RDMA性能优化经验浅谈
一、RDMA概述
首先我们介绍一下RDMA的一些核心概念,当然了,我并不打算写他的API以及调用方式,我们更多关注这些基础概念背后的硬件执行方式和原理,对于这些原理的理解是能够写出高性能RDMA程序的关键。
Memory Region
RDMA的网卡(下文以RNIC指代)通过DMA来读写系统内存,由于DMA只能根据物理地址访问,所以RNIC需要保存一份目标内存区域的虚拟内存到物理内存的映射表,这个映射表被存储在RNIC的Memory Translation Table(MTT)中。同时,由于目前RDMA的访问大都基于Direct Cache Access,不支持page-fault,所以我们还需要保证目标内存区域是被pagelock住以防止操作系统将这部分内存页换出。
总结一下就是,当我们使用RDMA来访问一块内存的时候,这部分内存首先要被pagelock,接着我们还需要把这块内存虚拟地址到逻辑地址的映射表发送给RNIC用于后续的访问查找,这个过程就叫Memory Registeration,这块被注册的内存就是Memory Region。同时我们注册内存的时候需要指定这块内存的访问权限,RNIC将这个访问权限信息存储在Memory Protection Tables(MPT)中用于用户请求时的权限验证。
MTT和MPT被存储在内存中,但是RNIC的SRAM中会进行缓存。当RNIC接收到来自用户的READ/WRITE请求的时候,首先在SRAM中的缓存中查找用户请求的目标地址对应的物理地址以及这块地址对应的访问权限,如果缓存命中了,就直接基于DMA进行操作,如果没有命中,就得通过PCIe发送请求,在内存的MTT和MPT中进行查找,这带来了相当的额外开销,尤其是当你的应用场景需要大量的、细粒度的内存访问的时候,此时RNIC SRAM中的MTT/MPT命中缺失带来的影响可能是致命的。

Memory Region的注册是一个耗时的操作,但大部分情况下,我们都只需要在最开始的时候做一次或者多次。现在也有不需要注册MR基于on-demand paging的方式来访问的,比如AWS的EFA协议。但今天先不展开这块的内容,因为这块更多是Unified Memory这个话题下的,之后我可能会把这个和GPU的UVM放在一起介绍下,因为他们的核心原理其实是一样的。
RDMA Verbs
用户通过RDMA的Verbs API向RNIC发送指令,Verbs分为Memory Verbs和Message Verbs,Memory Verbs主要就是READ、WRITE以及一些ATOMIC的操作,Message Verbs主要包含SEND、RECV。Memory verbs是真正的CPU Bypass以及Kernel Bypass,所以总归是性能比较好的。Message Verbs需要Responder的CPU的参与,相对而言更灵活,但是性能相比Memory Verbs而言一般不太行。
Queue Pair
RDMA的hosts之间是通过Queue Pair(QP)来通信的,一个QP包含一个Send Queue(SQ),一个Receive Queue(RQ)以及对应的Send Completion Queue(SCQ)和Receive Completion Queue(RCQ)。用户发送请求的时候,把请求封装为一个Work Queue Element(WQE)发送到SQ里面,然后RDMA网卡会把这个WQE发送出去,当这个WQE完成的时候,对应的SCQ里面会被放一个Completion Queue Element(CQE),然后用户可以从SCQ里面Poll这个CQE并通过检查状态来确认对应的WQE是否成功完成。需要指出的是,不同的QP可以共用CQ来减少SRAM的存储消耗。

接下来,我们重点介绍一下QP背后的知识。
首先,当我们创建了QP之后,系统是需要保存状态数据的,比如QP的metadata,拥塞控制状态等等,除去QP中的WQE、MTT、MPT,一个QP大约对应375B的状态数据。这在以前RNIC的SRAM比较小的时候会是一个比较重的存储负担,所以以前的RDMA工作会有QP Sharing的研究,就是不同的处理线程去共用QP来减少meta data的存储压力,但是这会带来一定的性能的损失[1]。现在新的RNIC的SRAM已经比较大了,Mellanox的CX4、CX5系列的网卡的SRAM大约2MB,所以现在新网卡上,大家还是比较少去关注QP带来的存储开销,除非你要创建几千个,几万个QP。
其次,RNIC是包含多个Processing Unit(PU)的[2],同时由于QP内的请求处理是具有顺序的,且为了避免cross-PU的同步,一般而言我们认为一个QP对应一个PU来处理。所以,我们可以在一个线程内建立多个QP来加速你数据处理,避免RDMA程序性能瓶颈卡在PU的处理上[3]。

二、RDMA性能优化
RDMA性能优化这个东西说复杂也复杂,说简单也简单。简单的点在于,从性能优化角度而言,其实软件层面我们可以做的设计和选择不会太多,因为性能上限是被硬件卡住的,所以我们为了追求尽可能逼近硬件上限的性能表现,其核心就在于按照硬件最友好的方式去做数据访问即可,没有特别多复杂的算法在这里面,当你想要高性能的时候,多多了解硬件就对了。对照着我们在上面介绍的三个核心概念,我们一一介绍性能优化的经验。
2.1 关注地址翻译的性能开销
前面我们提到,当待请求的数据地址在RNIC SRAM中的MTT/MPT没有命中的时候,RNIC需要通过PCIe去在内存中的MTT和MPT进行查找,这是一个耗时的操作。尤其是当我们需要 high fan-out、fine-grained的数据访问时,这个开销会尤为的明显。现有针对这个问题的优化方式主要有两种:
- Large Page:无论是MTT亦或者操作系统的Page Table,虚拟地址到物理地址的映射表项是Page粒度的,即一个Page对应一个MTT的Entry或者Page Table的Entry(PTE)。使用Large Page可以有效的减少MTT的Size,进而使得RNIC中的MTT Cache命中率更高。
- 使用Contiguous Memory + PA-MR[4, 5]。新一代的CX网卡支持用户基于物理地址访问,为了避免维护一个繁重的Page Table,我们可以通过Linux的CMA API来申请一大块连续的物理内存。这样我们的MTT就只有一项,可以保证100%的Cache命中率。但是这个本身有一些安全隐患,因为使用PA-MR会绕过访问权限验证,所以使用的时候要注意这点。
当然,其实还有一些别的优化手段,在最近我们的工作中提出一种新的方式来提升地址翻译的性能,具体等工作开源出来之后我再来介绍介绍。
2.2 关注RNIC PU/QP的执行模型
一个QP对应一个PU,这是我们对RNIC执行方式的一个简单建模。这个模型下,我们需要通过多QP来充分发挥多PU并行处理的能力,同时也要关注我们的操作减少PU之间的同步,PU之间同步对于性能有着较大的伤害。
2.3 RMDA Verbs
对于RDMA的Verbs的使用,以我个人的经验来看,就是优先使用READ/WRITE,在一些需要CPU介入且需要Batch处理逻辑的,可以尝试使用SEND/RECV。过往的工作有很多基于READ/WRITE去构建Message Passing处理语义的工作[1, 6, 7],可以着重参考。
同时,一个READ/WRITE的WQE可以通过设置对应的FLAG来设置其是否需要在完成时需要被SIGNALED,如果不需要则该WQE完成时不会产生一个CQE。此时一个常见的优化技巧是,当你需要连续在一个QP中发送K个READ/WRITE请求时,只把最后一个请求设置为SIGNALED,其他均为UNSIGNALED,由于QP的执行本身具备顺序关系,所以最后一个执行完了后一定意味着之前的WQE都已经执行完了。当然,是否执行成功需要Application-Specific的方法来确认。
三、 RNIC+ X
最经典的RNIC的使用方式自然是RNIC + System Memory,即直接通过RNIC来访问内存。但是随着GP-GPU、NVM的发展,通过RNIC来直接访问GPU或者通过RNIC来直接访问NVM都是目前比较成熟和热门的技术。RDMA + GPU可以大幅度加速GPU和GPU之间的通信,RDMA + NVM则可以大幅度的扩大内存容量,减少网络通信的需求。这块内容既涉及到硬件又涉及到操作系统的虚拟内存机制,要讲清楚需要不少篇幅,我们放在下一篇进行介绍。
四、总结
本篇文章主要是介绍一些RDMA的基础概念以及背后的原理,基于这些概念和原理我们介绍了RDMA的常见性能优化技巧,下一篇我们将会介绍RNIC + X,包括RNIC + GPU以及RNIC + NVM的内容介绍,感兴趣的读者朋友可以保持关注~。
相关文章:
RDMA性能优化经验浅谈
一、RDMA概述 首先我们介绍一下RDMA的一些核心概念,当然了,我并不打算写他的API以及调用方式,我们更多关注这些基础概念背后的硬件执行方式和原理,对于这些原理的理解是能够写出高性能RDMA程序的关键。 Memory Region RDMA的网…...

day 44 | ● 309.最佳买卖股票时机含冷冻期 ● 714.买卖股票的最佳时机含手续费
309.最佳买卖股票时机含冷冻期 此外,在返回的时候,由于状态234都是卖出的状态,所以要比较其最大值进行返回。 func maxProfit(prices []int) int {dp : make([][]int, len(prices))dp[0] make([]int, 4)dp[0][0] -prices[0]for i : 1; i &…...
电子科大软件系统架构设计——系统分析与设计概述(含课堂作业、练习答案)
系统分析与设计概述 信息系统概述 what 信息系统是一种能够完成对业务数据进行采集、转换、加工、计算、分析、传输、维护等信息处理,并能就某个方面问题给用户提供信息服务的计算机应用系统。 组成 信息化基础设施(计算机、计算机网络、服务器、系统…...
)
【SpringMVC】@RequestMapping注解(详解)
文章目录 前言1、RequestMapping注解的功能2、RequestMapping注解的位置3、RequestMapping注解的value属性4、RequestMapping注解的method属性1、对于处理指定请求方式的控制器方法,SpringMVC中提供了RequestMapping的派生注解2、常用的请求方式有get,po…...

8.(Python数模)马尔科夫链预测
Python实现马尔科夫链预测 马尔科夫链原理 马尔科夫链是一种进行预测的方法,常用于系统未来时刻情况只和现在有关,而与过去无关。 用下面这个例子来讲述马尔科夫链。 如何预测下一时刻计算机发生故障的概率? 当前状态只存在0(故…...

什么是浏览器缓存(browser caching)?如何使用HTTP头来控制缓存?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ 浏览器缓存和HTTP头控制缓存⭐ HTTP头控制缓存1. Cache-Control2. Expires3. Last-Modified 和 If-Modified-Since4. ETag 和 If-None-Match ⭐ 缓存策略⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记得点击…...

谁需要了解学习RPA?什么地方可以使用RPA?
RPA(Robotic Process Automation)是一种通过软件机器人自动化执行特定任务和流程的技术。以下是一些需要了解RPA的人群: 企业决策者:企业决策者需要了解RPA的潜在收益和风险,以及如何将其纳入企业的数字化转型战略中。…...

Qt各个版本下载及安装教程(离线和非离线安装)
Qt各个版本下载链接: Index of /archive/qthttps://download.qt.io/archive/qt/ 离线安装 ,离线安装很无脑,下一步下一步就可以。 我离线下载 半个小时把2G的exe下载下来了...

使用爬虫代码获得深度学习目标检测或者语义分割中的图片。
问题描述:目标检测或者图像分割需要大量的数据,如果手动从网上找的话会比较慢,这时候,我们可以从网上爬虫下来,然后自己筛选即可。 代码如下(不要忘记安装代码依赖的库): # -*- co…...
代码随想录算法训练营第39天 | ● 62.不同路径 ● 63. 不同路径II
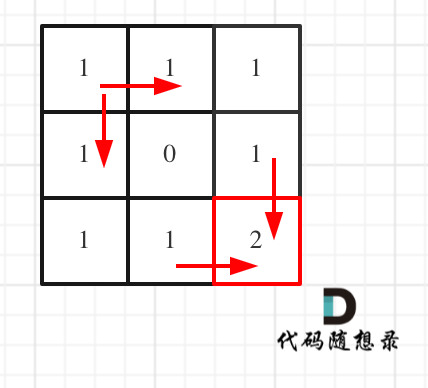
文章目录 前言一、62.不同路径二、63.不同路径II总结 前言 动态规划 一、62.不同路径 深搜动态规划数论 深搜: 注意题目中说机器人每次只能向下或者向右移动一步,那么其实机器人走过的路径可以抽象为一棵二叉树,而叶子节点就是终点&#…...

《网站建设:从规划到发布的全过程详解》
一、引言 在数字时代,网站已经成为企业和个人在互联网上的重要存在。一个优质网站的建立需要周全的规划、设计、开发、测试和发布。本文将详细介绍网站建设的全过程,帮助读者了解和掌握网站建设的流程和方法。 二、网站建设的意义 网站建设具有以下意…...
1分钟实现 CLIP + Annoy + Gradio 文搜图+图搜图 系统
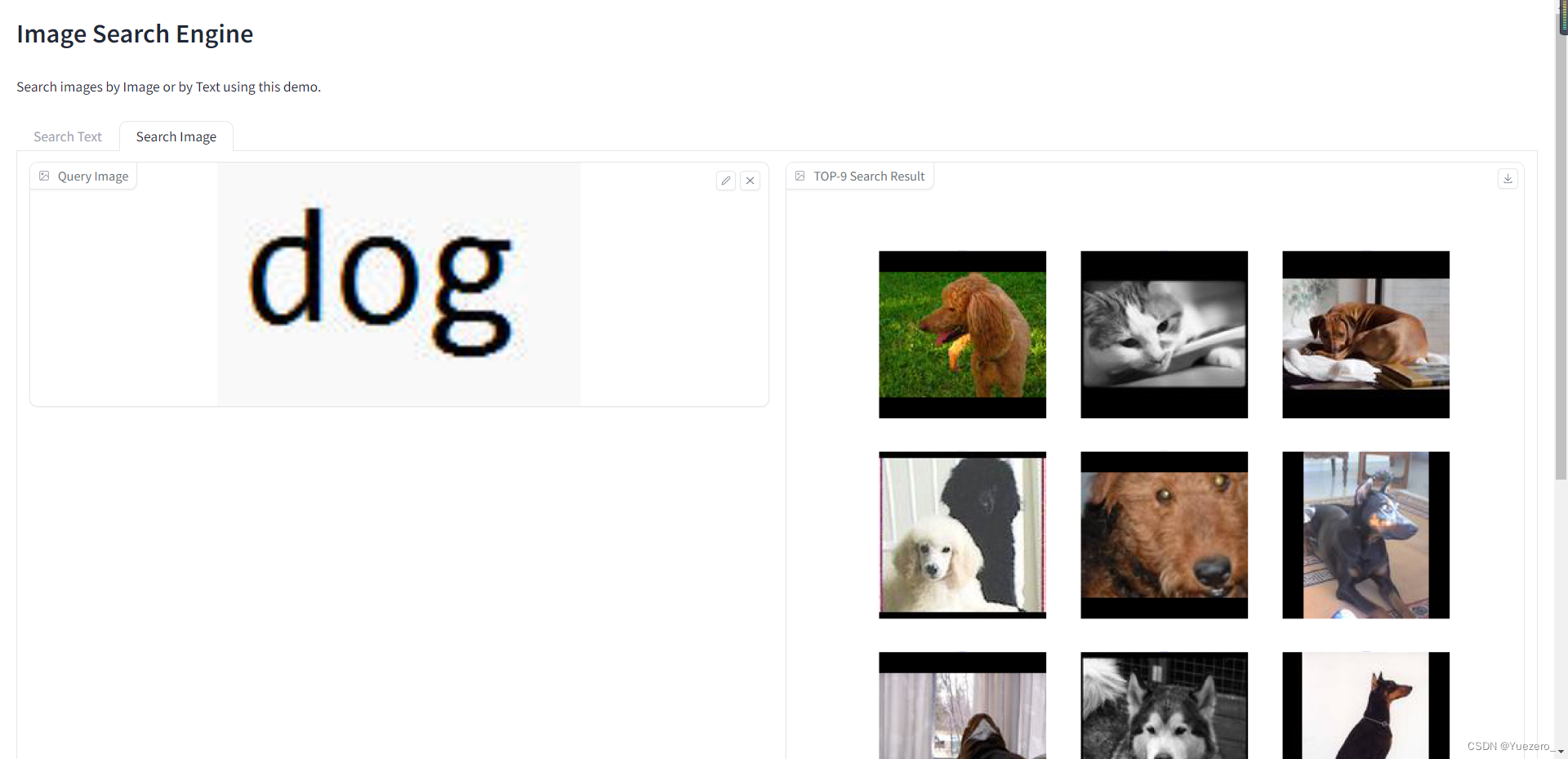
多模态图文搜索系统 CLIP 进行 Text 和 Image 的语义EmbeddingAnnoy 向量数据库实现树状结构索引来加速最近邻搜索Gradio 轻量级的机器学习 Web 前端搭建 文搜图 图搜图 CLIP图像语义提取功能!...

用树形dp+状压维护树上操作的计数问题:0902T3
发现操作数 k ≤ 6 k\le6 k≤6,可以考虑对操作进行状压。 然后找找性质,发现要么删掉一棵子树,要么进去该子树。可以视为每种操作有两种情况。 然后分讨一下当前该如何转移。 树形dp的顺序: 合并子树考虑当前往上的边的方向 …...
【python爬虫】批量识别pdf中的英文,自动翻译成中文上
不管是上学还是上班,有时不可避免需要看英文文章,特别是在写毕业论文的时候。比较头疼的是把专业性很强的英文pdf文章翻译成中文。我记得我上学的时候,是一段一段复制,或者碰到不认识的单词就百度翻译一下,非常耗费时间。本文提供批量识别pdf中英文的方法,后续文章实现自…...

Android笔记--Hilt
Hilt 是 Android 的依赖项注入库,可减少在项目中执行手动依赖项注入的样板代码。执行手动依赖项注入要求您手动构造每个类及其依赖项,并借助容器重复使用和管理依赖项。依赖注入的英文是Dependency Injection,简称DI,简单说一个类中使用的依赖…...

Oracle常用权限处理
对于Oracle来说,用户等于Schema,创建用户即创建Schema -- 创建用户 create user TCK_TEXT identified by "TCKTCK"; --赋予登陆权限 grant connect to TCK_TEXT; --查看权限列表 select * from user_role_privs ; select * from user_sys_priv…...
Stable Diffuse 之 本地环境部署 WebUI 进行汉化操作
Stable Diffuse 之 本地环境部署 WebUI 进行汉化操作 目录 Stable Diffuse 之 本地环境部署 WebUI 进行汉化操作 一、简单介绍 二、汉化操作 附录: 一、Install from URL 中出现 Failed to connect to 127.0.0.1 port 7890: Connection refused 错误…...

r 安装源码包 安装本地r包
总结一下手动安装R包 - 简书 (jianshu.com)https://www.jianshu.com/p/2a7a36414734 #BiocManager::install("simplifyEnrichment") #BiocManager::install("EnsDb.Hsapiens.v86")#下载包 之后 手动安装 #install.packages("~/datasets/EnsDb.Hsapien…...
webservice调用对接第三方系统
#webservice调用对接第三方系统# 最近接到一个任务,需要对接第三方数据,第三方提供对接方式的是通过webservice调用,webservice调用有好几种方式,具体可以自行了解,我选择的是通过wsdl文件自动生成客户端代码对接。 …...
实现不同局域网文件共享的解决方案:使用Python自带HTTP服务和端口映射
文章目录 1. 前言2. 本地文件服务器搭建2.1 python的安装和设置2.2 cpolar的安装和注册 3. 本地文件服务器的发布3.1 Cpolar云端设置3.2 Cpolar本地设置 4. 公网访问测试5. 结语 1. 前言 数据共享作为和连接作为互联网的基础应用,不仅在商业和办公场景有广泛的应用…...

Unity UGUI轻量UI框架:200行代码实现零GC界面管理
1. 为什么还要自己手写UI框架?——当UGUI原生方案开始“卡脖子”很多人看到这个标题第一反应是:“都2024年了,还手写UI框架?Asset Store里几十个成熟方案,NGUI、FairyGUI、TextMeshPro配套的UI系统一抓一大把ÿ…...

Python开发者首次使用Taotoken接入大模型API的完整步骤指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Python开发者首次使用Taotoken接入大模型API的完整步骤指南 对于Python开发者而言,接入大模型API进行应用开发已成为一…...

网易云音乐NCM转MP3终极指南:ncmdump工具完整使用教程
网易云音乐NCM转MP3终极指南:ncmdump工具完整使用教程 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾经从网易云音乐下载了心爱的歌曲,却发现只能在特定播放器上收听?NCM格式的限制让音乐…...

亚马逊 Rufus 关停,Alexa 正式上线:卖家必须读懂的6条新规则
2026年5月13日,亚马逊官方正式宣布,下线Rufus,推出全新AI购物助手:Alexa for Shopping。但是,这不是粗暴地直接下线 Rufus,而是一次购物AI底层架构的重组 —— 将 Rufus 的商品专长 与 Alexa的用户理解力&a…...
到panic:深入Linux 5.4内核,看异常处理如何层层递进)
从BUG()到panic:深入Linux 5.4内核,看异常处理如何层层递进
从BUG()到panic:Linux内核异常处理的防御体系全解析当你在深夜调试一个内核模块时,突然屏幕刷出一串红色警告——这可能是每个Linux内核开发者都经历过的噩梦时刻。但你是否想过,从第一行警告出现到系统完全崩溃,内核究竟经历了怎…...

别急着扔!12年老ThinkPad X230升级SSD和内存后,Win10流畅得像新电脑
12年老ThinkPad X230重生指南:极简升级打造流畅办公利器每次打开抽屉看到那台积灰的ThinkPad X230,总有种说不出的情感。这款2012年问世的经典商务本,曾陪伴无数人度过加班到凌晨的夜晚。如今性能确实有些力不从心,但直接丢弃又觉…...

为什么鸿蒙 App 最终都会走向状态驱动?
子玥酱 (掘金 / 知乎 / CSDN / 简书 同名) 大家好,我是 子玥酱,一名长期深耕在一线的前端程序媛 👩💻。曾就职于多家知名互联网大厂,目前在某国企负责前端软件研发相关工作,主要聚…...

约束感知图缩减算法在量子优化中的应用
1. 约束感知图缩减算法概述在量子计算领域,资源受限一直是制约算法实际应用的主要瓶颈。以当前主流的超导量子计算机为例,其量子比特数通常在50-100个之间,且存在显著的噪声干扰。这种硬件限制使得许多经典优化问题难以直接映射到量子设备上求…...

BetterJoy终极指南:3分钟让你的Switch手柄变身PC游戏神器
BetterJoy终极指南:3分钟让你的Switch手柄变身PC游戏神器 【免费下载链接】BetterJoy Allows the Nintendo Switch Pro Controller, Joycons and SNES controller to be used with CEMU, Citra, Dolphin, Yuzu and as generic XInput 项目地址: https://gitcode.c…...

怎么理解Filter不是在afterCompetition里面remove掉ThreadLocal里面的东西,而是说在finally块里面remove
文章目录1. 核心原因:Filter 的“套娃(洋葱圈)”执行模型2. 为什么不能(也无法)在这里用 afterCompletion?维度一:Filter 拿不到 afterCompletion维度二:生命周期顺序的致命冲突总结…...