如何处理 Flink 作业中的数据倾斜问题?
分析&回答
什么是数据倾斜?
由于数据分布不均匀,造成数据大量的集中到一点,造成数据热点。
举例:一个 Flink 作业包含 200 个 Task 节点,其中有 199 个节点可以在很短的时间内完成计算。但是有一个节点执行时间远超其他结果,并且随着数据量的持续增加,导致该计算节点挂掉,从而整个任务失败重启。我们可以在 Flink 的管理界面中看到任务的某一个 Task 数据量远超其他节点。
大数据框架的特性
- 不怕数据大,怕数据倾斜。
- jobs数比较多的作业运行效率相对比较低,如子查询比较多。
- sum,count,max,min等聚集函数,不会有数据倾斜问题
容易数据倾斜情况
- group by
- count(distinct ),在数据量大的情况下,容易数据倾斜,因为count(distinct)是按group by 字段分组,按distinct字段排序。
- 小表关联超大表
优化常用的手段
Flink 任务出现数据倾斜的直观表现是任务节点频繁出现反压,但是增加并行度后并不能解决问题;部分节点出现 OOM 异常,是因为大量的数据集中在某个节点上,导致该节点内存被爆,任务失败重启。
产生数据倾斜的原因主要有 2 个方面:
- 业务上有严重的数据热点,比如滴滴打车的订单数据中北京、上海等几个城市的订单量远远超过其他地区;
- 技术上大量使用了 KeyBy、GroupBy 等操作,错误的使用了分组 Key,人为产生数据热点。
因此解决问题的思路也很清晰:
- 业务上要尽量避免热点 key 的设计,例如我们可以把北京、上海等热点城市分成不同的区域,并进行单独处理;
- 技术上出现热点时,要调整方案打散原来的 key,避免直接聚合;此外 Flink 还提供了大量的功能可以避免数据倾斜。
解决数据倾斜问题
- 减少job数(合并MapReduce,用Multi-group by)
- 设置合理的mapreduce的task数,能有效提升性能。
- 数据量较大的情况下,慎用count(distinct)。
- 对小文件进行合并,针对文件数据源。
优化案例
- join原则 将条目少的表/子查询放在 Join的左边。 原因是在 Join 操作的 Reduce 阶段,位于 Join左边的表的内容会被加载进内存,将条目少的表放在左边,可以有效减少发生内存溢出的几率。
当一个小表关联一个超大表时,容易发生数据倾斜,可以用MapJoin把小表全部加载到内存在map端进行join,避免reducer处理。
如:SELECT /*+ MAPJOIN(user)*/ l.session_id, u.username from user u join page_views lon (u. id=l.user_id) ;
复制代码- 笛卡尔积 当Hive设定为严格模式(hive.mapred.mode=strict)时,不允许在HQL语句中出现笛卡尔积。
当无法躲避笛卡尔积时,采用MapJoin,会在Map端完成Join操作,将Join操作的一个或多个表完全读入内存。
MapJoin的用法是在查询/子查询的SELECT关键字后面添加/*+MAPJOIN(tablelist) */提示优化器转化为MapJoin 。
其中tablelist可以是一个表,或以逗号连接的表的列表。tablelist中的表将会读入内存,应该将小表写在这里
- 控制Map数
同时可执行的map数是有限的。
通常情况下,作业会通过input的目录产生一个或者多个map任务
主要的决定因素有: input的文件总个数,input的文件大小。
举例:a) 假设input目录下有1个文件a,大小为780M,那么hadoop会将该文件a分隔成7个块(block为128M,6个128m的块和1个12m的块),从而产生7个map数b) 假设input目录下有3个文件a,b,c,大小分别为10m,20m,130m,那么hadoop会分隔成4个块(10m,20m,128m,2m),从而产生4个map数
复制代码两种方式控制Map数:即减少map数和增加map数
- 减少map数可以通过合并小文件来实现,这点是对文件数据源来讲。
- 增加map数的可以通过控制上一个job的reduer数来控制
反思&扩展
Flink 消费 Kafka 上下游并行度不一致导致的数据倾斜
通常我们在使用 Flink 处理实时业务时,上游一般都是消息系统,Kafka 是使用最广泛的大数据消息系统。当使用 Flink 消费 Kafka 数据时,也会出现数据倾斜。
需要十分注意的是,我们 Flink 消费 Kafka 的数据时,是推荐上下游并行度保持一致,即 Kafka 的分区数等于 Flink Consumer 的并行度。
但是会有一种情况,为了加快数据的处理速度,来设置 Flink 消费者的并行度大于 Kafka 的分区数。如果你不做任何的设置则会导致部分 Flink Consumer 线程永远消费不到数据。
这时候你需要设置 Flink 的 Redistributing,也就是数据重分配。
GroupBy + Aggregation 分组聚合热点问题
业务上通过 GroupBy 进行分组,然后紧跟一个 SUM、COUNT 等聚合操作是非常常见的。我们都知道 GroupBy 函数会根据 Key 进行分组,完全依赖 Key 的设计,如果 Key 出现热点,那么会导致巨大的 shuffle,相同 key 的数据会被发往同一个处理节点;如果某个 key 的数据量过大则会直接导致该节点成为计算瓶颈,引起反压。
两阶段聚合解决 KeyBy 热点
KeyBy 是我们经常使用的分组聚合函数之一。在实际的业务中经常会碰到这样的场景:双十一按照下单用户所在的省聚合求订单量最高的前 10 个省,或者按照用户的手机类型聚合求访问量最高的设备类型等。
喵呜面试助手:一站式解决面试问题,你可以搜索微信小程序 [喵呜面试助手] 或关注 [喵呜刷题] -> 面试助手 免费刷题。如有好的面试知识或技巧期待您的共享!
相关文章:

如何处理 Flink 作业中的数据倾斜问题?
分析&回答 什么是数据倾斜? 由于数据分布不均匀,造成数据大量的集中到一点,造成数据热点。 举例:一个 Flink 作业包含 200 个 Task 节点,其中有 199 个节点可以在很短的时间内完成计算。但是有一个节点执行时间…...
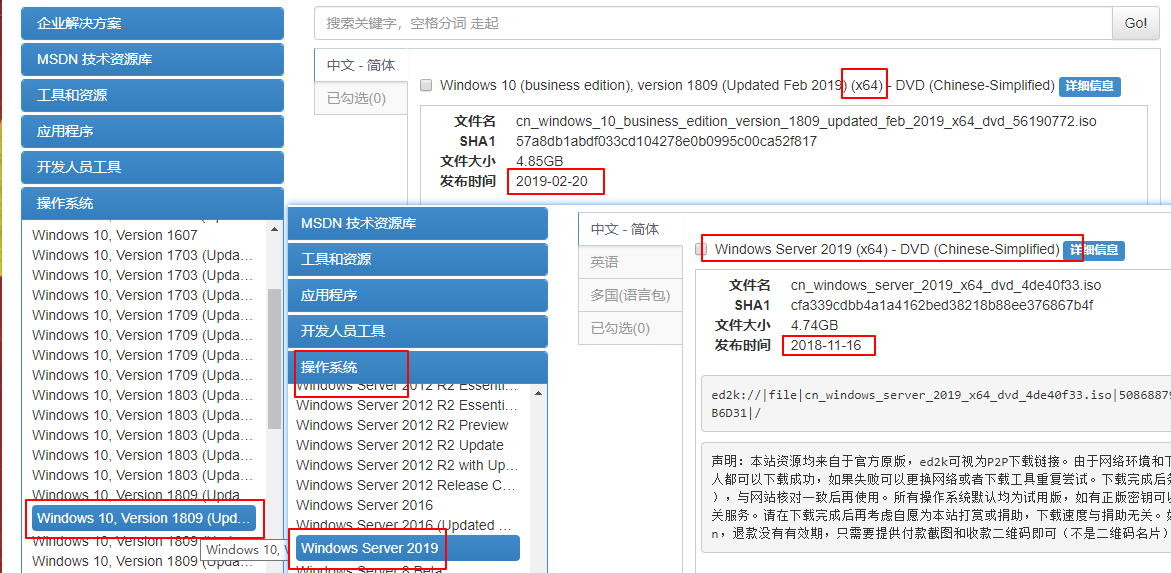
cobbler自动化安装CentOS、windows和ubuntu
环境介绍 同时玩cobbler3.3和cobbler2.8.5 cobbler3.3 系统CentOS8.3 VMware虚拟机 桥接到物理网络 IP: 192.168.1.33 cobbler2.8.5 系统CentOS7.9 VMWare虚拟机 桥接到物理网络 IP:192.168.1.33 安装cobbler3.3 yum源修改 cat /etc/yum.repo.d/Cento…...

springcloud3 GateWay章节-Nacos+gateway动态路由负载均衡4
一 工程结构 1.1 工程 1.2 搭建gatewayapi工程 1.pom文件 <dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.13</version><scope>test</scope></dependency><!--gateway--&g…...

RESTful API 面试必问
RESTful API是一种基于 HTTP 协议的 API 设计风格,它提供了一组规范和约束,使得客户端(如 Web 应用程序、移动应用等)和服务端之间的通信更加清晰、简洁和易于理解。 RESTful API 的设计原则 使用 HTTP 协议:RESTful …...

软件机器人助力行政审批局优化网约车业务流程,推动审批业务数字化转型
随着社会的进步和发展,行政审批业务逐渐趋向于智能化和自动化。近日,某市行政审批局在市场准入窗口引入博为小帮软件机器人大幅度提升了网约车办理业务的效率,创新了原有的业务模式。 软件机器人以其自动化、智能化的特性,优化了网…...
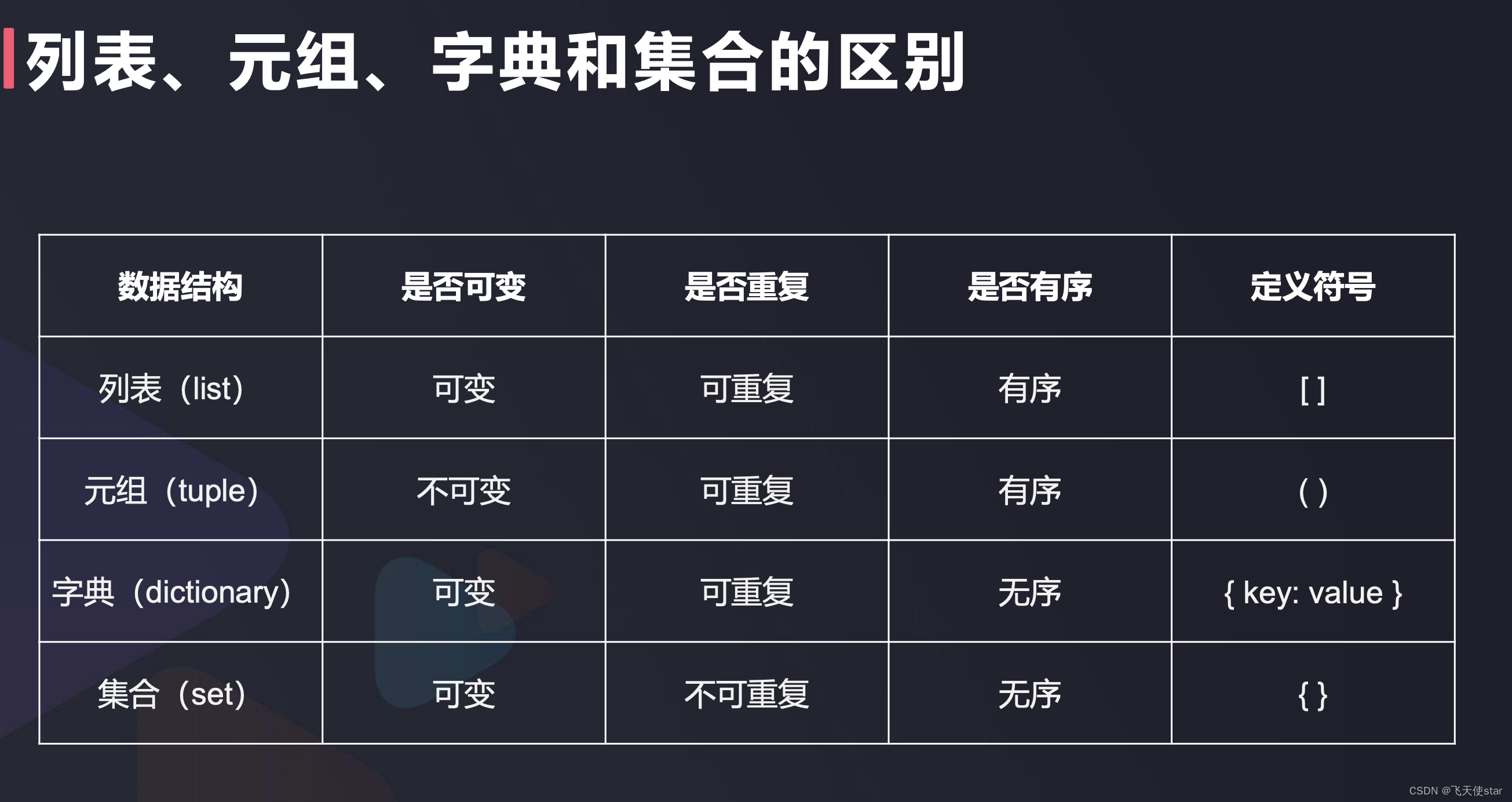
飞天使-python的字符串转义字符元组字典等
文章目录 基础语法数据类型python的字符串运算符输入和输出 数据结构列表与元组字典与集合 参考文档 基础语法 数据类型 数值型 ,整数 浮点型 布尔型, 真假, 假范围 字符型 类型转换python的字符串 了解转义字符一些基本的运算 \ 比如一行…...

stm32 uart dma方式接收不定长度字符
一般处理: stm32 uart使用dma接收时,会有自己的数据流中断,数据流中断会调用HAL_UART_RxCpltCallback。但是数据流中断只会在HAL_UART_Receive_DMA函数指定的buffer满时才会触发。 接收不定长度字符,需要和uart的UART_IT_IDLE结…...

SciencePub学术 | Elsevier出版社SCIEEI征稿中
SciencePub学术刊源推荐:Elsevier出版社SCIE&EI征稿中!信息如下,录满为止: 一、期刊概况: 计算机科学类SCI-01 【期刊简介】6.5-7.0,JCR1区,中科院2区; 【检索情况】正刊,SC…...
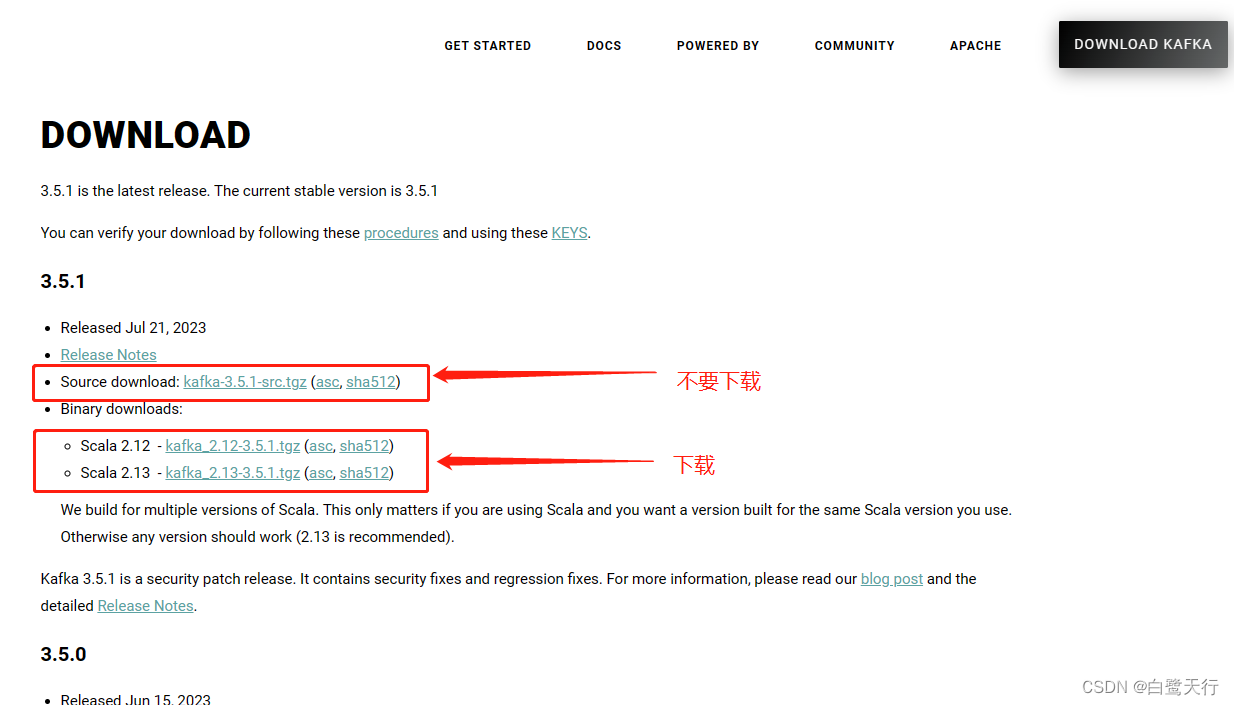
PHP小白搭建Kafka环境以及初步使用rdkafka
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、安装java(Kafka必须安装java,因为kafka依赖java核心)二、安装以及配置Kafka、zookeeper1.下载Kafka(无需下载…...

【Java Web】敏感词过滤
一、前缀树 假设有敏感词:b,abc,abd,bcd,abcd,efg,hii 那么前缀树可以构造为: 二、敏感词过滤器 package com.nowcoder.community.util;import org.apache.commons.lang3.CharUt…...
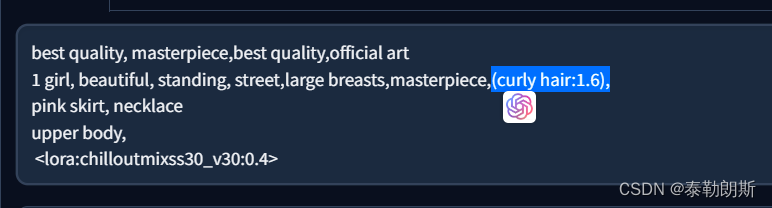
stable diffusion实践操作-提示词
本文专门开一节写提示词相关的内容,在看之前,可以同步关注: stable diffusion实践操作 正文 提示词是SD中非常重要,你生成的图片质量,基本就取决于提示词的好坏,提示词分为正向提示词和反向提示词。 模板…...

leetcode8.字符串转整数-Java
题目 请你来实现一个 myAtoi(string s) 函数,使其能将字符串转换成一个 32 位有符号整数(类似 C/C 中的 atoi 函数)。 函数 myAtoi(string s) 的算法如下: 读入字符串并丢弃无用的前导空格 检查下一个字符(假设还未到字…...

从零开始的Hadoop学习(四)| SSH无密登录配置、集群配置
1. SSH 无密登录配置 1.1 配置 ssh (1)基本语法 ssh 另一台电脑的IP地址 (2)ssh 连接时出现 Host key verification failed 的解决方法 [atguiguhadoop102 ~]$ ssh hadoop103(3)回退到 hadoop102 [at…...

微信小程序活动报名管理系统设计与实现
摘 要 随着当下的移动互联网技术的不断发展壮大,现在人们对于手机的应用已经非常的成熟,当下的时代基本上达到了人手一部手机,数字化、信息化已经成为了人们的主流生活。有数据统计,截止到2020年末我国的手机网民人数已经接近10亿…...

用Kubernetes(k8s)的ingress部署https应用
用Kubernetes的ingress部署https应用 环境准备Ingress安装域名证书准备 部署应用通过ingress暴露应用根据ssl证书生成对应的secret创建ingress暴露部署的应用确认自己安装了ingress创建ingress 访问你暴露的应用 环境准备 Ingress安装 我之前有一片文章写的是用ingress暴露应…...
【附安装包】MyEclipse2020安装教程
软件下载 软件:MyEclipse版本:2020语言:简体中文大小:1.61G安装环境:Win11/Win10/Win8/Win7硬件要求:CPU2.5GHz 内存4G(或更高)下载通道①百度网盘丨下载链接:https://pan.baidu.co…...
软件与软件工程
软件 软件的概念以及特点: 软件是计算机系统中不可或缺的一部分,与硬件共同构成特定的系统功能。 人们通常把各种不同功能的程序,包括系统程序、应用程序、用户自己编写的程序等称为软件 软件的概念: 软件不仅包括程序,还包括程序…...

记录一下:基于nginx配置的封禁真实IP
nginx Situation(背景)Task(任务)Action(行动)1:方法1:使用nginx 自带的deny 和 allow 来实现2:方法2:添加配置 Result(结果) Situati…...

【狂神】Spring5笔记(1-9)
目录 首页: 1.Spring 1.1 简介 1.2 优点 2.IOC理论推导 3.IOC本质 4.HelloSpring ERROR 5.IOC创建对象方式 5.1、无参构造 这个是默认的 5.2、有参构造 6.Spring配置说明 6.1、别名 6.2、Bean的配置 6.3、import 7.DL依赖注入环境 7.1 构造器注入 …...
)
Redis——急速安装并设置自启(CentOS)
现状 对于开发人员来说,部署服务器环境并不是一个高频操作。所以就导致绝大部分开发人员不会花太多时间去学习记忆,而是直接百度(有一些同学可能连链接都懒得收藏)。所以到了部署环境的时候就头疼,甚至是抗拒。除了每次…...
)
告别OnlyOffice限制!用Alist+KkFileView搭建全能文件预览中心(支持CAD/PSD/ZIP)
突破文件预览瓶颈:AlistKkFileView全格式支持实战指南 你是否曾因AlistOnlyOffice无法预览CAD图纸而焦头烂额?或是面对团队发来的PSD设计稿只能干瞪眼?这套组合方案虽能解决基础办公文档需求,但遇到专业格式就束手无策。本文将带你…...

Temu 运营进阶之路 工具选型与凌风体系分析
TEMU商家体量持续扩张,平台规则与收费体系愈发复杂,纯人工运营耗时费力,核算误差、合规疏漏问题频发。市面上运营工具繁杂,商家难以甄别适配工具。本文以行业实操角度,客观拆解凌风工具箱的适配能力与实用价值…...

WPF-VisionMasterOpenCV
WPF-VisionMasterOpenCV 一、项目概述 WPF-VisionMasterOpenCV 是一个基于 WPF EmguCV(OpenCV的.NET封装)开发的机器视觉软件框架。它采用节点流程图的方式,让用户可以通过拖拽节点来构建视觉检测流程。 项目架构 WPF-VisionMaster/ ├─…...

Linux命令:strace
strace 命令 基本介绍 strace 是 Linux 系统中用于跟踪进程系统调用和信号的强大调试工具。它可以捕获并记录进程执行的所有系统调用、传递的参数、返回值以及接收到的信号,是程序员和系统管理员进行程序调试、性能分析和问题诊断的必备工具。 资料合集:…...

YOLOv8 ROS:机器人视觉从2D感知到3D空间理解的架构演进
YOLOv8 ROS:机器人视觉从2D感知到3D空间理解的架构演进 【免费下载链接】yolov8_ros Ultralytics YOLOv8, YOLOv9, YOLOv10, YOLOv11, YOLOv12 for ROS 2 项目地址: https://gitcode.com/gh_mirrors/yo/yolov8_ros 在机器人智能化浪潮中,视觉感知…...

【Lovable CRM系统搭建终极指南】:20年实战沉淀的7大避坑法则与即插即用架构模板
更多请点击: https://intelliparadigm.com 第一章:Lovable CRM系统搭建的底层逻辑与价值定位 Lovable CRM并非传统CRM的功能叠加,而是以“人本交互”为原点重构客户关系管理范式——其底层逻辑根植于可扩展的微服务架构、领域驱动设计&#…...

知识图谱与推荐系统实战
一、传统推荐系统的“天花板”协同过滤的困境你刷电商、看视频时,推荐系统总在猜你喜欢什么。最经典的协同过滤思路是“物以类聚、人以群分”:你买过A,那么买过A的人也常买B,于是把B推给你。这套方法简单有效,但也有硬…...

手机和电脑怎样换背景颜色?2026 年最全操作指南来了
想要轻松改变设备背景颜色却不知道从何下手?无论你用的是手机还是电脑,换背景颜色其实比你想象的要简单得多。本篇文章将为你详细介绍各种设备和软件上的背景颜色更换方法,帮你快速掌握这项基础操作技能。手机换背景颜色操作方法完全指南iOS …...

咖啡一杯,Token 无限,Real-Time Cafe 深圳站来了!新增「硬件晒晒桌」与「AI 桌游试玩桌」
咖啡一杯,Token 无限——「Real-Time Cafe」是一个让开发者聚在一起实时 coding、实时 debug、实时互动的咖啡馆快闪计划。 Real-Time Cafe 深圳站来了!就在本周日 5 月 24 日下午。 本站特设「硬件晒晒桌」与「AI 桌游试玩桌」——带上你的电子宠物、…...

NoFences:免费开源桌面整理神器,让Windows桌面焕然一新
NoFences:免费开源桌面整理神器,让Windows桌面焕然一新 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 还在为Windows桌面上杂乱无章的图标而烦恼吗&a…...