如何对MySQL和MariaDB中的查询和表进行优化-提升查询效率
前言
MySQL和MariaDB是数据库管理系统的流行选择。两者都使用SQL查询语言来输入和查询数据。
尽管SQL查询是简单易学的命令,但并不是所有的查询和数据库函数都具有相同的效率。随着你存储的信息量的增长,如果你的数据库支持一个网站,随着网站的受欢迎程度的增加,这就变得越来越重要。
在本指南中,我们将讨论一些可以提高MySQL和MariaDB查询速度的简单方法。我们假设您已经使用我们的指南安装了MySQL或MariaDB,该指南适合您的操作系统。
表设计概述
提高查询速度的最基本方法之一是从表结构设计本身开始的。这意味着在开始使用软件之前,就需要开始考虑组织数据的最佳方式。
下面是一些你应该问自己的问题:
表的主要用途是什么?
预测如何使用表中的数据通常决定了设计数据结构的最佳方法。
如果需要经常更新某些数据,通常最好将它们放在单独的表中。如果做不到这一点,就会导致查询缓存(在软件中维护的内部缓存)被一次次地转储和重建,因为它发现有新的信息。如果这发生在单独的表中,其他列可以继续利用缓存。
更新操作通常在较小的表上更快,而对复杂数据的深入分析通常是一项最好留给大型表的任务,因为连接操作的开销很大。
需要什么样的数据类型?
有时,如果您能够预先对数据大小进行一些限制,从长远来看,它可以为您节省大量时间。
例如,如果某个字段的值为string,有效的条目数量有限,那么可以使用enum类型而不是varchar类型。这种数据类型很紧凑,因此查询起来很快。
例如,如果用户只有几种不同的类型,可以在处理enum的列中设置admin、moderator、poweruser、user。
要查询哪些列?
提前知道哪些字段会被重复查询可以极大地提高速度。
为你希望用于搜索的列建立索引大有帮助。你可以使用以下语法在创建表时添加索引:
CREATE TABLE example_table ( id INTEGER NOT NULL AUTO_INCREMENT, name VARCHAR(50), address VARCHAR(150)
, username VARCHAR(16), PRIMARY KEY (id), INDEX (username) );
如果我们知道用户将根据用户名搜索信息,这将很有用。这将创建一个表,这些属性:
explain example_table;
+----------+--------------+------+------+----------------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+--------------+------+------+----------------+-------+
| id | int(11) | NO | PRI | NULL | auto_increment | |
| name | varchar(50) | YES | | NULL | |
| address | varchar(150) | YES | | NULL | |
| username | varchar(16) | YES | MUL | NULL | |
+----------+--------------+------+------+----------------+-------+
4 rows in set (0.00 sec)
如你所见,我们的表有两个索引。第一个是主键,在本例中是id字段。第二个是我们为username字段添加的索引。这将改进利用该字段的查询。
虽然从概念的角度来看,在创建过程中考虑哪些字段应该被索引是很有用的,但向现有的表添加索引也很简单。你可以像这样添加一个:
CREATE INDEX index_name ON table_name(column_name);
另一种方法完成同样的事情是这样的:
ALTER TABLE table_name ADD INDEX ( column_name );
使用Explain在查询中查找要索引的点
如果你的程序以一种可预测的方式进行查询,你应该分析你的查询,以确保它们尽可能地使用索引。使用explain函数很容易做到这一点。
我们将导入一个MySQL sample数据库来看看其中的一些工作原理:
wget https://launchpad.net/test-db/employees-db-1/1.0.6/+download/employees_db-full-1.0.6.tar.bz2
tar xjvf employees_db-full-1.0.6.tar.bz2
cd employees_db
mysql -u root -p -t < employees.sql
现在我们可以登录到MySQL,以便运行一些查询:
mysql -u root -p
use employees;
首先,我们需要指定MySQL不应该使用它的缓存,这样我们就可以准确地判断这些任务完成所需的时间:
SET GLOBAL query_cache_size = 0;
SHOW VARIABLES LIKE "query_cache_size";+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| query_cache_size | 0 |
+------------------+-------+
1 row in set (0.00 sec)
现在,我们可以在大型数据集上运行一个简单的查询:
SELECT COUNT(*) FROM salaries WHERE salary BETWEEN 60000 AND 70000;
+----------+
| count(*) |
+----------+
| 588322 |
+----------+
1 row in set (0.60 sec)
要查看MySQL如何执行查询,你可以直接在查询之前添加explain关键字:
EXPLAIN SELECT COUNT(*) FROM salaries WHERE salary BETWEEN 60000 AND 70000;
+----+-------------+----------+------+---------------+------+---------+------+---------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+----------+------+---------------+------+---------+------+---------+-------------+
| 1 | SIMPLE | salaries | ALL | NULL | NULL | NULL | NULL | 2844738 | Using where |
+----+-------------+----------+------+---------------+------+---------+------+---------+-------------+
1 row in set (0.00 sec)
如果你查看key字段,你会发现它的值是NULL。这意味着此查询没有使用索引。
让我们添加一个并再次运行查询,看看它是否加快了速度:
ALTER TABLE salaries ADD INDEX ( salary );
SELECT COUNT(*) FROM salaries WHERE salary BETWEEN 60000 AND 70000;
+----------+
| count(*) |
+----------+
| 588322 |
+----------+
1 row in set (0.14 sec)
如你所见,这显著提高了我们的查询性能。
另一个使用指数一般规则是注意表连接。您应该创建指数和任何列上指定相同的数据类型,将用于连接表。
例如,如果你有一张名为cheeses的表和一张名为“ingredients”的表,你可能希望对这两张表的ingredient_id字段进行联结操作,这两个字段可以是INT类型。
然后,我们可以为这两个字段创建索引,我们的连接将加快速度。
优化查询以提高速度
在尝试加速查询时,等式的另一半是优化查询本身。某些操作比其他操作的计算量更大。通常有多种方法可以得到相同的结果,其中一些方法可以避免昂贵的操作。
根据你所使用的查询结果,你可能只需要一个有限数量的结果。例如,如果你只需要知道该公司是否有人年收入低于4万元,你可以使用:
SELECT * FROM SALARIES WHERE salary < 40000 LIMIT 1;
+--------+--------+------------+------------+
| emp_no | salary | from_date | to_date |
+--------+--------+------------+------------+
| 10022 | 39935 | 2000-09-02 | 2001-09-02 |
+--------+--------+------------+------------+
1 row in set (0.00 sec)
这个查询执行得非常快,因为它基本上在第一个正结果时短路。
如果你的查询使用“or”比较,并且两个组件测试不同的字段,你的查询可能会比必要的长。
例如,如果要搜索姓或名以“Bre”开头的员工,则必须搜索两个独立的列。
SELECT * FROM employees WHERE last_name like 'Bre%' OR first_name like 'Bre%';
如果在一个查询中搜索名字,在另一个查询中搜索姓氏,然后合并输出,那么这个操作可能会更快。我们可以使用union操作符:
SELECT * FROM employees WHERE last_name like 'Bre%' UNION SELECT * FROM employees WHERE first_name like 'Bre%';
在某些情况下,MySQL会自动使用union操作。上面的例子实际上是MySQL自动执行此操作的一种情况。你可以通过再次使用explain检查排序的类型来查看是否是这种情况。
总结
在MySQL和MariaDB表和数据库中对用例调整的方法有很多种。本文仅包含一些可能对您入门有用的技巧。
这些数据库管理系统提供很多的帮助文档教你如何优化和调整不同的场景。具体细节很大程度上取决于您希望优化的功能类型,否则它们将被完全优化,开箱即用。一旦你确定了你的需求,并掌握了执行的操作,你就可以学习调整这些查询的设置。
相关文章:

如何对MySQL和MariaDB中的查询和表进行优化-提升查询效率
前言 MySQL和MariaDB是数据库管理系统的流行选择。两者都使用SQL查询语言来输入和查询数据。 尽管SQL查询是简单易学的命令,但并不是所有的查询和数据库函数都具有相同的效率。随着你存储的信息量的增长,如果你的数据库支持一个网站,随着网…...

【Android】关于binder_calls_stats服务
Android 9上有了binder_calls_stats服务,提供了java层的binder统计, Android中的Binder Call Stats(Binder调用统计)是一项用于监控和记录Android系统中Binder通信的统计信息的功能。Binder是Android中的一种进程间通信ÿ…...

给前端返回http链接,由于浏览器缓存不能获取到最新资源怎么办?
1、问题描述 今天在工作中接到这样一个需求,接收前端的图片文件并上传到远程,将原有图片覆盖并返回一个http链接以供前端展示。用户使用后反馈没有修改成功,上了远程拉图片发现已经修改了,但是用户浏览器还是老的图片。排查原因是…...

【Java Web】检查用户登录状态,防止用户访问到非法页面
使用拦截器 在方法前标注自定义注解拦截所有请求,只处理带有该注解的方法 自定义注解: 常用元注解:Target, Rentention, Document, Inherited如何读取注解: - Method.getDeclaredAnnotations() - Method.getAnnotaion(Class<T&…...
数学建模——校园供水系统智能管理
import pandas as pd data1pd.read_excel("C://Users//JJH//Desktop//E//附件_一季度.xlsx") data2pd.read_excel("C://Users//JJH//Desktop//E//附件_二季度.xlsx") data3pd.read_excel("C://Users//JJH//Desktop//E//附件_三季度.xlsx") data4…...
分布式集群——搭建Hadoop环境以及相关的Hadoop介绍
系列文章目录 分布式集群——jdk配置与zookeeper环境搭建 分布式集群——搭建Hadoop环境以及相关的Hadoop介绍 文章目录 前言 一 hadoop的相关概念 1.1 Hadoop概念 补充:块的存储 1.2 HDFS是什么 1.3 三种节点的功能 I、NameNode节点 II、fsimage与edits…...

Python的os.walk()函数使用案例
在Python中,os模块是一个非常实用的工具,它可以让我们与操作系统进行交互,操作文件和目录。在本文中,我们将详细介绍os模块中的遍历文件功能,并通过具体案例和使用场景来解释。 首先,导入os模块。在Pytho…...

学习JAVA打卡第四十五天
StringBuffer类 StringBuffer对象 String对象的字符序列是不可修改的,也就是说,String对象的字符序列的字符不能被修改、删除,即String对象的实体是不可以再发生变化,例如:对于 StringBuffer有三个构造方法ÿ…...
创建K8s pod Webhook
目录 1.前提条件 2.开始创建核心组件Pod的Webhook 2.1.什么是Webhook 2.2.在本地k8s集群安装cert-manager 2.3.创建一个空的文件夹 2.4. 生成工程框架 2.5. 生成核心组件Pod的API 2.6.生成Webhook 2.7.开始实现Webhook相关代码 2.7.1.修改相关配置 2.7.2.修改代码 2…...

抓包-要抓取Spring Boot应用程序的请求
要抓取Spring Boot应用程序的请求,可以按照以下步骤进行操作: 1. 确保你已经按照之前提到的方法设置了Charles代理,并在Charles的SSL代理设置中添加了Spring Boot应用程序的域名。 2. 在Spring Boot应用程序的代码中,添加以下配…...

jmeter+nmon+crontab简单的执行接口定时压测
一、概述 临时接到任务要对系统的接口进行压测,上面的要求就是:压测,并发2000 在不熟悉系统的情况下,按目前的需求,需要做的步骤: 需要有接口脚本需要能监控系统性能需要能定时执行脚本 二、观察 >针…...
ZooKeeper基础命令和Java客户端操作
1、zkCli的常用命令操作 (1)Help (2)ls 使用 ls 命令来查看当前znode中所包含的内容 (3)ls2查看当前节点数据并能看到更新次数等数据 (4)stat查看节点状态 (5…...

【数据分享】2000-2020年全球人类足迹数据(无需转发\免费获取)
人类足迹(Human Footprint)是生态过程和自然景观变化对生态环境造成的压力,是世界各国对生物多样性和生态保护的关注重点。那如何才能获取长时间跨度的人类足迹时空数据呢? 之前我们分享了来自于中国农业大学土地科学与技术学院的城市环境监测及建模&am…...
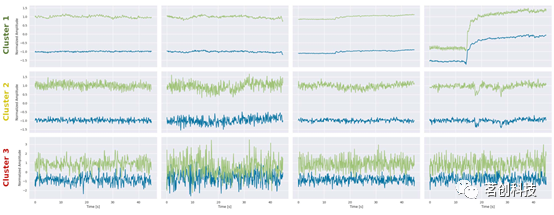
基于机器学习的fNIRS信号质量控制方法
摘要 尽管功能性近红外光谱(fNIRS)在神经系统研究中的应用越来越广泛,但fNIRS信号处理仍未标准化,并且受到经验和手动操作的高度影响。在任何信号处理过程的开始阶段,信号质量控制(SQC)对于防止错误和不可靠结果至关重要。在fNIRS分析中&…...
分布式锁的三种实现方式是什么?
分布式锁三种实现方式: 基于数据库实现分布式锁;基于缓存(Redis等)实现分布式锁;基于Zookeeper实现分布式锁; 一, 基于数据库实现分布式锁 悲观锁 利用select … where … for update 排他锁…...
华为云软件精英实战营——感受软件改变世界,享受Coding乐趣
机器人已经在诸多领域显现出巨大的商业价值,华为云计算致力于以云助端的方式为机器人产业带来全新机会 如果您是开发爱好者,想了解华为云,想和其他自由开发者交流经验; 如果您是学生,想和正在从事软件开发行业的大佬…...
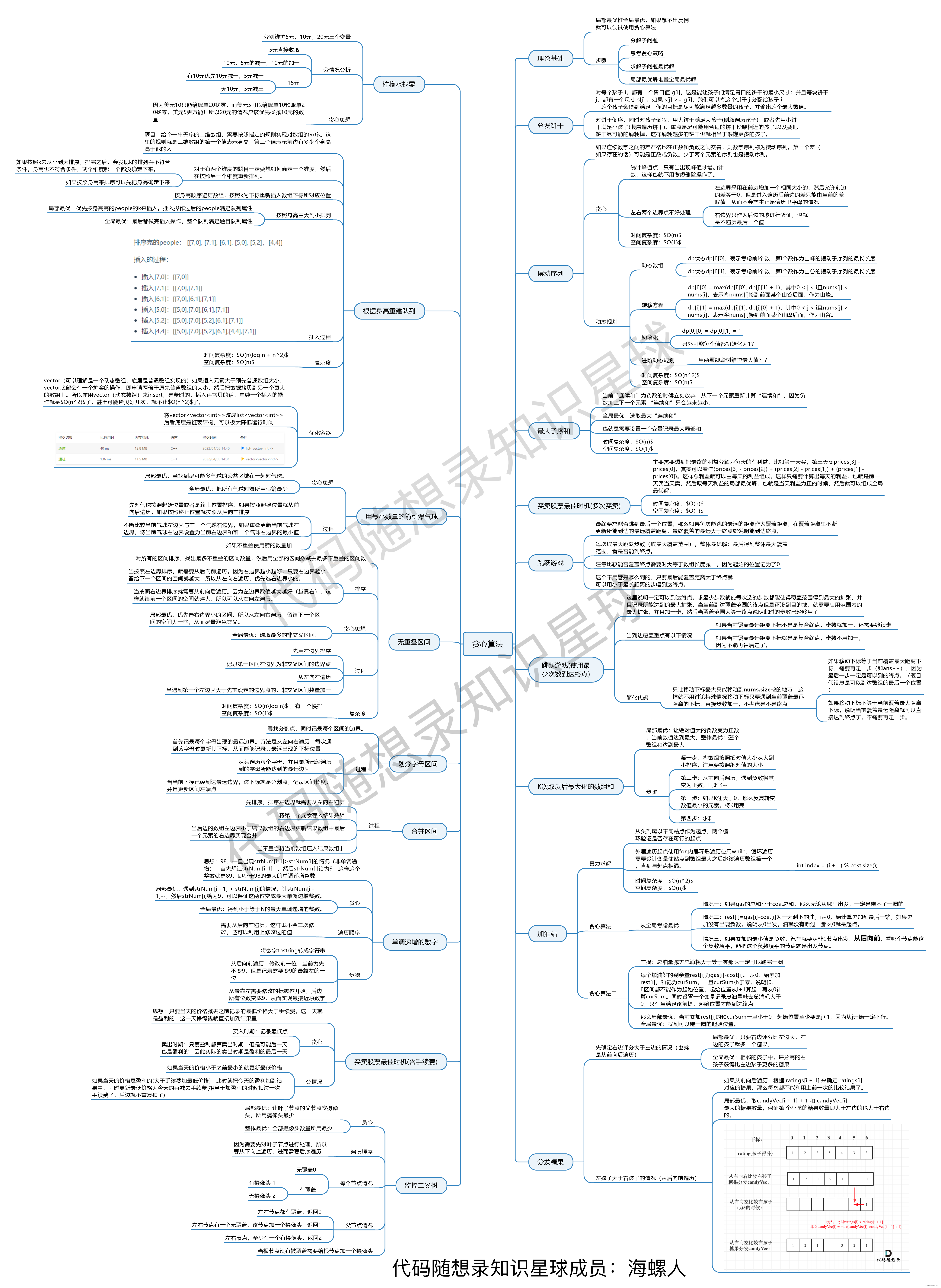
贪心算法总结篇
文章转自代码随想录 贪心算法总结篇 我刚刚开始讲解贪心系列的时候就说了,贪心系列并不打算严格的从简单到困难这么个顺序来讲解。 因为贪心的简单题可能往往过于简单甚至感觉不到贪心,如果我连续几天讲解简单的贪心,估计录友们一定会不耐…...

ICCV 2023 | 港中文MMLab: 多帧光流估计模型VideoFlow,首次实现亚像素级别误差
本文提出了一个多帧光流估计模型 VideoFlow,旨在充分挖掘视频中的时序信息和运动规律,避免当前主流方法只以两帧图片作为输入而面临的信息瓶颈,显著提升了光流估计的性能。 在公开的 Sintel Bechmark 上,VideoFlow 在 Clean 和 Fi…...
【python爬虫】—图片爬取
图片爬取 需求分析Python实现 需求分析 从https://pic.netbian.com/4kfengjing/网站爬取图片,并保存 Python实现 获取待爬取网页 def get_htmls(pageslist(range(2, 5))):"""获取待爬取网页"""pages_list []for page in pages:u…...

自动化运维工具—Ansible
一、Ansible概述1.1 Ansible是什么1.2 Ansible的特性1.3 Ansible的特点1.4 Ansible数据流向 二、Ansible 环境安装部署三、Ansible 命令行模块(1)command 模块(2)shell 模块(3)cron 模块(4&…...

3步实现AutoHotkey脚本独立运行:Ahk2Exe编译工具完全指南
3步实现AutoHotkey脚本独立运行:Ahk2Exe编译工具完全指南 【免费下载链接】Ahk2Exe Official AutoHotkey script compiler - written itself in AutoHotkey 项目地址: https://gitcode.com/gh_mirrors/ah/Ahk2Exe 你是否厌倦了每次运行AutoHotkey脚本都需要安…...

GEO优化实操框架:GEO优化的正确姿势是“带着答案去找客户”
如果你是B2B企业的老板或市场负责人,你一定听过这句话: “我们网上曝光是不少,但来的询盘都不对——问价格的比问方案的还多,还有不少是学生做调研的。” 这不是你一个人遇到的问题。这是传统SEO和竞价广告的天然缺陷——你只能“…...

【低功耗蓝牙】④ 蓝牙MIDI协议:从ESP32 MicroPython代码到智能乐器DIY
1. 蓝牙MIDI协议入门:从音乐小白到智能乐器开发者 第一次听说蓝牙MIDI协议时,我正盯着桌上的ESP32开发板发呆。作为一个只会弹几个和弦的编程爱好者,完全没想到自己能用代码"演奏"音乐。蓝牙MIDI就像音乐世界的通用语言,…...

抖音批量下载神器:5分钟学会免费高效下载视频、音乐和直播
抖音批量下载神器:5分钟学会免费高效下载视频、音乐和直播 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback s…...

Linuxbonding链路生产排障流程
Linuxbonding链路生产排障流程这是一篇面向中级 Linux 使用者的技术文章,主题聚焦在bonding链路,重点讨论链路聚合、冗余切换和接口状态。在真实生产环境中,bonding链路相关问题往往不会以单一错误形式出现,而是混杂在日志、权限、…...

番茄小说下载器:打造属于你的个人数字图书馆终极指南
番茄小说下载器:打造属于你的个人数字图书馆终极指南 【免费下载链接】fanqienovel-downloader 下载番茄小说 项目地址: https://gitcode.com/gh_mirrors/fa/fanqienovel-downloader 你是否曾经遇到过这样的场景?深夜追更小说时网络突然断线&…...

CompressO:终极跨平台视频图片压缩神器,轻松解决存储难题
CompressO:终极跨平台视频图片压缩神器,轻松解决存储难题 【免费下载链接】compressO Convert any video/image into a tiny size. 100% free & open-source. Available for Mac, Windows & Linux. 项目地址: https://gitcode.com/gh_mirrors/…...
:含12组经大英博物馆湿版藏品验证的Reference Prompt库)
Midjourney湿版摄影风格实战手册(从胶片化学原理到Prompt工程):含12组经大英博物馆湿版藏品验证的Reference Prompt库
更多请点击: https://intelliparadigm.com 第一章:湿版摄影的历史溯源与Midjourney风格化转译本质 湿版摄影(Wet Plate Collodion Process)诞生于1851年,由弗雷德里克斯科特阿彻(Frederick Scott Archer&a…...
:多智能体沙箱与工具配置)
OpenClaw从入门到应用——工具(Tools):多智能体沙箱与工具配置
通过OpenClaw实现副业收入:《OpenClaw赚钱实录:从“养龙虾“到可持续变现的实践指南》 概述 在多智能体设置中,每个智能体现在可以拥有自己的: 沙箱配置(agents.list[].sandbox 会覆盖 agents.defaults.sandbox&…...

g1810,g3810,ip2700,g5080,g1800,ts3380,TS8380,ts6480报错5B00,P07,E08,5b02,1704,1700,5b04,佳能v6.200,亲测有用。
下载:点这里下载 备用下载:https://pan.baidu.com/s/1WrPFvdV8sq-qI3_NgO2EvA?pwd0000 常见型号如下: G系列 G1000、G1100、G1200、G1400、G1500、G1800、G1900、G1010、G1110、G1120、G1410、G1420、G1411、G1510、G1520、G1810、G1820、…...