golang-bufio 缓冲写
1. 缓冲写
在阅读这篇博客之前,请先阅读上一篇:golang-bufio 缓冲读
// buffered output// Writer implements buffering for an io.Writer object.
// If an error occurs writing to a Writer, no more data will be
// accepted and all subsequent writes, and Flush, will return the error.
// After all data has been written, the client should call the
// Flush method to guarantee all data has been forwarded to
// the underlying io.Writer.
type Writer struct {err errorbuf []byten intwr io.Writer
}
缓冲写比缓冲读取更加简单,它的工作原来就是当缓冲区满(或者用户手动强制刷新)了,把整个缓冲区中的内容写入底层数据源。它提供了两种创建的方法:
func NewWriterSize(w io.Writer, size int) *Writer创建一个指定缓冲区大小的缓冲 Writer 并返回。func NewWriter(w io.Writer) *Writer创建默认缓冲区大小的缓冲 Writer 并返回。
注意:
- 缓冲 Reader 的默认缓冲区大小是 4096,最小是 16,如果你设置低于这个值,它会强制设置成 16。
- 缓冲 Writer 的默认缓冲区大小是 4096,但是没有最小值,所以你可以设置的很小,但是太小了会有问题,例如当你调用写入单个字符时。
2. 缓冲写测试
这里在正式介绍之前,我们先来使用一下它,不过这里只是演示一下缓冲写的作用。缓冲写其实就是延迟写入,所以它减少的是真正写入的次数(向磁盘文件写入或者写入网络流代价都是很高的)。下面的示例可以看到,不使用缓冲写入,调用一次写入就会实际写入一次。使用缓冲写入后,写满缓冲区或者手动调用 Flush() 才会实际写入。
package mainimport ("bufio""fmt""strings"
)func main() {BufioWriterTest()
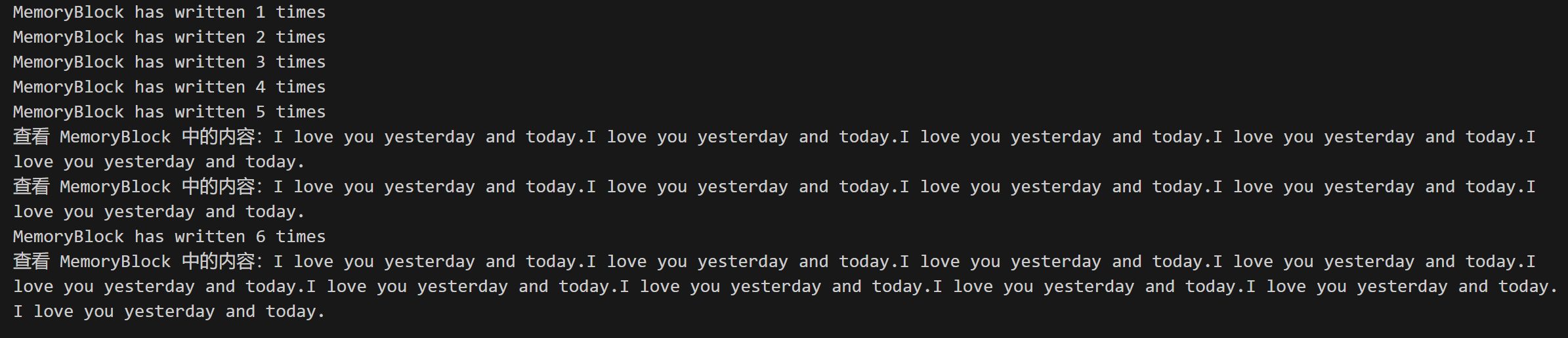
}func BufioWriterTest() {mBlock := NewMemoryBlock()// 直接写入,不使用缓冲流,调用几次就是写入几次。mBlock.Write([]byte("I love you yesterday and today."))mBlock.Write([]byte("I love you yesterday and today."))mBlock.Write([]byte("I love you yesterday and today."))mBlock.Write([]byte("I love you yesterday and today."))mBlock.Write([]byte("I love you yesterday and today."))fmt.Printf("查看 MemoryBlock 中的内容:%s\n", mBlock.String())bufWriter := bufio.NewWriter(mBlock)// 使用缓冲流,写满缓冲区或者手动调用 Flush() 才会实际写入。bufWriter.WriteString("I love you yesterday and today.")bufWriter.WriteString("I love you yesterday and today.")bufWriter.WriteString("I love you yesterday and today.")bufWriter.WriteString("I love you yesterday and today.")bufWriter.WriteString("I love you yesterday and today.")fmt.Printf("查看 MemoryBlock 中的内容:%s\n", mBlock.String())bufWriter.Flush()fmt.Printf("查看 MemoryBlock 中的内容:%s\n", mBlock.String())}// 实现一个简陋的 io.Writer,俄罗斯套娃
// 它只是简单的把写入的切片附加到原来的切片上。
type MemoryBlock struct {data []byte // 使用切片来存储数据n int // 写入次数
}func NewMemoryBlock() *MemoryBlock {return &MemoryBlock{data: make([]byte, 0)}
}// 写入数据
func (dw *MemoryBlock) Write(p []byte) (int, error) {// 每次写入 dw.n 次数加一dw.n += 1fmt.Printf("MemoryBlock has written %d times\n", dw.n)dw.data = append(dw.data, p...)return len(p), nil
}// 查看内部数据
func (dw *MemoryBlock) String() string {return string(dw.data)
}
3. 主要方法介绍
接下来会介绍缓冲写的主要方法的作用,并且会添加一些个人的注释。如果有不对的地方,欢迎指正。
3.1 刷新缓冲区 Flush()
缓冲 Writer 的写入都不是真的将数据写入底层数据源,而是写入缓冲区,真正写入靠的是 Flush() 方法。如果缓冲区满了,也是调用 Flush() 来写入的(清空缓冲区)。理解了这个方法,你就大概了解缓冲写入的原理了。
// Flush writes any buffered data to the underlying io.Writer.
func (b *Writer) Flush() error {// tip:如果有错误就返回,不再写入if b.err != nil {return b.err}// tip:如果缓冲区是空的,不写入,直接返回if b.n == 0 {return nil}// tip:把缓冲区内的所有数据一次性写入底层数据源n, err := b.wr.Write(b.buf[0:b.n])// tip:只写入部分数据,且错误为空(这应该很少发生的)if n < b.n && err == nil {err = io.ErrShortWrite}// tip:处理写入发生的错误if err != nil {// tip:只写入部分数据(写入错误不为空)if n > 0 && n < b.n {// 把未写入的数据复制到缓冲区的开头copy(b.buf[0:b.n-n], b.buf[n:b.n])}// 缓冲区缓冲字节数减去已经写入的数目b.n -= nb.err = errreturn err}// 写入成功,把缓冲区置空(即 n 设置为 0)b.n = 0return nil
}
3.2 可用缓冲区 AvailableBuffer()
这个方法返回一个容量为可用缓冲区大小的空切片,我有点不理解它的作用是什么。这里看注释是说,这个空切片是打算用来追加数据(append),然后传递给一个立即连续的写入 (Write)调用。并且,它只在下一次写入操作之前有效(因为写入会影响切片的内容)。
// AvailableBuffer returns an empty buffer with b.Available() capacity.
// This buffer is intended to be appended to and
// passed to an immediately succeeding Write call.
// The buffer is only valid until the next write operation on b.
func (b *Writer) AvailableBuffer() []byte {return b.buf[b.n:][:0]
}
3.3 缓冲区可用字节数 Available()
这个方法虽然很简单,但是后面会经常用到它,所以这里也提一下。它的功能很简单,返回缓冲区中的可用字节数(还能写入多少数据),即缓冲区大小 - 已经写入的字节数。
// Available returns how many bytes are unused in the buffer.
func (b *Writer) Available() int { return len(b.buf) - b.n }
3.4 写入字节切片 Write(p []byte)
如果需要写入的数据超过了缓冲区的剩余大小且没有错误则执行循环:
如果缓冲区已经缓冲的数据为 0,即空的缓冲区,那么直接写入底层数据源(先缓冲再写入就浪费时间了)。否则,把需要写入的数据复制到缓冲区后面,然后调用一次 Flush() 进行刷新 n = copy(b.buf[b.n:], p)。然后,累加实际写入的字节数,同时更新待写入的切片(这里就体现了切片的灵活性!)。
如果切片中数据加上缓冲区中的数据仍然不满一个缓冲区,只是把数据加入缓冲区中,并不实际写入。这就是缓冲的作用了,通过延迟写入来提高性能(但是牺牲了实时性)。
// Write writes the contents of p into the buffer.
// It returns the number of bytes written.
// If nn < len(p), it also returns an error explaining
// why the write is short.
func (b *Writer) Write(p []byte) (nn int, err error) {for len(p) > b.Available() && b.err == nil {var n intif b.Buffered() == 0 {// Large write, empty buffer.// Write directly from p to avoid copy.n, b.err = b.wr.Write(p)} else {n = copy(b.buf[b.n:], p)b.n += nb.Flush()}nn += np = p[n:]}if b.err != nil {return nn, b.err}n := copy(b.buf[b.n:], p)b.n += nnn += nreturn nn, nil
}
3.5 写入单个字节 WriteByte(c byte)
// WriteByte writes a single byte.
func (b *Writer) WriteByte(c byte) error {if b.err != nil {return b.err}// tip:如果缓冲区满了(不过这里应该不会小于 0 吧?),// 它会调用 Flush() 强制写入(会处理错误)if b.Available() <= 0 && b.Flush() != nil {return b.err}// tip:缓冲区还有足够的大小可以写入,直接把它写入缓冲区b.buf[b.n] = cb.n++return nil
}
3.6 写入单个字符 WriteRune(r rune)
这个方法是写入单个字符(多个字节)的,它基本和写入单个字节是一样的,不过这里需要把字符作为一个整体考虑。主要的区别在于,如果缓冲区可用字节数小于 utf8 的最大字节数(4字节),它会强制刷新,然后再把字符写入缓冲区。也就是说,它不会把一个 rune 拆分成多个字节发送,而是一次发送整个的字符,至于原因可能是分开发送会导致接收端乱码。
有一个比较有意思的地方,如果强制刷新之后,缓冲区的可用字节数还是 utf8 的最大字节数呢?此时缓冲区是空的,说明整个缓冲区的大小小于 4!官方也吐槽了一句:Can only happen if buffer is silly small.。
// WriteRune writes a single Unicode code point, returning
// the number of bytes written and any error.
func (b *Writer) WriteRune(r rune) (size int, err error) {// Compare as uint32 to correctly handle negative runes.if uint32(r) < utf8.RuneSelf {err = b.WriteByte(byte(r))if err != nil {return 0, err}return 1, nil}if b.err != nil {return 0, b.err}n := b.Available()if n < utf8.UTFMax {if b.Flush(); b.err != nil {return 0, b.err}n = b.Available()if n < utf8.UTFMax {// tip:这是哪个傻子设置的小缓冲区!// Can only happen if buffer is silly small.return b.WriteString(string(r))}}size = utf8.EncodeRune(b.buf[b.n:], r)b.n += sizereturn size, nil
}
3.7 写入字符串 WriteString(s string)
写入一个字符串,并不会把整个字符串的内容都写入底层数据源。如果字符串很大(超过了缓冲区的大小)且缓冲区是空的,那么它会直接写入底层数据源,不会先写入缓冲区再写入底层数据源(一次能完成的时候,当然不需要做多次了)。否则,就是将字符串内容填满缓冲区,然后每次写入一整个缓冲区,知道最后的内容不满一个缓冲区。这些内容就留在缓冲区中了,不会写入底层数据源,直到下一次写满缓冲区或者强制刷新 Flush()。
// WriteString writes a string.
// It returns the number of bytes written.
// If the count is less than len(s), it also returns an error explaining
// why the write is short.
func (b *Writer) WriteString(s string) (int, error) {var sw io.StringWritertryStringWriter := truenn := 0for len(s) > b.Available() && b.err == nil {var n intif b.Buffered() == 0 && sw == nil && tryStringWriter {// Check at most once whether b.wr is a StringWriter.sw, tryStringWriter = b.wr.(io.StringWriter)}if b.Buffered() == 0 && tryStringWriter {// Large write, empty buffer, and the underlying writer supports// WriteString: forward the write to the underlying StringWriter.// This avoids an extra copy.n, b.err = sw.WriteString(s)} else {n = copy(b.buf[b.n:], s)b.n += nb.Flush()}nn += ns = s[n:]}if b.err != nil {return nn, b.err}n := copy(b.buf[b.n:], s)b.n += nnn += nreturn nn, nil
}
3.8 写入其他数据源 ReadFrom(r io.Reader)
这个方法,我就把它叫做写入其他数据源了。它的作用就是直接写入一个数据源的数据,而不是先读取再写入(底层还是要读取再写入的,只不过提供了一个更易用的方法)。不过,这个方法的逻辑还是蛮复杂的,直接看注释吧。
// ReadFrom implements io.ReaderFrom. If the underlying writer
// supports the ReadFrom method, this calls the underlying ReadFrom.
// If there is buffered data and an underlying ReadFrom, this fills
// the buffer and writes it before calling ReadFrom.
func (b *Writer) ReadFrom(r io.Reader) (n int64, err error) {if b.err != nil {return 0, b.err}// 把底层数据源转成 io.ReaderFrom,看其是否实现该接口readerFrom, readerFromOK := b.wr.(io.ReaderFrom)var m intfor {// tip:缓冲区满if b.Available() == 0 {if err1 := b.Flush(); err1 != nil {return n, err1}}// tip:缓冲区空,直接让其写入(不写缓冲区了)if readerFromOK && b.Buffered() == 0 {nn, err := readerFrom.ReadFrom(r)b.err = errn += nnreturn n, err}// tip:读取传入的 reader 的数据,写入底层数据源,这里最大尝试100次失败nr := 0for nr < maxConsecutiveEmptyReads {m, err = r.Read(b.buf[b.n:])if m != 0 || err != nil {break}nr++}if nr == maxConsecutiveEmptyReads {return n, io.ErrNoProgress}b.n += mn += int64(m)if err != nil {break}}// 如果读取发生的错误是 io.EOF,这是正常情况,否则返回错误情况。// 如果缓冲区正好满了,那么把数据写入底层数据源,否则只是把数据写入缓冲区。if err == io.EOF {// If we filled the buffer exactly, flush preemptively.if b.Available() == 0 {err = b.Flush()} else {err = nil}}return n, err
}
4. 缓冲输入和输出
看到最后面,发现还有一个同时处理缓冲读写的结构体,不过这个就是把前面的缓冲 Reader 和 缓冲 Writer 结合起来了,只提供了一个创建的的方法:func NewReadWriter(r *Reader, w *Writer) *ReadWriter。读和写的方法就是前面已经介绍过的了。
// buffered input and output// ReadWriter stores pointers to a Reader and a Writer.
// It implements io.ReadWriter.
type ReadWriter struct {*Reader*Writer
}// NewReadWriter allocates a new ReadWriter that dispatches to r and w.
func NewReadWriter(r *Reader, w *Writer) *ReadWriter {return &ReadWriter{r, w}
}
相关文章:
golang-bufio 缓冲写
1. 缓冲写 在阅读这篇博客之前,请先阅读上一篇:golang-bufio 缓冲读 // buffered output// Writer implements buffering for an io.Writer object. // If an error occurs writing to a Writer, no more data will be // accepted and all subsequent…...
Windows修改电脑DNS
访问浏览器出现无法访问此页面,找不到DNS地址,则可以通过如下方式修改DNS 按下windows键R键(两个键一起按) 出现下面窗口 输入control按回车键(Enter键)就会出现下面的窗口 DNS可以填下面这些: 114.114.114.114 和 114.114.115.115 阿里DNS&a…...

Linux驱动之Linux自带的LED灯驱动
目录 一、简介 二、使能Linux自带LED驱动 三、Linux内核自带LED驱动框架 四、设备树节点编写 五、运行测试 一、简介 前面我们都是自己编写 LED 灯驱动,其实像 LED 灯这样非常基础的设备驱动, Linux 内核已经集成了。 Linux 内核的 LED 灯驱动采用 …...
C盘清理 “ProgramData\Microsoft\Search“ 文件夹过大
修改索引存放位置 进入控制面板->查找方式改成大图标, 选择索引选项 进入高级 填写新的索引位置 删除C盘索引信息 删除C:\ProgramData\Microsoft\Search\Data\Applications 下面的文件夹 如果报索引正在使用,参照第一步替换索引位置。关闭索引...

深入了解字符串处理算法与文本操作技巧
深入了解字符串处理算法与文本操作技巧 引言 字符串处理是计算机科学和数据处理的核心领域之一。本博客将深入介绍一些常见的字符串处理算法和文本操作技巧,包括字符串匹配、搜索、正则表达式、字符串操作和文本标准化等。 暴力匹配算法 什么是暴力匹配…...

Python爬虫:打开盈利大门的利器
导言: 随着互联网的迅速发展,越来越多的企业和个人开始意识到数据的重要性。而Python爬虫作为一种自动化获取互联网信息的技术,为人们提供了更便捷、高效的数据获取方式。本文将介绍基于Python爬虫的五种盈利模式,并提供实际案例…...

17.CSS发光按钮悬停特效
效果 源码 <!DOCTYPE html> <html> <head><title>CSS Modern Button</title><link rel="stylesheet" type="text/css" href="style.css"> </head> <body><a href="#" style=&quo…...

CSS中如何实现弹性盒子布局(Flexbox)的换行和排序功能?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ 换行(Flexbox Wrapping)⭐ 示例:实现换行⭐ 排序(Flexbox Ordering)⭐ 示例:实现排序⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记得…...

spark底层为什么选择使用scala语言开发
Spark 底层使用 Scala 开发有以下几个原因: 基于Scala的语言特性 集成性:Scala 是一种运行在 Java 虚拟机(JVM)上的静态类型编程语言,可以与 Java 代码无缝集成。由于 Spark 涉及到与大量 Java 生态系统的交互&#x…...

基于RabbitMQ的模拟消息队列之三——硬盘数据管理
文章目录 一、数据库管理1.设计数据库2.添加sqlite依赖3.配置application.properties文件4.创建接口MetaMapper5.创建MetaMapper.xml文件6.数据库操作7.封装数据库操作 二、文件管理1.消息持久化2.消息文件格式3.序列化/反序列化4.创建文件管理类MessageFileManager5.垃圾回收 …...

DHorse v1.3.2 发布,基于 k8s 的发布平台
版本说明 新增特性 构建版本、部署应用时的线程池可配置化; 优化特性 构建版本跳过单元测试; 解决问题 解决Vue应用详情页面报错的问题;解决Linux环境下脚本运行失败的问题;解决下载Maven安装文件失败的问题; 升…...
在vue.config.js中配置文件路径代理名
今天在公司项目中看到一个非常有趣的导入路径 crud 先是一蒙 这是个啥 突然想起一个被自己遗漏的知识点 在vue.config.js中配置路径指向 这里 我们随便找一个vue项目 在src下找到 components 目录 如果没有就创建一个 下面找到HelloWorld.vue 如果没有也是自己创建一个就好 然…...

深度学习优化算法相关文章
综述性文章 一个框架看懂优化算法之异同 SGD/AdaGrad/Adam 从 SGD 到 Adam —— 深度学习优化算法概览(一)...

echarts自定义Y轴刻度及其颜色
yAxis: [{min:0,max:5,axisLabel: {color: "#999",textStyle: {fontSize: 14,fontWeight: 400,// 设置分段颜色color: function (value) {console.log("试试", value);if (value 1) {return "rgba(140,198,63,1)";} else if (value 2) {return…...

【云原生进阶之PaaS中间件】第一章Redis-1.3Redis配置
1 Redis配置概述 Redis支持采用其内置默认配置的方式来进行启动,而不需要提前配置任何文件,但是这种启动方式只推荐在测试和开发环境中使用,但更好的方式是通过提供一个Redis的配置文件来对Redis进行配置, 这个配置文件一般命名为…...

C++ 动态内存
C 程序中的内存分为栈和堆两个部分: 栈:在函数内部声明的所有变量都将占用栈内存;堆:这是程序中未使用的内存,在程序运行时可用于动态分配内存。 堆与栈的详细请参考:一文读懂堆与栈的区别_堆和栈的区别_恋…...

swagger 接口测试,用 python 写自动化时该如何处理?
在使用Python进行Swagger接口测试时,可以使用requests库来发送HTTP请求,并使用json库和yaml库来处理响应数据。以下是一个简单的示例代码: import requests import json import yaml# Swagger API文档地址和需要测试的接口路径 swagger_url …...

QT使用QXlsx实现Excel图片与图表操作 QT基础入门【Excel的操作】
构建图表数据 /// 构建图表数据for (int i = 1; i < 10; ++i) {mxlsx.write(i, 1, i * i * i); // A1:A9mxlsx.write(i, 2, i * i); // B1:B9mxlsx.write(i, 3, i * i - 1); // C1:C9} 需要包含头文件 #include "xlsxchart.h" 1. 饼状图 Chart *pieChart = mxlsx.…...

【Python常用函数】一文让你彻底掌握Python中的numpy.clip函数
大数据时代的到来,使得很多工作都需要进行数据挖掘,从而发现更多有利的规律,或规避风险,或发现商业价值。而大数据分析的基础是学好编程语言。本文和你一起来探索Python中的clip函数,让你以最短的时间明白这个函数的原理。也可以利用碎片化的时间巩固这个函数,让你在处理…...
Matlab(GUI程式设计)
目录 1.MatlabGUI 1.1 坐标区普通按钮 1.1.1 对齐组件 1.1.2 按钮属性 1.1.3 脚本说明 1.1.4 选择呈现 1.3 编译GUI程序 在以前的时候,我们的电脑还是这样的 随着科技的不断进步,我们的电脑也发生着翻天覆地的改变1990s: 在未来,…...

作业本耐用度差距巨大?深圳大明印刷厂拆解合规工艺,告别定制作业本掉页开裂通病
在校园日常教学中,很多学校都会遇到同一个难题:同一学期采购的作业本、定制作业本,品质差距悬殊,有的完好无损用到期末,有的短短几周就出现书脊开裂、页面脱落、边角破损、翻页卡顿等问题。不少人误以为是学生使用习惯…...
)
从STM32迁移到普冉PY32F003:UART代码移植保姆级教程(附HAL库对比)
从STM32到普冉PY32F003的UART代码迁移实战指南 1. 国产MCU替代浪潮下的技术选择 近年来,半导体行业的供应链波动促使更多工程师将目光投向国产MCU解决方案。普冉PY32F003系列作为Cortex-M0内核的代表产品,以48MHz主频、64KB Flash和8KB RAM的配置&#x…...
:揭秘那个让虚拟世界“有重量感“的阴影魔法)
环境光遮蔽(Ambient Occlusion):揭秘那个让虚拟世界“有重量感“的阴影魔法
一、一个让我"开窍"的老木匠故事 我有个朋友是传统家具的修复师,他给我讲过一个让我至今难忘的故事。他说他刚入行时跟着一位 70 多岁的老木匠师父学习——师父让他做的第一件事不是雕花、不是榫卯——而是"看阴影"——这个看似奇怪的训练改变了…...

Unity主题系统设计:状态驱动的主题抽象与自动注入方案
1. 这不是换个颜色那么简单:为什么Unity项目里“换肤”总在发布前夜崩盘?你有没有经历过这样的场景:美术同学凌晨两点发来一套新主题资源包,UI设计师说“这次配色更符合品牌调性”,产品说“上线前必须支持深色模式”&a…...
Transient、QuickEye、VerifyEye傻傻分不清?一文讲透Ansys里三种眼图仿真方法的适用场景与避坑指南
Transient、QuickEye、VerifyEye深度解析:Ansys眼图仿真技术选型实战指南 在高速数字系统设计中,眼图分析是评估信号完整性的黄金标准。面对Ansys工具链中三种截然不同的眼图生成方法,工程师常常陷入选择困境——是追求精确度的传统瞬态分析&…...

搞定这 5 个全栈电商项目,面试别再用 Todo-List 凑数了
找独立开发练手项目或者写简历项目时,最忌讳两件事:一是太简单(纯前端 Mock 数据,点两下就没了),二是太假(一上来就硬套微服务、消息队列、高并发,结果自己根本Hold不住)…...

3步解锁网易云音乐NCM加密:让音乐真正属于你
3步解锁网易云音乐NCM加密:让音乐真正属于你 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为下载的网易云音乐只能在特定客户端播放而烦恼吗?当你精心收藏的歌曲被NCM格式"锁"在单一平台时&a…...

基于ATtiny84的智能冰箱监控器:低功耗温度与门状态监测方案
1. 项目概述:一个装在树莓派盒子里的智能冰箱管家如果你家里有台老冰箱,或者对食物储存温度特别在意,总担心冰箱门没关严或者突然断电导致内部升温,那么这个自己动手做的“冰箱看门狗”项目就太适合你了。它本质上是一个高度定制化…...

MongoDB Limit 与 Skip 方法详解
MongoDB Limit 与 Skip 方法详解 引言 MongoDB 是一个高性能、可伸缩的文档存储系统,它提供了强大的数据存储和查询功能。在处理大量数据时,Limit 与 Skip 方法是 MongoDB 中常用的查询优化工具。本文将详细介绍 MongoDB 中的 Limit 与 Skip 方法,包括其基本用法、性能影响…...

论文润色深度测评:GPT-5.5 + Gemini 3.1 Pro:教你学会1+1>2的论文润色方法
各位同仁好,我是七哥。一个在高校里从事人工智能相关领域研究,钻研用大模型AI实操的学术人。可以和七哥交流学术写作或Gemini、GPT、Claude等大模型学术实操相关问题,多多交流,相互成就,共同进步。 2026年的科研圈,AI工具的选择已经从有没有变成了强不强,七哥评测了GPT…...