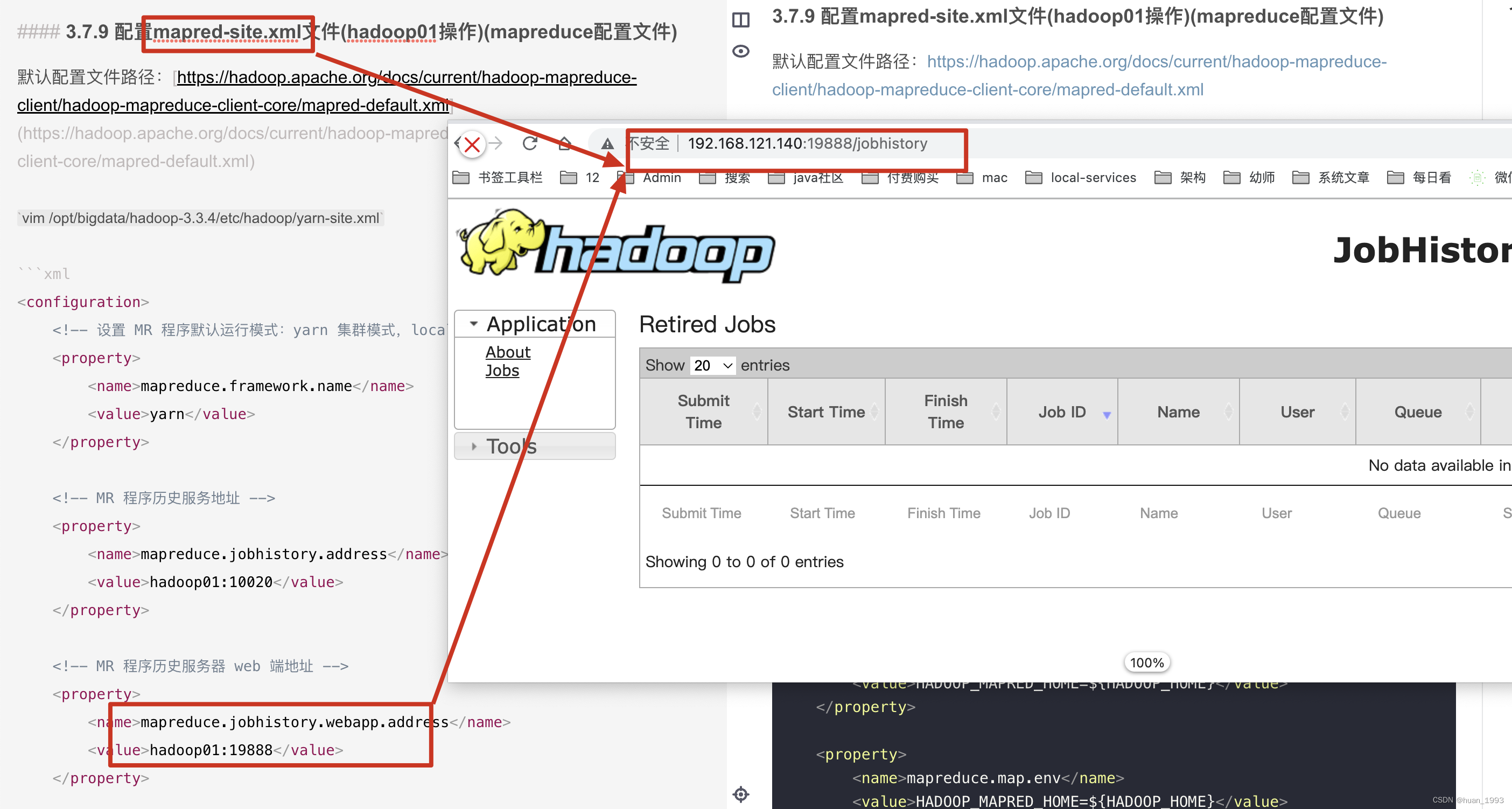
3.7.9 配置mapred-site.xml文件(hadoop01操作)(mapreduce配置文件)
默认配置文件路径:https://hadoop.apache.org/docs/current/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml
vim /opt/bigdata/hadoop-3.3.4/etc/hadoop/yarn-site.xml
<configuration><!-- 设置 MR 程序默认运行模式:yarn 集群模式,local 本地模式--><property><name>mapreduce.framework.name</name><value>yarn</value></property><!-- MR 程序历史服务地址 --><property><name>mapreduce.jobhistory.address</name><value>hadoop01:10020</value></property><!-- MR 程序历史服务器 web 端地址 --><property><name>mapreduce.jobhistory.webapp.address</name><value>hadoop01:19888</value></property><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property>
</configuration>
3.7.10 配置workers文件(hadoop01操作)
vim /opt/bigdata/hadoop-3.3.4/etc/hadoop/workers
hadoop01
hadoop02
hadoop03
workers配置文件中不要有多余的空格或换行。
3.7.11 3台机器hadoop配置同步(hadoop01操作)
1、同步hadoop文件
# 同步 hadoop 文件
[hadoopdeploy@hadoop01 hadoop]$ scp -r /opt/bigdata/hadoop-3.3.4/ hadoopdeploy@hadoop02:/opt/bigdata/hadoop-3.3.4
[hadoopdeploy@hadoop01 hadoop]$ scp -r /opt/bigdata/hadoop-3.3.4/ hadoopdeploy@hadoop03:/opt/bigdata/hadoop-3.3.4
2、hadoop02和hadoop03设置hadoop的环境变量
[hadoopdeploy@hadoop03 bigdata]$ su - root
Password:
Last login: Sun Feb 19 13:07:40 CST 2023 on pts/0
[root@hadoop03 ~]# vim /etc/profile
[root@hadoop03 ~]# tail -n 4 /etc/profile# 配置HADOOP
export HADOOP_HOME=/opt/bigdata/hadoop-3.3.4/
export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
[root@hadoop03 ~]# source /etc/profile
3、启动集群
3.1 集群格式化
当是第一次启动集群时,需要对hdfs进行格式化,在NameNode节点操作。
[hadoopdeploy@hadoop01 hadoop]$ hdfs namenode -format
3.2 集群启动
启动集群有2种方式
方式一:每台机器逐个启动进程,比如:启动NameNode,启动DataNode,可以做到精确控制每个进程的启动。方式二:配置好各个机器之间的免密登录并且配置好 workers 文件,通过脚本一键启动。
3.2.1 逐个启动进程
# HDFS 集群
[hadoopdeploy@hadoop01 hadoop]$ hdfs --daemon start namenode | datanode | secondarynamenode# YARN 集群
[hadoopdeploy@hadoop01 hadoop]$ hdfs yarn --daemon start resourcemanager | nodemanager | proxyserver
3.2.2 脚本一键启动
start-dfs.sh一键启动hdfs集群的所有进程start-yarn.sh一键启动yarn集群的所有进程start-all.sh一键启动hdfs和yarn集群的所有进程
3.3 启动集群
3.3.1 启动hdfs集群
需要在NameNode这台机器上启动
# 改脚本启动集群中的 NameNode、DataNode和SecondaryNameNode
[hadoopdeploy@hadoop01 hadoop]$ start-dfs.sh
3.3.2 启动yarn集群
需要在ResourceManager这台机器上启动
# 该脚本启动集群中的 ResourceManager 和 NodeManager 进程
[hadoopdeploy@hadoop02 hadoop]$ start-yarn.sh
3.3.3 启动JobHistoryServer
[hadoopdeploy@hadoop01 hadoop]$ mapred --daemon start historyserver
3.4 查看各个机器上启动的服务是否和我们规划的一致

可以看到是一致的。
3.5 访问页面
3.5.1 访问NameNode ui (hdfs集群)
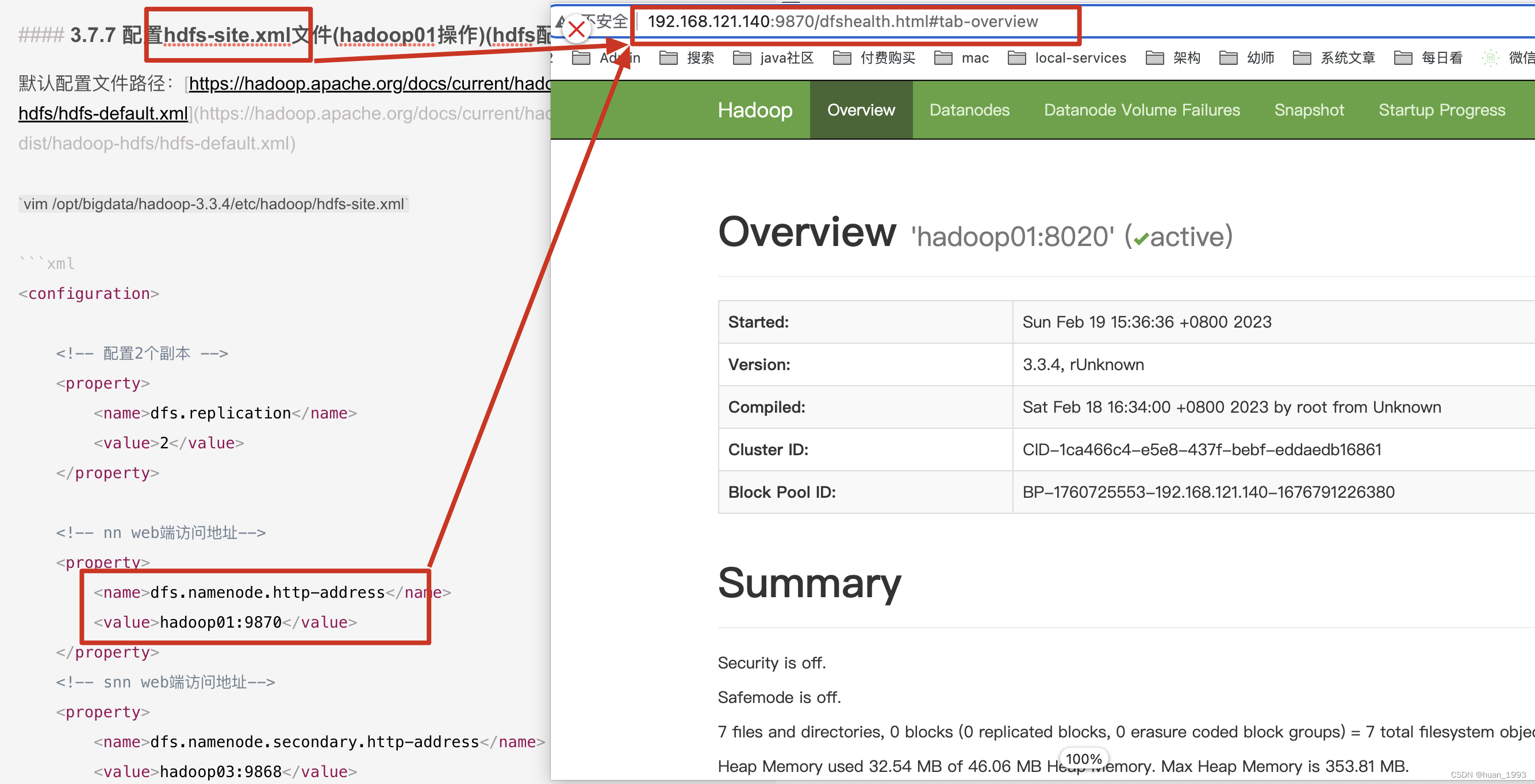
如果这个时候通过 hadoop fs 命令可以上传文件,但是在这个web界面上可以创建文件夹,但是上传文件报错,此处就需要在访问ui界面的这个电脑的hosts文件中,将部署hadoop的那几台的电脑的ip 和hostname 在本机上进行映射。
3.5.2 访问SecondaryNameNode ui
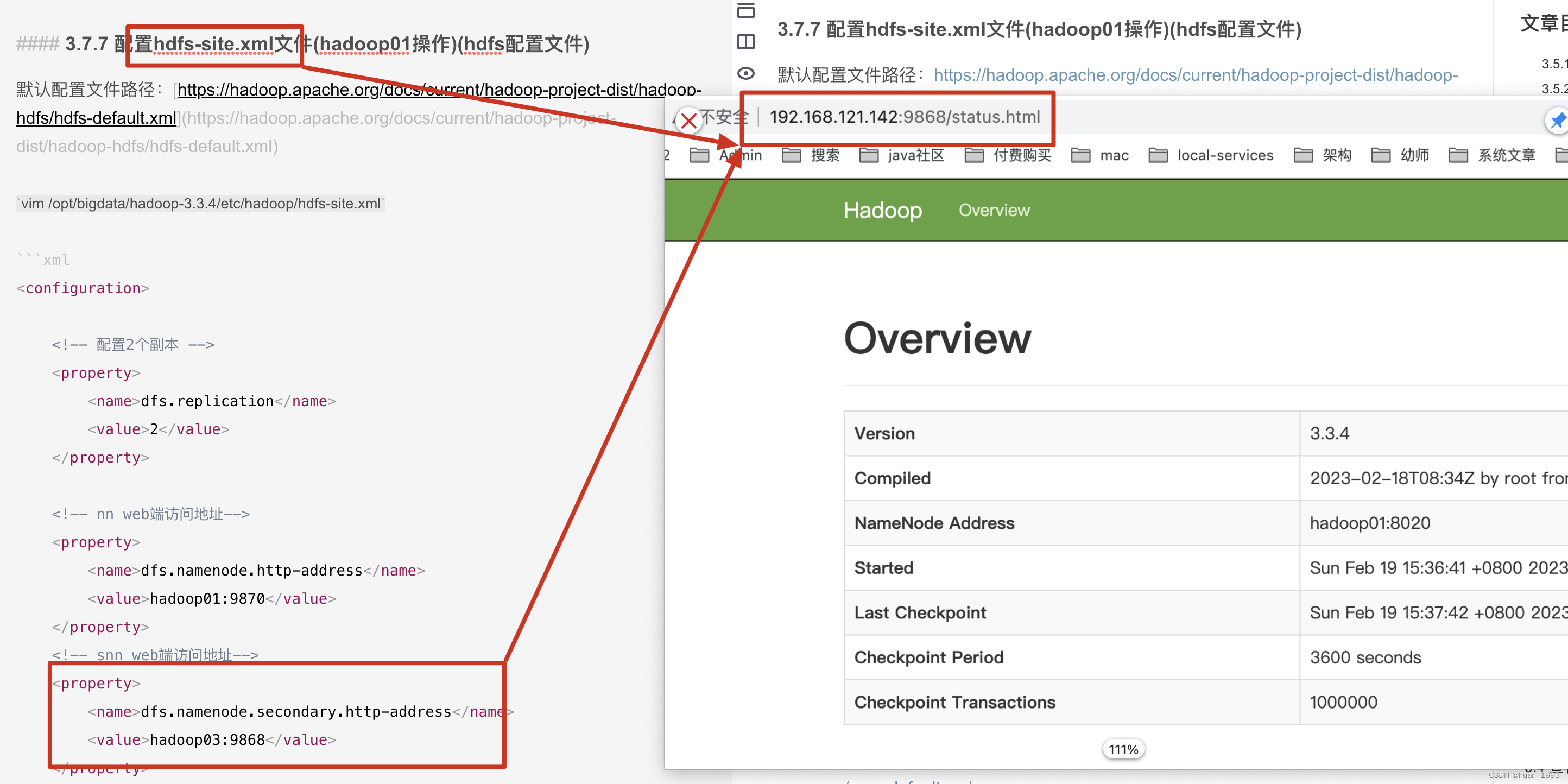
3.5.3 查看ResourceManager ui(yarn集群)
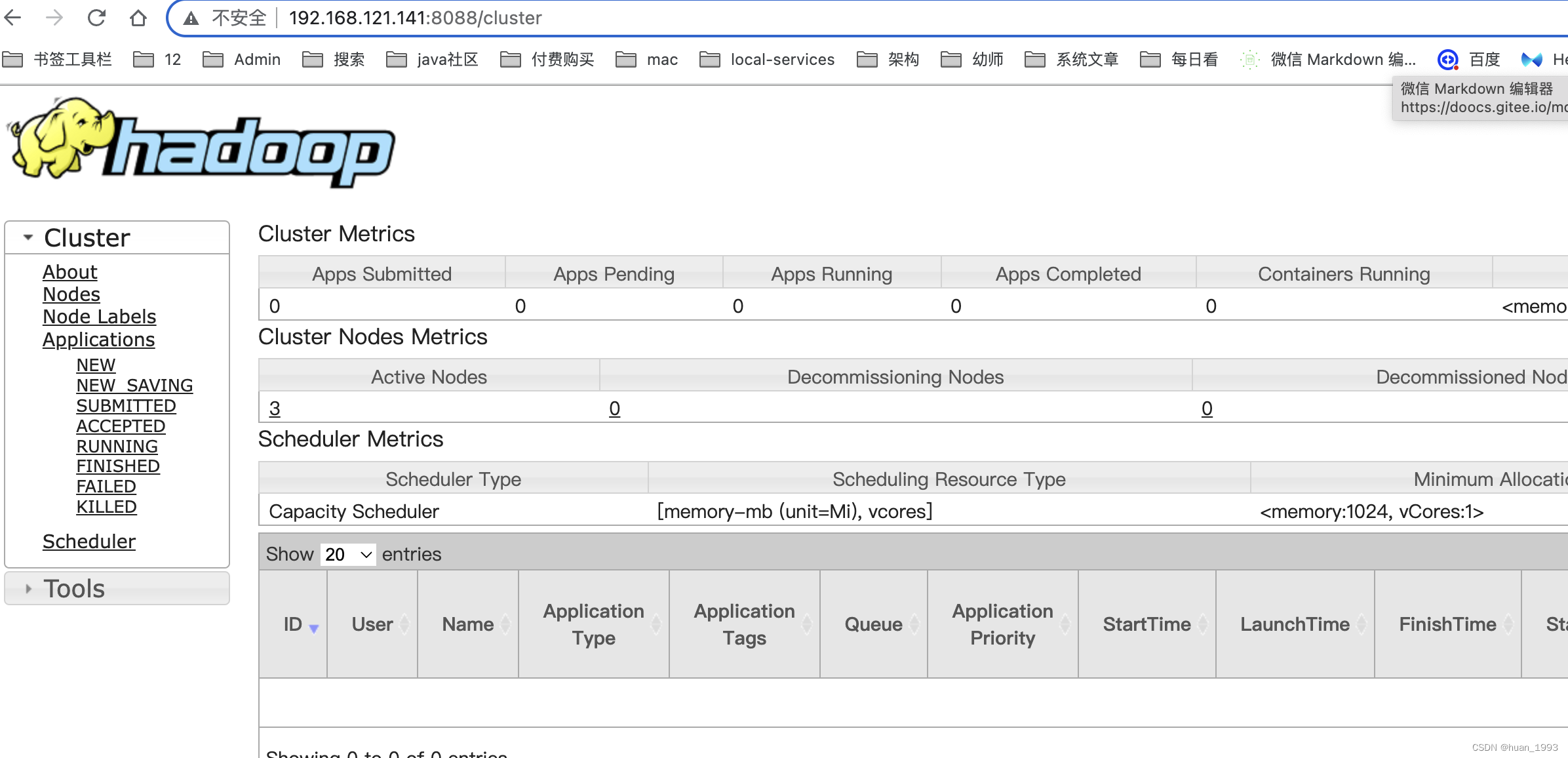
3.5.4 访问jobhistory
4、参考链接
1、https://cwiki.apache.org/confluence/display/HADOOP/Hadoop+Java+Versions
2、https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/ClusterSetup.html
相关文章:
Centos7搭建hadoop3.3.4分布式集群
文章目录1、背景2、集群规划2.1 hdfs集群规划2.2 yarn集群规划3、集群搭建步骤3.1 安装JDK3.2 修改主机名和host映射3.3 配置时间同步3.4 关闭防火墙3.5 配置ssh免密登录3.5.1 新建hadoop部署用户3.5.2 配置hadoopdeploy用户到任意一台机器都免密登录3.7 配置hadoop3.7.1 创建目…...

骨传导耳机工作原理,骨传导耳机优缺点
骨传导耳机虽说最近是十分火爆的一款单品,但还是有很多人对骨传导耳机不是很了解,骨传导耳机更多使用场景还是在户外运动使用,骨传导耳机对于长时间使用耳机的人来说十分友好,这主要还是得益于骨传导耳机传输声音的特殊性。 下面我…...
IDEA高效插件和设置
安装好Intellij idea之后,进行如下的初始化操作,工作效率提升十倍。 一. 安装插件 1. Codota 代码智能提示插件 只要打出首字母就能联想出一整条语句,这也太智能了,还显示了每条语句使用频率。 原因是它学习了我的项目代码&…...
Linux之网络流量监控工具ntopng YUM安装
一、ntopng简介 Ntop是一种监控网络流量工具,用ntop显示网络的使用情况比其他一些网络管理软件更加直观、详细。Ntop甚至可以列出每个节点计算机的网络带宽利用率。他是一个灵活的、功能齐全的,用来监控和解决局域网问题的工具;尤其当ntop与n…...
创建虚拟机,安装CentOS
在VMware上面创建虚拟机 文件->新建虚拟机 选定 自定义的高级,下一步 下一步 检查选定稍后安装操作系统 下一步 选择Linux,CentOS 7 64位 创建虚拟机名称,以及在存放该虚拟机的位置 选择处理器的数量和每个处理器的内核数量 …...
ilasm 和 ildasm编译和反编译工具介绍使用教程
目录前言一、使用 ildasm 反编译 dll 文件二、使用 ilasm 将il文件编译成 dll 或 exe 文件前言 文本讲述怎么通过 ildasm 工具将 dll 文件进行反编译为 il 文件,修改 il 文件后再如何通过 ilasm 工具将 il 文件反编译成 dll 或 exe 文件。 ildasm工具:…...

代码随想录【Day20】| 654. 最大二叉树、617. 合并二叉树、700. 二叉搜索树中的搜索、98. 验证二叉搜索树
654. 最大二叉树 题目链接 题目描述: 给定一个不含重复元素的整数数组。一个以此数组构建的最大二叉树定义如下: 二叉树的根是数组中的最大元素。 左子树是通过数组中最大值左边部分构造出的最大二叉树。 右子树是通过数组中最大值右边部分构造出的最…...
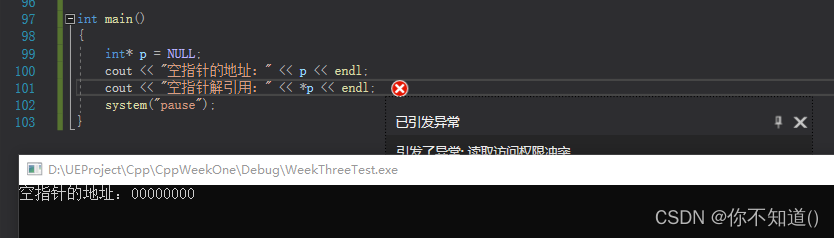
C++空指针和野指针
空指针:指针被赋值为空 例如: int* p nullptr;int* p NULL; 空指针指向的地址是00000000,但空指针不可以解引用 野指针:指针指向了不可控的位置 例如: 未初始化 int* p; //野指针 越界访问 int intArr[5]{0, 1, …...
LinkedList正确的遍历方式-附源码分析
1.引子 记得之前面试过一个同学,有这么一个题目: LinkedList<String> list new LinkedList<>();for (int i 0; i < 1000; i) {list.add(i "");}请根据上面的代码,请选择比较恰当的方式遍历这个集合,并…...
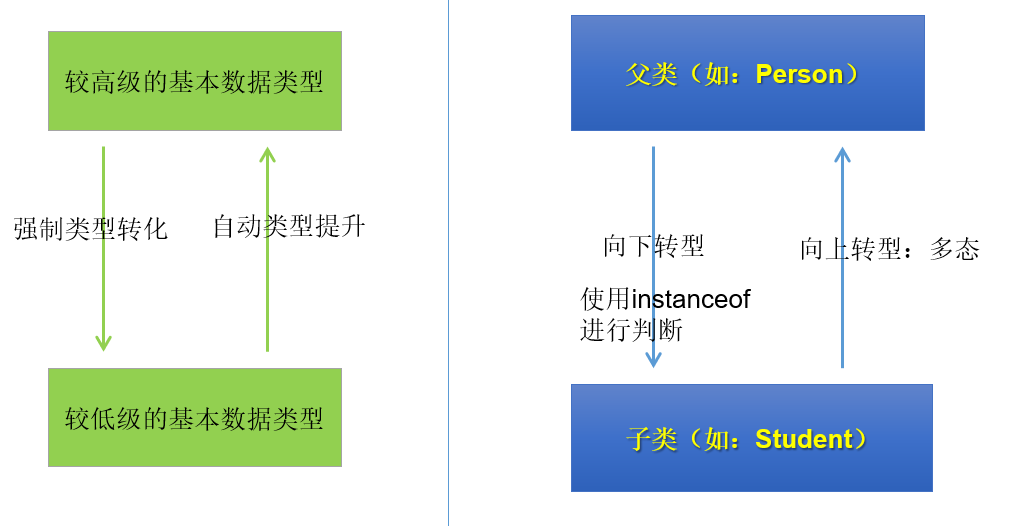
【蓦然回首忆Java·基础卷Ⅱ】
文章目录对象内存解析方法的参数传递机制关键字:package、importpackage(包)JDK中主要的包介绍import(导入)JavaBeanUML类图继承的一些细节封装性中的4种权限修饰关键字:supersuper的理解super的使用场景子类中调用父类被重写的方法子类中调用父类中同名…...
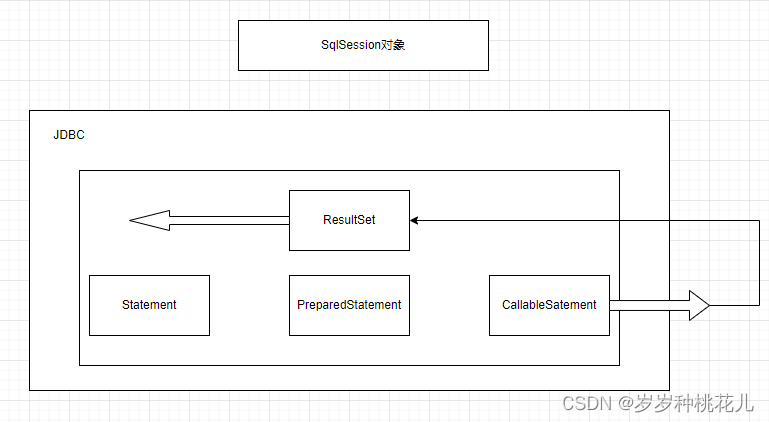
Mybatis源码分析系列之第二篇:Mybatis的数据存储对象
前言:SQLSession是对JDBC的封装 一:SQLSession和JDBC的对照说明 左边是我们的客户端程序,右边是我们的MySQL数据仓,或者叫MySQL实例 Mybatis是对JDBC的封装,将JDBC封装成了一个核心的SQLSession对象 JDBC当中的核心对…...

防护设备检测实验室建设完整方案SICOLAB
防护设备检测实验室建造布局方案SICOLAB一、防护设备检测实验室通常需要划分为几个功能区域,包括:1、样品准备区:用于样品的接收、处理、准备等工作,通常包括样品接收台、洗手池、样品切割机等设备。2、实验操作区:用于…...
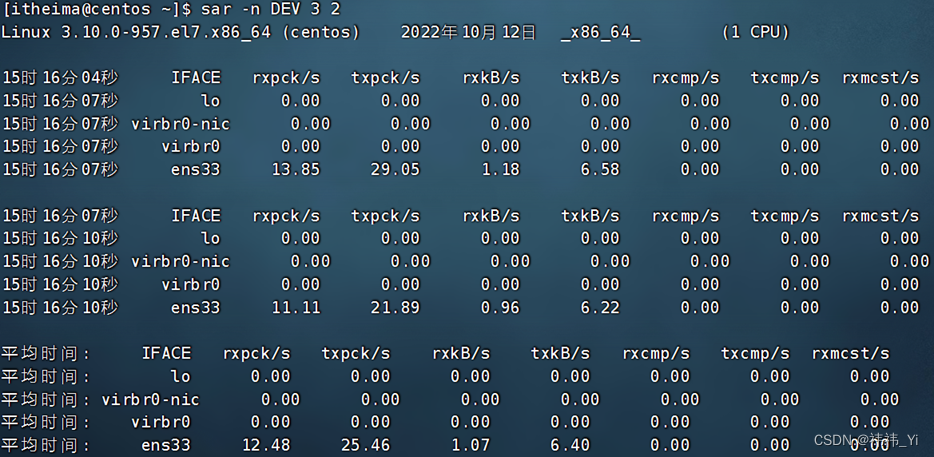
Linux知识之主机状态
1、查看系统资源占用 •可以通过top命令查看CPU、内存使用情况,类似Windows的任务管理器默认每5秒刷新一次,语法:直接输入top即可,按q或ctrl c退出 2、 top命令内容详解 •第一行:top:命令名称࿰…...

是时候为您的银行机构选择构建一个知识库了!
知识管理和自助服务客户支持在银行业至关重要。选择正确的知识库对于帮助客户和在内部共享信息同样重要。繁重的法规和合规性需求意味着银行必须在他们选择的知识库类型上投入大量思考。许多银行知识库已经过时,无法为客户提供成功使用您的产品和服务所需的信息。在…...
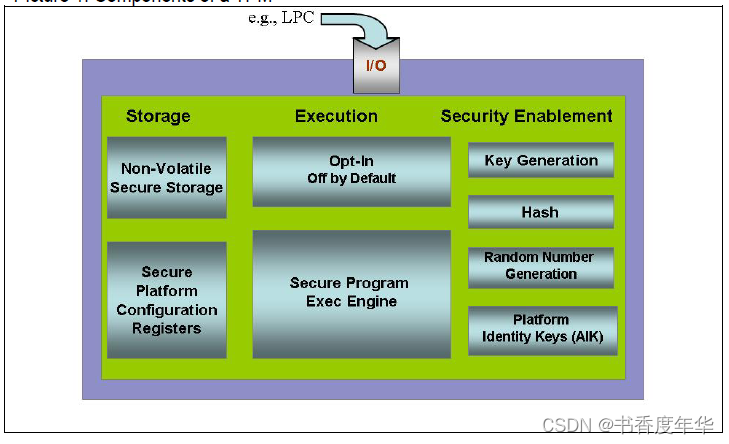
「TCG 规范解读」第7章 TPM工作组 TPM 总结
可信计算组织(Ttrusted Computing Group,TCG)是一个非盈利的工业标准组织,它的宗旨是加强在相异计算机平台上的计算环境的安全性。TCG于2003年春成立,并采纳了由可信计算平台联盟(the Trusted Computing Platform Alli…...

一、Plugin Constructing the Boilerplate
构建样板文件 在本章中,你将学习如何为一个新插件构建最少的代码。从起点开始,您将看到如何获取GStreamer模板源代码。然后,您将学习如何使用一些基本工具来复制和修改模板插件,以创建一个新的插件。如果您遵循这里的示例&#x…...

15、存储过程与函数
文章目录1 存储过程概述1.1 理解1.2 分类2 创建存储过程2.1 语法分析2.2 代码举例3 调用存储过程3.1 调用格式3.2 代码举例3.3 如何调试4 存储函数的使用4.1 语法分析4.2 调用存储函数4.3 代码举例4.4 对比存储函数和存储过程5 存储过程和函数的查看、修改、删除5.1 查看5.2 修…...
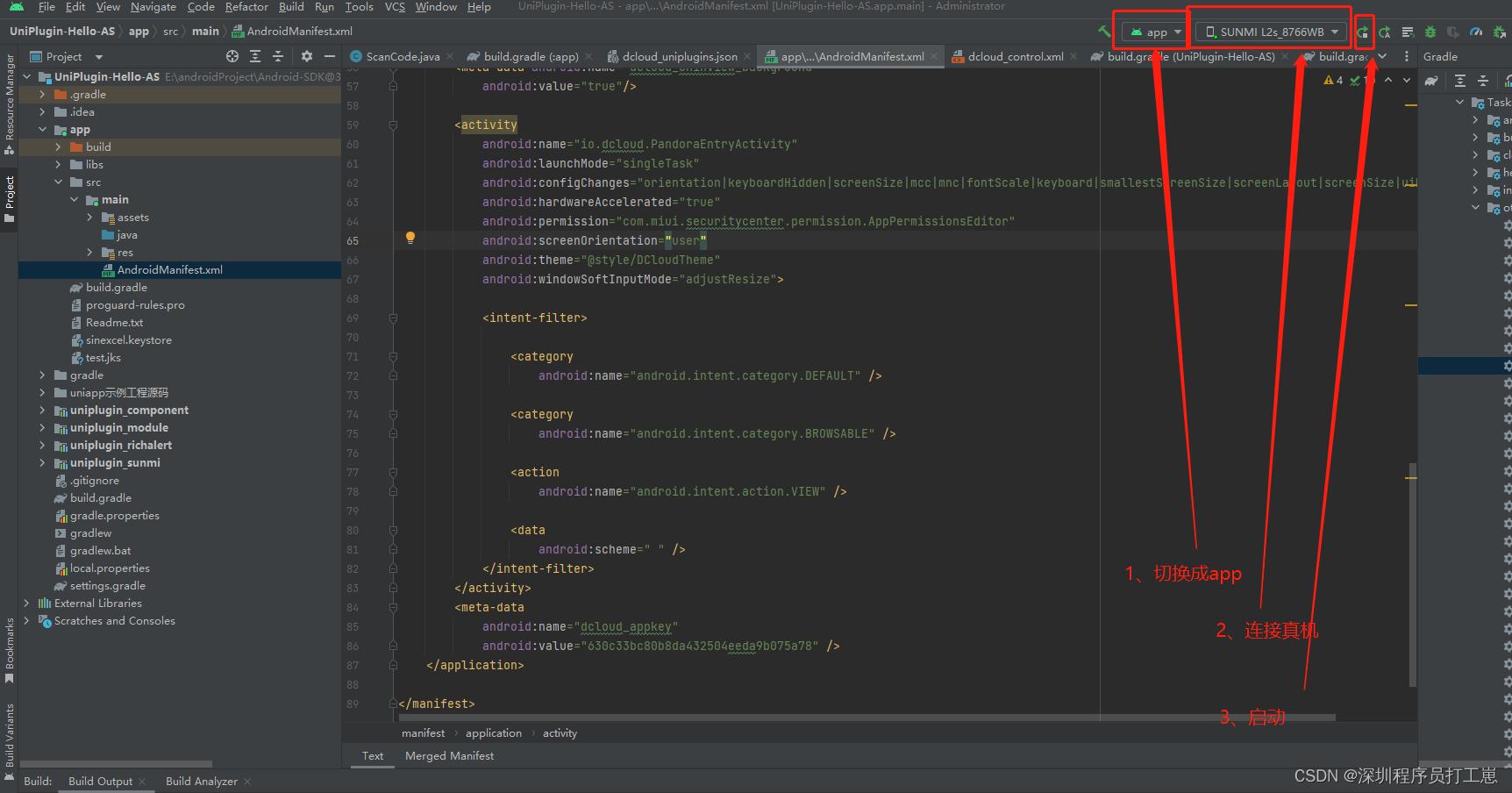
uniapp 原生安卓开发插件(module),以及android环境本地调试(二)
uniapp 原生安卓开发插件(module),以及android环境本地调试(一) 1、前景 承接上一篇文章,由于uniapp每天只有限定的打包次数,所以每次插件调试都打包成为基座,这个不太方便&#x…...
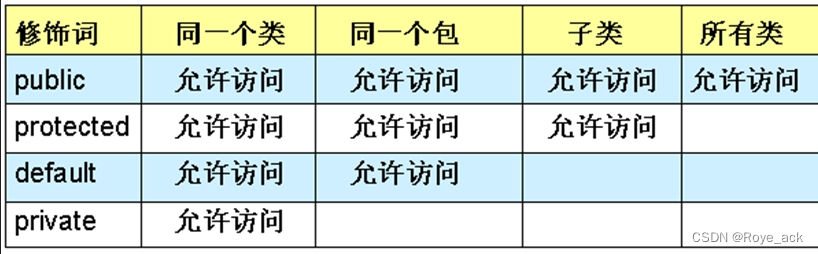
【Java期末复习】《面向对象程序设计》练习库
目录 一、单选题 二、填空题 三、程序填空题 1、 super使用--有如下父类和子类的定义,根据要求填写代码 2、简单加法计算器的实现 3、House类 4、矩形类 5、创建一个Box类,求其体积 四、函数题 6-1 求圆面积自定义异常类 6-2 判断一个数列是…...

照片文件损坏能修复吗?
很多时候,我们都是把相机拍的照片保存在电脑上,或手机照片太多,也会上传到电脑里保存。这样就能腾出更多的存储空间。但在电脑里的照片文件有时会莫名其妙的损坏,提示已损坏等情况,一旦发生这样的事,这些照…...

JAVA语法,接口和抽象类应该如何抉择
01.面向对象设计特性1.1 抽象和接口特性在面向对象编程中,抽象类和接口是两个经常被用到的语法概念,是面向对象四大特性,以及很多设计模式、设计思想、设计原则编程实现的基础。比如,我们可以使用接口来实现面向对象的抽象特性、多…...
核心特性与工业实践解析)
实时操作系统(RTOS)核心特性与工业实践解析
1. 实时操作系统核心特性解析实时操作系统(RTOS)的核心设计理念在于"确定性响应",这与我们日常使用的通用操作系统有着本质区别。我曾参与过工业控制系统的开发,深刻体会到RTOS在关键任务场景下的不可替代性。以数控机床…...
搞定电影推荐里的‘导演偏好’与‘演员偏好’)
告别‘一视同仁’:用HAN(异质图注意力网络)搞定电影推荐里的‘导演偏好’与‘演员偏好’
异构图注意力网络在电影推荐中的实战:如何让算法读懂导演偏好与演员偏好 想象这样一个场景:你刚看完詹姆斯卡梅隆执导的《终结者》,流媒体平台紧接着推荐了同样由施瓦辛格主演的《终结者2》和卡梅隆的另一部作品《泰坦尼克号》。虽然这三部电…...

产品经理、设计师必看:2026年6款AI界面生成工具实测,哪个最值得用?
过去,一款移动应用从需求文档到可交付原型,至少需要设计师投入 1~2 周时间。而今,借助 AI 界面生成工具,同样的工作可以压缩到几小时甚至几十分钟完成。目前AI界面生成工具正在重塑产品团队的工作方式。本文实测对比了 UXbot、Uiz…...

72小时数字记忆拯救计划:GetQzonehistory全方位备份方案
72小时数字记忆拯救计划:GetQzonehistory全方位备份方案 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 记忆保卫战:当十年说说面临消失危机 "您的QQ空间数…...

WandEnhancer终极指南:WeMod本地增强与功能解锁的完整实践
WandEnhancer终极指南:WeMod本地增强与功能解锁的完整实践 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer WandEnhancer是一款专为WeMod客户…...

第2篇:嵌入式芯片发展历程与全球主流厂商产品线全梳理
引言:嵌入式技术的诞生与电子产业智能化的发展关联 嵌入式技术的诞生与电子产业的智能化升级同频共振,是科技进步与产业需求深度融合的产物。自20世纪70年代第一块单片机问世以来,嵌入式芯片从最初简单的控制单元,逐步进化为支撑…...

CentOS7 无法输入中文 CentOS7 中文输入法设置
一、问题描述 安装完 CentOS7 后,不能输入中文,按 WIN空格 也无法切换到中文输入法 二、解决方案 右键桌面 -> 打开终端(E) -> 执行命令 ibus-setup -> 输入法 -> 添加(A) -> 汉语 -> Intelligent Pinyin -> 添加(A) ibus-setup&am…...

数据结构与算法学习笔记
java一.数据结构简介1. 为什么要有数据结构?数据太多、太乱 → 无法高效处理 → 必须结构化2. 数据结构的两大分类逻辑结构:数据之间的关系(怎么理解)物理结构:内存中的存储方式(怎么实现)3. 逻…...

LabVIEW视觉项目效率翻倍:海康相机+OpenCV/NI Vision混合编程实战
LabVIEW视觉项目效率翻倍:海康相机OpenCV/NI Vision混合编程实战 在工业自动化领域,视觉检测系统的开发效率往往决定了产品上市时间。作为一名长期奋战在产线调试一线的工程师,我发现许多同行在使用LabVIEW进行视觉项目开发时,都会…...