Python数据分析案例30——中国高票房电影分析(爬虫获取数据及分析可视化全流程)
案例背景
最近总看到《消失的她》票房多少多少,《孤注一掷》票房又破了多少多少.....
于是我就想自己爬虫一下获取中国高票房的电影数据,然后分析一下。
数据来源于淘票票:影片总票房排行榜 (maoyan.com)

爬它就行。
代码实现
首先爬虫获取数据:
数据获取
导入包
import requests; import pandas as pd
from bs4 import BeautifulSoup
传入网页和请求头
url = 'https://piaofang.maoyan.com/rankings/year'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.62'}
response1 = requests.get(url,headers=headers)
response.status_code
200表示获取网页文件成功
然后解析网页文件,获取电影信息数据
%%time
soup = BeautifulSoup(response.text, 'html.parser')
soup=soup.find('div', id='ranks-list')
movie_list = []for ul_tag in soup.find_all('ul', class_='row'):movie_info = {}li_tags = ul_tag.find_all('li')movie_info['序号'] = li_tags[0].textmovie_info['标题'] = li_tags[1].find('p', class_='first-line').textmovie_info['上映日期'] = li_tags[1].find('p', class_='second-line').textmovie_info['票房(亿)'] = f'{(float(li_tags[2].text)/10000):.2f}'movie_info['平均票价'] = li_tags[3].textmovie_info['平均人次'] = li_tags[4].textmovie_list.append(movie_info)数据获取完成了! 查看字典数据:
movie_list
可以,很标准,没什么问题,然后把它变成数据框,查看前三行
movies=pd.DataFrame(movie_list)
movies.head(3)
对数据进行一定的清洗,我们看到上映日期里面的数据有“上映”两个字,我们要去掉,然后把它变成时间格式,票房,票价,人次都要变成数值型数据。
我们只取票房前250的电影,对应豆瓣250.,,,,中国票房250好叭
然后我们还需要从日期里面抽取年份和月份两列数据,方便后面分析。
#清洗
movies=movies.set_index('序号').loc[:'250',:]
movies['上映日期']=pd.to_datetime(movies['上映日期'].str.replace('上映',''))
movies[['票房(亿)','平均票价','平均人次']]=movies.loc[:,['票房(亿)','平均票价','平均人次']].astype(float)
movies['年份']=movies['上映日期'].dt.year ; movies['月份']=movies['上映日期'].dt.month
movies.head(2)
数据处理完毕,开始画图分析!
画图分析
导入画图包
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams ['font.sans-serif'] ='SimHei' #显示中文
plt.rcParams ['axes.unicode_minus']=False 对票房排名前20的电影画柱状图
top_movies = movies.nlargest(20, '票房(亿)')
plt.figure(figsize=(7, 4),dpi=128)
ax = sns.barplot(x='票房(亿)', y='标题', data=top_movies, orient='h',alpha=0.5)
#plt.xticks(rotation=80, ha='center')# 在柱子上标注数值
for p in ax.patches:ax.annotate(f'{p.get_width():.2f}', (p.get_width(), p.get_y() + p.get_height() / 2.),va='center', fontsize=8, color='gray', xytext=(5, 0),textcoords='offset points')plt.title('票房前20的电影')
plt.xlabel('票房数量(亿)')
plt.ylabel('电影名称')
plt.tight_layout()
plt.show()
还不错,很好看,可以看到中国历史票房前20 的电影名称和他们的票房数量。
对平均票价和平均人次进行分析:
plt.figure(figsize=(7, 6),dpi=128)
# 绘制第一个子图:平均票价点图
plt.subplot(2, 2, 1)
sns.scatterplot(y='平均票价', x='年份', data=movies,c=movies['年份'],cmap='plasma')
plt.title('平均票价点图')
plt.ylabel('平均票价')
#plt.xticks([])plt.subplot(2, 2, 2)
sns.boxplot(y='平均票价', data=movies)
plt.title('平均票价箱线图')
plt.xlabel('平均票价')plt.subplot(2, 2, 3)
sns.scatterplot(y='平均人次', x='年份', data=movies,c=movies['年份'],cmap='plasma')
plt.title('平均人次点图')
plt.ylabel('平均人次')plt.subplot(2, 2, 4)
sns.boxplot(y='平均人次', data=movies)
plt.title('平均人次箱线图')
plt.xlabel('平均人次')
plt.tight_layout()
plt.show()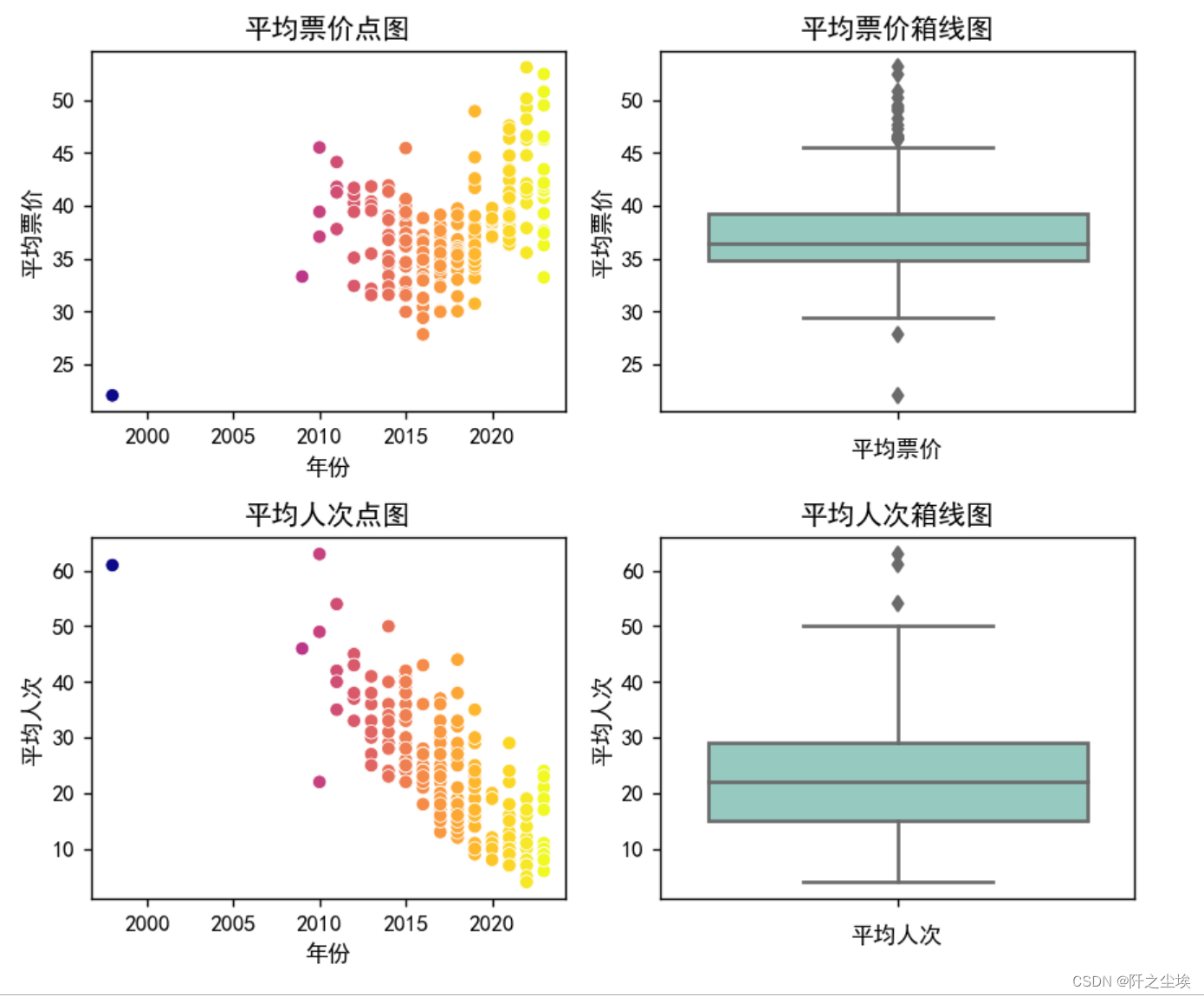
先看柱状图,可以看到平均票价和平均人次都是有一些离群点的,然后我们在左边画了他们和年份的的散点图,可以明细看到,随着年份越大,电影的平均人次越来越低,平均票价越来越高.....也就是最近的电影比起之前的电影来说,越来越贵,而且平均每场看的人越来越少......也侧面反映了我国电影业的一些“高票价”,‘幽灵剧场刷票房’ 等等乱象...
我注意到2000年之前有一个电影每场人次特别高,票价很低,它是什么电影我很好奇我就查看了一下:
movies[movies['年份']<2000]
原来是国民级别的《泰坦尼克号》,那没事了,名副实归。
不同年份的高票房电影数量:
plt.figure(figsize=(7, 3), dpi=128)
year_count = movies['年份'].value_counts().sort_index()
sns.lineplot(x=year_count.index, y=year_count.values, marker='o', lw=1.5, markersize=3)
plt.fill_between(year_count.index, 0, year_count, color='lightblue', alpha=0.8)
plt.title('不同年份高票房电影数量')
plt.xlabel('年份')
plt.ylabel('电影数量')
# 在每个数据点上标注数值
for x, y in zip(year_count.index, year_count.values):plt.text(x, y+0.2, str(y), ha='center', va='bottom', fontsize=8)plt.tight_layout()
plt.show()
可以看到,我国高票房的电影,从2010年开始高速增长,到2017年到达峰值,著名的《战狼2》就是2017年上映的,然后2018和2019略微下降,2020年断崖下跌,,为什么,懂得懂得,疫情原因嘛。
对高票房电影不同月份的占比百分比分析:
plt.figure(figsize=(4, 4),dpi=128)
month_count = movies['月份'].value_counts(normalize=True).sort_index()
# 绘制饼图
sns.set_palette("Set3")
plt.pie(month_count, labels=month_count.index, autopct='%.1f%%', startangle=140, counterclock=False,wedgeprops={'alpha': 0.9})
plt.axis('equal') # 保证饼图是正圆形
plt.text(-0.3,1.2,'不同月份高票房电影数量',fontsize=8)
plt.tight_layout()
plt.show()
我们可以看到,高票房电影主要集中在2月,7月,12月,三个月份区间。
理由也很简单,2月春节,7月暑假,12月跨年.....电影都喜欢这三个时间段上映。
自定义评价指标
我们上面都是之间拿票房进行分析的,我们发现,票房高的电影真的是反映了看的人多嘛?它真的是受观众喜欢的好电影嘛?
数据有限,虽然我们无法剔除宣传,时间热点,导演,社会风气等等影响因素,但是我们可以把票价进行一定的控制。因为票房高的电影也有可能是票价过高造成的,所以我们用‘票房/平均票价’,然后和‘平均人次’进行一个加权求和。
票房/平均票价 表示看电影的人群量,给7成权重,平均人次 给一个3层的权重,然后都进行标准化统一数据单位,加起来就成为我们自己的评价指标:
为了方便标准化我们先导入一个机器学习库里面sklearn的标准化函数
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()计算指标:
movies['我的评价指标']=(movies['票房(亿)'].astype(float)/movies['平均票价'].astype(float))
data1=scaler.fit_transform(movies[['我的评价指标', '平均人次']])
movies['我的评价指标']=0.7*data1[:,0]+0.3*data1[:,1]
movies=movies.sort_values(by='我的评价指标',ascending=False)画图查看:
my_top_movies = movies.nlargest(20, '我的评价指标')
plt.figure(figsize=(7, 4),dpi=128)
ax = sns.barplot(x='我的评价指标', y='标题', data=my_top_movies, orient='h',alpha=0.6,palette='rainbow_r')
#plt.xticks(rotation=80, ha='center')# 在柱子上标注数值
for p in ax.patches:ax.annotate(f'{p.get_width():.2f}', (p.get_width(), p.get_y() + p.get_height() / 2.),va='center', fontsize=8, color='gray', xytext=(5, 0),textcoords='offset points')plt.title('前20电影')
plt.xlabel('我的评价指标')
plt.ylabel('电影名称')
plt.tight_layout()
plt.show()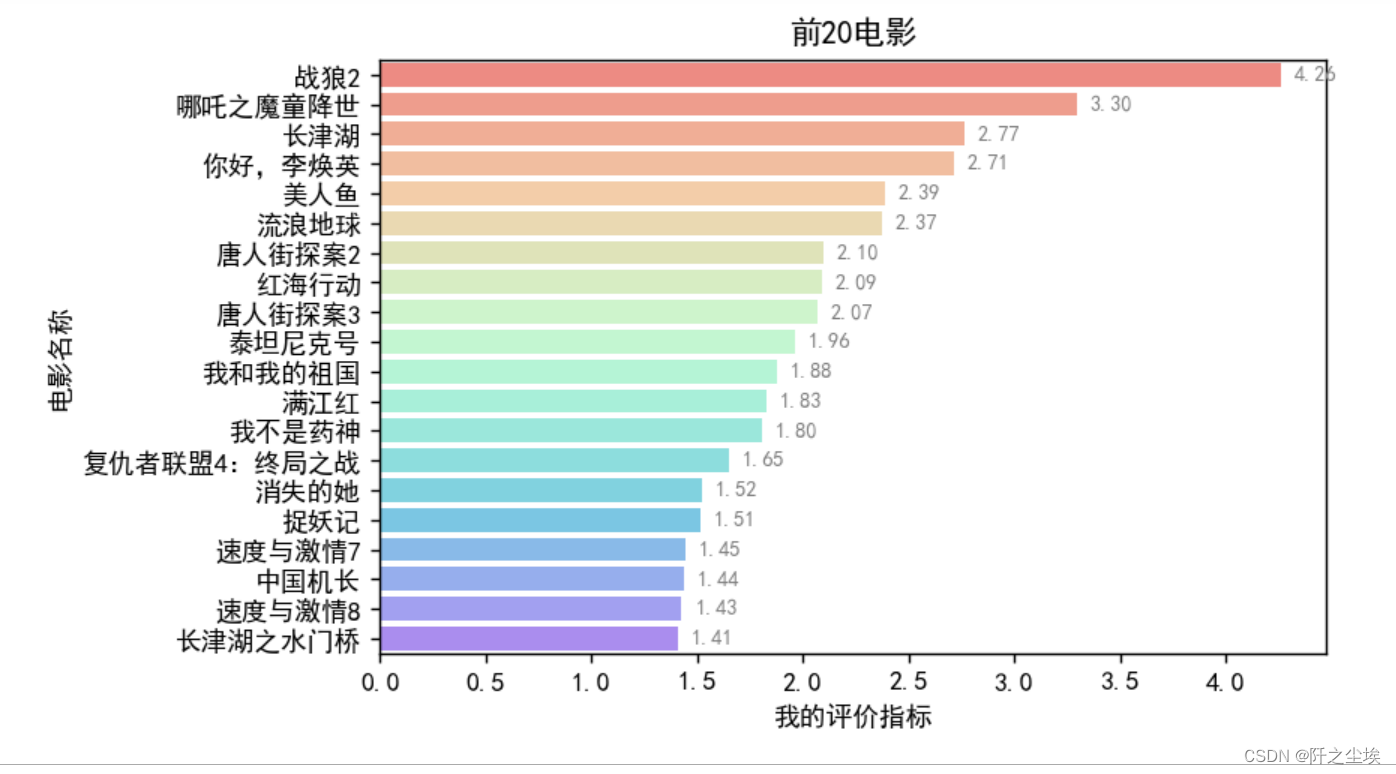
和之前的最高票房前20 的作对比,这样我们能比较哪些是票房过高的电影,哪些是可能被低估的电影。
def get_unique_elements(list1, list2):# 获取每个列表中的唯一元素set1 = set(list1) ; set2 = set(list2)unique_to_list1 = list(set1 - set2)unique_to_list2 = list(set2 - set1)common_elements = list(set1 & set2)return unique_to_list1, common_elements, unique_to_list2
票价过高的电影,确实是好电影,被低估的电影=get_unique_elements(top_movies['标题'].to_list(), my_top_movies['标题'].to_list())这个函数的作用是选出第一个列表特有的元素,两个列表共有的元素,第二个列表特有的元素。
若这个电影在票房前20里面,也在我们的评价指标前20里面,那么就是好电影。若它在在票房前20里面,不在我们的评价指标前20里面,那可能就是票价过高的“水分电影”。
print(f'票价过高的电影:{票价过高的电影},\n\n确实是好电影:{确实是好电影},\n\n低估的电影:{被低估的电影}')
票价过高的电影:['八佰', '我和我的家乡', '独行月球', '流浪地球2'],emmmm
这几个电影,我都没怎么深入了解就不评价了......
总结
本次演示了从数据爬虫获取,到清洗整理,再到计算和可视化分析的全流程,再多加点图和文字分析角度,加点模型,作为大多数的本科生的论文算是差不多的工作量了。
相关文章:
Python数据分析案例30——中国高票房电影分析(爬虫获取数据及分析可视化全流程)
案例背景 最近总看到《消失的她》票房多少多少,《孤注一掷》票房又破了多少多少..... 于是我就想自己爬虫一下获取中国高票房的电影数据,然后分析一下。 数据来源于淘票票:影片总票房排行榜 (maoyan.com) 爬它就行。 代码实现 首先爬虫获…...

科技资讯|苹果Vision Pro头显申请游戏手柄专利和商标
苹果集虚拟现实和增强现实于一体的头戴式设备 Vision Pro 推出一个月后,美国专利局公布了两项苹果公司申请的游戏手柄专利,其中一项的专利图如下图所示。据 PatentlyApple 报道,虽然专利本身并不能保证苹果公司会推出游戏手柄,但是…...

Compose学习 - remember、mutableStateOf的使用
一、需求 在显示界面中,数据变动,界面刷新是非常常见的操作,所以使用compose该如何实现呢? 二、remember、mutableStateOf的使用 我们可以借助标题的两个概念 remember、mutableStateOf来完成。这里先不写定义,定义…...
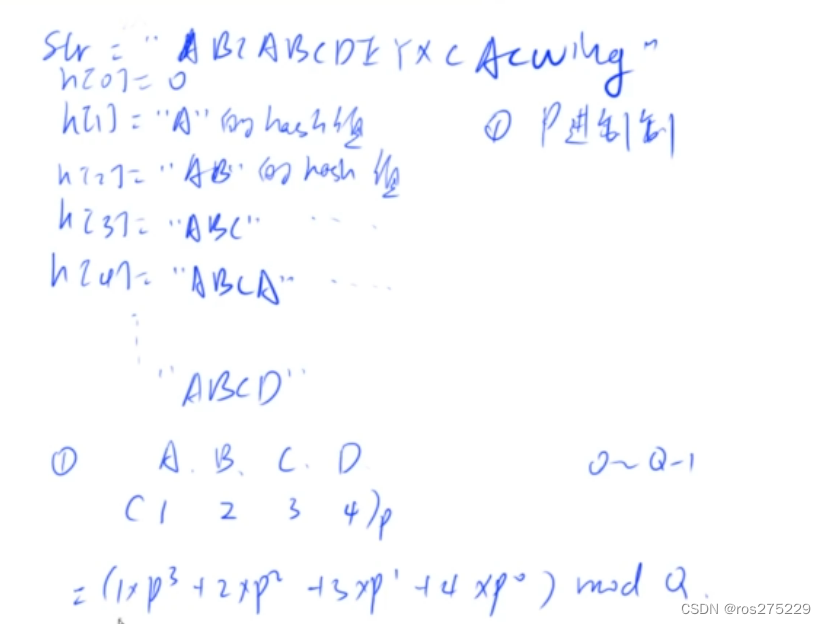
字符串哈希
字符串前缀哈希法 str "ABCABCDEHGJK" 预处理每一个前缀的哈希值,如 : h[0] 0; h[1] "A"的哈希值 h[2] "AB"的哈希值 h[3] "ABC"的哈希值 h[4] "ABCA"的哈希值 问题 : 如何定义一个前缀的哈希值 : 将字符串看…...

【python】【centos】使用python杀死进程后自身也会退出
问题 使用python杀死进程后自身程序也会退出,无法执行后边的代码 这样不行: # cmd " ps -ef | grep -v grep | grep -E task_pull_and_submit.py$|upgrade_system.py$| awk {print $2}"# pids os.popen(cmd).read().strip(\n).split(\n)# p…...
【ES系列】(一)简介与安装
首发博客地址 首发博客地址[1] 系列文章地址[2] 教学视频[3] 为什么要学习 ES? 强大的全文搜索和检索功能:Elasticsearch 是一个开源的分布式搜索和分析引擎,使用倒排索引和分布式计算等技术,提供了强大的全文搜索和检索功能。学习 ES 可以掌…...

opencv案例06-基于opencv图像匹配的消防通道障碍物检测与深度yolo检测的对比
基于图像匹配的消防通道障碍物检测 技术背景 消防通道是指在各种险情发生时,用于消防人员实施营救和被困人员疏散的通道。消防法规定任何单位和个人不得占用、堵塞、封闭消防通道。事实上,由于消防通道通常缺乏管理,导致各种垃圾࿰…...

练习2:88. 合并两个有序数组
这里写自定义目录标题 题目解体思路代码 题目 给你两个按非递减顺序排列的整数数组 nums1 和 nums2,另有两个整数 m和 n ,分别表示 nums1 和 nums2中的元素数目。 请你合并nums2 到 nums1 中,使合并后的数组同样按非递减顺序排列。 注意&a…...
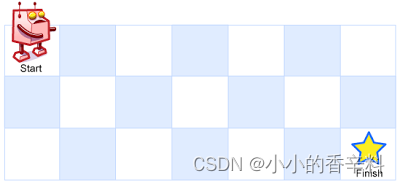
【代码随想录day23】不同路径
题目 一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。 机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish” )。 问总共有多少条不同的路径? 示…...
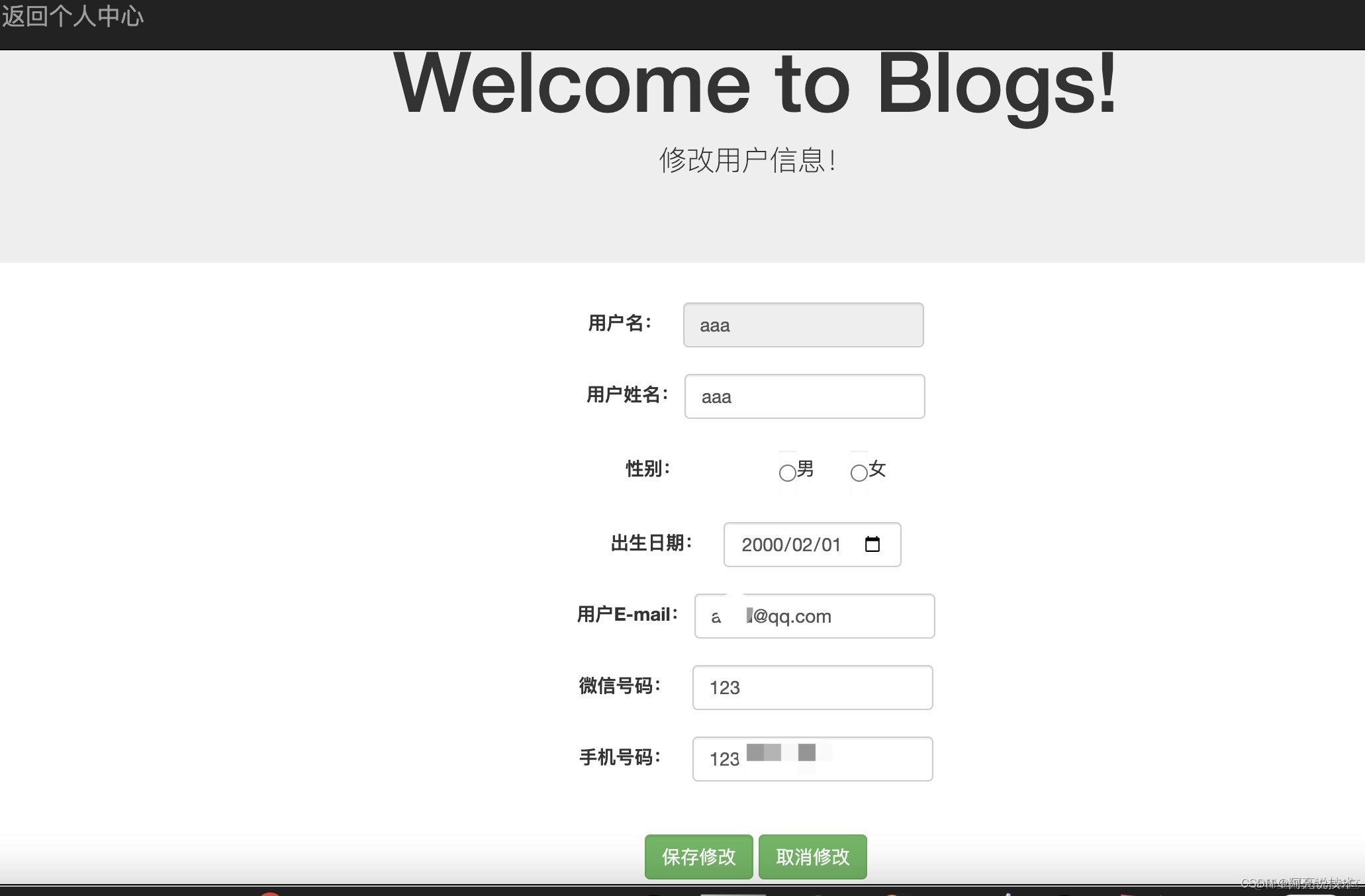
SpringBoot 博客网站
SpringBoot 博客网站 系统功能 登录注册 博客列表展示 搜索 分类 个人中心 文章分类管理 我的文章管理 发布文章 开发环境和技术 开发语言:Java 使用框架: SpringBoot jpa H2 Spring Boot是一个用于构建Java应用程序的开源框架,它是Spring框架的一…...
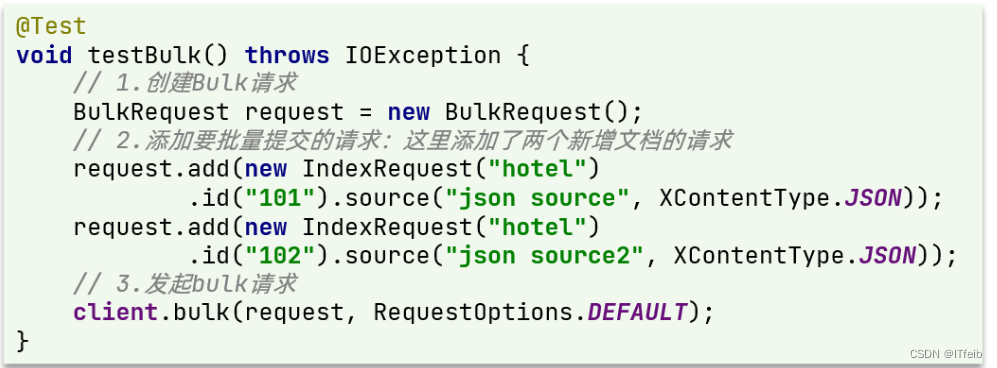
【分布式搜索引擎elasticsearch】
文章目录 1.elasticsearch基础索引和映射索引库操作索引库操作总结 文档操作文档操作总结 RestAPIRestClient操作文档 1.elasticsearch基础 什么是elasticsearch? 一个开源的分布式搜索引擎,可以用来实现搜索、日志统计、分析、系统监控等功能 什么是…...
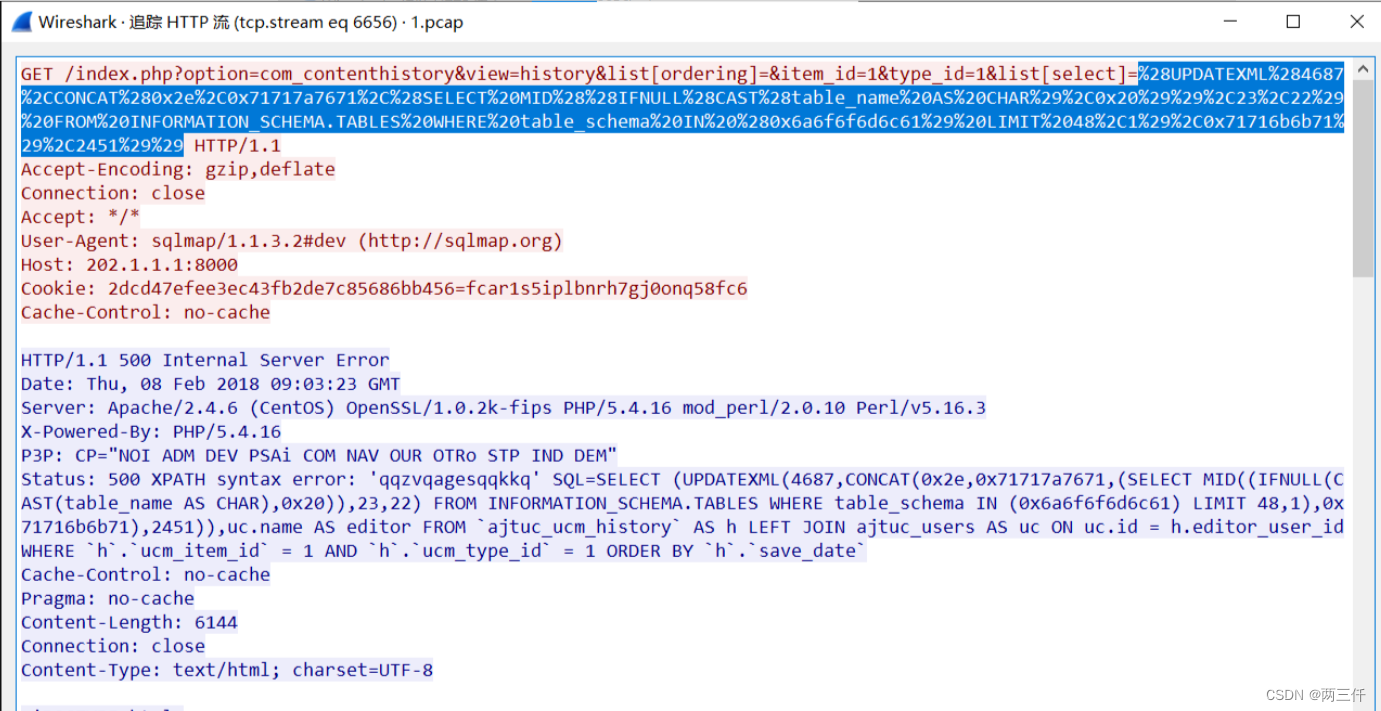
wireshark 流量抓包例题
一、题目一(1.pcap) 题目要求: 1.黑客攻击的第一个受害主机的网卡IP地址 2.黑客对URL的哪一个参数实施了SQL注入 3.第一个受害主机网站数据库的表前缀(加上下划线例如abc) 4.第一个受害主机网站数据库的名字 看到题目SQL注入,…...

【Axure视频教程】表格编号函数
今天教大家在Axure里如何使用表格编号函数,包括表格编号函数的基本原理、在需要翻页的中继器表格里如何正确使用该函数、函数作为条件的应用,包括让指定第几行的元件默认变色效果以及更新对应第几行内容的效果。该教程主要讲解表格编号函数,不…...

大数据-玩转数据-Flink定时器
一、说明 基于处理时间或者事件时间处理过一个元素之后, 注册一个定时器, 然后指定的时间执行. Context和OnTimerContext所持有的TimerService对象拥有以下方法: currentProcessingTime(): Long 返回当前处理时间 currentWatermark(): Long 返回当前watermark的时间戳 registe…...

Linux 操作系统实战视频课 - GPIO 基础介绍
文章目录 一、GPIO 概念说明二、视频讲解沉淀、分享、成长,让自己和他人都能有所收获!😄 📢本篇我们将讲解 GPIO 。 一、GPIO 概念说明 ARM 平台中的 GPIO(通用输入/输出)是用于与外部设备进行数字输入和输出通信的重要硬件接口。ARM 平台的 GPIO 特性可以根据具体的芯…...

ChatGPT在医疗保健信息管理和电子病历中的应用前景如何?
ChatGPT在医疗保健信息管理和电子病历中有着广阔的应用前景,可以提高医疗保健行业的效率、准确性和可访问性。本文将详细讨论ChatGPT在医疗保健信息管理和电子病历中的应用前景,以及相关的益处和挑战。 ### 1. ChatGPT在医疗保健信息管理中的应用前景 …...

安防监控/视频存储/视频汇聚平台EasyCVR接入海康Ehome车载设备出现收流超时的原因排查
安防视频监控/视频集中存储/云存储/磁盘阵列EasyCVR平台可拓展性强、视频能力灵活、部署轻快,可支持的主流标准协议有国标GB28181、RTSP/Onvif、RTMP等,以及支持厂家私有协议与SDK接入,包括海康Ehome、海大宇等设备的SDK等。视频汇聚平台既具…...

【zookeeper】zookeeper监控指标查看
zookeeper 监控指标 日常工作中,我们有时候需要对zookeeper集群的状态进行检查,下面分享一些常用的方法。 zookeeper获取监控指标已知的有两种方式: 通过zookeeper自带的四字命令 (four letter words command )获取各…...
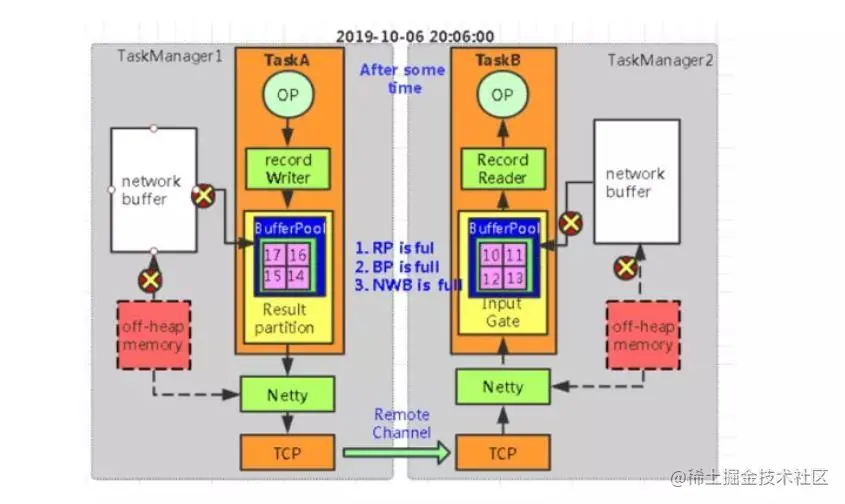
Flink 如何处理反压?
分析&回答 什么是反压(backpressure) 反压通常是从某个节点传导至数据源并降低数据源(比如 Kafka consumer)的摄入速率。反压意味着数据管道中某个节点成为瓶颈,处理速率跟不上上游发送数据的速率,而…...
JAVA基础-JDBC
本博客记录JAVA基础JDBC部分的学习内容 JDBC基本概念 JDBC : JAVA链接数据库,是JAVA链接数据库的技术的统称,包含如下两部分: 1. JAVA提供的JDBC规范(即各种数据库接口)存储在java.sql 和 javax.sql中的api 2. 各个数…...

从CST到ADS/Keysight:手把手教你导出精准的Touchstone文件做联合仿真
从CST到ADS/Keysight:手把手教你导出精准的Touchstone文件做联合仿真 在射频和微波系统设计中,电磁仿真与电路仿真的无缝衔接是提升设计效率的关键。许多工程师都曾遇到过这样的困境:在CST中精心优化的天线或滤波器模型,导出后却无…...

别再乱用userdel -r了!UOS Server用户管理避坑指南与最佳实践
UOS Server用户管理深度避坑指南:从原理到实践的全面解析 在国产化操作系统UOS Server的运维实践中,用户与组管理看似基础却暗藏玄机。许多中级运维工程师往往在删除测试账户、修改用户属性或调整组关系时遭遇意想不到的问题——残留的配置文件导致后续创…...

避坑指南:Ubuntu 20.04上VINS-Fusion环境搭建,从源码修改到手机数据实测的完整流程
Ubuntu 20.04下VINS-Fusion环境搭建全流程避坑手册 当你在Ubuntu 20.04上尝试搭建VINS-Fusion环境时,可能会遇到各种令人头疼的问题。从依赖项安装到源码修改,再到手机摄像头数据的适配,每一步都可能隐藏着意想不到的"坑"。本文将带…...

Frida-ps -U 连接失败的五层排查法
1. 这不是 Frida 的问题,是你的设备和 Frida 之间“没对上暗号” 你执行 frida-ps -U ,终端卡住三秒,然后甩出一句 Failed to enumerate processes: timeout was reached ——这行报错我见过太多次了。它不像编译错误那样指向某一行代码…...

向量化映射框架优化图着色问题的FPGA实现
1. 问题背景与核心挑战图着色问题作为组合优化领域的经典NP难问题,在集成电路布局分解、寄存器分配、逻辑最小化等场景中具有广泛应用。传统Ising机采用独热编码(one-hot encoding)方案,将每个节点的q种颜色状态映射为q个物理比特…...
)
Codex入门15-命令速查(实用工具:全部命令和快捷键一网打尽,打印贴墙上)
Codex入门15-命令速查(实用工具:全部命令和快捷键一网打尽,打印贴墙上) 📌 文章简介:这是一篇你一定要收藏的"字典文章"。本文把 Codex CLI 的所有交互式斜杠命令、命令行参数、键盘快捷键、环境变量整理成清晰的表格——打印出来贴墙上,随查随用。每条命令都…...

大数据搬运工 · Sqoop
🚛 在「关系型数据库」与「Hadoop 大仓库」之间 | 批量、高效、并行运输数据💡 生活比喻: 想象你的学校图书馆(关系型数据库)有一大堆超重的图书,而学校新建的“超级储藏大楼”(Hado…...

在 LangGraph 里做动态路由:意图分类+置信度阈值+回退链路
LangGraph 生产级动态路由实战:意图分类+置信度校准+多级回退链路全栈实现 关键词 LangGraph, 大语言模型Agent, 动态路由, 意图分类, 置信度阈值校准, 多级回退机制, 可控Agent架构 摘要 当前大模型Agent开发已从玩具级Demo走向生产级落地,静态路由的固定执行逻辑无法适…...

2026 谷歌 GEO 已成流量主战场,不懂 AI 搜索直接掉队
📉 三个信号同时出现,意味着一个时代结束了:① 你的Google/百度自然搜索流量,连续两个季度下滑超过15%② 你精心优化的"关键词"排名,依然带不来预期的转化③ 你的目标用户,开始在 ChatGPT、Perpl…...

3个步骤掌握Betaflight飞控固件:从零开始打造专业级无人机飞行体验
3个步骤掌握Betaflight飞控固件:从零开始打造专业级无人机飞行体验 【免费下载链接】betaflight Open Source Flight Controller Firmware 项目地址: https://gitcode.com/gh_mirrors/be/betaflight Betaflight作为全球最受欢迎的开源飞控固件,为…...