Elasticsearch 优化
Elasticsearch 优化
2.1硬件选择
#----------------------------------- Paths
------------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):
#
#path.data: /path/to/data
#
# Path to log files:
#
#path.logs: /path/to/logs
#- 使用 SSD。就像其他地方提过的, 他们比机械磁盘优秀多了。
- 使用 RAID 0。条带化 RAID 会提高磁盘 I/O,代价显然就是当一块硬盘故障时整个就故障了。不要使用镜像或者奇偶校验 RAID 因为副本已经提供了这个功能。
- 另外,使用多块硬盘,并允许 Elasticsearch 通过多个 path.data 目录配置把数据条带化分配到它们上 面。
- 不要使用远程挂载的存储,比如 NFS 或者 SMB/CIFS。这个引入的延迟对性能来说完全是背道而驰的。
2.2分片策略
合理设置分片数
分片和副本的设计为 ES 提供了支持分布式和故障转移的特性,但并不意味着分片和副本是可以无限分配的。而且索引的分片完成分配后由于索引的路由机制,我们是不能重新修改分片数的。
可能有人会说,我不知道这个索引将来会变得多大,并且过后我也不能更改索引的大小,所以为了保险起见,还是给它设为 1000 个分片吧。但是需要知道的是,一个分片并不是没有代价的。需要了解:
- 一个分片的底层即为一个 Lucene 索引,会消耗一定文件句柄、内存、以及 CPU运转。
- 每一个搜索请求都需要命中索引中的每一个分片,如果每一个分片都处于不同的节点还好, 但如果多个分片都需要在同一个节点上竞争使用相同的资源就有些糟糕了。
- 用于计算相关度的词项统计信息是基于分片的。如果有许多分片,每一个都只有很少的数据会导致很低的相关度。
一个业务索引具体需要分配多少分片可能需要架构师和技术人员对业务的增长有个预先的判断,横向扩展应当分阶段进行。为下一阶段准备好足够的资源。 只有当你进入到下一个阶段,你才有时间思考需要作出哪些改变来达到这个阶段。一般来说,我们遵循一些原则:
- 控制每个分片占用的硬盘容量不超过 ES 的最大 JVM 的堆空间设置(一般设置不超过 32G,参考下文的 JVM 设置原则),因此,如果索引的总容量在 500G 左右,那分片大小在 16 个左右即可;当然,最好同时考虑原则 2。
- 考虑一下 node 数量,一般一个节点有时候就是一台物理机,如果分片数过多,大大超过了节点数,很可能会导致一个节点上存在多个分片,一旦该节点故障,即使保持了 1 个以上的副本,同样有可能会导致数据丢失,集群无法恢复。所以, 一般都设置分片数不超过节点数的 3 倍。
- 主分片,副本和节点最大数之间数量,我们分配的时候可以参考以下关系:
节点数<=主分片数 *(副本数+1)
推迟分片分配
PUT /_all/_settings
{
"settings": {
"index.unassigned.node_left.delayed_timeout": "5m"
}
}2.3 路由选择
shard = hash(routing) % number_of_primary_shards
不带 routing 查询
- 分发:请求到达协调节点后,协调节点将查询请求分发到每个分片上。
- 聚合: 协调节点搜集到每个分片上查询结果,在将查询的结果进行排序,之后给用户返回结果。
带 routing 查询
2.4 写入速度优化
- 加大 Translog Flush ,目的是降低 Iops、Writeblock。
- 增加 Index Refresh 间隔,目的是减少 Segment Merge 的次数。
- 调整 Bulk 线程池和队列。
- 优化节点间的任务分布。
- 优化 Lucene 层的索引建立,目的是降低 CPU 及 IO。
2.4.1 批量数据提交
2.4.2 优化存储设备
2.4.3 合理使用合并
2.4.4 减少 Refresh 的次数
2.4.5 加大 Flush 设置
2.4.6 减少副本的数量
2.5 内存设置
ES 默认安装后设置的内存是 1GB,对于任何一个现实业务来说,这个设置都太小了。如果是通过解压安装的 ES,则在 ES 安装文件中包含一个 jvm.option 文件,添加如下命令来设置 ES 的堆大小, Xms 表示堆的初始大小, Xmx 表示可分配的最大内存,都是 1GB。
确保 Xmx 和 Xms 的大小是相同的,其目的是为了能够在 Java 垃圾回收机制清理完堆区后不需要重新分隔计算堆区的大小而浪费资源,可以减轻伸缩堆大小带来的压力。
假设你有一个 64G 内存的机器,按照正常思维思考,你可能会认为把 64G 内存都给ES 比较好,但现实是这样吗, 越大越好?虽然内存对 ES 来说是非常重要的,但是答案是否定的!
因为 ES 堆内存的分配需要满足以下两个原则:
- 不要超过物理内存的 50%: Lucene 的设计目的是把底层 OS 里的数据缓存到内存中。Lucene 的段是分别存储到单个文件中的,这些文件都是不会变化的,所以很利于缓存,同时操作系统也会把这些段文件缓存起来,以便更快的访问。如果我们设置的堆内存过大, Lucene 可用的内存将会减少,就会严重影响降低 Lucene 的全文本查询性能。
- 堆内存的大小最好不要超过 32GB:在 Java 中,所有对象都分配在堆上,然后有一个 Klass Pointer 指针指向它的类元数据。这个指针在 64 位的操作系统上为 64 位, 64 位的操作系统可以使用更多的内存(2^64)。在 32 位的系统上为 32 位, 32 位的操作系统的最大寻址空间为 4GB(2^32)。但是 64 位的指针意味着更大的浪费,因为你的指针本身大了。浪费内存不算,更糟糕的是,更大的指针在主内存和缓存器(例如 LLC, L1 等)之间移动数据的时候,会占用更多的带宽。
最终我们都会采用 31 G 设置
- -Xms 31g
- -Xmx 31g
假设你有个机器有 128 GB 的内存,你可以创建两个节点,每个节点内存分配不超过 32 GB。也就是说不超过 64 GB 内存给 ES 的堆内存,剩下的超过 64 GB 的内存给 Lucene。
2.6 重要配置
相关文章:
Elasticsearch 优化
Elasticsearch 优化 2.1硬件选择 Elasticsearch 的基础是 Lucene ,所有的索引和文档数据是存储在本地的磁盘中,具体的 路径可在 ES 的配置文件 ../config/elasticsearch.yml 中配置,如下: #----------------------------…...

spring boot的自动装配原理
spring boot的自动装配原理 解释和使用关键技术思想总结 解释和使用 自动装配是什么:自动将第三方组件的bean装载到ioc容器里,不需要开发人员再去写bean相关的一些配置 spring boot怎么做:在启动类上加SpringBootApplication注解就可以实现自…...

走进低代码平台| iVX-困境之中如何突破传统
前言: “工欲善其事,必先利其器”,找到和使用一个优质的工具平台,往往会事半功倍。 文章目录 1️⃣认识走近低代码2️⃣传统的低代码开发3️⃣无代码编辑平台一个代码生成式低代码产品iVX受面性广支持代码复用如何使用? 4️⃣总结…...

【UIPickerView案例03-点餐系统之随机点餐 Objective-C语言】
一、先来看看我们这个示例程序里面,随机点餐是怎么做的 1.点击:“随机点餐”按钮 大家能想到,它是怎么实现的吗 1)首先,点击”随机点餐“按钮,的时候,你要让这个pickerView,进行随机选中,那么,得监听它的点击 2)然后呢,让pickeView选中数据, 3)然后呢,把那个…...

论文阅读_扩散模型_SDXL
英文名称: SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis 中文名称: SDXL:改进潜在扩散模型的高分辨率图像合成 论文地址: http://arxiv.org/abs/2307.01952 代码: https://github.com/Stability-AI/generative-models 时间: 2023-…...
云原生Kubernetes:二进制部署K8S多Master架构(三)
目录 一、理论 1.K8S多Master架构 2.配置master02 3.master02 节点部署 4.负载均衡部署 二、实验 1.环境 2.配置master02 3.master02 节点部署 4.负载均衡部署 三、总结 一、理论 1.K8S多Master架构 (1) 架构 2.配置master02 (1)环境 关闭防…...

任意文件读取和下载
任意文件读取是什么? 一些网站的需求,可能会提供文件查看与下载的功能。如果对用户查看或下载的文件没有限制或者限制绕就可以查看或下载任意文件。这些文件可以是源代码文件配置文件敏感文件等等。过, 任意文件读取会造成(敏感)信息泄露;任意…...

mysql怎么查指定表的自增id?
要查看MySQL表的自增ID(Auto Increment ID),你可以使用SHOW TABLE STATUS命令。以下是一个示例: SHOW TABLE STATUS LIKE your_table_name; 替换your_table_name为你想查询的表名。这条语句会返回表的一些基本信息,其…...

【C++设计模式】单一职责原则
2023年8月26日,周六上午 目录 概述一个简单的例子用单一职责原则来设计一个简单的学生管理系统 概述 单一职责原则(Single Responsibility Principle,SRP),它是面向对象设计中的一个基本原则。 单一职责原则的核心思…...
Windows docker desktop 基于HyperV的镜像文件迁移到D盘
Docker desktop的HyperV镜像文件,默认是在C盘下 C:\ProgramData\DockerDesktop\vm-data\DockerDesktop.vhdx如果部署的软件较多,文件较大,或者产生日志,甚至数据等,这将会使此文件越来越大,容易导致C盘空间…...

LM-INFINITE: SIMPLE ON-THE-FLY LENGTH GENERALIZATION FOR LARGE LANGUAGE MODELS
本文是LLM系列文章,针对《LM-INFINITE: SIMPLE ON-THE-FLY LENGTH GENERALIZATION FOR LARGE LANGUAGE MODELS》的翻译。 LM-INFiNITE:大语言模型的一个简单长度上推广 摘要1 引言2 相关工作3 LLMs中OOD因素的诊断4 LM-INFINITE5 评估6 结论和未来工作 …...
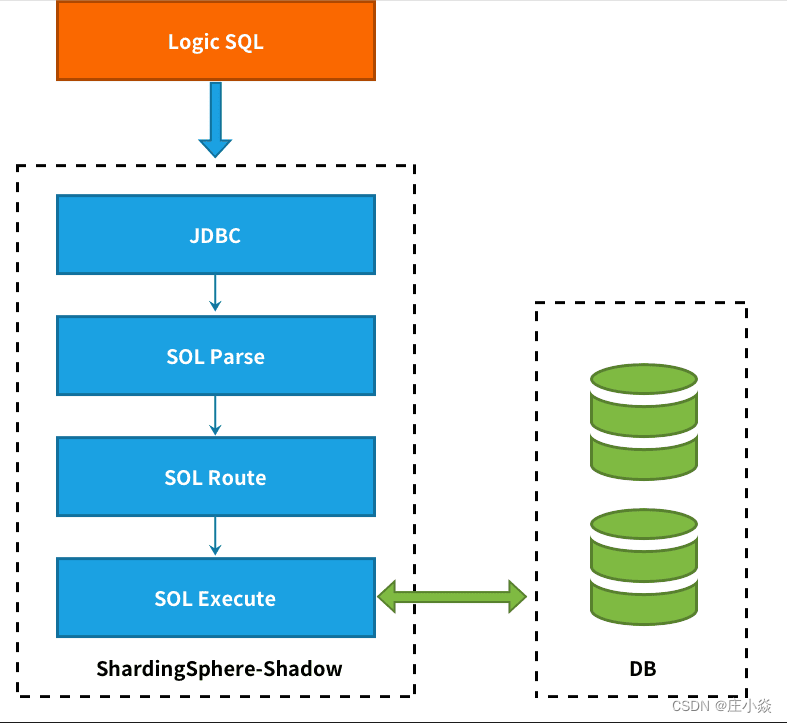
ShardingSphere——压测实战
摘要 Apache ShardingSphere 关注于全链路压测场景下,数据库层面的解决方案。 将压测数据自动路由至用户指定的数据库,是 Apache ShardingSphere 影子库模块的主要设计目标。 一、压测背景 在基于微服务的分布式应用架构下,业务需要多个服…...

二分图-染色法-dfs
1.判断一个图是否是二分图当且仅当图中不包含奇数环 2. dfs当前边为1 他的临边为2 看是否满足条件 3. 注意图有可能不是连通图 import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import java.util.Arrays;public class BinaryG…...

SQL优化案例教程0基础(小白必看)
前提准备:本案例准备了100W的数据进行SQL性能测试,数据库采用的是MySQL, 总共介绍了常见的14种SQL优化方式,每一种优化方式都进行了实打实的测试, 逐行讲解,通俗易懂! 一、前提准备 提前准备一…...

webpack(一)模块化
模块化演变过程 阶段一:基于文件的划分模块方式 概念:将每个功能和相关数据状态分别放在单独的文件里 约定每一个文件就是一个单独的模块,使用每个模块,直接调用这个模块的成员 缺点:所有的成员都可以在模块外被访问和…...
基于Java+SpringBoot+Vue前后端分离人力资源管理系统设计和实现
博主介绍:✌全网粉丝30W,csdn特邀作者、博客专家、CSDN新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专…...
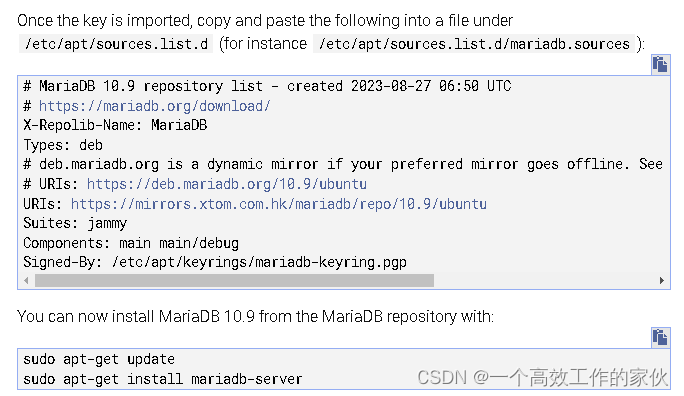
安装配置mariadb
记录下安装配置mariadb的经历。 环境:ubuntu22 一、apt在线安装 apt代理配置 APT是Ubuntu系统中用于安装和升级软件包的工具,如果本地没有可用的软件包,APT将会连接到远程软件包服务器下载软件包。在某些情况下,用户需要将APT的…...

Ant Design Vue 日期选择器DatePicker传给后台日期参数格式问题
花了一个下午才解决,官方组件文档里面是没有处理方案说明的。 项目版本:Ant Design Vue 2.0.2 前端部分代码: <template><a-modal:visible"visible":width"windowWidth":height"800":title"tit…...

springboot1.5.12升级至2.6.15
首先,加入springboot升级大版本依赖,会在升级过程中打印出错日志提示(升级完毕可去除) <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-properties-migrator</art…...
)
Android Event事件分发(新版本)
之前写过一个方案(添加链接描述),突然觉得很麻烦,于是有了新的方案: 首先先说要解决的问题: 当父布局能滑动,子View也能滑动,就会出现滑动冲突 解决思路:我们按下子Vie…...

终极LuaJIT反编译指南:如何快速恢复丢失的Lua源代码
终极LuaJIT反编译指南:如何快速恢复丢失的Lua源代码 【免费下载链接】luajit-decompiler https://gitlab.com/znixian/luajit-decompiler 项目地址: https://gitcode.com/gh_mirrors/lu/luajit-decompiler 你是否曾面对编译后的LuaJIT字节码文件束手无策&…...

3步解锁B站缓存视频:m4s-converter让你的离线收藏永不过期
3步解锁B站缓存视频:m4s-converter让你的离线收藏永不过期 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 当B站视频突然下架&#x…...

硬件选型干货|钡特电源DQ1-15D1709S与金升阳QA01-17属工业标准模块电源,避坑指南
在工业电子硬件研发中,工业DC-DC模块是板级隔离供电的核心器件,其标准化封装、性能稳定性及国产化水平,直接影响研发效率、系统可靠性与供应链安全。钡特电源DQ1-15D1709S与金升阳QA01-17作为国产直流电源模块领域的代表性型号,均…...

Aimmy AI瞄准辅助终极指南:从零开始到游戏高手
Aimmy AI瞄准辅助终极指南:从零开始到游戏高手 【免费下载链接】Aimmy Universal Second Eye for Gamers with Impairments (Universal AI Aim Aligner (AI Aimbot) - ONNX/YOLOv8 - C#) 项目地址: https://gitcode.com/gh_mirrors/ai/Aimmy Aimmy是一款基于…...

安捷伦E8257D/E8267D信号源不开机、输出不正常故障排查
安捷伦E8257D/E8267D信号源作为射频微波测试领域的常用设备,广泛应用于通信、半导体等行业,长期高负荷运行后,不开机、输出不正常等故障十分常见,给测试工作带来诸多困扰。常见故障一:安捷伦E8257D/E8267D不开机不开机…...

在Node.js服务中集成Taotoken实现统一的多模型调用网关
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js服务中集成Taotoken实现统一的多模型调用网关 对于构建在Node.js上的后端服务,直接对接多个大模型供应商的AP…...

拆解昇腾 CANN 五层架构:一个 MatMul 请求的完整旅程
适合人群:想从全局视角理解 CANN 架构的开发者 核心仓库:https://atomgit.com/cann 阅读时长:6 分钟 目录 一、为什么需要五层架构?二、第1层:昇腾计算语言层 AscendCL三、第2层:昇腾计算服务层四、第3层&…...

终极游戏光标解决方案:YoloMouse让你的鼠标在游戏中清晰可见
终极游戏光标解决方案:YoloMouse让你的鼠标在游戏中清晰可见 【免费下载链接】YoloMouse Game Cursor Changer 项目地址: https://gitcode.com/gh_mirrors/yo/YoloMouse 你是否曾在激烈的游戏战斗中迷失了鼠标光标?当屏幕上特效绚烂、技能乱飞时&…...

情感演绎有多强?顶伯实测愤怒、喜悦、悲伤等 9 种语气
🎭 微软 TTS 的情感演绎有多强?顶伯实测愤怒、喜悦、悲伤等 9 种语气🎯 引言:语音合成的情感革命在人工智能语音合成领域,情感表达一直是技术难点。微软 TTS(文本转语音)通过深度学习模型&#…...

论文被吐槽逻辑乱?,有哪些真正值得入手的的AI智能降重工具推荐?
毕业论文降AIGC率,优先选语义重构 学术优化 去AI痕迹的工具,免费与付费结合更高效。下面按中文、英文、免费/付费分类推荐,附实测效果与适用场景。 一、中文论文降重工具(最常用) 1. 千笔AI(综合全能首选…...