深度学习推荐系统(二)Deep Crossing及其在Criteo数据集上的应用
深度学习推荐系统(二)Deep Crossing及其在Criteo数据集上的应用
在2016年, 随着微软的Deep Crossing, 谷歌的Wide&Deep以及FNN、PNN等一大批优秀的深度学习模型被提出, 推荐系统全面进入了深度学习时代, 时至今日, 依然是主流。 推荐模型主要有下面两个进展:
-
与传统的机器学习模型相比, 深度学习模型的表达能力更强, 能够挖掘更多数据中隐藏的模式
-
深度学习模型结构非常灵活, 能够根据业务场景和数据特点, 灵活调整模型结构, 使模型与应用场景完美契合
深度学习推荐模型,以多层感知机(MLP)为核心, 通过改变神经网络结构进行演化。

1 Deep Crossing模型原理
2015年由澳大利亚国立大学提出AutoRec单隐层神经网络模型,由于比较简单, 表达能力不足, 并没有真正的被应用。
在2016年,微软基于ResNet的经典DNN结构, 提出了Deep Crossing模型, 该模型完整的解决了从特征工程、稀疏向量稠密化, 多层神经网络进行优化目标拟合等一系列深度学习在推荐系统中的应用问题。
1.1 Deep Crossing模型的网络结构
为了完成端到端的训练, DeepCrossing模型要在内部网络结构中解决如下问题:
-
离散类特征编码后过于稀疏, 不利于直接输入神经网络训练, 需要解决稀疏特征向量稠密化的问题
-
如何解决特征自动交叉组合的问题
-
如何在输出层中达成问题设定的优化目标
DeepCrossing分别设置了不同神经网络层解决上述问题。 模型结构如下:

-
Embedding层:将稀疏的类别型特征转成稠密的Embedding向量,Embedding的维度会远小于原始的系数特征向量。- 这里的Feature #1表示的类别特征(one-hot编码后的稀疏特征向量), Feature #2是数值型特征, 不用embedding, 直接到了Stacking层。
- 关于Embedding层的实现, Pytorch中有实现好的层可以直接用。
-
Stacking层:这个层是把不同的Embedding特征和数值型特征拼接在一起, 形成新的包含全部特征的特征向量, 该层通常也称为连接层。 -
Multiple Residual Units层:该层的主要结构是多层感知机, 但DeepCrossing采用了残差网络进行的连接。通过多层残差网络对特征向量各个维度充分的交叉组合, 使得模型能够抓取更多的非线性特征和组合特征信息, 增加模型的表达能力。 -
Scoring层:这个作为输出层, 为了拟合优化目标存在。 对于CTR预估二分类问题, Scoring往往采用逻辑回归, 对于多分类, 往往采用Softmax模型
总结一下:
-
DeepCrossing的结构比较清晰和简单, 没有引入特殊的模型结构, 只是常规的Embedding+多层神经网络。但这个网络模型的出现, 有革命意义。
-
DeepCrossing模型中没有任何人工特征工程的参与, 只需要清洗一下, 原始特征经Embedding后输入神经网络层, 自主交叉和学习。
-
相比于FM, FFM只具备二阶特征交叉能力的模型, DeepCrossing可以通过
调整神经网络的深度进行特征之间的“深度交叉”, 这也是Deep Crossing名称的由来。
1.2 Deep Crossing模型的网络的pytorch实现
1.2.1 实现细节说明
通过代码,我们更能理解这个模型的细节。
-
首先, 会有embedding层。这个由于不同的类别特征会通过不同的embedding, 且每个类别的取值个数不一样, 所以
有多少个类别特征就需要多少次embedding。- 在这里,类别特征的编码其实用的LabelEncoder而不是One-hotEncoder, 我觉得原因就是LabelEncoder就类似于把每个类别下的不同取值映射到了一个字典里面去。 通过这个LabelEncoder的取值, 就可以直接拿出对应的embedding向量来。
- Pytorch中, 实现这一层, 需要用一个ModuleDict来实现,
里面的每个值都是embedding层。 - 由于每个类别的取值不一样, 需要实现先把每个特征的取值个数记录下来, 这样是embedding的输入维度。
-
然后就是残差层,
因为Stacking不需要特殊的层, 只需要把特征拼接即可。 残差层其实就是实现了神经网络的运算过程, 只不过稍微有点不同的是残差网络加了跳远链接- 残差块网络结构, 两层线性可以用两个nn.Linear来搞定, 剩下的就是跳远那部分, 在前向传播的时候加过去即可。
- 实际应用中, 我们可能很多个这样的残差块结构, 下面代码中我们用了三个, 每一个里面神经单元的个数不一样。 所以用了
ModuleList,然后加了一层Dropout层缓解过拟合, 最后一个线性层加sigmoid完成scoring层的实现。

1.2.2 代码实现
import torch.nn as nn
import torch.nn.functional as F
import torch# 首先, 自定义一个残差块
class Residual_block(nn.Module):"""Define Residual_block注意:残差块的输入输出需要一致"""def __init__(self, hidden_unit, dim_stack):super(Residual_block, self).__init__()# 两个线性层 注意维度, 输出的时候和输入的那个维度一致, 这样才能保证后面的相加self.linear1 = nn.Linear(dim_stack, hidden_unit)self.linear2 = nn.Linear(hidden_unit, dim_stack)self.relu = nn.ReLU()def forward(self, x):orig_x = x.clone()x = self.relu(self.linear1(x))x = self.linear2(x)outputs = self.relu(x + orig_x)return outputs# 定义deep Crossing 网络
class DeepCrossing(nn.Module):def __init__(self, feature_info, hidden_units, dropout=0., embed_dim=10, output_dim=1):"""DeepCrossing:feature_info: 特征信息(数值特征, 类别特征, 类别特征embedding映射)hidden_units: 列表, 隐藏单元的个数(多层残差那里的)dropout: Dropout层的失活比例embed_dim: embedding维度"""super(DeepCrossing, self).__init__()self.dense_features, self.sparse_features, self.sparse_features_map = feature_info# embedding层, 这里需要一个列表的形式, 因为每个类别特征都需要embeddingself.embed_layers = nn.ModuleDict({'embed_' + str(key): nn.Embedding(num_embeddings=val, embedding_dim=embed_dim)for key, val in self.sparse_features_map.items()})# 统计embedding_dim的总维度# 一个离散型(类别型)变量 通过embedding层变为10纬embed_dim_sum = sum([embed_dim] * len(self.sparse_features))# stack layers的总维度 = 数值型特征的纬度 + 离散型变量经过embedding后的纬度dim_stack = len(self.dense_features) + embed_dim_sum# 残差层self.res_layers = nn.ModuleList([Residual_block(unit, dim_stack) for unit in hidden_units])# dropout层self.res_dropout = nn.Dropout(dropout)# 线性层self.linear = nn.Linear(dim_stack, output_dim)def forward(self, x):# 1、首先得先把输入向量x分成两部分处理、因为数值型和类别型的处理方式不一样, 类别型经过embedding, 数值型是直接进入stacking。dense_inputs, sparse_inputs = x[:, :len(self.dense_features)], x[:, len(self.dense_features):]# 需要转成长张量,这个是embedding的输入要求格式sparse_inputs = sparse_inputs.long()# 2、不同的类别特征分别embeddingsparse_embeds = [self.embed_layers['embed_' + key](sparse_inputs[:, i]) for key, i inzip(self.sparse_features_map.keys(), range(sparse_inputs.shape[1]))]# 3、把类别型特征进行拼接,即emdedding后,转换为一行sparse_embed = torch.cat(sparse_embeds, axis=-1)# 4、数值型和类别型拼接, 这就是stacking层的任务stack = torch.cat([sparse_embed, dense_inputs], axis=-1)r = stack# 5、经过残差网络for res in self.res_layers:r = res(r)# 6、dropout减轻过拟合、sigmoid激活输出r = self.res_dropout(r)outputs = torch.sigmoid(self.linear(r))return outputsif __name__ == '__main__':x = torch.rand(size=(1, 5), dtype=torch.float32)feature_info = [['I1','I2'], # 连续性特征['C1','C2','C3'],# 离散型特征{'C1': 20,'C2': 20,'C3': 20}]hidden_units = [256, 128, 64, 32]net = DeepCrossing(feature_info, hidden_units)print(net)print(net(x))
DeepCrossing((embed_layers): ModuleDict((embed_C1): Embedding(20, 10)(embed_C2): Embedding(20, 10)(embed_C3): Embedding(20, 10))(res_layers): ModuleList((0): Residual_block((linear1): Linear(in_features=32, out_features=256, bias=True)(linear2): Linear(in_features=256, out_features=32, bias=True)(relu): ReLU())(1): Residual_block((linear1): Linear(in_features=32, out_features=128, bias=True)(linear2): Linear(in_features=128, out_features=32, bias=True)(relu): ReLU())(2): Residual_block((linear1): Linear(in_features=32, out_features=64, bias=True)(linear2): Linear(in_features=64, out_features=32, bias=True)(relu): ReLU())(3): Residual_block((linear1): Linear(in_features=32, out_features=32, bias=True)(linear2): Linear(in_features=32, out_features=32, bias=True)(relu): ReLU()))(res_dropout): Dropout(p=0.0, inplace=False)(linear): Linear(in_features=32, out_features=1, bias=True)
)
tensor([[0.5532]], grad_fn=<SigmoidBackward0>)
前向传播部分的逻辑:
-
首先得先把输入向量X分成两部分处理, 因为数值型和类别型的处理方式不一样, 类别型经过embedding, 数值型是直接进入stacking。
-
而由于Pytorch中, embedding层输入要求是long类型, 需要转一下。
- 不熟悉embedding的可以参考Pytorch常用的函数(二)pytorch中nn.Embedding原理及使用
-
第三行代码就是不同的类别特征分别embedding。
-
第四行代码是把类别型特征进行拼接, 第五行代码是数值型和类别型拼接, 这就是stacking层的任务。
-
后面就是经过残差网络, sigmoid激活输出。
1.3 总结
这里直接引用王喆老师《深度学习推荐系统》一书page63:
-
从目前的时间节点上看,Deep Crossing模型是平淡无奇的,因为它没有引人任何诸如注意力机制、序列模型等特殊的模型结构,只是采用了常规的“Embedding+多层神经网络”的经典深度学习结构。
-
但从历史的尺度看,DeepCrossing模型的出现是有革命意义的。Deep Crossing模型中没有任何人工特征工程的参与,原始特征经Embedding后输入神经网络层,将全部特征交叉的任务交给模型。相比之前介绍的 FM、FFM 模型只具备二阶特征交叉的能力,DeepCrossing模型可以通过调整神经网络的深度进行特征之间的“深度交叉”,这也是 Deep Crossing名称的由来。
2 Deep Crossing在Criteo数据集的应用
Criteo数据集是非常经典的点击率预估比赛。训练集4千万行,特征连续型的有13个,类别型的26个,没有提供特征名称,样本按时间排序。测试集6百万行。
数据集下载地址:https://www.kaggle.com/datasets/mrkmakr/criteo-dataset
由于数据量太大, 为了在单机上能够运行,因此做了采样,取了很少的一部分进行实验。
2.1 数据预处理
import pandas as pd
from sklearn.preprocessing import MinMaxScaler, LabelEncoder
from sklearn.model_selection import train_test_splittrain_df = pd.read_csv('./data/train.csv')
test_df = pd.read_csv('./data/test.csv')print(train_df.shape)
print(test_df.shape) # 少了Label这一列
train_df.head()

# 将训练集和测试集进行合并,方便进行特征的预处理工作
label = train_df['Label']
del train_df['Label']data_df = pd.concat((train_df, test_df))del data_df['Id']data_df.columns
Index(['I1', 'I2', 'I3', 'I4', 'I5', 'I6', 'I7', 'I8', 'I9', 'I10', 'I11','I12', 'I13', 'C1', 'C2', 'C3', 'C4', 'C5', 'C6', 'C7', 'C8', 'C9','C10', 'C11', 'C12', 'C13', 'C14', 'C15', 'C16', 'C17', 'C18', 'C19','C20', 'C21', 'C22', 'C23', 'C24', 'C25', 'C26'],dtype='object')
# C开头是为类别特征
sparse_feas = [col for col in data_df.columns if col[0] == 'C']# I开头是为连续型特征
dense_feas = [col for col in data_df.columns if col[0] == 'I']
# 1、填充缺失值# 类别特征填充为-1
data_df[sparse_feas] = data_df[sparse_feas].fillna('-1')
# 连续特征填充为0
data_df[dense_feas] = data_df[dense_feas].fillna(0)# 2、对类别特征进行LabelEncoder编码(而非one-hot编码)
for feat in sparse_feas:le = LabelEncoder()data_df[feat] = le.fit_transform(data_df[feat])data_df[sparse_feas].head()

# 3、对于连续性变量进行归一化mms = MinMaxScaler()
data_df[dense_feas] = mms.fit_transform(data_df[dense_feas])data_df[dense_feas].head()

# 处理后,再分为训练集和测试集train = data_df[:train_df.shape[0]]
test = data_df[train_df.shape[0]:]train['Label'] = label# 对于训练数据集,划分为训练集及验证集
train_set, val_set = train_test_split(train, test_size = 0.2, random_state=2023)# 统计
train_set['Label'].value_counts()
val_set['Label'].value_counts()

# 保存预处理后的文件,方便以后其他的推荐模型直接使用
train_set.reset_index(drop=True, inplace=True)
val_set.reset_index(drop=True, inplace=True)train_set.to_csv('preprocessed_data/train_set.csv', index=0)
val_set.to_csv('preprocessed_data/val_set.csv', index=0)
test.to_csv('preprocessed_data/test.csv', index=0)
2.2 准备训练数据
import datetime
import pandas as pdimport torch
from torch.utils.data import TensorDataset, Dataset, DataLoaderimport torch.nn as nn
import torch.nn.functional as F# pip install torchkeras
from torchkeras import summaryfrom sklearn.metrics import auc, roc_auc_score, roc_curveimport warnings
warnings.filterwarnings('ignore')
# 封装为函数
def prepared_data(file_path):# 读入训练集,验证集和测试集train_set = pd.read_csv(file_path + 'train_set.csv')val_set = pd.read_csv(file_path + 'val_set.csv')test_set = pd.read_csv(file_path + 'test.csv')# 这里需要把特征分成数值型和离散型# 因为后面的模型里面离散型的特征需要embedding, 而数值型的特征直接进入了stacking层, 处理方式会不一样data_df = pd.concat((train_set, val_set, test_set))# 数值型特征直接放入stacking层dense_features = ['I' + str(i) for i in range(1, 14)]# 离散型特征需要需要进行embedding处理sparse_features = ['C' + str(i) for i in range(1, 27)]# 定义一个稀疏特征的embedding映射, 字典{key: value},# key表示每个稀疏特征, value表示数据集data_df对应列的不同取值个数, 作为embedding输入维度sparse_feas_map = {}for key in sparse_feas:sparse_feas_map[key] = data_df[key].nunique()feature_info = [dense_features, sparse_features, sparse_feas_map] # 这里把特征信息进行封装, 建立模型的时候作为参数传入# 把数据构建成数据管道dl_train_dataset = TensorDataset(# 特征信息torch.tensor(train_set.drop(columns='Label').values).float(),# 标签信息torch.tensor(train_set['Label'].values).float())dl_val_dataset = TensorDataset(# 特征信息torch.tensor(val_set.drop(columns='Label').values).float(),# 标签信息torch.tensor(val_set['Label'].values).float())dl_train = DataLoader(dl_train_dataset, shuffle=True, batch_size=16)dl_vaild = DataLoader(dl_val_dataset, shuffle=True, batch_size=16)return feature_info,dl_train,dl_vaild,test_set
# 保存的数据
file_path = './preprocessed_data/'feature_info,dl_train,dl_vaild,test_set = prepared_data(file_path)
2.3 建立Deep Crossing模型
from deep_crossing import DeepCrossing# 隐藏层
hidden_units = [256, 128, 64, 32]
# 创建DeepCrossing模型
net = DeepCrossing(feature_info, hidden_units)summary(net, input_shape=(train_set.shape[1],))
--------------------------------------------------------------------------
Layer (type) Output Shape Param #
==========================================================================
Embedding-1 [-1, 10] 790
Embedding-2 [-1, 10] 2,520
Embedding-3 [-1, 10] 12,930
Embedding-4 [-1, 10] 10,430
Embedding-5 [-1, 10] 300
Embedding-6 [-1, 10] 70
Embedding-7 [-1, 10] 11,640
Embedding-8 [-1, 10] 390
Embedding-9 [-1, 10] 20
Embedding-10 [-1, 10] 9,080
Embedding-11 [-1, 10] 9,260
Embedding-12 [-1, 10] 12,390
Embedding-13 [-1, 10] 8,240
Embedding-14 [-1, 10] 200
Embedding-15 [-1, 10] 8,190
Embedding-16 [-1, 10] 11,590
Embedding-17 [-1, 10] 90
Embedding-18 [-1, 10] 5,340
Embedding-19 [-1, 10] 2,010
Embedding-20 [-1, 10] 40
Embedding-21 [-1, 10] 12,040
Embedding-22 [-1, 10] 70
Embedding-23 [-1, 10] 120
Embedding-24 [-1, 10] 7,290
Embedding-25 [-1, 10] 330
Embedding-26 [-1, 10] 5,540
Linear-27 [-1, 256] 70,144
ReLU-28 [-1, 256] 0
Linear-29 [-1, 273] 70,161
ReLU-30 [-1, 273] 0
Linear-31 [-1, 128] 35,072
ReLU-32 [-1, 128] 0
Linear-33 [-1, 273] 35,217
ReLU-34 [-1, 273] 0
Linear-35 [-1, 64] 17,536
ReLU-36 [-1, 64] 0
Linear-37 [-1, 273] 17,745
ReLU-38 [-1, 273] 0
Linear-39 [-1, 32] 8,768
ReLU-40 [-1, 32] 0
Linear-41 [-1, 273] 9,009
ReLU-42 [-1, 273] 0
Dropout-43 [-1, 273] 0
Linear-44 [-1, 1] 274
==========================================================================
Total params: 394,836
Trainable params: 394,836
Non-trainable params: 0
--------------------------------------------------------------------------
Input size (MB): 0.000153
Forward/backward pass size (MB): 0.028061
Params size (MB): 1.506180
Estimated Total Size (MB): 1.534393
--------------------------------------------------------------------------
# 测试一下模型
for feature, label in iter(dl_train):out = net(feature)print(out)break
2.4 模型的训练
# 导入的这两个类可以参考
# https://blog.csdn.net/qq_44665283/article/details/130598697?spm=1001.2014.3001.5502
from AnimatorClass import Animator
from TimerClass import Timer# 模型的相关设置
def metric_func(y_pred, y_true):pred = y_pred.datay = y_true.datareturn roc_auc_score(y, pred)def try_gpu(i=0):if torch.cuda.device_count() >= i + 1:return torch.device(f'cuda:{i}')return torch.device('cpu')# 封装为函数,方便其他推荐模型进行复用
def train_ch(net, dl_train, dl_vaild, num_epochs, lr, device):"""⽤GPU训练模型"""print('training on', device)net.to(device)# 二值交叉熵损失loss_func = nn.BCELoss()optimizer = torch.optim.Adam(params=net.parameters(), lr=lr)animator = Animator(xlabel='epoch', xlim=[1, num_epochs],legend=['train loss', 'train auc', 'test loss', 'test auc'],figsize=(8.0, 6.0))timer, num_batches = Timer(), len(dl_train)log_step_freq = 10for epoch in range(1, num_epochs + 1):# 训练阶段net.train()loss_sum = 0.0metric_sum = 0.0step = 1for step, (features, labels) in enumerate(dl_train, 1):timer.start()# 梯度清零optimizer.zero_grad()# 正向传播predictions = net(features)loss = loss_func(predictions, labels.unsqueeze(1) )try: # 这里就是如果当前批次里面的y只有一个类别, 跳过去metric = metric_func(predictions, labels)except ValueError:pass# 反向传播求梯度loss.backward()optimizer.step()timer.stop()# 打印batch级别日志loss_sum += loss.item()metric_sum += metric.item()if step % log_step_freq == 0:animator.add(epoch + step / num_batches,(loss_sum/step, metric_sum/step, None, None))# 验证阶段net.eval()val_loss_sum = 0.0val_metric_sum = 0.0val_step = 1for val_step, (features, labels) in enumerate(dl_vaild, 1):with torch.no_grad():predictions = net(features)val_loss = loss_func(predictions, labels.unsqueeze(1))try:val_metric = metric_func(predictions, labels)except ValueError:passval_loss_sum += val_loss.item()val_metric_sum += val_metric.item()if val_step % log_step_freq == 0:animator.add(epoch + val_step / num_batches, (None,None,val_loss_sum / val_step , val_metric_sum / val_step))print(f'loss {loss_sum/len(dl_train):.3f}, auc {metric_sum/len(dl_train):.3f},'f' val loss {val_loss_sum/len(dl_vaild):.3f}, val auc {val_metric_sum/len(dl_vaild):.3f}')print(f'{num_batches * num_epochs / timer.sum():.1f} examples/sec on {str(device)}')
lr, num_epochs = 0.001, 4
train_ch(net, dl_train, dl_vaild, num_epochs, lr, try_gpu())

2.5 模型的预测
y_pred_probs = net(torch.tensor(test_set.values).float())
y_pred = torch.where(y_pred_probs>0.5,torch.ones_like(y_pred_probs),torch.zeros_like(y_pred_probs)
)
y_pred.data[:10]
2.6 模型的保存与加载
# 模型的保存与使用
torch.save(net.state_dict(), './model/net_parameter.pkl')# 创建模型
net_clone = DeepCrossing(feature_info, hidden_units)# 加载模型
net_clone.load_state_dict(torch.load('./model/net_parameter.pkl'))# 进行预测
y_pred_probs = net_clone(torch.tensor(test_set.values).float())y_pred = torch.where(y_pred_probs>0.5,torch.ones_like(y_pred_probs),torch.zeros_like(y_pred_probs)
)
y_pred.data[:10]
相关文章:
深度学习推荐系统(二)Deep Crossing及其在Criteo数据集上的应用
深度学习推荐系统(二)Deep Crossing及其在Criteo数据集上的应用 在2016年, 随着微软的Deep Crossing, 谷歌的Wide&Deep以及FNN、PNN等一大批优秀的深度学习模型被提出, 推荐系统全面进入了深度学习时代, 时至今日,…...

前端常用 Vue3 项目组件大全
Vue.js 是一种流行的 JavaScript 前端框架,它简化了构建交互式的用户界面的过程。Vue3 是 Vue.js 的最新版本,引入了许多新的特性和改进。在 Vue3 中,组件是构建应用程序的核心部分,它们可以重用、组合和嵌套。下面是一些前端开发…...
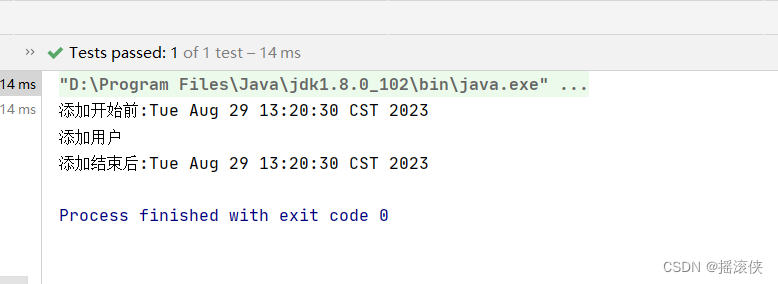
javaee spring 静态代理
静态代理 package com.test.staticProxy;public interface IUsersService {public void insert(); }package com.test.staticProxy;//目标类 public class UsersService implements IUsersService {Overridepublic void insert() {System.out.println("添加用户");…...

Java 包装类和Arrays类(详细解释)
目录 包装类 作用介绍 包装类的特有功能 Arrays类 Arrays.fill() Arrays.toString() Arrays.sort() 升序排序 降序排序 Arrays.equals() Arrays.copyOf() Arrays.binarySearch() 包装类 作用介绍 包装类其实就是8种基本数据类型对应的引用类型。 基本数据类型引用…...
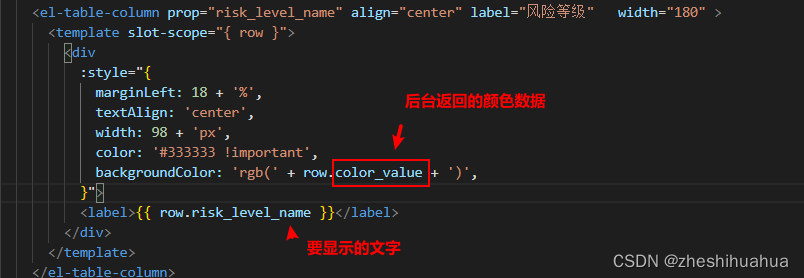
elementUi中的el-table表格的内容根据后端返回的数据用不同的颜色展示
效果图如下: 首先 首先:需要在表格行加入 <template slot-scope"{ row }"> </template>标签 <el-table-column prop"usable" align"center" label"状态" width"180" ><templ…...

在访问一个网页时弹出的浏览器窗口,如何用selenium 网页自动化解决?
相信大家在使用selenium做网页自动化时,会遇到如下这样的一个场景: 在你使用get访问某一个网址时,会在页面中弹出如上图所示的弹出框。 首先想到是利用Alert类来处理它。 然而,很不幸,Alert类处理的结果就是没有结果…...

python 基于http方式与基于redis方式传输摄像头图片数据的实现和对比
目录 0. 需求1. 基于http方式传递图片数据1.1 发送图片数据1.2 接收图片数据并可视化1.3 测试 2. 基于redis方式传递图片数据2.1 发送图片数据2.2 接收图片数据并可视化2.3 测试 3. 对比 0. 需求 在不同进程或者不同语言间传递摄像头图片数据,比如从java实现的代码…...

快速使用Git完整开发
本系列有两篇文章: 一是本篇,主要说明了关于Git工具的基础使用,包含三板斧(git add、git commit、git push)、Git基本配置、版本回退、分支管理、公钥与私钥、远端仓库和远端分支、忽略文件、命令别名、标签等内容。二…...

鲁棒优化入门(7)—Matlab+Yalmip两阶段鲁棒优化通用编程指南(下)
0.引言 上一篇博客介绍了使用Yalmip工具箱求解单阶段鲁棒优化的方法。这篇文章将和大家一起继续研究如何使用Yalmip工具箱求解两阶段鲁棒优化(默认看到这篇博客时已经有一定的基础了,如果没有可以看看我专栏里的其他文章)。关于两阶段鲁棒优化与列与约束生成算法的原…...
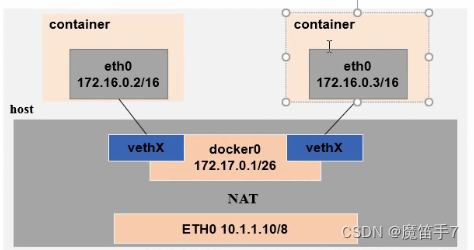
Docker技术--Docker中的网络问题
1.docker中的网络通信 如果想要弄清楚docker中的网络通信问题,其实需要弄清楚这几个问题就可以:容器与容器之间的通信、容器与外部网络之间的通信、外部网络与容器之间的通信。 -a:容器与容器之间的通信,如下所示: 在默认情况下,docker使用网桥(Bridge模式)与NAT通信。这…...

ASP.NET Core 中的两种 Web API
ASP.NET Core 有两种创建 RESTful Web API 的方式: 基于 Controller,使用完整的基于ControllerBase的基类定义接口endpoints。基于 Minimal APIs,使用Lambda表达式定义接口 endpoints。 基于 Controller 的 Web API 可以使用构造函数注入&a…...
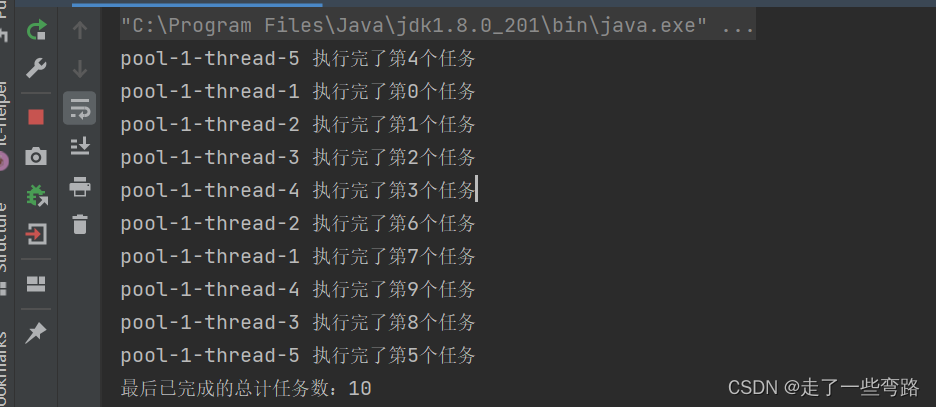
【线程池】如何判断线程池中的任务执行完毕(三)
目录 前言 1. isTerminated()方法 2. awaitTermination()方法 3.getTaskCount()方法和executor.getCompletedTaskCount()方法结合使用 4.使用CountDownlatch类 前言 通常我们使用线程池的时候,系统处于运行的状态,而线程池本身就是主要为了线程复用&…...

Qt/C++编写视频监控系统81-Onvif报警抓图和录像并回放
一、前言 视频监控系统中的图文警情模块,是通过Onvif协议的事件订阅拿到的,通过事件订阅后,设备的各种报警事件比如入侵报警/遮挡报警/越界报警/开关量报警等,触发后都会主动往订阅者发送,而且一般都是会发送两次&…...

浅谈安防视频监控平台EasyCVR视频汇聚平台对于夏季可视化智能溺水安全告警平台的重要性
每年夏天都是溺水事故高发的时期,许多未成年人喜欢在有水源的地方嬉戏,这导致了悲剧的发生。常见的溺水事故发生地包括水库、水坑、池塘、河流、溪边和海边等场所。 为了加强溺水风险的提示和预警,完善各类安全防护设施,并及时发现…...
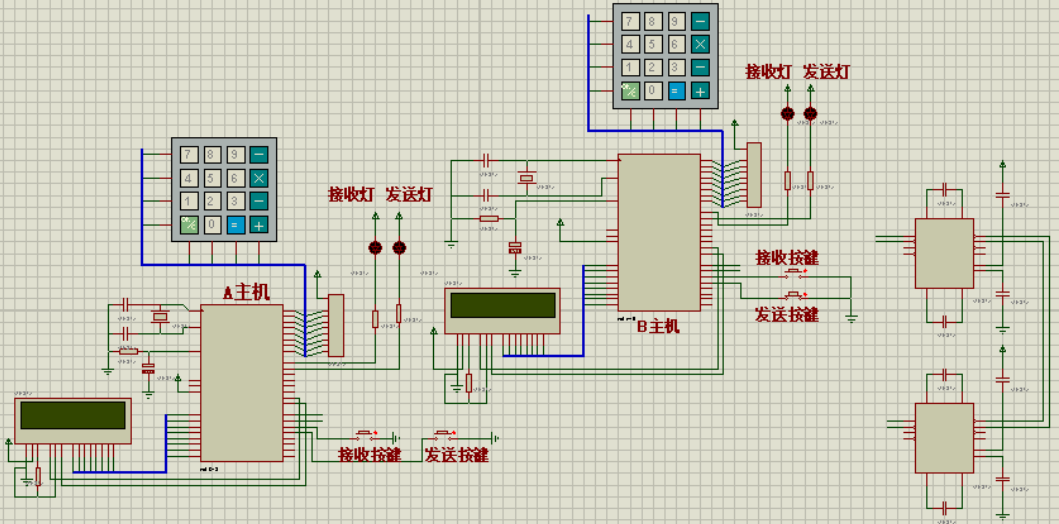
基于单片机的串行通信发射机设计
一、项目介绍 串行通信是一种常见的数据传输方式,允许将数据以比特流的形式在发送端和接收端之间传输。当前实现基于STC89C52单片机的串行通信发射机,通过红外发射管和接收头实现自定义协议的数据无线传输。 二、系统设计 2.1 单片机选择 在本设计中&…...

MySQL数据库——多表查询(3)-自连接、联合查询、子查询
目录 自连接 查询语法 自连接演示 联合查询 查询语法 子查询 介绍 标量子查询 列子查询 行子查询 表子查询 自连接 通过前面的学习,我们对于连接已经有了一定的理解。而自连接,通俗地去理解就是自己连接自己,即一张表查询多次。…...

day53 动规.p14 子序列
- 1143.最长公共子序列 cpp class Solution { public: int longestCommonSubsequence(string text1, string text2) { vector<vector<int>> dp(text1.size() 1, vector<int>(text2.size() 1, 0)); for (int i 1; i < text1.size(…...

将docker打包成镜像并保存到本地
如果想重装系统,又不想破坏docker里面配好的环境,那么可以将docker镜像打包到本地进行保存。 1. 将docker打包成镜像 命令:docker commit 容器id 镜像名:tag 使用docker ps -a即可查看容器相关信息 docker commit dd25c7c6bf17 zm_cu101:c…...

Harmony数据存储工具类
使用的是mmkv 1、安装mmkv ohpm install @ohos/mmkv2、封装 import{MMKV, SerializeBase} from @ohos/mmkv/*** 数据存储工具类*/ class MMKVUtil{private filePath:string = private cachePath:string = private mmkv:MMKVprivate mmapID:string="MMKV"construct…...
ROS 2官方文档(基于humble版本)学习笔记(一)
ROS 2官方文档(基于humble版本)学习笔记(一) 一、安装ROS 2二、按教程学习1.CLI 工具配置环境使用turtlesim,ros2和rqt安装 turtlesim启动 turtlesim使用 turtlesim安装 rqt使用 rqt重映射关闭turtlesim 由于市面上专门…...

终极AMD Ryzen性能调优指南:5分钟掌握SMUDebugTool免费调试神器
终极AMD Ryzen性能调优指南:5分钟掌握SMUDebugTool免费调试神器 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: h…...

Sunshine游戏串流服务器:如何5分钟内搭建私人云游戏平台?
Sunshine游戏串流服务器:如何5分钟内搭建私人云游戏平台? 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 想象一下,将你的高性能游戏PC变成一个…...

如何快速解锁QQ音乐加密音频的完整指南:QMCDecode工具终极解决方案
如何快速解锁QQ音乐加密音频的完整指南:QMCDecode工具终极解决方案 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录&…...

线粒体氧化磷酸化的新靶点:S-Gboxin的发现与研究进展
在肿瘤治疗的探索历程中,科学家们始终在寻找能够精准打击癌细胞而又最大限度保护正常组织的新型药物。2019年,一项发表在Nature杂志上的研究引起了学界广泛关注——施宇峰团队首次报道了Gboxin这一化合物的发现与独特的作用机制[1]。作为Gboxin的代谢稳定…...

基于SpringBoot 的实验设备预约系统的设计及实现
摘 要 随着高校与科研院所实验教学规模扩大,传统人工预约实验设备效率低、易冲突、管理混乱,已无法满足师生需求。为提升设备利用率、规范预约流程、减少时间冲突与资源浪费,构建一套基于网络的实验设备预约系统十分必要。该系统可实现在线预…...

DDD 中的代码组织:按技术层分 vs 按领域模块分,哪种才是正解?
前言 在实践领域驱动设计(DDD)时,你可能见过两种截然不同的代码组织方式:一种是传统的按技术层划分文件夹,另一种是按业务模块划分文件夹。两种写法的人都声称自己在做 DDD,那到底哪种更合理?本…...

Go语言CQRS模式:命令查询分离
Go语言CQRS模式:命令查询分离 1. CQRS实现 type CommandHandler interface {Handle(cmd *Command) error }type QueryHandler interface {Handle(query *Query) interface{} }2. 总结 CQRS将读操作和写操作分离,优化各自的性能和扩展性。...

如何快速上手Balena Etcher:新手必学的3种安装方法和实用技巧
如何快速上手Balena Etcher:新手必学的3种安装方法和实用技巧 【免费下载链接】etcher Flash OS images to SD cards & USB drives, safely and easily. 项目地址: https://gitcode.com/GitHub_Trending/et/etcher Balena Etcher是一款开源的镜像烧录工具…...

LangChain 是什么?从零开始学会 LangChain 的工程实践指南
LangChain 是什么?从零开始学会 LangChain 的工程实践指南 1. 文章背景:为什么这个主题重要 在大模型应用开发中,很多人第一次接触 LangChain,是因为想快速做一个“基于大模型的应用”:例如知识库问答、RAG 检索增强生…...

Word文档保护技巧:防止内容被轻易复制
Word文档如何防止复制呢?其实,Word根本没有真正意义上的禁止复制,因为用户按一下手机截图,或者拍张照片,内容照样能拿走。但是,我们可以提高复制门槛,也就是让其他用户通过“CtrlC”无法直接复制…...