Hive SQL 优化大全(参数配置、语法优化)
文章目录
- 参数配置优化
- yarn-site.xml 配置文件优化
- mapred-site.xml 配置文件优化
- 分组聚合优化 —— Map-Side
- 优化参数解析
- 优化案例
服务器环境说明
| 机器名称 | 内网IP | 内存 | CPU | 承载服务 |
|---|---|---|---|---|
| master | 192.168.10.10 | 8 | 4 | NodeManager、DataNode、NameNode、JobHistoryServer、Hive、HiveServer2、MySQL |
| slave1 | 192.168.10.11 | 8 | 4 | NodeManager、DataNode、ResourceManager |
| slave2 | 192.168.10.12 | 8 | 4 | NodeManager、DataNode、SecondaryNameNode |
操作系统均为:CentOS 7.5
组件版本
jdk 1.8mysql 5.7hadoop 3.1.3hive 3.1.2
参数配置优化
下面以我的集群配置为例来进行优化,请按说明根据实际需求、节点情况进行灵活调整。
yarn-site.xml 配置文件优化
参数一
该参数指定了 NodeManager 可以分配给该节点上的 YARN 容器的最大内存量(以 MB 为单位),默认 8G。
<property><name>yarn.nodemanager.resource.memory-mb</name><value>6144</value>
</property>
我的每台服务器内存为 8 G,这里给 NodeManager 分配 6 G 内存,我们必须考虑给系统以及其它服务预留内存。
注意,该参数不能超过单台服务器的总内存。
参数二
该参数指定了 NodeManager 在 YARN 集群中的每个节点上可以分配给容器的虚拟 CPU 核心数量,默认值为: 8 。
增加它可以提高容器的并行性和性能,但也可能导致 CPU 资源过度分配。减小它可能会限制容器的性能,但可以确保更多的容器在集群上同时运行。
<property><name>yarn.nodemanager.resource.cpu-vcores</name><value>6</value>
</property>
我的每台服务器物理 CPU 核数为 4 ,这里虚拟为 6 核,提高并发度。
参数三
该参数定义了 YARN 调度器允许的单个容器的最大内存分配。
这有助于确保在集群中合理分配内存资源,以防止某个应用程序或容器占用过多的内存,导致性能问题或资源争用。
该参数配置一般为 yarn.nodemanager.resource.memory-mb 的四分之一,结果最好能被 1024 整除。
<property><name>yarn.scheduler.maximum-allocation-mb</name><value>2048</value>
</property>
上面设置 yarn.nodemanager.resource.memory-mb 的配置是 6G,6144 / 4 = 1536,显然 1536 无法被 1024 整除,所以这里直接设置为 2G,向上取整。
参数四
该参数定义了 YARN 调度器允许的单个容器的最小内存分配,默认为 1G。
<property><name>yarn.scheduler.minimum-allocation-mb</name><value>512</value>
</property>
这里直接调为 512MB 就行了,如果内存很多,可以往上调。
参数五
分配给单个容器的最小与最大虚拟核心数量。
<!-- 容器最小虚拟核心数 -->
<property><name>yarn.scheduler.minimum-allocation-vcores</name><value>1</value>
</property><!-- 容器最大虚拟核心数 -->
<property><name>yarn.scheduler.maximum-allocation-vcores</name><value>2</value>
</property>
根据单节点虚拟总核心数来进行配置,最小设为 1 个,最大设置为虚拟总核心的四分之一,上面设置虚拟核心为 6 个,这里向上取整,所以最大设置为 2 个。
扩展配置1
设置 NodeManager 是否启用虚拟内存检查,默认值:true(启用虚拟内存检查)。
<property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value>
</property>
当设置为 true 时(默认值),NodeManager 将启用虚拟内存检查。这意味着 YARN 应用程序的每个容器将受到虚拟内存限制的限制,一旦超过就会直接 kill 掉该容器。
当设置为 false 时,NodeManager 将禁用虚拟内存检查。这意味着容器将不会受到虚拟内存的限制,容器可以使用尽其所能的虚拟内存,但这可能会增加系统的风险,因为应用程序可以在不受约束的情况下使用虚拟内存,可能导致系统不稳定。
根据当前集群环境用途自行决断吧,学习阶段尽量设置为 false,不然可能会导致很多任务都跑不了,直接被 kill 掉。
扩展配置2
用于设置虚拟内存与物理内存之间的比率,默认为 2.1 倍。
这个参数的目的是限制应用程序可以使用的虚拟内存量,以避免某个应用程序无限制地占用虚拟内存资源,导致其他任务和应用程序受影响。
<property><name>yarn.nodemanager.vmem-pmem-ratio</name><value>2.1</value>
</property>
扩展配置应用场景
未关闭虚拟内存检查之前,由于虚拟内存不足,在运行任务时,你可能会看到如下所示的 Hive SQL 报错信息:
Execution Error,return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
在历史服务器中,查看详细报错信息如下:
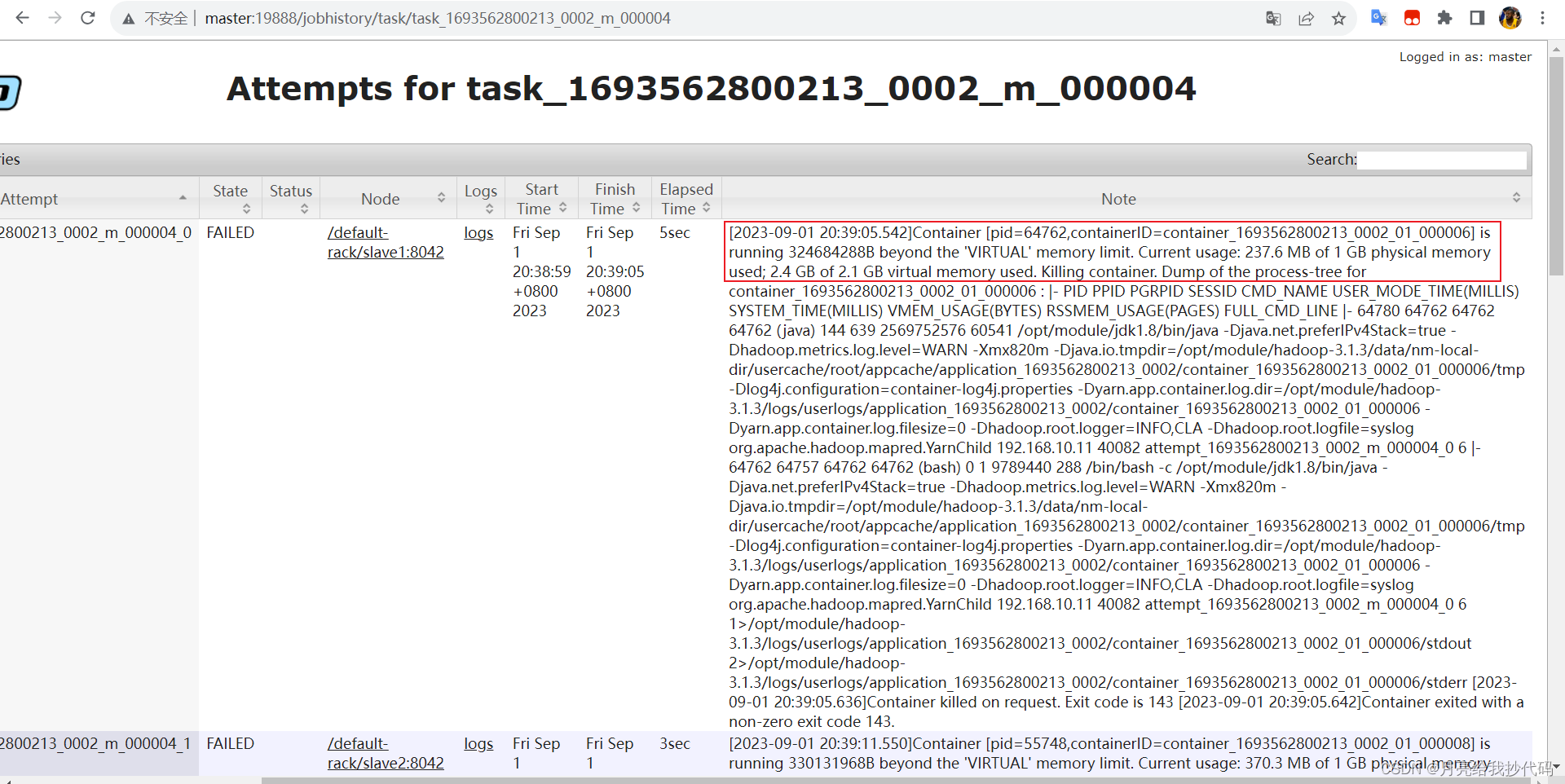
[2023-09-01 20:39:05.542]Container [pid=64762,containerID=container_1693562800213_0002_01_000006] is running 324684288B beyond the ‘VIRTUAL’ memory limit. Current usage: 237.6 MB of 1 GB physical memory used; 2.4 GB of 2.1 GB virtual memory used. Killing container.
提示,虚拟内存超出限制,当前容器正在使用 1G 物理内存中的 237.6MB 内存,正在使用 2.1G 虚拟内存中的 2.4G 虚拟内存,显然这超出了限制,那么为什么会出现这种情况呢?
这是因为我只给单个 Map 和 Reduce 任务分配了 1G 内存,所以这 1G 内存按照默认物理内存与虚拟内存转化率(yarn.nodemanager.vmem-pmem-ratio)来算,1024 * 2.1 = 2150.4,所以对应着虚拟内存最大为 2.1G,但是由于这个任务需要 2.4G 虚拟内存才可以运行,所以导致容器被直接 kill 掉。
这里不建议直接将虚拟内存比率调大,可以直接关闭虚拟内存检查来进行解决(实战别关,实战内存一般都很大,关了反而会影响系统稳定性)。
mapred-site.xml 配置文件优化
参数一
定义了单个 Map 与 Reduce 任务使用的最大内存分配量,以 MB 为单位,默认值都为 1024。
注意,这两项参数都不可以超过单个容器的最大内存分配量(yarn.scheduler.maximum-allocation-mb),避免单个 Mapper 或者 Reduce 任务使用超过 YARN 调度器允许的最大内存,导致任务运行异常。
<property><name>mapreduce.map.memory.mb</name><value>1024</value>
</property><property><name>mapreduce.reduce.memory.mb</name><value>1024</value>
</property>
前面我们设置单个容器的最大内存分配量为 2G,所以这里设置为默认值 1G 更合理,如果有条件,设置为 2G 更好。
其实,实际比例应该设置为 8:1(【单个容器最大内存分配量】 : 【单个 Map 与 Reduce 任务使用的最大内存分配量】)。但是说回来,没有绝对的比例,设置为 2G 也够用了,根据实际情况来吧。
参数二
定义了单个 Map 与 Reduce 任务使用的最大虚拟核心数,默认值都为 1。
注意,这两项参数都不可以超过单个容器的最大虚拟核心数(yarn.scheduler.maximum-allocation-vcores),避免单个 Mapper 或者 Reduce 任务使用超过 YARN 调度器允许的最大虚拟核心数,导致任务运行异常。
<property><name>mapreduce.map.cpu.vcores</name><value>1</value>
</property><property><name>mapreduce.reduce.cpu.vcores</name><value>1</value>
</property>
前面我们设置单个容器的最大虚拟核心数为 2,所以这里设置为默认值 1 更合理,根据实际条件向上调吧。
分组聚合优化 —— Map-Side
在 Hadoop MapReduce 中,Map-Side 聚合是一种优化技术,用于在 Map 任务阶段进行部分数据聚合,以减少数据传输到 Reducer 任务的量。
Map-Side 聚合是一种有效的性能优化技术,可以减少 MapReduce 作业中的数据传输和磁盘写入/读取,从而提高作业的执行速度。
优化参数解析
以下是在 Hive 中设置 Map-Side 聚合相关的关键参数,以及它们的详细解释:
1. hive.map.aggr
-
默认值:
true -
用于启用 Map-Side 聚合功能,默认开启。Hive 会尝试在 Map 任务中执行一些简单的聚合操作,例如 SUM、COUNT 等,以减少 Map 输出的数据量。这可以降低作业的整体负载,提高查询性能,特别是对于一些聚合型的查询。
这可能会降低 Reducer 的负载,但同时会增加 Map 任务的计算负担。如果查询需要更复杂的聚合操作或跨多个分组键的聚合,可能无法完全受益于 Map-Side 聚合。
2. hive.map.aggr.hash.min.reduction
-
默认值:
0.5 -
这个参数的值是一个浮点数,表示 Map-Side 聚合的最小减少量的阈值。阈值的范围是
0到1之间,0表示不启用 Map-Side 聚合,1表示始终启用 Map-Side 聚合。
如果设置为 0.5,表示只有当 Map 任务中的聚合操作可以减少至少 50% 的数据量时,才会启用 Map-Side 聚合。
如果设置为 1,表示无论聚合操作能否减少数据量,都始终启用 Map-Side 聚合。
如果设置为 0,表示禁用 Map-Side 聚合,不管聚合操作是否有助于减少数据传输到 Reducer 的数量。
要注意的是,过大的阈值可能导致 Map-Side 聚合不经常发生,从而减少其性能优势。过小的阈值可能导致频繁的 Map-Side 聚合,增加了 Map 任务的计算开销。因此,合适的阈值应该基于具体查询和数据集的特点进行调整和测试。
3. hive.groupby.mapaggr.checkinterval
-
默认值:
100000 -
控制 Map-Side 聚合的检查条数,用于验证任务是否满足聚合条件。
通俗来说就是,在开启 Map-Side 聚合操作后,当我们执行了聚合操作,在 Map 阶段系统会自动取前 100000 条数据取进行判断,此时,会出现下面两种情况:
-
如果其中的聚合键值大部分都一样,那么就会执行 Map-Side 聚合操作。
-
如果大部分聚合键值都不一样,那么就不会进行 Map-Side 聚合操作。
这个判断很容易会受到数据的分布影响,假设前 100000 行数据前面都不一样,只是因为数据量大,但其实后面有很多聚合键值都一样的数据,所以这就会造成判断不符合 Map-Side 聚合操作。
这种情况我们就需要根据实际情况进行判断了,如果聚合后数据量确实少了一半,我们可以强制开启 Map-Side 聚合操作。
4. hive.map.aggr.hash.force.flush.memory.threshold
-
默认值:
0.9 -
用于控制 Map-Side 聚合的内存阈值,指定 Map 任务在进行 Map-Side 聚合时,何时强制将内存中的数据写入磁盘以释放内存。
当 Map 任务的内存中数据占用达到或超过这个阈值时,Map 任务将强制将内存中的数据写入磁盘以释放内存,从而避免 OOM(内存溢出)错误。
优化案例
未开启 Map-Side 聚合执行
set hive.map.aggr = false;
执行如下 Hive SQL,数据量大约 1000w 行:
selectproduct_id,count(1)
from order_detail
group by product_id;
执行计划:
STAGE DEPENDENCIES:Stage-1 is a root stageStage-0 depends on stages: Stage-1
""
STAGE PLANS:Stage: Stage-1Map ReduceMap Operator Tree:TableScanalias: order_detailStatistics: Num rows: 13066777 Data size: 11760099340 Basic stats: COMPLETE Column stats: NONESelect Operatorexpressions: product_id (type: string)outputColumnNames: product_idStatistics: Num rows: 13066777 Data size: 11760099340 Basic stats: COMPLETE Column stats: NONEReduce Output Operatorkey expressions: product_id (type: string)sort order: +Map-reduce partition columns: product_id (type: string)Statistics: Num rows: 13066777 Data size: 11760099340 Basic stats: COMPLETE Column stats: NONEExecution mode: vectorizedReduce Operator Tree:Group By Operatoraggregations: count()keys: KEY._col0 (type: string)mode: complete
" outputColumnNames: _col0, _col1"Statistics: Num rows: 6533388 Data size: 5880049219 Basic stats: COMPLETE Column stats: NONEFile Output Operatorcompressed: falseStatistics: Num rows: 6533388 Data size: 5880049219 Basic stats: COMPLETE Column stats: NONEtable:input format: org.apache.hadoop.mapred.SequenceFileInputFormatoutput format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormatserde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
""Stage: Stage-0Fetch Operatorlimit: -1Processor Tree:ListSink
从执行计划中可以看出,这段代码在 Map 阶段并没有进行聚合操作,在进行 Reduce 操作前,数据量并未发生任何变化。
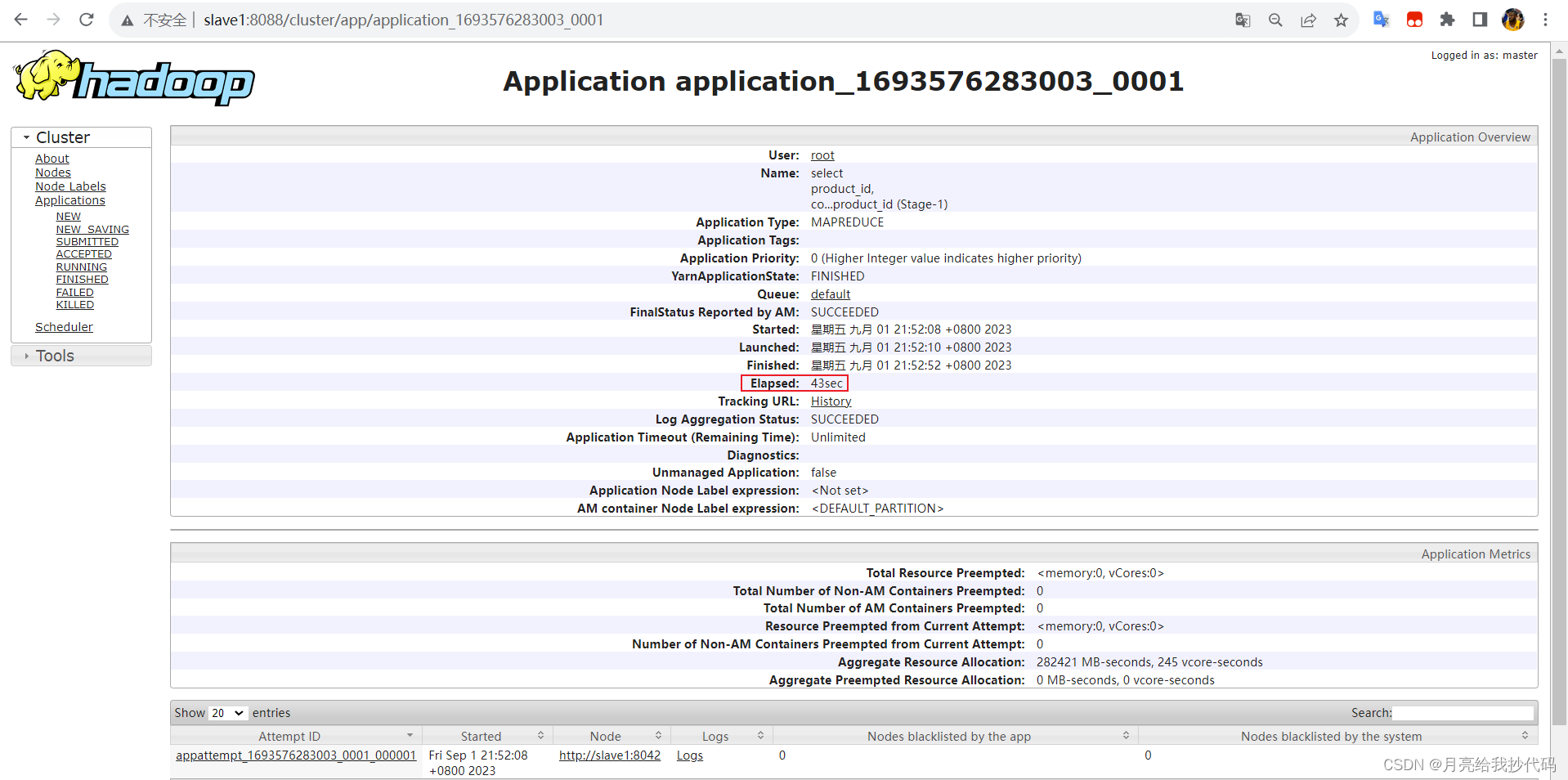
执行结果,运行 43 秒:
开启 Map-Side 聚合执行
set hive.map.aggr = true;
# 其余参数都保持默认
执行同上 Hive SQL:
selectproduct_id,count(1)
from order_detail
group by product_id;
执行计划:
STAGE DEPENDENCIES:Stage-1 is a root stageStage-0 depends on stages: Stage-1
""
STAGE PLANS:Stage: Stage-1Map ReduceMap Operator Tree:TableScanalias: order_detailStatistics: Num rows: 13066777 Data size: 11760099340 Basic stats: COMPLETE Column stats: NONESelect Operatorexpressions: product_id (type: string)outputColumnNames: product_idStatistics: Num rows: 13066777 Data size: 11760099340 Basic stats: COMPLETE Column stats: NONEGroup By Operatoraggregations: count()keys: product_id (type: string)mode: hash
" outputColumnNames: _col0, _col1"Statistics: Num rows: 13066777 Data size: 11760099340 Basic stats: COMPLETE Column stats: NONEReduce Output Operatorkey expressions: _col0 (type: string)sort order: +Map-reduce partition columns: _col0 (type: string)Statistics: Num rows: 13066777 Data size: 11760099340 Basic stats: COMPLETE Column stats: NONEvalue expressions: _col1 (type: bigint)Execution mode: vectorizedReduce Operator Tree:Group By Operatoraggregations: count(VALUE._col0)keys: KEY._col0 (type: string)mode: mergepartial
" outputColumnNames: _col0, _col1"Statistics: Num rows: 6533388 Data size: 5880049219 Basic stats: COMPLETE Column stats: NONEFile Output Operatorcompressed: falseStatistics: Num rows: 6533388 Data size: 5880049219 Basic stats: COMPLETE Column stats: NONEtable:input format: org.apache.hadoop.mapred.SequenceFileInputFormatoutput format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormatserde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
""Stage: Stage-0Fetch Operatorlimit: -1Processor Tree:ListSink
从执行计划中可以看到,我们虽然已经开启了 Map-Side 聚合操作,在 Mape 阶段出现了 Group By 聚合操作,可是我们进入 Reduce 阶段前的数据量并没有变少,和之前一样。
这是因为在上面提到的数据分布影响造成的问题,因为 hive.groupby.mapaggr.checkinterval 默认只检查前 100000 行来验证是否进行 Map-Side 聚合操作,由于这里数据量比较大,导致前 100000 行的聚合键值大部分不相同(它觉得即使对这 100000 行数据进行了聚合操作,也达不到数据量减少 50% 的程度),所以它才没有进行 Map-Side 聚合操作,在这种情况下,需要强制开启 Map-Side 聚合操作。
set hive.map.aggr.hash.min.reduction = 1;
执行结果,运行 29 秒:
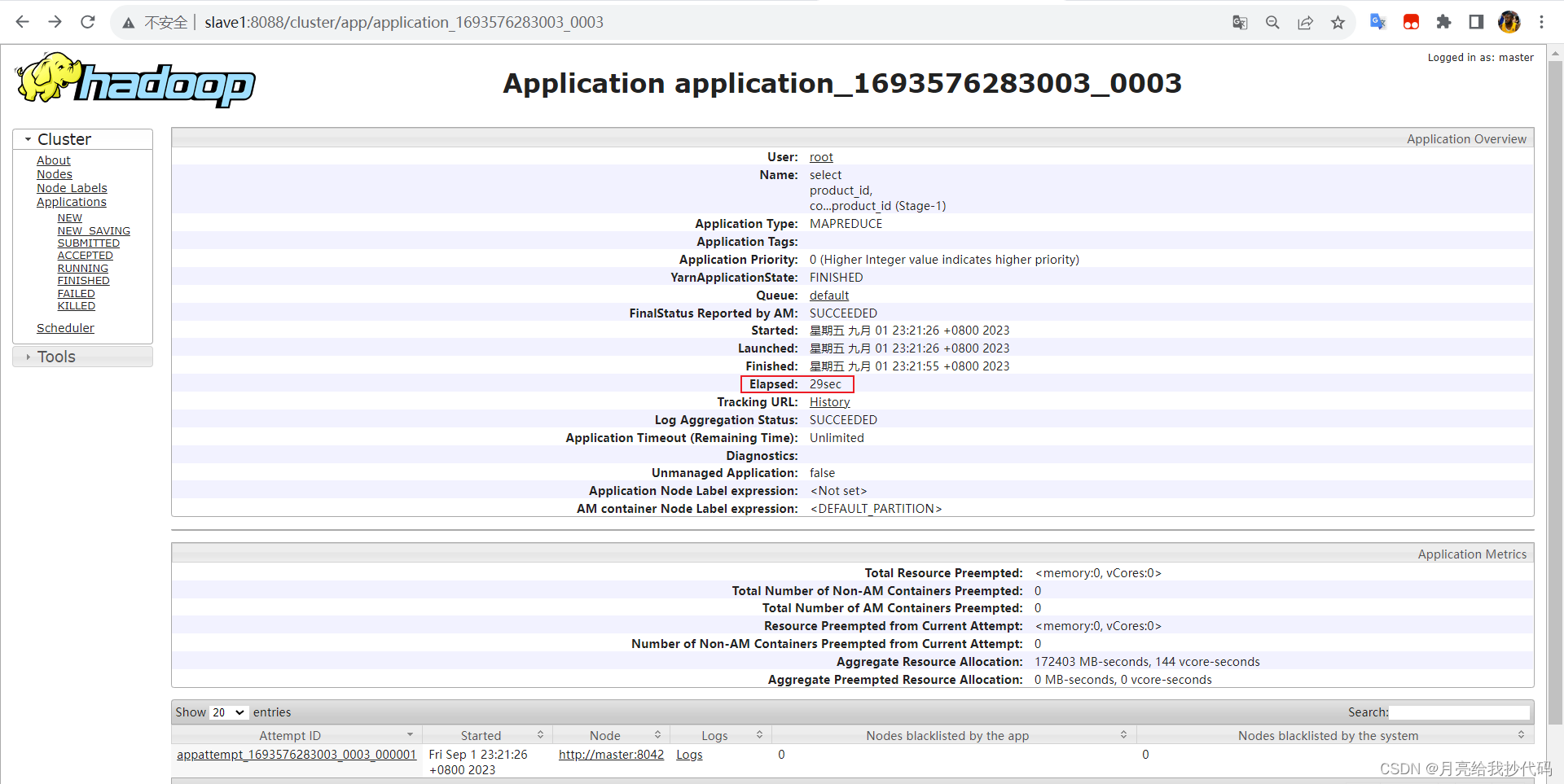
可见,速度的确得到大幅提升!
从历史服务器中查看执行该任务的一个 Map 中可以看出,在 Map 阶段的确发生了 Map-Side 聚合操作。
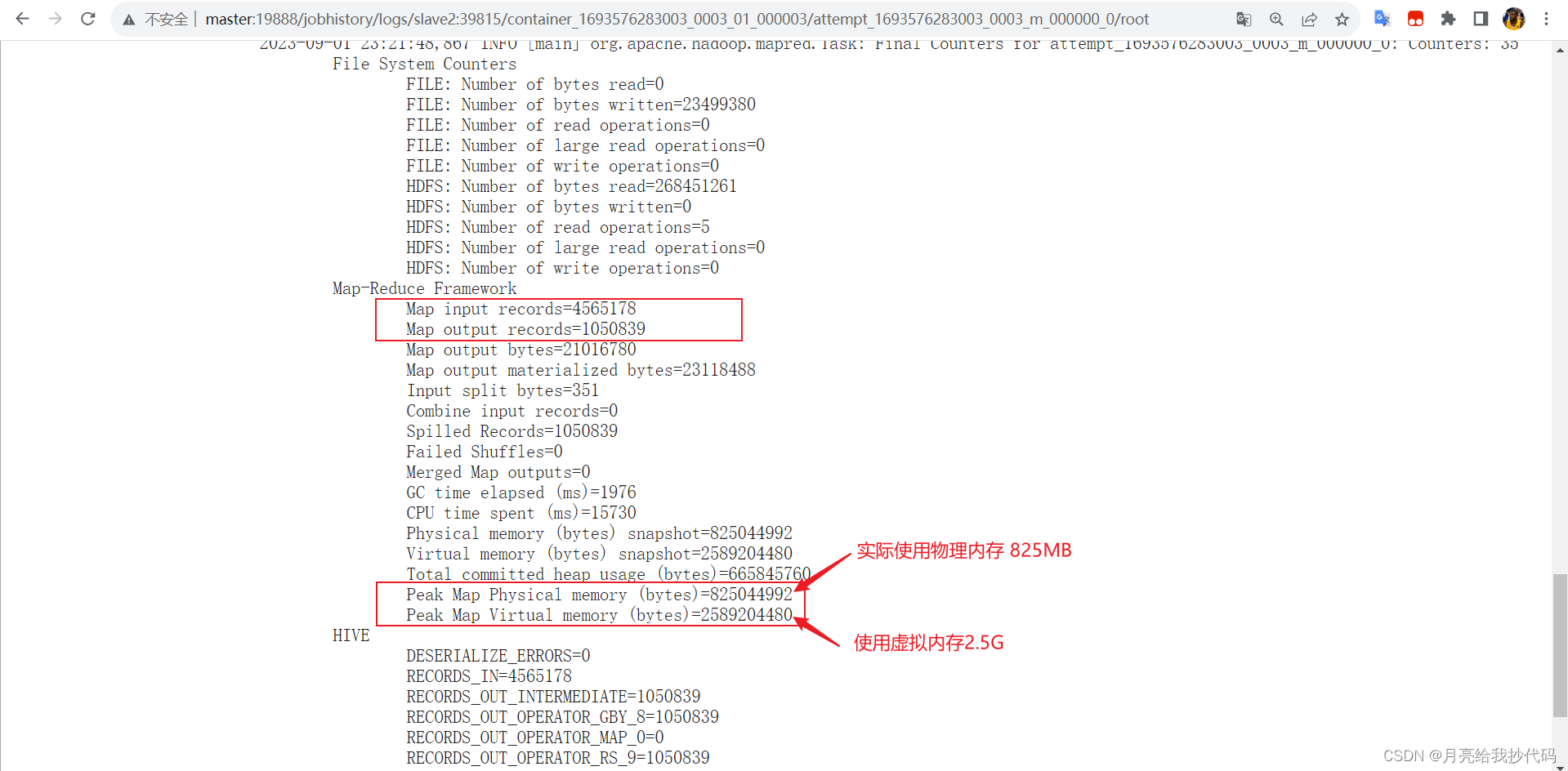
Map 阶段数据量前后对比少了很多,这就是 Map-Side 的玩法。
相关文章:
Hive SQL 优化大全(参数配置、语法优化)
文章目录 参数配置优化yarn-site.xml 配置文件优化mapred-site.xml 配置文件优化 分组聚合优化 —— Map-Side优化参数解析优化案例 服务器环境说明 机器名称内网IP内存CPU承载服务master192.168.10.1084NodeManager、DataNode、NameNode、JobHistoryServer、Hive、HiveServer…...
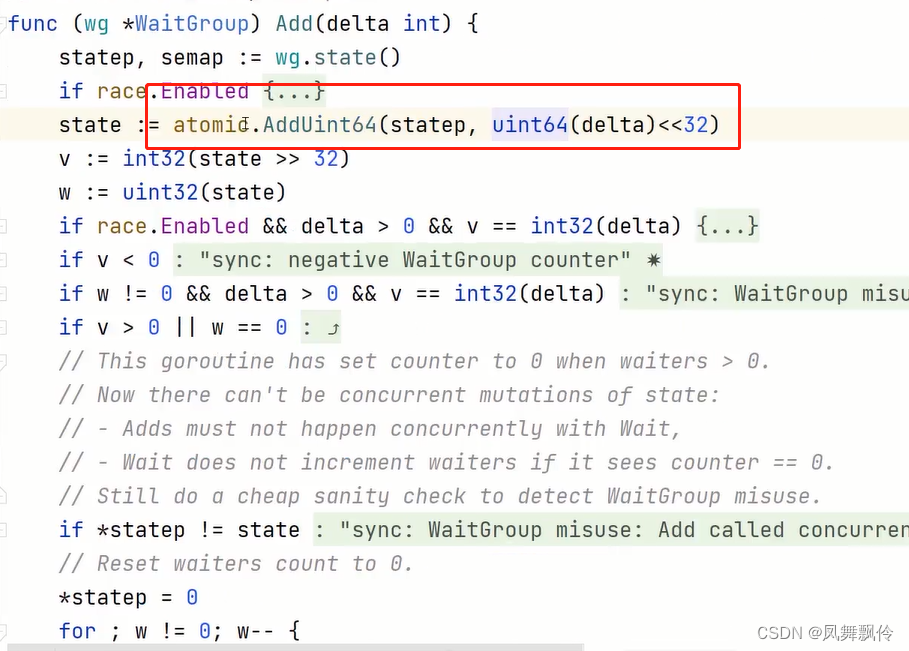
go锁-waitgroup
如果被等待的协程没了,直接返回 否则,waiter加一,陷入sema add counter 被等待协程没做完,或者没人在等待,返回 被等待协程都做完,且有人在等待,唤醒所有sema中的协程 WaitGroup实现了一组协程…...
访问0xdddddddd内存地址引发软件崩溃的问题排查
目录 1、问题描述 2、访问空指针或者野指针 3、常见的异常值 4、0xdddddddd内存访问违例问题分析与排查 5、关于0xcdcdcdcd和0xfeeefeee异常值的排查案例 6、最后 VC常用功能开发汇总(专栏文章列表,欢迎订阅,持续更新...)ht…...
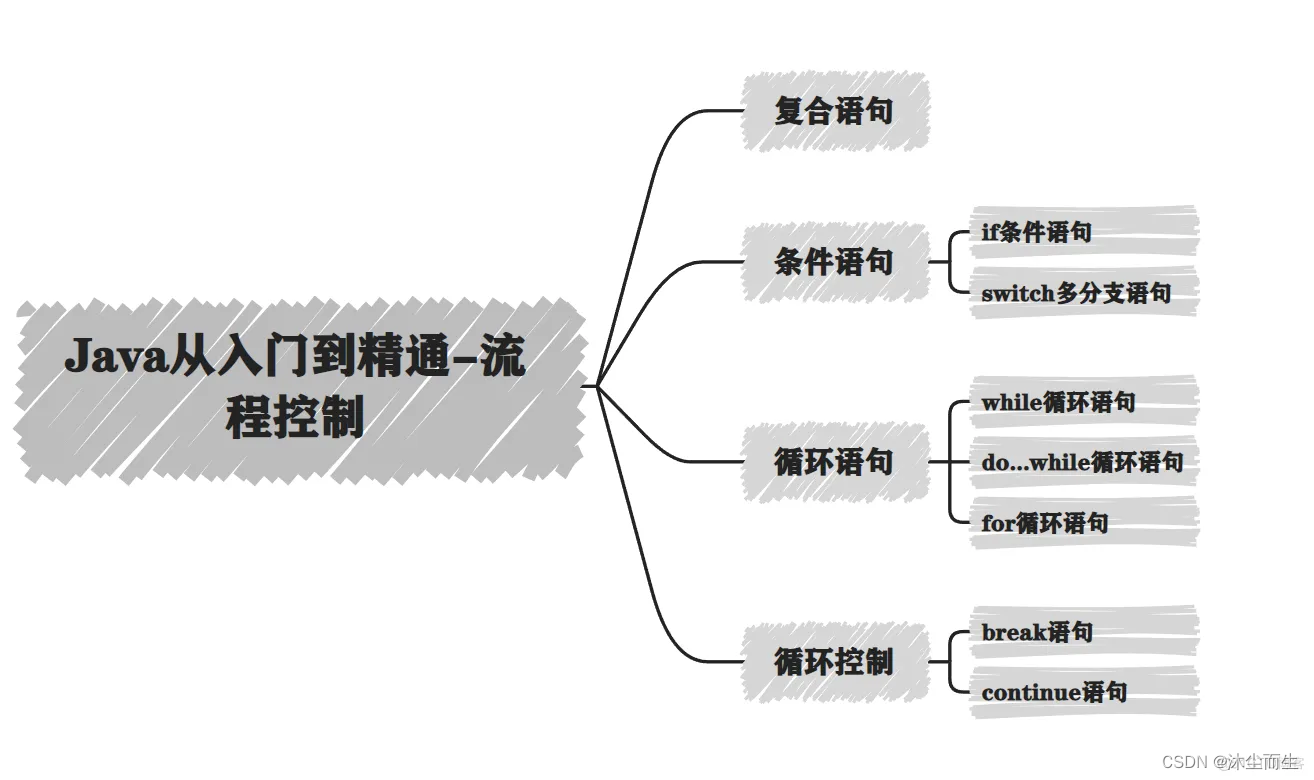
Java从入门到精通-流程控制(一)
流程控制 1.复合语句 复合语句,也称为代码块,是一组Java语句,用大括号 {} 括起来,它们可以被视为单个语句。复合语句通常用于以下情况: - 在控制结构(如条件语句和循环)中包含多个语句。 - …...

MybatisPlus(2)
前言🍭 ❤️❤️❤️SSM专栏更新中,各位大佬觉得写得不错,支持一下,感谢了!❤️❤️❤️ Spring Spring MVC MyBatis_冷兮雪的博客-CSDN博客 上篇我们简单介绍了MybatisPlus的方便之处,这篇来深入了解Myb…...

iOS UITableView上拉加载解决偶然跳动的Bug
最近做项目,测试测出来一个Bug,列表添加了上拉刷新和下拉加载,当我弹窗消失时,调用刷新列表后,在某个手机型号上,偶发列表刷新跳动的bug。(一般在列表上拉加载刷新到最后一页后,再弹窗消失,reload列表,会出现此bug) Bug复现如下:RPReplay_Final1693296737 解决方案…...

MySQL 外键使用详解
1、MySQL 外键约束语法 MySQL 支持外键,允许在表之间进行相关数据的交叉引用,并有助于保持相关数据的一致性。 一个外键关系涉及到一个父表,该父表保存初始列值,和一个子表,子表的列值引用父表的列值。外键约束定义在…...

MongoDB实验——在MongoDB集合中查找文档
在MongoDB集合中查找文档 一、实验目的二、实验原理三、实验步骤1.启动MongoDB数据库、启动MongoDB Shell客户端2.数据准备-->person.json3.指定返回的键4 .包含或不包含 i n 或 in 或 in或nin、$elemMatch(匹配数组)5.OR 查询 $or6.Null、$exists7.…...

事务的总结
数据库事务 数据库事务是一个被视为单一的工作单元的操作序列。这些操作应该要么完整地执行,要么完全不执行。事务管理是一个重要组成部分,RDBMS 面向企业应用程序,以确保数据完整性和一致性。事务的概念可以描述为具有以下四个关键属性描述…...
[ROS]yolov5-7.0部署ROS
YOLOv5是一种目标检测算法,它是YOLO(You Only Look Once)系列算法的最新版本。与其它目标检测算法相比,YOLOv5在速度和准确性方面取得了显著的提升。在ROS(Robot Operating System)中使用Python部署YOLOv5可…...

Java抽象方法、抽象类和接口——第七讲
前言 上一讲,我们深入了解面向对象,介绍了面向对象有三个特征——封装、继承、多态,以及介绍方法的重载和重写,这些都是开发中很常用的特征,基本都尊重面向对象思想。再上一讲我们了解到了继承的时候,子类要重新写父类的方法,才能遵循子类的规则,那么忘记重写怎么办呢?…...
kafka集群之kraft模式
一、概要 Kafka作为一种高吞吐量的分布式发布订阅消息系统,在消息应用中广泛使用,尤其在需要实时数据处理和应用程序活动跟踪的场景,kafka已成为首选服务;在Kafka2.8之前,Kafka强依赖zookeeper来来负责集群元数据的管理…...

虹科案例 | 缆索挖掘机维护—小传感器,大作用!
一、 应用背景 缆索挖掘机 缆索挖掘机的特点是具有坚固的部件,如上部结构、回转环和底盘。底盘是用于移动挖掘机的下部机械部件,根据尺寸和型号的不同,由轮子或履带引导,并承载可转动的上部车厢。回转环连接上部和下部机器部件&am…...
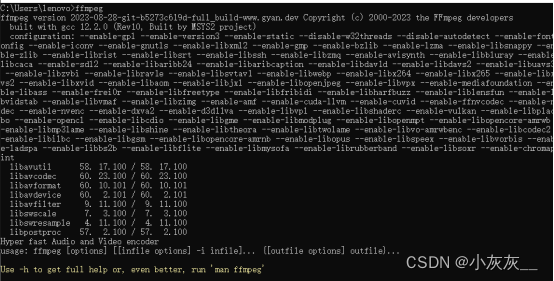
Windows安装FFmpeg说明
下载地址 官网 Download FFmpeg Csdn ffmpeg安装包,ffmpeg-2023-08-28-git-b5273c619d-full-build.7z资源-CSDN文库 解压安装,添加环境变量 命令行输入ffmpeg 安装成功...

电子电路原理题目整理(1)
电子电路原理题目整理(1) 最近在学习《电子电路原理》,记录一下书后面试题目,答案为个人总结,欢迎讨论。 1.电压源和电流源的区别? 电压源在不同的负载电阻下可提供恒定的负载电压,而电流源对于…...
iPhone 15预售:获取关键信息
既然苹果公司将于9月12日正式举办iPhone 15发布会,我们了解所有新机型只是时间问题。如果你是苹果的狂热粉丝,或者只是一个早期用户,那么活动结束后,你会想把所有的注意力都集中在iPhone 15的预购上——这样你就可以保证自己在发布日会有一款机型。 有很多理由对今年的iPh…...
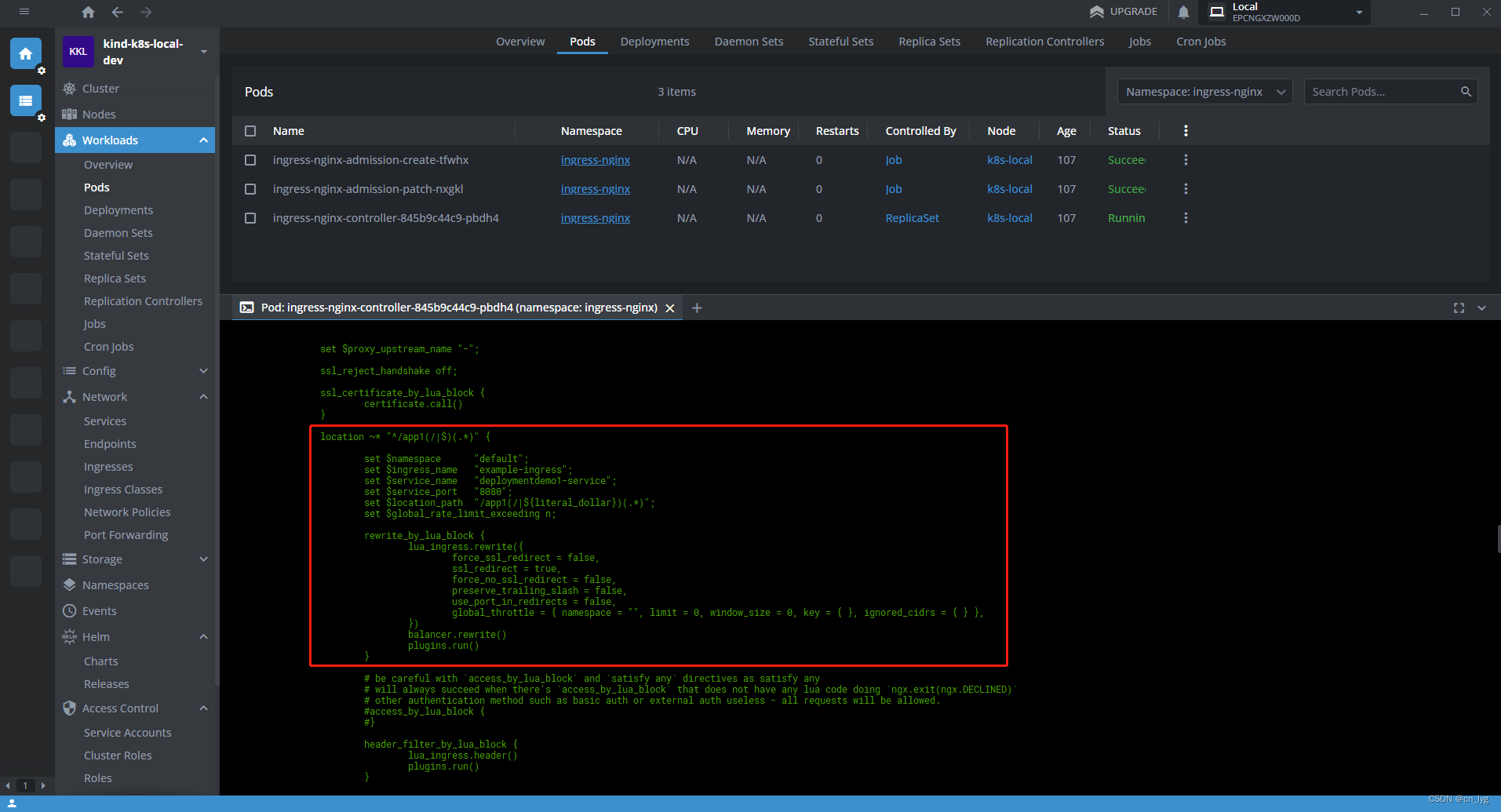
Kind创建本地环境安装Ingress
目录 1.K8s什么要使用Ingress 2.在本地K8s集群安装Nginx Ingress controller 2.1.使用Kind创建本地集群 2.1.1.创建kind配置文件 2.1.2.执行创建命令 2.2.找到和当前k8s版本匹配的Ingress版本 2.2.1.查看当前的K8s版本 2.2.2.在官网中找到对应的合适版本 2.3.按照版本安…...

MySQL与Oracle数据库通过系统命令导出导入
MySQL导出 mysqldump -uroot -ppassword 库名 表名 --where"s_dtend<2023-05-01 00:00:00 and s_dtend>2023-01-01 00:00:00 and (i_mbr!10000 OR (i_mbr 10000 AND I_ACTV IN (SELECT I_ACTV FROM t_mk_activity WHERE S_DTEND < 2023-05-01 00:00:00)))"…...
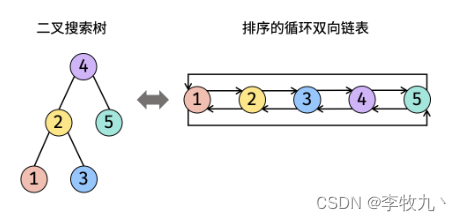
从零学算法(剑指 Offer 36)
123.输入一棵二叉搜索树,将该二叉搜索树转换成一个排序的循环双向链表。要求不能创建任何新的节点,只能调整树中节点指针的指向。 为了让您更好地理解问题,以下面的二叉搜索树为例: 我们希望将这个二叉搜索树转化为双向循环链表。…...

【Unity3D】UI Toolkit容器
1 前言 UI Toolkit简介 中介绍了 UI Builder、样式属性、UQuery,本文将介绍 UI Toolkit 中的容器,主要包含 VisualElement、ScrollView、ListView、UI Toolkit,官方介绍详见→UXML elements reference。 2 VisualElement(空容器&…...

AI编程工具 Codex 入门教程,带你7分钟上手 Codex !
大家好,我是程序员小灰。前一段时间,Anthropic旗下的AI编程工具 Claude Code 火了,小灰也为大家制作了Claude Code 相关的视频教程,得到了很多读者的肯定。尽管Claude Code很强大,但存在一个致命的问题,就是…...

经手100万+终端后,聊聊校园门锁Sub-1G和Cat.1怎么选
做校园联网门锁项目的人大概都遇到过这个纠结:组网方案到底选Sub-1G还是4G Cat.1?我们团队(KEENZY中科易安)经手了100万在线终端的运行数据,可以明确地说——两种方案没有绝对的优劣,只有场景是否匹配。选错…...

上海AI实验室发布WildClawBench:AI智能体究竟能走多远?
这项由上海人工智能实验室联合香港中文大学、复旦大学、中国科学技术大学、上海交通大学、清华大学、浙江大学及南洋理工大学等多所顶尖机构共同完成的研究,于2026年5月11日以预印本形式发布,论文编号为arXiv:2605.10912v1。感兴趣的读者可通过该编号在a…...

工控机厂家怎么选?20年从业者告诉你这5个关键点
在工业自动化领域,工控机的选择直接关系到生产线的稳定运行。作为一名在工业电脑行业摸爬滚打20年的从业者,我见过太多企业因为选错厂家而付出惨痛代价——设备频繁故障、售后推诿扯皮、项目延期损失百万。今天,我就从专业角度告诉你…...
)
【仅限前500名设计师获取】Midjourney双色调调色板生成器(含17组经Adobe Color验证的高转化配色矩阵)
更多请点击: https://codechina.net 第一章:Midjourney双色调调色范式的底层逻辑与设计价值 双色调(Duotone)并非简单叠加两种颜色,而是基于人眼视觉感知的非线性响应特性,在Midjourney中构建的一套语义化…...

告别IBus!在Ubuntu 22.04上为Fcitx5安装搜狗输入法并设置自启动的完整流程
在Ubuntu 22.04上深度配置Fcitx5与搜狗输入法的现代输入方案 对于追求高效输入的Linux用户而言,输入法框架的选择往往决定了日常使用的流畅度体验。传统IBus框架虽然预装在大多数发行版中,但在中文输入场景下常显力不从心——词库更新滞后、云输入支持有…...
)
告别盲测!用Arduino UNO和VL6180X做个桌面防撞小助手(OLED实时显示距离)
用Arduino UNO和VL6180X打造智能桌面防撞系统 每次在办公桌上不小心碰倒水杯或手机从桌边滑落时,那种手忙脚乱的场景想必大家都不陌生。今天我们就来解决这个日常小烦恼——利用Arduino UNO开发板和VL6180X传感器,配合OLED显示屏,制作一个能实…...

智能硬件适配引擎:92%成功率重构OpenCore EFI配置标准
智能硬件适配引擎:92%成功率重构OpenCore EFI配置标准 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 在开源系统定制领域,硬件…...

抓包科普小知识
1、什么是抓包 抓包就是将网络传输发送与接收的数据包进行截获、重发、编辑、转存等操作,通过抓包可以: 分析网络问思路就是设置一个中间人进程负责抓包,每次目标进程之间的会话都先与中间人进程通信,再进行转发。业务分析分析网…...

OpCore-Simplify:开源系统硬件适配的自动化配置引擎
OpCore-Simplify:开源系统硬件适配的自动化配置引擎 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 在跨平台系统部署领域,硬件…...