客户端读写HBase数据库的运行原理
1.HBase的特点
HBase是一个数据库,与RDMS相比,有以下特点:
① 它不支持SQL
② 不支持事务
③ 没有表关系,不支持JOIN
④ 有列族,列族下可以有上百个列
⑤ 单元格,即列值,可以存储多个版本的值,每个版本都有对应时间戳
⑥ 行键按照字典序升序排列
⑦ 元数据 和 数据 分开存储
- 元数据存储在zookeeper
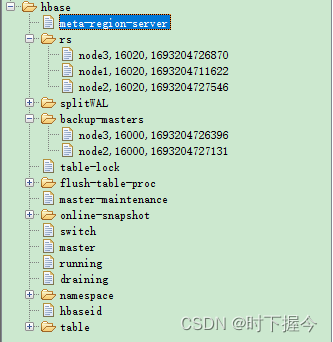
- 数据存储在HDFS,具体路径在hbase-site.xml指定

⑧ HBase的吞吐量不如HDFS,但具备HDFS不具备的随机读写,HDFS只支持顺序读写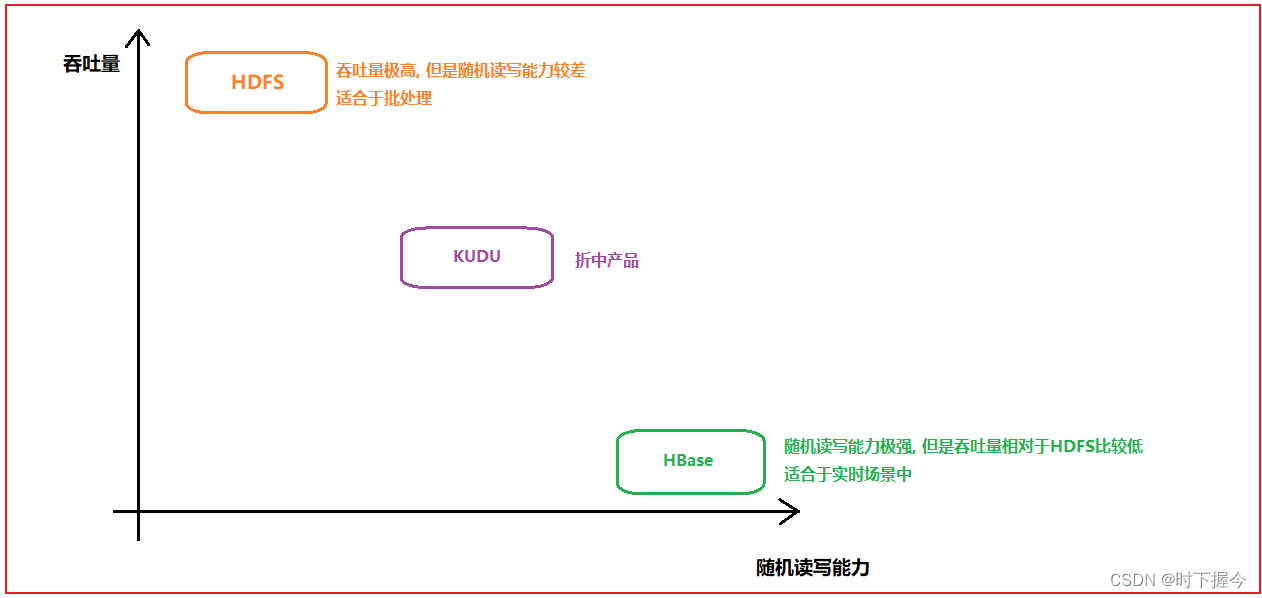
⑨ HBase以字节的形式存储数据,Null值不占用存储空间,支持稀疏存储
2.HBase表模型
表创建好之后,默认有一个分区,能存储10G大小的数据,随着数据量的不断增加,分区会按照rowkey分离,一个数据范围内的行数据分配到不同Region
不过,在创建表时,可以预先设置几个分区(预分区),每个分区指定rowkey范围,这样数据写入时,会写到不同Region
2.1 rowkey的设计原则
rowkey按照字典序升序在表中存储,若rowkey具有相同前缀,则数据可能在同一个rowkey范围内,会将数据存储在同一个Region,造成其它Region空闲。rowkey的设计主要是打乱rowkey的顺序,使rowkey分布在不同Region。
建议rowkey设计时:
①加盐:每个rowkey的前缀加上一个随机数
②反转:手机号、身份证号、时间戳反转
③HASH:MD5Hash方案生成rowkey
①和②能保证数据落在不同Region,但数据的相关性不能保证。③能保证相关性数据放到一起,相关性数据比较多的时候,依然导致数据分配到同一个分区
2.2 列族的设计原则
一个表有多个列族的话,一行数据会写入多处memstore、多处storefile。增加了IO写入次数和读取次数。一行数据的一个memstore触发溢写,该行数据的其它menstore也会同时触发溢写,增加了小文件的数量。
建议列族越少越好。
① 热点数据 和 冷备数据分两个列族存储
② 对接不同业务,建立对应业务的列族
2.3 名称空间的设计原则
名称空间类似于RDMS中的库,便于管理维护工作,使业务划分更加明确,权限管理能够细致
default:默认的名称空间, 在创建表的时候, 如果不指定名称空间, 默认就会将表创建在这个default名称空间下,类似于在HIVE中有一个default库
hbase:hbase专门用于放置hbase系统表,meta 表就是存储在这个名称空间下
3. 架构模型
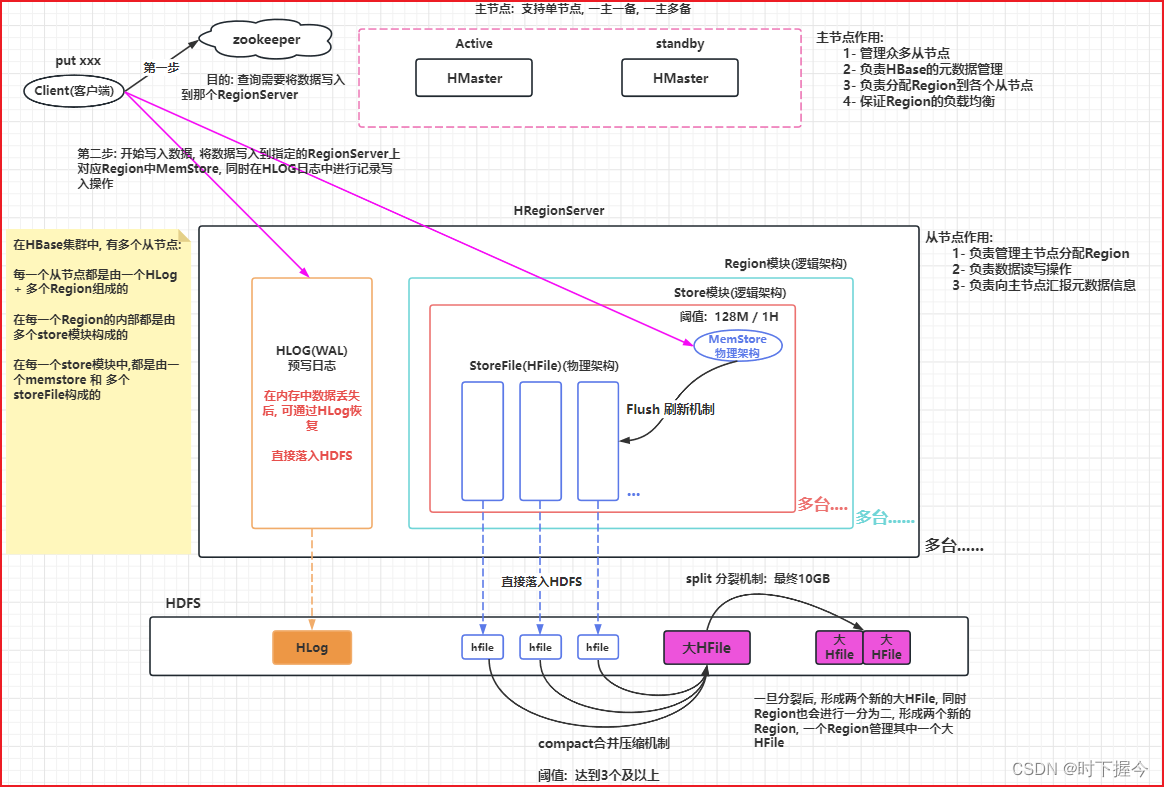
① HMaster
主节点,支持单节点、主从、主备主从架构、HMaster的高可用需要zookeeper参与。
② HRegionServer
从节点,负责管理主节点分配的Region,一个HRegionServer可以管理多个Region,但一个Region只能被一个HRegionServer管理
③ Region
逻辑上,HBase基于rowkey将一个表水平划分成多个Region,默认一个表只有一个Region,随着写入数据的增多,Region会分裂
④ Store
逻辑上,一个列族就是一个Store模块,一个Store模块由一个memStore和多个StoreFile构成
3.1 读数据流程
① 客户端发起读取数据的请求,首先连接zk集群,从zk中查询hbase:meta表,得到管理hbase元数据的Master结点地址
② 客户端连接Master结点,检索habse:meta表,得到客户端端要读的表的Region及管理Region的HRegionServer结点
说明: hbase:meta 是HBase专门用于存储元数据的表, 此表只会有一个Region, 也就说这个表只会被一个Region所管理, 一个Region也只能被一个RegionServer所管理
③ 客户端根据rowkey确定Region,连接管理该Region的HRegionServer,从Region中读取数据
如果执行scan, 返回这个表所有Region对应的RegionServer的地址
如果执行get, 返回查询rowkey所对应Region所在RegionServer的地址
读取顺序: 先内存 --> blockCache(块缓存) —> storeFile —> 大HFile
3.2 写数据流程
① 由客户端发起写入数据的请求, 首先 先连接zookeeper集群
② 从zookeeper集群中获取hbase:meta 表被那个RegionServer所管理
③ 连接对应RegionServer, 从meta表获取要写入数据的表的Region, 然后根据Region的startRow和endRow, 判断要写入数据的Region, 并确定管理该Region的HRegionServer
④连接对应RegionServer,开始进行数据写入操作, 写入时需要将数据写入到对应的Store模块下的MemStore中(可能写入多个MemStore),同时也会将本次写入操作记录在对应RegionServer的HLog中, 这个两个位置都写入完成后, 客户端写入完成
⑤ 随着客户端不断的写入操作, MemStore中数据会越来越多, 当MemStore的数据达到一定的阈值(128M/1H)后,就会启动Flush 刷新线程, 将内存中数据 “最终” 刷新到HDFS上,形成一个StoreFile文件
⑥ 随着不断地Flush的刷新, 在HDFS上StoreFile文件会越来越多, 当StoreFile文件达到一定的阈值(3个及以上)后, 就会启动compact合并压缩机制, 将多个StoreFile “最终” 合并为一个大的HFile
⑦ 随着不断的合并, HFile文件会越来越大,当这个大的HFile文件达到一定的阈值( “最终” 10GB)后,就会触发Split的分裂机制, 将大的HFile进行一分为二操作, 形成两个新的大HFile文件, 此时Region也会进行一分为二操作, 形成两个新的Region, 一个Region管理一个新的大HFile, 旧的大HFile和对应Region就会下线删除
4.写数据流程中的核心工作机制
4.1 刷新机制
memstore溢写storeFile的触发条件:
hbase.hregion.memstore.flush.size: 134217728 (128M)
hbase.regionserver.optionallogflushinterval : 3600000 (1h)
128M(Region级别) / 1H(RegionServer级别) 满足其一,即可触发Flush刷新机制
① 客户端不断向MemStore中写入数据, 当MemStore中数据达到阈值后, 就会启动Flush刷新操作
② 首先HBase会先关闭当前这个已经达到阈值的内存空间, 然后开启一个新的MemStore的空间, 继续写入
③ 将这个达到阈值的内存空间数据放入到内存队列中, 此队列的特性是只读的, 在HBase的2.x版本中, 可以设置此队列尽可能晚的刷新到HDFS中,当这个队列中数据达到某个阈值后(内存不足),这个时候触发Flush刷新操作(希望队列中尽可能多的memstore的数据, 让更多的数据存储在内存中)
④ Flush线程会将队列中所有的数据 全部都读取 出来, 然后对数据进行 排序合并 操作, 将合并后数据存储到HDFS中, 形成一个StoreFile的文件
HBase的2.x版本支持了推迟刷新, 合并刷新策略
hbase.systemtables.compacting.memstore.type:
NONE | BASIC | EAGER
basic(基础型): 直接将多个MemStore数据合并为一个StoreFile. 写入到HDFS上, 如果数据中存在过期的数据,或者已经标记为删除的数据, 基础型不做任何处理
eager(饥渴型): 在将多个memstore合并的过程中, 积极判断数据是否存在过期, 或者是否已经被标记删除了, 如果有, 直接过滤掉这些标记删除或者已经过期的数据
adaptive(适应性): 检测数据是否有过期的内容, 如果过期数据比较多的时候, 就会自动选择饥渴型,否则就是基础型
4.2 合并机制
storefile触发compact合并压缩机制,合并成一个HFile的条件:
整个Compact合并压缩机制分为二大阶段:
minor阶段
hbase.hstore.compaction.min: 3 (3个及以上)
将多个StoreFile合并为一个较大的HFile文件, 对数据进行排序操作, 如果此时有过期或者有标记删除的数据, 此时不做任何处理的(类似于: 内存合并中基础型合并方案)
major阶段
hbase.hregion.majorcompaction: 604800000 (7天)
将较大的HFile 和 之前的大HFile进行合并, 形成一个更大的HFile文件 (全局合并)。
合并过程中, 会将那些过期的数据或者已经标记删除的数据删除掉
4.3 分裂机制
HFile达到一定阈值, 触发Split分裂机制的条件:
hbase.hregion.max.filesize: 10737418240 (10G)
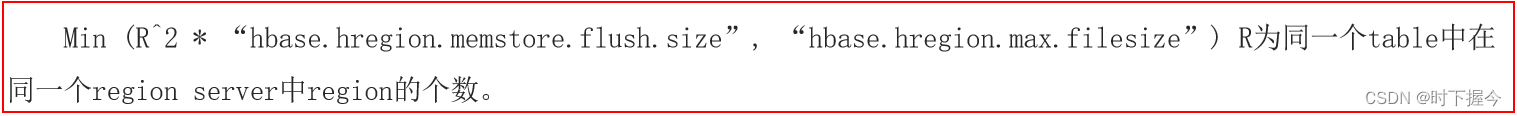
上述公式, 其实就是HBase用于计算在何时进行分裂
相关的变量说明:
R:表对应的Region的数量
hbase.hregion.memstore.flush.size : 默认为128M
hbase.hregion.max.filesize: 默认 10GB
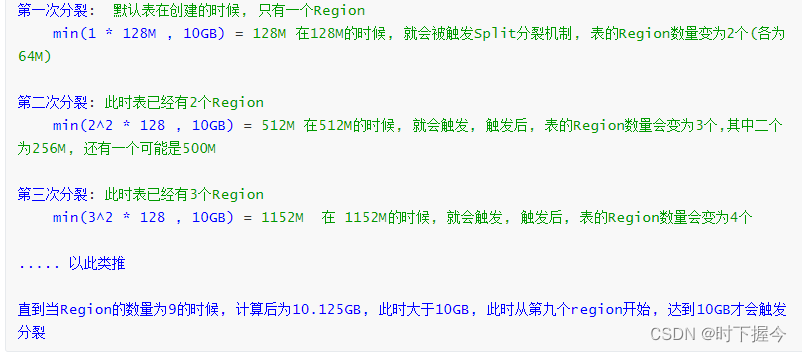 由于表一开始默认只有一个Region, 被一个HRegionServer管理, 如果此时这个表有大量的数据写入和数据读取操作, 这些请求全部负载到同一个HRegionServer, 这个HRegionServer可能负载过重 直接宕机。
由于表一开始默认只有一个Region, 被一个HRegionServer管理, 如果此时这个表有大量的数据写入和数据读取操作, 这些请求全部负载到同一个HRegionServer, 这个HRegionServer可能负载过重 直接宕机。
一旦宕机, 对应的Region就会被HMaster分配给其他的HRegionServer, 然后其他的RegionServer也会跟着一起宕机, 最终导致整个HBase集群从节点全部宕机(雪崩问题)
通过Region分离或预分区策略, HMaster就可以将Region分布给不同的HRegionServer, 大量的并发, 由多个HRegionServer共同负载
相关文章:
客户端读写HBase数据库的运行原理
1.HBase的特点 HBase是一个数据库,与RDMS相比,有以下特点: ① 它不支持SQL ② 不支持事务 ③ 没有表关系,不支持JOIN ④ 有列族,列族下可以有上百个列 ⑤ 单元格,即列值,可以存储多个版本的值&…...
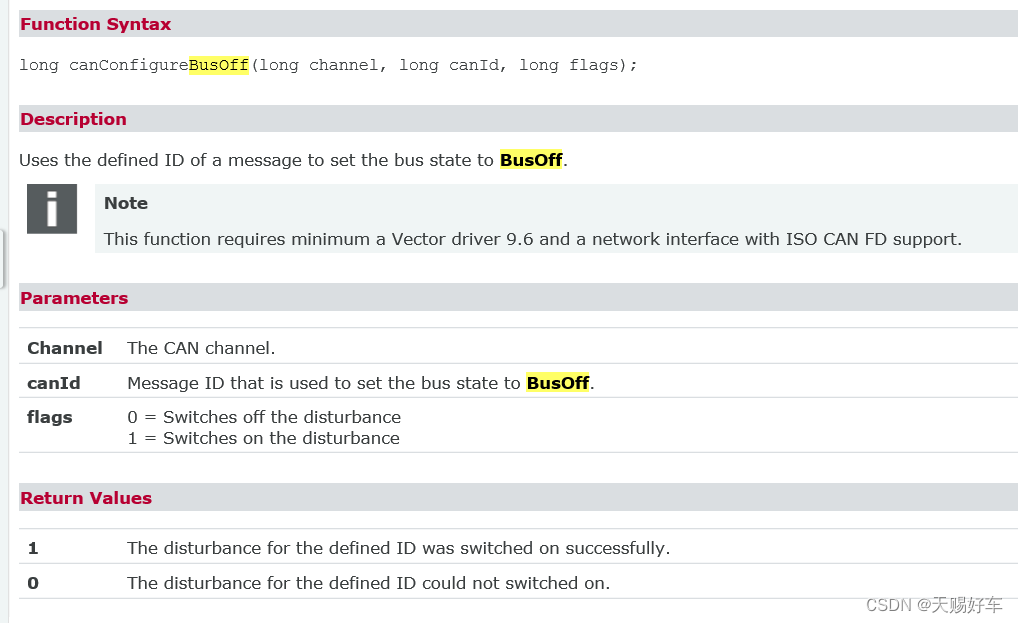
不使用VH6501设备,通过VN1630等普通设备使用canConfigureBusOff函数进行busoff干扰测试
** 特别注意一下,使用这个函数需要你的vector驱动在9.6以上以及支持 ISO CAN FD. ** 函数canConfigureBusOff 可以通过脚本的形式产生bus off,而VH6501可以通过干扰bit位来产生bus off(使用CANoe Demo - CANDisturbanceMain进行Bus Off测试)。 对于函数canConfigureBusOf…...

服务器数据恢复-服务器RAID6硬盘故障离线的数据恢复案例
服务器数据恢复环境: 服务器中有一组由6块磁盘组建的RAID6磁盘阵列。服务器作为WEB服务器使用,上面运行了MYSQL数据库以及存放了网站代码和其他数据文件。 服务器故障: 在服务器运行过程中该raid6阵列中有两块磁盘先后离线,但是管…...

DB2 HADR+TSA运维,TSA添加资源组的命令
Tivoli System Automation(TSA)是一个高可用性集群管理软件,DB2 TSAHADR高可用方案可以实现DB2 hadr主备的自动检测切换。本文详细介绍了TSA的常用命令,如何把CDC或者DSG添加到TSA集群中,以及TSA的错误分析方法 常用命令…...

LeetCode-135-分发糖果
题目描述:n 个孩子站成一排。给你一个整数数组 ratings 表示每个孩子的评分。 你需要按照以下要求,给这些孩子分发糖果: 每个孩子至少分配到 1 个糖果。 相邻两个孩子评分更高的孩子会获得更多的糖果。 请你给每个孩子分发糖果,计…...

Viva Workplace Analytics Employee Feedback SU Viva Glint部署方案
目录 一、Viva Workplace Analytics & Employee Feedback SU Viva Glint介绍 二、Viva Glint和Viva Pulse特点和优势 1. 简单易用...
系统任务)
ASIC-WORLD Verilog(14)系统任务
写在前面 在自己准备写一些简单的verilog教程之前,参考了许多资料----Asic-World网站的这套verilog教程即是其一。这套教程写得极好,奈何没有中文,在下只好斗胆翻译过来(加点自己的理解)分享给大家。 这是网站原文&…...
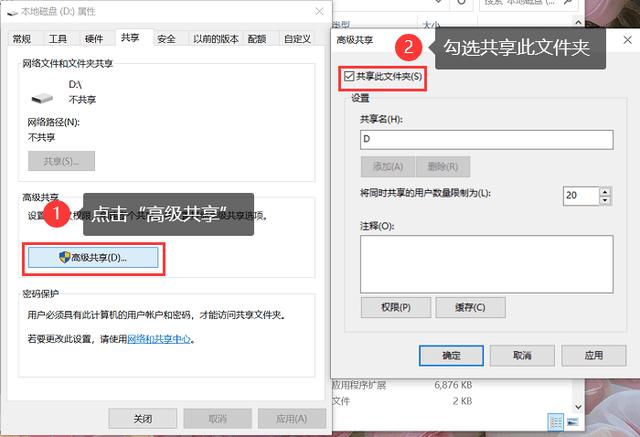
两台电脑共享文件设置
步骤一:确保网络连接正常,可网线直连。 两台电脑IP设置,例: 步骤二:启用共享功能。 1.在【控制面板】中选择【网络和Internet】; 2.点击【网络和共享中心】,在左侧导航栏中,点击【…...

《C和指针》笔记17:sizeof
sizeof操作符判断它的操作数的类型长度,以字节为单位表示。 操作数既可以是个表达式(常常是单个变量), sizeof x上面的式子返回变量x所占据的字节数。 也可以是两边加上括号的类型名。 sizeof(int)上面的式子返回整型变量的字…...

说说大表关联小表
分析&回答 Hive 大表和小表的关联 优先选择将小表放在内存中。小表不足以放到内存中,可以通过bucket-map-join(不清楚的话看底部文章)来实现,效果很明显。 两个表join的时候,其方法是两个join表在join key上都做hash bucket,…...

Unity 之 方括号[ ] 的用法以及作用
文章目录 在Unity中,方括号 [ ] 通常用于表示属性、特性(Attributes)或者元数据(Metadata)。这些标记提供了附加信息,可以用于修改类、方法、字段等的行为或者在编辑器中进行设置。 以下是一些常见的用法&…...

微服务nacos或者yml配置内容部分加密jasypt
写在最前:因业务需要把nacos配置中的部分密码加密,不能暴露在外,本想用nacos官方的插拔插件nacos-aes-encryption-plugin的,但是比较复杂且官方文档说的不清不楚所以弃用,有兴趣的可以参考。链接:https://n…...

Vue:插槽,与自定义事件
1.插槽slot <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>Title</title> </head> <body> <div id"app"><!-- <p>列表书籍</p>--> <!-- …...
Window11-Ubuntu双系统安装
一、制作Ubuntu系统盘 1.下载Ubuntu镜像源 阿里云开源镜像站:https://mirrors.aliyun.com/ubuntu-releases/ 清华大学开源软件镜像网站:https://mirrors.tuna.tsinghua.edu.cn/ubuntu-releases/ 选择想要的版本下载,我用的是20.04版本。 2…...
)
【React】React学习:从初级到高级(一)
React学习[一] 1 UI描述1.1 组件的创建与使用1.1.1 创建组件1.1.2 使用组件 1.2 组件的导入与导出1.2.1 根组件文件1.2.2 导出和导入一个组件1.2.3 从同一文件中导出和导入多个组件 1.3 使用JSX书写标签语言1.3.1 JSX:将标签引入JavaScript1.3.2 将HTML转换为JSX1.3.3 高级提示…...
Flutter 安装教程 + 运行教程
1.下载依赖 https://flutter.cn/docs/get-started/install/windows 解压完后根据自己的位置放置,如(D:\flutter) 注意 请勿将 Flutter 有特殊字符或空格的路径下。 请勿将 Flutter 安装在需要高权限的文件夹内,例如 C:\Program …...

正中优配:A股早盘三大股指微涨 华为概念表现活跃
周三(8月30日),到上午收盘,三大股指团体收涨。其间上证指数涨0.06%,报3137.72点;深证成指和创业板指别离涨0.33%、0.12%;沪深两市合计成交额6423.91亿元,总体来看,两市个…...
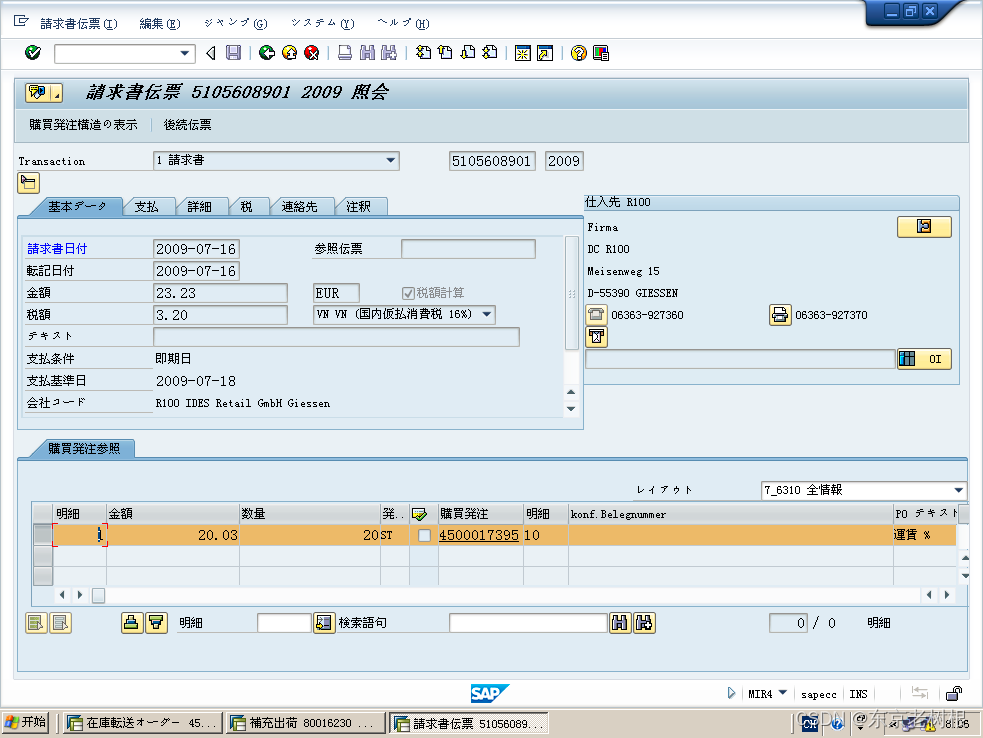
SAP MM学习笔记26- SAP中 振替转记(转移过账)和 在库转送(库存转储)4- Plant间在库转送 之 在库转送Order(有出荷)
SAP 中在库移动 不仅有入库(GR),出库(GI),也可以是单纯内部的转记或转送。 1,振替转记(转移过账) 2,在库转送(库存转储) 1ÿ…...

suricata规则字段解析
一、Payload关键字 1、content 可以匹配所有字符;从a到z,大写和小写及所有特殊标志。针对一些特殊符号或中文等,需要使用十六进制进行匹配,写法:|3A|表示冒号,以此类推。|0D| -> \r,|0A| -…...

韶音骨传导耳机好不好,韶音骨传导耳机值得入手吗
韶音耳机的质量还是很不错的,其实力相比于百元价位的耳机而言领先了不少,具备多种功能,佩戴起来也是有着舒适性。它自主研发了骨传导音频技术,不过在今年开始,似乎已经将方向开始往运动偏移。 而在韶音的骨传导耳机中&…...

AI Agent的协作竞争机制:多智能体博弈与协调
AI Agent的协作竞争机制:多智能体博弈与协调 本文面向中级AI算法工程师、软件架构师与AI产品经理,深度解析多智能体系统的核心原理、博弈机制、协调算法与落地实践,帮助读者掌握下一代AI系统的设计方法论。 一、核心概念与问题背景 1.1 核心概念定义 我们首先明确全文的核…...

FPGA无人机电源设计:集成PMIC方案如何解决多路供电与空间挑战
1. 项目概述与核心挑战最近在做一个由FPGA控制的无人机项目,其中电源管理系统的设计让我感触颇深。无人机这玩意儿,飞控、图传、传感器一个比一个耗电,但留给电源和PCB的空间却极其有限。更头疼的是,主控用上了高性能的FPGA或SoC&…...
)
保姆级教程:用Python脚本一键搞定OPIXray/HIXray数据集转YOLO格式(附避坑指南)
Python实战:OPIXray/HIXray数据集高效转YOLO格式全流程解析 在目标检测领域,数据格式转换往往是项目落地的第一道门槛。当我第一次拿到OPIXray和HIXray这两个专业X光安检数据集时,面对原始标注格式与YOLO训练需求的不匹配,也经历过…...

什么是数字员工?AI销冠系统与AI提效软件系统在提升销售效率中的关键角色是什么?
数字员工成为一种新兴的AI销售工具,正在为企业优化业务流程和提升运营效率提供巨大助力。这些智能化的虚拟职员能够处理大量的客户咨询,全天候地维护客户关系,显著减少了人力资源的消耗。依靠AI销冠系统,这些数字员工除了实时分析…...

制造协同:QNAP 软硬件架构化解汽车冲压车间大文件传输难题
制造协同:QNAP 软硬件架构化解汽车冲压车间大文件传输难题声明:本文围绕大型汽车零部件制造企业冲压车间的工程变更(ECO)数据流转场景构建虚拟技术方案,旨在探讨分布式网络与底层存储的实时同步逻辑,非特定…...

同样是芯片,为什么有的板子CPU强、有的GPU猛、还有的专门带NPU?三者到底怎么分工?日常选型怎么避坑?
做嵌入式开发、玩工控板、折腾端侧AI的朋友,大概率都纠结过一个问题:同样是芯片,为什么有的板子CPU强、有的GPU猛、还有的专门带NPU?三者到底怎么分工?日常选型怎么避坑?一、通俗拆解:CPU / GPU…...

嵌入式开源项目高效学习指南:从筛选评估到深度贡献
1. 项目概述:为什么我们需要一份“开源项目精选”?如果你是一名嵌入式开发者,或者正在向这个领域转型,那么你一定经历过这样的时刻:GitHub上项目浩如烟海,技术论坛帖子日更千条,想找一个靠谱的、…...
)
双人成行2026最新官方正版免费下载 520情侣必玩 一键转存 永久更新 (看到速转存 资源随时走丢)
下载链接 # 编织奇迹的合作历程:《双人成行》的幕后、机制与同类作品剖析 在现代电子游戏领域,纯粹专注于双人合作的游戏并不多见,而能将其做到极致并斩获行业高额荣誉的作品,更是凤毛麟角。由Hazelight Studios开发的《双人成行…...

VS2019编译OpenCASCADE 7.6.0避坑实录:从custom.bat修改到Demo测试,一次搞定
VS2019编译OpenCASCADE 7.6.0全流程避坑指南 在三维建模与CAD开发领域,OpenCASCADE作为开源几何内核引擎,其强大的BRep建模和STEP文件处理能力备受开发者青睐。然而对于初次接触OCC的Windows平台开发者而言,在Visual Studio 2019环境下完成从…...

告别机械音!用‘小蜗语音工具1.9’制作有声小说和视频字幕的保姆级教程
告别机械音!用‘小蜗语音工具1.9’制作有声小说和视频字幕的保姆级教程 在内容创作爆炸的时代,有声小说和视频字幕已成为吸引用户注意力的关键。然而,传统语音合成工具常因生硬的机械音、单调的语调让作品失去灵魂。小蜗语音工具1.9的多角色对…...