基于OpenCV+LPR模型端对端智能车牌识别——深度学习和目标检测算法应用(含Python+Andriod全部工程源码)+CCPD数据集
目录
- 前言
- 总体设计
- 系统整体结构图
- 系统流程图
- 运行环境
- Python 环境
- OpenCV环境
- Android环境
- 1. 开发软件和开发包
- 2. JDK设置
- 3. NDK设置
- 模块实现
- 1. 数据预处理
- 2. 模型训练
- 1)训练级联分类器
- 2)训练无分割车牌字符识别模型
- 3. APP构建
- 1)导入OpenCV库
- 2)导入动态链接库so文件
- 3)引入C++support、用CMake生成链接库
- 4. 导入训练好的模型
- 5.注册内容提供器、声明SD卡访问权限
- 6.配置Lite Pal数据库
- 系统测试
- 1. 训练分数和损失可视化
- 2. APP测试结果
- 工程源代码下载
- 其它资料下载
前言
本项目基于CCPD数据集和LPR(License Plate Recognition,车牌识别)模型,结合深度学习和目标检测等先进技术,构建了一个全面的车牌识别系统,实现了从车牌检测到字符识别的端到端解决方案。
首先,我们利用CCPD数据集,其中包含大量的中文车牌图像,用于模型的训练和验证。这个数据集的丰富性有助于模型更好地理解不同场景下的车牌特征。
接着,我们引入LPR模型,这是一种专门设计用于车牌识别的模型。通过深度学习技术,LPR模型可以学习和识别不同类型的车牌,无论是小轿车、卡车还是摩托车。
在模型设计中,我们使用目标检测技术,让模型能够自动定位和框选出图像中的车牌区域。这样,系统可以在不同图像中准确地找到车牌,并且不受不同角度、光照等因素的影响。
通过将车牌区域提取出来,我们将其输入到LPR模型中,进行字符识别。模型将车牌上的字符识别出来,从而实现了完整的车牌识别功能。
综合上述技术,本项目实现了一个端到端的车牌识别系统,能够高效准确地检测和识别车牌,无论是在不同的场景还是在各种环境下。这种系统在交通管理、安防监控等领域具有重要的应用价值。
总体设计
本部分包括系统整体结构图和系统流程图。
系统整体结构图
系统整体结构如图所示。

系统流程图
系统流程如图所示。
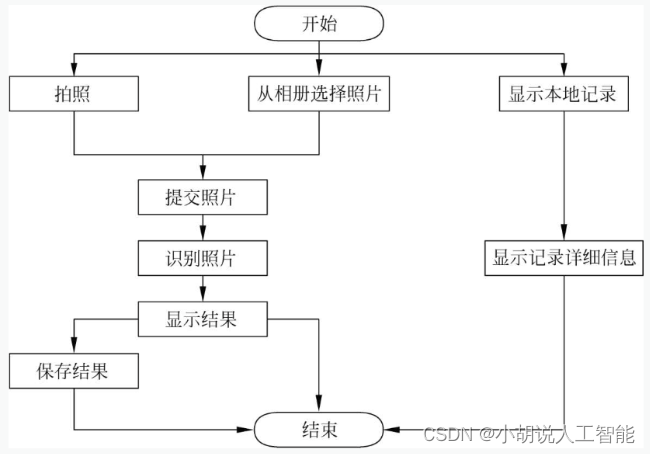
APP中应用的算法流程包括车牌粗定位、车牌精定位、快速倾斜矫正和无分割端到端字符识别的算法描述及流程,如下图所示。
运行环境
本部分包括 Python 环境、OpenCV 环境和 Andriod 环境。
Python 环境
在清华TUNA开源镜像站https://mirrors.tuna.tsinghua.edu.cn/下载Miniconda 3.4.7.12版本,根据自己的操作系统选择相应的版本。
在开始菜单中打开Anaconda Prompt ( miniconda3),进入命令行终端,并输入以下命令:
conda create -n tensorflow python=3.7#创建虛拟环境
conda install tensorflow-gpu #若没有独立GPU,可以选择安装CPU版本,去掉参数即可
conda install opencv-python=3.4.6
conda install pandas
#conda默认安装TensorFlow的2.1.0 stable版本
#其他常见的数据科学库如numpy在创建虚拟环境时或者安装TensorFlow
#若未安装,可以自行用conda或pip命令安装
OpenCV环境
进入OpenCV官网的release页面https://opencv.org/releases/中下载OpenCV 3.4.6 版本的Windows和Android两个包,并解压。
Android环境
安装相应版本的开发软件操作如下:
1. 开发软件和开发包
下载地址为https://developer.android.google.cn/studio/,APP开发使用Android Studio3.5.3版本。
创建NewProject,选择EmptyActivity->next,在Name输入框输入项目名称,Package name输入框中命名项目中java文件包名,Save location中指定项目存储路径,Language (语言)选择]ava,MinimumAPllevel指定项目兼容的最低API版本,设置后单击Finish按钮完成创建。
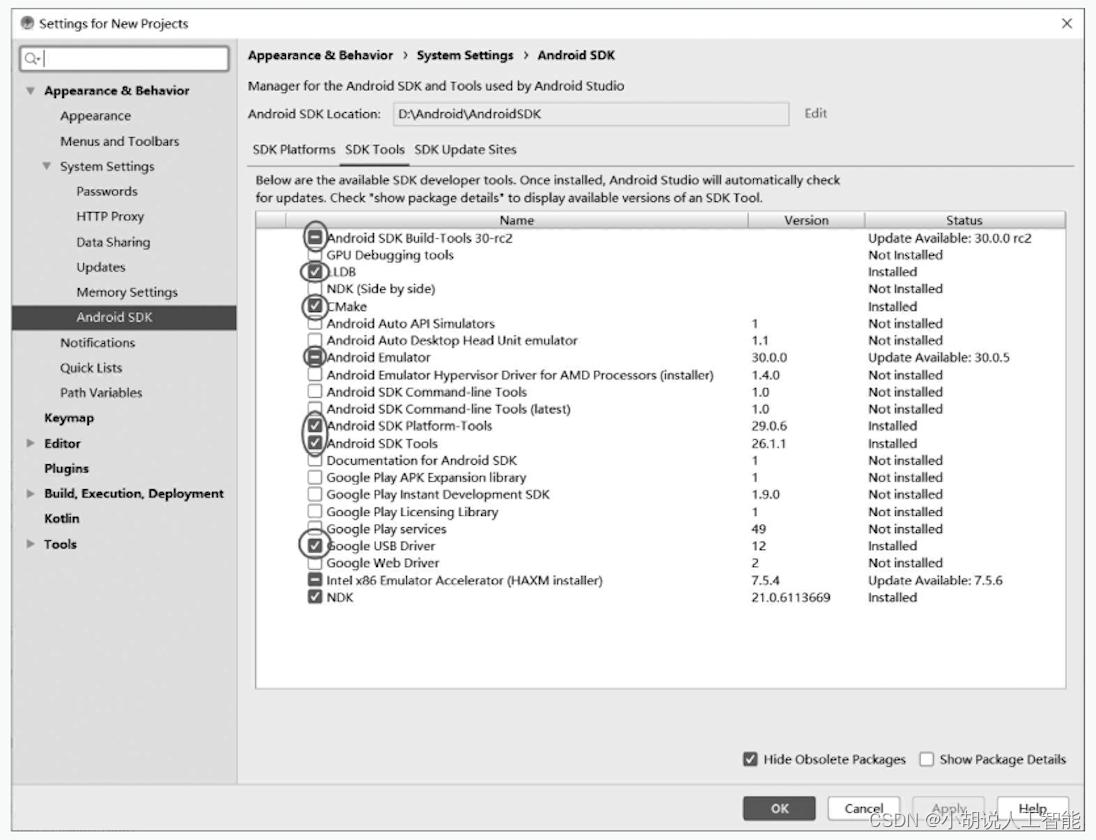
本项目的Package name命名为com.pcr.lpr。创建Project后,需安装SDK Platforms和SDKTools。单击窗口右上方右起第2个图标安装。
SDK Platforms只选中Android 9.0 (Pie) ,切换到SDK Tools选项卡,选中下图中画圈选项即可。
2. JDK设置
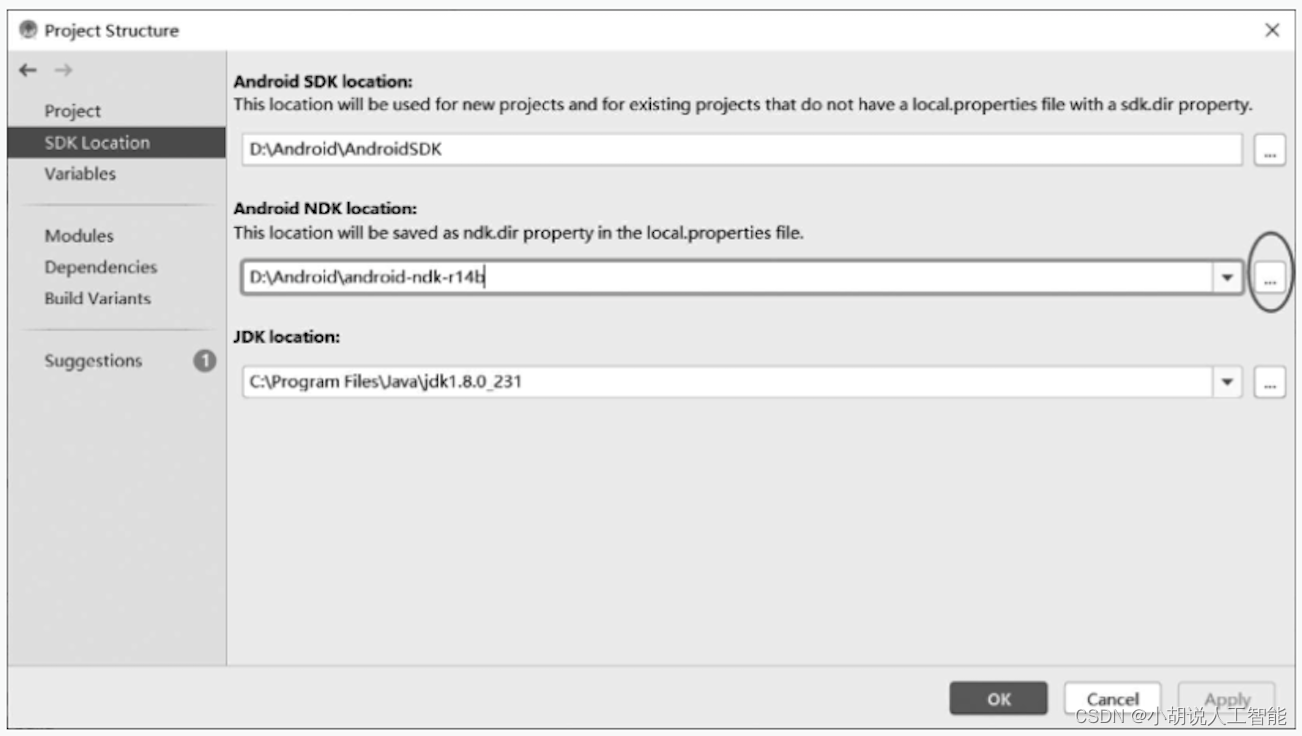
若系统中未安装JDK,可前往https://www.oracle.com/java/technologies/javase-downloads.html下载,单击Android Studio,单击下图界面右上方方框中的图标,打开Project Structure,并在JDK Location中填入JDK解压的文件夹路径。
3. NDK设置
在https://developer.android.google.cn/ndk/downloads/older_releases.html中下载Android-ndk-r14b版本NDK并解压。
打开Project Structure,在弹出的窗口中设置NDK路径,如图17-6所示。
模块实现
本项目包括3个模块:数据预处理、模型训练、APP构建,下面分别介绍各模块的功能及相关代码。
1. 数据预处理
从CCPD页面https://github.com/detectRecog/CCPD中下载数据集,解压得到图片数据如图所示。

获取数据集之后,进行预处理。依据数据集图片名称提供的信息对车牌进行裁剪,文件名依据“_”进行分割,第4组数据是图片中车牌的4个角点坐标,第5组数据是7位车牌信息,依据这两组数据可以得到分割后的车牌图片和车牌标签。
正样本和负样本的大小均为150X40,用于Cascade级联分类器训练。负样本可以随意裁剪,图片中没有车牌;正样本用于训练无分割车牌字符识别。相关代码如下:
#裁剪车牌
import cv2
import hashlib
import os, sys
import pandas as pd
import numpy as np
if not os.path.exists("output"):os.mkdir("output")
h = 40
w = 150
path = r"E:\ccpd_dataset\ccpd_base" #数据集所在路径
filenames = os.listdir(path)
fp = open("pos_image.txt", "w", encoding="utf-8")
fn = open("neg_image.txt", "w", encoding="utf-8")
#用于存储图片的每一位车牌信息
df = pd.DataFrame(columns=('pic_name', '0', '1', '2', '3', '4', '5', '6'))
#正样本分割图片中的车牌
count = 0
#for img_name in filenames[0:40000]:
#为保证省份全覆盖,采用全部数据,而不是40000张
for img_name in filenames:#读取图片的完整名字image_path = os.path.join(path, img_name)image = cv2.imread(image_path#以“-”为分隔符,将图片名切分,其中iname[4]为车牌字符,iname[2]为车牌坐标iname = img_name.rsplit('/', 1)[-1].rsplit('.', 1)[0].split('-')plateChar = iname[4].split("_")#将文件名,七位车牌写入dataframe中new_line = [new_name, plateChar[0], plateChar[1], plateChar[2], plateChar[3],plateChar[4], plateChar[5], plateChar[6]]df.loc[count, :] = new_line#crop车牌的左上角和右下角坐标[leftUp, rightDown] = [[int(eel) for eel in el.split('&')]for el in iname[2].split('_')]#crop图片img = image[leftUp[1]:rightDown[1], leftUp[0]:rightDown[0]]height, width, depth = img.shape#将图片压缩成40*150,计算压缩比imgScale = h / height#(目标宽-实际宽)/2,分别向左、右拓宽,所有除以2deltaD = int((w / imgScale - width) / 2)#切割宽度向左平移,保证补够250leftUp[0] = leftUp[0] - deltaD#切割宽度向右平移,保证补够250rightDown[0] = rightDown[0] + deltaD#如果向左平移为负,坐标为0if (leftUp[0] < 0):rightDown[0] = rightDown[0] - leftUp[0]leftUp[0] = 0#按照高/宽 =40/150的比例切割,注意切割的结果不是40和250img = image[leftUp[1]:rightDown[1], leftUp[0]:rightDown[0]]newimg = cv2.resize(img, (w, h)) #resize成40*250new_name = 'pic' + str(count + 1).rjust(6, '0')cv2.imwrite("../output/pos/" + new_name + '.jpg', newimg)#将图片信息写入.txt文件中fp.write('pos/'+new_name +'.jpg'+'1 0 0 150 40' + plateChar + '\n')count += 1
df.to_csv('./pos.csv')
fp.close()
#负样本图片中没有车牌
count = 0
for img_name in filenames[400000:80000]:#补充完整图片路径image_path = os.path.join(path, img_name)image = cv2.imread(image_path)#裁剪不含车牌的区域new_img = image[0:40, 0:150]new_name = 'pic' + str(count + 40001).rjust(6, '0')cv2.imwrite("../output/neg/" + new_name + '.jpg', new_img)#将图片信息写入.txt文件中fn.write('neg/' + new_name + '.jpg' '\n')count += 1
fn.close()
裁剪得到的正样本,如下图所示。

裁剪得到的负样本,如下图所示。

2. 模型训练
级联分类器和无分割车牌字符的卷积神经网络模型的训练,具体过程如下。
1)训练级联分类器
得到正样本和负样本后,在终端中切换到之前下载OpenCV的解压目录中\build\x64\vc15\bin\的目录。以D:\opencv\为例:
cd D:\opencv\build\x64\vc15\bin\
在终端中执行如下命令,其中-info填入正样本.txt文件的路径;-bg填入负样本.txt文件的路径;-num根据上一步分割得到的正样本数量修改;-W、-h分别为样本图片的宽和高,所有样本图片的宽高必须一致,故此处填入上一步裁剪车牌设置的样本宽高。
opencv_createsamples.exe -vec pos.vec -info pos_image.txt -bg neg_image.txt -w 150 -h 40 -num 40000
执行完毕后生成pos.vec文件,接着在终端中执行如下命令:
opencv_traincascade.exe -data xml -vec pos.vec -bg neg_image.txt -numPos 40000 -numNeg 80000 -numStages 15 -precalcValBufSize 5000 -precalcIdxBufSize 5000 -w 150 -h 40 -maxWeakCount 200 -mode ALL -minHitRate 0.990 -maxFalseAlarmRate 0.20
其中-vec填入上一步生成的pos.vec文件路径,-bg填入负样本.txt文件路径,-numPos和 -numNeg根据上一步分割得到的正样本数量修改,其他参数按命令提供的参数即可。
上述命令执行完毕后,会在样本目录下得到训练好的cascade.xml的级联分类器文件。
2)训练无分割车牌字符识别模型
无分割车牌字符识别使用卷积神经网络实现,相关代码如下:
import numpy as np
import pandas as pd
import pickle
import tensorflow as tf
from tensorflow.keras.layers import Dense, Conv2D, Flatten, MaxPooling2D
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras.callbacks import TensorBoard
BATCH_SIZE = 64
def process_info(img_info):#处理每条csv中的信息,返回图片名称和one-hot后的标签img_path = img_info[0]label = np.zeros([238]) #7*34for i in range(7):index = int(img_info[i + 1])label[i * 34 + index] = float(1)return (img_path, label)
def parse_function(filename, label):#返回归一化后的解码图片矩阵和标签矩阵#读取文件image_string = tf.io.read_file(filename)#解码image_decoded = tf.image.decode_jpeg(image_string, channels=3)#变型image_resized = tf.image.resize(image_decoded, [150, 40])#归一化image_normalized = image_resized / 255.0return image_normalized, label
def create_dataset(filenames, labels):#创建数据集管道#补充完整的图片路径filenames = "D:/DL & ML/output/pos/" + filenames#从张量切片创建自定义数据集dataset = tf.data.Dataset.from_tensor_slices((filenames, labels))#并行处理dataset = dataset.map(parse_function,num_parallel_calls=tf.data.experimental.AUTOTUNE)#数据集分批dataset = dataset.batch(BATCH_SIZE)#在训练时预先加载数据dataset = dataset.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)return dataset
def macro_f1(y, y_hat, thresh=0.5):#计算一个批次的宏f1分数,返回宏f1分数y_pred = tf.cast(tf.greater(y_hat, thresh), tf.float32)tp = tf.cast(tf.math.count_nonzero(y_pred * y, axis=0), tf.float32)fp = tf.cast(tf.math.count_nonzero(y_pred * (1 - y), axis=0), tf.float32)fn = tf.cast(tf.math.count_nonzero((1 - y_pred) * y, axis=0), tf.float32)f1 = 2 * tp / (2 * tp + fn + fp + 1e-16)macro_f1 = tf.reduce_mean(f1)return macro_f1
def myModel():#自定义模型
model = Sequential()
#两层卷积一层池化model.add(Conv2D(64,(3,3),padding='same', activation='relu',input_shape=[150, 40, 3]))model.add(Conv2D(64, (3, 3), padding='same', activation='relu'))model.add(MaxPooling2D())
#两层卷积一层池化model.add(Conv2D(128, (3, 3), padding='same', activation='relu'))model.add(Conv2D(128, (3, 3), padding='same', activation='relu'))model.add(MaxPooling2D())
#两层卷积一层池化model.add(Conv2D(256, (3, 3), padding='same', activation='relu'))model.add(Conv2D(256, (3, 3), padding='same', activation='relu'))model.add(Conv2D(256, (3, 3), padding='same', activation='relu'))model.add(MaxPooling2D())#全连接层model.add(Flatten())model.add(Dense(1024, activation='relu'))model.add(Dense(512, activation='relu'))model.add(Dense(238, activation='sigmoid'))return model
if __name__ == "__main__":#读取数据以及预处理img_info = pd.read_csv(r"D:\DL & ML\output\pos.csv")train_pic_name = img_info.pic_nametrain_label = np.zeros([len(img_info), 238])for i in range(len(img_info)):_, train_label[i, ] = process_info(img_info.loc[i])#创建网络model = myModel()model.compile(loss='binary_crossentropy',optimizer='adam',metrics=[macro_f1])train_ds = create_dataset(train_pic_name, train_label)#调用tensorboardtb=TensorBoard(log_dir='logs')#训练网络model.fit(train_ds, epochs=30, callbacks=[tb])#保存模型model.save("segmention_free.h5")
训练完成后,在代码文件所在目录下得到segmention_free.h5模型文件。
3. APP构建
APP构建相关步骤如下。
1)导入OpenCV库
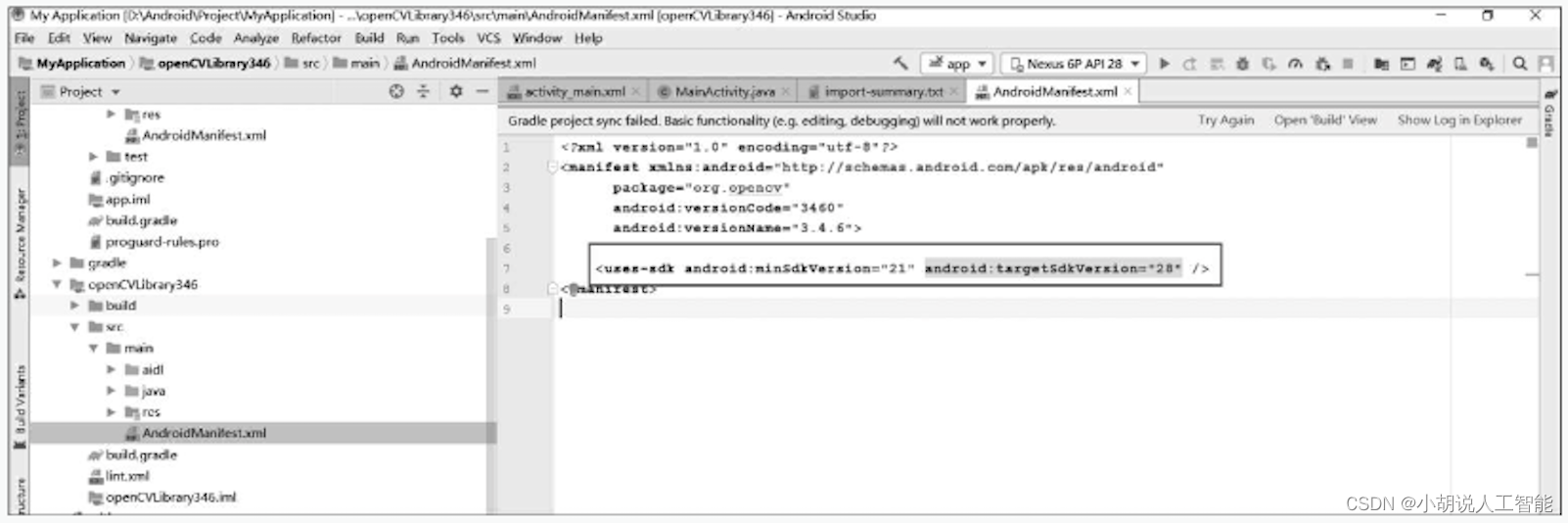
在Android Studiot左侧Project栏 , myApplicationk处右击→New→Module,创建新模块。单击ImportEclipseADTProject,选择sdk/java目录,单击next按钮完成导入。在界面左侧Project区打开openCVLibrary346\src\main\AndroidManifest.xml,删除下图方框中的文字。
在左侧Project区打开新引入的Module\build.gradle,修改compileSdkVersion和targetSdkVersion为28, 修改minSdkVersion为19。
在左侧Project区打开app\build.gradle , 在dependencies中添加下列语句:
implementation project(path:':openCVLibrary346')
2)导入动态链接库so文件
在app\build.gradle的android{defaultConfig{}}中添加下列语句:
ndk {abiFilters 'armeabi -v7a'
}
创建 app\src\main\jniLibs目录, 将OpenCV-android-sdk-3.4.6\sdk\native\libs下的armeabi-v7复制到jniLibs中。
3)引入C++support、用CMake生成链接库
在app\build.gradle的android{defaultConfig{}}中添加下列语句:
externalNativeBuild{cmake{cppFlags " - std=gnu++11"}
}
创建app\src\main\jniLibs目录。在jniLibs下创建javaWrapper.cpp,引入jni.h和string.h,所有用native声明的java本地函数将在该文件中用C++实现。
创建app\src\main\jniLibs\include目录,所有.h文件包含在该目录下。创建app\src\main\jniLibs\src目录,除javaWrapper.cpp外,所有.cpp文件都包含在该目录下。在APP目录下新建File命名为CMakeLists.txt,添加如下代码:
cmake_minimum_required(VERSION 3.4.1)
include_directories(src/main/jni/include)
include_directories(src/main/jni)
aux_source_directory(src/main/jni SOURCE_FILES)
aux_source_directory(src/main/jni/src SOURCE_FILES_CORE)
list(APPEND SOURCE_FILES ${SOURCE_FILES_CORE})
#修改为自己的opencv-android-sdk的jni路径
set(OpenCV_DIR D:\\Android\\OpenCV-android-sdk-3.4.6\\sdk\\native\\jni)
#查找包
find_package(OpenCV REQUIRED)
#添加库
add_library( #设置库的名称lprSHARED${SOURCE_FILES})
find_library( #设置变量路径名称log-liblog)
#将找到的库链接给lpr库
target_link_libraries( #指定目标库lpr${OpenCV_LIBS}#将目标库链接到NDK中包含的日志库${log-lib})
#在app\build.gradle的android{ }中添加下列代码
externalNativeBuild {cmake {path "CMakeLists.txt"}
}
4. 导入训练好的模型
创建目录app\src\main\assets\lpr,将训练好的模型复制到目录下。
5.注册内容提供器、声明SD卡访问权限
打开app\src\AndroidManifest.xml在<application> </application>内添加下列代码:
<providerandroid:name="androidx.core.content.FileProvider"android:authorities="com.example.cameraalbumtest.fileprovider"android:exported="false"android:grantUriPermissions="true"><meta-dataandroid:name="android.support.FILE_PROVIDER_PATHS"android:resource="@xml/file_paths" />
</provider>
在app\src\res下创建目录xml,xml中创建file_paths.xml并修改代码:
<?xml version="1.0" encoding="utf-8"?>
<paths xmlns:android="http://schemas.android.com/apk/res/android">
<external-pathname="my_images"path=""/>
</paths>
Name属性可以随意设置,path为空表示将整个SD卡进行共享,也可修改为使用provider的文件地址。
打开app\src\AndroidManifest.xml在<application> </application>外添加下列代码:
<uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE" />
6.配置Lite Pal数据库
打开app\build.gradle,在dependencies内添加代码:
implementation "org.litepal.android:core:2.0.0"
在app\src\main\assets内创建Android Resource File(安卓资源文件),修改代码为:
<?xml version="1.0" encoding="utf-8"?>
<litepal><dbname value="CarStore"></dbname><version value="1"></version><list><mapping class="com.pcl.lpr.Cars"/></list>
</litepal>
系统测试
本部分包含训练分数和损失可视化、APP测试结果。
1. 训练分数和损失可视化
无分割车牌字符识别模型训练完成后,在终端中输入以下命令:
tensorboard --logdir logs # 其中--logdir填写logs目录的路径
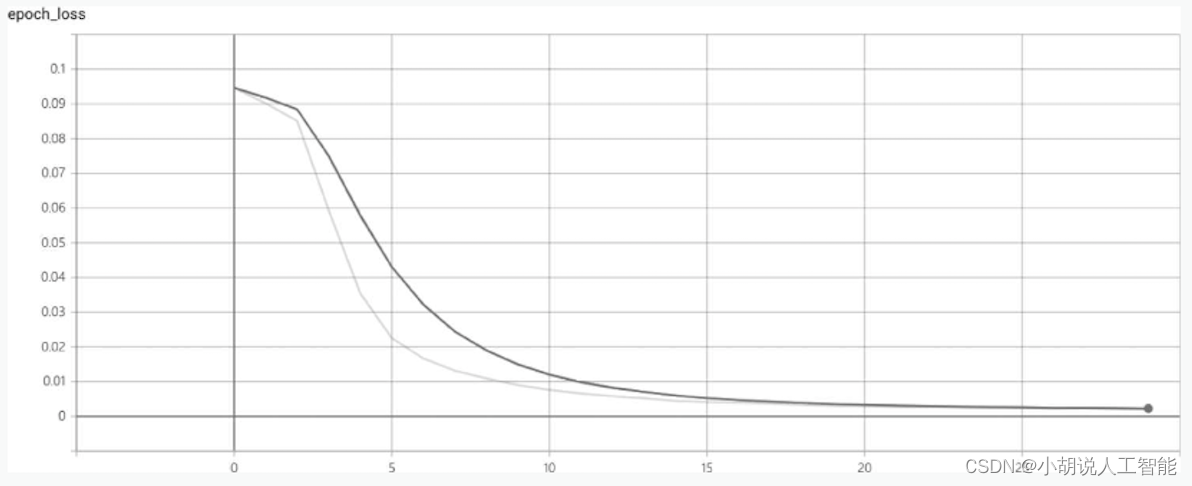
loss和macro_ f1score的曲线中,横轴是训练迭代次数,如图1和图2所示。
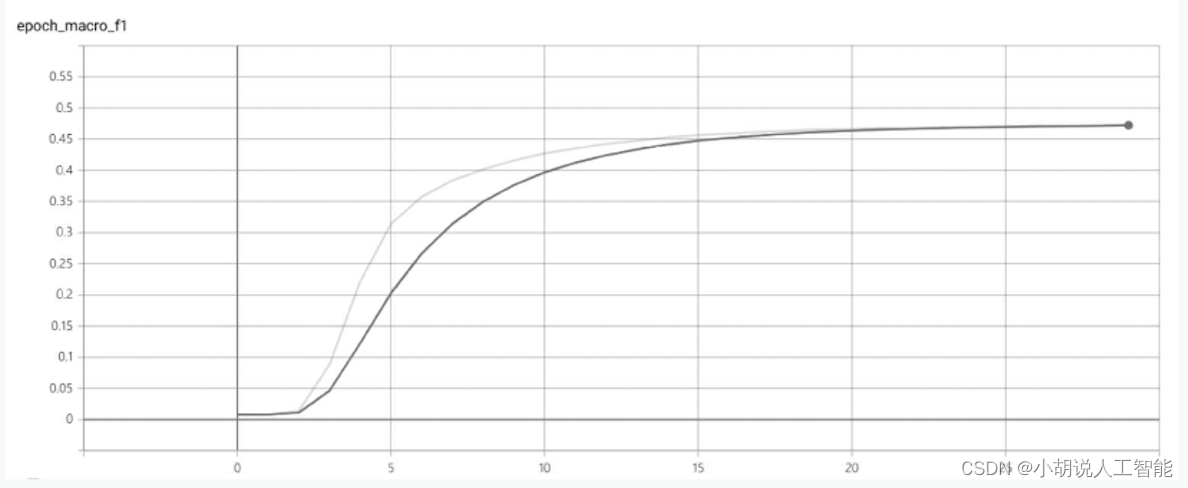
采用HyperLPR提供训练好的模型,识别准确率为95%~97%,下载地址为https://github.com/zeusees/HyperLPR/tree/master。
2. APP测试结果
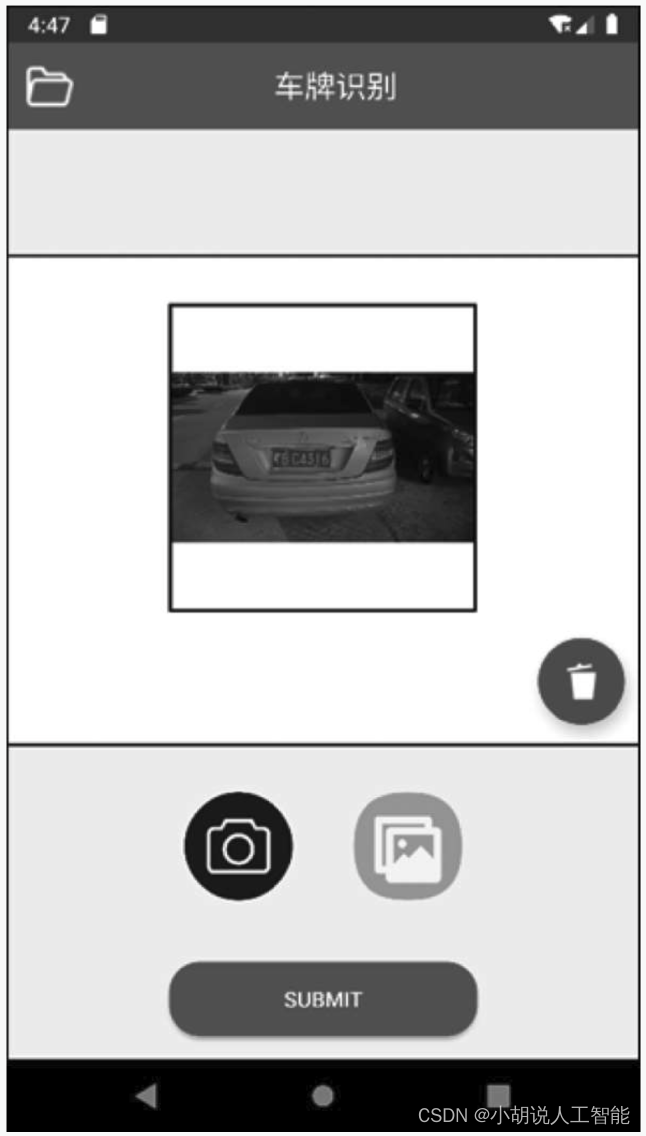
APP界面如下图所示。

单击主界面中的相机图标进入相机界面拍摄带车牌图片,或单击主界面中的图片图标进入选择带车牌图片。单击右上方垃圾桶图标可删除已导入的图片,单击SUBMIT按钮提交检测,如下图所示。
图片识别结果如下图所示。

单击“结果”页面右上方图标可保存识别结果。保存的记录可单击“车牌识别”页面左上角图标查看,如下图所示。
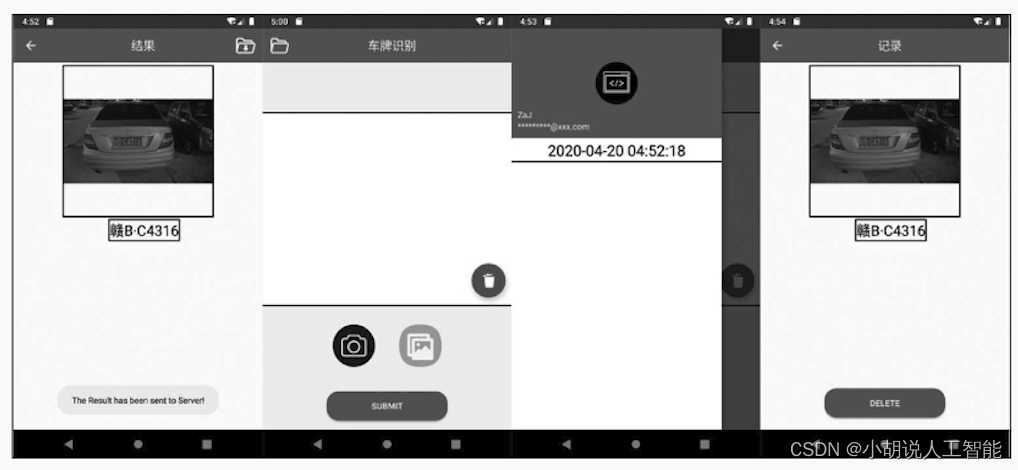
测试示例如图所示。

工程源代码下载
详见本人博客资源下载页
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。
相关文章:
基于OpenCV+LPR模型端对端智能车牌识别——深度学习和目标检测算法应用(含Python+Andriod全部工程源码)+CCPD数据集
目录 前言总体设计系统整体结构图系统流程图 运行环境Python 环境OpenCV环境Android环境1. 开发软件和开发包2. JDK设置3. NDK设置 模块实现1. 数据预处理2. 模型训练1)训练级联分类器2)训练无分割车牌字符识别模型 3. APP构建1)导入OpenCV库…...

C++学习6
C学习6 基础知识std::thread 实战boost domain socket server 基础知识 std::thread std::thread是C11标准库中的一个类,用于创建并发执行的线程。它的详细用法如下: 头文件 #include <thread>创建线程 std::thread t(func, args...);其中&am…...

bazel使用中存在的问题
只开远端缓存时。kernel采用的bazel编译,遇到如下问题: 1、Action 详情二进制文件解析为文本文件时报错,无法进一步比较分析导致缓存不命中的原因。--- JDK版本的问题 2、远端缓存全部命中时间收益不明显 ---需分析是否为网络原因 3、$HOM…...
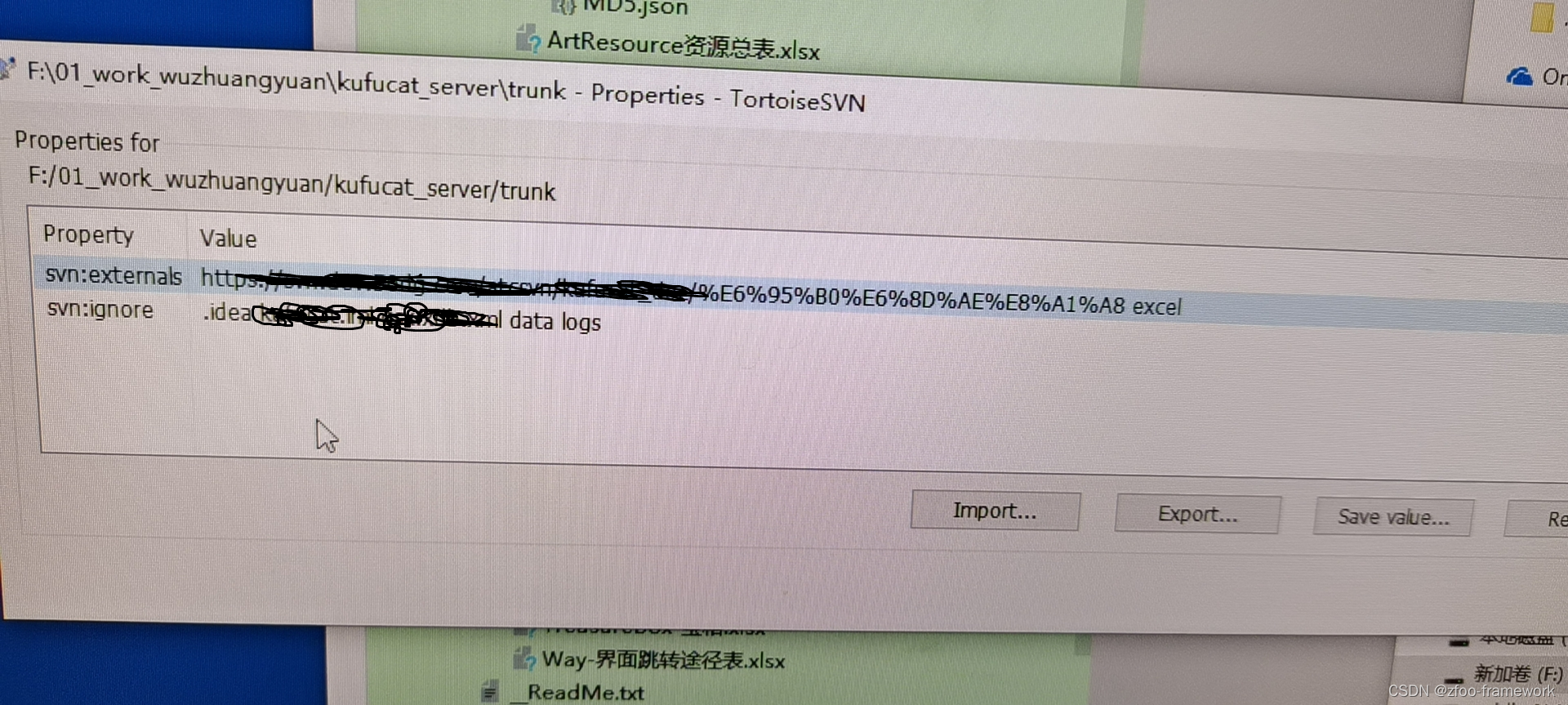
svn软连接和文件忽略
软连接 1)TortoiseSVN->Properties->New->Externals->New 2)填入软连接信息 Local path: 写下软连接后的文件夹的名字 URL: 想要软连接的牡蛎->TortoiseSVN->Repo-browser 复制下填入 文件忽略 以空格隔开就行...
自动驾驶攻城战,华为小鹏先亮剑
点击关注 文|刘俊宏 编|苏扬、王一粟 本文为光锥智能x腾讯科技联合出品 2023年过半,城市NOA(城市领航辅助驾驶)的元年如预期中到来了吗? 8月25日,成都车展开幕,与4个月之前的上海…...
企业供应链数字化怎么做?企业数字化供应链流程落地方式
什么是供应链?简单来说,供应链是围绕客户需求,以提高产品流通各个环节的效率为目标,通过资源整合的方式来实现产品从设计、生产到销售、服务整个环节的组织形态。如同人工智能、区块链、5G等技术的发展带来的各种行业变化…...

java八股文面试[多线程]——synchronized 和lock的区别
其他差别: synchronized是隐式的加锁,lock是显式的加锁; synchronized底层采用的是objectMonitor,lock采用的AQS; synchronized在进行加锁解锁时,只有一个同步队列和一个等待队列, lock有一个同步队列,可以有多个等待队列; synchronized使用了object类的wait和noti…...

实现一个简单的控制台版用户登陆程序, 程序启动提示用户输入用户名密码. 如果用户名密码出错, 使用自定义异常的方式来处理
//密码错误异常类 public class PasswordError extends Exception {public PasswordError(String message){super(message);} }//用户名错误异常类 public class UserError extends Exception{public UserError(String message){super(message);} }import java.util.Scanner;pu…...

Java 大厂八股文面试专题-设计模式 工厂方法模式、策略模式、责任链模式
面试专题-设计模式 前言 在平时的开发中,涉及到设计模式的有两块内容,第一个是我们平时使用的框架(比如spring、mybatis等),第二个是我们自己开发业务使用的设计模式。 面试官一般比较关心的是你在开发过程中ÿ…...
Anaconda Prompt输入jupyter lab无反应
问题:Anaconda Prompt界面输入指令无反应 原因:公司电脑勒索病毒防御工具阻止了进程 解决:找到黑名单恢复进程...

JavaScript Web APIs - 05 Window对象 、本地存储
Web APIs - 05 文章目录 Web APIs - 05js组成window对象定时器-延迟函数location对象navigator对象histroy对象本地存储(今日重点)localStorage(重点)sessionStorage(了解)localStorage 存储复杂数据类型 综…...
Ansible学习笔记6
stat模块:获取文件的状态信息,类似Linux的stat状态。 获取/etc/fstab文件的状态。 [rootlocalhost tmp]# ansible group1 -m stat -a "path/etc/fstab" 192.168.17.106 | SUCCESS > {"ansible_facts": {"discovered_inter…...
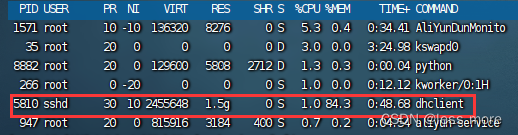
Linux挖矿程序清除
1. 找到挖矿进程 2.找到病毒的文件地址 ls -l /proc/进程ID/exe3.删除文件命令 rm -rf 文件地址4.杀死挖矿进程 kill -9 进程ID...

使用Git和Github上传代码文件
1. 先检查是否安装好git git --version2. 输入你的github用户名 git config --global user.name "用户名"3. 输入你的github邮件 git config --global user.email "邮件地址"4. 设定git推送本地仓库中与远程仓库中具有相同名称的所有分支。 git config…...
OpenAI发布ChatGPT企业级版本
本周一(2023年8月28日)OpenAI 推出了 ChatGPT Enterprise,这是它在 4 月份推出的以业务为中心的订阅服务。该公司表示,根据新计划,不会使用任何业务数据或对话来训练其人工智能模型。 “我们的模型不会从你的使用情况中…...

vue3中axios的使用方法
在Vue 3中使用axios发送HTTP请求的方法与Vue 2中基本相同。首先,需要安装axios库: npm install axios然后,在Vue组件中引入axios: import axios from axios;接下来,可以在Vue组件的方法中使用axios发送HTTP请求。例如…...
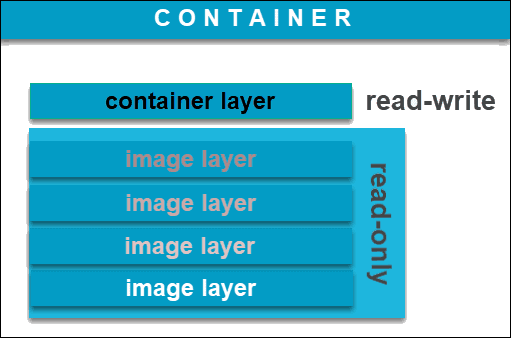
【docker】容器的运行、停止、查看等基本操作
容器与镜像的区别 image镜像 Docker image是一个read-only文件,位于磁盘上这个文件包含文件系统,源码,库文件,依赖,工具等一些运行application所需要的文件可以理解成一个模板docker image具有分层的概念 container…...
)
Python|OpenCV-鼠标自动绘制图像(4)
前言 本文是该专栏的第4篇,后面将持续分享OpenCV计算机视觉的干货知识,记得关注。 在本专栏之前,有详细介绍使用OpenCV绘制图形以及添加文字的方法,感兴趣的同学可往前翻阅查看“Python|OpenCV-绘制图形和添加文字的方法(2)”。 而本文重点来介绍使用OpenCV来操作鼠标,以…...
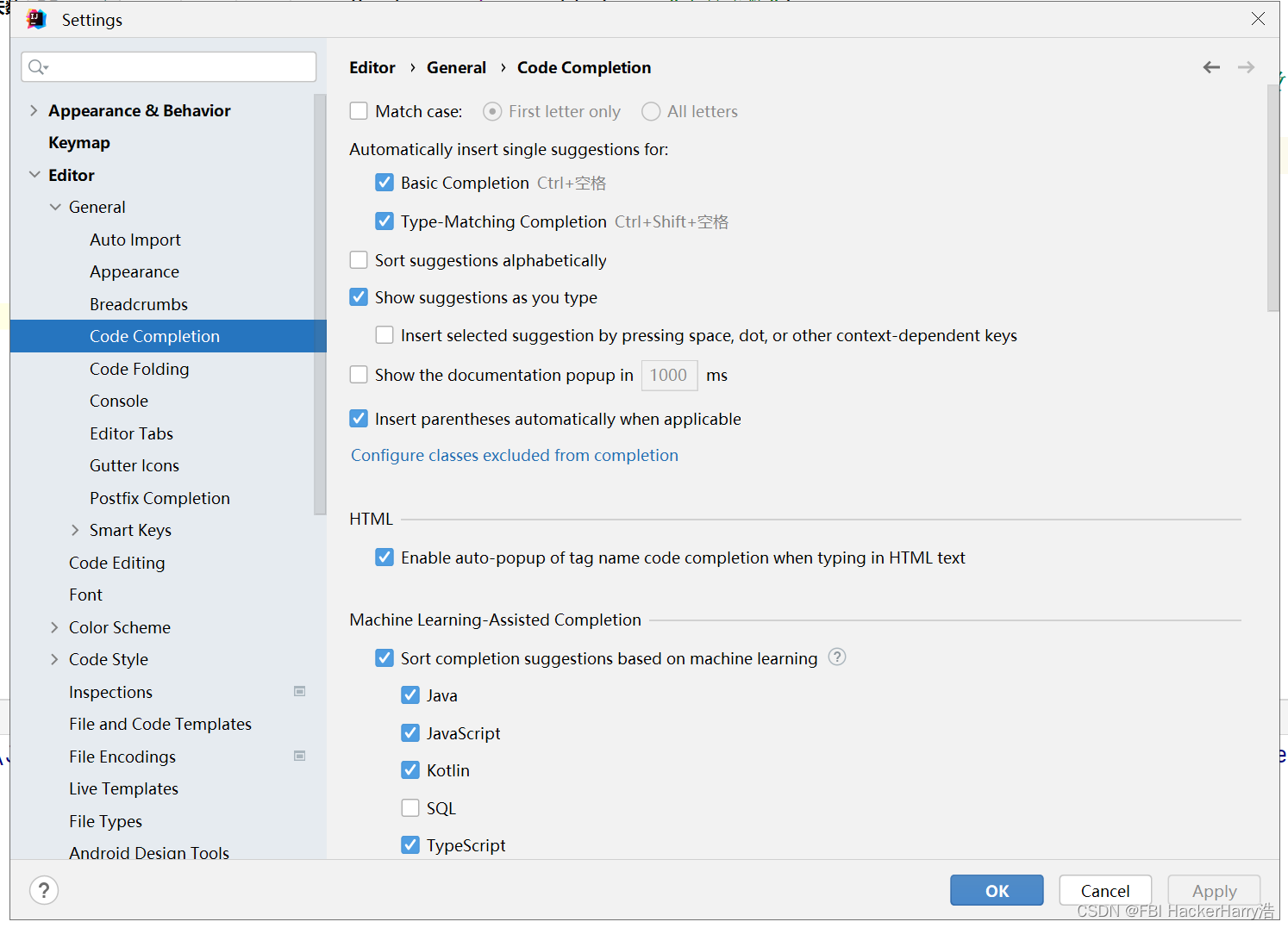
IDEA 设置提示信息
IDEA 设置提示信息 File->Settings->Editor->Code Completion 取消勾选 Math case...

清理docker镜像方法
首先stop ps -a里的容器,然后rm容器,最后再rmi镜像 先停止容器 rm容器 docker rmi 镜像 删除后可以发现已经不存在...

终极指南:5分钟学会使用html-to-docx将HTML完美转换为Word文档
终极指南:5分钟学会使用html-to-docx将HTML完美转换为Word文档 【免费下载链接】html-to-docx HTML to DOCX converter 项目地址: https://gitcode.com/gh_mirrors/ht/html-to-docx 你是否曾经需要将网页内容转换为专业的Word文档,却发现格式完全…...

Android设备标识获取难题:个人开发者如何合规获取OAID?
Android设备标识获取难题:个人开发者如何合规获取OAID? 【免费下载链接】Android_CN_OAID 安卓设备唯一标识解决方案,可替代移动安全联盟(MSA)统一 SDK 闭源方案。包括国内手机厂商的开放匿名标识(OAID&…...

咖啡一杯,Token 无限,Real-Time Cafe 深圳站来了!新增「硬件晒晒桌」与「AI 桌游试玩桌」
咖啡一杯,Token 无限——「Real-Time Cafe」是一个让开发者聚在一起实时 coding、实时 debug、实时互动的咖啡馆快闪计划。 Real-Time Cafe 深圳站来了!就在本周日 5 月 24 日下午。 本站特设「硬件晒晒桌」与「AI 桌游试玩桌」——带上你的电子宠物、…...
终极指南:如何利用Py Eddy Tracker实现海洋中尺度涡旋高效识别与追踪
终极指南:如何利用Py Eddy Tracker实现海洋中尺度涡旋高效识别与追踪 【免费下载链接】py-eddy-tracker Eddy identification and tracking 项目地址: https://gitcode.com/gh_mirrors/py/py-eddy-tracker 海洋涡旋识别与中尺度涡旋追踪是海洋科学研究中的核…...
)
跟着 MDN 学CSS day_7:(层叠优先级与继承)
CSS的全称是层叠样式表(Cascading Style Sheets),其中"层叠"这个词绝非随意选用的。理解层叠、优先级和继承这三个核心概念,是真正掌握CSS的关键所在。当你发现某个样式没有按预期生效时,十有八九是这三个机…...

AI不可靠性工程指南:从失效机理到五层防护网
1. 这不是一句抱怨,而是一条必须写进操作手册的警告 “AI Is Unreliable”——当我在第三个项目里连续两次被同一个大模型生成的Python函数在边界条件下 silently 返回 None 而不是抛出异常、导致下游数据管道静默丢失23%的样本后,我把这句话钉在了团队共…...
)
从厨房小白到AI大模型高手:小白程序员也能轻松掌握大模型的秘密(收藏版)
本文旨在打破对AI大模型的刻板印象,用通俗易懂的语言解释AI大模型的工作原理,并通过实例教学,帮助读者从零开始掌握AI大模型的应用。文章涵盖了AI大模型的基本概念、提示词工程、RAG技术、函数调用、智能体构建、微调与部署等关键知识点&…...

终极指南:如何快速实现Daz Studio到Blender的无缝资产迁移
终极指南:如何快速实现Daz Studio到Blender的无缝资产迁移 【免费下载链接】DazToBlender Daz to Blender Bridge 项目地址: https://gitcode.com/gh_mirrors/da/DazToBlender 还在为3D角色创作中的软件壁垒而烦恼吗?Daz Studio以其强大的角色创建…...
)
告别串口助手:用Python脚本实现YMODEM协议自动升级嵌入式固件(附源码)
告别串口助手:用Python脚本实现YMODEM协议自动升级嵌入式固件(附源码) 在嵌入式设备量产测试和远程维护场景中,传统的手动串口工具操作已成为效率瓶颈。每次固件升级都需要人工介入,不仅耗时费力,还容易因…...

CANN 生态工具链:ATC、ACL 与 MindX 全景
一、CANN 工具链全景 1.1 工具链架构 ┌──────────────────────────────────────────────────┐ │ CANN 工具链全景 │ ├──────────────────────────────…...