NLP(六十七)BERT模型训练后动态量化(PTDQ)
本文将会介绍BERT模型训练后动态量化(Post Training Dynamic Quantization,PTDQ)。
量化
在深度学习中,量化(Quantization)指的是使用更少的bit来存储原本以浮点数存储的tensor,以及使用更少的bit来完成原本以浮点数完成的计算。这么做的好处主要有如下几点:
- 更少的模型体积,接近4倍的减少
- 可以更快地计算,由于更少的内存访问和更快的int8计算,可以快2~4倍
PyTorch中的模型参数默认以FP32精度储存。对于量化后的模型,其部分或者全部的tensor操作会使用int类型来计算,而不是使用量化之前的float类型。当然,量化还需要底层硬件支持,x86 CPU(支持AVX2)、ARM CPU、Google TPU、Nvidia Volta/Turing/Ampere、Qualcomm DSP这些主流硬件都对量化提供了支持。

PTDQ
PyTorch对量化的支持目前有如下三种方式:
- Post Training Dynamic Quantization:模型训练完毕后的动态量化
- Post Training Static Quantization:模型训练完毕后的静态量化
- QAT (Quantization Aware Training):模型训练中开启量化
本文仅介绍Post Training Dynamic Quantization(PTDQ)。
对训练后的模型权重执行动态量化,将浮点模型转换为动态量化模型,仅对模型权重进行量化,偏置不会量化。默认情况下,仅对Linear和RNN变体量化 (因为这些layer的参数量很大,收益更高)。
torch.quantization.quantize_dynamic(model, qconfig_spec=None, dtype=torch.qint8, mapping=None, inplace=False)
参数解释:
- model:模型(默认为FP32)
- qconfig_spec:
- 集合:比如: qconfig_spec={nn.LSTM, nn.Linear} 。列出要量化的神经网络模块。
- 字典: qconfig_spec = {nn.Linear: default_dynamic_qconfig, nn.LSTM: default_dynamic_qconfig}
- dtype: float16 或 qint8
- mapping:就地执行模型转换,原始模块发生变异
- inplace:将子模块的类型映射到需要替换子模块的相应动态量化版本的类型
例子:
# -*- coding: utf-8 -*-
# 动态量化模型,只量化权重
import torch
from torch import nnclass DemoModel(torch.nn.Module):def __init__(self):super(DemoModel, self).__init__()self.conv = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=1)self.relu = nn.ReLU()self.fc = torch.nn.Linear(2, 2)def forward(self, x):x = self.conv(x)x = self.relu(x)x = self.fc(x)return xif __name__ == "__main__":model_fp32 = DemoModel()# 创建一个量化的模型实例model_int8 = torch.quantization.quantize_dynamic(model=model_fp32, # 原始模型qconfig_spec={torch.nn.Linear}, # 要动态量化的算子dtype=torch.qint8) # 将权重量化为:qint8print(model_fp32)print(model_int8)# 运行模型input_fp32 = torch.randn(1, 1, 2, 2)output_fp32 = model_fp32(input_fp32)print(output_fp32)output_int8 = model_int8(input_fp32)print(output_int8)输出结果如下:
DemoModel((conv): Conv2d(1, 1, kernel_size=(1, 1), stride=(1, 1))(relu): ReLU()(fc): Linear(in_features=2, out_features=2, bias=True)
)
DemoModel((conv): Conv2d(1, 1, kernel_size=(1, 1), stride=(1, 1))(relu): ReLU()(fc): DynamicQuantizedLinear(in_features=2, out_features=2, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
)
tensor([[[[0.3120, 0.3042],[0.3120, 0.3042]]]], grad_fn=<AddBackward0>)
tensor([[[[0.3120, 0.3042],[0.3120, 0.3042]]]])
模型量化策略
当前,由于量化算子的覆盖有限,因此,对于不同的深度学习模型,其量化策略不同,见下表:
| 模型 | 量化策略 | 原因 |
|---|---|---|
| LSTM/RNN | Dynamic Quantization | 模型吞吐量由权重的计算/内存带宽决定 |
| BERT/Transformer | Dynamic Quantization | 模型吞吐量由权重的计算/内存带宽决定 |
| CNN | Static Quantization | 模型吞吐量由激活函数的内存带宽决定 |
| CNN | Quantization Aware Training | 模型准确率不能由Static Quantization获取的情况 |
下面对BERT模型进行训练后动态量化,分析模型在量化前后,推理效果和推理性能的变化。
实验
我们使用的训练后的模型为中文文本分类模型,其训练过程可以参考文章:NLP(六十六)使用HuggingFace中的Trainer进行BERT模型微调 。
训练后的BERT模型动态量化实验的设置如下:
- base model: bert-base-chinese
- CPU info: x86-64, Intel® Core™ i5-10210U CPU @ 1.60GHz
- batch size: 1
- thread: 1
具体的实验过程如下:
- 加载模型及tokenizer
import torch
from transformers import AutoModelForSequenceClassificationMAX_LENGTH = 128
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
checkpoint = f"./sougou_test_trainer_{MAX_LENGTH}/checkpoint-96"
model = AutoModelForSequenceClassification.from_pretrained(checkpoint).to(device)
from transformers import AutoTokenizer, DataCollatorWithPaddingtokenizer = AutoTokenizer.from_pretrained(checkpoint)
- 测试数据集
import pandas as pdtest_df = pd.read_csv("./data/sougou/test.csv")test_df.head()
| text | label | |
|---|---|---|
| 0 | 届数比赛时间比赛地点参加国家和地区冠军亚军决赛成绩第一届1956-1957英国11美国丹麦6... | 0 |
| 1 | 商品属性材质软橡胶带加浮雕工艺+合金彩色队徽吊牌规格162mm数量这一系列产品不限量发行图案... | 0 |
| 2 | 今天下午,沈阳金德和长春亚泰队将在五里河相遇。在这两支球队中沈阳籍球员居多,因此这场比赛实际... | 0 |
| 3 | 本报讯中国足协准备好了与特鲁西埃谈判的合同文本,也在北京给他预订好了房间,但特鲁西埃爽约了!... | 0 |
| 4 | 网友点击发表评论祝贺中国队夺得五连冠搜狐体育讯北京时间5月6日,2006年尤伯杯羽毛球赛在日... | 0 |
- 量化前模型的推理时间及评估指标
import numpy as np
import times_time = time.time()
true_labels, pred_labels = [], []
for i, row in test_df.iterrows():row_s_time = time.time()true_labels.append(row["label"])encoded_text = tokenizer(row['text'], max_length=MAX_LENGTH, truncation=True, padding=True, return_tensors='pt').to(device)# print(encoded_text)logits = model(**encoded_text)label_id = np.argmax(logits[0].detach().cpu().numpy(), axis=1)[0]pred_labels.append(label_id)print(i, (time.time() - row_s_time)*1000, label_id)print("avg time: ", (time.time() - s_time) * 1000 / test_df.shape[0])
0 229.3872833251953 0
100 362.0314598083496 1
200 311.16747856140137 2
300 324.13792610168457 3
400 406.9099426269531 4
avg time: 352.44047810332944
from sklearn.metrics import classification_reportprint(classification_report(true_labels, pred_labels, digits=4))
precision recall f1-score support0 0.9900 1.0000 0.9950 991 0.9691 0.9495 0.9592 992 0.9900 1.0000 0.9950 993 0.9320 0.9697 0.9505 994 0.9895 0.9495 0.9691 99accuracy 0.9737 495macro avg 0.9741 0.9737 0.9737 495
weighted avg 0.9741 0.9737 0.9737 495
- 设置量化后端
# 模型量化
cpu_device = torch.device("cpu")
torch.backends.quantized.supported_engines
['none', 'onednn', 'x86', 'fbgemm']
torch.backends.quantized.engine = 'x86'
- 量化后模型的推理时间及评估指标
# 8-bit 量化
quantized_model = torch.quantization.quantize_dynamic(model, {torch.nn.Linear}, dtype=torch.qint8
).to(cpu_device)
q_s_time = time.time()
q_true_labels, q_pred_labels = [], [] for i, row in test_df.iterrows():row_s_time = time.time()q_true_labels.append(row["label"])encoded_text = tokenizer(row['text'], max_length=MAX_LENGTH, truncation=True, padding=True, return_tensors='pt').to(cpu_device)logits = quantized_model(**encoded_text)label_id = np.argmax(logits[0].detach().numpy(), axis=1)[0]q_pred_labels.append(label_id)print(i, (time.time() - row_s_time) * 1000, label_id)print("avg time: ", (time.time() - q_s_time) * 1000 / test_df.shape[0])
0 195.47462463378906 0
100 247.33805656433105 1
200 219.41304206848145 2
300 206.44831657409668 3
400 187.4992847442627 4
avg time: 217.63229466447928
from sklearn.metrics import classification_reportprint(classification_report(q_true_labels, q_pred_labels, digits=4))
precision recall f1-score support0 0.9900 1.0000 0.9950 991 0.9688 0.9394 0.9538 992 0.9900 1.0000 0.9950 993 0.9320 0.9697 0.9505 994 0.9896 0.9596 0.9744 99accuracy 0.9737 495macro avg 0.9741 0.9737 0.9737 495
weighted avg 0.9741 0.9737 0.9737 495
- 量化前后模型大小对比
import osdef print_size_of_model(model):torch.save(model.state_dict(), "temp.p")print("Size (MB): ", os.path.getsize("temp.p")/1e6)os.remove("temp.p")print_size_of_model(model)
print_size_of_model(quantized_model)
Size (MB): 409.155273
Size (MB): 152.627621
量化后端(Quantization backend)取决于CPU架构,不同计算机的CPU架构不同,因此,默认的动态量化不一定在所有的CPU上都能生效,需根据自己计算机的CPU架构设置好对应的量化后端。另外,不同的量化后端也有些许差异。Linux服务器使用uname -a可查看CPU信息。
重复上述实验过程,以模型的最大输入长度为变量,取值为128,256,384,每种情况各做3次实验,结果如下:
| 实验 | 最大长度 | 量化前平均推理时间(ms) | 量化前weighted F1值 | 量化前平均推理时间(ms) | 量化前weighted F1值 |
|---|---|---|---|---|---|
| 实验1 | 384 | 1066 | 0.9797 | 686 | 0.9838 |
| 实验2 | 384 | 1047.6 | 0.9899 | 738.1 | 0.9879 |
| 实验3 | 384 | 1020.9 | 0.9817 | 714.0 | 0.9838 |
| 实验1 | 256 | 668.7 | 0.9717 | 431.4 | 0.9718 |
| 实验2 | 256 | 675.1 | 0.9717 | 449.9 | 0.9718 |
| 实验3 | 256 | 656.0 | 0.9717 | 446.5 | 0.9718 |
| 实验1 | 128 | 335.8 | 0.9737 | 200.5 | 0.9737 |
| 实验2 | 128 | 336.5 | 0.9737 | 227.2 | 0.9737 |
| 实验3 | 128 | 352.4 | 0.9737 | 217.6 | 0.9737 |
综上所述,对于训练后的BERT模型(文本分类模型)进行动态量化,其结论如下:
- 模型推理效果:量化前后基本相同,量化后略有下降
- 模型推理时间:量化后平均提速约1.52倍
总结
本文介绍了量化基本概念,PyTorch模型量化方式,以及对BERT模型训练后进行动态量化后在推理效果和推理性能上的实验。
本文项目已开源至Github项目:https://github.com/percent4/dynamic_quantization_on_bert 。
本人已开通个人博客网站,网址为:https://percent4.github.io/ ,欢迎大家访问~
相关文章:
NLP(六十七)BERT模型训练后动态量化(PTDQ)
本文将会介绍BERT模型训练后动态量化(Post Training Dynamic Quantization,PTDQ)。 量化 在深度学习中,量化(Quantization)指的是使用更少的bit来存储原本以浮点数存储的tensor,以及使用更少的…...
机器学习和数据挖掘04-PowerTransformer与 MinMaxScaler
概念 PowerTransformer(幂变换器) PowerTransformer 是用于对数据进行幂变换(也称为Box-Cox变换)的预处理工具。幂变换可以使数据更接近正态分布,这有助于某些机器学习算法的性能提升。它支持两种常用的幂变换&#x…...
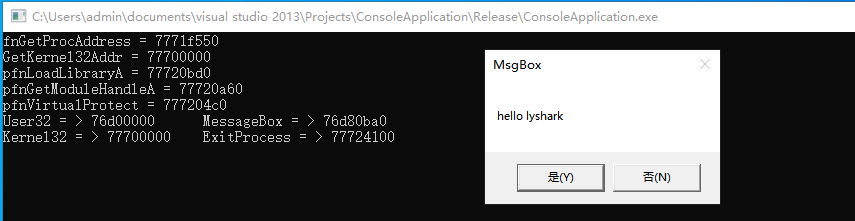
1.15 自实现GetProcAddress
在正常情况下,要想使用GetProcAddress函数,需要首先调用LoadLibraryA函数获取到kernel32.dll动态链接库的内存地址,接着在调用GetProcAddress函数时传入模块基址以及模块中函数名即可动态获取到特定函数的内存地址,但在有时这个函…...

总结ADX指标交易的好处
股神巴菲特从一个穷小子变成世界富豪,而闻名世界。anzo capital昂首资本以为这辈子再也不会和巴菲特产生任何交集,直到我看了巴菲特的发家史,才发现原来我们都使用过ADX指标盈利过,下面anzo capital昂首资本就总结一下使用ADX指…...
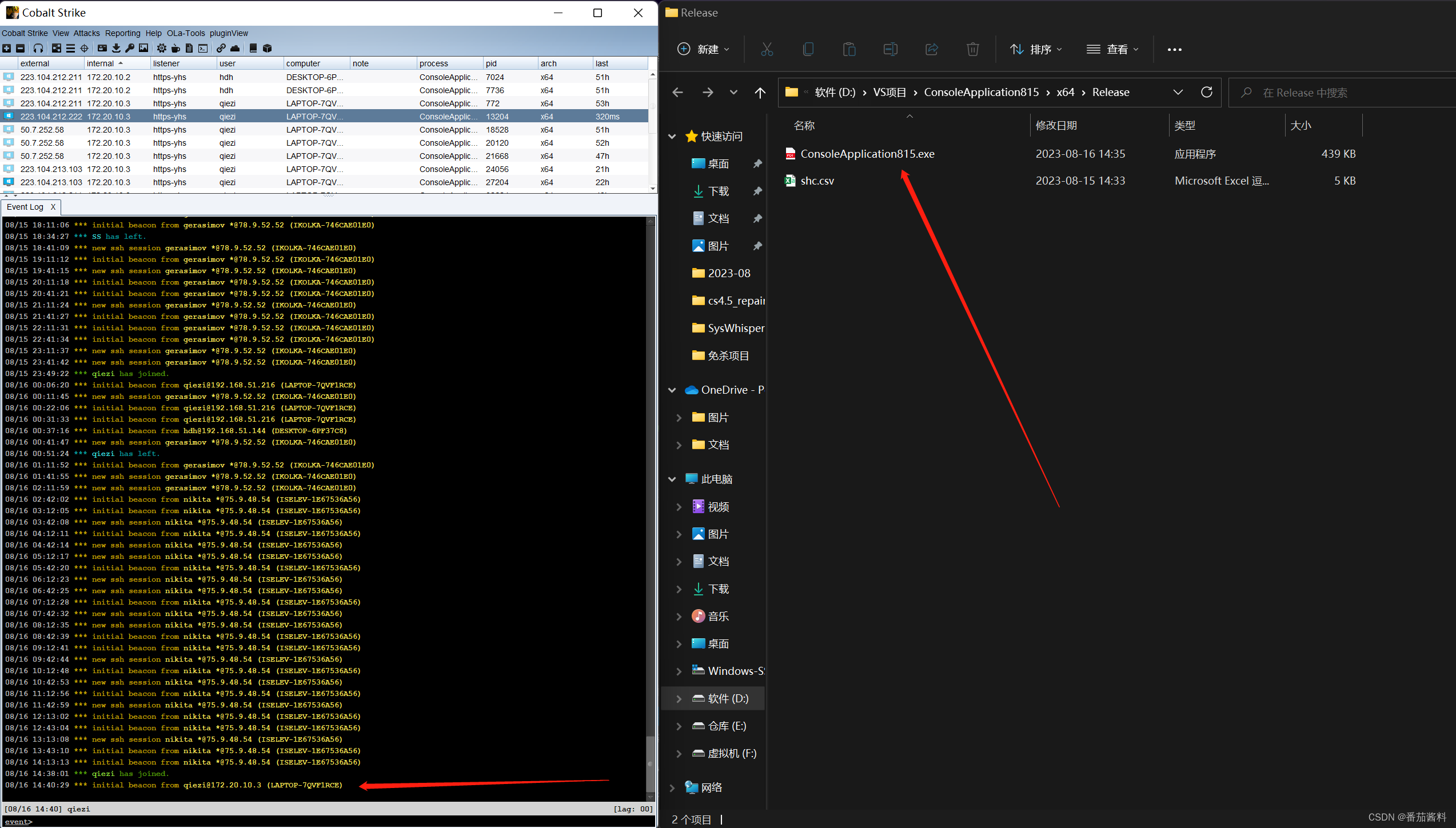
ConsoleApplication815项目(直接加载+VEH Hook Load)
上线图 ConsoleApplication815.cpp #include <iostream> #include<Windows.h> #include "detours.h" #include "detver.h" #pragma comment(lib,"detours.lib")#pragma warning(disable:4996)LPVOID Beacon_address; SIZE_T Beacon…...

事务(SQL)
事务概述 事务是一组操作的集合,他是一个不可分割的工作单位,事务会把所有的操作作为一个整体一起向西永提交或撤销操作请求。这组操作,要么全部执行成功,要么全部执行失败。 事务操作 查看/设置事务提交方式 -- 查看/设置事务…...
)
原型,原型链,继承(圣杯模式)
经典模式和圣杯模式区别 经典模式和圣杯模式都是用于解决构造函数继承和原型继承的问题,但它们在实现继承的方式上有所不同。 经典模式是通过将子类的原型对象设置为父类的实例来实现继承,然后将子类的构造函数设置为子类本身。这样子类既可以继承父类…...

远程方法调用中间件Dubbo在spring项目中的使用
Dubbo是一个分布式服务框架,它可以帮助我们快速开发和提供高性能、高可靠性的分布式服务,同时提供服务治理、容错、负载均衡等功能。 使用Dubbo可以分为以下步骤: 引入Dubbo依赖:在项目的pom.xml文件中引入Dubbo的依赖。编写服务…...

MFC -- Date Time Picker 控件使用
当前环境:VS2015 Windows 10 //(一)使用普通函数, 获取当前时间CString strCurrentTime; COleDateTime m_time COleDateTime::GetCurrentTime(); strCurrentTime m_time.Format(_T("%Y-%m-%d %H:%M:%S")); SetDlgIt…...
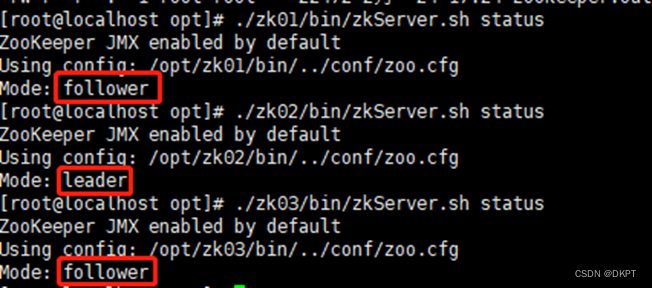
zookeeper 集群
zookeeper 集群 1、zookeeper 集群说明 initLimit 是Zookeeper用它来限定集群中的Zookeeper服务器连接到Leader的时限 syncLimit 限制了follower服务器与leader服务器之间请求和应答之间的时限 服务器名称与地址:集群信息(服务器编号,服务器…...

stable diffusion实践操作-随机种子seed
系列文章目录 stable diffusion实践操作 文章目录 系列文章目录前言一、seed是什么?二、使用步骤1.多批次随机生成多张图片2.提取图片seed3. 根据seed 再次培养4 seed使用4.1 复原别人图4.1 轻微修改4.2 固定某个人物-修改背景 三、差异随机种子1. webUI位置2. 什么…...
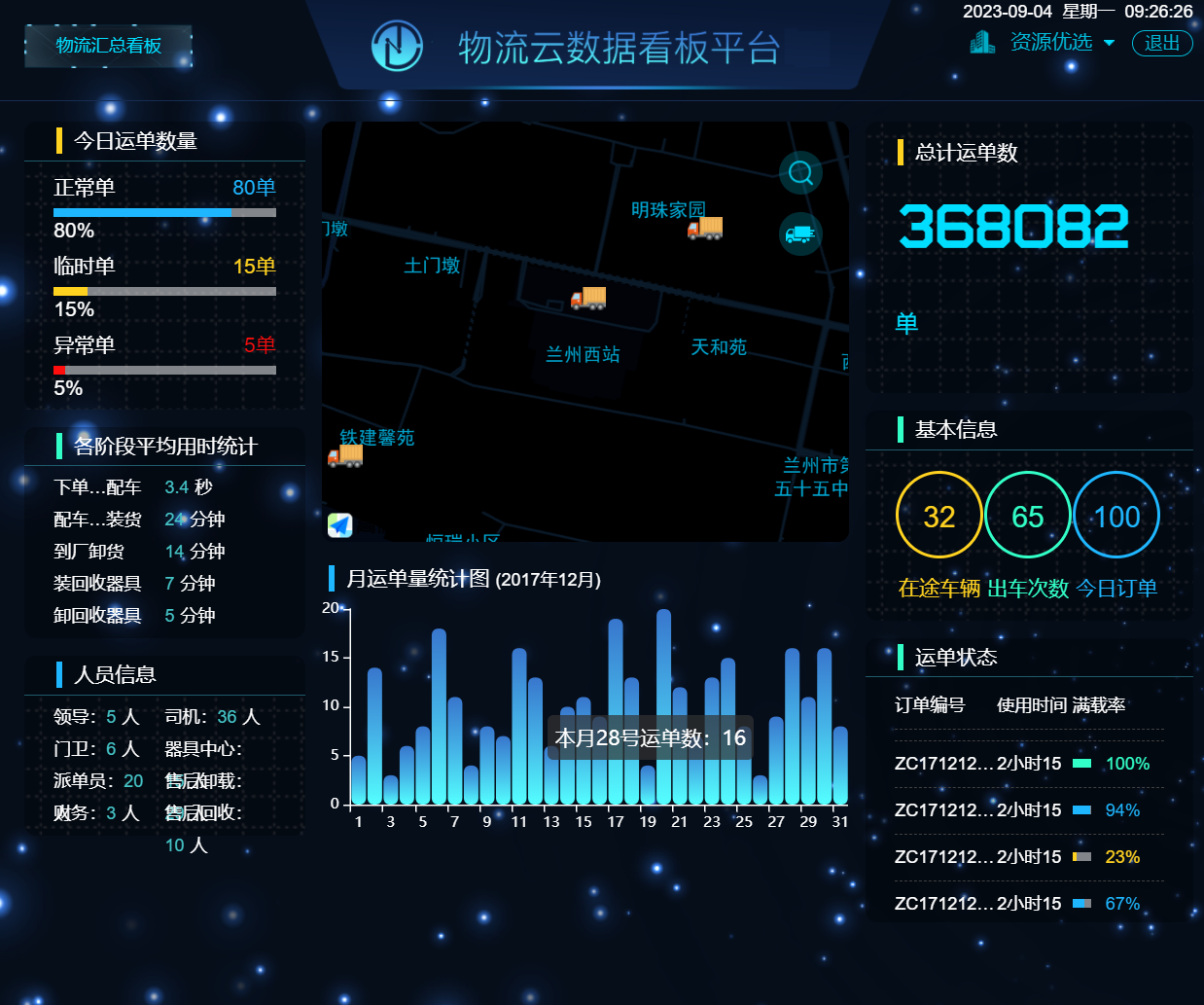
大数据可视化大屏实战项目(4)物流数据云看台(包括动态登陆页面)—HTML+CSS+JS【源码在文末】(可用于比赛项目或者作业参考中)
大数据可视化大屏实战项目(4)物流数据云看台(包括动态登陆页面)—HTMLCSSJS【源码在文末】(可用于比赛项目或者作业参考中🐕🐕🐕) 一,项目概览 ☞☞☞☞☞☞…...

在ubuntu下远程链接仓库gitte/github
后期适当加点图片,提高可读性。 本教程是最基础的连接教程,设计git的操作也仅仅局限于push/pull,如果想全面了解,可以参考廖雪峰git教程 在Ubuntu上初始化本地Git仓库并链接到远程Gitee仓库(github同理),需要按照以下步…...
一些自己整理的工具实用参数
工具实用参数 sqlmap -u: 指定需要测试的目标URL(格式:http://www.example.com/test.php?id1) --cookie: 设置需要发送的 HTTP Cookie,例如:--cookie"sid123456;PHPSESSID654321" --threads:…...

C# Timer定时器
C# Timer定时器 Timer定时器定时器主要用到的就是Timer的Tick事件,另外还要设置时间间隔: 下面这个实力演示了每隔一秒,picturebox中的图片来回切换,每隔一秒,文本框中显示当前时间。 using System; using System.Co…...

oracle怎么删除表索引
Oracle是目前常用的企业级关系型数据库管理系统,用于存储和管理大量数据。在Oracle中,表索引是用于提高查询效率的重要组成部分,但也有时候需要删除表索引。本文将介绍如何在Oracle中删除表索引。 一、查看表索引 在删除表索引之前ÿ…...

【Tkinter系列13/15】标准化外观和选项数据库
27. 标准化外观和选项数据库 可以轻松地将颜色、字体和其他选项应用于 小部件,当您创建它们时。然而 如果您希望很多小部件具有相同的 背景颜色或字体,指定每个都很乏味 每次选项,以及 让用户覆盖您的选择是很好的 他们最喜欢的配色方案、字…...
springboot 集成dubbo
上一篇我们一起认识了Dubbo与RPC,今天我们就来一起学习如何使用Dubbo,并将Dubbo集成到Spring Boot的项目中。我们来看下今天要使用到的软件及版本: 软件 版本 说明 Java 11 Spring Boot 2.7.13 Spring Boot 3.0版本开始,最…...

基于YOLOV8模型和CCPD数据集的车牌目标检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要:基于YOLOV8模型和CCPD数据集的车牌目标检测系统可用于日常生活中检测与定位车牌目标,利用深度学习算法可实现图片、视频、摄像头等方式的目标检测,另外本系统还支持图片、视频等格式的结果可视化与结果导出。本系统采用YOLOv8目标检测算…...

net user安全隐患
net user test 123456 /add #添加一个test账户,密码是123456net user test /delete #删除test账户windows administrator权限下删除其他账户,难道不需要知道该账户的密码吗? 以前没太注意,但是这算不算是一个漏洞呢? 另外&#…...

从Nautilus案看专利权利要求撰写:如何避免模糊性陷阱
1. 专利权利要求“模糊性”的边界:从Nautilus案看撰写核心 在科技行业,尤其是半导体、硬件和软件开发领域,专利是保护创新、构筑商业壁垒的生命线。但你是否想过,你或你的公司赖以生存的那份专利文件,其核心——权利要…...

告别MQTT!用Python Socket自建轻量数据通道,ESP32直连MySQL并更新网页状态
告别MQTT!用Python Socket自建轻量数据通道,ESP32直连MySQL并更新网页状态 在物联网项目开发中,MQTT协议因其轻量级和发布-订阅模式而广受欢迎。然而,当我们需要更精细地控制数据传输流程、减少中间件依赖或优化资源使用时&#x…...

RANSAC算法调参指南:迭代次数和容差阈值到底怎么设?附Python/Matlab实例
RANSAC算法实战调参手册:从理论到代码的深度解析 在三维重建、自动驾驶和工业检测等机器视觉应用中,数据噪声和异常值一直是模型拟合的噩梦。传统最小二乘法就像一位过分认真的学生,试图让所有数据点都满意,结果却被少数离群点带偏…...

QFN封装芯片手工焊接实战:从焊盘处理到拖焊技巧
1. QFN封装芯片手工焊接前的准备工作 QFN(Quad Flat No-lead)封装芯片因其体积小、散热好、电气性能优异等特点,在现代电子设备中越来越常见。但0.5mm甚至更小的引脚间距,让很多工程师和DIY爱好者在手工焊接时望而却步。其实只要掌…...
2025_NIPS_Unveiling Induction Heads: Provable Training Dynamics and Feature Learning in Transformers
文章核心内容与创新点总结 核心内容 本文聚焦Transformer在n元马尔可夫链数据上的上下文学习(ICL)机制,通过分析含相对位置嵌入、多头softmax注意力和归一化前馈网络的双层Transformer训练动态,证明梯度流会收敛到实现“广义归纳头”(GIH)机制的极限模型。该模型中,第…...

Gemini3.1Pro解决新媒体小编选题难痛点
做新媒体的小编,最怕的不是写,而是“今天写什么”。 选题总是来得很急,热点总是变化很快,账号又要求持续更新,结果就是:内容压力大、时间不够用、框架搭不出来。如果你每天都在追热点、找角度、写标题、搭结…...

跨设备代码同步工具cursor-sync:设计原理与工程实践指南
1. 项目概述:一个为开发者设计的代码同步工具如果你和我一样,经常在多个设备上切换着写代码——比如在公司用台式机,回家用笔记本,甚至偶尔在平板上改几行——那你一定对“代码同步”这个痛点深有体会。手动复制粘贴、用U盘倒腾、…...

维他动力获5亿Pre-A轮启动人形研发;优必选与日立达成合作人形机器人赋能制造; 前小米高管创业工业通用具身大脑小雨智造获B+轮融资
1. 维他动力获5亿Pre-A轮启动人形研发牛喀网获悉,Vbot维他动力正式完成近5亿元Pre-A轮融资,创下当前消费级具身智能领域的最大单笔融资纪录,本轮由东方嘉富、华泰紫金、复星锐正联合领投,上汽旗下尚颀资本等机构参投。技术层面&am…...

2018自动化测试核心价值与行业挑战解析
1. 2018自动化测试的核心价值与行业挑战在2018年这个技术转折点上,自动化测试已经从可选方案变成了工程团队的生存必需。作为经历过这个阶段的测试架构师,我亲眼见证了当时几个关键行业变化:5G标准竞赛进入白热化阶段、自动驾驶汽车传感器技术…...

联邦学习与RAG融合:构建隐私保护的跨机构智能检索系统
1. 项目概述与核心价值最近在折腾一个跨机构文档智能检索的原型,核心需求是:在不共享原始数据的前提下,让多个参与方(比如几家医院、几个研究实验室)能够联合起来,构建一个强大的、统一的文档知识库&#x…...