SSM整合~
构建并配置项目:
第一步:创建maven项目
第二步:配置pom.xml文件
设置打包方式:
为了方便部署,我们通常情况下,将项目打包为WAR,因为WAR文件是一种可执行的压缩文件,它可以将项目以独立的形式打包,包含了所有的项目资源以及配置文件,因此我们将项目打包成WAR包的形式,可以方便地将其部署到Tomcat,Jetty等这种支持Java Web应用的服务器中, 每个项目运行在独立的环境中,避免了不同项目之间的冲突,并且WAR文件能够自动解压并将项目部署到指定的服务器目录中,不需要我们手动复制文件和配置,能够减少人为错误的发生,此外WAR文件可以方便地进行发布,回滚以及分发和共享操作,可以快速的实现项目的发布和部署。
<packaging>war</packaging>
设置版本号为自定义属性:
<properties><!--将版本号通过自定义属性配置--><spring.version>5.3.1</spring.version>
</properties>
这样做的好处在于可以在整个项目中轻松地更改Spring版本。这样,如果未来需要升级到不同的Spring版本,只需更改一次属性值即可,而不需要在整个项目中的多个地方进行手动更改
导入依赖:
<dependencies><!--提供了spring框架的核心内容,包括IOC容器管理,以及AOP支持 --><dependency><groupId>org.springframework</groupId><artifactId>spring-context</artifactId><version>${spring.version}</version></dependency><!--提供了spring框架的bean管理功能 --><dependency><groupId>org.springframework</groupId><artifactId>spring-beans</artifactId><version>${spring.version}</version></dependency><!--提供了spring框架的文本开发功能 --><dependency><groupId>org.springframework</groupId><artifactId>spring-web</artifactId><version>${spring.version}</version></dependency><!--提供了spring框架的Web MVC支持 --><dependency><groupId>org.springframework</groupId><artifactId>spring-webmvc</artifactId><version>${spring.version}</version></dependency><!--提供了spring框架的jdbc支持 --><dependency><groupId>org.springframework</groupId><artifactId>spring-jdbc</artifactId><version>${spring.version}</version></dependency><!--提供了spring框架的AOP支持 --><dependency><groupId>org.springframework</groupId><artifactId>spring-aspects</artifactId><version>${spring.version}</version></dependency><!--mybatis数据库,持久化框架,用于对数据库进行操作 --><dependency><groupId>org.mybatis</groupId><artifactId>mybatis</artifactId><version>3.5.5</version></dependency><!--mybatis和spring整合的依赖 --><dependency><groupId>org.mybatis</groupId><artifactId>mybatis-spring</artifactId><version>1.2.1</version></dependency><!--数据库连接池,用于管理数据库连接 --><dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.2.16</version></dependency><!--用于进行单元测试 --><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.13.1</version></dependency><!--Mysql数据库的JDBC驱动 --><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.31</version></dependency><!--用于日志记录 --><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version></dependency><!--用于分页查询的插件--><dependency><groupId>com.github.pagehelper</groupId><artifactId>pagehelper</artifactId><version>5.1.2</version></dependency><!--用于日志记录 --><dependency><groupId>ch.qos.logback</groupId><artifactId>logback-classic</artifactId><version>1.2.3</version></dependency><!--Java Servlet API的依赖 --><dependency><groupId>javax.servlet</groupId><artifactId>javax.servlet-api</artifactId><version>3.1.0</version></dependency><!--用于JSON数据库的序列化和反序列化 --><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId><version>2.9.0</version></dependency><!--用于文件上传 --><dependency><groupId>commons-fileupload</groupId><artifactId>commons-fileupload</artifactId><version>1.4</version></dependency><!--模板引擎,用于生成动态的html页面 --><dependency><groupId>org.thymeleaf</groupId><artifactId>thymeleaf-spring5</artifactId><version>3.0.12.RELEASE</version></dependency></dependencies>
配置springMVC:
Spring MVC配置文件是用来配置Spring MVC框架的,它定义了请求的处理器映射、视图解析器、拦截器等内容。Spring MVC配置文件一般使用XML格式来定义,也可以使用Java配置类来代替。Spring MVC文件的主要作用是将请求分发给相应的处理器、处理器执行相应的业务逻辑,并将结果渲染成视图返回给客户端。
简单点来说spring mvc文件主要用于配置Spring MVC框架的相关配置,包括请求的处理和返回视图等。
第一步:配置springMVC.xml配置文件
配置视图解析器:
<!-- 配置Thymeleaf视图解析器--><bean id="viewResolver" class="org.thymeleaf.spring5.view.ThymeleafViewResolver"><property name="order" value="1"/><property name="characterEncoding" value="UTF-8"/><property name="templateEngine"><bean class="org.thymeleaf.spring5.SpringTemplateEngine"><property name="templateResolver"><bean class="org.thymeleaf.spring5.templateresolver.SpringResourceTemplateResolver"><!-- 视图前缀 --><property name="prefix" value="/WEB-INF/templates/"/><!-- 视图后缀 --><property name="suffix" value=".html"/><property name="templateMode" value="HTML5"/><property name="characterEncoding" value="UTF-8"/></bean></property></bean></property></bean>
通过context约束扫描控制层组件:
<context:component-scan base-package="控制层组件所在的包"></context:component-scan>
配置spring mvc的处理器和视图:
<!-- 用于配置默认的Servlet处理器:用于处理静态资源的请求,例如图片、CSS和JavaScript文件等。它会将这些请求转发给Web容器的默认Servlet处理器-->
<mvc:default-servlet-handler/>
<!--用于启用基于注解的Spring MVC功能:它会自动注册一些关键的组件,例如处理器映射器(HandlerMapping)、处理器适配器(HandlerAdapter)和数据绑定的支持等。-->
<mvc:annotation-driven/>
<!--用于配置简单的视图控制器:它将指定的URL路径映射到指定的视图名称,从而实现简单的页面跳转 -->
<mvc:view-controller path="/" view-name="index"></mvc:view-controller>
注意:上述这三个标签常常结合使用,如果我们只配置视图控制器,那么只有它所设置的路径下的资源才会被解析,控制层中的所有请求映射都无法被处理,而配置mvc的注解驱动就能很好的解决这个问题,如果只配置<mvc:default-servlet-handler/>处理静态资源,那么当前浏览器向服务器发送的所有请求都会被默认的servlet处理,那么会导致所有的控制器方法都无法被处理,而配置mvc的注解驱动就能很好的解决这个问题,因此三个标签常常结合使用
配置文件上传解析器:
<!--配置文件上传解析器,注意:该id是固定的值使用MultipartResolver来处理文件上传。它可以将上传的文件转换为MultipartFile对象,并提供了一系列的方法来获取文件的相关信息,如文件名、大小、内容等。--><bean id="multipartResolver" class="org.springframework.web.multipart.commons.CommonsMultipartResolver"></bean>
第二步:创建在XML文件中配置的控制层
package com.SSM;import org.springframework.stereotype.Controller;@Controller
public class EmployeeController {
}
第三步:创建在XML文件中的视图控制器所返回的对应的视图index.html
<!DOCTYPE html>
<html lang="en" xmlns:th="http://www.thymeleaf.org">
<head><meta charset="UTF-8"><title>index</title>
</head>
<body>
<h1>index.html</h1>
</body>
</html>
配置Spring文件:
Spring文件主要用于配置整个Spring应用程序的基本配置,它定义了应用程序中的bean、bean之间的依赖关系、AOP切面等内容。Spring配置文件可以通过XML、注解或Java代码来定义。
我们都知道只有控制层要交给spring mvc管理,其他层都交给spring管理
创建service层:
package com.SSM.service;public interface EmployeeService {
}
创建对应的实现类:
package com.SSM.service.impl;import com.SSM.service.EmployeeService;
import org.springframework.stereotype.Service;@Service
public class EmployeeServiceImpl implements EmployeeService {
}
第一步:将除了controller层的所有组件都交给spring管理
<context:component-scan base-package="com.SSM">
<!-- 通过exclude-filter排除controller层--><context:exclude-filter type="annotation" expression="org.springframework.stereotype.Controller"/>
</context:component-scan>
第二步:将数据源对象交给spring管理
<!--配置数据源 --><bean id="DruidDataSource" class="com.alibaba.druid.pool.DruidDataSource"><property name="driverClassName" value="${jdbc.driver}"></property><property name="url" value="${jdbc.url}"></property><property name="username" value="${jdbc.username}"></property><property name="password" value="${jdbc.password}"></property></bean>
第三步:创建关于数据源的properties文件
jdbc.driver=com.mysql.jdbc.Driver
jdbc.url=jdbc:mysql://localhost:3306/数据库名称?useSSL=false&useUnicode=true&characterEncoding=UTF-8
jdbc.user=root
jdbc.password=密码
第四步:将数据源的properties文件引入spring文件中
<!--properties文件默认放在resource目录下 -->
<context:property-placeholder location="classpath:jdbc.properties"></context:property-placeholder>
spring整合mybatis:
第一步:配置mybatis-config.xml文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configurationPUBLIC "-//mybatis.org//DTD Config 3.0//EN""https://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration><!--引入properties文件 --><properties resource="jdbc.properties"/><settings><!--将下划线映射成驼峰:将数据库表中下划线命名方式的列名映射成驼峰命名方式的属性名。例如,如果数据库表中有一个列名为"first_name",使用这个配置后,在映射到Java对象时,对应的属性名将变为"firstName"。这样做可以方便地在Java代码中使用驼峰命名的属性名,提高代码的可读性和可维护性--><setting name="mapUnderscoreToCamelCase" value="true"/></settings><typeAliases><package name=""/></typeAliases><environments default="development"><environment id="development"><transactionManager type="JDBC"/><dataSource type="POOLED"><property name="driver" value="${driver}"/><property name="url" value="${url}"/><property name="username" value="${username}"/><property name="password" value="${password}"/></dataSource></environment></environments><!--引入mybatis映射文件 --><mappers><mapper resource=""/></mappers>
</configuration>
第二步:创建mapper接口
package com.SSM.mapper;public interface EmployeeMapper {
}
映射文件(Mapper XML文件)需要放置在与当前接口所在的包相同的包路径下。此外,映射接口的名字也需要与Mapper接口的名字保持一致。因为MyBatis会通过动态代理的方式,根据接口的方法名来查找对应的映射语句。如果映射接口的名字与Mapper接口的名字不一致,MyBatis将无法正确找到对应的映射语句。
第三步:创建mapper接口对应的映射文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""https://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="该接口的全类名">
</mapper>
在之前的mybatis学习中,如果想对数据进行操作,我们是使用mybatis框架本身的配置文件,但由于mybatis配置文件是固定的,一般在应用启动时就加载并创建SqlSessionFactory对象,由此spring提供了使用SqlSessionFactoryBean来更好的为我们服务,SqlSessionFactoryBean它是一个工厂类,用于创建SqlSessionFactory对象,它是基于spring的配置方式,是在mybatis框架的基础上通过spring进行扩展和管理,在配置文件中通过定义bean的方式来创建,它更具有灵活性,可以通过spring的配置文件动态配置和管理SqlSessionFactory对象
具体操作为在spring配置文件中配置类型为SqlSessionFactoryBean的bean对象:
<bean class="org.mybatis.spring.SqlSessionFactoryBean"><!--设置mybatis核心配置文件的路径 --><property name="configLocation" value="classpath:mybatis-config.xml"></property><!--设置数据源 --><property name="dataSource" ref="DruidDataSource"></property></bean>
spring.xml文件和mybatis.xml文件都可以用来配置数据源,在此之前,spring.xml文件中本身就配置了数据源,我们只需要通过ref引用即可,由此在mybatis-config.xml文件中就不需要重复配置数据源了,我们可将该文件中的如下代码删除
<!--引入properties文件 -->
<properties resource="jdbc.properties"/><!--配置数据源 -->
<environments default="development"><environment id="development"><transactionManager type="JDBC"/><dataSource type="POOLED"><property name="driver" value="${driver}"/><property name="url" value="${url}"/><property name="username" value="${username}"/><property name="password" value="${password}"/></dataSource></environment></environments>
在spring配置文件中,设置类型别名所对应的包路径:
<!--设置类型别名所对应的包:可以将指定包下的所有类都注册为类型别名,然后在映射文件中可以直接使用类名来引用对应的类,而不需要写全限定名-->
<property name="typeAliasesPackage" value="com.SSM.pojo"></property>
在spring配置文件中设置映射文件的路径:
该配置并不是必需的,只有当映射文件的包和接口的包以及名字不一致时,我们才需要设置
<property name="mapperLocations" value="classpath:mapper/*.xml"></property>
在spring配置文件中配置分页插件:
<!-- 配置分页插件:用于实现数据库查询结果的分页功能-->
<property name="plugins"><array><bean class="com.github.pagehelper.PageInterceptor"></bean></array></property>
在spring配置文件中配置 MyBatis 的 Mapper 扫描器:
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer"><property name="basePackage" value="com.SSM.mapper"></property>
</bean>
在配置文件中添加该配置后,MyBatis 将会自动扫描指定包下的接口,并将其注册为 Mapper。这样,在使用 MyBatis 时,就可以直接注入这些 Mapper 接口,而不需要手动编写 Mapper 的实现类。这大大简化了 MyBatis 的配置和使用。
需要注意的是,MapperScannerConfigurer 需要和 SqlSessionFactoryBean 配合使用,确保 MyBatis 的 Mapper 扫描器能够正常工作。
配置到这里我们SSM整合的配置工作就完成啦,上述如此多的配置我们一会配置在spring配置文件中,一会配置在mybatis配置文件中,一会二者又都可以,那么该如何区分呢?
在Spring框架中,一些常见的配置必须通过Spring配置文件进行配置,常见的有:
Bean的定义和配置:Spring配置文件用于定义和配置应用程序中的Bean,包括依赖注入、作用域、初始化方法和销毁方法等。
AOP配置:Spring配置文件可以用于配置切面和通知,定义切点和切面的关系,以及配置事务管理等。
数据源配置:Spring配置文件可以配置数据源,包括数据库连接信息、连接池配置等。
MVC配置:Spring配置文件可以配置MVC相关的内容,包括视图解析器、拦截器、静态资源处理等。
在MyBatis框架中,一些常见的配置必须通过MyBatis配置文件进行配置,常见的有:
数据库连接配置:MyBatis配置文件中需要配置数据库连接的相关信息,包括数据库驱动、连接URL、用户名和密码等。
映射器配置:MyBatis配置文件中需要配置映射器(Mapper)的相关信息,包括SQL语句的映射关系、参数映射关系等。
缓存配置:MyBatis配置文件中可以配置缓存的相关信息,包括缓存类型、缓存策略等。
其他配置:MyBatis配置文件中还可以配置一些其他的属性,如全局配置、插件配置等。
除了上述必须通过Spring配置文件或MyBatis配置文件进行配置的内容外,还有一些配置可以通过两者均可配置,例如:
事务配置:可以通过Spring配置文件进行事务管理的配置,也可以通过MyBatis配置文件配置事务的相关属性。
数据库连接池配置:可以通过Spring配置文件配置数据源和连接池信息,也可以通过MyBatis配置文件配置数据库连接池的相关属性。
需要根据具体的需求和项目情况来确定使用哪种配置方式。
配置事务:
添加日志功能:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE log4j:configuration SYSTEM "log4j.dtd">
<log4j:configuration xmlns:log4j="http://jakarta.apache.org/log4j/"><appender name="STDOUT" class="org.apache.log4j.ConsoleAppender"><param name="Encoding" value="UTF-8"/><layout class="org.apache.log4j.PatternLayout"><param name="ConversionPattern" value="%-5p %d{MM-dd HH:mm:ss,SSS} %m(%F:%L) \n"/></layout></appender><logger name="java.sql"><level value="debug"/></logger><logger name="org.apache.ibatis"><level value="info"/></logger><root><level value="debug"/><appender-ref ref="STDOUT"/></root>
</log4j:configuration>
在spring.xml中添加事务管理器:
<!--配置事务管理器--><bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager"><property name="dataSource" ref="DruidDataSource"></property></bean><!--开启注解驱动->如果在tx:annotation-driven标签中,transaction-manager的属性值为transaction-manager,那么transaction-manager属性可以忽略不写,否则必须指明引用的事务管理器id将使用@Transactional注解标识的方法作为连接点通过transactionManager切面进行管理--><tx:annotation-driven transaction-manager="transactionManager"/>
实现列表功能:
创建显示列表的页面:
<!DOCTYPE html>
<html lang="en" xmlns:th="http://www.thymeleaf.org">
<head><meta charset="UTF-8"><title>员工列表</title><!--导入位于webapp目录下的外部静态资源 --><link rel="stylesheet" th:href="@{/static/css/index_work.css}">
</head>
<body>
<table><tr><th colspan="6">员工列表</th></tr><tr><th>流水号</th><th>员工姓名</th><th>年龄</th><th>性别</th><th>邮箱</th><th>操作</th></tr><!--"status"表示当前循环的状态信息。在每次循环迭代时,会执行each循环体内的代码 --><tr th:each="employee,status : ${list}"><td th:text="${status.count}"></td><td th:text="${employee.empName}"></td><td th:text="${employee.age}"></td><td th:text="${employee.gender}"></td><td th:text="${employee.email}"></td><td><a href="">删除</a><a href="">修改</a></td></tr>
</table>
</body>
</html>
首页中加入访问页面的超链接:
<a th:href="@{/employee}">查询员工的所有信息</a>
package com.atguigu.ssm.controller;import com.atguigu.ssm.pojo.Employee;
import com.atguigu.ssm.service.EmployeeService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import java.util.List;@Controller
public class EmployeeController {@Autowiredprivate EmployeeService employeeService;@RequestMapping(value = "/employee", method = RequestMethod.GET)public String getAllEmployee(Model model){List<Employee> list = employeeService.getAllEmployee();//通过model将数据共享到请求域中model.addAttribute("list", list);//跳转到employee_list.htmlreturn "employee_list";}
}
在EmployeeService中编写对应的方法:
package com.atguigu.ssm.service;import com.atguigu.ssm.pojo.Employee;
import java.util.List;public interface EmployeeService {//查询所有员工信息List<Employee> getAllEmployee();
}
实现类中实现对应的方法:
package com.atguigu.ssm.service.impl;import com.atguigu.ssm.mapper.EmployeeMapper;
import com.atguigu.ssm.pojo.Employee;
import com.atguigu.ssm.service.EmployeeService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.util.List;@Service
@Transactional
public class EmployeeServiceImpl implements EmployeeService {@Autowiredprivate EmployeeMapper employeeMapper;@Overridepublic List<Employee> getAllEmployee() {return employeeMapper.getAllEmployee();}
}
在对应的mapper接口中创建该方法:
package com.atguigu.ssm.mapper;
import com.atguigu.ssm.pojo.Employee;
import java.util.List;public interface EmployeeMapper {List<Employee> getAllEmployee();
}
在对应的mapper文件中添加查询语句:
<!--List<Employee> getAllEmployee();-->
<select id="getAllEmployee" resultType="com.atguigu.ssm.pojo.Employee">select * from employee
</select>
实现分页展示数据:
mybatis配置文件中必须包含分页插件:
<plugins><!--配置分页插件--><plugin interceptor="com.github.pagehelper.PageInterceptor"> </plugin>
</plugins>
编写分页显示数据的控制器方法:
//pageNum为当前显示第几页
@RequestMapping(value = "/employee/page/{pageNum}",method = RequestMethod.GET)public String getPageEmployee(@PathVariable("pageNum") Integer pageNum, Model model){//获取员工的分页信息PageInfo<Employee> page=employeeService.getPageEmployee(pageNum);//将分页数据共享到请求域中model.addAttribute("page",page);return "employee_list";}
在service接口中添加对应的方法:
PageInfo<Employee> getPageEmployee(Integer pageNum);
接口实现类中,实现对应的方法:
@Overridepublic PageInfo<Employee> getPageEmployee(Integer pageNum) {//开启分页功能-->每页展示4条数据PageHelper.startPage(pageNum,4);//查询所有员工信息List<Employee> list=employeeMapper.getAllEmployee();PageInfo<Employee> page=new PageInfo<Employee>(list,5);return page;}
向首页添加对应的超链接:
<a th:href="@{/employee/page/1}">查询员工的分页信息</a>
修改显示employee_list.html中的循环功能:
<!-- page为共享数据的对应,而list为分页插件中用来显示分页之后的数据-->
<tr th:each="employee,status : ${page.list}">
可通过修改地址栏的信息指定要显示哪一页的数据

增加导航栏信息:
<div style="text-align: center;"><!--if表达式的值为true,该超链接会被显示在页面上,否则不会被显示在页面上 --><!--hasPreviousPage是否有上一页,hasNextPage是否有下一页--><a th:if="${page.hasPreviousPage}" th:href="@{/employee/page/1}">首页</a><a th:if="${page.hasPreviousPage}" th:href="@{'/employee/page/'+${page.prePage}}">上一页</a><!--将当前页面的数据在导航栏显示为红色 --><span th:each="num:${page.navigatepageNums}"><a th:if="${page.pageNum==num}" style="color:red;" th:href="@{'/employee/page/'+${num}}" th:text="'['+${num}+']'"></a></span><a th:if="${page.hasNextPage}" th:href="@{'/employee/page/'+${page.nextPage}}">下一页</a><a th:if="${page.hasNextPage}" th:href="@{'/employee/page/'+${page.pages}}">末页</a>
</div>
相关文章:
SSM整合~
构建并配置项目: 第一步:创建maven项目 第二步:配置pom.xml文件 设置打包方式: 为了方便部署,我们通常情况下,将项目打包为WAR,因为WAR文件是一种可执行的压缩文件,它可以将项目…...
Self-supervised 3D Human Pose Estimation from a Single Image
基于单幅图像的自监督三维人体姿态估计 主页: https://josesosajs.github.io/ imagepose/ 源码:未开源 摘要 我们提出了一种新的自我监督的方法预测三维人体姿势从一个单一的图像。预测网络是从描绘处于典型姿势的人的未标记图像的数据集和一组未配对…...

ubuntu下cups部分场景
第一章:部分操作指令 在计算机领域中,cups 是“通用UNIX打印系统”(Common UNIX Printing System)的缩写,它是一种用于在UNIX-like操作系统上管理打印任务的开源打印系统。cups 提供了一个框架,允许用户和…...

通过geoserver imageMosic发布多张tif数据
通过geoserver imageMosic发布多张tif数据 reference: https://zhuanlan.zhihu.com/p/132388558 https://zhuanlan.zhihu.com/p/103674876 https://docs.geoserver.org/latest/en/user/tutorials/imagemosaic_timeseries/imagemosaic_timeseries.html 步骤 下载数据 http…...
输出图元(四)8-2 OpenGL画点函数、OpenGL画线函数
4.3 OpenGL画点函数 要描述一个点的几何要素,我们只需在世界坐标系中指定一个位置。然后该坐标位置和场景中已有的其他几何描述一起被传递给观察子程序。除非指定其他属性值,OpenGL 图元按默认的大小和颜色来显示。默认的图元颜色是白色&#x…...

java八股文
6. 如何保证消息的可靠性? 在RabbitMq的整个消息投递过程中,有三种情况下,会存在消息丢失的问题: 6. RabbitMq如何保证消息的可靠性? 所以从这三个维度保证消息的可靠性去可靠性传递就可以了,从生产者发送…...

算法通关村——解析堆的应用
在数组中找第K大的元素 LeetCode21 Medium 我们要找第 K 大的元素,如果我们找使用大堆的话那么就会造成这个堆到底需要多大的,而且哪一个是第 K 的的元素我们不知道是哪一个索引,我们更想要的结果就是根节点就是我们要找的值,所以…...

爬虫源码---爬取小猫猫交易网站
前言: 本片文章主要对爬虫爬取网页数据来进行一个简单的解答,对与其中的数据来进行一个爬取。 一:环境配置 Python版本:3.7.3 IDE:PyCharm 所需库:requests ,parsel 二:网站页面 我们需要…...

Python的由来和基础语法(一)
目录 一、Python 背景知识 1.1Python 是咋来的? 1.2Python 都能干啥? 1.3Python 的优缺点 二、基础语法 2.1常量和表达式 2.2变量和类型 变量的语法 (1) 定义变量 (2) 使用变量 变量的类型 (1) 整数 (2) 浮点数(小数) (3) 字符串 (4) 布尔 (5) 其他 动态类型…...
使用maven创建springboot项目
创建maven快速启动项目 命令行或者idea、eclipse快捷创建也可以 pom.xml下project项目下导入springboot 父工程 <!--导入springboot 父工程--> <parent><artifactId>spring-boot-starter-parent</artifactId><groupId>org.springframework.bo…...

MySQL 基本操作1
目录 Create insert 插入跟新 1 插入跟新 2 Retrive select where 子句查询 1.查找数学成绩小于 80 的同学。 2.查询数学成绩等于90分的同学。 3.查询总分大于240 的学生 4.查询空值或者非空值 5.查询语文成绩在70~80之间的同学 6.查询英语成绩是99 和 93 和 19 和…...
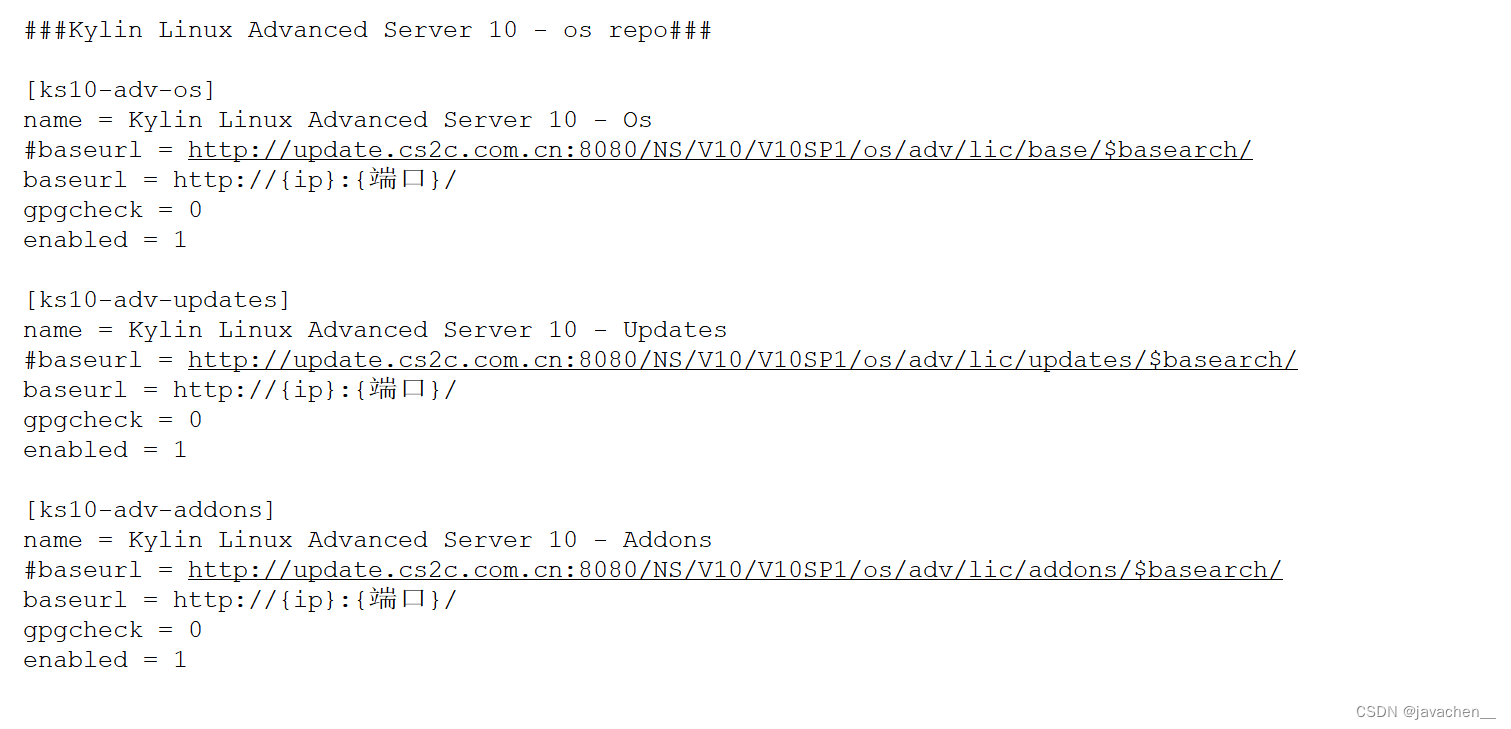
linux内网yum源服务器搭建
1.nginx: location / {root /usr/local/Kylin-Server-V10-SP3-General-Release-2303-X86_64;autoindex on;autoindex_localtime on;autoindex_exact_size off; } 注:指定到镜像的包名 2.修改yum源地址 cd /etc/yum.repos.d/vim kylin_x86_64.repo 注: --enabled设置为1 3.重…...
机器学习与数据分析
【数据清洗】 异常检测 孤立森林(Isolation Forest)从原理到实践 效果评估:F-score 【1】 保护隐私的时间序列异常检测架构 概率后缀树 PST – (异常检测) 【1】 UEBA架构设计之路5: 概率后缀树模型 【…...
项目总结知识点记录-文件上传下载(三)
(1)文件上传 代码: RequestMapping(value "doUpload", method RequestMethod.POST)public String doUpload(ModelAttribute BookHelper bookHelper, Model model, HttpSession session) throws IllegalStateException, IOExcepti…...

基于LinuxC语言实现的TCP多线程/进程服务器
多进程并发服务器 设计流程 框架一(使用信号回收僵尸进程) void handler(int sig) {while(waitpid(-1, NULL, WNOHANG) > 0); }int main() {//回收僵尸进程siganl(17, handler);//创建服务器监听套接字 serverserver socket();//给服务器地址信息…...

浅谈JVM垃圾回收机制
一、HotSpot VM中的GC分为两大类 1.部分收集(Partial GC): 新生代收集(Minor GC/Young GC):只对新生代进行垃圾收集老年代收集(Major GC/Old GC):只队老年代进行垃圾收集混合收集(Mixed GC):对整个新生代和老年代进行垃圾收集 2.整堆收集(Full GC) 收集整个Java堆和方法区 …...
【80天学习完《深入理解计算机系统》】第十二天3.6数组和结构体
专注 效率 记忆 预习 笔记 复习 做题 欢迎观看我的博客,如有问题交流,欢迎评论区留言,一定尽快回复!(大家可以去看我的专栏,是所有文章的目录) 文章字体风格: 红色文字表示&#…...
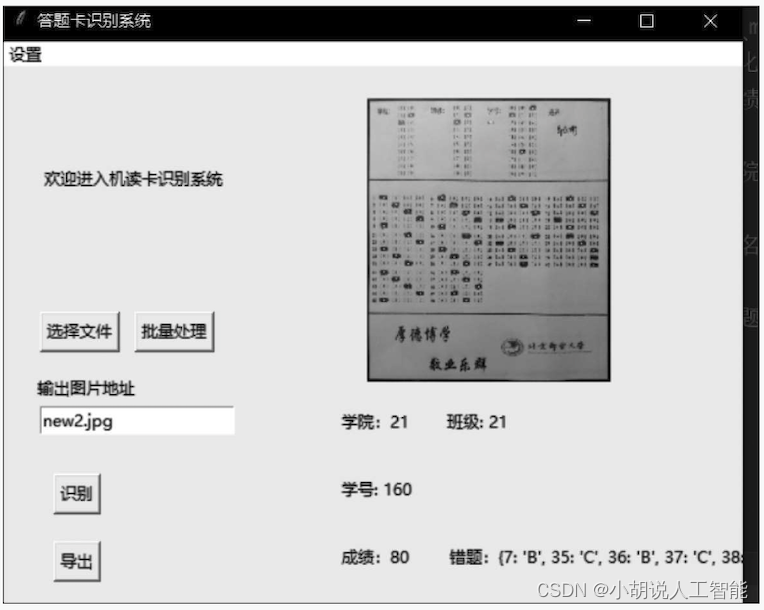
基于Python+OpenCV智能答题卡识别系统——深度学习和图像识别算法应用(含Python全部工程源码)+训练与测试数据集
目录 前言总体设计系统整体结构图系统流程图 运行环境Python 环境PyCharm安装OpenCV环境 模块实现1. 信息识别2. Excel导出模块3. 图形用户界面模块4. 手写识别模块 系统测试1. 系统识别准确率2. 系统识别应用 工程源代码下载其它资料下载 前言 本项目基于Python和OpenCV图像处…...
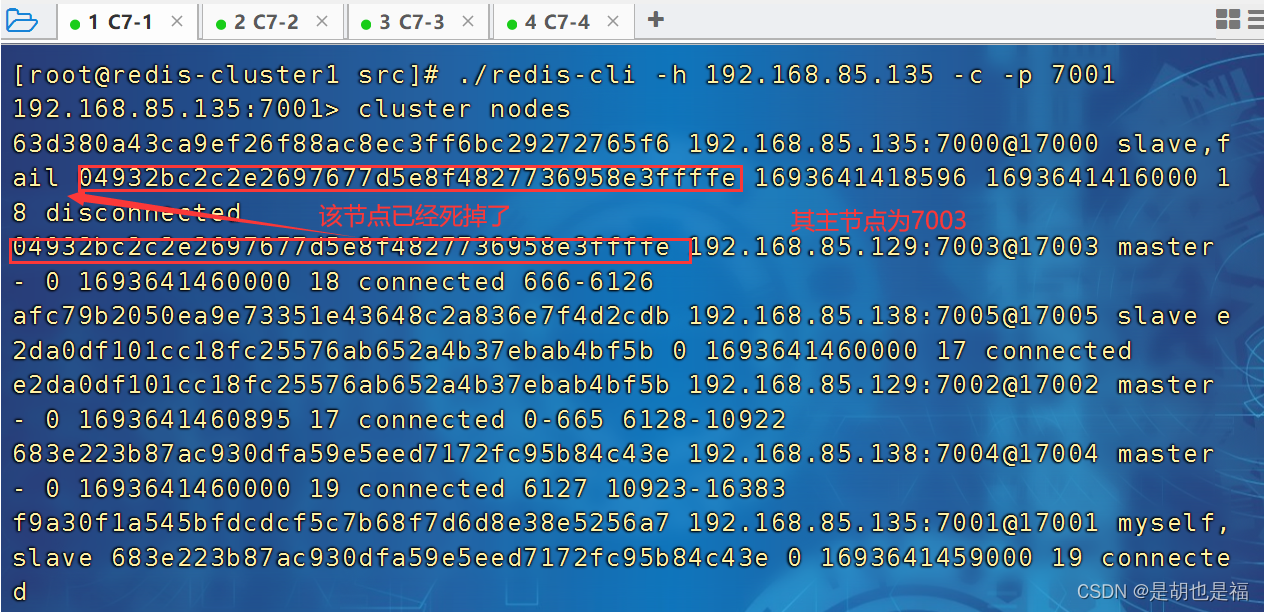
Redis集群操作-----主从互换
一、将节点cluster1的主节点7000端口的redis关掉 [rootredis-cluster1 src]# ps -ef |grep redis 二、查看集群信息:...

肖sir __linux命令拓展__05
linux命令拓展 1.追加内容到某文件 echo “i like learn linux” >>quzhi.txt 2.删除指定的空目录: rmdir 目录名 rmdir -p 目录名 (删除指定的空目录及其内子空目录) 3.显示zip包信息 zipinfo 压缩包名 (显示压缩包内的文…...

Go UUID终极指南:为什么选择go.uuid而非标准库的5大理由
Go UUID终极指南:为什么选择go.uuid而非标准库的5大理由 【免费下载链接】go.uuid UUID package for Go 项目地址: https://gitcode.com/gh_mirrors/go/go.uuid 在Go语言开发中,生成全局唯一标识符(UUID)是常见的需求。虽然…...

Node.js后端集成GTE-Base-ZH:构建语义化API服务实战
Node.js后端集成GTE-Base-ZH:构建语义化API服务实战 最近在做一个智能文档检索项目,需要处理大量中文文本的语义相似度计算。一开始尝试用传统的TF-IDF,效果总是不尽如人意,直到接触到了GTE-Base-ZH这个专门针对中文优化的文本嵌…...

告别996!用Google Antigravity的Agent-First模式,5分钟搞定React Native与Android原生桥接模块
告别996!用Google Antigravity的Agent-First模式,5分钟搞定React Native与Android原生桥接模块 如果你是一位长期奋战在Android与React Native混合开发一线的工程师,一定对"桥接模块"这个词汇又爱又恨。每当产品经理提出"我们…...
)
用Python和MATLAB/Simulink复现车辆二自由度模型:从理论公式到仿真验证(附代码)
从理论到实践:Python与MATLAB/Simulink实现车辆二自由度动力学仿真 在自动驾驶和车辆工程领域,理解车辆动力学模型是开发先进控制算法的基础。二自由度模型作为最简单的车辆动力学模型之一,能够有效描述车辆的侧向和横摆运动特性。本文将带您…...
)
别再重复积分了!手把手教你用IMU预积分优化LIO-SAM(附代码避坑点)
激光SLAM实战:IMU预积分在LIO-SAM中的高效实现与调优指南 当你在深夜调试LIO-SAM时,是否曾被重复积分导致的性能瓶颈折磨得抓狂?IMU预积分技术正是解决这一痛点的银弹。不同于传统惯性积分对初始状态的强依赖,预积分将相对运动量…...

Phi-4-reasoning-vision-15B高算力适配:双GPU显存占用监控与低并发稳定性验证
Phi-4-reasoning-vision-15B高算力适配:双GPU显存占用监控与低并发稳定性验证 1. 模型概述与技术背景 Phi-4-reasoning-vision-15B是微软推出的视觉多模态推理模型,专为复杂视觉理解任务设计。作为2026年发布的重要模型,它在图像理解、文档…...

3大颠覆:Umi-OCR如何重新定义离线文字识别体验?
3大颠覆:Umi-OCR如何重新定义离线文字识别体验? 【免费下载链接】Umi-OCR Umi-OCR: 这是一个免费、开源、可批量处理的离线OCR软件,适用于Windows系统,支持截图OCR、批量OCR、二维码识别等功能。 项目地址: https://gitcode.com…...

告别手动重标:基于Python脚本的Labelme数据集增强与JSON同步更新实战
1. 为什么我们需要自动化处理Labelme标注数据 做计算机视觉项目的朋友都知道,数据标注是个体力活。特别是使用Labelme这类工具进行语义分割标注时,每张图片都要手动勾勒物体轮廓,工作量巨大。更让人头疼的是,当我们对原始图片进行…...
)
ESP8266 AT指令实战:用NodeMCU连接WiFi并发送HTTP请求(2023最新版)
ESP8266 AT指令实战:用NodeMCU连接WiFi并发送HTTP请求(2023最新版) 当你拿起一块NodeMCU开发板时,它可能看起来只是块普通的电路板,但内置的ESP8266芯片让它成为了物联网开发的瑞士军刀。不同于Arduino需要额外WiFi模块…...
)
Debian GNU/Linux12高效运维指南(网络配置、远程管理、软件更新与安全防护)
1. Debian GNU/Linux12网络配置实战 刚接触Debian GNU/Linux12的朋友们,网络配置可能是你们遇到的第一个挑战。别担心,我会用最直白的方式带你们搞定这个环节。网络配置就像给新房子拉网线,得先把基础线路接好,后续的上网、远程控…...