详解4种类型的爬虫技术

-
聚焦网络爬虫是“面向特定主题需求”的一种爬虫程序,而通用网络爬虫则是捜索引擎抓取系统(Baidu、Google、Yahoo等)的重要组成部分,主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。
-
增量抓取意即针对某个站点的数据进行抓取,当网站的新增数据或者该站点的数据发生变化后,自动地抓取它新增的或者变化后的数据。
-
Web页面按存在方式可以分为表层网页(surface Web)和深层网页(deep Web,也称invisible Web pages或hidden Web)。
-
表层网页是指传统搜索引擎可以索引的页面,即以超链接可以到达的静态网页为主来构成的Web页面。
-
深层网页是那些大部分内容不能通过静态链接获取的、隐藏在搜索表单后的,只有用户提交一些关键词才能获得的Web页面。
01 聚焦爬虫技术
聚焦网络爬虫(focused crawler)也就是主题网络爬虫。聚焦爬虫技术增加了链接评价和内容评价模块,其爬行策略实现要点就是评价页面内容以及链接的重要性。
基于链接评价的爬行策略,主要是以Web页面作为半结构化文档,其中拥有很多结构信息可用于评价链接重要性。还有一个是利用Web结构来评价链接价值的方法,也就是HITS法,其通过计算每个访问页面的Authority权重和Hub权重来决定链接访问顺序。
而基于内容评价的爬行策略,主要是将与文本相似的计算法加以应用,提出Fish-Search算法,把用户输入查询词当作主题,在算法的进一步改进下,通过Shark-Search算法就能利用空间向量模型来计算页面和主题相关度大小。
面向主题爬虫,面向需求爬虫:会针对某种特定的内容去爬取信息,而且会保证信息和需求尽可能相关。一个简单的聚焦爬虫使用方法的示例如下所示。
-
【例1】一个简单的爬取图片的聚焦爬虫
import urllib.request# 爬虫专用的包urllib,不同版本的Python需要下载不同的爬虫专用包
import re# 正则用来规律爬取
keyname=""# 想要爬取的内容
key=urllib.request.quote(keyname)# 需要将你输入的keyname解码,从而让计算机读懂
for i in range(0,5): # (0,5)数字可以自己设置,是淘宝某产品的页数url="https://s.taobao.com/search?q="+key+"&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20180815&ie=utf8&bcoffset=0&ntoffset=6&p4ppushleft=1%2C48&s="+str(i*44)
# url后面加上你想爬取的网站名,然后你需要多开几个类似的网站以找到其规则
# data是你爬取到的网站所有的内容要解码要读取内容pat='"pic_url":"//(.*?)"'
# pat使用正则表达式从网页爬取图片
# 将你爬取到的内容放在一个列表里面print(picturelist)# 可以不打印,也可以打印下来看看for j in range(0,len(picturelist)):picture=picturelist[j]pictureurl="http://"+picture# 将列表里的内容遍历出来,并加上http://转到高清图片file="E:/pycharm/vscode文件/图片/"+str(i)+str(j)+".jpg"# 再把图片逐张编号,不然重复的名字将会被覆盖掉urllib.request.urlretrieve(pictureurl,filename=file)# 最后保存到文件夹
02 通用爬虫技术
通用爬虫技术(general purpose Web crawler)也就是全网爬虫。其实现过程如下。
-
第一,获取初始URL。初始URL地址可以由用户人为指定,也可以由用户指定的某个或某几个初始爬取网页决定。
-
第二,根据初始的URL爬取页面并获得新的URL。获得初始的URL地址之后,需要先爬取对应URL地址中的网页,接着将网页存储到原始数据库中,并且在爬取网页的同时,发现新的URL地址,并且将已爬取的URL地址存放到一个URL列表中,用于去重及判断爬取的进程。
-
第三,将新的URL放到URL队列中,在于第二步内获取下一个新的URL地址之后,会将新的URL地址放到URL队列中。
-
第四,从URL队列中读取新的URL,并依据新的URL爬取网页,同时从新的网页中获取新的URL并重复上述的爬取过程。
-
第五,满足爬虫系统设置的停止条件时,停止爬取。在编写爬虫的时候,一般会设置相应的停止条件。如果没有设置停止条件,爬虫便会一直爬取下去,一直到无法获取新的URL地址为止,若设置了停止条件,爬虫则会在停止条件满足时停止爬取。详情请参见图2-5中的右下子图。
通用爬虫技术的应用有着不同的爬取策略,其中的广度优先策略以及深度优先策略都是比较关键的,如深度优先策略的实施是依照深度从低到高的顺序来访问下一级网页链接。
关于通用爬虫使用方法的示例如下。
-
【例2】爬取京东商品信息
'''
爬取京东商品信息:请求url:https://www.jd.com/提取商品信息:1.商品详情页2.商品名称3.商品价格4.评价人数5.商品商家
'''
from selenium import webdriver # 引入selenium中的webdriver
from selenium.webdriver.common.keys import Keys
import timedef get_good(driver):try:# 通过JS控制滚轮滑动获取所有商品信息js_code = '''window.scrollTo(0,5000);'''driver.execute_script(js_code) # 执行js代码# 等待数据加载time.sleep(2)# 查找所有商品div# good_div = driver.find_element_by_id('J_goodsList')good_list = driver.find_elements_by_class_name('gl-item')n = 1for good in good_list:# 根据属性选择器查找# 商品链接good_url = good.find_element_by_css_selector('.p-img a').get_attribute('href')# 商品名称good_name = good.find_element_by_css_selector('.p-name em').text.replace("\n", "--")# 商品价格good_price = good.find_element_by_class_name('p-price').text.replace("\n", ":")# 评价人数good_commit = good.find_element_by_class_name('p-commit').text.replace("\n", " ")good_content = f'''商品链接: {good_url}商品名称: {good_name}商品价格: {good_price}评价人数: {good_commit}\n'''print(good_content)with open('jd.txt', 'a', encoding='utf-8') as f:f.write(good_content)next_tag = driver.find_element_by_class_name('pn-next')next_tag.click()time.sleep(2)# 递归调用函数get_good(driver)time.sleep(10)finally:driver.close()if __name__ == '__main__':good_name = input('请输入爬取商品信息:').strip()driver = webdriver.Chrome()driver.implicitly_wait(10)# 往京东主页发送请求driver.get('https://www.jd.com/')# 输入商品名称,并回车搜索input_tag = driver.find_element_by_id('key')input_tag.send_keys(good_name)input_tag.send_keys(Keys.ENTER)time.sleep(2)get_good(driver)03 增量爬虫技术
某些网站会定时在原有网页数据的基础上更新一批数据。例如某电影网站会实时更新一批最近热门的电影,小说网站会根据作者创作的进度实时更新最新的章节数据等。在遇到类似的场景时,我们便可以采用增量式爬虫。
增量爬虫技术(incremental Web crawler)就是通过爬虫程序监测某网站数据更新的情况,以便可以爬取到该网站更新后的新数据。
关于如何进行增量式的爬取工作,以下给出三种检测重复数据的思路:
-
在发送请求之前判断这个URL是否曾爬取过;
-
在解析内容后判断这部分内容是否曾爬取过;
-
写入存储介质时判断内容是否已存在于介质中。
-
第一种思路适合不断有新页面出现的网站,比如小说的新章节、每天的实时新闻等;
-
第二种思路则适合页面内容会定时更新的网站;
-
第三种思路则相当于最后一道防线。这样做可以最大限度地达到去重的目的。
不难发现,实现增量爬取的核心是去重。目前存在两种去重方法。
-
第一,对爬取过程中产生的URL进行存储,存储在Redis的set中。当下次进行数据爬取时,首先在存储URL的set中对即将发起的请求所对应的URL进行判断,如果存在则不进行请求,否则才进行请求。
-
第二,对爬取到的网页内容进行唯一标识的制定(数据指纹),然后将该唯一标识存储至Redis的set中。当下次爬取到网页数据的时候,在进行持久化存储之前,可以先判断该数据的唯一标识在Redis的set中是否存在,从而决定是否进行持久化存储。
关于增量爬虫的使用方法示例如下所示。
-
【例3】爬取4567tv网站中所有的电影详情数据
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from redis import Redis
from incrementPro.items import IncrementproItem
class MovieSpider(CrawlSpider):name = 'movie'# allowed_domains = ['www.xxx.com']start_urls = ['http://www.4567tv.tv/frim/index7-11.html']rules = (Rule(LinkExtractor(allow=r'/frim/index7-\d+\.html'), callback='parse_item', follow=True),)# 创建Redis链接对象conn = Redis(host='127.0.0.1', port=6379)def parse_item(self, response):li_list = response.xpath('//li[@class="p1 m1"]')for li in li_list:# 获取详情页的urldetail_url = 'http://www.4567tv.tv' + li.xpath('./a/@href').extract_first()# 将详情页的url存入Redis的set中ex = self.conn.sadd('urls', detail_url)if ex == 1:print('该url没有被爬取过,可以进行数据的爬取')yield scrapy.Request(url=detail_url, callback=self.parst_detail)else:print('数据还没有更新,暂无新数据可爬取!')# 解析详情页中的电影名称和类型,进行持久化存储def parst_detail(self, response):item = IncrementproItem()item['name'] = response.xpath('//dt[@class="name"]/text()').extract_first()item['kind'] = response.xpath('//div[@class="ct-c"]/dl/dt[4]//text()').extract()item['kind'] = ''.join(item['kind'])yield it
管道文件:
from redis import Redis
class IncrementproPipeline(object):conn = Nonedef open_spider(self,spider):self.conn = Redis(host='127.0.0.1',port=6379)def process_item(self, item, spider):dic = {'name':item['name'],'kind':item['kind']}print(dic)self.conn.push('movieData',dic) # 如果push不进去,那么dic变成str(dic)或者改变redis版本 pip install -U redis==2.10.6return item04 深层网络爬虫技术
在互联网中,网页按存在方式可以分为表层网页和深层网页两类。
所谓的表层网页,指的是不需要提交表单,使用静态的链接就能够到达的静态页面;而深层网页则隐藏在表单后面,不能通过静态链接直接获取,是需要提交一定的关键词后才能够获取到的页面,深层网络爬虫(deep Web crawler)最重要的部分即为表单填写部分。
在互联网中,深层网页的数量往往要比表层网页的数量多很多,故而,我们需要想办法爬取深层网页。
深层网络爬虫的基本构成:URL列表、LVS列表(LVS指的是标签/数值集合,即填充表单的数据源)、爬行控制器、解析器、LVS控制器、表单分析器、表单处理器、响应分析器。
深层网络爬虫的表单填写有两种类型:
-
基于领域知识的表单填写(建立一个填写表单的关键词库,在需要的时候,根据语义分析选择对应的关键词进行填写);
-
基于网页结构分析的表单填写(一般在领域知识有限的情况下使用,这种方式会根据网页结构进行分析,并自动地进行表单填写)。
相关文章:
详解4种类型的爬虫技术
聚焦网络爬虫是“面向特定主题需求”的一种爬虫程序,而通用网络爬虫则是捜索引擎抓取系统(Baidu、Google、Yahoo等)的重要组成部分,主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。 增量抓取意…...
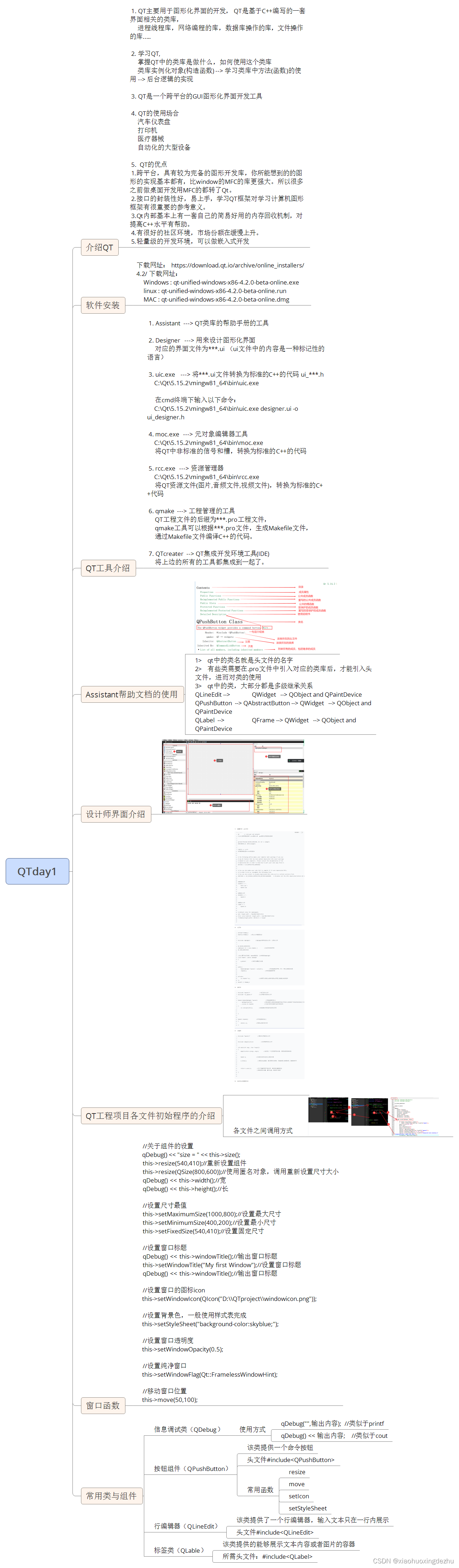
QTday1基础
作业 一、做个QT页面 #include "hqyj.h"HQYJ::HQYJ(QWidget *parent)//构造函数定义: QWidget(parent)//显性调用父类的有参构造 {//主界面设置this->resize(540,410);//设置大小this->setFixedSize(540,410);//设置固定大小this->setWindowIcon(QIcon(&q…...

activiti 通过xml上传 直接部署模型
通过流程xml 直接先发布模型,然后再通过发布模型之后的流程定义获取bpmn model来创建Model. 1、通过xml先发布模型 InputStream bpmnStream multipartFile.getInputStream() deployment repositoryService.createDeployment().addInputStream(multipartFile.getO…...

算法题打卡day56-编辑距离 | 583. 两个字符串的删除操作、72. 编辑距离
583. 两个字符串的删除操作 - 力扣(LeetCode) 状态:查看思路后AC。 和查找子序列的操作类似,但是考虑的是删除操作。代码如下: class Solution { public:int minDistance(string word1, string word2) {int len1 wor…...

SQL中的CASE WHEN语句:从基础到高级应用指南
SQL中的CASE WHEN语句:从基础到高级应用指南 准备工作 - 表1: products 示例数据: 我们使用一个名为"Products"的表,包含以下列:ProductID、ProductName、CategoryID、UnitPrice、StockQuantity。 -- 建表 CREATE TA…...

超时取消子线程任务
文章目录 前言一、编码思路二、使用步骤直接上代码 总结 前言 问题背景: 主线程需要执行一些任务,不能影响主任务执行,这些任务有超时时间,当超过处理时间后,应该不予处理;如果未超时,应该获取到这些任务的执行结果; 一、编码思路 由于主线程正常执行不能影响,任务会处理很久…...

模块化---common.js
入口文件:app.js // require是同步加载 // 客户端:common.js的模块化,需要browserify编译之后才能使用 // 服务端:运行时同步加载,无问题 let module1 require(./module1.js) let module2 require(./module2.js) co…...
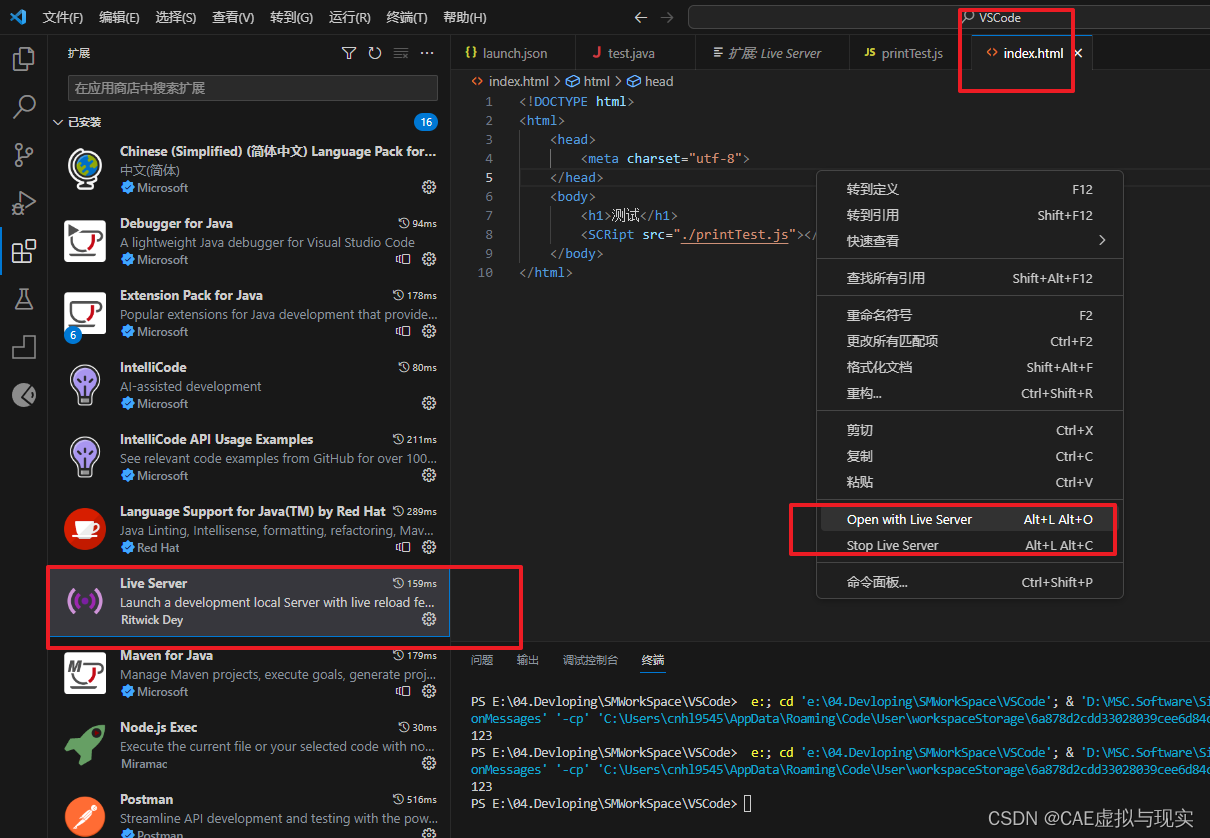
VSCode下载、安装及配置、调试的一些过程理解
第一步先下载了vscode,官方地址为:https://code.visualstudio.com/Download 第二步安装vscode,安装环境是win10,安装基本上就是一步步默认即可。 第三步汉化vscode,这一步就是去扩展插件里面下载一个中文插件即可&am…...
KC705开发板——MGT IBERT测试记录
本文介绍使用KC705开发板进行MGT的IBERT测试。 KC705开发板 KC705开发板的图片如下图所示。FPGA芯片型号为XC7K325T-2FFG900C。 MGT MGT是 Multi-Gigabit Transceiver的缩写,是Multi-Gigabit Serializer/Deserializer (SERDES)的别称。MGT包含GTP、GTX、GTH、G…...

前端代码优化散记
把import Button from xxx 的引入方式,变成import {Button} from xxx 的方式引入,以利于按需打包。原生监听事件、定时器等,必须在componentWillUnmount中清除,大型项目会发生内存泄露,极度影响性能。使用PureComponen…...

HTML <map> 标签的使用
map标签的用途:是与img标签绑定使用的,常被用来赋予给客户端图像某处区域特殊的含义,点击该区域可跳转到新的文档。 编写格式: <img src"图片" border"0" usemap"#planetmap" alt"Planets…...

stable diffusion实践操作-大模型介绍
本文专门开一节写大模型相关的内容,在看之前,可以同步关注: stable diffusion实践操作 模型下载网站 国内的是:https://www.liblibai.com 国外的是:https://civitai.com(科学上网) 一、发展历…...
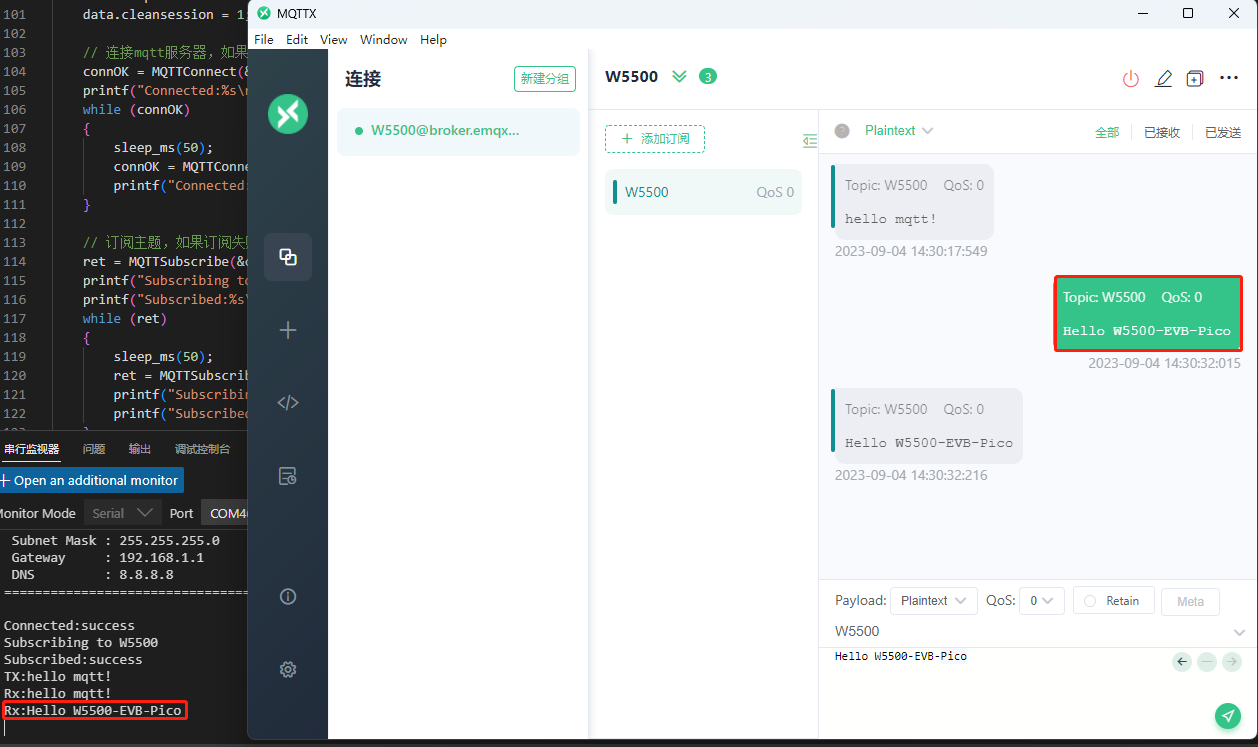
W5500-EVB-PICO进行MQTT连接订阅发布教程(十二)
前言 上一章我们用开发板通过SNTP协议获取网络协议,本章我们介绍一下开发板通过配置MQTT连接到服务器上,并且订阅和发布消息。 什么是MQTT? MQTT是一种轻量级的消息传输协议,旨在物联网(IoT)应用中实现设备…...
90、00后严选出的数据可视化工具:奥威BI工具
90、00后主打一个巧用工具,绝不低效率上班,因此当擅长大数据智能可视化分析的BI数据可视化工具出现后,自然而然地就成了90、00后职场人常用的数据可视化工具。 奥威BI工具三大特点,让职场人眼前一亮! 1、零编程&…...

删除maven中出现.lastUpdate结尾的文件
出现 .lastupdate 结尾的文件的原因:由于网络原因没有将maven的依赖下载完整. 解决方案: 1) 删除所有以 .lastupdate 结尾的文件 A) 1.切换到maven本地仓库 B)2.在当前目录打开cmd命令行(shift右键-->在此处打开命令窗口 或 直接在当前文件路径上敲cmd 或 右键-->…...

Cannot assign to read only property ‘exports‘ of object ‘#<Object>‘
webpack打包js文件中不允许混用import和module.exports。 方式①:babel.config.js添加sourceType: {"presets": [...],"sourceType": "unambiguous" }方式②:安装babel-plugin-transform-es2015-modules-commonjs npm …...

Dockerfile中编译、打包、部署spring boot项目
1、Dockerfile 1.1、什么是Dockerfile Dockerfile是自动构建docker镜像的配置文件,将镜像构建过程通过指令的方式定义在Dockerfile中。配合docker build命令行可以实现自动化的Docker镜像的构建。 1.2、Dockerfile语法解析 我们在学习一门语言或文档语法的时候&am…...
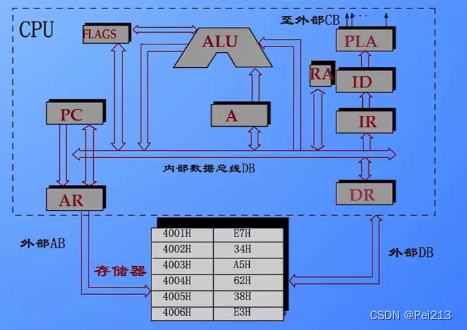
微型计算机原理知识点总结(一)
目录 一.微型计算机 二.微型计算机系统 1.微型计算机硬件系统 冯诺依曼体系结构 总线 (1)微处理器(CPU) 运算器 控制器 内部寄存器 (2)存储器 1.基本概念 2.内存的操作 3.内存的分类 (3)I/O接口与输入/输出设备 2.微型计算机软件系统 (1)系统软件 操作系统 …...

【postgresql 基础入门】psql客户端的使用方法
psql 客户端使用 专栏内容: postgresql内核源码分析手写数据库toadb并发编程 开源贡献: toadb开源库 个人主页:我的主页 管理社区:开源数据库 座右铭:天行健,君子以自强不息;地势坤…...

QTcpSocket发送数据方法
文章目录 一、简介二、write(const char *, qint64)三、isValid() 一、简介 本文主要记录QTcpSocket的write(const char *, qint64)和isValid()。 二、write(const char *, qint64) 概念:在QTcpSocket中,使用write(char* data, int size)函数将指定长…...

VSCode里Code Runner跑Python总报9009?别慌,检查一下你的setting.json文件
VSCode中Code Runner执行Python报错9009的终极排查指南 当你第一次在VSCode中用Code Runner插件运行Python脚本,满心期待看到输出结果时,终端却弹出"Process exited with code 9009"的红色错误提示——这种挫败感我深有体会。这个看似神秘的错…...

如何快速提高能力
人机协作,AI模型:Deepseek仅供参考如何快速提高能力在快节奏的现代社会中,每个人都渴望快速提升自己的能力,无论是职场竞争力、专业技能,还是通用素养。能力的提升并非一蹴而就,但遵循科学有效的方法&#…...

TrollInstallerX完整教程:3分钟搞定iOS越狱神器TrollStore一键安装
TrollInstallerX完整教程:3分钟搞定iOS越狱神器TrollStore一键安装 【免费下载链接】TrollInstallerX A TrollStore installer for iOS 14.0 - 16.6.1 项目地址: https://gitcode.com/gh_mirrors/tr/TrollInstallerX 还在为iOS设备上安装TrollStore而烦恼吗&…...

Beyond Compare 5密钥生成终极指南:从激活失败到完全使用
Beyond Compare 5密钥生成终极指南:从激活失败到完全使用 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen 你是否也遇到过Beyond Compare 5弹出"评估模式错误"的困扰&#…...

FPGA设计实战:别再乱用复位了!同步、异步与异步复位同步释放的Verilog代码避坑指南
FPGA设计实战:复位电路设计的黄金法则与Verilog避坑指南 在FPGA开发的世界里,复位电路就像交响乐团的指挥——它决定了整个系统能否从混沌走向有序。许多工程师往往低估了复位设计的重要性,直到项目后期遭遇难以追踪的亚稳态问题或时序收敛失…...

氨基酸表活洁面慕斯科普
一、什么是洁面慕斯洁面慕斯是一种预发泡型的洁面产品,和传统膏状、洗面奶不同,它从泵头挤出来就是细腻绵密的泡沫,不需要消费者手动打泡,使用起来更加方便快捷。从成分体系来看,洁面慕斯本质还是表面活性剂清洁产品&a…...

谷歌DeepMind让AI学会“主动查资料“
这项由爱丁堡大学与谷歌DeepMind联合开展的研究,以预印本形式发布于2026年5月13日,论文编号为arXiv:2605.13050v1,有兴趣深入了解的读者可以通过该编号查询完整论文。**研究概要**假设你有一位助理,学识渊博,但所有知识…...

AArch64架构TLB管理机制与优化实践
1. AArch64 TLB管理机制概述TLB(Translation Lookaside Buffer)是现代处理器内存管理单元(MMU)的核心组件,负责缓存虚拟地址到物理地址的转换结果。在AArch64架构中,TLB管理机制尤为复杂,涉及多…...

电机PID调参总翻车?试试VOFA+这个“示波器”功能,实时对比目标与实际值
电机PID调参实战:用VOFA实现波形可视化诊断 调试电机PID控制器时,最令人头疼的莫过于面对一堆抽象数据却无法直观理解系统行为。传统方法依赖串口打印数值或简单示波器观察,往往需要反复修改参数、重新烧录程序,效率低下且容易错过…...

PFC2D5.0_从零构建边坡开挖与稳定性分析模型
1. PFC2D5.0边坡建模基础入门 第一次接触PFC2D5.0时,我被它强大的颗粒流分析能力震撼到了。这个软件就像是用数字乐高搭建地质模型,每个颗粒都像真实的砂石一样可以自由运动。记得刚开始做边坡模拟时,我连最简单的矩形试样都建不好࿰…...