【Redis专题】Redis核心数据结构实战与高性能原理解析
目录
- 前言
- 课程内容
- 一、redis数据类型
- 1.1 字符串(string)类型:比较简单的一种使用
- 存储模型
- 常用命令:(截取自【菜鸟教程】)
- 部分演示
- 应用场景
- 1.2 哈希(hash)类型:同类数据归类
- 存储模型
- 常用命令:(截取自【菜鸟教程】)
- 部分演示
- 应用场景
- 优缺点
- 1.3 列表(list)类型:实现丰富的数据结构
- 存储模型
- 常用命令:(截取自【菜鸟教程】)
- 部分演示
- 应用场景
- 1.4 无序集合(set)类型:支持集合操作的类型
- 存储模型
- 常用命令:(截取自【菜鸟教程】)
- 部分演示
- 应用场景
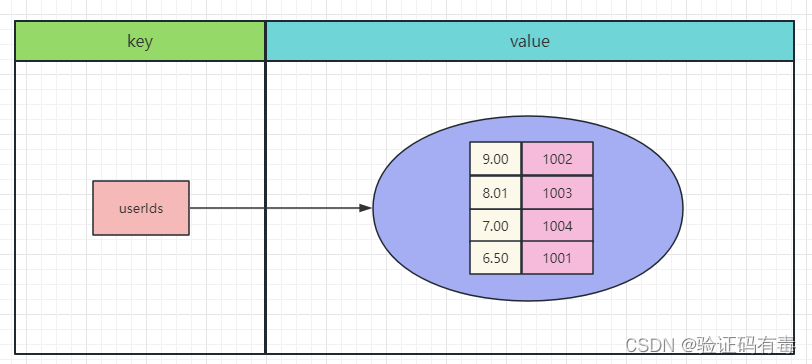
- 1.5 有序集合(ZSet,又叫Sorted Set):带分值的
- 存储模型
- 常用命令:(截取自【菜鸟教程】)
- 部分演示
- 应用场景
- 1.6 HyperLogLog:基数统计算法
- 什么是基数(该数据类型需要理解的概念)
- 实例
- 二、Keys命令
- 三、Redis的高性能原理(非常重要)
- 3.1 Redis的单线程
- 3.2 Redis的单线程为什么这么快?
- 3.3 Redis 单线程如何处理那么多的并发客户端连接?
- 3.3.1 什么是IO多路复用
- BIO:同步阻塞IO
- NIO:Non-BIO,非阻塞IO
- 3.3.2 什么是Epoll模型
- 3.3.3 Redis网络IO模型图
- 学习总结
- 感谢
前言
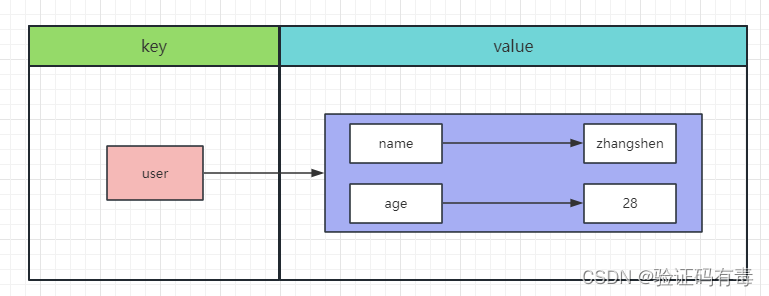
无论是什么数据类型,在Redis是以
K-V结构存储在内存中的。跟我们Java中的HashMap差不多道理。这里说的k是指缓存的键名,V是值。并且,K键都是字符串类型,而我们常说的数据类型其实是指V值的类型!
课程内容
一、redis数据类型
PS:这里的数据类型是指V,Value值的类型,务必理解
- Redis支持5种核心的数据类型,分别是字符串、哈希、列表、集合、有序集合
- Redis还提供了Bitmap、HyperLogLog、Geo类型,但这些类型都是基于上述核心数据类型实现 的;
- Redis在5.0新增加了Streams数据类型,它是一个功能强大的、支持多播的、可持久化的消息队列
1.1 字符串(string)类型:比较简单的一种使用
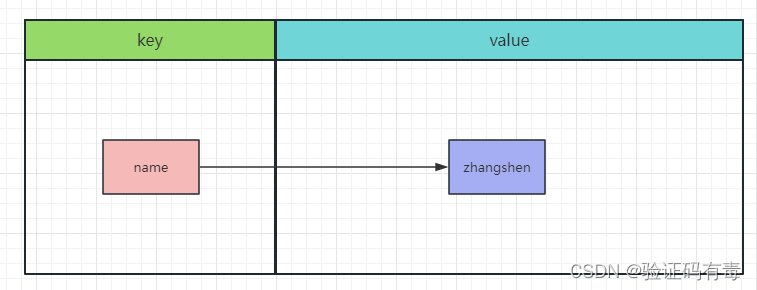
基本介绍:String类型是简单的
key-value类型,value其实不仅是String,也可以是数字,是包含很多种类型的特殊类型,并且是二进制安全的。比如序列化的对象进行存储,比如一张图片进行二进制存储,比如一个简单的字符串,数值等等。
存储模型
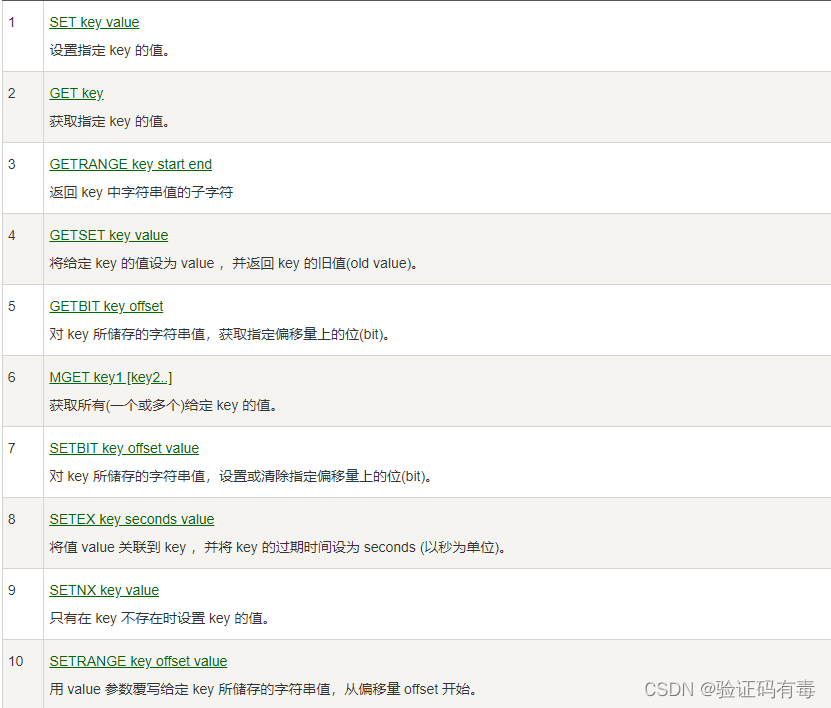
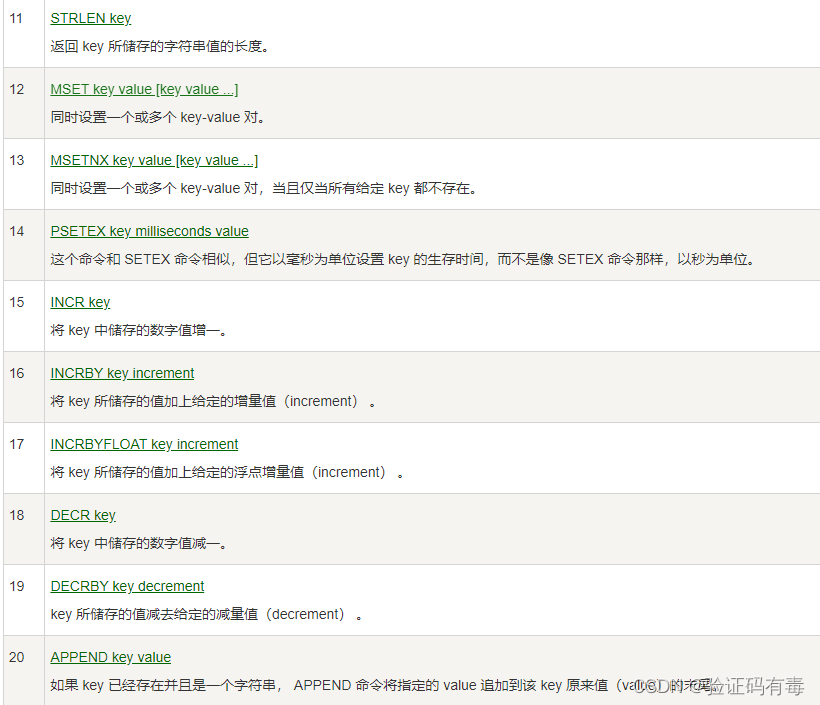
常用命令:(截取自【菜鸟教程】)
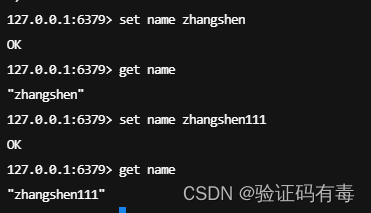
部分演示
-
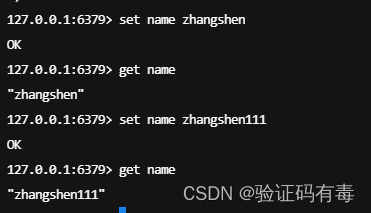
SET key value:Redis SET 命令用于设置给定 key 的值。如果 key 已经存储其他值, SET 就覆写旧值,且无视类型
-
GET key:Redis Get 命令用于获取指定 key 的值。如果 key 不存在,返回 nil 。如果key 储存的值不是字符串类型,返回一个错误
-
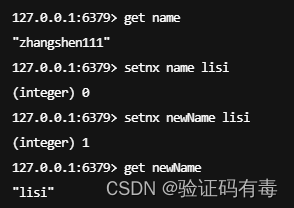
SETEX key value:Redis Setnx(SET if Not eXists) 命令在指定的 key 不存在时,为 key 设置指定的值
-
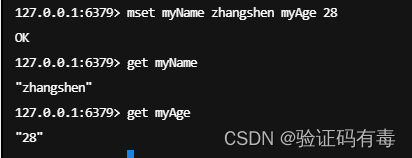
MSET key value [key value]:Redis Mset 命令用于同时设置一个或多个 key-value 对
-
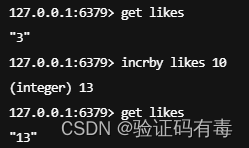
INCR key:Redis Incr 命令将 key 中储存的数字值增一。如果 key 不存在,那么 key 的值会先被初始化为 0 ,然后再执行 INCR 操作;如果值包含错误的类型,或字符串类型的值不能表示为数字,那么返回一个错误;本操作的值限制在 64 位(bit)有符号数字表示之内

-
INCRBY key increment:Redis Incrby 命令将 key 中储存的数字加上指定的增量值。如果 key 不存在,那么 key 的值会先被初始化为 0 ,然后再执行 INCRBY 命令;如果值包含错误的类型,或字符串类型的值不能表示为数字,那么返回一个错误;本操作的值限制在 64 位(bit)有符号数字表示之内
应用场景
- 在redis单线程io,天生线程安全的特性下,使用
setnx实现分布式锁 - web集群session共享(单点登录)
- 分布式系统全局序列号(
INCRBY orderId 1000)
1.2 哈希(hash)类型:同类数据归类
基本介绍:Hash类型其实也是一个
K-V结构的映射表。它特别适合存储对象,相比较而言,将一个对象类型存储在Hash类型,比存储在String类型里占用更少的内存空间,并方便整个对象的存取
存储模型
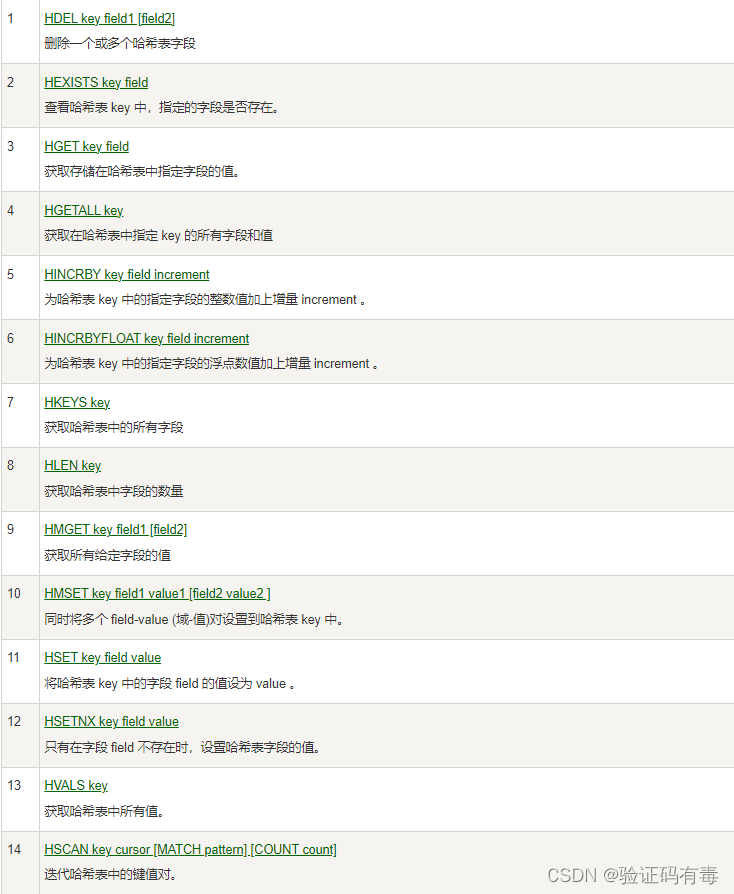
常用命令:(截取自【菜鸟教程】)
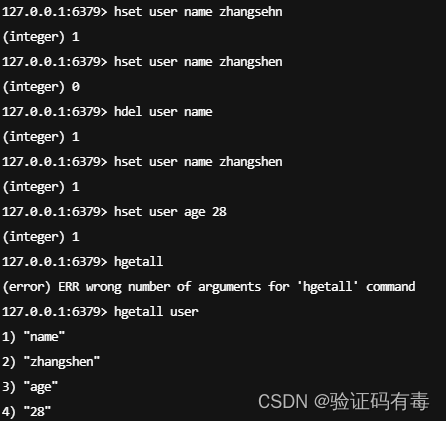
部分演示
HSET key filed value:Redis Hset 命令用于为哈希表中的字段赋值。如果哈希表不存在,一个新的哈希表被创建并进行 HSET 操作;如果字段已经存在于哈希表中,旧值将被覆盖HGET key filed:Redis Hget 命令用于返回哈希表中指定字段的值HGETALL key:Redis Hgetall 命令用于返回哈希表中,所有的字段和值。在返回值里,紧跟每个字段名(field name)之后是字段的值(value),所以返回值的长度是哈希表大小的两倍HDEL key filed:Redis Hdel 命令用于删除哈希表 key 中的一个或多个指定字段,不存在的字段将被忽略
应用场景
- 电商购物车(每个用户购物车是唯一的,但是购物车里面的东西可以是多个的,如下)
电商购物车:
1)以用户id为key
2)商品id为field
3)商品数量为value
购物车操作
添加商品hset cart:1001 10088 1
增加数量hincrby cart:1001 10088 1
商品总数hlen cart:1001
删除商品hdel cart:1001 10088
获取购物车所有商品hgetall cart:1001
优缺点
优点
1)同类数据归类整合储存,方便数据管理
2)相比string操作消耗内存与cpu更小
3)相比string储存更节省空间
缺点
过期功能不能使用在field上,只能用在key上
Redis集群架构下不适合大规模使用
1.3 列表(list)类型:实现丰富的数据结构
基本介绍:List类型是一个链表结构的集合,其主要功能有push、pop、获取元素等。更详细的说,List类型是一个双端链表的结构,我们可以通过相关的操作进行集合的头部或者尾部添加和删除元素,List的设计非常简单精巧,即可以作为栈,又可以作为队列,满足绝大多数的需求。
存储模型
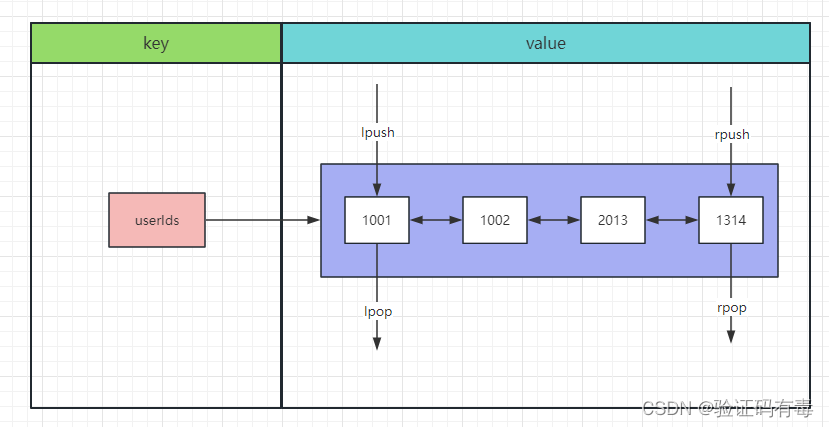
常用命令:(截取自【菜鸟教程】)
部分演示
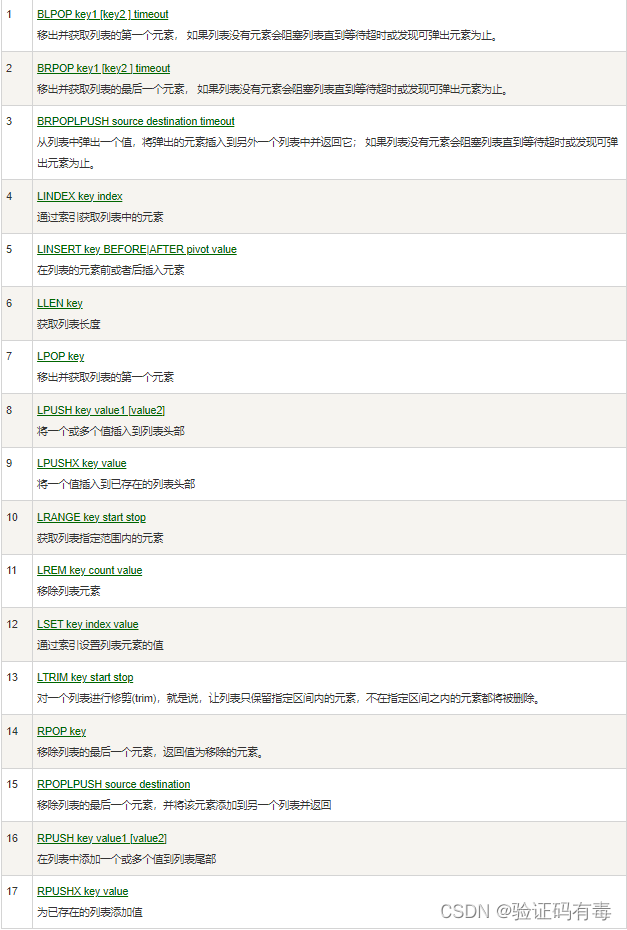
LPUSH key value [value1]或者RPUSH key value1 [value2]:Redis Lpush 命令将一个或多个值插入到列表头部。 如果 key 不存在,一个空列表会被创建并执行 LPUSH 操作。 当 key 存在但不是列表类型时,返回一个错误(RPUSH是插入到尾部,其余特性一样)LPOP key或者RPOP key:Redis Lpop 命令用于移除并返回列表的第一个元素。Rpop命令用于移除列表的最后一个元素,返回值为移除的元素
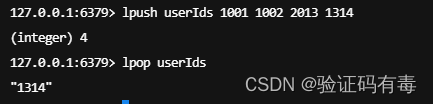
LRANGE key start end:Redis Lrange 返回列表中指定区间内的元素,区间以偏移量 START 和 END 指定。 其中 0 表示列表的第一个元素, 1 表示列表的第二个元素,以此类推。 你也可以使用负数下标,以 -1 表示列表的最后一个元素, -2 表示列表的倒数第二个元素,以此类推
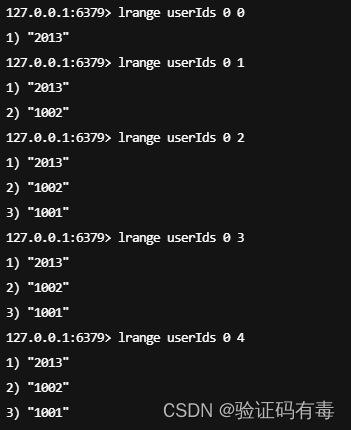
BLPOP key [key] timeout或者BRPOP key [key] timeout:Redis Blpop 命令移出并获取列表的第一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止;Redis Brpop 命令移出并获取列表的最后一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止
应用场景
- 可以利用list的特性,制作如下数据结构:
Stack(栈) = LPUSH + LPOP
Queue(队列)= LPUSH + RPOP
Blocking MQ(阻塞队列)= LPUSH + BRPOP
- 微博和微信公众号消息流
通过将我关注用户消息推流,push进我的缓存列表中,上线的时候,再全部pop出来。但当然这个办法并不是唯一的,只不过是说可以这么来而已。如下:
诸葛老师关注了MacTalk,备胎说车等大V
1)MacTalk发微博,消息ID为10018
LPUSH msg:{诸葛老师-ID} 10018
2)备胎说车发微博,消息ID为10086
LPUSH msg:{诸葛老师-ID} 10086
3)查看最新微博消息
LRANGE msg:{诸葛老师-ID} 0 4
1.4 无序集合(set)类型:支持集合操作的类型
基本介绍:Redis 的 Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据。集合对象的编码可以是 intset 或者 hashtable。Redis 中集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。集合中最大的成员数为 232 - 1 (4294967295, 每个集合可存储40多亿个成员)。
存储模型
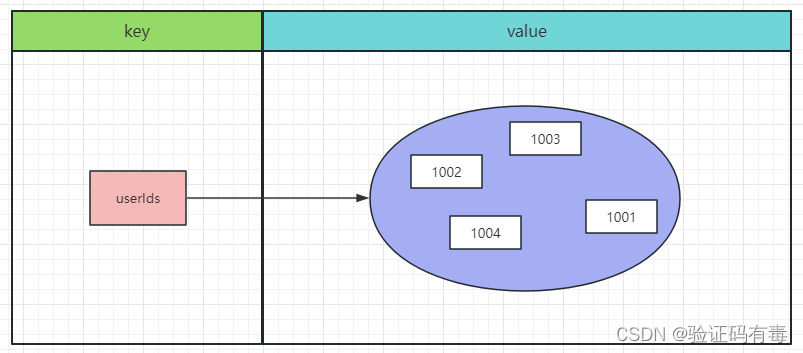
常用命令:(截取自【菜鸟教程】)

部分演示
这里就不太想演示一般操作了,这个东西还是需要大家自己去做。不过,redis关于set这个数据类型有一个很有趣的操作,就是数学概念里面的【交集】、【并集】、【差集】也能实现。
例如:
我在我的购物车里添加了:华为、oppo、小米
你在你的购物车里添加了:小米、vivo、一加
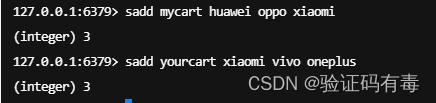
下面开始对这个集合做【交集】、【并集】、【差集】等操作
-
SINTER key [key]:Redis Sinter 命令返回给定所有给定集合的交集。 不存在的集合 key 被视为空集。 当给定集合当中有一个空集时,结果也为空集(根据集合运算定律)

-
SINTERSTORE destination key [key]:Redis Sinterstore 命令将给定集合之间的交集存储在指定的集合中。如果指定的集合已经存在,则将其覆盖
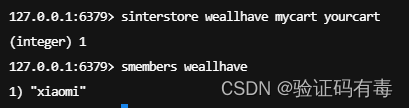
-
SUNION key [key]:Redis Sunion 命令返回给定集合的并集。不存在的集合 key 被视为空集
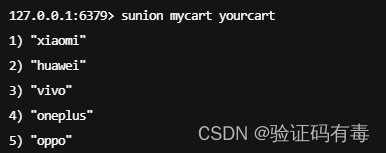
-
SUNIONSTORE key [key]:Redis Sunionstore 命令将给定集合的并集存储在指定的集合 destination 中。如果 destination 已经存在,则将其覆盖
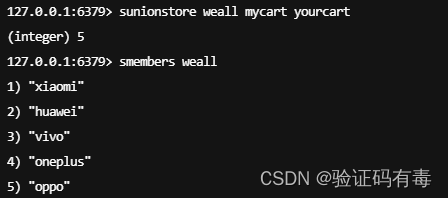
-
SDIFF key [key]:Redis Sdiff 命令返回第一个集合与其他集合之间的差异,也可以认为说前面的集合中独有的元素。不存在的集合 key 将视为空集。差集的结果来自前面的 FIRST_KEY,而不是后面的 OTHER_KEY1,也不是整个 FIRST_KEY OTHER_KEY1…OTHER_KEYN 的差集
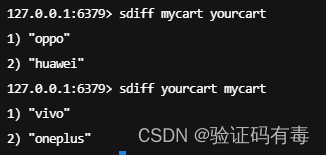
-
SDIFFSTORE destination key [key]:Redis Sdiffstore 命令将给定集合之间的差集存储在指定的集合中。如果指定的集合 key 已存在,则会被覆盖
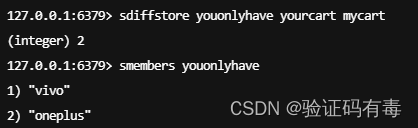
应用场景
- 微信抽奖小程序
由于参加活动的id是唯一的,并且开奖是随机的,所以可以利用sadd key member [members]添加唯一用户;srandmembers key [count]或者spop key [count]随机获取中奖名单
1)点击参与抽奖加入集合
SADD key {userlD}
2)查看参与抽奖所有用户
SMEMBERS key
3)抽取count名中奖者
SRANDMEMBER key [count] / SPOP key [count]
- 微信微博点赞,收藏,标签
微信点赞列表大家还记得吧?如果不是本人朋友圈,我们只能看到自己跟对方共同好友的点赞情况。这里就刚好可以用到交集了
微信好友的朋友圈
1)点赞
SADD like:{消息ID} {用户ID}
2)取消点赞
SREM like:{消息ID} {用户ID}
3)检查用户是否点过赞
SISMEMBER like:{消息ID} {用户ID}
4)获取我的好友也点赞了的用户列表
SINTER like:{消息ID} myfriend
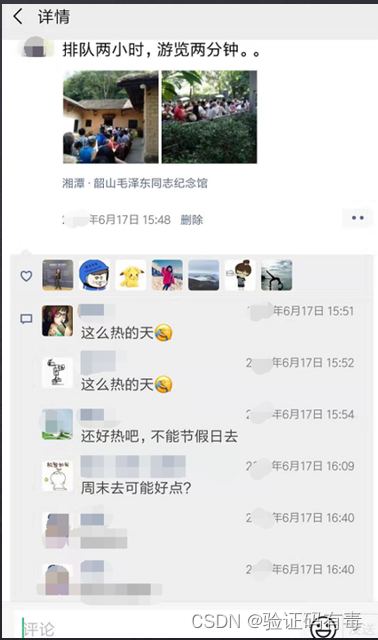
- 集合操作
SINTER set1 set2 set3得到:{ c }
SUNION set1 set2 set3得到:{ a,b,c,d,e }
SDIFF set1 set2 set3得到:{ a }
- 集合操作实现微博、微信关注模型
1)诸葛老师关注的人:
smembers zhugeSet得到 {guojia, xushu}
2)杨过老师关注的人:
smembers yangguoSet得到 {zhuge, baiqi, guojia, xushu}
3)郭嘉老师关注的人:
smembers guojiaSet得到 {zhuge, yangguo, baiqi, xushu, xunyu)
4)我和杨过老师共同关注:
SINTER zhugeSet yangguoSet得到 {guojia, xushu}
5)我关注的人也关注他(杨过老师):
SISMEMBER guojiaSet yangguo
SISMEMBER xushuSet yangguo
6)我可能认识的人:
SDIFF yangguoSet zhugeSet得到(zhuge, baiqi}
- 集合操作实现电商商品筛选
通过sadd给不同的标签添加商品,再使用sinter获取不同标签的交集
SADD brand:huawei P40
SADD brand:xiaomi mi-10
SADD brand:iPhone iphone12
SADD os:android P40 mi-10
SADD cpu:brand:intel P40 mi-10
SADD ram:8G P40 mi-10 iphone12
SINTER os:android cpu:brand:intel ram:8G {P40,mi-10}

1.5 有序集合(ZSet,又叫Sorted Set):带分值的
基本介绍:Redis 有序集合和前面的无序集合一样也是 string 类型元素的集合,且不允许重复的成员。不同的是每个元素都会关联一个 double 类型的分数,redis 正是通过分数来为集合中的成员进行从小到大的排序。有序集合的成员是唯一的,但分数(score)却可以重复。集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。 集合中最大的成员数为 232 - 1 (4294967295, 每个集合可存储40多亿个成员)。
存储模型
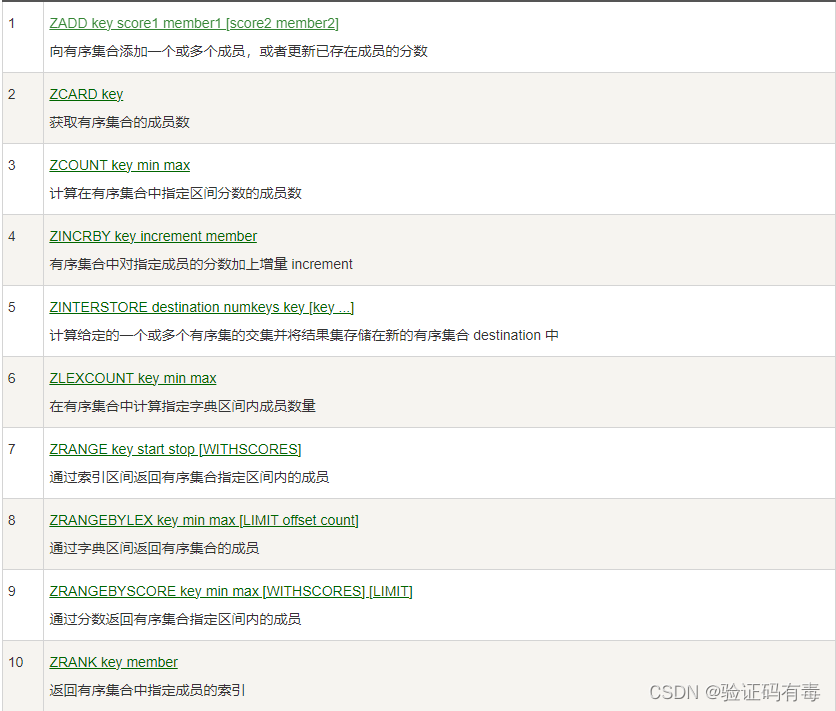
常用命令:(截取自【菜鸟教程】)
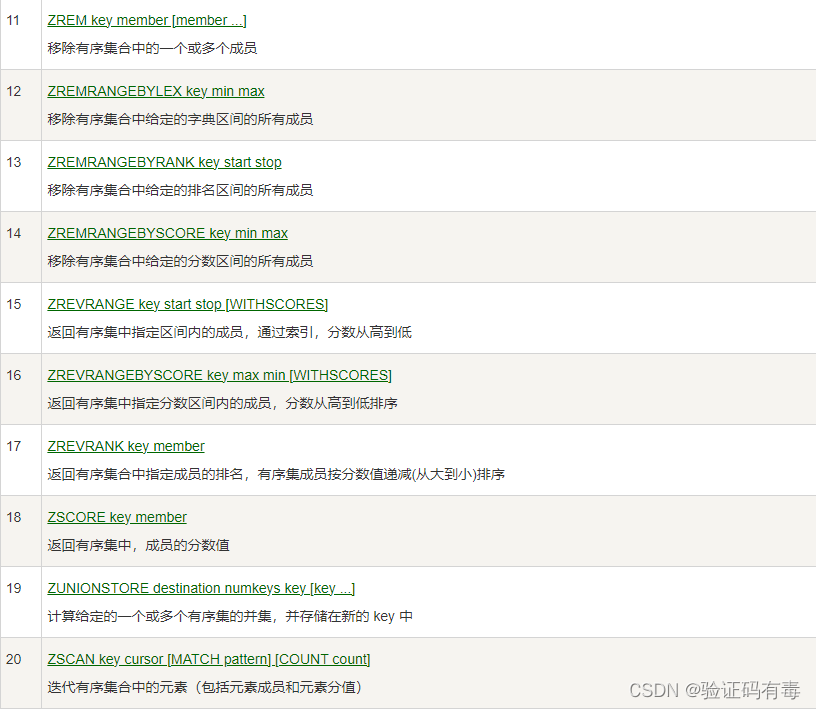
部分演示
这个数据类型的操作跟上面说的基本相似,但不同的是zset需要指定操作集合keys的数量。同也有集合的【交集】、【并集】操作。这里就不再演示了,当然这里最重要的还是关于分值的操作。
-
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT]:Redis Zrangebyscore 返回有序集合中指定分数区间的成员列表。有序集成员按分数值递增(从小到大)次序排列。具有相同分数值的成员按字典序来排列(该属性是有序集提供的,不需要额外的计算)。默认情况下,区间的取值使用闭区间 (小于等于或大于等于),你也可以通过给参数前增加 ( 符号来使用可选的开区间 (小于或大于)。举个例子:ZRANGEBYSCORE zset (1 5表示:返回所有符合条件 1 < score <= 5 的成员- 而
ZRANGEBYSCORE zset (5 (10则表示:则返回所有符合条件 5 < score < 10 的成员。

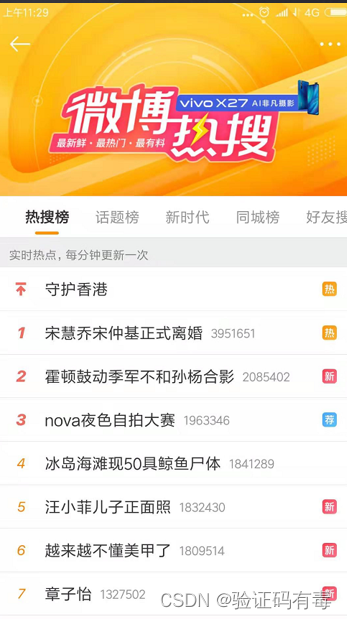
应用场景
- 实现新闻热搜榜
1)点击新闻
ZINCRBY hotNews:20190819 1守护香港
2)展示当日排行前十
ZREVRANGE hotNews:20190819 0 9 WITHSCORES
3)七日搜索榜单计算
ZUNIONSTORE hotNews:20190813-20190819 7 hotNews:20190813 ..(省略中间).. hotNews:20190819
4)展示七日排行前十
ZREVRANGE hotNews:20190813-20190819 0 9 WITHSCORES
1.6 HyperLogLog:基数统计算法
基本介绍:Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定 的、并且是很小的。在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
什么是基数(该数据类型需要理解的概念)
比如数据集 {1, 3, 5, 7, 5, 7, 8}, 那么这个数据集的基数集为{1, 3, 5 ,7, 8}, 基数(不重复元素)为5。 基数估计就是在误差可接受的范围内,快速计算基数
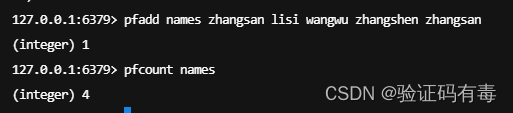
实例
PFADD key element [elements]:Redis Pfadd 命令将所有元素参数添加到 HyperLogLog 数据结构中。PFCOUNT key:Redis Pfcount 命令返回给定 HyperLogLog 的基数估算值PFMERGE destkey sourcekey [sourcekeys]:
二、Keys命令
下面是keys的命令,同样是截取自【菜鸟教程】。
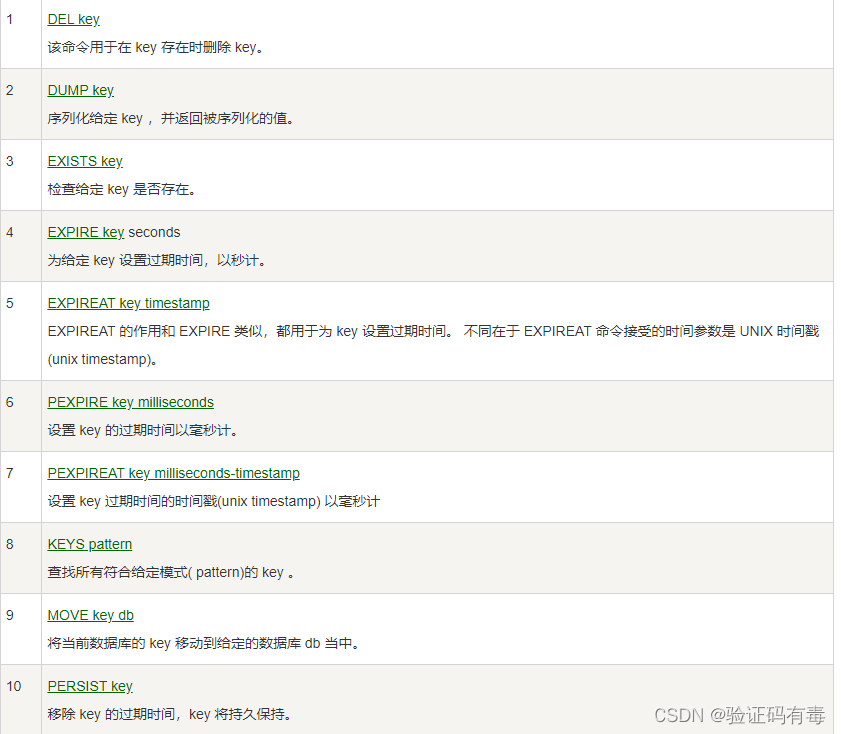
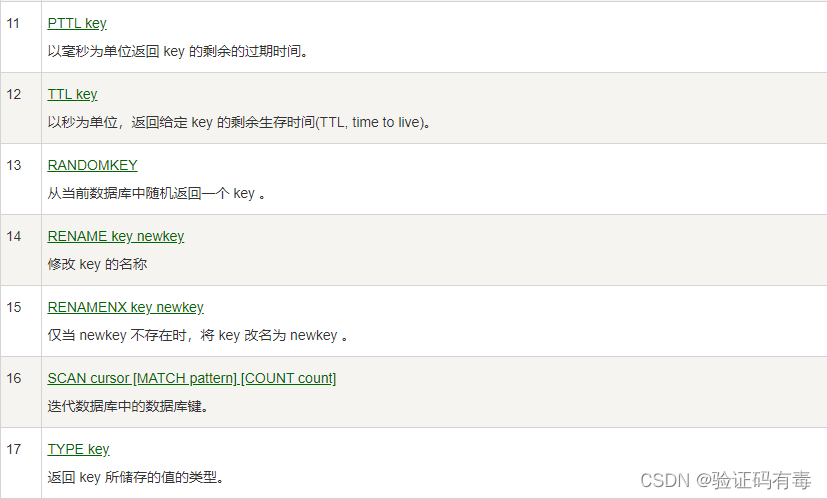
上面这些key的相关操作都是比较常用的。这里主要想说的是SCAN cursor [MATCH PATTERN] [COUNT count]命令,用来迭代数据库中键的。这个命令乍一看跟KEY pattern很像,确实,但是前者可以认为是含【分页】功能的。显然,在key比较多的时候,前者更好用一些。
SCAN cursor [MATCH PATTERN] [COUNT count]:Scan 命令用于迭代数据库中的数据库键。SCAN 命令是一个基于游标的迭代器,每次被调用之后, 都会向用户返回一个新的游标, 用户在下次迭代时需要使用这个新游标作为 SCAN 命令的游标参数, 以此来延续之前的迭代过程。SCAN 返回一个包含两个元素的数组, 第一个元素是用于进行下一次迭代的新游标, 而第二个元素则是一个数组, 这个数组中包含了所有被迭代的元素。如果新游标返回 0 表示迭代已结束。- cursor - 游标
- pattern - 匹配的模式
- count - 可选,用于指定每次迭代返回的 key 的数量,默认值为 10

三、Redis的高性能原理(非常重要)
3.1 Redis的单线程
Redis是单线程吗?不全对。Redis 的单线程主要是指:Redis的【网络IO】和【键值对读写】是由一个线程来完成的,这也是 Redis 对外提供键值存储服务的主要流程。但 Redis 的其他功能,比如持久化、异步删除、集群数据同步等,其实是由额外的线程执行的。
上面这里,估计没有经验,或者不懂什么是【持久化】、【异步删除】、【集群数据同步】的同学可能不懂。大部分人可能知道,并且了解的是【网络IO】和【键值对读写】。所以,大家可以认为,我们主流业务【网络连接(accept) -> 读取请求内容(read) -> 执行命令 -> 响应内容(write)】是单线程下执行的。(PS:其实redis6.0之后,网络连接IO这一块已经变成多线程了,这个我们会在3.3中详细讲解)
3.2 Redis的单线程为什么这么快?
因为它所有的数据都在内存中,所有的运算都是内存级别的运算,而且单线程避免了多线程的切换性能损耗问题。正因为 Redis 是单线程,所以要小心使用 Redis 指令,对于那些耗时的指令(比如
keys),一定要谨慎使用,一不小心就可能会导致Redis卡顿。
3.3 Redis 单线程如何处理那么多的并发客户端连接?
要想了解这个,其实真的可以单独另一个大章节来说了。不过说实在,网络上有很多篇文章写的很不错了,我就不想重复总结了。比如这篇博文:百度大佬【程序那点事】写的《详解redis网络IO模型》。如果大家想更系统的了解,我建议真的要看看。因为,我们需要从BIO -> NIO -> SELECT模型 -> POLL模型 -> EPOLL模型 -> Reactor模型的顺序,递进去学习会比较好一点。
当然,这里我依然还是会拎一些重点来简单给大家说说。
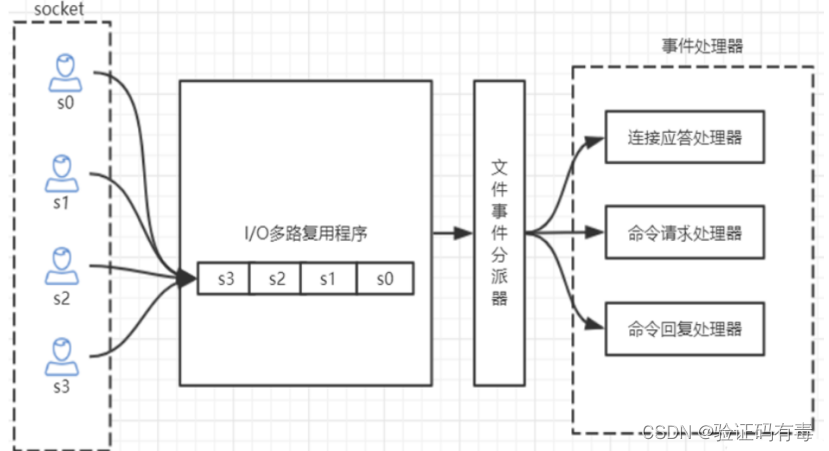
首先可以直接告诉大家的是,Redis单线程之所以也能处理那么多的并发客户端连接,是因为Redis采用了基于epoll模型来实现IO多路复用,将连接信息和事件放到队列中,依次放到文件事件分派器,事件分派器将事件分发给事件处理器。
什么是IO多路复用?什么是Epoll模型?
3.3.1 什么是IO多路复用
首先,【IO多路复用】是一种【复用机制】。是指一个线程能同时处理网络连接的多个IO流。
- IO:是指【网络IO事件,包括连接、读、写】
- 多路:是指多个【网络连接】
- 复用:指的是所有【网络连接】都在同一个线程中处理
为什么会有IO多路复用呢?因为在没有IO多路复用之前,只有BIO跟NIO两种。IO多路复用就是用来解决这两个存在的问题的!
BIO:同步阻塞IO
服务端采用单线程,一次只能处理一个请求(【网络连接(accept) -> 读取请求内容(read) -> 执行命令 -> 响应内容(write)】)。当接受一个请求后,开始调用【读取】事件,然后就阻塞在这里了。就算此时新来另一个请求,服务器也不会理睬。这就导致,后来的请求必须等上一个请求处理完了,才能被接受处理。这个估计理解单线程、串行概念的同学,应该都能理解这种IO有多么大的限制。直接放弃多核不用了,对CPU是一种极大的浪费。
欸,是不是有朋友会说,可以用多线程啊?是的,可以多线程,比如:每次新建一个线程处理。但是我们知道,线程多了机器肯定处理不了,正常每个人的电脑顶多能支持4、5K的线程数。使用线程池的话,也会受制于线程池数量而存在连接数瓶颈。
NIO:Non-BIO,非阻塞IO
相比阻塞IO,非阻塞IO会立即返回,调用者不会阻塞,此时可以做一些其它事情了,例如处理其它请求。但是非阻塞IO需要主动轮询是否有数据需要处理,且这种轮询需要从用户态切换到内核态,假如没有数据产生就会有很多空轮询,白白浪费cpu资源。
阻塞IO、非阻塞IO,要么需要开启更多线程去处理IO,要么需要从用户态切换到内核态轮询IO事件,那么有没有一种机制,用户程序只需要将请求提交给内核,由内核用少量的线程去监听,有事件就通知用户程序呢?这就是IO多路复用。
3.3.2 什么是Epoll模型
说实在这个有点难理解先,单这个东西就可以写一篇新的文章了。虽然我脑子里有点答案,但是自己都不敢保证完全正确,所以就不献丑了,还是需要大家去自己查询吧。
我个人理解,这个Epoll模型就是网络编程中的:事件驱动模型(又叫信号驱动模型)。毋庸置疑,这个是实现了IO多路复用的。
3.3.3 Redis网络IO模型图
学习总结
- 复习了redis基本数据类型
- 学习了Redis高性能原理,学习其IO模型
感谢
- 特别感谢【菜鸟教程】的【Redis教程篇】。非常推荐大家收藏的一个网站《菜鸟教程-Redis教程-传送门》
- 特别感谢西音同学的笔记,写得超级详细,建议大伙看看《传送门-Redis问题整理》
- 特别感谢百度大佬【程序那点事】的博文《详解redis网络IO模型》
相关文章:
【Redis专题】Redis核心数据结构实战与高性能原理解析
目录 前言课程内容一、redis数据类型1.1 字符串(string)类型:比较简单的一种使用存储模型常用命令:(截取自【菜鸟教程】)部分演示应用场景 1.2 哈希(hash)类型:同类数据归…...
常见的几种排序算法
目录 一、插入排序 1、直接插入排序 1.1、排序方法 1.2、图解分析 1.3、代码实现 2、希尔排序 2.1、排序方法 2.2、图解分析 2.3、代码实现 二、选择排序 1、直接选择排序 1.1、排序方法 1.2、图解分析 1.3、代码实现 2、堆排序 2.1、排序方法 2.2、图解分析 …...

动态贴纸、美颜SDK与AR:创造独特的互动体验
目前,动态贴纸、美颜SDK、增强现实(AR)等技术是比较热门的话题,它们所结合的新兴玩法更是收到大家推崇,正潜移默化的改变我们与数字世界互动的方式。 一、动态贴纸:个性化互动的开始 动态贴纸,…...

〔021〕Stable Diffusion 之 提示词反推、自动补全、中文输入 篇
✨ 目录 🎈 反推提示词 / Tagger🎈 反推提示词 Tagger 使用🎈 英文提示词自动补全 / Booru tag🎈 英文提示词自动补全 Booru tag 使用🎈 中文提示词自动补全 / tagcomplete🎈 中文提示词自动补全 tagcomple…...

如何实现响应式布局
要实现响应式布局,您可以采用以下方法: 视口设置: 在HTML的<head>部分中使用meta标签设置视口: <meta name"viewport" content"widthdevice-width, initial-scale1.0">使用百分比: 使…...

HTML <tr> 标签
实例 一个简单的 HTML 表格,包含两行两列: <table border="1"><tr><th>Month</th><th>Savings</th></tr><tr><td>January</td><td>$100</td></tr> </table>定义和用法 &l…...

点云从入门到精通技术详解100篇-点云多尺度分类网络
目录 前言 研究现状与发展趋势 国内外研究现状 点云处理应用研究现状...
电脑怎么设置定时关机,2个简单的操作
电脑作为现代生活中不可或缺的工具,我们通常会在工作或娱乐过程中使用它。但有时候,我们可能需要在一段时间后自动关机,例如在下载完成后或在睡觉前。那么电脑怎么设置定时关机呢?为了满足这种需求,电脑提供了多种定时…...

Uboot指令与烧录
目录 1 NAND Flash: 1)地址空间说明 2)烧写u-boot 3)烧写内核 4)烧写文件系统 5)设置启动参数 2 SPI Flash: 1)地址空间说明 2)烧写u-boot 3)烧写内…...

Visual Studio中使用预编译头文件
预编译头文件(Precompiled Header,PCH)是一种C/C编译优化技术,用于提高大型项目的编译速度。PCH 文件包含了常用的头文件的预编译结果,它可以在编译其他源文件之前被加载到内存中,从而减少了重复的头文件解…...

C语言:选择+编程(每日一练Day15)
目录 选择题: 题一: 题二: 题三: 题四: 题五: 编程题: 题一:寻找奇数 思路一: 题二:寻找峰值 思路一: 本人实力有限可能对一些地方解…...
,还是 arm64 架构)
确定Mac\Linux系统的架构类型是 x86-64(amd64),还是 arm64 架构
我们在下载软件或镜像时会有很多版本,那需要根据我们的系统架构选择正确的软件或镜像版本。 要确定你的系统使用的是 x86-64(amd64) 还是 arm64 架构,可以使用以下方法之一: 使用 uname 命令: 打开终端&am…...

Python脚本
update_format.py 批量转视频格式,超级慢,没什么卵用 import os import asyncio import subprocess import concurrent.futures import tracemalloctracemalloc.start()# 创建日志文件 log_file open(conversion_log.txt, w)async def convert_mkv_t…...

Kotlin的遍历方法
for循环 在下面代码中1…10表示的是1到10,两边都是闭包,输出12345678910 for (i in 1..10) println(i)加上花括号也支持 for (i: Int in 1..10) {println(i)}另外,当对整数进行for循环时,Kotlin还提供了一个step函数来定义迭代的…...

AskIt: Unified Programming Interface for Programming with Large Language Models
本文是LLM系列文章,针对《AskIt: Unified Programming Interface for Programming with Large Language Models》的翻译。 AskIt:用于大型语言模型编程的统一编程接口 摘要1 引言2 动机例子3 设计与实现4 实验评估5 相关工作6 结论 摘要 在不断发展的软…...
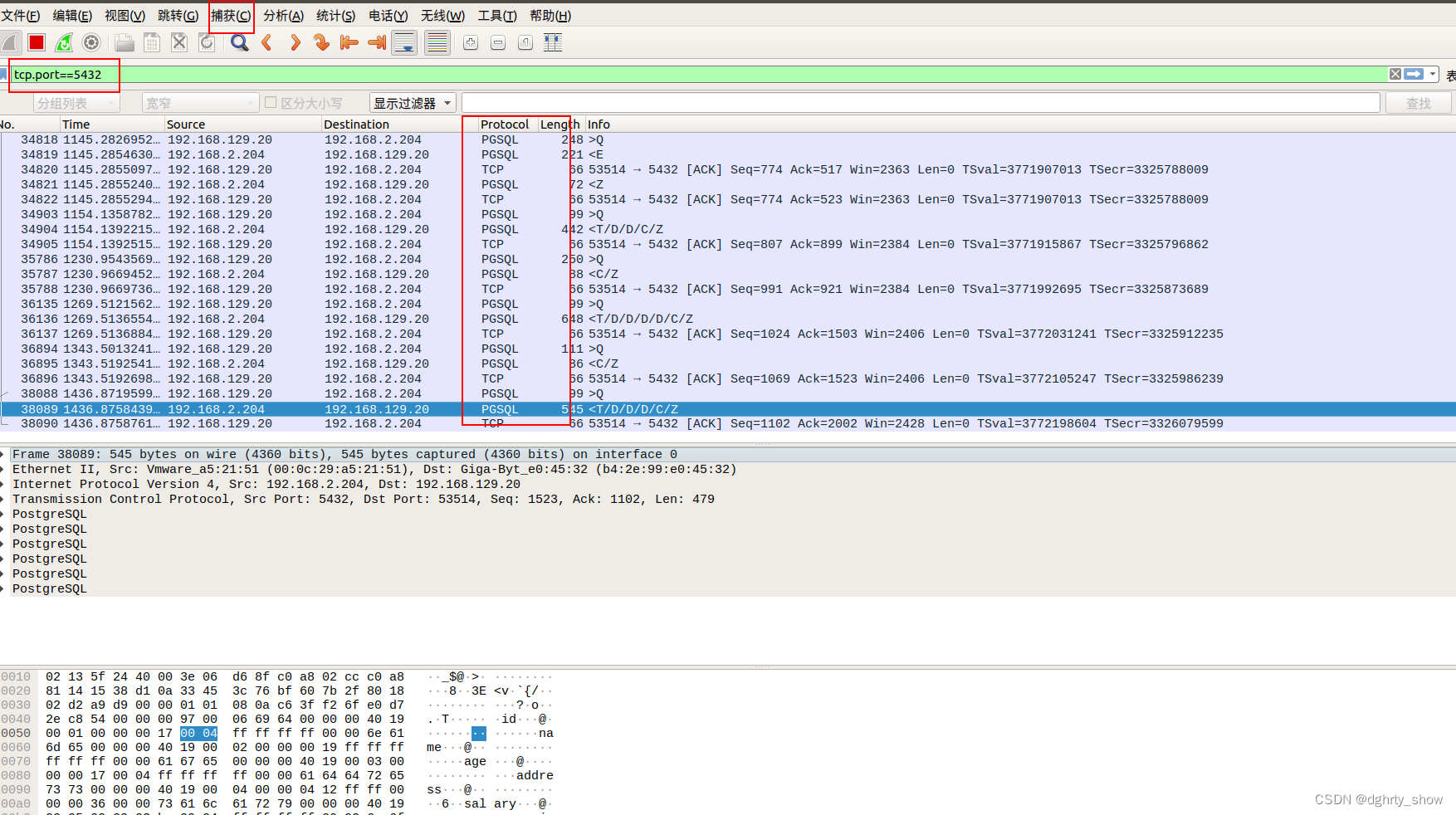
【wireshark抓取数据包-PGSQL协议】
测试查看PGSQL协议的网络流量数据明细 1)捕获过滤的条件设置,tcp.port5432(数据库的端口) 2)上面是wireshark的主窗口,分三大主块:Packlist List(数据包列表)…...

【idea学习】
1.debug: 文章详解 2.导入SpringBoot项目 文章详情...
ZooKeeper数据模型/znode节点深入
1、Znode的数据模型 1.1 Znode是什么? Znode维护了一个stat结构,这个stat包含数据变化的版本号、访问控制列表变化、还有时间戳。版本号和时间戳一起,可让Zookeeper验证缓存和协调更新。每次znode的数据发生了变化,版本号就增加。…...
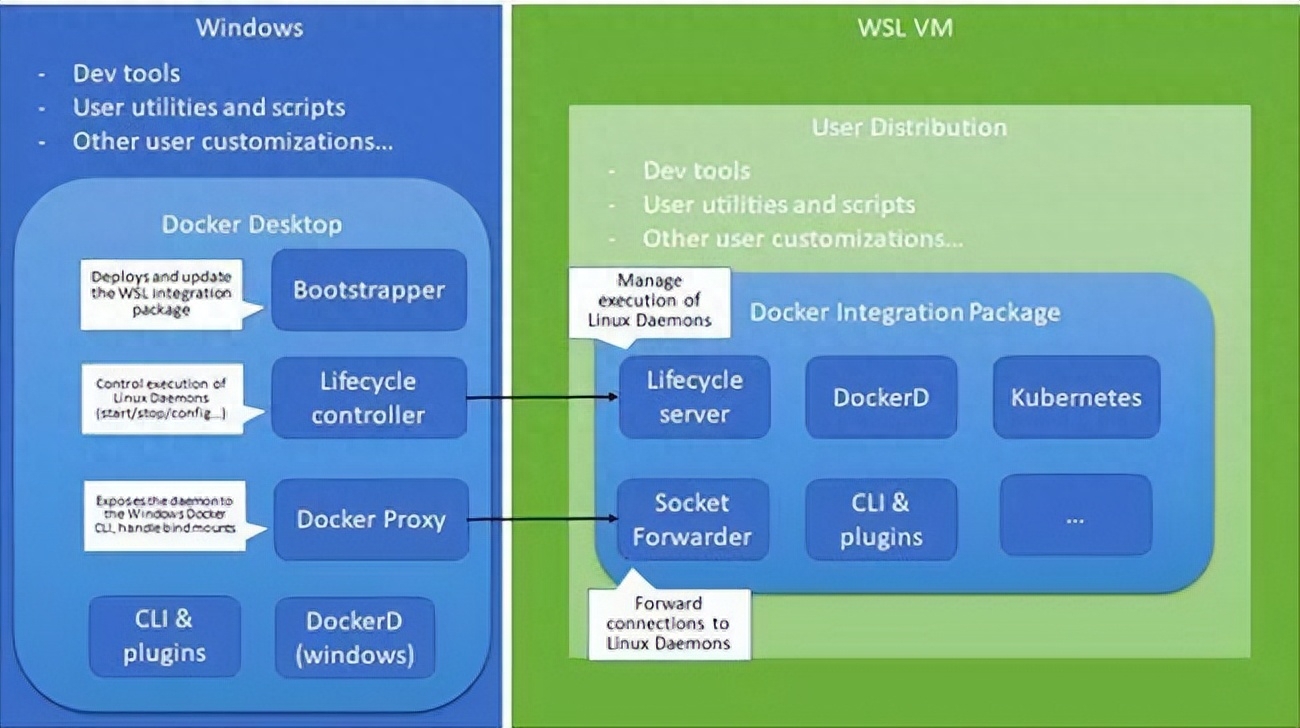
容器编排工具的比较:Kubernetes、Docker Swarm、Nomad
随着容器化技术的普及,容器编排工具成为了现代应用部署和管理的重要组成部分。容器编排工具能够自动化容器的部署、扩展和管理,从而提高应用的可靠性和可伸缩性。在众多的容器编排工具中,Kubernetes、Docker Swarm和Nomad是三个备受关注的主要…...

nginx--技术文档--架构体系--底层核心-原理
Nginx的架构体系可以概括为“一个核心、两个模型。” “一个核心”指Nginx的核心功能,即HTTP请求处理。Nginx作为一个高性能的Web服务器,其核心功能是处理HTTP请求,包括接收请求、解析请求、处理请求和返回响应等。 “两个模型”指Nginx的多…...

Vibe Vibe 未来展望:Vibe Coding 如何彻底改变编程教育生态
Vibe Vibe 未来展望:Vibe Coding 如何彻底改变编程教育生态 【免费下载链接】vibe-vibe The First Systematic Vibe Coding Open-Source Tutorial | From Zero to Full-Stack, Empowering Everyone to Build Products with AI | Live at: www.vibevibe.cn ÿ…...

QKeyMapper:重新定义Windows输入控制的终极解决方案
QKeyMapper:重新定义Windows输入控制的终极解决方案 【免费下载链接】QKeyMapper [按键映射工具] QKeyMapper,Qt开发Win10&Win11可用,不修改注册表、不需重新启动系统,可立即生效和停止。支持游戏手柄映射到键鼠,手…...

CANN/asc-devkit最新管理器模块
latest_manager Module Description 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地…...

深度解析Unity游戏实时翻译插件:XUnity.AutoTranslator的5大实战应用场景与架构设计
深度解析Unity游戏实时翻译插件:XUnity.AutoTranslator的5大实战应用场景与架构设计 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator XUnity.AutoTranslator是一款革命性的Unity游戏实时翻译插…...

【Midjourney新拟态风格实战指南】:20年AI视觉专家亲授7大参数调优公式与3类商业级提示词模板
更多请点击: https://intelliparadigm.com 第一章:Midjourney新拟态风格的视觉本质与演进逻辑 新拟态(Neumorphism)并非Midjourney原生支持的术语,而是社区在v6及Niji Mode迭代中通过提示词工程与风格迁移机制催生出的…...

从Bloodshed到Embarcadero:老牌轻量IDE Dev-C++还值得C++新手用吗?
从Bloodshed到Embarcadero:Dev-C在2024年仍是C新手的理想选择吗? 在C开发工具百花齐放的今天,一个诞生于2000年的轻量级IDE——Dev-C,历经Bloodshed、Orwell到Embarcadero的迭代,依然活跃在部分开发者的工具链中。对于…...

别再死记公式了!用Cadence仿真带你直观理解比较器的增益、失调与噪声
Cadence实战:用仿真可视化比较器的增益、失调与噪声特性 刚接触模拟电路设计时,那些复杂的公式和抽象概念总让人头疼。比较器的增益、失调电压、噪声——这些名词在教科书上看起来冰冷生硬,但当你第一次在Cadence Virtuoso中看到它们如何真实…...

微信小程序二维码生成实战指南:weapp-qrcode高效解决方案
微信小程序二维码生成实战指南:weapp-qrcode高效解决方案 【免费下载链接】weapp-qrcode 微信小程序快速生成二维码,支持回调函数返回二维码临时文件 项目地址: https://gitcode.com/gh_mirrors/weap/weapp-qrcode 在微信小程序开发中,…...

远程技术面试的潜规则:摄像头角度可能影响你的录用
一、摄像头角度:被忽视的专业细节在软件测试的工作中,我们习惯用严谨的态度去排查代码里的每一个bug,用精准的测试用例去验证产品的每一项功能。但在远程技术面试这个特殊的“测试场景”里,很多人却忽略了一个看似无关紧要&#x…...

YOLOv11公共场所人群年龄目标检测数据集-280张-pedestrian-1_5
YOLOv11公共场所人群年龄目标检测数据集 📊 数据集基本信息 目标类别: [‘adult’, ‘child’, ‘elder’]中文类别:[‘成人’, ‘儿童’, ‘老人’]训练集:196 张验证集:56 张测试集:28 张总计:…...