【DGL】图分类
目录
- 概述
- 数据集
- 定义Data Loader
- DGL中的batched graph
- 定义模型
- 训练
- 参考
概述
除了节点级别的问题——节点分类、边级别的问题——链接预测之外,还有整个图级别的问题——图分类。经过聚合、传递消息得到节点和边的新的表征后,映射得到整个图的表征。
数据集
dataset = dgl.data.GINDataset('PROTEINS', self_loop=True)
g = dataset[0]
print(g)
print("Node feature dimensionality:", dataset.dim_nfeats)
print("Number of graph categories:", dataset.gclasses)
(Graph(num_nodes=42, num_edges=204,ndata_schemes={'label': Scheme(shape=(), dtype=torch.int64), 'attr': Scheme(shape=(3,), dtype=torch.float32)}edata_schemes={}), tensor(0))
Node feature dimensionality: 3
Number of graph categories: 2
共1113个图,每个图中的节点的特征维度是3,图的类别数是2.
定义Data Loader
from torch.utils.data.sampler import SubsetRandomSamplerfrom dgl.dataloading import GraphDataLoadernum_examples = len(dataset)
num_train = int(num_examples * 0.8)train_sampler = SubsetRandomSampler(torch.arange(num_train))
test_sampler = SubsetRandomSampler(torch.arange(num_train, num_examples))train_dataloader = GraphDataLoader(dataset, sampler=train_sampler, batch_size=5, drop_last=False
)
test_dataloader = GraphDataLoader(dataset, sampler=test_sampler, batch_size=5, drop_last=False
)
取80%用作训练集,其余用作测试集
mini-batch操作,取5个graph打包成一个大的batched graph
it = iter(train_dataloader)
batch = next(it)
print(batch)
[Graph(num_nodes=259, num_edges=1201,ndata_schemes={'label': Scheme(shape=(), dtype=torch.int64), 'attr': Scheme(shape=(3,), dtype=torch.float32)}edata_schemes={}), tensor([0, 1, 0, 0, 0])]
DGL中的batched graph
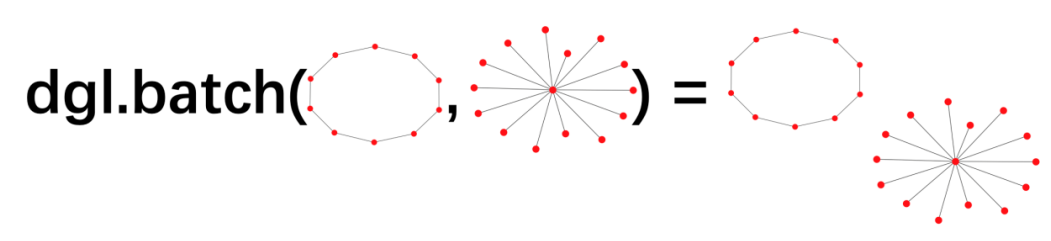
在每个mini-batch里面,batched graph是由dgl.batch对graph进行打包的
batched_graph, labels = batch
print("Number of nodes for each graph element in the batch:",batched_graph.batch_num_nodes(),
)
print("Number of edges for each graph element in the batch:",batched_graph.batch_num_edges(),
)# Recover the original graph elements from the minibatch
graphs = dgl.unbatch(batched_graph)
print("The original graphs in the minibatch:")
print(graphs)
Number of nodes for each graph element in the batch: tensor([ 55, 16, 116, 31, 41])
Number of edges for each graph element in the batch: tensor([209, 70, 584, 153, 185])
The original graphs in the minibatch:
[Graph(num_nodes=55, num_edges=209,ndata_schemes={'label': Scheme(shape=(), dtype=torch.int64), 'attr': Scheme(shape=(3,), dtype=torch.float32)}edata_schemes={}), Graph(num_nodes=16, num_edges=70,ndata_schemes={'label': Scheme(shape=(), dtype=torch.int64), 'attr': Scheme(shape=(3,), dtype=torch.float32)}edata_schemes={}), Graph(num_nodes=116, num_edges=584,ndata_schemes={'label': Scheme(shape=(), dtype=torch.int64), 'attr': Scheme(shape=(3,), dtype=torch.float32)}edata_schemes={}), Graph(num_nodes=31, num_edges=153,ndata_schemes={'label': Scheme(shape=(), dtype=torch.int64), 'attr': Scheme(shape=(3,), dtype=torch.float32)}edata_schemes={}), Graph(num_nodes=41, num_edges=185,ndata_schemes={'label': Scheme(shape=(), dtype=torch.int64), 'attr': Scheme(shape=(3,), dtype=torch.float32)}edata_schemes={})]
定义模型
class GCN(nn.Module):def __init__(self, in_feats, h_feats, num_classes):super(GCN, self).__init__()self.conv1 = GraphConv(in_feats, h_feats)self.conv2 = GraphConv(h_feats, num_classes)def forward(self, g, in_feat):h = self.conv1(g, in_feat)h = F.relu(h)h = self.conv2(g, h)g.ndata["h"] = hreturn dgl.mean_nodes(g, "h")#取所有节点的'h'特征的平均值来表征整个图 readoutmodel = GCN(dataset.dim_nfeats, 16, dataset.gclasses)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
一个batched graph中,不同的图是完全分开的,即没有边连接两个图,所有消息传递函数仍然具有相同的结果(和没有打包之前相比)。
其次,将对每个图分别执行readout功能。假设批次大小为B,要聚合的特征维度为D,则读取出的形状为(B, D)。
训练
for epoch in range(20):num_correct = 0num_trains = 0for batched_graph, labels in train_dataloader:pred = model(batched_graph, batched_graph.ndata['attr'].float())loss = F.cross_entropy(pred, labels)num_trains += len(labels)num_correct += (pred.argmax(1)==labels).sum().item()optimizer.zero_grad()loss.backward()optimizer.step()print('train accuracy: ', num_correct/num_trains)num_correct = 0
num_tests = 0
for batched_graph, labels in test_dataloader:pred = model(batched_graph, batched_graph.ndata['attr'].float())num_correct += (pred.argmax(1)==labels).sum().item()num_tests += len(labels)print("Test accuracy: ", num_correct/num_tests)
train accuracy: 0.7404494382022472
train accuracy: 0.7426966292134831
train accuracy: 0.7471910112359551
train accuracy: 0.7539325842696629
train accuracy: 0.7584269662921348
train accuracy: 0.7674157303370787
train accuracy: 0.7629213483146068
train accuracy: 0.7617977528089888
train accuracy: 0.7584269662921348
train accuracy: 0.7707865168539326
train accuracy: 0.7629213483146068
train accuracy: 0.7651685393258427
train accuracy: 0.7629213483146068
train accuracy: 0.7561797752808989
train accuracy: 0.7606741573033707
train accuracy: 0.7584269662921348
train accuracy: 0.7617977528089888
train accuracy: 0.7707865168539326
train accuracy: 0.7629213483146068
train accuracy: 0.7539325842696629Test accuracy: 0.26905829596412556
效果非常一般 明显过拟合 应该和没有边特征,节点特征信息不足有关。
参考
https://docs.dgl.ai/tutorials/blitz/5_graph_classification.html
相关文章:
【DGL】图分类
目录概述数据集定义Data LoaderDGL中的batched graph定义模型训练参考概述 除了节点级别的问题——节点分类、边级别的问题——链接预测之外,还有整个图级别的问题——图分类。经过聚合、传递消息得到节点和边的新的表征后,映射得到整个图的表征。 数据…...

时间复杂度的计算(2023-02-10)
时间复杂度的计算 时间复杂度的计算分为三大类:一层循环、二层循环和多层循环。 一层循环 1.找出循环趟数t及每轮循环i的变化值 2.确立循环停止的条件 3.得出t与i之间的关系 4.联立两式,得出结果 eg: void fun(int n) {int i0;while (i*i*i<n)i;…...

测试开发之Django实战示例 第六章 追踪用户行为
第六章 追踪用户行为在之前的章节里完成了小书签将外站图片保存至本站的功能,并且实现了通过jQuery发送AJAX请求,让用户可以对图片进行喜欢/不喜欢操作。这一章将学习如何创建一个用户关注系统和创建用户行为流数据,还将学习Django的信号框架…...

红米9a手动root方法
简介 已知红米6A/6/9/9A/9C/10A机器都可以快速解锁BL,无任何变砖风险 并且秒解锁BL后和官方解锁一样,无任何其他不良影响。推荐大家使用官网解锁,需要等待7天。 BootLoader BootLoader是在操作系统内核运行之前运行的一段小程序。其实…...
)
Open3D 点云最小二乘法拟合平面(剔除噪声,Python版本)
除了诱惑之外,我可以抵抗任何事物。 ----王尔德 文章目录 一、简介二、实现代码三、实现效果参考资料一、简介 这个算法的思路很简单,就是通过剔除一些异常点来拟合更为合适的平面,具体过程如下所示: 1、首先使用最小二乘法拟合一个平面系数的初值。 2、计算所有有效点到拟合…...

【SpringBoot】简述springboot项目启动数据加载内存中的三种方法
一、前言一般来说,SpringBoot工程环境配置放在properties文件中,启动的时候将工程中的properties/yaml文件的配置项加载到内存中。但这种方式改配置项的时候,需要重新编译部署,考虑到这种因素,今天介绍将配置项存到数据…...
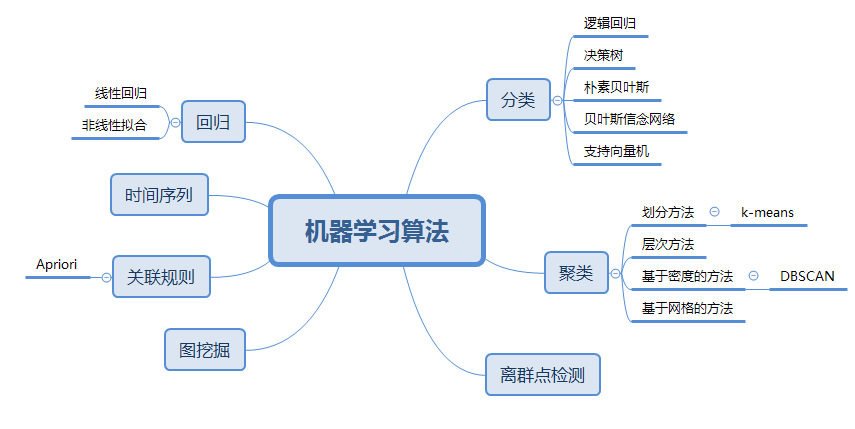
【一文速通】各种机器学习算法的特点及应用场景
近邻 (Nearest Neighbor)KNN算法的核心思想是,如果一个样本在特征空间中的K个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定…...

多传感器融合定位十四-基于图优化的定位方法
多传感器融合定位十四-基于图优化的定位方法1. 基于图优化的定位简介1.1 核心思路1.2 定位流程2. 边缘化原理及应用2.1 边缘化原理2.2 从滤波角度理解边缘化3. 基于kitti的实现原理3.1 基于地图定位的滑动窗口模型3.2 边缘化过程4. lio-mapping 介绍4.1 核心思想4.2 具体流程4.…...

PHP基于TCPDF第三方类生成PDF文件
最近在研发招聘的系统 遇到了这个问题 转换pdf 折腾了很久 分享一下PHP基于TCPDF第三方类生成PDF文件最近遇到一个需求,需要根据数据库的字段生成表格式的PDF文件并发送邮箱第一步、我们先去官网上面去下载tcpdf的类:http://www.tcpdf.org/或者是从githu…...
:Sentinel定义资源的方式)
SpringCloud(19):Sentinel定义资源的方式
Sentinel除了基本的定义资源的方式之外,还有其他的定义资源的方式,具体如下: 抛出异常的方式定义资源返回布尔值方式定义资源异步调用支持注解方式定义资源主流框架的默认适配1 抛出异常的方式定义资源 Sentinel中的SphU包含了try-catch风格的API。用这种方式,当资源发生了…...

前端 ES6 之 Promise 实践应用与控制反转
Promise 主要是为解决程序异步处理而生的,在现在的前端应用中无处不在,已然成为前端开发中最重要的技能点之一。它不仅解决了以前回调函数地狱嵌套的痛点,更重要的是它提供了更完整、更强大的异步解决方案。 同时 Promise 也是前端面试中必不…...

LightGBM
目录 1.LightGBM的直方图算法(Histogram) 直方图做差加速 2.LightGBM得两大先进技术(GOSS&EFB) 2.1 单边梯度抽样算法(GOSS) 2.2 互斥特征捆绑算法(EFB) 3.LightGBM得生长策略(leaf-wise) 通过与xgboost对比,在这里列出lgb新提出的几个方面的技术 1.Ligh…...
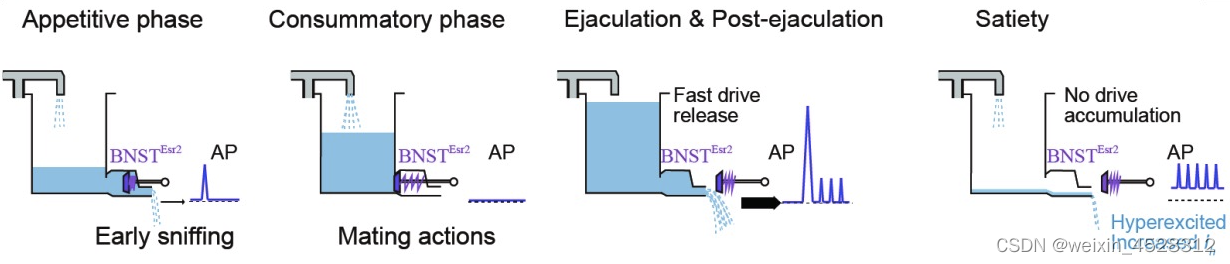
Science:北京脑研究中心李莹实验室揭示性满足感的分子机制
短暂的社交经历(例如,性经历)可导致内部状态的长期变化并影响社会行为,如交配、攻击。例如,在成功交配射精后,许多物种迅速表现出对交配倾向的抑制有数小时、数天或更长时间,这种效应称为性满足…...

Element UI框架学习篇(三)
Element UI框架学习篇(三) 实现简单登录功能(不含记住密码) 1 准备工作 1.1 在zlz包下创建dto包,并创建userDTO类(传输对象) package com.zlz.dto;import lombok.Data;/* DTO 数据传输对象 用户表的传输对象 调用控制器传参使用 VO 控制器返回的视图对象 与页面对应 PO 数据…...
尚硅谷的尚融宝项目
先建立一个Maven springboot项目 进来先把src删掉,因为是一个父项目,我们删掉src之后,pom里配置的东西,也能给别的模块使用。 改一下springboot的版本号码 加入依赖和依赖管理: <properties><java.versi…...

12 Day:内存管理
前言:今天我们要完成我们操作系统的内存管理,以及一些数据结构和小组件的实现,在此之前大家需要了解我们前几天一些重要文件的内存地址存放在哪,以便我们更好的去编写内存管理模块 一,实现ASSERT断言 不知道大家有没有…...

linux基本功系列之lsof命令实战
文章目录前言一. lsof命令介绍二. 语法格式及常用选项三. 参考案例3.1 显示系统打开的文件3.2 查找某个文件相关的进程3.3 列出某个用户打开的文件信息3.4 列出某个程序进程所打开的文件信息3.5 查看某个进程号打开的文件3.6 列出所有的网络连接3.7 列出谁在使用某个端口3.8 恢…...
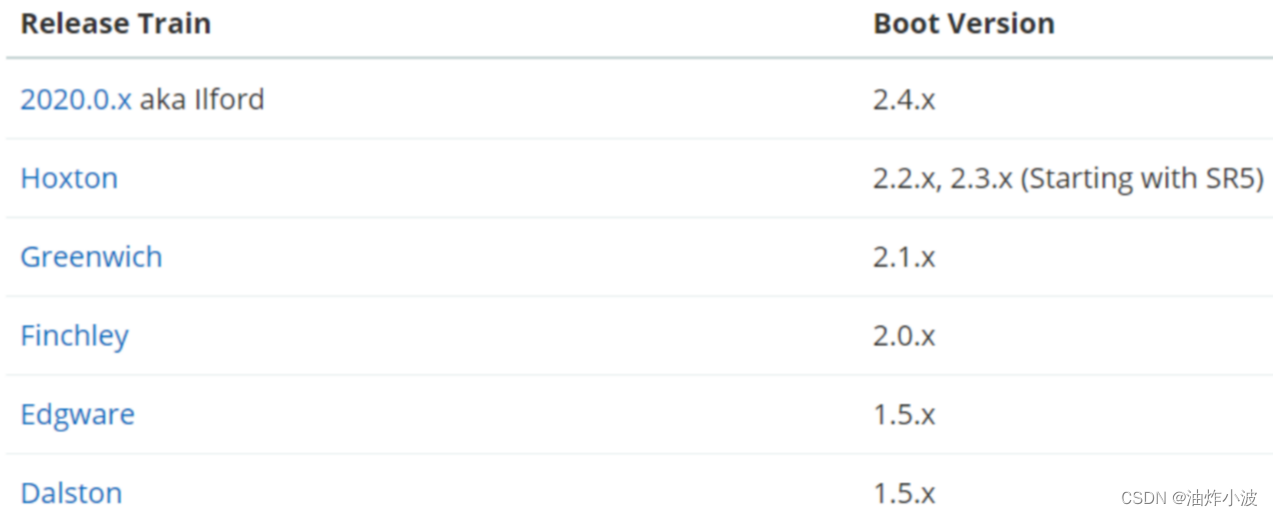
基础篇:02-SpringCloud概述
1.SpringCloud诞生 基于前面章节,我们深知微服务已成为当前开发的主流技术栈,但是如dubbo、zookeeper、nacos、rocketmq、rabbitmq、springboot、redis、es这般众多技术都只解决了一个或一类问题,微服务并没有一个统一的解决方案。开发人员或…...
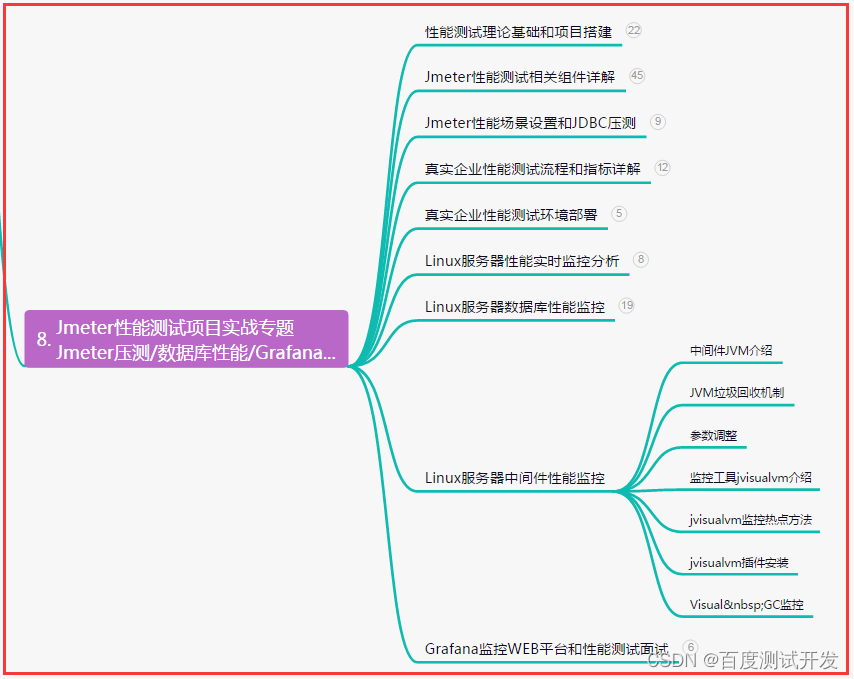
【软件测试】软件测试工作上95%会遇到的问题,你遇到多少?
目录:导读前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜)前言 1、测试负责人要进行…...

4.5.4 LinkedList
文章目录1.特点2.常用方法3.练习:LinkedList测试1.特点 链表,两端效率高,底层就是链表实现的 List接口的实现类,底层的数据结构为链表,内存空间是不连续的 元素有下标,有序允许存放重复的元素在数据量较大的情况下,查询慢&am…...

PvZ Toolkit终极指南:5分钟掌握植物大战僵尸PC版最强修改器
PvZ Toolkit终极指南:5分钟掌握植物大战僵尸PC版最强修改器 【免费下载链接】pvztoolkit 植物大战僵尸 PC 版综合修改器 项目地址: https://gitcode.com/gh_mirrors/pv/pvztoolkit 植物大战僵尸PC版玩家们,你是否想过拥有无限阳光、免费种植、自定…...

USB设备开发避坑指南:手把手教你读懂配置描述符的bmAttributes和bMaxPower
USB设备电源管理实战:深度解析配置描述符的bmAttributes与bMaxPower设计 当键盘突然在关键时刻失灵,或者医疗设备在手术中意外断电,背后往往隐藏着USB电源配置的致命错误。去年某知名外设厂商的召回事件,根源正是bMaxPower字段的2…...

在自动化脚本中集成Taotoken实现按需调用不同大模型的能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在自动化脚本中集成Taotoken实现按需调用不同大模型的能力 对于需要处理多种任务的自动化脚本,单一模型往往难以满足所…...

热成像与计算机视觉融合:打造免提可穿戴交互新范式
1. 项目概述:从一次“意外”到可穿戴交互新范式 在实验室里摆弄新到的热成像相机,这原本只是一个打发时间的“快乐意外”。我的咖啡杯、显示器,甚至是我自己的脸,在热成像镜头下都呈现出有趣的温度图案。但真正让我停下手中咖啡的…...

智能网联单轨捷运编组协同控制【附仿真】
✨ 长期致力于跨座式单轨车辆、单轨捷运系统、智能编组运行、协同避撞、协同控制研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)融合车距与速度的多层…...
分享2026最新版)
艾尔登法环风灵月影修改器下载(已汉化)分享2026最新版
《艾尔登法环》以交界地为舞台,打造了一款兼具开放世界探索与高难度挑战的角色扮演游戏。玩家将扮演褪色者,在破碎的土地上冒险,挑战强大敌人、收集装备、提升能力,最终成为艾尔登之王。游戏以硬核战斗与开放探索为核心࿰…...

带拉杆雨篷的拉杆和耳板的设置原则
带拉杆雨篷的拉杆和耳板的设置原则 同纯悬挑雨篷一样,带拉杆雨篷也常常被设计为静定体系,传力路径中某一环节发生问题,即可导致整体结构体系的破坏,结构容错能力较差。无法形成超静定结构体系所有的多道设防机制,对于设计或者施工缺陷过于敏感,这是带拉杆雨篷事故发生的…...

Cursor Pro功能解锁:3步实现免费无限制使用AI编辑器完整指南
Cursor Pro功能解锁:3步实现免费无限制使用AI编辑器完整指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached yo…...

ZimaOS Blue:本地优先AI代理运行时,打造私有化智能助手
1. 项目概述:ZimaOS Blue,一个为“大胆构建者”准备的本地优先AI代理运行时 如果你和我一样,对当前AI应用生态里那些动辄需要联网、依赖特定云服务、数据隐私存疑的“智能助手”感到厌倦,同时又渴望一个能真正运行在自己设备上、…...

Illustrator智能脚本终极指南:如何让设计效率提升300%
Illustrator智能脚本终极指南:如何让设计效率提升300% 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 还在为Adobe Illustrator中重复繁琐的操作而烦恼吗?想…...