处理时延降低24倍,联通云粒数据引擎优化实践

*作者:郑扬勇,云粒星河数据中台产品负责人
云粒智慧科技有限公司成立于 2018 年 6 月,是中国联通集团混改以来成立的首家合资公司,是中国智慧城市数智化建设者。一直以来,云粒智慧以数字化、智能化、集约化产品为核心,全面融合“5G+大数据+AI+CIM”等最新技术,致力于构建未来城市数字化基础设施平台,打造“绿色、互联、智能”的现代化智慧城市,为政企提供符合政策导向及智慧城市发展趋势的“三中台+智能化应用”解决方案,实现城市智脑与生态环境可持续发展。
这里说到的“三中台”,其最重要的中台即云粒星河数据中台,是一套集“数据建设与运营方法论、软件+行业资产包和数据技术服务”的中台体系,提供数据采集、融合、治理、计算、分析、服务、可视化的全链路一站式管理与服务。经过四年 4 个大版本的迭代,目前已累计完成 80+ 客户项目的落地交付,实现产品销售总额超过 1.2 亿元的好成绩。

云粒星河数据中台作为大数据处理系统,数据引擎是其最重要的核心中间件。云粒星河数据中台的数据引擎一直选用开源的 Apache Hive,自诞生,到 3.x 系列最后一个版本。总体上 Apache Hive 是一个非常优秀、久经考验的 OLAP 引擎,但在项目落地实施的过程中,我们也遇到了诸多痛点,导致最终交付成本偏高,拉低了项目的毛利率。
痛点 1:组件众多,运维困难,云原生化不友好
Hive 依赖 Hadoop,我们使用 HDFS 存储数据,YARN 作为资源管理框架,Tez 优化 Hive DAG 任务;由于需要高可用,每个节点都需要启动好几个相关进程,这些进程的配置、监控、伸缩、保活等都极大地增加了运维工作量。由于 Hive 和 Hadoop 使用的是已经老旧的按节点方式扩缩容的架构设计,因此云原生非常不友好,社区至今也没有提供容器化部署方案;自行尝试通过 Statefulset 方式运行在 Kubernetes 中并进行性能测试,发现性能竟然有 30% 以上的下降,因此我们仍然使用物理机或 VM 方式部署。
痛点 2:资源利用率低, 任务调优繁琐复杂
由于 YARN 是双层悲观并发资源管理(调度)框架,经过 Tez 优化后的 Hive DAG 任务向 YARN 申请资源仍然是按固定配额(vCore 和 Mem)的方式进行,为了能够最大化利用资源提高并发,需要在项目中根据任务处理数据量情况 Case By Case 做配置调优,并且随着数据中台数据处理量的不断变化(通常情况是逐步增加),配置调优的工作需要持续进行,无法一劳永逸。
痛点 3:数据处理时延大,用户体验差
由于诸多原因,我们没有使用 Hive 的 LLAP 特性,这会导致 Hive 即使处理极小的数据量如数百条记录,由于需要冷启动最低两个 YARN Container(含一个 App Master),至少需要数秒才能返回,无法做到亚秒级交互式查询,难以支持数据大屏等实时性要求较高的下游应用,为了解决这个问题,我们追加部署了基于 MPP 架构的 Presto 引擎解决了这个问题,但这也带来新的问题,即对内存资源的需求也大大增加了,这种成本的增加最终还是会转变为交付成本,降低项目利润。
痛点 4:不支持行级更新,灵活性较低
Hive 是一个为数仓而生经典的 OLAP 引擎,数据更新仅支持全表/分区级覆盖,极低的情况下如果需要对远景冷区部分数据进行更新,处理较为麻烦;另外分区设置策略也颇为费脑——粒度太大更新效率较低,粒度太小又容易发生分区和小文件数据量爆炸,表现为还是效率低下……
正是由于以上一些挑战,自云粒星河数据中台 3.0 大版本发布支持多引擎并行能力开始,公司内部一直在寻找一款稳定可靠、AP 和 TP 兼备、能够在集约资源环境下有较高效率表现的数据引擎。

但数据引擎作为基础软件百花齐放,我们如何在一堆“好”软件中最好的只有更挑选更适合自己的以及怎么判断适合?云粒总结了如下五点:
-
开源软件,友好的商业 License;
-
支持云原生;
-
支持集群模式;
-
支持私有化部署;
-
有较高成熟度(社区、生态等)。
经过较长时间的调研和比较,初步满足条件的数据引擎仅剩以下 CockroachDB、YugabyteDB、PingCap TiDB、OceanBase 四款。其中,CockroachDB 社区版限制较多,例如,较为基础的索引功能都需要获取商业版License 解锁;YugabyteDB 在内部性能测试对比过程中表现较差,因此两者排除较早;而对于后两款,OceanBase 相比 TiDB,更适合我们的点在于以下三个方面:
第一,OceanBase 的架构较为简洁,只有 OBServer 和 OBProxy。而 TiDB 由PD、TiDB、TiKV、TiFlash 四个组件构成。如果只是部署一套集群用于内部服务,那么二者的区别不大,但我们需要部署和运维几十甚至上百套集群,配置、部署、运维等方面用 OceanBase 较为便利。
第二,OceanBase 原生支持多租户,资源隔离和控制模型也比较清晰。而 TiDB 对于多租户支持很晚(生产可用应该是在 V7.0+),至今仍处于完善阶段。云粒数据中台作为一个原生多租户系统,使用 OceanBase 的多租户体验更舒服。
第三,OceanBase 的生态策略感觉更开放。例如,数据集成方面专门为 DataX 开发了插件,更贴合我们现有技术路线。TiDB 虽然提供了更丰富的数据集成组件包含 TiCDC、TiDB Data Migration、TiDB Lightning,但我们整合进产品会比较重,工作量会比较大。
基于上述因素,自 2021 年 OceanBase 宣布开源开始,其进入我们的候选名单,2022 年,OceanBase 发布 4.0 版本,其迭代速度和性能改进更是让我们惊叹,正是那时,我们果断确定产品选型并启动适配工作。
因为项目体量较大及产品功能较多,且大多数都与数据引擎相关,整个适配过程大概持续了两个多月完美收工。数据引擎更换为 OceanBase 后的云粒星河数据中台得到了如下优化,极大缓解甚至消除了之前的痛点。
优化 1:更简介的架构,更好的云原生
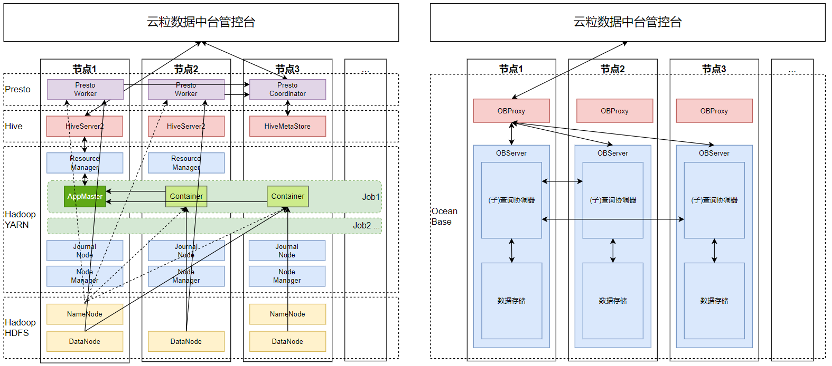
左-更换前(Hive+Presto);右-更换后(单一OceanBase)
从上图可以看出,相比 Hive 引擎,OceanBase 只需要在每个节点上启动 OBProxy 和 OBServer 两个进程即可,通过 Prometheus 导出 Metrics,监控运维便捷省力。得益于架构的简洁,OceanBase 很容易实现云原生化,官方已提供在 Kubernetes 中部署运行的详细方案,这对云粒星河数据中台本身实现彻底云原生化至关重要。
优化2:让每一核 CPU 发挥最大价值
私有化环境交付,客户能够提供的资源不足已经是“家常便饭“,这就要求云粒星河数据中台必须具备“螺蛳壳里做道场”的能力,即在较低资源配置下也能有良好的处理能力表现。例如,我们甚至遇到个别客户仅提供三台 8C32GB 规格的服务器部署数据引擎。以往采用 Hive 结合 Presto 作为数据引擎。部署完各类组件,每个节点能够提供给 YARN 调度的内存往往就只剩下 10GB 左右,每个作业(Job)还需要启动一个独立的用于协调的AppMaster(通常占用 1GB 内存),使得在小数据量高并发场景下的性能表现雪上加霜。
前文也提到需要对于 YARN 资源分配的参数反复调校,费时费力。采用 OceanBase 作为数据引擎后,单租户模式下,为 OBProxy 分配 2GB 内存,系统租户和租户 META 租户各分配 3GB 内存,剩余内存全部用于租户本身,通过试验,小数据量场景(单次处理数据量低于 1GB)并发能力相比 Hive 有十数倍提升,在较大的数据量(单次处理数据量超过 10GB)场景下也能做好处理,轻松榨干 CPU 每一核。
优化 3:数据治理从分钟级到准实时
准实时数据治理单次需要处理的数据量往往都较小,得益于高效的分布式计算调度和数据存储结构,即使是逻辑较为复杂的数据治理 SQL,OceanBase 也能游刃有余地快速完成,以下是测试数据治理工作流执行时间对比,它由一个数据接入节点和两个数据更新写入节点构成,每次处理的数据量接近 1GB,资源配置同为三台 8C32GB 服务器集群。
| Hive | OceanBase | |
| 数据接入 | 21s | 14s |
| 数据更新1(两个表关联) | 24s | <1s |
| 数据更新2(五个表关联) | 39s | 10s |
可以看出,OceanBase 在小数据量场景下各方面的时延都远低于 Hive。而相比定位为单一 OLAP 引擎的 Hive,定位为 HTAP 引擎的 OceanBase 在 TP 方面的诸多优势不再赘述,对于冷数据行级更新更不在话下。

当然,对于团队中习惯使用 Hive 做数据交付的同学,在使用 OceanBase 的过程中,也有少量感觉不太方便的地方,主要有两点:
第一,OceanBase 不支持 Insert Overwrite,还好可以使用 Truncate/Delete + Insert 曲线支持,问题不大;
第二,OceanBase 不支持使用 List 分区策略时动态分区,因此每次插入数据时,都需要检查对应的分区是否存在,如果不存在,则需要先 ALTER TABLE· ADD PARTITION,很不方便,希望未来能尽快支持。
另外,不可否认,当单次需要处理的数据量上升到一定级别如 100GB 以上,凭借 ORC 或 Parquet 列存格式优势,Hive执行数据分析的性能表现是优于 OceanBase 的,不过可喜的是,列存计划已列入产品 roadmap,希望在不久后可以看到更强的 AP 性能能力。

目前,更换为 OceanBase 作为数据引擎的云粒星河数据中台 4.0 已经在项目上实施落地。总的来说,OceanBase 更简洁的架构、更轻便的运维,帮助我们加速了数据中台云原生的进程,提升资源利用率的同时,并发性能提升 10+ 倍,数据处理时延降低 1.5-24 倍。这带来的直观效益是机器成本与运维人力的节约,进而带来了 20% 的毛利率提升。
非常感谢 OceanBase 贡献优秀的数据引擎,希望它能越做越好,成为数据引擎领域“国产之光”,向世界展现中国技术实力!
相关文章:
处理时延降低24倍,联通云粒数据引擎优化实践
*作者:郑扬勇,云粒星河数据中台产品负责人 云粒智慧科技有限公司成立于 2018 年 6 月,是中国联通集团混改以来成立的首家合资公司,是中国智慧城市数智化建设者。一直以来,云粒智慧以数字化、智能化、集约化产品为核心&…...
学习MATLAB
今日,在大学慕课上找了一门关于MATLAB学习的网课,MATLAB对于我们这种自动化的学生应该是很重要的,之前也是在大三的寒假做自控的课程设计时候用到过,画一些奈奎斯特图,根轨迹图以及伯德图,但那之后也就没怎…...

React 18 对 state 进行保留和重置
参考文章 对 state 进行保留和重置 各个组件的 state 是各自独立的。根据组件在 UI 树中的位置,React 可以跟踪哪些 state 属于哪个组件。可以控制在重新渲染过程中何时对 state 进行保留和重置。 UI 树 浏览器使用许多树形结构来为 UI 建立模型。DOM 用于表示 …...
MySQL之事务与引擎
目录 一、事物 1、事务的概念 2、事务的ACID特点 3、事务之间的相互影响 4、Mysql及事务隔离级别(四种) 1、查询会话事务隔离级别 2、查询会话事务隔离级别 3、设置全局事务隔离级别 4、设置会话事务隔离级别 5、事务控制语句 6、演示 1、测试提交事务 2、测试事务回滚 4…...

Flink集群常见的监控指标
为确保能够全面、实时地监控Flink集群的运行状态和性能指标。以下是监控方案的主要组成部分: Flink集群概览:通过访问Flink的JobManager页面,您可以获取集群的总体信息,包括TaskManager的数量、任务槽位数量、运行中的作业以及已…...

React常见知识点
1. setCount(10)与setCount(preCount > preCount 10) 的区别: import React, { useState } from react; export default function CounterHook() {const [count, setCount] useState(() > 10);console.log(CounterHook渲染);function handleBtnClick() {//…...
Vue-router路由
配置路由 相当于SpringMVC的Controller 路径然后,跳转到对应的组件 一键生成前端项目文档...
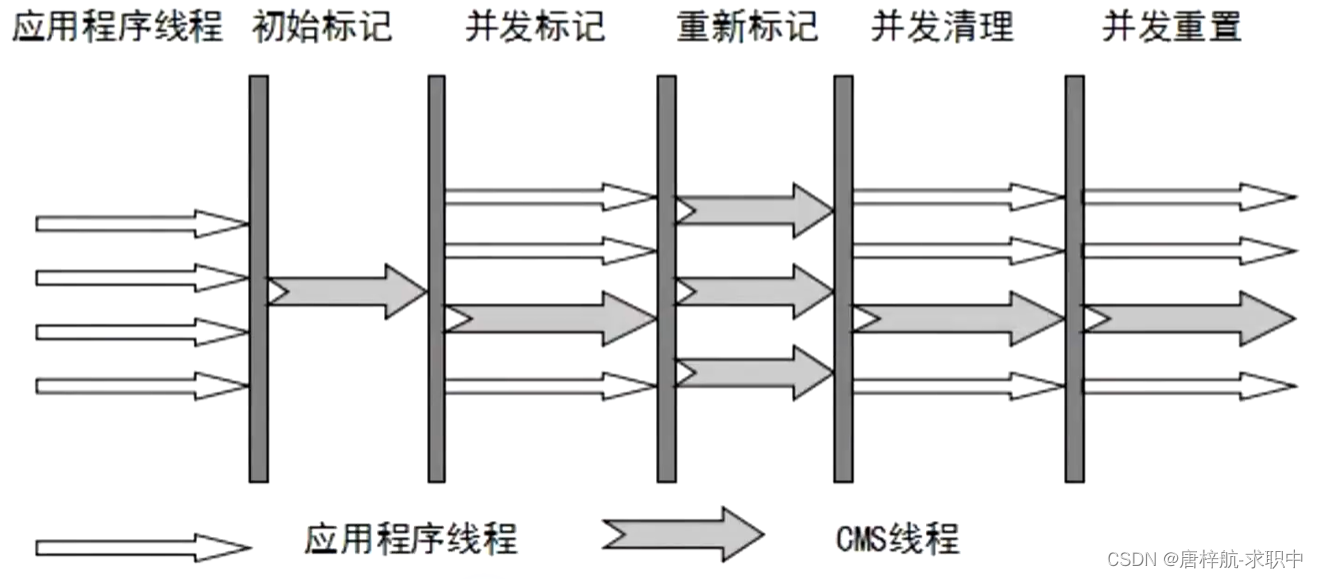
JVM-CMS
when 堆大小要求为4-8G 原理 初始标记:执行CMS线程->STW,标记GC Root直接关联的对象->低延迟 并发标记:执行CMS线程和业务线程,从GC Root直接关联的对象开始遍历整个对象图 重新标记:执行CMS线程->STW&a…...

无涯教程-Flutter - Dart简介
Dart是一种开源通用编程语言,它最初是由Google开发的, Dart是一种具有C样式语法的面向对象的语言,它支持诸如接口,类之类的编程概念,与其他编程语言不同,Dart不支持数组, Dart集合可用于复制数据…...
如何创建美观的邮件模板并通过qq邮箱的SMTP服务向用户发送
最近在写注册功能的自动发送邮箱告知验证码的功能,无奈根本没有学过前端,只有写Qt的qss基础,只好借助网页设计自己想要的邮箱格式,最终效果如下: 也推销一下自己的项目ShaderLab,可运行ShaderToy上的大部分着色器代码&…...

手机无人直播软件在苹果iOS系统中能使用吗?
在现代社交媒体的时代,直播带货已经成为了一种热门的销售途径。通过直播,人们可以远程分享自己的商品,与观众进行互动,增强沟通和参与感。而如今,手机无人直播软件更是成为了直播带货领域的一项火爆的技术。那么&#…...

创建2个线程并执行(STL/Windows/Linux)
C并发编程入门 目录 STL 写法 #include <thread> #include <iostream> using namespace std;void thread_fun1(void) {cout << "one STL thread 1!" << endl; }void thread_fun2(void) {cout << "one STL thread 2!" <…...

Redis可以干什么
Redis可以做什么? 缓存 Redis作为一款高性能的缓存数据库,能够将常用的数据存储在内存中,以提高读写效率。它支持多种数据结构,如字符串、哈希表、列表、集合等,让你可以根据业务需求选择合适的数据结构进行缓存。 …...
R语言+Meta分析;论文新方向
Meta分析是针对某一科研问题,根据明确的搜索策略、选择筛选文献标准、采用严格的评价方法,对来源不同的研究成果进行收集、合并及定量统计分析的方法,最早出现于“循证医学”,现已广泛应用于农林生态,资源环境等方面。…...

实战系列(二)| MybatisPlus详细介绍,包含代码详解
目录 1. MybatisPlus 的基本功能2. 基本用法3. MybatisPlus 的配置4. MybatisPlus 的实体类、Mapper 接口、Service 类和 Controller 类 MybatisPlus 是一个功能强大的 MyBatis 增强工具,它提供了丰富的特性来简化操作数据库的代码。它主要用于简化 JDBC 操作&#…...
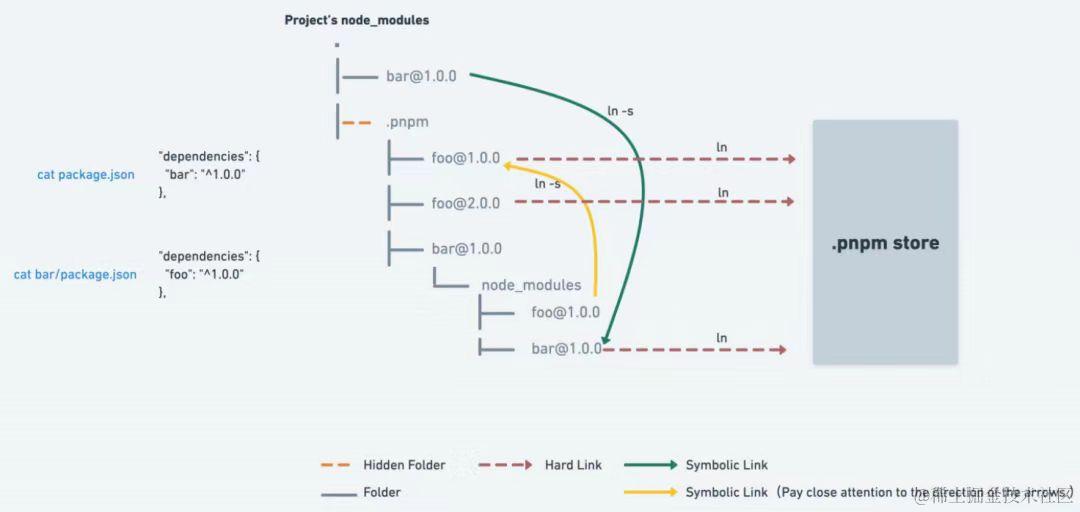
横向对比 npm、pnpm、tnpm、yarn 优缺点
前端工程化是现代Web开发中不可或缺的一环,它的出现极大地提升了前端开发的效率和质量。 在过去,前端开发依赖于手动管理文件和依赖,这导致了许多问题,如版本冲突、依赖混乱和构建繁琐等。而今,随着众多前端工程化工具…...
安防监控/视频汇聚/云存储/AI智能视频融合平台页面新增地图展示功能
AI智能分析网关包含有20多种算法,包括人脸、人体、车辆、车牌、行为分析、烟火、入侵、聚集、安全帽、反光衣等等,可应用在安全生产、通用园区、智慧食安、智慧城管、智慧煤矿等场景中。将网关硬件结合我们的视频汇聚/安防监控/视频融合平台EasyCVR一起使…...

机器人中的数值优化(九)——拟牛顿方法(下)、BB方法
本系列文章主要是我在学习《数值优化》过程中的一些笔记和相关思考,主要的学习资料是深蓝学院的课程《机器人中的数值优化》和高立编著的《数值最优化方法》等,本系列文章篇数较多,不定期更新,上半部分介绍无约束优化,…...

java 从resource下载excel打不开
GetMapping("/download/template")public void template(HttpServletResponse response) throws IOException {ServletOutputStream outputStream response.getOutputStream();InputStream inputStream null;try {//从resource获取excel文件流inputStream getClas…...
NS2安装及入门实例——(ns2.35 / Ubuntu20.04)
文章目录 一、ns2安装1、更新系统源2、准备工作3、下载安装包4、安装5、问题① 问题1② 问题2③ 问题3 6、安装成功7、环境配置 二、nam安装1、安装2、问题 三、实例 一、ns2安装 1、更新系统源 sudo apt-get update sudo apt-get upgrade2、准备工作 sudo apt-get install …...

深入解析Keil MDK FLM算法:SRAM运行原理与下载机制
1. 项目概述:FLM算法,Keil MDK下载的“灵魂引擎”如果你用Keil MDK给一块新的APM32或者STM32芯片下载程序,点下那个“Download”或“Load”按钮,几秒钟后“Programming Done”的提示框弹出,这个过程看似简单࿰…...

智能手表核心升级:三星OLED与4nm处理器如何重塑用户体验
1. 项目概述:一次旗舰智能手表核心元件的深度迭代最近看到一条关于谷歌Pixel Watch 2的消息,核心信息点很明确:屏幕将由三星供应OLED面板,同时处理器将升级到4纳米制程。这看起来只是两个硬件参数的简单罗列,但对于我们…...

微信虚拟支付求支招
最近微信小程序不是要求必须接入虚拟支付吗,然后我们接入了,并走通了流程。但是!!使用其它体验极差,具体如下: 1.这块的开发流程手册,狗看了都摇头。我看着流程自己理解的意思是,我们…...

告别TensorFlow!用Zylo117的PyTorch版EfficientDet-D0,手把手教你训练自己的Logo检测模型
从TensorFlow到PyTorch:用EfficientDet-D0打造高精度Logo检测器实战指南 在计算机视觉领域,目标检测一直是热门研究方向。EfficientDet作为谷歌大脑团队提出的高效检测架构,凭借其创新的BiFPN和复合缩放策略,在精度和效率之间取得…...

单频信号频谱检测仿真实验:从能量检测到匹配滤波器的性能对比
1. 项目概述:从“听”到“看”的信号世界 在无线通信、雷达探测、声学分析乃至医疗影像等众多领域,我们常常面对一个核心问题:如何从一段复杂的、充满噪声的波形中,准确地识别出一个特定频率的信号是否存在?这就像在一…...

RV1106开发板WiFi配置全攻略:从AP模式到STA模式,手把手教你搞定网络连接
RV1106开发板WiFi配置全攻略:从AP模式到STA模式,手把手教你搞定网络连接 刚拿到RV1106开发板时,最让人头疼的莫过于WiFi配置了。这块嵌入式开发板在网络连接上有着独特的配置逻辑,尤其是AP(接入点)和STA&am…...

为什么你的 Multi-Agent 系统越加 Agent 越慢:并发与调度的反直觉陷阱
为什么你的 Multi-Agent 系统越加 Agent 越慢:并发与调度的反直觉陷阱 一、引言 钩子:90% 大模型开发者都踩过的性能悖论 你是否有过这样的经历:花了两周时间把单 Agent 的文档分析系统改造成多 Agent 协作架构,原本预期 5 个 Agent 能把处理速度提升 4 倍,结果上线后发…...

当A*算法遇上真实山地DEM:一份给无人机/机器人路径规划者的Python避坑指南
当A*算法遇上真实山地DEM:无人机路径规划的Python实战与优化 山地路径规划的独特挑战 在无人机和机器人导航领域,山地地形带来了传统路径规划算法难以应对的复杂性。与平坦城市环境不同,山地DEM(数字高程模型)数据包含…...

CTF实战:从ZIP伪加密到二进制文件结构解析
1. ZIP伪加密:CTF中的经典陷阱 第一次参加CTF比赛时,我遇到一个看似简单的MISC题目——解压一个加密的ZIP文件。当时我花了整整两小时尝试各种密码爆破工具,直到队友提醒我:"这可能是伪加密"。这个经历让我深刻认识到&…...

深入浅出DPCM与DAPM:图解高通音频架构如何实现动态功耗管理与低延迟播放
深入浅出DPCM与DAPM:图解高通音频架构如何实现动态功耗管理与低延迟播放 在智能穿戴设备和移动终端领域,音频系统的功耗优化一直是工程师面临的重大挑战。想象一下,当你的智能手表在待机状态下播放通知铃声时,如果每次都需要唤醒主…...