Windows系统下MMDeploy预编译包的使用
Windows系统下MMDeploy预编译包的使用
MMDeploy步入v1版本后安装/使用难度大幅下降,这里以部署MMDetection项目的Faster R-CNN模型为例,将PyTorch模型转换为ONNX进而转换为Engine模型,部署到TensorRT后端,实现高效推理,主要参考了官方文档。
说明:制作本教程时,MMDeploy版本是v1.2.0
本机环境
-
Windows 11
-
Powershell 7
-
Visual Studio 2019
-
CUDA版本:11.7
-
CUDNN版本:8.6
-
Python版本:3.8
-
PyTorch版本:1.13.1
-
TensorRT版本:v8.5.3.1
-
mmdeploy版本:v1.2.0
-
mmdet版本:v3.0.0
1. 准备环境
每一步网上教程比较多,不多描述
-
安装
Visual Studio 2019,勾选C++桌面开发,一定要选中Win10 SDK,貌似现在还不支持VS2022 -
安装CUDA&CUDNN
- 注意版本对应关系
- 一定要先安装VS2019,否则
visual studio Integration无法安装成功,后面会报错 - 默认安装选项即可,如果不是默认安装,一定要勾选
visual studio Integration
-
Anaconda3/MiniConda3
安装完毕后,创建一个环境
conda create -n faster-rcnn-deploy python=3.8 -y conda activate faster-rcnn-deploy -
安装GPU版本的PyTorch
pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu117 -
安装OpenCV-Python
pip install opencv-python
2. 安装TensorRT
登录官网下载即可,这里直接给出我用的链接
https://developer.nvidia.com/downloads/compute/machine-learning/tensorrt/secure/8.5.3/zip/TensorRT-8.5.3.1.Windows10.x86_64.cuda-11.8.cudnn8.6.zip
下载完成后,解压,进入解压的文件夹
-
新建一个用户/系统变量
TENSORRT_DIR,值为当前目录 -
然后重启powershell,激活环境,此时可用
$env:TENSORRT访问TensorRT安装目录 -
将
$env:TENSORRT_DIR\lib加入PATH路径 -
然后重启powershell,激活环境
-
安装对应python版本的wheel包
pip install $env:TENSORRT_DIR\python\tensorrt-8.5.3.1-cp38-none-win_amd64.whl -
安装pycuda
pip install pycuda
3. 安装mmdeploy及runtime
-
mmdeploy:模型转换API
-
runtime:模型推理API
pip install mmdeploy==1.2.0 pip install mmdeploy-runtime-gpu==1.2.0
4. 克隆MMDeploy仓库
新建一个文件夹,后面所有的仓库/文件均放在此目录下
克隆mmdeploy仓库主要是需要用到里面的配置文件
git clone -b main https://github.com/open-mmlab/mmdeploy.git
5. 安装MMDetection
需要先安装MMCV:
pip install -U openmim
mim install "mmcv>=2.0.0rc2"
克隆并编译安装mmdet:
git clone https://github.com/open-mmlab/mmdetection.git
cd mmdetection
git checkout v3.0.0
pip install -v -e .
cd ..
4. 进行转换
文件目录如下:
./faster-rcnn-deploy/
├── app.py
├── checkpoints
├── convert.py
├── infer.py
├── mmdeploy
├── mmdeploy_model
├── mmdetection
├── output_detection.png
└── tmp.py
-
部署配置文件:
mmdeploy/configs/mmdet/detection/detection_tensorrt-fp16_dynamic-320x320-1344x1344.py -
模型配置文件:
mmdetection/configs/faster_rcnn/faster-rcnn_r50_fpn_1x_coco.py -
模型权重文件:
checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth,这里是用的openmmlab训练好的权重,粘贴到浏览器,或者可以通过windows下的 wget 下载:wget -P checkpoints https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth -
测试图片文件:
mmdetection/demo/demo.jpg -
保存目录:
mmdeploy_model/faster-rcnn-deploy-fp16
convert.py内容如下:
from mmdeploy.apis import torch2onnx
from mmdeploy.apis.tensorrt import onnx2tensorrt
from mmdeploy.backend.sdk.export_info import export2SDK
import osimg = "mmdetection/demo/demo.jpg"
work_dir = "mmdeploy_model/faster-rcnn-deploy-fp16"
save_file = "end2end.onnx"
deploy_cfg = "mmdeploy/configs/mmdet/detection/detection_tensorrt-fp16_dynamic-320x320-1344x1344.py"
model_cfg = "mmdetection/configs/faster_rcnn/faster-rcnn_r50_fpn_1x_coco.py"
model_checkpoint = "checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth"
device = "cuda"# 1. convert model to IR(onnx)
torch2onnx(img, work_dir, save_file, deploy_cfg, model_cfg, model_checkpoint, device)# 2. convert IR to tensorrt
onnx_model = os.path.join(work_dir, save_file)
save_file = "end2end.engine"
model_id = 0
device = "cuda"
onnx2tensorrt(work_dir, save_file, model_id, deploy_cfg, onnx_model, device)# 3. extract pipeline info for sdk use (dump-info)
export2SDK(deploy_cfg, model_cfg, work_dir, pth=model_checkpoint, device=device)运行结果:
[08/30/2023-17:36:13] [TRT] [I] [MemUsageChange] TensorRT-managed allocation in building engine: CPU +84, GPU +109, now: CPU 84, GPU 109 (MiB)
5. 推理测试
infer.py内容如下:
from mmdeploy.apis import inference_modeldeploy_cfg = "mmdeploy/configs/mmdet/detection/detection_tensorrt-fp16_dynamic-320x320-1344x1344.py"
model_cfg = "mmdetection/configs/faster_rcnn/faster-rcnn_r50_fpn_1x_coco.py"
backend_files = ["mmdeploy_model/faster-rcnn-fp16/end2end.engine"]
img = "mmdetection/demo/demo.jpg"
device = "cuda"
result = inference_model(model_cfg, deploy_cfg, backend_files, img, device)print(result)
运行结果:
08/30 17:42:43 - mmengine - INFO - Successfully loaded tensorrt plugins from F:\miniconda3\envs\faster-rcnn-deploy\lib\site-packages\mmdeploy\lib\mmdeploy_tensorrt_ops.dll
08/30 17:42:43 - mmengine - INFO - Successfully loaded tensorrt plugins from F:\miniconda3\envs\faster-rcnn-deploy\lib\site-packages\mmdeploy\lib\mmdeploy_tensorrt_ops.dll
...
...
inference_model每调用一次就会加载一次模型,效率很低,只是用来测试模型可用性,不能用在生产环境。要高效使用模型,可以集成Detector到自己的应用程序里面,一次加载,多次推理。如下:
6. 集成检测器到自己的应用中
app.py内容如下:
from mmdeploy_runtime import Detector
import cv2# 读取图片
img = cv2.imread("mmdetection/demo/demo.jpg")# 创建检测器
detector = Detector(model_path="mmdeploy_model/faster-rcnn-deploy-fp16",device_name="cuda",device_id=0,
)
# 执行推理
bboxes, labels, _ = detector(img)
# 使用阈值过滤推理结果,并绘制到原图中
indices = [i for i in range(len(bboxes))]
for index, bbox, label_id in zip(indices, bboxes, labels):[left, top, right, bottom], score = bbox[0:4].astype(int), bbox[4]if score < 0.3:continuecv2.rectangle(img, (left, top), (right, bottom), (0, 255, 0))cv2.imwrite("output_detection.png", img)调用这个API可以将训练的深度学习模型无缝集成到web后端里面,一次加载,多次推理
原图:

推理检测后:

相关文章:
Windows系统下MMDeploy预编译包的使用
Windows系统下MMDeploy预编译包的使用 MMDeploy步入v1版本后安装/使用难度大幅下降,这里以部署MMDetection项目的Faster R-CNN模型为例,将PyTorch模型转换为ONNX进而转换为Engine模型,部署到TensorRT后端,实现高效推理,…...
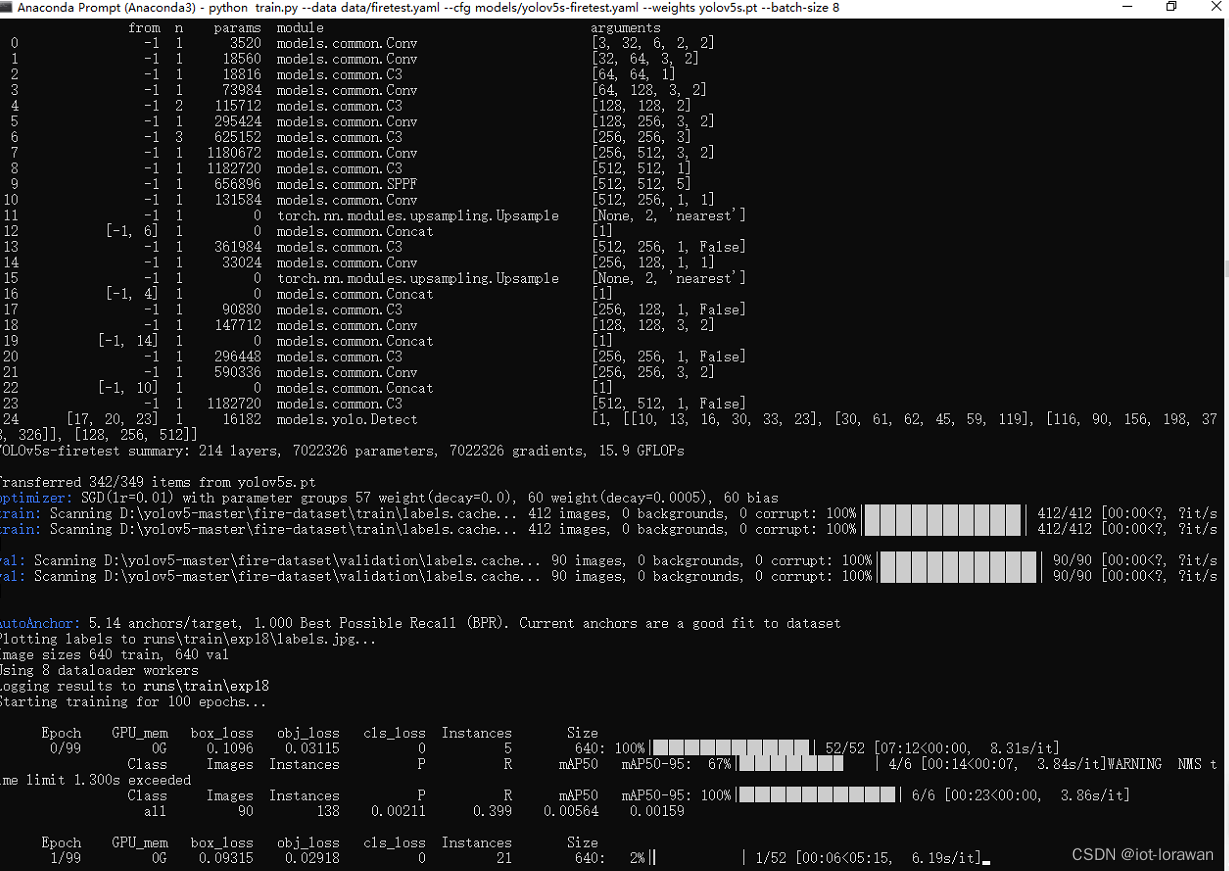
yolov5自定义模型训练二
前期准备好了用于训练识别是否有火灾的数据集后就可以开始修改yolo相关文件来进行训练 数据集放到yolov5目录里 在data目录下新建yaml文件设置数据集信息如下 在model文件夹下新增新的model文件 开始训练 训练出错 确认后是对训练数据集文件夹里的文件名字有要求,原…...
)
Spring框架获取用户真实IP(注解式)
文章目录 一、最终使用效果(ClientIp 注解获取)二、实现代码1.注解2.方法参数解析器(Resolver)3.全局增加Resolver配置 Spring 框架没有现成工具可以方便提取客户端的IP地址,普遍做法就是通过 HttpServletRequest 的 g…...

利用 IDEA IDE 的轻量编辑模式快速查看和编辑工程外的文本文件
作为程序员, 我们都知道 IDE 的很好用的, 它的文本编辑器功能也非常的强大, 用起来非常便捷. 在长年累月的使用中, 我们也变得对其非常熟悉, 以致于使用起其它简单地轻量级的文本编辑器来, 比如什么记事本, Notepad, UltraEdit 等等呀, 觉得既不方便又不熟悉. 关键是很多的操作…...
MyBatisx代码生成
MyBatisx代码生成 1.创建数据库表 CREATE TABLE sys_good (good_id int(11) NOT NULL,good_name varchar(255) COLLATE utf8mb4_general_ci DEFAULT NULL,good_desc varchar(255) COLLATE utf8mb4_general_ci DEFAULT NULL,PRIMARY KEY (good_id) ) ENGINEInnoDB DEFAULT CHA…...

【日记】文章更新计划
首发博客地址[1] 状态 这两天也没加班,也没干什么活。不知道怎么回事,到家就想睡觉。所以这两天睡得很早,基本上 11 点之前就睡了,文章也就鸽了两天。 计划 今早起来感觉还是要自律,我写文章的初衷是为了学习。基于这个…...

UML用例图三种关系(重点)-架构真题(十七)
某项目包括A、B、C、D四道工序,各道工序之间的衔接关系、正常进度下各工序所需的时间和直接费用、赶工进度下所需的时间和直接费用如下表所示。该项目每天需要间接费用为4.5万元,根据此表,最低成本完成需要()天。&…...

分层解耦介绍
三层架构 Controller:控制层,接受前端发送的请求,对请求进行处理,并响应数据 service:业务逻辑层,处理具体业务逻辑 dao:数据访问层,负责数据访问操作,包括数据的增、删、…...
Nginx百科之gzip压缩、黑白名单、防盗链、零拷贝、跨域、双机热备
引言 早期的业务都是基于单体节点部署,由于前期访问流量不大,因此单体结构也可满足需求,但随着业务增长,流量也越来越大,那么最终单台服务器受到的访问压力也会逐步增高。时间一长,单台服务器性能无法跟上业…...
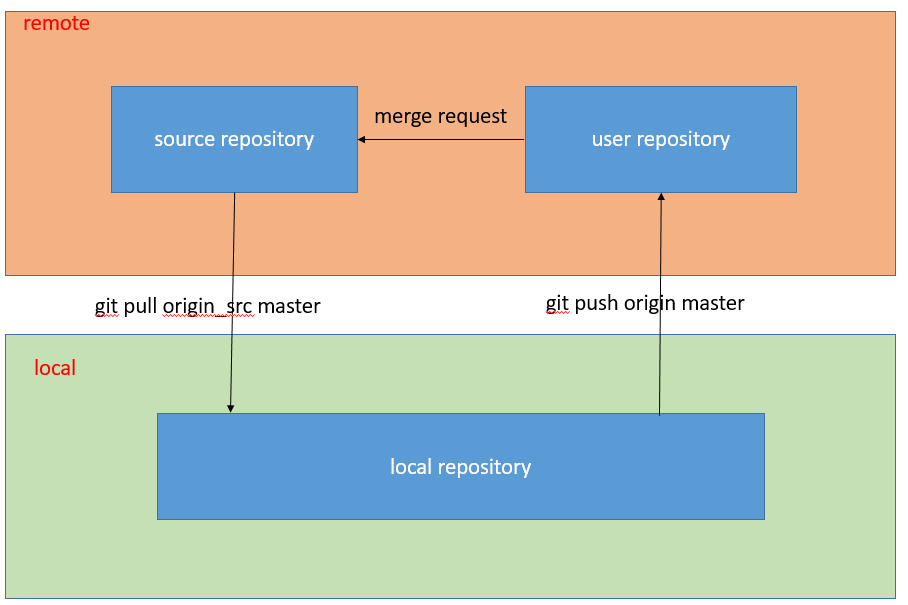
git通过fork-merge request实现多人协同
一、问题 对于一个项目,如果需要多人协同开发,大家都在原始仓库中进行修改提交,经常会发生冲突,而且一不小心会把别人的代码内容覆盖掉。为了避免这样的问题,git提供了fork-merge request这样的协同方式。 二、仓库框…...

元素居中的方法总结
目录 垂直居中 行内元素垂直居中 单行文本垂直居中 1.line-height: 200px; 多行文本垂直居中 1.tablevertical-align:middle 块级元素垂直居中 1.display: flex;align-items: center; 2.使用position top margin-top 水平居中 行内元素水平居中 1.text-align:cente…...

后端面试话术集锦第一篇:spring面试话术
这是后端面试集锦第一篇博文——spring面试话术❗❗❗ 1. 介绍一下spring 关于spring,我们平时做项目一直都在用,不管是使用ssh还是使用ssm,都可以整合。 Spring主要就三点,也就是核心思想: IOC控制反转 DI依赖注入 AOP切面编程 我先说说IOC吧,IOC就是spring里的控制反…...
elasticsearch8.9.1集群搭建
目录 1.官网文档 2.安装步骤 2.1 环境准备 2.2 添加用户 2.3 修改文件profile文件 2.4 修改elasticsearch.yml 2.5 修改 sysctl.conf 3.启动 3.1 切换到kibana 3.2 启动elasticsearch 3.3 启动kibana 3.4 验证节点情况 1.官网文档 elasticsearch文档:ht…...
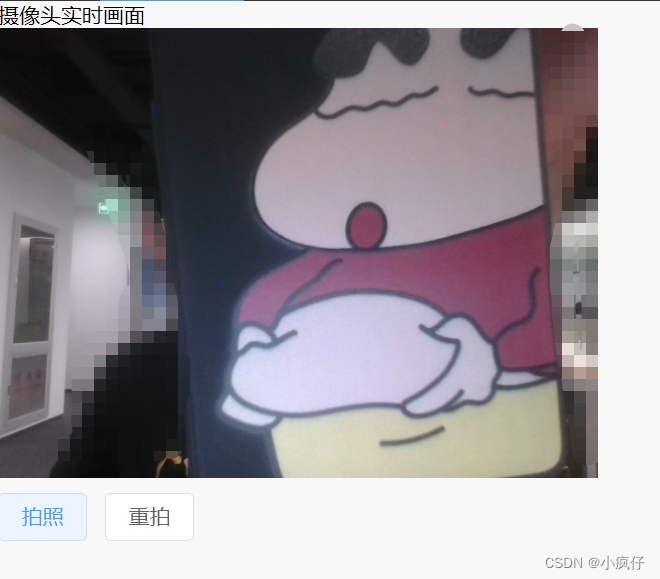
前端调用电脑摄像头
项目中需要前端调用,所以做了如下操作 先看一下效果吧 主要是基于vue3,通过canvas把画面转成base64的形式,然后是把base64转成 file文件,最后调用了一下上传接口 以下是代码 进入页面先调用一下摄像头 navigator.mediaDevices.ge…...

网络编程day1——进程间通信-socket套接字
基本特征:socket是一种接口技术,被抽象了一种文件操作,可以让同一计算机中的不同进程之间通信,也可以让不同计算机中的进程之间通信(网络通信) 本地进程间通信编程模型: 进程A …...
Android-关于页面卡顿的排查工具与监测方案
作者:一碗清汤面 前言 关于卡顿这件事已经是老生常谈了,卡顿对于用户来说是敏感的,容易被用户直接感受到的。那么究其原因,卡顿该如何定义,对于卡顿的发生该如何排查问题,当线上用户卡顿时,在线…...
VueX 与Pinia 一篇搞懂
VueX 简介 Vue官方:状态管理工具 状态管理是什么 需要在多个组件中共享的状态、且是响应式的、一个变,全都改变。 例如一些全局要用的的状态信息:用户登录状态、用户名称、地理位置信息、购物车中商品、等等 这时候我们就需要这么一个工…...
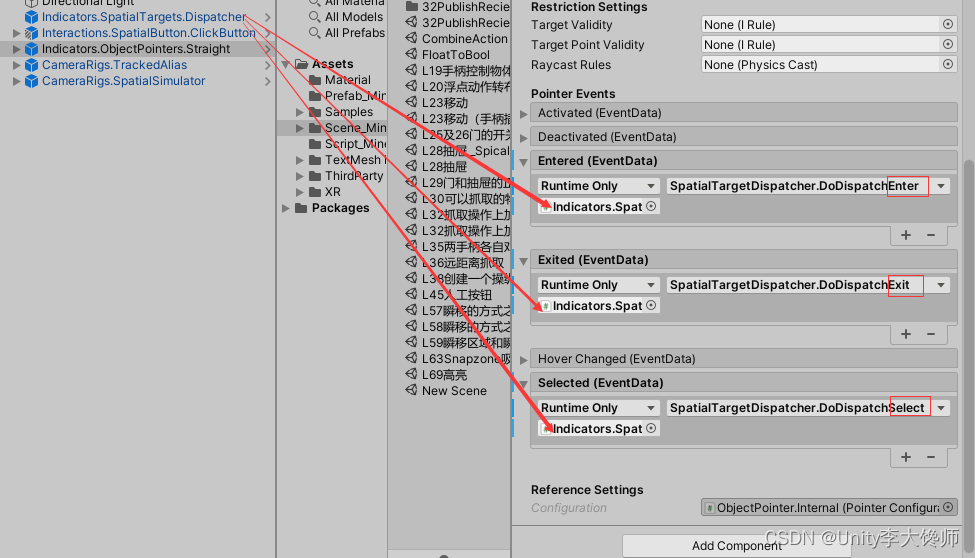
指针与空间按钮的交互
文章目录 原理案例:“直线指针”和“点击按钮”的交互1、效果2、步骤 原理 指针不能直接和空间按钮交互,得借助一个中间层——分发器——它分发指针的进入、退出、选择事件,空间按钮自动监听这些事件 案例:“直线指针”和“点击…...
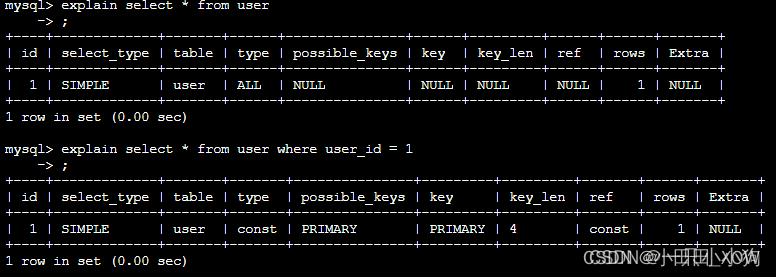
java八股文面试[数据库]——慢查询优化
分析慢查询日志 直接分析慢查询日志, mysql使用explain sql语句进行模拟优化器来执行分析。 oracle使用explain plan for sql语句进行模拟优化器来执行分析。 table | type | possible_keys | key |key_len | ref | rows | Extra EXPLAIN列的解释: ta…...
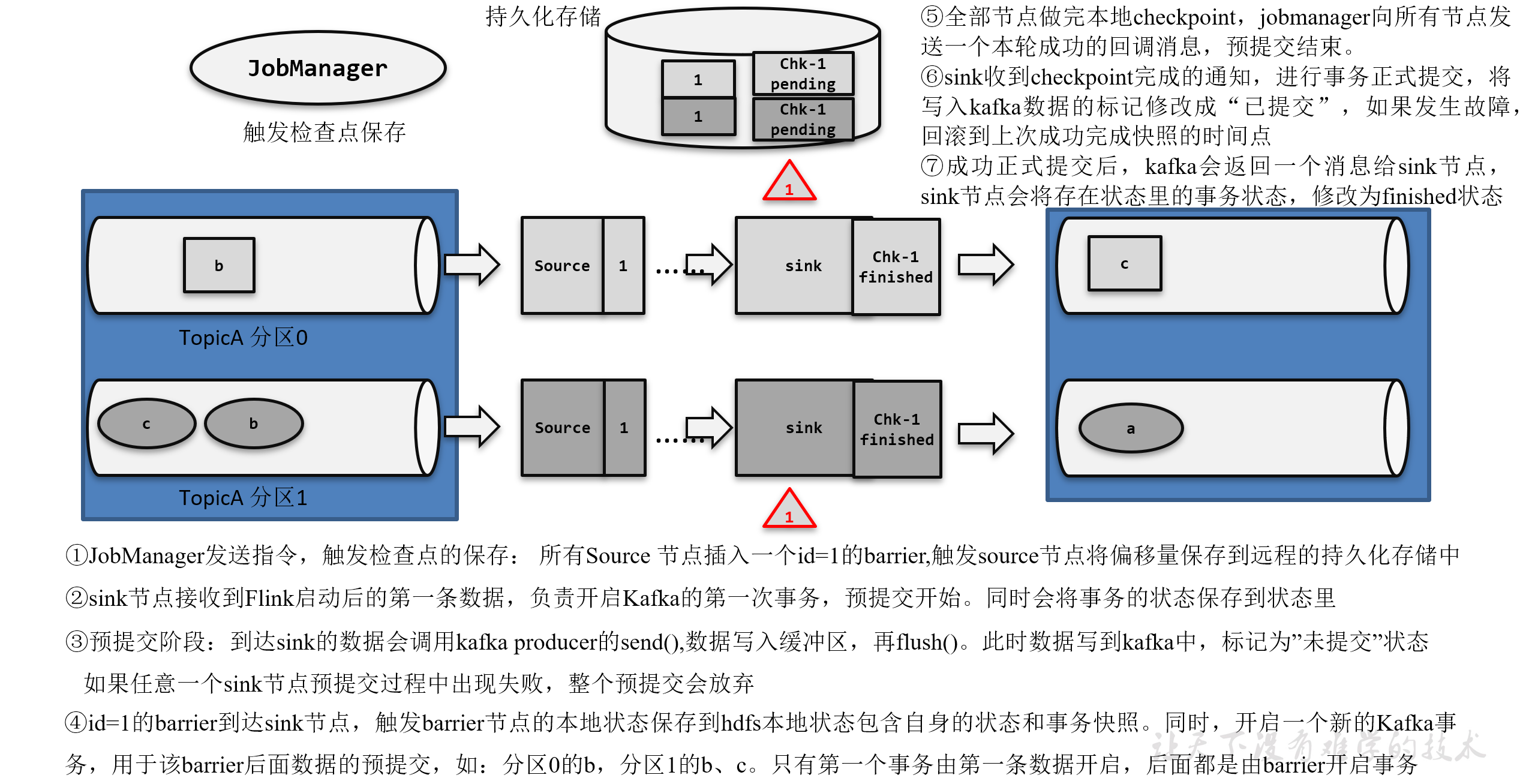
《Flink学习笔记》——第十章 容错机制
10.1 检查点(Checkpoint) 为了故障恢复,我们需要把之前某个时间点的所有状态保存下来,这份“存档”就是“检查点” 遇到故障重启的时候,我们可以从检查点中“读档”,恢复出之前的状态,这样就可以…...

初创公司如何利用Taotoken以可控成本试用多模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创公司如何利用Taotoken以可控成本试用多模型 对于资源有限的初创团队而言,在产品开发中引入大模型能力是一个充满机…...

Agent 工程化系列 · 第 13 篇_Agent安全与可靠性如何保障
Agent 工程化系列 第 13 篇 Agent 的安全与可靠性如何保障? Agent 最危险的不是回答错,而是执行错开篇定位 前面我们已经讲过:LLM 是能力核心,Agent 是执行系统;Function Call 让模型能够调用工具;MCP 负责…...

2026年同一机器两服务偶发`ECONNRESET`错误:实验室复现、场景分析与后续解决思路
突发!偶发 ECONNRESET 错误背后:实验室复现、场景分析与后续解决思路2026年5月5日,同一台机器上运行的两个服务出现问题,发起连接的服务读取数据时偶发 ECONNRESET 错误,且日志无其他错误信息、无崩溃情况。下面我们来…...

FastbootEnhance:面向Windows用户的终极Fastboot工具箱与Payload提取器指南
FastbootEnhance:面向Windows用户的终极Fastboot工具箱与Payload提取器指南 【免费下载链接】FastbootEnhance A user-friendly Fastboot ToolBox & Payload Dumper for Windows 项目地址: https://gitcode.com/gh_mirrors/fa/FastbootEnhance FastbootE…...

OAuth 2.0 and OIDC 三大安全机制对比:State vs Nonce vs PKCE
一、问题背景 OAuth 2.0 和 OpenID Connect 的授权流程依赖浏览器重定向,这天然暴露了多种攻击面: 攻击类型描述CSRF攻击者诱导用户的浏览器携带恶意授权码完成绑定Token 重放窃取的 id_token 被重复提交给客户端授权码劫持恶意应用在同一设备上拦截授…...
)
极简风项目交付倒计时!:紧急修复MJ --v 6.2中隐藏的1.33倍宽高比偏移Bug,避免客户验收驳回(含补救Prompt包)
更多请点击: https://intelliparadigm.com 第一章:极简风项目交付倒计时! 当交付周期压缩至 72 小时,极简风不再是一种美学选择,而是工程效率的刚性约束。我们摒弃冗余文档、跳过非核心评审环节,聚焦于可…...

终极指南:如何使用Autoclick实现Mac自动点击900次/秒
终极指南:如何使用Autoclick实现Mac自动点击900次/秒 【免费下载链接】Autoclick A simple Mac app that simulates mouse clicks 项目地址: https://gitcode.com/gh_mirrors/au/Autoclick 你是否厌倦了重复性的鼠标点击工作?无论是游戏中的重复操…...

如何快速掌握openpilot:从零到精通的自动驾驶系统终极指南
如何快速掌握openpilot:从零到精通的自动驾驶系统终极指南 【免费下载链接】openpilot openpilot is an operating system for robotics. Currently, it upgrades the driver assistance system on 300 supported cars. 项目地址: https://gitcode.com/GitHub_Tre…...

Allegro 16.6 高效布线实战:Region规则、Xnet等长与模块复用的进阶技巧
Allegro 16.6 高效布线实战:Region规则、Xnet等长与模块复用的进阶技巧 在高速PCB设计领域,Allegro 16.6作为行业标杆工具,其深度功能往往决定了设计效率的天花板。当面对BGA封装密度突破1000pin、信号速率迈入10Gbps时代的复杂主板时&#x…...
)
别再点‘忽略’了!开机弹出Visual C++ Runtime Library错误的终极排查指南(附Adobe软件关联排查)
Visual C Runtime Library错误:从崩溃到根治的全链路解决方案 每次开机时那个刺眼的Visual C Runtime Library错误弹窗,就像一位不请自来的访客,固执地打断你的工作节奏。对于依赖Adobe Creative Cloud或达芬奇等创意工具的专业人士来说&…...