orm_sqlalchemy总结
sqlalchemy使用总结
1 sqlalchemy ORM基础操作
官方文档:https://docs.sqlalchemy.org/en/13/orm/tutorial.html
创建连接 - 创建基类 - 创建实体类 - 创建表 - 创建session
import logging
import pymysql
from pymysql.cursors import DictCursor
import sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy import text
from sqlalchemy.orm import declarative_base
from sqlalchemy import String, Integer, Date, Column
from sqlalchemy.orm import sessionmakerlogging.basicConfig(level=logging.INFO)
ip = "127.0.0.1"
port = 9998
addr = (ip, port)kwargs = {"host": ip, "password": "cli*963.", "user": "root", "database": "test"}# pymysql操作数据库
try:with pymysql.connect(**kwargs) as conn:with conn.cursor(DictCursor) as cursor:cursor.execute("select * from tee where id=%s", args=(10,))logging.info(cursor.fetchall())
except Exception as err:logging.error(err)# 实体类的基类
Base = declarative_base()# 实体类
class Student(Base): # 表映射为类,行映射为类的实例,字段映射为属性__tablename__ = "student" # 约定的每一个实体类必须定义此属性id = Column(Integer, primary_key=True) # 字段映射为属性name = Column(String(20))age = Column(Integer, nullable=True)def __repr__(self):return "<{} id={},name={},age={}>".format(self.__class__.__name__, self.id, self.name, self.age)# 引擎,管理连接池
conn_str = "mysql+pymysql://{user}:{password}@{hostname}/{database}".format(user="root", password="cli*963.", hostname=ip, database="test") # conn_str连接字符串,约定俗成名字,最好都用这个名字。
engine = create_engine(conn_str, echo=True) # echo=True,便于在调试过程中查看生成了哪些sql语句
with engine.connect() as conn:result = conn.execute(text("select * from tee where id=10"))print(result.fetchall())# 创建表、删除表
Base.metadata.create_all(engine)
Base.metadata.drop_all(engine)# 创建Session
Session = sessionmaker(bind=engine) # Session类
session = Session() # Session实例instance, session对象线程不安全的,所以每个线程最好基于全局的Session类实例化一个
2 sqlalchemy CRUD操作
sqlalchemy的CRUD操作。
import sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy.orm import declarative_base
from sqlalchemy import String, Integer, Date, Column
from sqlalchemy.orm import sessionmakerconn_str = "mysql+pymysql://{user}:{password}@{hostname}/{database}".format(user="root", password="cli*963.", hostname=ip, database="test")
engine = create_engine(conn_str, echo=True)
Base = declarative_base()
Session = sessionmaker(bind=engine)
session = Session()class Student(Base): # 表映射为类,行映射为类的实例,字段映射为属性__tablename__ = "student" # 约定的每一个实体类必须定义此属性id = Column(Integer, primary_key=True) # 字段映射为属性name = Column(String(20))age = Column(Integer, nullable=True)def __repr__(self):return "<{} id={},name={},age={}>".format(self.__class__.__name__, self.id, self.name, self.age)# 1 增:创建记录的实例并增加到表中
try:tom = Student(name="tom")tom.age = 12session.add(tom)session.add_all([Student(name="Jerry", age=12),Student(name="Lily", age=33),Student(name="Xiao", age=21)]) # pending状态session.commit()
except Exception as err:print(err)session.rollback() # 回滚
finally:# session.close()pass# 一条记录的增加、修改状态变化分析
try:lim = Student(name="lim")lim.age = 12session.add(lim)session.commit()session.add(lim) # 注意这里,两次add,第一次add因为没有lim这一条记录,为insert语句;第二次add为update,因为存在lim这条记录了、有主键了,就对比状态有没有变化,没有任何变化,所以不做任何修改;如果对lim的属性做修改,则会有update语句。session.commit()
except Exception as err:print(err)session.rollback()
finally:# session.close()pass# 2 基础查询
print(session.query(Student).filter_by(name="tom").first())
print(session.query(Student).filter(Student.id == 1))
for instance in session.query(Student).order_by(Student.age):print(instance.name, instance.age)# 3 修改
# 修改过程:方法一、先增加后修改(上述两次add);方法二、先查询后修改(不先查后改的话,认为是insert)
# 查询:使用get方法:get方法通过主键查询
try:student = session.query(Student).get(1)student.age = 23session.add(student) # 修改update:需要先查询、再修改。 add相当于在session这里注册一下,pending状态,待session提交,有任何异常则回滚session.commit()
except Exception as err:print(err)session.rollback()
finally:# session.close()pass# 4 删除
# 删除过程:先查询后拿到主键,然后删除
try:student = session.query(Student).get(1)session.delete(student)session.commit()
except Exception as err:print(err)session.rollback()
finally:# session.close()passif __name__ == '__main__':print(sqlalchemy.__version__)
3 sqlalchemy 实体的状态分析
状态:每一个实体都有一个状态属性_sa_instance_state,其类型是sqlalchemy.orm.state.InstanceState,可以使用sqlalchemy.inspect()函数查看实体状态。
常见的状态值有transient、pending、persistent、deleted、detached。
| 状态 | 说明 |
|---|---|
persistent | 实体类尚未加入到session中,同时并没有保存到数据库中 |
transient | transient的实体被addO到session中,状态切换到pending,但它还没有flush到数据库中 |
pending | session中的实体对象对应着数据库中的真实记录。pending状态在提交成功后可以变成persistent状态,或者查询成功返回的实体也是persistent状态 |
deleted | 实体被删除且已经flush但未commit完成。《事务提交成功了,实体变成detached,事务失败,返回persistent状态 |
detached | 删除成功的实体进入这个状态 |
import sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy.orm import declarative_base
from sqlalchemy import Column, Integer, String, inspect
from sqlalchemy.orm import sessionmaker
from sqlalchemy.orm.state import InstanceStatehost = "127.0.0.1"
user = "root"
password = "cli*963."
database = "test"def show(entity):ins = inspect(entity)print("transient={}, pending={}, persistent={}, deleted={}, detached={}".format(ins.transient, ins.pending, ins.persistent, ins.deleted, ins.detached))conn_str = "mysql+pymysql://{user}:{pwd}@{hostname}/{database}".format(user=user, pwd=password, hostname=host, database=database)
engine = create_engine(conn_str, echo=True)
Base = declarative_base()class Employee(Base):__tablename__ = "employee"id = Column(Integer, primary_key=True)first_name = Column(String(20))second_name = Column(String(20))age = Column(Integer)department = Column(String(30))def __repr__(self):return "<{}(id={}, dept={}, age={}, name={})>".format(self.__class__.__name__, self.id, self.department, self.age, self.first_name + " " + self.second_name)Base.metadata.create_all(engine)
Session = sessionmaker(bind=engine)
session = Session()# 状态分析
emp = Employee(first_name="Tom", second_name="shit", age=19, department="product")
show(emp)
session.add(emp)
show(emp)
session.commit()
show(emp)
emp.age = 29
show(emp)
session.commit()
show(emp)if __name__ == '__main__':print(sqlalchemy.__version__)print(Employee.__table__)-
新建一个实体,状态是
transient临时的。 -
一旦
add()后从transient变成pending状态。成功commit()后从pending变成persistent状态。成功查询返回的实体对象,也是persistent状态。 -
persistent状态的实体,修改依然是persistent状态。 -
persistent状态的实体,删除后,flush后但没有commit,就变成deteled状态,成功提交,变为detached状态,提交失败,还原到persistent状态。 -
删除、修改操作,需要对应一个真实的记录,所以要求实体对象是
persistent状态。
4 sqlalchemy 复杂查询
4.1 各种查询方法汇总
import datetimeimport sqlalchemy
from sqlalchemy import create_engine, ForeignKey
from sqlalchemy.orm import declarative_base
from sqlalchemy import Column, Integer, String, inspect, Date, Enum
from sqlalchemy.orm import sessionmaker
from sqlalchemy.orm.state import InstanceState
import enumhost = "127.0.0.1"
user = "root"
password = "cli*963."
database = "test"class MyEnum(enum.Enum):M = "M"F = "F"def show(empys):"""打印函数"""for ins in empys:print(ins, end='\n\n')Base = declarative_base()class Employee(Base):__tablename__ = "employee"emp_no = Column(Integer, primary_key=True)birth_date = Column(Date, nullable=False)first_name = Column(String(20), nullable=False)last_name = Column(String(20), nullable=False)gender = Column(Enum(MyEnum), nullable=False)age = Column(Integer)hire_date = Column(Date, nullable=False)def __repr__(self):return "<{}(id={}, name={}, age={}, gender={})>".format(self.__class__.__name__, self.emp_no, self.first_name + " " + self.last_name, self.age, self.gender)conn_str = "mysql+pymysql://{user}:{pwd}@{hostname}/{database}".format(user=user, pwd=password, hostname=host, database=database)
engine = create_engine(conn_str, echo=True)
Base.metadata.create_all(engine)
Session = sessionmaker(bind=engine)
session = Session()
session.add_all([Employee(first_name="Tom", last_name="shit", age=19, birth_date=datetime.datetime.now(), gender=MyEnum.M, hire_date=datetime.datetime.now()),Employee(first_name="Lily", last_name="Gaga", age=18, birth_date=datetime.datetime.now(), gender=MyEnum.F, hire_date=datetime.datetime.now()),Employee(first_name="Jerry", last_name="Port", age=23, birth_date=datetime.datetime.now(), gender=MyEnum.M, hire_date=datetime.datetime.now()),Employee(first_name="Jack", last_name="Jos", age=21, birth_date=datetime.datetime.now(), gender=MyEnum.F, hire_date=datetime.datetime.now())
])
session.commit()# 1、简单查询
emps = session.query(Employee).filter(Employee.emp_no > 2)
show(emps)# 与或非
from sqlalchemy import or_, not_, and_
# and
emps = session.query(Employee).filter(and_(Employee.emp_no > 2, Employee.gender == MyEnum.M))
show(emps)
emps = session.query(Employee).filter(Employee.emp_no > 2).filter(Employee.gender == MyEnum.M)
show(emps)
show(session.query(Employee).filter((Employee.emp_no > 2) & (Employee.gender == MyEnum.M)))# or
emps = session.query(Employee).filter((Employee.emp_no > 5) | (Employee.emp_no < 2))
show(emps)
emps = session.query(Employee).filter(or_(Employee.emp_no > 5, Employee.emp_no < 2))
show(emps)# not
emps = session.query(Employee).filter(not_(Employee.emp_no > 5))
show(emps)
emps = session.query(Employee).filter(~(Employee.emp_no > 5)) # 一定注意加括号
show(emps)# in
emps_list = [1, 3, 4]
emps = session.query(Employee).filter(Employee.emp_no.in_(emps_list))
show(emps)
# not in
emps = session.query(Employee).filter(~Employee.emp_no.in_(emps_list))
show(emps)
# like
emps = session.query(Employee).filter(Employee.last_name.like("J%")) # like可以忽略大小匹配
show(emps)# 2、 排序
# 升序
show(session.query(Employee).filter(Employee.emp_no > 3).order_by(Employee.emp_no))
show(session.query(Employee).filter(Employee.emp_no > 3).order_by(Employee.emp_no).asc())
# 降序
show(session.query(Employee).filter(Employee.emp_no > 3).order_by(Employee.emp_no).desc())
# 多列排序
show(session.query(Employee).filter(Employee.emp_no > 3).order_by(Employee.emp_no).order_by(Employee.last_name).desc())# 3、分页
show(session.query(Employee).limit(4))
show(session.query(Employee).limit(4).offset(6))# 3、消费者方法:消费者方法调用后,query对象转换成一个容器
# 总行数
emps = session.query(Employee)
print(len(list(emps))) # 返回大量结果集,然后转换为list
print(emps.count()) # 聚合函数count(*)的查询。使用聚合函数取总行数效率更高更合理
# 取所有数据
print(emps.all())
# 取一行
print(emps.one()) # 返回一行,如果查询结果是多行会抛异常
print(emps.limit(1).one())
# 删除
session.query(Employee).filter(Employee.emp_no < 3).delete()
# session.commit() # 提交则删除# 4、聚合、分组
# 聚合函数
from sqlalchemy import func
query = session.query(func.count(Employee.emp_no))
print(query.one()) # 只能有一行结果
print(query.scalar()) # 取one()返回元组的第一个元素
# max/min/avg
print(session.query(func.max(Employee.emp_no)).scalar())
print(session.query(func.min(Employee.emp_no)).scalar())
print(session.query(func.avg(Employee.emp_no)).scalar())
# 分组
print(session.query(func.count(Employee.emp_no)).group_by(Employee.gender).a11())if __name__ == '__main__':print(sqlalchemy.__version__)print(Employee.__table__)
4.2 关联查询
根据下列三张表,查询10010号员工的所在部门编号:
CREATE TABLE `employees` (`emp_no` int(11) NOT NULL,`birth_date` date NOT NULL,`first_name` varchar(14) NOT NULL,`last_name` varchar(16) NOT NULL,`gender` enum('M','F') NOT NULL,`hire_date` date NOT NULL,PRIMARY KEY (`emp_no`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3;CREATE TABLE `departments` (`dept_no` char(4) NOT NULL,`dept_name` varchar(40) NOT NULL,PRIMARY KEY (`dept_no`),UNIQUE KEY `dept_name` (`dept_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3;CREATE TABLE `dept_emp` (`emp_no` int(11) NOT NULL,`dept_no` char(4) NOT NULL,`from_date` date NOT NULL,`to_date` date NOT NULL,PRIMARY KEY (`emp_no`,`dept_no`),KEY `dept_no` (`dept_no`),CONSTRAINT `dept_emp_ibfk_1` FOREIGN KEY (`emp_no`) REFERENCES `employees` (`emp_no`) ON DELETE CASCADE,CONSTRAINT `dept_emp_ibfk_2` FOREIGN KEY (`dept_no`) REFERENCES `departments` (`dept_no`) ON DELETE CASCADE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3;从语句可以看出,员工、部门之间的关系是多对多的关系。先把这些表的Model类和字段属性建立起来。
使用ForeignKey(“employees.emp_no”, ondelete=“CASCADE”), 定义外键约束
需求: 查询10010号员工的所在部门编号:
from sqlalchemy import create_engine, ForeignKey
from sqlalchemy.orm import declarative_base
from sqlalchemy import Column, Integer, String, Date, Enum
from sqlalchemy.orm import sessionmaker
import enum
from sqlalchemy.orm import relationshiphost = "127.0.0.1"
user = "root"
password = "cli*963."
database = "test"class MyEnum(enum.Enum):M = "M"F = "F"def show(empys):"""打印函数"""for ins in empys:print(ins, end='\n\n')Base = declarative_base()
conn_str = "mysql+pymysql://{user}:{pwd}@{hostname}/{database}".format(user=user, pwd=password, hostname=host, database=database)
engine = create_engine(conn_str, echo=True)
Base.metadata.create_all(engine)
Session = sessionmaker(bind=engine)
session = Session()class Employees(Base):__tablename__ = "employees"emp_no = Column(Integer, primary_key=True)birth_date = Column(Date, nullable=False)first_name = Column(String(20), nullable=False)last_name = Column(String(20), nullable=False)gender = Column(Enum(MyEnum), nullable=False)# age = Column("age", Integer) # 第一个参数是字段名,如果属性名与字段名不一致,一定要指定字段名。hire_date = Column(Date, nullable=False)def __repr__(self):return "<{}(id={}, name={}, gender={})>".format(self.__class__.__name__, self.emp_no, self.first_name + " " + self.last_name, self.gender)class Departments(Base):__tablename__ = "departments"dept_no = Column(String(4), primary_key=True)dept_name = Column(String(40), nullable=False, unique=True)def __repr__(self):return "<{}(dept_no={}, dept_name={})>".format(self.__class__.__name__, self.dept_no, self.dept_name)class DeptEmp(Base):__tablename__ = "dept_emp"emp_no = Column(Integer, ForeignKey("employees.emp_no", ondelete="CASCADE"), primary_key=True)dept_no = Column(String(4), ForeignKey("departments.dept_no", ondelete="CASCADE"), primary_key=True)from_date = Column(Date, nullable=False)to_date = Column(Date, nullable=False)def __repr__(self):return "<{}(dept_no={}, emp_no={})>".format(self.__class__.__name__, self.dept_no, self.emp_no)# 需求:查询10010号员工的所在部门编号
# 1、使用隐式内连接
res = session.query(Employees, DeptEmp).filter(Employees.emp_no == DeptEmp.emp_no).filter(Employees.emp_no == 10010).all()
show(res)
# 查询结果
# (Employee no=10010 name=Duangkaew Piveteau gender=F, Dept_emp empno-10010 deptno=d004)
# (Employee no=10010 name=Duangkaew Piveteau gender=F, Dept_emp empno=10010 deptno=d006)
# 这种方式产生隐式连接语句:
# SELECT * FROM employees, dept_emp WHERE employees.emp_no = dept_emp.emp_no AND employees.emp_no = %(emp_no_1)s;# 2、使用join
# 第一种写法:不推荐,由ORM来查找内连接,有风险
show(session.query(Employees).join(DeptEmp).filter(Employees.emp_no == 10010).all())
# 第二种写法:
show(session.query(Employees).join(DeptEmp, Employees.emp_no == DeptEmp.emp_no).filter(Employees.emp_no == 10010).all())# 这两种写法,返回都只有一行数据,为什么?
# 原因在于query(Employee)这个只能返回一个实体对象中去,为了解决这个问题,需要修改实体类Employee,增加属性用来存放部门信息
# sqlalchemy.orm.relationship(实体类名字符串)
class Employees1(Employees):dept_emps = relationship("DeptEmp") # tells the ORM that the Address class itself should be linked to the User class,def __repr__(self):return "<{}(id={}, name={}, age={}, gender={}, no={})>".format(self.__class__.__name__, self.emp_no, self.first_name + " " + self.last_name, self.age, self.gender,self.dept_emps)results = session.query(Employees).join(DeptEmp, (Employees1.emp_no == DeptEmp.emp_no)&(Employees1.emp_no == 10010))
show(results.all())
-
第一种方法join(DeptEmp)中没有等值条件,会自动生成一个等值条件,如果后面有fiter,哪怕是filter(Employees.emp_no==DeptEmp.emp_no),这个条件会在where中出现。第一种这种自动增加join的等值条件的方式不好,不要这么写
-
第二种方法在join中增加等值条件,阳止了自动的等值条件的生成。这种方式推荐
-
第三种方法就是第二种,这种方式也可以。
相关文章:

orm_sqlalchemy总结
sqlalchemy使用总结 1 sqlalchemy ORM基础操作 官方文档:https://docs.sqlalchemy.org/en/13/orm/tutorial.html 创建连接 - 创建基类 - 创建实体类 - 创建表 - 创建session import logging import pymysql from pymysql.cursors import DictCursor import sqla…...
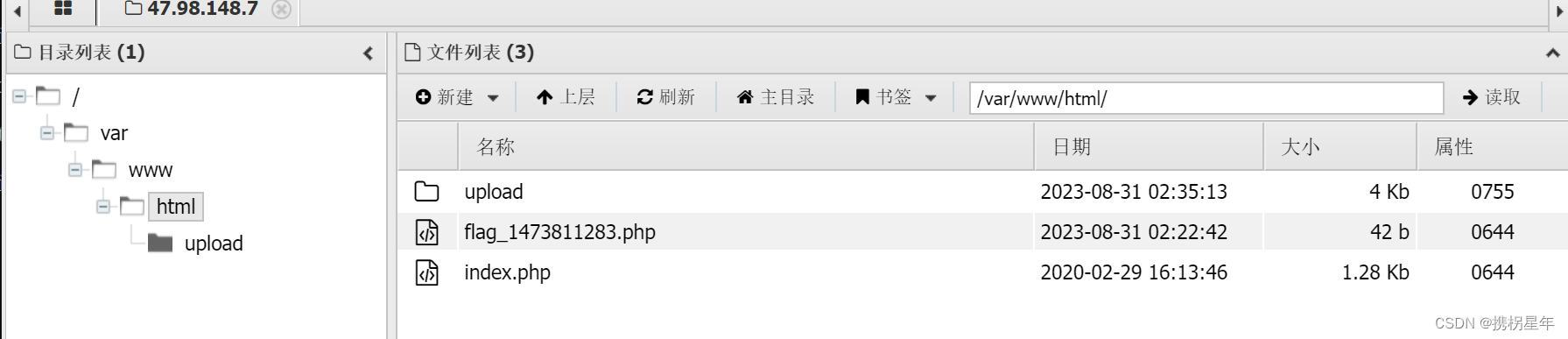
CTFhub-文件上传-MIME绕过
用哥斯拉生成 php 木马文件 1.php 抓包---> 修改 conten-type 类型 为 imge/jpeg 用蚁剑连接 ctfhub{8e6af8109ca15932bad4747a}...

【校招VIP】前端校招考点之UDP
考点介绍: UDP是非面向连接协议,使用udp协议通讯并不需要建立连接,它只负责把数据尽可能发送出去,并不可靠,在接收端,UDP把每个消息断放入队列中,接收端程序从队列中读取数据。 『前端校招考点…...
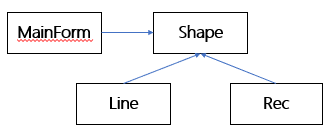
C++设计模式_02_面向对象设计原则
文章目录 1. 面向对象设计,为什么?2. 重新认识面向对象3. 面向对象设计原则3.1 依赖倒置原则(DIP)3.2 开放封闭原则(OCP )3.3 单一职责原则( SRP )3.4 Liskov 替换原则 ( LSP )3.5 接口隔离原则 ( ISP )3.6 优先使用对象组合,而不是类继承3.7…...
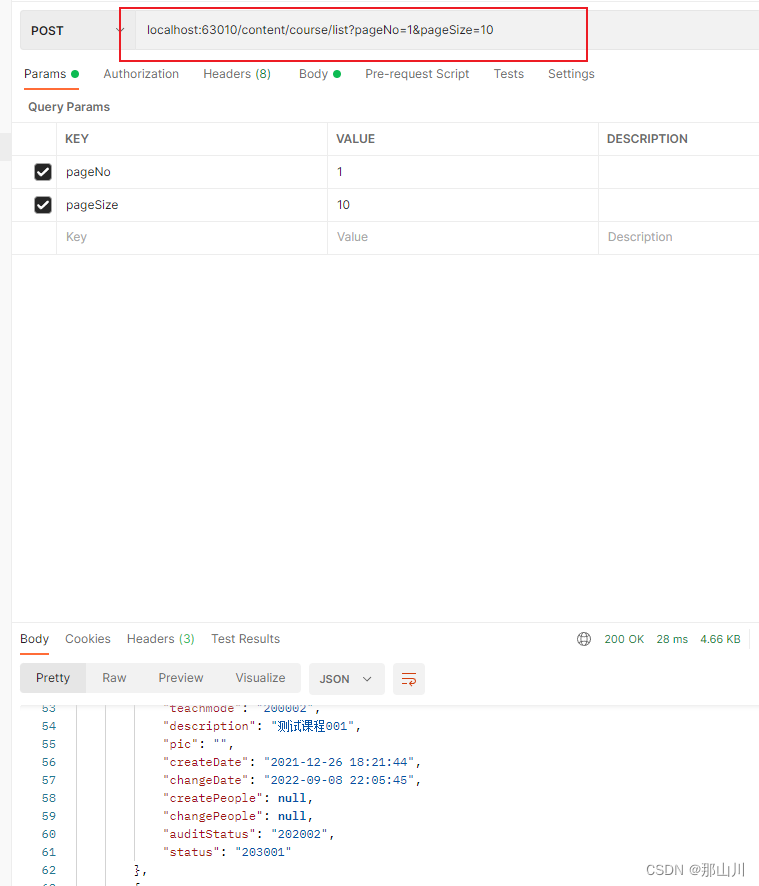
springcloud-gateway简述
Spring Cloud Gateway 是一个用于构建 API 网关的项目,它是 Spring Cloud 生态系统中的一部分,旨在为微服务架构提供动态路由、负载均衡、安全性和监控等功能。 网关工程对应pom文件 <?xml version"1.0" encoding"UTF-8"?>…...
【大虾送书第七期】深入浅出SSD:固态存储核心技术、原理与实战
目录 ✨写在前面 ✨内容简介 ✨作者简介 ✨名人推荐 ✨文末福利 🦐博客主页:大虾好吃吗的博客 🦐专栏地址:免费送书活动专栏地址 写在前面 近年来国家大力支持半导体行业,鼓励自主创新,中国SSD技术和产业…...

常见矿石材质鉴定VR实训模拟操作平台提高学员的学习效果和实践能力
随着“元宇宙”概念的不断发展,在矿山领域中,长期存在传统培训内容不够丰富、教学方式单一、资源消耗大等缺点,无法适应当前矿山企业发展需求的长期难题。元宇宙企业借助VR虚拟现实、web3d开发和计算机技术构建的一个虚拟世界,为用…...

Verilog 学习路线
参考知乎 首先得学习数电和 Verilog 基础。 常问的 Verilog 基础 二分频是怎么写的 阻塞和非阻塞及其应用 写一个100MHz的时钟 Reg 和 wire 的区别 Logic 和 wire 的区别,两者可以转换吗 用你最擅长的语言找出1-100的质数 一个最简单的八位加法器应该怎么验…...
前端三剑客中简单的两个:HTMLCSS
HTML&CSS 1,HTML1.1 介绍1.2 快速入门1.3 基础标签1.3.1 标题标签1.3.2 hr标签1.3.3 字体标签 1.4 图片、音频、视频标签1.5 超链接标签1.6 列表标签1.7 表格标签1.8 布局标签1.9 表单标签1.9.1 表单标签概述1.9.2 form标签属性1.9.3 代码演示 1.10 表单项标签 …...
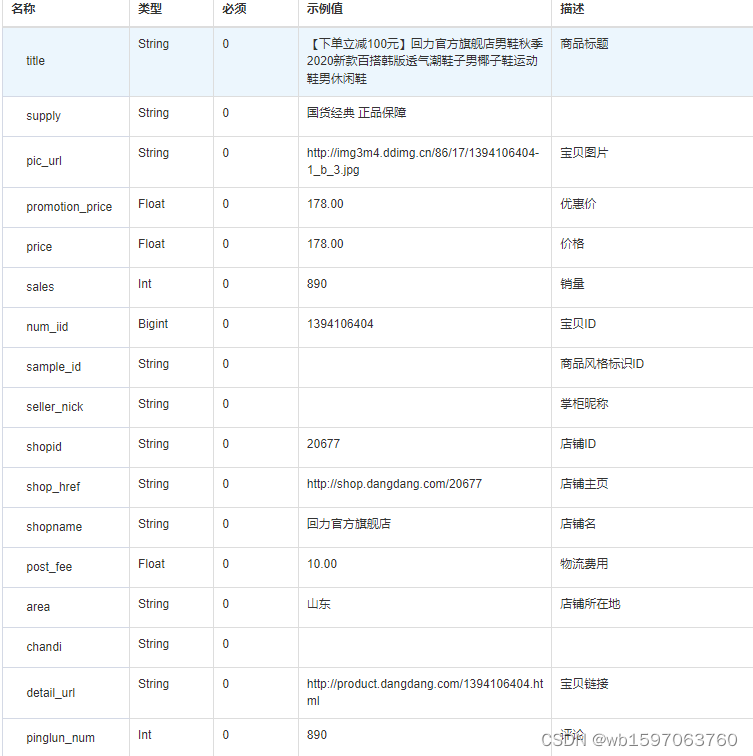
Java实现根据关键词搜索当当商品列表数据方法,当当API接口申请指南
要通过当当网的API获取商品列表数据,您可以使用当当开放平台提供的接口来实现。以下是一种使用Java编程语言实现的示例,展示如何通过当当开放平台API获取商品列表: 首先,确保您已注册成为当当开放平台的开发者,并创建…...

【HBZ分享】TCP可靠性传输如何保证的?
ACK机制 ACK机制是发送方与接收方的一个相互确认客户端向服务端发送连接请求,此时服务端要回馈给客户端ACK,以表示服务端接到了客户端请求,这是第一和的第二次握手客户端接收到服务端响应后,同样也要回馈服务端的响应,…...
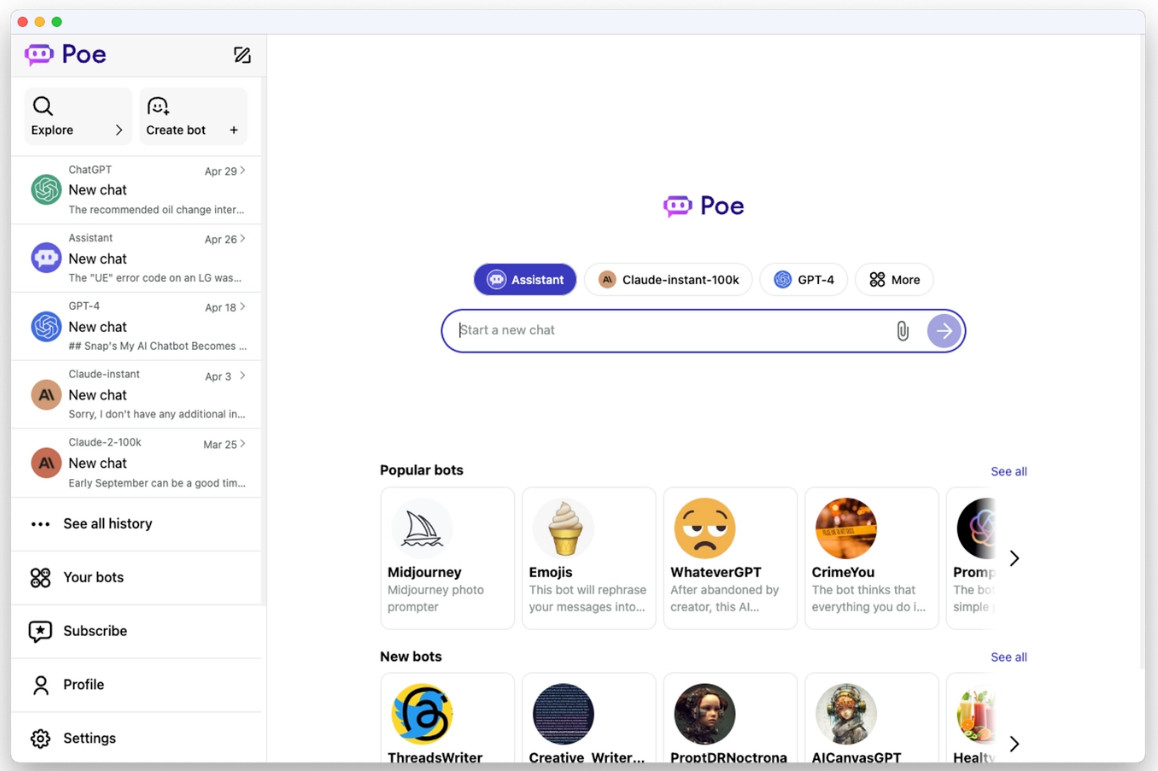
AI聊天机器人平台Poe发布更新;自然语言理解课程概要
🦉 AI新闻 🚀 AI聊天机器人平台Poe发布更新 突破功能限制 增加企业级服务 摘要:知名问答网站Quora旗下的AI聊天机器人平台Poe发布了一系列更新,包括推出Mac应用、支持同时进行多个对话、接入Meta的Llama 2模型等功能。用户只需支…...
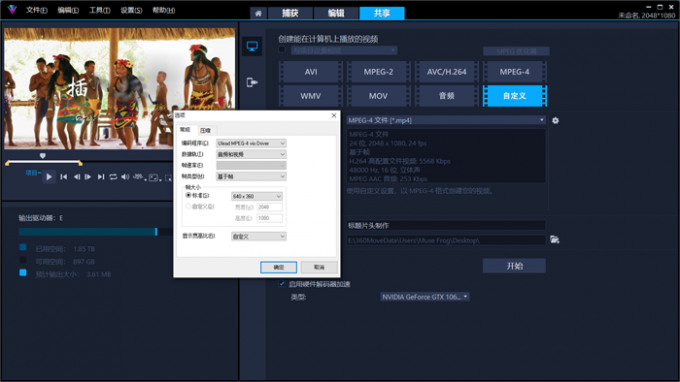
电脑视频编辑软件前十名 电脑视频编辑器怎么剪辑视频
对于大多数创作者而言,视频后期工作基本都是在剪辑软件上进行的。一款适合自己的视频剪辑软件,能够节省出大量的时间和金钱成本,让剪辑师省钱又省心。那么有关电脑视频编辑软件前十名,电脑视频编辑器怎么剪辑视频的相关问题&#…...

Springboot整合AOP和注解实现日志记录——Java入职第十二天
前言 作为java开发工程师,日常curd工作少不了,特别是后台系统的操作,对于每一项操作我们都要记录,所以就得有操作日志,操作日志能够排除是开发的锅,是运营或者产品自己操作的。那么就有个问题,每次在业务处理最后,调用操作日志服务保存响应的日志,但是这段代码是很冗余…...

shell脚本监控ip和端口的运行状态并触发邮件告警
ping端口shell代码 ping不通发邮件通知 直到ping通再次发送成功邮件 #!/bin/bash Datedate -d "today" "%Y-%m-%dT%H-%M-%S" #echo "根据当前时间创建日志文件" mkdir -p /log/Ping/ping_server touch /log/Ping/${Date}_ping_server.log ip_li…...
二三维电子沙盘数字沙盘虚拟现实开发教程第14课
二三维电子沙盘数字沙盘开发教程第14课 很久没有写了,主要前段时间在针对怎么显示高精度的 倾斜数据而努力,现在终于实现了效果不错。以前的版本显示倾斜数据控制不太好。 对了。目前系统暂只支持smart3d生成的kml格式的数据,由专有的录入程…...
如何五分钟设计制作自己的蛋糕店小程序
在现如今的互联网时代,小程序已成为企业推广和销售的重要利器。对于蛋糕店来说,搭建一个小程序可以为其带来更多的品牌曝光和销售渠道。下面,我们将以乔拓云平台为例,来教你如何从零开始搭建自己的蛋糕店小程序。 首先,…...
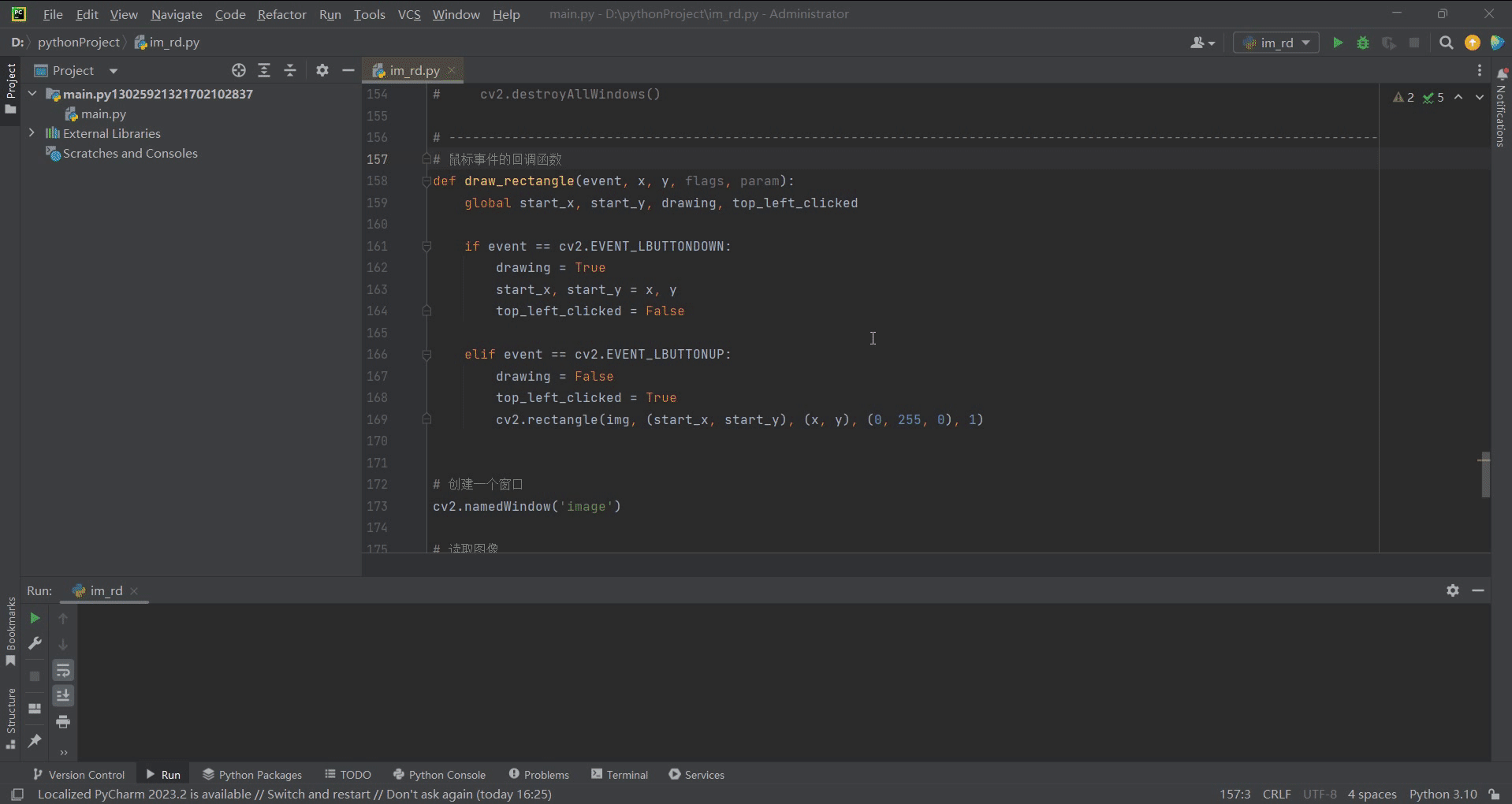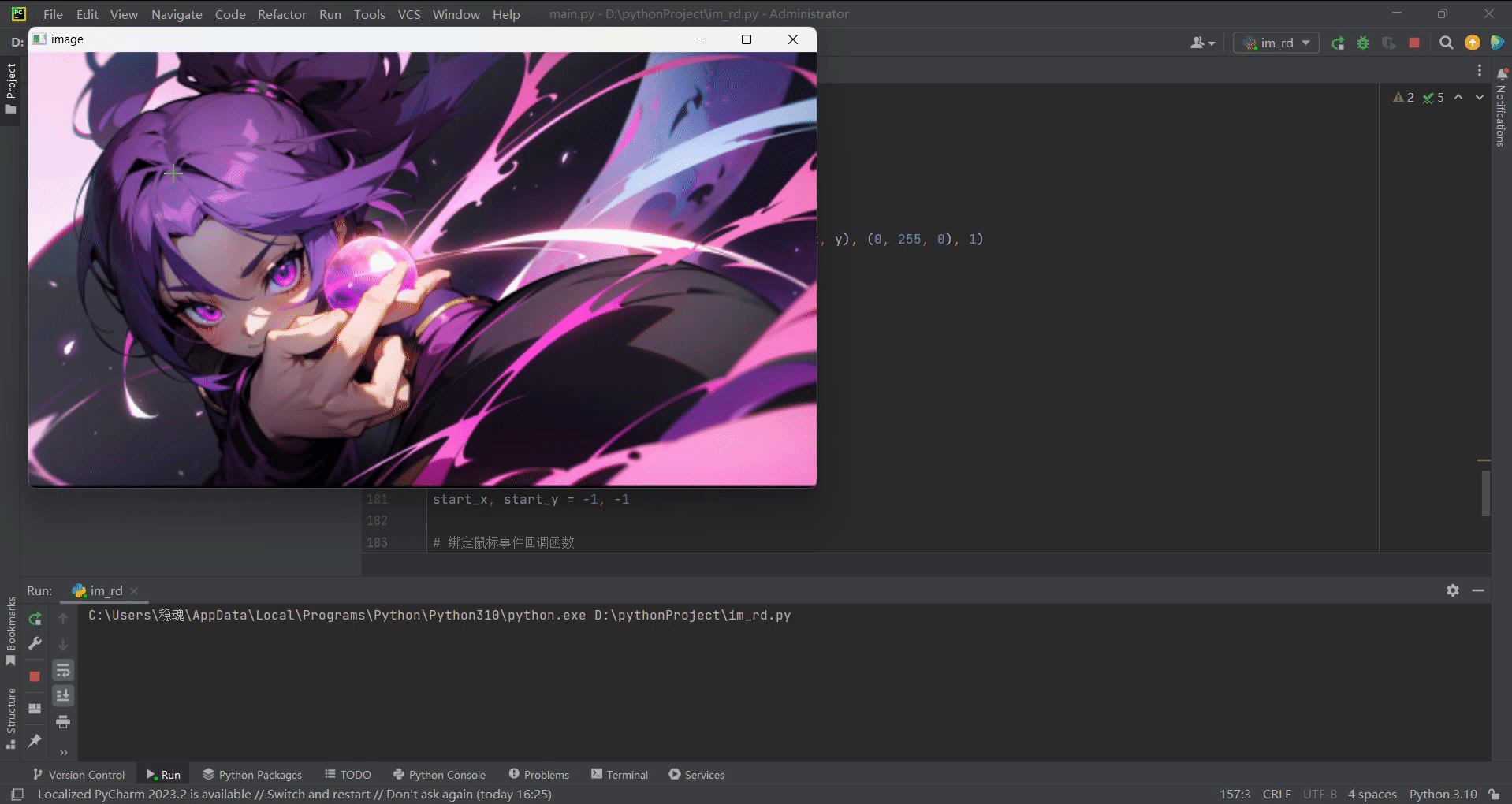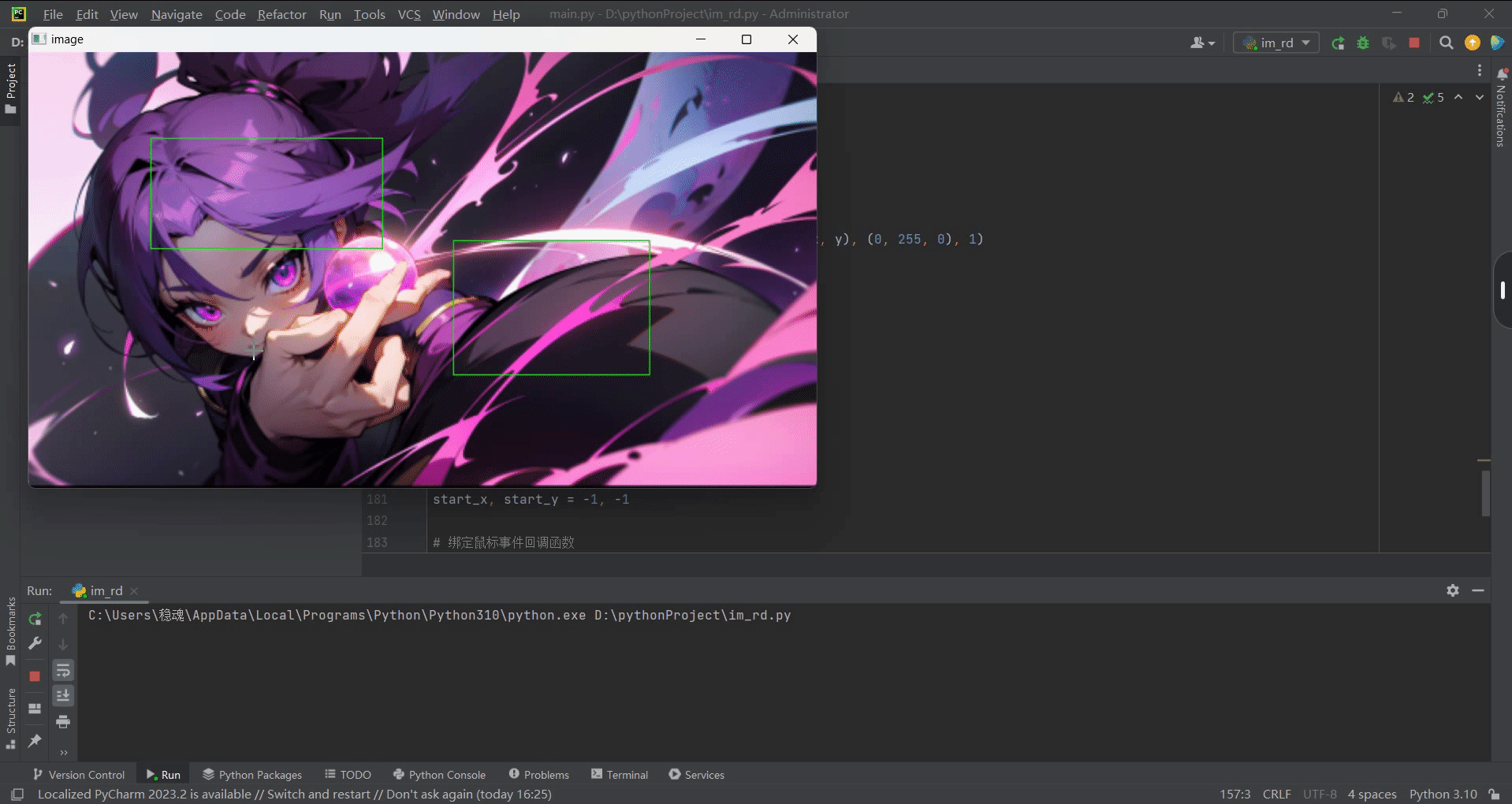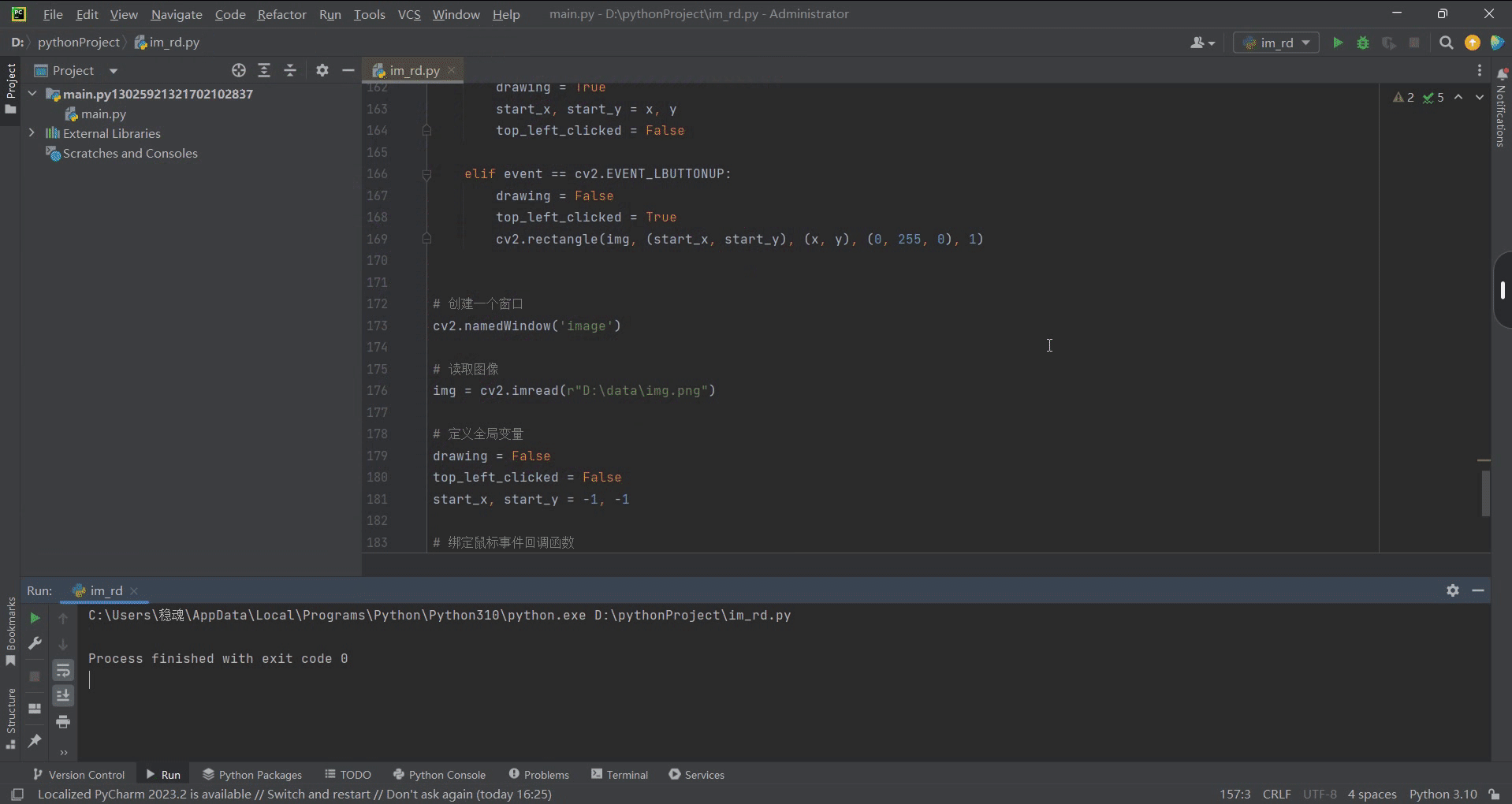
(笔记二)利用opencv调用鼠标事件在图像上绘制图形
目录 (1)查看cv2所支持的鼠标事件(2)通过鼠标事件在图像上做标记(3)高级操作:通过移动鼠标在图像绘制图形、曲线 该功能主要创建一个鼠标事件发生时执行的回调函数。鼠标事件可以是任何与鼠标有…...
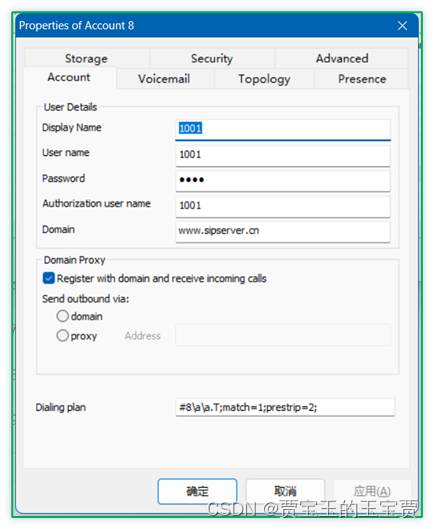
FreeSWITCH 1.10.10 简单图形化界面4 - 腾讯云NAT设置
FreeSWITCH 1.10.10 简单图形化界面4 - 腾讯云NAT设置 0、 界面预览1、 查看IP地址2、 修改协议配置3、 开放腾讯云防火墙4、 设置ACL5、 设置协议中ACL,让PBX匹配内外网6、 重新加载SIP模块7、 查看状态8、 测试一下 0、 界面预览 http://myfs.f3322.net:8020/ 用…...

Debezium系列之:Debezium Server Offset编辑器
Debezium系列之:Debezium Server Offset编辑器 一、认识Offset编辑器二、Offset编辑器目录结构三、Offset编辑器系统环境要求四、pom.xml五、Main.java六、CommandLineInterface.java七、OffsetFileController.java八、OffsetEditorApp.java九、编译项目十、启动Offset编辑器一…...

穿越机老鸟踩坑实录:MPU6000传感器在F4飞控上的IMU方向“玄学”配置
穿越机IMU方向配置实战:从MPU6000异常自旋到飞控底层校准 当你的穿越机在通电瞬间像被无形大手狠狠抽了一记耳光般疯狂自旋,而Betaflight地面站里陀螺仪数据却显示"一切正常"时,这往往意味着你正遭遇IMU方向配置的"量子纠缠态…...

SmarterRouter:基于软件定义与模块化构建智能路由器系统
1. 项目概述:一个更聪明的路由器,它到底想做什么?如果你和我一样,折腾过家里的网络,从刷第三方固件到组软路由,那你肯定对“路由器”这三个字有复杂的感情。它本该是默默无闻的网络基石,却常常因…...

工作流编排核心原理与实践:从概念到MiniFlow系统实现
1. 项目概述:从代码仓库到工作流编排的实践最近在梳理团队内部的一些自动化流程,发现很多脚本和任务散落在各个角落,执行依赖混乱,出了问题排查起来像大海捞针。正好看到GitHub上有个叫dnh33/workflow-orchestration的项目&#x…...

终极ThinkPad风扇控制指南:告别噪音,拥抱静音高效
终极ThinkPad风扇控制指南:告别噪音,拥抱静音高效 【免费下载链接】TPFanCtrl2 ThinkPad Fan Control 2 (Dual Fan) for Windows 10 and 11 项目地址: https://gitcode.com/gh_mirrors/tp/TPFanCtrl2 你是否曾经因为ThinkPad风扇的"直升机起…...

从仿生结构到步态算法:8自由度并联腿机器狗行走全解析
1. 8自由度并联腿机器狗的结构奥秘 第一次拆解机器狗时,我对着那些复杂的连杆结构发了半小时呆。直到发现它的腿部运动原理和公园里的跷跷板惊人相似——这个发现让我瞬间理解了8自由度并联腿的精妙之处。这种结构就像给机器人装上了"机械肌腱"࿰…...

开源技能安全仪表盘:从架构解析到CI/CD集成的DevSecOps实践
1. 项目概述:一个面向技能开发者的安全仪表盘最近在折腾一些智能设备上的技能开发,发现一个挺普遍但容易被忽视的问题:我们花大量时间在功能实现和用户体验上,但技能本身的安全性评估,往往只能等到上线后,通…...

Arduino与手机蓝牙通信:nRF8001 BLE模块硬件连接与软件配置全解析
1. 项目概述与核心价值如果你手头有一个Arduino项目,想让它和你的手机“说说话”,比如把传感器数据无线传到手机App上显示,或者用手机App远程控制几个LED灯,那么nRF8001这个蓝牙低功耗(BLE)模块绝对是你绕不…...

基于CircuitPython与加速度计的魔法9号球:嵌入式交互项目实践
1. 项目概述:当硬件遇上玄学,用代码打造你的专属“决策神器”在嵌入式开发的世界里,我们常常与传感器、显示屏和逻辑代码打交道,构建着一个个解决实际问题的智能设备。但谁说硬件项目就一定要严肃刻板?今天,…...

Claude模型思维链评估框架claweval:原理、实战与高级定制指南
1. 项目概述:一个专为Claude模型设计的“思维链”评估框架最近在AI应用开发圈里,一个名为claweval的项目开始被频繁提及。如果你正在使用Anthropic的Claude系列模型(无论是Claude 3 Opus、Sonnet还是Haiku)来构建需要复杂推理能力…...

动态提示词工程:让AI提示词具备上下文学习能力的实践指南
1. 项目概述:当提示词遇上上下文学习最近在折腾大语言模型应用时,我反复遇到一个痛点:精心设计的提示词(Prompt)在特定任务上效果拔群,但换个场景或数据,效果就大打折扣。每次都得重新调整、测试…...