【MySQL】七种SQL优化方式 你知道几条
1.插入数据
1.1insert
insert into tb_test values(1,'tom');
insert into tb_test values(2,'cat');
insert into tb_test values(3,'jerry');Insert into tb_test values(1,'Tom'),(2,'Cat'),(3,'Jerry');start transaction;
insert into tb_test values(1,'Tom'),(2,'Cat'),(3,'Jerry');
insert into tb_test values(4,'Tom'),(5,'Cat'),(6,'Jerry');
insert into tb_test values(7,'Tom'),(8,'Cat'),(9,'Jerry');
commit;主键乱序插入 : 8 1 9 21 88 2 4 15 89 5 7 3
主键顺序插入 : 1 2 3 4 5 7 8 9 15 21 88 891.2大批量插入数据
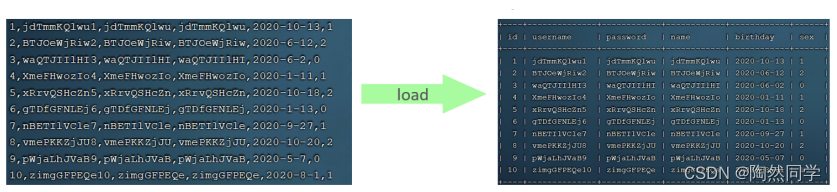
-- 客户端连接服务端时,加上参数 -–local-infile
mysql –-local-infile -u root -p
-- 设置全局参数local_infile为1,开启从本地加载文件导入数据的开关
set global local_infile = 1;
-- 执行load指令将准备好的数据,加载到表结构中
load data local infile '/root/sql1.log' into table tb_user fields
terminated by ',' lines terminated by '\n' ;CREATE TABLE `tb_user` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`username` VARCHAR(50) NOT NULL,
`password` VARCHAR(50) NOT NULL,
`name` VARCHAR(20) NOT NULL,
`birthday` DATE DEFAULT NULL,
`sex` CHAR(1) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `unique_user_username` (`username`)
) ENGINE=INNODB DEFAULT CHARSET=utf8 ;-- 客户端连接服务端时,加上参数 -–local-infile
mysql –-local-infile -u root -p
-- 设置全局参数local_infile为1,开启从本地加载文件导入数据的开关
set global local_infile = 1;load data local infile '/root/load_user_100w_sort.sql' into table tb_user
fields terminated by ',' lines terminated by '\n' ;
在 load 时,主键顺序插入性能高于乱序插入
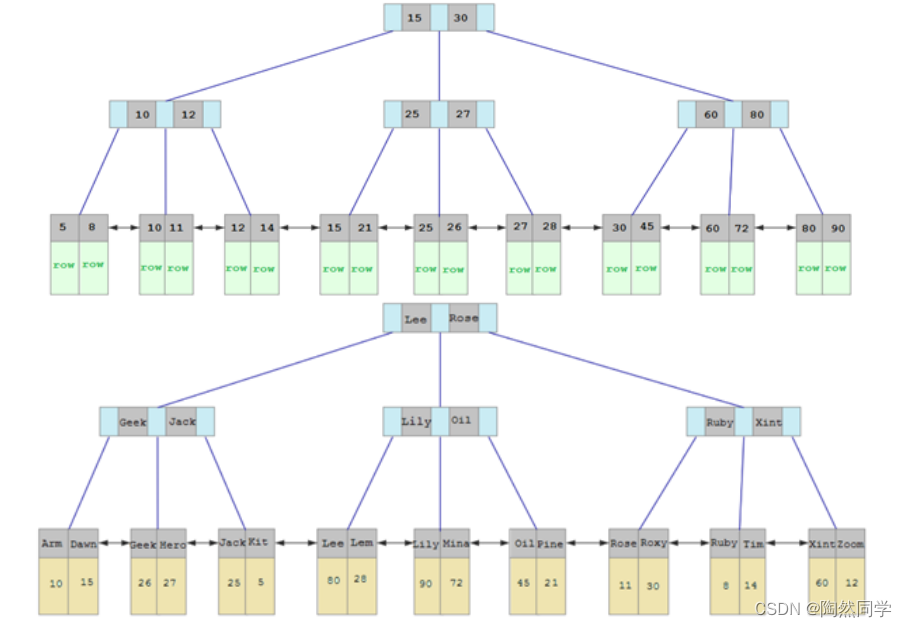
2.主键优化
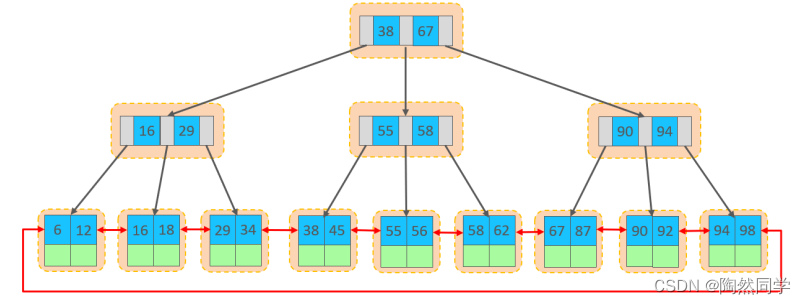
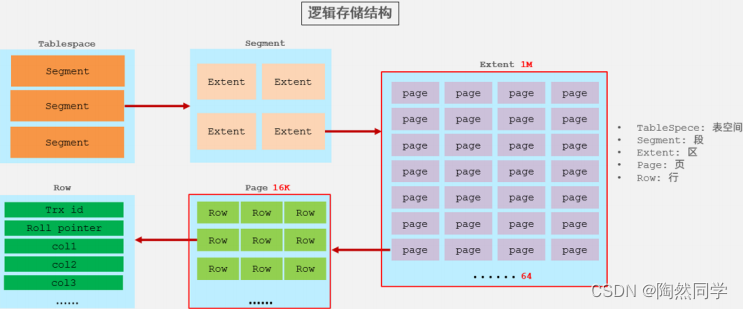
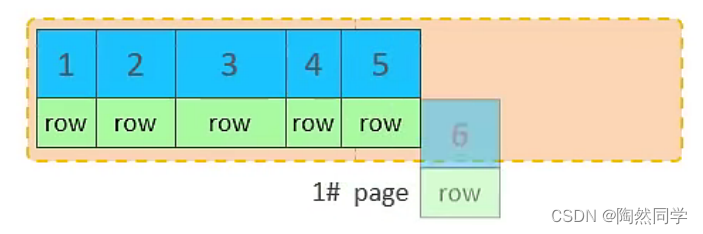
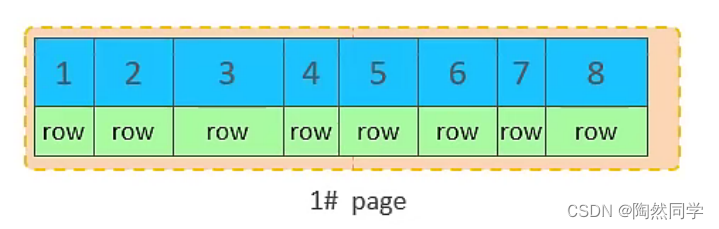



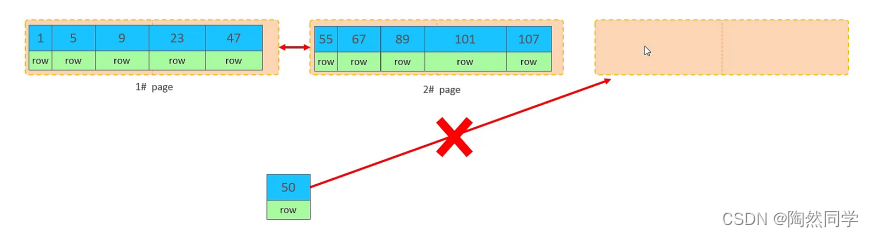
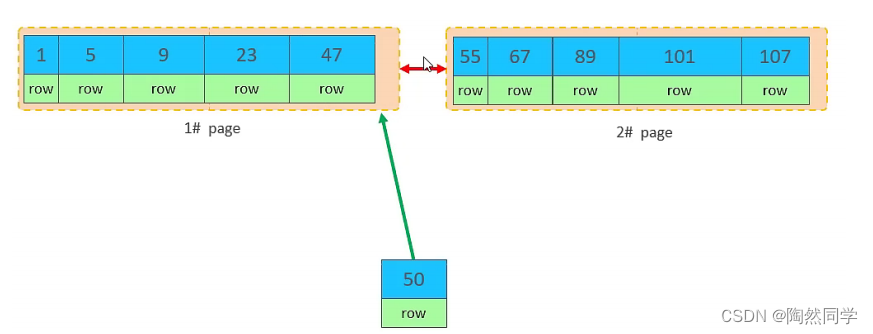





当我们继续删除2#的数据记录

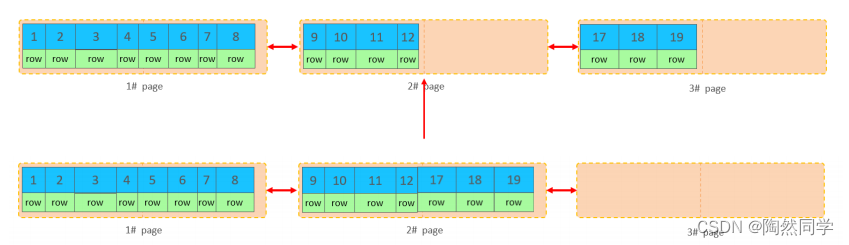
删除数据,并将页合并之后,再次插入新的数据21,则直接插入3#页
这个里面所发生的合并页的这个现象,就称之为 "页合并"。
知识小贴士:MERGE_THRESHOLD :合并页的阈值,可以自己设置,在创建表或者创建索引时指定。
3.order by优化
drop index idx_user_phone on tb_user;
drop index idx_user_phone_name on tb_user;
drop index idx_user_name on tb_user;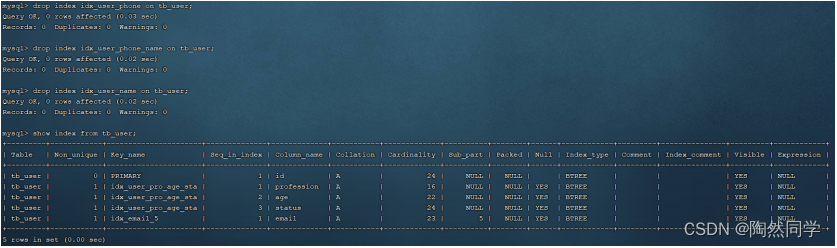 B. 执行排序SQL
B. 执行排序SQL
explain select id,age,phone from tb_user order by age ;
explain select id,age,phone from tb_user order by age, phone ; 
-- 创建索引
create index idx_user_age_phone_aa on tb_user(age,phone);explain select id,age,phone from tb_user order by age; 1
explain select id,age,phone from tb_user order by age , phone; 1
explain select id,age,phone from tb_user order by age desc , phone desc ;
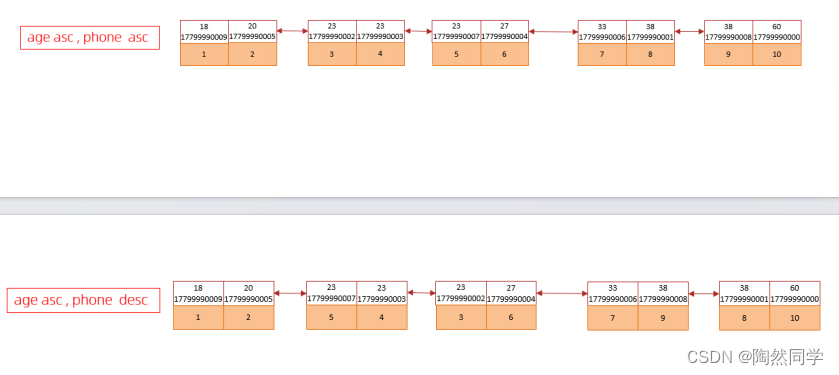
explain select id,age,phone from tb_user order by phone , age;explain select id,age,phone from tb_user order by age asc , phone desc ;

create index idx_user_age_phone_ad on tb_user(age asc ,phone desc);
H. 然后再次执行如下SQL
explain select id,age,phone from tb_user order by age asc , phone desc ;升序/降序联合索引结构图示:
4.group by优化
drop index idx_user_pro_age_sta on tb_user;
drop index idx_email_5 on tb_user;
drop index idx_user_age_phone_aa on tb_user;
drop index idx_user_age_phone_ad on tb_user;
explain select profession , count(*) from tb_user group by profession ;
create index idx_user_pro_age_sta on tb_user(profession , age , status);explain select profession , count(*) from tb_user group by profession ;

5.limit优化

explain select * from tb_sku t , (select id from tb_sku order by id
limit 2000000,10) a where t.id = a.id;6.count优化
6.1概述
select count(*) from tb_user ;
6.2count用法
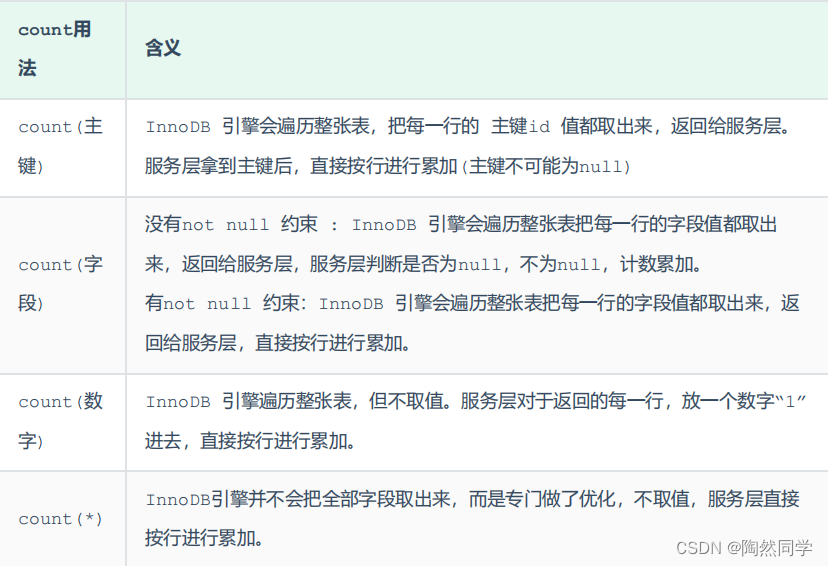
按照效率排序的话, count( 字段 ) < count( 主键 id) < count(1) ≈ count(*) ,所以尽量使用 count(*) 。
7.update优化
update course set name = 'javaEE' where id = 1 ; 1update course set name = 'SpringBoot' where name = 'PHP' ;InnoDB 的行锁是针对索引加的锁,不是针对记录加的锁 , 并且该索引不能失效,否则会从行锁升级为表锁 。
相关文章:
【MySQL】七种SQL优化方式 你知道几条
1.插入数据 1.1insert 如果我们需要一次性往数据库表中插入多条记录,可以从以下三个方面进行优化。 insert into tb_test values(1,tom); insert into tb_test values(2,cat); insert into tb_test values(3,jerry); 1). 优化方案一 批量插入数据 Insert into t…...
MySQL8.xx 解决1251 client does not support ..解决方案
MySQL8.0.30一主两从复制与配置(一)_蜗牛杨哥的博客-CSDN博客 MySQL8.xx一主两从复制安装与配置 MySQL8.XX随未生成随机密码解决方案 一、客户端连接mysql,问题:1251 client does not support ... 二、解决 1.查看用户信息 备注:host为 % …...

SpringBoot常用的简化开发注解
一、引言 在Spring Boot框架中,有许多常用的注解可用于开发项目。下面是其中一些常见的注解及其功能和属性的说明: 1、RestController RestController 是 Spring Framework 中的一个注解,用于标识一个类是 RESTful 服务的控制器。它结合了…...

python相关
1、更改用户名之后,C盘下的文件夹下名称没有改?这样设置 https://blog.csdn.net/qq_56088882/article/details/127470766 2、安装python和pycharm 链接 3、vscod中import requests出错:亲测有效: 链接...

C语言的类型转换
C语言的类型转换很重要,经常出现,但是往往不被人注意,而在汇编代码当中就暴露无遗了。 如下列代码: char ch; while ((ch getchar()) ! #) putchar(ch); 反汇编后: .text:00401006 mov…...
从零构建深度学习推理框架-11 Resnet
op和layer结构 在runtime_ir.cpp中,我们上一节只构建了input和output,对于中间layer的具体实现一直没有完成: for (const auto& kOperator : this->operators_) {if (kOperator->type "pnnx.Input") {this->input_o…...

多线程练习-顺序打印
wait和notify的使用推荐看通过wait和notify来协调线程执行顺序 题目 有三个线程,线程名称分别为:a,b,c。 每个线程打印自己的名称。 需要让他们同时启动,并按 c,b,a的顺序打印 代码及其注释…...
)
一文读懂MQTT各参数定义(非ChatGPT生成版)
文章目录 前言主流使用MQTT协议的云平台连接参数连接参数详解1.服务器地址(Server Address)2.端口(Port)3.客户端标识符(Client Identifier)4.用户名和密码(Username and Password)5…...

redis-lua脚本-无参-比较2个数值
以下是演变的过程: eval " return haha " 0 eval " local res haha; return res; " 0 eval " local value1 redis.call(get,value1); local value2 redis.call(get,value2);return value1; " 0 eval " return 1 < 2;…...
Lesson5-1:OpenCV视频操作---视频读写
学习目标 掌握读取视频文件,显示视频,保存视频文件的方法 1 从文件中读取视频并播放 在OpenCV中我们要获取一个视频,需要创建一个VideoCapture对象,指定你要读取的视频文件: 创建读取视频的对象 cap cv.VideoCapt…...

Lesson5-2:OpenCV视频操作---视频追踪
学习目标 理解meanshift的原理知道camshift算法能够使用meanshift和Camshift进行目标追踪 1.meanshift 1.1原理 m e a n s h i f t meanshift meanshift算法的原理很简单。假设你有一堆点集,还有一个小的窗口,这个窗口可能是圆形的,现在你可…...

1778_树莓派系统安装
全部学习汇总: GitHub - GreyZhang/little_bits_of_raspberry_pi: my hacking trip about raspberry pi. 一段视频学习教程的总结,对我来说基本上用处不大。因为我自己的树莓派简简单单安装完就开机成功了,而且实现了很多视频中介绍的功能。 …...
关闭jenkins插件提醒信息
jenkins提醒信息和安全警告可以帮助我们了解插件或者jenkins的更新情况,但是有些插件是已经不维护了,提醒却一直存在,看着糟心,就像下面的提示 1、关闭插件提醒 找到如下位置:系统管理-系统配置-管理监控配置 打开管…...
JixiPix Artista Impresso Pro for mac(油画滤镜效果软件)
JixiPix Artista Impresso pro Mac是一款专业的图像编辑软件,专为Mac用户设计。它提供了各种高质量的图像编辑工具,可以帮助您创建令人惊叹的图像。该软件具有直观的用户界面,使您可以轻松地浏览和使用各种工具。 它还支持多种文件格式&…...
机器学习之 Jupyter Notebook 使用
🎈 作者:Linux猿 🎈 简介:CSDN博客专家🏆,华为云享专家🏆,Linux、C/C、云计算、物联网、面试、刷题、算法尽管咨询我,关注我,有问题私聊! &…...

Unity引擎修改模型顶点色的工具
大家好,我是阿赵。 之前分享过怎样通过MaxScript在3DsMax里面修改模型的顶点色。不过由于很多时候顶点色的编辑需要根据在游戏引擎里面的实际情况和shader的情况来动态调整,所以如果能在引擎里面直接修改模型的顶点色,将会方便很多。于是…...
linux安装minio以及springboot整合使用
文章目录 1.linux安装minio2.springboot整合minio使用 1.linux安装minio 1.新建文件夹 mkdir /home/minio # 数据文件夹 mkdir /home/minio/data # 创建日志文件夹 mkdir /home/minio/log2.进入文件夹 cd /home/minio3.下载minio,链接可从官网获取 wget https://…...

javaee 事务 事务的特性 事务的并发问题 事务的隔离级别
什么是事务(Transaction) 是并发控制的单元,是用户定义的一个操作序列。这些操作要么都做,要么都不做,是一个不可分割的工作单位。通过事务,sql 能将逻辑相关的一组操作绑定在一起,以便服务器 保持数据的完整性。事务…...

Matlab怎么引入外部的latex包?Matlab怎么使用特殊字符?
Matlab怎么引入外部的latex包?Matlab怎么使用特殊字符? Matlab怎么使用特殊字符?一种是使用latex方式,Matlab支持基本的Latex字符【这里】,但一些字符需要依赖外部的包,例如“𝔼”,需…...
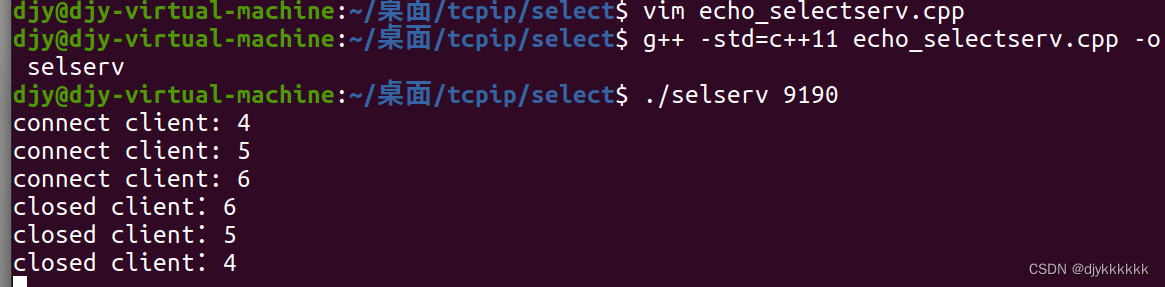
day-07 I/O复用(select)
一.I/O复用 (一)基于I/O复用的服务器端 1.多进程服务器 每次服务都需要创建一个进程,需要大量的运算和内存空间 2.复用 只需创建一个进程。 3.复用技术在服务器端的应用 (二)select函数实现服务器端 (…...

AI Agent在智能风控中的实战:多智能体欺诈检测与预警
AI Agent在智能风控中的实战:多智能体欺诈检测与预警 你有没有过明明是正常交易却被银行冻结账户的糟糕体验?或是听说过某电商平台上线新活动首日就被黑产团伙薅走数千万补贴的新闻?随着黑产欺诈向团伙化、专业化、动态化演进,传统依赖规则引擎、单模型机器学习的风控体系已…...

机器学习模型评估中的构念效度:超越基准测试分数的科学推断
1. 项目概述与核心问题在机器学习的日常研究和工程实践中,我们每天都在和各种各样的基准测试(Benchmark)打交道。无论是为了比较新提出的ResNet变体在ImageNet上的Top-1准确率,还是评估一个大型语言模型在MMLU上的常识推理能力&am…...

Wechat2RSS:微信公众号转RSS订阅工具
文章目录Wechat2RSS:微信公众号转RSS订阅工具Wechat2RSS:微信公众号转RSS订阅工具 ttttmr开源的Wechat2RSS项目,目前在GitHub上获得1409颗Star,项目地址为https://github.com/ttttmr/Wechat2RSS。该工具的核心作用是将微信公众号…...

全链路压测实战:双十一级别的流量,我是这样扛住的
作为一名在质量保障领域摸爬滚打多年的测试工程师,我深知传统的单接口压测在如今分布式架构下的无力感。当业务流量达到双十一这种脉冲式、高并发的级别时,任何一个非核心链路上的“短板”都可能引发系统性的雪崩。全链路压测不再是选择题,而…...

科华UPS电源全品类汇总:选型与场景适配指南
科华UPS电源作为国内智慧电能领域的主流产品,覆盖家用、办公、机房、工业等全场景,产品系列丰富、规格齐全,但多数用户在选型时,常因分不清系列差异、功率适配、架构类型而踩坑。本文系统汇总科华UPS电源的核心分类、主流系列、核…...

Linux平台终极Jellyfin客户端:如何用Tsukimi打造专业级媒体中心体验?
Linux平台终极Jellyfin客户端:如何用Tsukimi打造专业级媒体中心体验? 【免费下载链接】tsukimi A simple third-party Jellyfin client for Linux 项目地址: https://gitcode.com/gh_mirrors/ts/tsukimi 你是否厌倦了网页版Jellyfin的笨重体验&am…...

AICoverGen终极指南:快速创建AI翻唱歌曲的完整教程
AICoverGen终极指南:快速创建AI翻唱歌曲的完整教程 【免费下载链接】AICoverGen A WebUI to create song covers with any RVC v2 trained AI voice from YouTube videos or audio files. 项目地址: https://gitcode.com/gh_mirrors/ai/AICoverGen 想要让你的…...

智能知识学习平台
智能知识学习平台项目简介技术架构:问答驱动的开发模式前端架构后端架构核心功能:问答式交互贯穿始终1. 自定义构建知识库2.文档查看3.智能问答:知识触手可及4. 智能题目生成:严格遵循文档内容项目亮点用问答驱动的方式构建智慧学…...

关于我第九次博客作业
(1)Flex布局核心概念一、Flex 是什么Flex 是 CSS3 一维弹性布局,专治元素对齐、自适应、空间分配问题,布局更高效灵活。二、两大核心角色1. 父容器(Flex容器)设置 display: flex 即为弹性父盒子,负责统一规定子元素排列…...

XZ9971,60V,5A,NMOS 封装:SOT223
封装:SOT223类型:NVDS:60V VGS: 20V ID:5ARDS(ON):10V <50mΩRDS(ON):4.5V <60mΩ型号: XZ9971 封装:SOT223类型&…...