Redis进阶-缓存问题
Redis 最常用的一个场景就是作为缓存,本文主要探讨Redis作为缓存,在实践中可能会有哪些问题?比如一致性、击穿、穿透、雪崩、污染等。
为什么要理解Redis缓存问题
在高并发业务场景下,数据库大多数情况都是用户并发访问最薄弱的环节。所以,使用Redis做一个缓冲操作,让请求先访问到Redis,而不是直接访问数据库。这样可以大大缓解数据库的压力。
当使用缓存库时,必须要考虑如下问题:
缓存穿透
缓存击穿
缓存雪崩
缓存污染(或者满了)
缓存和数据库一致性
缓存穿透
问题来源
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求。由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。
在流量大时,可能DB就挂掉了,要是有人利用不存在的key频繁攻击我们的应用,这就是漏洞。
如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
解决方案
接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击
布隆过滤器。bloomfilter就类似于一个hash set,用于快速判某个元素是否存在于集合中,其典型的应用场景就是快速判断一个key是否存在于某容器,不存在就直接返回。布隆过滤器的关键就在于hash算法和容器大小。
缓存击穿
问题来源
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力。
解决方案
1、设置热点数据永远不过期。
2、接口限流与熔断,降级。重要的接口一定要做好限流策略,防止用户恶意刷接口,同时要降级准备,当接口中的某些 服务 不可用时候,进行熔断,失败快速返回机制。
3、加互斥锁
缓存雪崩
问题来源
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
解决方案
缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
如果缓存数据库是分布式部署,将热点数据均匀分布在不同的缓存数据库中。
设置热点数据永远不过期。
缓存污染(或满了)
缓存污染问题说的是缓存中一些只会被访问一次或者几次的的数据,被访问完后,再也不会被访问到,但这部分数据依然留存在缓存中,消耗缓存空间。
缓存污染会随着数据的持续增加而逐渐显露,随着服务的不断运行,缓存中会存在大量的永远不会再次被访问的数据。缓存空间是有限的,如果缓存空间满了,再往缓存里写数据时就会有额外开销,影响Redis性能。这部分额外开销主要是指写的时候判断淘汰策略,根据淘汰策略去选择要淘汰的数据,然后进行删除操作。
最大缓存设置多大
系统的设计选择是一个权衡的过程:大容量缓存是能带来性能加速的收益,但是成本也会更高,而小容量缓存不一定就起不到加速访问的效果。一般来说,我会建议把缓存容量设置为总数据量的 15% 到 30%,兼顾访问性能和内存空间开销。
对于 Redis 来说,一旦确定了缓存最大容量,比如 4GB,你就可以使用下面这个命令来设定缓存的大小了:
1.CONFIG SET maxmemory 4gb不过,缓存被写满是不可避免的, 所以需要数据淘汰策略。
缓存淘汰策略
Redis共支持八种淘汰策略,分别是noeviction、volatile-random、volatile-ttl、volatile-lru、volatile-lfu、allkeys-lru、allkeys-random 和 allkeys-lfu 策略。
怎么理解呢?主要看分三类看:
-
不淘汰
-
noeviction (v4.0后默认的)
-
-
对设置了过期时间的数据中进行淘汰
-
随机:volatile-random
-
ttl:volatile-ttl
-
lru:volatile-lru
-
lfu:volatile-lfu
-
-
全部数据进行淘汰
-
随机:allkeys-random
-
lru:allkeys-lru
-
lfu:allkeys-lfu
-
-
noeviction
该策略是Redis的默认策略。在这种策略下,一旦缓存被写满了,再有写请求来时,Redis 不再提供服务,而是直接返回错误。这种策略不会淘汰数据,所以无法解决缓存污染问题。一般生产环境不建议使用。
其他七种规则都会根据自己相应的规则来选择数据进行删除操作。
volatile-random
这个算法比较简单,在设置了过期时间的键值对中,进行随机删除。因为是随机删除,无法把不再访问的数据筛选出来,所以可能依然会存在缓存污染现象,无法解决缓存污染问题。
volatile-ttl
这种算法判断淘汰数据时参考的指标比随即删除时多进行一步过期时间的排序。Redis在筛选需删除的数据时,越早过期的数据越优先被选择。
volatile-lru
LRU算法:LRU 算法的全称是 Least Recently Used,按照最近最少使用的原则来筛选数据。这种模式下会使用 LRU 算法筛选设置了过期时间的键值对。
Redis优化的LRU算法实现:
Redis会记录每个数据的最近一次被访问的时间戳。在Redis在决定淘汰的数据时,第一次会随机选出 N 个数据,把它们作为一个候选集合。接下来,Redis 会比较这 N 个数据的 lru 字段,把 lru 字段值最小的数据从缓存中淘汰出去。通过随机读取待删除集合,可以让Redis不用维护一个巨大的链表,也不用操作链表,进而提升性能。
Redis 选出的数据个数 N,通过 配置参数 maxmemory-samples 进行配置。个数N越大,则候选集合越大,选择到的最久未被使用的就更准确,N越小,选择到最久未被使用的数据的概率也会随之减小。
volatile-lfu
会使用 LFU 算法选择设置了过期时间的键值对。
LFU 算法:LFU 缓存策略是在 LRU 策略基础上,为每个数据增加了一个计数器,来统计这个数据的访问次数。当使用 LFU 策略筛选淘汰数据时,首先会根据数据的访问次数进行筛选,把访问次数最低的数据淘汰出缓存。如果两个数据的访问次数相同,LFU 策略再比较这两个数据的访问时效性,把距离上一次访问时间更久的数据淘汰出缓存。Redis的LFU算法实现:
当 LFU 策略筛选数据时,Redis 会在候选集合中,根据数据 lru 字段的后 8bit 选择访问次数最少的数据进行淘汰。当访问次数相同时,再根据 lru 字段的前 16bit 值大小,选择访问时间最久远的数据进行淘汰。
Redis 只使用了 8bit 记录数据的访问次数,而 8bit 记录的最大值是 255,这样在访问快速的情况下,如果每次被访问就将访问次数加一,很快某条数据就达到最大值255,可能很多数据都是255,那么退化成LRU算法了。所以Redis为了解决这个问题,实现了一个更优的计数规则,并可以通过配置项,来控制计数器增加的速度。
参数 :
lfu-log-factor ,用计数器当前的值乘以配置项 lfu_log_factor 再加 1,再取其倒数,得到一个 p 值;然后,把这个 p 值和一个取值范围在(0,1)间的随机数 r 值比大小,只有 p 值大于 r 值时,计数器才加 1。
lfu-decay-time, 控制访问次数衰减。LFU 策略会计算当前时间和数据最近一次访问时间的差值,并把这个差值换算成以分钟为单位。然后,LFU 策略再把这个差值除以 lfu_decay_time 值,所得的结果就是数据 counter 要衰减的值。
lfu-log-factor设置越大,递增概率越低,lfu-decay-time设置越大,衰减速度会越慢。
我们在应用 LFU 策略时,一般可以将 lfu_log_factor 取值为 10。如果业务应用中有短时高频访问的数据的话,建议把 lfu_decay_time 值设置为 1。可以快速衰减访问次数。
volatile-lfu 策略是 Redis 4.0 后新增。
allkeys-lru
使用 LRU 算法在所有数据中进行筛选。具体LFU算法跟上述 volatile-lru 中介绍的一致,只是筛选的数据范围是全部缓存,这里就不在重复。
allkeys-random
从所有键值对中随机选择并删除数据。volatile-random 跟 allkeys-random算法一样,随机删除就无法解决缓存污染问题。
allkeys-lfu
使用 LFU 算法在所有数据中进行筛选。具体LFU算法跟上述 volatile-lfu 中介绍的一致,只是筛选的数据范围是全部缓存,这里就不在重复。
allkeys-lfu 策略是 Redis 4.0 后新增。
数据库和缓存一致性
问题来源
使用redis做一个缓冲操作,让请求先访问到redis,而不是直接访问MySQL等数据库:

读取缓存步骤一般没有什么问题,但是一旦涉及到数据更新:数据库和缓存更新,就容易出现缓存(Redis)和数据库(MySQL)间的数据一致性问题。
不管是先写MySQL数据库,再删除Redis缓存;还是先删除缓存,再写库,都有可能出现数据不一致的情况。举一个例子:
1.如果删除了缓存Redis,还没有来得及写库MySQL,另一个线程就来读取,发现缓存为空,则去数据库中读取数据写入缓存,此时缓存中为脏数据。
2.如果先写了库,在删除缓存前,写库的线程宕机了,没有删除掉缓存,则也会出现数据不一致情况。
因为写和读是并发的,没法保证顺序,就会出现缓存和数据库的数据不一致的问题。
Cache Aside Pattern
更新缓存的的Design Pattern有四种:Cache aside, Read through, Write through, Write behind caching; 我强烈建议你看看这篇,左耳朵耗子的文章:缓存更新的套路
节选最最常用的Cache Aside Pattern, 总结来说就是
读的时候,先读缓存,缓存没有的话,就读数据库,然后取出数据后放入缓存,同时返回响应。
更新的时候,先更新数据库,然后再删除缓存。
其具体逻辑如下:
失效:应用程序先从cache取数据,没有得到,则从数据库中取数据,成功后,放到缓存中。
命中:应用程序从cache中取数据,取到后返回。
更新:先把数据存到数据库中,成功后,再让缓存失效。


注意,我们的更新是先更新数据库,成功后,让缓存失效。那么,这种方式是否可以没有文章前面提到过的那个问题呢?我们可以脑补一下。
一个是查询操作,一个是更新操作的并发,首先,没有了删除cache数据的操作了,而是先更新了数据库中的数据,此时,缓存依然有效,所以,并发的查询操作拿的是没有更新的数据,但是,更新操作马上让缓存的失效了,后续的查询操作再把数据从数据库中拉出来。而不会像文章开头的那个逻辑产生的问题,后续的查询操作一直都在取老的数据。
这是标准的design pattern,包括Facebook的论文《Scaling Memcache at Facebook (opens new window)》也使用了这个策略。为什么不是写完数据库后更新缓存?你可以看一下Quora上的这个问答《Why does Facebook use delete to remove the key-value pair in Memcached instead of updating the Memcached during write request to the backend? (opens new window)》,主要是怕两个并发的写操作导致脏数据。
那么,是不是Cache Aside这个就不会有并发问题了?不是的,比如,一个是读操作,但是没有命中缓存,然后就到数据库中取数据,此时来了一个写操作,写完数据库后,让缓存失效,然后,之前的那个读操作再把老的数据放进去,所以,会造成脏数据。
但,这个case理论上会出现,不过,实际上出现的概率可能非常低,因为这个条件需要发生在读缓存时缓存失效,而且并发着有一个写操作。而实际上数据库的写操作会比读操作慢得多,而且还要锁表,而读操作必需在写操作前进入数据库操作,而又要晚于写操作更新缓存,所有的这些条件都具备的概率基本并不大。
所以,这也就是Quora上的那个答案里说的,要么通过2PC或是Paxos协议保证一致性,要么就是拼命的降低并发时脏数据的概率,而Facebook使用了这个降低概率的玩法,因为2PC太慢,而Paxos太复杂。当然,最好还是为缓存设置上过期时间。
方案:队列 + 重试机制
流程如下所示

-
更新数据库数据;
-
缓存因为种种问题删除失败
-
将需要删除的key发送至消息队列
-
自己消费消息,获得需要删除的key
-
继续重试删除操作,直到成功
然而,该方案有一个缺点,对业务线代码造成大量的侵入。于是有了方案二,在方案二中,启动一个订阅程序去订阅数据库的binlog,获得需要操作的数据。在应用程序中,另起一段程序,获得这个订阅程序传来的信息,进行删除缓存操作。
方案:异步更新缓存(基于订阅binlog的同步机制)
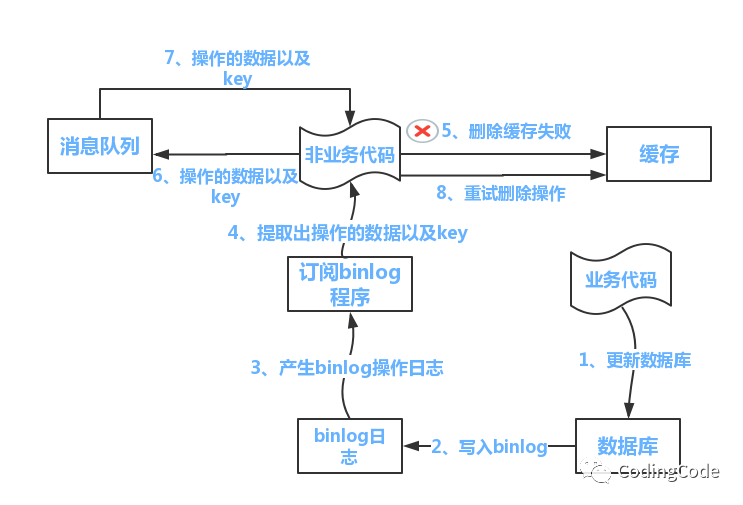
MySQL binlog增量订阅消费+消息队列+增量数据更新到redis
1)读Redis:热数据基本都在Redis
2)写MySQL: 增删改都是操作MySQL
3)更新Redis数据:MySQ的数据操作binlog,来更新到Redis
技术整体思路:
Redis更新
1)数据操作主要分为两大块:
一个是全量(将全部数据一次写入到redis)
一个是增量(实时更新)
这里说的是增量,指的是mysql的update、insert、delate变更数据。
2)读取binlog后分析 ,利用消息队列,推送更新各台的redis缓存数据。
这样一旦MySQL中产生了新的写入、更新、删除等操作,就可以把binlog相关的消息推送至Redis,Redis再根据binlog中的记录,对Redis进行更新。
其实这种机制,很类似MySQL的主从备份机制,因为MySQL的主备也是通过binlog来实现的数据一致性。
这里可以结合使用canal(阿里的一款开源框架),通过该框架可以对MySQL的binlog进行订阅,而canal正是模仿了mysql的slave数据库的备份请求,使得Redis的数据更新达到了相同的效果。
当然,这里的消息推送工具你也可以采用别的第三方:kafka、rabbitMQ等来实现推送更新Redis。
参考文章
https://coolshell.cn/articles/17416.html
https://www.cnblogs.com/rjzheng/p/9041659.html
https://my.oschina.net/jiagouzhan/blog/2990423
https://blog.csdn.net/qq_38261137/article/details/106949963
转自:Redis进阶-缓存问题
相关文章:
Redis进阶-缓存问题
Redis 最常用的一个场景就是作为缓存,本文主要探讨Redis作为缓存,在实践中可能会有哪些问题?比如一致性、击穿、穿透、雪崩、污染等。 为什么要理解Redis缓存问题 在高并发业务场景下,数据库大多数情况都是用户并发访问最薄弱的…...

VS Code Spring 全新功能来了!
大家好,欢迎来到我们 2023 年的第一篇博客!我们想与您分享几个与 Spring 插件、代码编辑和性能相关的激动人心的更新,让我们开始吧! Spring 插件包的新入门演练 演练(Walkthrough) 是一种多步骤、向导式的体…...

关于大数据导入流程引擎ccflow的方案
问题: 1. 现在的流程系统里有几百万条已经运行的流程其它的流程架构上 2. 需要把这样的数据导入到ccflow流程引擎里面去。 数据结构分析: 1. ccflow有流程引擎注册表,工作人表,业务数据表与日志表4大表. 2. ccflow的流程实例是一个int类型的…...

AI 生成二次元女孩,免费云端部署(仅需5分钟)
首先需要google的colab,免费版本GPU有额度。其次,打开github网站,选择一个进入colab,修改代码 !apt-get -y install -qq aria2 !pip install -q https://github.com/camenduru/stable-diffusion-webui-colab/releases/download/0.0.16/xforme…...
掌握MySQL分库分表(六)解决主键重复问题--Snowflake雪花算法
文章目录问题及需求常用ID解决方案数据库自增IDUUIDRedis发号器Snowflake雪花算法分布式 ID 生成算法Snowflake原理关于bit与byte雪花算法的位数Snowflake必须注意的地方全局唯⼀、不能重复保证各个系统时间一致Snowflake雪花算法实现雪花算法测试结果问题及需求 单库下⼀般使…...

Melis4.0[D1s]:1.启动流程(与adc按键初始化相关部分)跟踪笔记
文章目录1.启动流程1.1 最先进入的文件:head_s.S1.2 start_kernel()函数所在的文件:init.c1.3 input_init()函数所在文件:sys_input.c1.4 INPUT_LKeyDevInit()所在文件:keyboarddev.c1.5 esINPUT_RegLdev()所在文件:in…...

GNU make 中文手册 第三章:Makefile 总述
一、Makefile 总述 3.1 Makefile 的内容 在一个完整的 Makefile 中,包含了 5 个东西:显式规则、隐含规则、变量定义、指示符和注释。关于“规则”、“变量” 和 “Makefile 指示符” 将在后续的章节进行详细的讨论。本章讨论的是一些基本概念。 显式规…...
简历的专业技能怎么写?排版需要注意的事项
一、简历的专业技能怎么写? 首先,先问一下你自己会什么,然后看看你意向的公司需要什么。一般HR可能并不太懂技术,所以他在筛选简历的时候可能就盯着你专业技能的关键词来看。对于公司有要求而你不会的技能,你可以花几 天时间学习一下,然后在简历上可以写上自己了解这个技…...

【Git】为什么需要版本控制?版本控制工具有那些?
目录 一、为什么需要版本控制? 二、版本控制工具有那些? 💟 创作不易,不妨点赞💚评论❤️收藏💙一下 一、为什么需要版本控制? 首先我们要知道什么是版本控制?对版本控制进行文字…...

SSH远程执行Python3 Error: UnicodeEncodeError: ‘ascii‘ codec
首先确定要执行脚本服务器的语言编码环境,执行 # locale -a C en_US.utf8 POSIX # locale LANGen_US.utf8 LC_CTYPE"en_US.utf8" LC_NUMERIC"en_US.utf8" LC_TIME"en_US.utf8" LC_COLLATE"en_US.utf8" LC_MONETARY"…...

极简TypeScript教程--面向对象
在早期的JavaScript开发中(ES5)我们需要通过函数和原型链来实现类和继承,从ES6开始,引入了class关键字,可以更加方便的定义和使用类。TypeScript作为JavaScript的超集,也是支持使用class关键字的࿰…...
java TCP/UDP、Socket、URL网络编程详解
文章目录网络通信协议通信双方地址端口号IP地址InetAddress类Socket 网路编程Socket类的常用构造器Socket类的常用方法UDP协议什么是UDP协议UDP网络编程DatagramSocket 构造方法DatagramSocket 常用方法DatagramPacket常用方法实现步骤单向数据发收的UDP程序双向数据发收的UDP程…...

【C语言】宏
🚀write in front🚀 📜所属专栏:> c语言学习 🛰️博客主页:睿睿的博客主页 🛰️代码仓库:🎉VS2022_C语言仓库 🎡您的点赞、关注、收藏、评论,是…...
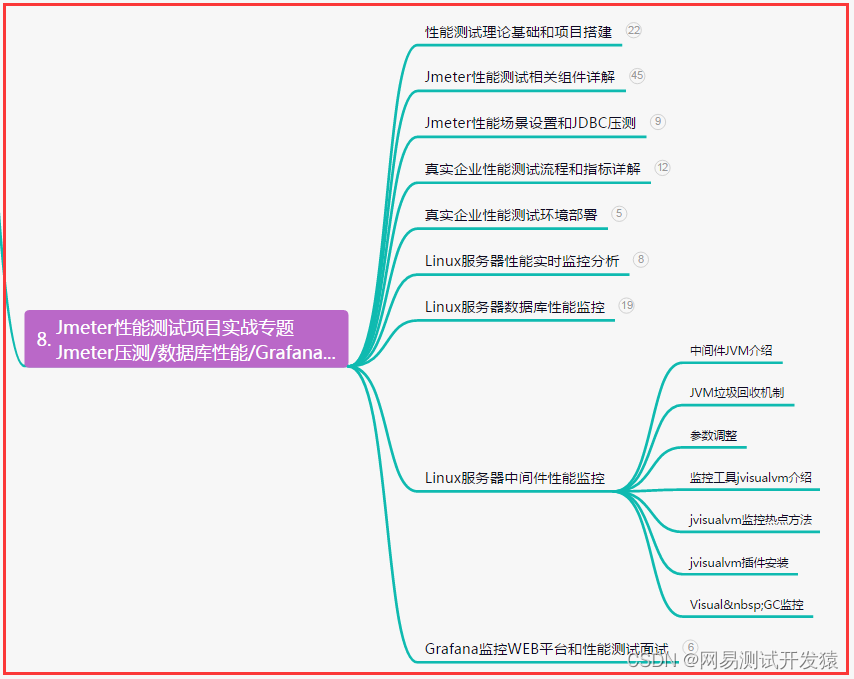
【测试面试】自我分析+功能+接口自动化+性能测试面试题(大全),知己知彼百战百胜......
目录:导读前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜)前言 分析自己和面试企业…...

ASE4N65SE-ASEMI高压MOS管ASE4N65SE
编辑-Z ASE4N65SE在TO-220F封装里的静态漏极源导通电阻(RDS(ON))为2.5Ω,是一款N沟道高压MOS管。ASE4N65SE的最大脉冲正向电流ISM为16A,零栅极电压漏极电流(IDSS)为10uA,其工作时耐温度范围为-55~150摄氏度。ASE4N65S…...
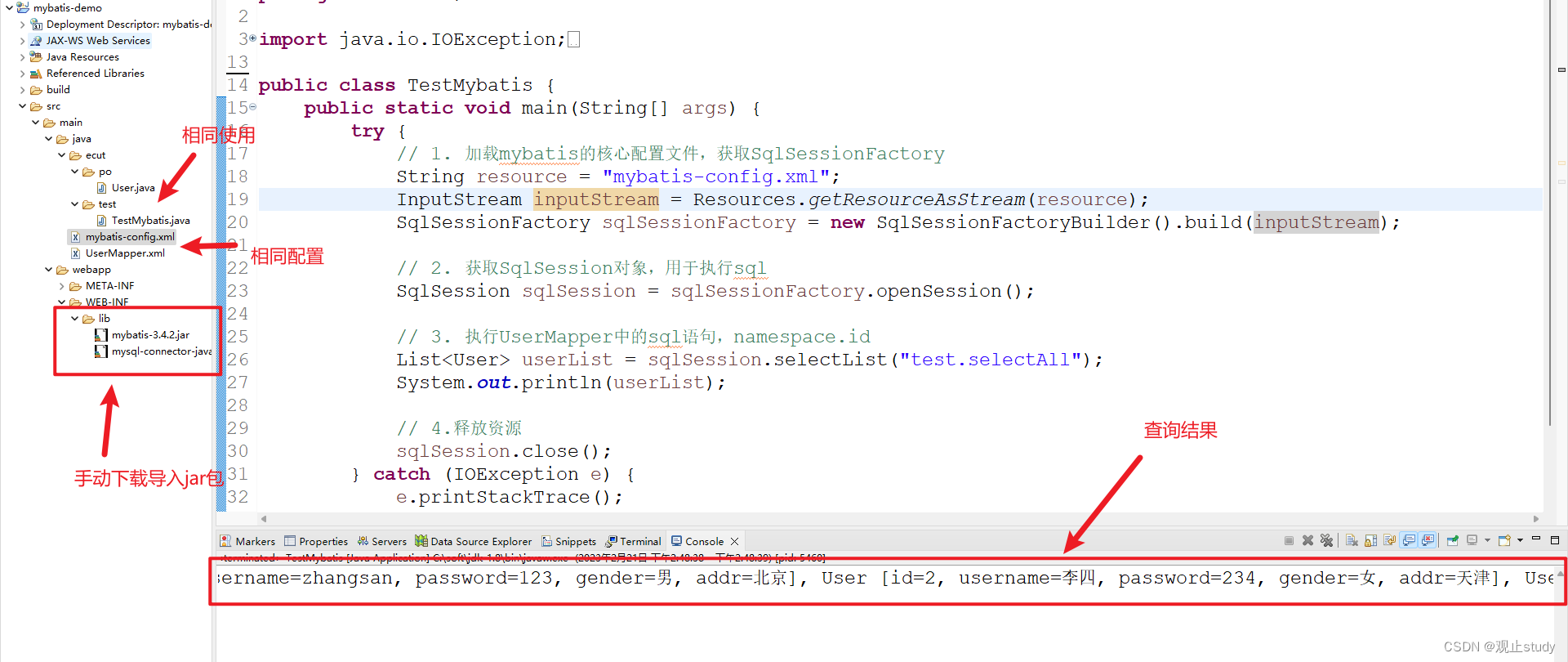
MyBatis概述环境搭建(一)
🚗MyBatis学习起始站~ 🚩本文已收录至专栏:数据库学习之旅 👍希望您能有所收获 一.什么是MyBatis (1) 引言 MyBatis 是一款优秀的持久层框架,它支持自定义 SQL、存储过程以及高级映射。MyBatis 免除了几乎所有的 JDB…...

3.8国际妇女节即将到来,跨境卖家如何做好选品和营销?
不知不觉,时间已来到了2月末,一年一度的三八国际妇女节也即将来临。三八节又称女神节,这不仅是庆祝女性伟大贡献的日子,也是跨境卖家们促销的大好时机。 有数据显示,女性是跨境消费的主力人群,占比超七成&…...

Glue Connector 和 Connection 的关系与区别
AWS Glue作为一种无服务器产品,其运行环境是“不可预知”的,也就是“一个黑盒”,所以如何能连接一些自有数据源是Glue必须考虑并给予满足的,为此,Glue给出的解决方案就是Connector和Connection,一个connect…...
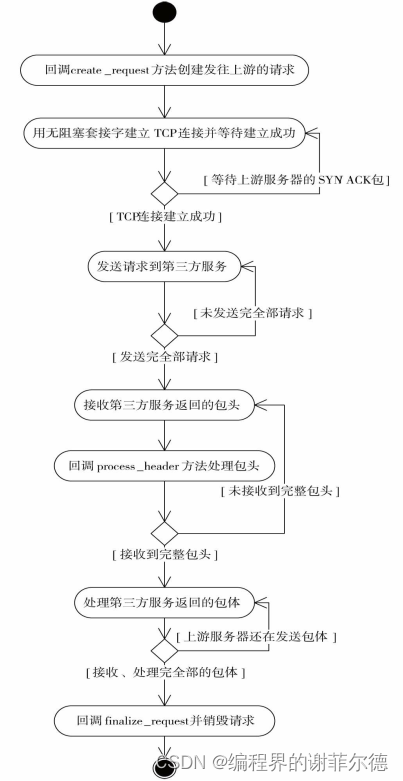
如何使用ngxin的 upstream
1.引言: 1.1反向代理: 反向代理是充当Web服务器网关的代理服务器。当您将请求发送到使用反向代理的Web服务器时,他们将先转到反向代理,由该代理将确定是将其路由到Web服务器还是将其阻止。 这意味着有了反向代理,您…...

Java数组,超详细整理,适合新手入门
目录 一、什么是Java中的数组? 二、数组有哪些常见的操作? 三、数组的五种赋值方法和使用方法 声明数组 声明数组并且分配空间 声明数组同时赋值(1) 声明数组同时赋值(2) 从控制台输入向数组赋值 四、求总和平均 五、求数组中最大值最小值 六…...

T型翼/尾板导向的穿浪双体船姿态控制【附代码】
✨ 长期致力于穿浪双体船、T型翼、尾板、多自由度姿态控制、舒适性评估研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)动态水翼升力模型与耦合运动方…...

Unity安卓打包实战指南:从环境配置到APK生成全链路排错
1. 这不是“入门教程”,而是一份写给真实开发现场的生存指南你打开Unity,新建一个3D项目,拖进一个Cube,点击Play——它动了。你松了口气,觉得“Unity好像也没那么难”。但当你把APK打包发给测试同事,对方回…...
)
从STM32迁移到普冉PY32F003:UART代码移植保姆级教程(附HAL库对比)
从STM32到普冉PY32F003的UART代码迁移实战指南 1. 国产MCU替代浪潮下的技术选择 近年来,半导体行业的供应链波动促使更多工程师将目光投向国产MCU解决方案。普冉PY32F003系列作为Cortex-M0内核的代表产品,以48MHz主频、64KB Flash和8KB RAM的配置&#x…...

别急着扔!12年老ThinkPad X230升级SSD和内存后,Win10流畅得像新电脑
12年老ThinkPad X230重生指南:极简升级打造流畅办公利器每次打开抽屉看到那台积灰的ThinkPad X230,总有种说不出的情感。这款2012年问世的经典商务本,曾陪伴无数人度过加班到凌晨的夜晚。如今性能确实有些力不从心,但直接丢弃又觉…...

3步快速解密中兴光猫配置:ZET工具终极实战指南
3步快速解密中兴光猫配置:ZET工具终极实战指南 【免费下载链接】ZET-Optical-Network-Terminal-Decoder 项目地址: https://gitcode.com/gh_mirrors/ze/ZET-Optical-Network-Terminal-Decoder 中兴光猫配置解密工具是每个网络管理员必备的神器!Z…...

操作符从浅入深的讲解
1. 操作符的分类 2. ⼆进制和进制转换 3. 原码、反码、补码 4. 移位操作符 5. 位操作符:&、|、^、~ 6. 单⽬操作符 7. 逗号表达式 8. 下标访问[]、函数调⽤() 9. 结构成员访问操作符 10. 操作符的属性:优先级、结合性 11. 表达式求值1.操作符的分类以…...

反向海淘站点常见配置故障复盘与数据一致性优化方案
摘要反向海淘独立站运行过程中,容易出现价格换算异常、页面语种错乱、商品同步失败、订单状态停滞、运费计算偏差等问题。多数故障并非系统底层缺陷,而是配置逻辑理解偏差、数据规范不统一引发。本文结合实际运维场景,汇总高频故障成因&#…...

Facebook登录协议逆向解析:appsecret_proof与e2e加密机制
1. 这不是“爬虫教程”,而是一次对现代Web身份协议的解剖实验你有没有试过,在调试一个Facebook登录集成时,浏览器Network面板里突然冒出一串带sig、access_token、e2e、c_user的请求,参数长度动辄上千字符,加密方式五花…...

机器学习力场攻克Peierls相变动力学:从对称性描述符到畴生长标度律
1. 项目概述:当机器学习遇见Peierls相变在凝聚态物理和材料科学的前沿,我们常常被一个核心问题所困扰:如何精确地模拟那些由电子和晶格(原子)强烈耦合所驱动的复杂动力学过程?这类系统,比如电荷…...

3步终结Windows热键冲突:Hotkey Detective终极排查指南
3步终结Windows热键冲突:Hotkey Detective终极排查指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是否曾…...