【MySQL】3、MySQL的索引、事务、存储引擎
create table class (id int not null,name char(10),score decimal(5,2));
insert into class values (1,'zhangsan',80.5);
update class set name='wangwu',passwd='123' where id=2;
select * from class where id=2;
drop索引的概念
是一种帮助系统,能够更快速的查询信息的结构作用
数据库利用各种快速定位技术,能够大大加快查询速率
当表很大或涉及到多个表时,可以成千上万倍地提高查询速度
可以降低数据库的IO成本,并且还可以降低数据库的排序成本
通过创建唯一性索引保证数据表数据的唯一性
可以加快表与表之间的连接
在使用分组和排序时,可以减少分组和排序的时间副作用
1.索引需要占用额外的磁盘空间对于MyISAM引擎而言,索引文件和数据文件是分离的,索引文件用于保存数据记录的地址。而InnoDB引擎的表数据文件本身就是索引文件。当表很大或查询涉及到多个表时,可以成千上万倍地提高查询速度2.在插入和修改数据时要花费更多时间,因为索引也要随之变动索引是一个排序的列表,存储着索引值和这个值所对应的物理地址
通过物理地址就可以找到所需数据,不必对整个表扫描
是表中一列或者若干列值排序的方法
需要额外的磁盘空间
创建索引的规则
mysql的优化,哪些字段/场景适合创建索引,哪些不适合?
1.小字符
2.唯一性强的字段
3.更新不频繁,但查询表比较高的字段
4.表记录超过300行
5.主键、外键、唯一键创建索引的原则依据
表的主键、外键必须有索引
记录数据超过300行的表应该有索引
经常与其他表进行连接的表,在连接字段上应该建立索引唯一性太差的字段不适合建立索引
更新太频繁地字段不适合创建索引经常出现在where子句中的字段,特别是大表的字段,应该建立索引索引应该建立在选择性高的字段上索引应该建在小字段上,对于大的文本字段甚至超长字段不要建索引索引的分类
普通索引:针对所有字段,没有特殊的需求和规则
唯一索引:针对唯一字段,仅允许出现一次空值
组合索引:多列/多字段组合形式的索引,按照组合中的排序进行索引,否则无效
全局索引:
主键索引:针对唯一字段,且不可为空,同一张表只允许有一个主键索引
全文索引:fulltext,通过varchar、char、text、blob、clob检索内部信息来做字段的索引
创建方式:
三种:1.直接创建索引,并指向索引的字段
create index 索引名 on 表名(类名);
2.通过修改表的字段来添加索引
alter table 表名 add index 索引名
3.创建表时,直接指定索引
create table 表名 (id int not null,name char (10),score decimal(5,2), passwd varchar(48),primary key (id),index 索引名 (name));查看表的配置信息
show create table 表名;普通索引:可以直接创建,没有唯一性的限制;针对所有的字段做索引,没有特殊的需求和规则
直接创建索引
create index in_name on test(name);修改表方式创建
ALTER TABLE 表名 ADD INDEX 索引名 (列名);alter table test add index in_phone(phone);创建表的时候指定索引
CREATE TABLE 表名 (字段1 数据类型,字段2 数据类型[,...],UNIQUE 索引名 (列名));create table test (id int,name char(10),cardid int(18),phone int(11),address varchar(50),remark text,index in_name(name));
唯一性索引:
与普通索引基本相同,索引列的所有值只能出现一次,必须唯一;
与普通索引类似,但区别是唯一索引列的每个值都唯一。唯一索引允许有空值(注意和主键不同)。
如果是用组合索引创建,则列值的组合必须唯一。添加唯一键将自动创建唯一索引。直接创建唯一索引
CREATE UNIQUE INDEX 索引名 ON 表名(列名);create unique index in_cardid on test(cardid);修改表方式创唯一索引
ALTER TABLE 表名 ADD UNIQUE 索引名 (列名);alter table test add unique in_phone(phone);创建表的时候指定唯一索引
CREATE TABLE 表名 (字段1 数据类型,字段2 数据类型[,...],UNIQUE 索引名 (列名));create table test (id int(10),name varchar(10),cardid int(18),phone int(11),address varchar(50),remark text,unique in_id(id));
主键索引(unique)
是一种特殊的唯一索引,必须指定为“PRIMARY KEY”。一个表只能有一个主键,不允许有空值。 添加主键将自动创建主键索引。
1.创建表的时候指定索引
CREATE TABLE 表名 ([...],PRIMARY KEY (列名));create table test1 (id int(10),name varchar(10),cardid int(18),phone int(11),address varchar(50),remark text,primary key(id));
2.修改表方式创建主键索引
ALTER TABLE 表名 ADD PRIMARY KEY (列名); alter table test add primary key(id);组合索引
可以是单列上创建的索引,也可以是在多列上创建的索引。
需要满足最左原则,因为 select 语句的 where 条件是依次从左往右执行的,
所以在使用 select 语句查询时 where 条件使用的字段顺序必须和组合索引中的排序一致,否则索引将不会生效。
直接创建组合索引
CREATE TABLE 表名 (列名1 数据类型,列名2 数据类型,列名3 数据类型,INDEX 索引名 (列名1,列名2,列名3));
create index in_sum on test(name,cardid,phone);select 查询时 where 语句中的条件字段 要与组合索引的字段排列顺序一致(最左原则)
select * from 表名 where 列名1='...' AND 列名2='...' AND 列名3='...';修改表方式创建组合索引
alter table 表名 add index 索引名 (字段1,字段2,字段3,...); alter table test1 add index in_sum1(name,phone,cardid);创建表的时候指定组合索引
CREATE TABLE 表名 (列名1 数据类型,列名2 数据类型,列名3 数据类型,INDEX 索引名 (列名1,列名2,列名3));
create table test2 (id int(10),name varchar(10),cardid int(18),phone int(11),address varchar(50),remark text,index in_sum2(id,cardid,phone));全文索引(fulltext)
直接创建索引
CREATE FULLTEXT INDEX 索引名 ON 表名 (列名);create fulltext index in_remark on test(remark);修改表方式创建
alter table test1 add fulltext in_remark(remark);创建表的时候指定索引
CREATE TABLE 表名 (字段1 数据类型[,...],FULLTEXT 索引名 (列名));
#数据类型可以为 CHAR、VARCHAR 或者 TEXTcreate table test2 (id int(10),name varchar(10),cardid int(18),phone int(11),address varchar(50),remark text,fulltext in_full(cardid));使用全文索引查询
SELECT * FROM 表名 WHERE MATCH(列名) AGAINST('查询内容');select * from test1 where match(remark) against('vip');
select * from test1 where remark='vip';查看索引
1.show index from 表名;show index from 表名\G; 竖向显示表的索引信息
2.show keys from 表名;show keys from 表名\G; 删除索引的方法
直接删除索引
drop index 索引名 on 表名;drop index in_name on test;修改表的方式删除索引
alter table 表名 drop index 索引名;alter table test drop index in_phone;删除主键索引
alter table 表名 drop primary key;alter table test drop primary key;事务
事物的概念
ACID,是指在可靠数据库管理系统(DBMS)中,事务(transaction)应该具有的四个特性:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。这是可靠数据库所应具备的几个特性。
事务的ACID特点
原子性
指事务是一个不可再分割的工作单位,事务中的操作要么都发生,要么都不发生。
事务是一个完整的操作,事务的各元素是不可分的。
事务中的所有元素必须作为一个整体提交或回滚。
如果事务中的任何元素失败,则整个事务将失败。
案例:
A转账B,A扣款后突然断电断网,B没能收到加款,就会引起纠纷
一致性
指在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏。
当事务完成时,数据必须处于一致状态。
在事务开始前,数据库中存储的数据处于一致状态。
在正在进行的事务中,数据可能处于不一致的状态。
当事务成功完成时,数据必须再次回到已知的一致状态。
案例:
对银行转帐事务,不管事务成功还是失败,应该保证事务结束后表中A和B的存款总额跟事务执行前一致。
隔离性
指在并发环境中,当不同的事务同时操纵相同的数据时,每个事务都有各自的完整数据空间。
对数据进行修改的所有并发事务是彼此隔离的,表明事务必须是独立的,它不应以任何方式依赖于或影响其他事务。
修改数据的事务可在另一个使用相同数据的事务开始之前访问这些数据,或者在另一个使用相同数据的事务结束之后访问这些数据。
也就是说并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的
事务之间的相互影响分为几种
当多个客户端并发地访问同一个表时,可能出现下面的一致性问题:
(1)脏读:读取未提交数据当一个事务A正在访问数据X,并且对数据X进行了修改,而这种修改还没有提交到数据库中,这时,另外一个事务B也访问这个数据X(被修改的),然后使用了这个数据,如果A不提交,那么数据就会发生回滚。
(2)不可重复读:前后多次读取,数据内容不一致指在一个事务内,多次读同一数据。在这个事务还没有结束时,另外一个事务也访问该同一数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改,那么第一个事务两次读到的的数据可能是不一样的。这样就发生了在一个事务内两次读到的数据是不一样的,因此称为是不可重复读。(即不能读到相同的数据内容)
(3)幻读:前后多次读取,数据总量不一致一个事务对一个表中的数据进行了修改,这种修改涉及到表中的全部数据行。同时,另一个事务也修改这个表中的数据,这种修改是向表中插入一行新数据。那么,操作前一个事务的用户会发现表中还有一个没有修改的数据行,就好象发生了幻觉一样。
(4)丢失更新:两个事务同时读取同一条记录,A先修改记录,B也修改记录(B不知道A修改过),B提交数据后B的修改结果覆盖了A的修改结果。
事务的隔离级别决定了事务之间可见的级别。
MySQL事务支持如下四种隔离,用以控制事务所做的修改,并将修改通告至其它并发的事务:
(1)未提交读(Read Uncommitted(RU)):
允许脏读,即允许一个事务可以看到其他事务未提交的修改。
安全性最差,性能最好(不使用)(2)提交读(Read Committed(RC)):
允许一个事务只能看到其他事务已经提交的修改,未提交的修改是不可见的。防止脏读。
安全性较差,性能较好(3)可重复读(Repeatable Read(RR)):---mysql默认的隔离级别
确保如果在一个事务中执行两次相同的SELECT语句,都能得到相同的结果,不管其他事务是否提交这些修改。可以防止脏读和不可重复读。
安全性较高,性能较差(4)串行读(Serializable):---相当于锁表
完全串行化的读,将一个事务与其他事务完全地隔离。每次读都需要获得表级共享锁,读写相互都会阻塞。可以防止脏读,不可重复读取和幻读,(事务串行化)会降低数据库的效率。
安全性最高,性能最差(不使用)mysql默认的事务处理级别是 repeatable read ,而Oracle和SQL Server是 read committed 。
事务隔离级别的作用范围分为两种
全局级:对所有的会话有效
会话级:只对当前的会话有效1.查询全局事务隔离级别:
show global variables like '%isolation%';
SELECT @@global.tx_isolation;2.查询会话事务隔离级别:
show session variables like '%isolation%';
SELECT @@session.tx_isolation;
SELECT @@tx_isolation;3.设置全局事务隔离级别:
set global transaction isolation level read committed;
set @@global.tx_isolation='read-committed'; #重启服务后失效4.设置会话事务隔离级别:
set session transaction isolation level repeatable read;
set @@session.tx_isolation='repeatable-read';
持久性
在事务完成以后,该事务所对数据库所作的更改便持久的保存在数据库之中,并不会被回滚。
指不管系统是否发生故障,事务处理的结果都是永久的。
一旦事务被提交,事务的效果会被永久地保留在数据库中。
总结:在事务管理中,原子性是基础,隔离性是手段,一致性是目的,持久性是结果。

事务控制语句
BEGIN 或 START TRANSACTION:显式地开启一个事务。
COMMIT 或 COMMIT WORK:提交事务,并使已对数据库进行的所有修改变为永久性的。
ROLLBACK 或 ROLLBACK WORK:回滚会结束用户的事务,并撤销正在进行的所有未提交的修改。
SAVEPOINT S1:使用 SAVEPOINT 允许在事务中创建一个回滚点,一个事务中可以有多个 SAVEPOINT;“S1”代表回滚点名称。
ROLLBACK TO [SAVEPOINT] S1:把事务回滚到标记点。
#查看当前的隔离级别
show session variables like '%isolation%';修改隔离级别
set session transaction isolation level read committed;使用set设置控制事务
SET AUTOCOMMIT=0; #禁止自动提交
SET AUTOCOMMIT=1; #开启自动提交,Mysql默认为1
SHOW VARIABLES LIKE 'AUTOCOMMIT'; #查看Mysql中的AUTOCOMMIT值如果没有开启自动提交,当前会话连接的mysql的所有操作都会当成一个事务直到你输入rollback|commit;当前事务才算结束。当前事务结束前新的mysql连接时无法读取到任何当前会话的操作结果。
如果开起了自动提交,mysql会把每个sql语句当成一个事务,然后自动的commit。
当然无论开启与否,begin; commit|rollback; 都是独立的事务。#查看事务的自动提交功能是否开启
show variables like 'autocommit';
#默认是开启的1.测试提交事务
begin;
update info set money=money - 100 where name='A';
select * from info;commit;
quitmysql -u root -p
use school;
select * from info;2.测试回滚事务
begin;
update info set money=money + 100 where name='A';
select * from info;rollback;
quitmysql -u root -p
use school;
select * from info;3.测试多点回滚
begin;你
update info set money=money + 100 where name='A';
select * from info;
savepoint s1;update info set money=money + 100 where name='B';
select * from info;
savepoint s2;insert into info values (3,'C',1000);select * from info;
rollback to s1;
select * from info;4.使用set设置控制事务
#禁止自动提交
SET AUTOCOMMIT=0;
#开启自动提交,Mysq1默认为1
SET AUTOCOMMIT=1;
#个Mvsgl的AUTOCOMMIT值
SHOW VARIABLES LIKE AUTOCOMMIT';如果没有开启自动提交,当前会话连接的mysql的所有操作都会当成一个事务直到你输入rollback commit;当前事务才算结束。当前事务结束前新的mysql连接时无法读取到任何当前会话的操作结果。
如果开起了自动提交,mysql会把每个sql语句当成一个事务,然后自动的commit。
当然无论开启与否,begin;commit、rollback;都是独立的事务存储引擎
(1)静态(固定长度)表
静态表是默认的存储格式。静态表中的字段都是非可变字段,这样每个记录都是固定长度的;
优点:存储非常迅速,容易缓存,出现故障容易恢复;
缺点:占用的空间通常比动态表多。
(2)动态表
动态表包含可变字段,记录不是固定长度的;
这样存储的优点是占用空间较少,但是频繁的更新、删除记录会产生碎片,需要定期执行 OPTIMIZE TABLE 语句或 myisamchk -r 命令来改善性能,并且出现故障的时候恢复相对比较困难。
(3)压缩表
压缩表由 myisamchk 工具创建,占据非常小的空间,因为每条记录都是被单独压缩的,所以只有非常小的访问开支。
常用存储引擎
InnoDB:支持事务、外键约束,支持行级锁定(在全表扫描时仍然表级锁定);
读写并发能力较好,在5.5版本才支持全文索引,缓存能力较好可以减少磁盘IO的压力,数据和索引是存储在一个文件中。
使用场景:适用于一致性要求较高,数据频繁更新,高并发读写的业务场景。MyISAM:不支持事务、外键约束,只支持表级锁定;
适合单独的查询或写入,读写并发能力较差,支持全文索引,占用资源较小适合硬件资源相对比较差的服务器使用,数据和索引是分开存储的。
使用场景:适用于不需要事务处理,单独的查询或插入数据的业务场景。
查看系统支持的存储引擎
show engines;查看表使用的存储引擎
方法一:
show table status from 库名 where name='表名'\G方法二:
use 库名;
show create table 表名;修改存储引擎
方法一:
通过 alter table 修改
use 库名;
alter table 表名 engine=MyISAM;eg:
alter table member engine=myisam;
show create table member;相关文章:
【MySQL】3、MySQL的索引、事务、存储引擎
create table class (id int not null,name char(10),score decimal(5,2)); insert into class values (1,zhangsan,80.5); update class set namewangwu,passwd123 where id2; select * from class where id2; drop 索引的概念 是一种帮助系统,能够更快速的查询信…...

【Hello Algorithm】链表相关算法题
本篇博客介绍: 介绍下链表相关的算法题 链表相关算法题 快慢指针回文结构链表将单向链表按某值划分为左边小,中间相等,右边大的形式复制带随机指针的链表 链表相关的算法题其实都算不上难 我们真正要考虑的是一些边界问题 事实上链表题就是在…...
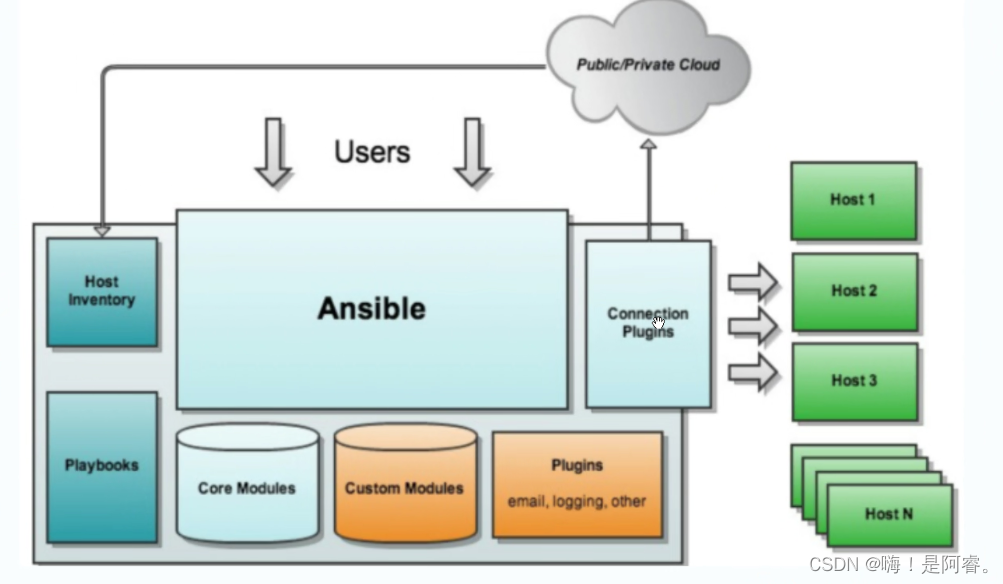
自动化管理管理工具----Ansible
目录 编辑 一、Ansible概念 1.1特点 二、工作机制(日常模块) 2.1 核心程序 三、Ansible 环境安装部署 四、ansible 命令行模块 4.1command 模块 4.2shell 模块 4.3cron 模块 4.4user 模块 4.5group 模块 4.6copy模块 4.7file模块 4.8ho…...

深入理解css3背景图边框
border-image知识点 重点理解 border-image-slice 设置的值将边框背景图分为9份,图像中间的舍弃,其他部分图像对应边框的相应区域放置,上右下左四角固定,border-image-repeat设置的是除四角外其他部分的显示方式。 截图来自菜鸟教…...

【rust/egui】(六)看看template的app.rs:TextEdit
说在前面 rust新手,egui没啥找到啥教程,这里自己记录下学习过程环境:windows11 22H2rust版本:rustc 1.71.1egui版本:0.22.0eframe版本:0.22.0上一篇:这里 TextEdit 文本编辑框 其定义为&#…...

Redis内存空间预估与内存优化策略:保障数据安全与性能的架构实践
推荐阅读 AI文本 OCR识别最佳实践 AI Gamma一键生成PPT工具直达链接 玩转cloud Studio 在线编码神器 玩转 GPU AI绘画、AI讲话、翻译,GPU点亮AI想象空间 资源分享 史上最全文档AI绘画stablediffusion资料分享 AI绘画关于SD,MJ,GPT,SDXL百科全书 「java、python面试题」…...

【zookeeper】zookeeper集群安装
环境规划 实际的生产使用中,我们一般推荐搭建奇数多节点的zookeeper集群,如3/5/7。在本次测试中,我使用了centos7 三台服务器搭建,复用了我搭建k8s集群的环境,如下表。 IPhostname192.168.2.140k8s-m1192.168.2.141k…...
CUDA小白 - NPP(2) - Arithmetic and Logical Operations(1)
cuda小白 原文链接 NPP GPU架构近些年也有不少的变化,具体的可以参考别的博主的介绍,都比较详细。还有一些cuda中的专有名词的含义,可以参考《详解CUDA的Context、Stream、Warp、SM、SP、Kernel、Block、Grid》 常见的NppStatus,…...

计算机视觉-LeNet
目录 LeNet LeNet在手写数字识别上的应用 LeNet在眼疾识别数据集iChallenge-PM上的应用 LeNet LeNet是最早的卷积神经网络之一。1998年,Yann LeCun第一次将LeNet卷积神经网络应用到图像分类上,在手写数字识别任务中取得了巨大成功。LeNet通过连续使用…...

Java 复习笔记 - 面向对象篇
文章目录 一,面向对象概述二,类和对象(一)类和对象的概述(二)定义类的补充注意事项 三,封装四,就近原则和this关键字(一)就近原则(二)…...
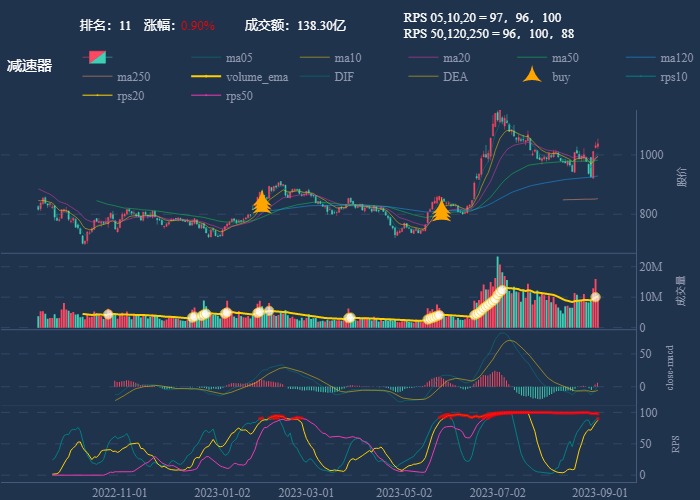
行业追踪,2023-08-31
自动复盘 2023-08-31 凡所有相,皆是虚妄。若见诸相非相,即见如来。 k 线图是最好的老师,每天持续发布板块的rps排名,追踪板块,板块来开仓,板块去清仓,丢弃自以为是的想法,板块去留让…...

科技资讯|苹果发布新专利:可在车内定位苹果的智能设备
根据美国商标和专利局近期公示的清单,苹果公司获得了一项名为《车内定位移动设备的系统和方式》专利,概述了在车内狭窄空间内如何定位 iPhone 等移动设备。 Find My 服务现阶段没有使用 UWB 来追踪 iPhone 或者 iPad,而是依赖 GPS 等相关辅…...

浅析Linux SCSI子系统:IO路径
文章目录 概述scsi_cmd:SCSI命令result字段proto_op字段proto_type字段 SCSI命令下发scsi_request_fnscsi_dev_queue_readyscsi_host_queue_ready SCSI命令响应命令请求完成的软中断处理 相关参考 概述 SCSI子系统向上与块层对接,由块层提交的对块设备的…...

linux系统(centos、Ubuntu、银河服务器)备份
制作u盘启动盘 下载usblive系统镜像 Get Kali | Kali Linux 下载u盘启动工具 balenaEtcher - Flash OS images to SD cards & USB drives 点击下载,等待下载完成 双击安装,等待安装完成 双击 启动 选择镜像 选择U盘 开始烧录 等地制作完成 进入…...

堆栈深度超过限制
报错:Cause: com.kingbase8.util.KSQLException: 错误: 堆栈深度超过限制 Hint: 在确定了平台的堆栈深度限制是足够大后,增加配置参数 "max_stack_depth"的值(当前值为2048kB).; 错误: 堆栈深度超过限制 Hint: 在确定了平台的堆栈深度限制是足…...

Linux ptrace系统调用
文章目录 一、ptrace 简介二、ptrace 参数request2.1 PTRACE_TRACEME2.2 PTRACE_PEEKTEXT, PTRACE_PEEKDATA2.3 PTRACE_PEEKUSER2.4 PTRACE_POKETEXT, PTRACE_POKEDATA2.5 PTRACE_POKEUSER2.6 PTRACE_GETREGS, PTRACE_GETFPREGS2.7 PTRACE_GETREGSET2.8 PTRACE_SETREGS, PTRACE…...

CSDN每日一练 |『贝博士发奖金』『Longest Continuous Increasing Subsequence』『最小差值』2023-09-01
CSDN每日一练 |『贝博士发奖金』『Longest Continuous Increasing Subsequence』『最小差值』2023-09-01 一、题目名称:贝博士发奖金二、题目名称:Longest Continuous Increasing Subsequence三、题目名称:最小差值一、题目名称:贝博士发奖金 时间限制:1000ms内存限制:25…...

二维数组创建方式比较
暑假跟着地质队去跑山了,到现在还没结束,今天休息的时候突然刷到了一篇关于C二维数组创建方面的文章,我觉得还是非常不错滴,就将其中提到的新方法和我已经使用过的三种方法进行了比较,发现该方法提高了二维数组的分配、…...

安达发|富士康科技集团利用自动排程APS软件打造智慧工厂
富士康科技集团作为全球领先的3C产品研发制造企业,近年来积极布局智能制造领域,通过引入先进的自动化排程系统(APS),成功打造了智慧工厂,提高了生产质量与效率,降低了生产成本。 富士康集团自2019年下半年提出在观澜厂区建立数字可…...

云计算在大数据分析中的应用与优势
文章目录 云计算在大数据分析中的应用云计算在大数据分析中的优势云计算在大数据分析中的示例未来发展和拓展结论 🎉欢迎来到AIGC人工智能专栏~云计算在大数据分析中的应用与优势 ☆* o(≧▽≦)o *☆嗨~我是IT陈寒🍹✨博客主页:IT陈寒的博客&…...

Kubernete
简介 Kubernetes(简称 K8s)是一个 开源的容器编排平台,用于自动化 部署、扩展、管理容器化应用 的工具。 假设你有很多个应用(比如用 Docker 打包的服务),Kubernetes 能帮你: ✅ 自动部署&#…...

深入拆解 MySQL InnoDB 隔离级别:从 MVCC 到临键锁
前言 关于 MySQL InnoDB 的事务隔离级别,90% 的开发者都存在至少一个致命误区: 误区1:RR(可重复读) 临键锁 彻底解决了幻读误区2:Serializable 只是比 RR 加的锁更多,本质还是用 MVCC误区3&a…...

把SAC model的数据导出到BW的ADSO中
目录 1. SAC 侧的准备 1.1 OData连接要做好 1.2 SAC里的model设置要配置好允许导出到Odata 2. BW侧要做的准备(先跟着SAP的note走) 3. SAC 模型数据导出 一般都是把planning model的数据导出到一个ADSO中,然后再用Composite Provider里…...

AI设计泳装,效率能翻几倍?
炎夏未至,泳装行业的备战硝烟却已弥漫。设计师灵感枯竭、打版反复修改、样衣成本高企……每一个痛点都像一座大山,压得品牌方喘不过气。面对Z世代瞬息万变的审美,“快”与“准”成了决胜关键。北京先智先行科技有限公司,正携旗下“…...

AssetStudio v0.16.5深度解析:Unity资源解包原理与工程化实践
1. 为什么你还在手动解包Unity游戏资源?AssetStudio不是“点开即用”的万能钥匙AssetStudio这个名字,听上去像某个高端建模插件,或者Unity官方出的资源管理器——其实它既不是Unity原生工具,也不带任何图形化向导。它是个开源、无…...

详细讲解 Spring MVC 的 HandlerInterceptor 接口
目录 一、核心定位 二、接口完整定义 三、三个核心方法详解(执行顺序 作用) 1. preHandle () —— 【请求前置处理】 2. postHandle () —— 【请求后置处理】 3. afterCompletion () —— 【请求完成清理】 四、执行流程(生命周期&a…...

Unity游戏配置管线实战:Luban Schema与Data分离设计
1. 为什么表格配置不是“偷懒”,而是Unity项目规模化生存的刚需在Unity游戏开发里,我见过太多团队把角色属性、武器参数、任务对话全写死在C#脚本里——刚上线时改个血量要改三处代码,策划提个新武器需求得等程序员下班后加字段,版…...

透明化智慧港口码头•装载·存储·集散全流程透明化管控方案
一、方案前言本方案依托黎阳之光镜像孪生、时空AI拓扑、无感全域定位、视频实景融合、边缘实时算力五大核心技术,聚焦港口码头货物装载、堆场存储、集疏运集散三大核心业务,打造实景可视、数字镜像、智能调度、全程透明、风险可控、全程可溯的智慧管控体…...

阅读落地灯哪个牌子好?优质款阅读落地灯推荐,买前建议收藏!
想要真正舒服又省心的照明,就别只会盯着参数看。说实话,挑护眼大路灯我就盯两点:光线柔不柔、用久了会不会累眼。像我家书桌前那种容易眩光的,我用一会儿就觉得不对劲;但像下面这些护眼大路灯,调光调色做…...

2026年AI面试助手深度测评:鹅来面 OfferGoose如何革新你的求职体验?
随着2026年求职市场的白热化,传统的“海投简历 裸面”模式已难以为继。无论是职场老将寻求突破,还是应届生初入职场,面对日益复杂的JD要求和瞬息万变的面试场景,一个高效的求职“第二大脑”变得至关重要。过去,求职者…...