Kaldi语音识别技术(七) ----- 训练GMM
Kaldi语音识别技术(七) ----- GMM
文章目录
- Kaldi语音识别技术(七) ----- GMM
- 训练GMM
- train_mono.sh 用于训练GMM
- 训练GMM—生成文件
- 训练GMM—final模型查看
- 训练GMM—final.occs查看
- 训练GMM—对齐信息查看
- 训练GMM—fsts.*.gz查看
- 训练GMM—tree决策树查看
- align_si.sh 用于对齐
- 训练GMM—查看mono_ali.sh 生成内容
- 训练GMM—比对mono和mono_ali对齐信息
训练GMM
前面文章中我们讲了相比DTW,GMM的优点,那么我们怎么获取训练GMM呢?
GMM的训练流程如下图:
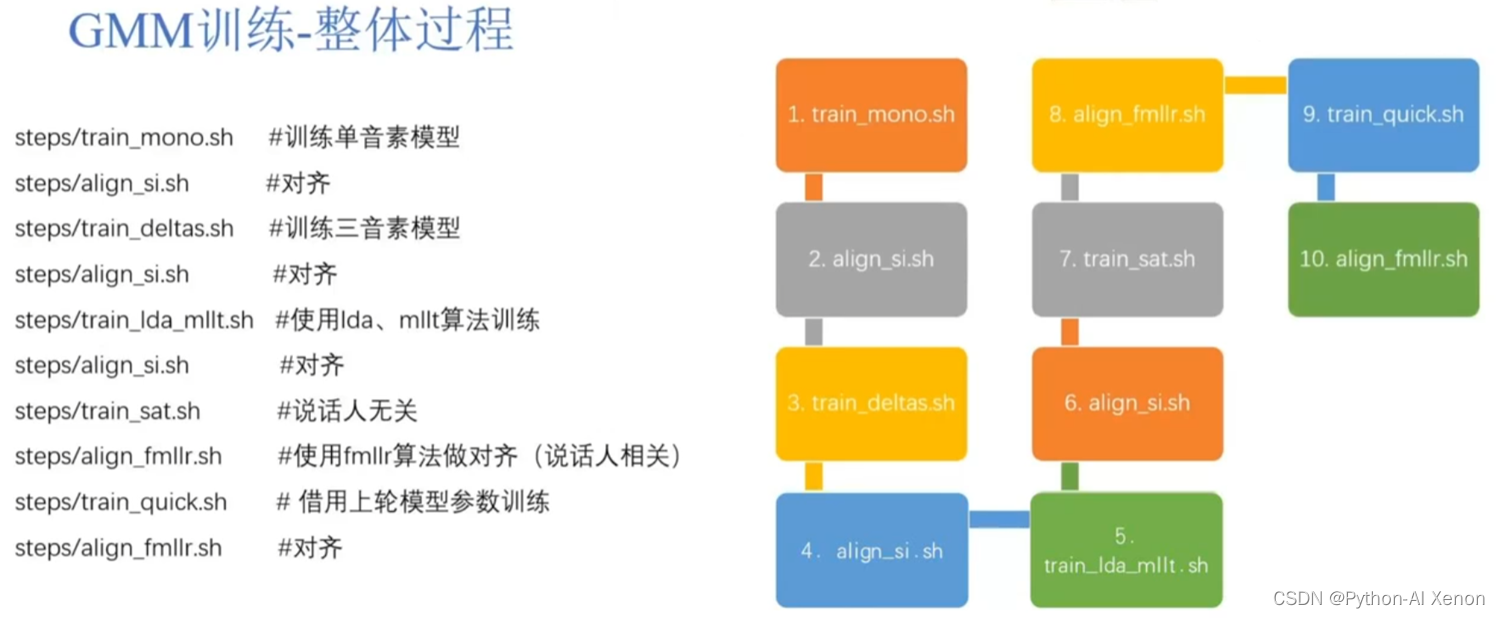
整个过程分为10个环节,其中有5个是与对齐相关的,为了方便理解,这10个环节,只讲其中的2个(train_mono 单因素训练模型和align_si对齐),其他的基本都是进行优化,大家以后涉及这一块可以自行百度。大致的流程是先训练一个高斯模型,使用这个高斯模型对训练数据进行对齐,然后使用对齐后的数据再训练一个高斯模型。如(上面右侧的图),最开始,先训练一个单音素模型,然后使用单音素模型对训练数据进行对齐,然后基于这些对齐数据,再训练一个三音素模型,然后再使用三音素模型对训练数据进行对齐,然后再使用lda、mllt等算法重估GMM模型,然后再对训练数据进行对齐,然后对模型进行说话人无关和相关操作,最后再次对训练数据进行对齐。整个GMM训练模型的过程就是这样。总的来说,模型训练得越好,对齐就对得越准,就越可以提高语音识别的准确度。
训练GMM—mono训练流程
我们来看下单音素模型是怎么训练的,首先训练一个模型,必须先要有一个起始模型,然后在再这个起始模型上进行迭代训练。所以kaldi就调用了gmm-init-mono来初始化模型,它使用了训练数据中特征来初始化模型。初始化好模型后,就是制作graph,这个图的输入有好几个,有初始化的模型,有lang文件中的L.fst,还有词典及训练数据中的文本,生成的结果是一个句子到音素级别的fst的压缩包(gz)。
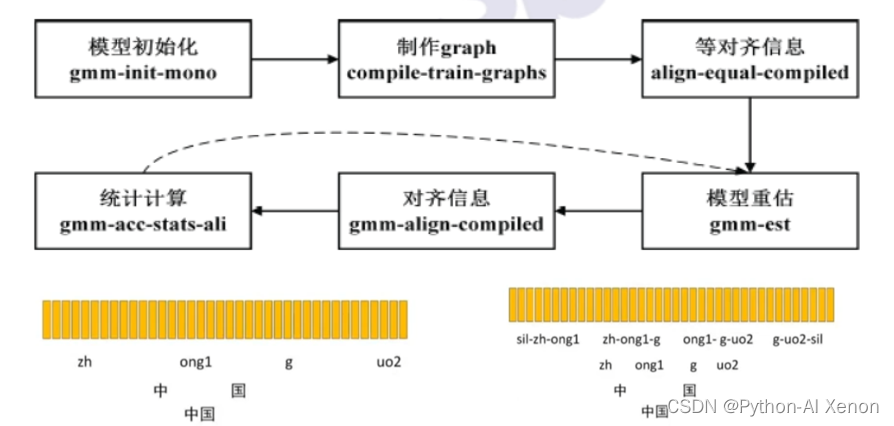
我们完成前面2步后,如何使用我们提取好的特征与制作的FST图对应起来,这就需要对齐。第三步使用了均匀对齐(图中的等对齐),前面也讲过FST是把标签文件的句子细化拆分到词、到字、到音素,再到HMM中的状态。
为了方便理解,图中我们只细化到音素,将词(中国)拆分为字(中和国),再拆分为音素(zh,ong1,g,uo2),每一个字有2个音素,总共4个音素,上面的黄色竖条分别代表一帧特征(MFCC特征),这里的均匀对齐就是假设有上诉4个音素,有100帧特征,每个音素就均匀分到了25帧特征,分别求这25帧特征的均值和方差,就可以得到相应的高斯模型了。
图下部分为我们的三音素模型(考虑了协同发音),三音素模型的数据量很大,所以在kaldi中使用了决策树聚类,将一些相近发音的音素聚合在一起归为一类,然后集中训练。在均匀对齐后,我们就要进行模型重估了,初始化模型是在部分训练数据中随机出来的,现在我们已经统计了全部音频数据的特征,及通过均匀对齐,每帧特征对应的状态及跳转概率。基于这些信息,我们对模型进行重估,下一步,对重估后的模型对齐数据(第五步),此时我们就不是使用均匀对齐的方式,而是使用重估模型后的统计量,并结合前面所做的fst生成新的对齐信息,这个过程可以简单理解为一个模型对训练集的解码过程,把每帧数据对应的特征放到每个音素或者每个状态对应的GMM中算概率,概率最大的音素就是这一帧对应的音素,如前面我们说的每个音素对应25帧,经过这一步后,每个音素对应的就变化了(假设第一个音素就对应20帧了)。基于这些对齐信息,我们就可以统计计算每个音素的跳转次数占全部跳转次数的比列,这样就可以重估HMM网络中每个状态的跳转概率,然后更新这些状态转移概率和每一帧的对齐信息后,又可以重估我们的GMM模型(第六步跳到第四步),就这样反复的重估模型,生成新的对齐信息,统计转移概率,然后再重估模型。具体这样多少次由我们自行设置,默认为40次。
train_mono.sh 用于训练GMM
我们来看下单音素模型在Kaldi中具体是怎么训练的,是调用step文件夹下的train_mono.sh脚本。特别要注意,如果使用多线程参数,nj数不能超过说话人数(spekerid),它是按照说话人数来进行分线程数的。
train_mono.sh 用法:
./steps/train_mono.sh
Usage: steps/train_mono.sh [options] <data-dir> <lang-dir> <exp-dir>e.g.: steps/train_mono.sh data/train.1k data/lang exp/mono
main options (for others, see top of script file)--config <config-file> # config containing options--nj <nj> # number of parallel jobs--cmd (utils/run.pl|utils/queue.pl <queue opts>) # how to run jobs.
参考:Kaldi 入门详解 train_mono.sh 官方文档
首先准备一下kaldi环境
. ~/kaldi/utils/path.sh
mkdir H_learn
cd ~/kaldi/data
然后执行脚本
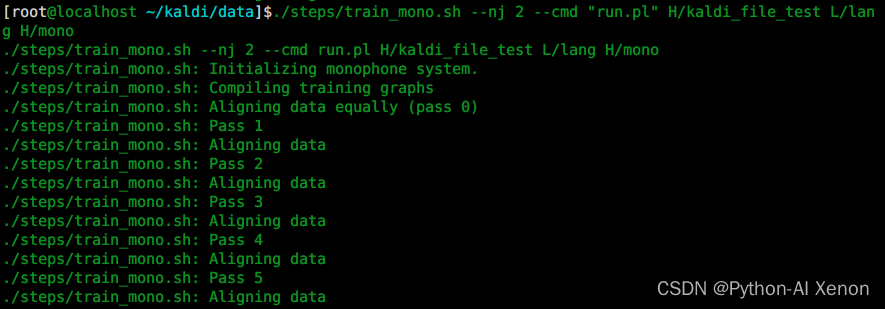
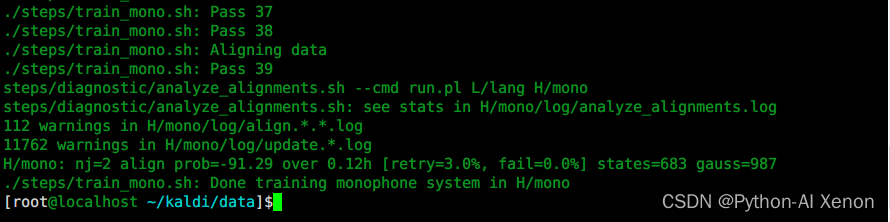
./steps/train_mono.sh --nj 2 --cmd "run.pl" H/kaldi_file_test L/lang H/mono
参数详解:
第一个参数:–nj 几个线程并行训练 (注:如果是提取的每个说话人的特征,nj数不能超过说话人数)
第二个参数:run.pl 本机运行
第三个参数:特征文件夹(含cmvn以及原始的mfcc特征,见专栏博文五)
第四个参数:lang文件夹(L文件夹中的lang文件夹)
第五个参数:输出GMM训练数据(单音素模型)文件夹
训练GMM—生成文件
使用train_mono.sh训练单音素模型后,我们生成了这些文件,首先最重要的肯定是模型(mdl,其中0.mdl表示初始化的模型;40.mdl表示迭代了40次的结果;final.mdl表示最终模型),其次是occs结尾的文件,可以简单理解为是一个全局统计量,统计每个音素或者每个音素对应几个状态的信息。ali..gz是对齐信息,每迭代一次模型,对齐信息就会更新一次。fst..gz是网格信息,就是我们前面所讲的一些FST信息。tree是决策树,是将发音类似的一些音素聚集成一类,方便计算。log是训练过程中产生的日志,如果训练过程中出现错误,基本都能在这里面找到相应的错误信息。

*.mdl:模型 0.mdl表示初始化的模型;40.mdl表示迭代了40次的结果;final.mdl表示最终结果。
*.occs:每个pdf出现的个数
ali.*.gz:对齐信息
fst.*.gz:网格信息
tree:决策树
log :训练过程log
训练GMM—final模型查看
将final.mdl的数据转换为文本并输出到final_mdl.txt文本中 (–binary=false 表示不使用二进制数据)
gmm-copy --binary=false final.mdl final_mdl.txt
vim final_mdl.txt 打开文件如下:
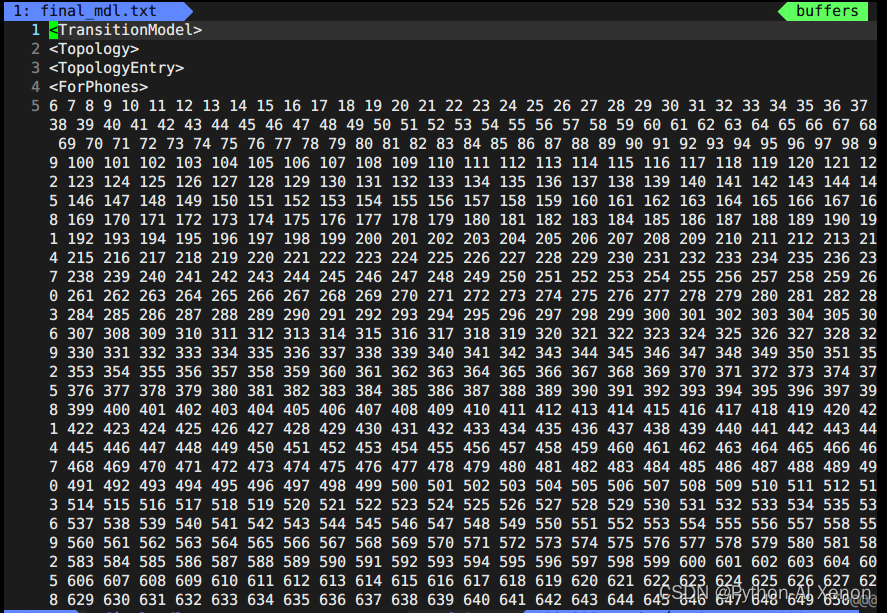
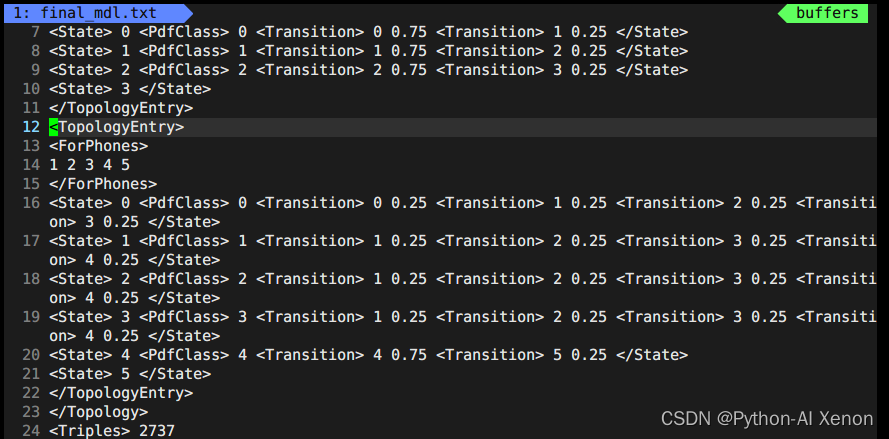
这里面前面23行前面我们生成G.fst时生成的topo文件中有这部分信息。我们可以画出相应的HMM状态,即6-909状态共用一个HMM3状态,1-5(静音音素)共用一个HMM5状态,第24行2727表示我们决策树聚类的个数。决策树信息中:第一列为音素索引(phone-id),第二列为HMM状态,第三列为PDF索引(决策树的类)
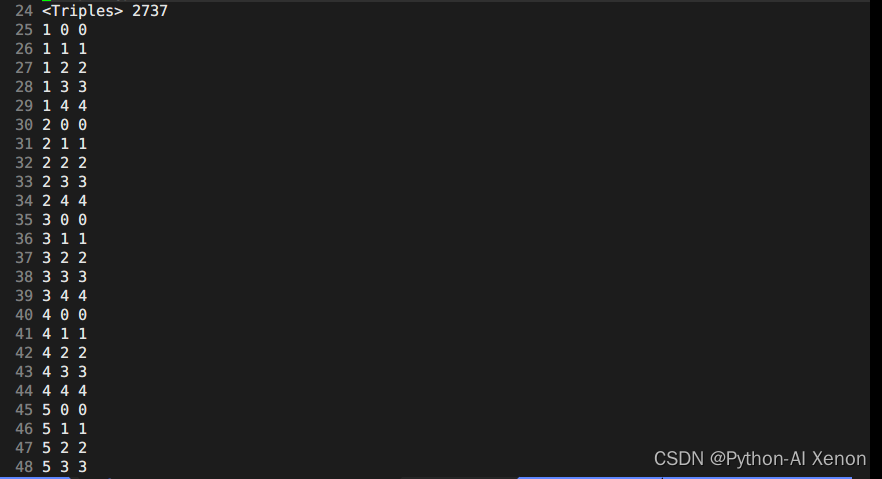
我们可以看见我们的音素总共有909个,那么为什么可以聚为2737个类呢?可以在图中看见,从25行开始到49行总共25行的第二列看出,他们都属于静音音素(为什么?序号都是0-4,5个状态,只有静音音素才有5个状态)。最终我们可以得出聚类的个数公式为:
决策树类的个数 = 静音音素数 * 5 + 非静音音素 * 3


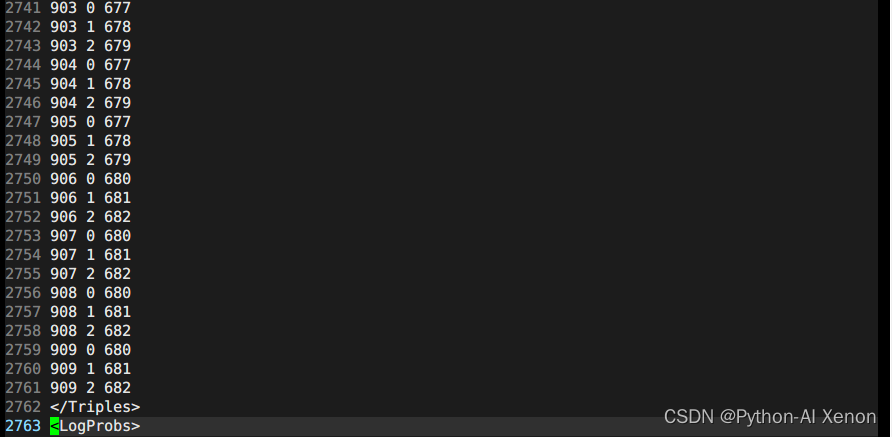
由于决策树中其他信息较多,大家可自行打开本机决策树信息查看,<LogProbs> 中的信息为每个类的转移概率,<dimension>中的数字为输入特征(MFCC)的3倍,是因为输入的特征做了一阶差分和二阶差分,再加上原来的特征就是这个数字39,<numpdfs>就是我们的决策树类的个数,每一个类都可以对应一个高斯混合模型(GMM)。下面的就是对图中的656个GMM的描述,一个高斯模型的描述只需要均值和方差即可(知道就行),如果是一个混合高斯的话,就需要多个高斯组合在一起,就需要每个高斯的在混合高斯中的权重,如上图中的权重<weights>中有2个权重,那么就说明描述这个音素的概率的混合高斯是由2个单高斯组成的,各自的权重分别是XXX,XXX,均值有39列,1个高斯对应1个39维的均值,2个高斯就有2个均值。同样的,方差也是一样的。除了权重,这里还有一个超参<gconsts>,也是一个高斯对应一个。这里不在过多的进行深度介绍。
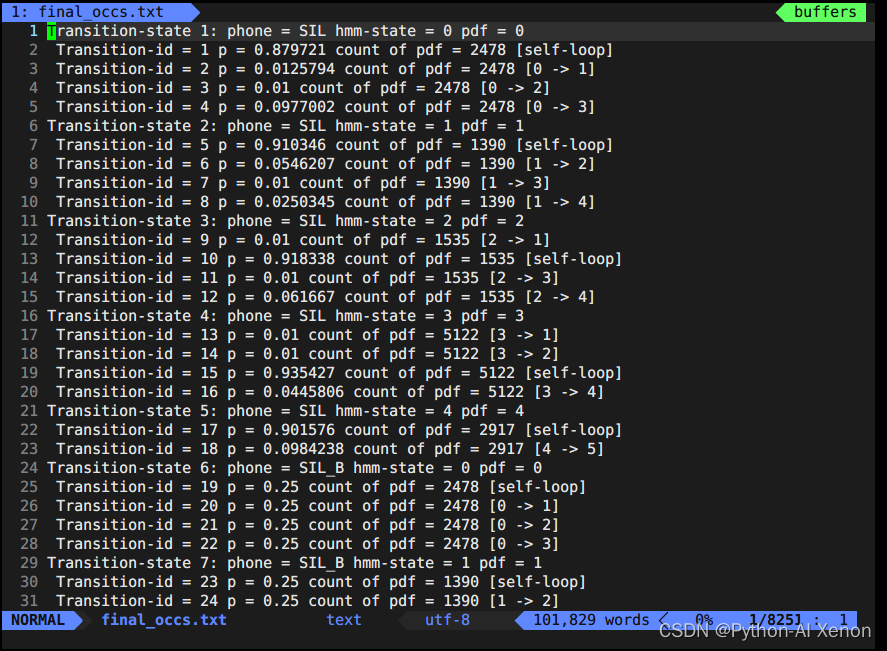
训练GMM—final.occs查看
接下来我们看下final.occs文件,可以简单把它理解为是一个全局统计量,统计每个音素或者每个音素对应几个状态的信息。即对每个HMM网络的描述。前面我们讲过每个音素又可以细分为BEIS(分别对应几个状态),我们知道HMM静音音素有5个状态(BEIS+自身5个状态),非静音音素BEI3个状态。occs就是将每个音素拆分后分别进行统计。Transition-state是对每个状态的描述,其中count of pdf中的数字表示这个边出现的次数。
统计每个音素或者每个音素对应几个状态的信息
show-transitions phones.txt final.mdl final.occs > final_occs.txt
vim final_occs.txt 打开文件如下:
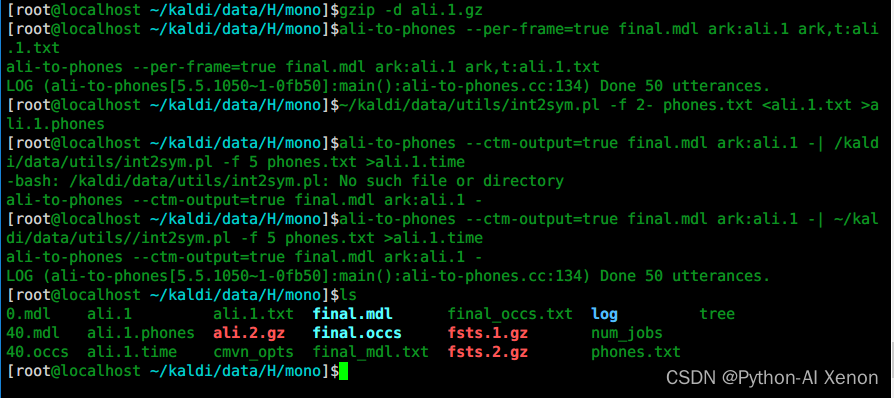
训练GMM—对齐信息查看
# 1 解压
gzip -d ali.1.gz
提特征按帧级别提的,训练也是按帧级别训练的,训练的结果是什么?可以通过ali-to-phones 命令查看我们哪几帧对应哪一个音素,图中每一个数字表示一个音素Id,为方便查看,我们需要将音素id转换为对应音素。
# 2 使用ali-to-phones进行查看
ali-to-phones --per-frame=true final.mdl ark:ali.1 ark,t:ali.1.txt
每个phone-id对应的音素是什么?使用int2sym.pl 脚本可以将音素id转换为对应的音素,我们就可以看见每个音素的时间信息。
# 3 将音素id转换为对应的音素
~/kaldi/data/utils/int2sym.pl -f 2- phones.txt <ali.1.txt >ali.1.phones
每个音素持续的时间是多久? 比如这一句话“设定二十九度”,大家可以通过音频查看软件查看核实,由于我们现在使用的是单音素训练模型,对齐的不一定完全准确,所以需要多次反复对模型进行训练。
# 4 各音素的对齐时间信息
ali-to-phones --ctm-output=true final.mdl ark:ali.1 -| ~/kaldi/data/utils//int2sym.pl -f 5 phones.txt >ali.1.time
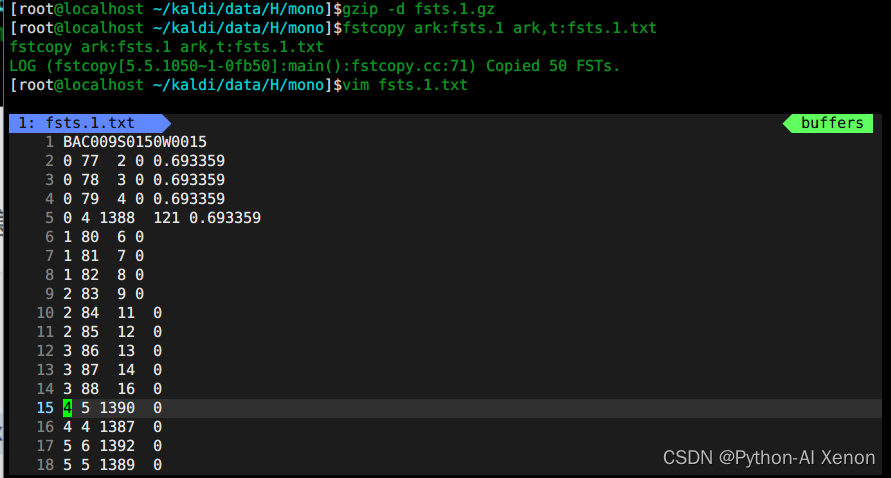
训练GMM—fsts.*.gz查看
这里面存储的是每个语句对应的fst网络结构信息,这里不过多赘述
# 1、解压
gzip -d fsts.1.gz
# 2、查看
fstcopy ark:fsts.1 ark,t:fsts.1.txt
vim fsts.1.txt
训练GMM—tree决策树查看
- 文本查看
tree-info tree

num-pdfs 683 表示:决策树类的个数,一共分了683个类
context-width 1 单音素模型不考虑相互音素,所以为1,如果是3音素模型的话,这里就是3
central-position 0 表示决策树的位置是0,如果是3音素,这里就是1(central表示中间音素,前面的为0,后面的为2)
- 可视化决策树
draw-tree phones.txt tree | dot -Gsize=8,10.5 -Tps | ps2pdf - tree.pdf
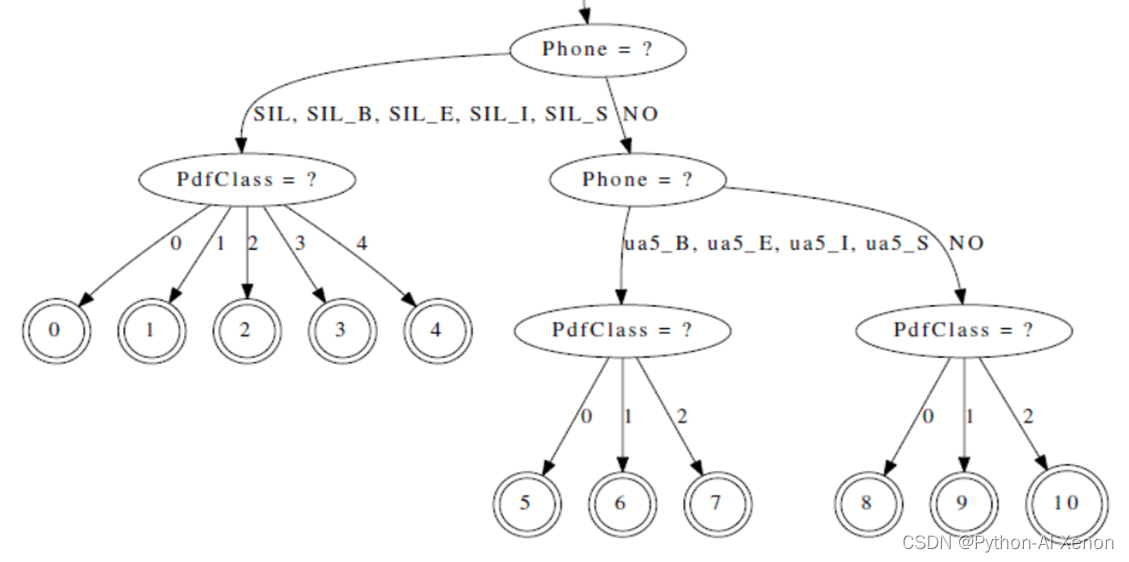
可以通过draw-tree命令把决策树可视化画出来,由于决策树很大,这里只截取了一部分,未显示完全,可在pdf中打开查看。从上图中可以看见,SIL静音音素是一个子节点,对应着5个节点(0-4节点),音素ua5对应着3个节点(5-7节点),就与前面所讲的对应起来了(静音音素5个状态,非静音音素3个状态)
align_si.sh 用于对齐
用于对齐
单音素模型训练好后,接下来,我们就可以使用单音素模型对训练数据进行对齐。对齐命令为align_si.sh,这就是GMM训练模型的第二步。
cd ~/kaldi/data
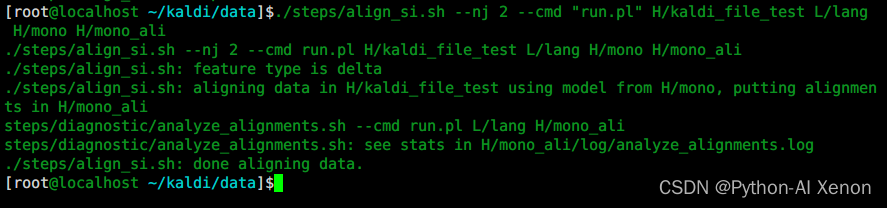
./steps/align_si.sh --nj 2 --cmd "run.pl" H/kaldi_file_test L/lang H/mono H/mono_ali
参数详解:
第一个参数:–nj 几个线程并行训练 (注:如果是提取的每个说话人的特征,nj数不能超过说话人数)
第二个参数:run.pl 本机运行
第三个参数:特征文件夹(含cmvn以及原始的mfcc特征)
第四个参数:lang文件夹(L文件夹中的lang文件夹)
第五个参数:单音素训练模型文件夹
第六个参数:对齐后的数据文件夹
训练GMM—查看mono_ali.sh 生成内容

# 1、解压
gzip -d ali.1.gz
# 2、生成各音素的对齐时间信息
ali-to-phones --ctm-output=true final.mdl ark:ali.1 -|~/kaldi/data/utils/int2sym.pl -f 5 phones.txt >ali.1.time
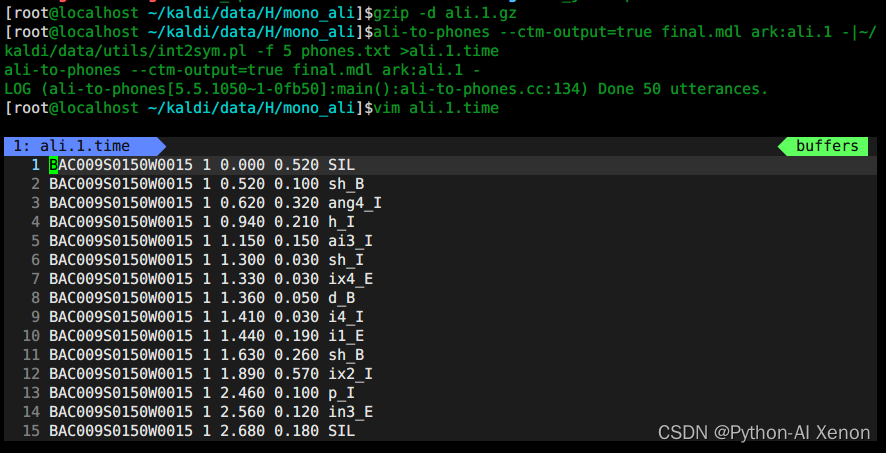
ps: 同样,我们也可以使用ali-to-phones命令查看对齐信息。
训练GMM—比对mono和mono_ali对齐信息
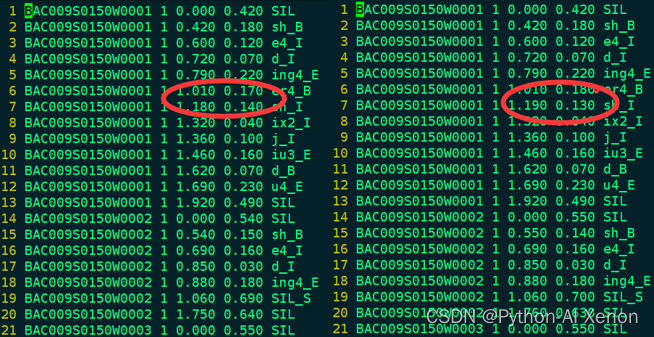
我们可以比较我们对齐后的信息与训练Mono时的对齐信息,可以看出2个文件的总行数相差不大,大部分对齐信息相差不大,说明单音素模型的对齐能力就这样了,需要换新的算法来提高模型的对齐能力。
相关文章:
Kaldi语音识别技术(七) ----- 训练GMM
Kaldi语音识别技术(七) ----- GMM 文章目录Kaldi语音识别技术(七) ----- GMM训练GMMtrain_mono.sh 用于训练GMM训练GMM—生成文件训练GMM—final模型查看训练GMM—final.occs查看训练GMM—对齐信息查看训练GMM—fsts.*.gz查看训练GMM—tree决策树查看align_si.sh 用于对齐训练G…...

Java 集合基础
文章目录一、集合概念二、ArrayList1. 构造方法和添加方法2. 常用方法三、案例演示1. 存储字符串并遍历2. 存储学生对象并遍历3. 键盘录入学生对象并遍历一、集合概念 编程的时候如果要存储多个数据,使用长度固定的数组存储格式,不一定满足我们的需要&a…...

Day896.MySql的kill命令 -MySQL实战
MySql的kill命令 Hi,我是阿昌,今天学习记录的是关于MySql的kill命令的内容。 在 MySQL 中有两个 kill 命令: 一个是 kill query 线程 id,表示终止这个线程中正在执行的语句;一个是 kill connection 线程 id&#…...

L2-010 排座位
布置宴席最微妙的事情,就是给前来参宴的各位宾客安排座位。无论如何,总不能把两个死对头排到同一张宴会桌旁!这个艰巨任务现在就交给你,对任何一对客人,请编写程序告诉主人他们是否能被安排同席。 输入格式࿱…...
C++的完美讲解,还不快来看看?
目录 简介: 创建C程序: Windows编译简介: Hello,C World! 简介: C融合了3中不同的编程传统:C语言代表的过程性传统、C在C语言基础上添加的类代表的面向对象语言的传统以及C模板支持的通用编程传统。一般来说,计算机语言…...
C语言学习_DAY_5_循环结构while和for语句【C语言学习笔记】
高质量博主,点个关注不迷路🌸🌸🌸! 目录 I. 案例引入 II. while语句 III. do while语句 IV. for语句 前言: 书接上回,判断结构已经解决,接下来是另一种很重要的结构:循环结构的实…...

JavaScript高级程序设计读书分享之4章——4.3垃圾回收
JavaScript高级程序设计(第4版)读书分享笔记记录 适用于刚入门前端的同志 4.3.3 性能 垃圾回收程序会周期性运行,如果内存中分配了很多变量,则可能造成性能损失,因此垃圾回收的 时间调度很重要。尤其是在内存有限的移动设备上,垃圾…...
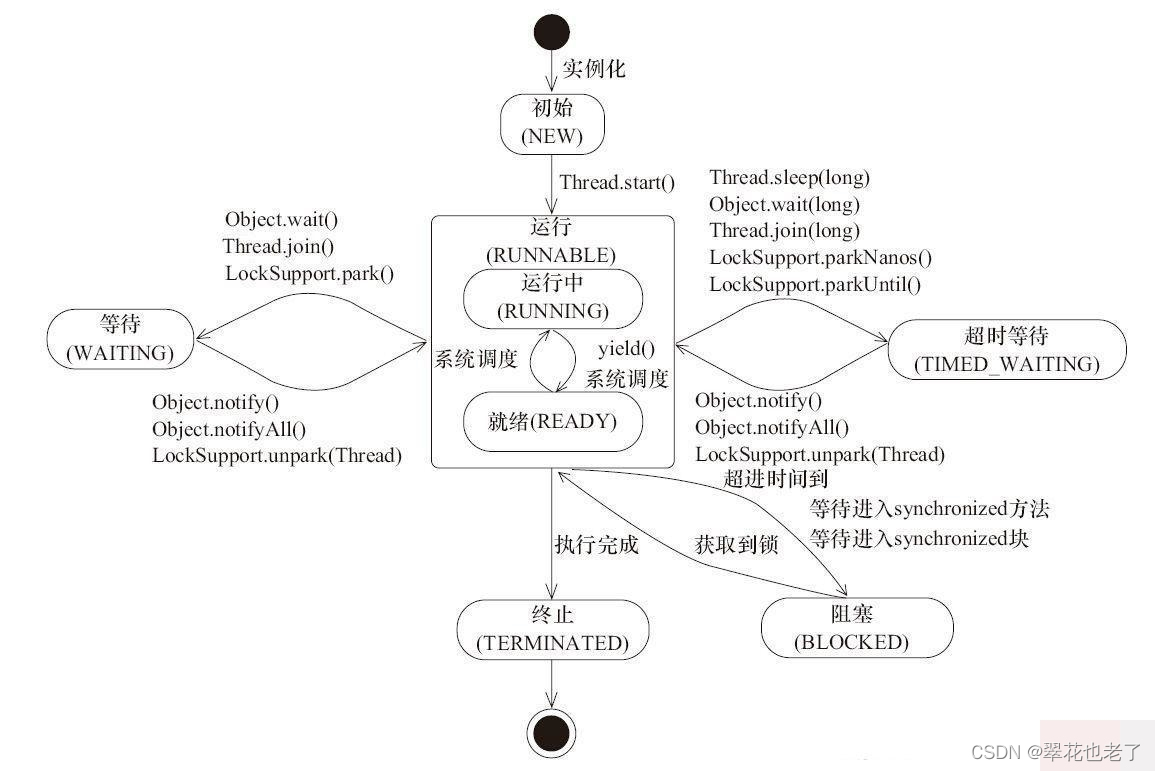
Java线程的6 种状态
Java 线程的状态 Java线程有六种状态: 初始(NEW)、运行(RUNNABLE)、阻塞(BLOCKED)、 等待(WAITING)、超时等待(TIMED_WAITING)、终止(…...
5年测试在职经验之谈:3年手工测试、2年的自动化测试,从入门到不可自拔...
毕业3年了,学的是环境工程专业,毕业后零基础转行做软件测试。 已近从事测试行业8年了,自己也从事过3年的手工测试,从事期间越来越觉得如果一直在手工测试的道路上前进,并不会有很大的发展,所以通过自己的努…...

QHash-官翻
QHash 类 template <typename Key, typename T> class QHash QHash 类是一种模板类,提供基于哈希表的字典类结构。更多内容… 头文件:#include <QHash>qmake:QT core派生类:QMultiHash 所有成员列表,包括继承的成员废弃的成员 注意&…...
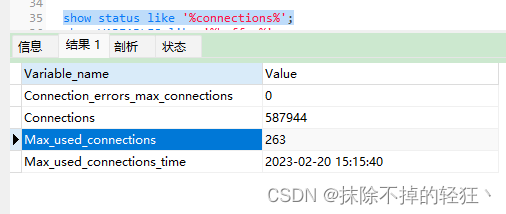
MYSQL 配置优化
max_connections 允许客户端并发连接的最大数量,默认值是151。 show status like %connections%; 设置参数值应大于Max_used_connections。如果使用连接池,可参考连接池的最大连接数和每个连接池的数量作为参考设置 innodb_buffe_pool_instances Inno…...

多 态
1多态的基本概念多态是C面向对象三大特性之一多态分为两类静态多态: 函数重载和运算符重载属于静态多态,复用函数名动态多态: 派生类和虚函数实现运行时多态静态多态和动态多态区别:静态多态的函数地址早绑定–--编译阶段确定函数地址动态多态的函数地址晚绑定–--运…...

Java集合
集合、数组都是对多个数据进行存储操作的结构,简称java容器 (此时的存储,主要指的是内存层面的存储,不涉及持久化的存储) 数组存储的特点: 一旦初始化,其长度就确定了。数组一旦定义好&#x…...
高校借力泛微,搭建一体化、流程化的内控管理平台
财政部《行政事业单位内部控制规范(试行)》中明确规定:行政事业单位内部控制是指通过制定制度、实施措施和执行程序,实现对行政事业单位经济活动风险的防范和管控,包括对其预算管理、收支管理、采购管理、资产管理、建…...

使用人工智能赚钱的方式,行业领域有哪些?
使用人工智能赚钱的方式,行业领域有哪些?不少于2000字。 一、人工智能的应用领域 1、金融服务:金融服务行业是人工智能应用的领域之一,它可以帮助银行、信用卡公司等金融机构实现快速、有效的贷款审批,以及客户分析、…...

【数组中重复的数字】-C语言-题解
原题链接:数组中重复的数字 一、描述: 在一个长度为 n 的数组 nums 里的所有数字都在 0~n-1 的范围内。数组中某些数字是重复的,但不知道有几个数字重复了,也不知道每个数字重复了几次。请找出数组中任意一个重复的数…...
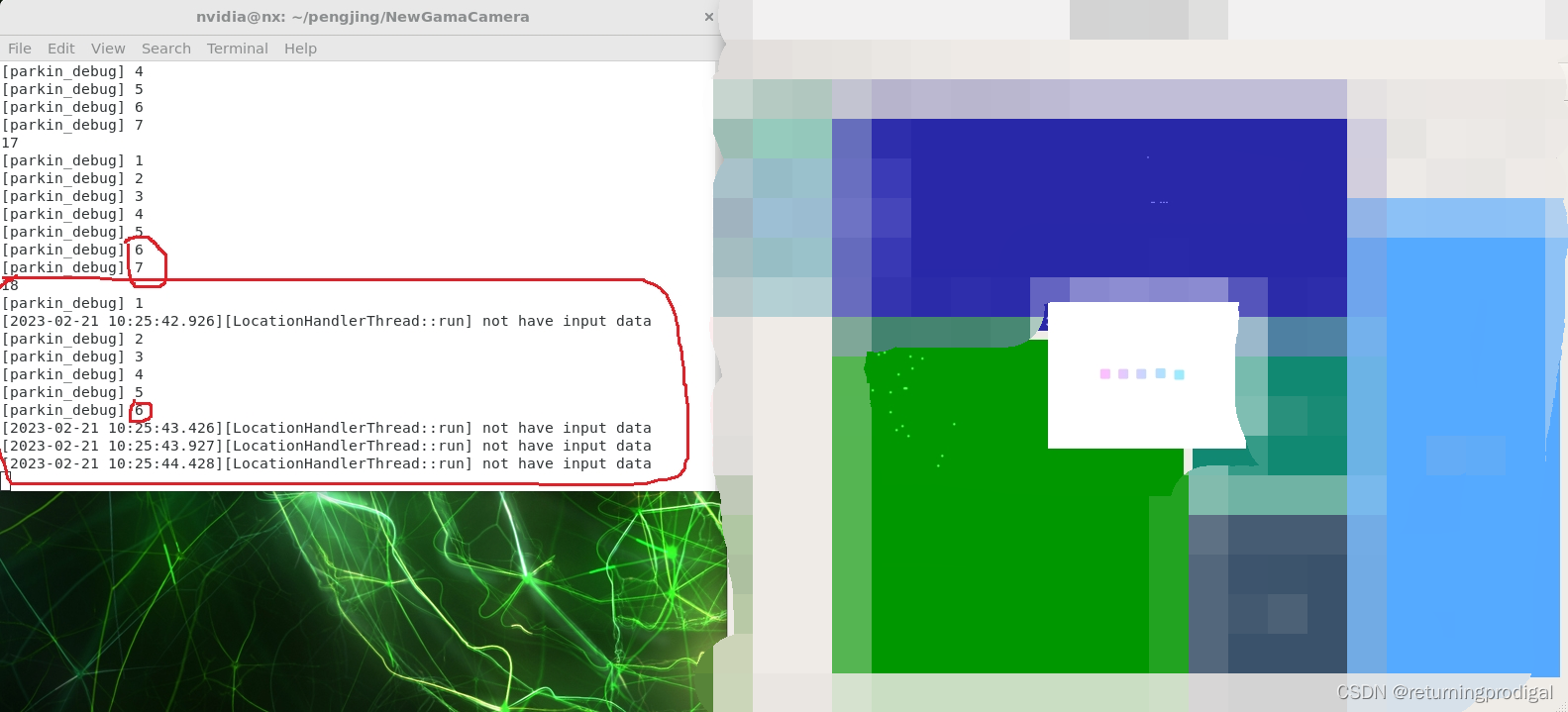
C++调用Python脚本进行18次循环操作后,脚本不执行
C调用Python脚本进行18次循环操作后,脚本不执行 现象: 发送端接收端 从第二张图中可以看出,python脚本卡在’[parkin_debug] 6’与’[parkin_debug] 7’之间 该测试经过多次反复测试,均在第18次循环执行时,出现上述问…...

字节10年架构师职业发展经历,助你做好职业规划
一直以来程序员这一职业都给人高薪资的印象,近年来随着互联网行业的快速发展,程序员更是人满为患,然而很多人关注的却是程序员的薪资,而非职业本身。 一批批程序员进入工作岗位,但是很多人并没有对自己的职业生涯有清…...

ArrayList真的是因为实现了RandomAccess接口才能做到快速随机访问的吗
ArrayList和RandomAccess接口RandomAccess 接口Collections.binarySearch()源码总结RandomAccess 接口 首先,RandomAccess接口是什么,以下代码可见: public interface RandomAccess { }RandomAccess接口其实是一个标记接口,它只…...
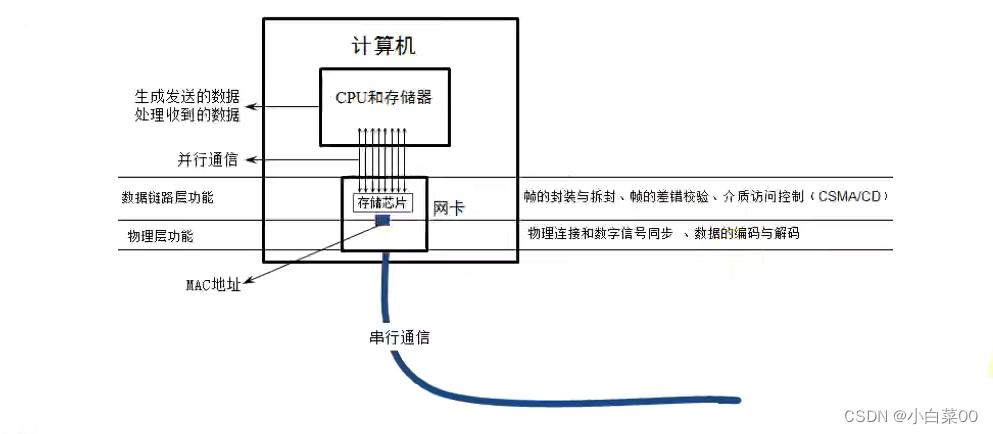
OSI七层模型与物理层与设备链路层
目录 协议 举例 OSI七层模型 理解七层模型 以下为OSI七层模型数据逐层封装和数据逐层解封的过程 TCP/IP参考模型 数据包的层层封装与层层拆包 各层的数据以及协议 封装所用的协议的数字表示形式 物理层 模拟信号 模拟信号特点 数字信号 数字信号特点 数据通信模…...

Unity Il2CppDumper原理与实战:解析元数据与二进制对齐
1. 这不是“破解工具”,而是Unity开发者该懂的二进制真相课 你刚在Unity Asset Store下载了一个功能惊艳的插件,却在打包iOS后发现部分逻辑失效;或者接手一个没有源码的旧项目,只有一堆 .dll 和 .so 文件,连主入口…...

如何用deberta-v3-base-zeroshot-v2.0构建企业级NLP应用?完整教程来了
如何用deberta-v3-base-zeroshot-v2.0构建企业级NLP应用?完整教程来了 【免费下载链接】deberta-v3-base-zeroshot-v2.0 项目地址: https://ai.gitcode.com/hf_mirrors/NingBo_Ascend/deberta-v3-base-zeroshot-v2.0 deberta-v3-base-zeroshot-v2.0是一款基…...
)
Goframe项目实战:从数据库表到API接口的全链路开发指南(含避坑点)
Goframe项目实战:从数据库表到API接口的全链路开发指南(含避坑点)在当今微服务架构盛行的时代,Go语言因其高性能和并发优势成为后端开发的热门选择。而Goframe作为一款企业级的Go应用开发框架,提供了从数据库操作到API…...

从入门到实践:EEG公开数据集分类与应用场景全解析
1. EEG公开数据集入门指南刚接触脑电信号分析的研究者,常常会被一个问题困扰:"我应该从哪里获取可靠的EEG数据?"作为一个在这个领域摸爬滚打多年的研究者,我完全理解这种困惑。记得我第一次接触EEG研究时,光…...

如何进行TVA仿真引擎的“光照地狱”训练?
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

厨房空调技术白皮书:从风冷到水冷,制冷系统在厨房场景中的工程化演进
厨房空调是暖通行业近三年技术迭代最密集的细分品类。从最初的"凉霸"(本质是风扇),到风冷分体式,再到水冷一体式,每代技术都在解决上一代没有覆盖的用户痛点。本文以工程技术视角,梳理四代厨房制…...

【与我学 ClaudeCode】协作篇 之 Worktree + Task Isolation :目录隔离的并行执行通道
作者:逆境不可逃 技术永无止境 希望我的内容可以帮助到你!!!! 大家吼 ! 我是 逆境不可逃 今天给大家带来文章《【与我学 ClaudeCode】协作篇 之 Worktree Task Isolation :目录隔离的并行执行通道》. Le…...

AWS DevOps Agent 完全指南
AWS DevOps Agent 是 AWS 推出的前沿 AI 运维代理,自主调查和解决事件、持续预防故障、提升系统可靠性。本文档覆盖从原理到实战的全生命周期管理。 一、定位与价值 一句话定义 AWS DevOps Agent = AI 驱动的 SRE 队友,724 自主调查告警、定位根因、生成修复方案、预防未来…...

基于EMA与轻量级机器学习的Wi-Fi链路质量预测实战
1. 项目概述与核心价值在工业自动化、仓储物流和智能制造等场景里,无线网络的稳定性正变得前所未有的重要。想象一下,一个自动导引运输车(AGV)正在执行物料搬运任务,或者一个机械臂正在与中央控制系统进行实时数据同步…...

Metabase:零代码 BI 数据可视化工具,自建数据看板
Metabase:零代码 BI 数据可视化工具,自建数据看板 在数据驱动决策的时代,能快速看到业务数据的变化趋势至关重要。然而,专业 BI 工具(如 Tableau、Power BI)价格昂贵,而让每个业务同学都学 SQL …...