13.108.Spark 优化、Spark优化与hive的区别、SparkSQL启动参数调优、四川任务优化实践:执行效率提升50%以上
13.108.Spark 优化
1.1.25.Spark优化与hive的区别
1.1.26.SparkSQL启动参数调优
1.1.27.四川任务优化实践:执行效率提升50%以上
13.108.Spark 优化:
1.1.25.Spark优化与hive的区别
先理解spark与mapreduce的本质区别,算子之间(map和reduce之间多了依赖关系判断,即宽依赖和窄依赖。)
优化的思路和hive基本一致,比较大的区别就是mapreduce算子之间都需要落磁盘,而spark只有宽依赖才需要落磁盘,窄依赖不落磁盘。


1.1.26.SparkSQL启动参数调优

1)先对比结果:executors优化
Hive执行了30分钟(1800秒)的sql,没有优化过的SparkSQL执行需要,
最少化的Executor执行需要640秒(提高了Executor的并行度,牺牲了HDFS的吞吐量:5个core最合适),
最大化的Executor 281.634秒(最大限度的利用HDFS的吞吐量,牺牲Executor的并行度),
优化取中间值,253.189秒。
方案1:最少化 Fat executors
--------------------------------- Fat executors --------------------------------------------------------------------------------
./spark-sql --master yarn \ # Fat executors (每个节点一个Executor)【优势:最佳吞吐量】
--num-executors 3 \ # 集群中的节点的数目 = 3
--executor-memory 30G \ # 每个节点的内存/每个节点的executor数目 = 30GB/1 = 30GB
--executor-cores 16 \ # 每个executor独占节点中所有的cores = 节点中的core的数目 = 16
--driver-memory 1G # AM大约需要1024MB的内存和一个Executor
耗时:Time taken: 640 seconds
方案2:最大化Tiny executors
--------------------------------- Tiny executors --------------------------------------------------------------------------------
./spark-sql --master yarn \ # Tiny executors [每个Executor一个Core]【优势:并行性】
--num-executors 48 \ # 集群中的core的总数 = 每个节点的core数目 * 集群中的节点数 = 16*3
--executor-memory 1.6G \ # 每个节点的内存/每个节点的executor数目 = 30GB/16 = 1.875GB
--executor-cores 1 \ # 每个executor一个core
--driver-memory 1G # AM大约需要1024MB的内存和一个Executor
耗时:Time taken: 281.634 seconds
executor并发度只有45,task的并发度,1个executor 50左右,总数 18382
方案3:折中方案
--------------------------------- Balance between Fat (vs) Tiny --------------------------------------------------------------------------------
./spark-sql --master yarn \ # Balance between Fat (vs) Tiny
--num-executors 8 \ # (16-1)*3/5 = 9 留一个executor给ApplicationManager => --num-executors = 9-1 = 8# 每个节点的executor的数目 = 9 / 3 = 3
--executor-memory 10G \ # 每个executor的内存 = 30GB / 3 = 10GB【默认分配的是8G,需要修改配置文件支持到10G。】# 计算堆开销 = 7% * 10GB = 0.7GB。因此,实际的 --executor-memory = 10 - 0.7 = 9.3GB
--executor-cores 5 \ # 给每个executor分配5个core,保证良好的HDFS吞吐。# 每个节点留一个core给Hadoop/Yarn守护进程 => 每个节点可用的core的数目= 16 - 1
--driver-memory 1G
耗时:Time taken: 253 seconds
Task并行度优化
1.调整 Executors 下 每个stage的默认task数量,即设置Task 的并发度:
【当集群数量比较大时】
很多人常犯的一个错误就是不去设置这个参数,那么此时就会导致Spark自己根据底层HDFS的block数量来设置task的数量,
!【默认是一个HDFS block对应一个task(如果不设置那么可以通过第三种方案来优化!)】。
通常来说,Spark默认设置的数量是偏少的(比如就几十个task),
如果task数量偏少的话,就会导致你前面设置好的Executor的参数都前功尽弃。
试想一下,无论你的Executor进程有多少个,内存和CPU有多大,但是task只有1个或者10个,
那么90%的Executor进程可能根本就没有task执行,也就是白白浪费了资源!
因此Spark官网建议的设置原则是,设置该参数为num-executors * executor-cores的2~3倍较为合适,
比如Executor的总CPU core数量为300个,那么设置1000个task是可以的,此时可以充分地利用Spark集群的资源。
30 G 16 core
/home/admin/bigdata/spark-2.2.0-bin-hadoop2.6/bin/spark-sql \
--master yarn \
--num-executors 16 \
--executor-memory 1G \
--executor-cores 10 \
--driver-memory 1G \
--conf spark.default.parallelism=450 \
--conf spark.storage.memoryFraction=0.5 \
--conf spark.shuffle.memoryFraction=0.3
1.1.27.四川任务优化实践:执行效率提升50%以上
一、四川的信息
账号:xxxxxx 密码: xxxxxxxx
一、事实表优化
1、**优化结果: 20 分钟左右,优化完成后 5 分钟左右。**数据量:5.8亿
2、原SQL:(spark不一定快)
drop table if exists dc_f_organization;
create table if not exists dc_f_organization (orgid int,orgcode string,yearmonth string ,zzdate string,orgname string,orglevel int,id int,orgtagging int, createdate timestamp
);insert into dc_f_organization
select a.orgid, .orgcode, a.yearmonth, a.zzdate, n.orgname, n.orglevel, n.id, n.orgtagging, n.createdate
from ( select o.id orgid, o.orgcode, d.yearmonth, d.zzdate from dc_d_organization o, dc_d_wddate ) aleft join dc_d_organization n on to_date(n.createdate)=a.zzdate and n.orgcode = a.orgcode;3、优化方案:
– ############################## HIVE 执行:增加 block 的数量,提高Spark的并发度(当前任务文件比较小,设置了26;一般参考数量:300左右;) #################################
– (1) 单独执行笛卡尔积,
– 先拆分文件:(改用hive,拆分文件,增加并行度)
– 【耗时:101.586 seconds;结果文件数量 26】
– 检查文件块数量:hadoop fs -ls /user/hive/warehouse/test.db/dc_d_org_date 26 个block
set mapreduce.map.memory.mb=1024;
set mapred.max.split.size=524288;
set mapred.min.split.size.per.node=524288;
set mapred.min.split.size.per.rack=524288;
drop table if exists dc_d_org_date;
create table dc_d_org_date as select o.id orgid,o.orgcode,d.yearmonth,d.zzdate from dc_d_organization o CROSS JOIN dc_d_wddate d;
-- ############################## SPARK 执行;参数:spark-sql --master yarn --num-executors 100 --executor-memory 5G --executor-cores 3 --driver-memory 3G #################################
-- (2)【Spark:Time taken: 115.78 seconds;】
set spark.shuffle.consolidateFiles=true;
drop table if exists dc_f_organization;
create table if not exists dc_f_organization
(orgid int,orgcode string,YEARMONTH string ,ZZDATE string,ORGNAME string,orglevel int,id int,ORGTAGGING int, createdate timestamp);insert into dc_f_organization
select a.orgid,a.orgcode,a.YEARMONTH,a.ZZDATE,n.ORGNAME,n.orglevel,n.id,n.ORGTAGGING,n.createdate
from dc_d_org_date a
left join DC_D_ORGANIZATION n on to_date(n.CREATEDATE)=a.ZZDATE and n.orgcode = a.orgcode;
– ############################## 持续优化方向:将上述两者合并到一起在 spark 中执行 ##############################
问题:可能是因为文件太小,spark 分区命令没有生效。set spark.sql.shuffle.partitions=300;
注意:SPARK中笛卡尔积需要改成 CROSS JOIN,否则语法报错。
二、优化CUBE表
1、优化结果:原来1小时左右,优化后26分钟。总结:shuffle时间:16分钟,数据量 35.2亿任务含有宽依赖(group)被分成2个stage✔采用方案 1:改用spark执行。提高并行度。执行参数:spark-sql --master yarn --num-executors 100 --executor-memory 5G --executor-cores 3 --driver-memory 3Gstage 1 执行时间:11(partitions=300)stage 2 执行时间:15(partitions=200)设置分区数量,默认是200:set spark.sql.shuffle.partitions=300;(理论上可以提高 stage 2 30%的速度,实际运行的时候可能会丢失executor,运行不稳定,不建议设置。)(原因可能是设置了虚拟核心数量。)方案 2:将case when的操作独立出一张表,去除部分重复扫描计算,减少cube阶段的计算量。抽取的时间增加了2分钟,节省的 shuffle 时间也是2分钟。没有意义。预处理时间:2-3分钟stage 1 执行时间:11stage 2 执行时间:13(节省的时间也是2-3分钟)方案 3:提高 shuffle 使用内存的占比 设置为60%执行参数:spark-sql --master yarn --num-executors 100 --executor-memory 5G --executor-cores 3 --driver-memory 3G --conf spark.storage.memoryFraction=0.3 --conf spark.shuffle.memoryFraction=0.5执行结果:效果不明显,多次执行时间也不太一致。方案 4:减少CUBE的维度数量, orgid 和 orgcode是一对一关系,可以去掉1个维度,计算完成之后再join执行结果:join 消耗的时间更久。2、采用的方案1:SPARK执行-- 执行参数 spark-sql --master yarn --num-executors 100 --executor-memory 5G --executor-cores 3 --driver-memory 3G-- set spark.sql.shuffle.partitions=300;drop table if exists dc_c_organization;create table if not exists dc_c_organization(YEARMONTH string,ZZDATE string,orgid int ,orgcode string,total int,provinceNum int,cityNum int,districtNum int, newDistrictNum int,townNum int,streetNum int,otherNum int,communityNum int,villageNum int,gridNum int);-- 如果用 hive 执行可以开启 combiner,map端先预聚合,减少reduce端的数据量和计算量,减少磁盘的IO和网络传输时间。-- set hive.map.aggr = true;-- set hive.groupby.mapaggr.checkinterval = 10000;-- ############################## SPARK #################################-- set spark.sql.shuffle.partitions=300;insert into dc_c_organizationselect n.YEARMONTH,n.ZZDATE,n.orgid,n.orgcode,count(n.id) total,nvl(SUM(case when pt.displayname='省' then 1 else 0 end),0) AS provinceNum,nvl(SUM(case when pt.displayname='市' then 1 else 0 end),0) as cityNum,nvl(SUM(case when pt.displayname='县(区)' then 1 else 0 end),0) AS districtNum,(nvl(SUM(case when pt.displayname='县(区)' then 1 else 0 end),0) -nvl(SUM(case when pt.displayname='县(区)' AND n.ORGTAGGING= 31 then 1 else 0 end),0)) as newDistrictNum,nvl(SUM(case when ((n.ORGNAME LIKE '%乡%' OR n.ORGNAME LIKE '%镇%' OR n.ORGNAME LIKE '%乡镇%')) AND pt.displayname='乡镇(街道)' then 1 else 0 end),0) townNum,nvl(SUM(case when (n.ORGNAME LIKE '%街道%') AND pt.displayname='乡镇(街道)' then 1 else 0 end),0) streetNum,(nvl(SUM(case when pt.displayname='乡镇(街道)'then 1 else 0 end),0)-nvl(SUM(case when ((n.ORGNAME LIKE '%乡%' OR n.ORGNAME LIKE '%镇%' OR n.ORGNAME LIKE '%乡镇%') ) AND pt.displayname='乡镇(街道)' then 1 else 0 end),0)-nvl(SUM(case when (n.ORGNAME LIKE '%街道%' ) AND pt.displayname='乡镇(街道)' then 1 else 0 end),0)) otherNum,(nvl(SUM(case when pt.displayname='村(社区)' then 1 else 0 end),0)-nvl(SUM(case when ((n.ORGNAME LIKE '%村' OR n.ORGNAME LIKE '%村民委员会' OR n.ORGNAME LIKE '%农村工作中心站' OR n.ORGNAME LIKE '%村委会')) AND pt.displayname='村(社区)' then 1 else 0 end),0)) communityNum,nvl(SUM(case when ((n.ORGNAME LIKE '%村' OR n.ORGNAME LIKE '%村民委员会' OR n.ORGNAME LIKE '%农村工作中心站' OR n.ORGNAME LIKE '%村委会')) AND pt.displayname='村(社区)' then 1 else 0 end),0) villageNum,nvl(SUM(case when pt.displayname='片组片格'then 1 else 0 end),0) gridNumfrom dc_f_organization nleft join dc_d_property pt on n.orglevel = pt.idGROUP BY n.YEARMONTH,n.ZZDATE,n.orgid,n.orgcodeWITH CUBE;3、优化方案2:从业务逻辑上进行优化。(发现SQL逻辑中存在重复的计算)-- ############################ 预处理:去除重复计算和减少CUBE的计算量 ############################drop table if exists temp_dc_c_organization;create table temp_dc_c_organizationas selectn.yearmonth,n.zzdate,n.orgid,n.orgcode,n.id as id,case when pt.displayname='省' then 1 else 0 end as provincenum,case when pt.displayname='市' then 1 else 0 end as citynum,case when pt.displayname='县(区)' then 1 else 0 end as districtnum,case when pt.displayname='县(区)' and n.orgtagging= 31 then 1 else 0 end as old_districtnum,
【重复1】 case when ((n.orgname like '%乡%' or n.orgname like '%镇%' or n.orgname like '%乡镇%')) and pt.displayname='乡镇(街道)' then 1 else 0 end townnum,
【重复2】 case when (n.orgname like '%街道%') and pt.displayname='乡镇(街道)' then 1 else 0 end streetnum,case when pt.displayname='乡镇(街道)'then 1 else 0 end as total_streetnum_01,
【重复1】 case when ((n.orgname like '%乡%' or n.orgname like '%镇%' or n.orgname like '%乡镇%')) and pt.displayname='乡镇(街道)' then 1 else 0 end as total_streetnum_02,
【重复2】 case when (n.orgname like '%街道%') and pt.displayname='乡镇(街道)' then 1 else 0 end as total_streetnum_03,case when pt.displayname='村(社区)' then 1 else 0 end as communitynum_01,
【重复3】 case when ((n.orgname like '%村' or n.orgname like '%村民委员会' or n.orgname like '%农村工作中心站' or n.orgname like '%村委会')) and pt.displayname='村(社区)' then 1 else 0 end as communitynum_02,
【重复3】 case when ((n.orgname like '%村' or n.orgname like '%村民委员会' or n.orgname like '%农村工作中心站' or n.orgname like '%村委会')) and pt.displayname='村(社区)' then 1 else 0 end villagenum,case when pt.displayname='片组片格'then 1 else 0 end gridnumfromdc_f_organization nleft join dc_d_property pt on n.orglevel = pt.id;-- ############################ CUBE:节省的时间相当于预处理的时间。############################create table dc_c_organization_02as select yearmonth,zzdate,orgid,count(id) total,sum(provincenum) as provincenum,sum(citynum) as citynum,sum(districtnum) as districtnum,sum(districtnum)-sum(old_districtnum) as newdistrictnum,sum(townnum) townnum,sum(streetnum) streetnum,sum(total_streetnum_01)-sum(townnum)-sum(streetnum) othernum,sum(communitynum_01)-sum(villagenum) communitynum,sum(villagenum) villagenum,sum(gridnum) gridnumfrom temp_dc_c_organization as ngroup by yearmonth, zzdate, orgid with cube;相关文章:
13.108.Spark 优化、Spark优化与hive的区别、SparkSQL启动参数调优、四川任务优化实践:执行效率提升50%以上
13.108.Spark 优化 1.1.25.Spark优化与hive的区别 1.1.26.SparkSQL启动参数调优 1.1.27.四川任务优化实践:执行效率提升50%以上 13.108.Spark 优化: 1.1.25.Spark优化与hive的区别 先理解spark与mapreduce的本质区别,算子之间(…...

大模型综述论文笔记6-15
这里写自定义目录标题 KeywordsBackgroud for LLMsTechnical Evolution of GPT-series ModelsResearch of OpenAI on LLMs can be roughly divided into the following stagesEarly ExplorationsCapacity LeapCapacity EnhancementThe Milestones of Language Models Resources…...

树的介绍(C语言版)
前言 在数据结构中树是一种很重要的数据结构,很多其他的数据结构和算法都是通过树衍生出来的,比如:堆,AVL树,红黑色等本质上都是一棵树,他们只是树的一种特殊结构,还有其他比如linux系统的文件系…...

Android studio实现圆形进度条
参考博客 效果图 MainActivity import androidx.appcompat.app.AppCompatActivity; import android.graphics.Color; import android.os.Bundle; import android.widget.TextView;import java.util.Timer; import java.util.TimerTask;public class MainActivity extends App…...

基于Halcon的喷码识别方法
具体步骤如下: 1. 读入一幅图片(彩色或黑白); 2. 将RGB图像转化为灰度图像; 3. 提取图片中的圆点特征(喷码图片中多是圆点特征),在Halcon中dots_image() 函数非常适合喷码检测; 4. 通过设定阈值,增强明显特征部分; 5. 进行一系列形态学操作(如闭运算等),将…...
【Sword系列】Vulnhub靶机HACKADEMIC: RTB1 writeup
靶机介绍 官方下载地址:https://www.vulnhub.com/entry/hackademic-rtb1,17/ 需要读取靶机的root目录下key.txt 运行环境: 虚拟机网络设置的是NAT模式 靶机:IP地址:192.168.233.131 攻击机:kali linux,IP地…...

idea使用maven时的java.lang.IllegalArgumentException: Malformed \uxxxx encoding问题解决
idea使用maven时的java.lang.IllegalArgumentException: Malformed \uxxxx encoding问题解决 欢迎使用Markdown编辑器1、使用maven clean install -X会提示报错日志2、在Poperties.java文件的这一行打上断点3、maven debug进行调试4、运行到断点位置后,查看报错char…...

linux深入理解多进程间通信
1.进程间通信 1.1 进程间通信目的 数据传输:一个进程需要将它的数据发送给另一个进程资源共享:多个进程之间共享同样的资源。通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件…...

使用自定义注解+aop实现公共字段的填充
问题描述:对于每个表都有cratetime,updatetime,createby,updateby字段,每次插入数据或者更改数据的时候,都需要对这几个字段进行设置。 Target(ElementType.METHOD) Retention(RetentionPolicy.RUNTIME) public interface AutoFill {//数据库…...
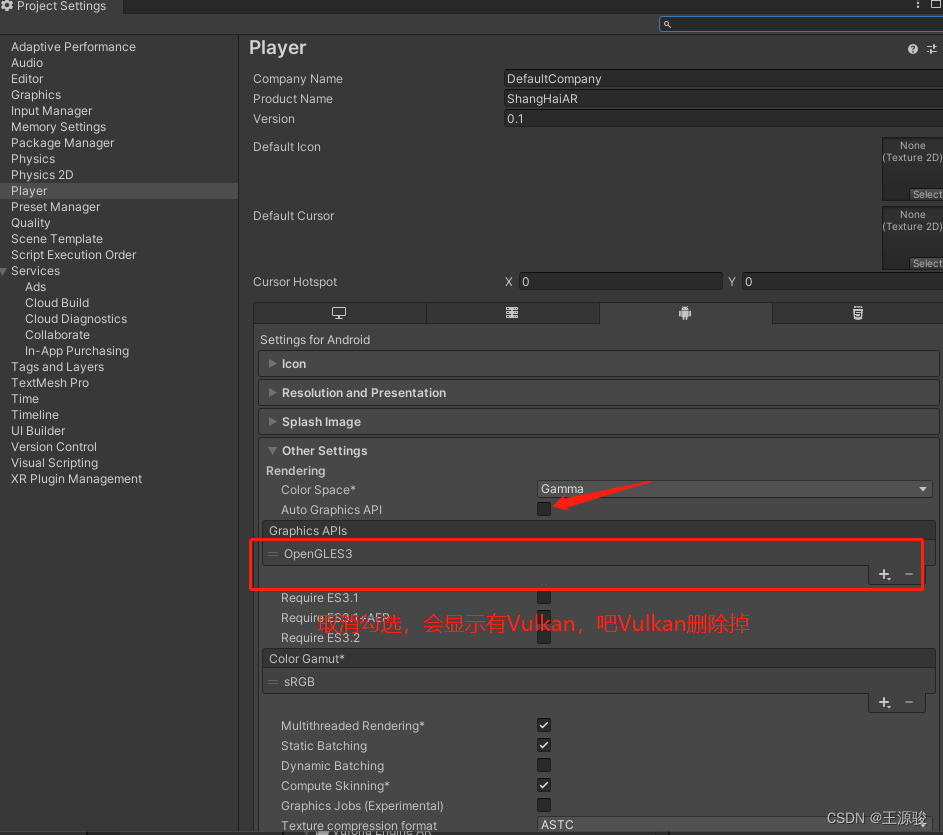
Unity 安卓(Android)端AVProVideo插件播放不了视频,屏幕一闪一闪的
编辑器运行没有问题,但是安卓就有问题,在平板上运行就会报错: vulkan graphics API is notsupported 说不支持Vulkan图形API,解决方法:把Vulkan删除掉...

无涯教程-JavaScript - DMIN函数
描述 DMIN函数返回列表或数据库中符合您指定条件的列中的最小数字。 语法 DMIN (database, field, criteria)争论 Argument描述Required/Optionaldatabase 组成列表或数据库的单元格范围。 数据库是相关数据的列表,其中相关信息的行是记录,数据的列是字段。列表的第一行包含…...
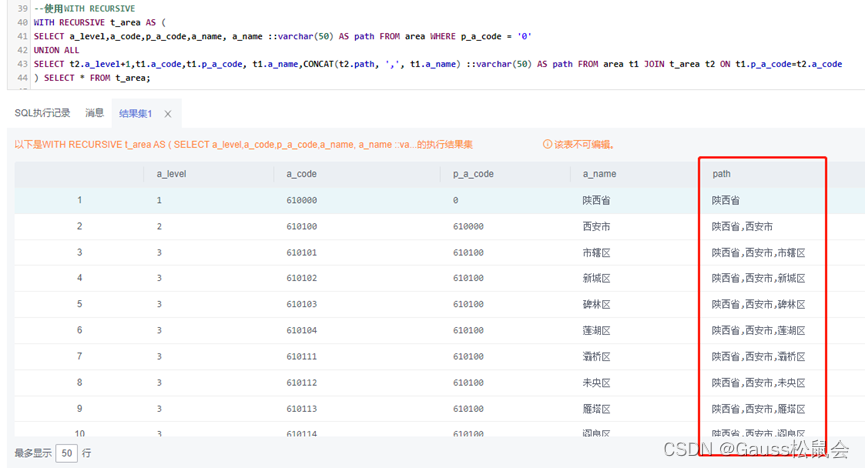
GaussDB数据库SQL系列-层次递归查询
目录 一、前言 二、GuassDB数据库层次递归查询概念 三、GaussDB数据库层次递归查询实验示例 1、创建实验表 2、sys_connect_by_path(col, separator) 3、connect_by_root(col) 4、WITH RECURSIVE 四、递归查询的优缺点 1、优点 2、缺点 五、总结 一、前言 层次递归…...
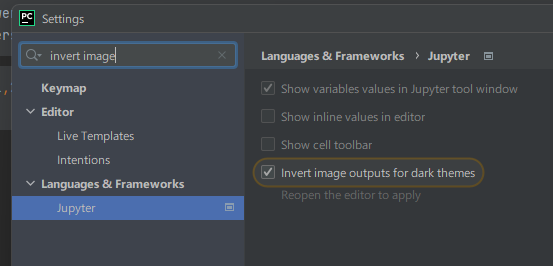
pycharm 下jupyter noteobook显示黑白图片不正常
背景现象: 1、显示一张黑白图片,颜色反过来了。 from IPython.display import display source Image.open(examples/images/forest_pruned.bmp) display(source) 2、原因: 是pycharm会在深色皮肤下默认反转jupyter notebook输出图片的颜…...
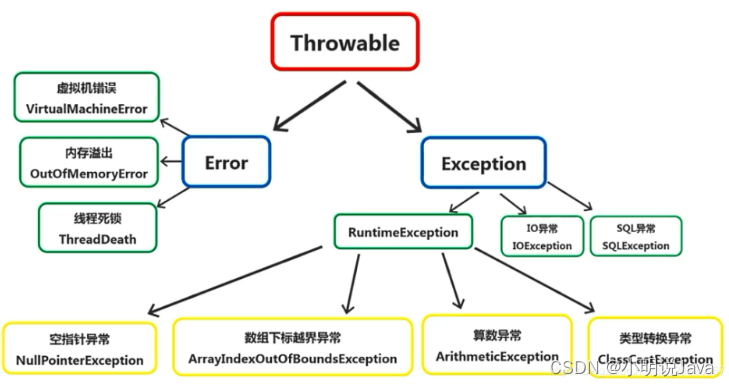
Java异常(Error与Exception)与常见异常处理——第八讲
前言 前面我们讲解了Java的基础语法以及面向对象的思想,相信大家已经基本掌握了Java的基本编程。在之前代码中,我们也看到代码写错了编译器会提示报错,或者编译器没有提示,但是运行的时候报错了,比如前面的数组查询下标超过数组的长度。所以在使用计算机语言进行项目开发的…...
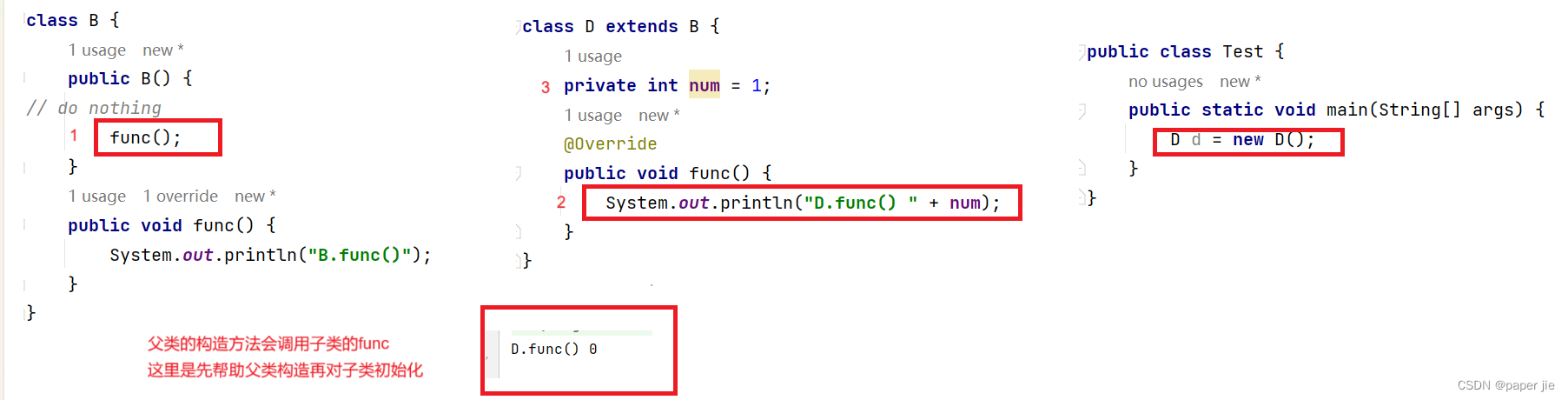
【JAVA】多态
作者主页:paper jie_的博客 本文作者:大家好,我是paper jie,感谢你阅读本文,欢迎一建三连哦。 本文录入于《JAVASE语法系列》专栏,本专栏是针对于大学生,编程小白精心打造的。笔者用重金(时间和…...

android 12 第三方apk系统签名
需求:客户有两个供应商,我们是其中之一,然后客户想将我们的apk 用 另一家供应商的系统签名,安装到另一家供应商的设备上,另一家供应商提供了系统签名文件 用之前的方法 (platform.x509.pem platform.pk8客户…...

【论文阅读】自动驾驶中车道检测系统的物理后门攻击
文章目录 Abstract1.Introduction2.Background2.1.DNN-based Lane Detection2.2.Backdoor Attacks2.3.Threat Model2.4.Image Scaling 3.Methodology3.1.Physical Trigger Design3.2.Poison-Annotation Attack3.3.Clean-Annotation Attack 4.Evaluation4.1.Poison-Annotation A…...
ArrayList、LinkedList、Collections.singletonList、Arrays.asList与ImmutableList.of
文章目录 ListArrayListLinkedListArrayList与LinkedList的区别快速构建list集合Collections.singletonListArrays.asListImmutableList.of Java集合类型有三种:set(集)、list(列表)和map(映射),而List集合是很常用的一种集合类型, List 我…...

恒运资本:沪指涨逾1%,金融、地产等板块走强,北向资金净买入超60亿元
4日早盘,两市股指盘中强势上扬,沪指、深成指涨超1%,上证50指数涨近2%;两市半日成交约5500亿元,北向资金大举流入,半日净买入超60亿元。 截至午间收盘,沪指涨1.12%报3168.38点,深成指…...

解决WebSocket通信:前端拿不到最后一条数据的问题
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...

2026年管棒材检测系统十强厂商最新深度评测
进入2026年下半年,全球管棒材检测系统行业正式迈入高质量发展攻坚期,行业发展主线聚焦于AI多模态融合与全流程数字化转型,技术迭代呈现“多技术协同、全场景适配”的核心特征。其中,相控阵超声(PAUT)、全聚…...

为什么顶级作曲家都在弃用Shazam转投Perplexity?——基于127万条音乐查询日志的权威对比报告
更多请点击: https://codechina.net 第一章:Perplexity音乐知识搜索的崛起背景与行业影响 近年来,音乐产业正经历从“内容分发”向“知识理解”的范式迁移。传统搜索引擎在处理音乐相关查询时,常受限于语义模糊性——例如用户输入…...

深入解析C/C++栈空间:Windows/Linux默认大小、设置方法与溢出防御实战
1. 栈空间:一个被忽视的“内存边界”写C/C代码,尤其是涉及到递归、大数组或者复杂函数调用时,你肯定遇到过“栈溢出”(Stack Overflow)这个老朋友。它不像内存泄漏那样悄无声息,而是直接给你一个程序崩溃&a…...

STM32F103C8T6的MODBUS-RTU从机实战:基于RS485的寄存器读写
1. MODBUS-RTU与STM32F103C8T6的工业应用价值 在工业自动化领域,设备间的可靠通信是系统稳定运行的基础。STM32F103C8T6作为一款性价比极高的Cortex-M3内核微控制器,配合MODBUS-RTU协议和RS485物理层,能够构建出稳定高效的设备监控网络。这种…...

如何在VSCode中实现高效Mermaid图表实时预览:一站式解决方案
如何在VSCode中实现高效Mermaid图表实时预览:一站式解决方案 【免费下载链接】vscode-mermaid-preview Previews Mermaid diagrams 项目地址: https://gitcode.com/gh_mirrors/vs/vscode-mermaid-preview 还在为技术文档中的图表制作而头疼吗?你是…...

终极指南:掌握WinPmem Windows内存取证采集核心技术
终极指南:掌握WinPmem Windows内存取证采集核心技术 【免费下载链接】WinPmem The multi-platform memory acquisition tool. 项目地址: https://gitcode.com/gh_mirrors/wi/WinPmem WinPmem作为Windows平台物理内存采集的标杆工具,为安全分析师和…...

二层与三层交换机核心差异解析:从MAC地址到IP路由的实战指南
1. 项目概述:从“傻”到“聪明”的进化之路如果你刚接触网络设备,看到“二层交换机”和“三层交换机”这两个名词,可能会有点懵。它们长得都差不多,都是方方正正的铁盒子,前面板一堆网口,后面插着电源和风扇…...

深入Delphi二进制世界:用IDR揭开编译代码的神秘面纱
深入Delphi二进制世界:用IDR揭开编译代码的神秘面纱 【免费下载链接】IDR Interactive Delphi Reconstructor 项目地址: https://gitcode.com/gh_mirrors/id/IDR 你是否曾经面对一个Delphi编译的程序,却无法理解它的内部逻辑?或者需要…...
了!用Celery的Canvas原语(Group/Chain/Chord)构建复杂异步工作流)
别再只会用delay()了!用Celery的Canvas原语(Group/Chain/Chord)构建复杂异步工作流
别再只会用delay()了!用Celery的Canvas原语构建复杂异步工作流 在异步任务处理领域,Celery早已成为Python生态中的标配工具。但令人惊讶的是,大多数开发者仅仅停留在task.delay()的基础用法上,就像只学会了加减法却从未接触过微积…...

setup-java企业级实践:大型项目的依赖缓存和版本矩阵测试
setup-java企业级实践:大型项目的依赖缓存和版本矩阵测试 【免费下载链接】setup-java Set up your GitHub Actions workflow with a specific version of Java 项目地址: https://gitcode.com/gh_mirrors/se/setup-java 在现代软件开发中,Java环…...