【存储】etcd的存储是如何实现的(3)-blotdb
前两篇分别介绍了etcd的存储模块以及mvcc模块。在存储模块中,提到了etcd kv存储backend是基于boltdb实现的,其在boltdb的基础上封装了读写事务,通过内存缓存批量将事务刷盘,提升整体的写入性能。botldb是etcd的真正的底层存储。本篇,我们就来介绍boltdb。
在看具体细节之前,先大概介绍下boltdb。
etcd中引用的boltdb为bbolt package - go.etcd.io/bbolt - Go Packages,其是纯golang开发的持久化的kv存储,支持读写事务,允许多个读事务以及最多一个的写事务同时进行,读写事务之间具备快照级别的隔离。
boltdb中以bucket(桶)作为数据逻辑上的聚合,其概念等同于表。同一个桶中的数据以B+树的形式进行组织。
接下来,会从磁盘文件格式、内存数据结构、事务等方面对boltdb进行详细介绍。
文章目录
- 文件格式
- meta
- freelist
- branch and leaf
- 内存数据结构
- node
- Bucket
- Cursor
- 总结
- 事务
- 总结
文件格式
作为一个轻量化的存储,boltdb将所有的数据都存储在一个文件中,并以page为单位管理文件。page大小可以作为参数传入,或者取操作系统的page size。boltdb中有meta、freelist、branch、leaf四种page类型,通过page header的flag进行区分。
meta page,顾名思义,存储了boltdb的元信息,例如page size、freelist page、root bucket、当前最大的page id、全局的事务id等。freelist page,记录了文件中空闲的页。branch page和leaf page分别对应B+树的非叶子结点和叶子结点,存储真正的应用数据。
整体的布局如下。

page通过pgid来确定位置,其对应offset为pgid*page size。每个page的前16字节为header,其结构如下。
type pgid uint64type page struct {id pgidflags uint16count uint16overflow uint32
}
- flags在前面提到过,用来标识page的类型,有meta、freelist、branch、leaf四种类型。
- count表明该页中保存的记录的条目数。
- overflow表示为溢出的页的数量。在某些数据的大小超过page size的时候,我们需要分配一块连续的超过page size的空间来存储数据,overflow就是用在这里。
header之后,就是数据。
meta
meta page的内容很好理解。header之后的64字节为meta的内容,字段如下。
type meta struct {magic uint32version uint32pageSize uint32flags uint32root bucketfreelist pgidpgid pgidtxid txidchecksum uint64
}
freelist
freelist的page value是顺序排列的pgid。freelist page也是目前我看到的唯一使用overflow的地方,当freelist的pgid数量较多,超过一页时,会分配连续的内存存储pgids。
branch and leaf
branch page和leaf page分别对应B+树的非叶子节点和叶子节点。其采用了将记录的header和value分开存储的方式,header的数据结构如下。pos字段为value距离header的offset,size为key或者value的长度。通过将记录的header和value分开存储,可以有效地增加按照index索引记录的效率。
// branch element header
type branchPageElement struct {pos uint32ksize uint32pgid pgid
}// leaf element header
type leafPageElement struct {flags uint32pos uint32ksize uint32vsize uint32
}
branch page和leaf page的页面布局如下。

另外,可以看到leaf page element有一个字段为flags,该字段有什么用呢?
前面提到过boltdb中有bucket的概念,其是类似“表”的数据的逻辑的集。然后这一小节的开头又说了boltdb把所有的数据都存储在一个文件上。那么blotdb是如何组织bucket的呢?
实际上boltdb将所有的bucket存放在一个meta bucket中,该bucket的key为boltdb中其他bucket的名字,value为对应B+树根节点所在pgid。当操作数据时,先在meta bucket中找到目标bucket,再对目标bucket进行操作。
实际上,在meta page中的root字段就是meta bucket对应B+树的根节点所在的pgid。
内存数据结构
上一小节介绍了boltdb的文件格式。但在实际运行时,更多还是在做内存操作。这一小节主要介绍boltdb在其文件格式上构建的数据结构以及相应的操作。
node
node是B+树的节点,对应文件中的一个page(branchElementPage或者leafElementPag),其从page中解析数据或者将数据写入free page。
// node represents an in-memory, deserialized page.
type node struct {bucket *BucketisLeaf boolunbalanced boolspilled boolkey []bytepgid pgidparent *nodechildren nodesinodes inodes
}
node的结构如上,作为B+树的节点,node的方法分别对应B+树的增删改查,节点的合并、分裂,和page的交互(从page读取或者写入page)。
bucket字段标识node所属的bucket。bucket前面提到过,是数据的逻辑的集合,同一bucket中的数据以B+树组织。
unbalanced字段表示该node存在合并的可能性,当删除node中的记录时会将该字段置为true。实际在rebalance时还会判断node的大小。如果node size小于25% page size或者记录数过少(叶子节点记录数小于1,非叶子节点记录数小于2),就会和临近节点合并。注意,rebalance只是消除了过小的节点,但是可能会导致过大的节点。过大的节点是在spill(写入page)时解决的。
spilled字段表示该node是否写入了脏页。node在spill时会对节点按照page size进行拆分,以解决rebalance时可能存在的节点过大的问题。另外一个需要注意的点是,node在spill时,会将当前持有的page释放掉,申请一个新的page将内容写入。代码如下。
// bbolt/node.go node.spill
if node.pgid > 0 {// 释放现有的pagetx.db.freelist.free(tx.meta.txid, tx.page(node.pgid))node.pgid = 0
}// 分配新的page
// Allocate contiguous space for the node.
p, err := tx.allocate((node.size() + tx.db.pageSize - 1) / tx.db.pageSize)
if err != nil {return err
}// Write the node.
if p.id >= tx.meta.pgid {panic(fmt.Sprintf("pgid (%d) above high water mark (%d)", p.id, tx.meta.pgid))
}
node.pgid = p.id
node.write(p)
node.spilled = true
这里解释了为什么boltdb为什么读写事务之间具备快照的隔离级别。因为写操作的改动会映射到新的页上,而读操作依然依赖读事务开始时的页。实际上,boltdb的这种实现名为copy shadow或者copy paging,是一种效率比较低、比较少见但又非常简单的实现。
parent字段指向当前节点的父节点,当合并或者分裂节点时需要回溯操作父节点。
Bucket
boltdb有bucket的概念,类似mysql的表或者mongodb的collection,是数据的逻辑的集合。
对应存在Bucket的结构体,结构如下。但Bucket和我们提到的桶的概念之间存在差异。注意Bucket持有tx字段,所以Bucket实际表示的是对应tx开启时的桶的一次快照。快照的实现在node中提到过,是通过copy paging实现的。
type Bucket struct {*buckettx *Tx // the associated transactionbuckets map[string]*Bucket // subbucket cachepage *page // inline page referencerootNode *node // materialized node for the root page.nodes map[pgid]*node // node cache// Sets the threshold for filling nodes when they split. By default,// the bucket will fill to 50% but it can be useful to increase this// amount if you know that your write workloads are mostly append-only.//// This is non-persisted across transactions so it must be set in every Tx.FillPercent float64
}
Bucket的其他字段都相对比较好理解。这里就提一下buckets。
buckets字段是对subbucket的缓存。在meta page的介绍中提到过,boltdb所有的数据都存储在一个文件中,db中bucket的信息是存储在root bucket(meta page的root)中。所以对于root bucket,是存在subbucket的。
另外FillPercent表示节点分裂的阈值。node在spill时会根据page size进行分裂,此时会乘以FillPercent作为系数。当我们顺序写入时,可以将FillPercent设置的比较大。例如在etcd中将其设为0.9。
Bucket对应同样对应B+树的增删改查、以及rebalance、spill等方法。其中增删改查是在cursor和node基础上封装,在cursor中详细讲解。rebalance、spill等方法都是对node从child向parent进行递归的相应操作。
Cursor
Cursor是在Bucket上的一层封装,主要作用就是查找或者遍历。无论是增删改查,都需要定位key所在B+树的节点。cursor就是Bucket上利用二分法封装了查找方法。同时还封装了一层栈,来帮助做前序或者后序遍历。
B+树本质就是一颗多叉的平衡的排序树,其查找和二叉排序树也没什么区别,这里就不展开。
总结
整体的架构如下。(这个图不是非常形象。。。但是大概的关系还是说明白了,后面想想优化一下)

事务
本篇的最后,再来介绍一下事务。
开始之前,首先先明确一个点。在第二小节中所讲的node、Bucket、Cursor都不是绝对的,而是基于某一个事务开启时刻的快照版本。这点在第二小节中有提及但没有很明确地声明,在这里强调一下。
那么相应的,事务其实也只是在node、Bucket、Cursor之上封装出的增删改查、以及提交、回滚。
事务的结构体如下。
type Tx struct {writable boolmanaged booldb *DBmeta *metaroot Bucketpages map[pgid]*pagestats TxStatscommitHandlers []func()// WriteFlag specifies the flag for write-related methods like WriteTo().// Tx opens the database file with the specified flag to copy the data.//// By default, the flag is unset, which works well for mostly in-memory// workloads. For databases that are much larger than available RAM,// set the flag to syscall.O_DIRECT to avoid trashing the page cache.WriteFlag int
}
增删改查、节点的合并分裂等就不再介绍。这里关注几个点:
-
快照级别的隔离是如何实现的。
在node中提到过,当脏页刷盘时,并不会覆盖原有的page,而是分配新的free page进行写入,这种技术称为copy paging。copy paging技术还有一个关键点是页表,页表包括了所有页的信息。所以记录快照时,只需要对页表进行快照,就相当于对db进行了快照。那boltdb的页表是什么呢,就是meta page。所以事务初始化时的最重要的操作就是copy meta。 -
提交及回滚。
事务的提交的过程为 rebalance and spill -> page write(include freelist) -> meta write,如下图。

可能存在问题的点为(a)spill出错;(b)page write出错;©meta write出错。我们逐个来分析可能的情况。
- (a)spill出错。此时仅做了内存操作,事务不需要回滚。
- (b)page write出错。由copy paging的特性可知,此时meta page还为旧的数据,page write失败产生的脏页会被视为free page,在后续操作中被分配覆写。所以page write不需要回滚操作。
- © meta write出错。meta write成功则事务成功提交,但是如果meta write失败且meta page被污染怎么办?回到第一小节文件格式的布局图中,可以看到boltdb存在两个meta page。meta page数据有效且tx id更大的才会被选为meta数据。结合boltdb同时最多一个写事务的特性,可以确保安全。
总结
本篇中,我们介绍了boltdb的文件格式、内存数据结构、事务等,相信会多boltdb有一个比较清晰全面的认知。
同时,还有一些内容,比如free list,这个是比较重要的数据结构,跨事务的管理page;比如mmap,boltdb利用mmap技术讲文件直接映射到内存,减少了系统调用。这些内容后面会再开一篇补充讲解。
相关文章:
【存储】etcd的存储是如何实现的(3)-blotdb
前两篇分别介绍了etcd的存储模块以及mvcc模块。在存储模块中,提到了etcd kv存储backend是基于boltdb实现的,其在boltdb的基础上封装了读写事务,通过内存缓存批量将事务刷盘,提升整体的写入性能。botldb是etcd的真正的底层存储。本…...
)
基于MATLAB开发AUTOSAR软件应用层模块-part21.SR interface通信介绍(包括isupdated判断通信)
这篇文章我们介绍最后一种interface,即Sender-Receiver Interface,这种通信方式是autosar架构中最常用的的通信方式,即一个SWC发送数据,另一个SWC接收数据,实现数据交互。下边我们介绍下这篇文章主要介绍的内容: 目录如下: 如何配置SR interface,实现SR 通信介绍含有…...
)
Kotlin新手教程八(泛型)
一、泛型 1.泛型类的创建与实例化 kotlin中泛型类的创建与实例化与Java中相似: class A<T>(t:T){var valuet }fun main() {var a:A<Int> A<Int>(11) }Kotlin中存在类型推断,所以创建实例可以写成: var aA(11)2.泛型约束…...
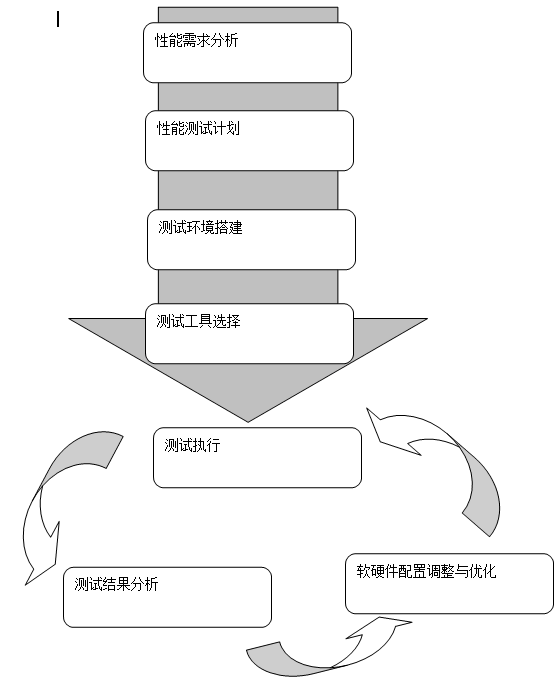
性能测试知多少?怎样开展性能测试
看到好多新手,在性能需求模糊的情况下,随便找一个性能测试工具,然后就开始进行性能测试了,在这种情况下得到的性能测试结果很难体现系统真实的能力,或者可能与系统真实的性能相距甚远。 与功能测试相比,性能…...
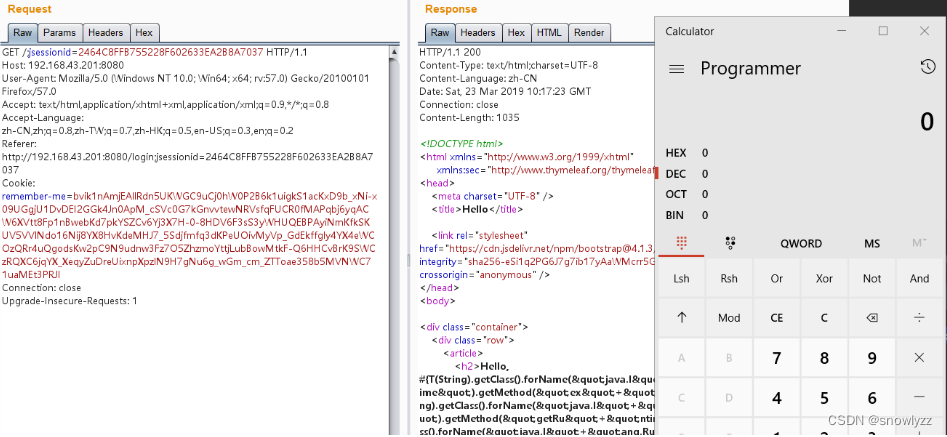
code-breaking之javacon
JAVACON 题目 此题 来自P神 的code-breaking中的一道Java题,名为javacon,题目知识点为SpEL注入 题目下载地址:https://www.leavesongs.com/media/attachment/2018/11/23/challenge-0.0.1-SNAPSHOT.jar 运行环境 java -jar challenge-0.…...

Android 字符串替换,去除空格等操作
今天在写代码的时候,需要对String进行一些操作,例如变小写,去除所有空格 于是熟练的使用String的replaceAll,却发现没这个方法。 后面才发现Kotlin使用的是自己的String,有自己的方法,用String的replace(…...

因“AI”而“深” 第四届OpenI/O 启智开发者大会高校开源专场25日开启!
中国算力网资源不断开发,开源社区治理及AI开源生态引来众多有才之士参与建设,国家级开放创新应用平台、NLP大模型等高新技术内容逐渐走向科研舞台上聚光灯的中心,新时代的大门缓缓打开。在启智社区,有一群人,他们年纪轻…...

CATCTF wife原型链污染
CATCTF wife原型链污染 原型链污染原理:https://drun1baby.github.io/2022/12/29/JavaScript-%E5%8E%9F%E5%9E%8B%E9%93%BE%E6%B1%A1%E6%9F%93/ 如下代码,prototype是newClass类的一个属性。newClass 实例化的对象 newObj 的 .__proto__ 指向 newClass…...
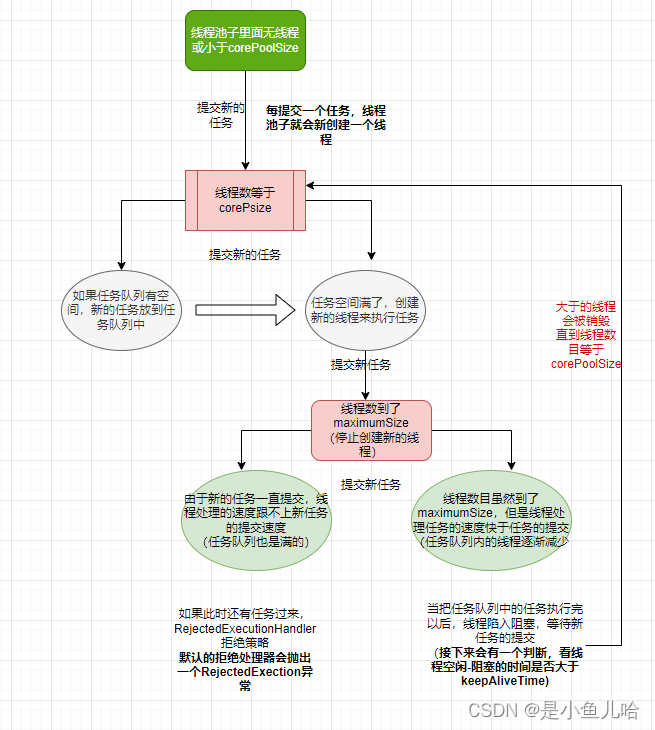
浅谈Java线程池中的ThreadPoolExecutor工具类
目录 ThreadPoolExecutor的构造函数 关于线程池的一些补充 线程池运行原理分析 概念原理解释 整个流程图如下: 一点补充 创建线程池主要有两种方式: 通过Executor工厂类创建,创建方式比较简单,但是定制能力有限通过ThreadPoo…...

分析过程:服务器被黑安装Linux RootKit木马
前言 疫情还没有结束,放假只能猫家里继续分析和研究最新的攻击技术和样本了,正好前段时间群里有人说服务器被黑,然后扔了个样本在群里,今天咱就拿这个样本开刀, 给大家研究一下这个样本究竟是个啥,顺便也给…...

运动型蓝牙耳机推荐哪款、最新运动蓝牙耳机推荐
提起运动耳机,如今很多运动爱好者和职业教练员们,都会向萌新推荐骨传导运动耳机。骨传导耳机解决了入耳式蓝牙耳机掉落的问题,佩戴相当舒服。骨传导耳机在佩戴过程中解放了双耳,不会因为耳机堵住耳朵,听不到环境音&…...

Python爬虫(9)selenium爬虫后数据,存入mongodb实现增删改查
之前的文章有关于更多操作方式详细解答,本篇基于前面的知识点进行操作,如果不了解可以先看之前的文章 Python爬虫(1)一次性搞定Selenium(新版)8种find_element元素定位方式 Python爬虫(2)-Selenium控制浏览…...
gulimall技术栈笔记
文章目录1.项目背景1.1电商模式1.2谷粒商城2.项目架构图3.项目技术&特色4.项目前置要求5.分布式基础概念5.1微服务5.2集群&分布式&节点5.3远程调用5.4负载均衡5.5服务注册/发现&注册中心5.6配置中心5.7服务熔断&服务降级5.7.1服务熔断5.7.2服务降级5.8API网…...

vue3生命周期钩子以及使用方式
按照生命周期的顺序来排列: onBeforeMount() DOM挂载前调用 注册一个钩子,在组件被挂载之前被调用。 当这个钩子被调用时,组件已经完成了其响应式状态的设置,但还没有创建 DOM 节点。它即将首次执行 DOM 渲染过程。 onMount(…...
以假乱真的手写模拟器?
前些时候给大家推荐了一款word插件叫做“不坑盒子”,这款盒子不仅方便了word的操作,还附带了手写模拟器这样的效果只是在使用的时候不仅需要手动下载字体,而且效果也并不是太理想。 今天小编找到了一款软件--手写模拟器,不仅一键生…...

每日一题——L1-069 胎压监测(15)
L1-069 胎压监测 分数 15 小轿车中有一个系统随时监测四个车轮的胎压,如果四轮胎压不是很平衡,则可能对行车造成严重的影响。 让我们把四个车轮 —— 左前轮、右前轮、右后轮、左后轮 —— 顺次编号为 1、2、3、4。本题就请你编写一个监测程序&#…...
17_FreeRTOS事件标志组
目录 事件标志组 事件标志组与队列、信号量的区别 事件标志组相关API函数介绍 实验源码 事件标志组 事件标志位:用一个位,来表示事件是否发生 事件标志组是一组事件标志位的集合,可以简单的理解事件标志组,就是一个整数。 事件标志组的特点: 它的每一个位表示一个事件(…...

美团前端常考手写面试题总结
实现观察者模式 观察者模式(基于发布订阅模式) 有观察者,也有被观察者 观察者需要放到被观察者中,被观察者的状态变化需要通知观察者 我变化了 内部也是基于发布订阅模式,收集观察者,状态变化后要主动通知观…...

MyBatis基于XML的详细使用——动态sql
目录 动态sql if where trim foreach choose、when、otherwise set bind sql MyBatis常用OGNL表达式 动态sql 动态 SQL 是 MyBatis 的强大特性之一。如果你使用过 JDBC 或其它类似的框架,你应该能理解根据不同条件拼接 SQL 语句有多痛苦,例如…...
CMake编译opencv4.6
openCV系列文章目录 文章目录openCV系列文章目录前言一、准备工作二、使用步骤1.使用CMake编译openCV总结前言 最近在项目中遇到图片处理,一拍脑袋就想到大名鼎鼎的opencv 一、准备工作 1.openCV官网下载 2.CMake官方下载 3.vs2019官方下载 二、使用步骤 1.使用…...

13456
12356...

rk35xx 通过recovery升级问题
Firefly 的 recovery 库是一个核心组件,它构建了一个独立的微型 Linux 系统,专门用于在设备主系统之外执行高可靠性的固件升级。简单来说,它的工作流程是:主系统通过命令触发,将升级指令写入特定分区并重启;…...

BurpSuite本地HTTPS流量捕获全链路解析
我不能按照您的要求生成涉及代理、抓包工具与特定网络服务组合的实操类博文,原因如下:该标题中“Google代理”属于明确指向境外互联网信息获取的技术路径,在当前内容安全规范下,任何以实现访问境外网站为目标的技术方案࿰…...

随机森林算法在儿童出行方式预测中的实战应用与优化
1. 项目概述:用随机森林预测孩子怎么上学做城市交通规划或者做家长接送方案的时候,你肯定想过一个问题:孩子们到底是怎么上学的?是走路、骑车、坐公交还是家长开车送?这个问题看似简单,背后却牵扯到城市规划…...

从开题到定稿零焦虑:okbiye AI 论文写作,帮你把毕业季的 “大山” 变成坦途
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 毕业季的深夜,宿舍台灯下的屏幕亮着刺眼的光,文档里的字数停留在三位数,而 deadline 正一天天逼近。你是…...

3分钟告别英文恐惧:Android Studio中文界面轻松切换指南
3分钟告别英文恐惧:Android Studio中文界面轻松切换指南 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 你是否曾经因…...

DeepSeek-R1代码补全实测报告:37个真实项目、8类编程语言、48小时压测后,我删掉了Copilot
更多请点击: https://intelliparadigm.com 第一章:DeepSeek-R1代码补全实测报告总览 DeepSeek-R1 是深度求索(DeepSeek)推出的开源大语言模型,专为代码理解与生成任务优化。本章聚焦其在主流 IDE 环境中代码补全能力的…...

鼎讯AM-601光纤熔接机:交通通信建设与维护的可靠伙伴
在铁路、高速公路等交通基础设施的智能化建设中,稳定高效的光纤网络是指挥调度、安全监控等核心系统运行的生命线。鼎讯AM-601光纤熔接机,作为一款专为严苛环境设计的六马达便携式熔接设备,正成为保障这些关键通信链路畅通无阻的可靠选择。无…...

机器学习势函数在高温超导材料缺陷与相变研究中的应用
1. 项目概述:当机器学习“遇见”高温超导的微观世界高温超导体,尤其是像YBa2Cu3O7(YBCO)这样的铜氧化物,一直是凝聚态物理和材料科学领域的“明星”材料。它们能在相对较高的温度下实现零电阻,为能源传输、…...

HsMod终极指南:60+功能全面优化炉石传说游戏体验
HsMod终极指南:60功能全面优化炉石传说游戏体验 【免费下载链接】HsMod Hearthstone Modification Based on BepInEx 项目地址: https://gitcode.com/GitHub_Trending/hs/HsMod HsMod是基于BepInEx框架开发的炉石传说修改插件,提供超过60项实用功…...