YOLOV8实例分割——详细记录环境配置、自定义数据处理到模型训练与部署
前言
Ultralytics YOLOv8是一种前沿的、最先进的(SOTA)模型,它在前代YOLO版本的成功基础上进行了进一步的创新,引入了全新的特性和改进,以进一步提升性能和灵活性。作为一个高速、精准且易于操作的设计,YOLOv8在广泛的领域中,包括目标检测与跟踪、实例分割、图像分类以及姿势估计等任务中,都表现出色。
实例分割在物体检测的基础上迈出了更进一步的步伐,它不仅可以识别图像中的单个物体,还能够精确地将这些物体从图像的其他部分中分割出来。
目标识别:

实例分割模型的输出是一组mask(或轮廓),这些遮罩清晰地勾勒出图像中的每个对象,同时还提供了每个对象的类别标签和置信度分数。当需要了解物体的准确形状时,实例分割变得非常有用,因为这不仅仅是关于物体位置的信息。
实例分割:

一、环境安装
1.直接安装
yolov8有两种安装方式,一种可直接安装U神的库,为了方便管理,还是在conda里面安装:
conda create -n yolov8 python=3.8
pip install ultralytics
2.源码安装
源码安装时,要单独安装torch,要不然训练的时候,有可能用不了GP,我的环境是cuda 11.7。
#新建虚拟环境
conda create -n yolov8 python=3.8
#激活
conda activate yolov8
#安装torch,
conda install pytorch==2.0.0 torchvision==0.15.0 torchaudio==2.0.0 pytorch-cuda=11.7 -c pytorch -c nvidia
#下载源码
git clone https://github.com/ultralytics/ultralytics.gitcd ultralytics
#将requirements.txt中torch torchbision 注释掉,下载其他包
pip install -r requirements.txt
3.验证
安装完成之后,验证是否安装成功。
yolo task=segment mode=predict model=yolov8s-seg.pt source='1.jpg' show=True

4.安装错误
1.OMP: Error #15: Initializing libomp.dylib, but found libiomp5.dylib already initialize
如果在训练时出现这个错误,要么就降低numpy的版本,要么就是python的版本太高,降到3.9以下就可以了。
二、数据处理
1.数据集标注
标注工具是使用LabelMe进行标注,LabelMe允许用户在图像中绘制边界框、多边形、线条和点等来标注不同类型的对象或特征。也可以标注标注类别,用户可以定义不同的标注类别,使其适应不同的项目需求。每个类别都可以有自己的名称和颜色。
这里标注了湖面的区域,用来做目标入侵检测。

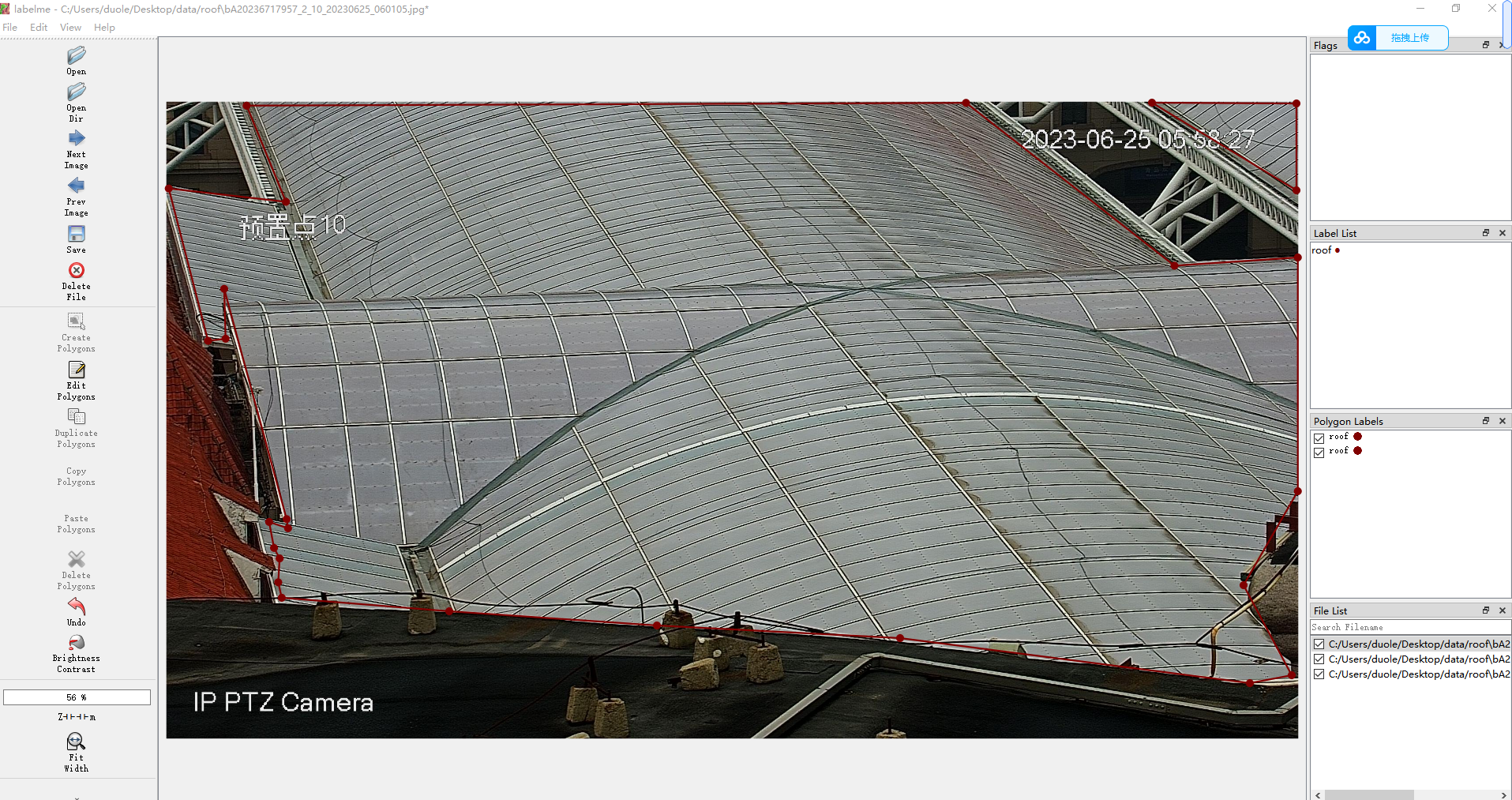

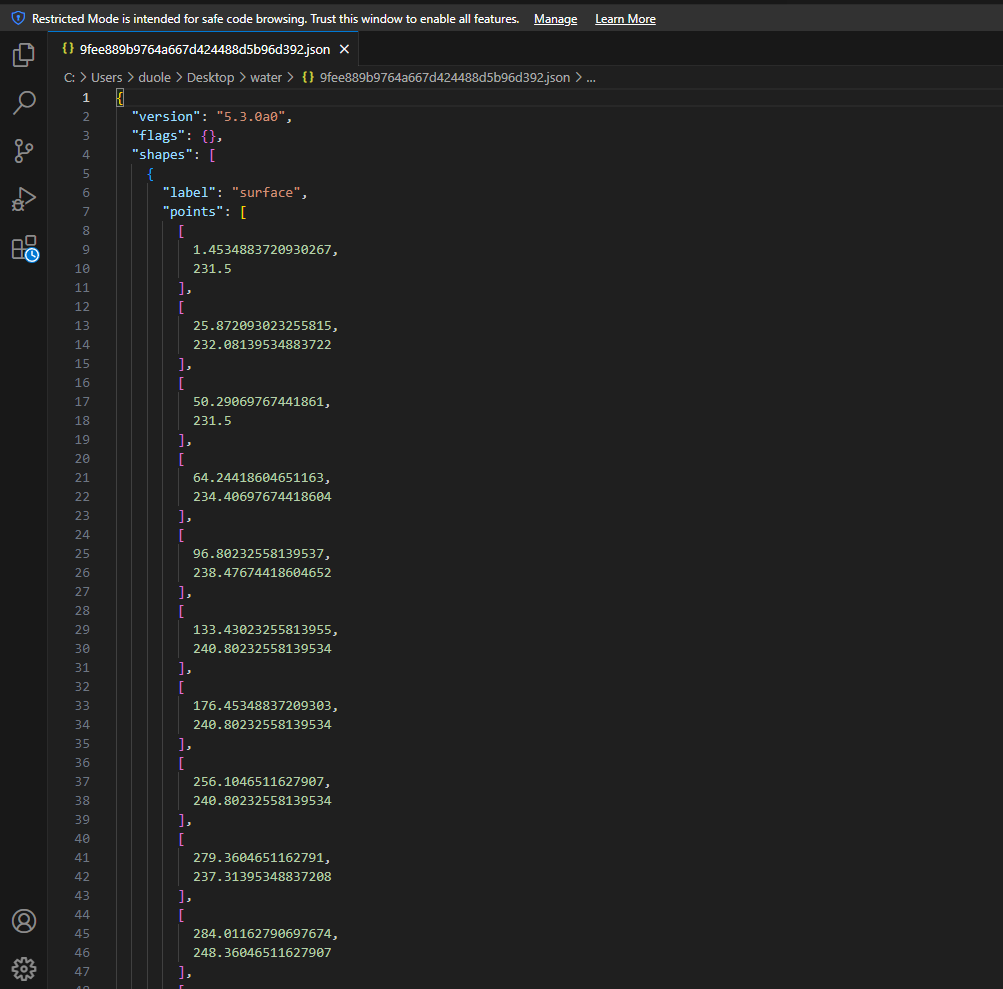
标注出来的数据格式是json如下:
2.数据集转换
标注完数据之后,在工程目录下创建一个dataset目录,dataset目录下包含有images、json_labels、labels三个目录,images存放数据集的所有的图像,json_labels目录下存放labelme标注出来的所有json标签,labels为空目录。
在当前目录下创建json2txt.py文件
# -*- coding: utf-8 -*-
import json
import os
import argparse
from tqdm import tqdm
import glob
import cv2
import numpy as npdef convert_label_json(json_dir, save_dir, classes):json_paths = os.listdir(json_dir)classes = classes.split(',')for json_path in tqdm(json_paths):# for json_path in json_paths:path = os.path.join(json_dir, json_path)# print(path)with open(path, 'r') as load_f:print(load_f)json_dict = json.load(load_f, )h, w = json_dict['imageHeight'], json_dict['imageWidth']# save txt pathtxt_path = os.path.join(save_dir, json_path.replace('json', 'txt'))txt_file = open(txt_path, 'w')for shape_dict in json_dict['shapes']:label = shape_dict['label']label_index = classes.index(label)points = shape_dict['points']points_nor_list = []for point in points:points_nor_list.append(point[0] / w)points_nor_list.append(point[1] / h)points_nor_list = list(map(lambda x: str(x), points_nor_list))points_nor_str = ' '.join(points_nor_list)label_str = str(label_index) + ' ' + points_nor_str + '\n'txt_file.writelines(label_str)if __name__ == "__main__":parser = argparse.ArgumentParser(description='json convert to txt params')parser.add_argument('--json-dir', type=str, default='dataset/json_labels', help='json path dir')parser.add_argument('--save-dir', type=str, default='dataset/labels', help='txt save dir')parser.add_argument('--classes', type=str, default='surface', help='classes')args = parser.parse_args()json_dir = args.json_dirsave_dir = args.save_dirclasses = args.classesconvert_label_json(json_dir, save_dir, classes)运行json2txt.py之后,在labels里面生成txt标签文件,格式如下:
0 0.0019379844961240355 0.411190053285968 0.034496124031007755 0.41222272708496843 0.06705426356589148 0.411190053285968 0.08565891472868217 0.4163534222809699 0.1290697674418605 0.4235821388739725 0.17790697674418607 0.42771283406997396 0.23527131782945737 0.42771283406997396 0.34147286821705425 0.42771283406997396 0.3724806201550388 0.42151679127597175 0.37868217054263564 0.44113759345697884 0.42054263565891475 0.44630096245198064 0.9972868217054264 0.5227188235780081 0.9972868217054264 0.9946507497211781 0.0019379844961240355 0.9946507497211781
转换之后,一定要使用代码验证所转的数据是否正确:
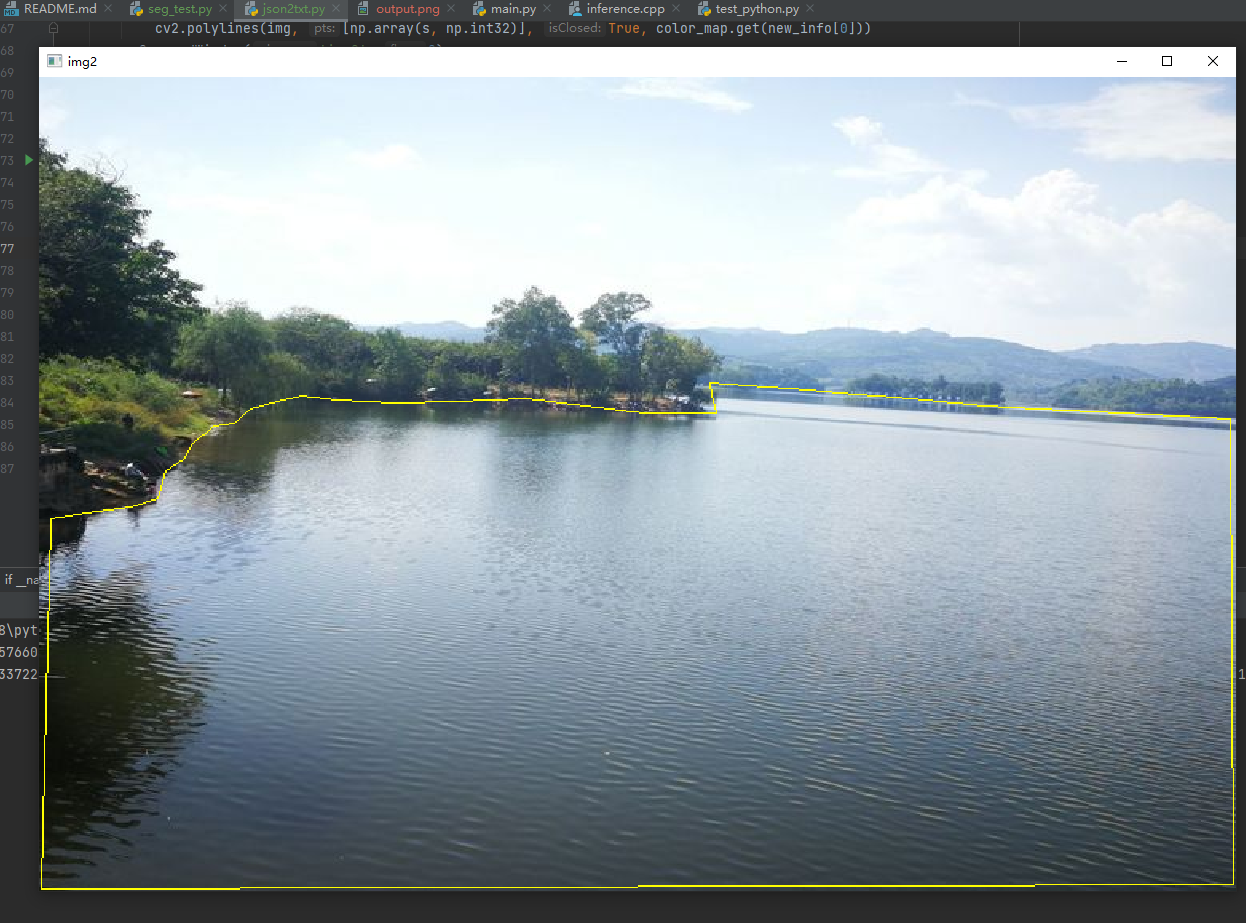
def check_labels(txt_labels, images_dir):txt_files = glob.glob(txt_labels + "/*.txt")for txt_file in txt_files:filename = os.path.splitext(os.path.basename(txt_file))[0]pic_path = images_dir + filename + ".jpg"img = cv2.imread(pic_path)height, width, _ = img.shapefile_handle = open(txt_file)cnt_info = file_handle.readlines()new_cnt_info = [line_str.replace("\n", "").split(" ") for line_str in cnt_info]color_map = {"0": (0, 255, 255)}for new_info in new_cnt_info:print(new_info)s = []for i in range(1, len(new_info), 2):b = [float(tmp) for tmp in new_info[i:i + 2]]s.append([int(b[0] * width), int(b[1] * height)])cv2.polylines(img, [np.array(s, np.int32)], True, color_map.get(new_info[0]))cv2.namedWindow('img2', 0)cv2.imshow('img2', img)cv2.waitKey()
调用函数,显示转换后的效果:
3.数据集分割
一般数据集划分为训练集和验证集是在开发深度学习模型时的常见做法。这种划分有助于评估模型的性能并进行超参数调整,以便提高模型的泛化能力。通常,常见的训练集和验证集的划分比例是9:1或者8:2,其中训练集占大部分,验证集占较小部分。
关训练集和验证集划分的指导原则:
数据量考虑: 数据集的大小是选择划分比例的一个关键因素。如果数据集较小,可能希望将更大的比例分配给训练集,以确保模型有足够的数据来学习。
数据的随机性: 确保在划分数据集时要随机混洗数据,以防止数据集中的任何特定模式或顺序影响模型的性能评估。
代表性: 确保训练集和验证集都代表了整个数据集的不同方面,以避免在验证模型性能时出现偏差。
交叉验证: 对于较小的数据集,您可以考虑使用交叉验证,将数据划分为多个折(folds),并在每次训练中使用不同的折作为验证集,从而更全面地评估模型性能。
超参数调整: 验证集通常用于调整模型的超参数,例如学习率、正则化强度等,以获得更好的性能。
不要在验证集上过拟合: 避免在验证集上进行过多的超参数调整或模型选择,以免模型在验证集上产生过拟合。
划分数据集的目的是确保模型在未见过的数据上具有良好的泛化能力。选择适当的训练集和验证集比例以及遵循上述指导原则将有助于提高深度学习项目的成功率。
数据集分割spilit_dataset.py代码:
# -*- coding:utf-8 -*
import os
import random
import os
import shutil
def data_split(full_list, ratio):n_total = len(full_list)offset = int(n_total * ratio)if n_total == 0 or offset < 1:return [], full_listrandom.shuffle(full_list)sublist_1 = full_list[:offset]sublist_2 = full_list[offset:]return sublist_1, sublist_2train_p="dataset/train"
val_p="dataset/val"
imgs_p="images"
labels_p="labels"#创建训练集
if not os.path.exists(train_p):#指定要创建的目录os.mkdir(train_p)
tp1=os.path.join(train_p,imgs_p)
tp2=os.path.join(train_p,labels_p)
print(tp1,tp2)
if not os.path.exists(tp1):#指定要创建的目录os.mkdir(tp1)
if not os.path.exists(tp2): # 指定要创建的目录os.mkdir(tp2)#创建测试集文件夹
if not os.path.exists(val_p):#指定要创建的目录os.mkdir(val_p)
vp1=os.path.join(val_p,imgs_p)
vp2=os.path.join(val_p,labels_p)
print(vp1,vp2)
if not os.path.exists(vp1):#指定要创建的目录os.mkdir(vp1)
if not os.path.exists(vp2): # 指定要创建的目录os.mkdir(vp2)#数据集路径
images_dir="D:/DL/ultralytics/dataset/images"
labels_dir="D:/DL/ultralytics/dataset/labels"
#划分数据集,设置数据集数量占比
proportion_ = 0.9 #训练集占比total_file = os.listdir(images_dir)num = len(total_file) # 统计所有的标注文件
list_=[]
for i in range(0,num):list_.append(i)list1,list2=data_split(list_,proportion_)for i in range(0,num):file=total_file[i]print(i,' - ',total_file[i])name=file.split('.')[0]if i in list1:jpg_1 = os.path.join(images_dir, file)jpg_2 = os.path.join(train_p, imgs_p, file)txt_1 = os.path.join(labels_dir, name + '.txt')txt_2 = os.path.join(train_p, labels_p, name + '.txt')if os.path.exists(txt_1) and os.path.exists(jpg_1):shutil.copyfile(jpg_1, jpg_2)shutil.copyfile(txt_1, txt_2)elif os.path.exists(txt_1):print(txt_1)else:print(jpg_1)elif i in list2:jpg_1 = os.path.join(images_dir, file)jpg_2 = os.path.join(val_p, imgs_p, file)txt_1 = os.path.join(labels_dir, name + '.txt')txt_2 = os.path.join(val_p, labels_p, name + '.txt')shutil.copyfile(jpg_1, jpg_2)shutil.copyfile(txt_1, txt_2)print("数据集划分完成: 总数量:",num," 训练集数量:",len(list1)," 验证集数量:",len(list2))运行之后,在dataset下面多出train和val两个目录:
三、模型训练
1.数据文件
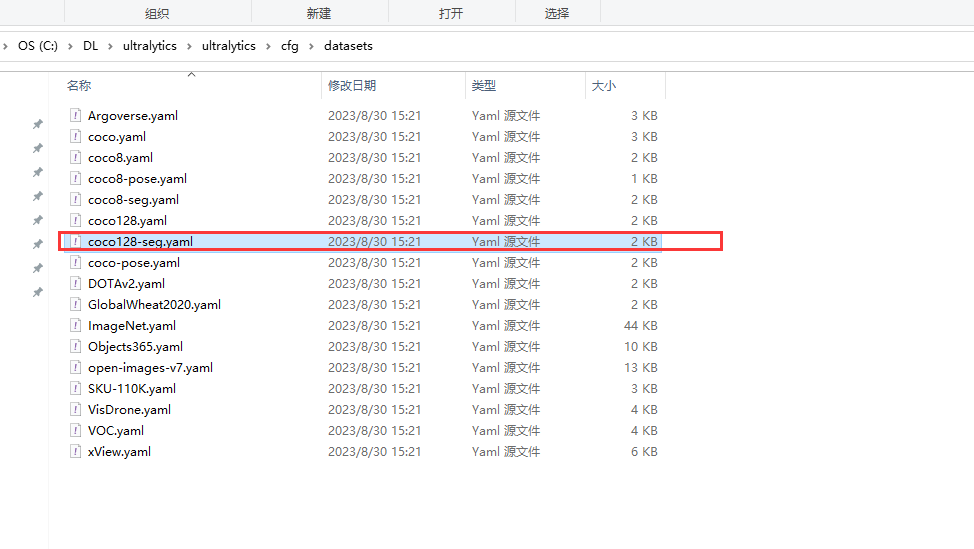
在ultralytics/cfg/datasets目录下复制一份coc128-seg.yaml复制ultralytics目录,重新命名成water-seg.yaml。
然后抒文件内容改成自己的数据路径:
# Ultralytics YOLO 🚀, AGPL-3.0 license
# COCO128-seg dataset https://www.kaggle.com/ultralytics/coco128 (first 128 images from COCO train2017) by Ultralytics
# Example usage: yolo train data=coco128.yaml
# parent
# ├── ultralytics
# └── datasets
# └── coco128-seg ← downloads here (7 MB)# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: D:/DL/ultralytics # dataset root dir
train: dataset/train # train images (relative to 'path') 128 images
val: dataset/val # val images (relative to 'path') 128 images
test: # test images (optional)# Classes
names:0: surface# Download script/URL (optional)
download: https://ultralytics.com/assets/coco128-seg.zip2.模型训练
模型训练有两种方式,直接pip安装ultralytics库的和源码安装的训练方法有差异。
2.1 直接安装ultralytics库
单卡
yolo detect train data=water-seg.yaml model=./weights/yolov8s-seg.pt epochs=150 imgsz=640 batch=4 workers=0
多卡训练
yolo detect train data=water-seg.yaml model=./weights/yolov8s-seg.pt epochs=150 imgsz=640 batch=4 workers= \'0,1,2,3\'2.2 源码安装训练方法
在根目录下新建一个train.py的文件
'''
实例分割训练
'''
from ultralytics import YOLO#train
model = YOLO('water-seg.yaml').load('yolov8s-seg.pt') # build from YAML and transfer weights# Train the model
model.train(data='./ultralytics/datasets/coco128-seg.yaml', epochs=150, imgsz=640,batch=2, workers=0)3.参数说明

相关文章:
YOLOV8实例分割——详细记录环境配置、自定义数据处理到模型训练与部署
前言 Ultralytics YOLOv8是一种前沿的、最先进的(SOTA)模型,它在前代YOLO版本的成功基础上进行了进一步的创新,引入了全新的特性和改进,以进一步提升性能和灵活性。作为一个高速、精准且易于操作的设计,YO…...

2309ddocx02文档
风格,页眉和页脚等内容与主要分开,允许在起始文档中放大量自定义,然后在生成文档中显示. 打开文档 from docx import Document document Document() document.save("test.docx")真正打开文档 要用文件名打开文档: document Document("existing-document-f…...
第一章初识微服务
文章目录 认识微服务单体架构分布式架构需要考虑的问题 微服务微服务的具体架构微服务技术对比企业中的技术需求 总结 服务拆分注意事项 认识微服务 随着互联网行业的发展,对服务的要求也越来越高,服务架构也从单体架构逐渐演变为现在流行的微服务架构。…...

微信小程序电影票订票小程序软件设计与实现
摘 要 我们的生活水平正在不断的提高,然而提高的一个重要的侧面表现就是更加注重我们的娱乐生活。电影是我们都喜欢的一种娱乐方式,各式各样的电影给我们带来的喜悦也是大不相同的。带来快乐的同时也因为其复杂、繁琐的流程让电影爱好者们变得烦躁起来。…...
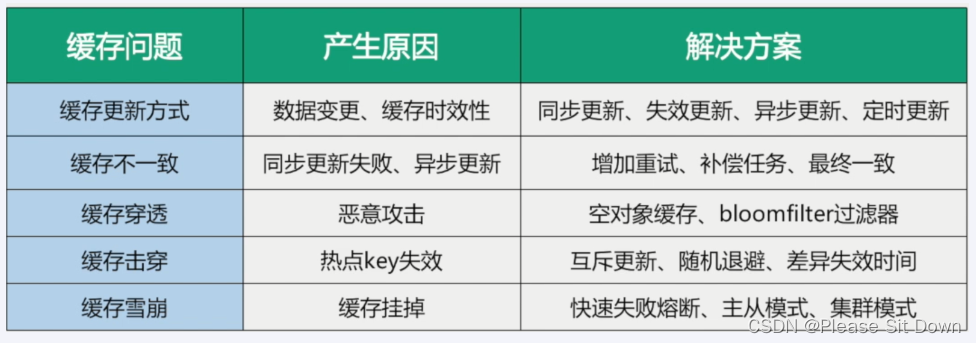
Redis 缓存预热+缓存雪崩+缓存击穿+缓存穿透
面试题: 缓存预热、雪萌、穿透、击穿分别是什么?你遇到过那几个情况?缓存预热你是怎么做的?如何造免或者减少缓存雪崩?穿透和击穿有什么区别?他两是一个意思还是载然不同?穿适和击穿你有什么解…...

java 面试题汇总整理
java有哪四种引用类型 在Java中,有四种引用类型,用于控制对象的生命周期和垃圾回收行为。这些引用类型包括: 强引用(Strong Reference): 强引用是最常见的引用类型,它们是默认的引用类型。当一…...

淘宝开放平台免审核接入 获取淘宝卖家订单列表订单详情API
taobao.open.trades.sold.get 搜索当前会话用户作为卖家已卖出的交易数据(只能获取到三个月以内的交易信息) 1. 返回的数据结果是以订单的创建时间倒序排列的。 注意:type字段的说明,如果该字段不传,接口默认只查4种类…...

Mybatis中的关系映射
1.一对一的映射关系 一对一关系(One-to-One)表示两个实体对象之间存在唯一的关联关系。例如,一个学生只能拥有一个身份证。在 MyBatis 中,我们可以使用结果嵌套或一对一映射来处理一对一关系。 1.1 创建模型类和Vo类 package com…...
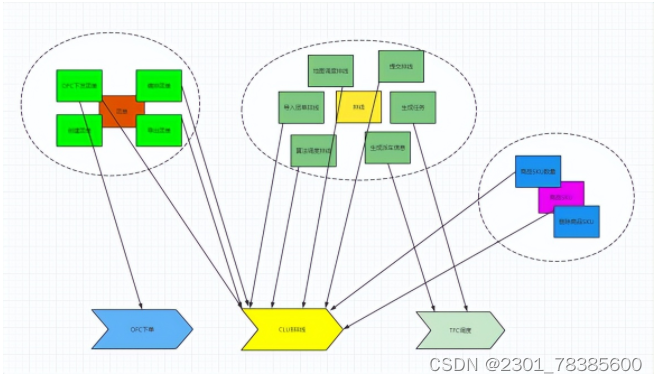
领域建模之数据模型设计方法论
本文通过实际业务需求场景建模案例,为读者提供一种业务模型向数据模型设计的方法论,用于指导实际开发中如何进行业务模型向数据模型转化抽象,并对设计的数据模型可用性、扩展性提供了建议性思考。通过文章,读者可以收获到业务模型…...

springboot毕业生信息招聘平台设计与实现
摘 要 随着社会的发展,社会的各行各业都在利用信息化时代的优势。计算机的优势和普及使得各种信息系统的开发成为必需。 毕业生信息招聘平台,主要的模块包括查看管理员;首页、个人中心、企业管理、空中宣讲会管理、招聘岗位管理、毕业生管理…...
开发前期准备工作
开发前期准备工作 文章目录 开发前期准备工作0 代码规范0.1 强制0.2 推荐0.3 参考dao:跟数据库打交道service:业务层,人类思维解决controller:抽象化 0.4 注释规范0.5 日志规范0.6 专有名词0.7 控制层统一异常统一结构体控制层提示…...

k8s deployment服务回滚,设置节点为不可调度
服务回滚 通过滚动升级的策略可以平滑的升级Deployment,若升级出现问题,需要最快且最好的方式回退到上一次能够提供正常工作的版本。为此K8S提供了回滚机制。 revision:更新应用时,K8S都会记录当前的版本号,即为revi…...

信息系统安全运维和管理指南
声明 本文是学习 信息系统安全运维管理指南. 而整理的学习笔记,分享出来希望更多人受益,如果存在侵权请及时联系我们 安全运维支撑系统 信息系统安全服务台 目的 对信息系统安全事件进行统一监控与处理。 要求 建立一个集中的信息系统运行状态收集、处理、显示及报警的系…...

现货黄金代理好吗?
做黄金代理这个职业好吗?从目前的市场现状来看,其实做黄金代理很不错的。在股票市场中,投资者只能通过买涨进盈利,所以当市场行情不好的时候,股票经纪人的业务将很难展开,而现货黄金投资者不一样࿰…...
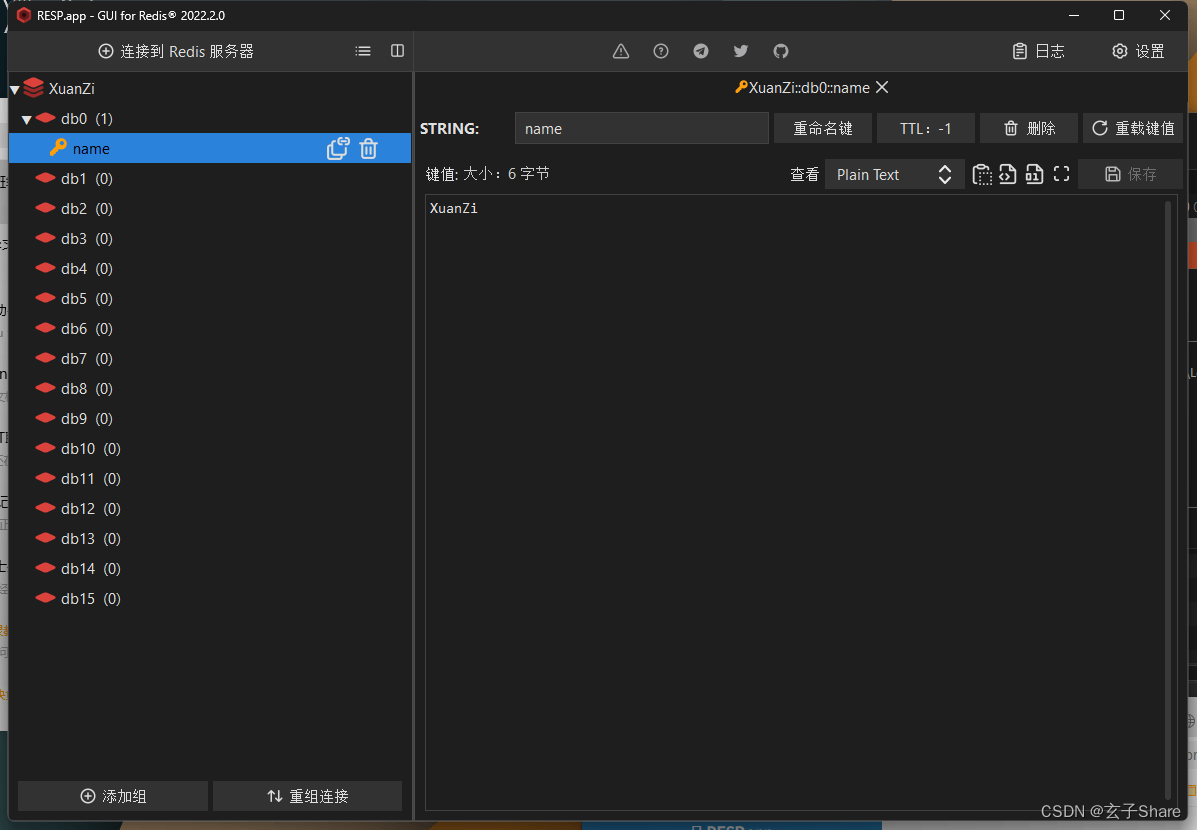
BCSP-玄子Share-Java框基础_双系统Redis安装与基础语法
四、Redis 4.1 Redis 简介 Redis 是开源、高性能的key-value数据库,属于 NoSQL 数据库 NoSQL 数据库与关系型数据库 关系型数据库:采用关系模型来组织数据,主要用于存储格式化的数据结构NoSQL 数据库:泛指非关系型数据库&…...

android system_server WatchDog简介
简介 android系统中SystemServer WatchDog的主要作用是监控SystemServer进程的运行状态,防止其卡住或者死锁。 具体来说,watchDog线程会定期去检查SystemServer线程的运行情况。如果发现SystemServer线程超过一定时间未有响应,watchDog会认为SystemServer进程发生了问题,这时…...
华为---OSPF协议优先级、开销(cost)、定时器简介及示例配置
OSPF协议优先级、开销、定时器简介及示例配置 路由协议优先级:由于路由器上可能同时运行多种动态路由协议,就存在各个路由协议之间路由信息共享和选择的问题。系统为每一种路由协议设置了不同的默认优先级,当在不同协议中发现同一条路由时&am…...

MEMORY-VQ: Compression for Tractable Internet-Scale Memory
本文是深度学习相关文章,针对《MEMORY-VQ: Compression for Tractable Internet-Scale Memory》的翻译。 MEMORY-VQ:可追溯互联网规模存储器的压缩 摘要1 引言2 背景3 MEMORY-VQ4 实验5 相关工作6 结论 摘要 检索增强是一种强大但昂贵的方法࿰…...
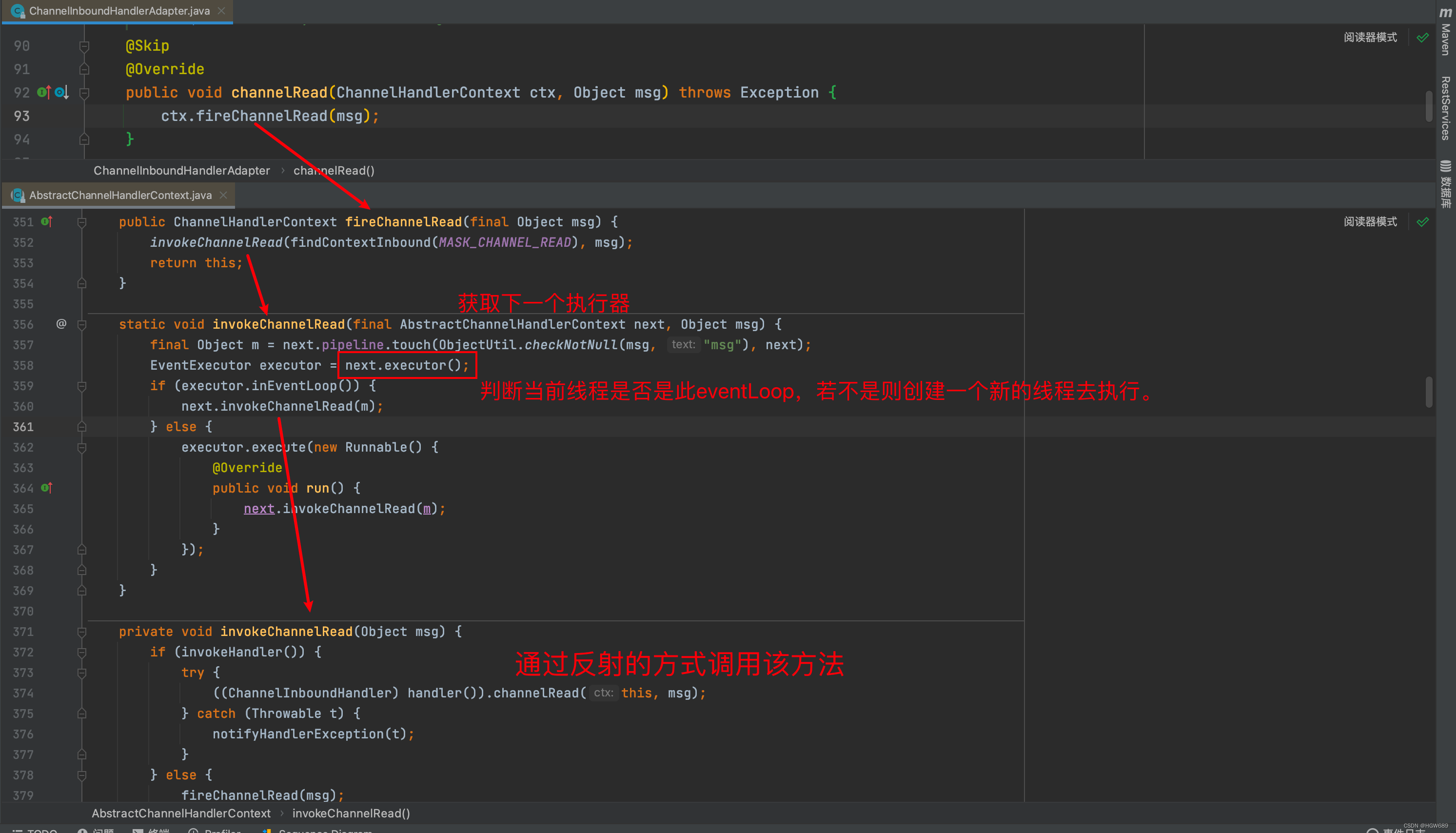
Netty—ChannelHandler
文章目录 一、Channel、ChannelPipeline 以及ChannelHandler 三者的关系❓二、ChannelHandler 是什么?🤔️三、ChannelInboundHandler四、ChannelOutboundHandler 一、Channel、ChannelPipeline 以及ChannelHandler 三者的关系❓ 通过以上对Channel和Ch…...

Android 集成onenet物联网平台
一,在Android应用程序中集成OneNet物联网平台,您可以按照以下步骤进行操作: 注册OneNet账户:首先,您需要在OneNet官方网站上注册一个账户。访问OneNet网站(https://open.iot.10086.cn/ ↗)&…...

2026年阿里云2分钟超速步骤:OpenClaw搭建及大模型API Key、Skill集成
2026年阿里云2分钟超速步骤:OpenClaw搭建及大模型API Key、Skill集成。OpenClaw作为2026年主流的AI自动化助理平台,可通过阿里云轻量服务器实现724小时稳定运行,并快速接入钉钉,让AI在企业群聊、个人工作流中自动执行任务、处理消…...

终极指南:3分钟上手res-downloader,轻松下载全网视频音频资源
终极指南:3分钟上手res-downloader,轻松下载全网视频音频资源 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-download…...

亚洲美女-造相Z-Turbo效果展示:超写实皮肤纹理、毛发细节与光影反射真实感
亚洲美女-造相Z-Turbo效果展示:超写实皮肤纹理、毛发细节与光影反射真实感 本文展示的AI生成内容仅为技术效果演示,所有生成的人物形象均为虚拟创作,不存在真实对应人物。 1. 惊艳效果预览:为什么这个模型值得关注 如果你正在寻找…...

MusePublic艺术创作引擎保姆级教程:从安装到生成高清艺术图
MusePublic艺术创作引擎保姆级教程:从安装到生成高清艺术图 1. 准备工作与环境搭建 在开始使用MusePublic艺术创作引擎前,我们需要确保系统环境满足基本要求。这个轻量化的艺术创作工具对硬件配置相对友好,但仍有几个关键点需要注意。 1.1…...

OpenClaw本地部署指南:千问3.5-9B接口配置与调试技巧
OpenClaw本地部署指南:千问3.5-9B接口配置与调试技巧 1. 为什么选择OpenClaw千问3.5-9B组合 去年我在尝试自动化处理日常工作报告时,发现市面上的RPA工具要么功能臃肿,要么需要将数据上传到云端处理。直到遇到OpenClaw这个开源框架…...

Qwen3-VL-8B分步部署教程:vLLM服务+proxy_server+chat.html独立启动详解
Qwen3-VL-8B分步部署教程:vLLM服务proxy_serverchat.html独立启动详解 1. 项目概述 今天给大家分享一个完整的AI聊天系统部署方案,基于Qwen3-VL-8B大语言模型,包含前端界面、反向代理服务器和vLLM推理后端。这个系统采用模块化设计…...

Obsidian: 图片管理插件-Local Images Plus与Paste Image Rename的进阶配置指南
1. 为什么需要图片管理插件 如果你经常用Obsidian写笔记,肯定遇到过这样的烦恼:从网页复制粘贴的图片默认存放在系统剪贴板,关闭笔记后图片就消失了;或者随手粘贴的图片文件名杂乱无章,过段时间根本分不清是哪篇笔记的…...

Natron Rotoscoping与跟踪技术:专业影视特效制作终极指南
Natron Rotoscoping与跟踪技术:专业影视特效制作终极指南 【免费下载链接】Natron Open-source video compositing software. Node-graph based. Similar in functionalities to Adobe After Effects and Nuke by The Foundry. 项目地址: https://gitcode.com/gh_…...

MacBook安装OpenClaw全记录:Phi-3-vision-128k-instruct多模态初体验
MacBook安装OpenClaw全记录:Phi-3-vision-128k-instruct多模态初体验 1. 为什么选择OpenClawPhi-3组合 去年第一次听说OpenClaw时,我就被这个"能直接操作电脑的AI助手"吸引了。作为一个经常需要处理多模态内容的创作者,传统AI工具…...

从零构建:麦克纳姆轮底盘的运动学模型与O-长方形布局解析
1. 麦克纳姆轮基础原理与结构解析 第一次接触麦克纳姆轮时,我被它那酷似"风火轮"的外观吸引了。这种特殊设计的轮子由瑞典工程师Bengt Ilon在1973年发明,如今已成为移动机器人领域的明星组件。让我带你从最基础的物理结构开始,逐步…...