SQL优化案例教程0基础(小白必看)
前提准备:本案例准备了100W的数据进行SQL性能测试,数据库采用的是MySQL,
总共介绍了常见的14种SQL优化方式,每一种优化方式都进行了实打实的测试,
逐行讲解,通俗易懂!
一、前提准备
提前准备一张学生表数据和一张特殊学生表数据,用于后面的测试用。
1.1 创建表结构
创建一个学生表:
CREATE TABLE student (id int(11) unsigned NOT NULL AUTO_INCREMENT,name varchar(50) DEFAULT NULL,age tinyint(4) DEFAULT NULL,id_card varchar(20) DEFAULT NULL,sex tinyint(1) DEFAULT '0', address varchar(100) DEFAULT NULL,phone varchar(20) DEFAULT NULL, create_time timestamp NULL DEFAULT CURRENT_TIMESTAMP,remark varchar(200) DEFAULT NULL,PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;再创建一个特殊学生表:
CREATE TABLE special_student (id int(11) unsigned NOT NULL AUTO_INCREMENT,stu_id int(11) DEFAULT NULL,PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;1.2 创建存储过程
在学生表中插入100w条数据,手动开启和提交事务,每插入1w条记录后,手动COMMIT一次事务,最后再COMMIT一次以提交剩下的记录,这样可以让插入速度更快,因为不需要为每条记录都 COMMIT,从而降低 IO 次数。
CREATE PROCEDURE insert_student_data()
BEGINDECLARE i INT DEFAULT 0; DECLARE done INT DEFAULT 0; DECLARE continue HANDLER FOR NOT FOUND SET done = 1;START TRANSACTION; WHILE i < 1000000 DOINSERT INTO student(name,age,id_card,sex,address,phone,remark)VALUES(CONCAT('姓名_',i), FLOOR(RAND()*100),FLOOR(RAND()*10000000000),FLOOR(RAND()*2),CONCAT('地址_',i), CONCAT('12937742',i),CONCAT('备注_',i));SET i = i + 1; IF MOD(i,10000) = 0 THEN COMMIT;START TRANSACTION;END IF; END WHILE; COMMIT;
END执行学生表的存储过程:
CALL insert_student_data();在特殊学生表中随机插入100条学生表中的id:
CREATE PROCEDURE insert_special_student()
BEGINDECLARE i INT DEFAULT 0; WHILE i < 100 DOINSERT INTO special_student (stu_id) VALUES (FLOOR(RAND()*1000000)); SET i = i + 1; END WHILE;
END执行特殊学生表的存储过程:
CALL insert_special_student();二、SQL优化案例详细介绍
2.1 返回必要的行
如果数量较大,可以使用 LIMIT 子句来限制返回的行数
select id,name from student limit 102.2 limit 优化
平日开发工作中,我们对于分页的处理一般是这样的:
SELECT * FROM student LIMIT 900000,10执行结果如图所示:
 耗时0.56s。当id为自增的情况下可以进行优化,优化的SQL如下:
耗时0.56s。当id为自增的情况下可以进行优化,优化的SQL如下:
SELECT * FROM student WHERE ID >= 900000 LIMIT 10优化后执行结果如图所示:
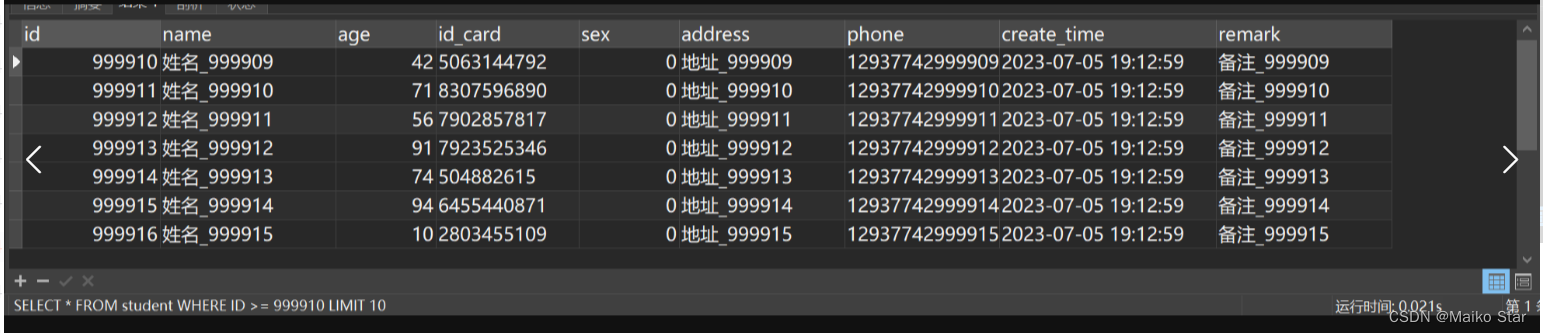
耗时0.02s,速度提升很多!
2.3 返回必要的列,避免使用SELECT *
有的时候,我们为了图方便,会直接使用SELECT * 一次性查出表中所有的数据:
SELECT * FROM student执行结果如图所示:

可以看到,执行时间花了2s左右,耗时很长!
在实际开发中,我们给页面展示的数据可能就只要2-3个字段,如果直接全部查出来了,岂不是白白浪费了字段,同时也损耗了性能,这是因为SELECT * 不会走覆盖索引,会出现大量的回表操作,从而导致SQL性能大幅度降低。
我们上面建立了联合索引,我们就可以只查询索引列,这样会大幅度提升查询效率,优化的SQL如下:
SELECT name,address,phone FROM student优化后执行结果如图所示:

耗时0.780s,速度提升很多!
2.4 or连接的条件(注意)

当使用OR操作符将多个条件组合在一起时,如果其中一个条件的列没有索引,那么涉及的索引不会被用到。
为了解决这个问题,可以考虑以下方案:
- 确保所有涉及的条件列都有适当的索引,以提高查询性能。
- 对于大型表,可以考虑重构查询,将OR操作符拆分成多个独立的查询,并使用UNION或UNION ALL来合并结果。这样可以确保每个子查询都能够使用适当的索引,并避免OR操作符导致的索引失效问题。
2.5 避免使用or条件,使用UNION或UNION ALL替代(有争议)
如果我们要查询指定的性别或者指定的身份证号码的学生,执行SQL如下:
SELECT * FROM student WHERE sex = 0 OR id_card = '7121877527789'
执行结果如图所示:

总共查询了近50w条数据,耗时1.4s左右,我们改用UNION ALL关键字查询:
SELECT * FROM student WHERE sex = 0
UNION ALL
SELECT * FROM student WHERE id_card = '7121877527789'改用后执行结果如图所示:
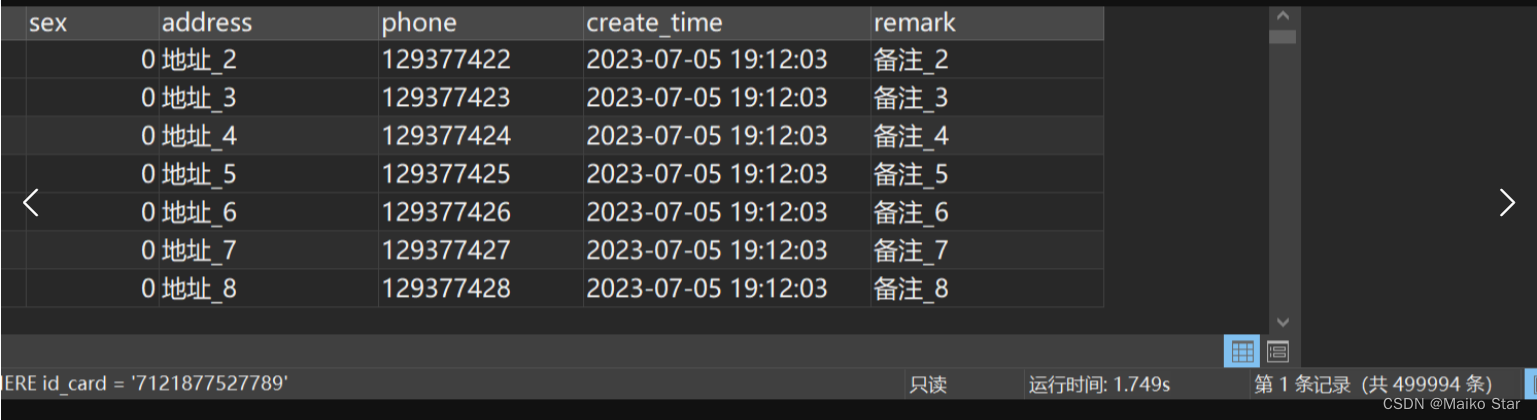
速度没有提升,反而慢了,故有争议
分析SQL:
使用EXPLAIN关键字分析一下使用OR关键字的这段SQL:
EXPLAIN SELECT * FROM student WHERE SEX = 0 OR id_card = '7121877527789'执行结果如图所示:

很明显,虽然可能会用到建立id_card的索引,正因为sex这个字段没有建立索引,还是走了一次全表扫描。
使用EXPLAIN关键字执行这段SQL:
EXPLAIN
SELECT * FROM student WHERE sex = 0
UNION ALL
SELECT * FROM student WHERE id_card = '7121877527789'执行结果如图所示:

很明显条件是sex的走了全表,但是id_card走了索引,所以依旧还是走了一次全表扫描,所以网上说的关于UNION ALL代替OR的,我这边实测感觉还是存在争议的!
2.6 非必要情况下,慎用UNION关键字,使用UNION ALL替代
例如我们根据性别去查询所有学生的信息,虽然这种操作多此一举,直接SELECT *就好了,为了演示这2个关键字的详细区别,使用UNION关键字执行的SQL如下:
SELECT * FROM student WHERE sex = 0
UNION
SELECT * FROM student WHERE sex = 1执行结果如图所示:

查了100w条足足整整等了32s左右,这个速度要是放到系统上,查个数据等到娃娃菜都凉了!
这是因为在使用UNION执行完SQL后,会帮我们获取所有数据并去掉重复的数据,性能的损耗就在这里,而UNION ALL和UNION相反,帮我们获取所有数据但会保留重复的数据。
我们改用UNION ALL关键字,优化的SQL如下:
SELECT * FROM student WHERE sex = 0
UNION ALL
SELECT * FROM student WHERE sex = 1替换后执行结果如图所示:
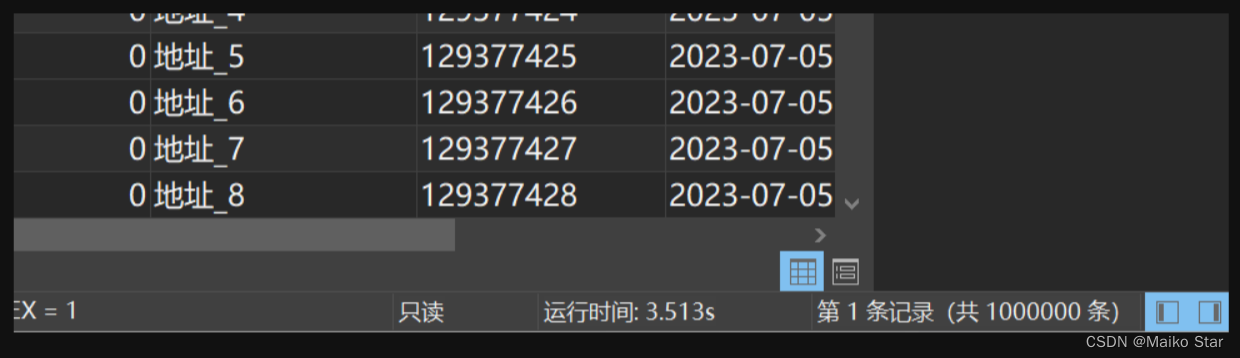
同样查询100w条数据,这边执行速度大大提高了,只用到了3s左右!
速度提升很多!
2.7 LIKE语句优化
平时我们日常开发用到的LIKE关键字进行模糊匹配会非常多,但是有的情况会使索引失效,导致查询效率变慢,例如:
只要身份证字段包含50就查出来,执行SQL如下:
SELECT * FROM student WHERE id_card like '%50%'执行结果如图所示:

用了0.8s左右。
只要身份证号码以50结尾就查出来,执行SQL如下:
SELECT * FROM student WHERE id_card like '%50'执行结果如图所示:

用了0.4s左右。
只要身份证号码以50开头的就查出来,执行SQL如下:
SELECT * FROM student WHERE id_card like '50%'执行结果如图所示:
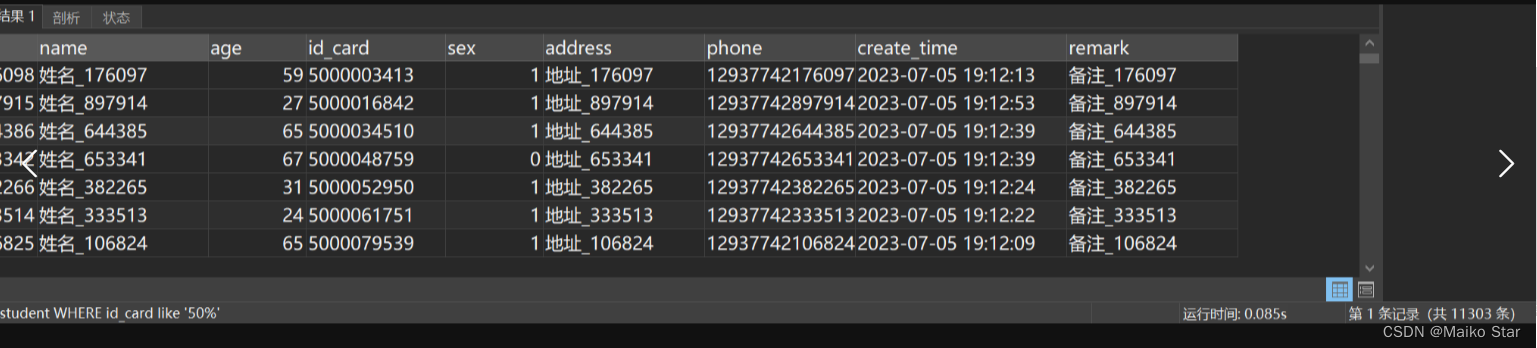
这次执行非常快,0.08s左右。
分析SQL:
使用EXPLAIN关键字执行这段SQL:
EXPLAIN SELECT * FROM student WHERE id_card like '%50%'执行结果如图所示:

很明显走了全表扫描!
使用EXPLAIN关键字执行这段SQL:
EXPLAIN SELECT * FROM student WHERE id_card like '%50'执行结果如图所示:

依旧走了全表扫描!
使用EXPLAIN关键字执行这段SQL:
EXPLAIN SELECT * FROM student WHERE id_card like '50%'执行结果如图所示:

这次便走了索引!速度快很多
2.8 尽量避免使用!=,导致索引失效
尽量避免使用!=或<>操作符,下面直接分析SQL:
SQL分析:
使用EXPLAIN关键字执行这段SQL:
EXPLAIN SELECT * FROM student WHERE id_card != '5031520645'执行结果如图所示:

虽然我们给了id_card字段建立了索引,但还是走了全表扫描!
2.9 尽量避免使用NULL值,IS NOT NULL会导致索引失效,IS NULL则不会
为了确保没有NULL值,我们可以设定一个默认值,下面直接分析SQL:
SQL分析:
使用EXPLAIN关键字执行这段SQL:
EXPLAIN SELECT * FROM student WHERE id_card IS NOT NULL执行结果如图所示:

依旧还是走了全表扫描。
使用EXPLAIN关键字执行这段SQL:
EXPLAIN SELECT * FROM student WHERE id_card IS NULL执行结果如图所示:
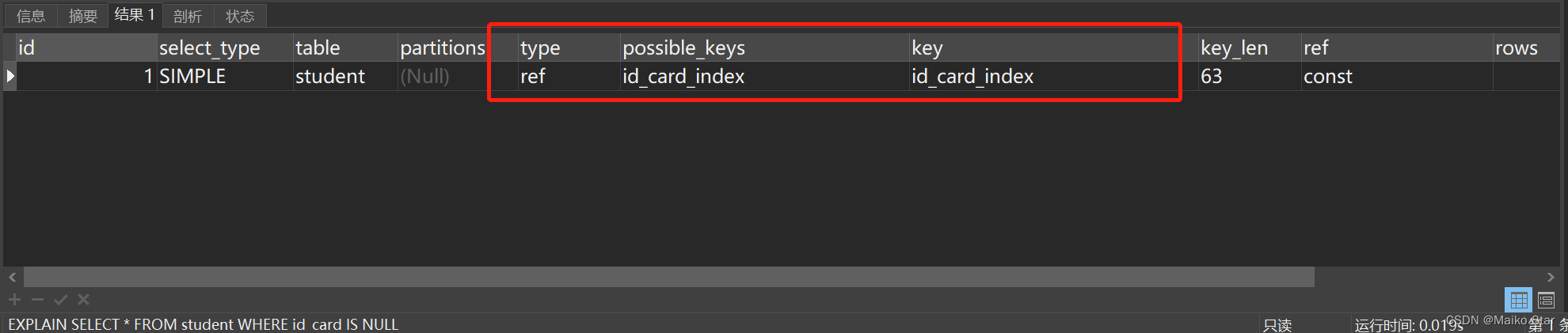
这样是走索引的!
2.10 使用小表驱动大表 ,避免大表驱动小表
言简意赅,意思就是让小表查出来的数据去再查询大表当中的数据。比如我们想查询学生表当中特殊学生的信息,我们就可以使用以special_student这个小表去驱动student这个大表,SQL如下:
SELECT * FROM student WHERE id
IN (SELECT stu_id FROM special_student)执行结果如图所示:

只用了0.02s,速度很可观!因为IN关键字中的子查询语句,子查询语句的数据量很少,所以查询速度会很快!
2.11 避免字符串不加引号,导致索引失效
如果在查询条件或创建索引时字符串没有加上引号,会导致索引失效。
查询指定的身份证号码的学生,如果我们平时疏忽了给身份证号码加上单引号,执行SQL如下:
SELECT * FROM student WHERE id_card = 5040198345执行结果如图所示:
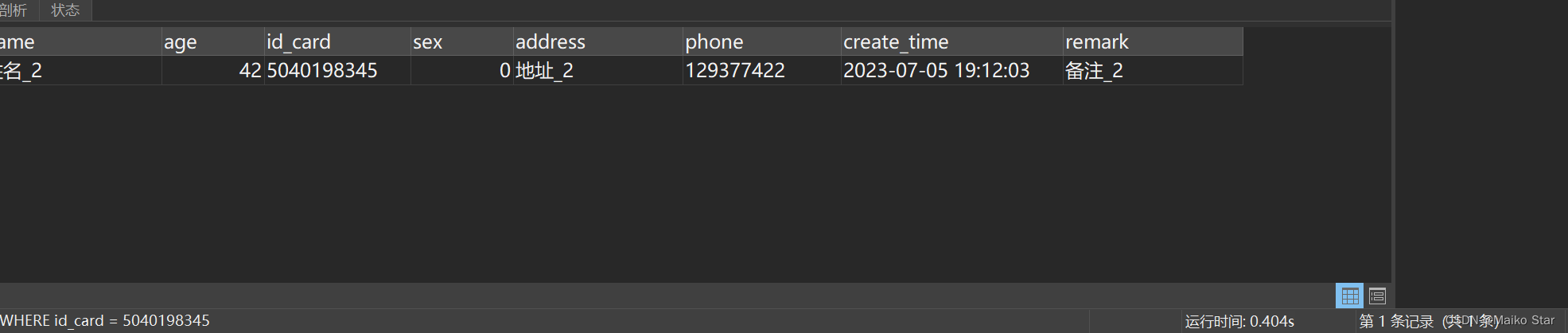
耗时0.4s左右。
给身份证号码加上单引号,优化的SQL如下:
SELECT * FROM student WHERE id_card = '5040198345'执行结果如图所示:
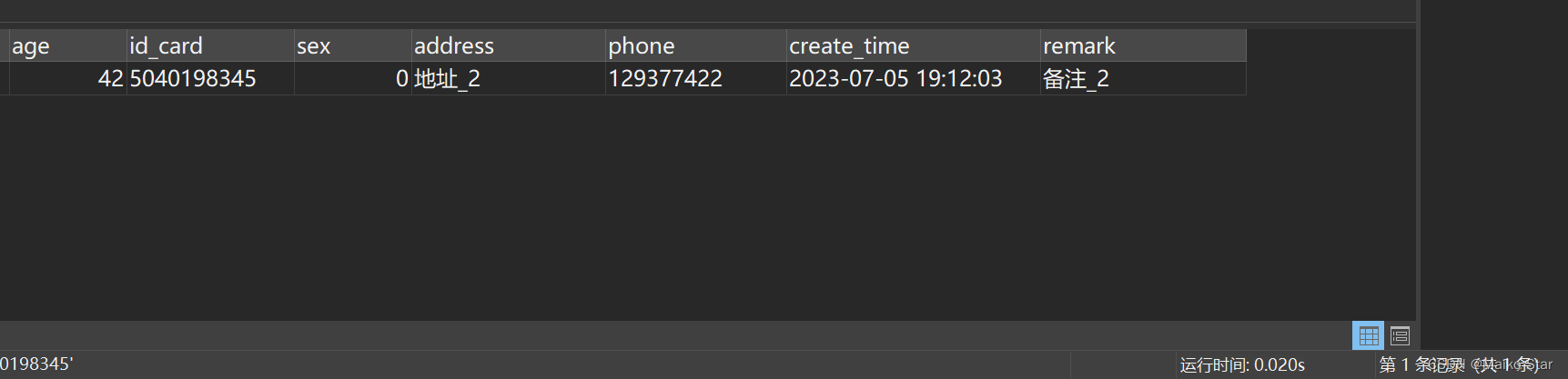
耗时0.02s左右,这次明显快多了!
分析SQL:
使用EXPLAIN关键字执行这段SQL:
EXPLAIN SELECT * FROM student WHERE id_card = 5040198345执行结果如图所示:

可能用到了id_card的索引,但是还是走了全表扫描!
使用EXPLAIN关键字执行这段SQL:
EXPLAIN SELECT * FROM student WHERE id_card = '5040198345'执行结果如图所示:

加上引号,走了索引,速度快了很多!
2.12 避免对索引列上字段操作,导致索引失效
为了避免索引失效的问题,应该尽量避免在查询条件或者索引创建时对索引列进行运算。如果确实需要使用运算,可以考虑以下解决方案:
- 对索引列进行逆转运算:如果运算是可逆的,可以通过将运算应用到查询参数上,而不是索引列上来维持索引的有效性。
- 使用函数索引:某些数据库管理系统提供了函数索引的功能,可以根据特定的函数操作创建索引,以满足特定的查询需求。
2.13 遵循最左匹配原则(重要)
上面我们按照name,address和phone这个顺序建立了复合索引,相当于建立了(name),(name、address)和(name、address、phone)三个索引,如果我们查询的where条件违背了建立的顺序,则复合索引就失效了,下面直接进行SQL分析:
分析SQL:
使用EXPLAIN关键字执行这段SQL:
EXPLAIN SELECT * FROM student WHERE name = '姓名_4' and phone = '7121877527' and address = '地址_4'执行结果如图:
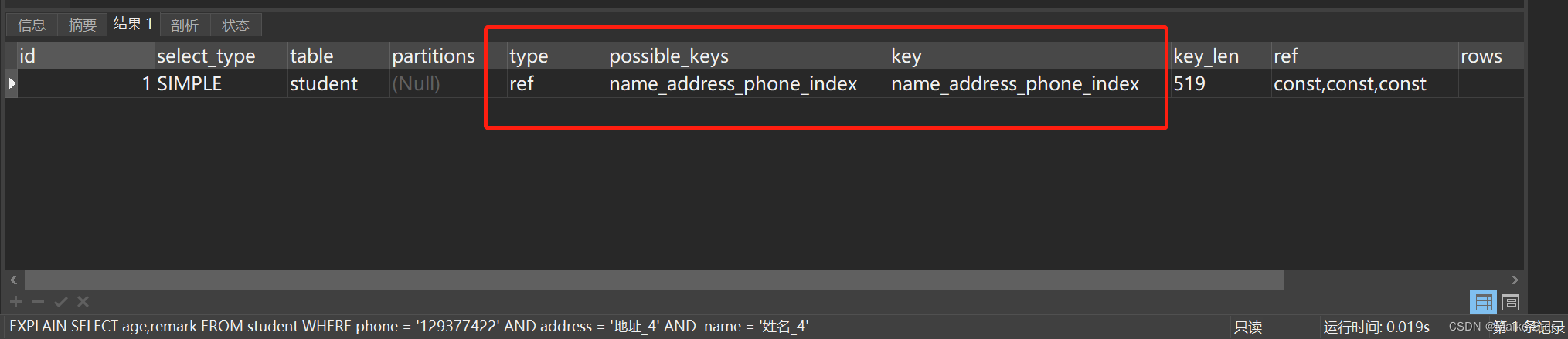
为什么明明违背了最左匹配原则,依旧还是走了复合索引呢?可能是如下原因:
1、通过索引过滤性能足够好,所以还是选择利用索引。
2、联合索引中前几个字段过滤效果较好,所以仍然选择利用索引。
可能的执行计划大概是:
1、优先通过phone字段过滤,将要扫描的记录减少一部分。
2、然后通过address字段继续过滤,再减少一部分记录。
3、最后通过name字段过滤,已经剩下很少的记录需要扫描。
4、尽管违反了最左匹配,解释器可能认为仍然利用索引效率比较高。
所以总的来说,就是解释器会根据实际情况进行权衡,即使是违反最左匹配原则,也可能会选择利用索引。但这并不是一个良好的查询优化,最好还是严格遵守最左匹配原则。
以下是严格遵守最左匹配原则的SQL:
SELECT * FROM student WHERE name = '姓名_4'
SELECT * FROM student WHERE name = '姓名_4' and address = '地址_4'
SELECT * FROM student WHERE name = '姓名_4' and address = '地址_4' and phone = '7121877527' 2.14 提升GROUP BY的效率
我们平日写SQL需要多多少少会使用GROUP BY关键字,它主要的功能是去重和分组。 通常它会跟HAVING一起配合使用,表示分组后再根据一定的条件过滤数据,常规执行的SQL如下:
SELECT age,COUNT(1) FROM student GROUP BY age HAVING age > 18执行结果如图所示:

耗时总计0.53s左右,不过还可以进行优化,我们可以在分组之前缩小筛选的范围,然后再进行分组,优化的SQL如下:
SELECT age,COUNT(1) FROM student where age > 18 GROUP BY age 执行结果如图所示:

耗时0.51s左右,虽然不明显,也是一种不错的思路。
相关文章:
SQL优化案例教程0基础(小白必看)
前提准备:本案例准备了100W的数据进行SQL性能测试,数据库采用的是MySQL, 总共介绍了常见的14种SQL优化方式,每一种优化方式都进行了实打实的测试, 逐行讲解,通俗易懂! 一、前提准备 提前准备一…...

webpack(一)模块化
模块化演变过程 阶段一:基于文件的划分模块方式 概念:将每个功能和相关数据状态分别放在单独的文件里 约定每一个文件就是一个单独的模块,使用每个模块,直接调用这个模块的成员 缺点:所有的成员都可以在模块外被访问和…...
基于Java+SpringBoot+Vue前后端分离人力资源管理系统设计和实现
博主介绍:✌全网粉丝30W,csdn特邀作者、博客专家、CSDN新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专…...
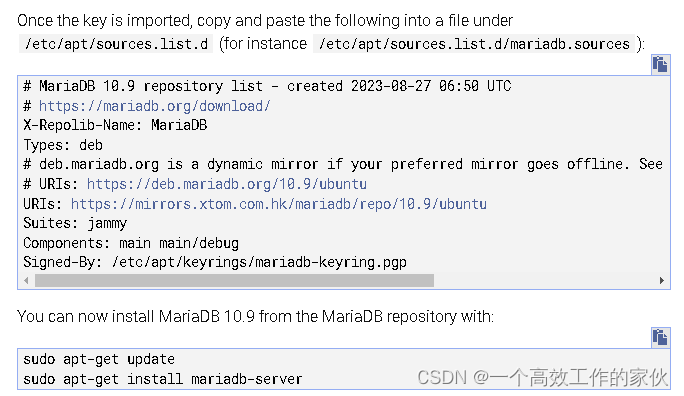
安装配置mariadb
记录下安装配置mariadb的经历。 环境:ubuntu22 一、apt在线安装 apt代理配置 APT是Ubuntu系统中用于安装和升级软件包的工具,如果本地没有可用的软件包,APT将会连接到远程软件包服务器下载软件包。在某些情况下,用户需要将APT的…...

Ant Design Vue 日期选择器DatePicker传给后台日期参数格式问题
花了一个下午才解决,官方组件文档里面是没有处理方案说明的。 项目版本:Ant Design Vue 2.0.2 前端部分代码: <template><a-modal:visible"visible":width"windowWidth":height"800":title"tit…...

springboot1.5.12升级至2.6.15
首先,加入springboot升级大版本依赖,会在升级过程中打印出错日志提示(升级完毕可去除) <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-properties-migrator</art…...
)
Android Event事件分发(新版本)
之前写过一个方案(添加链接描述),突然觉得很麻烦,于是有了新的方案: 首先先说要解决的问题: 当父布局能滑动,子View也能滑动,就会出现滑动冲突 解决思路:我们按下子Vie…...
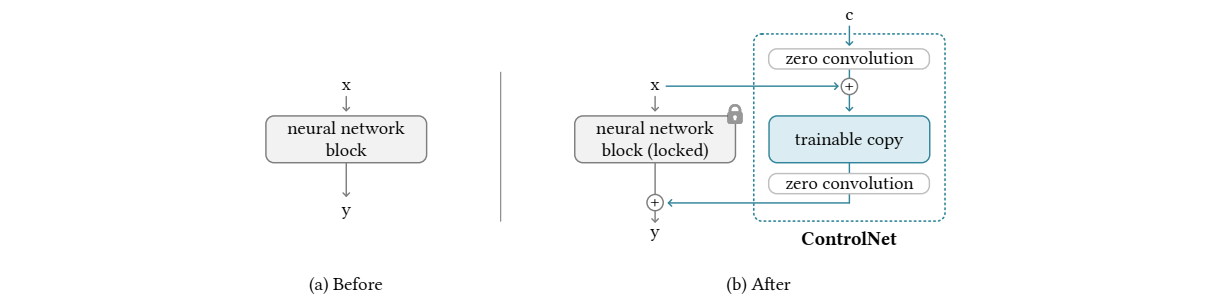
可控生成:ControlNet原理
🤗关注公众号funNLPer体验更佳阅读🤗 论文:Adding Conditional Control to Text-to-Image Diffusion Models 代码:lllyasviel/ControlNet 简单来说ControlNet希望通过输入额外条件来控制大型图像生成模型,使得图像生成模型根据可控。 文章目录 1. 动机2. ControlNet原理…...

【极客时间】MySQL 必知必会-20230901
03 | 表:怎么创建和修改数据表? 新增数据表 CREATE DATABASE demo;CREATE TABLE goodsmaster (barcode TEXT,goodsname TEXT,price DOUBLE, itemnumber INT PRIMARY KEY AUTO_INCREMENT);INSERT INTO demo.goodsmaster (barcode, goodsname,price) VAL…...
53 个 CSS 特效 3(完)
53 个 CSS 特效 3(完) 前两篇地址: 53 个 CSS 特效 153 个 CSS 特效 2 这里是第 33 到 53 个,很多内容都挺重复的,所以这里解释没之前的细,如果漏了一些之前的笔记会补一下,写过的就会跳过。…...

简单数学题:找出最大的可达成数字
来看一道简单的数学题:力扣2769. 找出最大的可达成数字 题目描述的花里胡哨,天花乱坠,但这道题目非常简单。我们最多执行t次操作,只需每次操作都让x-1,让num1,执行t次操作后,x就变为xtÿ…...
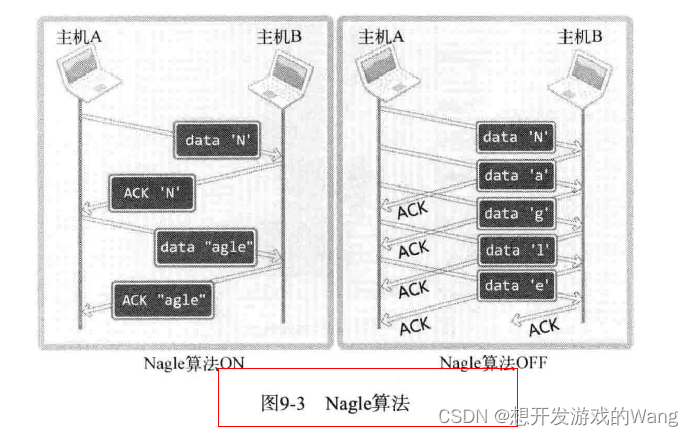
[C++ 网络协议] 套接字的多种可选项
目录 1. 套接字的可选项 2. 获取/设置套接字可选项 2.1 getsockopt函数(获取套接字可选项) 2.2 setsockopt函数(设置套接字可选项) 3. 常用套接字可选项 3.1 SOL_SOCKET协议层的SO_TYPE可选项 3.2 SOL_SOCKET协议层的SO_SN…...

2022年03月 C/C++(五级)真题解析#中国电子学会#全国青少年软件编程等级考试
第1题:数字变换 给定一个包含 5 个数字(0-9)的字符串, 例如 “02943”, 请将“12345”变换到它。 你可以采取 3 种操作进行变换 (1)交换相邻的两个数字 (2)将一个数字加 1。 如果加 1 后大于 9, 则变为 0 (3)将一个数字加倍。 如果加倍后大于 9,则将其变为加倍后的…...

***数据转换中常用的两个函数 sscanf,sprintf
1、sscanf将字符串转换成想要的整数或浮点数 (HMI屏中输入浮点数据,到mcu后要转换成对应的浮点数据) sscanf(“0.9”,“%f”,getData) /*! \brief 文本控件通知 \details 当文本通过键盘更新(或调用GetControlValue)时,执行此函数 \details 文本控件的内容以字符串形…...
 软件测试)
软件工程(十九) 软件测试
软件测试主要了解软件测试的方法和软件的调试。 1、软件测试方法 1.1、测试基本思想 尽早、不断的进行测试 在V模型其实已经凸显出这种思想了程序员避免测试自己设计的程序 因为测试自己设计的程序,其实是不容易发现问题的,因为人从本质上都不愿意找自己的茬。而且由于你的…...
源码解读实现原理)
go中读写锁(rwmutex)源码解读实现原理
go读写锁的实现原理 1、RWMutex读写锁的概念 读写锁也就是我们所使用的RWMutex,其实是对于go本身的mutex做的一个拓展,当一个goroutine获得了读锁后,其他goroutine同样可以获得读锁,但是不能获得写锁。相反,当一个go…...

【人工智能】—_深度优先搜索、代价一致搜索、深度有限搜索、迭代深度优先搜索、图搜索
【人工智能】无信息搜索—BFS 、代价一致、DFS、深度受限、迭代深入深度优先、图搜索 什么是搜索 搜索问题是指既不能通过数学建模解决,又没有其他算法可以套用或者非遍历所有情况才能得出正确结果。这时就需要采用搜索算法来解决问题。搜索就是一种通过穷举所有解…...

uni-app 客服按钮可上下拖动动
项目需求: 因为悬浮客服有时候会遮挡住界面内容,故需要对悬浮的气泡弹窗做可拖动操作 movable-area:可拖动区域 movable-view:可移动的视图容器,在页面中可以拖拽滑动或双指缩放。 属性说明 属性名类型默认值说…...
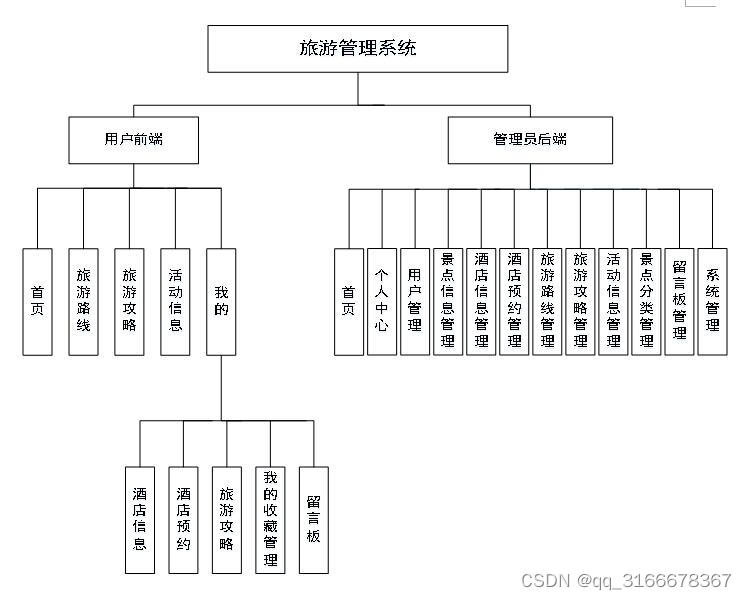
基于Android的旅游管理系统 微信小程序
随着网络科技的发展,移动智能终端逐渐走进人们的视线,相关应用越来越广泛,并在人们的日常生活中扮演着越来越重要的角色。因此,关键应用程序的开发成为影响移动智能终端普及的重要因素,设计并开发实用、方便的应用程序…...
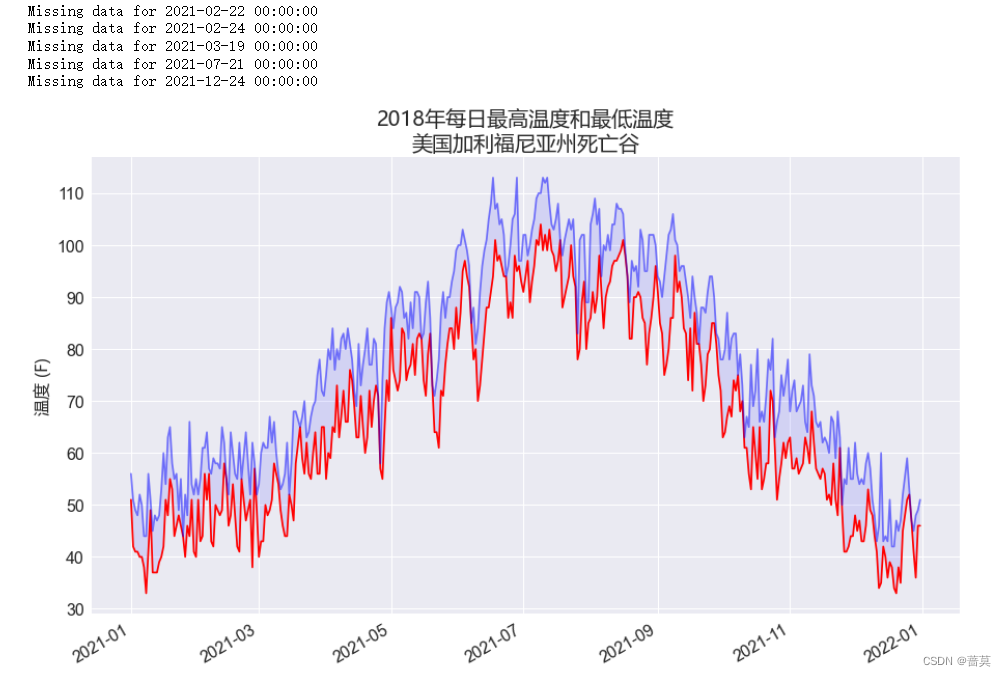
python-数据可视化-下载数据-CSV文件格式
数据以两种常见格式存储:CSV和JSON CSV文件格式 comma-separated values import csv filename sitka_weather_07-2018_simple.csv with open(filename) as f:reader csv.reader(f)header_row next(reader)print(header_row) # [USW00025333, SITKA AIRPORT, A…...

国产车规芯片崛起,如何用东软睿驰NeuSAR或经纬恒润方案快速适配?
国产车规芯片与AUTOSAR方案融合实战:从芯驰MCU到NeuSAR/经纬恒润的适配指南 当一颗国产车规级MCU遇上自主AUTOSAR基础软件,这场"中国芯"与"中国魂"的相遇,正在重构汽车电子开发的成本结构与技术生态。去年某新能源车企的…...

ChromeKeePass终极指南:如何在Chrome浏览器中实现KeePass密码自动填充
ChromeKeePass终极指南:如何在Chrome浏览器中实现KeePass密码自动填充 【免费下载链接】ChromeKeePass Chrome extensions for automatically filling credentials from KeePass 项目地址: https://gitcode.com/gh_mirrors/ch/ChromeKeePass ChromeKeePass是…...

集装箱箱号与ISO代码区域检测数据集VOC+YOLO格式887张2类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)图片数量(jpg文件个数):887标注数量(xml文件个数):887标注数量(txt文件个数):887标注类别数&…...
)
用一台旧笔记本和朋友联机玩《我的世界》Fear Nightfall整合包,保姆级开服教程(含SakuraFrp配置)
用旧笔记本搭建《我的世界》Fear Nightfall联机服务器的完整指南 1. 为什么选择旧笔记本作为服务器主机? 对于许多《我的世界》玩家来说,和朋友一起体验大型整合包是件令人兴奋的事,但租用云服务器的高昂成本往往让人望而却步。实际上&…...

RK3568与RK3399深度对比:从架构到实战,边缘计算如何选型?
1. 项目概述:为什么我们需要重新审视RK3568与RK3399?最近在给一个边缘计算项目做硬件选型,客户的需求很明确:需要一块性能足够、接口丰富、功耗可控且长期供货稳定的核心板。在国产处理器的候选名单里,瑞芯微的RK3399和…...

机器人仿真终极指南:使用WPR系列从零构建ROS虚拟测试环境 [特殊字符]
机器人仿真终极指南:使用WPR系列从零构建ROS虚拟测试环境 🚀 【免费下载链接】wpr_simulation 项目地址: https://gitcode.com/gh_mirrors/wp/wpr_simulation 在机器人开发领域,硬件成本高昂、测试周期漫长是每个开发者面临的现实挑战…...

chatgpt-web-midjourney-proxy的TypeScript类型系统:类型安全的AI应用开发
chatgpt-web-midjourney-proxy的TypeScript类型系统:类型安全的AI应用开发 在当今AI技术快速发展的时代,如何构建稳定可靠的AI应用成为开发者面临的重要挑战。chatgpt-web-midjourney-proxy项目通过精心设计的TypeScript类型系统,为开发者提供…...

手把手教你用复旦微FM7Z045芯片在线调试DDR:JTAG与QSPI模式切换避坑指南
复旦微FM7Z045芯片DDR调试实战:模式切换与JTAG连接深度解析 第一次拿到复旦微FM7Z045开发板时,许多工程师都会遇到一个令人困惑的问题——明明按照手册步骤操作,DDR调试却总是失败。这往往不是代码问题,而是模式选择不当导致的。本…...

会议记录差点搞砸,直到遇见这个“录音转文字”神器
上周三下午,我差点因为一场两小时的跨部门评审会被老板“请喝茶”。事情是这样的:作为产品经理,我负责主持一场涉及技术、运营、销售三方的季度复盘会。会上大家争论激烈,我一边控场一边记笔记,结果手忙脚乱——技术总…...

爬虫实战复盘:山东政务噪声数据逆向爬取踩坑全记录
爬虫实战复盘:山东政务噪声数据逆向爬取踩坑全记录 前言 近期在做全国各省市环境噪声实时数据爬虫、清洗、入库标准化项目,已经稳定跑通北京(静态HTML)、天津(SM3国密签名接口)两大站点。今天攻坚山东省噪声…...