【python爬虫】5.爬虫实操(歌词爬取)
文章目录
- 前言
- 项目:寻找周杰伦
- 分析过程
- 代码实现
- 重新分析过程
- 什么是Network
- Network怎么用
- 什么是XHR?
- XHR怎么请求?
- json是什么?
- json数据如何解析?
- 实操:完成代码实现
- 一个总结
- 一个复习
前言
这关让我们一起来寻找周杰伦!如果你已经满怀期待。那么毫无疑问,你和我一样,都非常喜欢他的音乐。
当然,还要有复习。在上一关,我们使用两种方式,爬取了热门菜谱清单,内含:菜名、原材料、详细烹饪流程的URL。代码如下:
# 引用requests库
import requests
# 引用BeautifulSoup库
from bs4 import BeautifulSoup# 获取数据
res_foods = requests.get('http://www.xiachufang.com/explore/')
# 解析数据
bs_foods = BeautifulSoup(res_foods.text,'html.parser')# 查找包含菜名和URL的<p>标签
tag_name = bs_foods.find_all('p',class_='name')
# 查找包含食材的<p>标签
tag_ingredients = bs_foods.find_all('p',class_='ing ellipsis')
# 创建一个空列表,用于存储信息
list_all = []
# 启动一个循环,次数等于菜名的数量
for x in range(len(tag_name)):# 提取信息,封装为列表。此处[18:-14]切片的主要功能是切掉空格list_food = [tag_name[x].text[18:-14],tag_name[x].find('a')['href'],tag_ingredients[x].text[1:-1]]# 将信息添加进list_alllist_all.append(list_food)# 打印
print(list_all)# 以下是另外一种解法# 查找最小父级标签
list_foods = bs_foods.find_all('div',class_='info pure-u')
# 创建一个空列表,用于存储信息
list_all = []for food in list_foods:# 提取第0个父级标签中的<a>标签tag_a = food.find('a')# 菜名,使用[17:-13]切掉了多余的信息name = tag_a.text[17:-13]# 获取URLURL = 'http://www.xiachufang.com'+tag_a['href']# 提取第0个父级标签中的<p>标签tag_p = food.find('p',class_='ing ellipsis')# 食材,使用[1:-1]切掉了多余的信息ingredients = tag_p.text[1:-1]# 将菜名、URL、食材,封装为列表,添加进list_alllist_all.append([name,URL,ingredients])# 打印
print(list_all)
将想要的数据分别提取,再组合是一种不错的思路。但是,如果数据的数量对不上,就会让事情比较棘手。比如,在我们的案例里,如果一个菜有多个做法,其数量也没规律,那么菜名和URL的数量就会对不上。
寻找最小共同父级标签是一种很常见的提取数据思路,它能有效规避这个问题。但有时候,可能需要你反复操作,提取数据。
所以在实际项目实操中,需要根据情况,灵活选择,灵活组合。我们本关卡所做的项目,只是刚刚好两种方式都可以爬取。
text获取到的是该标签内的纯文本信息,即便是在它的子标签内,也能拿得到。但提取属性的值,只能提取该标签本身的。
from bs4 import BeautifulSoupbs = BeautifulSoup('<p><a>惟有痴情难学佛</a>独无媚骨不如人</p>','html.parser')
tag = bs.find('p')
print(tag.text)
在爬虫实践当中,其实常常会因为标签选取不当,或者网页本身的编写没做好板块区分,你可能会多提取到出一些奇怪的东西。
当遇到这种糟糕的情况,一般有两种处理方案:数量太多而无规律,我们会换个标签提取;数量不多而有规律,我们会对提取的结果进行筛选——只要列表中的若干个元素就好。
项目:寻找周杰伦
就像标题里描述的那样,这是一个和周杰伦相关的关卡。我还记得自己年少时,沉迷于收集他的专辑、歌单,生怕有缺漏……在当时,互联网不像今天这样普及,做这事可一点都不容易——你必须和小镇上卖CD的老板,打成一片。
但在今天,我能借助爬虫非常轻松地满足自己的收藏癖。接下来,我也会教给你怎么去做。这就是本关项目:寻找周杰伦,爬取周杰伦的歌曲清单。
我们会尝试用前几关的知识,完成这个项目。很快,你会发现事情仿佛不是那样简单。你需要一些新工具的帮助,它们的名字叫Network,XHR,json。稍后,我会为你一一介绍。
分析过程
当接手一个新项目,开发人员们并不会一上来就去写代码,他们会先去思考这个项目应当如何实现。我们,也是如此。
比方说我们要爬取周杰伦的歌单,那么首先要思考的是:哪家网站,拥有周杰伦的歌曲版权?
获取这个问题答案的方法有两种:【1】自己上网搜,【2】听我这个资深乐迷讲——答案是QQ音乐。
请你务必新建一个浏览器标签,跟随我操作。首先,我们先去QQ音乐的官网,看看它的robots协议https://y.qq.com/robots.txt,结果应如下:
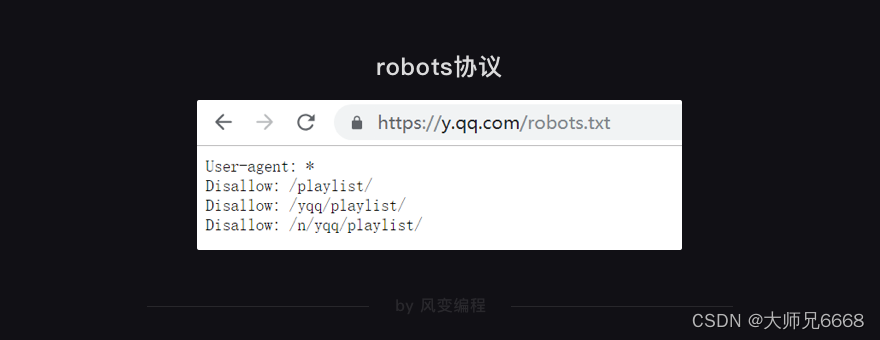
从robots协议看,只是禁止了playlist相关的信息爬取,问题不大,放心去吧!我们来进入QQ音乐的官网首页:https://y.qq.com

接着,在上图的搜索框内输入“周杰伦”,然后点击回车。此时,页面会发生跳转,结果如下图所示:
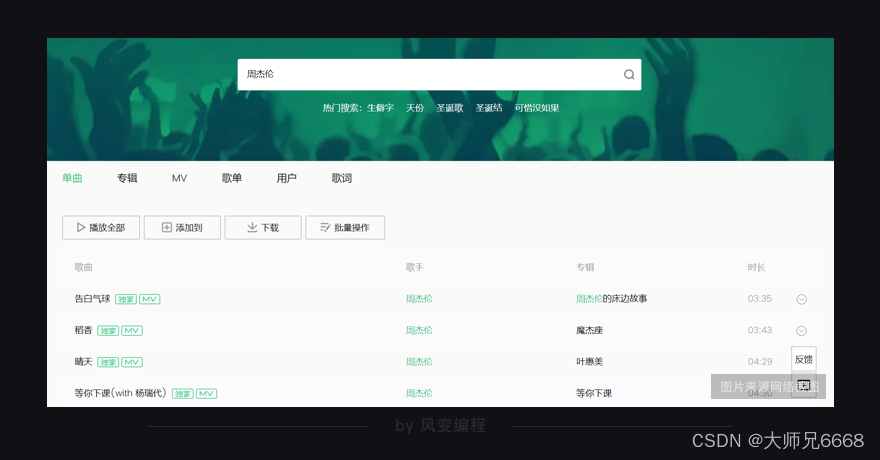
你能看到,我们想要的歌曲信息,就在这个页面里。这个页面,它的网址会是:
https://y.qq.com/portal/search.html#page=1&searchid=1&remoteplace=txt.yqq.top&t=song&w=%E5%91%A8%E6%9D%B0%E4%BC%A6
剩下的事情就简单了,根据我们已经学过的知识,我们可以借助requests和BeautifulSoup,来爬取想要的数据。它的过程,大概会是这样:
根据爬虫四步,我们会利用requests.get()去请求该网址;使用BeautifulSoup对请求结果进行解析;利用find_all方法拿到我们想要的标签;提取歌曲清单。
现在,我们可以尝试写代码。
代码实现
根据前两关所学的知识,如果不出意外,我们的代码大概可以写成这幅模样:
import requests
from bs4 import BeautifulSoup# 请求html,得到response
res_music = requests.get('https://y.qq.com/portal/search.html#page=1&searchid=1&remoteplace=txt.yqq.top&t=song&w=%E5%91%A8%E6%9D%B0%E4%BC%A6')
# 解析html
bs_music = BeautifulSoup(res_music.text,'html.parser')
# 查找class属性值为“js_song”的a标签,得到一个由标签组成的列表
list_music = bs_music.find_all('a',class_='js_song')
# 对查找的结果执行循环
for music in list_music:# 打印出我们想要的音乐名print(music['title'])
看上去仿佛没什么问题,但其实这个代码是没办法工作的。你可以先试试看,我再为你解释原因:
程序运行的结果,是什么都找不到……当我们写代码遇到这种情况,我们首先要确认自己的代码是否有问题。
我们可以从下往上,倒推着一步一步排查:看提取是不是出错,看解析是不是出错,看请求是不是出错。现在,我们先去print(list_music)看看它里面的值。请运行下方代码:
import requests
from bs4 import BeautifulSoup# 请求html,得到response
res_music = requests.get('https://y.qq.com/portal/search.html#page=1&searchid=1&remoteplace=txt.yqq.top&t=song&w=%E5%91%A8%E6%9D%B0%E4%BC%A6')
# 解析html
bs_music = BeautifulSoup(res_music.text,'html.parser')
# 查找class属性值为“js_song”的a标签,得到一个由标签组成的列表
list_music = bs_music.find_all('a',class_='js_song')
# 打印它
print(list_music)
运行结果:
[]
list_music,空无一物,它是一个空列表。解析不太可能出问题,因为就一行代码而且符合规范。难道说请求本身就错误了,网页源代码中,根本没有我们要找的歌曲名?我们来print(res_music)。
import requests
from bs4 import BeautifulSoup# 请求html,得到response
res_music = requests.get('https://y.qq.com/portal/search.html#page=1&searchid=1&remoteplace=txt.yqq.top&t=song&w=%E5%91%A8%E6%9D%B0%E4%BC%A6')
# 打印它
print(res_music.text)
运行结果太多了,就不在这里展示了。
认真翻找它,果然!网页源代码里根本没有我们想要的歌曲清单。
事已至此,已经验证不是代码本身的问题,但目标却未能得到实现。我们就得往前回滚一步:思考,是不是上一步的分析出了问题?
重新分析过程
网页源代码里没有我们想要的数据,那它究竟藏到了哪里呢?
想找到答案,需要用到一项新技能——翻找Network!下面,我来一步步带你做。
什么是Network
我们先去看看Network的页面。在你刚才打开的QQ音乐页面,调用“检查”(ctrl+shift+i)工具,然后点击Network。
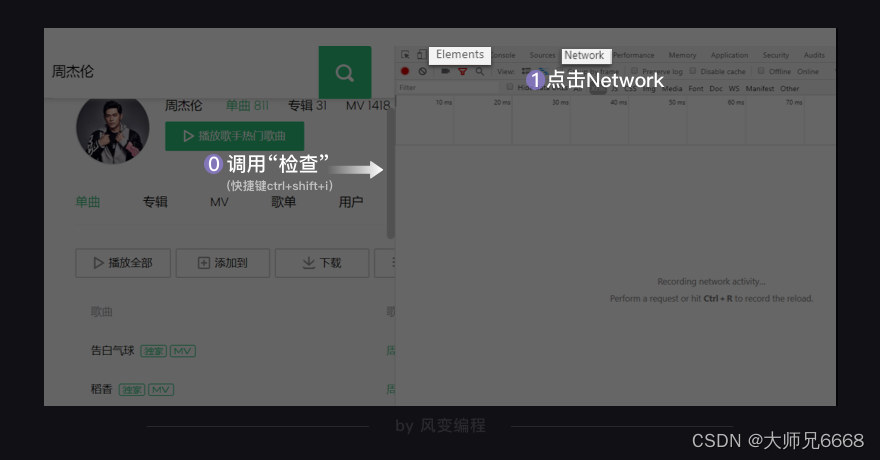
如上图左边框框里的是Elements,我们在那里查看网页源代码。右边框框是我们现在要关注的Network。
Network的功能是:记录在当前页面上发生的所有请求。现在看上去好像空空如也的样子,这是因为Network记录的是实时网络请求。现在网页都已经加载完成,所以不会有东西。
我们点击一下刷新,浏览器会重新访问网络,这样就会有记录。如下图:
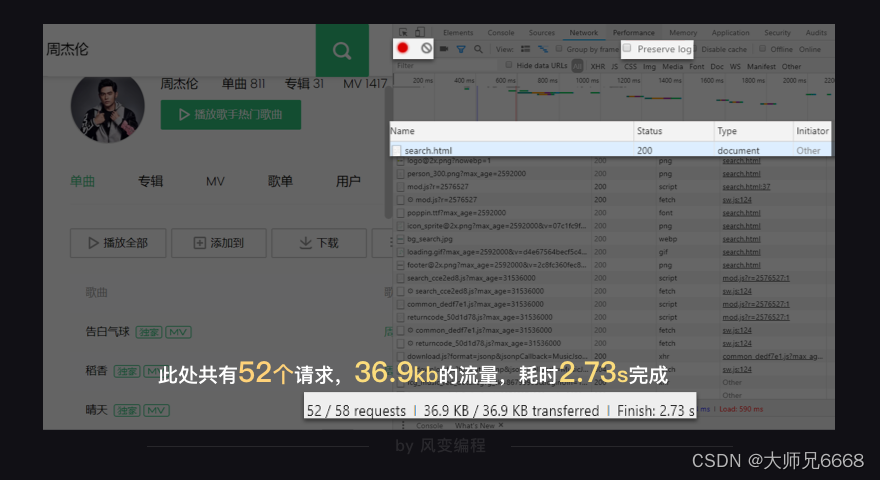
哗~密密麻麻地出来了许多,在图最下面,它告诉我们:此处共有52个请求,36.9kb的流量,耗时2.73s完成。
这个,正是我们的浏览器每时每刻工作的真相:它总是在向服务器,发起各式各样的请求。当这些请求完成,它们会一起组成我们在Elements中看到的网页源代码。
为什么我们刚才没办法拿到歌曲清单呢?答,这是因为我们刚刚写的代码,只是模拟了这52个请求中的一个(准确来说,就是第0个请求),而这个请求里并不包含歌曲清单。
现在请挪动鼠标,找到这个页面的第0个请求:search.html,然后点击它,如下图,我们来查看它的Response(官方翻译叫“响应”,你可以理解为服务器对浏览器这个请求的回应内容,即请求的结果)。
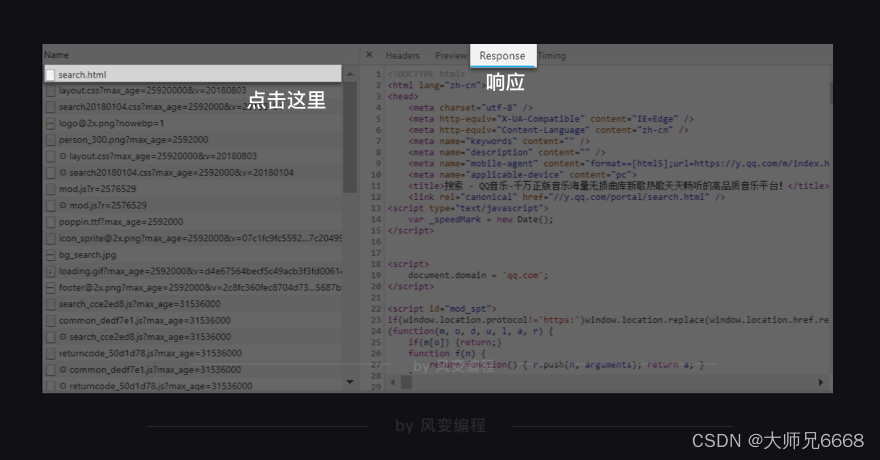
其实,它就是我们刚刚用requests.get()获取到的网页源代码,它里面不包含歌曲清单。
一般来说,都是这种第0个请求先启动了,其他的请求才会关联启动,一点点地将网页给填充起来。做一个比喻,第0个请求就好比是人的骨架,确定了这个网页的结构。在此之后,众多的请求接连涌入,作为人的血脉经络。如此,人就变好看。

当然啦,也有一些网页,直接把所有的关键信息都放在第0个请求里,尤其是一些比较老(或比较轻量)的网站,我们用requests和BeautifulSoup就能解决它们。比如我们体验过的“这个书苑不太冷”,比如你看过的“人人都是蜘蛛侠”博客,比如豆瓣。
总之,为了成功抓取到歌曲清单。我们得先找到,歌名藏在哪一个请求当中。再用requests库,去模拟这个请求。
Network怎么用
想做这个,我们需要先去了解下Network面板怎么用。回头看我们之前给的图:
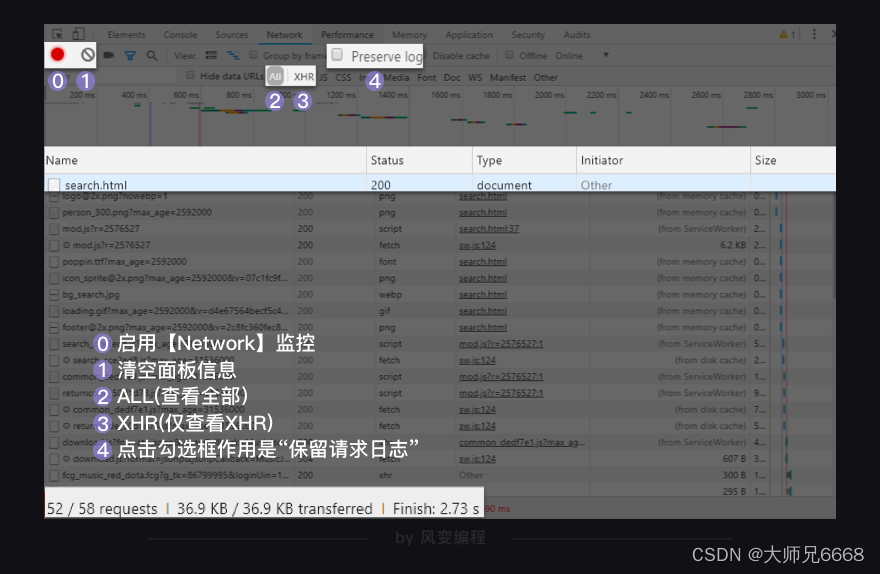
从上往下,只看我圈起来的内容的话,它有四行信息。下面,我来为你介绍它。
第0行的左侧,红色的圆钮是启用Network监控(默认高亮打开),灰色圆圈是清空面板上的信息。右侧勾选框Preserve log,它的作用是“保留请求日志”。如果不点击这个,当发生页面跳转的时候,记录就会被清空。所以,我们在爬取一些会发生跳转的网页时,会点亮它。
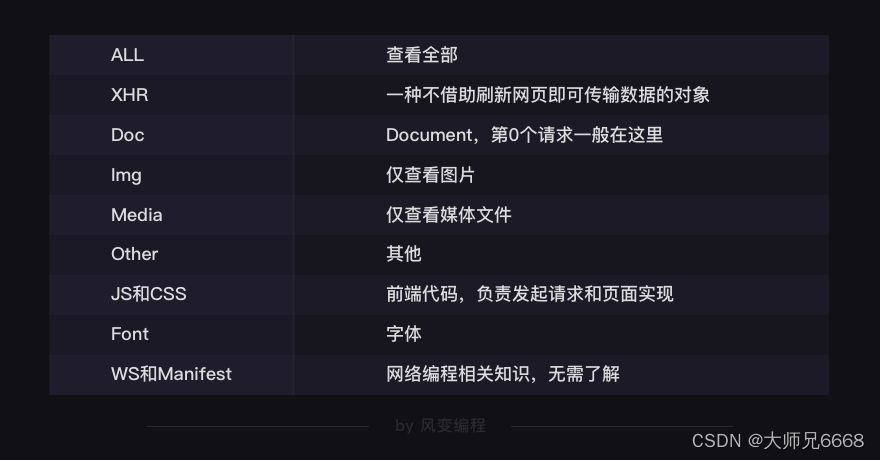
第1行,是对请求进行分类查看。我们最常用的是:ALL(查看全部)/XHR(仅查看XHR,我们等会重点讲它)/Doc(Document,第0个请求一般在这里),有时候也会看看:Img(仅查看图片)/Media(仅查看媒体文件)/Other(其他)。最后,JS和CSS,则是前端代码,负责发起请求和页面实现;Font是文字的字体;而理解WS和Manifest,需要网络编程的知识,倘若不是专门做这个,你不需要了解。

夹在第2行和第1行中间的,是一个时间轴。记录什么时间,有哪些请求。而第2行,就是各个请求,你可以看下面这张表来理解(读,但不需要记忆)。

在第3行,我们讲过了,是个统计:有多少个请求,一共多大,花了多长时间。
什么是XHR?
在Network中,有一类非常重要的请求叫做XHR(当你把鼠标在XHR上悬停,你可以看到它的完整表述是XHR and Fetch),未来我们几乎每一关都要和它打交道。下面,我来为你重点介绍它。
我们平时使用浏览器上网的时候,经常有这样的情况:浏览器上方,它所访问的网址没变,但是网页里却新加了内容。
典型代表:如购物网站,下滑自动加载出更多商品。在线翻译网站,输入中文实时变英文。比如,你正在使用的教学系统,每点击一次Enter就有新的内容弹出。
这个,叫做Ajax技术(技术本身和爬虫关系不大,在此不做展开,你可以通过搜索了解)。应用这种技术,好处是显而易见的——更新网页内容,而不用重新加载整个网页。又省流量又省时间的,何乐而不为。
如今,比较新潮的网站都在使用这种技术来实现数据传输。只剩下一些特别老,或是特别轻量的网站,还在用老办法——加载新的内容,必须要跳转一个新网址。
这种技术在工作的时候,会创建一个XHR(或是Fetch)对象,然后利用XHR对象来实现,服务器和浏览器之间传输数据。在这里,XHR和Fetch并没有本质区别,只是Fetch出现得比XHR更晚一些,所以对一些开发人员来说会更好用,但作用都是一样的。
XHR怎么请求?
显而易见,对照前面的表单。我们的歌曲清单不在网页源代码里,而且也不是图片,不是媒体文件,自然只会是在XHR里。我们现在去找找看,点击XHR按钮。

这个网页里一共有14个XHR或Fetch,我们要从里面找出带有歌单的那一个。
笨办法当然是一个一个实验,但聪明的办法是去尝试阅读它们的名字。比如你一眼就看到:client_search(客户端搜索)……而且它最大,有10.9KB,我们来点击它。
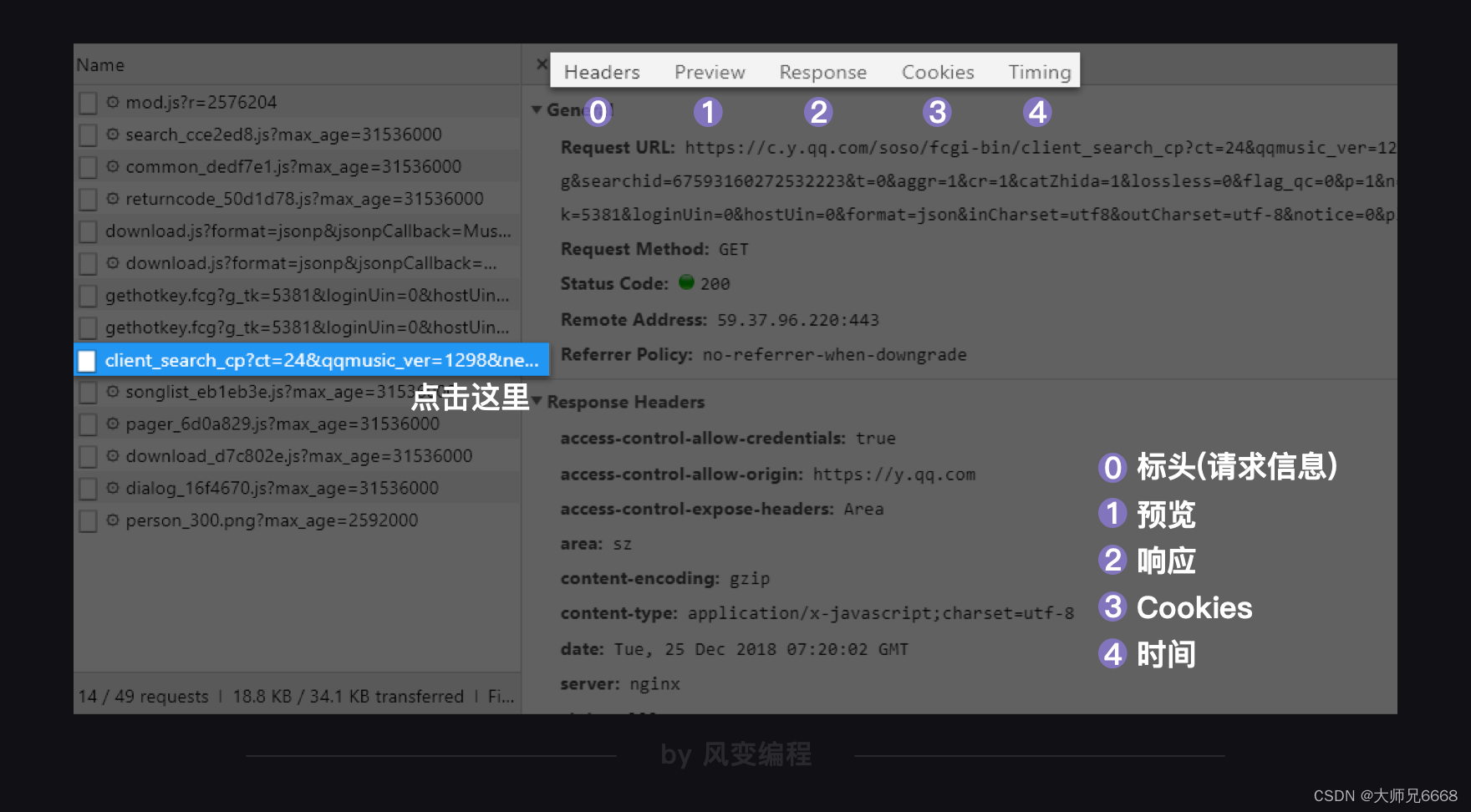
出现了如上图这样的一个窗口,我们先来看右上方框里标号的内容,从左往右分别是:Headers:标头(请求信息)、Preview:预览、Response:响应、Cookies:Cookies、Timing:时间。
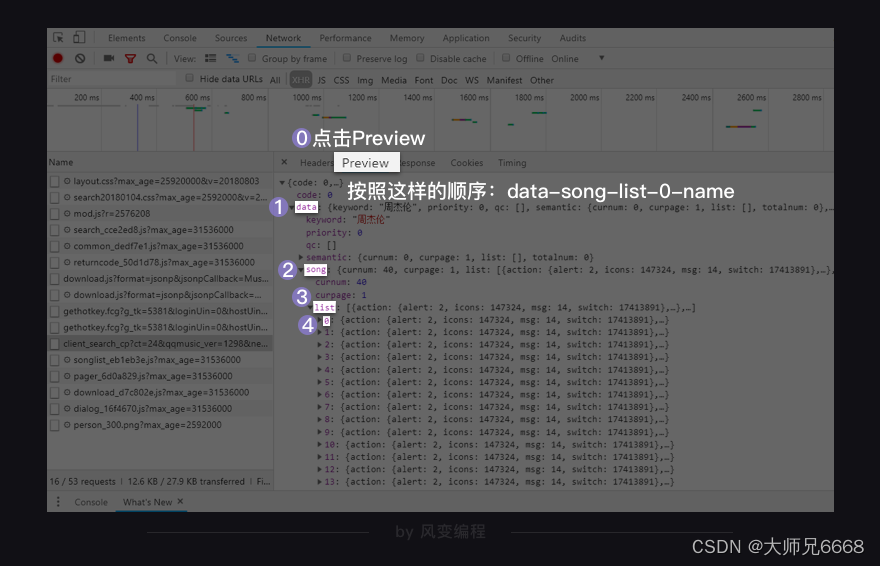
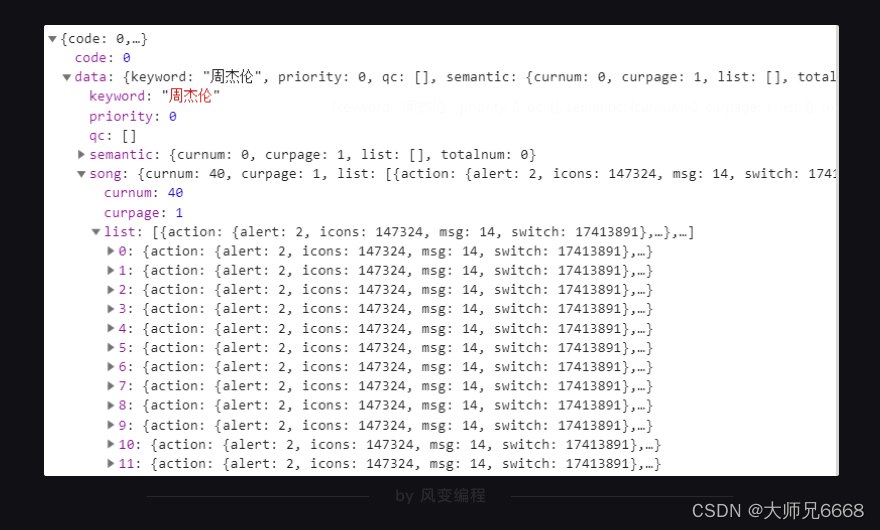
点击Preview,你能在里面发现我们想要的信息:歌名就藏在里面!(只是有点难找,需要你一层一层展开:data-song-list-0-name,然后就能看到“告白气球”)
那如何把这些歌曲名拿到呢?这就需要我们去看看最左侧的Headers,点击它。如下所示,它被分为四个板块。
我们把后面的三个,留待后续关卡详细解释。今天,你只是看看它们就好,然后将注意力放在第0个General上面。点开它,你会看到:
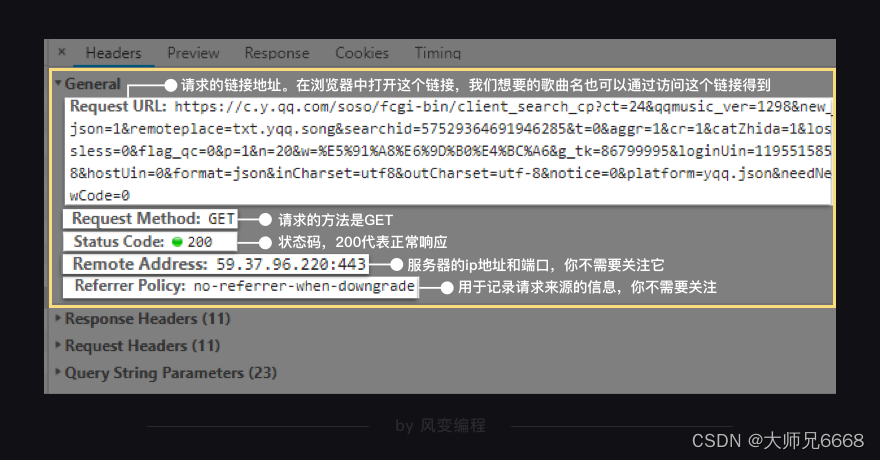
看到了吗?General里的Requests URL就是我们应该去访问的链接。如果在浏览器中打开这个链接,你会看到一个让人绝望的结构:最外层是一个字典,然后里面又是字典,往里面又有列表和字典……

它就和你在Response里看到的一个样。还是放弃挣扎吧,回到原网址,直接用Preview来看就好。列表和字典在此都会有非常清晰的结构,层层展开。
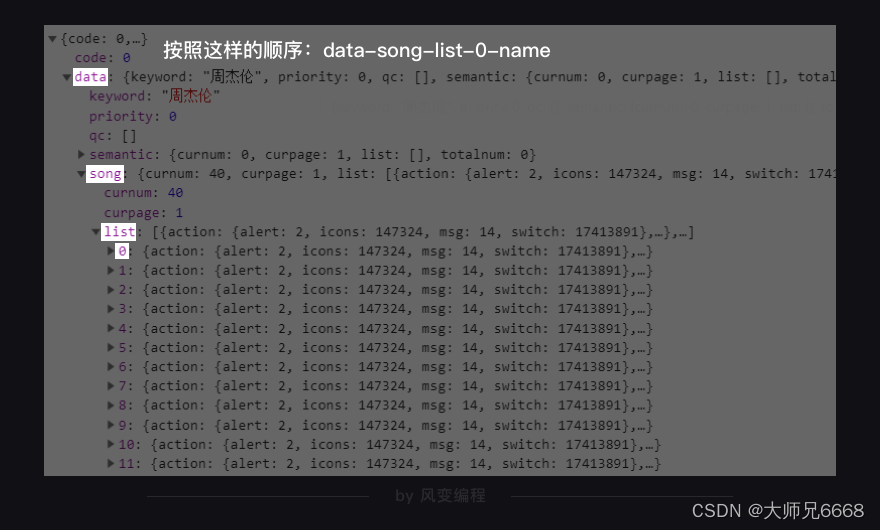
如上,我们一层一层地点开,按照这样的顺序:data-song-list-0-name,看到:
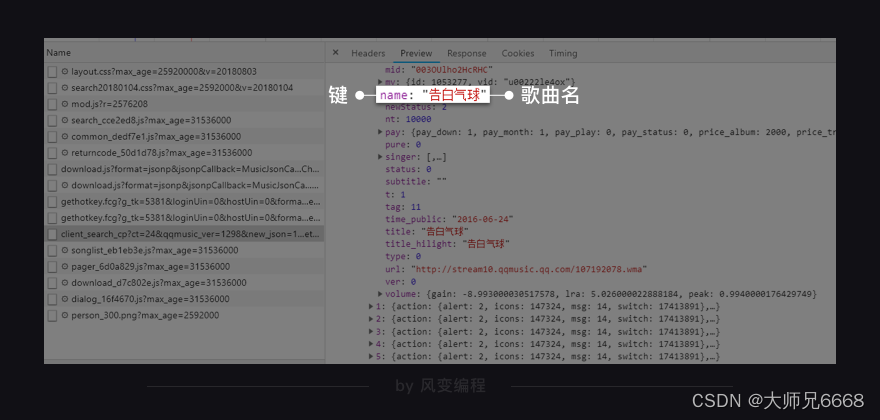
歌曲名就在这里,它的键是name。理解这句话:这个XHR是一个字典,键data对应的值也是一个字典;在该字典里,键song对应的值也是一个字典;在该字典里,键list对应的值是一个列表;在该列表里,一共有10个元素;每一个元素都是一个字典;在每个字典里,键name的值,对应的是歌曲名。
此刻的你有了一个大胆的想法:利用requests.get()访问这个链接,把这个字典下载到本地。然后去一层一层地读取,拿到歌曲名。
到此,我们的代码可以写成这样,你可以尝试运行看看:
# 引用requests库
import requests
# 调用get方法,下载这个字典
res = requests.get('https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.song&searchid=60997426243444153&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=20&w=%E5%91%A8%E6%9D%B0%E4%BC%A6&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0')
# 把它打印出来
print(res.text)打印结果(节选):
{"alert":41,"icons":12861308,"msg":13,"switch":17405185},"album":{"id":20612,"mid":"003DFRzD192KKD","name":"七里香","pmid":"003DFRzD192KKD_1","subtitle":"","title":"七里香","title_hilight":"七里香"},"chinesesinger":0,"desc":"","desc_hilight":"","docid":"13932817310379068326","es":"","file":{"b_30s":78000,"e_30s":138000,"media_mid":"003RCeQW4JBZi3","size_128":4090342,"size_128mp3":4090342,"size_320":10225565,"size_320mp3":10225565,"size_aac":6167826,"size_ape":0,"size_dts":0,"size_flac":29345075,"size_ogg":5645289,"size_try":960887,"strMediaMid":"003RCeQW4JBZi3","try_begin":78121,"try_end":111898},"fnote":4009,"genre":1,"grp":[],"id":102065753,"index_album":9,"index_cd":0,"interval":255,"isonly":1,"ksong":{"id":10123,"mid":"002G5b020DXADc"},"language":0,"lyric":"","lyric_hilight":"","mid":"003nEQHr3Ceet5","mv":{"id":55236,"vid":"n0013xat9z2"},"name":"园游会","newStatus":2,"nt":2563665896,"ov":0,"pay":{"pay_down":1,"pay_month":1,"pay_play":1,"pay_status":0,"price_album":0,"price_track":200,"time_free":0},"pure":0,"sa":0,"singer":[{"id":4558,"mid":"0025NhlN2yWrP4","name":"周杰伦","title":"周杰伦","title_hilight":"<em>周杰伦</em>","type":0,"uin":0}],"status":0,"subtitle":"","t":1,"tag":11,"tid":0,"time_public":"2004-08-03","title":"园游会","title_hilight":"园游会","type":0,"url":"http://stream10.qqmusic.qq.com/102065753.wma","ver":0,"volume":{"gain":-9.623000144958496,"lra":2.069000005722046,"peak":1.0}}],"totalnum":150},"tab":0,"taglist":[],"totaltime":0,"zhida":{"type":1,"zhida_singer":{"albumNum":35,"hotalbum":[{"albumID":1458791,"albumMID":"003RMaRI1iFoYd","albumName":"周杰伦的床边故事","albumname_hilight":"周杰伦的床边故事"},{"albumID":33021,"albumMID":"002eFUFm2XYZ7z","albumName":"我很忙","albumname_hilight":"我很忙"},{"albumID":852856,"albumMID":"001uqejs3d6EID","albumName":"哎呦,不错哦","albumname_hilight":"哎呦,不错哦"},{"albumID":194021,"albumMID":"003Ow85E3pnoqi","albumName":"十二新作","albumname_hilight":"十二新作"},{"albumID":36062,"albumMID":"002Neh8l0uciQZ","albumName":"魔杰座","albumname_hilight":"魔杰座"},{"albumID":8218,"albumMID":"000f01724fd7TH","albumName":"Jay","albumname_hilight":"Jay"},{"albumID":56705,"albumMID":"000bviBl4FjTpO","albumName":"跨时代","albumname_hilight":"跨时代"},{"albumID":60671,"albumMID":"0024bjiL2aocxT","albumName":"十一月的萧邦","albumname_hilight":"十一月的萧邦"},{"albumID":8220,"albumMID":"000MkMni19ClKG","albumName":"叶惠美","albumname_hilight":"叶惠美"},{"albumID":8217,"albumMID":"000I5jJB3blWeN","albumName":"范特西","albumname_hilight":"范特西"}],"hotsong":[{"f":"97773|晴天|4558|周杰伦|8220|叶惠美|0|269|-1|1|0|10792516|4317292|0|0|0|31430142|5864688|6528081|0|0039MnYb0qxYhV|0025NhlN2yWrP4|000MkMni19ClKG|0|4009","songID":97773,"songMID":"0039MnYb0qxYhV","songName":"晴天","songname_hilight":"晴天"},{"f":"449201|兰亭序|4558|周杰伦|36062|魔杰座|0|253|-1|1|0|10160781|4064429|0|0|0|28309022|5544577|6133907|0|00128N3r2SYKMF|0025NhlN2yWrP4|002Neh8l0uciQZ|0|4009","songID":449201,"songMID":"00128N3r2SYKMF","songName":"兰亭序","songname_hilight":"兰亭序"},{"f":"449198|花海|4558|周杰伦|36062|魔杰座|0|264|-1|1|0|10586772|4234954|0|0|0|29128486|5624534|6401459|0|003cI52o4daJJL|0025NhlN2yWrP4|002Neh8l0uciQZ|0|4009","songID":449198,"songMID":"003cI52o4daJJL","songName":"花海","songname_hilight":"花海"},{"f":"102065756|七里香|4558|周杰伦|20612|七里香|0|299|-1|1|0|11970297|4788294|0|0|0|35845646|7078399|7214942|0|004Z8Ihr0JIu5s|0025NhlN2yWrP4|003DFRzD192KKD|0|4009","songID":102065756,"songMID":"004Z8Ihr0JIu5s","songName":"七里香","songname_hilight":"七里香"},{"f":"718477|夜曲|4558|周杰伦|60671|十一月的萧邦|0|226|-1|1|0|9075745|3630591|0|0|0|26691277|5600056|5499068|0|001zMQr71F1Qo8|0025NhlN2yWrP4|0024bjiL2aocxT|0|4009","songID":718477,"songMID":"001zMQr71F1Qo8","songName":"夜曲","songname_hilight":"夜曲"},{"f":"5105986|一路向北|4558|周杰伦|14311|J III MP3 Player|0|295|-1|1|0|11830556|4732355|0|0|0|35323866|6667274|7159409|0|001xd0HI0X9GNq|0025NhlN2yWrP4|002MAeob3zLXwZ|0|4009","songID":5105986,"songMID":"001xd0HI0X9GNq","songName":"一路向北","songname_hilight":"一路向北"},{"f":"449205|稻香|4558|周杰伦|36062|魔杰座|0|223|-1|1|0|8941053|3576668|0|0|0|26012257|5136737|5431599|0|003aAYrm3GE0Ac|0025NhlN2yWrP4|002Neh8l0uciQZ|0|4009","songID":449205,"songMID":"003aAYrm3GE0Ac","songName":"稻香","songname_hilight":"稻香"},{"f":"101091484|给我一首歌的时间|4558|周杰伦|36062|魔杰座|0|253|-1|1|0|10144968|4058169|0|0|0|31541730|6063552|6137781|0|004BhQke4adHcf|0025NhlN2yWrP4|002Neh8l0uciQZ|0|4009","songID":101091484,"songMID":"004BhQke4adHcf","songName":"给我一首歌的时间","songname_hilight":"给我一首歌的时间"},{"f":"107192078|告白气球|4558|周杰伦|1458791|周杰伦的床边故事|0|215|-1|1|0|8608859|3443771|0|0|0|43845959|5007453|5180289|0|003OUlho2HcRHC|0025NhlN2yWrP4|003RMaRI1iFoYd|0|4009","songID":107192078,"songMID":"003OUlho2HcRHC","songName":"告白气球","songname_hilight":"告白气球"},{"f":"102065750|搁浅|4558|周杰伦|20612|七里香|0|240|-1|1|0|9607864|3843167|0|0|0|26174554|5218730|5785073|0|001Bbywq2gicae|0025NhlN2yWrP4|003DFRzD192KKD|0|4009","songID":102065750,"songMID":"001Bbywq2gicae","songName":"搁浅","songname_hilight":"搁浅"}],"mvNum":1346,"singerID":4558,"singerMID":"0025NhlN2yWrP4","singerName":"周杰伦","singerPic":"http://y.gtimg.cn/music/photo_new/T001R150x150M0000025NhlN2yWrP4.jpg","singername_hilight":"周杰伦","songNum":951}}},"message":"","notice":"","subcode":0,"time":1616422691,"tips":""}
在这里,我们又遇到一个障碍:使用res.text取到的,是字符串。它不是我们想要的列表/字典,数据取不出来。老虎吃天,没处下嘴。
json是什么?
或许你会问:老师,我们已经学过如何把response对象转成字符串,那有没有什么属性或者方法,能把response对象转成列表/字典呢?
办法自然有,但我要先讲给你一个新的知识点——json。
json是什么呢?粗暴地来解释,json是一种数据交换的语法。对我们来说,它只是一种规范数据传输的格式,形式有点像字典和列表的结合体。
# 定义一个字典
a = {'name':'刘备'}
# 定义一张列表
b = [1,2,3,4]
# 定义一个json
c = {"forchange": [{ "name":"张飞" , "gender":"male"}, { "name":"孙尚香" , "gender":"female"}, { "name":"关羽" , "gender":"male"},]}
从它的组成上来看,有花括弧、方括弧,冒号和逗号,一种字典和列表相互嵌套的体系。
这种特殊的写法决定了,json能够有组织地存储信息。
我们在生活当中,总是在接触林林总总的数据。如果它们直接以堆砌的形式出现在你面前,你很难阅读它。比如:想象一个乱序排布的字典,一个堆满文件的电脑桌面,一本不分段落章节的小说……
数据需要被有规律地组织起来,我们才能去查找、阅读、分析、理解。比如:汉语字典应该按照拼音排序,文件应该按照一定规律放进不同的文件夹,小说要有章节目录——大标题、中标题、小标题。
可以发现,组织数据的方式也有规律,规律有三条:

一般来说,这三条占得越多,数据的结构越清晰;占得越少,数据的结构越混沌。
生活如此,网络之间的数据传输也是如此。在之前,我们已经学习过html,它通过标签、属性来实现分层和对应。
json则是另一种组织数据的格式,长得和Python中的列表/字典非常相像。它和html一样,常用来做网络数据传输。刚刚我们在XHR里查看到的列表/字典,严格来说其实它不是列表/字典,它是json。
或许你会有疑问:那直接写成列表/字典不就好了,为什么要把它表示成字符串?答案很简单,因为不是所有的编程语言都能读懂Python里的数据类型(如,列表/字典),但是所有的编程语言,都支持文本(比如在Python中,用字符串这种数据类型来表示文本)这种最朴素的数据类型。
如此,json数据才能实现,跨平台,跨语言工作。
而json和XHR之间的关系:XHR用于传输数据,它能传输很多种数据,json是被传输的一种数据格式。就是这样而已。
我们总是可以将json格式的数据,转换成正常的列表/字典,也可以将列表/字典,转换成json。
json数据如何解析?
说回到我们的案例,当我们请求得到了json数据,应该如何读取呢?我们可以在requests库的官方文档中,找到答案。我们打开浏览器,搜索“requests 官方文档”,会来到这个界面:
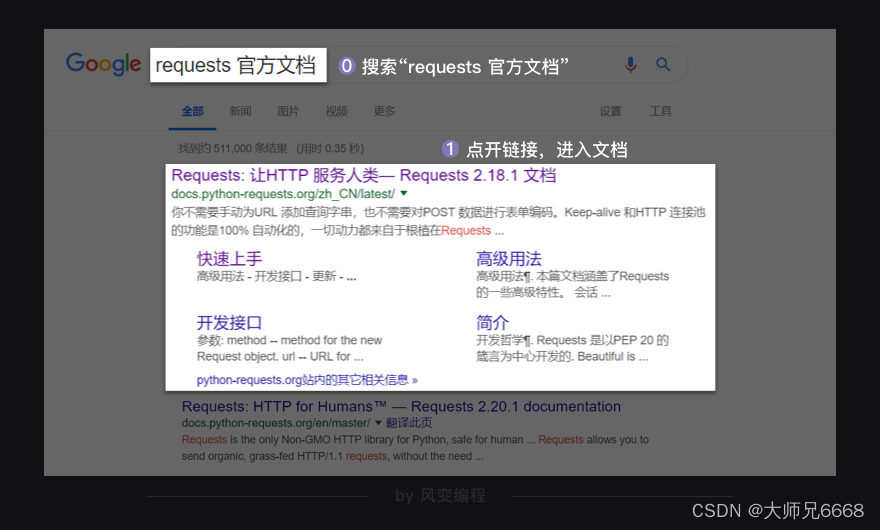
点开链接,进入文档,你会看到一个非常傲娇的作者。
使用浏览器的ctrl+f功能,在网页内搜索关键词json,能够非常快捷地找到这里:
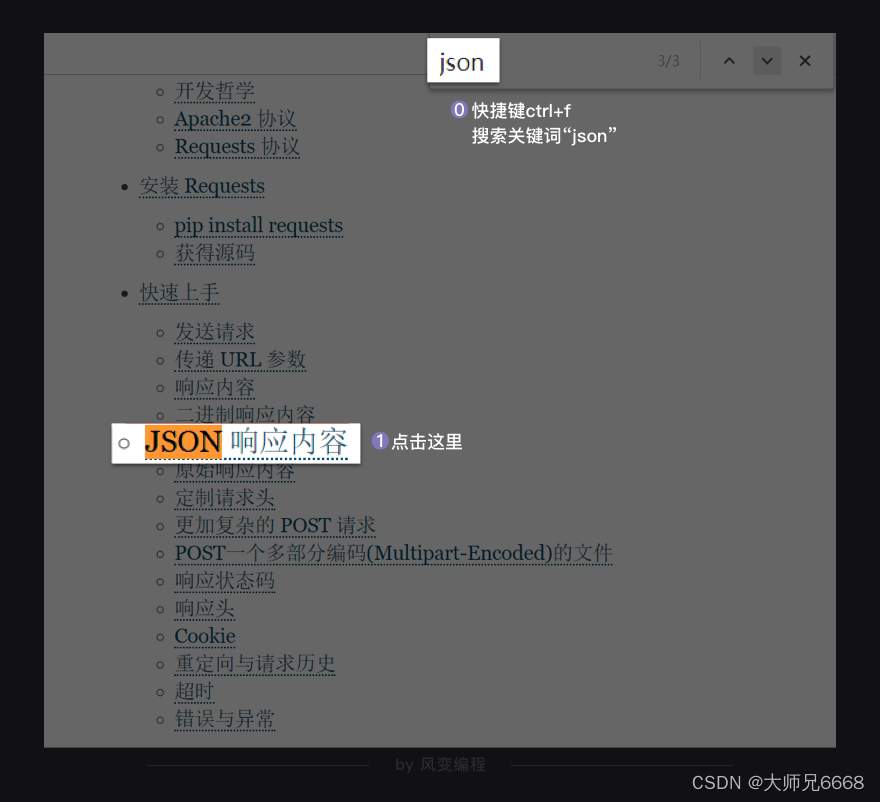
点击进入,你将看到requests库处理json数据的方法。

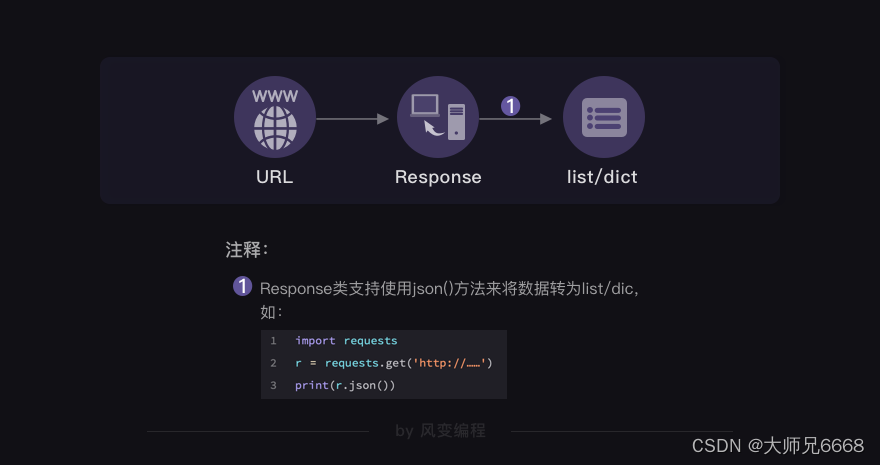
你看方法很简单,请求到数据之后,使用json()方法即可成功读取。接下来的操作,就和列表/字典相一致。

下面来体验一下,运行下方代码:
# 引用requests库
import requests
# 调用get方法,下载这个字典
res_music = requests.get('https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.song&searchid=60997426243444153&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=20&w=%E5%91%A8%E6%9D%B0%E4%BC%A6&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0')
# 使用json()方法,将response对象,转为列表/字典
json_music = res_music.json()
# 打印json_music的数据类型
print(type(json_music))运行结果:
<class 'dict'>
实操:完成代码实现
现在,我们至少可以写代码,提取出20个周杰伦的歌曲名。你可以尝试续写这个代码,稍后我会提供参考答案。
参考代码:
# 引用requests库
import requests
# 调用get方法,下载这个字典
res_music = requests.get('https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.song&searchid=60997426243444153&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=20&w=%E5%91%A8%E6%9D%B0%E4%BC%A6&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0')
# 使用json()方法,将response对象,转为列表/字典
json_music = res_music.json()
# 一层一层地取字典,获取歌单列表
list_music = json_music['data']['song']['list']
# list_music是一个列表,music是它里面的元素
for music in list_music:# 以name为键,查找歌曲名print(music['name'])
你应该能看到类似这样的结果(反正我写这个教程的时候是这样,不知道现在会不会变):
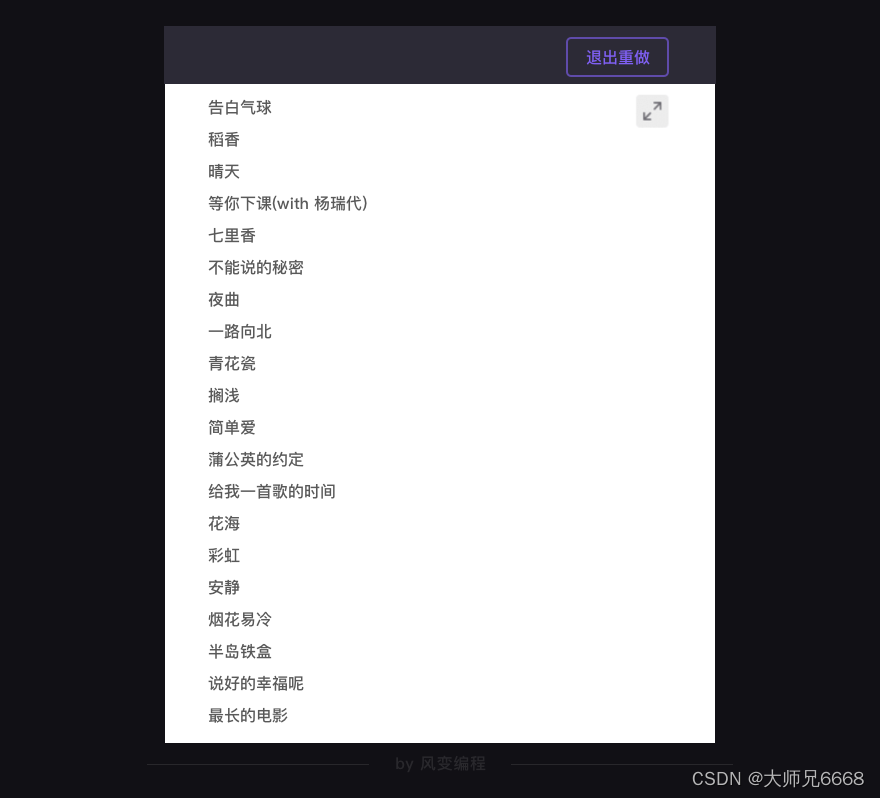
成功!撒花!
就是这样一个代码,它能拿到周杰伦在QQ音乐上,前20个歌曲的名单。
事实上,如果对这个程序稍加延展,它就能拿到:歌曲名、所属专辑、播放时长,以及播放链接。因为这些信息都在那个XHR里,认真观察分析,如果有必要的话还可以配合翻译软件。最终,你可以用同样的方法把它们提取出来。就像这样:
# 引用requests库
import requests
# 调用get方法,下载这个字典
res_music = requests.get('https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.song&searchid=60997426243444153&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=20&w=%E5%91%A8%E6%9D%B0%E4%BC%A6&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0')
# 使用json()方法,将response对象,转为列表/字典
json_music = res_music.json()
# 一层一层地取字典,获取歌单列表
list_music = json_music['data']['song']['list']
# list_music是一个列表,music是它里面的元素
for music in list_music:# 以name为键,查找歌曲名print(music['name'])# 查找专辑名print('所属专辑:'+music['album']['name'])# 查找播放时长print('播放时长:'+str(music['interval'])+'秒')# 查找播放链接print('播放链接:https://y.qq.com/n/yqq/song/'+music['mid']+'.html\n\n')
你也可以尝试在之前的基础上续写这个代码,将歌曲名、所属专辑、播放时长,以及播放链接自己给提取出来。
其中,拿到歌曲链接这一步可能稍有难度。你可以先试试看,如果写不出,查看后续的参考代码。
参考代码:
# 引用requests库
import requests
# 调用get方法,下载这个字典
res_music = requests.get('https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.song&searchid=60997426243444153&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=20&w=%E5%91%A8%E6%9D%B0%E4%BC%A6&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0')
# 使用json()方法,将response对象,转为列表/字典
json_music = res_music.json()
# 一层一层地取字典,获取歌单列表
list_music = json_music['data']['song']['list']
# list_music是一个列表,music是它里面的元素
for music in list_music:# 以name为键,查找歌曲名print(music['name'])print(music['album']['name'])print(music['time_public'])print(str(music['interval'])+'秒')print(music['url'])
一个总结
截至当前,我们已经部分完成了初定目标:爬取周杰伦的歌曲清单。
为什么说部分?一方面是我们只拿到20首歌曲的信息,远不能满足一个狂热粉丝的需要。另一方面,只拿到歌名/专辑/时长……这些数据还不够酷,狂热粉丝还想拿到所有的歌词,甚至还有歌曲的评论。
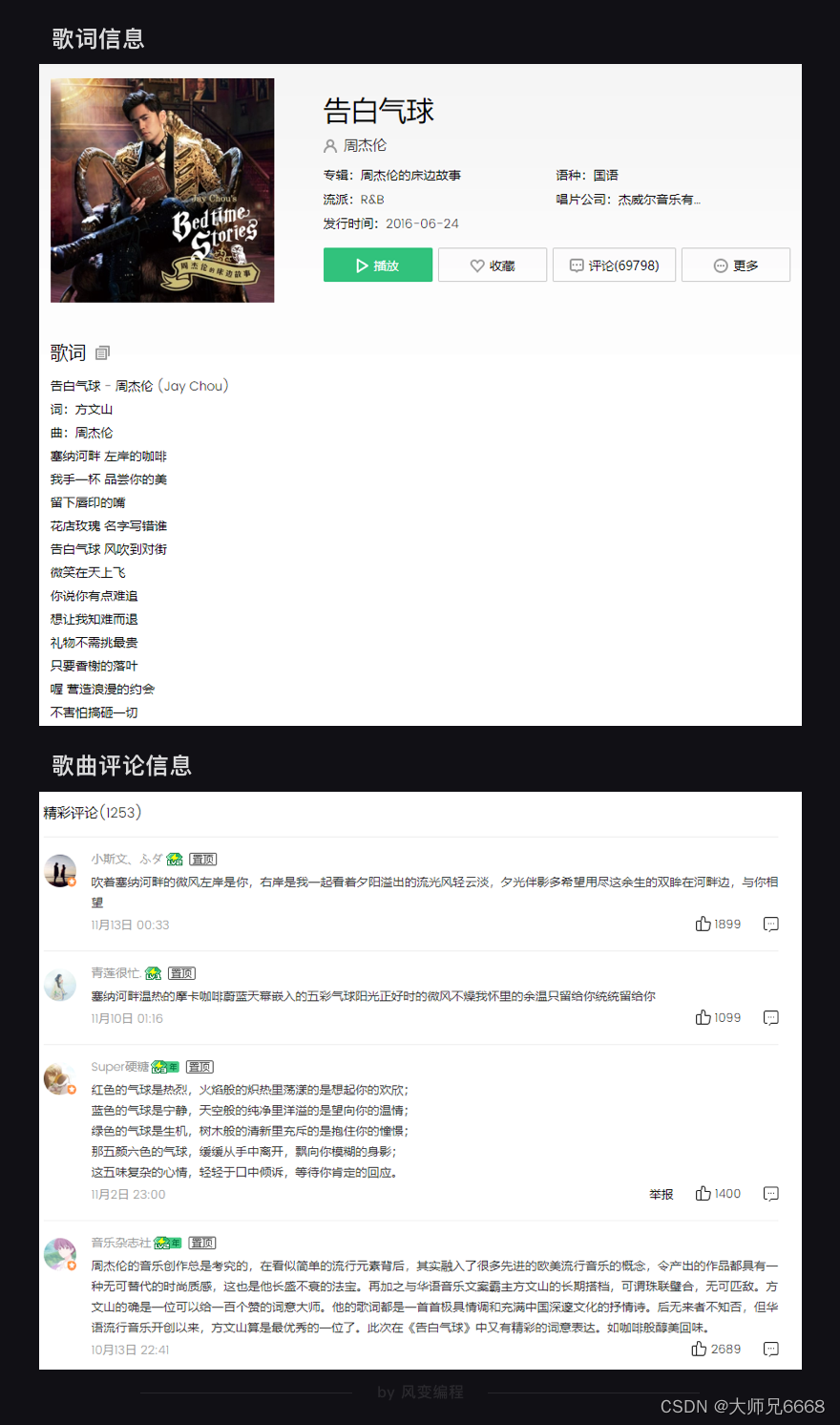
这会是一个浩荡的工程,因为有相当量的数据要爬取。但拿到这些数据,它就有了数据分析价值:周杰伦的歌最常出现哪些关键词?用户都在评论些什么内容?他们都喜欢在什么时间听?
同理,你可以拿到任何一个歌手的这些信息。如果你是一个音乐行业的从业者,那么它们将对于你产生价值。如果你不是,那么这个爬虫技术,可以帮助你在自己行业创造价值——换自己领域的网站去爬就好。
想拿到这么多数据,你需要学习下一关的知识:狂热粉丝——带参数请求数据。
拿到这么多数据,想要有规律地存储,你要学习第6关的知识:爬到的数据存哪里?——csv&excel文件
这么多的数据,爬起来太慢想要对它进行加速怎么办?你就需要学习11、12关的知识……
如是种种,学无止境,说的就是这样一回事。但事情的最开始,这所有一切的底层原理,一定还是这寥寥几行代码。
截止到这一关,你已经能够看懂绝大多数的网络数据请求组,并且尝试用Python去模拟这些请求,再往后,都是基于此的延伸。
下面,我们来总结下今日份的知识点。
一个复习
Network能够记录浏览器的所有请求。我们最常用的是:ALL(查看全部)/XHR(仅查看XHR)/Doc(Document,第0个请求一般在这里),有时候也会看看:Img(仅查看图片)/Media(仅查看媒体文件)/Other(其他)。最后,JS和CSS,则是前端代码,负责发起请求和页面实现;Font是文字的字体;而理解WS和Manifest,需要网络编程的知识,倘若不是专门做这个,你不需要了解。
在Network,有非常重要的一类请求是XHR(或Fetch),因为有它的存在,人们不必刷新/跳转网页,即可加载新的内容。随着技术发展,XHR的应用频率越来越高,我们常常需要在这里找我们想要的数据。
XHR的功能是传输数据,其中有非常重要的一种数据是用json格式写成的,和html一样,这种数据能够有组织地存储大量内容。json的数据类型是“文本”,在Python语言当中,我们把它称为字符串。我们能够非常轻易地将json格式的数据转化为列表/字典,也能将列表/字典转为json格式的数据。
如何解析json数据?答案如下:
而如果你想在Python语言中,实现列表/字典转json,json转列表/字典,则需要借助json模块。json模块不在我们的教学范围之内,所以不做展开。你可阅读它的官方文档来了解,地址在这里:https://docs.python.org/3/library/json.html
一个简单的应用示例,是这样:
# 引入json模块
import json
# 创建一个列表a
a = [1,2,3,4]
# 使用dumps()函数,将列表a转换为json格式的字符串,赋值给b
b = json.dumps(a)
# 打印b
print(b)
# 打印b的数据类型
print(type(b))
# 使用loads()函数,将json格式的字符串b转为列表,赋值给c
c = json.loads(b)
# 打印c
print(c)
# 打印c的数据类型
print(type(c))
从过程上来说呢:我们先是制定一个目标(爬取周杰伦的歌曲清单);根据目标,确认一个方案(爬取QQ音乐);带着方案,去分析它的网站结构;最后去写代码。
在写代码的过程当中,我们会遇到困难(如分析错了,如json数据不知如何解析);我们去学习新知识,去网络上搜索官方文档找到解决方案;最终完成项目。
我们今天做这样一个小项目是如此。程序员们在工作的时候,其实也是这样解决问题:根据目标找方案,根据方案做执行,执行遇到问题就去学习、搜索。
如此,就没有解决不了的问题。
我们下一关见!
相关文章:
【python爬虫】5.爬虫实操(歌词爬取)
文章目录 前言项目:寻找周杰伦分析过程代码实现重新分析过程什么是NetworkNetwork怎么用什么是XHR?XHR怎么请求?json是什么?json数据如何解析?实操:完成代码实现 一个总结一个复习 前言 这关让我们一起来寻…...
浅探Android 逆向前景趋势~
前段时间,我和朋友偶然间谈起安卓逆向,他问我安卓逆向具体是什么,能给我们带来什么实质性的东西,我也和朋友大概的说了一下,今天在这里拿出来和大家讨论讨论,也希望帮助大家来了解安卓逆向。 谈起安卓逆向…...
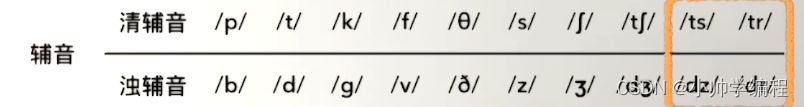
国际音标学习笔记
目录 1.单元音2.双元音3.辅音4.音节5.自然拼读法则5.1辅音字母的音标 1.单元音 我觉得单纯的音标并不好记住,所以就跟着老师整,根据单词记住音标的发音,以下是我的理解 音标对应的单词汉化iis衣əer饿ɔorigin奥u/ʊwoman五ʌart啊eanything哎…...

Azure - AzCopy学习
使用 AzCopy 将本地数据迁移到云存储空间 azcopy login 创建存储账号 ./azcopy login --tenant-id 40242385-c249-4746-95dc-4a0b64d49dc5这里的—tenant-id 在下面的地方查看:目录 ID;需要拥有Storage Blob Data Owner 的权限账号下可能会有很多目录&am…...
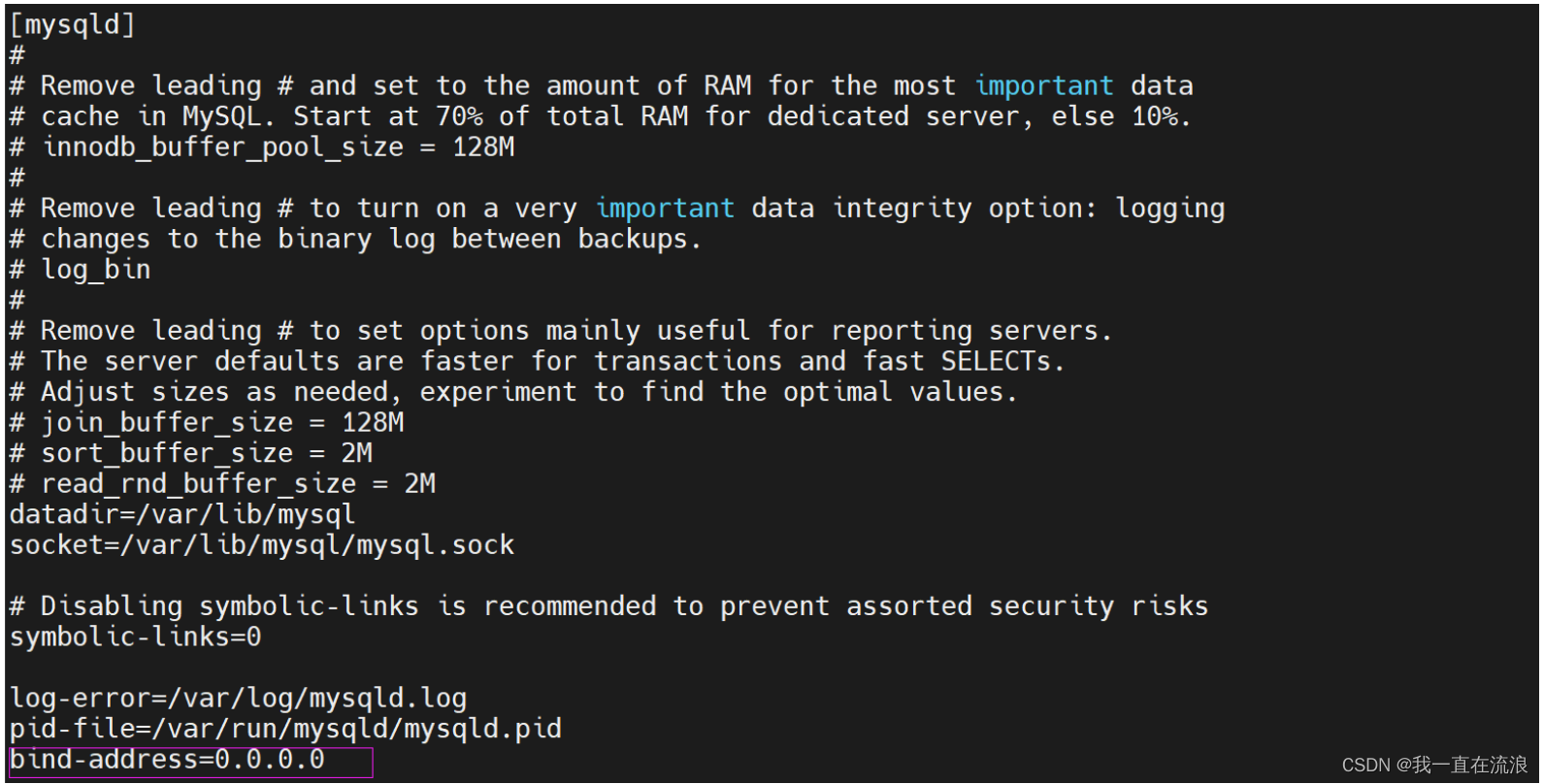
解决无法远程连接MySQL服务的问题
① 设置MySQL中root用户的权限: [rootnginx-dev etc]# mysql -uroot -pRoot123 mysql> use mysql; mysql> GRANT ALL PRIVILEGES ON *.* TO root% IDENTIFIED BY Root123 WITH GRANT OPTION; mysql> select host,user,authentication_string from user; -…...

mybatiplus代码生成器
目录 1.pom文件引入 2.引入模板引擎 3.注意 新版本,老版本配置和用法都不太一样,此处暂不展示;另外也可以尝试一下MyBatis-Flex 总之mybatisplus有的或者收费的,它都有MyBatis-Flex 是什么 - MyBatis-Flex 官方网站 1.pom文件…...
(三、循环存在问题))
leetcode分类刷题:哈希表(Hash Table)(三、循环存在问题)
1、当需要快速判断某元素是否出现在序列中时,就要用到哈希表了。 2、本文针对的总结题型为给定的序列或需要构造的序列中是否存在循环,与 160. 相交链表、 141. 环形链表、142. 环形链表 II的题型一样。 202. 快乐数 这道题还考察如何对正整数求解各个位…...
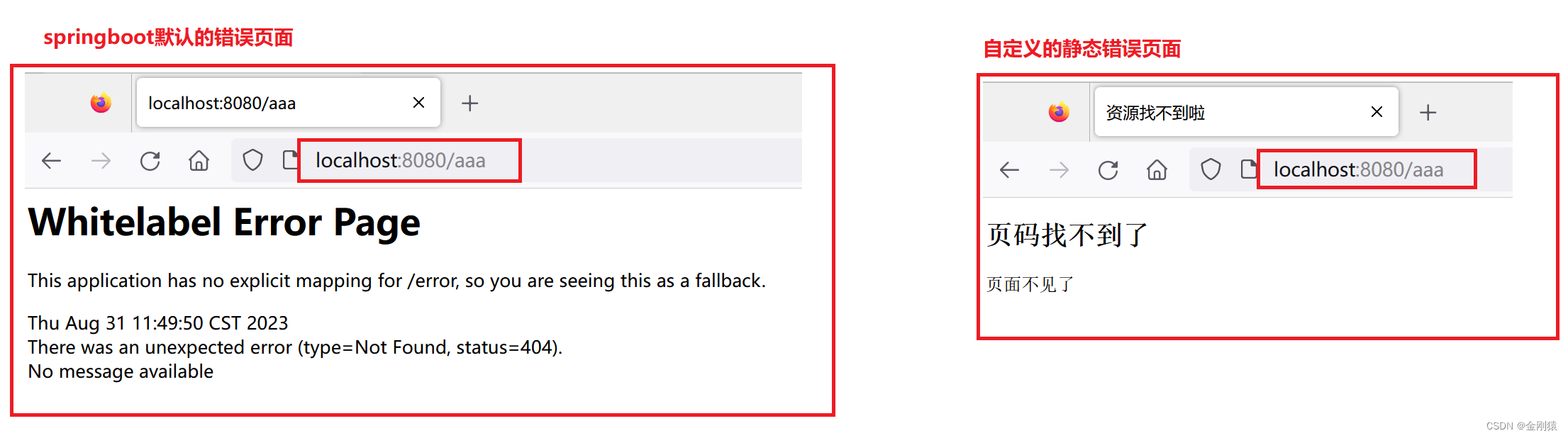
43、基于 springboot 自动配置的 spring mvc 错误处理,就是演示项目报错后,跳转到自定义的错误页面
Spring MVC 的错误处理:基于 SpringBoot 自动配置之后的 Spring MVC 错误处理。 就是访问方法时出错,然后弄个自定义的错误页面进行显示。 ★ 两种错误处理方式 方式一: 基于Spring Boot自动配置的错误处理方式,只要通过属性文件…...

干货分享,现代列式数据库系统如何设计与实现? | StoneData 论文选读
作者:袁洋 | StoneData 技术架构师 审核:王博 论文链接:columnstoresfntdbs.pdf (harvard.edu) 列存四先驱和 MIT 知名教授 Samuel Madden 于 2013 年在某期刊上写的一篇当时列存相关技术的综述。文章还挺全面也很经典,通过剖析三…...

说说构建流批一体准实时数仓
分析&回答 基于 Hive 的离线数仓往往是企业大数据生产系统中不可缺少的一环。Hive 数仓有很高的成熟度和稳定性,但由于它是离线的,延时很大。在一些对延时要求比较高的场景,需要另外搭建基于 Flink 的实时数仓,将链路延时降低…...

北京筑龙受邀出席中物联“采购供应链中国行—走进雄安”活动
日前,“采购供应链中国行—走进雄安”活动在河北雄安新区成功举办,来自30家相关单位的50余名领导和代表参加了本次活动。活动由中国物流与采购联合会公共采购分会主办,中国物流与采购联合会采购委、中国雄安集团有限公司、河北雄安新区招标投…...

【Tkinter界面:练习-01】窗口-部件-布局
一、说明 python在用户界面开发中,其中有QT5,和Tkinter;对于实际项目,界面需要高大上,因此用QT5,对于开发人员的演示程序,或简单程序中,不建议QT5;用Tkinter已经足够。本…...
)
LeetCode每日一题:823. 带因子的二叉树(2023.8.29 C++)
目录 823. 带因子的二叉树 题目描述: 实现代码与解析: dp hash 原理思路: 823. 带因子的二叉树 题目描述: 给出一个含有不重复整数元素的数组 arr ,每个整数 arr[i] 均大于 1。 用这些整数来构建二叉树&#x…...

【教学类-35-01】学号+姓名+班级(描字帖)A4一页
背景说明: 本学期我带机动班,其中大4班去的频率比较高,与是我用大四班的名单做了一份 “描字帖”,在9月1日第一天见面时,孩子们用记号笔描字帖时,我也可以对这些孩子初步混个眼熟(聪明的&#x…...

UE5 里的一些常用的了解
# ACharacter、APawn的继承关系 ACharacter -继承自-> APawn -继承自-> AActor和 INavAgentInterface AActor -继承自-> UObject -继承自->UObjectBaseUtility -继承自-> UObjectBase(一个独立的类)INavAgentInterface是一个独立的类 #…...
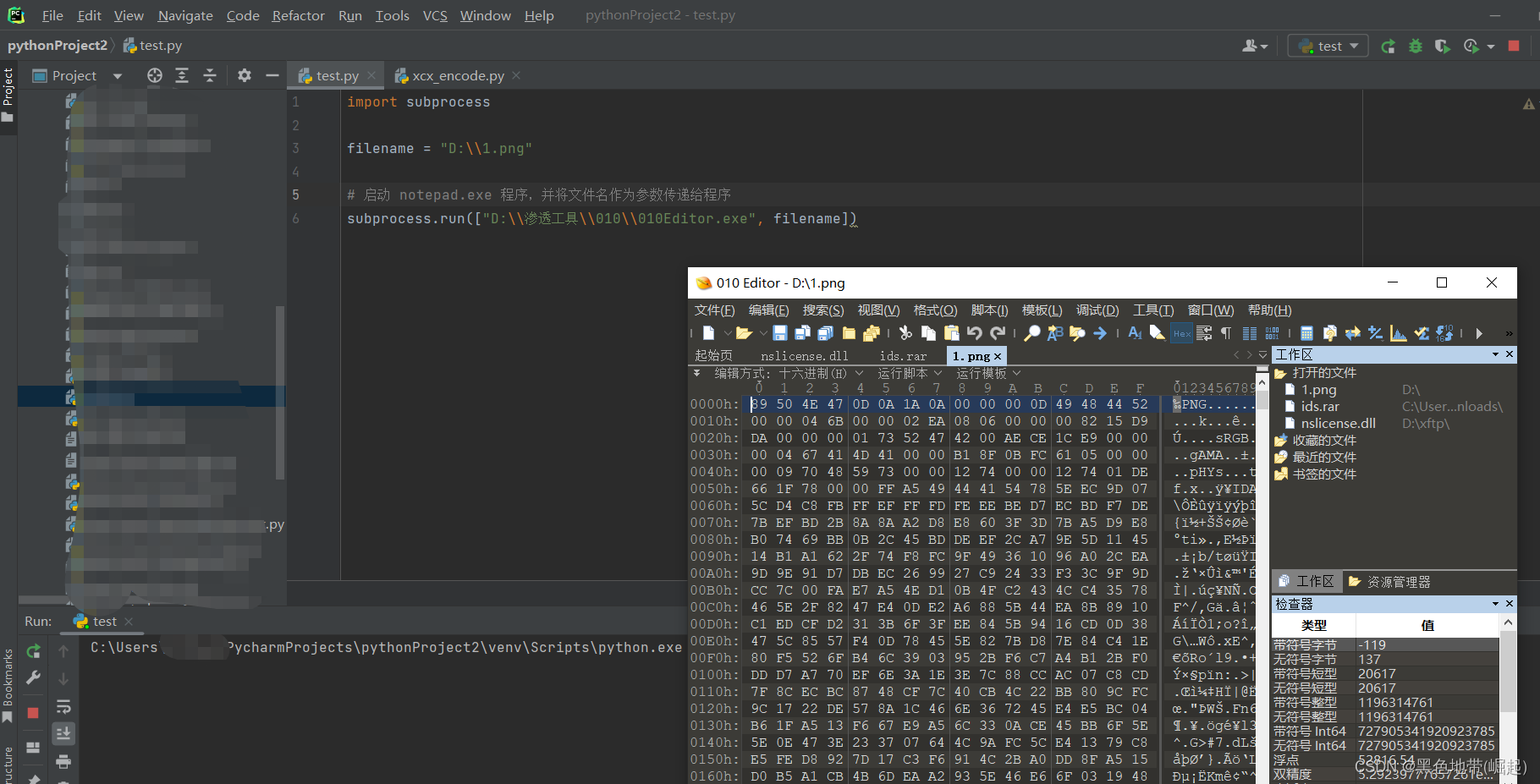
【网络安全带你练爬虫-100练】第19练:使用python打开exe文件
目录 一、目标1:调用exe文件 二、目标2:调用exe打开文件 一、目标1:调用exe文件 1、subprocess 模块允许在 Python 中启动一个新的进程,并与其进行交互 2、subprocess.run() 函数来启动exe文件 3、subprocess.run(["文件路…...
【2D/3D RRT* 算法】使用快速探索随机树进行最佳路径规划(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
用反射实现自定义Java对象转化为json工具类
传入一个object类型的对象获取该对象的class类getFields方法获取该类的所有属性对属性进行遍历,并且拼接成Json格式的字符串,注意:通过属性名来推断方法名获取Method实例通过invoke方法调用 public static String objectToJsonUtil(Object o…...

rk3568 nvme硬盘分区,格式化,挂载测试
前言 环境介绍: 1.编译环境 Ubuntu 18.04.5 LTS 2.SDK rk356x_linux 3.单板 迅为itop-3568开发板 自制底板 一、查看硬盘 插上硬盘上电,进入系统后通过命令lspci查看nvme硬盘识别情况 [rootRK356X:/]# lspci -k 21:00.0 Class 0108: 1e4b:1202…...
Failed to load ApplicationContext解决办法,spring版本问题
有如下报错: "D:\Program Files\Java\jdk-13.0.1\bin\java.exe" -agentlib:jdwptransportdt_socket,address127.0.0.1:7325,suspendy,servern -ea -Didea.test.cyclic.buffer.size1048576 -Dfile.encodingUTF-8 -classpath "D:\Program Files\JetBr…...

全链路追踪:OpenTelemetry与Jaeger实战
全链路追踪:OpenTelemetry与Jaeger实战 大家好,我是欧阳瑞(Rich Own)。今天想和大家聊聊全链路追踪这个重要话题。作为一个全栈开发者,在微服务架构中,全链路追踪是定位问题和性能优化的关键工具。今天就来…...

Autosar Crypto Driver配置避坑指南:从CryptoPrimitive到CryptoKeyType,手把手教你配出安全又高效的加密服务
AUTOSAR Crypto Driver实战配置:从算法选型到密钥管理的安全工程实践 在汽车电子系统开发中,加密服务已成为保障车载通信安全的核心组件。AUTOSAR标准定义的Crypto Driver模块为开发者提供了统一的加密接口,但实际配置过程中,工程…...

集成网口设计全攻略:带磁性RJ45的选型、PoE适配与EMC布局实战
📌 摘要: 集成网口(带网络变压器的RJ45连接器)将隔离变压器、共模扼流圈和RJ45插座合为一体,极大简化了以太网物理层设计。但不同PHY驱动类型、PoE功率等级、EMC性能要求以及工业环境振动等因素,都直接影响…...

Lavalink插件开发从入门到精通:自定义音频源完整指南
Lavalink插件开发从入门到精通:自定义音频源完整指南 【免费下载链接】Lavalink Standalone audio sending node based on Lavaplayer. 项目地址: https://gitcode.com/gh_mirrors/la/Lavalink Lavalink是一个基于Lavaplayer的独立音频发送节点,通…...

如何快速实现 CoffeeScript 实时编译和预览:vim-coffee-script 终极指南 [特殊字符]
如何快速实现 CoffeeScript 实时编译和预览:vim-coffee-script 终极指南 🚀 【免费下载链接】vim-coffee-script CoffeeScript support for vim 项目地址: https://gitcode.com/gh_mirrors/vi/vim-coffee-script 对于 CoffeeScript 开发者来说&am…...

终极智慧树刷课插件指南:如何实现自动化高效学习
终极智慧树刷课插件指南:如何实现自动化高效学习 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 还在为智慧树平台枯燥的手动操作而烦恼吗?智慧…...

GNSS信号丢了也不怕:这款组合导航系统真硬核
在无人系统快速发展的今天,精准可靠的定位导航已成为各类智能装备的核心刚需。然而,传统高精度组合导航系统往往价格昂贵,让许多项目团队望而却步。ER-GNSS/MINS-03为了打破这一僵局——将战术级MEMS惯性器件与全系统全频点双天线GNSS模块深度…...

应对每日大赛突发需求,用Taotoken多模型聚合能力灵活选型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 应对每日大赛突发需求,用Taotoken多模型聚合能力灵活选型 在每日大赛这类节奏快、任务多变的场景里,开发者…...

卡梅德生物技术快报|噬菌体随机肽库筛选实战:花生过敏原 Ara h 5 模拟表位鉴定全流程
摘要本文面向生物研发、体外诊断、蛋白质工程开发者,系统讲解噬菌体随机肽库筛选过敏原模拟表位完整工程化流程:从问题分析、实验设计、关键参数到结果验证,提供可复现技术方案,基于真实研究数据,聚焦高可靠性表位筛选…...
)
ElevenLabs荷兰文语音生成速度对比实测:从4.2s→0.8s的WebSocket流式优化路径(附可复用代码片段)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs荷兰文语音生成速度对比实测:从4.2s→0.8s的WebSocket流式优化路径(附可复用代码片段) ElevenLabs 的 Dutch(nl-NL)语音合成在默认…...