Go语言入门记录:从基础到变量、函数、控制语句、包引用、interface、panic、go协程、Channel、sync下的waitGroup和Once等
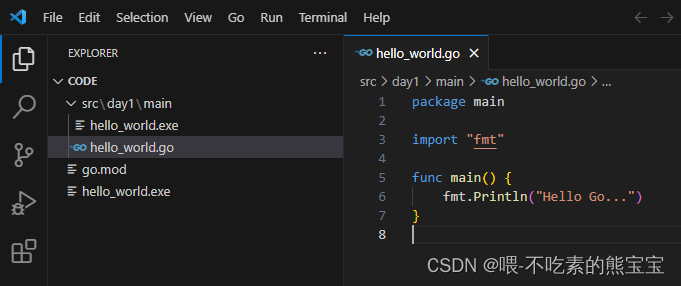
- 程序入口文件的包名必须是main,但主程序文件所在文件夹名称不必须是
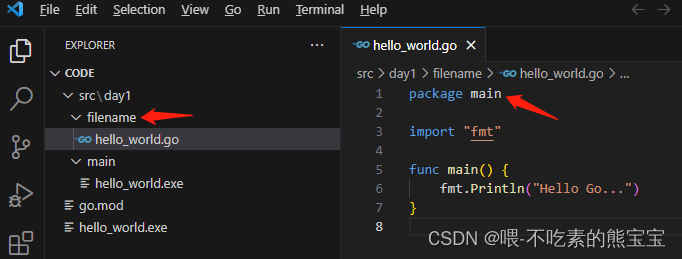
main,即我们下图hello_world.go在main中,所以感觉package main写顺理成章,但是如果我们把main目录名称改成随便的名字如filename也是可以运行的,所以迷思就在于写在文件开头的那个package main和java中不是一个概念。主程序中函数是固定的。运行这个文件用go run hello_world.go,使用go build hello_world.go会在同目录下生成一个执行文件,在windows上就是一个同名的exe文件,如hello_world.exe,使用.\hello_world.exe也可以执行得到结果。
main函数没有参数,但它可直接通过os.Args获取,os.Args是个数组,如以下代码:
package mainimport ("fmt""os"
)func main() {fmt.Println(os.Args)if len(os.Args) > 1 {fmt.Println("Hello Go...", os.Args[1])}os.Exit(0)
}
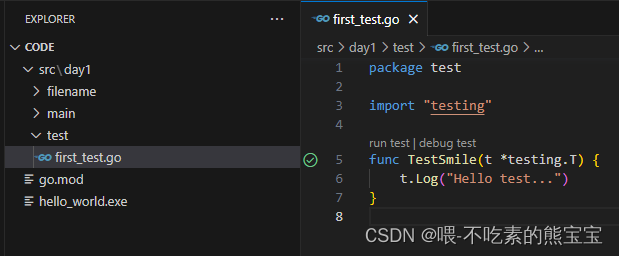
- 快速测试的方法,单元测试。文件名用
_test.go结尾,方法用TestXXX开头。包名和其他不论。在VS Code中左边会有一个按钮,点击即可测试,在其他编辑器中,可能点击保存就会运行。
- 以下是变量使用方法。go支持变量类型推断,即可以省略类型定义。
func TestFib(t *testing.T) {var a inta = 1var b int = 1// var (// a int// b int = 1// )t.Log(a)for i := 1; i < 10; i++ {t.Log(b)tmp := aa = bb = tmp + a}
}
以下这个一句语句对多个变量赋值也是常用交换功能了:
func TestSwap(t *testing.T) {a := 1b := 2a, b = b, at.Log(a, b)
}
- 常量使用。注意
iota是个语法糖,出现时会被设置位0,代码运行到下一行时iota自动加1,所以以下用到它的代码定义的常量是左移操作,每次乘以2。
const (Monday = 1Tuesday = 2
)const (Friday = 1 << iotaSaturdaySunday
)const ttt int = 1func TestWeekDay(t *testing.T) {t.Log(ttt)t.Log(Monday, Tuesday)t.Log(Friday, Saturday, Sunday)a := 7 // 0111t.Log(a&Friday == Friday, a&Saturday == Saturday, a&Sunday == Sunday)
}
- 基本数据类型后面会添加位数,C#和其他语言中也会有部分影子。注意的是go不支持数据类型
隐式转换。
bool
string
uint8 uint16 uint32 uint64 int8 int16 int32 int64
float32、float64
complex64 complex128
byte 类似 uint8
rune 类似 int32
uint:32 或 64 位
uintptr:无符号整型,用于存放一个指针// 非要转换的话,就显示转换
b = int64(a)
go语言的指针不支持运算
func TestPointer(t *testing.T) {a := 1aPtr := &a// aPtr = aPtr + 1 // 不支持指针运算t.Log(a, aPtr) //1 0xc000018320t.Logf("%T %T", a, aPtr) //int *int
}
string默认是空字符串,而不是null或nil。
func TestString(t *testing.T) {var s stringt.Log("*" + s + "*") //**t.Log(s == "") //true
}
- go中没有前置的自增和自减,之后后置的
a++和a--。go中数组的比较不是比较引用地址,而是直接比较数组长度和值,只有数组长度相同才能比较,不然直接编译报错,其次每个元素都相等,数组才相等。
func TestArray(t *testing.T) {a := [...]int{1, 2, 3, 4}//b := [...]int{1, 2, 3, 4, 5}c := [...]int{1, 2, 3, 4}d := [...]int{1, 2, 3, 5}//t.Log(a == b) // 直接编译报错t.Log(a == c) //truet.Log(a == d) //false
}
有个按位清零的运算符&^,即当右边运算数的位为1时结果直接清零,如果是0则左边运算数的位是什么结果就是什么。相当于右边操作数对左边操作数定向位清零。
a := 7 // 0111
Readable := 1 << 0 // 00000001
a = a &^ Readable // 结果是0110赋值给a
- 控制语句。go语言关键字很少大概20多个,这体现在它的循环只有for循环一种。
n := 0
for n < 5 {n++...
}// 无限循环
for {...
}// 条件语句
if a == b {
} else if c == d {
} else {
}
// 比较特殊的是if后面可以有赋值和条件,如前面定义个a后面条件就用这个a
if res,err := someFunc(), err == nil {// 如果错误为空,即返回正确则...
} else {
}// switch不局限于常量或整数,还可以充当if的角色,case后面可以写多个匹配项,以省略break。
switch i {case 0,2: // 可以多个项... // 可以省略breakcase 1:...default:...
}
switch {case i > 1 && i < 3: // 类似if判断语句...default:....
}
- 数组相关。
func TestArrayLearning(t *testing.T) {var a [3]inta[0] = 1t.Log(a) // [1 0 0]arr1 := [4]int{1, 2, 3}t.Log(arr1) // [1 2 3 0] 没赋值的初始化为0arr2 := [...]int{1, 3, 5, 7}t.Log(arr2) //[...]表示数组长度会按照后面的值得数量初始化for i := 0; i < len(arr2); i++ {t.Log(arr2[i])}// 快捷方法for idx, v := range arr2 {t.Log(idx, v)}// 如果不要索引,则用下划线占位,不能直接去掉,不然报错for _, v := range arr2 {t.Log(v)}// 包含开始,不包含结束t.Log(arr2[1:3]) //[3 5]t.Log(arr2[1:]) //[3 5 7]t.Log(arr2[:3]) //[1 3 5]
}
- 切片相关。
func TestSlice(t *testing.T) {var s0 []intt.Log(len(s0), cap(s0)) //0s0 = append(s0, 1)t.Log(len(s0), cap(s0)) //1 1s1 := []int{1, 2, 3, 4}t.Log(len(s1), cap(s1)) //4 4s2 := make([]int, 3, 5)//t.Log(s2[0], s2[1], s2[2], s2[3])// 会报错,因为虽然初始化容量是5,但是只有3个元素可访问s2 = append(s2, 1)t.Log(s2[0], s2[1], s2[2], s2[3]) //0 0 0 1
}
切片其实是共享了存储空间,即如果两个切片有重叠元素,那么修改时会相互影响。
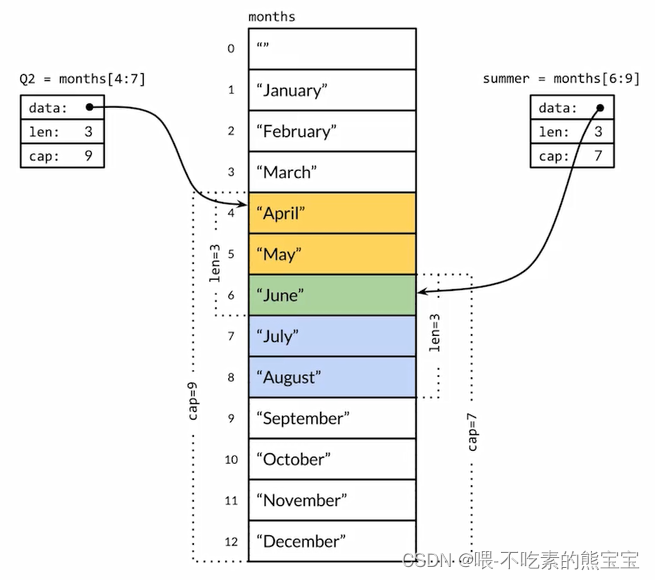
func TestSliceShare(t *testing.T) {var s = []int{1, 2, 3, 4, 5, 6, 7, 8, 9}s1 := s[3:6]s2 := s[5:8]t.Log(s1, len(s1), cap(s1)) // [4 5 6] 3 6t.Log(s2, len(s2), cap(s2)) // [6 7 8] 3 4s2[0] = 100t.Log(s1) // [4 5 100]//t.Log(s1 == s2) // 切片不能互相比较,和数组不同t.Log(s1 == nil) // 切片只能和nil比较
}
- map,主要注意的是判断key是否存在。遍历也是用range得到k,v。
func TestMap(t *testing.T) {m1 := map[int]int{1: 100, 2: 200, 3: 300}t.Log(m1[1]) //100m2 := map[string]string{"name": "eric", "gender": "male"}t.Logf("len m2 = %d", len(m2)) //len m2 = 2m3 := map[string]int{}m3["math"] = 59m3["language"] = 61t.Logf("len m3 = %d", len(m3)) //len m3 = 2m4 := make(map[int]int, 10) // 10是capacityt.Logf("len m4 = %d", len(m4)) //len m4 = 0// 如果key不存在则根据value类型反馈对应的初始化的值,如int的0或string的空字符串t.Log(m1[4]) // 0t.Log(m2["age"]) // 空字符串// 所以无法判断原先就是0值和空字符串,go提供了判断方法if v, ok := m1[4]; ok {t.Log("value is %i", v)} else {t.Log("key is not existing")}// 遍历map,也是rangefor k, v := range m2 {t.Logf("%s : %s", k, v)}
}
比较牛的是map的value还可以是函数:
m8 := map[int]func(num int) int{}
m8[1] = func(num int) int { return num }
m8[2] = func(num int) int { return num * num }
m8[3] = func(num int) int { return num * num * num }
t.Log(m8[1](2)) //2
t.Log(m8[2](2)) //4
t.Log(m8[3](2)) //8
go集合没有set,可以用map[type]bool来变相实现。
m9 := map[int]bool{}
m9[1] = true
t.Log(m9[1] == true) // true
delete(m9, 1)
t.Log(m9[1] == true) // false
- 字符串。
func TestString1(t *testing.T) {var s1 strings1 = "hello"t.Log(len(s1)) // 5//s1[1] = "k" // 字符串其实是不可更改的切片s2 := "\x53\xbb"t.Log(s2) // 是个乱码t.Log(len(s2)) // 2,不管实际写的是什么,长度最终看看byte的长度s3 := "中"t.Log(len(s3))c := []rune(s3) //3t.Logf("Unicode:%x", c[0]) //Unicode:4e2dt.Logf("UTF8:%x", s3) //UTF8:e4b8ads4 := "\xe4\xb8\xad"t.Log(len(s4)) //3t.Log(s4) //中// range返回的是rune,但是我们可以通过格式化输出进行转换成字符或者二进制等形式// 中 4e2d 20013// 华 534e 21326// 民 6c11 27665// 族 65cf 26063s5 := "中华民族"for _, c := range s5 {t.Logf("%[1]c %[1]x %[1]d", c)}
}
两个库用户扩展字符串操作的:
import ("strings""strconv"
)
func TestOperateString(t *testing.T) {s1 := "1,2,3,4"parts := strings.Split(s1, ",")for _, part := range parts {t.Log(part)}t.Log(strings.Join(parts, "-")) //1-2-3-4t.Logf("string is %s", strconv.Itoa(100)) //string is 100if v, err := strconv.Atoi("100"); err == nil {t.Logf("result is %d", 100+v) //result is 200}
}
- 函数,一等公民。
- 可返回多个值
- 所有参数都是值传递
- 函数可以作为变量的值,作为参数值,可以作为返回值
- 如果多个返回值,不需要多个时,用下划线代替,之前有演示过
func ComputeFunction(op1 int, op2 int) (int, int, int, int) {return op1 + op2, op1 - op2, op1 * op2, op1 / op2
}func TestCompute(t *testing.T) {t.Log(ComputeFunction(3, 5)) //8 -2 15 0
}
再看看函数作为参数和返回值的情况:
func timeSpent(innerFunc func(op int) int) func(op int) int {return func(n int) int {start := time.Now()ret := innerFunc(n)fmt.Println("time spent seconds:", time.Since(start).Seconds())return ret}
}func slowFunc(n int) int {time.Sleep(time.Second * 2)return n
}func TestFunc(t *testing.T) {resFunc := timeSpent(slowFunc) // 得到了一个给slowFunc增强的函数,即增加了打印计时功能t.Log(resFunc(100)) // 100,得到的函数可以直接使用
}
再来看看可变参数,这个其他语言也有:
func sum(ops ...int) int {s := 0for _, v := range ops {s += v}return s
}func TestSum(t *testing.T) {t.Log(sum(1, 2, 3, 4, 5)) //15t.Log(sum(1, 2, 3)) //6
}
再看看延迟执行:
func ClearResource() {fmt.Println("Clear resource...")//2.不管有无报错,最后都会先输出Clear resource...
}func TestDeferFunc(t *testing.T) {defer ClearResource() // defer相当于try-catch中的finally,函数最后会执行它,尽管有panic报错也会执行它fmt.Println("Start") // 1.先输出Startpanic("error")
}
最后补充自定义类型type,可以简化代码:
// 自定义一个类型,下面就能用这个,相当于定一个类型别名
type convFunc func(op int) int
func timeSpent(innerFunc convFunc ) convFunc {return func(n int) int {start := time.Now()ret := innerFunc(n)fmt.Println("time spent seconds:", time.Since(start).Seconds())return ret}
}
- go语言不支持继承(黑魔法写法除外),建议使用复合。go语言中定义结构和行为如下:
type User struct {Id stringName stringAge int
}func TestStruct(t *testing.T) {e1 := User{"1", "Eric", 18}t.Log(e1) //{1 Eric 18}e2 := User{Id: "2", Name: "Tom"}t.Log(e2.Name) //Tome3 := new(User) // 这种其实返回的是一个引用/指针e3.Id = "3"e3.Name = "Jerry"t.Log(e3.Age) //0t.Logf("%T", e1) //test.Usert.Logf("%T", e3) //*test.User
}
定义行为和普通函数不太一样,需要注意一下,建议使用引用方式,即结构体参数使用user *User之类的格式:
unc (user User) StringFmt1() string {fmt.Printf("StringFmt1:The Name Address is %x\n", unsafe.Pointer(&user.Name))return fmt.Sprintf("%s-%s-%d", user.Id, user.Name, user.Age)
}// 建议使用这种引用方法,避免复制产生的消耗
func (user *User) StringFmt2() string {fmt.Printf("StringFmt2: The Name Address is %x\n", unsafe.Pointer(&user.Name))return fmt.Sprintf("%s/%s/%d", user.Id, user.Name, user.Age)
}// 这是普通函数
func StringFmt3(user User) string {fmt.Printf("StringFmt3: The Name Address is %x\n", unsafe.Pointer(&user.Name))return fmt.Sprintf("%s/%s/%d", user.Id, user.Name, user.Age)
}func TestStructFunc(t *testing.T) {u := User{Id: "100", Name: "Robin", Age: 99}fmt.Printf("The Name Address is %x\n", unsafe.Pointer(&u.Name)) //The Name Address is c000114910t.Log(u.StringFmt1()) //StringFmt1:The Name Address is c000114940t.Log(u.StringFmt2()) //StringFmt2: The Name Address is c000114910t.Log(StringFmt3(u)) //StringFmt3: The Name Address is c0001149a0
}
- go的接口比较解耦,不会强相互依赖,这可以从下面的例子看出来。下面的例子先写了一个普通的结构体并定义了一个行为,这时候没有任何接口。如果我们愿意的话,可以把这个行为单独提取出来形成一个接口。这个过程我们发现,提取接口完全不需要修改原先行为的代码和使用。只需要方法签名一致就行。
type Employee struct {Age int
}func (e *Employee) AgeAddOneYear() int {return e.Age + 1
}func TestInterface(t *testing.T) {e := Employee{Age: 18}t.Log(e.AgeAddOneYear()) // 19
}
然后在文件任何位置提取一个接口,保证签名一致即可。原先代码正常运行。我们称这种接口为没有侵入性。我们的实现也不依赖这个接口定义,即没有这个接口的时候我们也能正常运行使用。
type MyInterface interface {AgeAddOneYear() int
}
- 复合。
- go有没有继承,只要使用父类去定义子类即可发现
var pet Pet := new(Dog)是不可以的,连强制转换也是不行的。 - 所以一个变量在初始化的时候就决定了它的类型是Pet还是Dog,那么它接下来的行为就好说了:以为Dog复合了Pet的数据和行为,如果Dog自己有就调用自己的,自己没有就调用Pet的。所以下面的
func (d *Dog) SpeakTo(host string)是关键。
type Pet struct{}type Dog struct {Pet
}func (p *Pet) Speak() {fmt.Printf("Pet is speaking")
}func (p *Pet) SpeakTo(host string) {p.Speak()fmt.Print(":", host)
}func (d *Dog) Speak() {fmt.Printf("Dog is speaking")
}// 如果没有这个行为,则输出的是Pet的行为,因为复合了Pet的代码:Pet is speaking:Eric
// 如果有这个行为,则输出的是Dog的行为:Dog is speaking:Eric
func (d *Dog) SpeakTo(host string) {d.Speak()fmt.Print(":", host)
}func TestInherit(t *testing.T) {d := new(Dog)d.SpeakTo("Eric")
}
- 多态的实现,主要在于那个方法的参数使用接口参数。
type Duck struct{}
type Goose struct{}func (d *Duck) bark() string {return "gua gua gua..."
}func (g *Goose) bark() string {return "e e e..."
}// 这个方法是关键,使用了接口作为参数,这样就能实现多态
func diffrentbark(interf MyInterface2) string {return interf.bark()
}func TestBark(t *testing.T) {duck := new(Duck)t.Log(diffrentbark(duck)) //gua gua gua...goose := new(Goose)t.Log(diffrentbark(goose)) //e e e...
}
- 接口的常见使用方法。
- 按照上述的多态的情况,定义函数的时候参数我们经常用接口,但更常用的是我们使用空接口
- 配合断言判断不同情况
- 好的习惯是让接口尽量小,一般包含一个方法,如果需要大的接口则使用小接口组合而成
// 注意这里的参数,是一个空接口,然后在代码里判断这个接口实际传过来的可能的值或者类型,做相应的行为
func UseEmptyInterface(p interface{}) {// if v, ok := p.(int); ok {// fmt.Println("int is", v)// } else if v, ok := p.(string); ok {// fmt.Println("string is", v)// }switch v := p.(type) {case int:fmt.Println("int is", v)case string:fmt.Println("string is", v)default:fmt.Println("unknown")}
}func TestEmptyInterface(t *testing.T) {UseEmptyInterface(100) //int is 100UseEmptyInterface("100") //string is 100
}
- 错误的处理方法,正常情况下使用
errors.New("")即可。如果错误类型比较多,可以定义错误类型var xxx = errors.New()。这里需要注意的是,要习惯于go这种返回多个值得形式,并利用多个参数这个将返回值和提示信息一并返回。
var LessThanTwo = errors.New("The num should not less that 2.")func GetFib(n int) ([]int, error) {if n < 2 {return nil, LessThanTwo}if n > 100 {return nil, errors.New("The num should not more than 100.")}fibList := []int{1, 1}for i := 2; i < n; i++ {fibList = append(fibList, fibList[i-2], fibList[i-1])}return fibList, nil
}func TestError(t *testing.T) {if lst, err := GetFib(2); err != nil {t.Log(err)} else {t.Log(lst)}
}
看一下recover的使用方法,配合defer使用,可以获得错误信息,在这里释放资源或者做一些其他操作:
func TestRecover(t *testing.T) {defer func() {if err := recover(); err != nil {t.Log("recover from error:", err) //recover from error: crashed...}}()t.Log("start...")panic(errors.New("crashed..."))
}
需要注意的是如果使用os.Exist(0)退出的话,是不会执行defer的。
- 包的引用方式不同版本的go不一样,早期的go项目通过设置GOPATH,所有项目共用一套GOOATH以及包版本,所有的代码写在src文件夹中。后来有
go mod的模块管理工具,每个项目都可以写在不同位置,只要先使用go mod init projectName初始化项目即可。后面就可以互相使用本地包,从项目名开始写,比如下面初始化了一个goProjects项目。
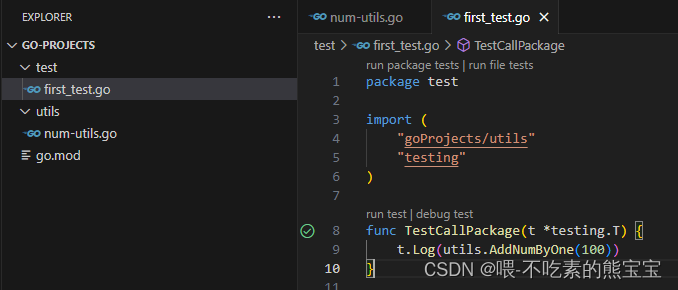
第三方包的引用和使用:
- 先下载
- 后引用
// 去官网查询包https://pkg.go.dev
// go get下载 -u强制更新
go get -u github.com/google/go-cmp/cmp// 在项目中使用
import ("testing"cmp "github.com/google/go-cmp/cmp"
)func TestImportThirdPackage(t *testing.T) {t.Log(cmp.Equal(1, 2)) // false
}
这个时候项目中有2个文件:
- go.mod,里面记录了依赖版本的全部信息
- go.sum,记录了所有依赖module的校验信息
注意一些历史小知识:最早的没有模块管理和包管理,后来有了vendor+利用第三方glide或dep来管理,它们会生成一个配置文件,在这个配置文件里记录了项目使用的依赖包信息。再后来官方退出了module功能。这就是简单的go项目管理和依赖管理的发展。
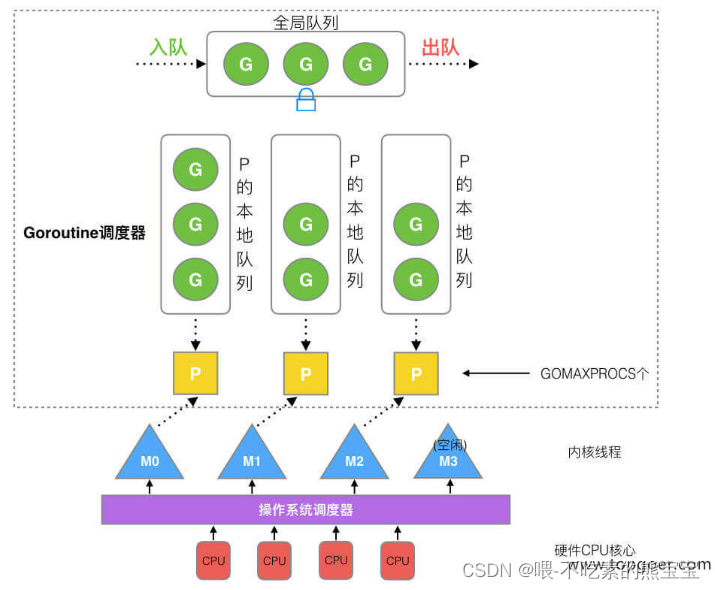
- 协程。关于goroutine协程们可以参考这边文章GMP 原理与调度。原先只有线程M和协程G,虽然实现了M对N的关系。但是仍然存在问题,后来增加了处理器P即调度器。
在 Go 中,线程是运行 goroutine 的实体,调度器的功能是把可运行的 goroutine 分配到工作线程上。
1、全局队列(Global Queue):存放等待运行的 G。
2、P 的本地队列:同全局队列类似,存放的也是等待运行的 G,存的数量有限,不超过 256 个。新建 G’时,G’优先加入到 P 的本> 地队列,如果队列满了,则会把本地队列中一半的 G 移动到全局队列。
3、P 列表:所有的 P 都在程序启动时创建,并保存在数组中,最多有 GOMAXPROCS(可配置) 个。
4、M:线程想运行任务就得获取 P,从 P 的本地队列获取 G,P 队列为空时,M 也会尝试从全局队列拿一批 G 放到 P 的本地队> 列,或从其他 P 的本地队列偷一半放到自己 P 的本地队列。M 运行 G,G 执行之后,M 会从 P 获取下一个 G,不断重复下去。
以下的协程代码,在函数前加go就进入协程了。
func TestRoutine(t *testing.T) {for i := 0; i < 10; i++ {go func(num int) {fmt.Println(num)}(i)}time.Sleep(time.Second * 1)
}
- 紧接着就是不同协程之间的数据安全,即锁。还有waitgroup。
// 没有锁
func TestNotLock(t *testing.T) {counter := 0for i := 0; i < 5000; i++ {go func() {counter++}()}time.Sleep(time.Second * 2)fmt.Println(counter)
}
// 有锁,注意defer中释放
func TestLock(t *testing.T) {var mut sync.Mutexcounter := 0for i := 0; i < 5000; i++ {go func() {defer func() {mut.Unlock()}()mut.Lock()counter++}()}time.Sleep(time.Second * 2)fmt.Println(counter)
}
waitgroup使用wait的时候就是等所有的都执行完,所有指的多少个,就是add的数量。使用done相当于减1。
func TestLockWaitGroup(t *testing.T) {var mut sync.Mutexvar wg sync.WaitGroupcounter := 0for i := 0; i < 5000; i++ {wg.Add(1)go func() {defer func() {mut.Unlock()wg.Done()}()mut.Lock()counter++}()}wg.Wait()fmt.Println(counter)
}
- csp并发机制:channel。分为两种一种是一对一交换数据,只有双方发送和接收都完成了才能往下进行否则阻塞,即这个指需要从channel中拿走才行。第二种是给channel加buffer,即发送和接收解耦,不会阻塞。注意channel的符号
<-往channel中放数据和取数据。
func doTask() chan string {// 如果使用这种一对一的channel,那么只有当fmt.Println(<-retCh)执行时相当于接收数据后,这个retCh <- "init data..."才取消阻塞继续执行// 所以fmt.Println("doing task done")总是在fmt.Println(<-retCh)后执行//retCh := make(chan string)// 如果使用这种channel,1就是buffer,这时候不用阻塞,retCh <- "init data..."执行完直接执行fmt.Println("doing task done"),不用管最后fmt.Println(<-retCh)何时从channel中接收数据retCh := make(chan string, 1)go func() {fmt.Println("doing task")retCh <- "init data..."fmt.Println("doing task done")}()return retCh
}func doOtherTask() {fmt.Println("doing other task")time.Sleep(time.Second * 3)fmt.Println("doing other task is done")
}func TestAsyncChannel(t *testing.T) {retCh := doTask()doOtherTask()fmt.Println(<-retCh)
}
另外有一个select多路选择器,了解一下,类似于switch,可以从不同channel中获取结果进行处理:
func TestSelect(t *testing.T) {select {case retCh := <-doTask():fmt.Print(retCh)case <-time.After(time.Second * 1):fmt.Print("time out")}
}
channel还有一个close方法。假如有个生产者和消费者,因为消费者不知道生产者生产数量,所以我们用无限for循环,但如果一直没有生产,那么就会一直阻塞在消费者获取数据处,如果生产结束时给一个关闭通道的信号,消费者判断是否已经传送结束,那么就能针对性处理。以下就是通过取值时不仅可以取值还能获取状态,如果是true就正常,如果是false意味着关闭了:
- 如果通道已关闭,无法传数据,会报错
- 如果通道关闭,则会唤醒所有的订阅者,并且传状态为false,可以用于信号订阅发布
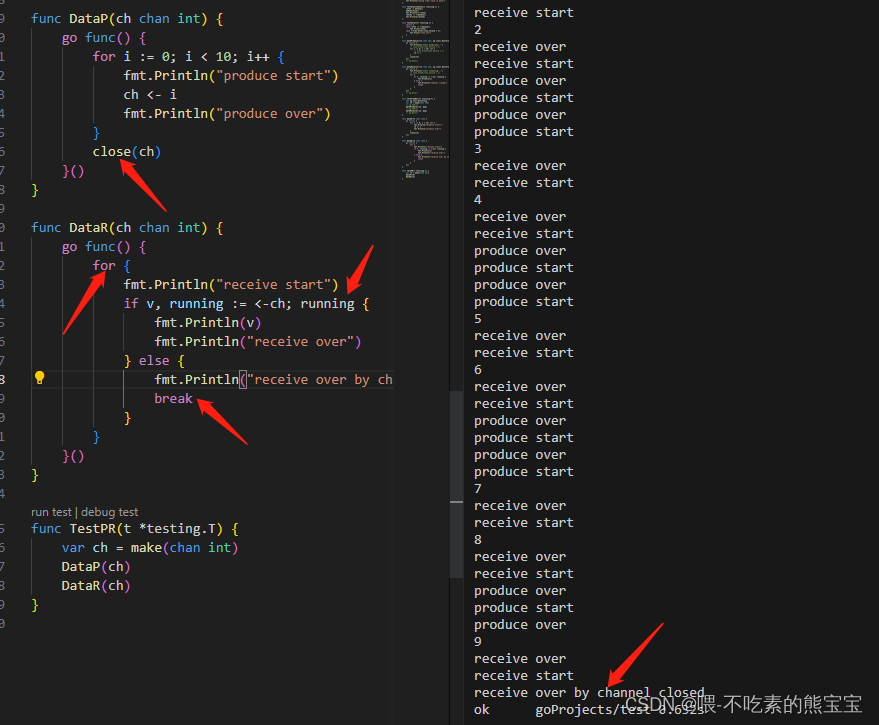
上面说的利用这个close实现订阅发布比如关闭所有协程。
// 比如我们这边判断要不要关闭协程,则可以用
func isCanceled(ch chan struct{}) bool {select {// 只要收到消息,就会走case <-ch,当然这个消息我们一般用于关闭case <-ch:return truedefault:return false}
}
// 此时,在程序中使用channel,有需要时就关闭这个channel,在需要用到isCanceled判断的地方就能判断已关闭,然后做相应操作
- context和取消。如果遇到一个嵌套的任务,取消一个节点时需要取消其子节点,就可以用context实现。
func isCanceled(ctx context.Context) bool {select {case <-ctx.Done():return truedefault:return false}
}func TestContextCancel(t *testing.T) {ctx, cancel := context.WithCancel(context.Background())for i := 0; i < 5; i++ {go func(i int, ctx context.Context) {for {if isCanceled(ctx) {break}time.Sleep(time.Millisecond * 10)}fmt.Println(i, "canceled")}(i, ctx)}cancel()time.Sleep(time.Second * 1)
}
// 输出结果:
4 canceled
1 canceled
3 canceled
2 canceled
0 canceled
- 还是sync下的一个Once,类似懒汉模式,只运行一次的功能。
type Singleton struct{}var once sync.Once
var singleInstance *Singletonfunc GetSingleton() *Singleton {// 这里代码调用多次,只执行一次once.Do(func() {fmt.Println("create instance ...")singleInstance = new(Singleton)})return singleInstance
}func TestSyncOnce(t *testing.T) {var wg sync.WaitGroupfor i := 0; i < 5; i++ {wg.Add(1)go func() {obj := GetSingleton()fmt.Printf("obj is %x\n", unsafe.Pointer(obj))wg.Done()}()}wg.Wait()
}
// 输出
create instance ...
obj is ec2ba0
obj is ec2ba0
obj is ec2ba0
obj is ec2ba0
obj is ec2ba0
相关文章:
Go语言入门记录:从基础到变量、函数、控制语句、包引用、interface、panic、go协程、Channel、sync下的waitGroup和Once等
程序入口文件的包名必须是main,但主程序文件所在文件夹名称不必须是main,即我们下图hello_world.go在main中,所以感觉package main写顺理成章,但是如果我们把main目录名称改成随便的名字如filename也是可以运行的,所以…...

位运算进阶操作
位运算的进阶操作,适合做题的时候用,共10点 1.通过位运算与特定的位模式进行掩码操作,可以提取、设置或清除特定的位信息。例如,我们可以使用位掩码来检查一个数的二进制表示中特定位置是否为1。 bool checkBit(int num, int po…...

sql:SQL优化知识点记录(四)
(1)explain之ref介绍 type下的ref是非唯一性索引扫描具体的一个值 ref属性 例如:ti表先加载,const是常量 t1.other_column是个t1表常量 test.t1.ID:test库t1表的ID字段 t1表引用了shared库的t2表的col1字段&#x…...

Java----Sentinel持久化规则启动
java -jar -Dnacos.add8848 你的sentinel源码修改包.jar 前期准备: 1.引入依赖 在order-service中引入sentinel监听nacos的依赖: <dependency><groupId>com.alibaba.csp</groupId><artifactId>sentinel-datasource-nacos</…...
Java版工程行业管理系统源码-专业的工程管理软件- 工程项目各模块及其功能点清单
鸿鹄工程项目管理系统 Spring CloudSpring BootMybatisVueElementUI前后端分离构建工程项目管理系统 1. 项目背景 一、随着公司的快速发展,企业人员和经营规模不断壮大。为了提高工程管理效率、减轻劳动强度、提高信息处理速度和准确性,公司对内部工程管…...

无涯教程-Android - Grid View函数
Android GridView在二维滚动网格(行和列)中显示项目,并且网格项目不一定是预定的,但它们会使用ListAdapter自动插入到布局中 Grid View - Grid view ListView 和 GridView 是 AdapterView 的子类,可以通过将它们绑定到 Adapter 来填充&#x…...
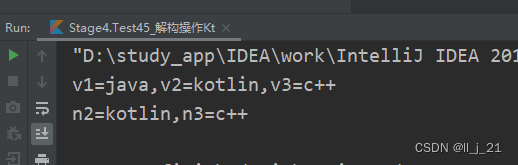
【第四阶段】kotlin语言的解构语法过滤元素
1.list集合的解构操作 package Stage4fun main() {val list listOf("java","kotlin","c")//元素解构var(v1,v2,v3)listprint("v1$v1,v2$v2,v3$v3") }执行结果 2.将上述代码转化为Java代码 使用Java 代码需要大量书写 3.解构过滤元…...

和24考研说拜拜,不考研读中外合作办学硕士——人大女王金融硕士
23考研失利同学,大多都会有这样的疑虑,是再试一次还是选择其他方式呢?其实,并不用执着于全国联考,中外合作办学硕士或许更适合你。近年来,经济迅速发展,经济全球化不断扩大,金融方向…...

https比http安全在哪
HTTPS(Hypertext Transfer Protocol Secure)是HTTP的安全版本,它在HTTP的基础上添加了安全性和加密机制。以下是HTTPS相对于HTTP的主要安全性优势: 数据加密:HTTPS使用TLS(Transport Layer Security&#x…...
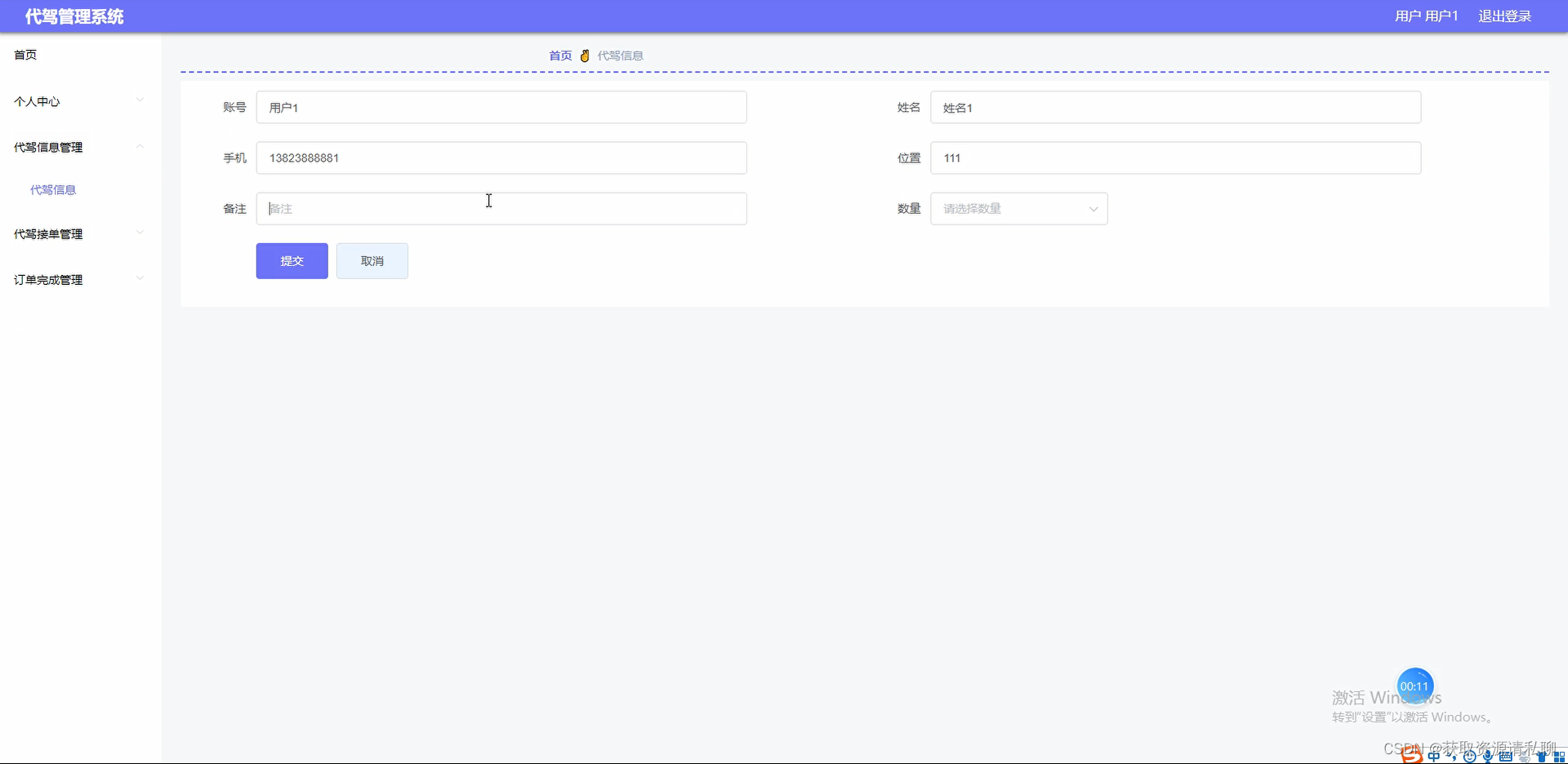
基于Java的代驾管理系统 springboot+vue,mysql数据库,前台用户、商户+后台管理员,有一万五千字报告,完美运行
基于Java的代驾管理系统 springbootvue,mysql数据库,前台用户、商户后台管理员,有一万五千字报告,完美运行。 系统完美实现用户下单叫车、商户接单、管理员管理系统,页面良好,系统流畅。 各角色功能&#x…...

广播、组播
1.广播 向子网中多台计算机发送消息,并且子网中所有的计算机都可以接收到发送方发送的消息,每个广播消息都包含一个特殊的IP地址,这个IP中子网内主机标志部分的二进制全部为1。 a.只能在局域网中使用。 b.客户端需要绑定服务器广播使用的端口…...

Spring MVC 三 :基于注解配置
Servlet3.0 Servlet3.0是基于注解配置的理论基础。 Servlet3.0引入了基于注解配置Servlet的规范,提出了可拔插的ServletContext初始化方式,引入了一个叫ServletContainerInitializer的接口。 An instance of the ServletContainerInitializer is looke…...

机器学习基础16-建立预测模型项目模板
机器学习是一项经验技能,经验越多越好。在项目建立的过程中,实 践是掌握机器学习的最佳手段。在实践过程中,通过实际操作加深对分类和回归问题的每一个步骤的理解,达到学习机器学习的目的 预测模型项目模板 不能只通过阅读来掌握…...
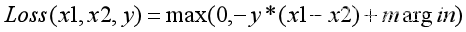
ReID网络:MGN网络(4) - Loss计算
1. MGN Loss MGN采用三元损失(Triplet Loss)。 三元损失主要用于ReID算法,目的是帮助网络学习到一个好的Embedding信息。之所以称之为三元损失,主要原因在于在训练中,参与计算Loss的分别有Anchor、Positive和Negative三方。 2. Triplet Lo…...
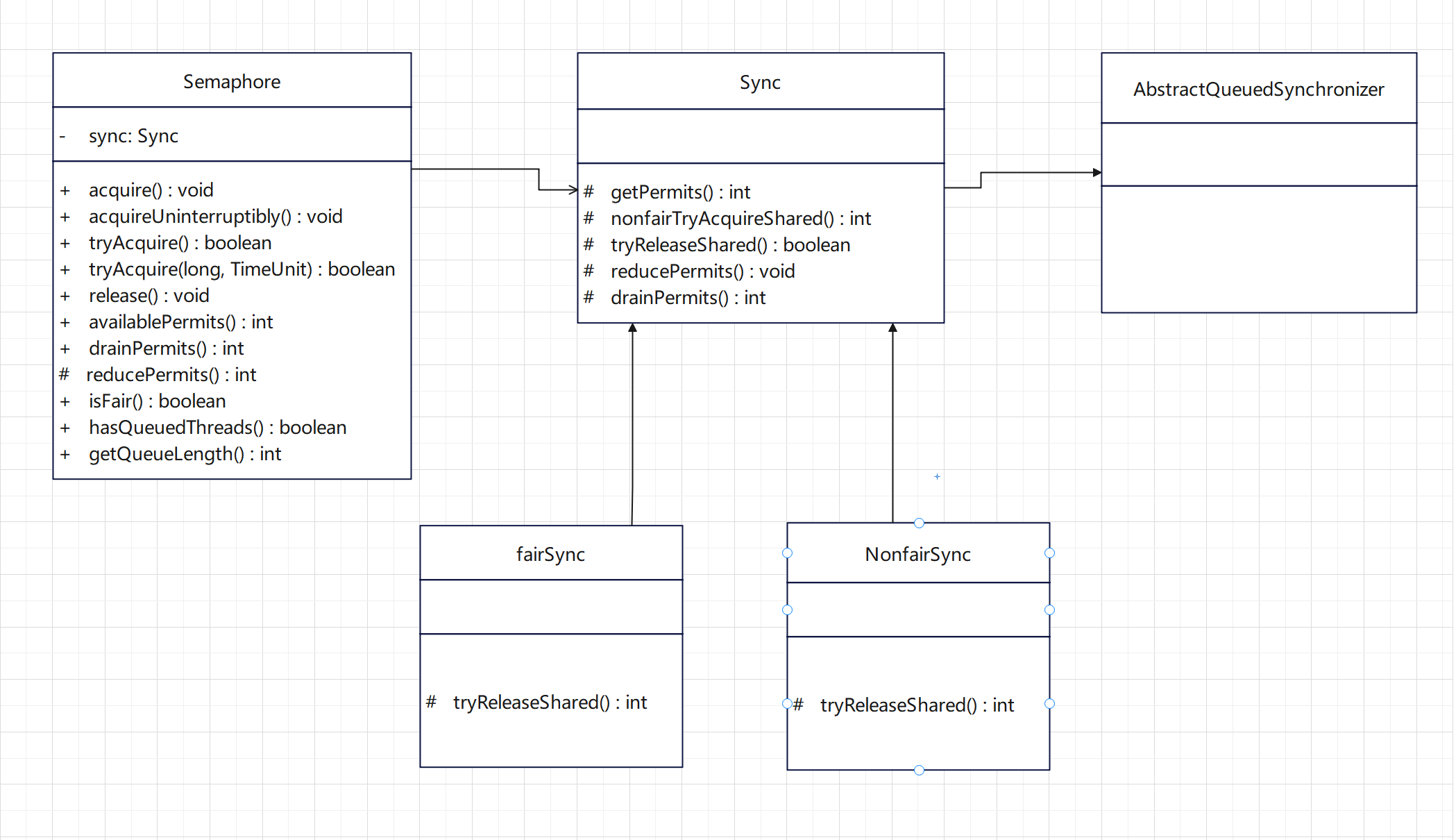
CountDownLatch、Semaphore详解——深入探究CountDownLatch、Semaphore源码
这篇文章将会详细介绍基于AQS实现的两个并发类CountDownLatch和Semaphore,通过深入底层源代码讲解其具体实现。 目录 CountDownLatch countDown() await() Semaphore Semaphore类图 Semaphore的应用场景 acquire() tryAcquire() CountDownLatch /*** A synchroni…...
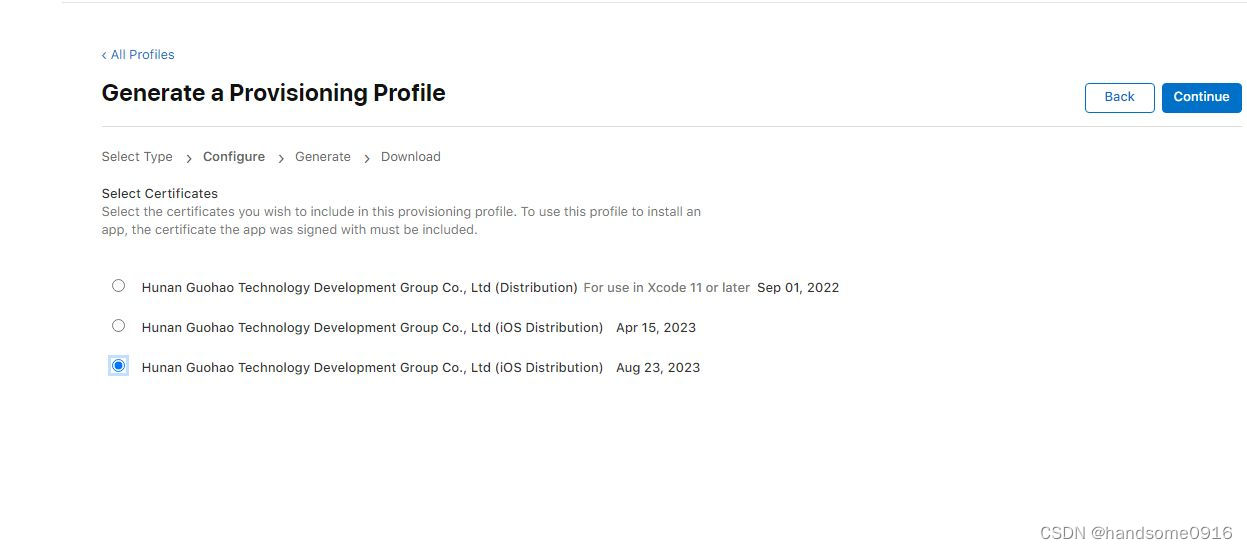
windows生成ios证书的方法
使用hbuilderx的uniapp框架开发ios应用,在测试阶段和发布阶段,需要ios证书进行打包,云打包的界面提供了生成ios证书的教程,但是教程令人很失望,它只能使用mac电脑来生成ios证书。假如没有mac电脑,就无法安照…...

【小沐学Unity3d】3ds Max 骨骼动画制作(Physique 修改器)
文章目录 1、简介2、Physique 工作流程3、Physique 对象类型4、Physique 增加骨骼5、Physique 应用和初始化6、Physique 顶点子对象7、Physique 封套子对象8、设置关键点和自动关键点模式的区别8.1 自动关键点8.2 设置关键点 结语 1、简介 官方网址: https://help.…...

生态项目|Typus如何用Sui特性制作动态NFT为DeFi赋能
对于许多人来说,可能因其涉及的期权、认购和价差在内的DeFi而显得晦涩难懂,但Typus Finance找到了一种通过动态NFT使体验更加丰富的方式。Typus NFT系列的Tails为用户带来一个外观逐渐演变并在平台上提升活动水平时获得新特权的角色。 Typus表示&#x…...

IOS打包上架AppStore被驳回信息记录
1:错误码5.2.1错误信息如下 Your app includes content or features from 公司名, or is marketed to control external hardware from 公司名, without the necessary authorization. The inclusion of third-party content within your app, whether retrieved fr…...

【Python自学笔记】Python好用的模块收集(持续更新...)
文章目录 日志模块钉钉机器人命令助手持续更新中,如果您有其他实用好用的模块欢迎留言...日志模块 写代码离不开日志,自定义一个理想的日志对于小白来说可能是一件很反锁的事情,就像我刚学习Python的时候自己写的一个自定义日志,为了解决这个痛点,今天就和大家分享一个可以…...

Autosar Crypto Driver配置避坑指南:从CryptoPrimitive到CryptoKeyType,手把手教你配出安全又高效的加密服务
AUTOSAR Crypto Driver实战配置:从算法选型到密钥管理的安全工程实践 在汽车电子系统开发中,加密服务已成为保障车载通信安全的核心组件。AUTOSAR标准定义的Crypto Driver模块为开发者提供了统一的加密接口,但实际配置过程中,工程…...

手算反向传播:从链式法则到梯度消失的物理直觉
1. 项目概述:这不是又一节“神经网络入门”,而是一次真正踩进反向传播泥潭的实操复盘“Intro to Neural Networks Part II — Brilliant.org”这个标题乍看平平无奇,像是在线教育平台里再普通不过的一节进阶课。但如果你真点开它,…...

如何选择最佳视频播放器?Awesome Video推荐15款跨平台解决方案
如何选择最佳视频播放器?Awesome Video推荐15款跨平台解决方案 【免费下载链接】awesome-video A curated list of awesome streaming video tools, frameworks, libraries, and learning resources. 项目地址: https://gitcode.com/gh_mirrors/aw/awesome-video …...

YOLOv11光伏板二极管异常目标检测数据集-45张-Solar-panel-anomalies-1
YOLOv11光伏板二极管异常目标检测数据集 📊 数据集基本信息 目标类别: [‘Diode anomaly’, ‘Hot Spots’, ‘Reverse polarity’]中文类别:[‘二极管异常’, ‘热点’, ‘反向极性’]训练集:31 张验证集:9 张测试集&…...

干翻特斯拉?雷军说输给特斯拉不丢人
一周前的晚上,雷军和马斯克合照上了热搜。一周后的晚上,“雷军说输给特斯拉不丢人”又上了热搜。①5 月 21 日晚间小米有个发布会,雷军期间自问:“Model Y 是全球纯电车型的销冠,每年都有很多车型站出来要挑战 Model Y…...

SurfaceFlinger 调用 libdrm 的详细代码流程分析
1. 整体架构图 ┌─────────────────────────────────────────────────────────────────┐ │ 应用层框架 │ │ ┌──────────────…...

CANN 算子调优:榨干昇腾硬件性能
一、算子性能分析基础 1.1 算子执行模型 昇腾上每个算子的执行都会经历:编译时优化 → 运行时调度 → 硬件执行。任何一个环节出问题都会导致性能下降。 ┌────────────────────────────────────────┐ │ 算子执…...

Minecraft性能监控终极指南:如何用Spark快速诊断服务器卡顿
Minecraft性能监控终极指南:如何用Spark快速诊断服务器卡顿 【免费下载链接】spark A performance profiler for Minecraft clients, servers, and proxies. 项目地址: https://gitcode.com/gh_mirrors/spark6/spark Minecraft服务器性能优化一直是管理员面临…...

人工模仿智能在专业领域中的挣扎
原文:towardsdatascience.com/the-struggle-of-artificially-imitated-intelligence-in-specialist-domains-6e63a4e0ebfc?sourcecollection_archive---------4-----------------------#2024-05-08 为什么通向真正智能的道路要经过本体论和知识图谱 https://mediu…...

CANN/asc-devkit算子动态库配置
KernelSo 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/c…...