python利用pandas统计分析—groupby()函数的使用
文章目录
- 一、groupby使用场景
- 二、groupby基本原理
- 三、groupby分组运算
- 基础聚合操作:只能选择一种聚合操作
- agg 聚合操作:可以针对同列选择不同聚合方法
- transform
- apply
- 四、groupby分组后去重统计nunique()
- 五、groupby分组后重命名列名
- rename()
- 直接重新命名列名
- 重命名所有的列名:add_prefix() /add_suffix()
一、groupby使用场景
在日常数据分析中,经常需要将数据根据某个(多个)字段划分为不同群体(group)进行分析,如电商领域将全国的总销售额根据省份进行划分,分析各省销售额的变化情况,社交领域将用户根据画像(性别、年龄)进行细分,研究用户的使用情况和偏好,如电信诈骗领域,研究诈骗用户与非诈骗用户的语音通话行为等。在Pandas中,上述的数据处理操作主要运用groupby完成,这篇文章就介绍一下groupby的基本原理、对应的agg、transform和apply操作、groupby后的去重统计及重命名列名。
二、groupby基本原理
模拟的样本数据
import pandas as pd
import numpy as np
#主叫号码
calling_nbr=["13389012374","13389012375","13389012376","13389012377","13389012379","13389012378","16758439532","16758439533","16758439534","16758439535","16758439536","16758439537"]
#对端号码
called_nbr=["14374397533","14374397533","14374397533","15926372438","15926372439"]
#通话时间
start_date=["20230404","20230406","20230408"]
data=pd.DataFrame({
"calling_nbr":[calling_nbr[x] for x in np.random.randint(0,len(calling_nbr),20)],
"called_nbr":[called_nbr[x] for x in np.random.randint(0,len(called_nbr),20)],
"calling_duration":np.random.randint(10,120,20),
"start_date":[start_date[x] for x in np.random.randint(0,len(start_date),20)]})data

将上面的样本数据集按照start_date字段划分:
group=data.groupby(["start_date"])
group
会得到一个DataFrameGroupBy对象

如何理解DataFrameGroupBy?对data进行groupby后发生了什么,ipython所返回的结果是其内存地址,并不利于直观地理解,为了看看group内部究竟是什么,把group转为list的形式看看:
list(group)

转成列表的形式后,可以看到,列表由三个元组组成,每个元组中,第一元素是组别,这里是按时start_date进行分组,所以最后分为了20230404、20230406、20230408,第二个元素的是对应组别下的DataFrame。
总结:groupby的过程就是将原有的DataFrame按照groupby的字段(这里是start_date),划分为若干个分组DataFrame,被分为多少个组就有多少个分组DataFrame。所以说,在groupby之后的一系列操作(如agg、apply等),均是基于子DataFrame的操作。理解了这点,也就基本摸清了Pandas中的groupby操作的主要原理。
三、groupby分组运算
聚合操作是groupby后非常常见的操作,聚合操作可以用来求和、均值、最大值、最小值等,下面的表格列出了Pandas中常见的聚合操作。
| 函数 | 作用 |
|---|---|
| min | 最小值 |
| max | 最大值 |
| sum | 求和 |
| mean | 均值 |
| median | 中位数 |
| std | 标准差 |
| var | 方差 |
| count | 计数 |
基础聚合操作:只能选择一种聚合操作
单列分组
1、单组其他所有列
按calling_nbr分组(groupby),获取数据表其他所列的统计值。因为called_nbr和start_date不是数字类型,所以会自动忽略。
data.groupby('calling_nbr').mean()
2、单组单列
按calling_nbr分组(groupby),仅获取calling_duration的平均值。
data.groupby('calling_nbr')['calling_duration'].mean()
3、单组多列
按calling_nbr分组(groupby),获取calling_duration和calling_fee列的平均值。
data.groupby('calling_nbr')[['calling_duration','calling_fee']].mean()
多列分组
1、多组其他所有列
按calling_nbr和start_date分组(groupby),获取数据表其他所列的统计值。只针对数字类型的列。
data.groupby(['calling_nbr','start_date']).mean()
2、多组单列
按calling_nbr和start_date分组(groupby),仅获取calling_duration的平均值。
data.groupby(['calling_nbr','start_date'])['calling_duration'].mean()
3、多组多列
按calling_nbr和start_date分组(groupby),获取calling_duration和calling_fee列的平均值。
data.groupby(['calling_nbr','start_date'])[['calling_duration','calling_fee']].mean()
agg 聚合操作:可以针对同列选择不同聚合方法
单列分组
1、单组单列
一种聚合方法,多种写法
比如求主叫号码通话时长的平均值
data.groupby('calling_nbr').agg({'calling_duration':'mean'})data.groupby('calling_nbr')['calling_duration'].agg(['mean'])
多种聚合方法,多种写法
比如:求主叫号码通话时长的平均值,总和和标准差
data.groupby('calling_nbr').agg({'calling_duration':['mean','sum','std']})
data.groupby('calling_nbr').agg({'calling_duration':['mean',np.sum,'std']})data.groupby('calling_nbr')['calling_duration'].agg([np.mean,np.sum,np.std])
data.groupby('calling_nbr')['calling_duration'].agg([np.mean,'sum',np.std])
2、单组多列
一种聚合方法,多种写法
data.groupby('calling_nbr').agg({'calling_duration':['mean'],'calling_fee':['sum']})data.groupby('calling_nbr')[['calling_duration','calling_fee']].agg(['mean'])
多种聚合方法,多种写法
data.groupby('calling_nbr').agg({'calling_duration':['mean','sum','std'],'calling_fee':['mean','sum','std']})
data.groupby('calling_nbr').agg({'calling_duration':['mean',np.sum,'std'],'calling_fee':['mean',np.sum,'std']})data.groupby('calling_nbr')[['calling_duration','calling_fee']].agg([np.mean,np.sum,np.std])
data.groupby('calling_nbr')[['calling_duration','calling_fee']].agg([np.mean,'sum',np.std])
多列分组
1、多组单列
一种聚合方法,多种写法
比如求主叫号码当天通话时长总和
data.groupby(['calling_nbr','start_date']).agg({'calling_duration':'sum'})data.groupby(['calling_nbr','start_date'])['calling_duration'].agg(['sum'])
多种聚合方法,多种写法
data.groupby(['calling_nbr','start_date']).agg({'calling_duration':'sum','calling_duration':np.mean})data.groupby(['calling_nbr','start_date'])['calling_duration'].agg(['sum',np.mean])
2、多组多列
一种聚合方法,多种写法
data.groupby(['calling_nbr','start_date']).agg({'calling_fee':'mean','calling_duration':'mean'})data.groupby(['calling_nbr','start_date'])[['calling_duration','calling_fee']].agg(['mean'])
多种聚合方法,多种写法
比如求主叫号码不同天的主叫次数和平均通话时长,代码如下:
data.groupby(['calling_nbr','start_date']).agg({'calling_fee':'count','calling_duration':'mean'})
比如求主叫号码不同天的主叫次数与通话时长的总和、标准差和平均值
data.groupby(['calling_nbr','start_date']).agg({'calling_fee':['sum','count','mean'],'calling_duration':['sum','count','mean']})data.groupby(['calling_nbr','start_date'])[['calling_duration','calling_fee']].agg(['sum','count','mean'])
注意:对于单组单列的分组来说,基础聚合操作与agg聚合操作,得到的对象有什么不同??
- 基础聚合操作,由于只选择一列数据,所以生成的对象是Series数据结构。
- agg聚合操作后生成的对象是DataFrame数据结构。
a=data.groupby('calling_nbr')['calling_duration'].mean()
print(type(a))

a=data.groupby('calling_nbr')['calling_duration'].agg(['mean'])
a=data.groupby('calling_nbr').agg({'calling_duration':'mean'})
print(type(a))

transform
在agg 聚合中,我们学会了如何求不同主叫号码同一天的平均通话时长,agg 聚合操作形成的新DataFrame,如果现在需要在原数据集中新增加一列avg_calling_duration,代表主叫号码同一天的平均通话时长(相同一天具有一样的平均通话时长)。
如何实现?
1、正常过程:先求得主叫号码不同天的平均通话时长,然后按照主叫号码和通话时间的对应关系填充到对应的位置
avg_calling_duration=data.groupby(['calling_nbr','start_date'])['calling_duration'].mean().rename("avg_calling_duration").reset_index()data_1 = data.merge(mean_calling_duration)
data_1

2、使用transform函数,仅需要一行代码
data['avg_calling_duration']=data.groupby(['calling_nbr','start_date'])['calling_duration'].transform('mean')data

transform与agg对比:
- 对agg而言,会计算得到不同号码当天的通话时长的均值并直接返回。
- 对transform而言,则会对第每一条数据求得相应的结果,同一组内的样本会有相同的值,组内求完均值后会按照原索引的顺序返回结果。
可以看下图agg与transform过程图解:


apply
对于groupby后的apply,以分组后的子DataFrame作为参数传入指定函数的,基本操作单位是DataFrame。
如果现在需要获取当天主叫与同一个被叫号码的通话次数top1的数据,如何实现?
#统计主叫与同一个被叫号码的通话次数
data['calling_called_max']=data.groupby(['calling_nbr','called_nbr','start_date'])['calling_nbr'].transform('count')#统计主叫与同一个被叫号码的通话次数top1
def get_max_calling_called_num(x):df=x.sort_values(by='calling_called_max',ascending=True)return df.iloc[-1:]get_max_calling_called_num_data=data.groupby(['calling_nbr','called_nbr','start_date'],as_index=False).apply(get_max_calling_called_num)
注意:关于apply的使用,这里有个小建议,虽然说apply拥有更大的灵活性,但apply的运行效率会比agg和transform更慢。所以,groupby之后能用agg和transform解决的问题还是优先使用这两个方法,实在解决不了了才考虑使用apply进行操作。
四、groupby分组后去重统计nunique()
nunique():统计groupby()分组后组内不同值的个数,比如适用于统计主叫号码拨打去重后的对端号码个数。
举例1
要求:统计主叫号码拨打去重后的对端号码个数。
#方法二选一。
data.groupby('calling_nbr')['called_nbr'].nunique()
data.groupby('calling_nbr').agg({ "called_nbr": pd.Series.nunique})

与unique()的区别:unique()方法返回的是去重之后的不同值。
data.groupby('calling_nbr')['called_nbr'].unique()

五、groupby分组后重命名列名
groupby分组后对某列进行聚合计算,需要对聚合计算后的新列进行重命名。
- 第一:先观察数据类型,要转变为DataFrame数据类型,再重命名。
- 第二:查看groupby后DataFrame.columns是什么格式。
- 第三:再选择合适的方法进行重命名。
rename()
rename()重命名,reset_index()将DataFrame的索引转成DataFrame的列。
1、对单列进行重命名。
举例1
data_1=data.groupby('calling_nbr').agg({'calling_duration':'mean'})
print(type(data_1)) #查看数据类型
print(data_1.colunms) #查看列名格式

我们可以看到,是DataFrame数据类型且DataFrame的列名格式是含单元素的列表,可以直接使用rename重命名。
data_1.rename(columns={'calling_duration':'calling_duration_avg'}).reset_index()
举例2
data_1=data.groupby('calling_nbr')['calling_duration'].mean()
print(type(data_1)) #查看数据类型

我们可以看到,对单列进行聚合得到是Series数据类型,因此先转换成DataFrame数据类型,再重命名。
data_1.to_frame() #将Series数据类型转成DataFrame数据类型。
data_1.rename(columns={'calling_duration':'calling_duration_avg'}).reset_index()
注意:如果是对单列进行聚合得到是Series数据类型,要先转换成DataFrame数据类型,再重命名。
2、对多列进行重命名
举例1
#两种常用的聚合方法,二选一。
data_1=data.groupby('calling_nbr')[['calling_duration','calling_fee']].mean()
data_1=data.groupby('calling_nbr').agg({'calling_duration':'mean','calling_fee':'mean'})
使用这两种方法都可以对多列进行聚合计算,groupby聚合计算后的数据情况如下。

print(type(data_1)) #查看数据类型

都是DataFrame数据类型。
print(data_1.columns) #查看列名格式

DataFrame的列名格式都是含单元素的列表。
我们可以看到,是DataFrame数据类型且DataFrame的列名格式是含单元素的列表,可以直接使用rename()重命名。
data_1.rename(columns={'calling_duration':'calling_duration_avg','calling_fee':'calling_fee_avg'})
举例2
data_1=data.groupby('calling_nbr')[['calling_duration','calling_fee']].agg(['mean'])
data_1

print(type(data_1)) #查看数据类型
是DataFrame数据类型。
print(data_1.columns) #查看列名格式

查看dataframe的列名格式,发现聚合后的列名是MultiIndex类型。此时,必须通过元组的复合索引方式,才能有效提取列的信息。
data_1.columns.values

查看列名的元素,我们可以看到每个列都是一个元组。通过下面两种方法都可以重命名:
- 方法一:通过遍历columns的方式,将MultiIndex的一级和二级索引拼接在一起,作为data的新列名。
data_1.columns=[i[0] + "_" + i[1] for i in data_1.columns]
data_1

- 方法二:只需要将元组拼接成字符串,然后替换原来的列名就可以了。
data_1.columns = ['_'.join(col).strip() for col in data_1.columns.values]
data_1
直接重新命名列名
使用"dataframe.columns=[‘新列名’]或dataframe.columns=pd.Series([‘新列名’])" 重命名。
1、要求:对单列进行重命名。
举例1
#对单列进行聚合计算的两种方式,二选一
data_1=data.groupby('calling_nbr').agg({'calling_duration':'mean'})data_1=data.groupby('calling_nbr')['calling_duration'].mean()
data_1.to_frame()#生成是Series数据类型,因此使用to_frame()转换成DataFrame数据类型。
#直接重命名的两种方法,二选一。
data_1.columns = pd.Series(['calling_duration_avg'])
data_1.columns = ['calling_duration_avg']#reset_index()将DataFrame的索引转成DataFrame的列。
data_1.reset_index(inplace=True)
2、要求:对多列进行重命名。
举例1
#对多列进行聚合计算的两种方式,二选一
data_1=data.groupby('calling_nbr')[['calling_duration','calling_fee']].mean()
data_1=data.groupby('calling_nbr').agg({'calling_duration':'mean','calling_fee':'mean'})
#直接重命名的两种方法,二选一。
data_1.columns = pd.Series(['calling_duration_avg','calling_fee_avg'])
data_1.columns = ['calling_duration_avg','calling_fee_avg']#reset_index()将DataFrame的索引转成DataFrame的列。
data_1.reset_index(inplace=True)
举例2
data_1=data.groupby('calling_nbr')[['calling_duration','calling_fee']].agg(['mean'])
print(data_1.columns) #查看列名格式
聚合后的列名是MultiIndex类型,不能使用"dataframe.columns=[‘新列名’]或dataframe.columns=pd.Series([‘新列名’])" 直接重命名。要多做一个步骤的处理,可以通过遍历columns的方式,先将MultiIndex的一级和二级索引拼接在一起,作为data的新列名或者先将元组拼接成字符串,再替换原来的列名就可以了。(具体例子见rename()目录下“对多列进行重命名”的举例2)
注意
- 对单列进行重命名,注意基础聚合方法:data_1=data.groupby(‘calling_nbr’)[‘calling_duration’].mean()生成的是Series数据类型。
- 对多列进行重命名,注意agg聚合方法写法:data_1=data.groupby(‘calling_nbr’)[[‘calling_duration’,‘calling_fee’]].agg([‘mean’]),生成的列名格式是MultiIndex类型,不能直接使用rename方法和"dataframe.columns=[‘新列名’]或dataframe.columns=pd.Series([‘新列名’])" 重命名。
重命名所有的列名:add_prefix() /add_suffix()
在处理大量dataframe数据时,我们可能对所有列名进行重命名操作。
pandas.DataFrame.add_prefix() 函数来修改列名的前缀,
pandas.DataFrame.add_suffix() 函数来修改列名的后缀。
聚合后的列名是MultiIndex类型,不能使用这种方法。
#三种方法达到效果是一致
data_1=data.groupby('calling_nbr').agg({'calling_duration':'mean','calling_fee':'mean'}).add_prefix('new_')data_1=data.groupby('calling_nbr')[['calling_duration','calling_fee']].mean().add_prefix('new_')data_1=data.groupby('calling_nbr').mean().add_prefix('new_')

参考文章:
https://zhuanlan.zhihu.com/p/101284491
https://blog.csdn.net/qq_39657585/article/details/114789396
https://blog.csdn.net/yeshang_lady/article/details/105345653
https://blog.csdn.net/weixin_43609275/article/details/86220907
https://blog.csdn.net/weixin_39923556/article/details/123002620
https://blog.csdn.net/pz789as/article/details/106059610
https://zhuanlan.zhihu.com/p/358006128
相关文章:
python利用pandas统计分析—groupby()函数的使用
文章目录 一、groupby使用场景二、groupby基本原理三、groupby分组运算基础聚合操作:只能选择一种聚合操作agg 聚合操作:可以针对同列选择不同聚合方法transformapply 四、groupby分组后去重统计nunique()五、groupby分组后重命名列名rename()直接重新命…...

OPENCV实现ORB特征检测
# -*- coding:utf-8 -*- """ 作者:794919561 日期:2023/8/31 """ import cv2 import numpy as np# 读图像 img = cv2.imread(F:\\learnOpenCV\\openCVLearning\\pictures\\chess.jpg)...
W5100S-EVB-PICO主动PING主机IP检测连通性(十)
前言 上一章节我们用我们开发板在UDP组播模式下进行数据回环测试,本章我们用开发板去主动ping主机IP地址来检测与该主机之间网络的连通性。 什么是PING? PING是一种命令, 是用来探测主机到主机之间是否可通信,如果不能ping到某台…...

使用 Nginx 搭建文件下载服务器
文章目录 一、基础环境二、适用场景三、方法和步骤四、其他说明 版权声明:本文为CSDN博主「杨群」的原创文章,遵循 CC 4.0 BY-SA版权协议,于2023年8月27日首发于CSDN,转载请附上原文出处链接及本声明。 原文链接:http…...

链式栈StackT
C关键词:内部类/模板类/头插 C自学精简教程 目录(必读) C数据结构与算法实现(目录) 栈的内存结构 空栈: 有一个元素的栈: 多个元素的栈: 成员函数说明 0 clear 清空栈 clear 函数负责将栈的对内存释放…...

Fiddler中 AutoResponder 使用
Fiddler的 AutoResponder ,即URL重定向功能非常强大。不管我们做URL重定向,还是做mock测试等,都可以通过该功能进行实践。 下面,小酋就来具体讲下该功能的用法。 Enable rules 启用规则Unmatched requests passthrough 没有匹配…...
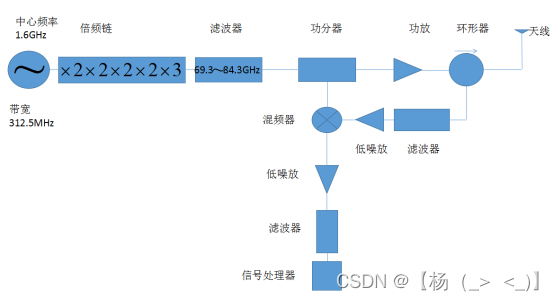
77GHz线性调频连续波雷达
文章目录 前言 一、背景 二、优缺点 三、工作原理 四、电路模块设计 4.1.LFMCW信号源 4.2.发射电路 4.3.接收电路 4.4.信号处理器 五、应用 5.1.汽车测距 5.2.军事方面 5.3.气象方面 总结 前言 这篇文章是博主本科期间整理的关于77GHz线性调频连续波雷达的相关资料,…...

YOLOV8改进:更换为MPDIOU,实现有效涨点
1.该文章属于YOLOV5/YOLOV7/YOLOV8改进专栏,包含大量的改进方式,主要以2023年的最新文章和2022年的文章提出改进方式。 2.提供更加详细的改进方法,如将注意力机制添加到网络的不同位置,便于做实验,也可以当做论文的创新点。 2.涨点效果:更换为MPDIOU,实现有效涨点! 目录…...
BookStack开源免费知识库docker-compose部署
BookStack(书栈)是一个功能强大且易于使用的开源知识管理平台,适用于个人、团队或企业的文档协作和知识共享。 一、BookStack特点 简单易用:BookStack提供了一个直观的用户界面,使用户能够轻松创建、编辑和组织文档多…...
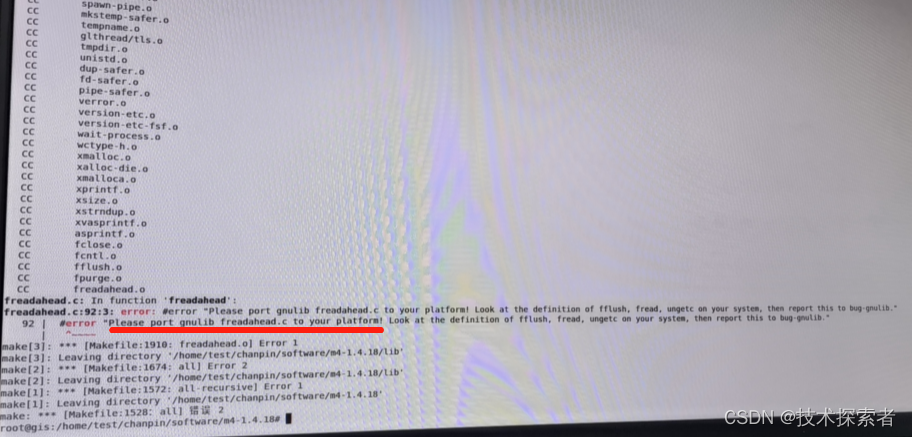
Linux:编译遇到 Please port gnulib freadahead.c to your platform ,怎么破
问题背景 编译m4时遇到以下错误,该怎么解决呢? 解决方法 进入m4的build目录:build/host-m4-1.4.17 输入命令: sed -i s/IO_ftrylockfile/IO_EOF_SEEN/ lib/*.c echo "#define _IO_IN_BACKUP 0x100" >> lib/std…...
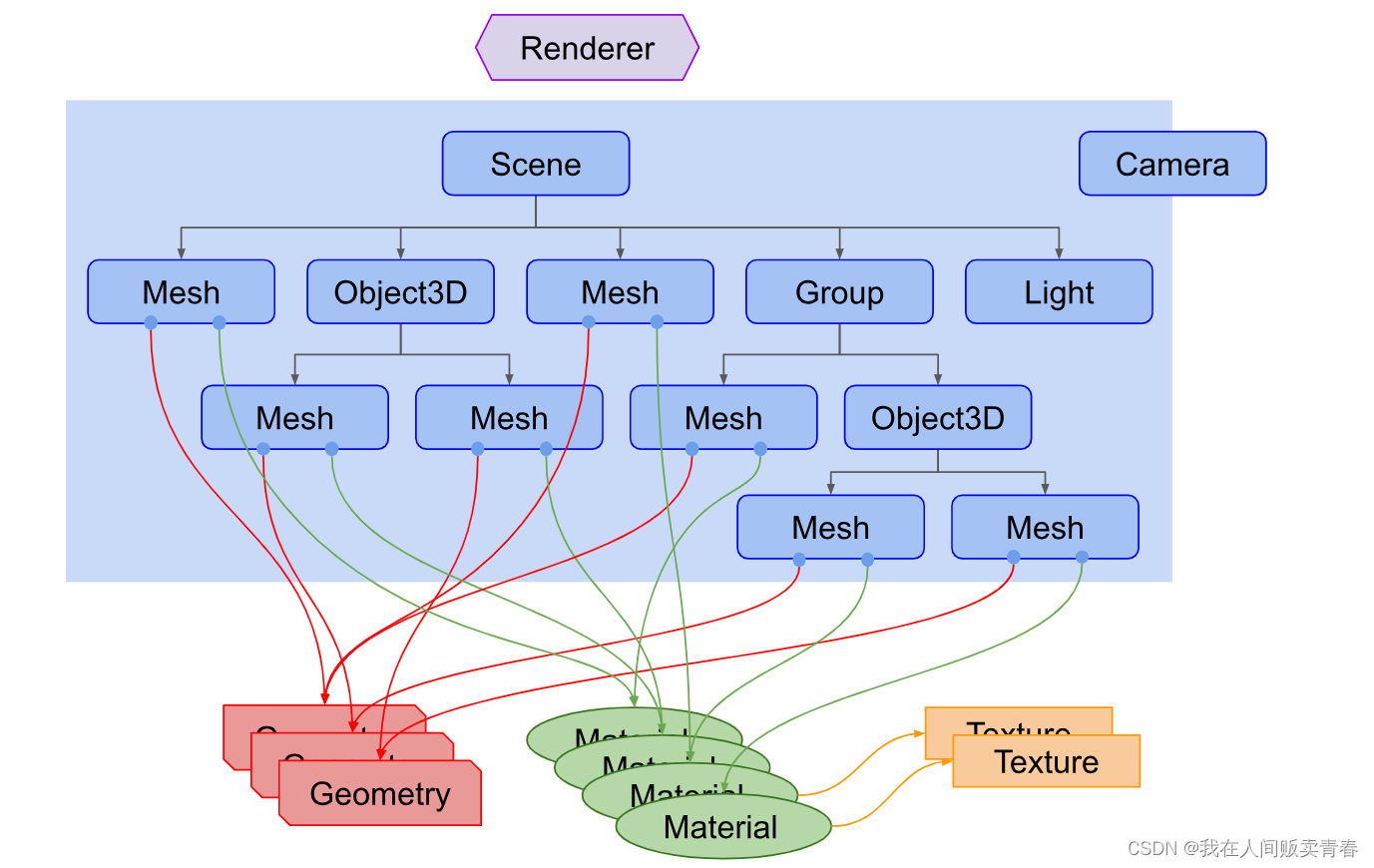
three.js(三):three.js的渲染结构
three.js 的渲染结构 概述 three.js 封装了场景、灯光、阴影、材质、纹理和三维算法,不必在直接用WebGL 开发项目,但有的时候会间接用到WebGL,比如自定义着色器。three.js 在渲染三维场景时,需要创建很多对象,并将它…...
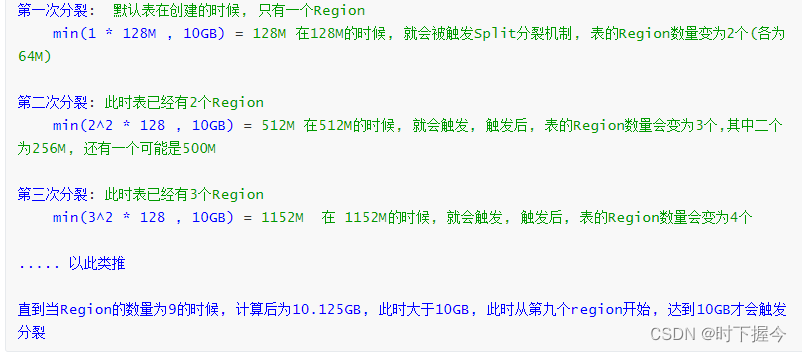
客户端读写HBase数据库的运行原理
1.HBase的特点 HBase是一个数据库,与RDMS相比,有以下特点: ① 它不支持SQL ② 不支持事务 ③ 没有表关系,不支持JOIN ④ 有列族,列族下可以有上百个列 ⑤ 单元格,即列值,可以存储多个版本的值&…...
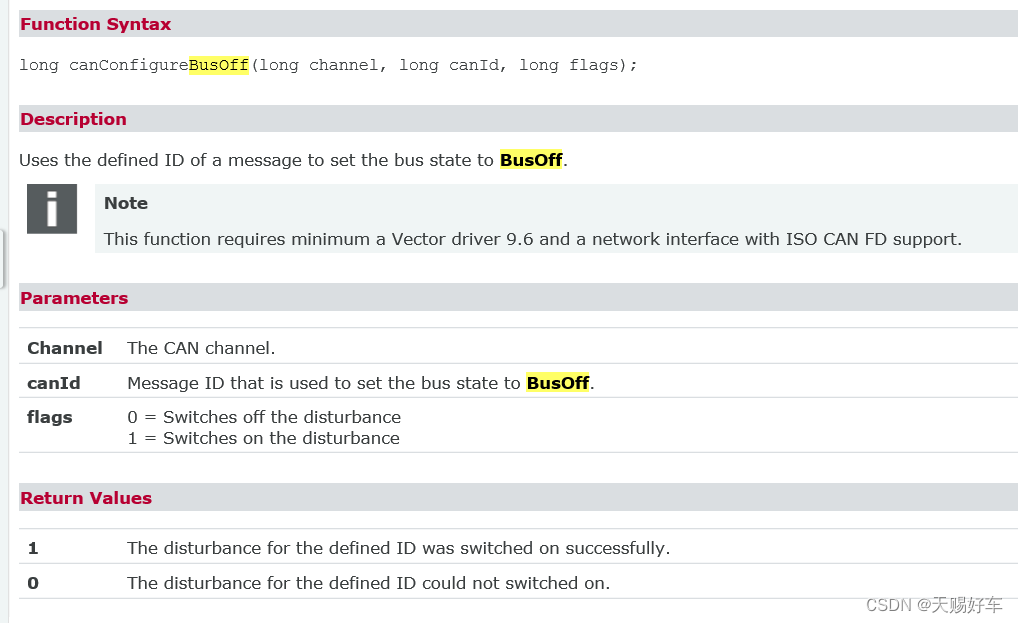
不使用VH6501设备,通过VN1630等普通设备使用canConfigureBusOff函数进行busoff干扰测试
** 特别注意一下,使用这个函数需要你的vector驱动在9.6以上以及支持 ISO CAN FD. ** 函数canConfigureBusOff 可以通过脚本的形式产生bus off,而VH6501可以通过干扰bit位来产生bus off(使用CANoe Demo - CANDisturbanceMain进行Bus Off测试)。 对于函数canConfigureBusOf…...

服务器数据恢复-服务器RAID6硬盘故障离线的数据恢复案例
服务器数据恢复环境: 服务器中有一组由6块磁盘组建的RAID6磁盘阵列。服务器作为WEB服务器使用,上面运行了MYSQL数据库以及存放了网站代码和其他数据文件。 服务器故障: 在服务器运行过程中该raid6阵列中有两块磁盘先后离线,但是管…...

DB2 HADR+TSA运维,TSA添加资源组的命令
Tivoli System Automation(TSA)是一个高可用性集群管理软件,DB2 TSAHADR高可用方案可以实现DB2 hadr主备的自动检测切换。本文详细介绍了TSA的常用命令,如何把CDC或者DSG添加到TSA集群中,以及TSA的错误分析方法 常用命令…...

LeetCode-135-分发糖果
题目描述:n 个孩子站成一排。给你一个整数数组 ratings 表示每个孩子的评分。 你需要按照以下要求,给这些孩子分发糖果: 每个孩子至少分配到 1 个糖果。 相邻两个孩子评分更高的孩子会获得更多的糖果。 请你给每个孩子分发糖果,计…...

Viva Workplace Analytics Employee Feedback SU Viva Glint部署方案
目录 一、Viva Workplace Analytics & Employee Feedback SU Viva Glint介绍 二、Viva Glint和Viva Pulse特点和优势 1. 简单易用...
系统任务)
ASIC-WORLD Verilog(14)系统任务
写在前面 在自己准备写一些简单的verilog教程之前,参考了许多资料----Asic-World网站的这套verilog教程即是其一。这套教程写得极好,奈何没有中文,在下只好斗胆翻译过来(加点自己的理解)分享给大家。 这是网站原文&…...
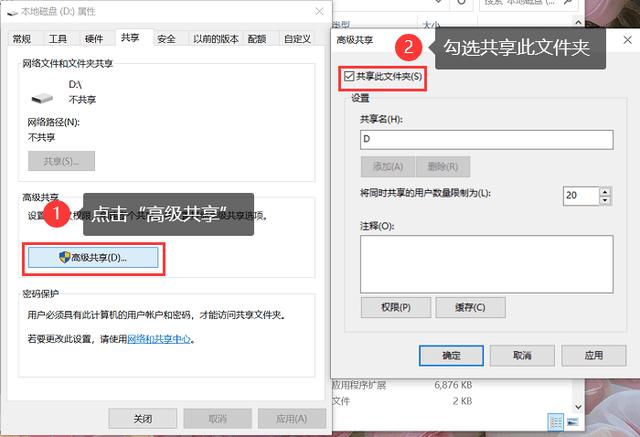
两台电脑共享文件设置
步骤一:确保网络连接正常,可网线直连。 两台电脑IP设置,例: 步骤二:启用共享功能。 1.在【控制面板】中选择【网络和Internet】; 2.点击【网络和共享中心】,在左侧导航栏中,点击【…...

《C和指针》笔记17:sizeof
sizeof操作符判断它的操作数的类型长度,以字节为单位表示。 操作数既可以是个表达式(常常是单个变量), sizeof x上面的式子返回变量x所占据的字节数。 也可以是两边加上括号的类型名。 sizeof(int)上面的式子返回整型变量的字…...

猫抓浏览器扩展:基于网络请求拦截的智能资源嗅探技术实现
猫抓浏览器扩展:基于网络请求拦截的智能资源嗅探技术实现 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(Cat Catch&a…...
)
Docker容器化高可用架构部署方案(十二)
11-MySQL-MGR初始化 本文档详细介绍MySQL MGR(Group Replication)集群的初始化步骤。 初始化前提 三个MySQL容器已正常运行 MySQL容器healthcheck通过 网络连通性正常 初始化步骤 步骤1:等待MySQL容器就绪 # 查看MySQL容器状态 docke…...

极域电子教室防控制软件JiYuTrainer:重获学习自主权的智能解决方案
极域电子教室防控制软件JiYuTrainer:重获学习自主权的智能解决方案 【免费下载链接】JiYuTrainer 极域电子教室防控制软件, StudenMain.exe 破解 项目地址: https://gitcode.com/gh_mirrors/ji/JiYuTrainer 你是否曾在计算机课堂上被极域电子教室的全屏广播限…...

Visual C++运行库终极修复指南:如何3步解决95%的DLL缺失问题?
Visual C运行库终极修复指南:如何3步解决95%的DLL缺失问题? 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist Visual C运行库是Windows系统…...

Nginx、Tengine、OpenRestry的http和tcp后端健康检查【20260520-003篇】
文章目录 一、Nginx 开源版(无第三方模块) 1. 被动健康检查(内置,默认) TCP 后端(stream 四层) HTTP 后端(http 七层) 2. Nginx + 第三方模块(主动检查) 编译 Nginx 加模块 HTTP 主动检查 TCP 主动检查 二、Tengine(原生带主动检查) HTTP 健康检查 TCP 健康检查 查…...
——从寄存器到子系统:驱动演进之路)
嵌入式Linux驱动开发pinctrl篇(1)——从寄存器到子系统:驱动演进之路
嵌入式Linux驱动开发pinctrl篇(1)——从寄存器到子系统:驱动演进之路 仓库已经开源!所有教程,主线内核移植,跑新版本imx-linux/uboot都在这里,或者一起来尝试跑7.0的Linux!欢迎各位大…...

Sunshine游戏串流完整指南:5分钟搭建你的个人游戏云
Sunshine游戏串流完整指南:5分钟搭建你的个人游戏云 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 还在为无法在客厅大屏上畅玩书房电脑里的3A大作而烦恼吗࿱…...

电池级硫酸锂粉碎工艺与设备选型全解析
一、硫酸锂粉碎核心需求与特性 1. 硫酸锂基础物性(决定粉碎工艺边界) 形态与硬度:白色结晶 / 颗粒(无水 / 一水),莫氏硬度约 2–3,质地脆、易结块、吸湿性强。 纯度要求:工业级≥99.…...

给硬件工程师的芯片FT测试入门:从ATE、Handler到Socket,一次搞懂所有‘治具’
芯片FT测试全流程实战指南:从设备选型到治具配置 第一次走进芯片测试车间时,我被眼前那些闪烁着信号灯的庞大设备和精密治具震撼到了。作为硬件工程师,我们可能更熟悉PCB设计和电路仿真,但当芯片进入量产阶段,如何确保…...

蓝桥杯嵌入式模拟赛2实战复盘:用STM32G431搞定LCD、LED、按键、PWM和串口
蓝桥杯嵌入式模拟赛2全流程实战解析:从零构建STM32G431多模块协同系统 当开发板的电源指示灯第一次亮起,LCD屏幕浮现出清晰的白色字符时,我知道这不仅仅是一次普通的练习——这是将分散的模块知识整合成完整系统的关键时刻。蓝桥杯嵌入式模拟…...