LLM - LLaMA-2 获取文本向量并计算 Cos 相似度
目录
一.引言
二.获取文本向量
◆ model config
◆ get Embedding
三.获取向量 Cos 相似度
1.向量选择
2.Cos 相似度
3.BERT-whitening 特征白化
四.总结
一.引言
前面提到了两种基于统计的机器翻译评估方法: Rouge 与 BLEU,二者通过统计概率计算 N-Gram 的准确率与召回率,在机器翻译这种回答相对固定的场景该方法可以作为一定参考,但在当前大模型更加多样性的场景以及发散的回答的情况下,Rouge 与 BLEU 有时候并不能更好的描述文本之间的相似度,下面我们尝试从 LLM 大模型提取文本的 Embedding 并进行向量相似度计算。
二.获取文本向量
1.hidden_states 与 last_hidden_states
根据 LLM 模型类型的不同,有的 Model 提供 hidden_states 方法,例如 LLaMA-2-13B,有的模型提供 last_hidden_states 方法,例如 GPT-2。查找模型对应方法 API 可以在 Transformer 官网。
◆ hidden_states
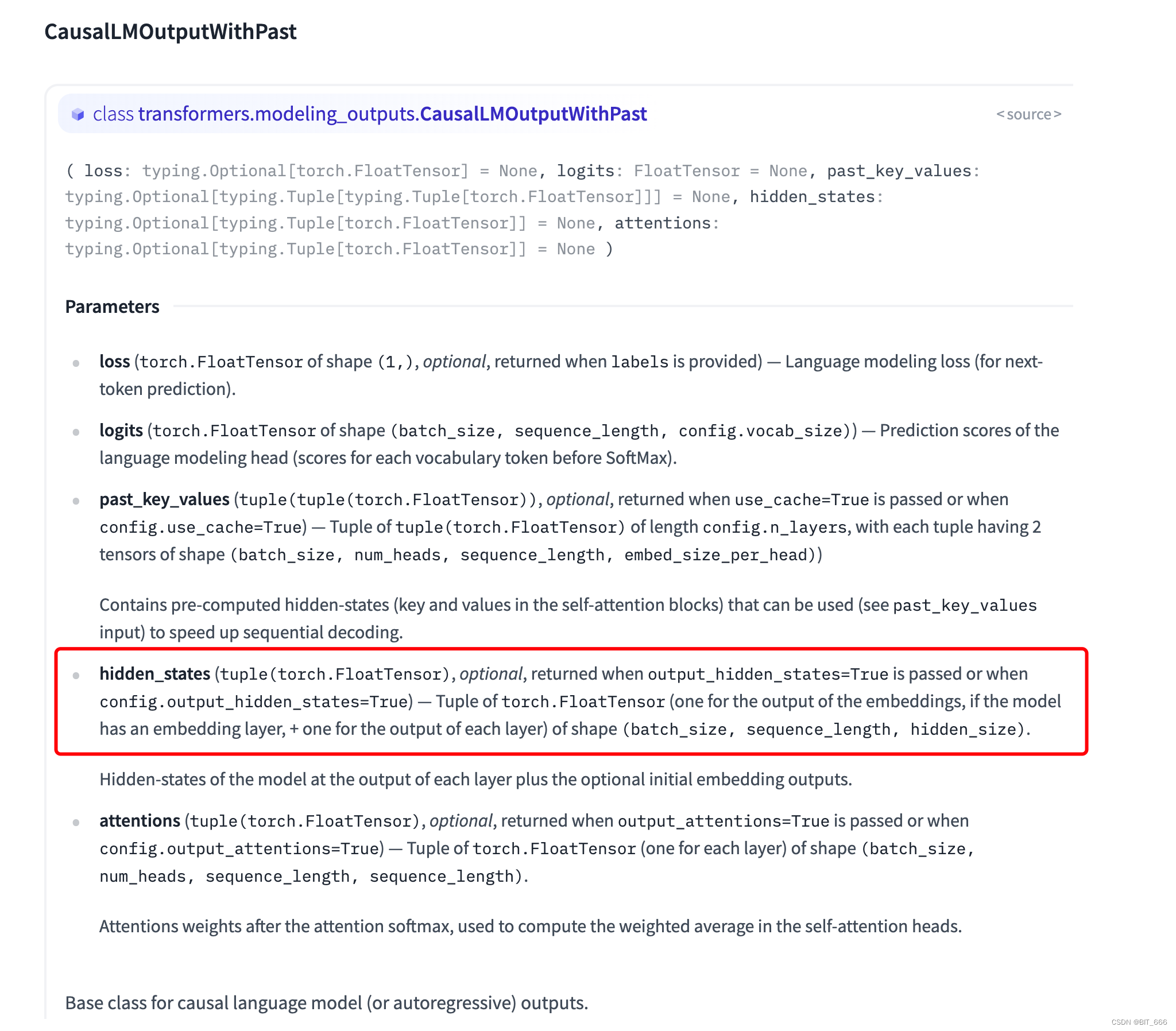
hidden_states 类型为 typing.Optional[typing.Tuple[torch.FloatTensor]],其提供一个 Tuple[Tensor] 分别记录了每层的输出,完整的解释在参数下方:

模型在每一层输出处的隐藏状态加上可选的初始嵌入输出。这里我们可以通过打印模型 Layer 和索引从而获取 hidden_states 中隐层的输出。
◆ last_hidden_states

一些传统的模型例如 GPT-2,还有当下一些的新模型例如 ChatGLM2 都有 last_hidden_states 的 API,可以直接获取最后一层的 Embedding 输出,而如果使用 hidden_states 则只需要通过 [-1] 索引即可获得 last_hidden_states,相比来如前者更全面后者更方便。
2.LLaMA-2 获取 hidden_states
◆ model config
config_kwargs = {"trust_remote_code": True,"cache_dir": None,"revision": 'main',"use_auth_token": None,"output_hidden_states": True}config = AutoConfig.from_pretrained(ori_model_path, **config_kwargs)llama_model = AutoModelForCausalLM.from_pretrained(ori_model_path,config=config,torch_dtype=torch.float16,low_cpu_mem_usage=True,trust_remote_code=True,revision='main')根据 CausalLMOutputWithPast hidden_states 参数的提示,我们只需要在模型 config 中添加:
"output_hidden_states": True◆ get Embedding
def get_embeddings(result, llm_tokenizer, model, args):fw = open(args.output, 'w', encoding='utf-8')for qa in result:q = qa[0]a = qa[1]# 对输出文本进行 tokenize 和编码tokens = llm_tokenizer.encode_plus(a, add_special_tokens=True, padding='max_length', truncation=True,max_length=128, return_tensors='pt')input_ids = tokens["input_ids"]attention_mask = tokens['attention_mask']# 获取文本 Embeddingwith torch.no_grad():outputs = model(input_ids=input_ids.cuda(), attention_mask=attention_mask)embedding = list(outputs.hidden_states)last_hidden_states = embedding[-1].cpu().numpy()first_hidden_states = embedding[0].cpu().numpy()last_hidden_states = np.squeeze(last_hidden_states)first_hidden_states = np.squeeze(first_hidden_states)fisrt_larst_avg_status = np.mean(first_hidden_states + last_hidden_states, axis=0)log = "%s\t%s\t%s\n" % (q, a, toString(fisrt_larst_avg_status))fw.write(log)fw.close()predict 预测 ➔ 将 model 基于 Question generate 得到的 Answer 存入 result
encode 编码 ➔ 对 Answer 进行编码获取对应 Token 与 input_ids、attention_mask
output 模型输出 ➔ 直接调用 model 进行输出,有的也可以调用 model.transform 方法进行输出
hidden_states ➔ outputs.hidden_states 获取各隐层输出
最后获取的向量需要先 cpu 然后再转为 numpy 数组,一般的做法是采用 mean 获得句子的平均表征。
三.获取向量 Cos 相似度
1.向量选择
在 BERT-flow 的论文中,如果不加任何后处理手段,那么基于 BERT 抽取句向量的最好 Pooling 方法是 BERT 的第一层与最后一层的所有 token 向量的平均,即 fisrt-larst-avg,对应 hidden_state 的 0 和 -1 索引,所以后面的相似度计算我们都以 fisrt-larst-avg 为基准来评估 Embedding 相似度。
# 获取文本 Embedding
with torch.no_grad():outputs = model(input_ids=input_ids.cuda(), attention_mask=attention_mask)embedding = list(outputs.hidden_states)last_hidden_states = embedding[-1].cpu().numpy()first_hidden_states = embedding[0].cpu().numpy()last_hidden_states = np.squeeze(last_hidden_states)first_hidden_states = np.squeeze(first_hidden_states)fisrt_larst_avg_status = np.mean(first_hidden_states + last_hidden_states, axis=0)2.Cos 相似度
# 计算 Cos 相似度
def compute_cosine(a_vec, b_vec):norms1 = np.linalg.norm(a_vec, axis=1)norms2 = np.linalg.norm(b_vec, axis=1)dot_products = np.sum(a_vec * b_vec, axis=1)cos_similarities = dot_products / (norms1 * norms2)return cos_similaritiesa_vec 为预测文本转化得到的 Embedding,b_vec 为人工标注正样本文本转化得到的 Embedding,通过计算二者相似度,评估预测文本与人工文本的相似程度。
3.BERT-whitening 特征白化
苏神在 BERT-whitening 一文中提出了一种基于 PCA 降维的无监督 Embedding 评估方式,Bert-whitening 又叫特征白化,其思路与 PCA 降维类似,意在对 SVD 分解后的主成分矩阵取前 λ 个特征向量构造特征值矩阵,提取向量中的关键信息,使输出向量矩阵每个维度均值为零,协方差矩阵为单位阵,λ 个特征值也对应前 λ 个主成分。其算法逻辑如下:

下面我们调用 Sklearn 的 PCA 库简单实现下:
from sklearn.decomposition import PCA
from sklearn.preprocessing import normalize# 取出句子的平均表示 -> 使用 PCA 降维 -> 白化处理concatenate = np.concatenate((answer_vector, predict_vector))pca = PCA(n_components=2048)pca.fit(concatenate)ans_white_vec = pca.transform(answer_vector)ans_norm_vec = normalize(ans_white_vec)pre_white_vec = pca.transform(predict_vector)pre_norm_vec = normalize(pre_white_vec)pca_cos_similarities = compute_cosine(ans_norm_vec, pre_norm_vec)answec_vector 和 predict_vector 均通过 first_and_last 方法从 hidden_states 中获取,n_components 即 top_k 的选择,以 LLaMA-2 为例,原始得到的向量维度为 5120,原文中也有使用 n_components = 256 实验。
四.总结
博主采用 1500+ 样本分别使用 cos、pca 和 self_pca [自己实现 SVD 与特征矩阵] 三种方法对向量相似度进行评估,n_components 设为 1024:

可以看到 SVD 处理后得到的 W 和 mu 的 shape,通过下述操作可完成向量的降维:
vecs = (vecs + bias).dot(kernel)最终得到的结果 Cosine 与 PCA 降维的相似度差距较大,由于自然语言生成的样本没有严格意义的正样本,上面计算采用的参考文本也是人工标注,有一定的不确定性,所以基于不同的度量,我们也可以统计分析,定一个 threshold,认为大于该 threshold 的输入样本为可用。
相关文章:
LLM - LLaMA-2 获取文本向量并计算 Cos 相似度
目录 一.引言 二.获取文本向量 1.hidden_states 与 last_hidden_states ◆ hidden_states ◆ last_hidden_states 2.LLaMA-2 获取 hidden_states ◆ model config ◆ get Embedding 三.获取向量 Cos 相似度 1.向量选择 2.Cos 相似度 3.BERT-whitening 特征白化 …...

【创建型设计模式】C#设计模式之工厂模式,以及通过反射实现动态工厂。
题目如下: 假设你正在为一家汽车制造公司编写软件。公司生产多种类型的汽车,包括轿车、SUV和卡车。每种汽车都有不同的特点和功能。请设计一个工厂模式,用于创建不同类型的汽车对象。该工厂模式应具有以下要求:工厂类名为 CarFac…...
可拖拽编辑的流程图X6
先上图 //index.html,有时候可能加载失败,那就再找一个别的cdn 或者npm下载,如果npm下载, //那么需要全局引入或者局部引入,代码里面写法也会不同,详细的可以看示例<script src"https://cdn.jsdeli…...

神经网络与卷积神经网络
全连接神经网络 概念及应用场景 全连接神经网络是一种深度学习模型,也被称为多层感知机(MLP)。它由多个神经元组成的层级结构,每个神经元都与前一层的所有神经元相连,它们之间的连接权重是可训练的。每个神经元都计算…...

《Java极简设计模式》第05章:原型模式(Prototype)
作者:冰河 星球:http://m6z.cn/6aeFbs 博客:https://binghe.gitcode.host 文章汇总:https://binghe.gitcode.host/md/all/all.html 源码地址:https://github.com/binghe001/java-simple-design-patterns/tree/master/j…...

OceanBase 4.1解读:读写兼备的DBLink让数据共享“零距离”
梁长青,OceanBase 高级研发工程师,从事 SQL 执行引擎相关工作,目前主要负责 DBLink、单机引擎优化等方面工作。 沈大川,OceanBase 高级研发工程师,从事 SQL 执行引擎相关工作,曾参与 TPC-H 项目攻坚&#x…...
STM32的HAL库的定时器使用
用HAL库老是忘记了定时器中断怎么配置,该调用哪个回调函数。今天记录一下,下次再忘了就来翻一下。 系统的时钟配置,定时器的时钟是84MHz 这里定时器时钟是84M,分频是8400后,时基就是1/10000s,即0.1ms。Per…...
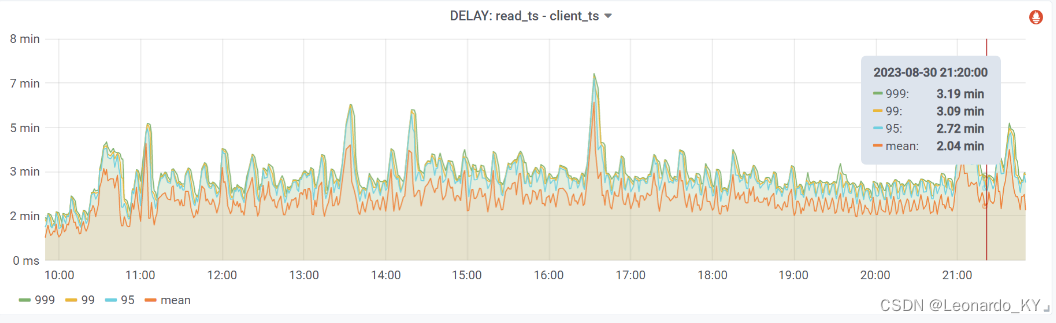
Flink+Paimon多流拼接性能优化实战
目录 (零)本文简介 (一)背景 (二)探索梳理过程 (三)源码改造 (四)修改效果 1、JOB状态 2、Level5的dataFile总大小 3、数据延迟 (五&…...
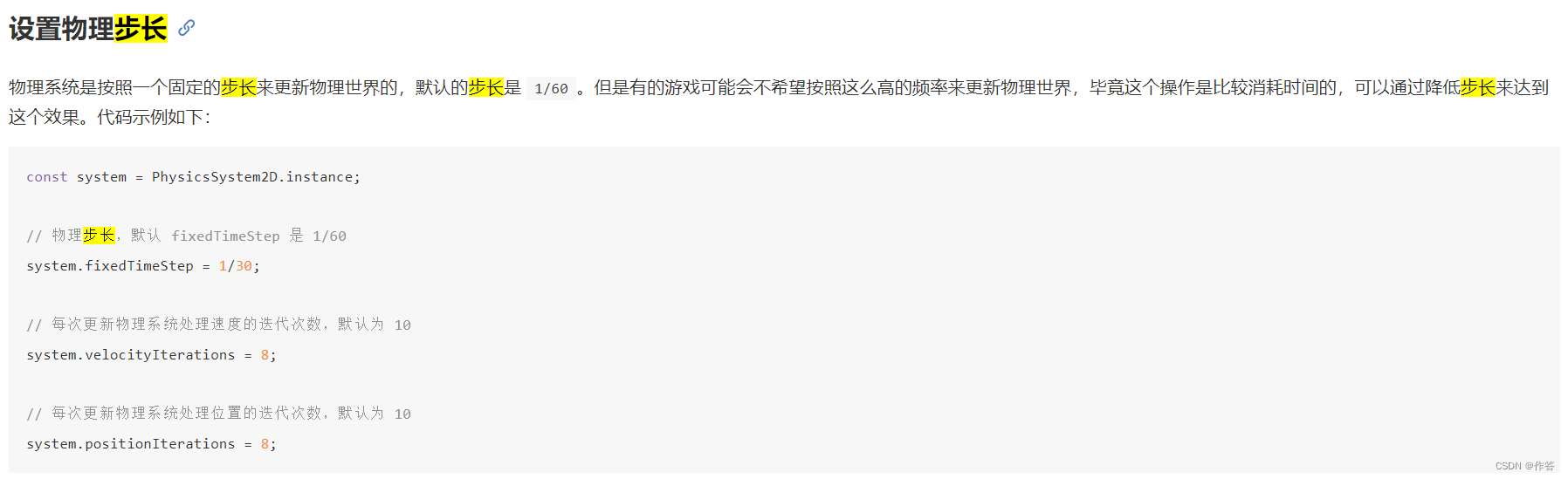
cocos 2.4 版本 设置物理引擎步长 解决帧数不一致的设备 物理表现不一致问题 设置帧刷新率
官网地址Cocos Creator 3.8 手册 - 2D 物理系统 官网好像写的不太对 下面是我自己运行好使的 PhysicsManager.openPhysicsSystem()var manager cc.director.getPhysicsManager();// 开启物理步长的设置manager.enabledAccumulator true;// cc.PhysicsManagercc.PhysicsManag…...
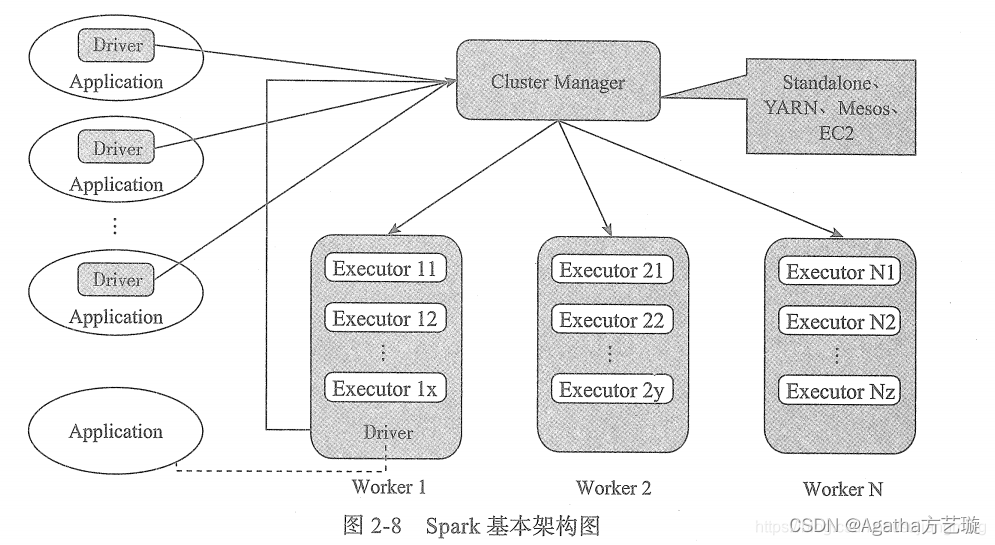
Spark及其生态简介
一、Spark简介 Spark 是一个用来实现快速而通用的集群计算的平台,官网上的解释是:Apache Spark™是用于大规模数据处理的统一分析引擎。 Spark 适用于各种各样原先需要多种不同的分布式平台的场景,包括批处理、迭代算法、交互式查询、流处理…...
从Instagram到TikTok:利用社交媒体平台实现业务成功
自 2000年代初成立和随后兴起以来,社交媒体一直被大大小小的品牌用作高度针对性的营销工具,自 Facebook推出近二十年以来,这些网站继续彻底改变企业处理广告的方式。 在这篇博文中,我们将讨论订阅企业应该如何从整体上对待社交媒…...

单元测试
1. 单元测试Junit 1.1 什么是单元测试?(掌握) 对部分代码进行测试。 1.2 Junit的特点?(掌握) 是一个第三方的工具。(把别人写的代码导入项目中)(专业叫法:…...

科技云报道:AI+云计算共生共长,能否解锁下一个高增长空间?
科技云报道原创。 在过去近一年的时间里,AI大模型从最初的框架构建,逐步走到落地阶段。 然而,随着AI大模型深入到千行百业中,市场开始意识到通用大模型虽然功能强大,但似乎并不能完全满足不同企业的个性化需求。 大…...

ReactPy:使用 Python 构建动态前端应用程序
在 Web 开发领域,ReactJS 已成为主导者,为开发人员提供了用于创建动态和交互式用户界面的强大工具集。但是,如果您更喜欢 Python 的多功能性和简单性作为后端,并且希望在前端也利用它的功能,该怎么办?ReactPy 是一个 Python 库,它将熟悉的 ReactJS 语法和灵活性带入了 P…...

安全攻防基础以及各种漏洞库
安全攻防基础以及各种漏洞库 信息搜集企业信息搜集1. 企业架构2. ICP备案查询,确定目标子域名3. 员工信息(搜集账号信息、钓鱼攻击)4. 社交渠道 域名信息搜集IP搜集信息泄露移动端搜集打点进内网命令和控制(持续控制)穿…...

护眼灯值不值得买?开学给孩子买什么样的护眼台灯
如果不想家里的孩子年纪小小的就戴着眼镜,从小就容易近视,那么护眼灯的选择就非常重要了,但是市场上那么多品类,价格也参差不齐,到底怎么选呢?大家一定要看完本期内容。为大家推荐五款热门的护眼台灯 一、…...
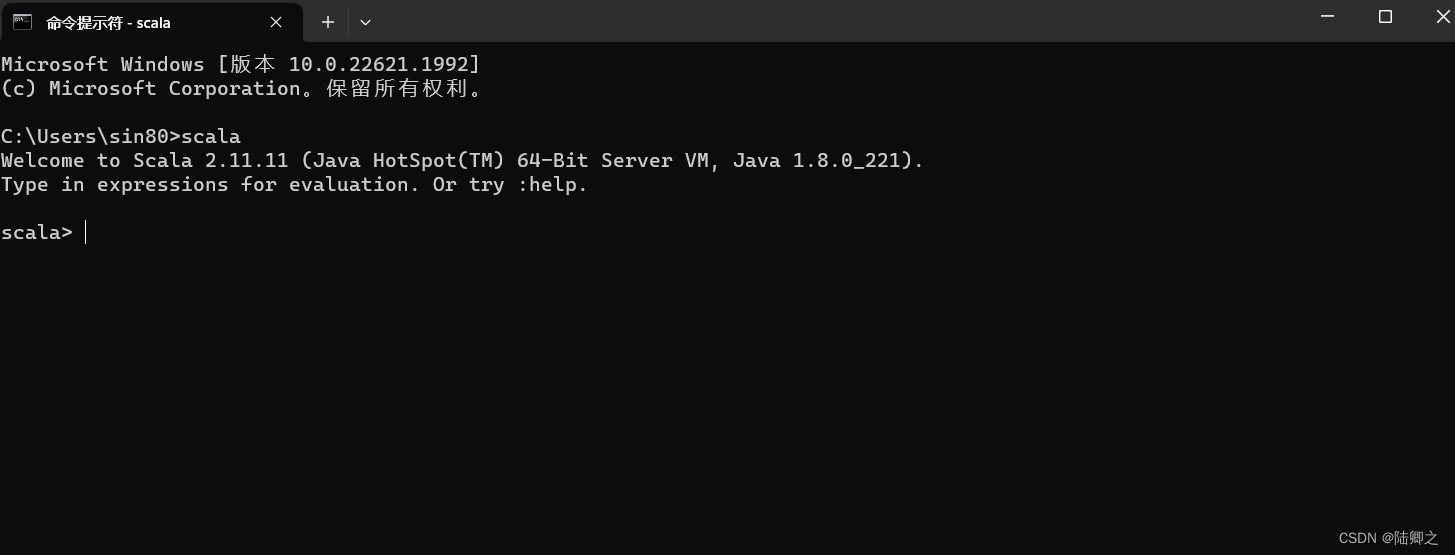
windows安装Scala
Windows安装Scala 下载地址:https://downloads.lightbend.com/scala/2.11.11/scala-2.11.11.zip 解压完成之后 配置环境变量...

API类型和集成规范指南
在我们的常见应用中,往往包含着大量服务于各种数据交换的API类型、以及各种常见的API架构与协议。下面,我将从集成的角度和您讨论,在准备将多个服务相互集成时,使用不同类型、架构和协议的API意味着什么?我们可以使用哪些工具&am…...
[ES]mac安装es、kibana、ik分词器
一、安装es和kibana 1、创建一个网络,网络内的框架(eskibana)互联 docker network create es-net 2、下载es和kibana docker pull elasticsearch:7.12.1 docker pull kibana:7.12.1 3、运行docker命令部署单点eskibana(用来操作es) doc…...

YOLO目标检测——视觉显著性检测MSRA1000数据集下载分享
MSRA1000数据集是一个常用的视觉显著性检测数据集,它包含了1000张图像和对应的显著性标注。在以下几个应用场景中,MSRA1000数据集可以发挥重要作用:图像编辑和后期处理、图像检索和分类、视觉注意力模型、自动驾驶和智能交通等等 数据集点击下…...

边缘AI闭环数控系统:基于IIoT的轻量级CNC智能改造实践
1. 项目概述:这不是在改装一台机床,而是在给金属切削装上“神经系统”“AI-Driven Machining: Building a Closed-Loop CNC System with IIoT Feedback (Building the CNC)”——这个标题里没有一个词是虚的。它不是讲怎么用AI生成G代码,也不…...

Windows右键菜单终极优化指南:用ContextMenuManager让你的右键菜单秒开如飞
Windows右键菜单终极优化指南:用ContextMenuManager让你的右键菜单秒开如飞 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 你是否经历过这样的烦恼&…...

企业数字化破局:AI低代码为何是唯一刚需?
聊企业数字化转型,现在最绕不开的就是AI低代码。但很多技术人仍有偏见:“低代码低技术”“AI能写代码,没必要用低代码”“中小企业用不起,大企业用不上”。真相很扎心:信通院2026年数据显示,AI低代码化率已…...

Frida-server魔改实战:Android native层反调试对抗七步法
1. 这不是“绕过检测”,而是让frida-server从“被识别对象”变成“系统一部分”在安卓逆向和安全测试一线干了十多年,我见过太多人把Frida检测对抗理解成一场猫鼠游戏:App加个检测逻辑,测试方就写个绕过脚本;检测逻辑升…...

Claude Mythos:AI自主攻防与零日漏洞发现的范式革命
1. 项目概述:一场静默却震耳欲聋的AI能力跃迁这周,整个AI安全圈没有爆炸性新闻稿,没有铺天盖地的发布会直播,只有一份措辞克制、数据密集的系统卡片(System Card)和一份由英国AI安全研究所(AISI…...

Unity URDF导入器终极指南:快速实现机器人仿真环境搭建
Unity URDF导入器终极指南:快速实现机器人仿真环境搭建 【免费下载链接】URDF-Importer URDF importer 项目地址: https://gitcode.com/gh_mirrors/ur/URDF-Importer 在机器人仿真开发领域,Unity URDF导入器是一个革命性的工具,它让开…...

鸿蒙备考题库页面构建:学习进度可视化与练习模式网格设计
鸿蒙备考题库页面构建:学习进度可视化与练习模式网格设计 前言 在 HarmonyOS 6.0 应用开发中,在线教育类页面的核心挑战在于如何将学习进度、练习入口、知识图谱等多维信息高效整合。本文将以“备考题库”应用的主页面为例,深入解析如何在鸿…...

Amphenol ICC线束MSPEC6P2A5010应用与替代分析
随着工业通信、车载网络以及高速数据互联的发展,越来越多设备开始采用高性能线束组件来保证数据稳定传输。在工业自动化与智能设备领域,Amphenol ICC推出的MSPE系列近年来关注度持续提升,其中MSPEC6P2A5010就是比较典型的一款工业级线束组件。…...

纤维增强复合材料神经协同优化技术解析
1. 纤维增强复合材料协同优化技术概述纤维增强复合材料因其优异的比强度和比刚度特性,在航空航天、汽车制造等领域得到广泛应用。传统设计方法通常将结构拓扑优化与制造工艺规划分离处理,导致优化结果难以实际制造或性能大幅下降。我们提出的神经协同优化…...

干翻特斯拉?雷军说输给特斯拉不丢人
一周前的晚上,雷军和马斯克合照上了热搜。一周后的晚上,“雷军说输给特斯拉不丢人”又上了热搜。①5 月 21 日晚间小米有个发布会,雷军期间自问:“Model Y 是全球纯电车型的销冠,每年都有很多车型站出来要挑战 Model Y…...