《Flink学习笔记》——第十二章 Flink CEP
12.1 基本概念
12.1.1 CEP是什么
1.什么是CEP?
答:所谓 CEP,其实就是“复杂事件处理(Complex Event Processing)”的缩写;而 Flink CEP,就是 Flink 实现的一个用于复杂事件处理的库(library)。
2.那到底什么是“复杂事件处理”呢?
答:就是可以在事件流里,检测到特定的事件组合并进行处理,比如说“连续登录失败”,或者“订单支付超时”等等。具体的处理过程是,把事件流中的一个个简单事件,通过一定的规则匹配组合起来,这就是“复杂事件”;然后基于这些满足规则的一组组复杂事件进行转换处理,得到想要的结果进行输出。
3.CEP的目的是什么?
答:就是在无界流中检测出特定的数据组合,让我们有机会掌握数据中重要的高阶特征
CEP的流程可以分成三个步骤:
(1)定义一个匹配规则
(2)将匹配规则应用到事件流上,检测满足规则的复杂事件
(3)对检测到的复杂事件进行处理,得到结果进行输出
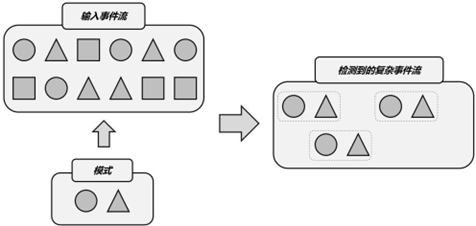
示例:
输入是不同形状的事件流,我们可以定义一个匹配规则:在圆形后面紧跟着三角形。那么将这个规则应用到输入流上,就可以检测到三组匹配的复杂事件。它们构成了一个新的“复杂事件流”,流中的数据就变成了一组一组的复杂事件,每个数据都包含了一个圆形和一个三角形。接下来,我们就可以针对检测到的复杂事件,处理之后输出一个提示或报警信息了。
12.1.2 模式(Pattern)
CEP定义的匹配规则,我们把它叫做模式。
模式的定义主要有两部分:
- 每个简单事件的特征
- 简单事件之间的组合关系
当然,我们也可以进一步扩展模式的功能。比如,匹配检测的时间限制;每个简单事件是否可以重复出现;对于事件可重复出现的模式,遇到一个匹配后是否跳过后面的匹配;等等。
所谓“事件之间的组合关系”,一般就是定义“谁后面接着是谁”,也就是事件发生的顺序。我们把它叫作“近邻关系”。可以定义严格的近邻关系,也就是两个事件之前不能有任何其他事件;也可以定义宽松的近邻关系,即只要前后顺序正确即可,中间可以有其他事件。另外, 还可以反向定义,也就是“谁后面不能跟着谁”。
CEP 做的事其实就是在流上进行模式匹配。根据模式的近邻关系条件不同,可以检测连续的事件或不连续但先后发生的事件;模式还可能有时间的限制,如果在设定时间范围内没有满足匹配条件,就会导致模式匹配超时(timeout)。
12.1.3 应用场景
CEP主要用于实时流数据的分析处理
-
风险控制
设定一些行为模式,可以对用户的异常行为实时检测
-
用户画像
精准营销,如客户买了什么那大概率还会买什么,和精准推荐相似
-
运维监控
对于企业服务的运维管理,可以利用 CEP 灵活配置多指标、多依赖来实现更复杂的监控模式。
12.2 快速上手
12.2.1 引入依赖
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-cep</artifactId><version>${flink.version}</version>
</dependency>
12.2.2 一个简单实例
需求:检测用户行为,如果连续三次登录失败,就输出报警信息。很显然,这是一个复杂事件的检测处理,我们可以使用 Flink CEP 来实现
定义一个登录事件POJO类
@Data
@AllArgsConstructor
@NoArgsConstructor
@ToString
public class LoginEvent {private String userId;private String ipAddress;private String eventType;private Long timestamp;
}
主函数
public class LoginFailDetect {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);KeyedStream<LoginEvent, String> keyedStream = env.fromElements(new LoginEvent("user_1", "192.168.0.1", "fail", 2000L),new LoginEvent("user_1", "192.168.0.2", "fail", 3000L),new LoginEvent("user_2", "192.168.1.29", "fail", 4000L),new LoginEvent("user_1", "171.56.23.10", "fail", 5000L),new LoginEvent("user_2", "192.168.1.29", "success", 6000L),new LoginEvent("user_2", "192.168.1.29", "fail", 7000L),new LoginEvent("user_2", "192.168.1.29", "fail", 8000L)).assignTimestampsAndWatermarks(WatermarkStrategy.<LoginEvent>forMonotonousTimestamps().withTimestampAssigner((SerializableTimestampAssigner<LoginEvent>) (loginEvent, l) -> loginEvent.getTimestamp())).keyBy(LoginEvent::getUserId);// 1. 定义一个模式,连续三次登录失败Pattern<LoginEvent, LoginEvent> pattern = Pattern.<LoginEvent>begin("first").where(new SimpleCondition<LoginEvent>() {@Overridepublic boolean filter(LoginEvent loginEvent) {return "fail".equals(loginEvent.getEventType());}}).next("second").where(new SimpleCondition<LoginEvent>() {@Overridepublic boolean filter(LoginEvent loginEvent) {return "fail".equals(loginEvent.getEventType());}}).next("third").where(new SimpleCondition<LoginEvent>() {@Overridepublic boolean filter(LoginEvent loginEvent) {return "fail".equals(loginEvent.getEventType());}});// 2. 将 Pattern 应用到流上,检测匹配的复杂事件,得到一个 PatternStreamPatternStream<LoginEvent> patternStream = CEP.pattern(keyedStream, pattern);// 3. 将匹配到的复杂事件选择出来,然后包装成字符串报警信息输出patternStream.select((PatternSelectFunction<LoginEvent, String>) map -> {LoginEvent first = map.get("first").get(0);LoginEvent second = map.get("second").get(0);LoginEvent third = map.get("third").get(0);return first.getUserId() + " 连续三次登录失败!登录时间:" +first.getTimestamp() + ", " + second.getTimestamp() + ", " + third.getTimestamp();}).print();env.execute();}
}
输出结果:
user_1 连续三次登录失败!登录时间:2000, 3000, 5000
12.3 模式API
Flink CEP 的核心是复杂事件的模式匹配。Flink CEP 库中提供了 Pattern 类,基于它可以调用一系列方法来定义匹配模式,这就是所谓的模式 API(Pattern API)。Pattern API 可以让我们定义各种复杂的事件组合规则,用于从事件流中提取复杂事件
12.3.1 个体模式
模式就是由一组简单的事件的匹配规则组成,单个事件的匹配规则叫做个体模式。如上面的每一个登录失败事件都是个体模式。
1、基本形式
一般由一个连接词begin、next开始,然后where定义事件特征/匹配规则,并且个体模式通过量词和条件也能接收多个事件。
.begin
.where
.next
.where
2、量词
个体模式后面可以跟一个“量词”,用来指定循环的次数。从这个角度分类,个体模式可以包括“单例(singleton)模式”和“循环(looping)模式”。默认情况下,个体模式是单例模式,匹配接收一个事件;当定义了量词之后,就变成了循环模式,可以匹配接收多个事件。
在循环模式中,对同样特征的事件可以匹配多次。比如我们定义个体模式为“匹配形状为三角形的事件”,再让它循环多次,就变成了“匹配连续多个三角形的事件”。注意这里的“连续”,只要保证前后顺序即可,中间可以有其他事件,所以是“宽松近邻”关系。
在 Flink CEP 中,可以使用不同的方法指定循环模式,主要有:
- .oneOrMore()
- .times(times)
- .times(fromTimes,toTimes)
- .greedy()——贪心模式,尽可能多个匹配
- .optional()——使当前模式成为可选的,也就是说可以满足这个匹配条件,也可以不满足
// 匹配事件出现 4 次
pattern.times(4);// 匹配事件出现 4 次,或者不出现
pattern.times(4).optional();// 匹配事件出现 2, 3 或者 4 次
pattern.times(2, 4);// 匹配事件出现 2, 3 或者 4 次,并且尽可能多地匹配
pattern.times(2, 4).greedy();// 匹配事件出现 2, 3, 4 次,或者不出现
pattern.times(2, 4).optional();// 匹配事件出现 2, 3, 4 次,或者不出现;并且尽可能多地匹配
pattern.times(2, 4).optional().greedy();// 匹配事件出现 1 次或多次
pattern.oneOrMore();// 匹配事件出现 1 次或多次,并且尽可能多地匹配
pattern.oneOrMore().greedy();// 匹配事件出现 1 次或多次,或者不出现
pattern.oneOrMore().optional();// 匹配事件出现 1 次或多次,或者不出现;并且尽可能多地匹配
pattern.oneOrMore().optional().greedy();// 匹配事件出现 2 次或多次
pattern.timesOrMore(2);// 匹配事件出现 2 次或多次,并且尽可能多地匹配
pattern.timesOrMore(2).greedy();// 匹配事件出现 2 次或多次,或者不出现
pattern.timesOrMore(2).optional()// 匹配事件出现 2 次或多次,或者不出现;并且尽可能多地匹配
pattern.timesOrMore(2).optional().greedy();
3、条件
对于每个个体模式,匹配事件的核心在于定义匹配条件,也就是选取事件的规则
有以下几种条件类型:
- 限定子类型:当流中的数据类型为事件类型的子类型时满足条件
- 简单条件:只根据当前事件的特征来决定是否满足条件
- 迭代条件:简单条件只能依靠当前事件做判断,能够处理的逻辑有限。迭代条件可以依靠之前的事件做判断。
- 组合条件:可以通过where后面接一个where或者where后面接or等等,实现多个条件的组合。(其实在一个where里面也可以使用多个if-else来判断,但是代码臃肿可读性差)
- 终止条件:终止循环模式。注意:一般只与 oneOrMore() 或者 oneOrMore().optional()结合使用。因为只有这两个是可以匹配无穷尽的,所以要有终止条件。
12.3.2 组合模式
就是多个个体模式组成
1、初始模式
所有的组合模式都以begin开始
Pattern.begin()
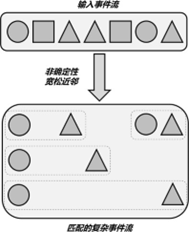
2、近邻条件
在初始模式之后,我们就可以按照复杂事件的顺序追加模式,组合成模式序列了
Flink CEP 中提供了三种近邻关系:
-
严格近邻(next)——两个事件紧挨着
-
宽松近邻(followedBy)——先后顺序正确就行,无序紧挨着出现
-
非确定性宽松近邻(followedByAny)——可以重复使用之前已经匹配过的事件
3、其它条件
(1)notNext()
(2)notFollowedBy()
(3)within()
这是模式序列中第一个事件到最后一个事件之间的最大时间间隔,只有在这期间成功匹配的复杂事件才是有效的
4、循环模式中近邻关系
循环模式——个体模式加了量词
在循环模式中,近邻关系同样有三种:严格近邻、宽松近邻以及非确定性宽松近邻
对于定义了量词(如 oneOrMore()、times())的循环模式,默认内部采用的是宽松近邻,那么可以通过以下方法可以更改近邻关系
(1)consecutive()
如果要为循环模式中的匹配事件增加严格的近邻条件,保证所有匹配事件是严格连续的
(2)allowCombinations()
除严格近邻外,也可以为循环模式中的事件指定非确定性宽松近邻条件,表示可以重复使用已经匹配的事件。
12.3.3 模式组
多个模式的组合、嵌套,返回的类型为GroupPattern,为Pattern的子类型
12.3.4 匹配后跳过策略
如果我们想要精确控制事件的匹配应该跳过哪些情况,就需要制定另外的策略
使用:
// begin的第二个参数传入,默认跳过处理
Pattern.begin("start", AfterMatchSkipStrategy.noSkip())
不同的跳过策略:
(1)不跳过(默认)
AfterMatchSkipStrategy.noSkip()
(2)跳至下一个
AfterMatchSkipStrategy.skipToNext()
(3)跳至所有子匹配
AfterMatchSkipStrategy.skipPastLastEvent()
(4)跳至第一个
AfterMatchSkipStrategy.skipToFirst(“a”)
(5)跳至最后一个
AfterMatchSkipStrategy.skipToLast(“a”)
public class PatternTest {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);KeyedStream<LoginEvent, String> keyedStream = env.fromElements(new LoginEvent("user1", "192.168.0.1", "a", 2000L),new LoginEvent("user1", "192.168.0.2", "a", 3000L),new LoginEvent("user1", "192.168.1.29", "a", 4000L),new LoginEvent("user1", "171.56.23.10", "b", 5000L)).assignTimestampsAndWatermarks(WatermarkStrategy.<LoginEvent>forMonotonousTimestamps().withTimestampAssigner((SerializableTimestampAssigner<LoginEvent>) (loginEvent, l) -> loginEvent.getTimestamp())).keyBy(LoginEvent::getUserId);// 1. 定义一个模式,连续三次登录失败Pattern<LoginEvent, LoginEvent> pattern = Pattern.<LoginEvent>begin("first", AfterMatchSkipStrategy.noSkip()).where(new SimpleCondition<LoginEvent>() {@Overridepublic boolean filter(LoginEvent loginEvent) {return "a".equals(loginEvent.getEventType());}}).oneOrMore().followedBy("second").where(new SimpleCondition<LoginEvent>() {@Overridepublic boolean filter(LoginEvent loginEvent) {return "b".equals(loginEvent.getEventType());}});// 2. 将 Pattern 应用到流上,检测匹配的复杂事件,得到一个 PatternStreamPatternStream<LoginEvent> patternStream = CEP.pattern(keyedStream, pattern);// 3. 将匹配到的复杂事件选择出来,然后包装成字符串报警信息输出patternStream.select(new PatternSelectFunction<LoginEvent, String>() {@Overridepublic String select(Map<String, List<LoginEvent>> map) throws Exception {return String.format("--------%n first: %s%n second: %s%n--------%n", map.get("first"), map.get("second"));}}).print();env.execute();}
}12.4 模式的检测处理
将模式应用到事件流上、检测提取匹配的复杂事件并定义处理转换的方法,最终得到想要的输出信息
12.4.1 将模式应用到流上
PatternStream<Event> patternStream = CEP.pattern(DataStream/KeyedStream, Pattern);
模式中定义的复杂事件发生是有先后顺序的,这取决于使用哪种时间语义。对于时间戳相同(事件时间)或是同时到达(处理时间)的事件,我们还可以通过比较器,来进行更精确的排序
// 可选的事件比较器
EventComparator<Event> comparator = ...
PatternStream<Event> patternStream = CEP.pattern(input, pattern, comparator);
12.4.2 处理匹配事件
1、匹配事件的选择提取
(1)PatternSelectFunction
DataStream<String> result = patternStream.select(new PatternSelectFunction());
(2)PatternFlatSelectFunction
将匹配到的元素“扁平化”,通过收集器输出
DataStream<String> result = patternStream.select(new PatternFlatSelectFunction());
2、匹配事件的通用处理
patternStream.process(new PatternProcessFunction())
PatternProcessFunction 功能更加丰富、调用更加灵活,可以完全覆盖其他接口,也就成为了目前官方推荐的处理方式。
PatternProcessFunction 中必须实现一个 processMatch()方法;这个方法与之前的 flatSelect()类似,只是多了一个上下文 Context 参数。利用这个上下文可以获取当前的时间信息,比如事件的时间戳(timestamp)或者处理时间(processing time);还可以调用.output()方法将数据输出到侧输出流。
12.4.3 处理超时事件
比如我们用.within()指定了模式检测的时间间隔,超出这个时间当前这组检测就应该失败了.
在 Flink CEP中,提供了一个专门捕捉超时的部分匹配事件的接口,叫作TimedOutPartialMatchHandler。这个接口需要实现一个 processTimedOutMatch()方法,可以将超时的、已检测到的部分匹配事件放在一个 Map 中,作为方法的第一个参数;方法的第二个参数则是 PatternProcessFunction 的上下文 Context。所以这个接口必须与 PatternProcessFunction 结合使用,对处理结果的输出则需要利用侧输出流来进行
1、使用 PatternProcessFunction 的侧输出流
class MyPatternProcessFunction extends PatternProcessFunction<Event, String>
implements TimedOutPartialMatchHandler<Event>
2、使用 PatternTimeoutFunction
上文提到的PatternProcessFunction 通过实现TimedOutPartialMatchHandler 接口扩展出了处理超时事件的能力,这是官方推荐的做法
3、应用实例
代码略
12.4.4 处理迟到的数据
patternStream.sideOutputLateData(lateDataOutputTag) // 将迟到数据输出到侧输出流.select(// 处理正常匹配数据new PatternSelectFunction<Event, ComplexEvent>() {...});
12.5 CEP的状态机实现
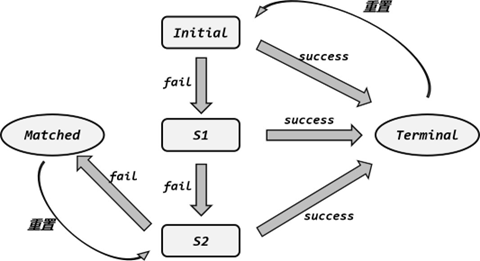
举例:
代码略
相关文章:
《Flink学习笔记》——第十二章 Flink CEP
12.1 基本概念 12.1.1 CEP是什么 1.什么是CEP? 答:所谓 CEP,其实就是“复杂事件处理(Complex Event Processing)”的缩写;而 Flink CEP,就是 Flink 实现的一个用于复杂事件处理的库(…...

谷歌IndexedDB客户端存储数据
IndexedDB 具有以下主要特点: 1.存储大量数据:IndexedDB 可以存储大量的数据,比如存储离线应用程序的本地缓存或存储在线应用程序的大量数据。 2.结构化数据:IndexedDB 使用对象存储空间(Object Stores)来…...

天气数据的宝库:解锁天气预报API的无限可能性
前言 天气预报一直是我们日常生活中的重要组成部分。我们依赖天气预报来决定穿什么衣服、何时出行、规划户外活动以及做出关于农业、交通和能源管理等方面的重要决策。然而,要提供准确的天气预报,需要庞大的数据集和复杂的计算模型。这就是天气预报API的…...
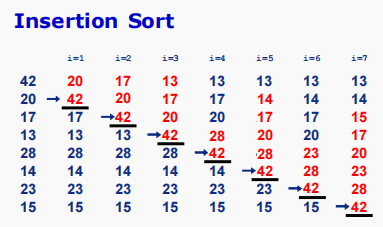
插入排序(Insertion Sort)
C自学精简教程 目录(必读) 插入排序 每次选择未排序子数组中的第一个元素,从后往前,插入放到已排序子数组中,保持子数组有序。 打扑克牌,起牌。 输入数据 42 20 17 13 28 14 23 15 执行过程 完整代码 #include <iostream…...
2023蓝帽杯初赛
最近打完蓝帽杯 现在进行复盘 re 签到题 直接查看源代码 输出的内容就是 变量s 变量 number 而这都是已经设定好了的 所以flag就出来了 WhatisYourStory34982733 取证 案件介绍 取证案情介绍: 2021年5月,公安机关侦破了一起投资理财诈骗类案件&a…...
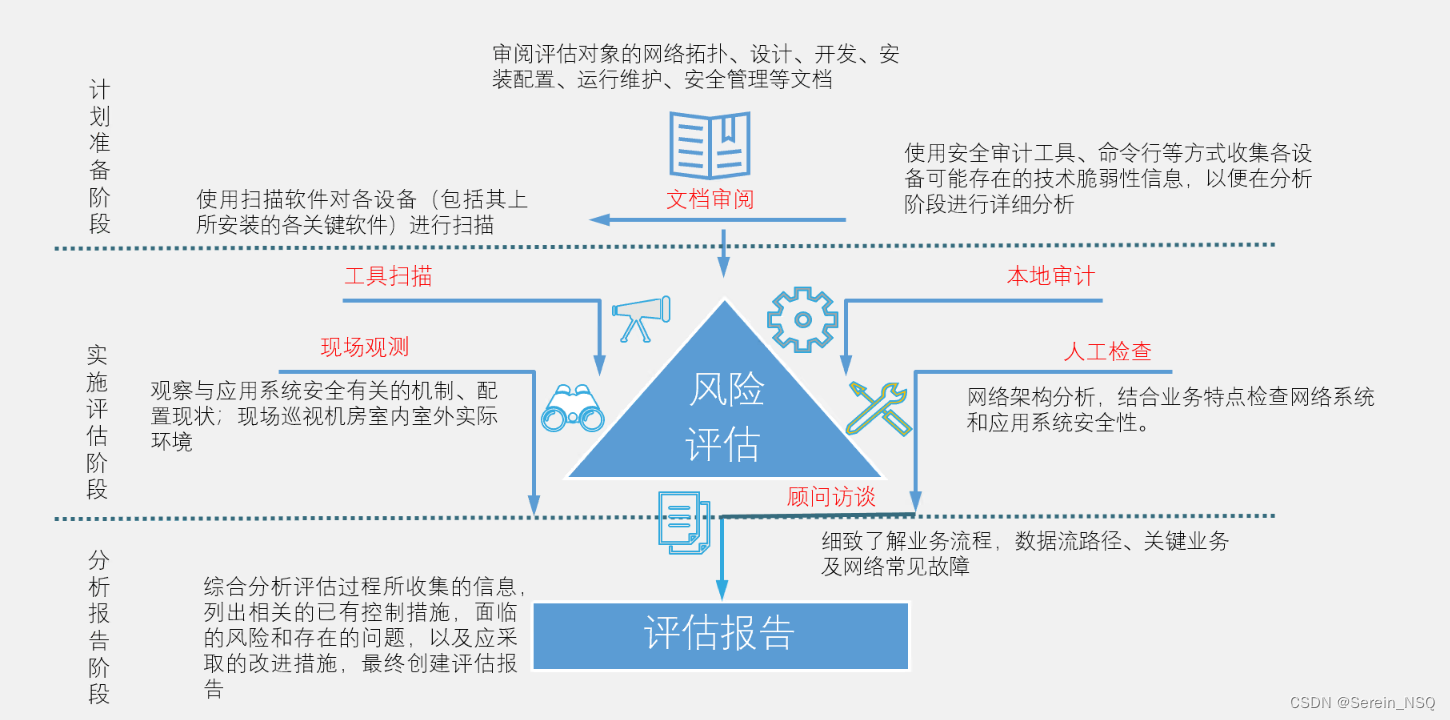
风险评估
风险评估概念 风险评估是一种系统性的方法,用于识别、评估和量化潜在的风险和威胁,以便组织或个人能够采取适当的措施来管理和减轻这些风险。 风险评估的目的 风险评估要素关系 技术评估和管理评估 风险评估分析原理 风险评估服务 风险评估实施流程...

直播软件app开发中的AI应用及前景展望
在当今数字化时代,直播市场蓬勃发展,而直播软件App成为人们获取实时信息和娱乐的重要渠道。随着人工智能(AI)技术的迅猛发展,直播软件App开发正逐渐融入AI的应用,为用户带来更智能、更个性化的直播体验。 …...

vscode html使用less和快速获取标签less结构
扩展插件里面搜索 css tree 插件 下载 使用方法 选择你要生成的标签结构然后按CTRLshiftp 第一次需要在输入框输入 get 然后选择 Generate CSS tree less结构就出现在这个里面直接复制到自己的less文件里面就可以使用了 在html里面使用less 下载 Easy LESS 插件 自己创建…...
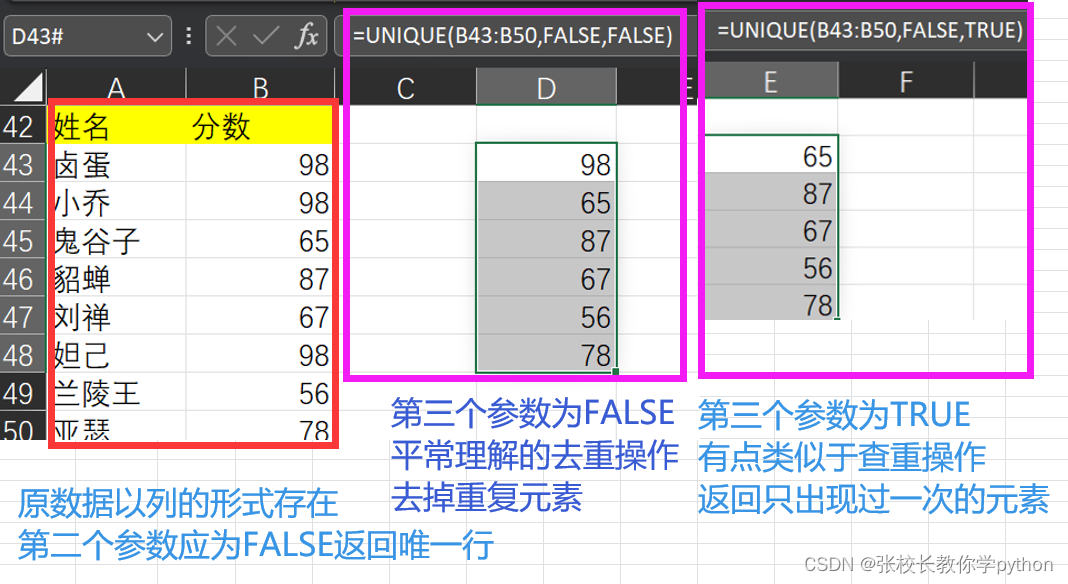
excel中的引用与查找函数篇1
1、COLUMN(reference):返回与列号对应的数字 2、ROW(reference):返回与行号对应的数字 参数reference表示引用/参考单元格,输入后引用单元格后colimn()和row()会返回这个单元格对应的列号和行号。若参数reference没有引用单元格,…...
【python】—— 函数详解
前言: 本期,我们将要讲解的是有关python中函数的相关知识!!! 目录 (一)函数是什么 (二)语法格式 (三)函数参数 (四)函…...
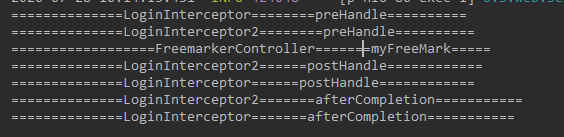
springboot web开发登录拦截器
在SpringBoot中我们可以使用HandlerInterceptorAdapter这个适配器来实现自己的拦截器。这样就可以拦截所有的请求并做相应的处理。 应用场景 日志记录,可以记录请求信息的日志,以便进行信息监控、信息统计等。权限检查:如登陆检测ÿ…...
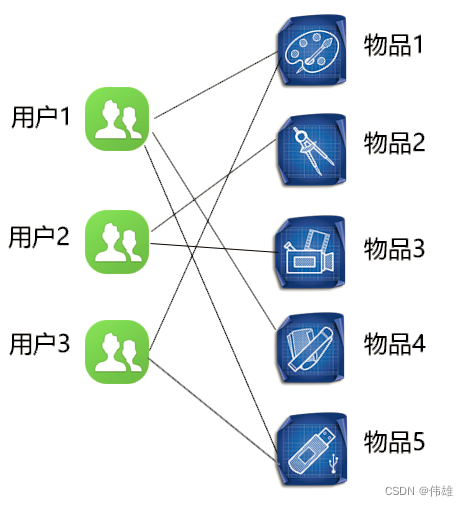
大数据课程K17——Spark的协同过滤法
文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州 ▲ 本章节目的 ⚪ 了解Spark的协同过滤概念; 一、协同过滤概念 1. 概念 协同过滤是一种借助众包智慧的途径。它利用大量已有的用户偏好来估计用户对其未接触过的物品的喜好程度。其内在思想是相似度的定义…...

【力扣】1588. 所有奇数长度子数组的和 <前缀和>
【力扣】1588. 所有奇数长度子数组的和 给你一个正整数数组 arr ,请你计算所有可能的奇数长度子数组的和。子数组 定义为原数组中的一个连续子序列。请你返回 arr 中 所有奇数长度子数组的和 。 示例 1: 输入:arr [1,4,2,5,3] 输出&#x…...

socket,tcp,http三者之间的原理和区别
目录 1、TCP/IP连接 2、HTTP连接 3、SOCKET原理 4、SOCKET连接与TCP/IP连接 5、Socket连接与HTTP连接 socket,tcp,http三者之间的区别和原理 http、TCP/IP协议与socket之间的区别 下面的图表试图显示不同的TCP/IP和其他的协议在最初OSI模型中的位置…...

【FPGA零基础学习之旅#11】数码管动态扫描
🎉欢迎来到FPGA专栏~数码管动态扫描 ☆* o(≧▽≦)o *☆嗨~我是小夏与酒🍹 ✨博客主页:小夏与酒的博客 🎈该系列文章专栏:FPGA学习之旅 文章作者技术和水平有限,如果文中出现错误,希望大家能指正…...
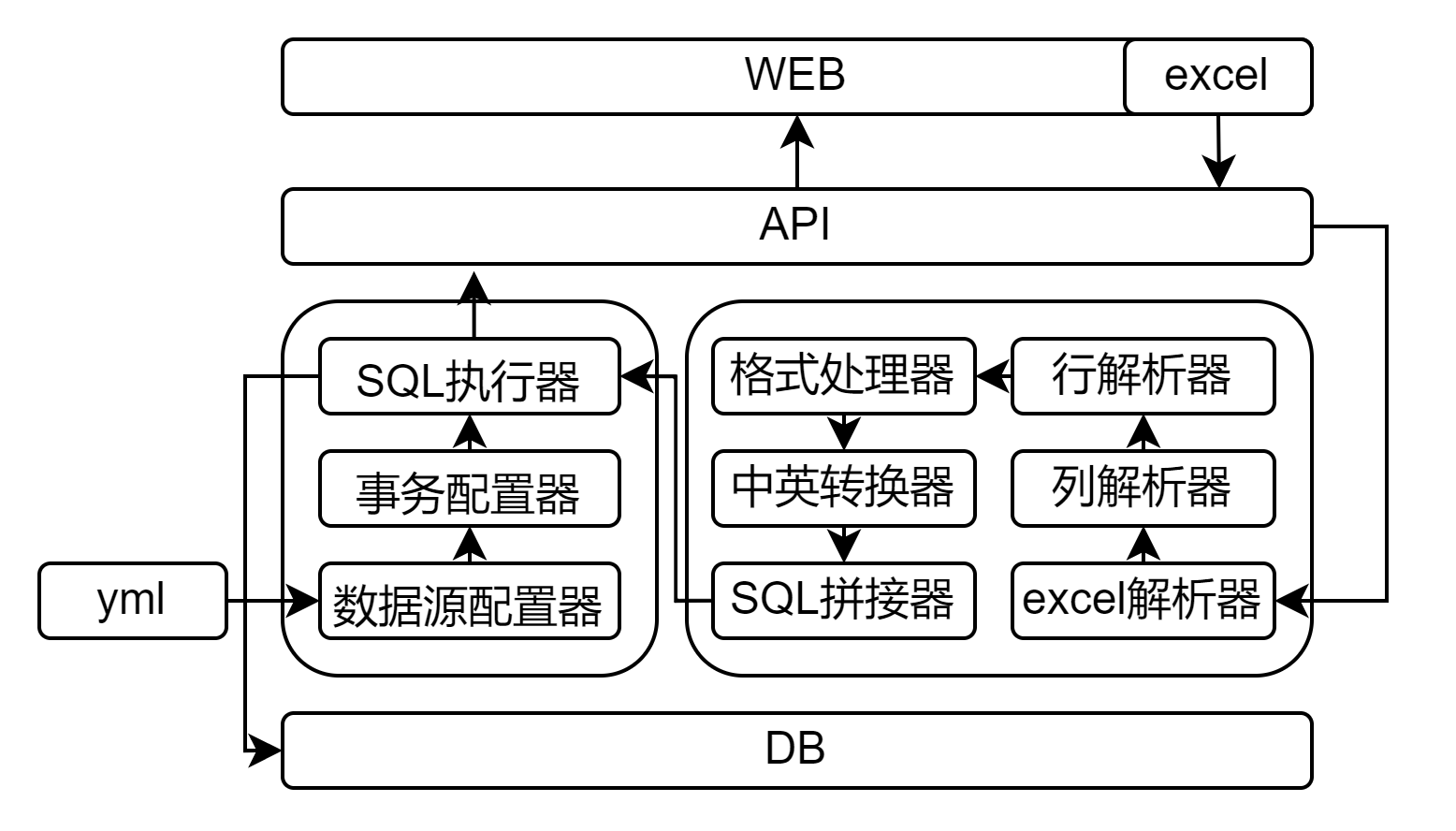
JavaExcel:自动生成数据表并插入数据
故事背景 出于好奇,当下扫描excel读取数据进数据库 or 导出数据库数据组成excel的功能层出不穷,代码也是前篇一律,poi或者easy excel两种SDK的二次利用带来了各种封装方法。 那么为何不能直接扫描excel后根据列的属性名与行数据的属性建立S…...
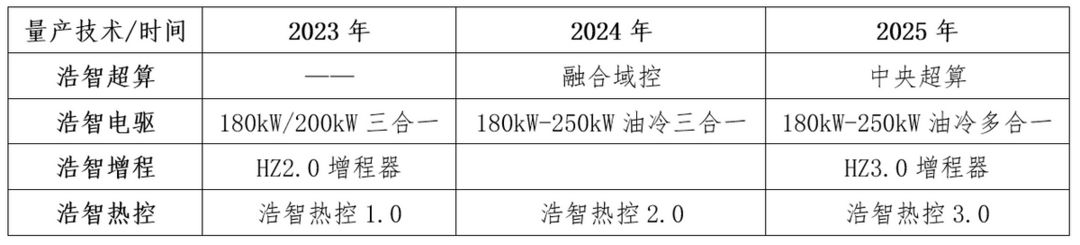
哪吒汽车“三头六臂”之「浩智电驱」
撰文 / 翟悦 编审 / 吴晰 8月21日,在哪吒汽车科技日上,哪吒汽车发布“浩智战略2025”以及浩智技术品牌2.0。根据公开信息,主编梳理了以下几点:◎浩智滑板底盘支持400V/800V双平台◎浩智电驱包括180kW 400V电驱系统和250kW 800…...

补码的反码加1为什么是原码?
搞了半个小时,终于弄懂了。 168421原码10011反码01100补码01101 学到这里了,我们肯定知道,原码补码 0,在这里也就是 19 13 32,溢出来的一位正好舍去了; 所以说,对啊,只要保证…...

光刻机是怎么做出来的
文章目录 一、光刻机的基本原理二、光刻机的制造过程三、光刻机的制造要求四、光刻机的发展趋势 光刻机是半导体工艺制造中非常重要的设备之一,它是用来制作微细结构的关键工具之一。相信大家都知道,半导体工艺中最小的制造单位是晶体管,而制…...
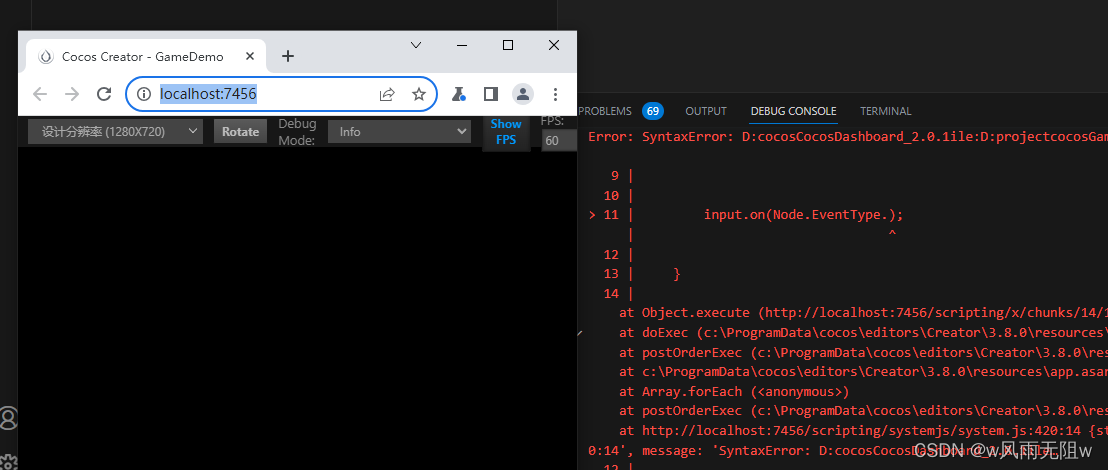
CocosCreator3.8研究笔记(二)windows环境 VS Code 编辑器的配置
一、设置文件显示和搜索过滤步骤 为了提高搜索效率以及文件列表中隐藏不需要显示的文件, VS Code 需要设置排除目录用于过滤。 比如 cocoscreator 中,编辑器运行时会自动生成一些目录:build、temp、library, 所以应该在搜索中排除…...

长期使用Token Plan套餐,我的大模型调用成本降低了多少
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Token Plan套餐,我的大模型调用成本降低了多少 1. 从按量付费到套餐订阅的转变 在深度使用大模型API进行项目…...

构建自动化编译系统:Makefile递归遍历与智能目录生成实践
1. 为什么需要自动化编译系统 如果你曾经维护过一个包含几十个源文件的中大型C/C项目,肯定经历过这样的痛苦:每次新增一个源文件,都要手动修改Makefile;项目结构调整时,编译规则需要全部重写;不同模块之间的…...

3个步骤让你在Windows上轻松安装安卓应用:APK安装器完全指南
3个步骤让你在Windows上轻松安装安卓应用:APK安装器完全指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经想过,如果能在Windows电…...

3分钟掌握罗技鼠标宏:PUBG自动压枪脚本终极指南
3分钟掌握罗技鼠标宏:PUBG自动压枪脚本终极指南 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 还在为《绝地求生》中难以控制的枪械…...

终极KMS激活指南:如何永久免费激活Windows和Office系统
终极KMS激活指南:如何永久免费激活Windows和Office系统 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows激活弹窗而烦恼吗?是否遇到过Office突然变成只读模式…...

ReRAM与PCM存内计算:突破冯·诺依曼瓶颈,赋能边缘AI与类脑计算
1. 从冯诺依曼瓶颈到存内计算:一场芯片架构的范式转移最近几年,但凡关注芯片和人工智能领域的朋友,肯定对“存内计算”这个词不陌生。它听起来像是一个技术术语,但背后直指一个困扰了我们半个多世纪的计算机根本性难题:…...

插入排序,选择排序,希尔排序
一、插入排序从头开始依次选取一个元素,和他前面的数比较,先把值存为 c ,这样就不用交换值了若比前面的元素大,就让 qq 1的位置的值改为前面的数,qq 往前移一位若前面的数小,就把 qq 1的位置的值改为cvo…...

开发者行为数据挖掘:从Stack Overflow发现隐性需求
1. 项目概述:从开发者行为数据挖掘隐性需求在软件开发领域,需求工程一直面临着如何准确捕捉用户真实需求的挑战。传统方法如用户访谈、问卷调查等依赖于用户的主动表达,但开发者往往不会明确说出他们需要什么,而是通过日常行为无意…...

如何高效处理RPG Maker加密资源:纯前端解密方案深度解析
如何高效处理RPG Maker加密资源:纯前端解密方案深度解析 【免费下载链接】RPG-Maker-MV-Decrypter You can decrypt RPG-Maker-MV Resource Files with this project ~ If you dont wanna download it, you can use the Script on my HP: 项目地址: https://gitco…...
)
别再复制粘贴了!手把手教你为51单片机LCD12864制作自定义中文字库(Keil C51环境)
从零构建51单片机LCD12864自定义中文字库的完整实战指南 在嵌入式显示领域,标准字库往往无法满足个性化需求。当我们需要在LCD12864屏幕上显示特殊符号、品牌LOGO或艺术字体时,自定义字库技术就成为关键突破点。本文将彻底解析从字模提取到ROM优化的全流…...