深度学习推荐系统(四)WideDeep模型及其在Criteo数据集上的应用
深度学习推荐系统(四)Wide&Deep模型及其在Criteo数据集上的应用
在2016年, 随着微软的Deep Crossing, 谷歌的Wide&Deep以及FNN、PNN等一大批优秀的深度学习模型被提出, 推荐系统全面进入了深度学习时代, 时至今日, 依然是主流。 推荐模型主要有下面两个进展:
-
与传统的机器学习模型相比, 深度学习模型的表达能力更强, 能够挖掘更多数据中隐藏的模式
-
深度学习模型结构非常灵活, 能够根据业务场景和数据特点, 灵活调整模型结构, 使模型与应用场景完美契合
深度学习推荐模型,以多层感知机(MLP)为核心, 通过改变神经网络结构进行演化。

1 Wide&Deep模型原理
1.1 Wide&Deep模型提出的背景
-
简单的模型, 比如协同过滤, 逻辑回归等,能够从历史数据中学习到高频共现的特征组合能力, 但是泛化能力不足
-
而像矩阵分解, embedding再加上深度学习网络, 能够利用相关性的传递性去探索历史数据中未出现的特征组合, 挖掘数据潜在的关联模式, 但是对于某些特定的场景(数据分布长尾, 共现矩阵稀疏高秩)很难有效学习低纬度的表示, 造成推荐的过渡泛化。
因此,在2016年,Google提出Wide&Deep模型,将线性模型与DNN很好的结合起来,在提高模型泛化能力的同时,兼顾模型的记忆性。Wide&Deep这种线性模型与DNN的并行连接模式,后来成为推荐领域的经典模式, 奠定了后面深度学习模型的基础,是一个里程碑式的改变。
1.2 模型的记忆能力和泛化能力
1.2.1 记忆能力的理解
记忆能力可以被理解为模型直接学习并利用历史数据中物品和特征的共现频率的能力。
一般来说, 协同过滤、逻辑回归这种都具有较强的“记忆能力”, 由于这类模型比较简单, 原始数据往往可以直接影响推荐结果, 产生类似于如果点击A, 就推荐B这类规则的推荐, 相当于模型直接记住了历史数据的分布特点, 并利用这些记忆进行推荐。
以谷歌APP推荐场景为例理解一下:
假设在Google Play推荐模型训练过程中,设置如下组合特征:AND(user_installed_app=netflix,
impression_app=pandora),它代表了用户安装了netflix这款应用,而且曾在应用商店中看到过pandora这款应用。
如果以“最终是否安装pandora”为标签,可以轻而易举的统计netfilx&pandora这个特征与安装pandora标签之间的共现频率。比如二者的共现频率高达10%,那么在设计模型的时候,就希望模型只要发现这一特征,就推荐pandora这款应用(像一个深刻记忆点一样印在脑海),这就是所谓的“记忆能力”。
像逻辑回归这样的模型,发现这样的强特,就会加大权重,对这种特征直接记忆。
但是对于神经网络这样的模型来说,特征会被多层处理,不断与其他特征进行交叉,因此模型这个强特记忆反而没有简单模型的深刻。
1.2.2 泛化能力的理解
泛化能力可以被理解为模型传递特征的相关性, 以及发掘稀疏甚至从未出现过的稀有特征与最终标签相关性的能力。
比如矩阵分解, embedding等, 使得数据稀少的用户或者物品也能生成隐向量, 从而获得由数据支撑的推荐得分, 将全局数据传递到了稀疏物品上, 提高泛化能力。
再比如神经网络, 通过特征自动组合, 可以深度发掘数据中的潜在模式,提高泛化等。
所以, Wide&Deep模型的直接动机就是将两者进行融合, 使得模型既有了简单模型的这种“记忆能力”, 也有了神经网络的这种“泛化能力”, 这也是记忆与泛化结合的伟大模式的初始尝试。
1.3 Wide&Deep的模型结构
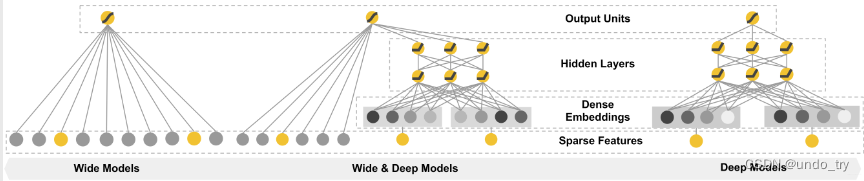
经典的W&D的模型如图所示:
-
左边的是wide部分, 也就是一个简单的线性模型, 右边是deep部分, 一个经典的DNN模型
-
W&D模型把单输入层的
Wide部分和Embedding+多层的全连接的部分(deep部分)连接起来, 一起输入最终的输出层得到预测结果 -
单层的wide层善于处理大量的稀疏的id类特征, Deep部分利用深层的特征交叉, 挖掘在特征背后的数据模式。 最终, 利用逻辑回归, 输出层部分和Deep组合起来, 形成统一的模型。
1.3.1 Wide部分

-
对于wide部分训练时候使用的优化器是
带正则的FTRL算法(Follow-the-regularized-leader),可以把FTRL当作一个稀疏性很好,精度又不错的随机梯度下降方法, 该算法是非常注重模型稀疏性质的。 -
也就是说W&D模型采用L1 FTRL是
想让Wide部分变得更加的稀疏,即Wide部分的大部分参数都为0,这就大大压缩了模型权重及特征向量的维度。 -
Wide部分模型训练完之后留下来的特征都是非常重要的,
模型的“记忆能力”可以理解为发现"直接的",“暴力的”,“显然的”关联规则的能力。
1.3.2 Deep部分
-
Deep部分主要是
一个Embedding+MLP的神经网络模型。 -
大规模稀疏特征通过embedding转化为低维密集型特征。然后特征进行拼接输入到MLP中,挖掘藏在特征背后的数据模式。
-
输入的特征有两类, 一类是数值型特征, 一类是类别型特征(经过embedding)。
-
DNN模型随着层数的增加,中间的特征就越抽象,也就提高了模型的泛化能力。
-
对于Deep部分的DNN模型作者使用了深度学习常用的
优化器AdaGrad,这也是为了使得模型可以得到更精确的解。
1.3.3 Wide&Deep的模型详细结构

从上图我们可以详细地了解Google Play推荐团队设计的 Wide&Deep 模型到底将哪些特征作为 Deep 部分的输入,将哪些特征作为 Wide 部分的输入。
-
Wide 部分的输入仅仅是
已安装应用和曝光应用两类特征,其中已安装应用代表用户的历史行为,而曝光应用代表当前的待推荐应用。选择这两类特征的原因是充分发挥 Wide部分记忆能力强的优势。 -
Deep 部分的输入是全量的特征向量,包括用户年龄 (Age )、已安装应用数量(#App Installs )、设备类型(Device Class )、已安装应用(User Installed App)、曝光应用(Impression App)等特征。已安装应用、曝光应用等类别型特征,需要经过 Embedding 层输人连接层(Concatenated Embedding),拼接成1200维的再依次经过3层ReLU全连接层,最终输入 LogLoss 输出层Embedding向量。
1.4 Wide&Deep模型代码
import torch.nn as nn
import torch.nn.functional as F
import torchclass Linear(nn.Module):"""Linear part"""def __init__(self, input_dim):super(Linear, self).__init__()self.linear = nn.Linear(in_features=input_dim, out_features=1)def forward(self, x):return self.linear(x)class Dnn(nn.Module):"""Dnn part"""def __init__(self, hidden_units, dropout=0.5):"""hidden_units: 列表, 每个元素表示每一层的神经单元个数, 比如[256, 128, 64], 两层网络, 第一层神经单元128, 第二层64, 第一个维度是输入维度dropout: 失活率"""super(Dnn, self).__init__()self.dnn_network = nn.ModuleList([nn.Linear(layer[0], layer[1]) for layer in list(zip(hidden_units[:-1], hidden_units[1:]))])self.dropout = nn.Dropout(p=dropout)def forward(self, x):for linear in self.dnn_network:x = linear(x)x = F.relu(x)x = self.dropout(x)return x'''
WideDeep模型:主要包括Wide部分和Deep部分
'''
class WideDeep(nn.Module):def __init__(self, feature_info, hidden_units, embed_dim=8):"""DeepCrossing:feature_info: 特征信息(数值特征, 类别特征, 类别特征embedding映射)hidden_units: 列表, 隐藏单元dropout: Dropout层的失活比例embed_dim: embedding维度"""super(WideDeep, self).__init__()self.dense_features, self.sparse_features, self.sparse_features_map = feature_info# embedding层, 这里需要一个列表的形式, 因为每个类别特征都需要embeddingself.embed_layers = nn.ModuleDict({'embed_' + str(key): nn.Embedding(num_embeddings=val, embedding_dim=embed_dim)for key, val in self.sparse_features_map.items()})# 统计embedding_dim的总维度# 一个离散型(类别型)变量 通过embedding层变为8纬embed_dim_sum = sum([embed_dim] * len(self.sparse_features))# 总维度 = 数值型特征的纬度 + 离散型变量经过embedding后的纬度dim_sum = len(self.dense_features) + embed_dim_sumhidden_units.insert(0, dim_sum)# dnn网络self.dnn_network = Dnn(hidden_units)# 线性层self.linear = Linear(input_dim=len(self.dense_features))# 最终的线性层self.final_linear = nn.Linear(hidden_units[-1], 1)def forward(self, x):# 1、先把输入向量x分成两部分处理、因为数值型和类别型的处理方式不一样dense_input, sparse_inputs = x[:, :len(self.dense_features)], x[:, len(self.dense_features):]# 2、转换为long形sparse_inputs = sparse_inputs.long()# 2、不同的类别特征分别embeddingsparse_embeds = [self.embed_layers['embed_' + key](sparse_inputs[:, i]) for key, i inzip(self.sparse_features_map.keys(), range(sparse_inputs.shape[1]))]# 3、把类别型特征进行拼接,即emdedding后,由3行转换为1行sparse_embeds = torch.cat(sparse_embeds, axis=-1)# 4、数值型和类别型特征进行拼接dnn_input = torch.cat([sparse_embeds, dense_input], axis=-1)# Wide部分,使用的特征为数值型类型wide_out = self.linear(dense_input)# Deep部分,使用全部特征deep_out = self.dnn_network(dnn_input)deep_out = self.final_linear(deep_out)# out 将Wide部分的输出和Deep部分的输出进行合并outputs = F.sigmoid(0.5 * (wide_out + deep_out))return outputsif __name__ == '__main__':x = torch.rand(size=(1, 5), dtype=torch.float32)feature_info = [['I1', 'I2'], # 连续性特征['C1', 'C2', 'C3'], # 离散型特征{'C1': 20,'C2': 20,'C3': 20}]# 建立模型hidden_units = [256, 128, 64]net = WideDeep(feature_info, hidden_units)print(net)print(net(x))
WideDeep((embed_layers): ModuleDict((embed_C1): Embedding(20, 8)(embed_C2): Embedding(20, 8)(embed_C3): Embedding(20, 8))(dnn_network): Dnn((dnn_network): ModuleList((0): Linear(in_features=26, out_features=256, bias=True)(1): Linear(in_features=256, out_features=128, bias=True)(2): Linear(in_features=128, out_features=64, bias=True))(dropout): Dropout(p=0.5, inplace=False))(linear): Linear((linear): Linear(in_features=2, out_features=1, bias=True))(final_linear): Linear(in_features=64, out_features=1, bias=True)
)
tensor([[0.6531]], grad_fn=<SigmoidBackward0>)
2 Wide&Deep模型在Criteo数据集的应用
数据的预处理及一些函数或类可以参考:
深度学习推荐系统(二)Deep Crossing及其在Criteo数据集上的应用
2.1 准备训练数据
import pandas as pdimport torch
from torch.utils.data import TensorDataset, Dataset, DataLoaderimport torch.nn as nn
from sklearn.metrics import auc, roc_auc_score, roc_curveimport warnings
warnings.filterwarnings('ignore')
# 封装为函数
def prepared_data(file_path):# 读入训练集,验证集和测试集train_set = pd.read_csv(file_path + 'train_set.csv')val_set = pd.read_csv(file_path + 'val_set.csv')test_set = pd.read_csv(file_path + 'test.csv')# 这里需要把特征分成数值型和离散型# 因为后面的模型里面离散型的特征需要embedding, 而数值型的特征直接进入了stacking层, 处理方式会不一样data_df = pd.concat((train_set, val_set, test_set))# 数值型特征直接放入stacking层dense_features = ['I' + str(i) for i in range(1, 14)]# 离散型特征需要需要进行embedding处理sparse_features = ['C' + str(i) for i in range(1, 27)]# 定义一个稀疏特征的embedding映射, 字典{key: value},# key表示每个稀疏特征, value表示数据集data_df对应列的不同取值个数, 作为embedding输入维度sparse_feas_map = {}for key in sparse_features:sparse_feas_map[key] = data_df[key].nunique()feature_info = [dense_features, sparse_features, sparse_feas_map] # 这里把特征信息进行封装, 建立模型的时候作为参数传入# 把数据构建成数据管道dl_train_dataset = TensorDataset(# 特征信息torch.tensor(train_set.drop(columns='Label').values).float(),# 标签信息torch.tensor(train_set['Label'].values).float())dl_val_dataset = TensorDataset(# 特征信息torch.tensor(val_set.drop(columns='Label').values).float(),# 标签信息torch.tensor(val_set['Label'].values).float())dl_train = DataLoader(dl_train_dataset, shuffle=True, batch_size=16)dl_vaild = DataLoader(dl_val_dataset, shuffle=True, batch_size=16)return feature_info,dl_train,dl_vaild,test_set
file_path = './preprocessed_data/'feature_info,dl_train,dl_vaild,test_set = prepared_data(file_path)
2.2 建立Wide&Deep模型
from _01_wide_deep import WideDeephidden_units = [256, 128, 64]
net = WideDeep(feature_info, hidden_units)
2.3 模型的训练
from AnimatorClass import Animator
from TimerClass import Timer# 模型的相关设置
def metric_func(y_pred, y_true):pred = y_pred.datay = y_true.datareturn roc_auc_score(y, pred)def try_gpu(i=0):if torch.cuda.device_count() >= i + 1:return torch.device(f'cuda:{i}')return torch.device('cpu')def train_ch(net, dl_train, dl_vaild, num_epochs, lr, device):"""⽤GPU训练模型"""print('training on', device)net.to(device)# 二值交叉熵损失loss_func = nn.BCELoss()# 注意:这里没有使用原理提到的优化器optimizer = torch.optim.Adam(params=net.parameters(), lr=lr)animator = Animator(xlabel='epoch', xlim=[1, num_epochs],legend=['train loss', 'train auc', 'val loss', 'val auc'],figsize=(8.0, 6.0))timer, num_batches = Timer(), len(dl_train)log_step_freq = 10for epoch in range(1, num_epochs + 1):# 训练阶段net.train()loss_sum = 0.0metric_sum = 0.0for step, (features, labels) in enumerate(dl_train, 1):timer.start()# 梯度清零optimizer.zero_grad()# 正向传播predictions = net(features)loss = loss_func(predictions, labels.unsqueeze(1) )try: # 这里就是如果当前批次里面的y只有一个类别, 跳过去metric = metric_func(predictions, labels)except ValueError:pass# 反向传播求梯度loss.backward()optimizer.step()timer.stop()# 打印batch级别日志loss_sum += loss.item()metric_sum += metric.item()if step % log_step_freq == 0:animator.add(epoch + step / num_batches,(loss_sum/step, metric_sum/step, None, None))# 验证阶段net.eval()val_loss_sum = 0.0val_metric_sum = 0.0for val_step, (features, labels) in enumerate(dl_vaild, 1):with torch.no_grad():predictions = net(features)val_loss = loss_func(predictions, labels.unsqueeze(1))try:val_metric = metric_func(predictions, labels)except ValueError:passval_loss_sum += val_loss.item()val_metric_sum += val_metric.item()if val_step % log_step_freq == 0:animator.add(epoch + val_step / num_batches, (None,None,val_loss_sum / val_step , val_metric_sum / val_step))print(f'final: loss {loss_sum/len(dl_train):.3f}, auc {metric_sum/len(dl_train):.3f},'f' val loss {val_loss_sum/len(dl_vaild):.3f}, val auc {val_metric_sum/len(dl_vaild):.3f}')print(f'{num_batches * num_epochs / timer.sum():.1f} examples/sec on {str(device)}')
lr, num_epochs = 0.001, 10
# 其实发生了过拟合
train_ch(net, dl_train, dl_vaild, num_epochs, lr, try_gpu())

2.4 模型的预测
y_pred_probs = net(torch.tensor(test_set.values).float())
y_pred = torch.where(y_pred_probs>0.5,torch.ones_like(y_pred_probs),torch.zeros_like(y_pred_probs)
)
y_pred.data[:10]
相关文章:
深度学习推荐系统(四)WideDeep模型及其在Criteo数据集上的应用
深度学习推荐系统(四)Wide&Deep模型及其在Criteo数据集上的应用 在2016年, 随着微软的Deep Crossing, 谷歌的Wide&Deep以及FNN、PNN等一大批优秀的深度学习模型被提出, 推荐系统全面进入了深度学习时代, 时至今日&#x…...
)
第十二章 YOLO的部署实战篇(中篇)
cuda教程目录 第一章 指针篇 第二章 CUDA原理篇 第三章 CUDA编译器环境配置篇 第四章 kernel函数基础篇 第五章 kernel索引(index)篇 第六章 kenel矩阵计算实战篇 第七章 kenel实战强化篇 第八章 CUDA内存应用与性能优化篇 第九章 CUDA原子(atomic)实战篇 第十章 CUDA流(strea…...

面试题查漏补缺 i++和 ++ i哪个效率更高
i 和 i 哪个效率更高? 在这里声明,简单地比较前缀自增运算符和后缀自增运算符的效率是片面的,因为存在很多因素影响这个问题的答案。首先考虑内建数据类型的情况:如果自增运算表达式的结果没有被使用,而是仅仅简单地用于增加一员…...
Docker的数据管理(持久化存储)
文章目录 一、概述二、数据卷三、数据卷容器四、端口映射五、容器互联(使用centos镜像)总结 一、概述 管理 Docker 容器中数据主要有两种方式:数据卷(Data Volumes)和数据卷容器(DataVolumes Containers&a…...

定时脚本自动自动将文件push到git
写脚本 绝对路径 环境注意 写python,bash脚本执行调用 py程序 定制crontab -e 日志要指定输入文件中 项目地址 https://gitee.com/stdev_1/sshpi10/ bash脚本 #!/bin/bash 设置要监控的仓库路径 #path~/github/ #watch_dir“/home/pi/gittest/ipset/sshpi10” p…...

025: vue父子组件中传递方法控制:$emit,$refs,$parent,$children
第025个 查看专栏目录: VUE ------ element UI 专栏目标 在vue和element UI联合技术栈的操控下,本专栏提供行之有效的源代码示例和信息点介绍,做到灵活运用。 (1)提供vue2的一些基本操作:安装、引用,模板使…...

使用js搭建简易的WebRTC实现视频直播
首先需要一个信令服务器,我们使用nodejs来搭建。两个端:发送端和接收端。我的目录结构如下图:流程 创建一个文件夹 WebRTC-Test。进入文件夹中,新建一个node的文件夹。使用终端并进入node的目录下,使用 npm init 创建p…...

LeetCode 2707. Extra Characters in a String【动态规划,记忆化搜索,Trie】1735
本文属于「征服LeetCode」系列文章之一,这一系列正式开始于2021/08/12。由于LeetCode上部分题目有锁,本系列将至少持续到刷完所有无锁题之日为止;由于LeetCode还在不断地创建新题,本系列的终止日期可能是永远。在这一系列刷题文章…...
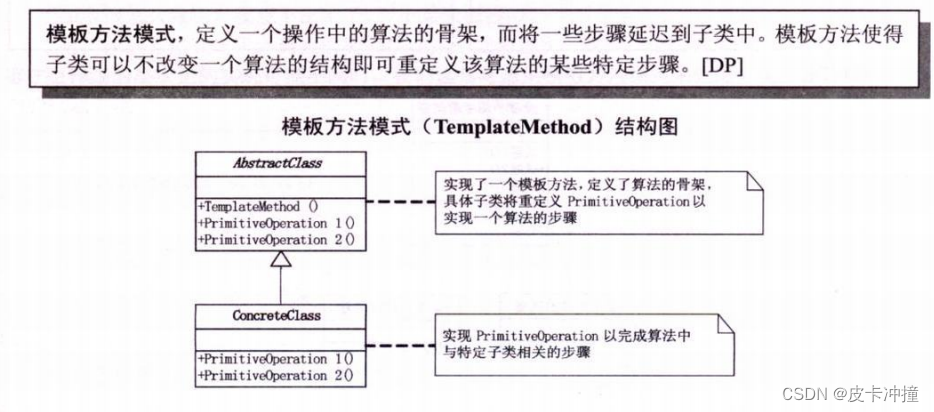
设计模式行为型-模板模式
文章目录 一:模板方法设计模式概述1.1 简介1.2 定义和目的1.3 关键特点1.4 适用场景 二:模板方法设计模式基本原理2.1 抽象类2.1.1 定义和作用2.1.2 模板方法2.1.3 具体方法 2.2 具体类2.2.1 定义和作用2.2.2 实现抽象类中的抽象方法2.2.3 覆盖钩子方法 …...

9.3.tensorRT高级(4)封装系列-自动驾驶案例项目self-driving-车道线检测
目录 前言1. 车道线检测总结 前言 杜老师推出的 tensorRT从零起步高性能部署 课程,之前有看过一遍,但是没有做笔记,很多东西也忘了。这次重新撸一遍,顺便记记笔记。 本次课程学习 tensorRT 高级-自动驾驶案例项目self-driving-车道…...
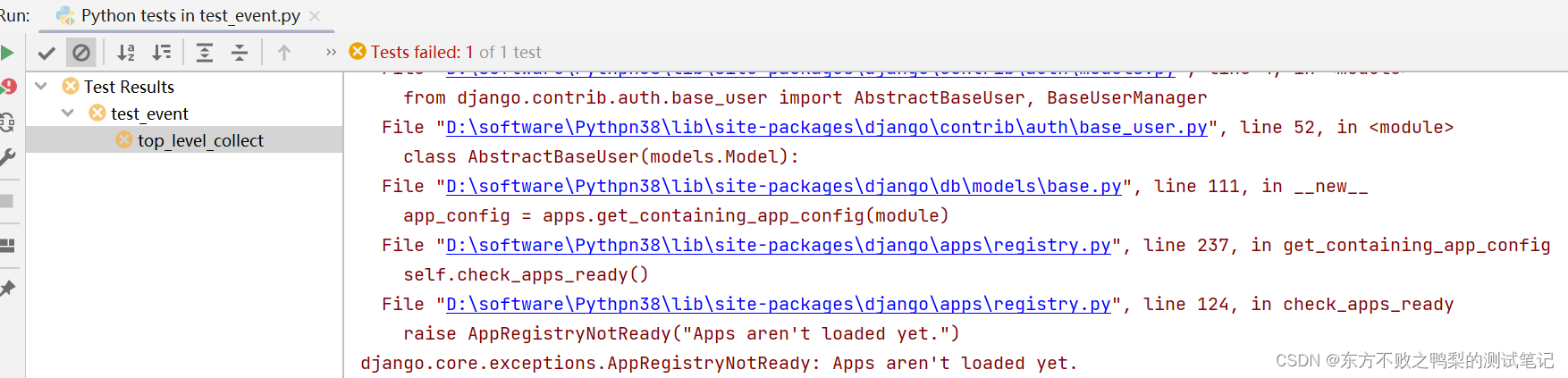
django.core.exceptions.AppRegistryNotReady: Apps aren‘t loaded yet.
运行django测试用例报错django.core.exceptions.AppRegistryNotReady: Apps arent loaded yet. 解决:在测试文件上方加上 django.setup() django.setup()是Django框架中的一个函数。它用于在非Django环境下使用Django的各种功能、模型和设置。 在常规的Django应用…...
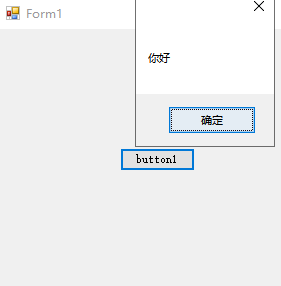
【C#】C#调用进程打开一个exe程序
文章目录 一、过程二、效果总结 一、过程 新建WinForm程序,并写入代码,明确要调用的程序的绝对路径(或相对路径)下的exe文件。 调用代码: 这里我调用的另一个程序的路径是: F:\WindowsFormsApplication2…...

宝塔面板定时监控和重启MySQL数据库(计划任务)
往期教程 如果还有不了解宝塔面板怎么使用的小伙伴,可以看下我总结的系列教程,保证从新手变老鸟: 【建站流程科普】 个人和企业搭建网站基本流程及六个主要步骤常见的VPS主机运维面板汇总—网站运维面板云服务器,VPS࿰…...
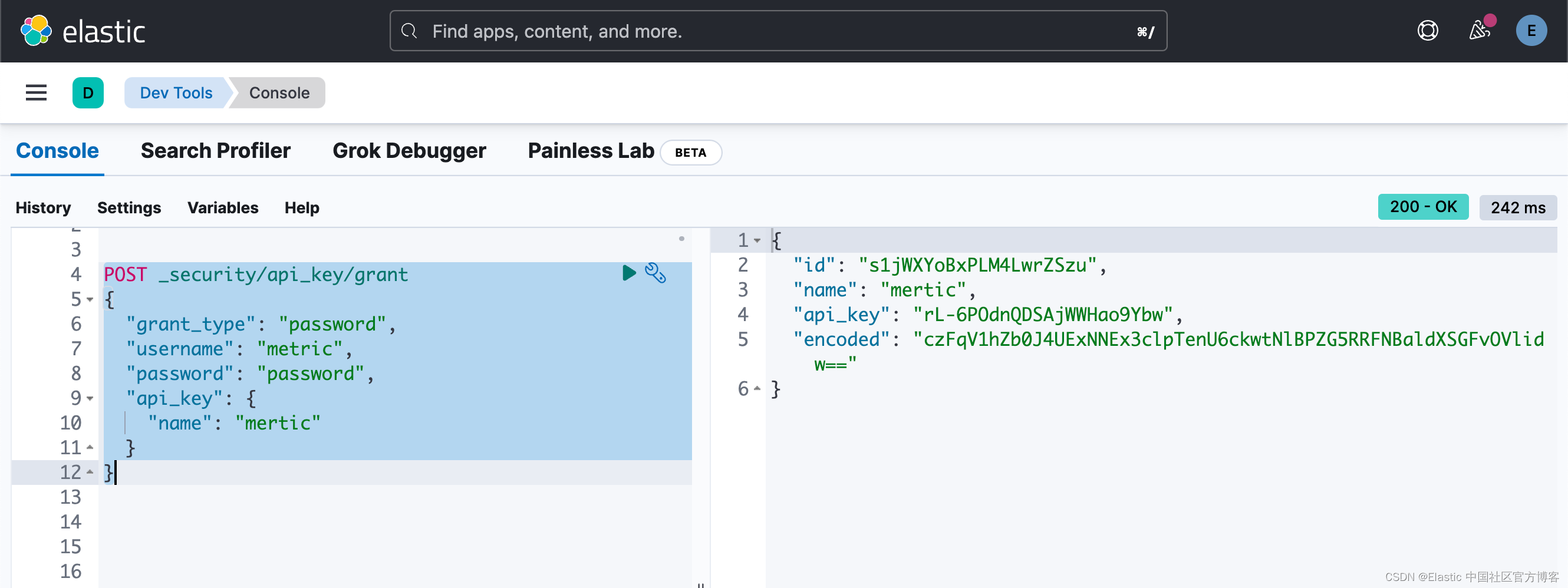
Beats:安装及配置 Metricbeat (二)- 8.x
这篇文章是继文章 “Beats:安装及配置 Metricbeat (一)- 8.x” 的续篇。你可以先阅读之前的那篇文章再继续阅读这篇文章。我们在这篇文章中继续之前的探讨。 使用 fingerprint 来代替证书 在实际的使用中,我们需要从 Elasticsear…...

Redis之哨兵模式解读
目录 基本介绍 单哨兵模式 多哨兵模式 哨兵的本质 配置哨兵模式 故障恢复原理 哨兵监控工作流程 哨兵模式缺点 基本介绍 当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,费事费力,还会造成一段时间内服务不可用。这不是一种推荐的方式,更多…...

题目:2644.找出可整除性得分最大的整数
题目来源: leetcode题目,网址:2644. 找出可整除性得分最大的整数 - 力扣(LeetCode) 解题思路: 遍历计算即可。 解题代码: class Solution {public int maxDivScore(int[] nums, int[] di…...
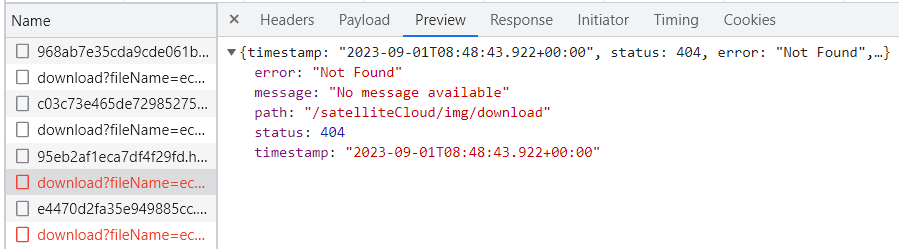
报错:axios 发送的接口请求 404
axios 发送的接口请求 404 一、问题二、分析 一、问题 二、分析 axios 发送的接口请求 404,根本没有把接口信息发送到后端,这个时候你可以查看检查一下自己的接口名字,或让后端配合换一个接口名字再发送一次接口请求...

三年前端还不会配置Nginx?刷完这篇就够了
什么是Nginx Nginx是一个开源的高性能HTTP和反向代理服务器。它可以用于处理静态资源、负载均衡、反向代理和缓存等任务。Nginx被广泛用于构建高可用性、高性能的Web应用程序和网站。它具有低内存消耗、高并发能力和良好的稳定性,因此在互联网领域非常受欢迎。 为…...
blender 场景灯光基础设置
在 blender 中,打光分为两个部分,一个是世界光,一个是场景光; 世界光: 世界光:在 Blender 中,世界光指的是用于设置场景整体照明的环境光。它可以通过调整颜色、强度、阴影等参数来影响场景的…...
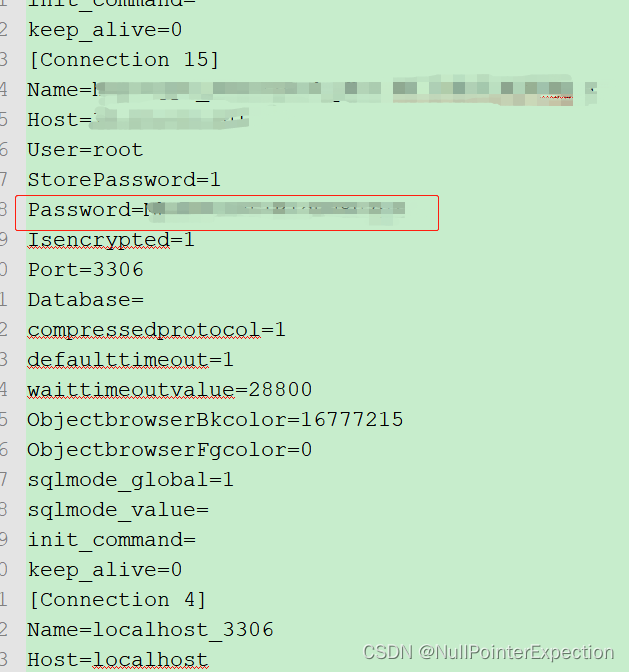
如何查看 SQLyog 中数据库连接信息中的密码
SQLyog 数据库连接信息中的密码无法选择明文展示,也无法复制 可以将数据库连接信息导出到文本查看明文密码 工具--》导入/导出连接详情:...

ChromaControl终极指南:如何用一个软件控制所有RGB设备?[特殊字符]
ChromaControl终极指南:如何用一个软件控制所有RGB设备?🎮 【免费下载链接】ChromaControl 3rd party device lighting support for Razer Synapse. 项目地址: https://gitcode.com/gh_mirrors/ch/ChromaControl 你是否厌倦了桌面上堆…...

KRTS实时内核开发环境搭建:手把手教你配置隔离CPU与Visual Studio联调
KRTS实时内核开发环境搭建:手把手教你配置隔离CPU与Visual Studio联调 在工业自动化、机器人控制和高频交易等硬实时应用领域,毫秒级的延迟差异可能导致整个系统失效。KRTS(Kithara RealTime Suite)作为Windows平台上的实时扩展解…...

LibSVM在Matlab里的实战:从分类到回归,手把手调参与结果解读
LibSVM在Matlab里的实战:从分类到回归,手把手调参与结果解读 当你第一次在Matlab中成功运行LibSVM时,看到命令行窗口跳出"Accuracy 86.6667%"的那一刻,可能既兴奋又困惑。兴奋的是工具终于跑通了,困惑的是那…...

OpenStack 12大组件说明-blog
OpenStack 12大组件说明 OpenStack 是开源Iaas云计算平台,由12大核心组件构成,各组件独立部署、协同工作,覆盖计算、存储、网络、认证等全场景,以下是各组件核心说明(精简版)。 1. Nova(计算服务…...

企业号码认证服务:实现座机、手机来电显示公司名称+品牌LOGO
在如今的商业环境下,一通没有身份标识的电话,想要敲开客户的大门已经变得越来越难。反诈意识的普及,让人们对陌生呼叫筑起了厚厚的防御墙。许多企业在开展客户回访、售后跟进或业务接洽时,频繁遭遇拒接、秒挂的窘境。投入了大笔的…...
)
国产FT-M6678 DSP内存布局实战:从L1到DDR,手把手教你配置CMD文件(附避坑指南)
FT-M6678 DSP内存配置实战:从L1到DDR的CMD文件设计精要 在国产DSP开发领域,FT-M6678作为对标TI C6678的高性能处理器,其内存架构的合理配置直接决定了算法执行的效率。本文将深入探讨如何通过连接命令文件(.cmd)对L1P、…...

终极USB安全弹出解决方案:告别Windows设备占用烦恼
终极USB安全弹出解决方案:告别Windows设备占用烦恼 【免费下载链接】USB-Disk-Ejector A program that allows you to quickly remove drives in Windows. It can eject USB disks, Firewire disks and memory cards. It is a quick, flexible, portable alternativ…...
百科全书从“深“到“无限深“)
深度神经网络(DNN)百科全书从“深“到“无限深“
一、开篇:深度的奇迹 2012 年 9 月 30 日。 ImageNet 挑战赛的结果在 Florence 公布。所有人都以为冠军会延续过去 3 年的传统——传统计算机视觉方法(SIFT、HOG、SVM)小幅领先。 但那一年,一个叫 AlexNet 的"怪物"出现了。8 层的卷积神经网络,Top-5 错误率 …...

别再只用BLAST了!试试MAFFT+HMMER这套组合拳,挖掘基因家族新成员更精准
基因家族分析进阶指南:MAFFT与HMMER的高效组合策略 在基因组学研究领域,识别基因家族成员是一项基础而关键的工作。传统方法如BLAST虽然广为人知,但在面对远缘同源基因或高度分化的基因家族时,其灵敏度往往不尽如人意。这时&#…...

探索Artisan:用开源软件解码咖啡烘焙的数据科学
探索Artisan:用开源软件解码咖啡烘焙的数据科学 【免费下载链接】artisan artisan: the worlds most trusted roasting software 项目地址: https://gitcode.com/gh_mirrors/ar/artisan 在咖啡烘焙的世界里,每一次烘焙都是一次精确的化学反应。从…...