golang逃逸技术分析
“申请到栈内存好处:函数返回直接释放,不会引起垃圾回收,对性能没有影响。
申请到堆上面的内存才会引起垃圾回收。
func F() {
a := make([]int, 0, 20)
b := make([]int, 0, 20000)
l := 20
c := make([]int, 0, l)
}
“a和b代码一样,就是申请的空间不一样大,但是它们两个的命运是截然相反的。a前面已经介绍过,会申请到栈上面,而b,由于申请的内存较大,编译器会把这种申请内存较大的变量转移到堆上面。即使是临时变量,申请过大也会在堆上面申请。
而c,对我们而言其含义和a是一致的,但是编译器对于这种不定长度的申请方式,也会在堆上面申请,即使申请的长度很短。
堆(Heap)和栈(Stack)
参考 此文[1] <内存模型:Heap>, <内存模型:Stack>部分的内容:
Heap:
堆的一个重要特点就是不会自动消失,必须手动释放,或者由垃圾回收机制来回收。
Stack:
栈是由于函数运行而临时占用的内存区域
执行main函数时,会为它在内存里面建立一个帧(frame),所有main的内部变量(比如a和b)都保存在这个帧里面。main函数执行结束后,该帧就会被回收,释放所有的内部变量,不再占用空间。
一般来说,调用栈有多少层,就有多少帧。
所有的帧都存放在 Stack,由于帧是一层层叠加的,所以 Stack 被翻译为栈。 (栈这个字的原始含义,就有栅栏的意思,所谓 栈道,栈桥,都是指比较简陋的用栅栏做的道路/桥梁)
即 在函数中申请一个新的对象:
如果分配 在栈中,则函数执行结束可自动将内存回收;不会引起垃圾回收,对性能没有影响。
如果分配在堆中,则函数执行结束可交给GC(垃圾回收)处理;如果这个过程(特指垃圾回收不断被触发)过于高频就会导致 gc 压力过大,程序性能出问题。
C/C++中的new都是分配到堆上,Go则不一定(Java亦然)[2]
何为逃逸分析(Escape analysis)
在堆上分配的内存,需要GC去回收,而在栈上分配,函数执行完就销毁,不存在垃圾回收的问题. 所以应尽可能将内存分配在栈上.
但问题是,对于一个函数或变量,并不能知道还有没有其他地方在引用. 所谓的逃逸分析,就是为了确定这个事儿~
Go编译器会跨越函数和包的边界进行全局的逃逸分析。它会检查是否需要在堆上为一个变量分配内存,还是说可以在栈本身的内存里对其进行管理。
何时发生逃逸分析?
“Go编译器决定变量应该分配到什么地方时会进行逃逸分析
“From a correctness standpoint, you don’t need to know. Each variable in Go exists as long as there are references to it. The storage location chosen by the implementation is irrelevant to the semantics of the language.
The storage location does have an effect on writing efficient programs. When possible, the Go compilers will allocate variables that are local to a function in that function’s stack frame.
However, if the compiler cannot prove that the variable is not referenced after the function returns, then the compiler must allocate the variable on the garbage-collected heap to avoid dangling pointer errors. Also, if a local variable is very large, it might make more sense to store it on the heap rather than the stack.
In the current compilers, if a variable has its address taken, that variable is a candidate for allocation on the heap. However, a basic escape analysis recognizes some cases when such variables will not live past the return from the function and can reside on the stack.
Q:如何得知变量是分配在栈(stack)上还是堆(heap)上?
A: 准确地说,你并不需要知道。Golang 中的变量只要被引用就一直会存活,存储在堆上还是栈上由内部实现决定而和具体的语法没有关系。
但知道变量的存储位置确实对程序的效率有帮助。如果可能,Golang 编译器会将函数的局部变量分配到函数栈帧(stack frame)上。然而,如果编译器不能确保变量在函数 return 之后不再被引用,编译器就会将变量分配到堆上。而且,如果一个局部变量非常大,那么它也应该被分配到堆上而不是栈上。 当前情况下,如果一个变量被取地址,那么它就有可能被分配到堆上。然而,还要对这些变量做逃逸分析,如果函数 return 之后,变量不再被引用,则将其分配到栈上。
可以使用go命令的 -gcflags="-m"选项,来观察逃逸分析的结果以及GC工具链的内联决策[3] ([内联是一种手动或编译器优化,用于将简短函数的调用替换为函数体本身。这么做的原因是它可以消除函数调用本身的开销,也使得编译器能更高效地执行其他的优化策略。我们可以显式地在函数定义前面加一行//go:noinline 注释让编译器不对函数进行内联)
实例
对于escape1.go代码如下:
package main
import "fmt"
func main() {
fmt.Println("Called stackAnalysis", stackAnalysis())
}
//go:noinline
func stackAnalysis() int {
data := 100
return data
}
通过 go build -gcflags "-m -l" escape1.gogo build -gcflags=-m escape1.go 来查看和分析逃逸分析:
./escape1.go:6:13: inlining call to fmt.Println
./escape1.go:6:14: "Called stackAnalysis" escapes to heap
./escape1.go:6:51: stackAnalysis() escapes to heap
./escape1.go:6:13: []interface {}{...} does not escape
<autogenerated>:1: .this does not escape
escapes to heap 即代表该行该处 内存分配发生了逃逸现象. 变量需要在函数栈之间共享(这个例子就是在main和fmt.Println之间在栈上共享)
-
第6行第13个字符处的字符串标量"Called stackAnalysis"逃逸到堆上
-
第6行51个字符处的函数调用stackAnalysis()逃逸到了堆上
对于escape2.go代码如下:
package main
import "fmt"
func main() {
fmt.Println("Called heapAnalysis", heapAnalysis())
}
//go:noinline
func heapAnalysis() *int {
data := 100
return &data
}
执行go build -gcflags=-m escape2.go:
# command-line-arguments
./escape2.go:6:13: inlining call to fmt.Println
./escape2.go:11:2: moved to heap: data
./escape2.go:6:14: "Called heapAnalysis" escapes to heap
./escape2.go:6:13: []interface {}{...} does not escape
<autogenerated>:1: .this does not escape
函数heapAnalysis返回 int类型的指针,在main函数中会使用该指针变量. 因为是在heapAnalysis函数外部访问,所以data变量必须被移动到堆上
主函数main会从堆中访问该data变量
(可见指针虽能够减少变量在函数间传递时的数据值拷贝,但不该所有类型数据都返回其指针.如果分配到堆上的共享变量太多会增加了GC的压力)
逃逸类型
1. 指针逃逸:
对于 escape_a.go:
package main
type Student struct {
Name string
Age int
}
func StudentRegister(name string, age int) *Student {
s := new(Student) //局部变量s逃逸到堆
s.Name = name
s.Age = age
return s
}
func main() {
StudentRegister("dashen", 18)
}
执行 go build -gcflags=-m escape_a.go
# command-line-arguments
./escape_a.go:8:6: can inline StudentRegister
./escape_a.go:17:6: can inline main
./escape_a.go:18:17: inlining call to StudentRegister
./escape_a.go:8:22: leaking param: name
./escape_a.go:9:10: new(Student) escapes to heap
./escape_a.go:18:17: new(Student) does not escape
**s 虽然为 函数StudentRegister()内的局部变量, 其值通过函数返回值返回. 但s 本身为指针类型. 所以其指向的内存地址不会是栈而是堆. **
这是一种典型的变量逃逸案例
2. 栈空间不足而导致的逃逸(空间开辟过大):
对于 escape_b.go:
package main
func InitSlice() {
s := make([]int, 1000, 1000)
for index := range s {
s[index] = index
}
}
func main() {
InitSlice()
}
执行go build -gcflags=-m escape_b.go
# command-line-arguments
./escape_b.go:11:6: can inline main
./escape_b.go:4:11: make([]int, 1000, 1000) does not escape
此时并没有发生逃逸
将切片的容量增大10倍,即:
package main
func InitSlice() {
s := make([]int, 1000, 10000)
for index := range s {
s[index] = index
}
}
func main() {
InitSlice()
}
执行go build -gcflags=-m escape_b.go
# command-line-arguments
./escape_b.go:11:6: can inline main
./escape_b.go:4:11: make([]int, 1000, 10000) escapes to heap
发生了逃逸
当栈空间不足以存放当前对象,或无法判断当前切片长度时,会将对象分配到堆中
ps:
package main
func InitSlice() {
s := make([]int, 1000, 1000)
for index := range s {
s[index] = index
}
println(s)
}
func main() {
InitSlice()
}
执行go build -gcflags=-m escape_b.go
# command-line-arguments
./escape_b.go:12:6: can inline main
./escape_b.go:4:11: make([]int, 1000, 1000) does not escape
没有逃逸.
而改成
package main
import "fmt"
func InitSlice() {
s := make([]int, 1000, 1000)
for index := range s {
s[index] = index
}
fmt.Println(s)
}
func main() {
InitSlice()
}
执行go build -gcflags=-m escape_b.go,则
# command-line-arguments
./escape_b.go:11:13: inlining call to fmt.Println
./escape_b.go:14:6: can inline main
./escape_b.go:6:11: make([]int, 1000, 1000) escapes to heap
./escape_b.go:11:13: s escapes to heap
./escape_b.go:11:13: []interface {}{...} does not escape
<autogenerated>:1: .this does not escape
发生了逃逸
这是为何? 参见下文!
3. 动态类型逃逸(不确定长度大小):
当函数参数为**interface{}**类型, 如最常用的fmt.Println(a …interface{}), 编译期间很难确定其参数的具体类型,也会产生逃逸
对于 escape_c1.go:
package main
import "fmt"
func main() {
s := "s会发生逃逸"
fmt.Println(s)
}
执行go build -gcflags=-m escape_c1.go
# command-line-arguments
./escape_c1.go:7:13: inlining call to fmt.Println
./escape_c1.go:7:13: s escapes to heap
./escape_c1.go:7:13: []interface {}{...} does not escape
<autogenerated>:1: .this does not escape
对于 escape_c1.go:
package main
func main() {
InitSlice2()
}
func InitSlice2() {
a := make([]int, 0, 20) // 栈 空间小
b := make([]int, 0, 20000) // 堆 空间过大 逃逸
l := 20
c := make([]int, 0, l) // 堆 动态分配不定空间 逃逸
_, _, _ = a, b, c
}
执行go build -gcflags=-m escape_c2.go
# command-line-arguments
./escape_c2.go:7:6: can inline InitSlice2
./escape_c2.go:3:6: can inline main
./escape_c2.go:4:12: inlining call to InitSlice2
./escape_c2.go:4:12: make([]int, 0, 20) does not escape
./escape_c2.go:4:12: make([]int, 0, 20000) escapes to heap
./escape_c2.go:4:12: make([]int, 0, l) escapes to heap
./escape_c2.go:8:11: make([]int, 0, 20) does not escape
./escape_c2.go:9:11: make([]int, 0, 20000) escapes to heap
./escape_c2.go:12:11: make([]int, 0, l) escapes to heap
4. 闭包引用对象逃逸:
对于如下斐波那契数列escape_d.go:
package main
import "fmt"
func Fibonacci() func() int {
a, b := 0, 1
return func() int {
a, b = b, a+b
return a
}
}
func main() {
f := Fibonacci()
for i := 0; i < 10; i++ {
fmt.Printf("Fibonacci: %d\n", f())
}
}
执行go build -gcflags=-m escape_d.go
# command-line-arguments
./escape_d.go:7:9: can inline Fibonacci.func1
./escape_d.go:17:13: inlining call to fmt.Printf
./escape_d.go:6:2: moved to heap: a
./escape_d.go:6:5: moved to heap: b
./escape_d.go:7:9: func literal escapes to heap
./escape_d.go:17:34: f() escapes to heap
./escape_d.go:17:13: []interface {}{...} does not escape
<autogenerated>:1: .this does not escape
Fibonacci()函数中原本属于局部变量的a和b,由于闭包的引用,不得不将二者放到堆上,从而产生逃逸
总结
-
逃逸分析在编译阶段完成
-
逃逸分析目的是决定内分配地址是栈还是堆
-
栈上分配内存比在堆中分配内存有更高的效率
-
栈上分配的内存不需要GC处理
-
堆上分配的内存使用完毕会交给GC处理
通过逃逸分析,不逃逸的对象分配在栈上,当函数返回时就回收了资源,不需gc标记清除,从而减少gc的压力
同时,栈的分配比堆快,性能好(逃逸的局部变量会在堆上分配,而没有发生逃逸的则有编译器在栈上分配)
另外,还可以进行同步消除: 如果定义的对象的方法上有同步锁,但在运行时却只有一个线程在访问,此时逃逸分析后的机器码会去掉同步锁运行
全文参考自:
Go内存管理之代码的逃逸分析
Golang内存分配逃逸分析[4]
推荐阅读:
golang如何优化编译、逃逸分析、内联优化
java逃逸技术分析[5]
译文 Go 高性能系列教程之三:编译器优化[6]
参考资料
此文: http://www.ruanyifeng.com/blog/2018/01/assembly-language-primer.html
[2]Go则不一定(Java亦然): https://dashen.tech/2017/06/18/golang%E4%B8%ADnew-%E5%92%8Cmake-%E7%9A%84%E5%8C%BA%E5%88%AB/
[3]内联决策: https://dashen.tech/2021/05/22/Go%E4%B8%AD%E7%9A%84%E5%86%85%E8%81%94%E4%BC%98%E5%8C%96/
[4]Golang内存分配逃逸分析: https://www.cnblogs.com/shijingxiang/articles/12200355.html
[5]java逃逸技术分析: https://blog.csdn.net/iechenyb/article/details/80925876
[6]译文 Go 高性能系列教程之三:编译器优化: https://zhuanlan.zhihu.com/p/377397367
本文由 mdnice 多平台发布
相关文章:

golang逃逸技术分析
“ 申请到栈内存好处:函数返回直接释放,不会引起垃圾回收,对性能没有影响。 申请到堆上面的内存才会引起垃圾回收。 func F() { a : make([]int, 0, 20) b : make([]int, 0, 20000) l : 20 c : make([]int, 0, l)} “ a和b代码一样࿰…...

说说你了解的 Nginx
分析&回答 nginx性能数据 高并发连接: 官方称单节点支持5万并发连接数,实际生产环境能够承受2-3万并发。内存消耗少: 在3万并发连接下,开启10个nginx进程仅消耗150M内存 (15M10150M) 1. 正向、反向代理 所谓“代理”,是指在内网边缘 …...
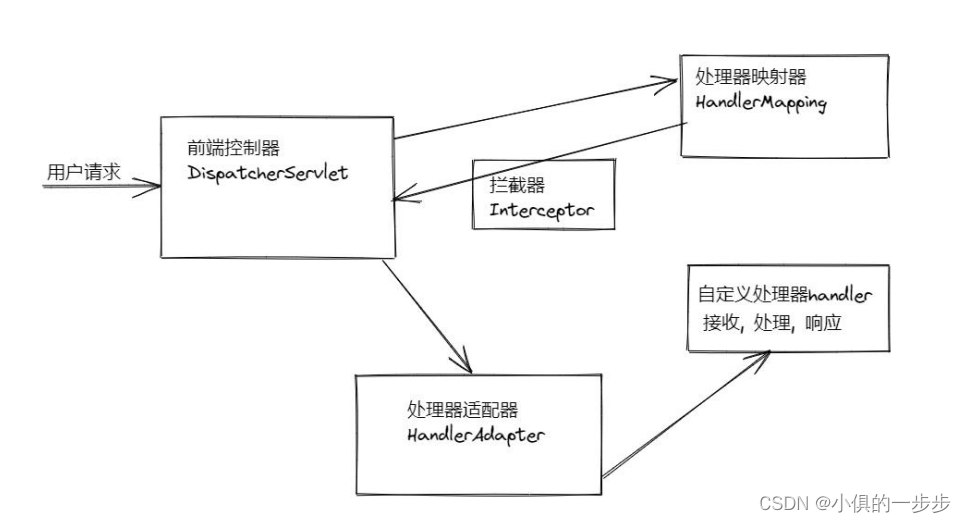
SpringWeb(SpringMVC)
目录 SpringWeb介绍 搭建 SpringWeb SpringWeb介绍 Spring Web是一个基于 Servlet API 构建的原始 web 框架,用于构建基于MVC模式的Web应用程序。在 web 层框架历经 Strust1,WebWork,Strust2 等诸多产品的历代更选 之后,目前业界普…...

Mysql 语句
数据库管理 SQL语言分类 DDL 数据定义语言,用于创建数据库对象,如库、表、索引等 create 创建 create database/table; 数据库/表 create table 表名 (括号内添加类型和字段);drop 删除 drop database/table; 数据库/表…...
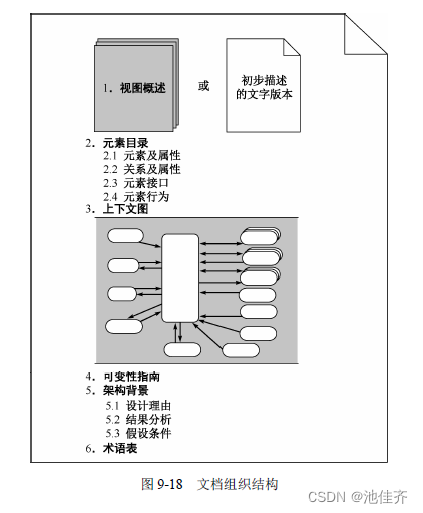
软考高级架构师——6、软件架构设计
像学写文章一样,在学会字、词、句之后,就应上升到段落,就应追求文章的“布局谋 篇”,这就是架构。通俗地讲,软件架构设计就是软件系统的“布局谋篇”。 人们在软件工程实践中,逐步认识到了软件架构的重要性…...

虚拟内存相关笔记
虚拟内存是计算机系统内存管理的一个功能,它允许程序认为它们有比实际物理内存更多的可用内存。它使用硬盘来模拟额外的RAM。当物理内存不足时,操作系统将利用磁盘空间作为虚拟内存来存储数据。这种机制提高了资源的利用率并允许更大、更复杂的应用程序的…...

【linux】定时任务讲解
文章目录 一. 在某时刻只执行一次:at1. 设置定时任务2. 查看和删除定时任务 二. 周期性执行任务:cron1. 启动crond进程2. 编辑定时任务3. 查看和删除4. 用户权限4.1. 黑名单4.2指定用户 三. /etc/crontab的管理 一. 在某时刻只执行一次:at 1…...
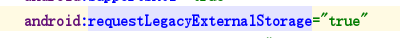
安卓10创建文件夹失败
最近在做拍照录像功能,已经有了文件读写权限,却发现在9.0手机上正常使用,但是在安卓12系统上根本没有创建文件夹。经过研究发现,创建名称为“DCIM”的文件夹可以,别的又都不行。而且是getExternalStorageDirectory和ge…...
)
文件操作(c/c++)
文件操作可以概括为几步: 打开文件,写入文件,读取文件,关闭文件 FILE FILE 是一个在C语言中用于文件操作的库函数,它提供了一系列函数来实现文件的创建、打开、读取、写入、关闭等操作。FILE 库函数可以帮助开发者处理…...
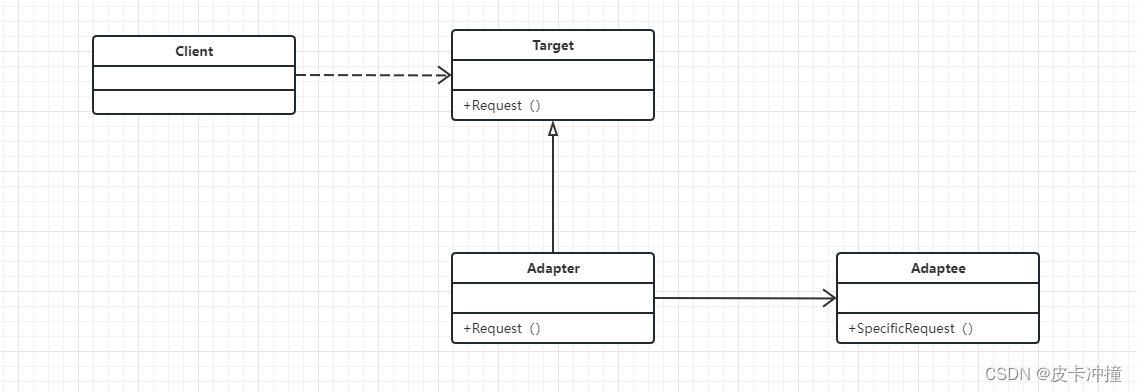
设计模式-适配器
文章目录 一、简介二、适配器模式基础1. 适配器模式定义与分类2. 适配器模式的作用与优势3.UML图 三、适配器模式实现方式1. 类适配器模式2. 对象适配器模式3.类适配器模式和对象适配器模式对比 四、适配器模式应用场景1. 继承与接口的适配2. 跨平台适配 五、适配器模式与其他设…...
C. Queries for the Array - 思维
分析: 分析出现矛盾的地方,也就是可能遇到0,并且已有字符串的长度小于等于1,另一种情况就是,遇到了1并且已有字符串不是排好序的,或者遇到了0已有字符串是排好序的,那么可以遍历字符串ÿ…...
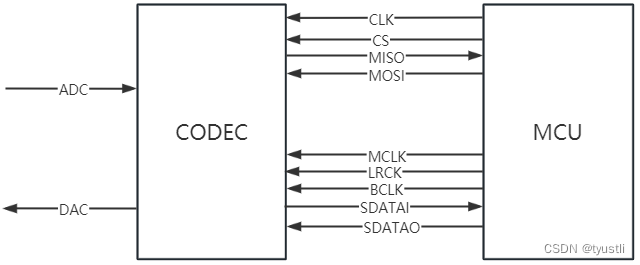
音频——硬件拓扑
文章目录 硬件拓扑I2S 数据通路五线模式四线模式两线 TX两线 RX 典型应用硬件连接数据流 硬件拓扑 控制路径:UART/I2C/SPI数据路径:I2S 简略图如下 I2S 数据通路 五线模式 四线模式 两线 TX 两线 RX 典型应用 硬件连接 控制信号:SPI 用…...
)
Oracle表索引查看方法总结(查看oracle表索引)
Oracle表索引查看方法总结 Oracle是当前应用最广泛的关系数据库,也是多数大型企业使用的数据库。Oracle表索引在提高查询效率方面起着至关重要的作用,掌握该方法也是技术人员必备技能之一。本文总结了几种常见的查看Oracle表索引信息的方法,…...

react css 污染解决方法
上代码 .m-nav-bar {background: #171a21;.content {height: 104px;margin: 0px auto;} }import React from "react"; import styles from ./css.module.scssexport default class NavBar extends React.Component<any, any> {constructor (props: any) {supe…...

volatile 关键字 与 CPU cache line 的效率问题
分析&回答 Cache Line可以简单的理解为CPU Cache中的最小缓存单位。目前主流的CPU Cache的Cache Line大小都是64Bytes。假设我们有一个512字节的一级缓存,那么按照64B的缓存单位大小来算,这个一级缓存所能存放的缓存个数就是512/64 8个。具体参见下…...

又一关键系统上线,理想车云和自动驾驶系统登陆OceanBase
8 月 1 日,理想汽车公布 7 月交付数据,理想汽车 2023 年 7 月共交付新车 34,134 辆,同比增长 227.5%,并已连续两个月交付量突破三万。至此,理想汽车 2023 年累计交付量已经达到 173,251 辆,远超 2022 年全年…...

SIEM(安全信息和事件管理)解决方案
什么是SIEM 安全信息和事件管理(SIEM)是一种可帮助组织在安全威胁危害到业务运营之前检测、分析和响应安全威胁的解决方案,将安全信息管理 (SIM) 和安全事件管理 (SEM) 结合到一个安全管理系统中。SIEM 技术从广泛来源收集事件日志数据&…...

Go 自学:map关联数组
以下代码展示了如何建立一个map。 我们可以使用delete删除map中的元素。 我们还可以使用loop遍历map中的所有元素。 package mainimport ("fmt" )func main() {languages : make(map[string]string)languages["JS"] "Javascript"languages[&qu…...
的使用)
c#多态(override)的使用
方法重写(override):多态,通过父类类型对象,调用子类当中对应方法的实现。 细节:子类当中的override方法会“抹杀”父类当中对应virtual方法 不使用多态时,父类调用子类方法时,会调用父类的方法…...

kafka 动态扩容现有 topic 的分区数和副本数
文章目录 [toc]创建一个演示 topic生产一些数据使用消费者组消费数据增加分区无新数据产生,有旧数据未消费有新数据产生,有旧数据未消费 增加副本创建 json 文件使用指定的 json 文件增加 topic 的副本数使用指定的 json 文件查看 topic 的副本数增加的进…...

解锁桌面音乐新体验:LyricsX让你的Mac成为私人KTV
解锁桌面音乐新体验:LyricsX让你的Mac成为私人KTV 【免费下载链接】Lyrics Swift-based iTunes plug-in to display lyrics on the desktop. 项目地址: https://gitcode.com/gh_mirrors/lyr/Lyrics 还在为听歌时找不到歌词而烦恼吗?LyricsX这款基…...

3步彻底解决Visual C++运行库问题:告别DLL缺失和应用崩溃
3步彻底解决Visual C运行库问题:告别DLL缺失和应用崩溃 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist Visual C Redistributable(微软Vi…...

终极免费方案:3分钟掌握ViGEmBus虚拟游戏手柄驱动的完整部署与应用
终极免费方案:3分钟掌握ViGEmBus虚拟游戏手柄驱动的完整部署与应用 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 你是否曾为游戏不支持你的手柄…...

DASD-4B-Thinking部署教程:Docker镜像内vLLM服务健康检查脚本编写与自动重启
DASD-4B-Thinking部署教程:Docker镜像内vLLM服务健康检查脚本编写与自动重启 1. 项目背景与需求 DASD-4B-Thinking是一个专门针对数学、代码生成和科学推理任务优化的40亿参数语言模型。它通过vLLM框架部署,配合chainlit前端提供交互式体验。但在实际使…...

从零封装Vue版JSMpeg播放器:支持截图/录制/旋转的直播流组件开发指南
从零封装Vue版JSMpeg播放器:支持截图/录制/旋转的直播流组件开发指南 1. 技术选型与架构设计 在Web端实现低延迟视频直播需要解决三个核心问题:编解码效率、传输协议选择和渲染性能。基于JSMpeg的方案优势在于: 超低延迟(可达50ms…...

多模态扩展:OpenClaw结合Qwen3.5-4B-Claude处理截图信息
多模态扩展:OpenClaw结合Qwen3.5-4B-Claude处理截图信息 1. 为什么需要多模态能力 作为一个长期依赖文本交互的技术爱好者,我最初对OpenClaw的理解停留在"能通过自然语言控制电脑的AI助手"层面。直到上个月需要处理大量产品截图中的文字信息…...

基于DWS构建RAG框架生成行业调研报告
1. 前言 适用版本:【DWS 9.1.1.200(及以上)】 在信息爆炸的时代,行业调研报告的生成正面临数据规模庞大、信息碎片化、人工处理效率低等多重挑战。检索增强生成(RAG, Retrieval-Augmented Generation)作为…...

音频处理必备:5分钟搞懂IIR和FIR滤波器的区别与应用场景
音频处理必备:5分钟搞懂IIR和FIR滤波器的区别与应用场景 在音乐制作和音频工程领域,滤波器是塑造声音的核心工具之一。无论是调整均衡、消除噪声还是创造特殊音效,都离不开对IIR和FIR这两类滤波器的深入理解。许多刚入门的音频工程师常常困惑…...

Java面试题精讲:Qwen-Image-Edit-F2P集成开发常见问题
Java面试题精讲:Qwen-Image-Edit-F2P集成开发常见问题 1. 引言 最近在Java技术面试中,我发现很多候选人在AI模型集成方面存在不少困惑。特别是像Qwen-Image-Edit-F2P这样的人脸驱动图像生成模型,虽然功能强大,但在实际Java项目集…...

给ESP32-S3智能音箱选个好麦克风:从灵敏度到阵列布局的实战避坑指南
给ESP32-S3智能音箱选个好麦克风:从灵敏度到阵列布局的实战避坑指南 在智能家居设备井喷式发展的今天,语音交互已成为人机交互的核心方式之一。作为语音入口的关键部件,麦克风的选择与设计直接决定了用户体验的优劣。本文将深入探讨如何为ESP…...