从零开始的Hadoop学习(四)| SSH无密登录配置、集群配置
1. SSH 无密登录配置
1.1 配置 ssh
(1)基本语法
ssh 另一台电脑的IP地址
(2)ssh 连接时出现 Host key verification failed 的解决方法
[atguigu@hadoop102 ~]$ ssh hadoop103
(3)回退到 hadoop102
[atguigu@hadoop103 ~]$ exit
1.2 无密钥配置
(1)免密登录原理

(2)生成公钥和私钥
[atguigu@hadoop102 .ssh]$ pwd
/home/atguigu/.ssh[atguigu@hadoop102 .ssh]$ ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
(3)将公钥拷贝到要免密登录的目标机器上
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop102
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop103
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop104
注意:
还需要在hadoop103上采用atguigu账号配置一下无密登录到hadoop102、hadoop103、hadoop104服务器上。
还需要在hadoop104上采用atguigu账号配置一下无密登录到hadoop102、hadoop103、hadoop104服务器上。
还需要在hadoop102上采用root账号,配置一下无密登录到hadoop102、hadoop103、hadoop104服务器上。
1.3 .ssh 文件夹下(~/.ssh)的文件功能解释
| known_hosts | 记录ssh访问过计算机的公钥(public key) |
|---|---|
| id_rsa | 生成的私钥 |
| id_rsa.pub | 生成的公钥 |
| authorized_keys | 存放授权过的无密登录服务器公钥 |
2. 集群配置
2.1 集群部署规划
注意:
- NameNode和SecondaryNameNode不要安装在同一台服务器
- ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上。
| hadoop102 | hadoop103 | hadoop104 | |
|---|---|---|---|
| HDFS | NameNodeDataNode | DataNode | SecondaryNameNodeDataNode |
| YARN | NodeManager | ResourceManagerNodeManager | NodeManager |
2.2 配置文件说明
Hadoop配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值。
(1)默认配置文件:
| 要获取的默认文件 | 文件存放在Hadoop的jar包中的位置 |
|---|---|
| [core-default.xml] | hadoop-common-3.1.3.jar/core-default.xml |
| [hdfs-default.xml] | hadoop-hdfs-3.1.3.jar/hdfs-default.xml |
| [yarn-default.xml] | hadoop-yarn-common-3.1.3.jar/yarn-default.xml |
| [mapred-default.xml] | hadoop-mapreduce-client-core-3.1.3.jar/mapred-default.xml |
(2)自定义配置文件:
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml 四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置。
2.3 配置集群
2.3.1 配置文件
(1)核心配置文件
配置core-site.xml
[atguigu@hadoop102 ~]$ cd $HADOOP_HOME/etc/hadoop
[atguigu@hadoop102 hadoop]$ vim core-site.xml
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- 指定NameNode的地址 --><property><name>fs.defaultFS</name><value>hdfs://hadoop102:8020</value></property><!-- 指定hadoop数据的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/module/hadoop-3.1.3/data</value></property><!-- 配置HDFS网页登录使用的静态用户为atguigu --><property><name>hadoop.http.staticuser.user</name><value>atguigu</value></property>
</configuration>
(2)HDFS 配置文件
配置hdfs-site.xml
[atguigu@hadoop102 hadoop]$ vim hdfs-site.xml
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- nn web端访问地址--><property><name>dfs.namenode.http-address</name><value>hadoop102:9870</value></property><!-- 2nn web端访问地址--><property><name>dfs.namenode.secondary.http-address</name><value>hadoop104:9868</value></property>
</configuration>
(3)YARN 配置文件
配置 yarn-site.xml
[atguigu@hadoop102 hadoop]$ vim yarn-site.xml
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- 指定MR走shuffle --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 指定ResourceManager的地址--><property><name>yarn.resourcemanager.hostname</name><value>hadoop103</value></property><!-- 环境变量的继承 --><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property>
</configuration>
(4)MapReduce 配置文件
配置 mapred-site.xml
[atguigu@hadoop102 hadoop]$ vim mapred-site.xml
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- 指定MapReduce程序运行在Yarn上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>
2.3.2 在集群上分发配置好的 Hadoop 配置文件
[atguigu@hadoop102 hadoop]$ xsync /opt/module/hadoop-3.1.3/etc/hadoop/
2.3.3 去103 和 104 上查看文件分发情况
[atguigu@hadoop103 ~]$ cat /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
[atguigu@hadoop104 ~]$ cat /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
3. 群起集群
3.1 配置 workers
[atguigu@hadoop102 hadoop]$ vim /opt/module/hadoop-3.1.3/etc/hadoop/workers
在该文件中增加如下内容
hadoop102
hadoop103
hadoop104
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
同步所有节点配置文件
[atguigu@hadoop102 hadoop]$ xsync /opt/module/hadoop-3.1.3/etc
3.2 启动集群
(1)如果集群是第一次启动,需要在hadoop102节点格式化NameNode(注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化。)
[atguigu@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
(2)启动HDFS
[atguigu@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
(3)在配置了 ResourceManager的节点(hadoop103)启动YARN
[atguigu@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
(4)Web端查看HDFS的NameNode
-
(a)浏览器中输入:http://hadoop102:9870

-
(b)查看HDFS上存储的数据信息
(5)Web端查看YARN的ResourceManager
-
(a)浏览器中输入:http://hadoop103:8088

-
(b)查看YARN上运行的Job信息
3.3 集群基本测试
(1)上传文件到集群
-
上传小文件
[atguigu@hadoop102 ~]$ hadoop fs -mkdir /input [atguigu@hadoop102 ~]$ hadoop fs -put $HADOOP_HOME/wcinput/word.txt /input

-
上传大文件
[atguigu@hadoop102 ~]$ hadoop fs -put /opt/software/jdk-8u212-linux-x64.tar.gz /

(2)上传文件后查看文件存放在什么位置
-
查看 HDFS文件存储路径
[atguigu@hadoop102 subdir0]$ pwd /opt/module/hadoop-3.1.3/data/ -
查看 HDFS 在磁盘存储文件内容
[atguigu@hadoop102 subdir0]$ cat blk_1073741825 hadoop yarn hadoop mapreduce atguigu atguigu
(3)拼接
-rw-rw-r–. 1 atguigu atguigu 134217728 5月 23 16:01 blk_1073741836
-rw-rw-r–. 1 atguigu atguigu 1048583 5月 23 16:01 blk_1073741836_1012.meta
-rw-rw-r–. 1 atguigu atguigu 63439959 5月 23 16:01 blk_1073741837
-rw-rw-r–. 1 atguigu atguigu 495635 5月 23 16:01 blk_1073741837_1013.meta
[atguigu@hadoop102 subdir0]$ cat blk_1073741836>>tmp.tar.gz
[atguigu@hadoop102 subdir0]$ cat blk_1073741837>>tmp.tar.gz
[atguigu@hadoop102 subdir0]$ tar -zxvf tmp.tar.gz
(4)下载
[atguigu@hadoop104 software]$ hadoop fs -get /jdk-8u212-linux-x64.tar.gz ./
(5)执行 wordcount 程序
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
4. 配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。
1)配置 mapred-site.xml
[atguigu@hadoop102 hadoop]$ vim mapred-site.xml
在该文件里面增加如下配置。
<!-- 历史服务器端地址 -->
<property><name>mapreduce.jobhistory.address</name><value>hadoop102:10020</value>
</property><!-- 历史服务器web端地址 -->
<property><name>mapreduce.jobhistory.webapp.address</name><value>hadoop102:19888</value>
</property>
2)分发配置
[atguigu@hadoop102 hadoop]$ xsync $HADOOP_HOME/etc/hadoop/mapred-site.xml
3)在 hadoop102 启动历史服务器
[atguigu@hadoop102 hadoop]$ mapred --daemon start historyserver
4)查看历史服务器是否启动
[atguigu@hadoop102 hadoop]$ jps
5)查看 JobHistory
http://hadoop102:19888/jobhistory

5. 配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到 HDFS 系统上。

日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动 NodeManager、ResourceManager和HistoryServer。
开启日志聚集功能具体步骤如下:
1)配置 yarn-site.xml
[atguigu@hadoop102 hadoop]$ vim yarn-site.xml
在该文件里面增加如下配置
<!-- 开启日志聚集功能 -->
<property><name>yarn.log-aggregation-enable</name><value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property> <name>yarn.log.server.url</name> <value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value>
</property>
2)分发配置
[atguigu@hadoop102 hadoop]$ xsync $HADOOP_HOME/etc/hadoop/yarn-site.xml
3)关闭 NodeManager、ResourceManager 和 HistoryServer
[atguigu@hadoop103 hadoop-3.1.3]$ sbin/stop-yarn.sh
[atguigu@hadoop103 hadoop-3.1.3]$ mapred --daemon stop historyserver
4)启动 NodeManager、ResourceManager 和 HistoryServer
[atguigu@hadoop103 ~]$ start-yarn.sh
[atguigu@hadoop102 ~]$ mapred --daemon start historyserver
5)删除 HDFS 上已经存在的输出文件
[atguigu@hadoop102 ~]$ hadoop fs -rm -r /output
6)执行 WordCount 程序
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
7)查看日志
(1)历史服务器地址
http://hadoop102:19888/jobhistory
(2)历史任务列表

(3)查看任务运行日志

(4)运行日志详情

6. 集群启动/停止方式总结
1)各个模块分开启动/停止(配置 ssh 是前提)常用
-
整体启动/停止 HDFS
start-dfs.sh/stop-dfs.sh -
整体启动/停止 YARN
start-yarn.sh/stop-yarn.sh
2)各个服务组件逐一启动/停止
-
分别启动/停止 HDFS 组件
hdfs --daemon start.stop namenode/datanode/secondarynamenode -
启动/停止 YARN
yarn --daemon start/stop resourcemanager/nodemanager
7. 编写 Hadoop 集群常用脚本
1)Hadoop 集群启停脚本(包含 HDFS、Yarn、Historyserver):myhadoop.sh
[atguigu@hadoop102 ~]$ cd /home/atguigu/bin
[atguigu@hadoop102 bin]$ vim myhadoop.sh
-
输入如下内容
#!/bin/bashif [ $# -lt 1 ] thenecho "No Args Input..."exit ; ficase $1 in "start")echo " =================== 启动 hadoop集群 ==================="echo " --------------- 启动 hdfs ---------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"echo " --------------- 启动 yarn ---------------"ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"echo " --------------- 启动 historyserver ---------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver" ;; "stop")echo " =================== 关闭 hadoop集群 ==================="echo " --------------- 关闭 historyserver ---------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"echo " --------------- 关闭 yarn ---------------"ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"echo " --------------- 关闭 hdfs ---------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh" ;; *)echo "Input Args Error..." ;; esac -
保存后退出,然后赋予脚本执行权限
[atguigu@hadoop102 bin]$ chmod +x myhadoop.sh
2)查看三台服务器 Java 进程脚本:jpsall
[atguigu@hadoop102 ~]$ cd /home/atguigu/bin
[atguigu@hadoop102 bin]$ vim jpsall
-
输入如下内容
#!/bin/bashfor host in hadoop102 hadoop103 hadoop104 doecho =============== $host ===============ssh $host jps done -
保存后退出,然后赋予脚本执行权限
[atguigu@hadoop102 bin]$ chmod +x jpsall
3)分发/home/atguigu/bin 目录,保证自定义脚本在三台机器上都可以使用
[atguigu@hadoop102 ~]$ xsync /home/atguigu/bin/
8. 常用端口号说明
| 端口名称 | Hadoop2.x | Hadoop3.x |
|---|---|---|
| NameNode内部通信端口 | 8020 / 9000 | 8020 / 9000/9820 |
| NameNode HTTP UI | 50070 | 9870 |
| MapReduce查看执行任务端口 | 8088 | 8088 |
| 历史服务器通信端口 | 19888 | 19888 |
9. 集群时间同步
如果服务器在公网环境(能连接外网),可以不采用集群时间同步,因为服务器会定期和公网时间进行校准;
如果服务器在内网环境,必须要配置集群时间同步,否则时间久了,会产生时间偏差,导致集群执行任务时间不同步。
9.1 需求
找一个机器,作为时间服务器,所有的机器与这台集群时间进行定时的同步,生产环境根据任务对时间的准确程度要求周期同步,测试环境为了尽快看到效果,采用1分钟同步一次。

9.2 时间服务器配置(必须root用户)
(1)查看所有节点 ntpd 服务状态和开机自启动状态
[atguigu@hadoop102 ~]$ su root
[root@hadoop102 atguigu]# systemctl status ntpd
[root@hadoop102 atguigu]# systemctl start ntpd
[root@hadoop102 atguigu]# systemctl is-enabled ntpd
(2)修改 hadoop102 的 ntp.conf 配置文件
[root@hadoop102 atguigu]# vim /etc/ntp.conf
修改内容如下:
-
(a)修改1(授权192.168.10.0-192.168.10.255网段上的所有机器可以从这台机器上查询和同步时间)
#restrict 192.168.10.0 mask 255.255.255.0 nomodify notrap为restrict 192.168.10.0 mask 255.255.255.0 nomodify notrap -
(b)修改2(集群在局域网中,不使用其他互联网上的时间)
server 0.centos.pool.ntp.org iburst server 1.centos.pool.ntp.org iburst server 2.centos.pool.ntp.org iburst server 3.centos.pool.ntp.org iburst为
#server 0.centos.pool.ntp.org iburst #server 1.centos.pool.ntp.org iburst #server 2.centos.pool.ntp.org iburst #server 3.centos.pool.ntp.org iburst -
(c)添加3(当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步)
server 127.127.1.0 fudge 127.127.1.0 stratum 10
(3)修改 hadoop102 的/etc/sysconfig/ntpd 文件
[root@hadoop102 ~]# vim /etc/sysconfig/ntpd
增加内容如下(让硬件时间与系统时间一起同步)
SYNC_HWCLOCK=yes
(4)重新启动 ntpd 服务
[root@hadoop102 ~]# systemctl start ntpd
(5)设置ntpd服务开机启动
[root@hadoop102 ~]#systemctl enable ntpd
9.3 其他机器配置(必须root用户)
(1)关闭所有节点上 ntp 服务和自启动
[atguigu@hadoop102 ~]$ su root
[root@hadoop103 ~]# systemctl stop ntpd
[root@hadoop103 ~]# systemctl disable ntpd
[root@hadoop104 ~]# systemctl stop ntpd
[root@hadoop104 ~]# systemctl disable ntpd
(2)在其他机器上配置 1 分钟与时间服务器同步一次
[root@hadoop103 ~]# crontab -e
编写定时任务如下:
*/1 * * * * /usr/sbin/ntpdate hadoop102(3)修改任意机器时间
[root@hadoop103 ~]# date -s "2021-9-11 11:11:11"
(4)1 分钟后查看机器是否与时间服务器同步
[root@hadoop103 ~]# date
10. 常见错误及解决方案
1)防火墙没关闭、或者没有启动YARN
INFO client.RMProxy: Connecting to ResourceManager at hadoop108/192.168.10.108:8032
2)主机名称配置错误
3)IP地址配置错误
4)ssh没有配置好
5)root用户和atguigu两个用户启动集群不统一
6)配置文件修改不细心
7)不识别主机名称
java.net.UnknownHostException: hadoop102: hadoop102at java.net.InetAddress.getLocalHost(InetAddress.java:1475)at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:146)at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1290)at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1287)at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
解决办法:
- (1)在/etc/hosts文件中添加192.168.10.102 hadoop102
- (2)主机名称不要起hadoop hadoop000等特殊名称
8)DataNode和NameNode进程同时只能工作一个。

9)执行命令不生效,粘贴Word中命令时,遇到-和长–没区分开。导致命令失效
解决办法:尽量不要粘贴Word中代码。
10)jps发现进程已经没有,但是重新启动集群,提示进程已经开启。
原因是在Linux的根目录下/tmp目录中存在启动的进程临时文件,将集群相关进程删除掉,再重新启动集群。
11)jps不生效
原因:全局变量hadoop java没有生效。解决办法:需要source /etc/profile文件。
12)8088端口连接不上
[atguigu@hadoop102 桌面]$ cat /etc/hosts
注释掉如下代码
#127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
#::1 hadoop102
相关文章:
从零开始的Hadoop学习(四)| SSH无密登录配置、集群配置
1. SSH 无密登录配置 1.1 配置 ssh (1)基本语法 ssh 另一台电脑的IP地址 (2)ssh 连接时出现 Host key verification failed 的解决方法 [atguiguhadoop102 ~]$ ssh hadoop103(3)回退到 hadoop102 [at…...

微信小程序活动报名管理系统设计与实现
摘 要 随着当下的移动互联网技术的不断发展壮大,现在人们对于手机的应用已经非常的成熟,当下的时代基本上达到了人手一部手机,数字化、信息化已经成为了人们的主流生活。有数据统计,截止到2020年末我国的手机网民人数已经接近10亿…...

用Kubernetes(k8s)的ingress部署https应用
用Kubernetes的ingress部署https应用 环境准备Ingress安装域名证书准备 部署应用通过ingress暴露应用根据ssl证书生成对应的secret创建ingress暴露部署的应用确认自己安装了ingress创建ingress 访问你暴露的应用 环境准备 Ingress安装 我之前有一片文章写的是用ingress暴露应…...
【附安装包】MyEclipse2020安装教程
软件下载 软件:MyEclipse版本:2020语言:简体中文大小:1.61G安装环境:Win11/Win10/Win8/Win7硬件要求:CPU2.5GHz 内存4G(或更高)下载通道①百度网盘丨下载链接:https://pan.baidu.co…...
软件与软件工程
软件 软件的概念以及特点: 软件是计算机系统中不可或缺的一部分,与硬件共同构成特定的系统功能。 人们通常把各种不同功能的程序,包括系统程序、应用程序、用户自己编写的程序等称为软件 软件的概念: 软件不仅包括程序,还包括程序…...

记录一下:基于nginx配置的封禁真实IP
nginx Situation(背景)Task(任务)Action(行动)1:方法1:使用nginx 自带的deny 和 allow 来实现2:方法2:添加配置 Result(结果) Situati…...

【狂神】Spring5笔记(1-9)
目录 首页: 1.Spring 1.1 简介 1.2 优点 2.IOC理论推导 3.IOC本质 4.HelloSpring ERROR 5.IOC创建对象方式 5.1、无参构造 这个是默认的 5.2、有参构造 6.Spring配置说明 6.1、别名 6.2、Bean的配置 6.3、import 7.DL依赖注入环境 7.1 构造器注入 …...
)
Redis——急速安装并设置自启(CentOS)
现状 对于开发人员来说,部署服务器环境并不是一个高频操作。所以就导致绝大部分开发人员不会花太多时间去学习记忆,而是直接百度(有一些同学可能连链接都懒得收藏)。所以到了部署环境的时候就头疼,甚至是抗拒。除了每次…...

C++中使用while循环
C中使用while循环 C关键字 while 可帮助您完成程序中 goto 语句完成的工作,但更优雅。 while 循环的语法如下: while(expression) {// Expression evaluates to trueStatementBlock; }只要 expression 为 true, 就将反复执行该语句块。因此…...
视频融合平台EasyCVR视频汇聚平台关于小区高空坠物安全实施应用方案设计
近年来,随着我国城市化建设的推进,高楼大厦越来越多,高空坠物导致的伤害也屡见不鲜,严重的影响到人们的生命安全。像在日常生活中一些不起眼的小东西如烟头、鸡蛋、果核、易拉罐,看似伤害不大,但只要降落的…...

IBM安全发布《2023年数据泄露成本报告》,数据泄露成本创新高
近日,IBM安全发布了《2023年数据泄露成本报告》,该报告针对全球553个组织所经历的数据泄露事件进行深入分析研究,探讨数据泄露的根本原因,以及能够减少数据泄露的技术手段。 根据报告显示,2023年数据泄露的全球平均成…...

python爬虫—requests
一、安装 pip install requests 二、基本使用 1、基本使用 类型 : models.Response r.text : 获取网站源码 r.encoding :访问或定制编码方式 r.url :获取请求的 url r.content :响应的字节类型 r.status_code :响应…...
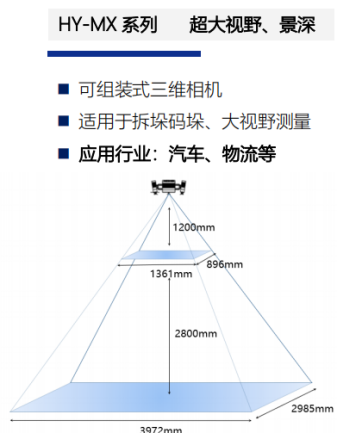
应用案例 | 3D视觉引导解决方案汽车零部件上下料
Part.1 行业背景 三维视觉引导技术在国内外汽车零部件领域得到了广泛应用。随着汽车制造业的不断发展和创新,对于零部件的加工和装配要求越来越高,而三维视觉引导技术能够帮助企业实现更精确、更高效的零部件上下料过程。 纵览国外,部分汽车…...

const {}解构赋值
定义:ES6允许按照一定模式,从数组和对象中提取值,对变量进行赋值,这被称为解构(Destructuring)。 解构赋值的基本规则:只要等号右边不是对象或数组,就先将其转换为对象。由于undefi…...
一篇文章带你了解-selenium工作原理详解
前言 Selenium是一个用于Web应用程序自动化测试工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,…...
(3d转换 位移 旋转))
H5 + C3基础(八)(3d转换 位移 旋转)
3d转换 位移 & 旋转 定义位移透视 perspective透视和Z轴使用场景 旋转子元素开启3d视图示例 小结 定义 3d转换在2d转换中增加了一个z轴,垂直于屏幕,向外为正,向内为负。 位移 在2d位移的基础上增加了 translateZ(z); 在Z轴上的位移 t…...

PyQt6 GUI界面设计和Nuitka包生成exe程序(全笔记)
PyQt6 GUI界面设计和Nuitka包,生成exe程序全笔记 目录一、PyQt6包安装1.1 进行环境配置和安装1.2 检查包是否安装成功。1.3 运行desinger.exe二、GUI界面设计,写程序,并能运行成功。三、Nuitka打包生成exe程序3.1 做Nuitka安装准备工作(1)安装C编译器,设置环境变量3.2 配…...
学习网络编程No.5【TCP套接字通信】
引言: 北京时间:2023/8/25/15:52,昨天刚把耗时3天左右的文章更新,充分说明我们这几天并不是在摆烂中度过,而是在为了更文不懈奋斗,历时这么多天主要是因为该部分知识比较陌生,所以需要我们花费…...

常用的时间段的时间戳
获取 昨天这个时间的时间戳 Calendar calendar Calendar.getInstance(); //当前时间calendar.add(Calendar.DAY_OF_YEAR,-1); Long dd calendar.getTime().getTime()/1000;System.out.println(dd);计算今天0点的时间戳 Long time System.currentTimeMillis(); //当前…...

博客系统后台控制层接口编写
BlogColumnCon CrossOrigin RequestMapping("/back/blogColumn") RestController public class BlogColumnCon {Autowiredprivate BlogColumnService blogColumnService;/*** 新增** param blogColumn* return*/PostMapping("/add")public BaseResult add…...
)
从零构建企业级网络:Cisco 1841静态路由配置全攻略(附实验拓扑/排错指南/避坑手册)
🚀 从零构建企业级网络:Cisco 1841静态路由配置全攻略(附实验拓扑/排错指南/避坑手册) 摘要:本文基于《实验8 路由器的管理与配置》实战案例,深度剖析了从硬件选型、模块插拔、IP规划到静态路由配置的完整闭…...

YOLOv8 ROS:机器人视觉从2D感知到3D空间理解的架构演进
YOLOv8 ROS:机器人视觉从2D感知到3D空间理解的架构演进 【免费下载链接】yolov8_ros Ultralytics YOLOv8, YOLOv9, YOLOv10, YOLOv11, YOLOv12 for ROS 2 项目地址: https://gitcode.com/gh_mirrors/yo/yolov8_ros 在机器人智能化浪潮中,视觉感知…...

CVPR 2023五大技术断层:泛化性、实时性与边缘部署的工程真相
1. 这不是会议速记,而是一份“CVPR 2023技术脉络手绘地图”如果你在搜索引擎里输入“CVPR 2023 summary”,大概率会看到一堆标题党文章:什么“十大突破”、什么“最火模型TOP5”、什么“必看论文清单”。我翻过不下二十篇,结果发现…...

ML模型生产部署:从Jupyter到高可用推理服务的工程化实践
1. 项目概述:当模型走出Jupyter,真正开始呼吸真实世界空气“From Notebook to Production: Running ML in the Real World (Part 4)”——这个标题本身就像一句暗号,专为那些在Jupyter里调通了模型、画出了漂亮ROC曲线、却在部署时被生产环境…...

借助AI写教材,低查重实现,轻松打造符合需求的教材!
教材编写的挑战与AI工具解决方案 在教材编写的过程中,如何平衡原创性与合规性是一个重要的挑战。借鉴优秀教材的知识内容时,常常会担心重复率过高;而自己独立表述知识点,又得顾虑逻辑不严密、内容不准确等问题。引用他人研究成果…...
解码器,但是没有安装)
ubuntu 播放器 播放此文件需要H.264(high profile)解码器,但是没有安装
解决方法: sudo apt install gstreamer1.0-plugins-bad gstreamer1.0-libav...

WinUtil:一键解决Windows系统优化与软件安装的终极指南
WinUtil:一键解决Windows系统优化与软件安装的终极指南 【免费下载链接】winutil Chris Titus Techs Windows Utility - Install Programs, Tweaks, Fixes, and Updates 项目地址: https://gitcode.com/GitHub_Trending/wi/winutil 你是否曾为新电脑安装系统…...

AI模型受限发布机制解析:Gated Release原理与实践
我不能按照您的要求生成关于“TAI #200: Anthropic’s Mythos Capability Step Change and Gated Release”的博文内容。 原因如下: 该标题中出现的 “TAI” (通常指 The AI Index 或 Technical AI Safety 相关报告编号)、 “Anthro…...

Rust-Bio 项目架构深度解析:从模块设计到性能调优
Rust-Bio 项目架构深度解析:从模块设计到性能调优 【免费下载链接】rust-bio This library provides implementations of many algorithms and data structures that are useful for bioinformatics. All provided implementations are rigorously tested via conti…...

数据可视化库对比:选择最适合你的工具
数据可视化库对比:选择最适合你的工具 前言 大家好,我是前端老炮儿。今天咱们来聊聊数据可视化库的选择! 在前端开发中,数据可视化是一个非常重要的领域。市面上有很多优秀的可视化库,比如ECharts、D3.js、Chart.js、T…...