Glue Connector 和 Connection 的关系与区别
AWS Glue作为一种无服务器产品,其运行环境是“不可预知”的,也就是“一个黑盒”,所以如何能连接一些自有数据源是Glue必须考虑并给予满足的,为此,Glue给出的解决方案就是Connector和Connection,一个connector就是一个用于协助访问数据源的程序包(容器镜像或Jar包),如果你要使用一个connector,必须先创建一个针对该connector的connection。一个connection包含了连接一个特定数据源的属性。connector和connections联合起来为目标数据源提供访问通路。本文地址:https://laurence.blog.csdn.net/article/details/129139176,转载请注明出处!
1. 关系与区别
下面是一些明确切且重要的结论:
- 先创建Connector,再创建Connection,后者依附于前者,Connector与Connection是一对多的映射关系
- Connector与Connection非常类似于数据库客户端工具(例如DataGrip)中的Driver和DataSource之间的关系,Connector类似Driver,主要包含JAR包和基础属性(如JDBC类型的Connector需要配置Base的JDBC URL),DataSource类似于DataSource,主要包含身份认证信息和网络配置
- 能在Glue控制台上编辑的主要是Custom Connector & Connection,以及Marketplace Connector关联的Connection
- Marketplace Connector是只读的,不可配置,对应Connection可由用户创建和编辑
- Marketplace Connector在架构上有更大的“运作空间”,一般以容器形式运行于EKS/ECS上
- Custom Connector只能是一个Jar包,所以它只有Spark、Athena、JDBC三种类型(对应Glue提供的三种集成API)
- Custom Connection可以独立于Connector存在,依赖Jar包可通过Job Dependent Jar配置给Job,故不一定非要依赖Connector
- 再进一步,如果配置了VPC Connection,再通过Job Dependent Jar配置Jar包,则Connection也可以省去(未必所有的Connection都可以,但测试过部分,确实是可行的)
- 尽管上述两点都已证明可行,还是建议始终使用Custom Connector + Custom Connection的标准方式配置数据源连接。跳过Connector直接创建Custom Connection会丢失一个优势:由于在Glue图形化编辑器上,只有Connector是可以直接拖放的Source/Sink组件,所以如果跳过Custom Connector直接创建Custom Connection,在Glue图形化编辑器上就没有这个数据源对应的连接器可以拖放了。
下图对以上要点进行了总结:

来自于marketplace的connector显然拥有“特权”,它们拥有更加复杂的架构,这些connector往往都有自己docker镜像,并使用ECS/EKS部署和运行镜像,独立的镜像给了connector最大化的定制空间。而自定义connector的“运作空间”远远没有marketplace上的connector大,它不能拥有自定义镜像,只能以jar包形式存在,并依附于Glue的运行环境(通过三套API接口集成),所以,自定义的connector只有三种类型,只能以Jar包形式存在:
- Spark DataSource API -> connectionType=custom.spark
- Amazon Athena Data Source API -> connectionType=custom.athena
- Java JDBC API -> connectionType=custom.jdbc
2. Connection的加载时机
此外,我们一直想找出:Glue的Connection与Spark原生数据加载方式(例如:spark.read.format(“jdbc”))之间到底有什么差异,我们以JDBC类型的Connection做了如下一些测试:
| 测试场景 | 测试结果 |
|---|---|
| Custom JDBC Connection + Glue Context with Connection | 成功 |
| Custom VPC Connection + Job Dependent Jar + Glue Context with Connection | 成功 |
| Custom JDBC Connection + Spark原生数据加载方式 ( spark.read.format(“jdbc”) ) | 失败 |
上述三个测试用例可有力地证明:在Glue中,对于一个数据源的连接配置只能通过Glue专属的GlueContext加载才能生效。关于这一点,我们没有办法从源代码上获得验证,但是一种合理的解释是:我们知道,Glue作为Serverless产品,其工作节点(Worker)的网络环境是不可见的“黑盒”,为了能和目标数据源打通,Glue会根据Connction中的网络配置给它的工作节点创建临时的ENI(虚拟网卡),用于连接到Connection配置的子网中,这些工作节点也因此获得了指定子网内的私有IP地址,从上面的测试结果来看,真正触发Glue去完成这一系列操作的“开关”是在代码中通过GlueContext加载Connection时(根据Spark Lazy Loading的一贯特性,触发的时机可能会更晚,有可能是在初次读取DynamicFrame时),而不是只要在Job属性中关联了一个Connection,在Job启动时就会被自动激活。
3. 重要细节
最后,补充一些测试中的细节:
-
Trino JDBC Driver的URL中user参数不得为空
-
Trino JDBC Driver的URL中user和passoword,只能通过secret manager配置方可生效
-
通过Glue专属的GlueContext加载Connection指的是类似下面的代码:
# author: https://laurence.blog.csdn.net/ Trino_node1676884948138 = glueContext.create_dynamic_frame.from_options(connection_type="custom.jdbc",connection_options={"tableName": "orders","dbTable": "orders","jobBookmarkKeys": ["orderkey"],"jobBookmarkKeysSortOrder": "asc","connectionName": "my-trino-connection",},transformation_ctx="Trino_node1676884948138", ) -
通过Spark原生数据加载方式读取数据源指的是类似下面的代码:
# author: https://laurence.blog.csdn.net/ spark.read.format("jdbc").option("url", "jdbc:trino://localhost:8889/hive/default").option("driver", "io.trino.jdbc.TrinoDriver").option("user", "hadoop").option("dbtable", "orders").load().show() -
Glue的官方文档对于创建ENI有专门的解释:
AWS Glue sets up elastic network interfaces that enable your jobs to connect securely to other resources within your VPC. Each elastic network interface is assigned a private IP address from the IP address range within the subnet you specified.
4. 相关资源
4.1. 内置Connectors
connectionType | Connects To |
|---|---|
| custom.* | Spark, Athena, or JDBC data stores (see Custom and AWS Marketplace connectionType values |
| documentdb | Amazon DocumentDB (with MongoDB compatibility) database |
| dynamodb | Amazon DynamoDB database |
| kafka | Kafka or Amazon Managed Streaming for Apache Kafka |
| kinesis | Amazon Kinesis Data Streams |
| marketplace.* | Spark, Athena, or JDBC data stores (see Custom and AWS Marketplace connectionType values) |
| mongodb | MongoDB database |
| mysql | MySQL database (see JDBC connectionType Values) |
| oracle | Oracle database (see JDBC connectionType Values) |
| orc | Files stored in Amazon Simple Storage Service (Amazon S3) in the Apache Hive Optimized Row Columnar (ORC) file format |
| parquet | Files stored in Amazon S3 in the Apache Parquet file format |
| postgresql | PostgreSQL database (see JDBC connectionType Values) |
| redshift | Amazon Redshift database (see JDBC connectionType Values) |
| s3 | Amazon S3 |
| sqlserver | Microsoft SQL Server database (see JDBC connectionType Values) |
4.2. Marketplace Connectors
通过下面的链接可以查找到Marketplace上所有的连接器:
https://aws.amazon.com/marketplace/search/results?searchTerms=glue+connector
4.3. Custom Connectors
这里有一篇整体介绍,建议先阅读此文:
Developing, testing, and deploying custom connectors for your data stores with AWS Glue
4.3.1. 基于Spark DataSource API的自定义连接器
文档:
https://github.com/aws-samples/aws-glue-samples/tree/master/GlueCustomConnectors/development/Spark/glue-3.0
示例:
MinimalSpark3Connector.scala
4.3.2. 基Java JDBC API的自定义连接器
文档:
https://docs.aws.amazon.com/glue/latest/ug/connectors-chapter.html#code-jdbc-connector
示例:
https://github.com/aws-samples/aws-glue-samples/blob/master/GlueCustomConnectors/development/Spark/SparkConnectorMySQL.scala
4.3.3. 基Java JDBC API的自定义连接器
文档:
https://github.com/aws-samples/aws-glue-samples/tree/master/GlueCustomConnectors/development/Athena
示例:
https://github.com/aws-samples/aws-glue-samples/tree/master/GlueCustomConnectors/development/Athena
本文地址:https://laurence.blog.csdn.net/article/details/129139176,转载请注明出处!
相关文章:
Glue Connector 和 Connection 的关系与区别
AWS Glue作为一种无服务器产品,其运行环境是“不可预知”的,也就是“一个黑盒”,所以如何能连接一些自有数据源是Glue必须考虑并给予满足的,为此,Glue给出的解决方案就是Connector和Connection,一个connect…...
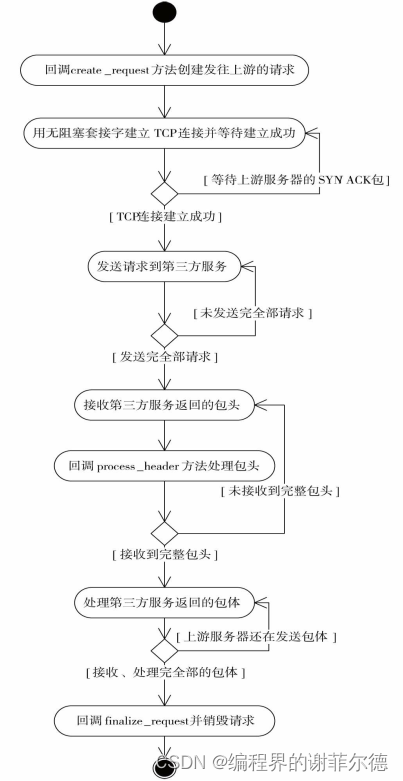
如何使用ngxin的 upstream
1.引言: 1.1反向代理: 反向代理是充当Web服务器网关的代理服务器。当您将请求发送到使用反向代理的Web服务器时,他们将先转到反向代理,由该代理将确定是将其路由到Web服务器还是将其阻止。 这意味着有了反向代理,您…...

Java数组,超详细整理,适合新手入门
目录 一、什么是Java中的数组? 二、数组有哪些常见的操作? 三、数组的五种赋值方法和使用方法 声明数组 声明数组并且分配空间 声明数组同时赋值(1) 声明数组同时赋值(2) 从控制台输入向数组赋值 四、求总和平均 五、求数组中最大值最小值 六…...
方式、程序中断方式、DMA方式、通道方式、I/O处理机)
1.3数据传输控制方式:IO数据传输控制方式、程序控制(查询)方式、程序中断方式、DMA方式、通道方式、I/O处理机
1.3数据传输控制方式:IO数据传输控制方式、程序控制(查询)方式、程序中断方式、DMA方式、通道方式、I/O处理机程序控制(查询)方式程序中断方式DMA方式通道方式、I/O处理机I/O数据传输方式,由软件到硬件发展…...

Linux 设置语言
文章目录1. 临时设置环境变量2. 默认语言设置3. 语言包4. 安装浏览器 chromium1. 临时设置环境变量 通过设置环境变量,可以使单个命令使用另一种语言LANG $ LANGfr_FR.utf8 date mar. mai 24 12:16:51 CDT 2022后续命令将恢复为使用系统的默认语言进行输出。该loc…...

Python基础-数据类型之集合
一、集合的定义 集合:是一个无序的没有重复元素的序列,因此不能通过索引来进行操作 1:使用set()创建集合 set(object) # 参数为一个序列,整型不能作为参数 set_a set("abcb") print(set_a) # {b, a, c} 2&…...
[Css]Grid属性简单陈列(适合开发时有基础的快速过一眼)
[css进阶]Grid属性简介 文章目录[css进阶]Grid属性简介典型需求网格容器的属性displaygrid-template-columns和grid-template-rowsgrid-template-areasgrid-templategrid-column-gap grid-row-gapgrid-gapjustify-itemsalign-itemsjustify-contentalign-contentgrid-auto-colum…...

100种思维模型之启发式偏差思维模型-017
曾国藩在给儿子的一封家书中曾写道:余于凡事皆用困知勉行工夫,尔不可求名太骤,求效太捷也。熬过此关,便可少进。再进再困,再熬再奋,自有亨通精进之日。 不急躁不求捷径,小火慢炖,将事…...

微服务 feign远程调用时 显示服务不可用 timed-out and no fallback
目录 第一种: failed and no fallback available 1 服务挂掉了 2 服务没有开启 3 注册中心没注册进去 -> ps: 直接调用的接口 通过网关转发失败 会报503 4 高并发下的服务熔断了 第二种: timed-out and no fallback 2.1 业务场景: A服务一切正常 但是B服务显示timeo…...

第一个Java程序(初识Java)
个人主页:平行线也会相交 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 平行线也会相交 原创 收录于专栏【JavaSE_primary】 文章目录1.Java概述1.1什么是Java1.2Java之父2.0第一个Java程序编译运行.class3.0程序如何跑起来的?3.1J…...
vulnhub LordOfTheRoot_1.0.1
总结:端口敲门,CVE-2015-8660提权, 目录 下载地址 漏洞分析 信息收集 端口敲门 网站分析 方法一 ssh登录提权 方法二 下载地址 LordOfTheRoot_1.0.1.ova (Size: 1.6 GB)Download: http://www.mediafire.com/download/m5tbx0dua05szjm…...

MutationObserver与IntersectionObserver
MutationObserver 出现原因:当我们需要监听元素发生变化时,不借助使元素发生变化的业务动作的情况下,使用无污染方式监听非常困难,为了解决这个问题,MutationObserver诞生! 概述 可以用来监听DOM的任何变化…...

【ESP 保姆级教程】玩转巴法云篇② ——MQTT设备云,MQTT协议下的数据通信
忘记过去,超越自己 ❤️ 博客主页 单片机菜鸟哥,一个野生非专业硬件IOT爱好者 ❤️❤️ 本篇创建记录 2023-02-21 ❤️❤️ 本篇更新记录 2023-02-21 ❤️🎉 欢迎关注 🔎点赞 👍收藏 ⭐️留言📝🙏 此博客均由博主单独编写,不存在任何商业团队运营,如发现错误,请…...
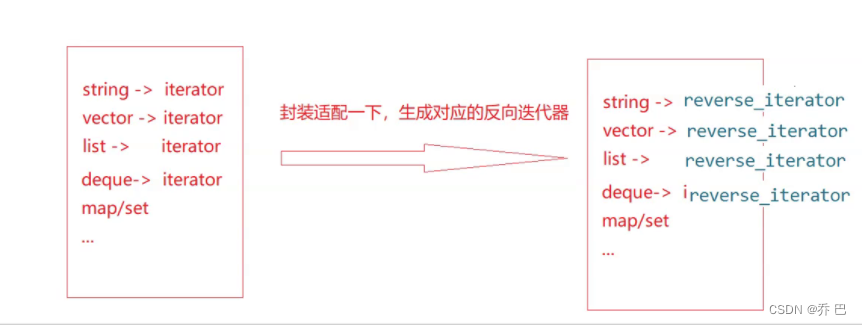
植物大战 仿函数——C++
容器适配器 容器适配器不支持迭代器。栈这个东西,让你随便去遍历,是不好的。他是遵循后进先出的。所以他提供了一个街头top取得栈顶数据。 仿函数 仿函数(functor)是C中一种重载了函数调用运算符(operator()&#x…...

【C语言】浮点型数据在内存中的存储
🚀🚀🚀 如果文章对你有帮助不要忘记点赞关注收藏哦🚀🚀🚀 文章目录⭐浮点数在内存中的存储1.1 🤓举个例子:1.2浮点数存储规则🌈:对于M与E有一些特别规定1.3解释前面题目&…...

impala中的刷新元数据和刷新表
impala是Cloudera公司主导开发的新型查询系统,它提供SQL语义,能查询存储在Hadoop的HDFS和HBase中的PB级大数据。 虽然Hive系统也提供了SQL语义,但由于Hive底层执行使用的是MapReduce引擎,仍然是一个批处理过程,难以满…...
Vscode创建vue项目的详细步骤
目录 一、概述 操作的前提 二、操作步骤 一、概述 后端人员想在IDEA里面创建一个Vue的项目,但是这非常麻烦,用vscode这个前端专用软件创建就会非常快速。 操作的前提 1.安装vscode软件的步骤:vscode下载和安装教程和配置中文插件&#…...

如何在面试中介绍自己的项目,才能让软件测试面试官无可挑剔,
四、项目 4.1 简单介绍下最近做过的项目 根据自己的项目整理完成,要点: 1)项目背景、业务、需求、核心业务的流程 2)项目架构,B/S还是C/5,数据库用的什么? 中间件用的什么?后台什么语言开发…...
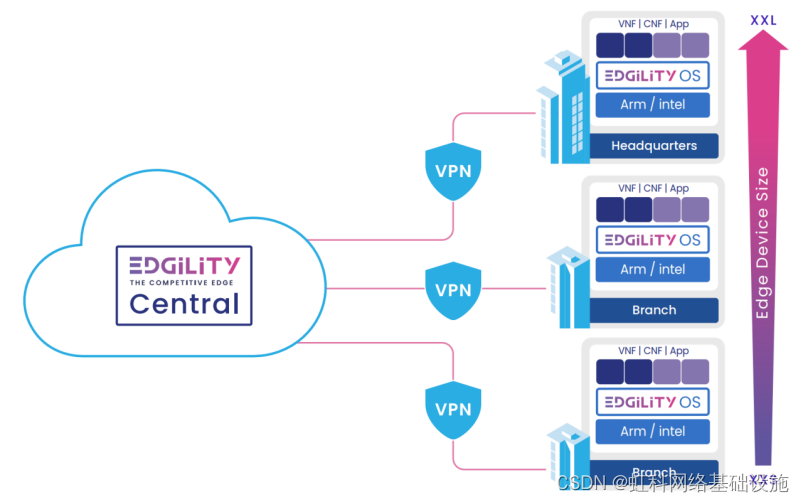
虹科方案|从 uCPE 到成熟的边缘计算平台
基于开放硬件平台,通用客户端设备 (uCPE) 支持快速添加、集成或删除任意数量的集中管理虚拟功能。 为了增加收入并保持竞争优势,托管服务提供商 (MSP) 和企业正在部署 uCPE 以增强业务敏捷性、加速新服务的引入并提高运营效率。最初,uCPE被部…...
计算机是怎么读懂C语言的?
文章目录前言程序环境翻译环境翻译环境分类编译预处理预处理符号预定义符号#define#undef命令行定义条件编译文件包含头文件包含查找规则嵌套文件包含其他预处理指令编译阶段汇编链接🎉welcome🎉 ✒️博主介绍:博主大一智能制造在读ÿ…...

Ventoy终极指南:一个U盘启动所有系统,告别重复格式化烦恼 [特殊字符]
Ventoy终极指南:一个U盘启动所有系统,告别重复格式化烦恼 😎 【免费下载链接】Ventoy A new bootable USB solution. 项目地址: https://gitcode.com/GitHub_Trending/ve/Ventoy 还在为每次安装系统都要重新制作启动盘而烦恼吗&#x…...

从理论推导到代码实现:手把手教你用Python/Numpy写出守恒形式的NS方程求解器
从理论推导到代码实现:手把手教你用Python/Numpy写出守恒形式的NS方程求解器计算流体力学(CFD)的魅力在于它将抽象的数学方程转化为可执行的代码,让流体运动的奥秘在计算机中重现。对于已经掌握流体力学理论的中高级学习者来说&am…...

从Office功能区的“局外人“到“掌控者“:Office RibbonX Editor深度指南
从Office功能区的"局外人"到"掌控者":Office RibbonX Editor深度指南 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/g…...
上午题回忆与解析(非标答版))
2026上半年数据库系统工程师(软考)上午题回忆与解析(非标答版)
本文为考后回忆整理,非官方标准答案,旨在为考后对答案及下半年备考的同学提供参考。题目顺序和表述可能与原卷有出入,欢迎在评论区指正、补充。📊 整体考情分析 刚结束的2026年上半年数据库系统工程师考试,上午题的风格…...

通过用量看板分析团队大模型API消耗发现优化调用策略的机会
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过用量看板分析团队大模型API消耗发现优化调用策略的机会 作为团队的技术负责人,确保大模型API调用在满足业务需求的…...

在模型广场灵活选型让我找到了更适合代码生成的Taotoken模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在模型广场灵活选型让我找到了更适合代码生成的Taotoken模型 开发代码辅助工具时,选择合适的模型是平衡效果与成本的关…...
)
Claude端到端测试设计终极清单:覆盖17类非功能需求(含延迟敏感度分级、幻觉熔断阈值、多轮对话状态持久化验证)
更多请点击: https://kaifayun.com 第一章:Claude端到端测试设计的演进逻辑与核心范式 Claude端到端测试并非静态产物,而是随模型能力边界拓展、交互场景复杂化及可靠性要求升级而持续演化的工程实践。其演进逻辑根植于三个关键张力…...
)
Windows开机自动全屏打开指定网页?一个快捷方式参数就搞定(Chrome/Edge/Firefox教程)
Windows开机自动全屏展示网页的终极方案每次开机都要手动打开浏览器、输入网址、切换全屏模式?这种重复操作不仅浪费时间,还容易在重要演示时手忙脚乱。想象一下:电脑启动后自动全屏显示你的仪表盘、会议日程或是监控大屏,整个过程…...

XZ6128A工作电压5-100V 输出电流5A 升压型大功率LED灯恒流驱动控制芯片
概述 XZ6128A是一款高效率、高精度的升压型大功率LED灯恒流驱动控制芯片。 XZ6128A内置高精度误差放大器,固定关断时间控制电路,恒流驱动电路等,特别适合大功率、多个高亮度LED灯串的恒流驱动。 XZ6128A采用固定关断时间的控制方式࿰…...

终极指南:用AlwaysOnTop免费开源工具彻底改变你的Windows工作方式
终极指南:用AlwaysOnTop免费开源工具彻底改变你的Windows工作方式 【免费下载链接】AlwaysOnTop Make a Windows application always run on top 项目地址: https://gitcode.com/gh_mirrors/al/AlwaysOnTop 你是否经常在多个窗口间来回切换,浪费宝…...