爬虫项目(二):中国大学排名
《Python网络爬虫入门到实战》京东购买地址,这里讲解了大量的基础知识和实战,由本人编著:https://item.jd.com/14049708.html配套代码仓库地址:https://github.com/sfvsfv/Crawer
文章目录
- 分析
- 第一步:获取源码
- 分析第一页
- 获取页数
- AJAX分析,获取完整数据
- 数据保存到CSV文件中
- 完整源码
- 视频讲解
分析
目标:https://www.shanghairanking.cn/rankings/bcur/2023
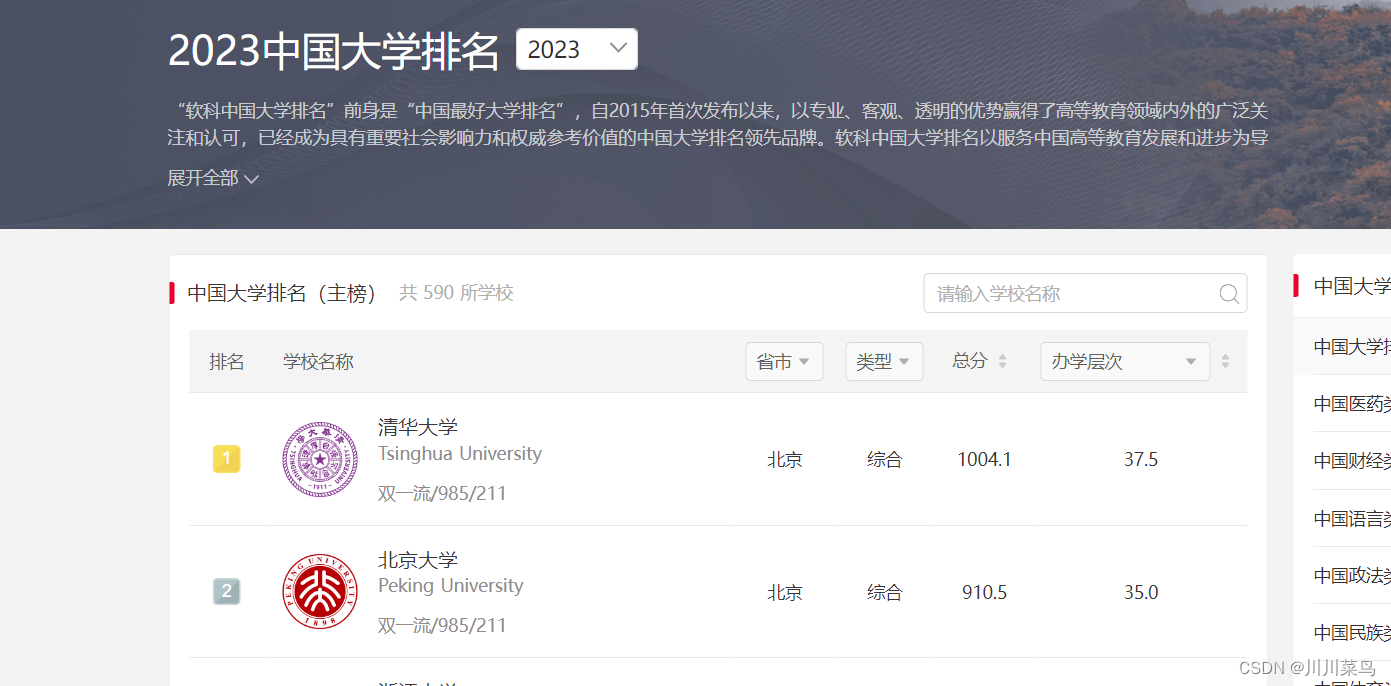
感兴趣的会发现:
2022年为:https://www.shanghairanking.cn/rankings/bcur/202211
2021年为:https://www.shanghairanking.cn/rankings/bcur/202111
同理。。。。
第一步:获取源码
def get_one_page(year):try:headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36'}# https://www.shanghairanking.cn/rankings/bcur/%s11url = 'https://www.shanghairanking.cn/rankings/bcur/%s11' % (str(year))print(url)response = requests.get(url, headers=headers)if response.content is not None:content = response.content.decode('utf-8')print(content.encode('gbk', errors='ignore').decode('gbk'))else:content = ""print(content.encode('gbk', errors='ignore').decode('gbk'))except RequestException:print('爬取失败')get_one_page(2023)
输出如下:
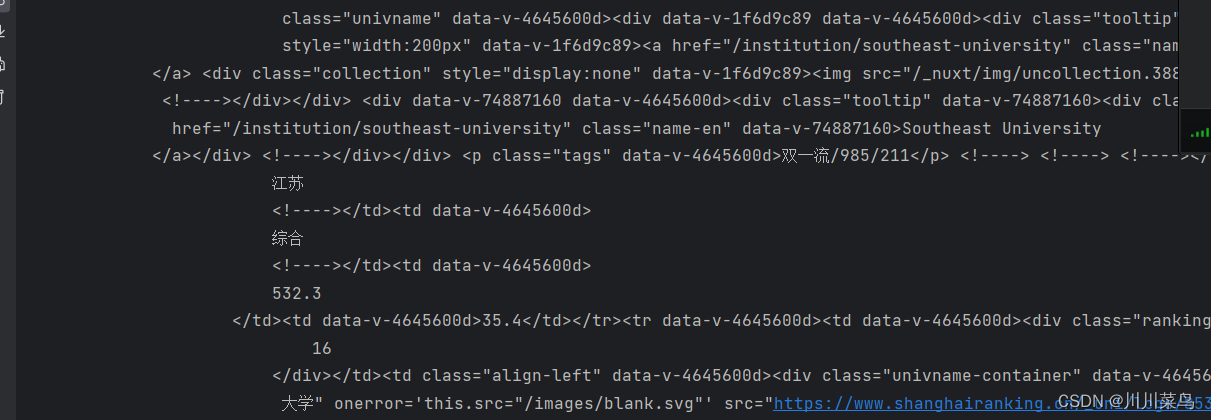
正式则改为return即可:
return content.encode('gbk', errors='ignore').decode('gbk')
于是你就完成了一个完整的源码获取函数:
# coding= gbk
import pandas as pd
import csv
import requests
from requests.exceptions import RequestException
from bs4 import BeautifulSoup
import time
import restart_time = time.time() # 计算程序运行时间# 获取网页内容
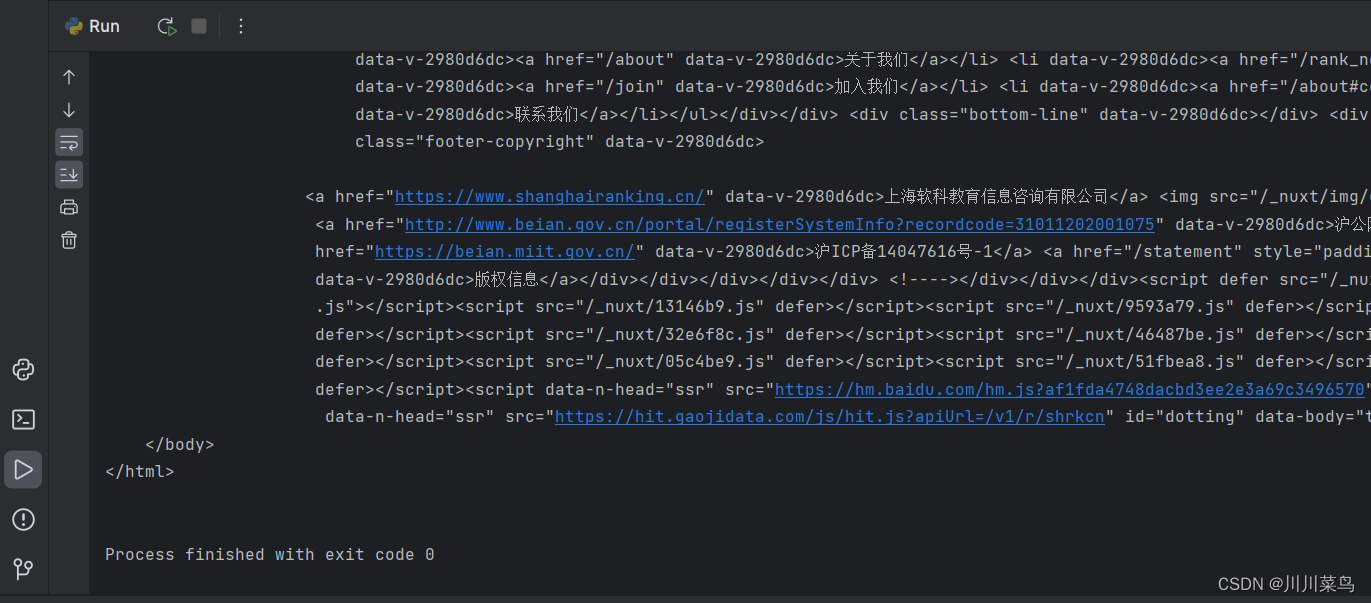
def get_one_page(year):try:headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36'}# https://www.shanghairanking.cn/rankings/bcur/%s11url = 'https://www.shanghairanking.cn/rankings/bcur/%s11' % (str(year))# print(url)response = requests.get(url, headers=headers)if response.content is not None:content = response.content.decode('utf-8')# print(content.encode('gbk', errors='ignore').decode('gbk'))return content.encode('gbk', errors='ignore').decode('gbk')else:content = ""return content.encode('gbk', errors='ignore').decode('gbk')# print(content.encode('gbk', errors='ignore').decode('gbk'))except RequestException:print('爬取失败')data = get_one_page(2023)
print(data)运行如下:
分析第一页
定位内容:
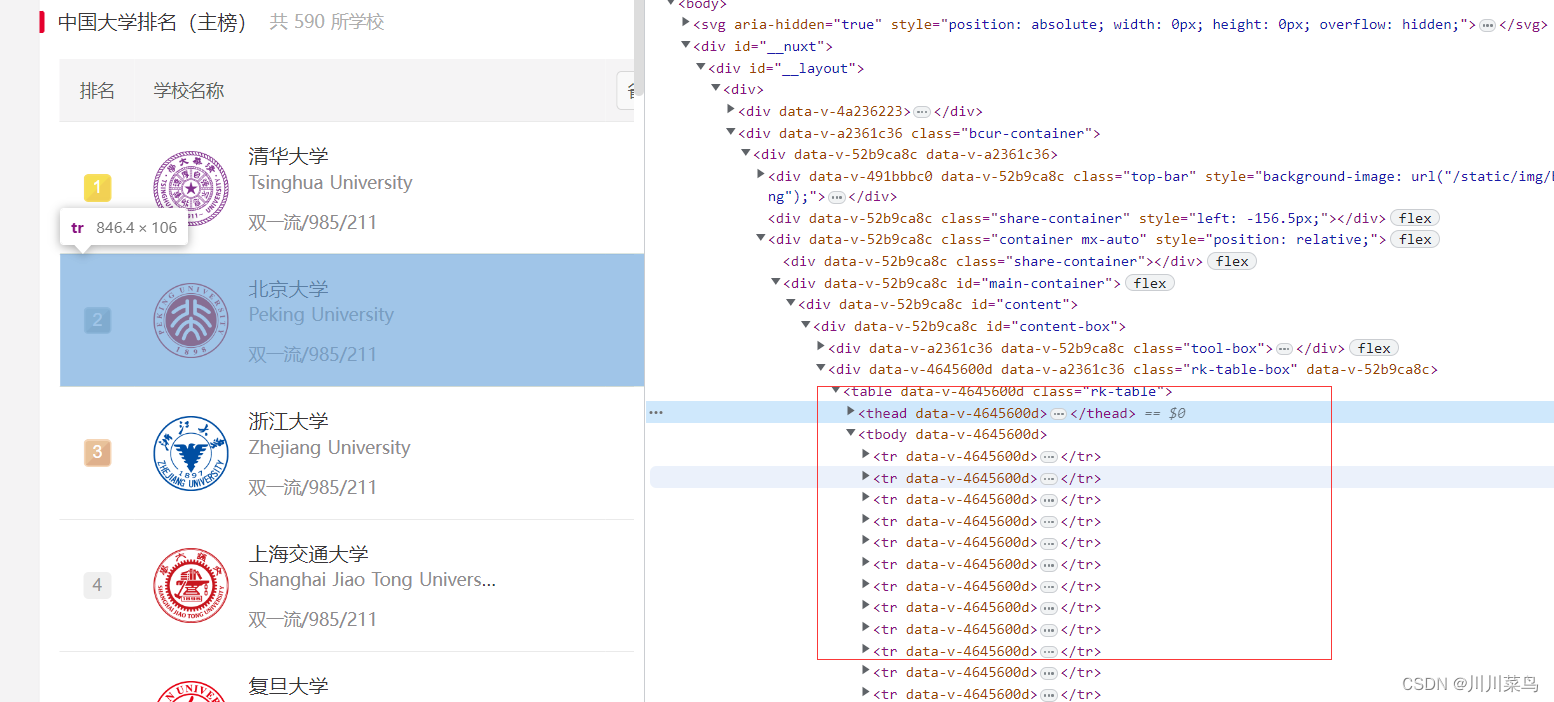
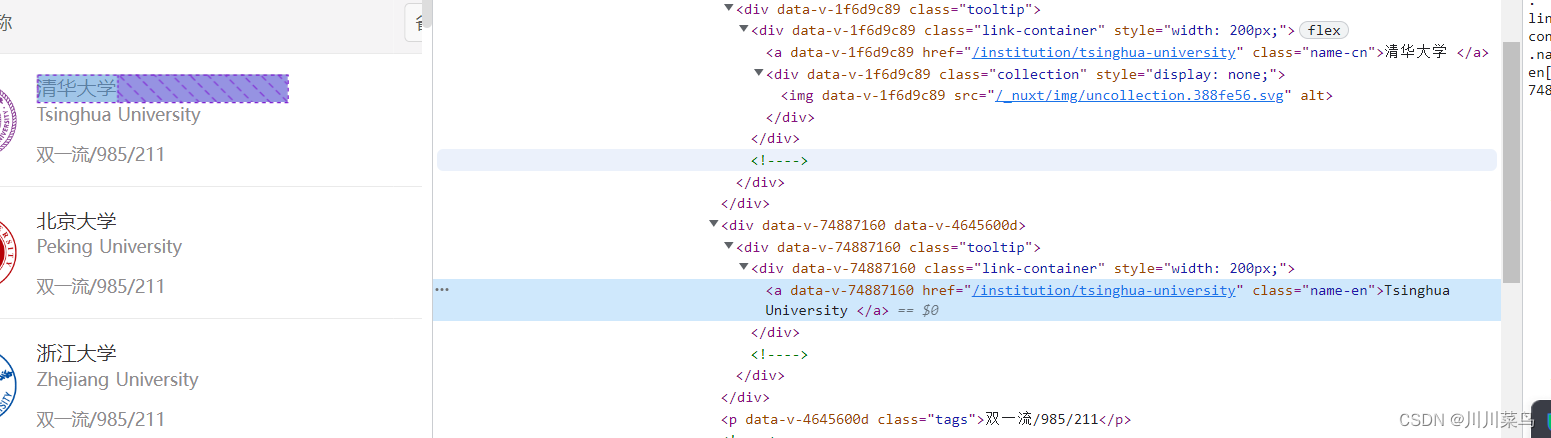
代码如下:
def extract_university_info(data):soup = BeautifulSoup(data, 'html.parser')table = soup.find('table', {'data-v-4645600d': "", 'class': 'rk-table'})tbody = table.find('tbody', {'data-v-4645600d': ""})rows = tbody.find_all('tr')university_info = []for row in rows:rank = row.find('div', {'class': 'ranking'}).text.strip()univ_name_cn = row.find('a', {'class': 'name-cn'}).text.strip()univ_name_en = row.find('a', {'class': 'name-en'}).text.strip()location = row.find_all('td')[2].text.strip()category = row.find_all('td')[3].text.strip()score = row.find_all('td')[4].text.strip()rating = row.find_all('td')[5].text.strip()info = {"排名": rank,"名称": univ_name_cn,"Name (EN)": univ_name_en,"位置": location,"类型": category,"总分": score,"评分": rating}university_info.append(info)return university_infodata = get_one_page(2023)
print(extract_university_info(data))运行如下:
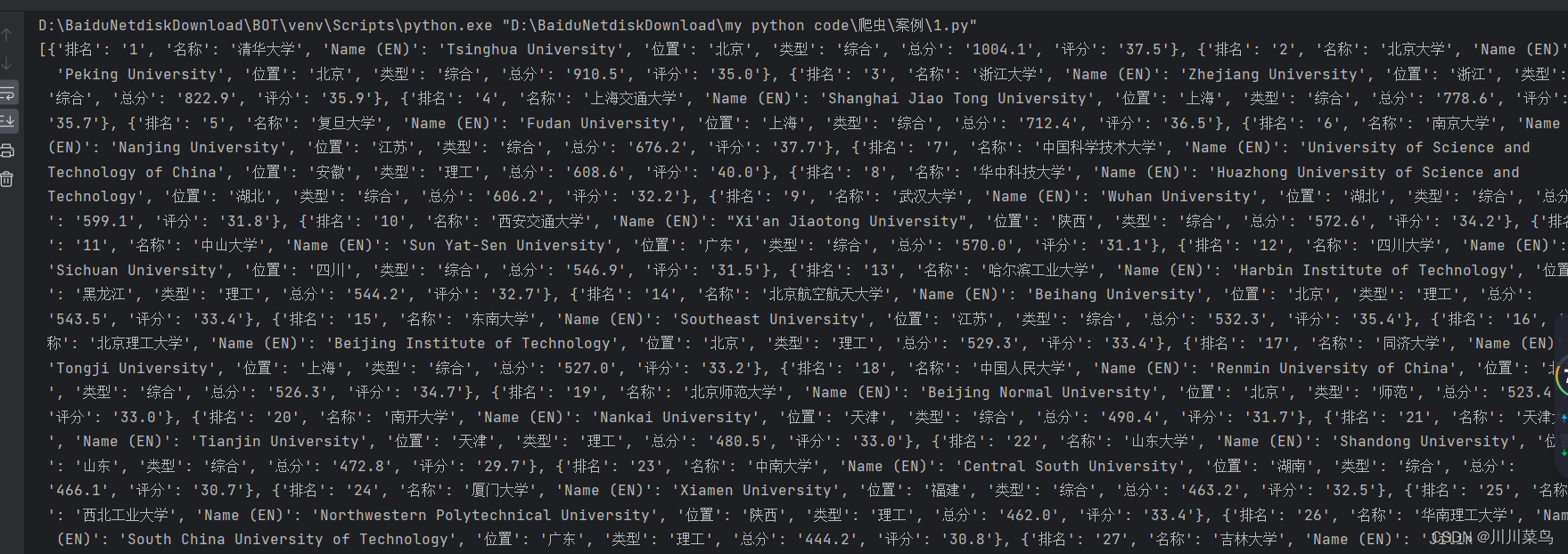
获取页数
数据在多个页面中,如下:
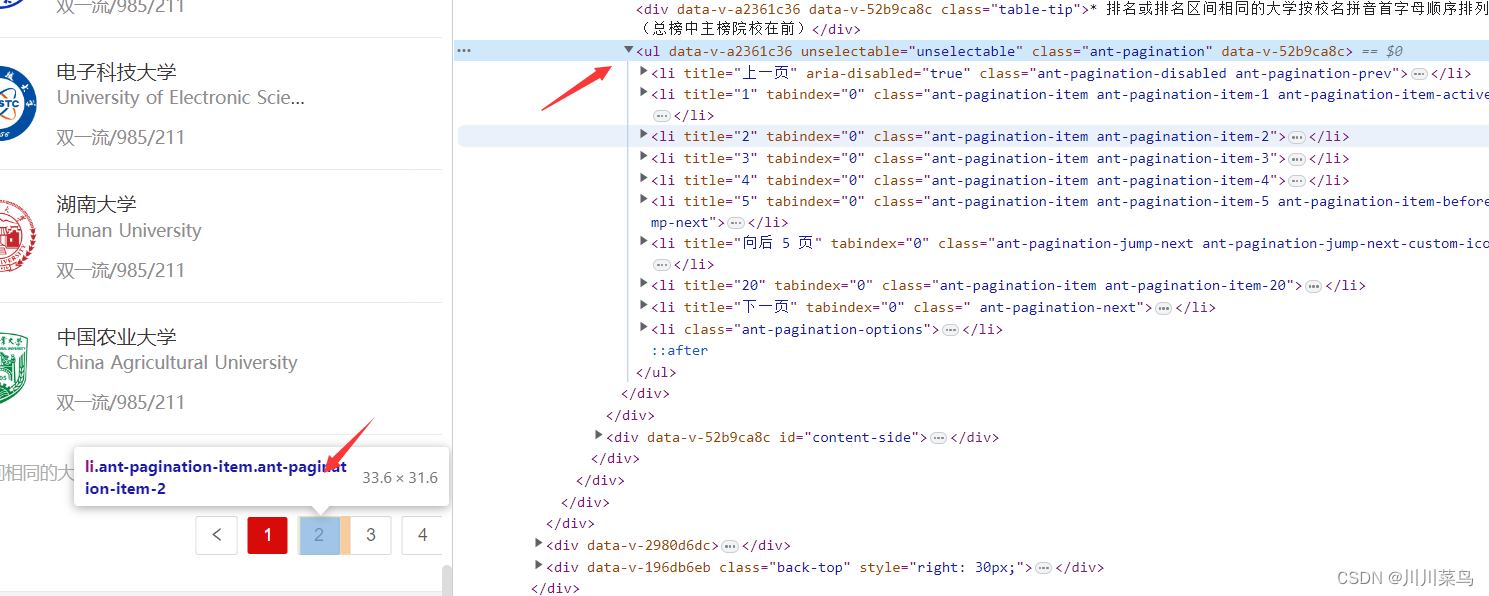
获取总页面代码如下:
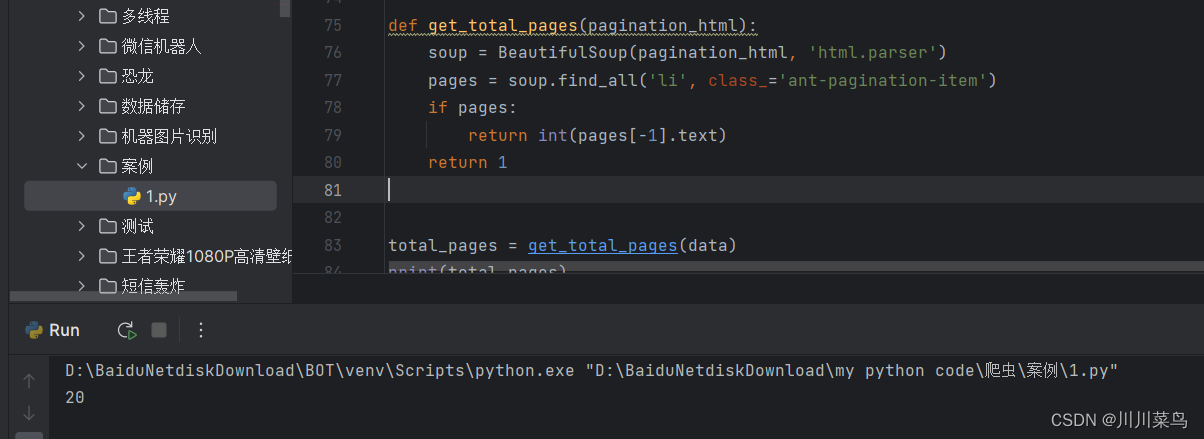
def get_total_pages(pagination_html):soup = BeautifulSoup(pagination_html, 'html.parser')pages = soup.find_all('li', class_='ant-pagination-item')if pages:return int(pages[-1].text)return 1total_pages = get_total_pages(data)
print(total_pages)
运行如下:
AJAX分析,获取完整数据
由于页面的 URL 在切换分页时不发生变化,这通常意味着页面是通过 AJAX 或其他 JavaScript 方法动态加载的。所以直接循环行不通。所以只能用selenium来。
完整代码如下:
# coding= gbk
import pandas as pd
import csv
import requests
from requests.exceptions import RequestException
from bs4 import BeautifulSoup
import time
from selenium.webdriver.chrome.service import Service # 新增
from selenium.webdriver.common.by import Bystart_time = time.time() # 计算程序运行时间# 获取网页内容
def get_one_page(year):try:headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36'}# https://www.shanghairanking.cn/rankings/bcur/%s11url = 'https://www.shanghairanking.cn/rankings/bcur/%s11' % (str(year))# print(url)response = requests.get(url, headers=headers)if response.content is not None:content = response.content.decode('utf-8')# print(content.encode('gbk', errors='ignore').decode('gbk'))return content.encode('gbk', errors='ignore').decode('gbk')else:content = ""return content.encode('gbk', errors='ignore').decode('gbk')# print(content.encode('gbk', errors='ignore').decode('gbk'))except RequestException:print('爬取失败')def extract_university_info(data):soup = BeautifulSoup(data, 'html.parser')table = soup.find('table', {'data-v-4645600d': "", 'class': 'rk-table'})tbody = table.find('tbody', {'data-v-4645600d': ""})rows = tbody.find_all('tr')university_info = []for row in rows:rank = row.find('div', {'class': 'ranking'}).text.strip()univ_name_cn = row.find('a', {'class': 'name-cn'}).text.strip()univ_name_en = row.find('a', {'class': 'name-en'}).text.strip()location = row.find_all('td')[2].text.strip()category = row.find_all('td')[3].text.strip()score = row.find_all('td')[4].text.strip()rating = row.find_all('td')[5].text.strip()info = {"排名": rank,"名称": univ_name_cn,"Name (EN)": univ_name_en,"位置": location,"类型": category,"总分": score,"评分": rating}university_info.append(info)# 打印数据print(f"排名: {rank}, 名称: {univ_name_cn}, Name (EN): {univ_name_en}, 位置: {location}, 类型: {category}, 总分: {score}, 评分: {rating}")return university_info# data = get_one_page(2023)
# 获取一个页面内容
# print(extract_university_info(data))def get_total_pages(pagination_html):soup = BeautifulSoup(pagination_html, 'html.parser')pages = soup.find_all('li', class_='ant-pagination-item')if pages:return int(pages[-1].text)return 1html = get_one_page(2023)def get_data_from_page(data):content = extract_university_info(data)return contenttotal_pages=get_total_pages(html)
print(total_pages)from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.keys import Keysservice = Service(executable_path='chromedriver.exe')
browser = webdriver.Chrome(service=service)
browser.get("https://www.shanghairanking.cn/rankings/bcur/202311")for page in range(1, total_pages + 1):jump_input_locator = (By.XPATH, '//div[@class="ant-pagination-options-quick-jumper"]/input')jump_input = WebDriverWait(browser, 10).until(EC.element_to_be_clickable(jump_input_locator))jump_input.clear()jump_input.send_keys(page) # 输入页码jump_input.send_keys(Keys.RETURN) # 模拟 Enter 键time.sleep(3) # 等待页面加载html = browser.page_sourceget_data_from_page(html)time.sleep(3)
browser.quit()
运行如下:

数据保存到CSV文件中
写一个函数用来存储:
def write_to_csv(data_list, filename='output.csv'):with open(filename, 'w', newline='', encoding='utf-8') as csvfile:fieldnames = ["排名", "名称", "Name (EN)", "位置", "类型", "总分", "评分"]writer = csv.DictWriter(csvfile, fieldnames=fieldnames)writer.writeheader() # 写入表头for data in data_list:writer.writerow(data)
添加到获取部分:
content = get_data_from_page(html)
write_to_csv(content)
完整源码
到我的仓库复制即可:
https://github.com/sfvsfv/Crawer
视频讲解
https://www.bilibili.com/video/BV1j34y1T7WJ/
相关文章:
爬虫项目(二):中国大学排名
《Python网络爬虫入门到实战》京东购买地址,这里讲解了大量的基础知识和实战,由本人编著:https://item.jd.com/14049708.html配套代码仓库地址:https://github.com/sfvsfv/Crawer文章目录 分析第一步:获取源码分析第一…...

十二、MySQL(DQL)分组/排序/分页查询如何实现?
总括 select 字段列表 from 表名 [where 条件] (group by)/(order by)/(limit) 分组字段名 分组查询 1、分组查询 (1)基础语法: select 字段列表 from 表名 [where 条件] group by 分组字段名 [having 分组之后的过滤条件] (…...

设计模式概念学习
创建类型 单例模式 饿汉 构建时就创建 懒汉 单线程-访问到的时候才创建多线程-低效率 做法:加锁->若未创建则创建->获取资源->解锁 缺点:效率低,每次访问之前都要加锁,资源创建之后不能被同时被多个线程访问多线程-…...
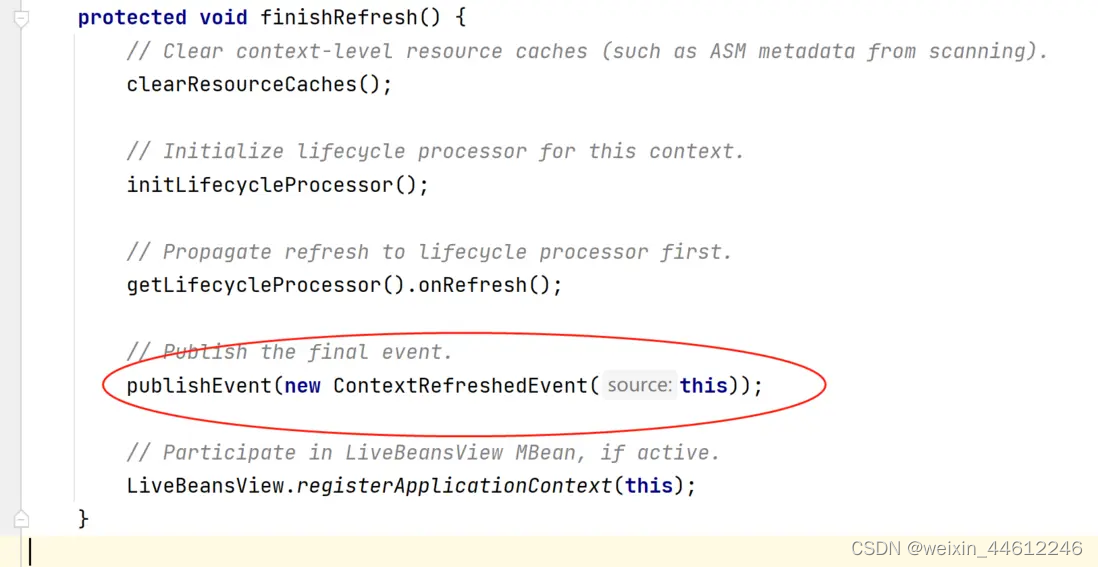
Spring MVC 五 - DispatcherServlet初始化过程(续)
今天的内容是SpringMVC的初始化过程,其实也就是DispatcherServilet的初始化过程。 Special Bean Types DispatcherServlet委托如下一些特殊的bean来处理请求、并渲染正确的返回。这些特殊的bean是Spring MVC框架管理的bean、按照Spring框架的约定处理相关请求&…...

day36:网编day3,TCP、UDP模型
下载: #include <myhead.h>#define ERR(s) do\ {\fprintf(stderr,"__%d__",__LINE__);\perror(s);\ }while(0) #define PORT 69 #define IP "192.168.115.184"int do_download(int cfd,struct sockaddr_in sin); //int do_upload(); int…...

MySQL——MySQL的基础操作部分
使用命令行登录 mysql -u root -p 直接敲击回车后输入密码即可: 当看到出现“mysql>“的符号之后,就表示已经进入到了MySQL系统中,就可以输入My…...

编译OpenWrt内核驱动
编译OpenWrt内核驱动可以参考OpenWrt内部其它驱动的编写例程,来修改成自己需要的驱动 一、OpenWrt源代码获取与编译 1.1、搭建环境 下载OpenWrt的官方源码: git clone https://github.com/openwrt/openwrt.git1.2、安装编译依赖项 sudo apt update -…...
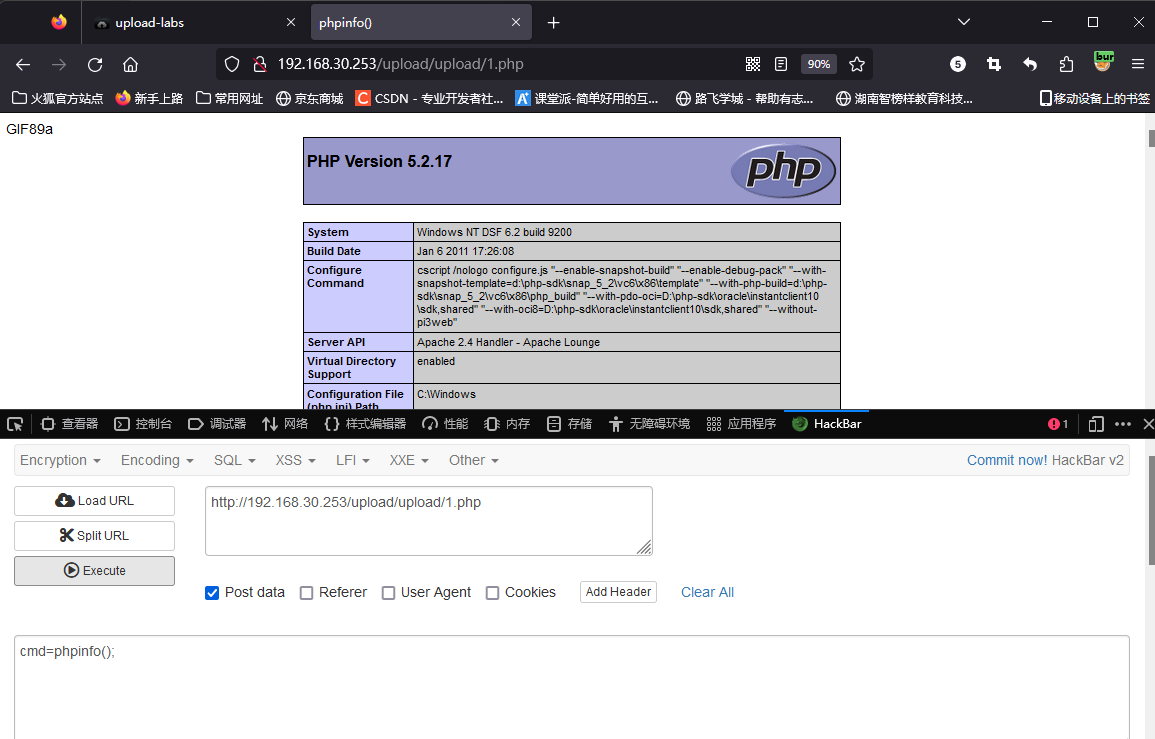
文件上传漏洞-upload靶场5-12关
文件上传漏洞-upload靶场5-12关通关笔记(windows环境漏洞) 简介 在前两篇文章中,已经说了分析上传漏的思路,在本篇文章中,将带领大家熟悉winodws系统存在的一些上传漏洞。 upload 第五关 (大小写绕过…...
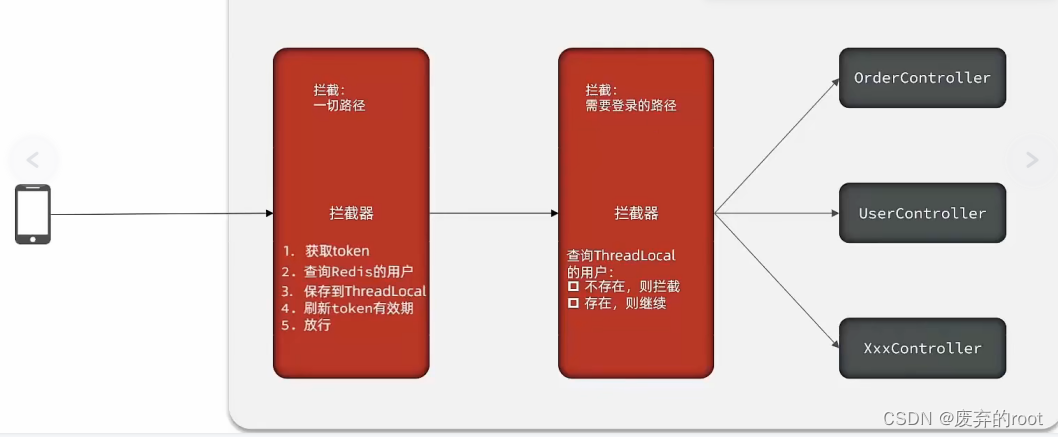
Redis功能实战篇之Session共享
1.使用redis共享session来实现用户登录以及token刷新 当用户请求我们的nginx服务器,nginx基于七层模型走的事HTTP协议,可以实现基于Lua直接绕开tomcat访问redis,也可以作为静态资源服务器,轻松扛下上万并发, 负载均衡…...

leetcode235. 二叉搜索树的最近公共祖先(java)
二叉搜索树的最近公共祖先 题目描述递归 剪枝代码演示: 上期经典 题目描述 难度 - 中等 LC235 二叉搜索树的最近公共祖先 给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。 百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q…...
2023物联网新动向:WEB组态除了用于数据展示,也支持搭建业务逻辑,提供与蓝图连线和NodeRed规则链类似的可视化编程能力
前言 组态编辑在工业控制、物联网场景中十分常见,越来越多的物联网平台也把组态作为一项标配功能。 物联网产业链自下往上由“端 - 边 - 管 - 云 -用”多个环节构成,组态通常是用于搭建数据展示类型的应用,而随着系统集成度越来越高&#x…...

react将文件转为base64进行上传
需求 将图片、pdf、word、excel等文件进行上传。图片、pdf等调接口A、word、excel等附件调接口B。接口关于文件是base64格式的参数 业务场景 上传资源,区分影像与附件 逻辑思路 使用原生input标签,typefile,进行上传上传后的回调&#x…...

生成式人工智能能否使数字孪生在能源和公用事业行业成为现实?
推荐:使用 NSDT场景编辑器 快速搭建3D应用场景 克服障碍,优化数字孪生优势 要实现数字孪生的优势,您需要数据和逻辑集成层以及基于角色的演示。如图 1 所示,在任何资产密集型行业(如能源和公用事业)中&…...
SpringBoot集成JWT token实现权限验证
JWTJSON Web Token 1. JWT的组成 JWTHeader,Payload,Signature>abc.def.xyz 地址:JSON Web Tokens - jwt.er 1.1 Header Header:标头。 两个组成部分:令牌的类型(JWT)和所使用的签名算法,经过Base64 Url编码后形成…...

算法通关村第11关【青铜】| 位运算基础
1.数字在计算机中的表示 原码、反码和补码都是计算机中用于表示有符号整数的方式。它们的使用旨在解决计算机硬件中的溢出和算术运算问题。 原码(Sign-Magnitude): 原码最简单,它的表示方式是用最高位表示符号位,0表示…...

无涯教程-Android - RadioGroup函数
RadioGroup类用于单选按钮集。 如果我们选中属于某个单选按钮组的一个单选按钮,它将自动取消选中同一组中以前选中的任何单选按钮。 RadioGroup属性 以下是与RadioGroup控制相关的重要属性。您可以查看Android官方文档以获取属性的完整列表以及可以在运行时更改这些属性的相关…...
降噪音频转录 Krisp: v1.40.7 Crack
主打人工智能降噪服务的初创公司「Krisp」近期宣布推出音频转录功能,能对电话和视频会议进行实时设备转录。该软件还整合的ChatGPT,以便快速总结内容,开放测试版于今天上线。 随着线上会议越来越频繁,会议转录已成为团队工作的重…...

基于React实现:弹窗组件与Promise的有机结合
背景 弹窗在现代应用中是最为常见的一种展示信息的形式,二次确认弹窗是其中最为经典的一种。当我们在React,Vue这种数据驱动视图的前端框架中渲染弹窗基本是固定的使用形式。 使用方式:创建新的弹窗组件,在需要弹窗的地方引用并…...

docker使用(一)生成,启动,更新(容器暂停,删除,再生成)
docker使用(一) 编写一个 Dockerfile构建镜像构建失败构建成功 运行镜像运行成功 修改代码后再次构建请不要直接进行构建,要将原有的旧容器删除或暂停停止成功删除成功再次构建且构建成功! 要创建一个镜像,你可以按照以…...
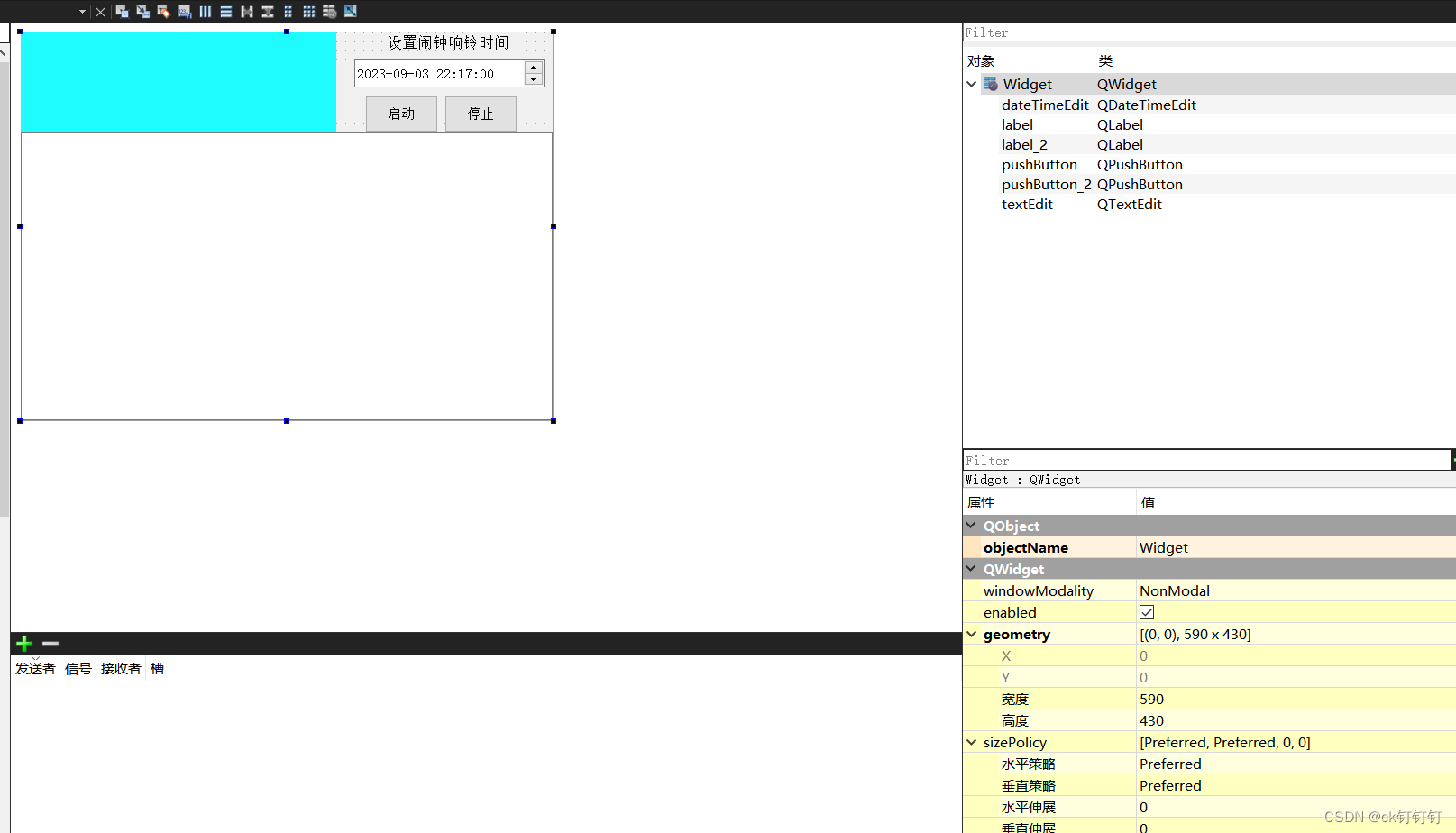
用Qt自制一个小闹钟
小闹钟 功能 当按下启动按钮时,停止按钮可用,启动按钮不可用,闹钟无法设置,无法输入自定义内容 当按下停止按钮时,暂停播报,启动按钮可用,闹钟可以设置,可以输入自定义内容 .pro文…...

从宿舍区隔离到无线网配置:手把手教你用Cisco Packet Tracer实现企业级网络策略
企业级网络隔离与无线接入实战:Cisco Packet Tracer全流程配置指南 在数字化转型浪潮中,网络架构设计已成为企业IT基础设施的核心竞争力。想象这样一个场景:某科技园区需要为研发部门、行政部门和访客区域构建差异化的网络访问策略——研发数…...

phpenv终极指南:5分钟掌握PHP多版本管理的完整解决方案
phpenv终极指南:5分钟掌握PHP多版本管理的完整解决方案 【免费下载链接】phpenv Simple PHP version management 项目地址: https://gitcode.com/gh_mirrors/ph/phpenv 还在为不同PHP项目间的版本冲突而烦恼吗?phpenv为您提供了一站式PHP版本管理…...

未来5年,程序员换工作,请做好降薪准备!
最近看到不少大厂的去年和一季度财报都公布了,不少人年终奖也发的差不多了,再加上金三银四也过了有一段时间了。按理来说,该晋升的晋升,该跳槽的跳槽,该加薪的加薪,基本尘埃落定,我公号后台应该…...

今天开课!相关性≠因果,因果推断与机器学习训练营,10天带你写出能“下结论”的论文!
为什么有些人服药后康复,而另一些人却毫无改善?为什么大学学位能改变收入水平?这些如果……会怎样的问题,其实都属于因果推断的范畴。在医疗研究中,许多问题都涉及因果概念,因此因果推断在健康研究领域越来…...
)
用Python和Matplotlib搞定高光谱图像可视化:从.mat文件到伪彩色图(附完整代码)
PythonMatplotlib高光谱图像可视化实战:从.mat文件到伪彩色合成 高光谱图像处理正逐渐从专业遥感领域走向更广泛的工业应用场景。当一位农业科技公司的算法工程师第一次拿到作物生长监测的高光谱数据时,面对.mat格式文件中那个神秘的三维矩阵,…...

车标识别平台
车标识别平台选题背景分析随着全球汽车产业的蓬勃发展以及智能交通系统(ITS)的加速建设,车标识别技术作为计算机视觉与人工智能领域的重要应用分支,其市场需求与技术价值日益凸显。开发一个高效、精准的车标识别平台,其…...

L298N驱动模块进阶玩法:用Arduino实现直流电机的软启动、缓停与速度曲线控制
L298N驱动模块进阶玩法:用Arduino实现直流电机的软启动、缓停与速度曲线控制 在创客和嵌入式开发领域,直流电机的控制是基础但至关重要的技能。大多数初学者会从简单的正反转和调速开始,但当项目需要更精细的运动控制时,粗暴的启…...

创业团队如何利用taotoken多模型能力快速进行产品原型验证
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 创业团队如何利用Taotoken多模型能力快速进行产品原型验证 对于资源有限的创业团队而言,开发一个智能对话产品原型时&a…...

嵌入式LCD与RTC驱动实战:从时序模拟到系统整合
1. 项目概述:当LCD遇见RTC,一个经典嵌入式显示方案的深度剖析最近在整理一个老项目的资料,翻出来一个挺有意思的模块:用一块字符型LCD屏,搭配一颗实时时钟芯片,实现一个带时间显示的简易信息板。这个组合—…...

树莓派TFT LCD屏幕连接全攻略:从SPI到DPI的选型与驱动配置
1. 项目概述:为什么是TFT LCD与树莓派? 如果你玩过树莓派,大概率会从一块小小的HDMI显示器或者SSH终端开始。但当你想要做一个便携的天气站、一个复古游戏机,或者一个嵌入在机器人里的控制面板时,拖着笨重的HDMI显示器…...